

























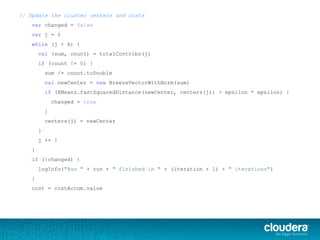
.asInstanceOf[BV[Double]])
val counts = Array.fill(k)(0L)
points.foreach { point =>
val (bestCenter, cost) = KMeans.findClosest(centers, point)
costAccum += cost
sums(bestCenter) += point.vector
counts(bestCenter) += 1
}
val contribs = for (j <- 0 until k) yield {
(j, (sums(j), counts(j)))
}
contribs.iterator
}.reduceByKey(mergeContribs).collectAsMap()](https://image.slidesharecdn.com/greetalk-140516140114-phpapp02/85/Large-Scale-Machine-Learning-with-Apache-Spark-49-320.jpg)



































.asInstanceOf[BV[Double]])
val counts = Array.fill(k)(0L)
points.foreach { point =>
val (bestCenter, cost) = KMeans.findClosest(centers, point)
costAccum += cost
sums(bestCenter) += point.vector
counts(bestCenter) += 1
}
val contribs = for (j <- 0 until k) yield {
(j, (sums(j), counts(j)))
}
contribs.iterator
}.reduceByKey(mergeContribs).collectAsMap()](https://image.slidesharecdn.com/greetalk-140516140114-phpapp02/75/Large-Scale-Machine-Learning-with-Apache-Spark-49-2048.jpg)







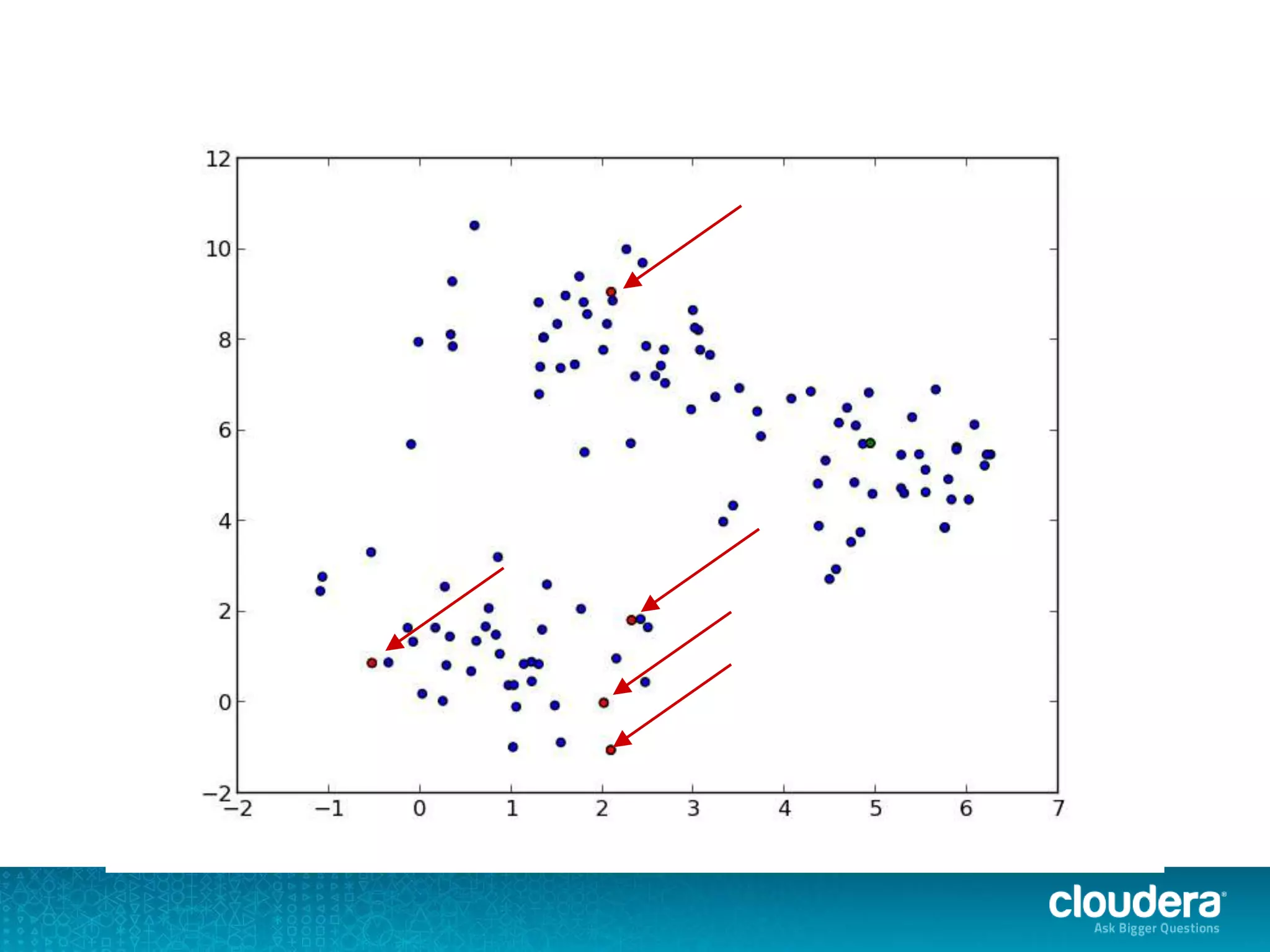
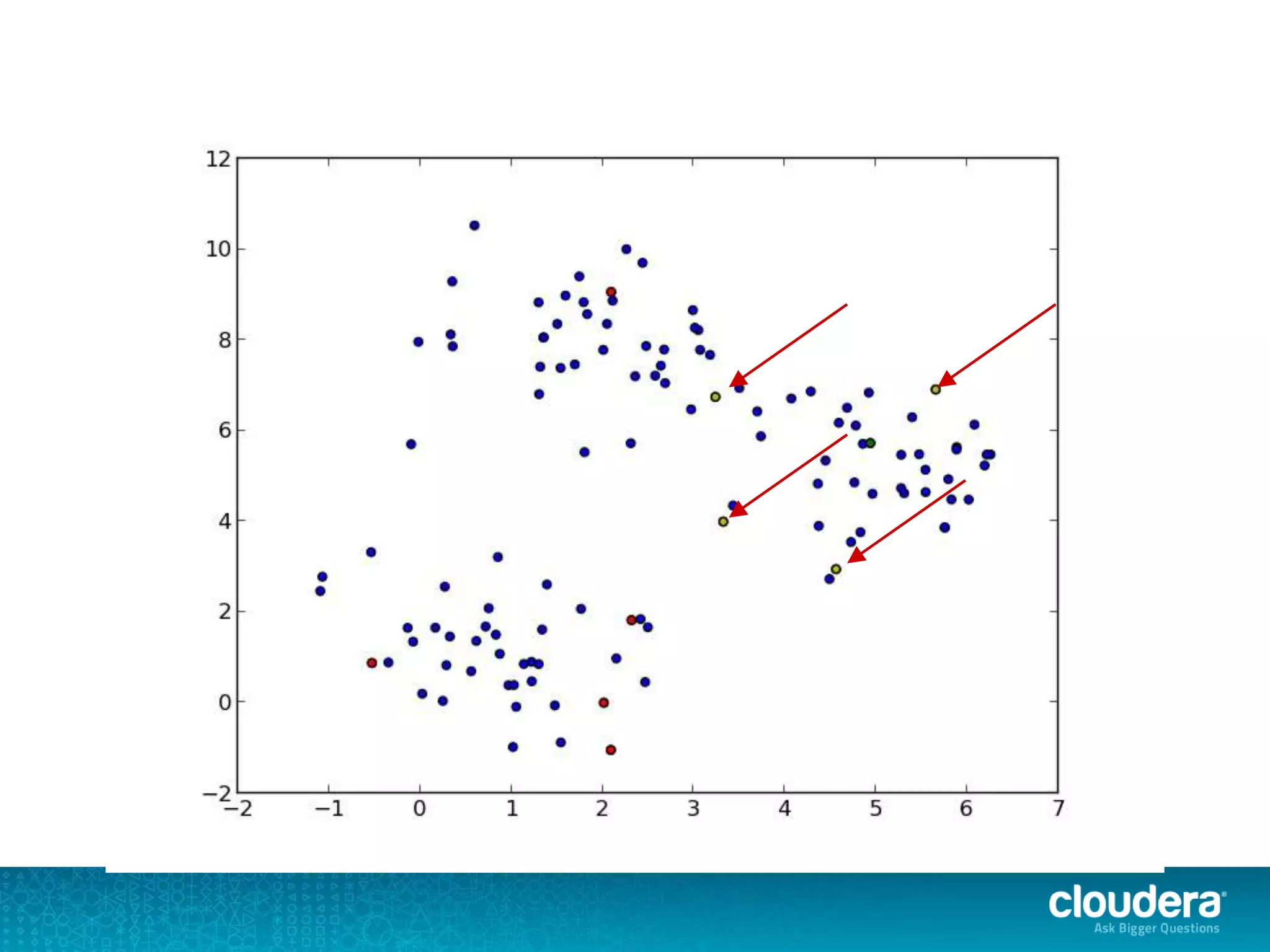
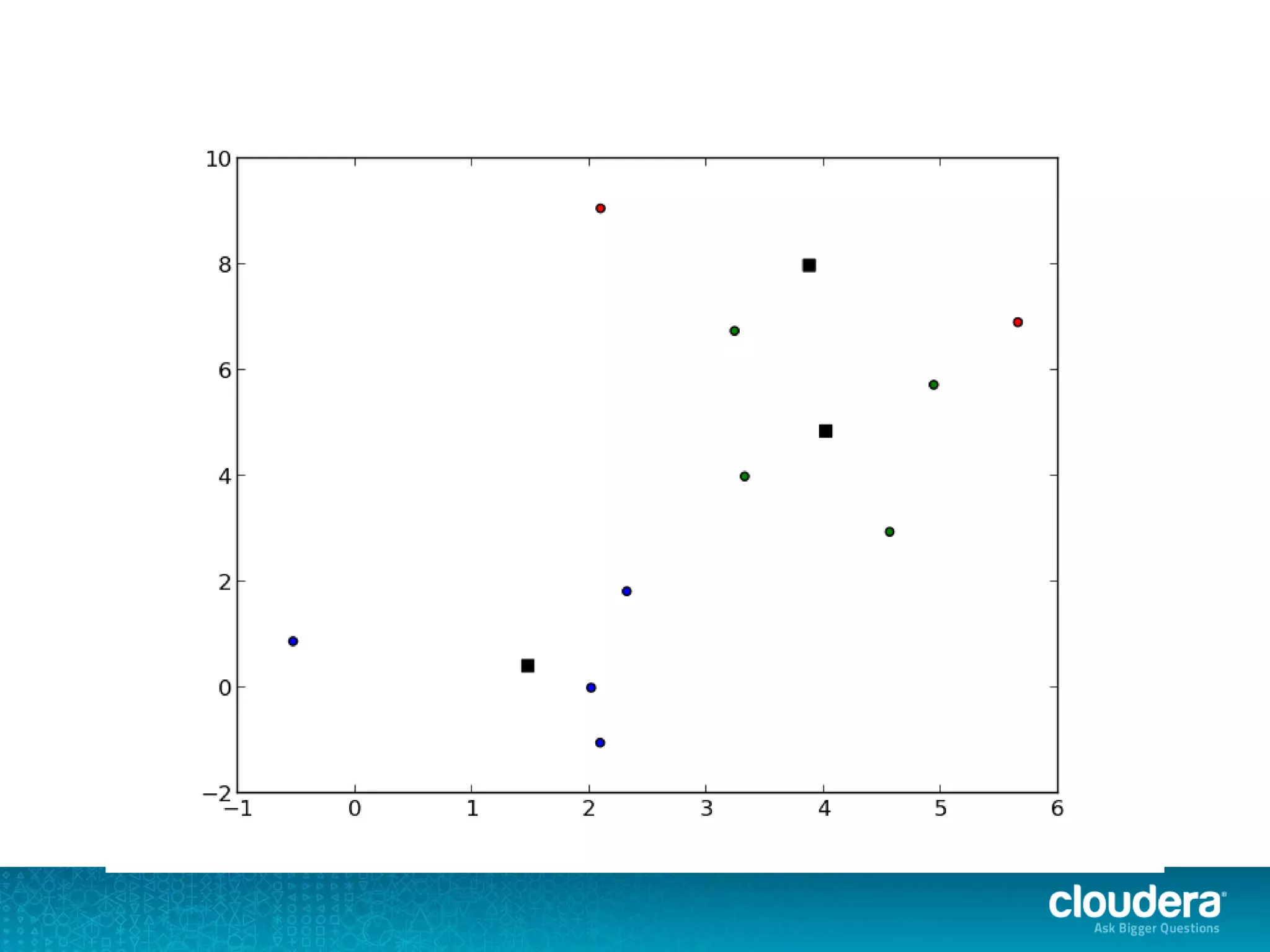
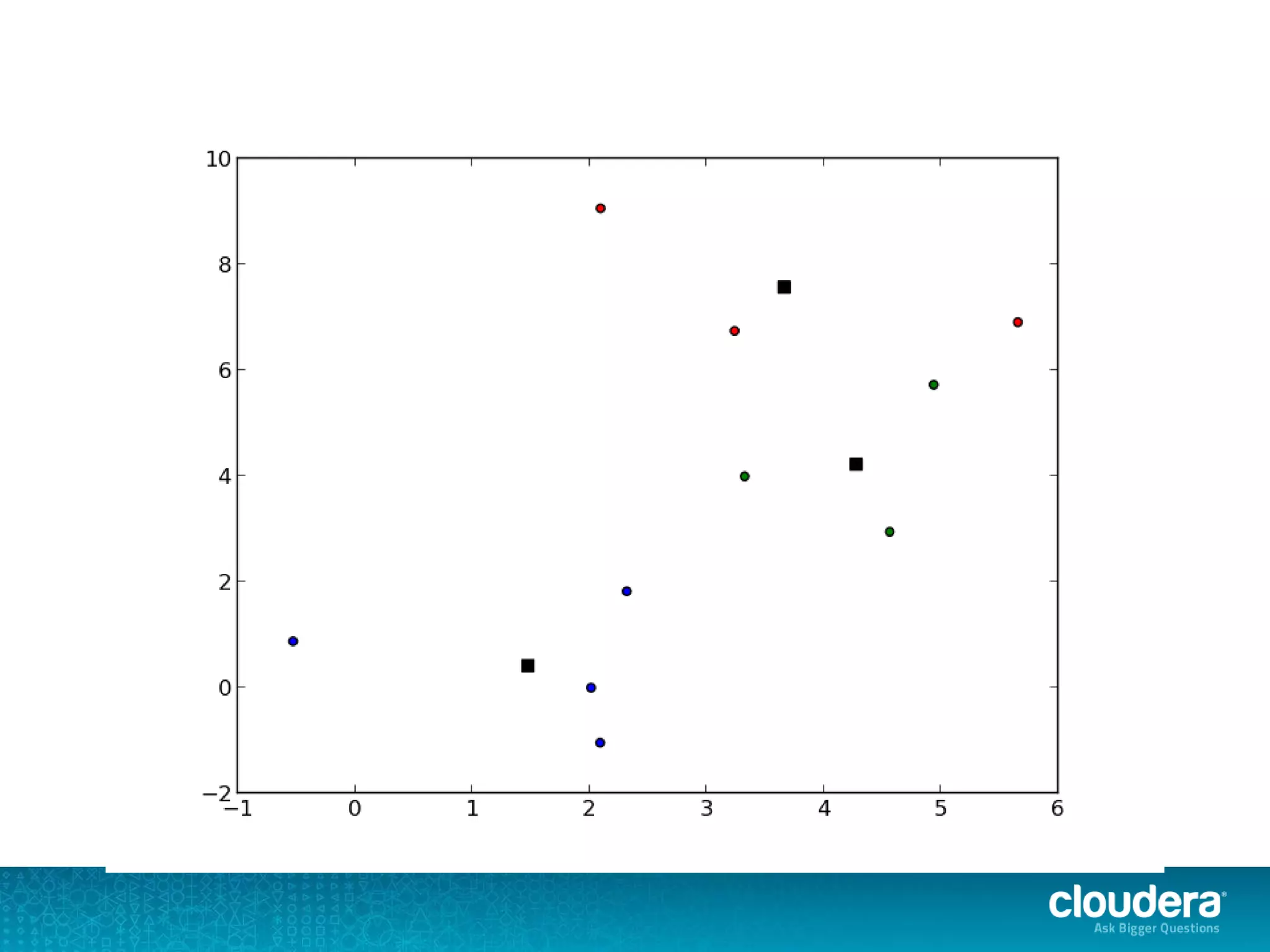
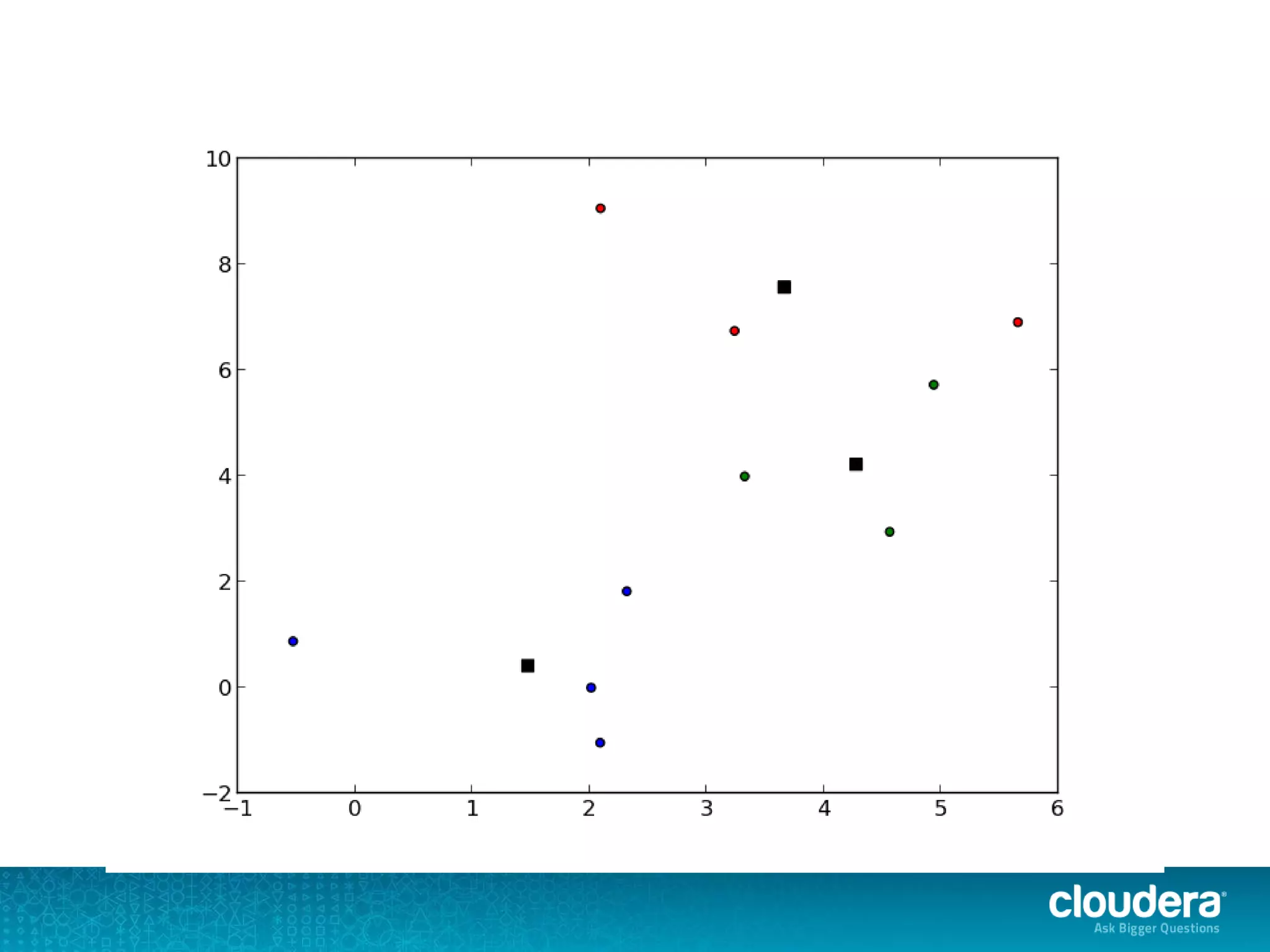


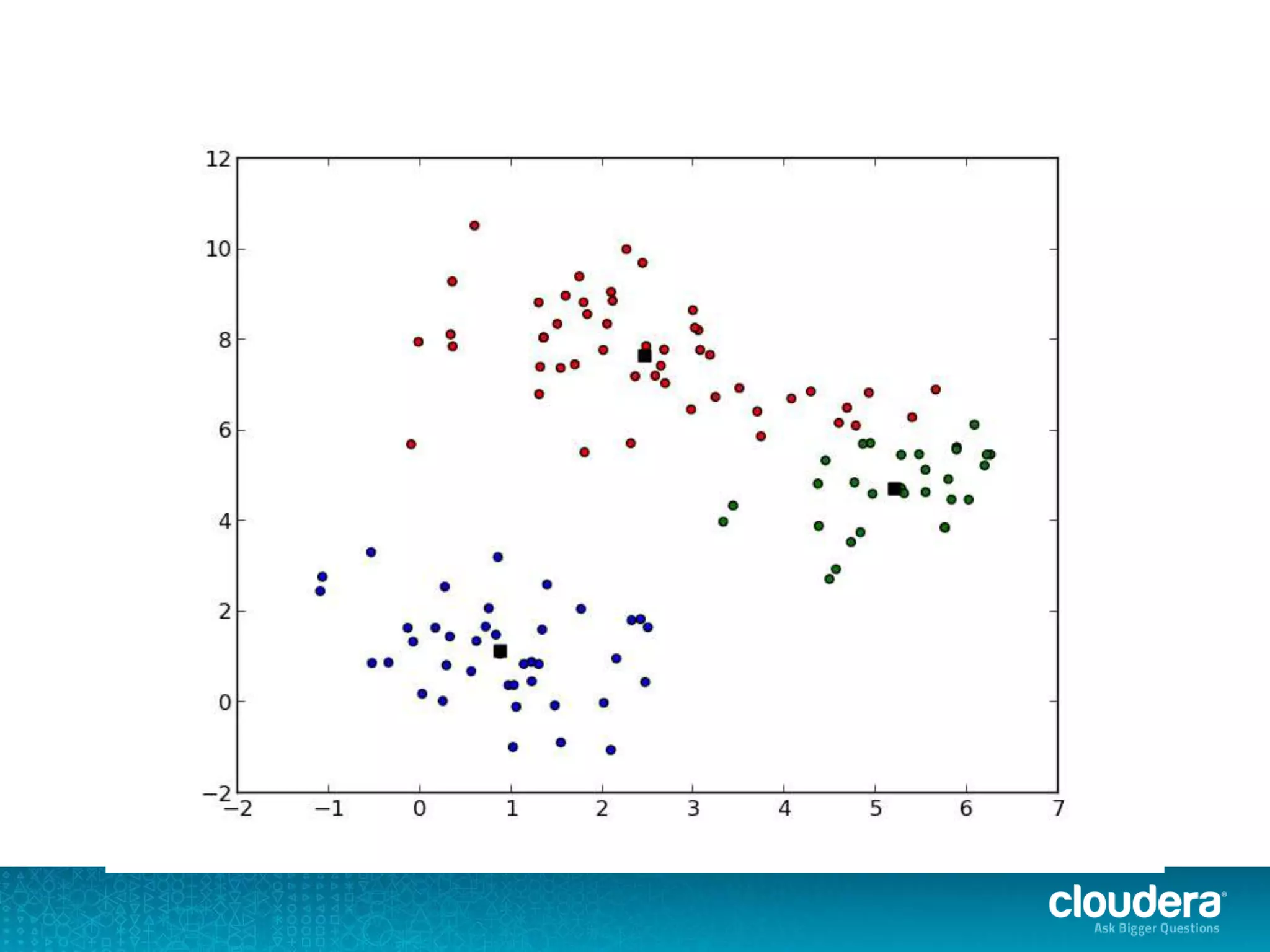

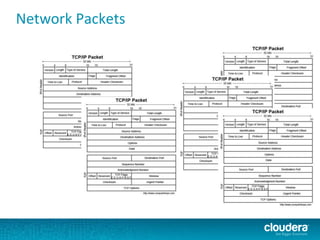
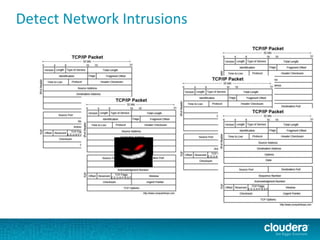
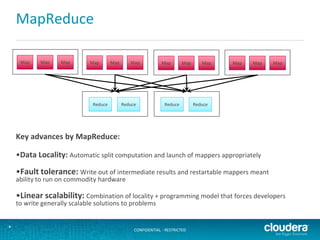
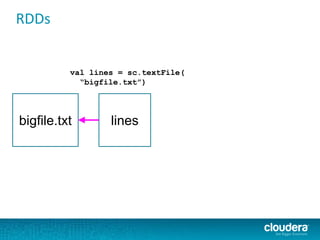
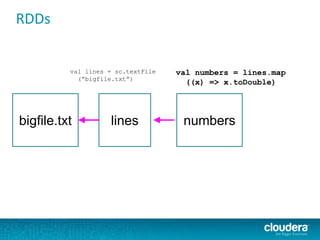
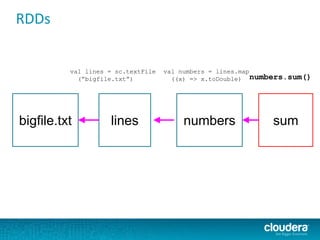
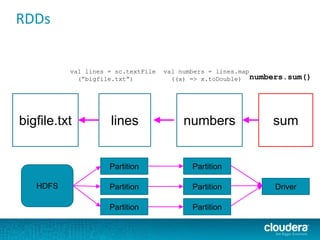
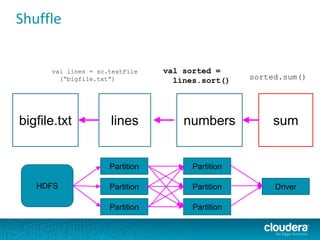
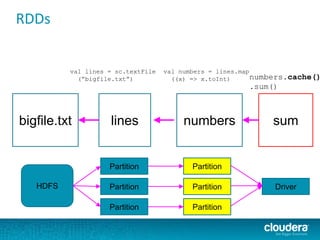
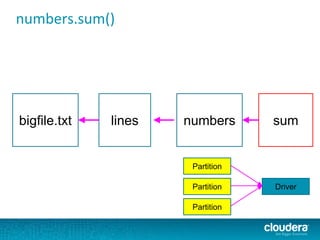
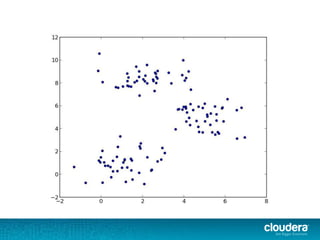
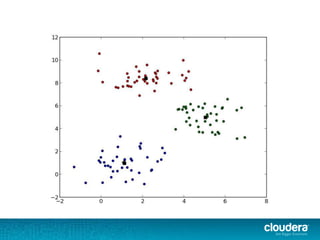
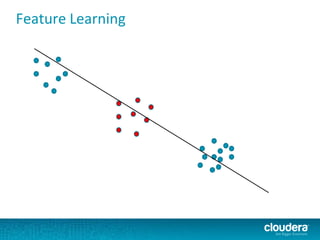
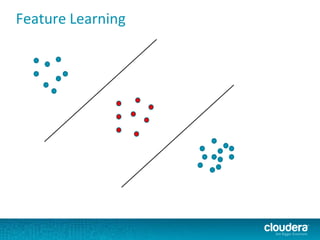
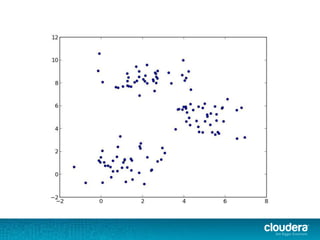
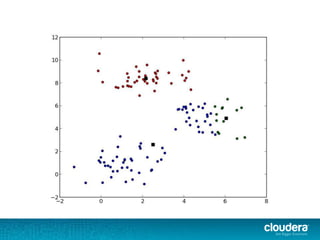
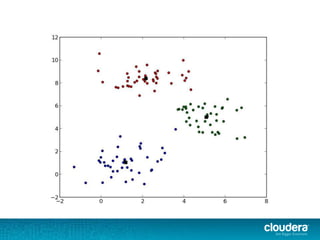
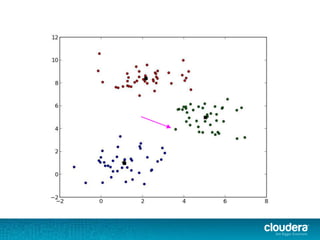
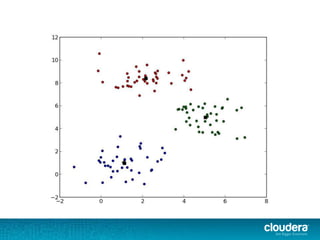
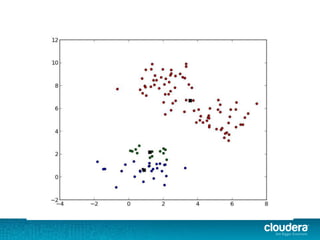
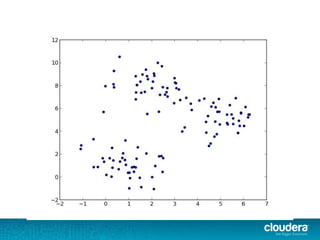
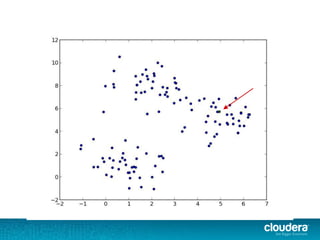
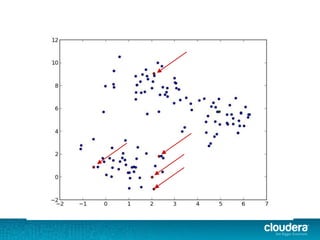
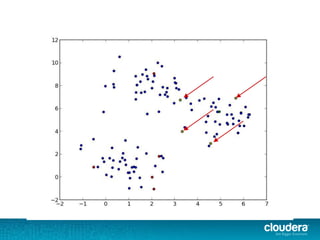
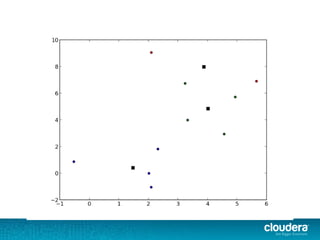
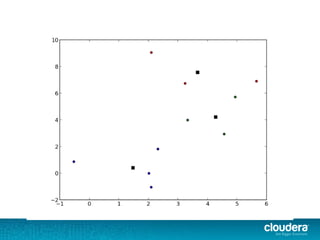
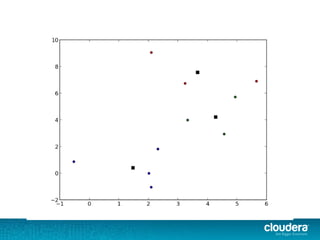
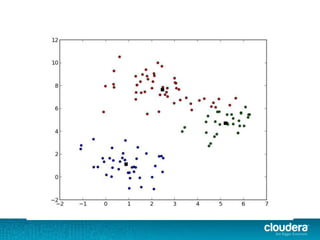
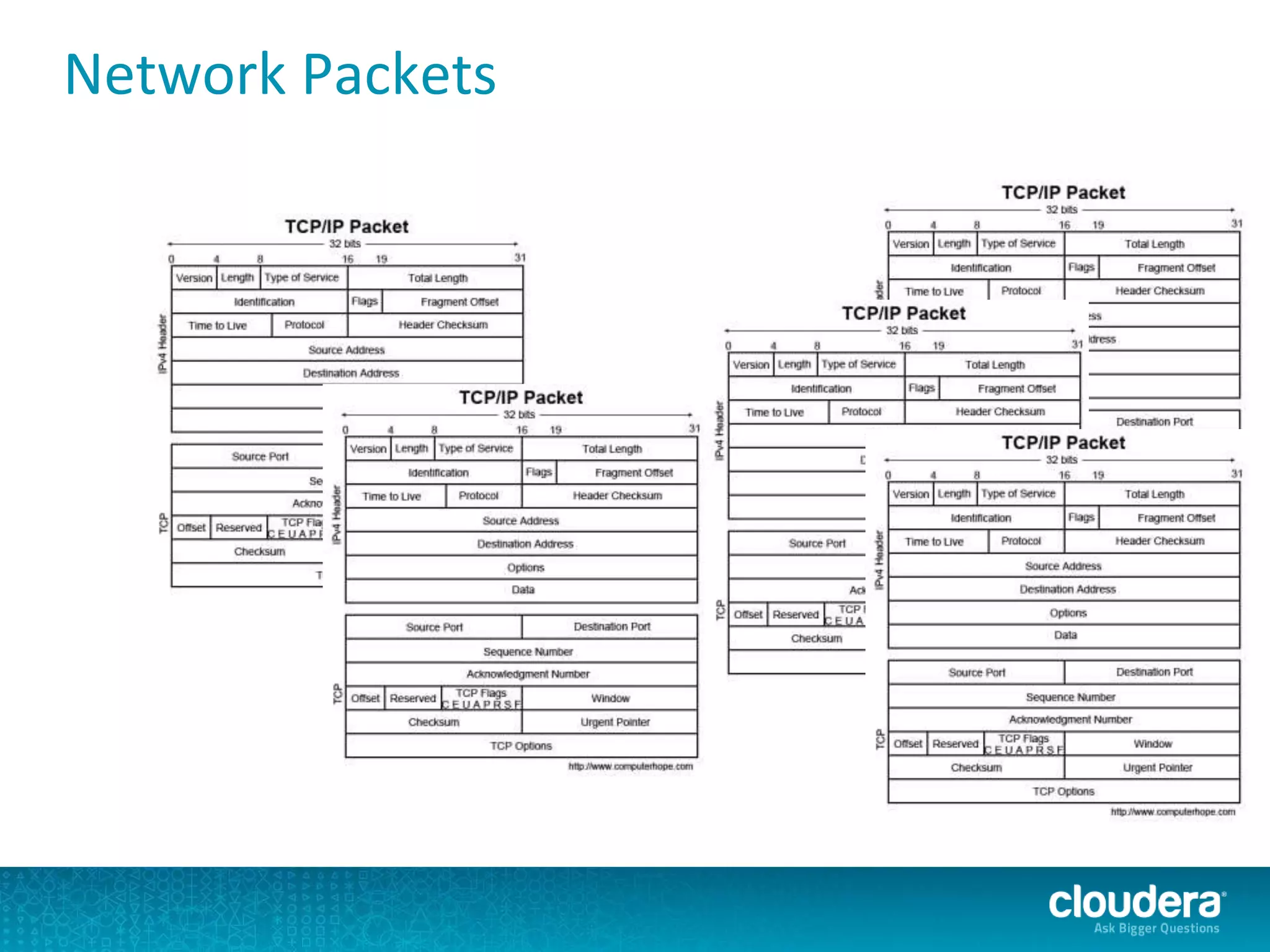
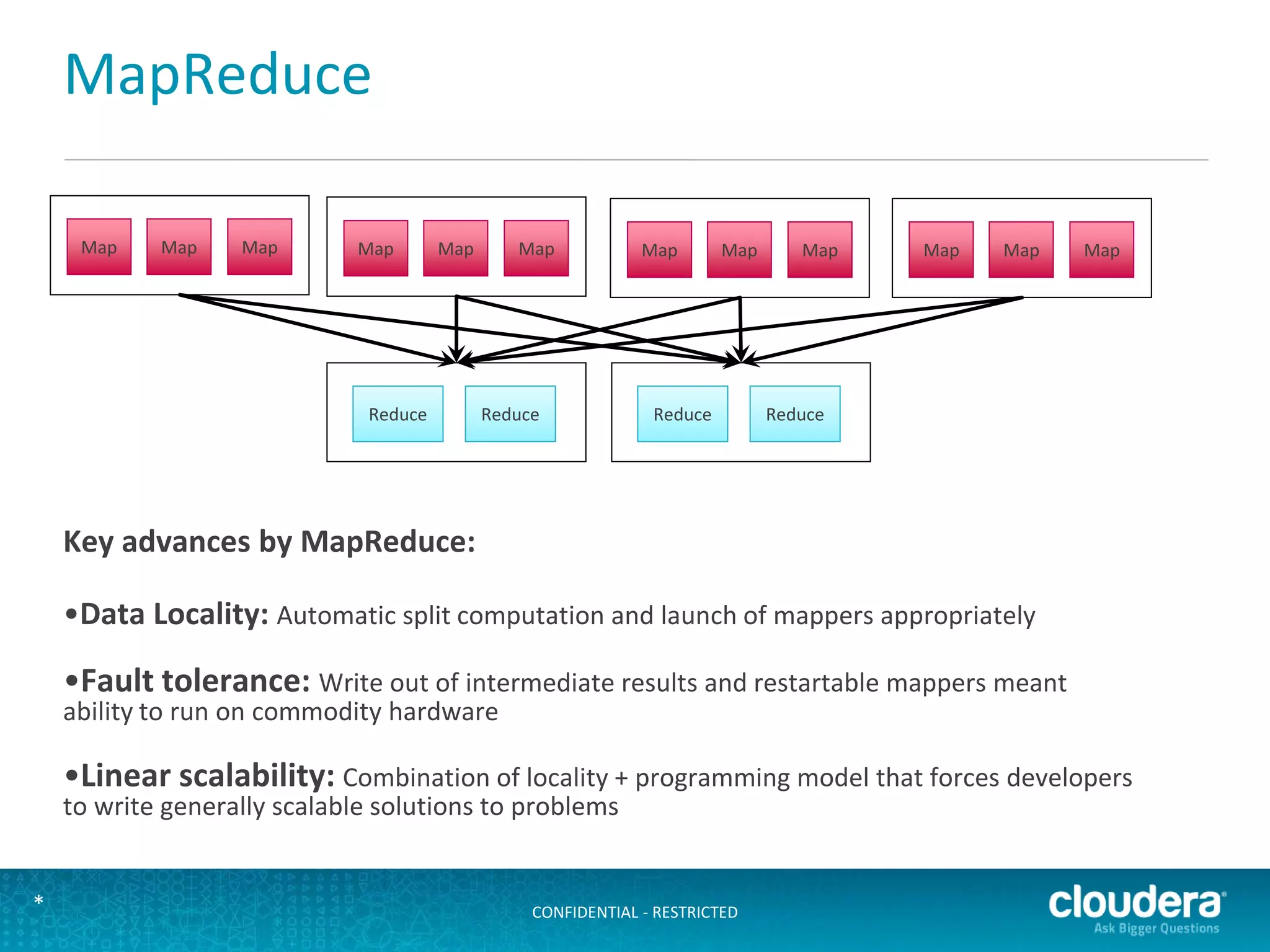
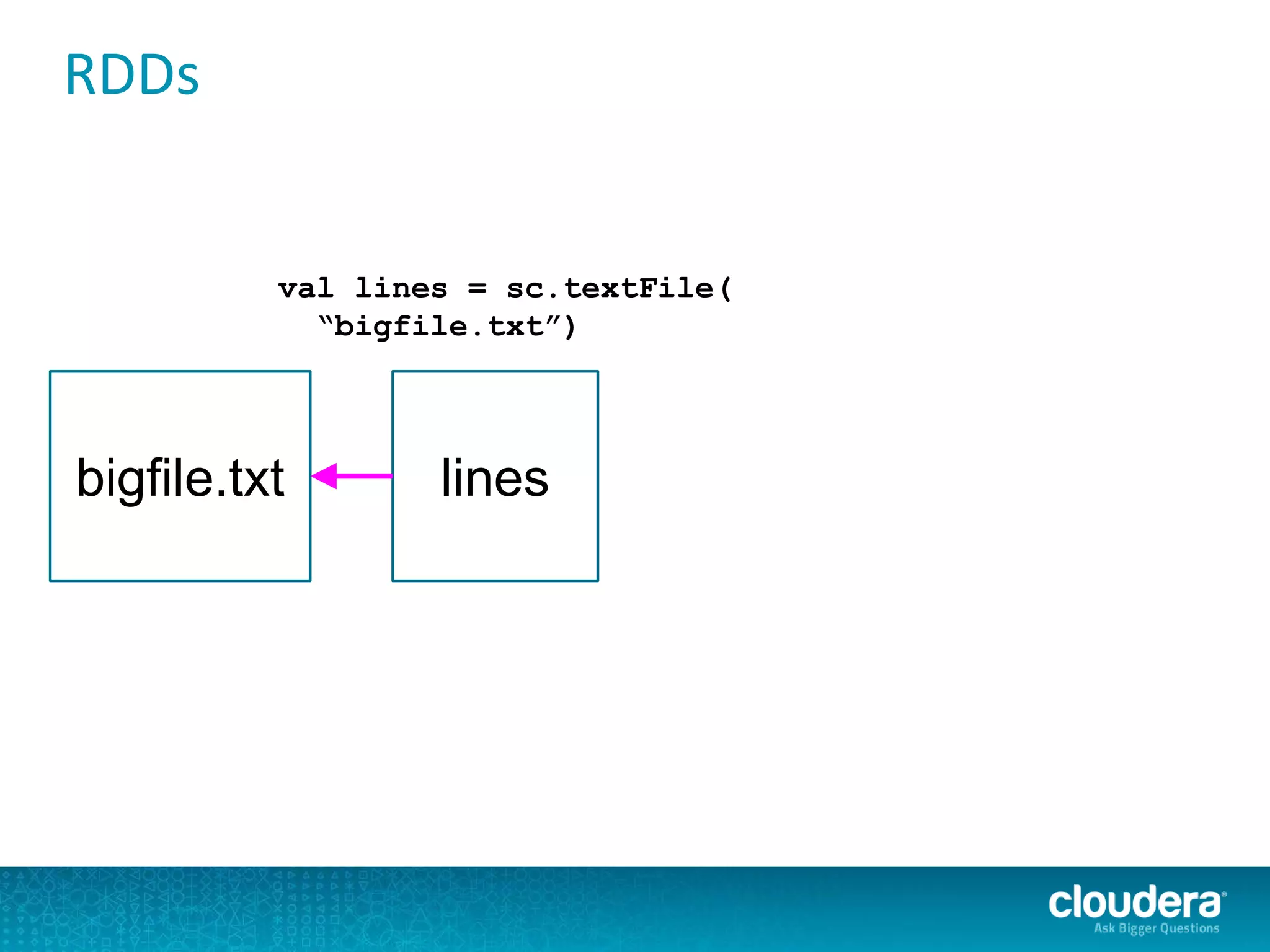
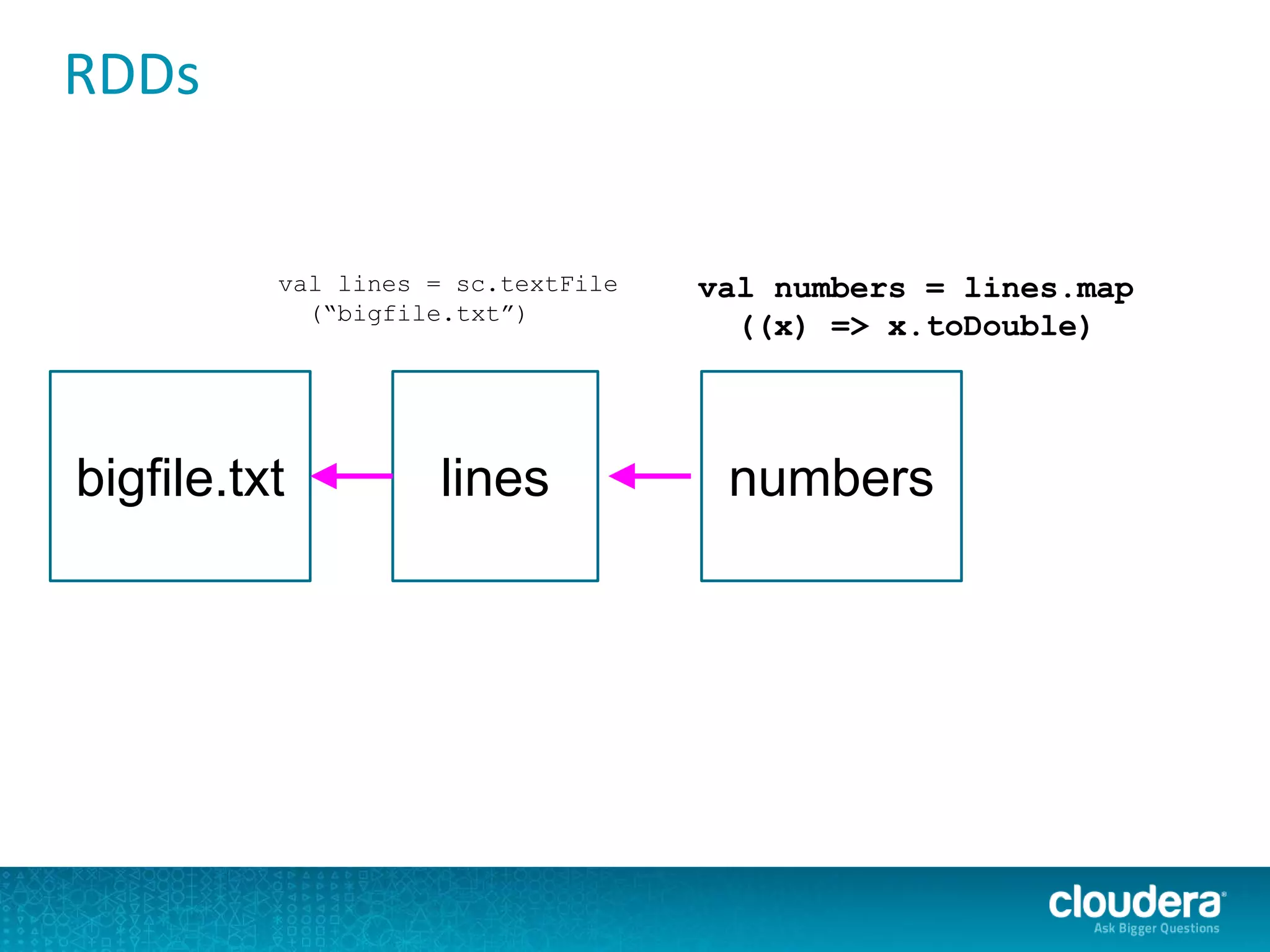
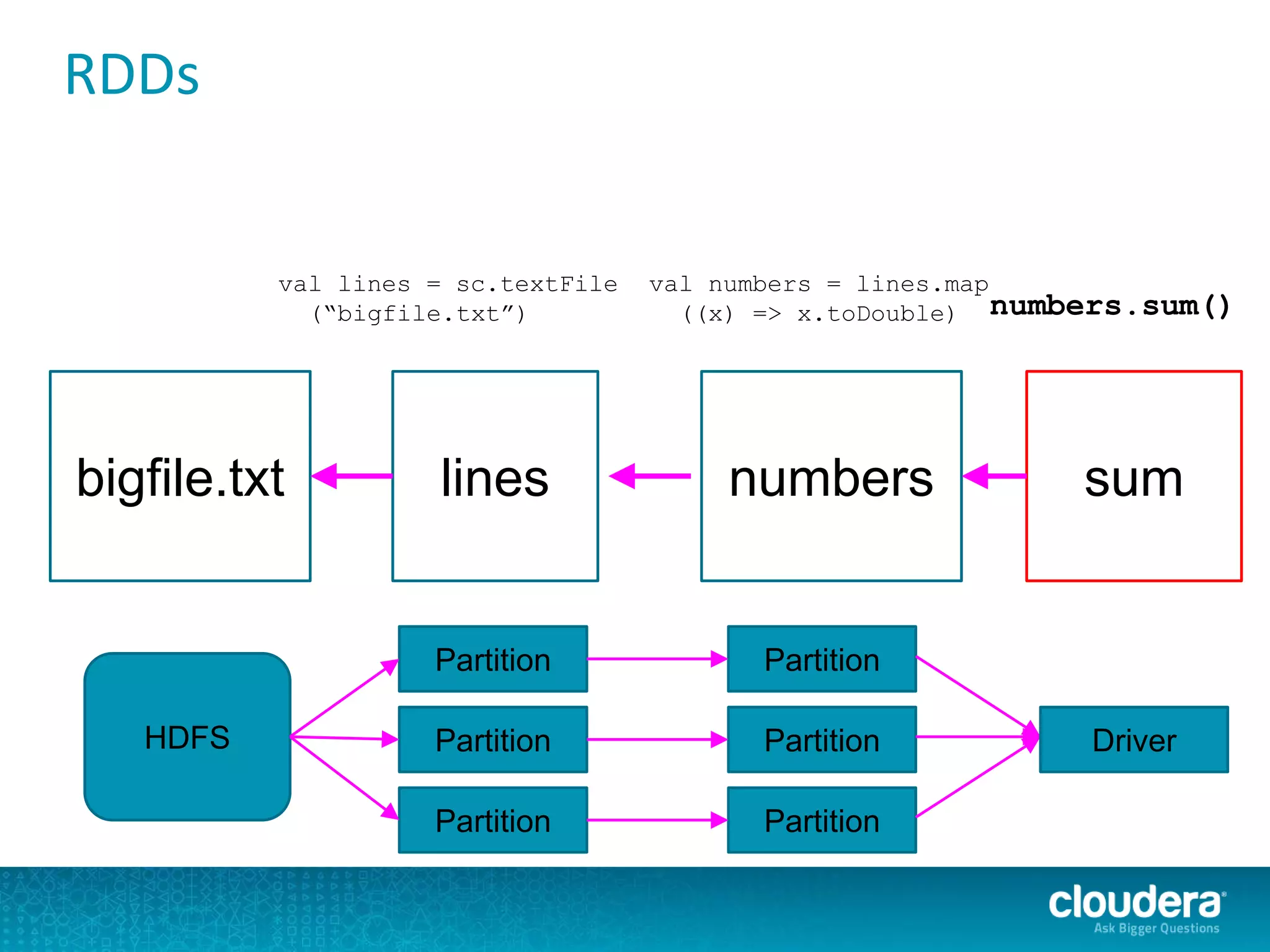
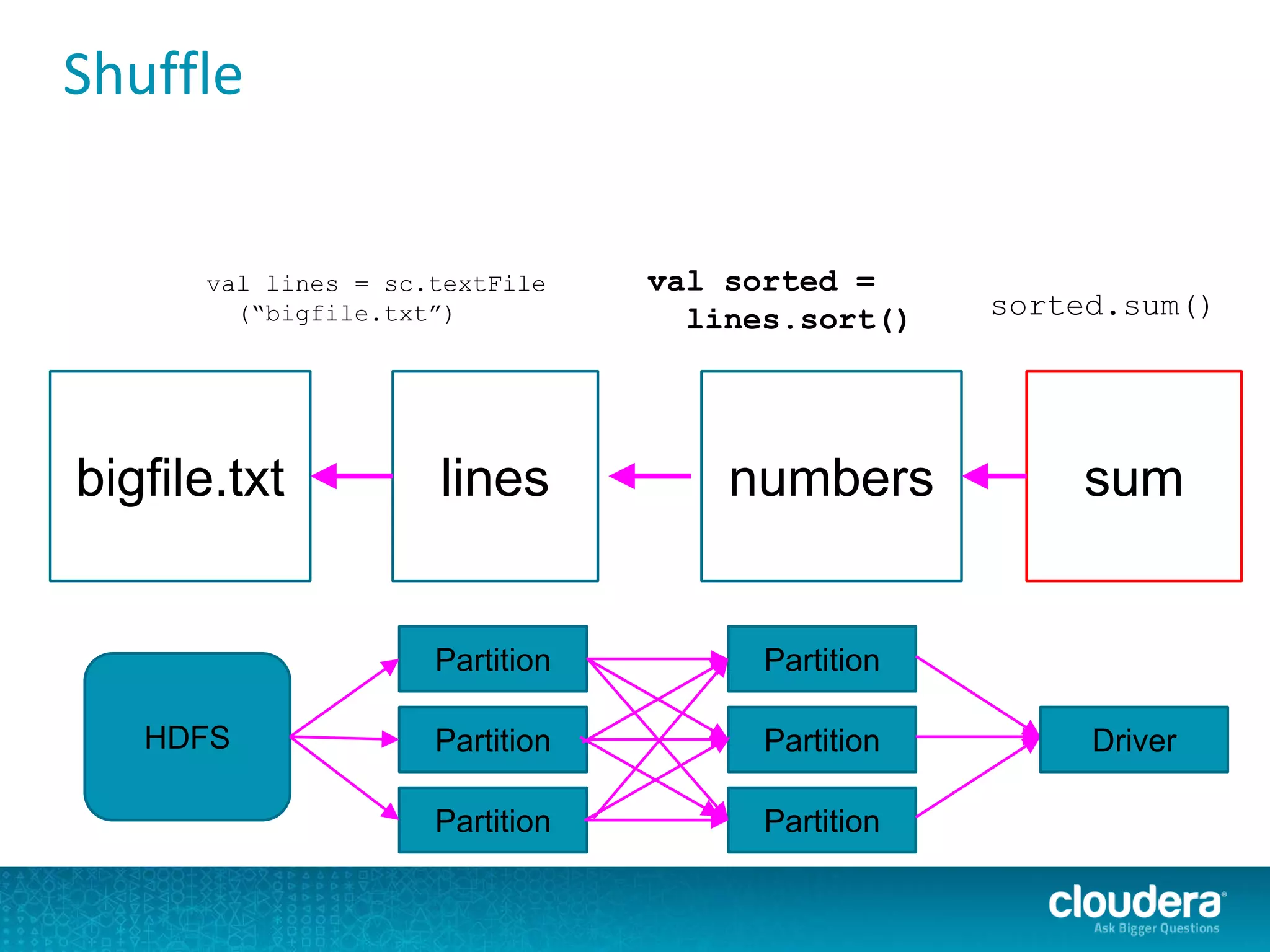
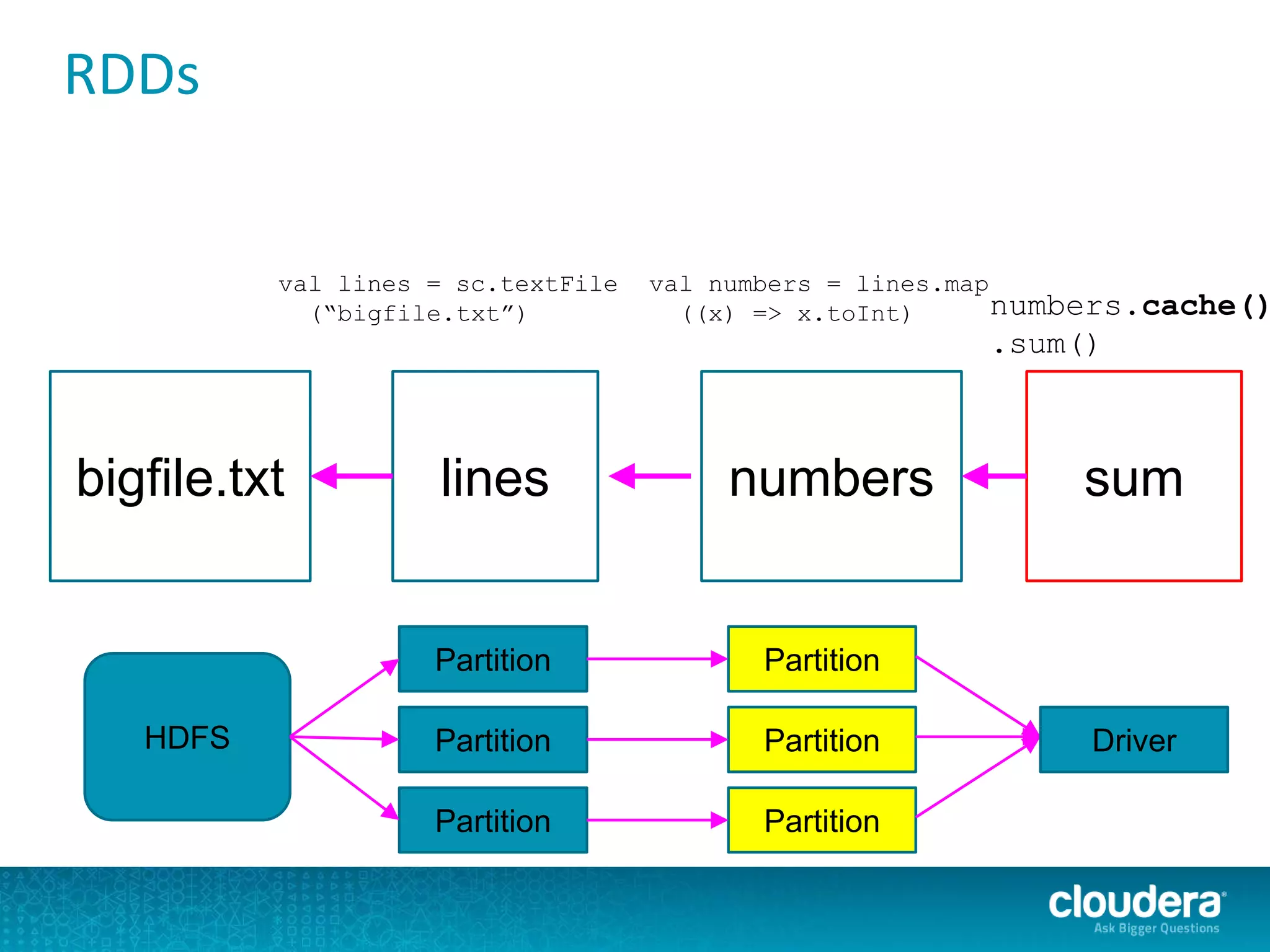
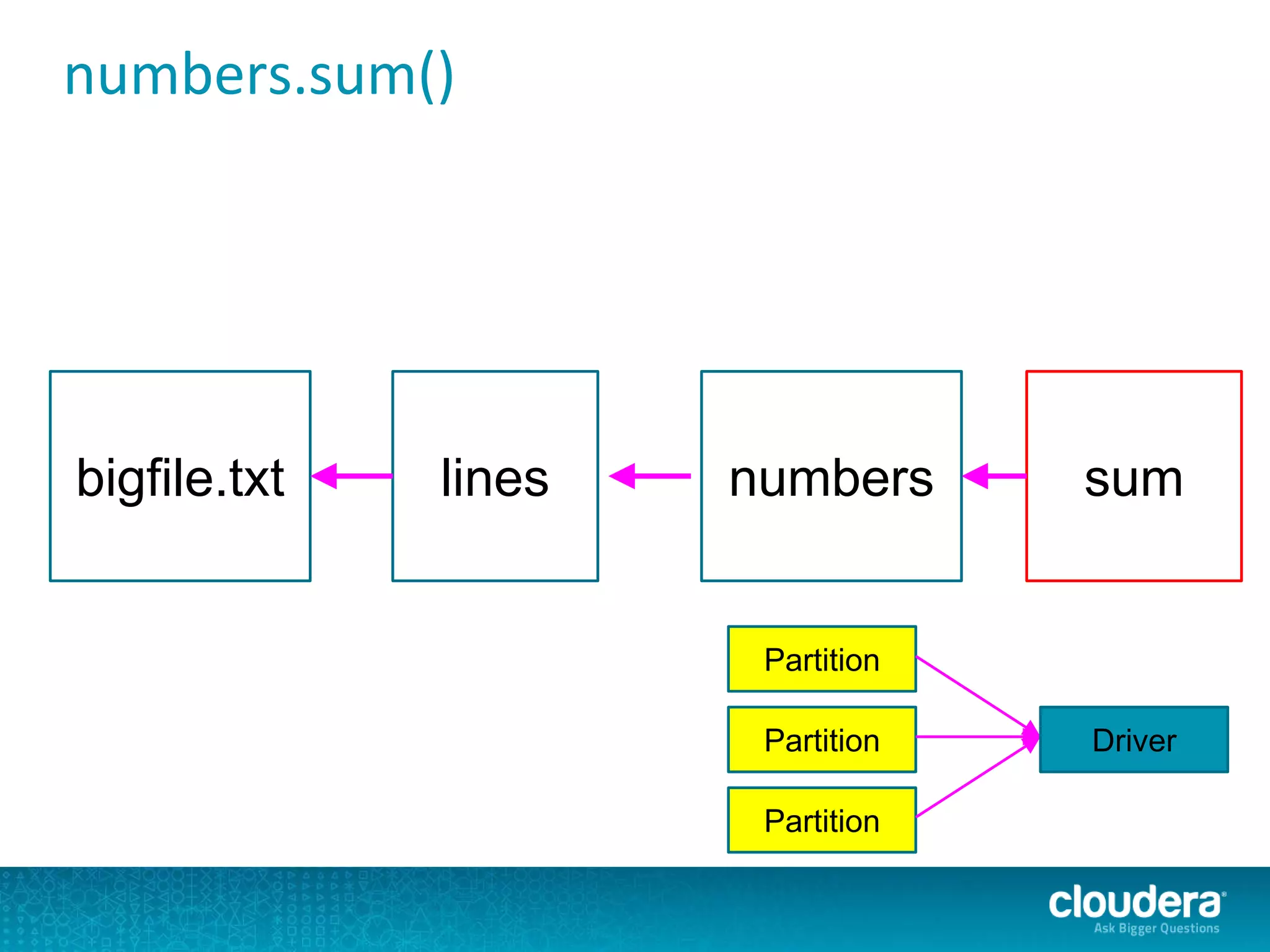
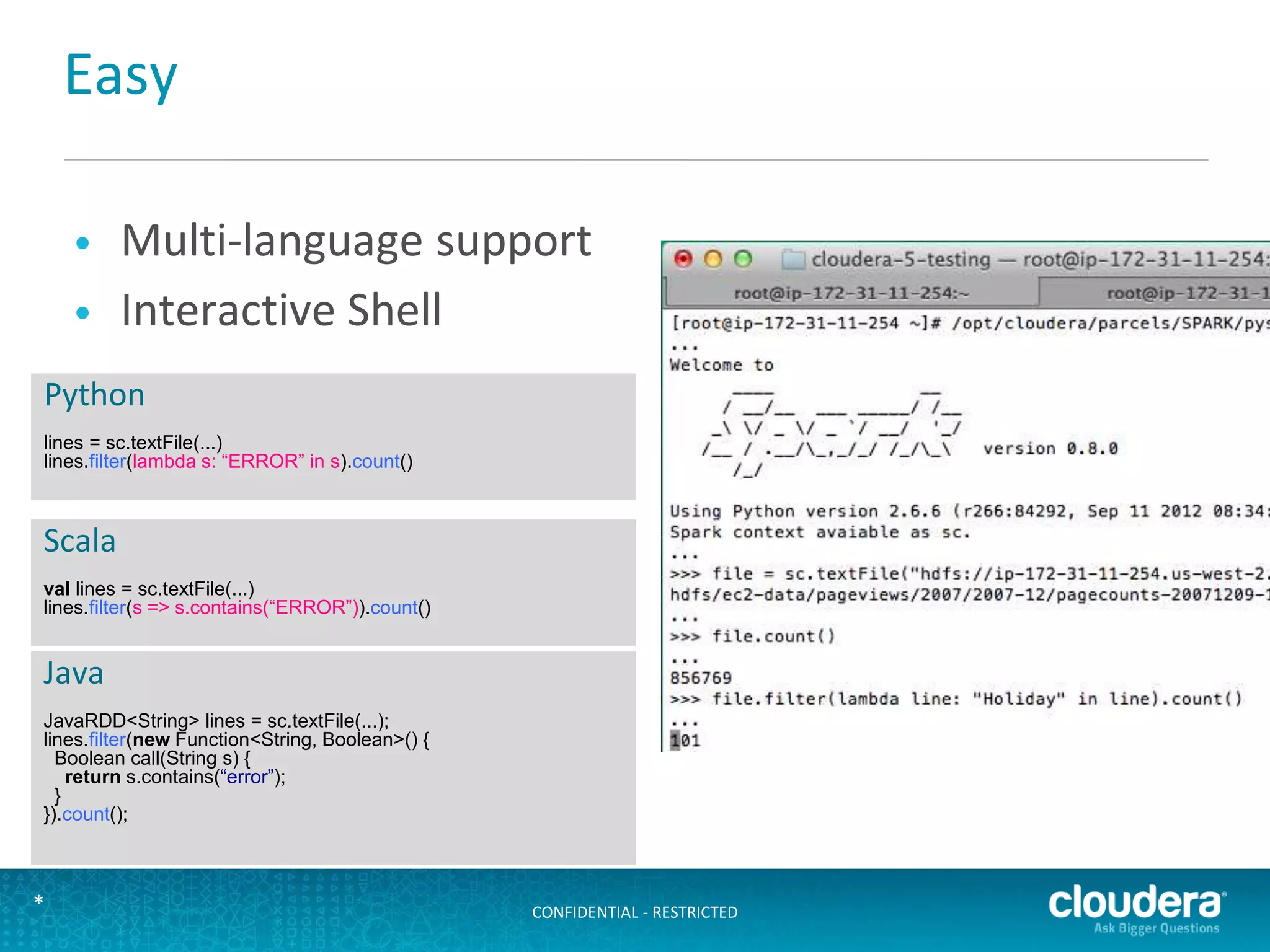
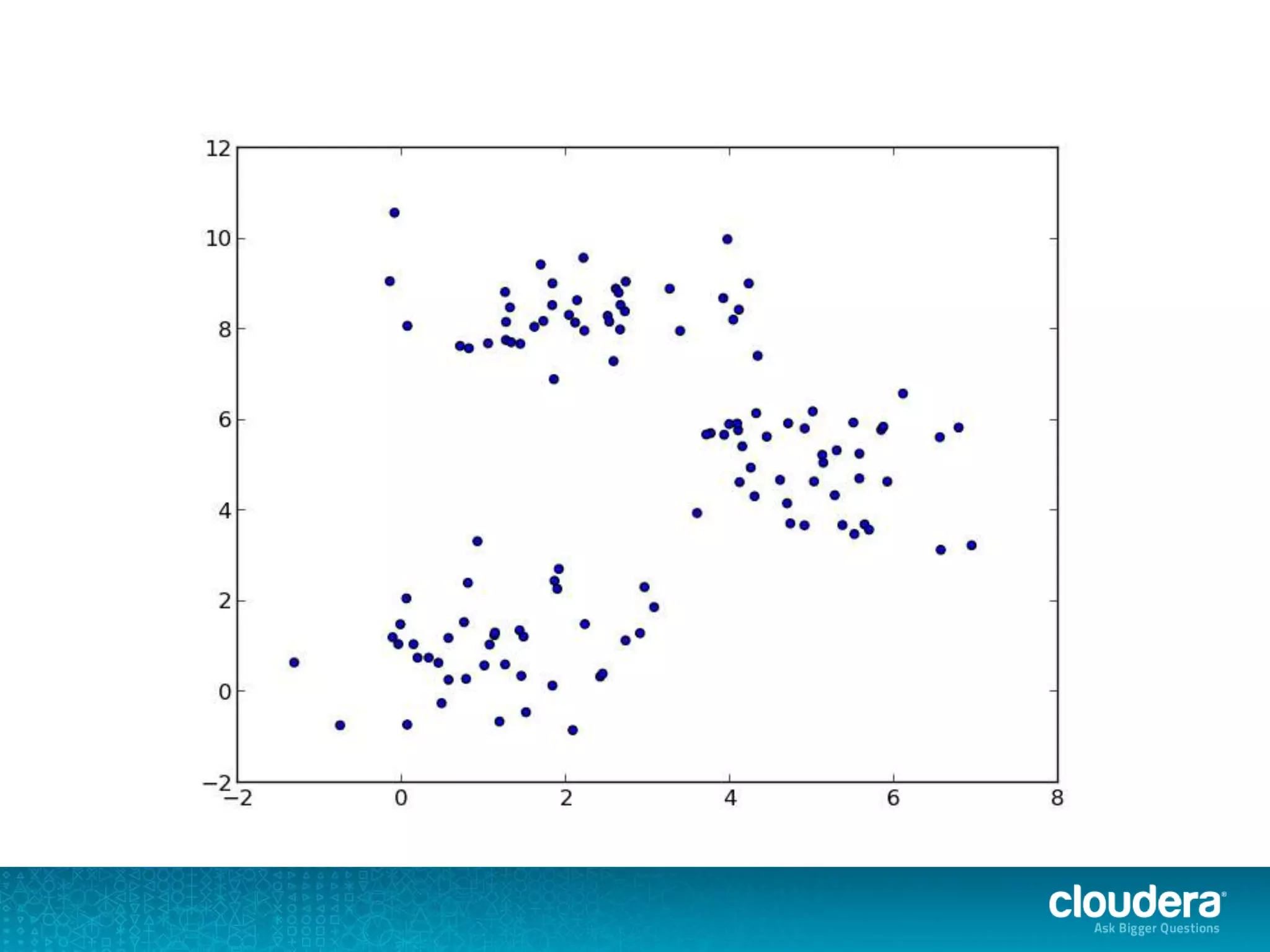
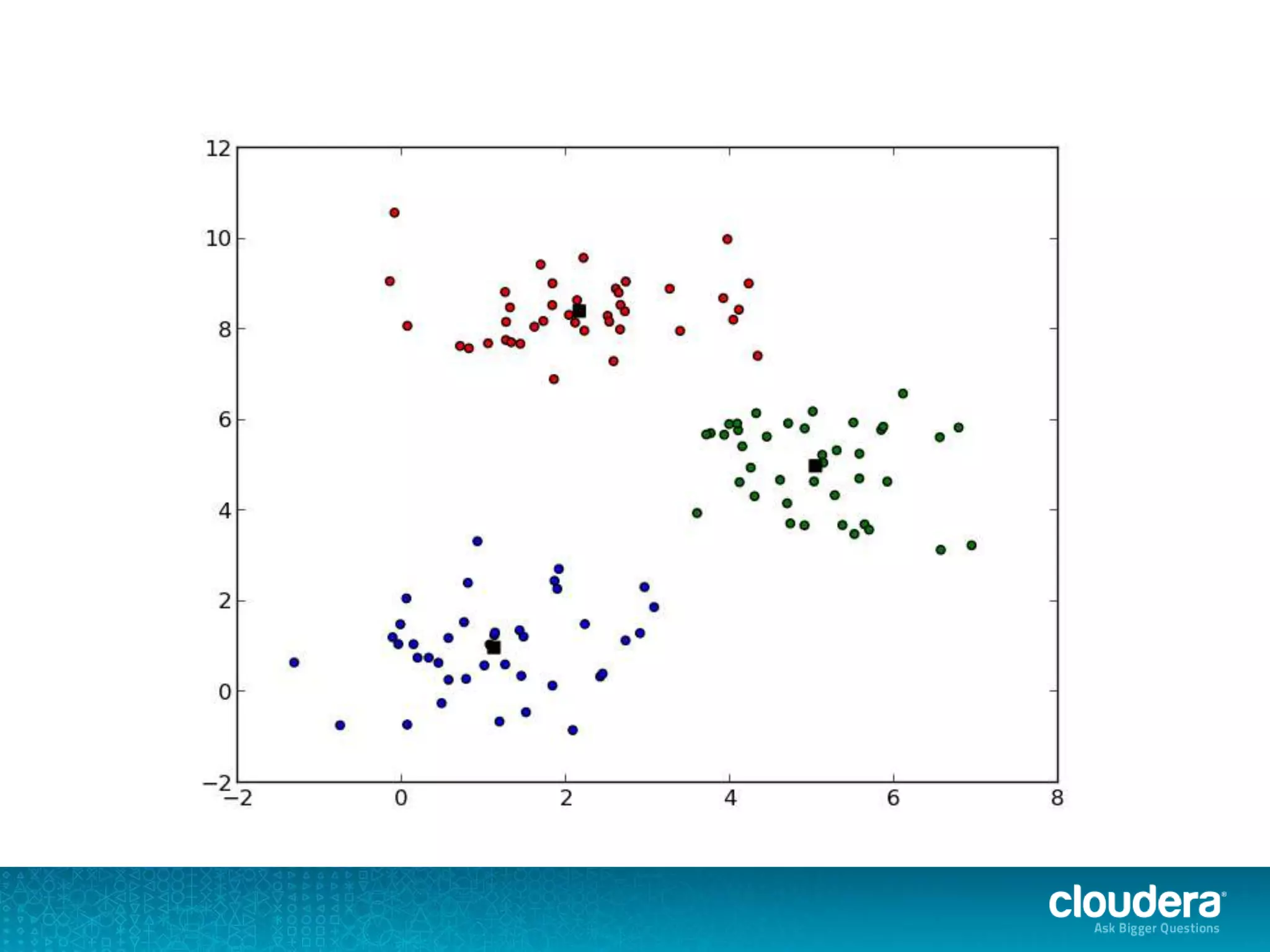
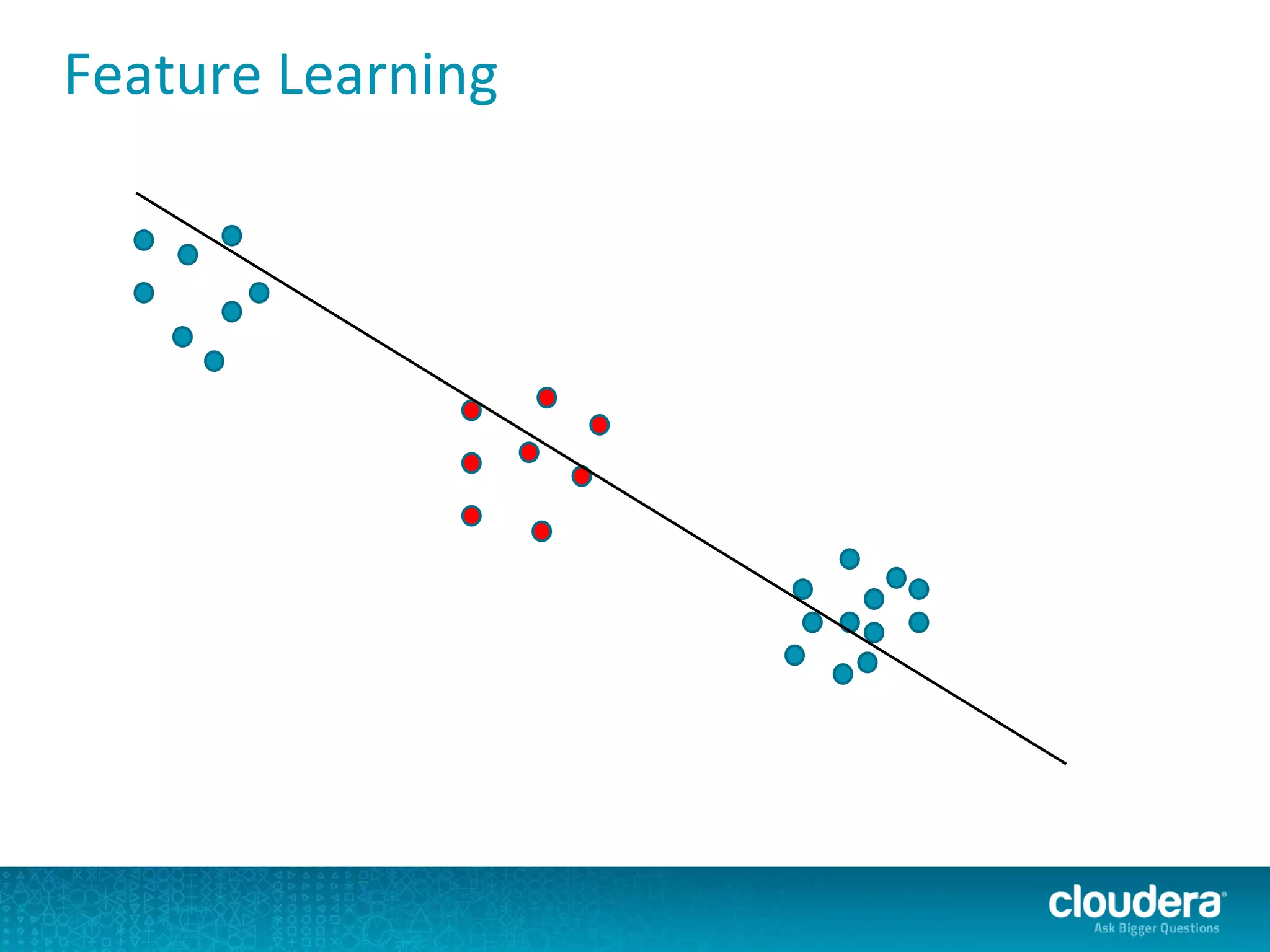
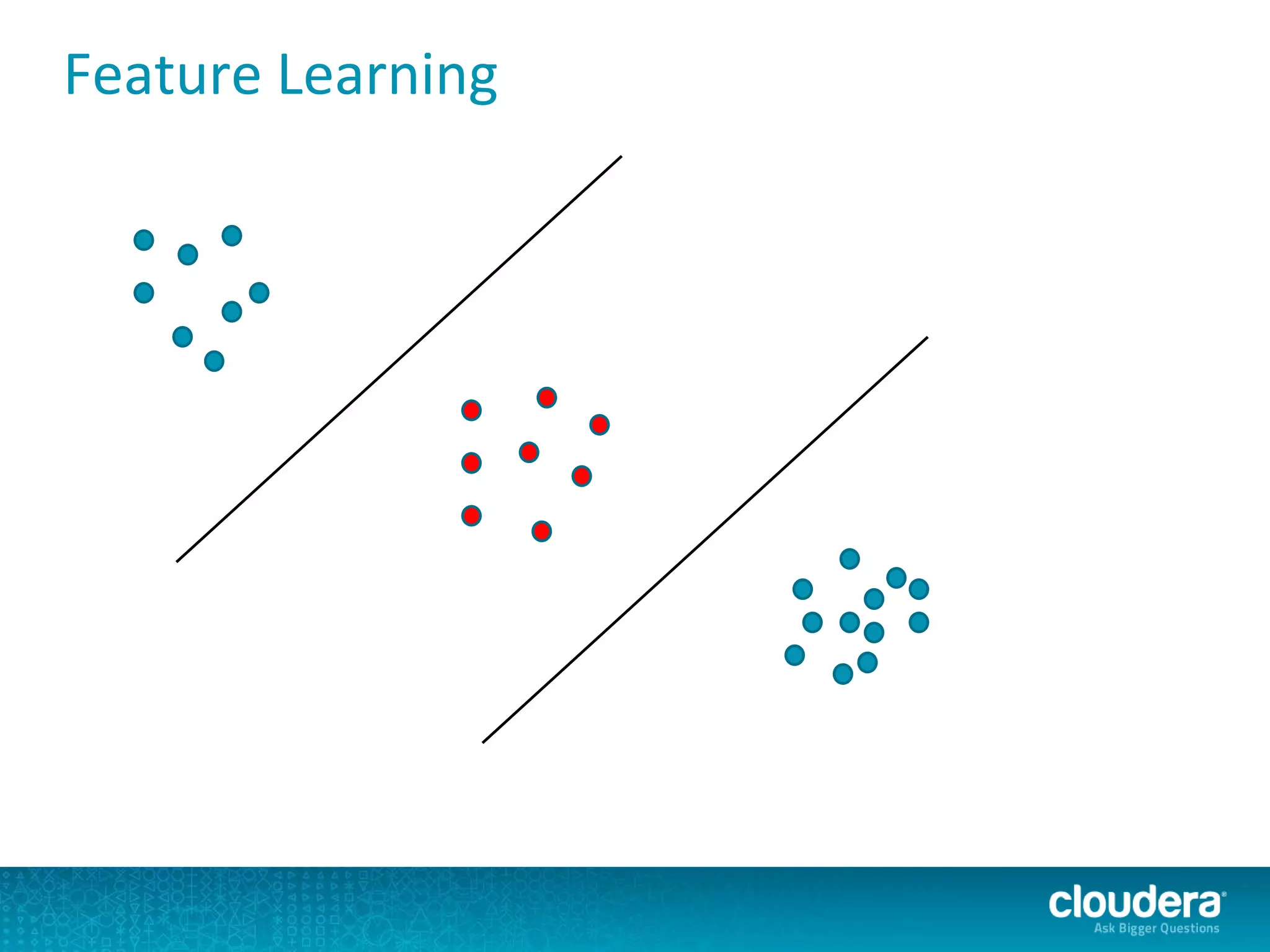
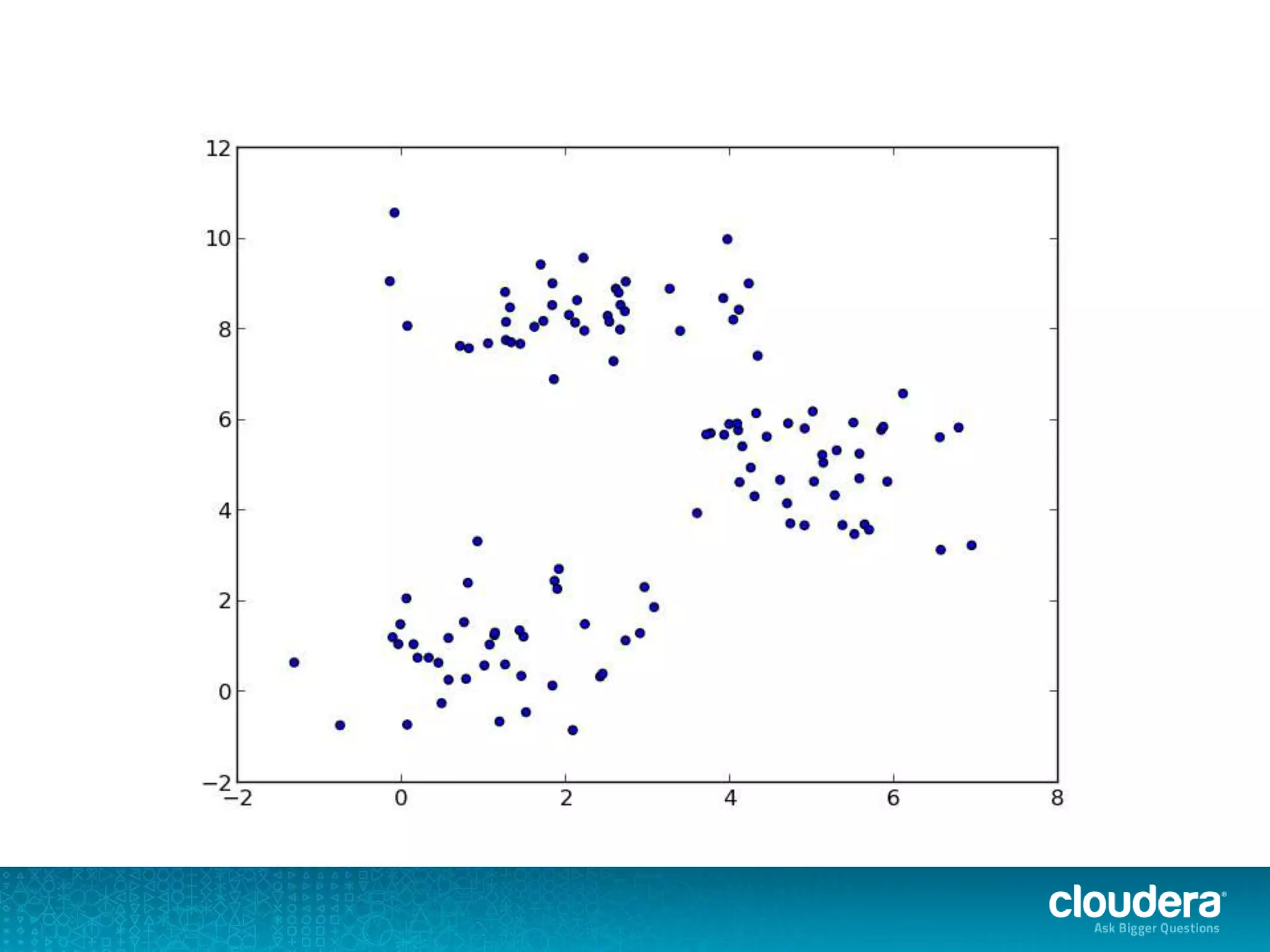
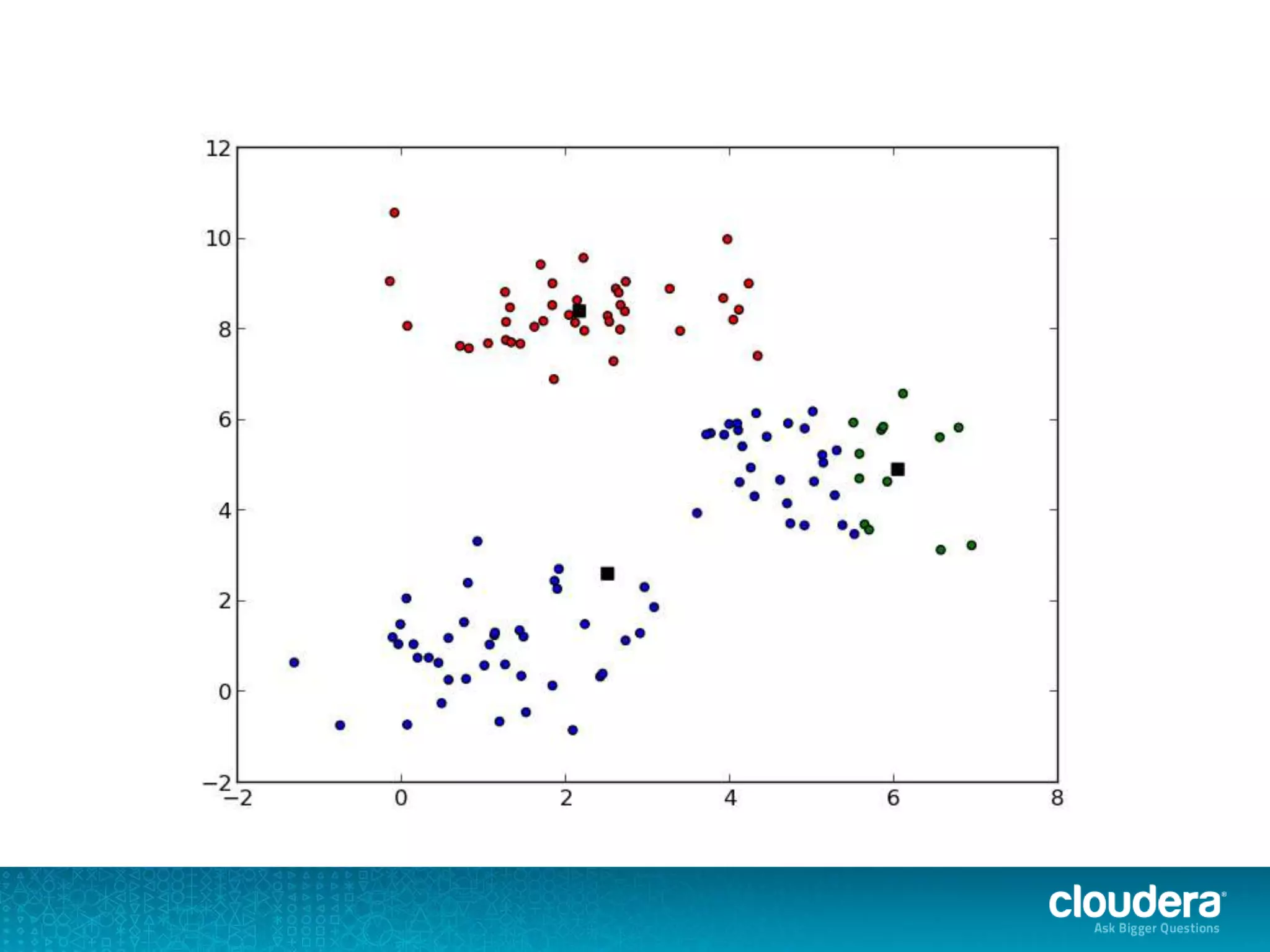
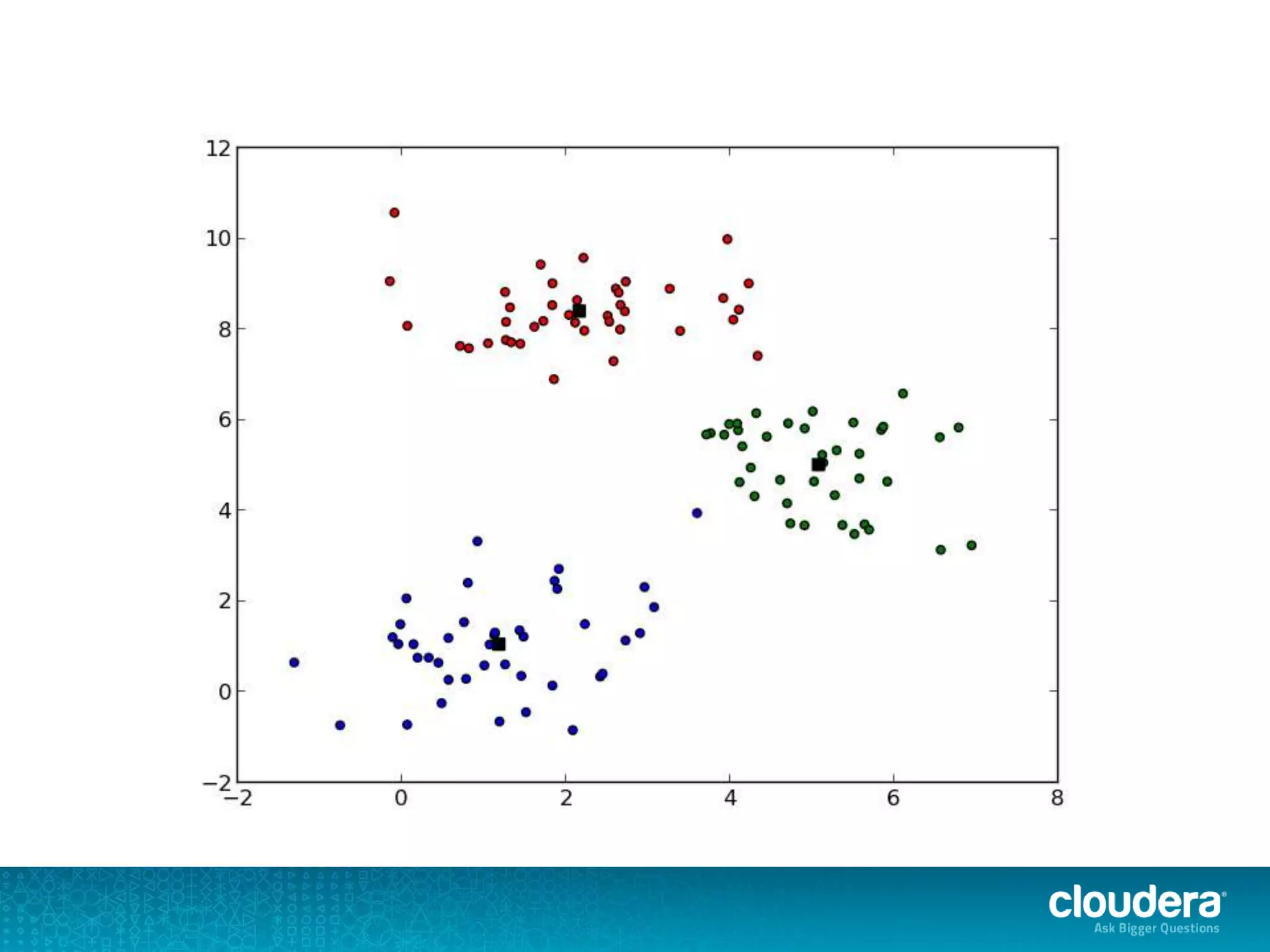
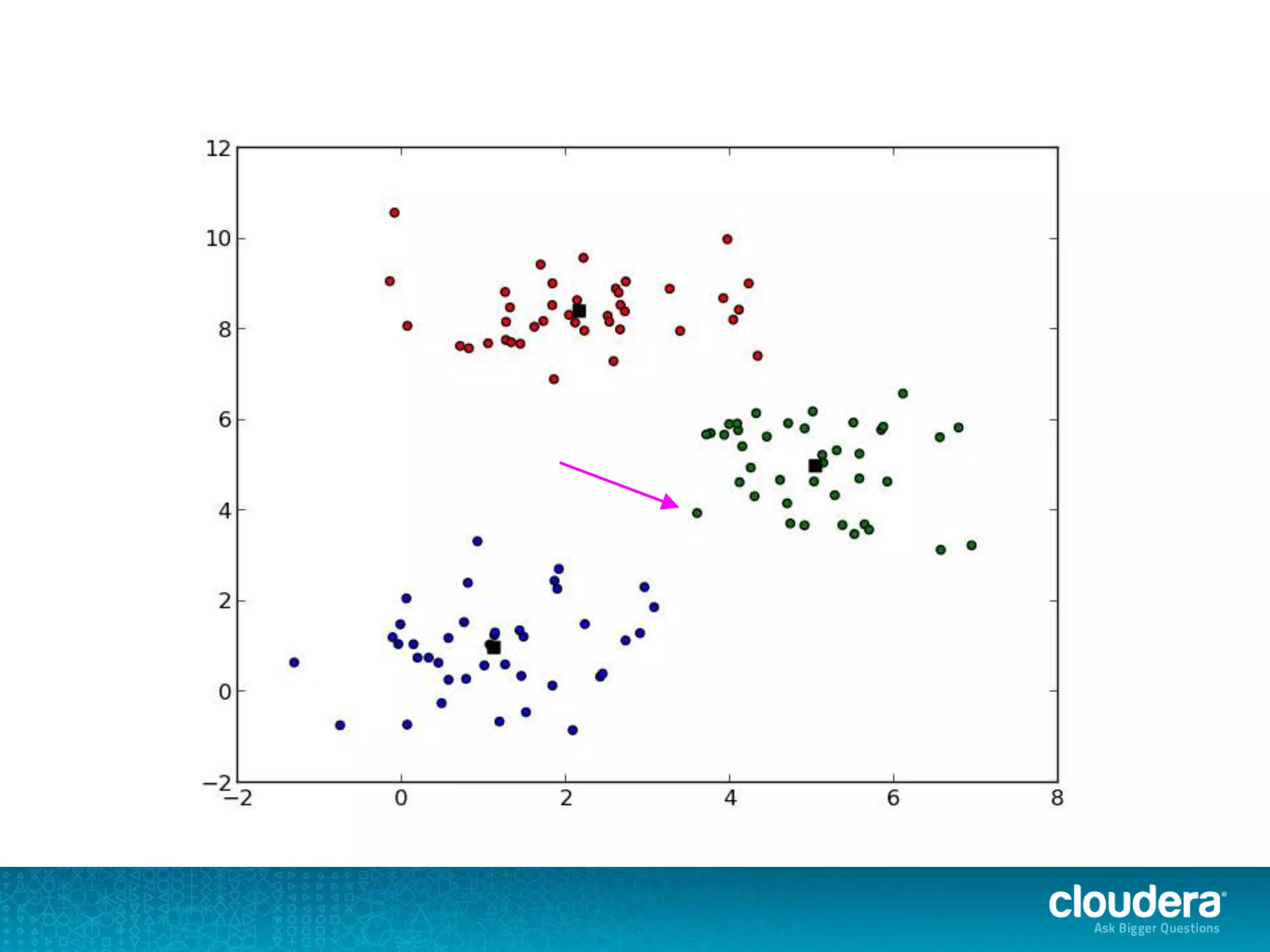
The document discusses large-scale learning using Apache Spark, highlighting its advantages over MapReduce, such as ease of development, performance, and a flexible programming model. It introduces key concepts like Resilient Distributed Datasets (RDDs) and demonstrates Spark’s machine learning capabilities through libraries like Spark MLlib. The document also covers various clustering methods, specifically focusing on k-means and the challenges related to selecting initial centroids.























































































