KEMBAR78
Daftar
Login
Kafka와 ZooKeeper의 헤어질 결심🌊 | PDF
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
JongwonYoun2
74 views
Kafka와 ZooKeeper의 헤어질 결심🌊
Kafka와 ZooKeeper 간의 이야기를 통해 분산 시스템을 찍먹해봅니다 🚌
Software
◦
Read more
0
Save
Share
Embed
1
/ 115
2
/ 115
3
/ 115
4
/ 115
5
/ 115
6
/ 115
7
/ 115
8
/ 115
9
/ 115
10
/ 115
11
/ 115
12
/ 115
13
/ 115
14
/ 115
15
/ 115
16
/ 115
17
/ 115
18
/ 115
19
/ 115
20
/ 115
21
/ 115
22
/ 115
23
/ 115
24
/ 115
25
/ 115
26
/ 115
27
/ 115
28
/ 115
29
/ 115
30
/ 115
31
/ 115
32
/ 115
33
/ 115
34
/ 115
35
/ 115
36
/ 115
37
/ 115
38
/ 115
39
/ 115
40
/ 115
41
/ 115
42
/ 115
43
/ 115
44
/ 115
45
/ 115
46
/ 115
47
/ 115
48
/ 115
49
/ 115
50
/ 115
51
/ 115
52
/ 115
53
/ 115
54
/ 115
55
/ 115
56
/ 115
57
/ 115
58
/ 115
59
/ 115
60
/ 115
61
/ 115
62
/ 115
63
/ 115
64
/ 115
65
/ 115
66
/ 115
67
/ 115
68
/ 115
69
/ 115
70
/ 115
71
/ 115
72
/ 115
73
/ 115
74
/ 115
75
/ 115
76
/ 115
77
/ 115
78
/ 115
79
/ 115
80
/ 115
81
/ 115
82
/ 115
83
/ 115
84
/ 115
85
/ 115
86
/ 115
87
/ 115
88
/ 115
89
/ 115
90
/ 115
91
/ 115
92
/ 115
93
/ 115
94
/ 115
95
/ 115
96
/ 115
97
/ 115
98
/ 115
99
/ 115
100
/ 115
101
/ 115
102
/ 115
103
/ 115
104
/ 115
105
/ 115
106
/ 115
107
/ 115
108
/ 115
109
/ 115
110
/ 115
111
/ 115
112
/ 115
113
/ 115
114
/ 115
115
/ 115
More Related Content
PPTX
How to configure a hive high availability connection with zeppelin
by
Tiago Simões
PPTX
Introduction to Kafka and Zookeeper
by
Rahul Jain
PDF
IBM Integration Bus High Availability Overview
by
Peter Broadhurst
PPTX
MuleSoft Integration with AWS Cognito Client Credentials and Mule JWT Validat...
by
Manish Kumar Yadav
PPTX
Deploying and managing IBM MQ in the Cloud
by
Robert Parker
PDF
WebLogic FAQs
by
Amit Sharma
PPTX
CQRS and what it means for your architecture
by
Richard Banks
PPTX
Domain Driven Design: Zero to Hero
by
Fabrício Rissetto
How to configure a hive high availability connection with zeppelin
by
Tiago Simões
Introduction to Kafka and Zookeeper
by
Rahul Jain
IBM Integration Bus High Availability Overview
by
Peter Broadhurst
MuleSoft Integration with AWS Cognito Client Credentials and Mule JWT Validat...
by
Manish Kumar Yadav
Deploying and managing IBM MQ in the Cloud
by
Robert Parker
WebLogic FAQs
by
Amit Sharma
CQRS and what it means for your architecture
by
Richard Banks
Domain Driven Design: Zero to Hero
by
Fabrício Rissetto
What's hot
PDF
WebSphere MQ tutorial
by
Joseph's WebSphere Library
PPTX
Container Orchestration
by
jeetendra mandal
PDF
From airflow to google cloud composer
by
Bruce Kuo
PPTX
The RabbitMQ Message Broker
by
Martin Toshev
PPTX
ACI Hands-on Lab
by
Cisco Canada
PDF
Hearts Of Darkness - a Spring DevOps Apocalypse
by
Joris Kuipers
PDF
Verified CKAD Exam Questions and Answers
by
dalebeck957
PDF
Kubernetes in Docker
by
Docker, Inc.
PDF
[AWS Dev Day] 앱 현대화 | AWS Fargate를 사용한 서버리스 컨테이너 활용 하기 - 삼성전자 개발자 포털 사례 - 정영준...
by
Amazon Web Services Korea
PDF
Oracle WebLogic Diagnostics & Perfomance tuning
by
Michel Schildmeijer
PPTX
MVVM ( Model View ViewModel )
by
Ahmed Emad
PDF
Deploying Kafka Streams Applications with Docker and Kubernetes
by
confluent
PDF
Kubernetes a comprehensive overview
by
Gabriel Carro
PDF
React state management with Redux and MobX
by
Darko Kukovec
PPTX
Kubernetes
by
Henry He
PPTX
What’s Mule 4.3? How Does Anytime RTF Help? Our insights explain.
by
Kellton Tech Solutions Ltd
PDF
Quick introduction to Kubernetes
by
Eduardo Garcia Moyano
PDF
Kubernetes dealing with storage and persistence
by
Janakiram MSV
WebSphere MQ tutorial
by
Joseph's WebSphere Library
Container Orchestration
by
jeetendra mandal
From airflow to google cloud composer
by
Bruce Kuo
The RabbitMQ Message Broker
by
Martin Toshev
ACI Hands-on Lab
by
Cisco Canada
Hearts Of Darkness - a Spring DevOps Apocalypse
by
Joris Kuipers
Verified CKAD Exam Questions and Answers
by
dalebeck957
Kubernetes in Docker
by
Docker, Inc.
[AWS Dev Day] 앱 현대화 | AWS Fargate를 사용한 서버리스 컨테이너 활용 하기 - 삼성전자 개발자 포털 사례 - 정영준...
by
Amazon Web Services Korea
Oracle WebLogic Diagnostics & Perfomance tuning
by
Michel Schildmeijer
MVVM ( Model View ViewModel )
by
Ahmed Emad
Deploying Kafka Streams Applications with Docker and Kubernetes
by
confluent
Kubernetes a comprehensive overview
by
Gabriel Carro
React state management with Redux and MobX
by
Darko Kukovec
Kubernetes
by
Henry He
What’s Mule 4.3? How Does Anytime RTF Help? Our insights explain.
by
Kellton Tech Solutions Ltd
Quick introduction to Kubernetes
by
Eduardo Garcia Moyano
Kubernetes dealing with storage and persistence
by
Janakiram MSV
Similar to Kafka와 ZooKeeper의 헤어질 결심🌊
PPTX
Apache ZooKeeper 로 분산 서버 만들기
by
iFunFactory Inc.
PDF
3.[d2 오픈세미나]분산시스템 개발 및 교훈 n base arc
by
NAVER D2
PDF
Apache ZooKeeper 소개
by
중선 곽
PPTX
Zoo keeper 소개
by
주표 홍
PDF
Building Large Scale Distributed System on AWS - Korean
by
Amazon Web Services Korea
PPTX
Backend Master | 2.1.4 Cache - Redis Clustering part.1
by
Kyunghun Jeon
PDF
Zookeeper 소개
by
beom kyun choi
PPTX
Hadoop High Availability Summary
by
Chan Shik Lim
PPT
Redis Overview
by
kalzas
PPTX
[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술
by
NAVER D2
PPT
Hadoop Introduction (1.0)
by
Keeyong Han
PPTX
네트워크 프로그래밍 입출력 다중화 & 논블록소켓
by
Eutark Park
PDF
Lossless Stream Processing SKT
by
Taewook Eom
PPTX
게임 분산 서버 구조
by
Hyunjik Bae
PPTX
분산저장시스템 개발에 대한 12가지 이야기
by
NAVER D2
PPTX
개발자가 설명하는 블록체인 세미나
by
Taegyun Kim
PDF
weather-data-processing-using-python
by
marc_kth
PPTX
[자바카페] 람다 일괄처리 계층
by
용호 최
PDF
OpenDaylight의 High Availability 기능 분석
by
Seung-Hoon Baek
PDF
주키퍼
by
Junkwang Lee
Apache ZooKeeper 로 분산 서버 만들기
by
iFunFactory Inc.
3.[d2 오픈세미나]분산시스템 개발 및 교훈 n base arc
by
NAVER D2
Apache ZooKeeper 소개
by
중선 곽
Zoo keeper 소개
by
주표 홍
Building Large Scale Distributed System on AWS - Korean
by
Amazon Web Services Korea
Backend Master | 2.1.4 Cache - Redis Clustering part.1
by
Kyunghun Jeon
Zookeeper 소개
by
beom kyun choi
Hadoop High Availability Summary
by
Chan Shik Lim
Redis Overview
by
kalzas
[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술
by
NAVER D2
Hadoop Introduction (1.0)
by
Keeyong Han
네트워크 프로그래밍 입출력 다중화 & 논블록소켓
by
Eutark Park
Lossless Stream Processing SKT
by
Taewook Eom
게임 분산 서버 구조
by
Hyunjik Bae
분산저장시스템 개발에 대한 12가지 이야기
by
NAVER D2
개발자가 설명하는 블록체인 세미나
by
Taegyun Kim
weather-data-processing-using-python
by
marc_kth
[자바카페] 람다 일괄처리 계층
by
용호 최
OpenDaylight의 High Availability 기능 분석
by
Seung-Hoon Baek
주키퍼
by
Junkwang Lee
Kafka와 ZooKeeper의 헤어질 결심🌊
1.
©AUSG2023 Kafka 와 ZooKeeper의 헤어질
결심 🌊 @AUSG 7기 윤종원
2.
©AUSG2023 Kafka와 ZooKeeper를 통해 분산
시스템 알아보기 @AUSG 7기 윤종원
3.
©AUSG2023 Kafka와 ZooKeeper를 통해 분산
시스템 알아보기 @AUSG 7기 윤종원
4.
©AUSG2023 ©AUSG2023 분산 시스템(Distributed System) A
distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another Wikipedia
5.
©AUSG2023 ©AUSG2023 분산 시스템(Distributed System) 분산
시스템(Distributed System)은 네트워크로 연결된 여러 컴퓨터에서 실행되는 여러 개의 독립적인 시스템의 집합입니다. 각 시스템은 서로 정보를 교환하고, 조정하기 위해 링크를 통해 메시지를 주고 받습니다.
6.
©AUSG2023 ©AUSG2023 분산 시스템(Distributed System) -
분산 시스템은 여러 개의 독립적인 시스템의 집합입니다. - 여러 개의 독립적인 시스템은 하나의 컴퓨터가 아니라 네트워크로 연결된 여러 개의 컴퓨터에서 실행됩니다. - 시스템은 서로 정보를 주고받고, 조정을 위해 링크를 통해 메시지를 주고 받습니다.
7.
©AUSG2023 ©AUSG2023 분산 시스템(Distributed System) -
분산 시스템은 여러 개의 독립적인 시스템의 집합입니다. - 독립적인 시스템은 자신만의 상태를 지니고 있습니다. - 시스템은 서로 링크(네트워크)를 통해 메시지를 주고 받습니다.
8.
©AUSG2023 ©AUSG2023 분산 알고리즘 (Distributed
Algorithm) - Distributed algorithms are algorithms designed to run on multiple processors, without tight centralized control. - In general, they are harder to design and harder to understand than single-processor sequential algorithms. Wikipedia
9.
©AUSG2023 ©AUSG2023 분산 알고리즘 (Distributed
Algorithm) - 분산 시스템을 위한 알고리즘 - 단일 머신에서 실행되는 알고리즘보다 만들기도 어렵고 이해하기도 어렵습니다
10.
©AUSG2023 ©AUSG2023 분산 시스템의 특성 -
부분 실패(Partial Failure) - 비결정성(Nondeterminism) - 이는 단일 컴퓨터에서 실행할 때는 나타나지 않는 특성들
11.
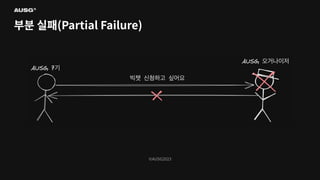
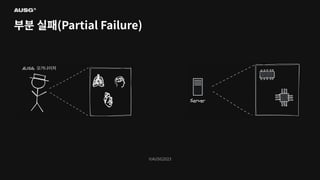
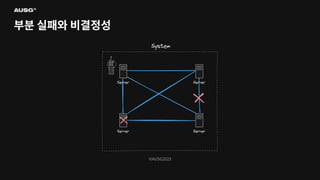
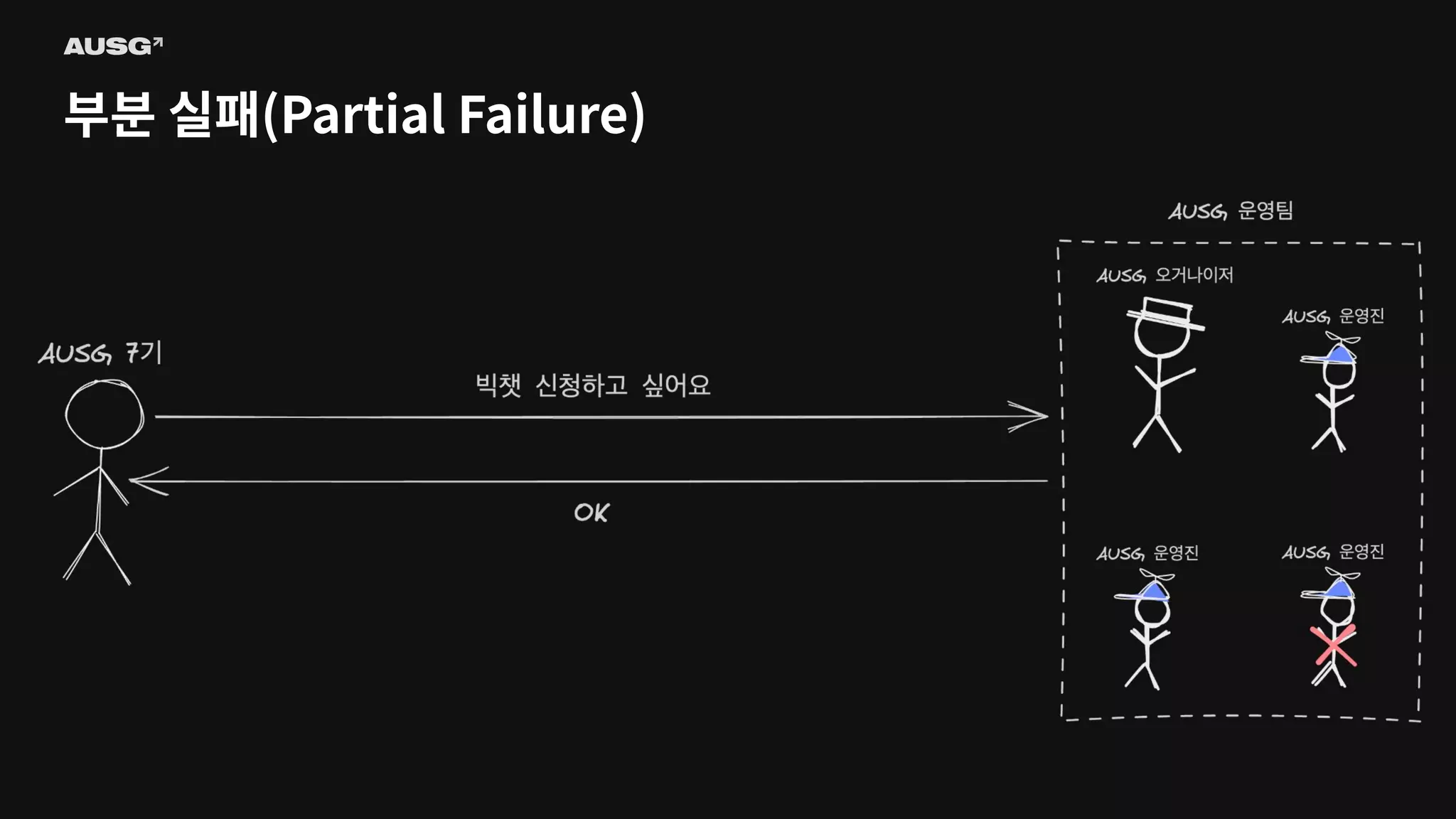
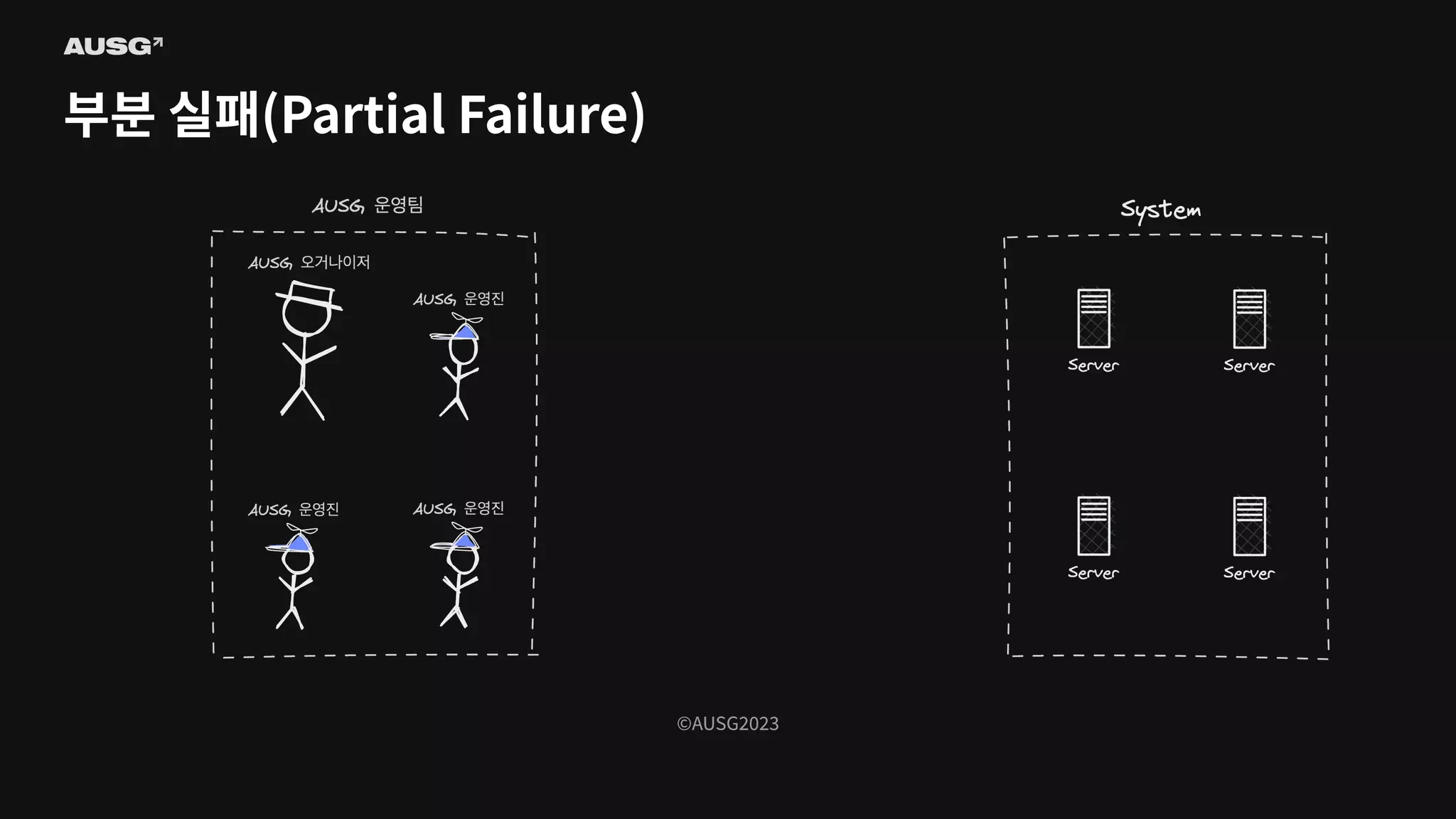
©AUSG2023 부분 실패(Partial Failure)
12.
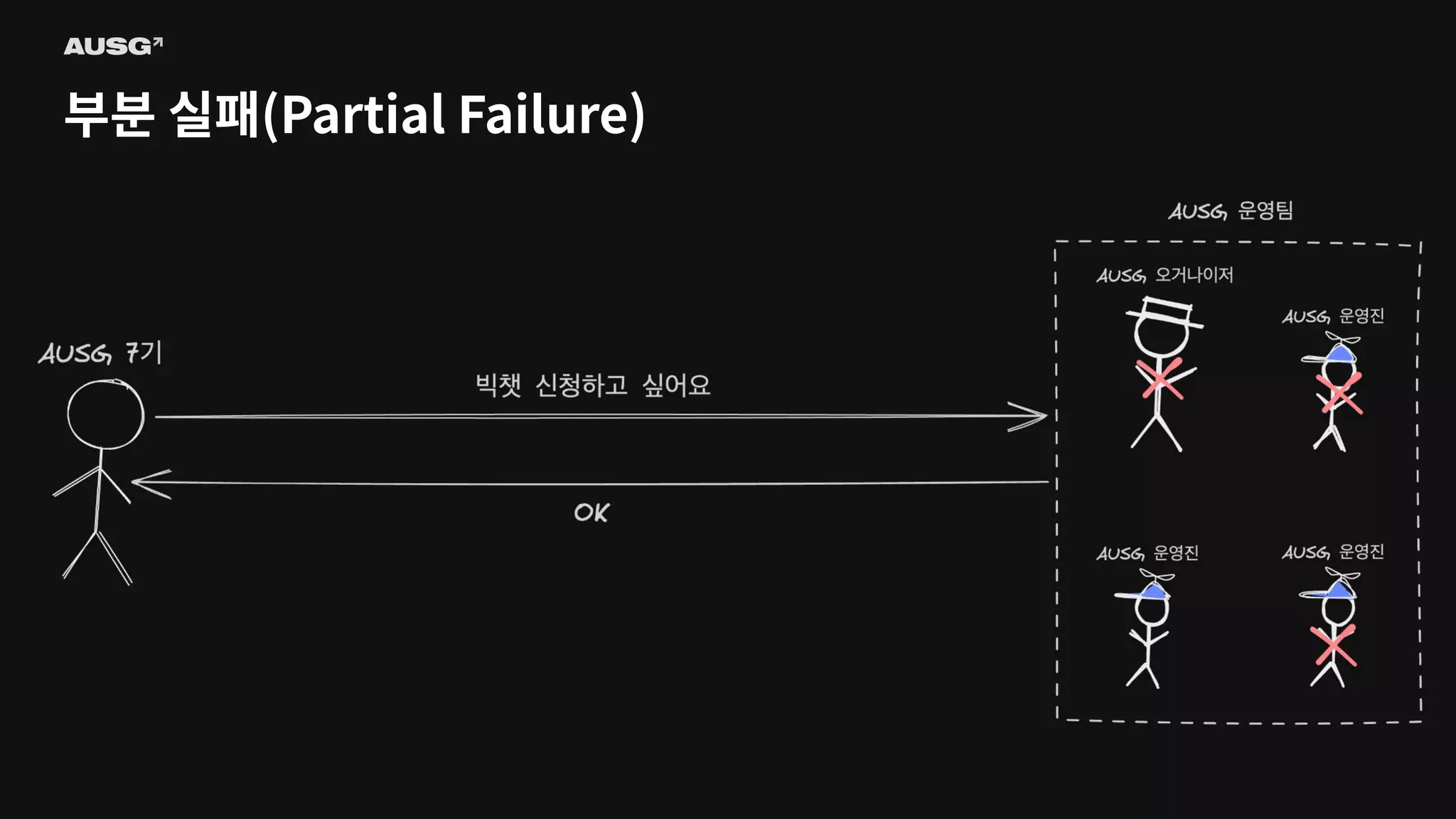
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure) In
a distributed system, there will always be systems that are broken while others function normally. It is known as a partial failure geeksforgeeks
13.
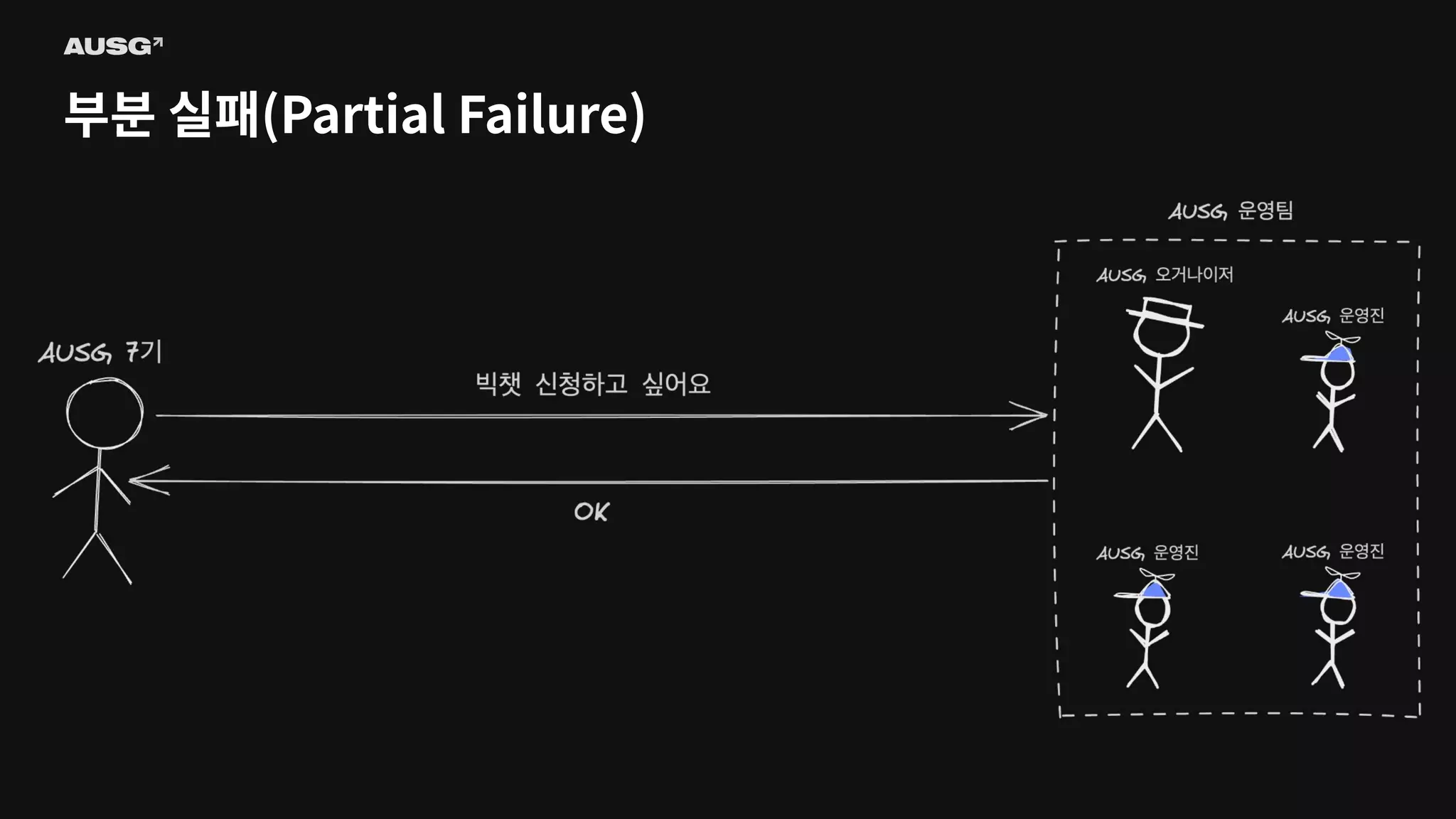
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure) 분산
시스템에선 일부 시스템에 장애가 생기더라도 나머지 시스템이 정상 작동한다면 분산 시스템은 정상적으로 작동합니다. 이를 부분 실패(Partial Failure)라고 부릅니다.
14.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
15.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
16.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
17.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
18.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
19.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
20.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
21.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
22.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
23.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
24.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
25.
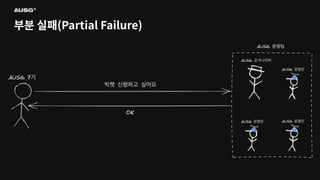
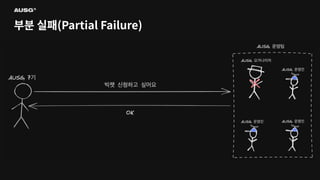
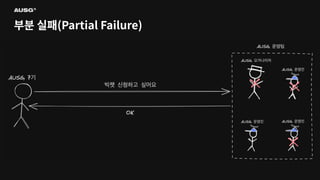
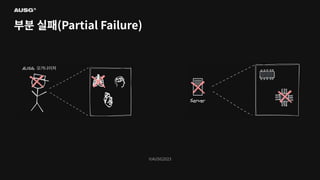
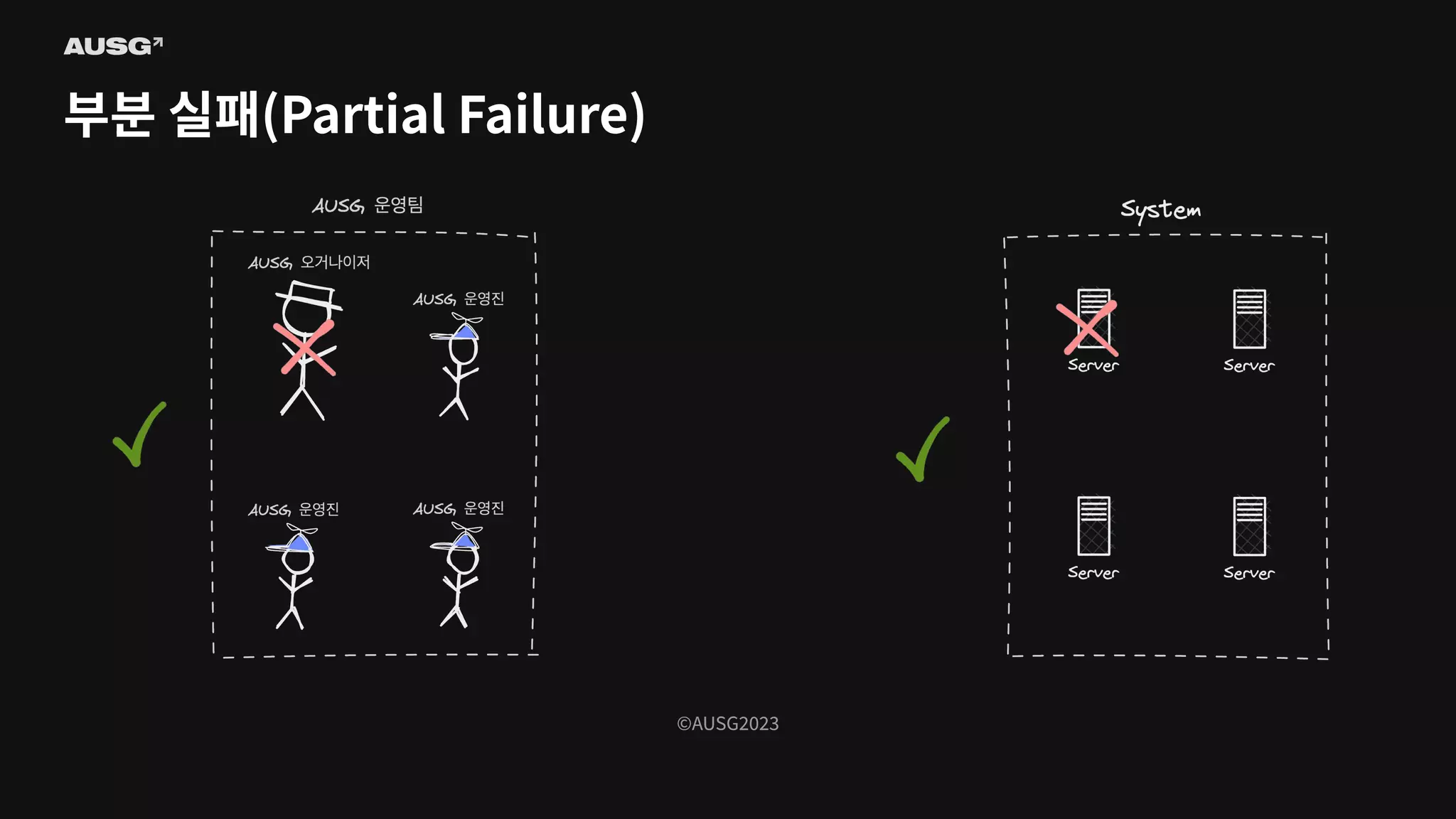
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure) 분산
시스템에선 일부 시스템에 장애가 생기더라도 나머지 시스템이 정상 작동한다면 분산 시스템은 정상적으로 작동합니다. 이를 부분 실패(Partial Failure)라고 부릅니다.
26.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
27.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
28.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
29.
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure)
30.
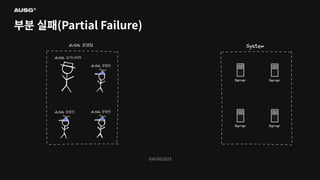
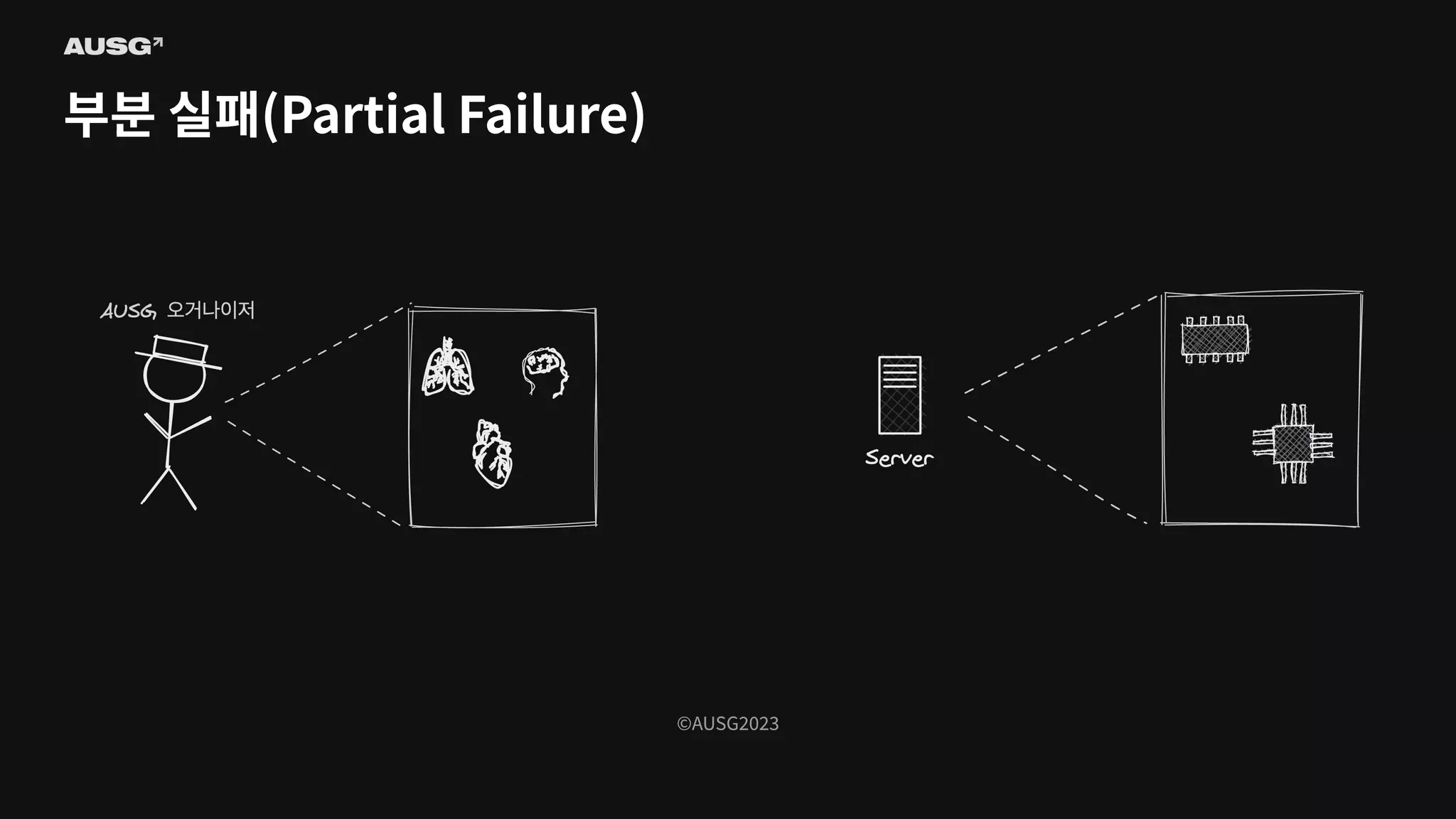
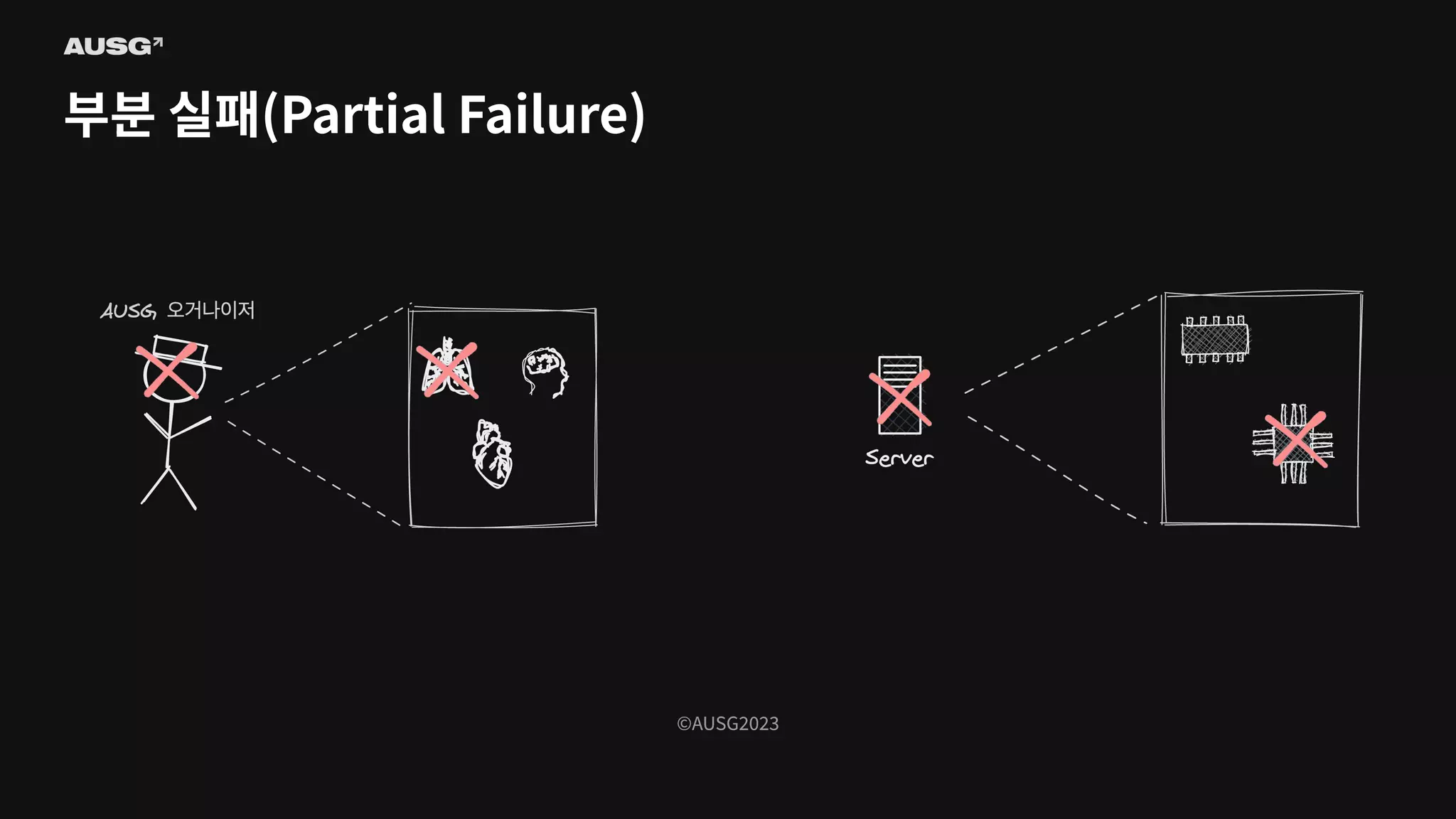
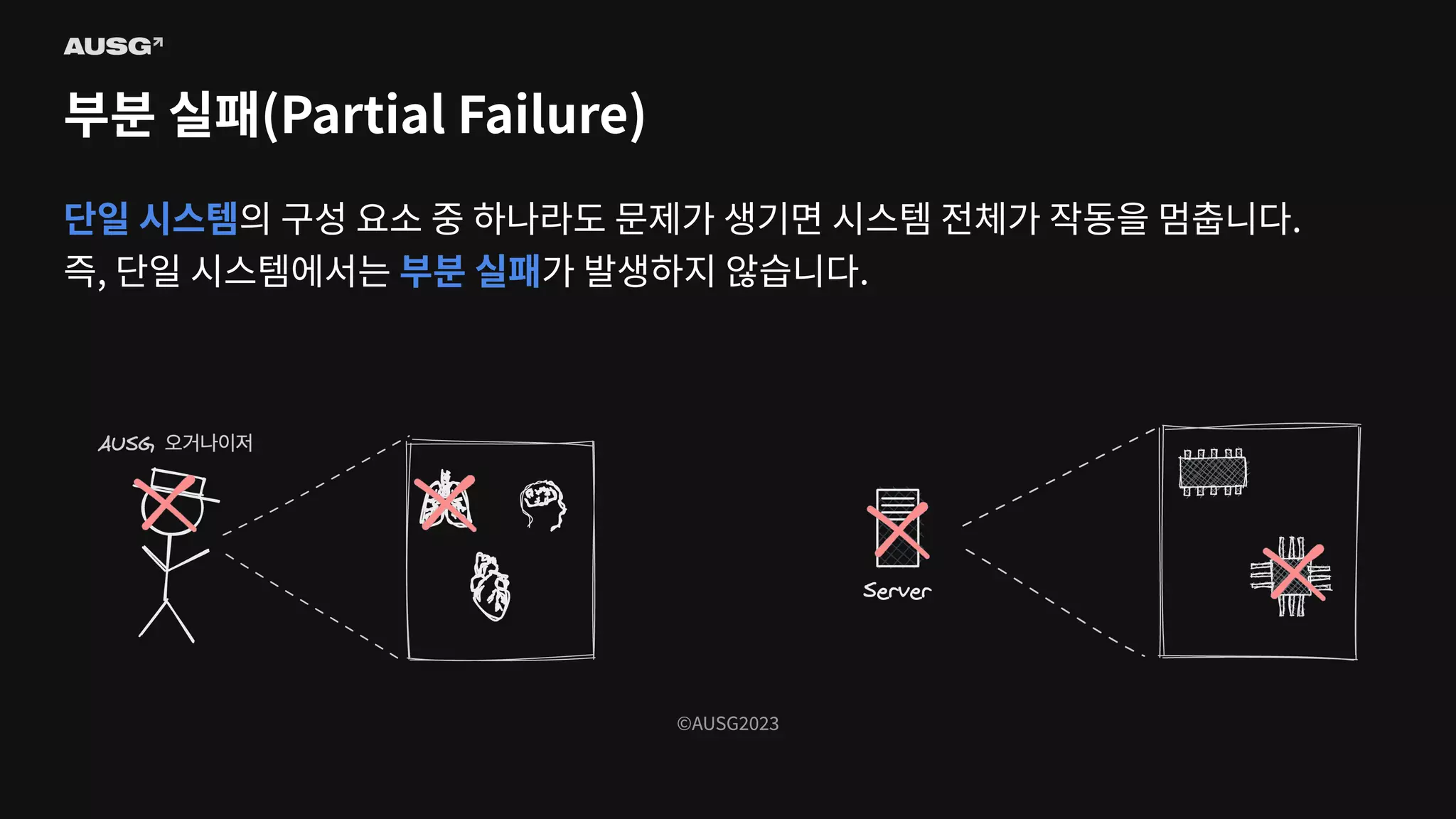
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure) 단일
시스템의 구성 요소 중 하나라도 문제가 생기면 시스템 전체가 작동을 멈춥니다. 즉, 단일 시스템에서는 부분 실패가 발생하지 않습니다.
31.
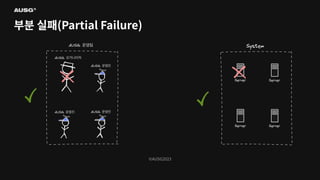
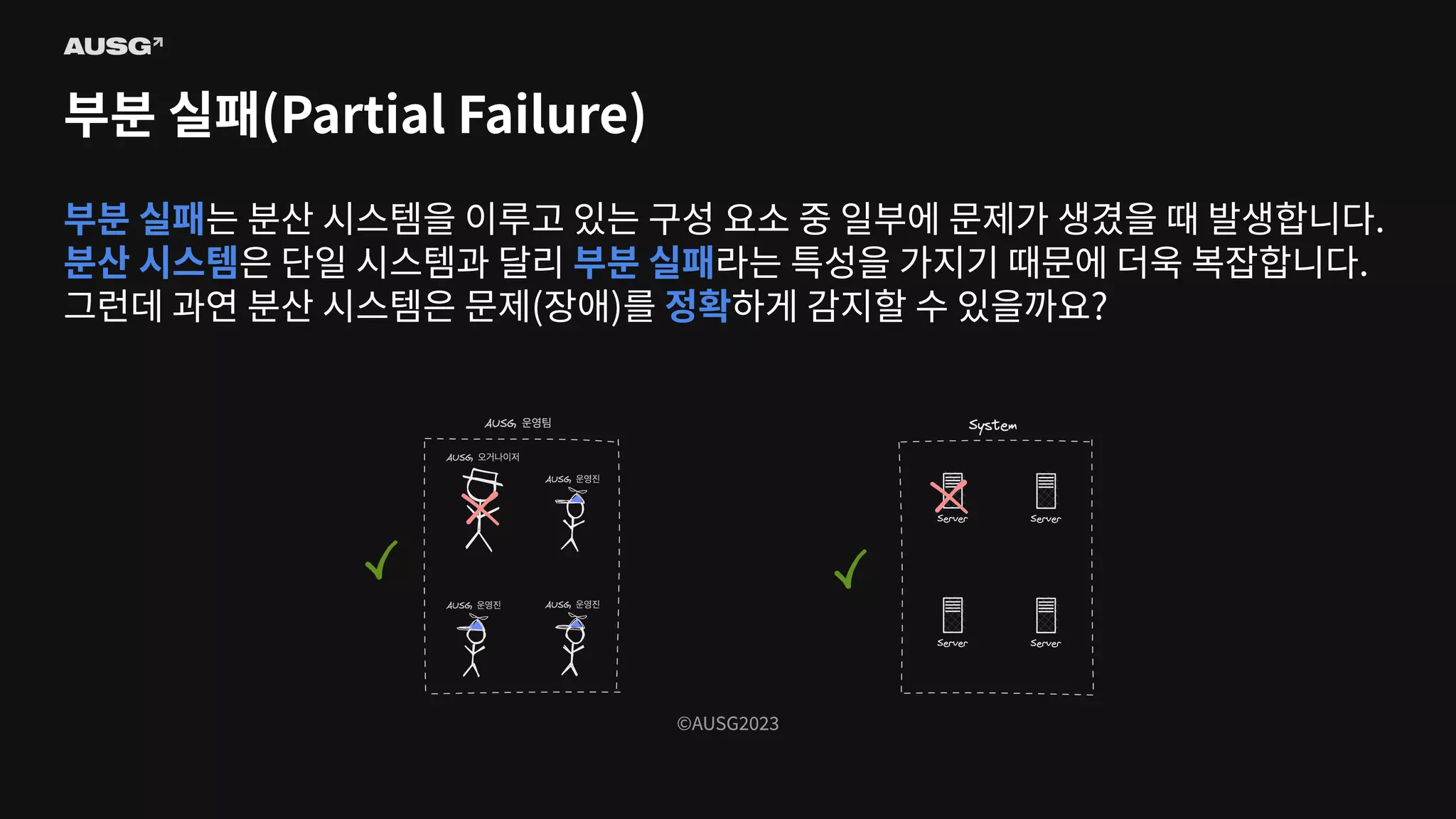
©AUSG2023 ©AUSG2023 부분 실패(Partial Failure) 부분
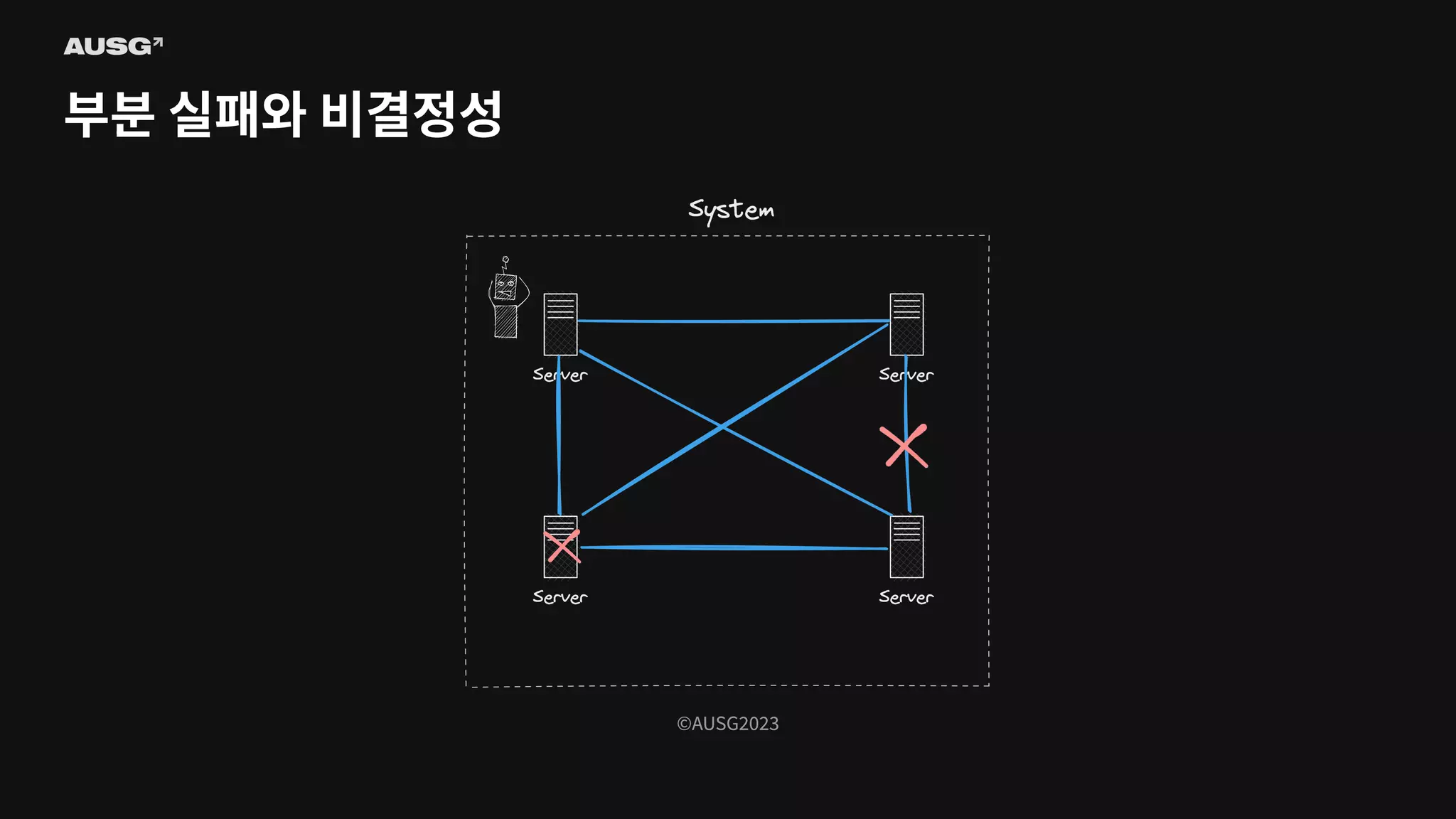
실패는 분산 시스템을 이루고 있는 구성 요소 중 일부에 문제가 생겼을 때 발생합니다. 분산 시스템은 단일 시스템과 달리 부분 실패라는 특성을 가지기 때문에 더욱 복잡합니다. 그런데 과연 분산 시스템은 문제(장애)를 정확하게 감지할 수 있을까요?
32.
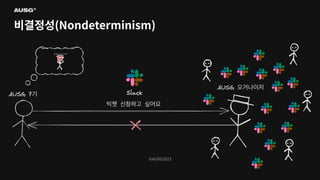
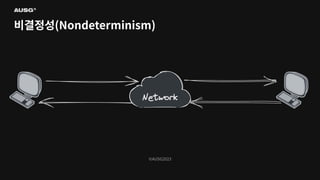
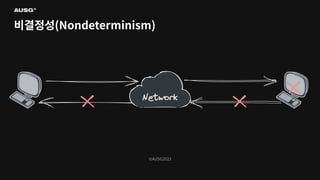
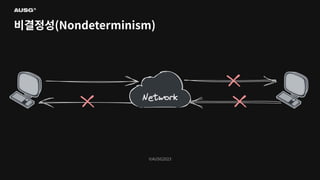
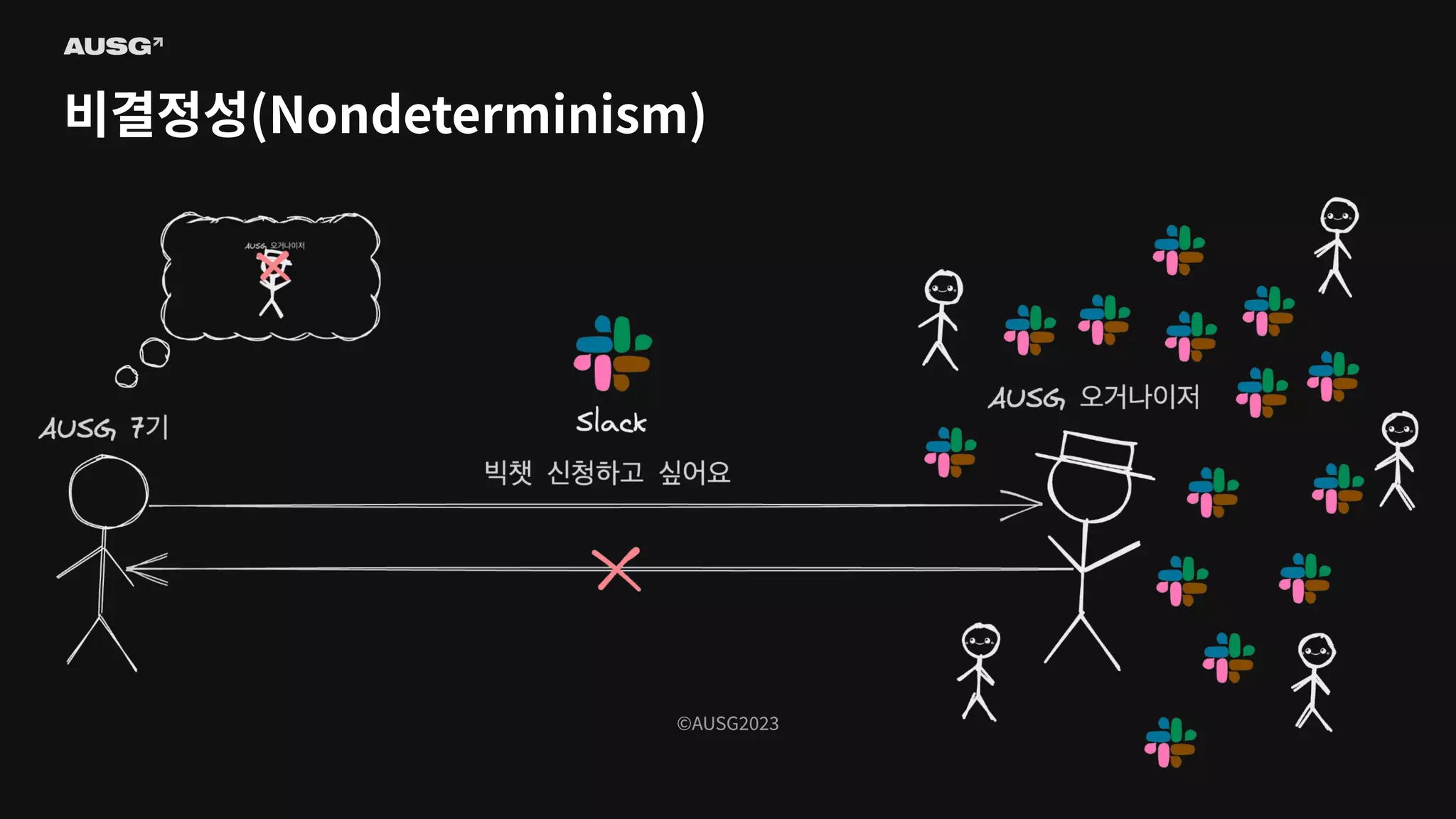
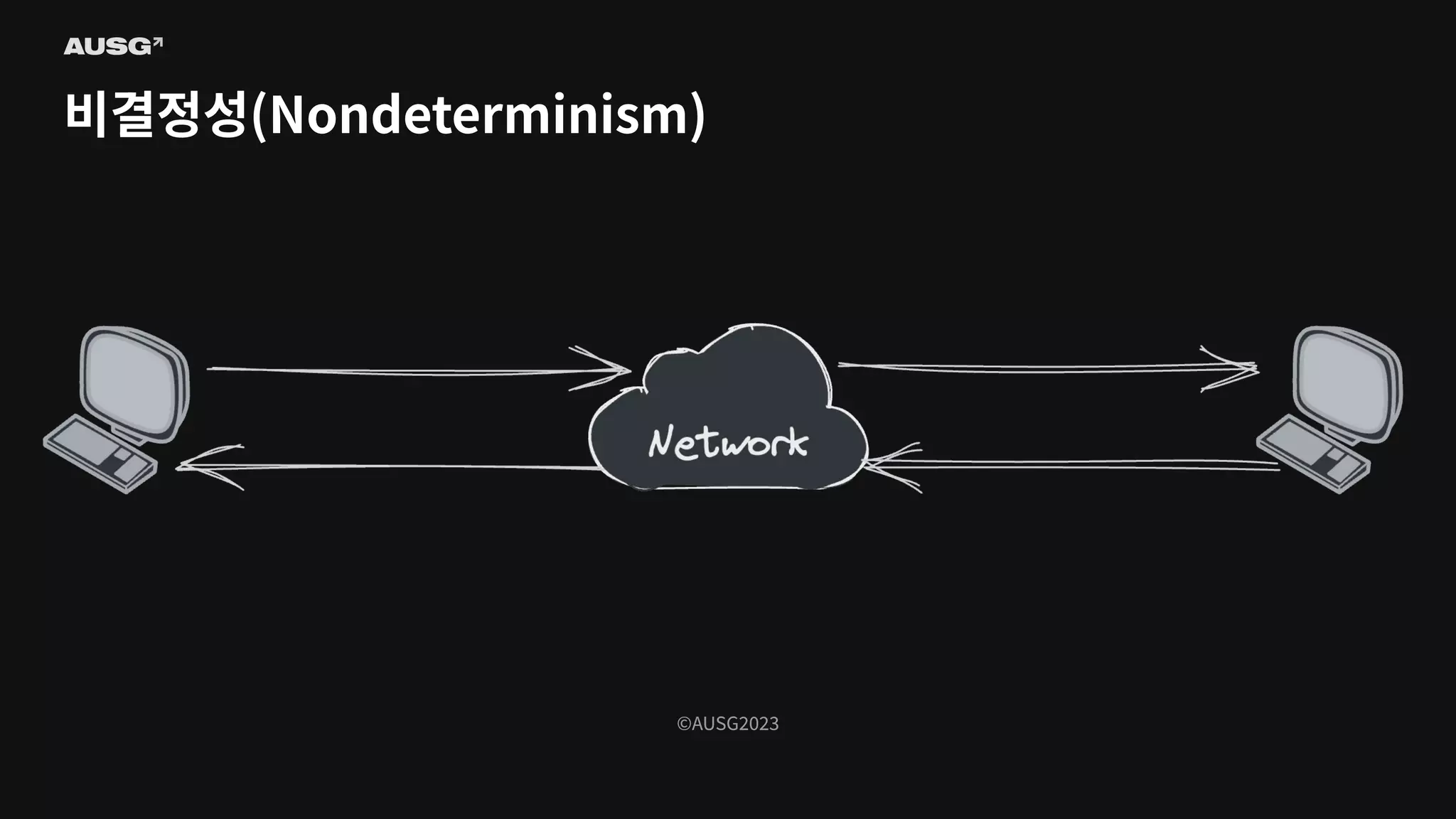
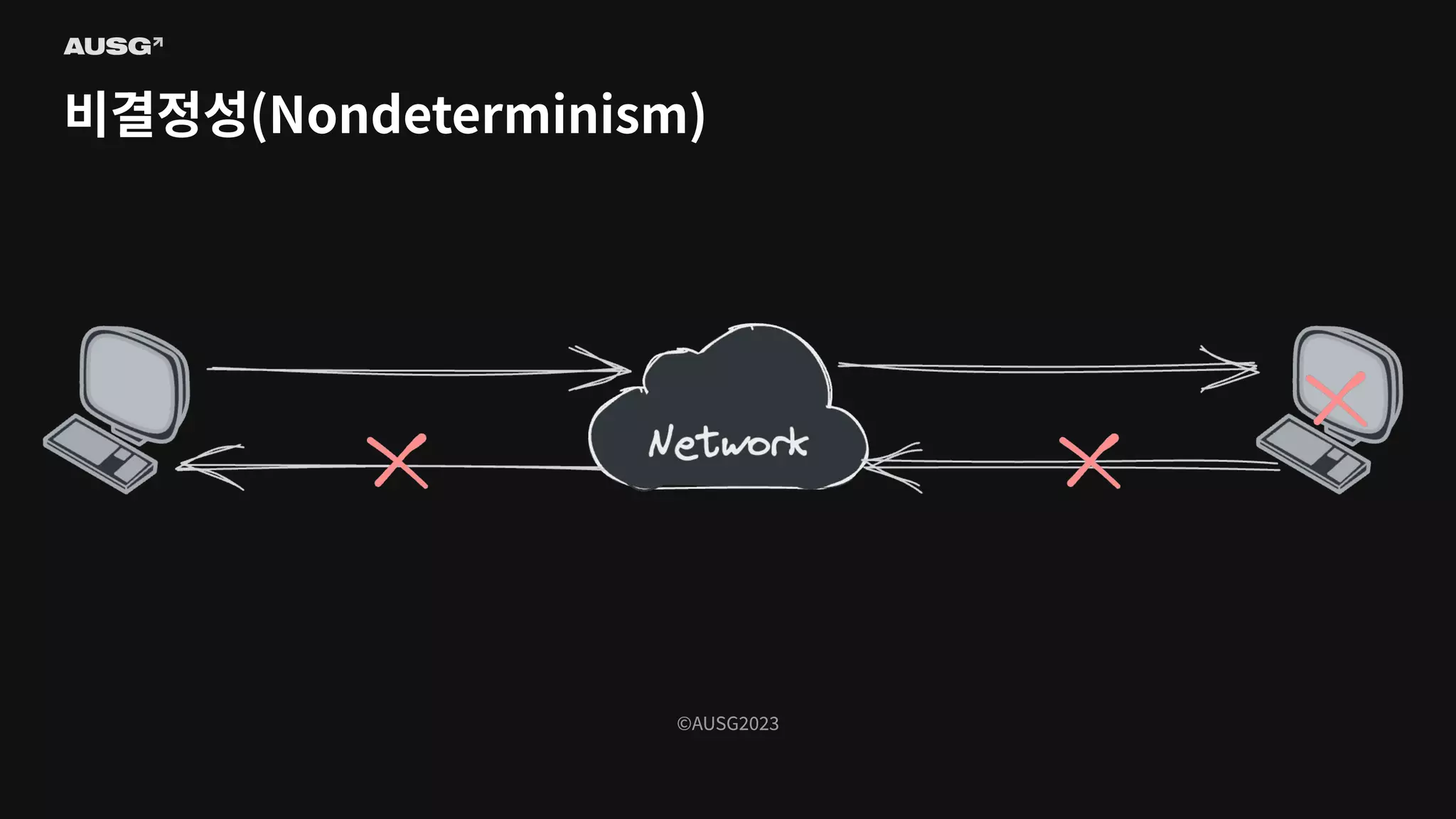
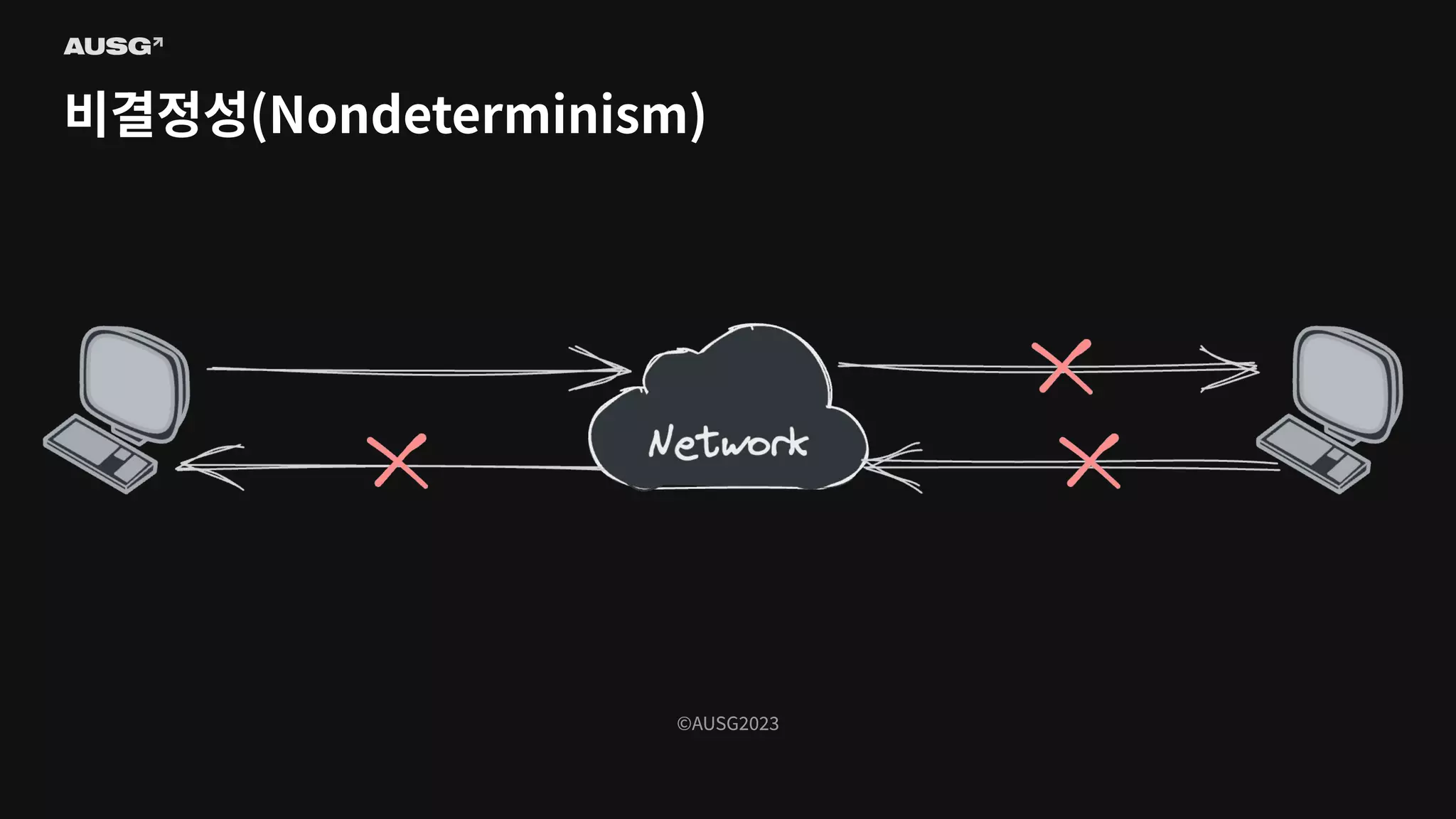
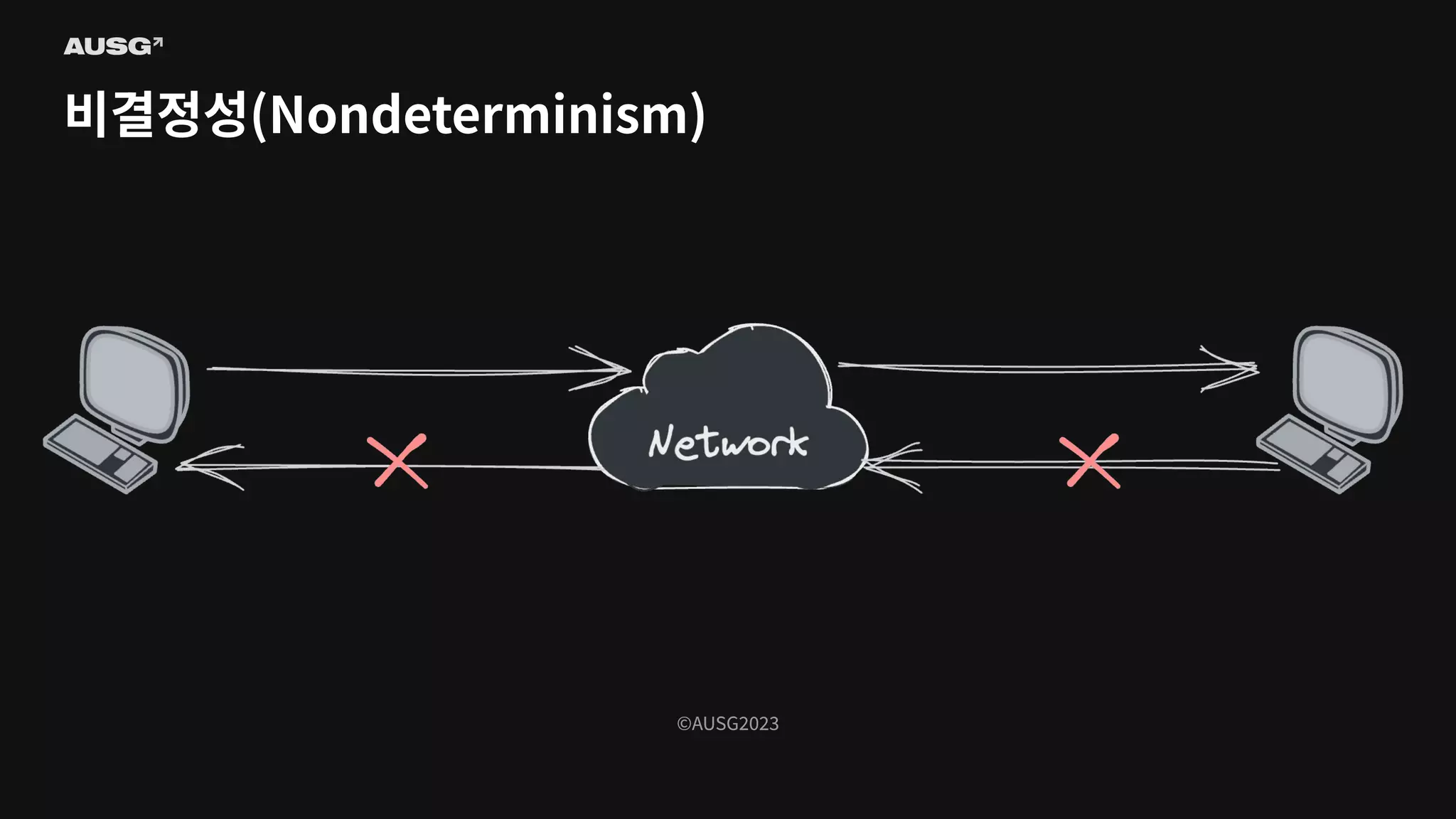
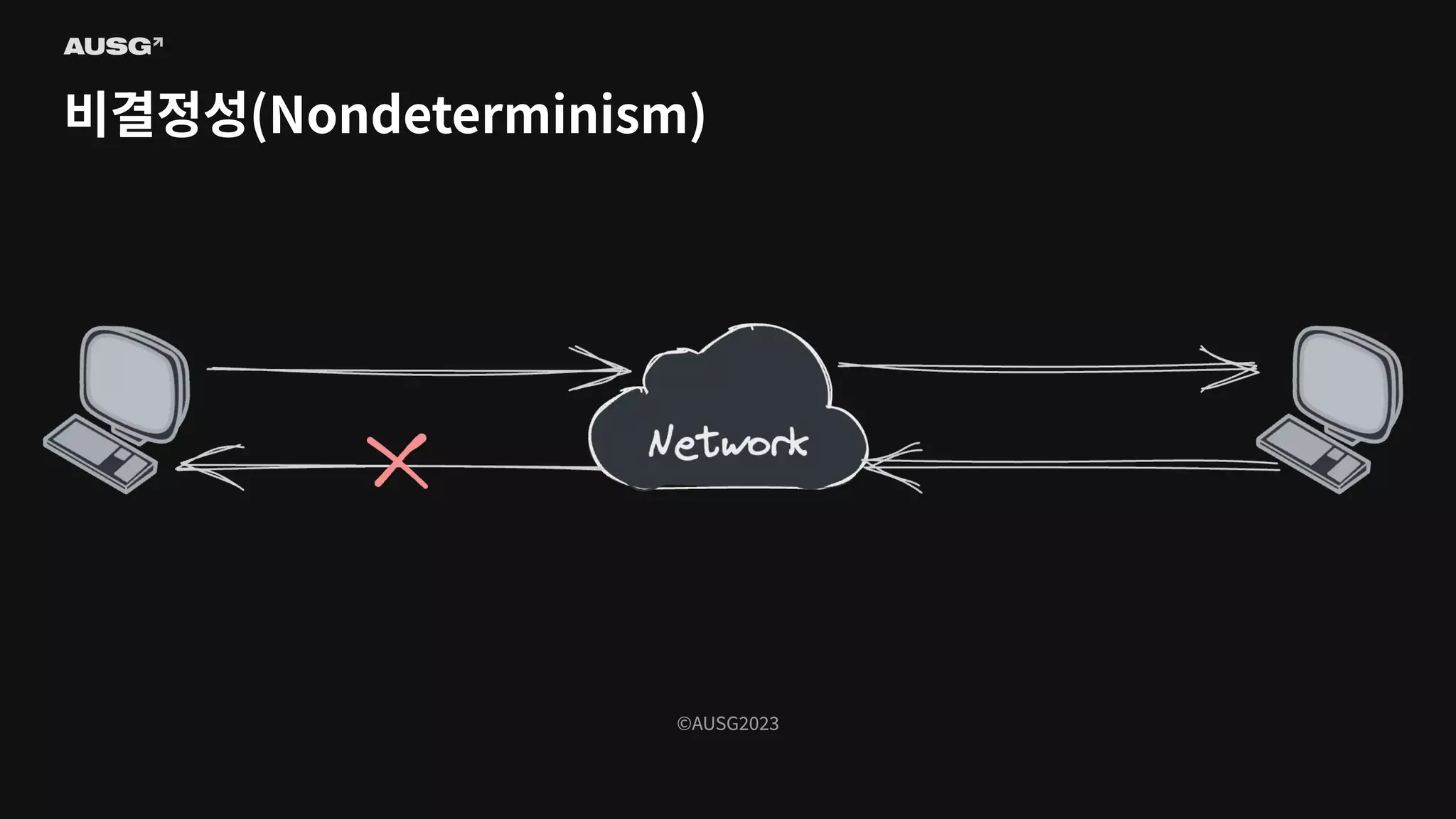
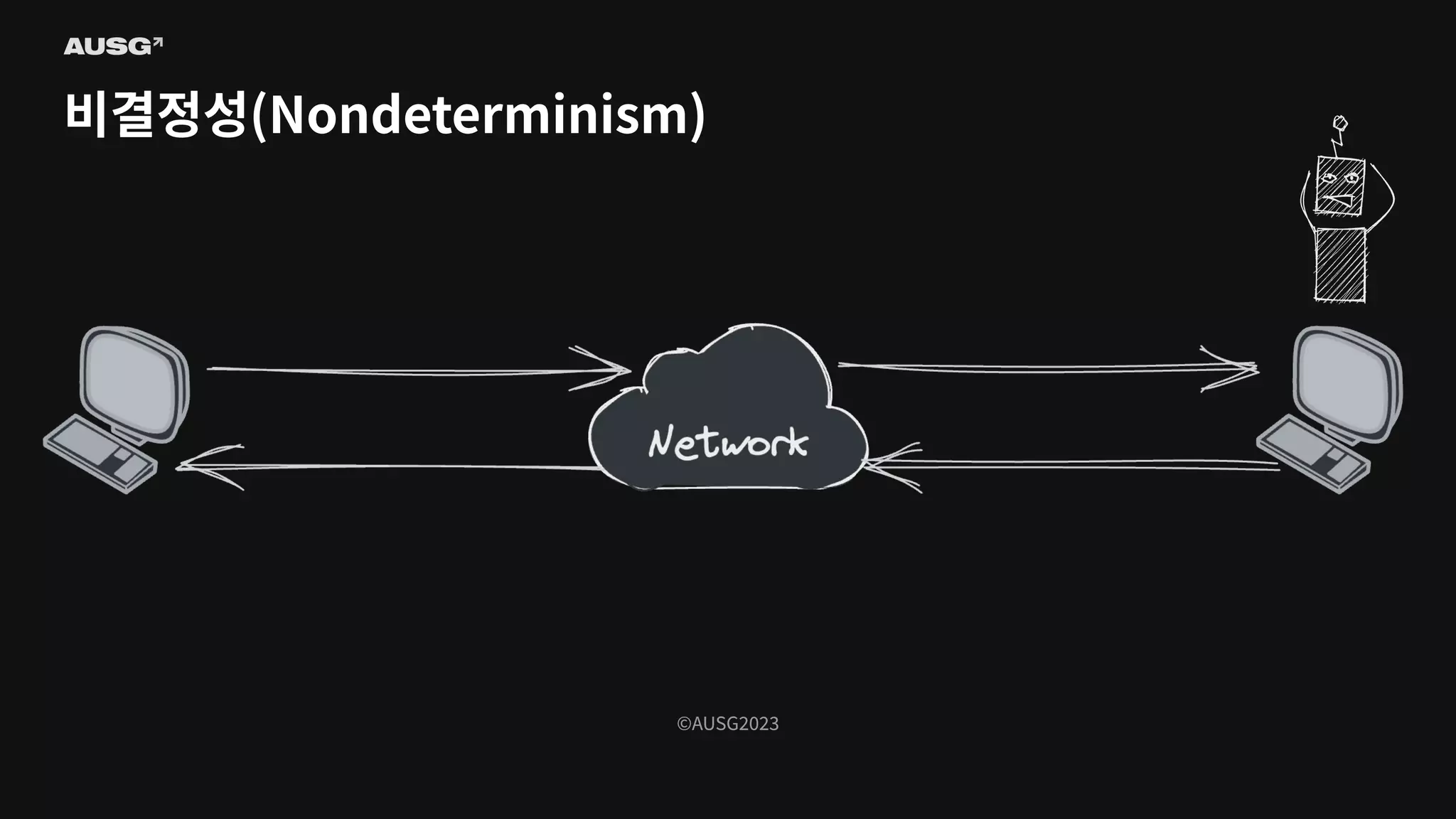
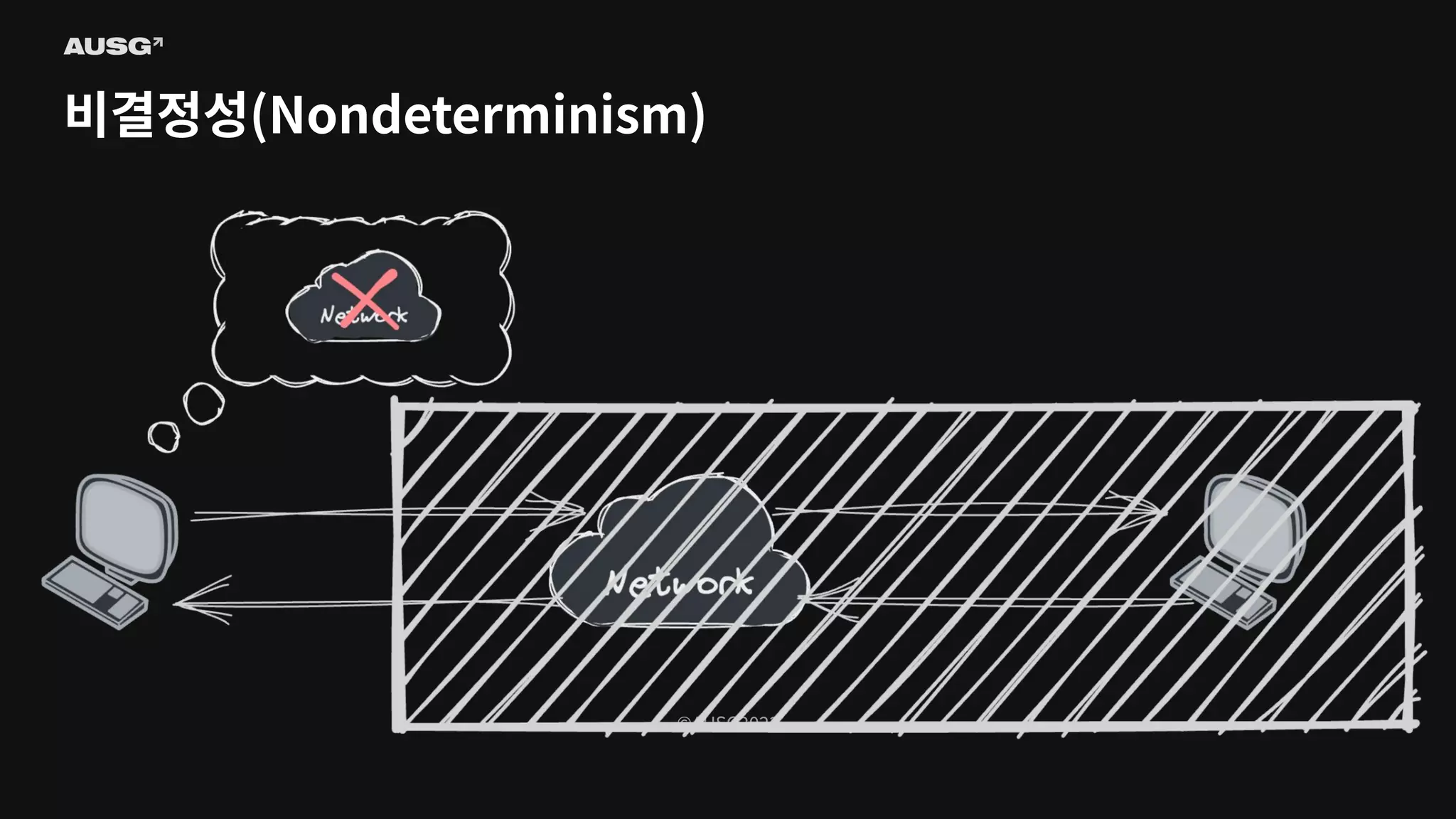
©AUSG2023 비결정성(Nondeterminism)
33.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
34.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
35.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
36.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
37.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
38.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
39.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
40.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
41.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
42.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
43.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
44.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
45.
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism)
46.
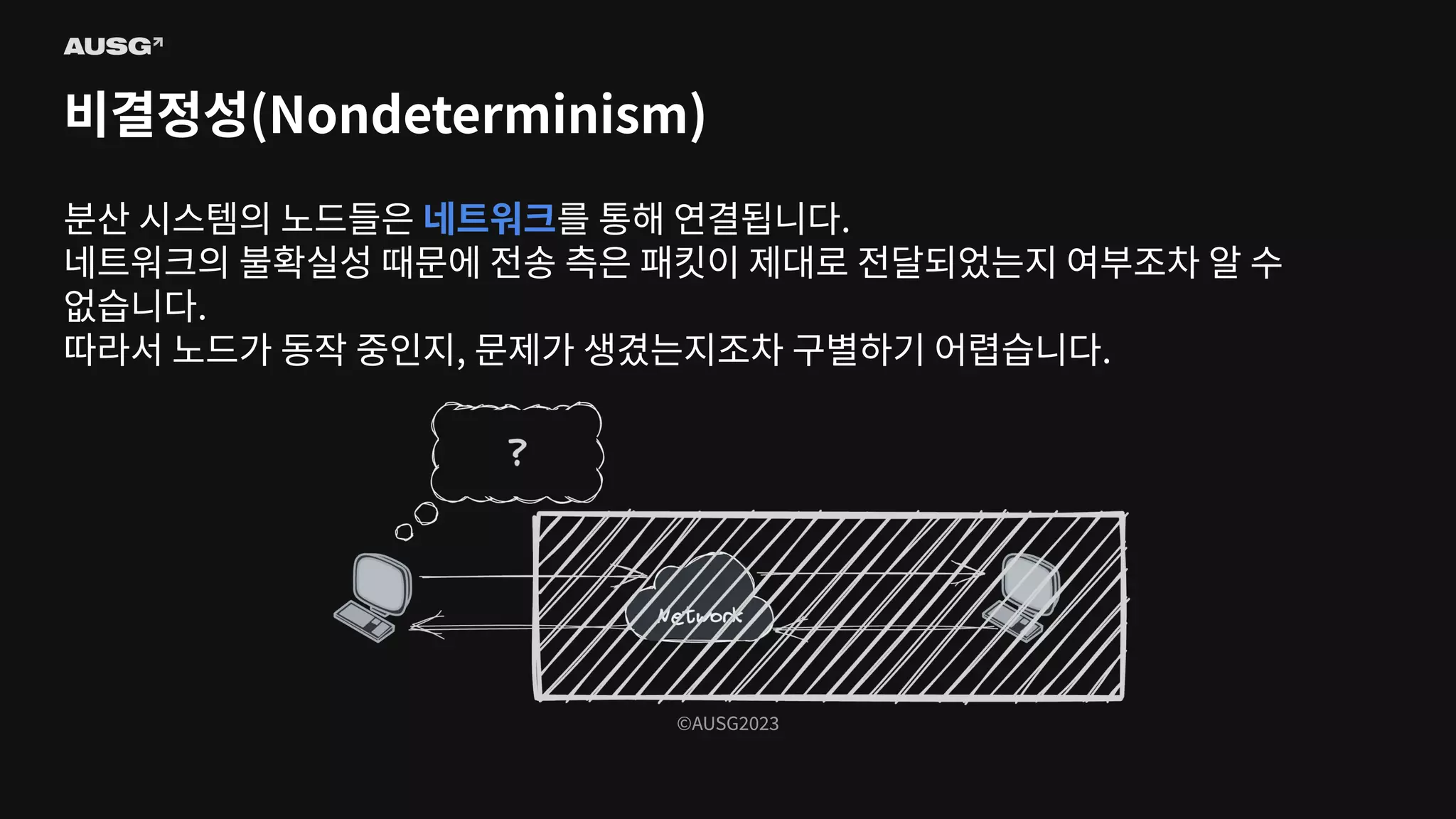
©AUSG2023 ©AUSG2023 비결정성(Nondeterminism) 분산 시스템의 노드들은
네트워크를 통해 연결됩니다. 네트워크의 불확실성 때문에 전송 측은 패킷이 제대로 전달되었는지 여부조차 알 수 없습니다. 따라서 노드가 동작 중인지, 문제가 생겼는지조차 구별하기 어렵습니다.
47.
©AUSG2023 ©AUSG2023 부분 실패와 비결정성
48.
©AUSG2023 ©AUSG2023 장애 감지 - Ping -
Heartbeat - Heartbeat outsourcing - φ-accrual detection
49.
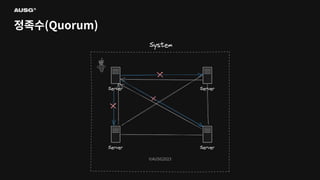
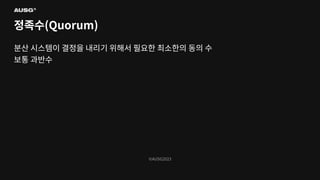
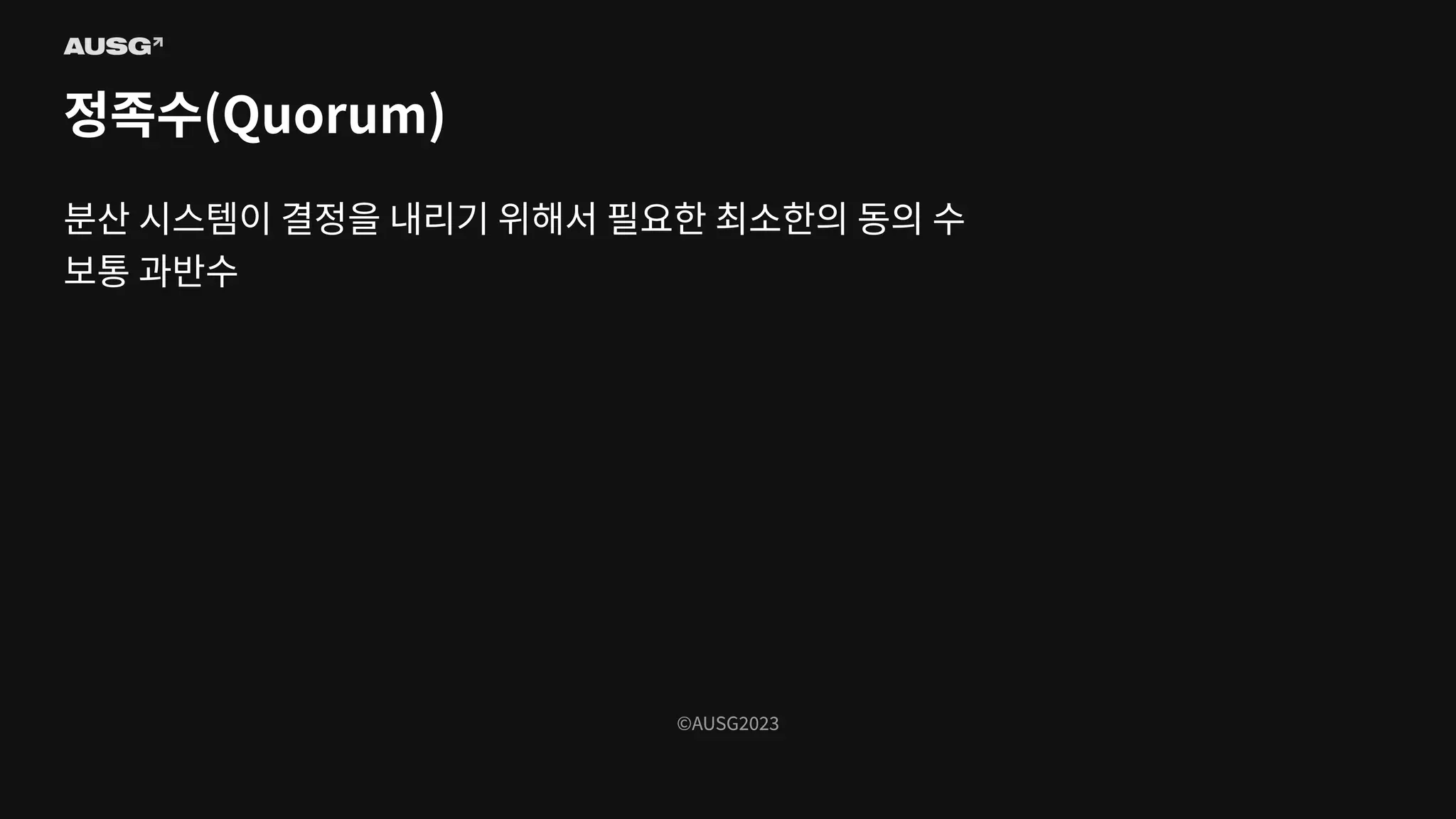
©AUSG2023 ©AUSG2023 정족수(Quorum)
50.
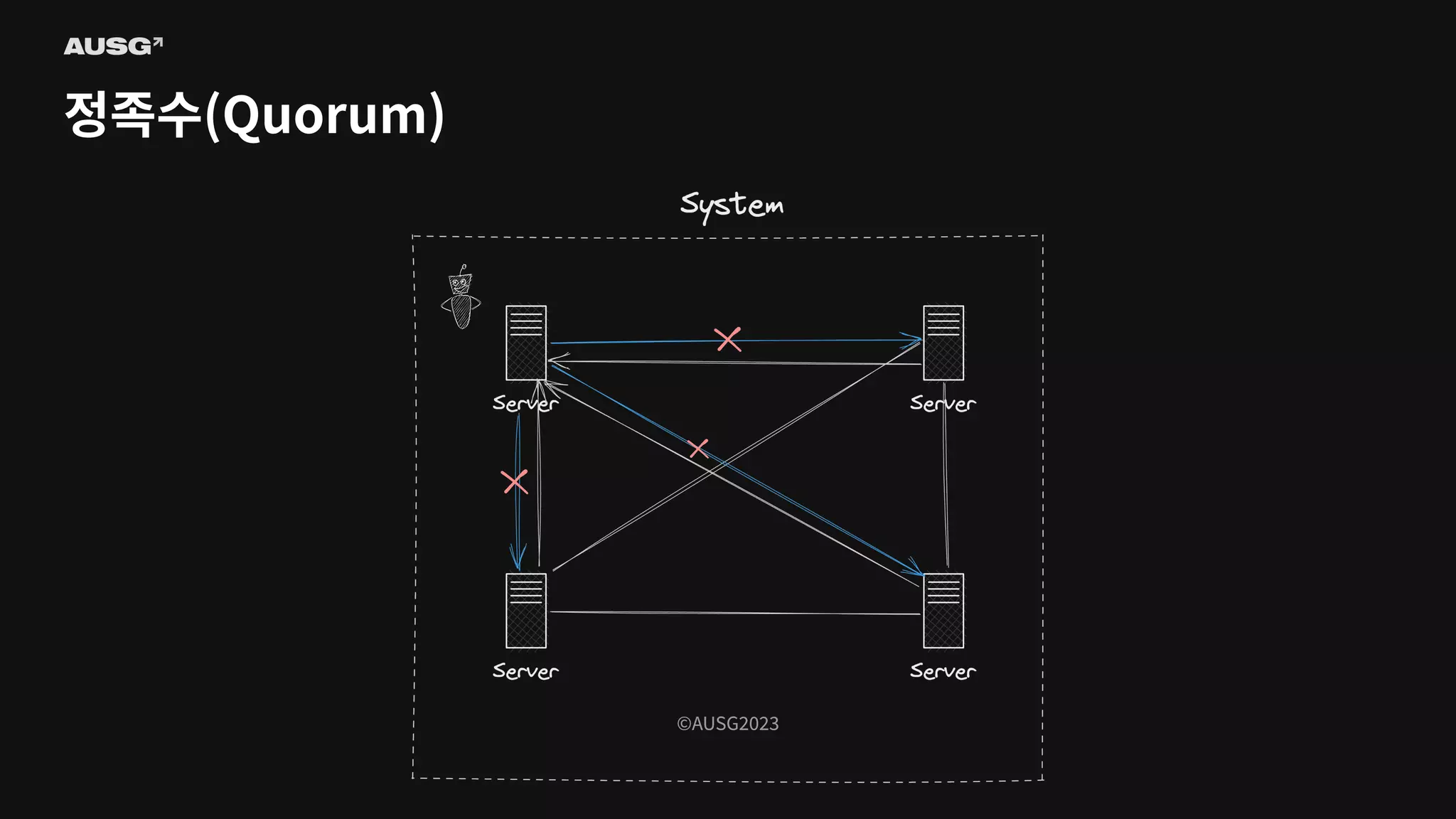
©AUSG2023 ©AUSG2023 정족수(Quorum) 분산 시스템에서 각
노드의 판단은 틀릴 수 있습니다. 따라서 분산 알고리즘에서 어떠한 결정을 내릴 때는 투표에 의존합니다.
51.
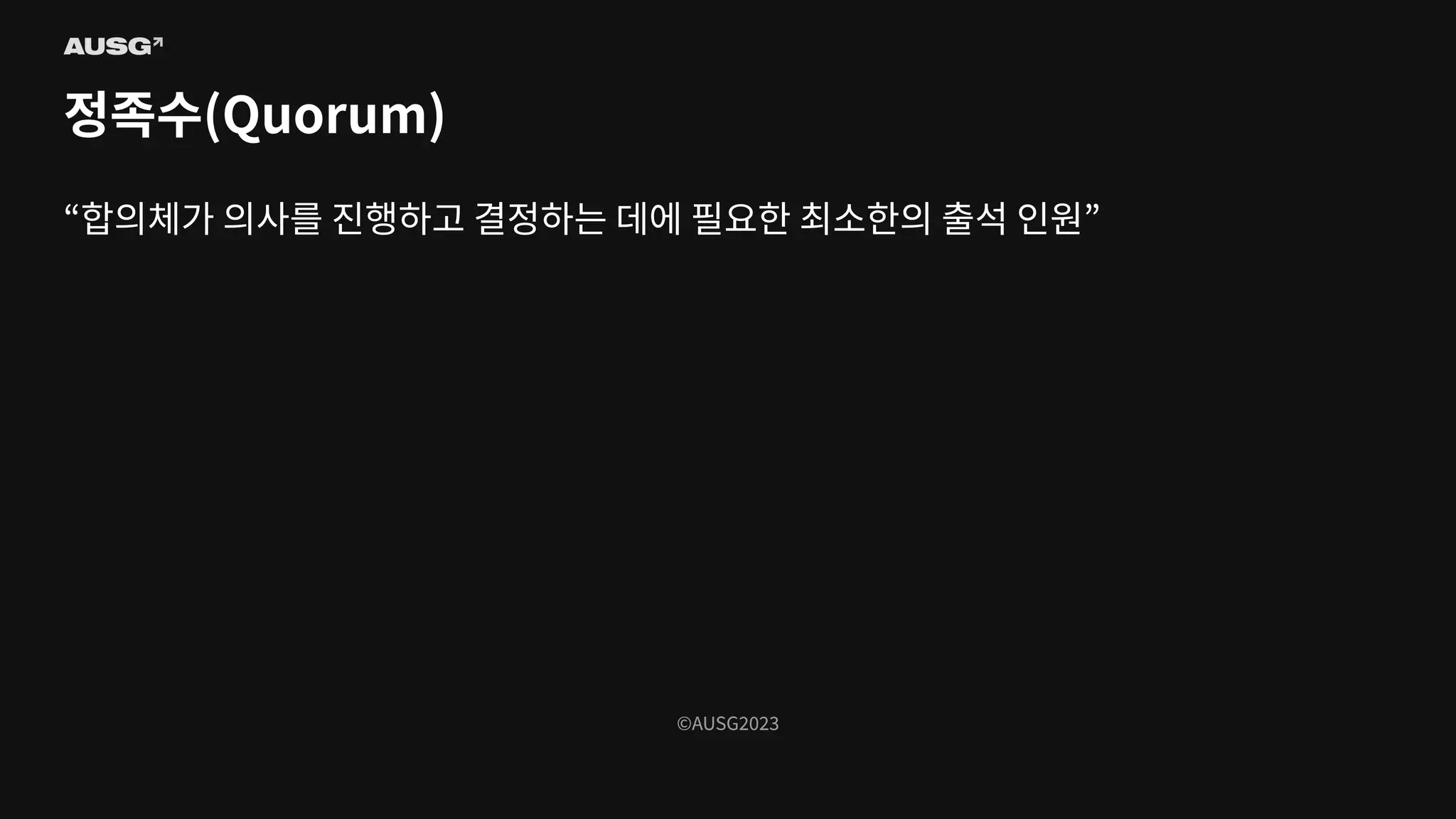
©AUSG2023 ©AUSG2023 정족수(Quorum) “합의체가 의사를 진행하고
결정하는 데에 필요한 최소한의 출석 인원”
52.
©AUSG2023 ©AUSG2023 정족수(Quorum) 분산 시스템이 결정을
내리기 위해서 필요한 최소한의 동의 수 보통 과반수
53.
©AUSG2023 ©AUSG2023 분산 시스템의 특성 -
부분 실패(Partial Failure) - 비결정성(Nondeterminism)
54.
©AUSG2023 ©AUSG2023 분산 시스템의 특성 -
부분 실패(Partial Failure) - 비결정성(Nondeterminism) - 신뢰성 없는 시계 - 비잔틴 장애 허용(BFT; Byzantine Fault Tolerance) - 동기 모델 - 부분 동기 모델 - 비동기 모델 - 장애 감지 - φ Accrual Failure Detector
55.
©AUSG2023 합의(Consensus)
56.
©AUSG2023 왜 분산 시스템에서
합의가 어려운가?
57.
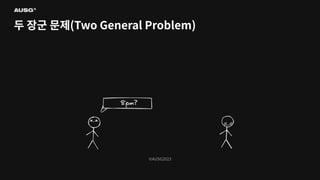
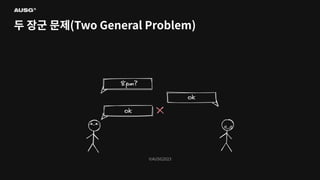
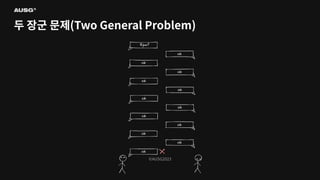
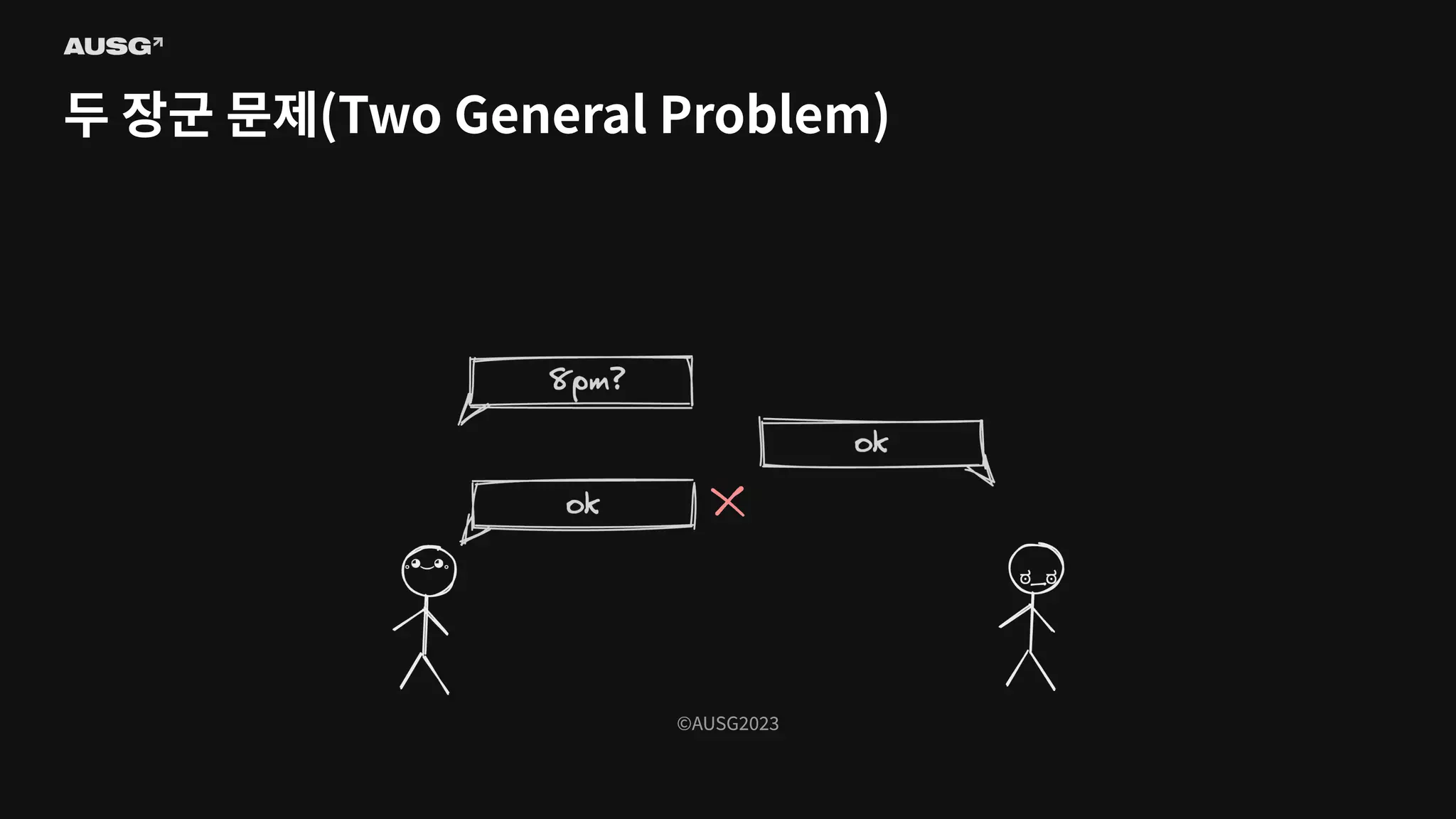
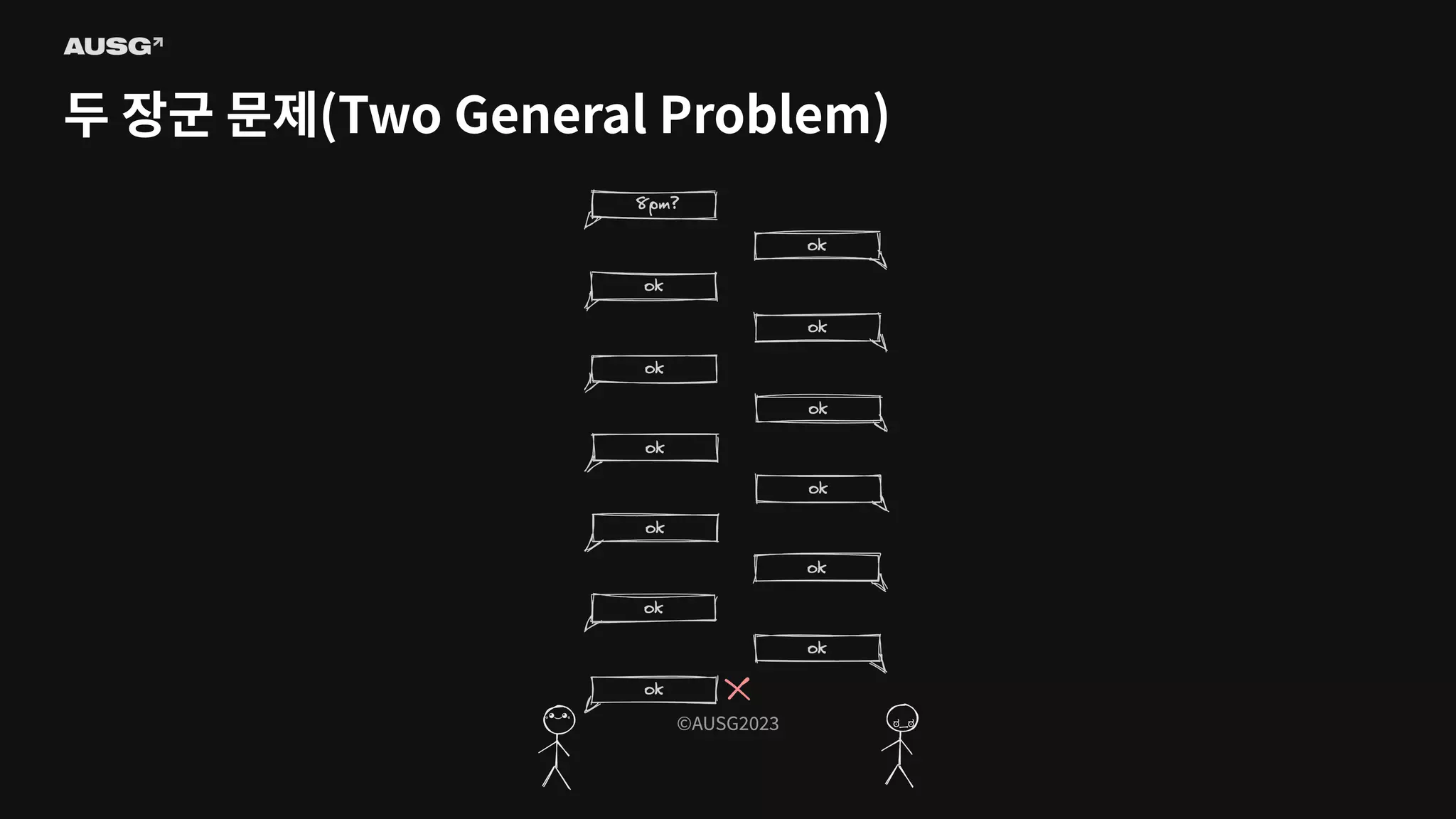
©AUSG2023 ©AUSG2023 두 장군 문제(Two
General Problem)
58.
©AUSG2023 ©AUSG2023 두 장군 문제(Two
General Problem)
59.
©AUSG2023 ©AUSG2023 두 장군 문제(Two
General Problem)
60.
©AUSG2023 ©AUSG2023 두 장군 문제(Two
General Problem)
61.
©AUSG2023 ©AUSG2023 두 장군 문제(Two
General Problem)
62.
©AUSG2023 ©AUSG2023 두 장군 문제(Two
General Problem)
63.
©AUSG2023 ©AUSG2023 두 장군 문제(Two
General Problem) 신뢰할 수 없는 두 네트워크 간의 합의는 불가능하다
64.
©AUSG2023 ©AUSG2023 두 장군 문제(Two
General Problem) https://www.youtube.com/watch?v=s8Wbt0b8bwY https://www.youtube.com/watch?v=IP-rGJKSZ3s
65.
©AUSG2023 ©AUSG2023 비잔틴 장군 문제(Byzantine
Generals Problem)
66.
©AUSG2023 ©AUSG2023 FLP Impossibility - 비동기
네트워크 모델(asynchronous network model)에서 - 다음 3가지 속성을 모두 만족하는 합의 알고리즘은 불가능하다 - Liveness - Safety - Fault Tolerance
67.
©AUSG2023 ©AUSG2023 FLP Impossibility - 비동기
네트워크 모델(asynchronous network model)에서 - 다음 3가지 속성을 모두 만족하는 합의 알고리즘은 불가능하다 - Liveness - Safety - Fault Tolerance
68.
©AUSG2023 ©AUSG2023 FLP Impossibility - 비동기
네트워크 모델(asynchronous network model)에서 - 다음 3가지 속성을 모두 만족하는 합의 알고리즘은 불가능하다 - Liveness - Safety - Fault Tolerance
69.
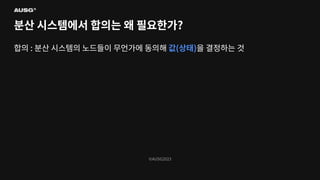
©AUSG2023 분산 시스템에서 합의는
왜 필요한가?
70.
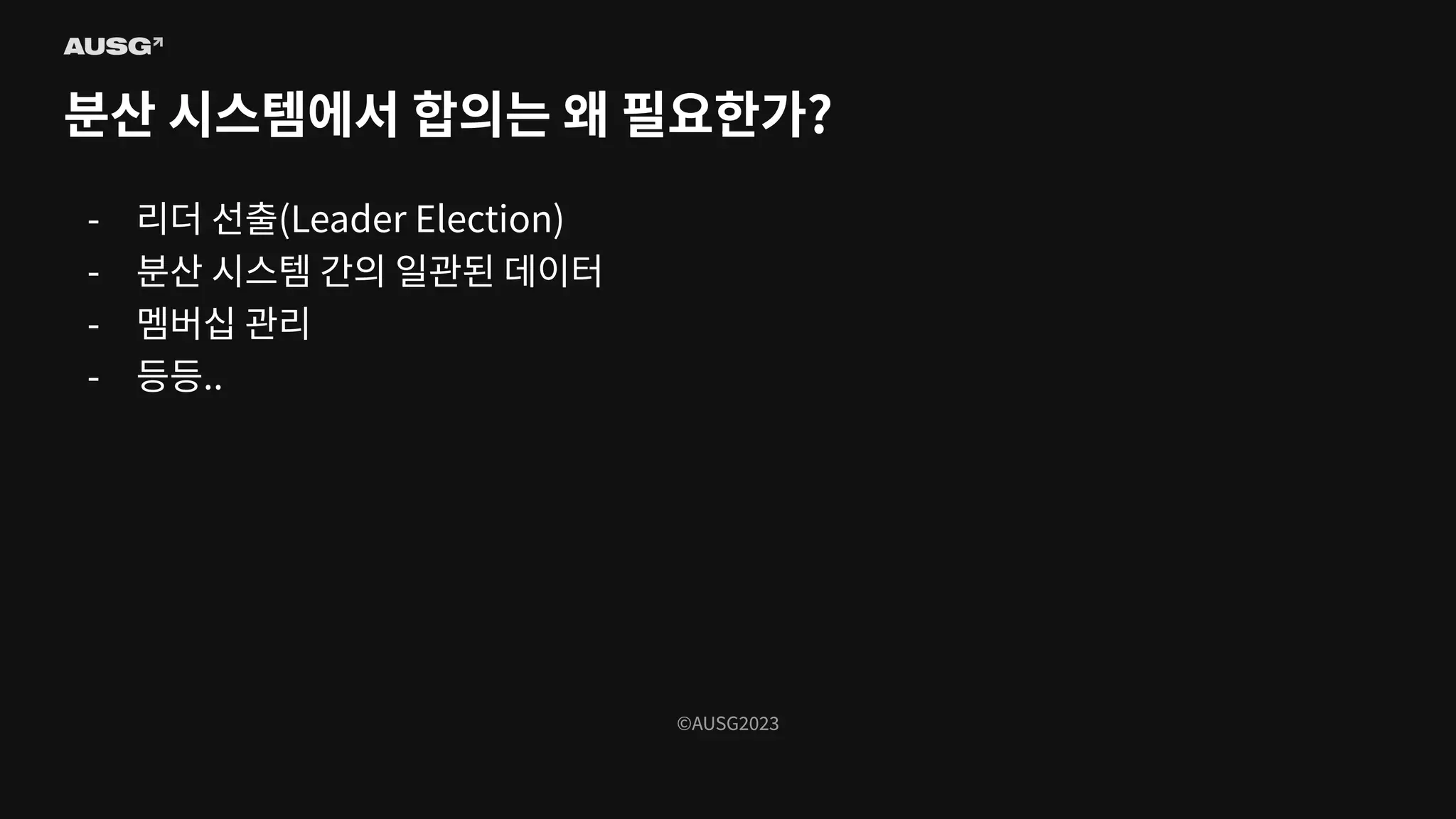
©AUSG2023 ©AUSG2023 분산 시스템에서 합의는
왜 필요한가? - 리더 선출(Leader Election) - 분산 시스템 간의 일관된 데이터 - 멤버십 관리 - 등등..
71.
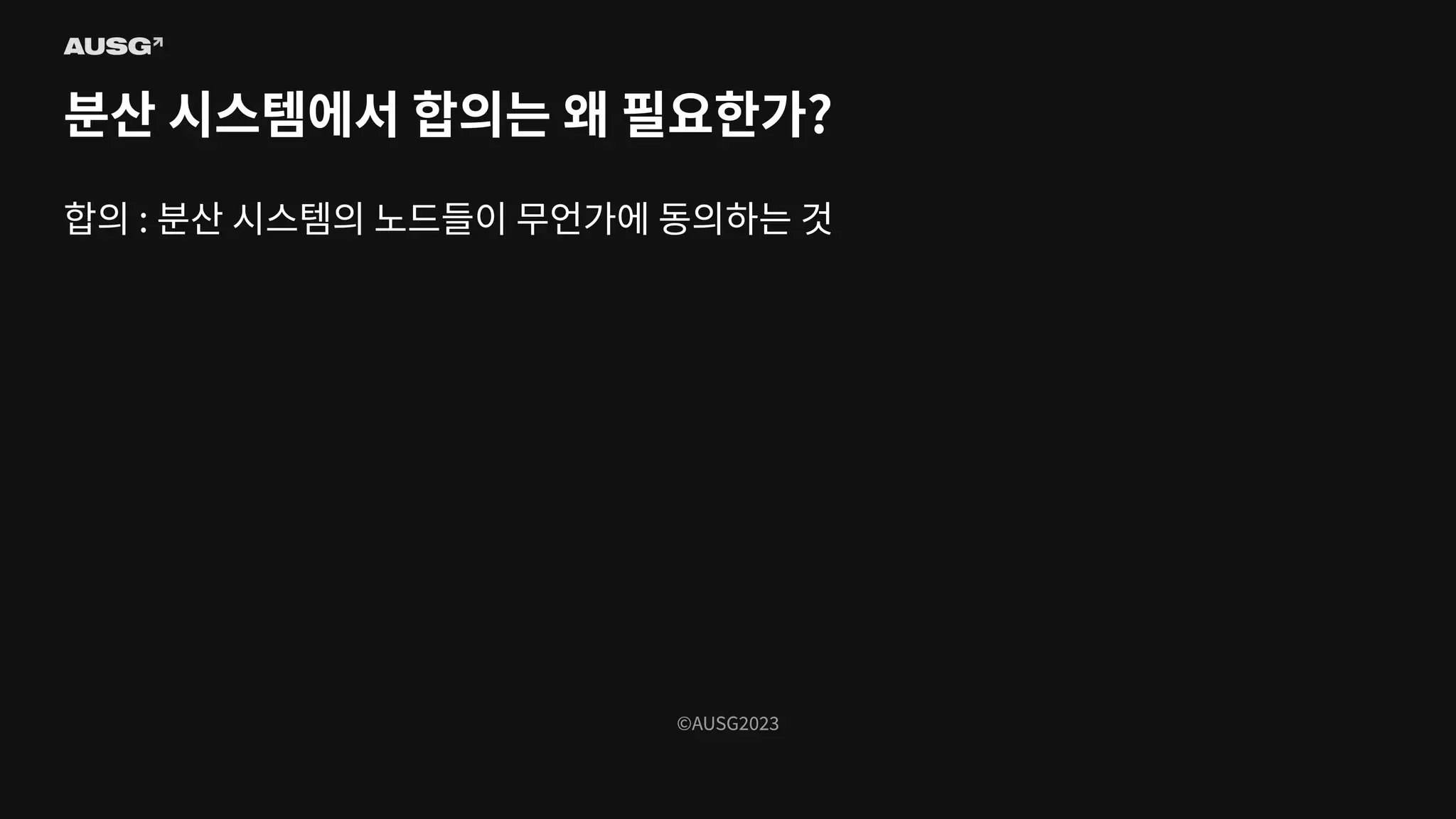
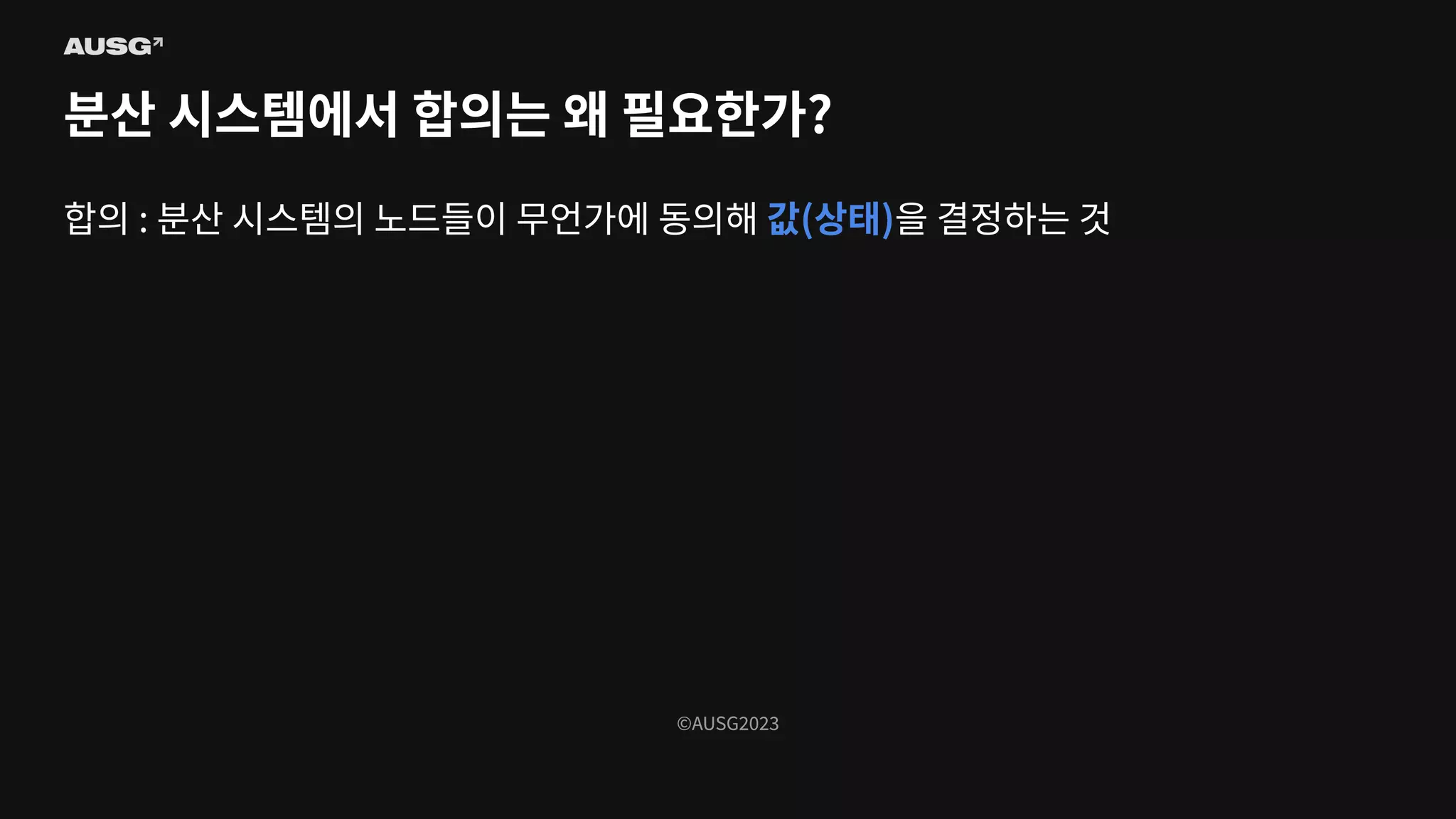
©AUSG2023 ©AUSG2023 분산 시스템에서 합의는
왜 필요한가? 합의 : 분산 시스템의 노드들이 무언가에 동의하는 것
72.
©AUSG2023 ©AUSG2023 분산 시스템에서 합의는
왜 필요한가? 합의 : 분산 시스템의 노드들이 무언가에 동의해 값(상태)을 결정하는 것
73.
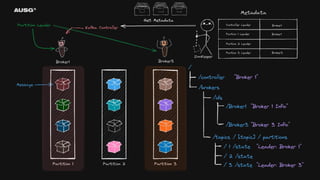
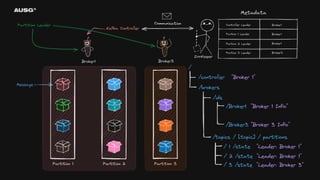
©AUSG2023 ©AUSG2023 분산 시스템에서 합의는
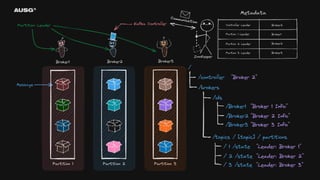
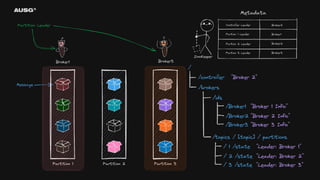
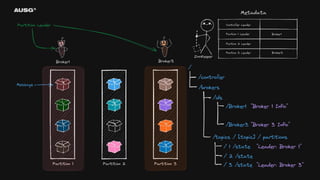
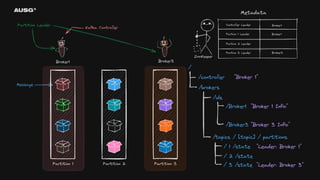
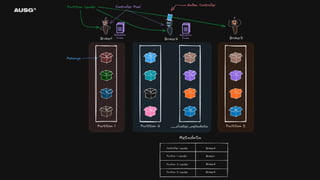
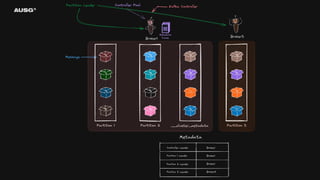
왜 필요한가? - 리더 선출(Leader Election) - Leader : Broker1 - 분산 시스템 간의 일관된 데이터 - Cluster Name : My-Cluster - 멤버십 관리 - Members : [Broker1, Broker2, Broker3]
74.
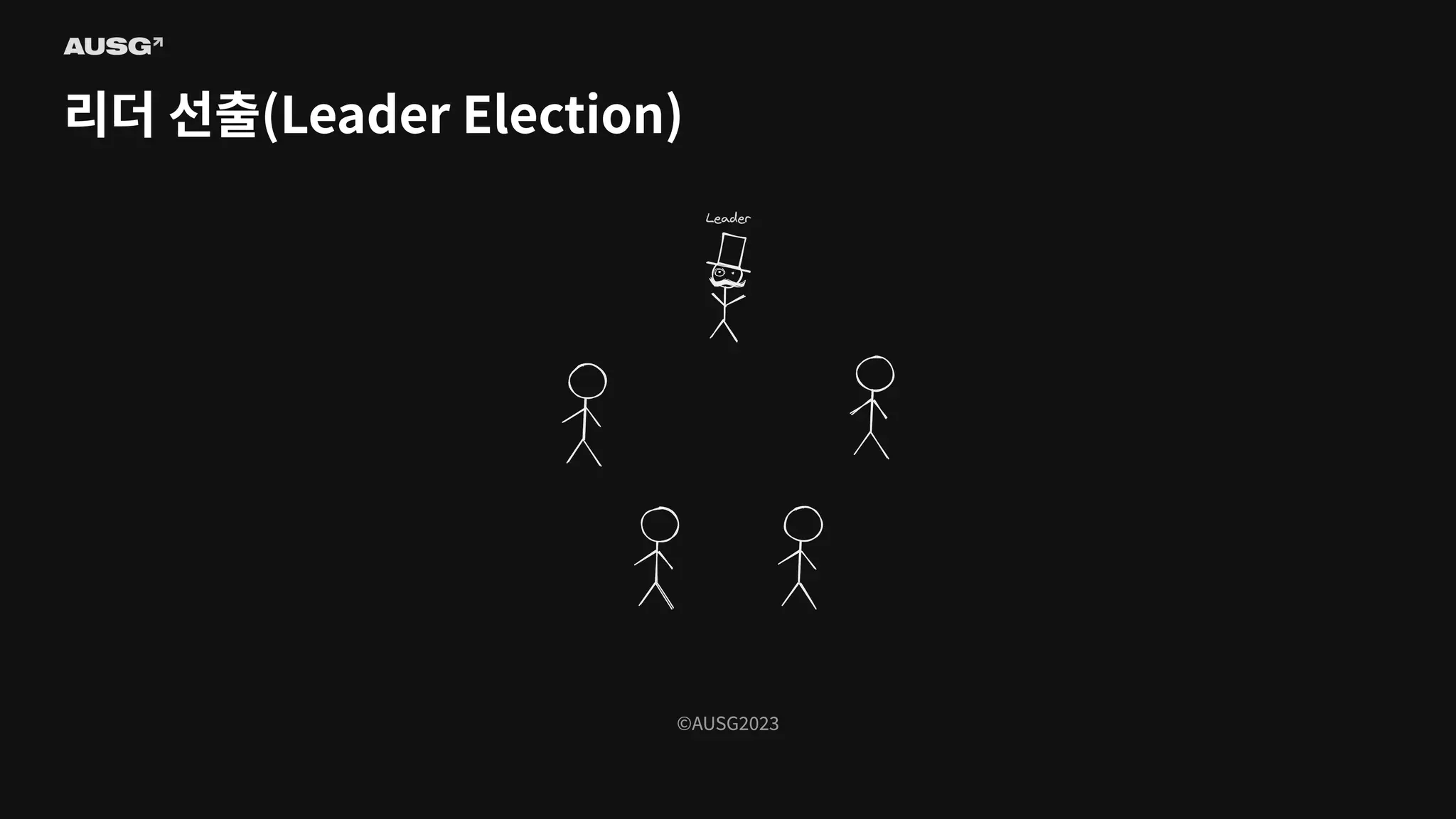
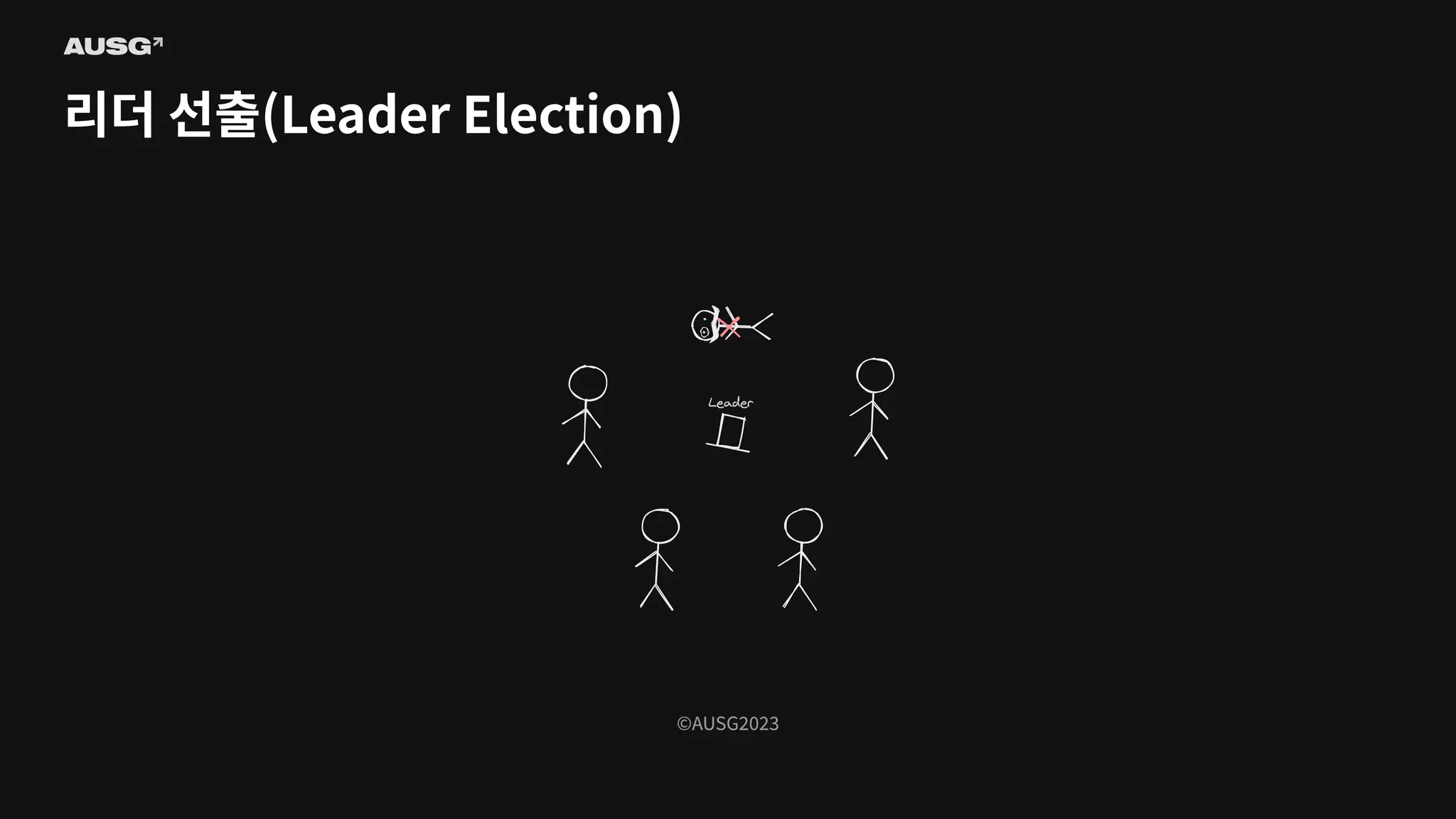
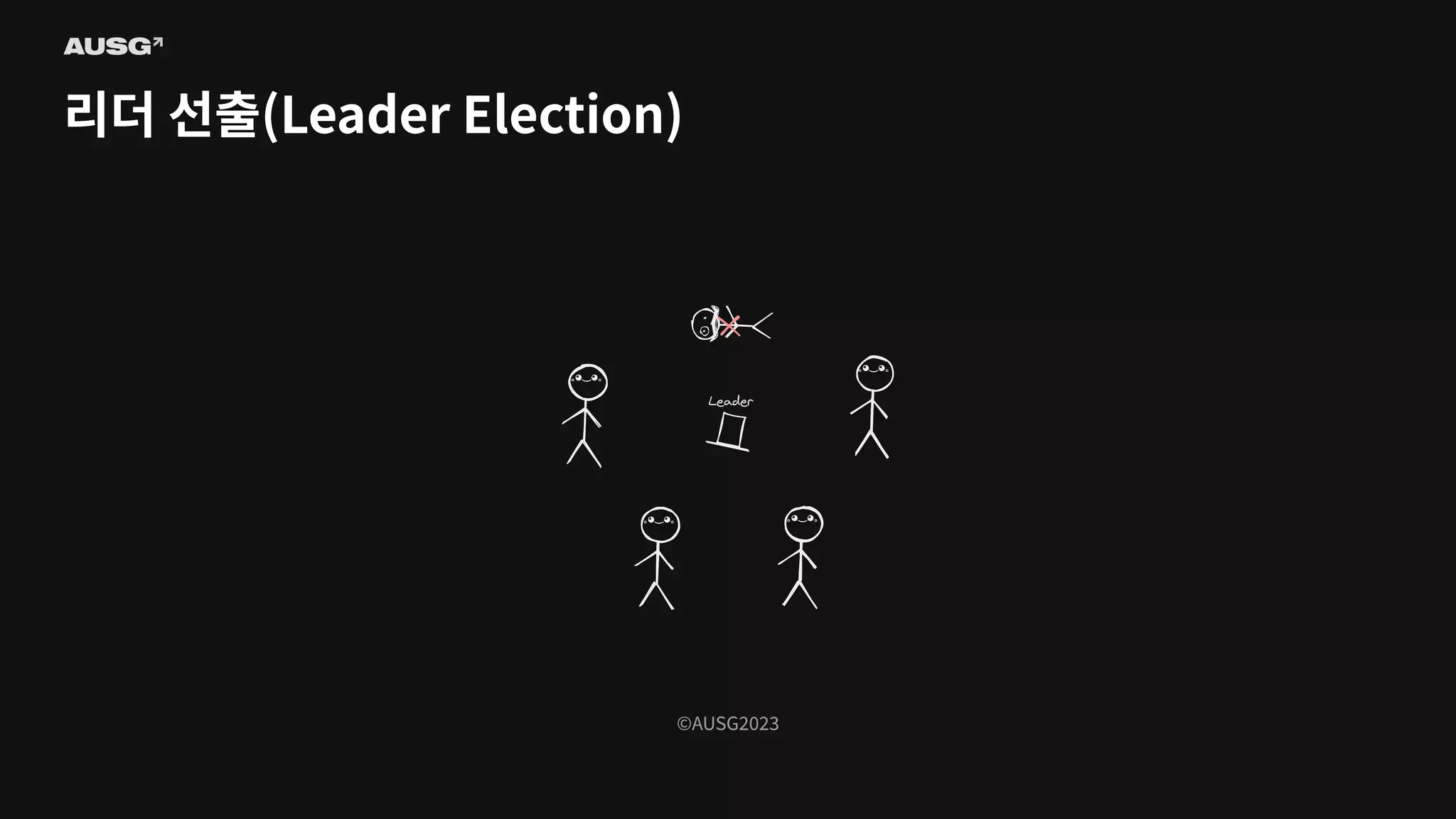
©AUSG2023 ©AUSG2023 리더 선출(Leader Election)
75.
©AUSG2023 ©AUSG2023 리더 선출(Leader Election)
76.
©AUSG2023 ©AUSG2023 리더 선출(Leader Election)
77.
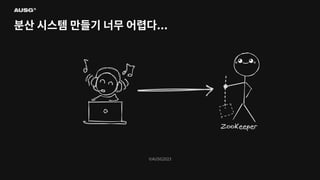
©AUSG2023 ©AUSG2023 분산 시스템 만들기
너무 어렵다...
78.
©AUSG2023 ©AUSG2023 분산 시스템 만들기
너무 어렵다...
79.
©AUSG2023 ©AUSG2023 Apache ZooKeeper ZooKeeper is
a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them, which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
80.
©AUSG2023 ©AUSG2023 Apache ZooKeeper - 다음
기능들은 분산 시스템에서 자주 쓰입니다. - 설정 정보 관리(maintaining configuration information) - 분산 동기화(Distributed Synchronization) - Naming service - Group Service - 하지만 구현도 어렵고, 문제가 생기기도 쉽습니다. - ZooKeeper는 centralized service로 이러한 기능들을 제공해줍니다.
81.
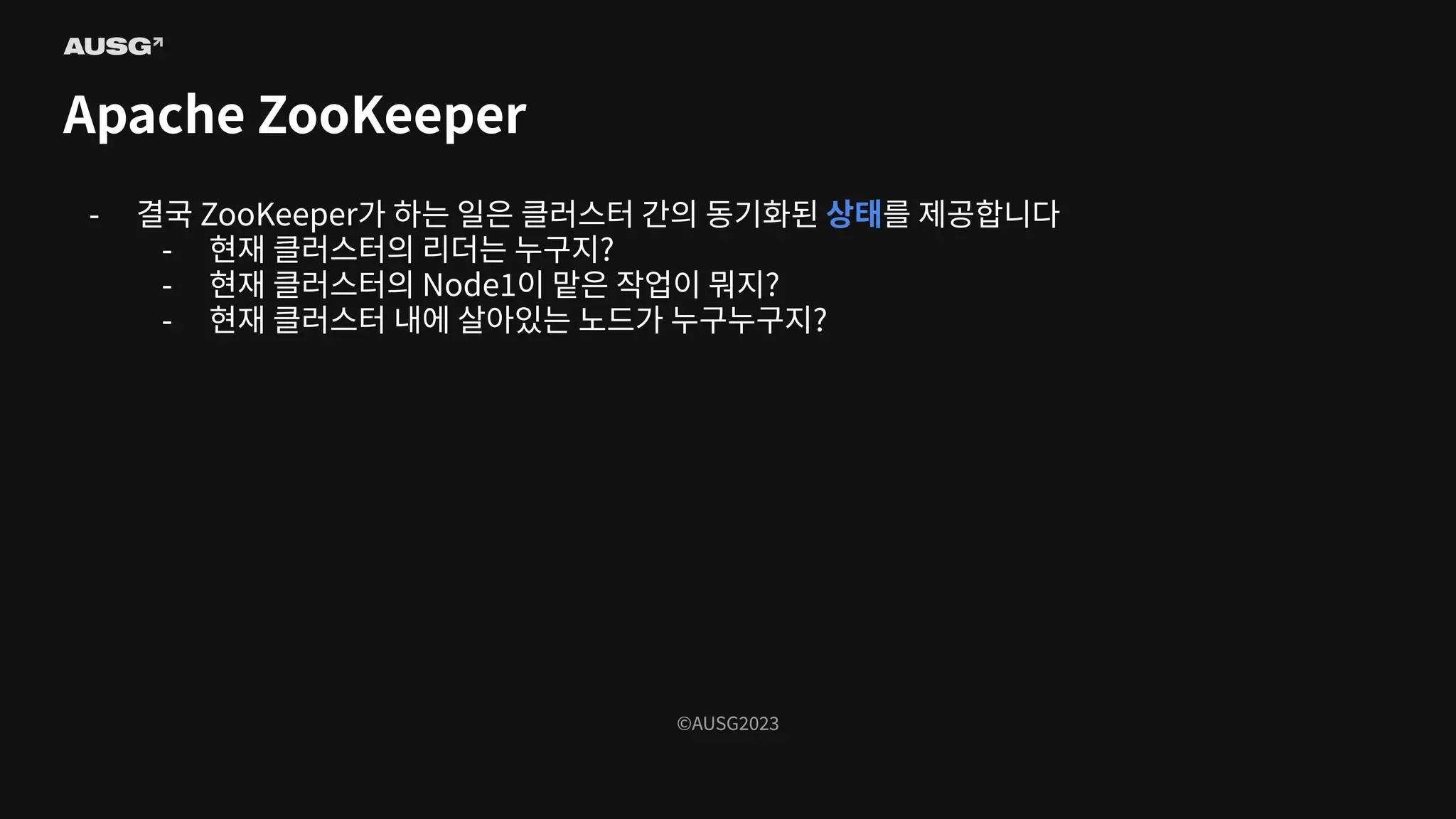
©AUSG2023 ©AUSG2023 Apache ZooKeeper - 결국
ZooKeeper가 하는 일은 클러스터 간의 동기화된 상태를 제공합니다 - 현재 클러스터의 리더는 누구지? - 현재 클러스터의 Node1이 맡은 작업이 뭐지? - 현재 클러스터 내에 살아있는 노드가 누구누구지?
82.
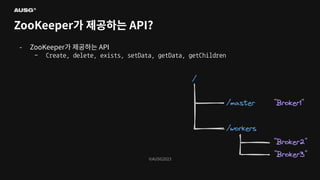
©AUSG2023 ©AUSG2023 ZooKeeper가 제공하는 API? -
그렇다면 ZooKeeper는 어떠한 API를 제공하고 있을까요? - electNewLeader()? - getAliveNodes()? - leaveGroup()? - joinGroup()?
83.
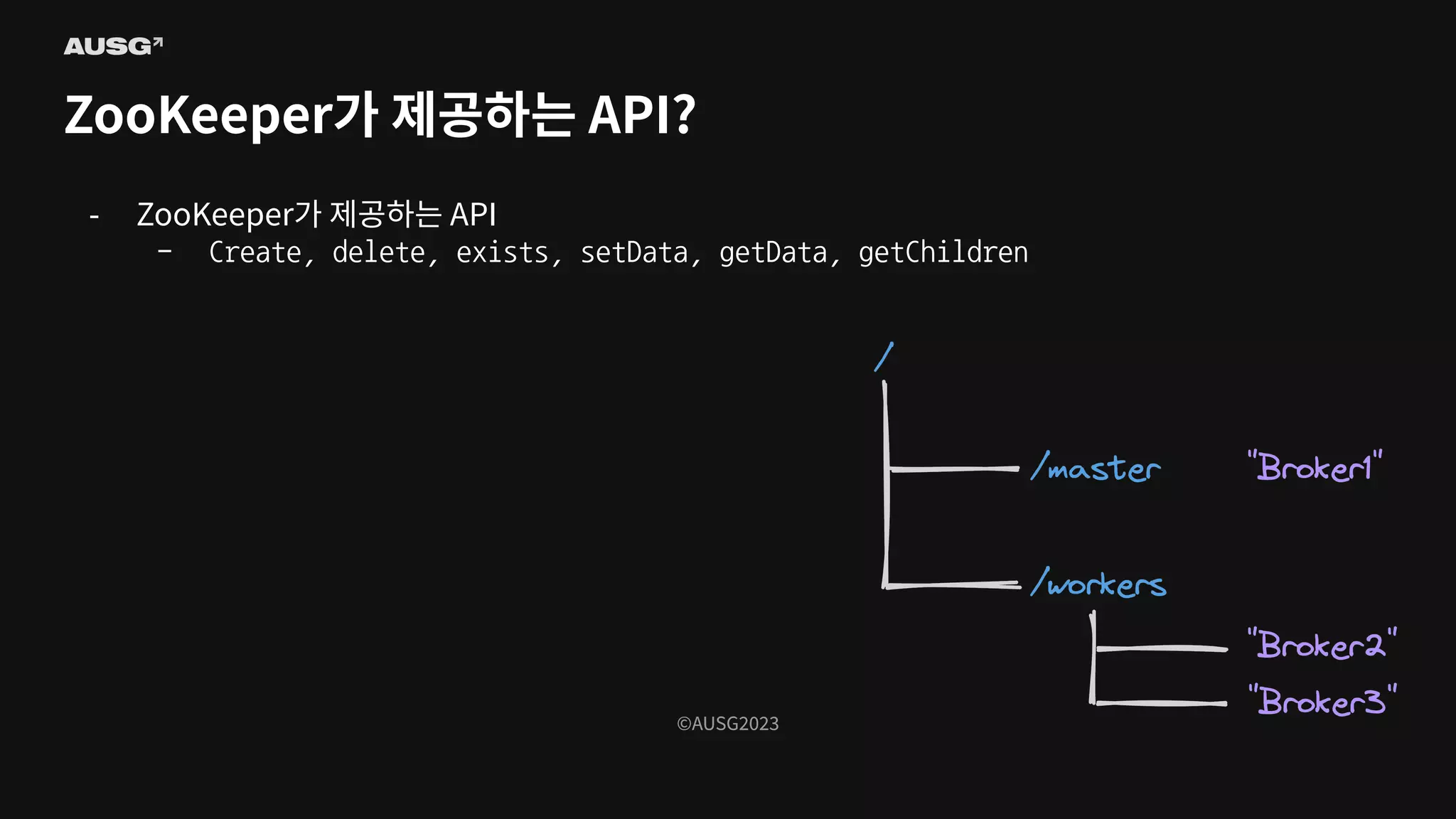
©AUSG2023 ©AUSG2023 ZooKeeper가 제공하는 API? -
ZooKeeper는 일종의 작은 분산 파일시스템에 대한 API를 제공합니다. - 강한 일관성(Consistency)이 곁들여진 - 이때 각 파일을 “file”이 아니라 “znode”라고 부릅니다.
84.
©AUSG2023 ©AUSG2023 ZooKeeper가 제공하는 API? -
ZooKeeper가 제공하는 API - Create, delete, exists, setData, getData, getChildren
85.
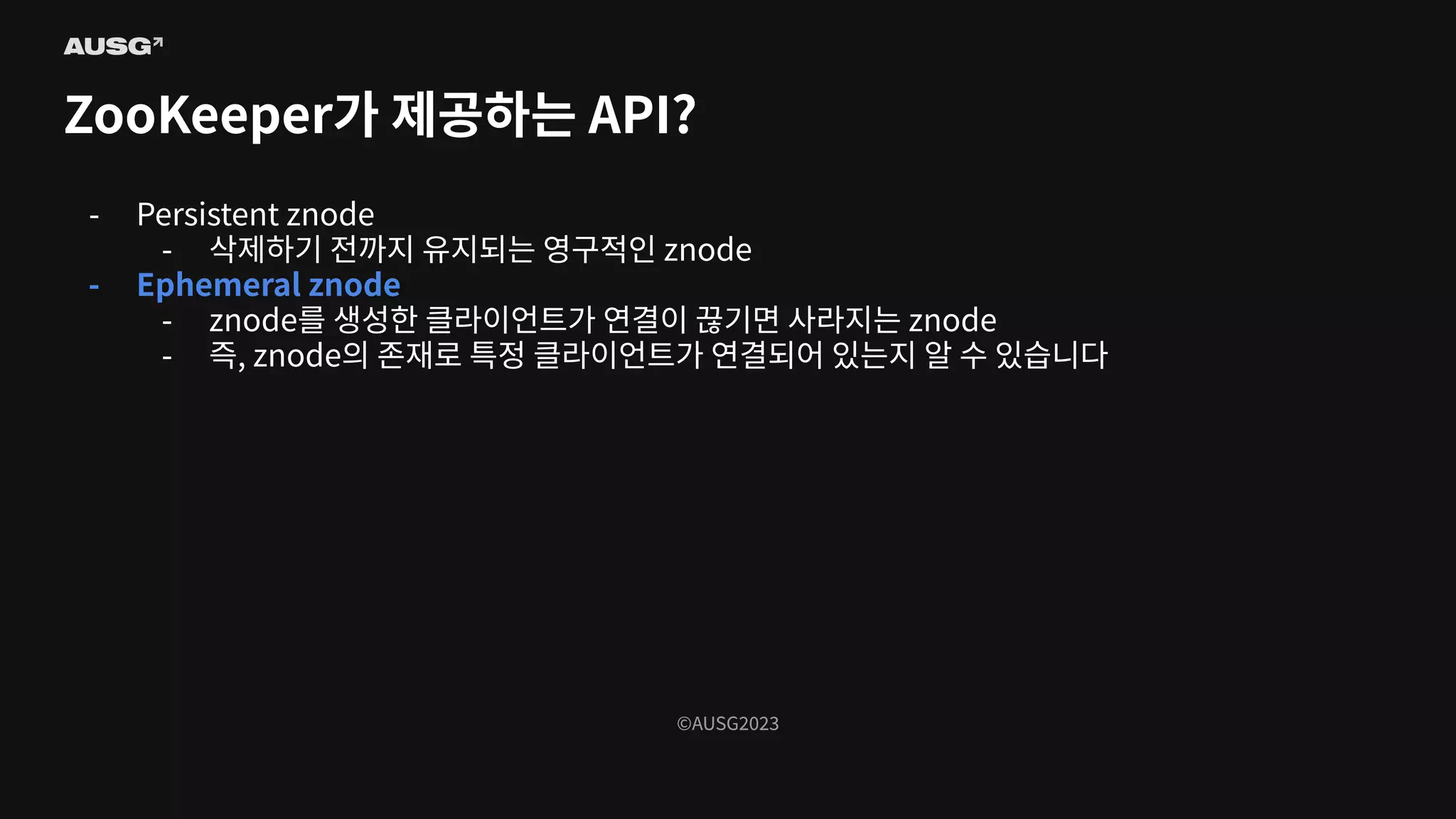
©AUSG2023 ©AUSG2023 ZooKeeper가 제공하는 API? -
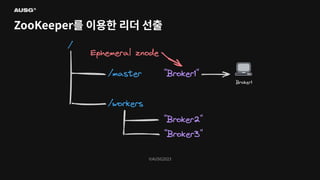
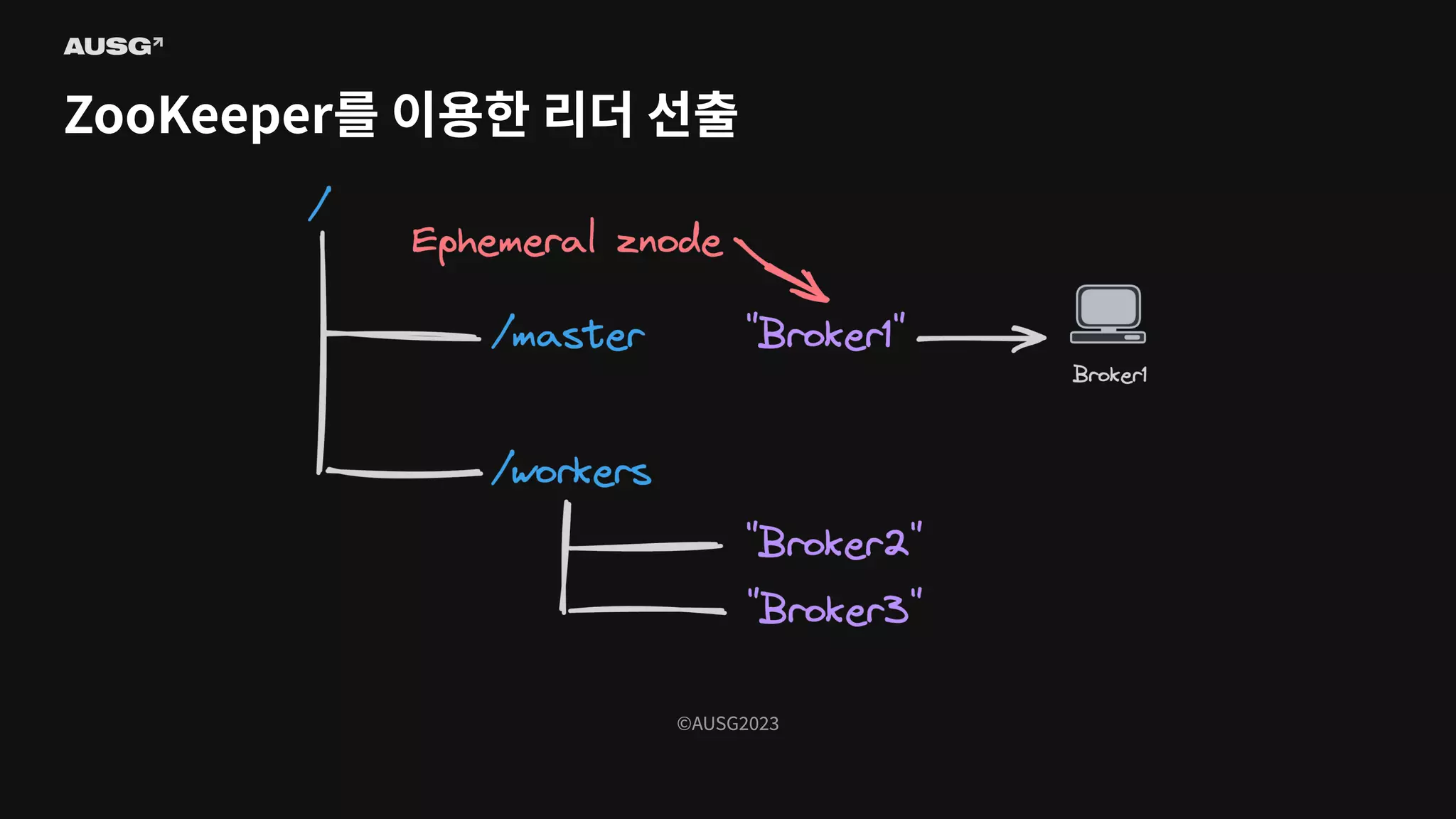
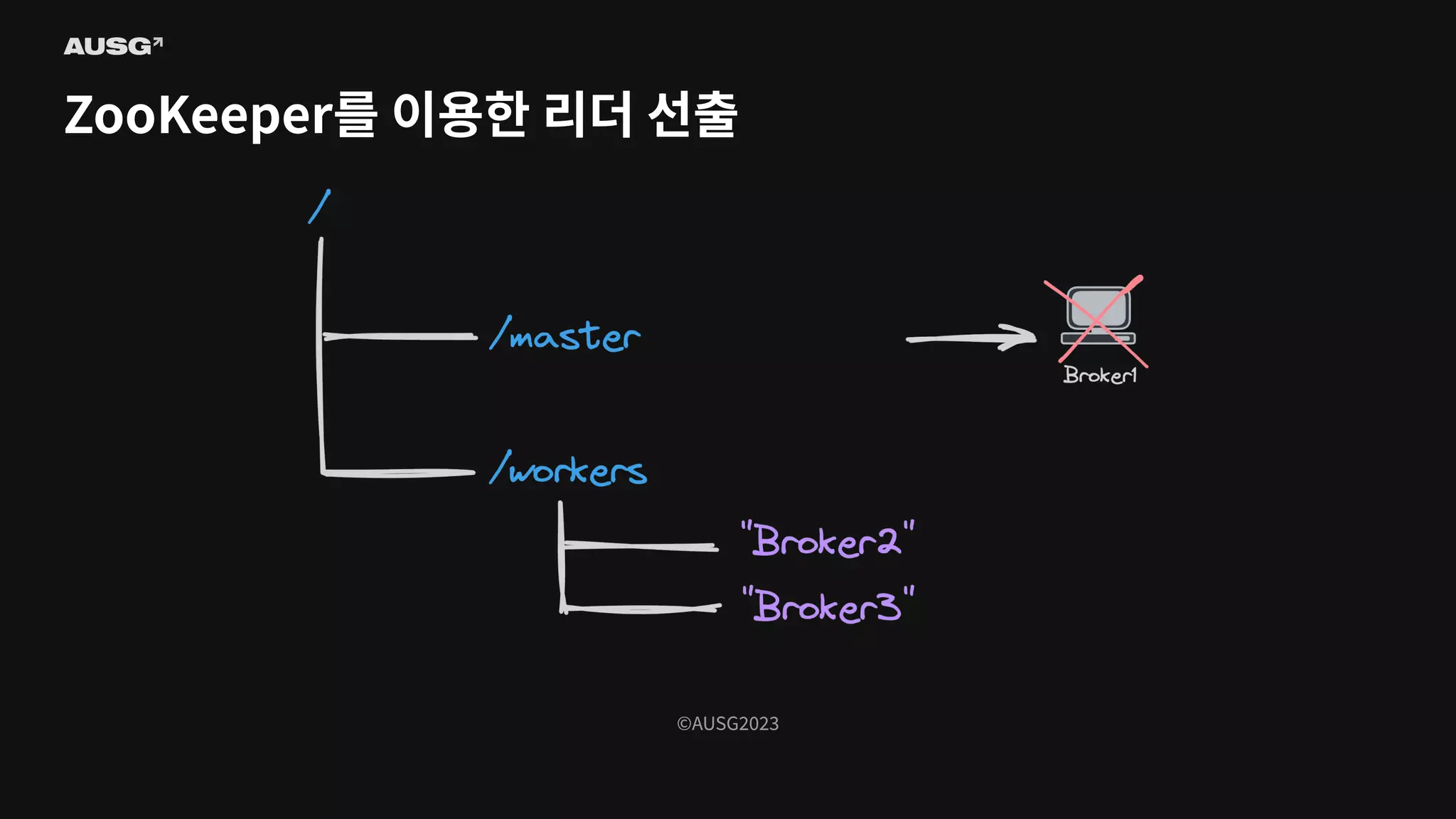
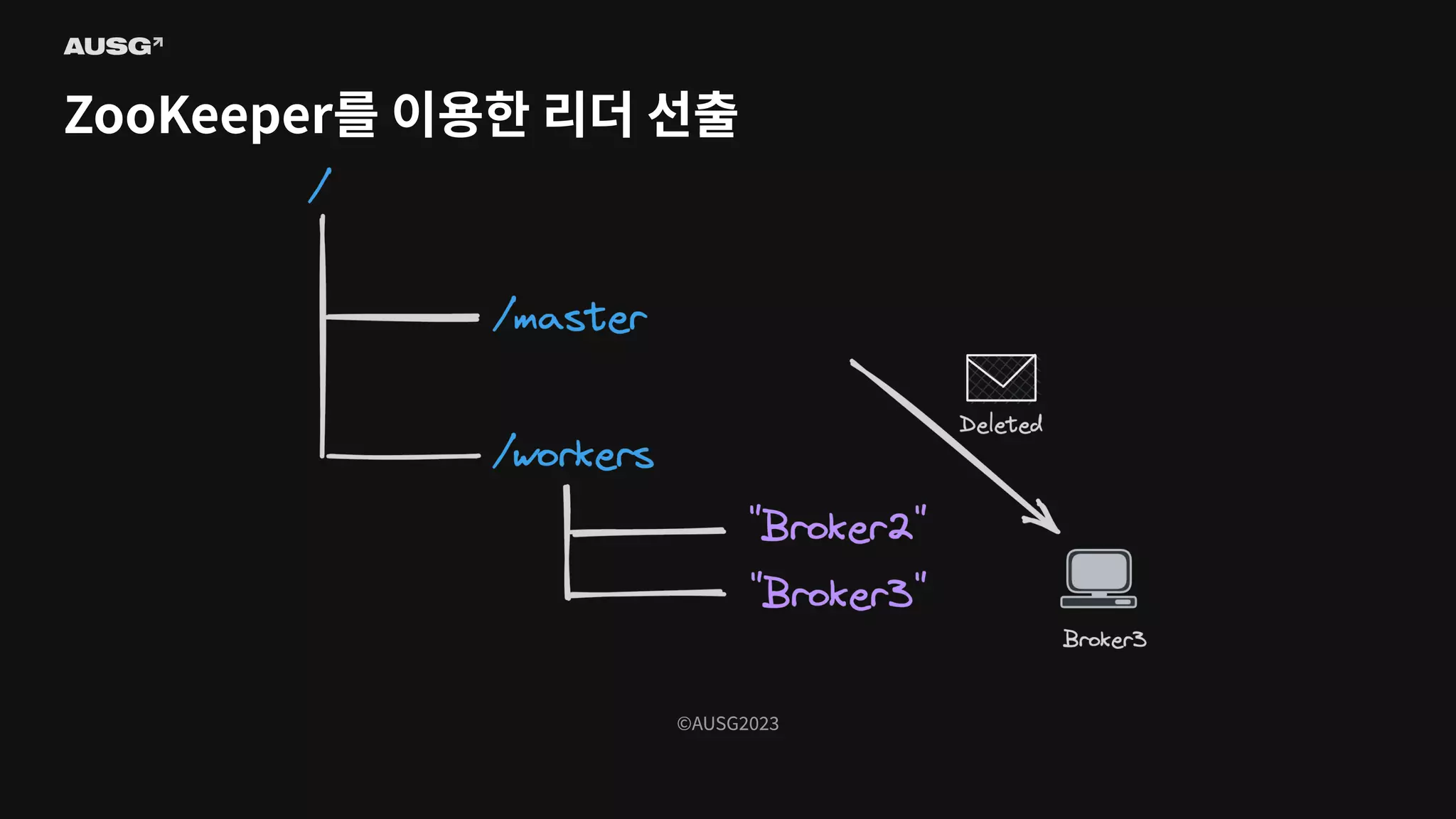
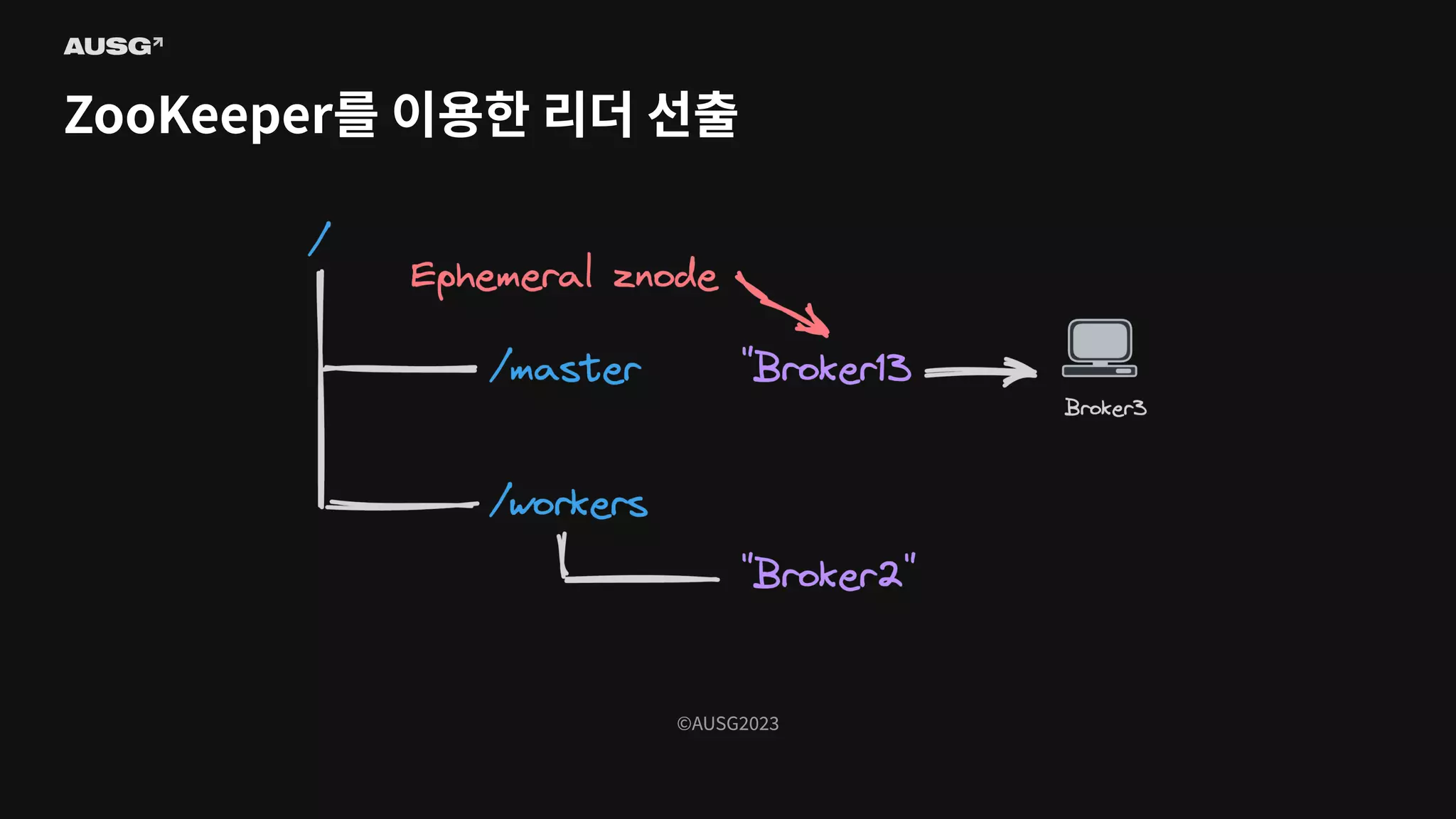
Persistent znode - 삭제하기 전까지 유지되는 영구적인 znode - Ephemeral znode - znode를 생성한 클라이언트가 연결이 끊기면 사라지는 znode - 즉, znode의 존재로 특정 클라이언트가 연결되어 있는지 알 수 있습니다
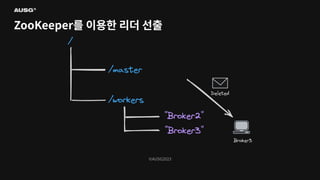
86.
©AUSG2023 ©AUSG2023 ZooKeeper를 이용한 리더
선출
87.
©AUSG2023 ©AUSG2023 ZooKeeper를 이용한 리더
선출
88.
©AUSG2023 ©AUSG2023 ZooKeeper의 Watch - znode에
변화가 생기면 미리 Watch를 설정했던 Watcher에게 이벤트를 보내줍니다 - NODE_CREATED: 노드가 생성 됨을 감지 - NODE_DELETED: 노드가 삭제 됨을 감지 - NODE_DATA_CHANGED: 노드의 데이터가 변경 됨을 감지 - NODE_CHILDREN_CHANGED: 자식 노드가 변경 됨을 감지
89.
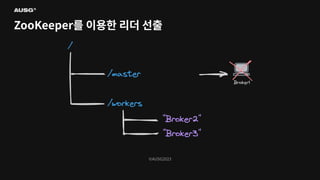
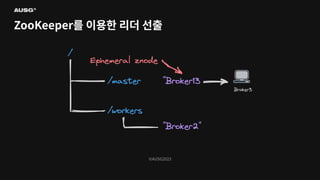
©AUSG2023 ©AUSG2023 ZooKeeper를 이용한 리더
선출
90.
©AUSG2023 ©AUSG2023 ZooKeeper를 이용한 리더
선출
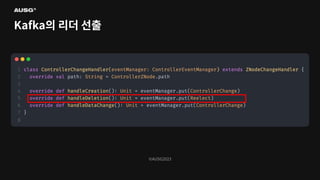
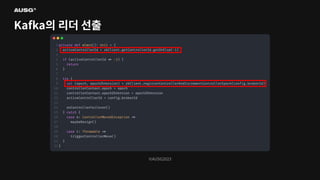
91.
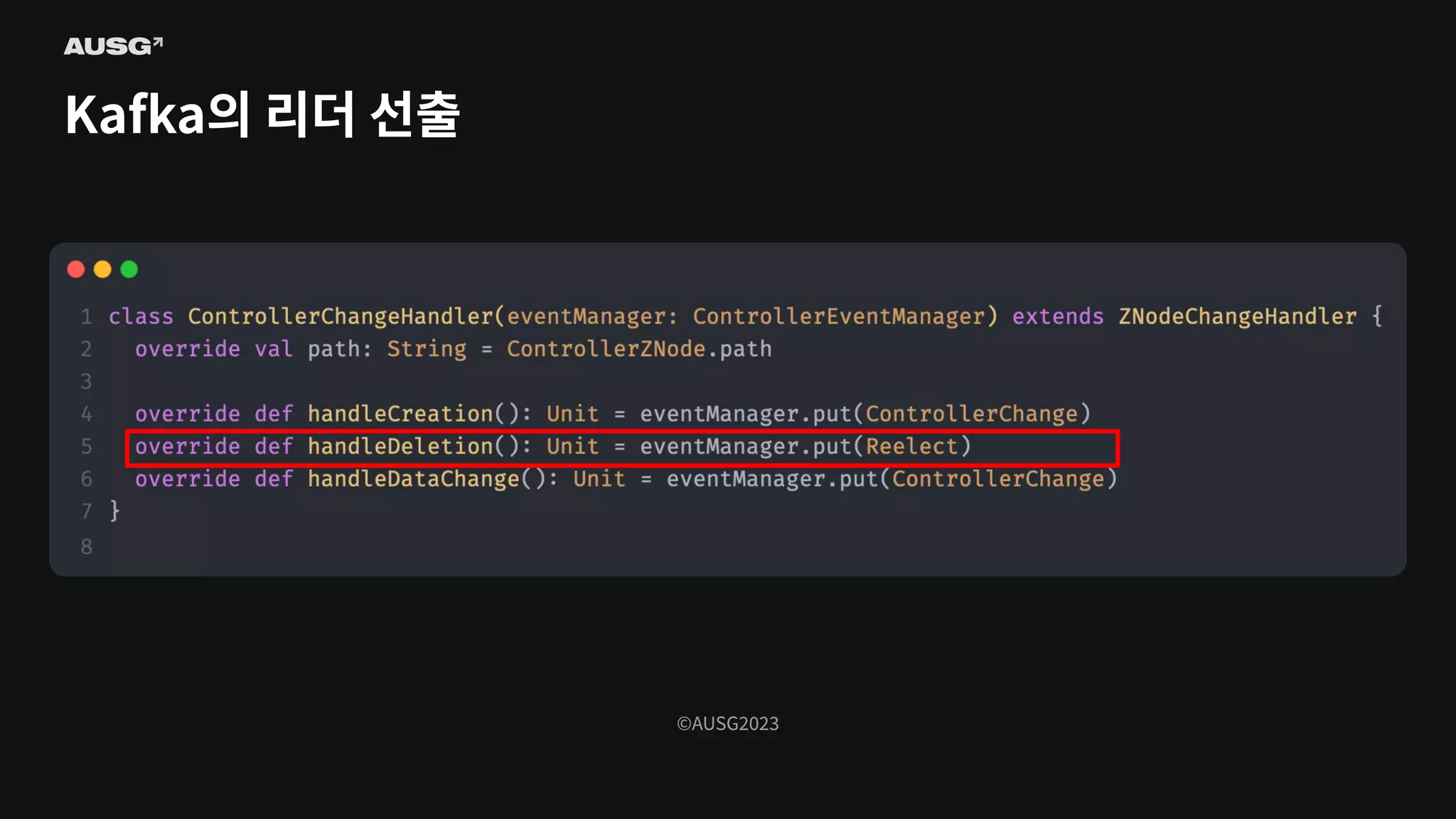
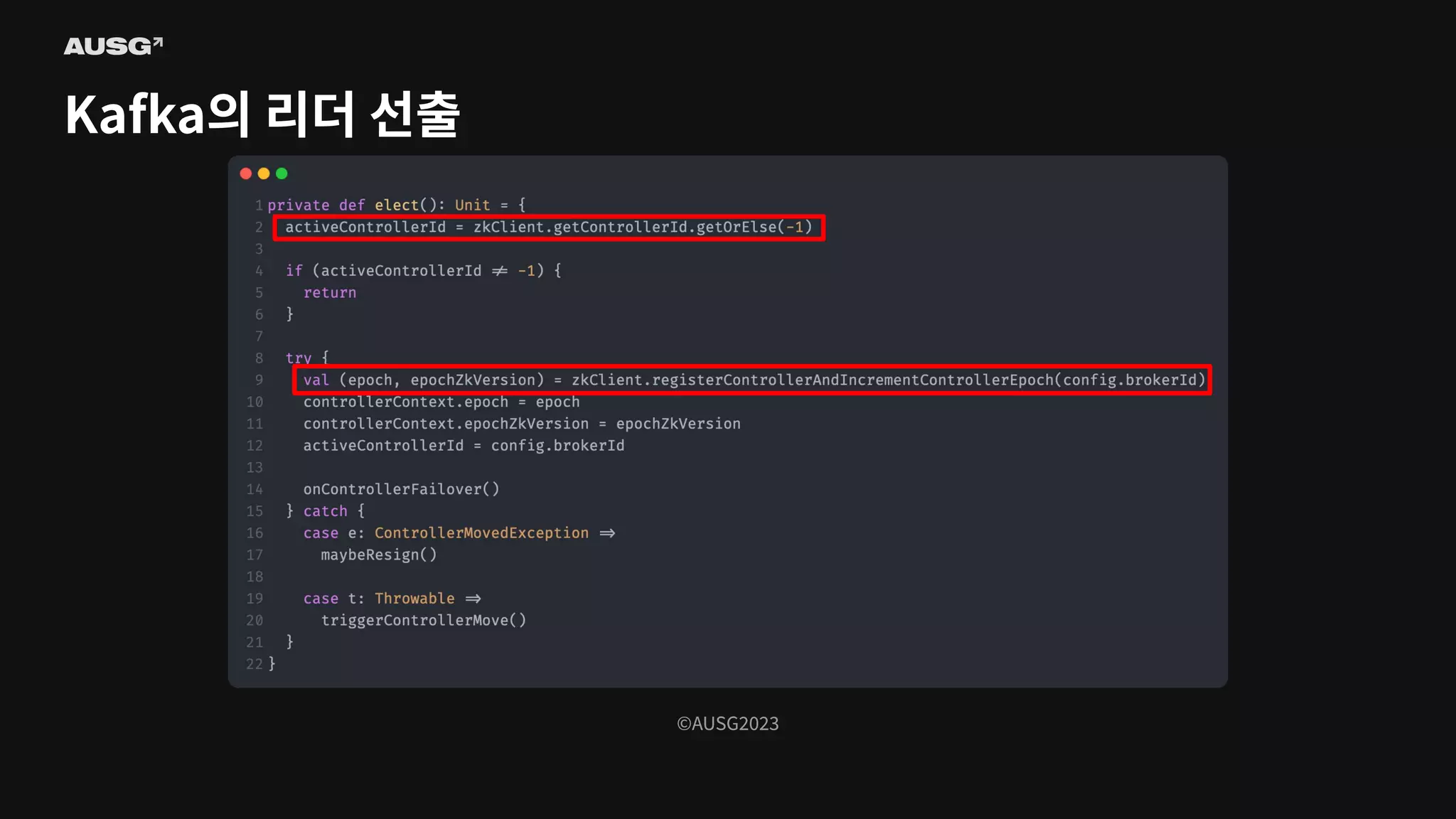
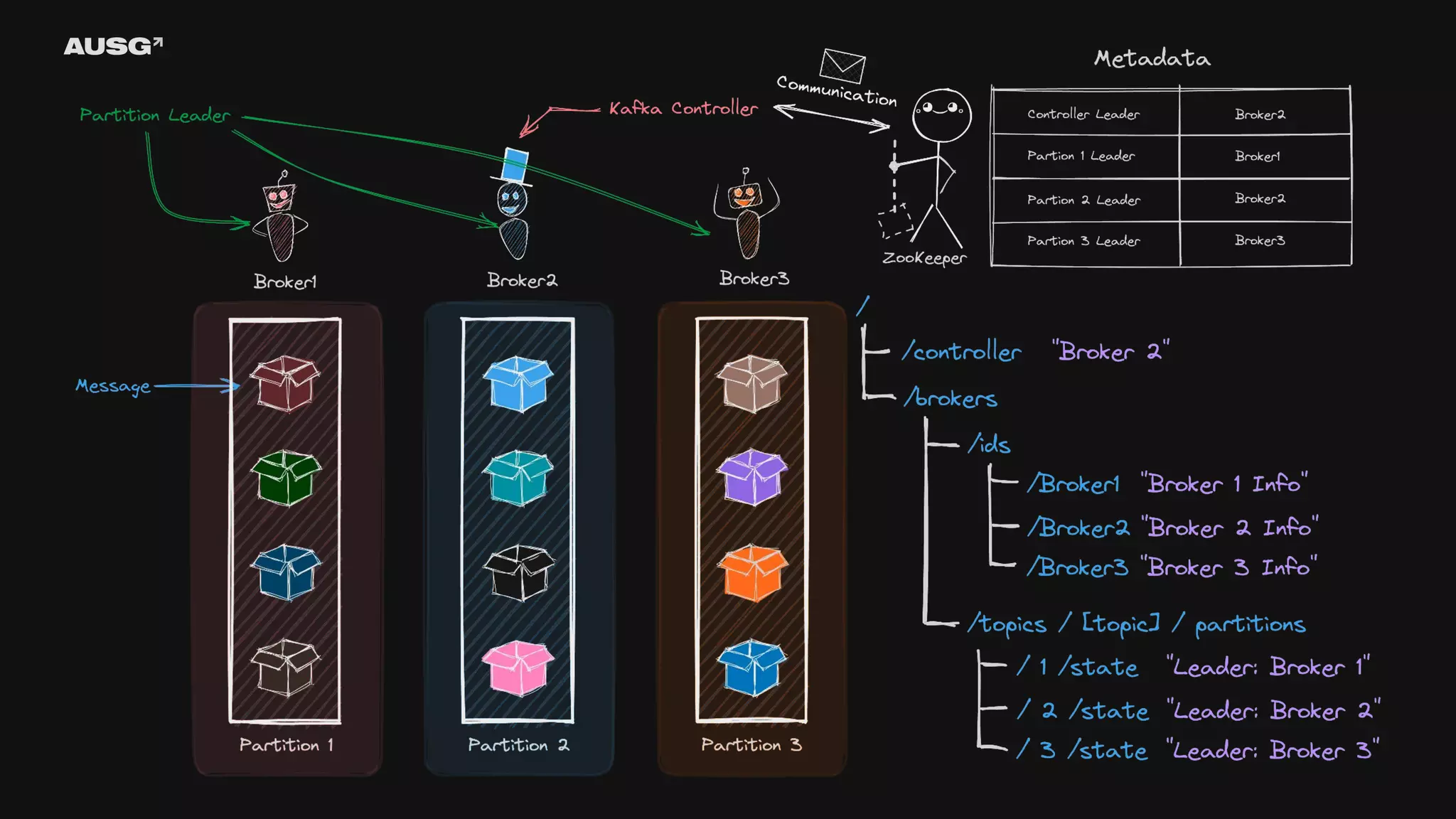
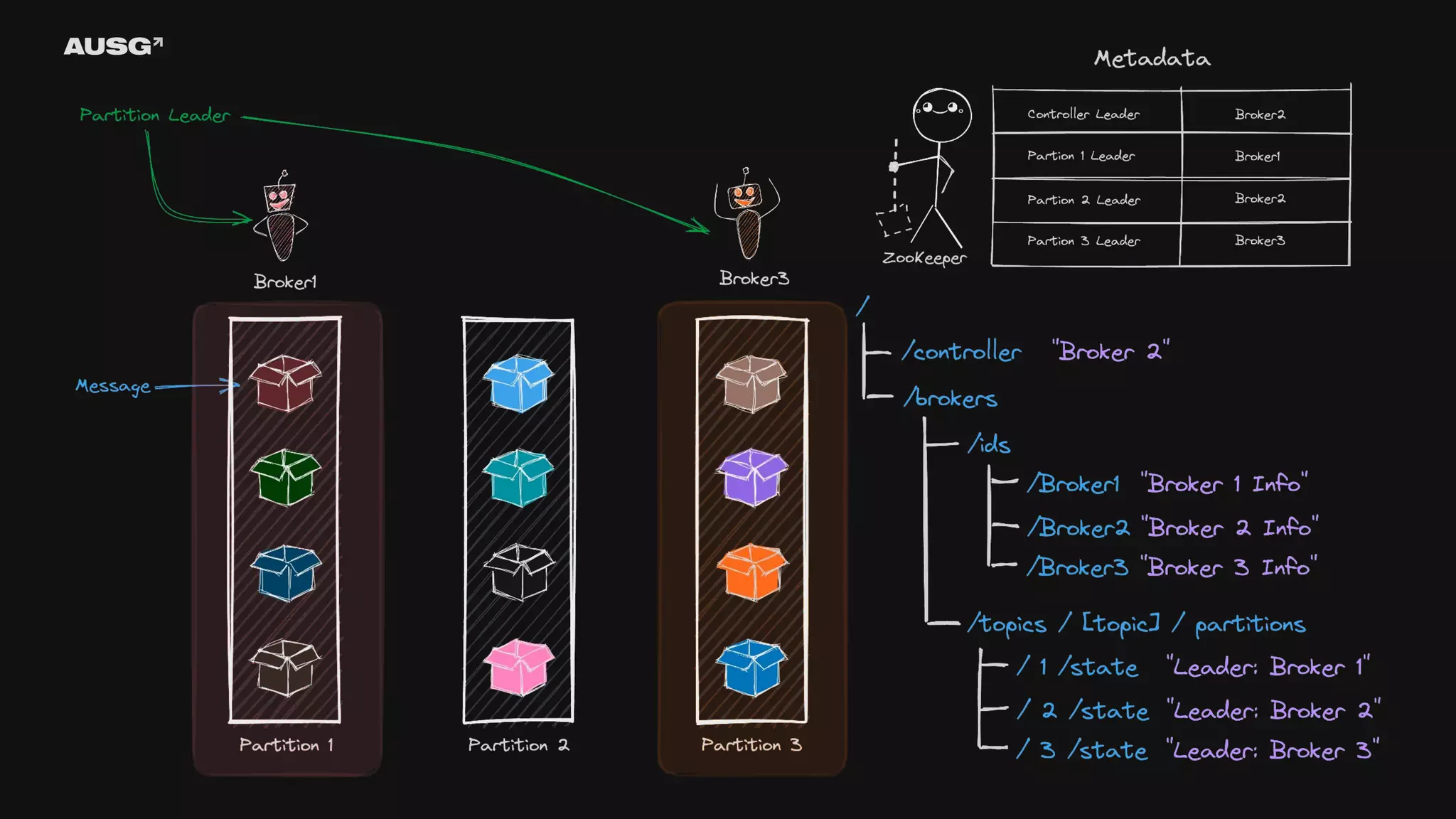
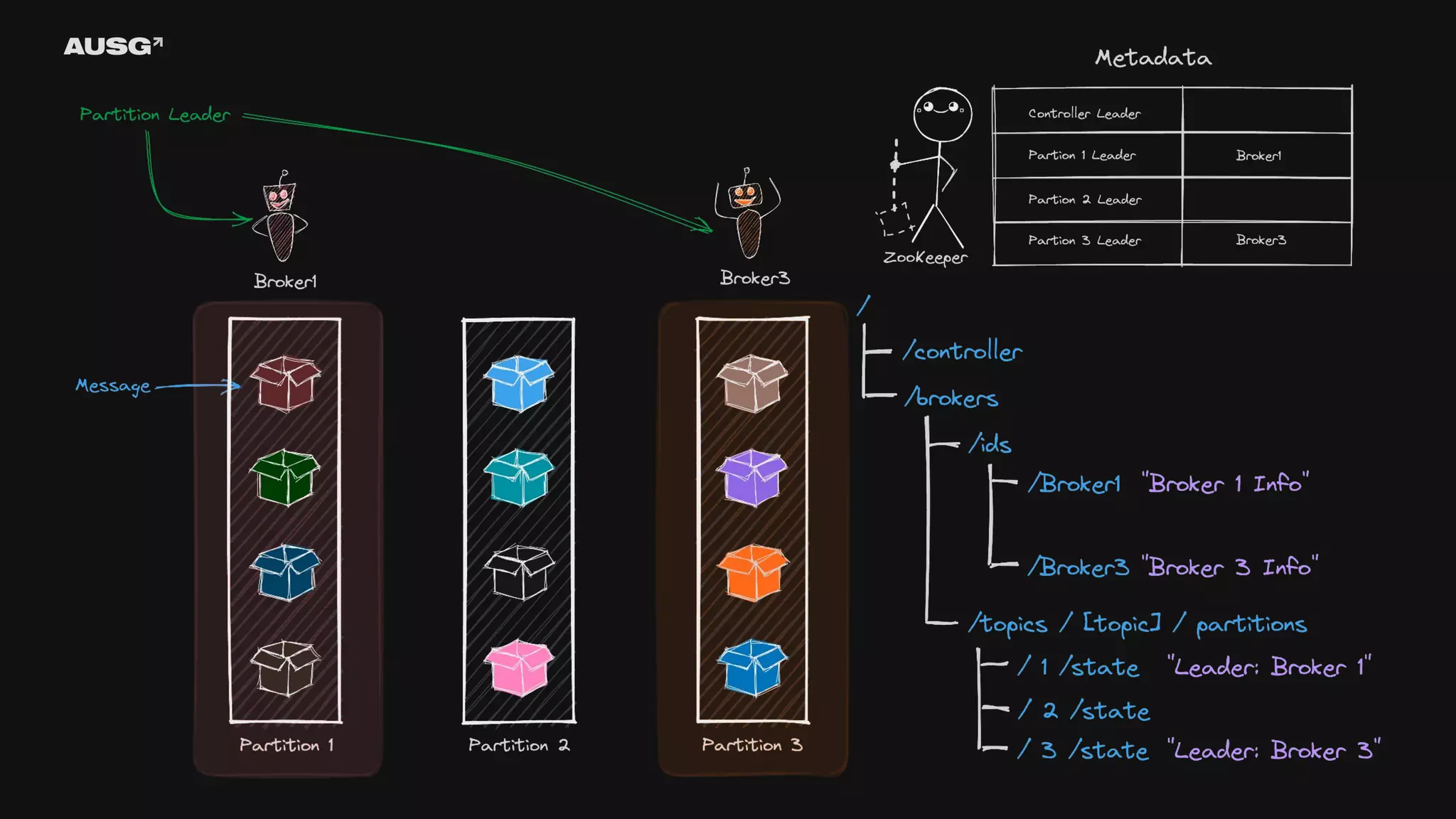
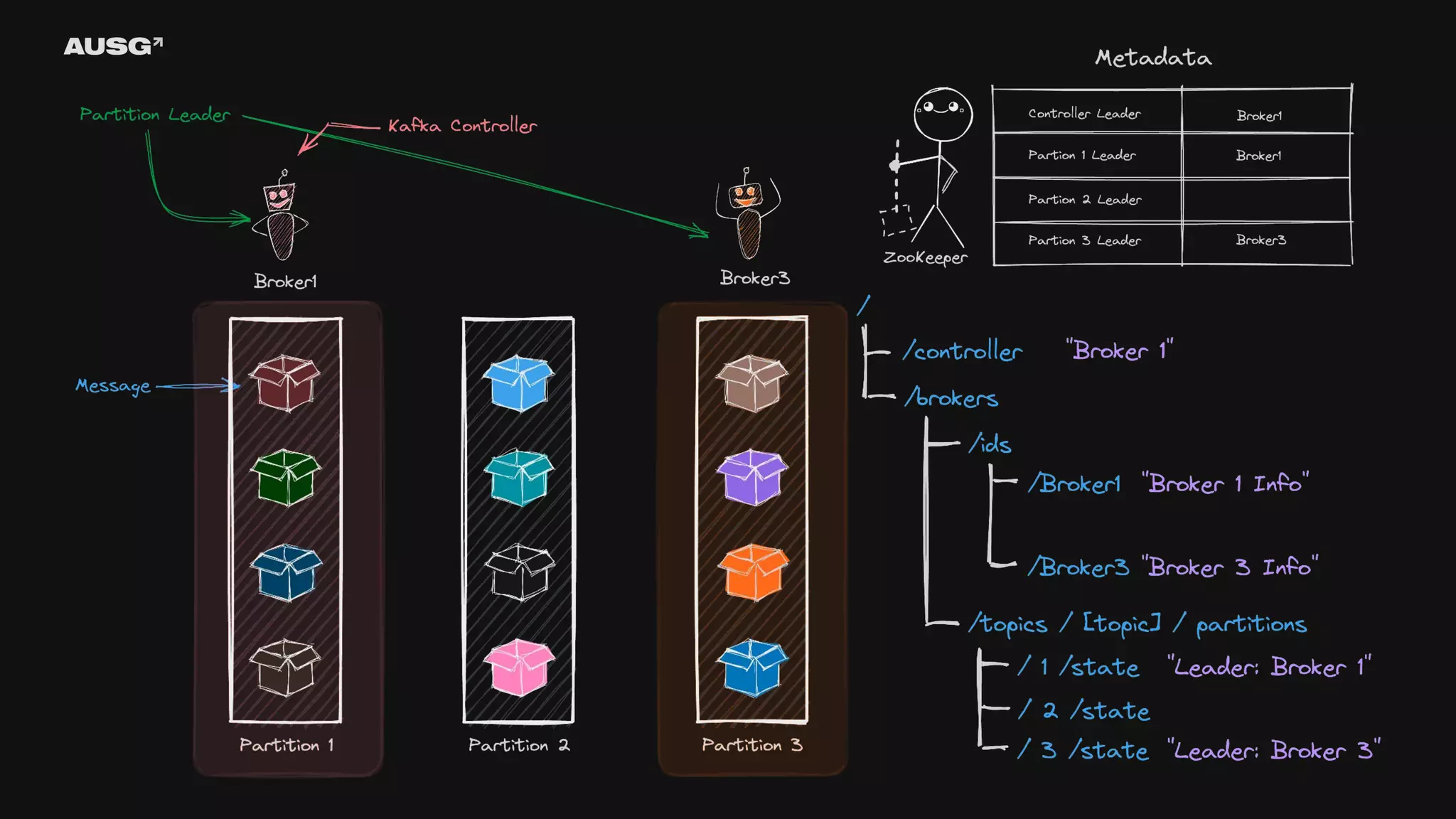
©AUSG2023 ©AUSG2023 Kafka의 리더 선출
92.
©AUSG2023 ©AUSG2023 Kafka의 리더 선출
93.
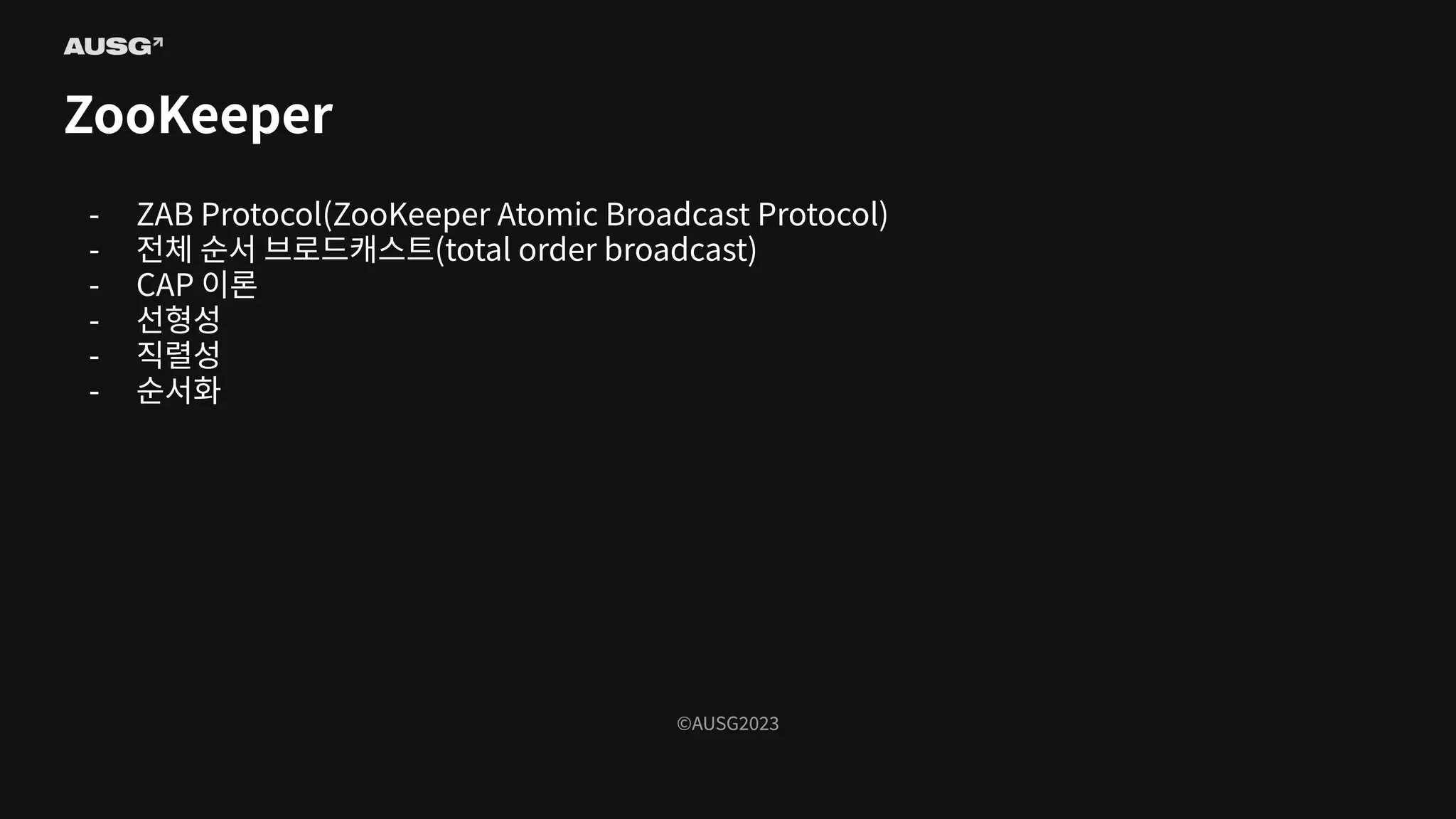
©AUSG2023 ©AUSG2023 ZooKeeper - ZAB Protocol(ZooKeeper
Atomic Broadcast Protocol) - 전체 순서 브로드캐스트(total order broadcast) - CAP 이론 - 선형성 - 직렬성 - 순서화
94.
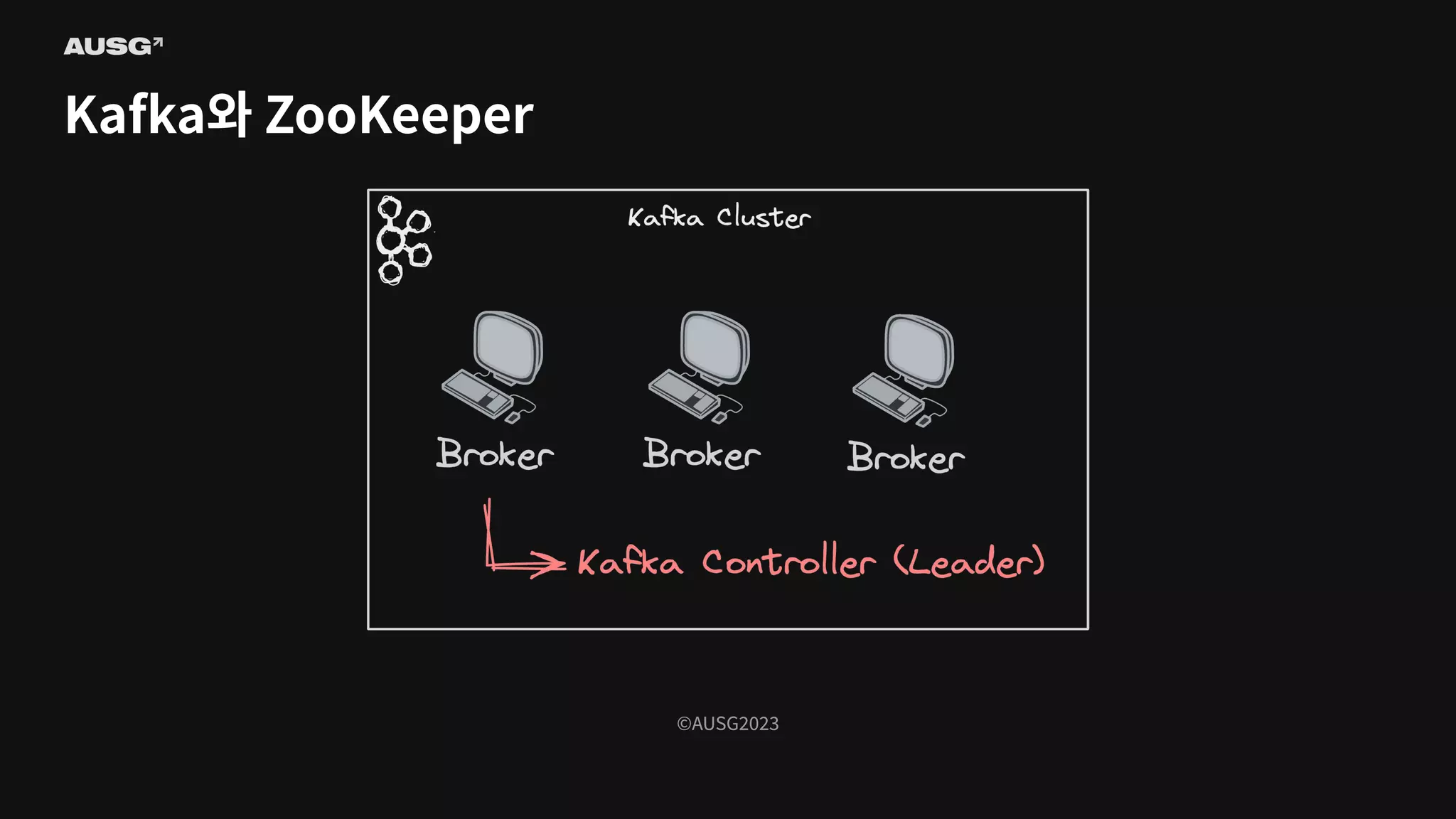
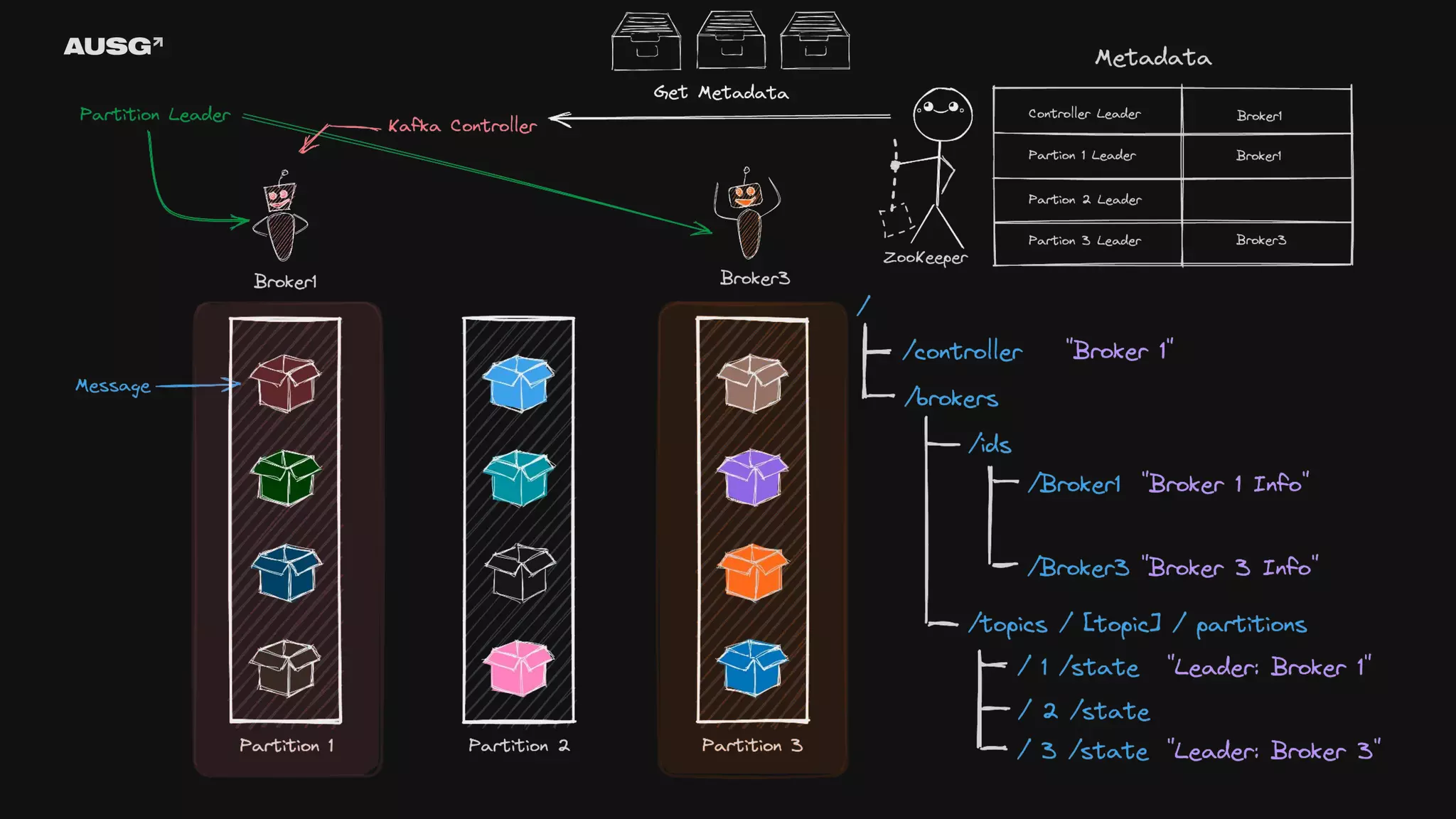
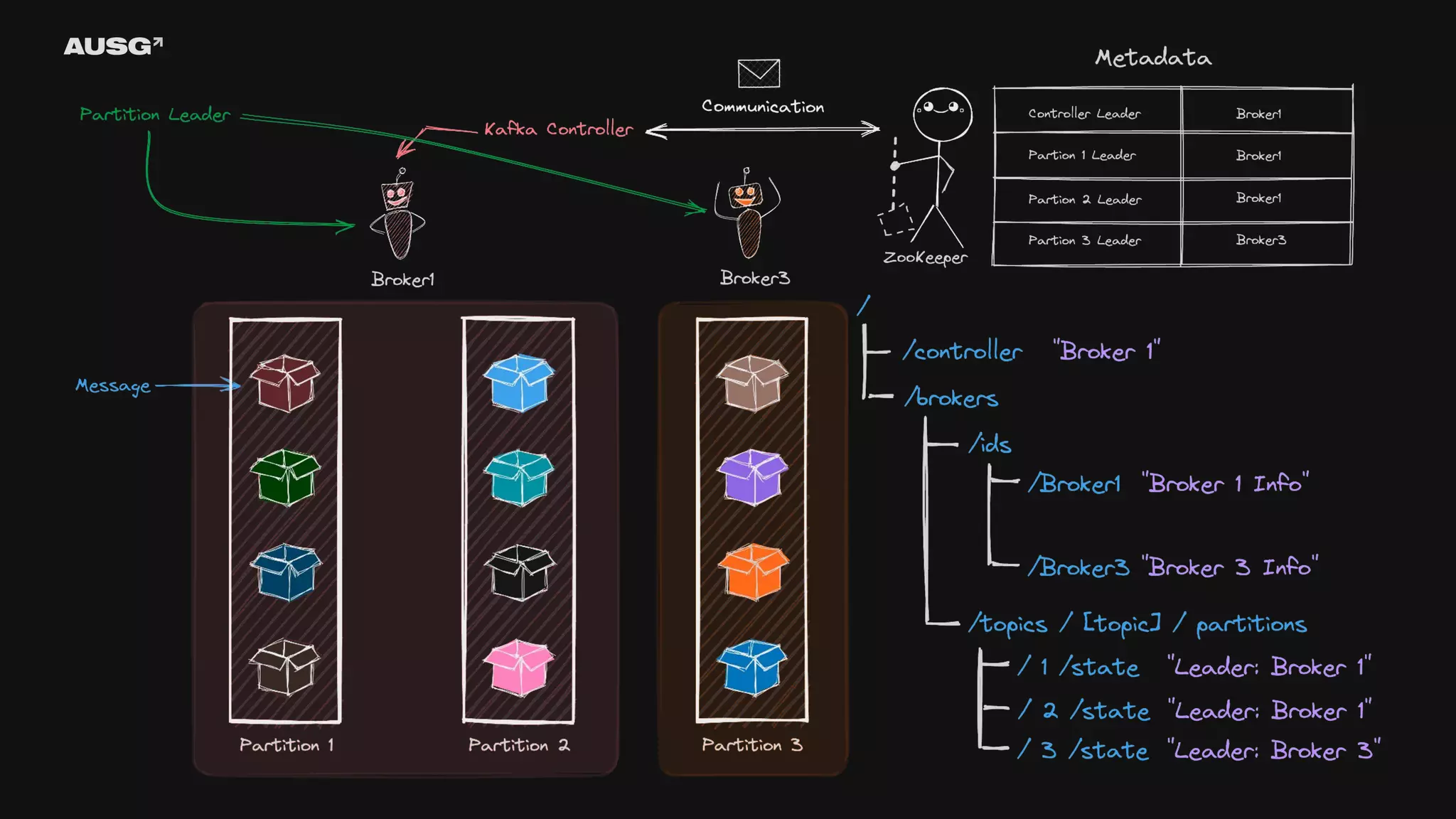
©AUSG2023 Kafka와 ZooKeeper
95.
©AUSG2023 ©AUSG2023 Kafka와 ZooKeeper
96.
©AUSG2023 ©AUSG2023
97.
©AUSG2023 ©AUSG2023
98.
©AUSG2023 ©AUSG2023
99.
©AUSG2023 ©AUSG2023
100.
©AUSG2023 ©AUSG2023
101.
©AUSG2023 ©AUSG2023
102.
©AUSG2023 KIP-500 Replace ZooKeeper with
a Metadata Quorum
103.
©AUSG2023 KRaft Mode (Kafka
Raft metadata mode)
104.
©AUSG2023 ZooKeeper의 문제점
105.
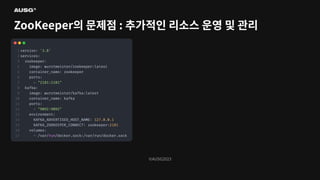
©AUSG2023 ©AUSG2023 ZooKeeper의 문제점 :
추가적인 리소스 운영 및 관리
106.
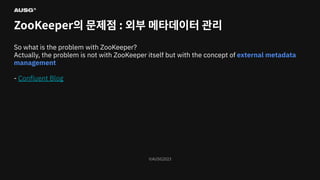
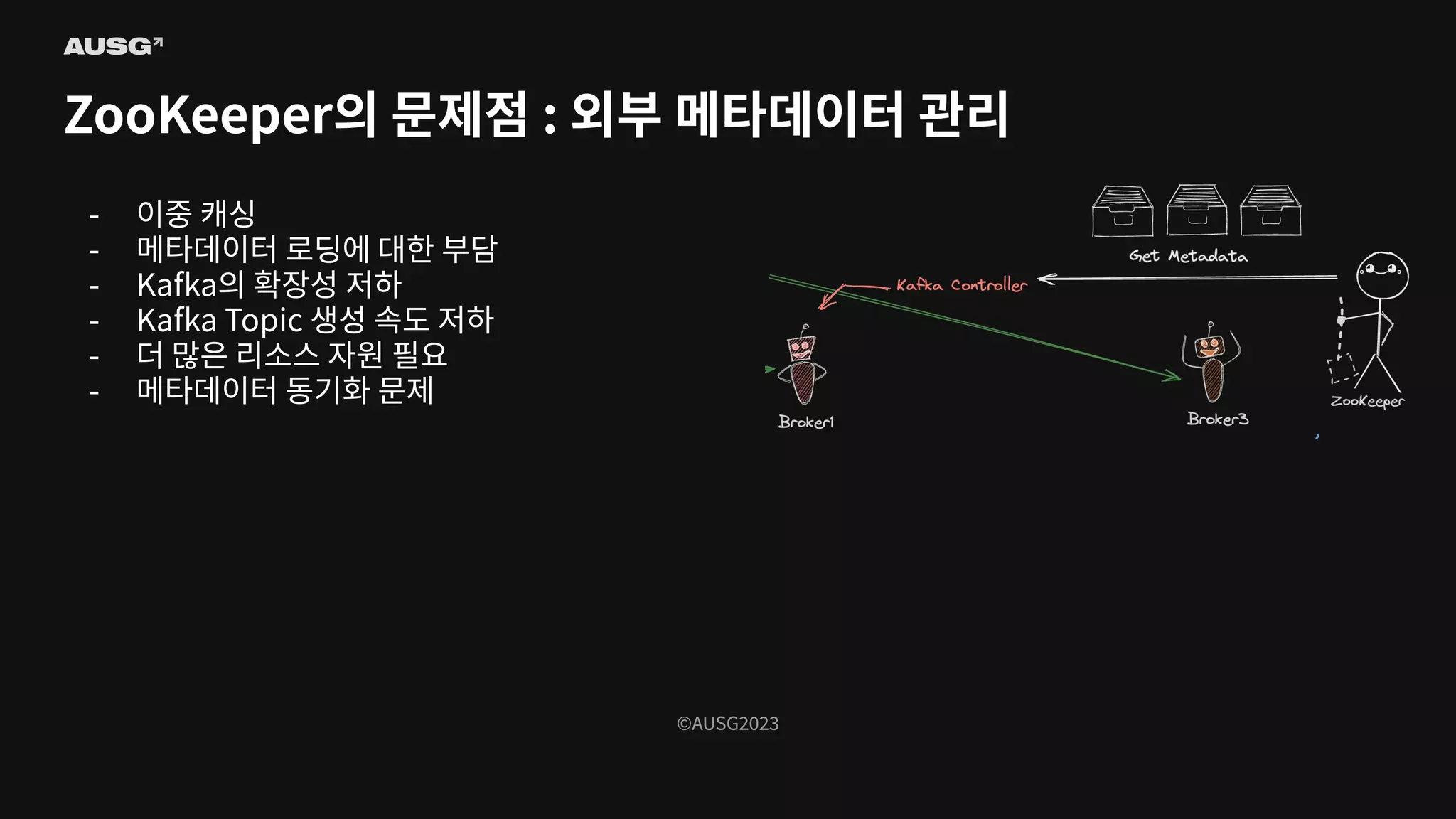
©AUSG2023 ©AUSG2023 ZooKeeper의 문제점 :
외부 메타데이터 관리 So what is the problem with ZooKeeper? Actually, the problem is not with ZooKeeper itself but with the concept of external metadata management - Confluent Blog
107.
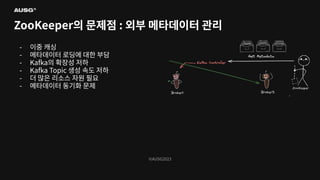
©AUSG2023 ©AUSG2023 ZooKeeper의 문제점 :
외부 메타데이터 관리 - 이중 캐싱 - 메타데이터 로딩에 대한 부담 - Kafka의 확장성 저하 - Kafka Topic 생성 속도 저하 - 더 많은 리소스 자원 필요 - 메타데이터 동기화 문제
108.
©AUSG2023 RAFT
109.
©AUSG2023 ©AUSG2023 - 2014년 USENIX에서
발표된 “In Search of an Understandable Consensus Algorithm” 라는 논문에서 소개 - 즉, 이해가능한 합의 알고리즘 - Paxos - CockroachDB, MongoDB, Etcd, ClickHouse 등 다양한 곳에서 사용 RAFT
110.
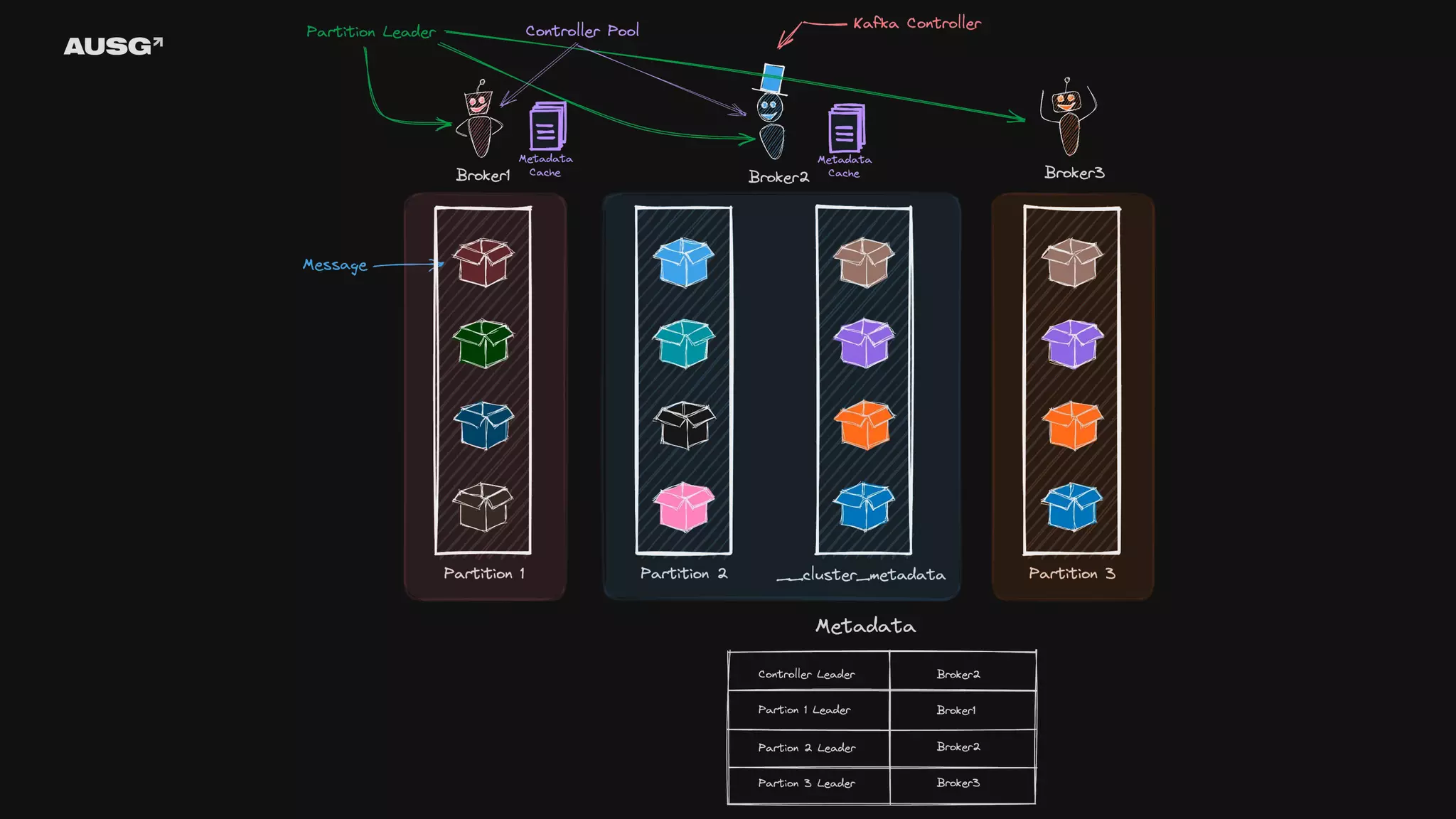
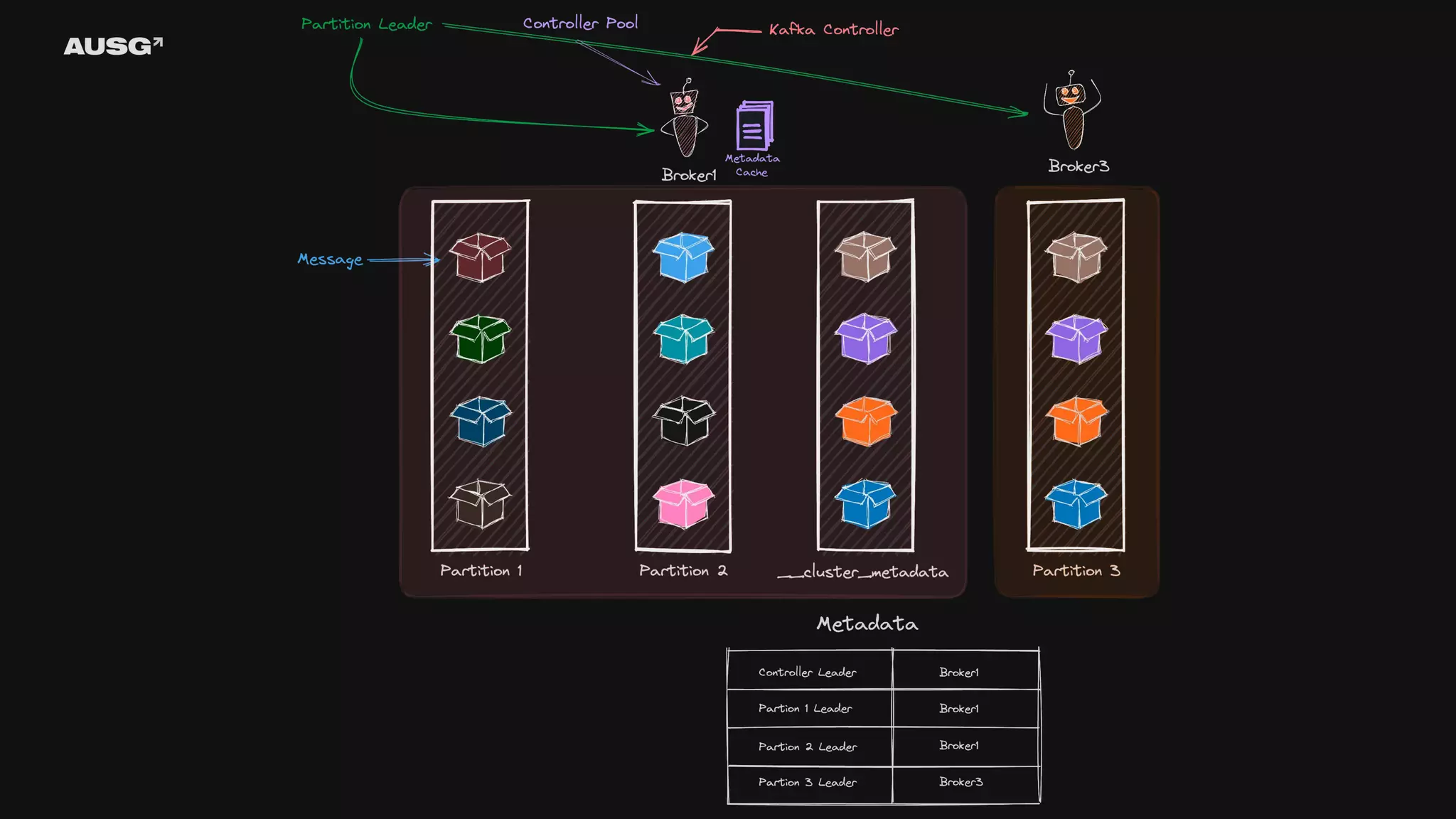
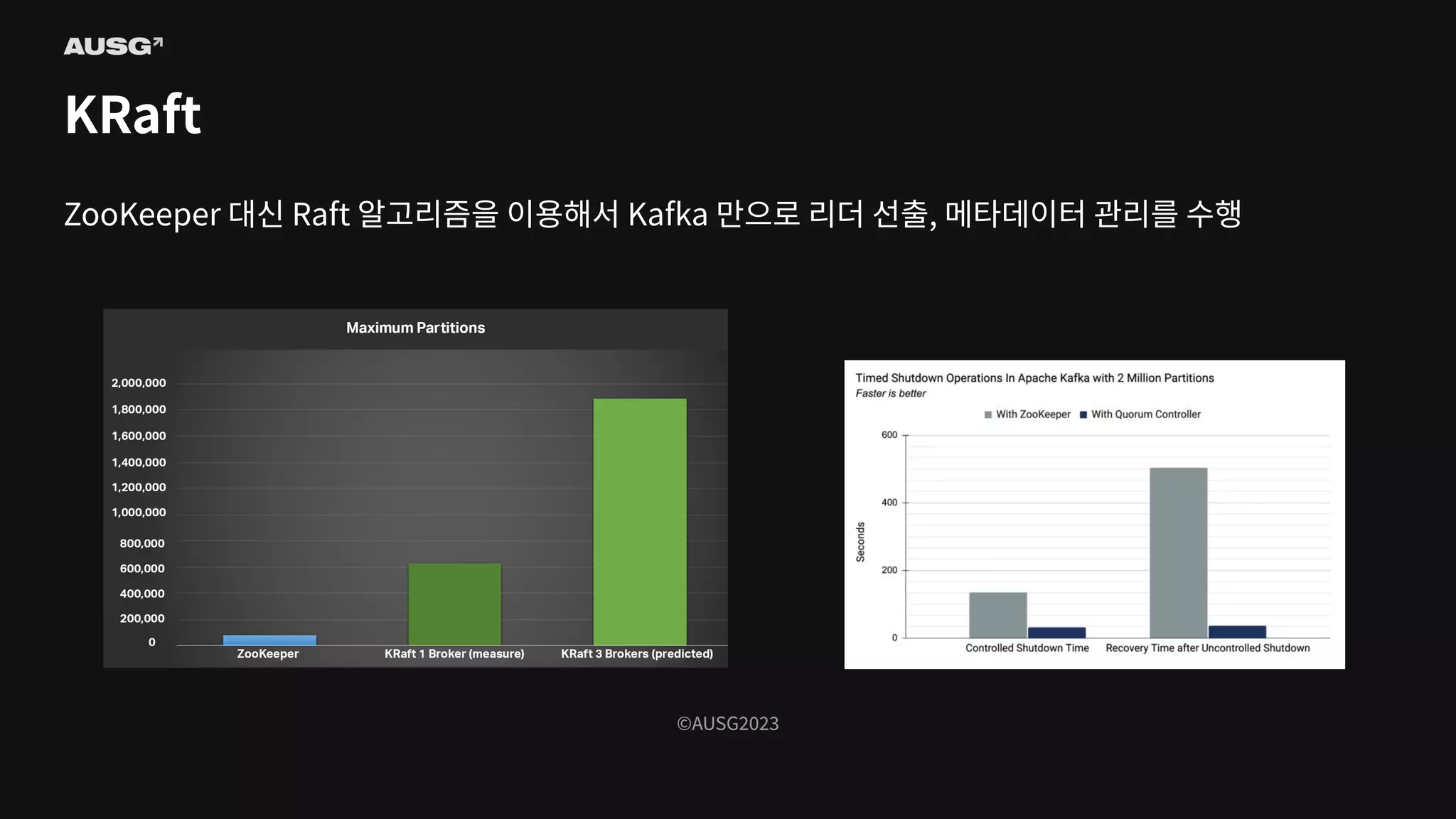
©AUSG2023 ©AUSG2023 KRaft ZooKeeper 대신 Raft
알고리즘을 이용해서 Kafka 만으로 리더 선출, 메타데이터 관리를 수행
111.
©AUSG2023 ©AUSG2023
112.
©AUSG2023 ©AUSG2023
113.
©AUSG2023 ©AUSG2023 KRaft ZooKeeper 대신 Raft
알고리즘을 이용해서 Kafka 만으로 리더 선출, 메타데이터 관리를 수행
114.
©AUSG2023 ©AUSG2023 KRaft - Kafka 2.8
버전부터 KRaft Mode 사용 가능 (2021년 4월) - Kafka 3.3.1 버전에서 KRaft Mode가 Production Ready 되었음을 발표 (2022년 10월) - Kafka 3.5 버전부터 ZooKeeper Mode Deprecated (2023년 6월) - Kafka 3.7 버전이 ZooKeeper를 지원하는 마지막 버전 (미정) - Kafka 4.0 버전부터 KRaft 모드만 지원 - Confluent Platform도 7.5 버전부터 ZooKeeper 모드를 Deprecated 시켜버림 - 새 배포에는 KRaft 모드를 적용하는 것을 권장
115.
©AUSG2023 긴 발표를 들어주셔서
감사합니다

















































![©AUSG2023
©AUSG2023
분산 시스템에서 합의는 왜 필요한가?
- 리더 선출(Leader Election)
- Leader : Broker1
- 분산 시스템 간의 일관된 데이터
- Cluster Name : My-Cluster
- 멤버십 관리
- Members : [Broker1, Broker2, Broker3]](https://image.slidesharecdn.com/zpvrrko5q8g1229bssj2-20230904-yunjongweon-kafka-wa-zookeeperyi-heeojil-gyeolsim-230906080538-452abe16/85/Kafka-ZooKeeper-73-320.jpg)
































































![©AUSG2023
©AUSG2023
분산 시스템에서 합의는 왜 필요한가?
- 리더 선출(Leader Election)
- Leader : Broker1
- 분산 시스템 간의 일관된 데이터
- Cluster Name : My-Cluster
- 멤버십 관리
- Members : [Broker1, Broker2, Broker3]](https://image.slidesharecdn.com/zpvrrko5q8g1229bssj2-20230904-yunjongweon-kafka-wa-zookeeperyi-heeojil-gyeolsim-230906080538-452abe16/75/Kafka-ZooKeeper-73-2048.jpg)































![[AWS Dev Day] 앱 현대화 | AWS Fargate를 사용한 서버리스 컨테이너 활용 하기 - 삼성전자 개발자 포털 사례 - 정영준...](https://cdn.slidesharecdn.com/ss_thumbnails/appmodernizationawsfargate-190930044252-thumbnail.jpg?width=600ounds&width=560&fit=bounds)










![3.[d2 오픈세미나]분산시스템 개발 및 교훈 n base arc](https://cdn.slidesharecdn.com/ss_thumbnails/3-140905000012-phpapp01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







![[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/244nms-171017030833-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







![[자바카페] 람다 일괄처리 계층](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatalambdabatch-190419124939-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

