Downloaded 147 times



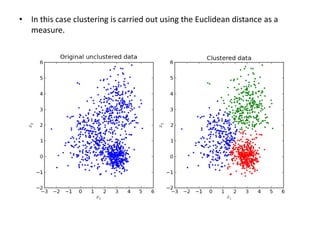


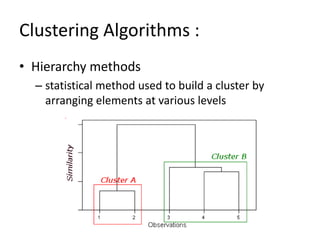

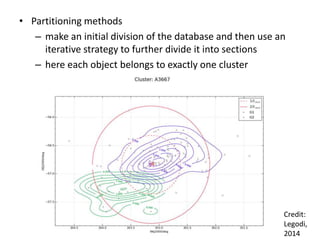
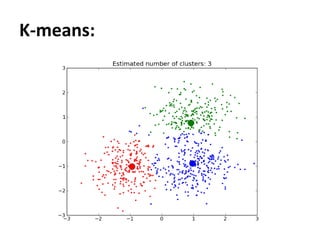


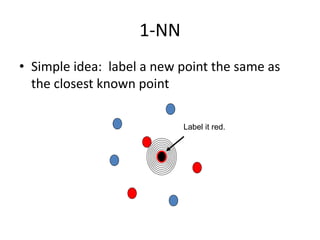

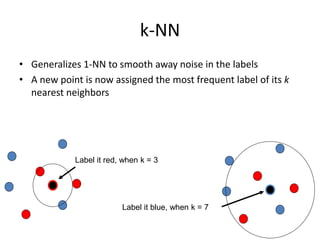



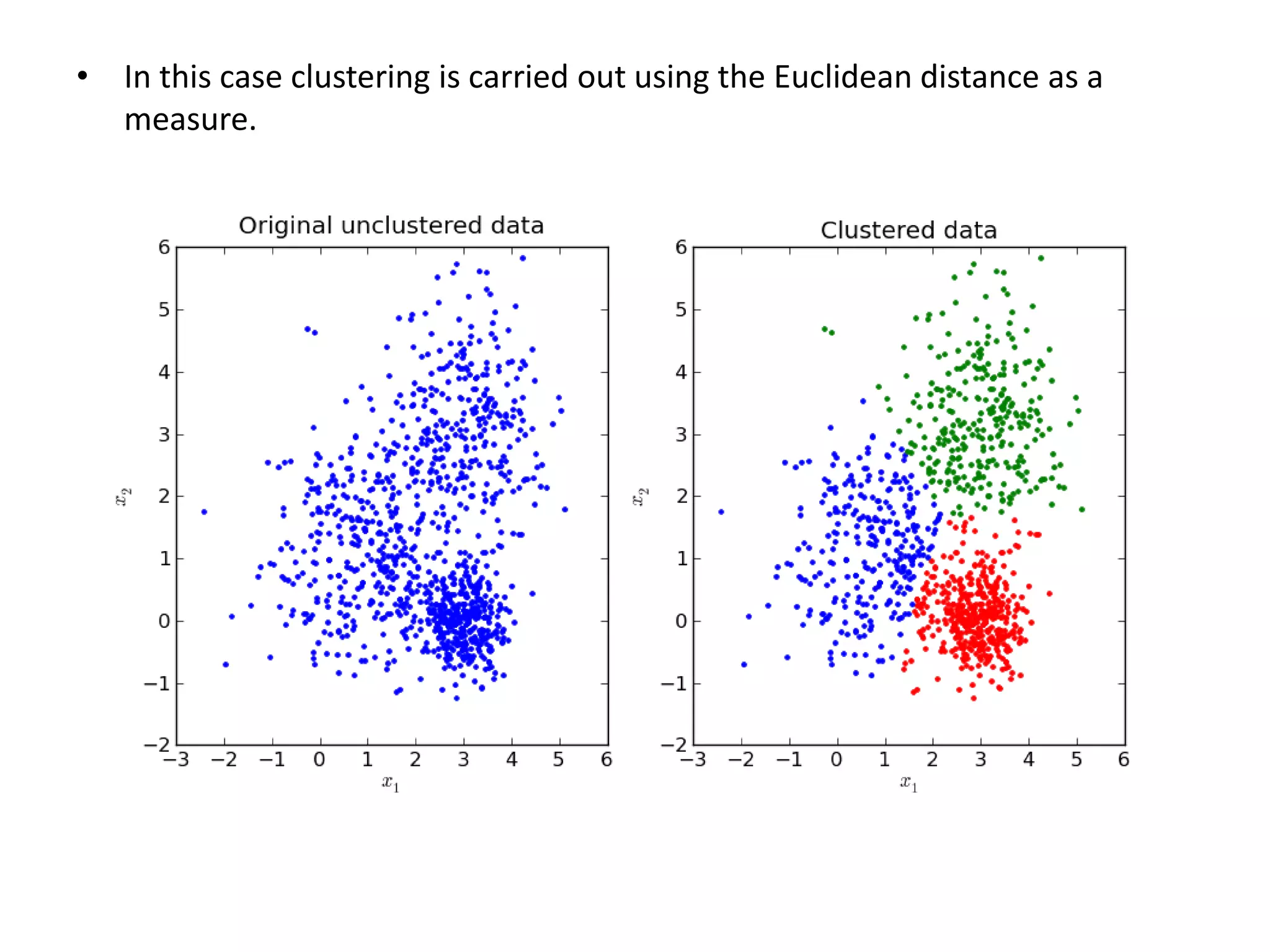


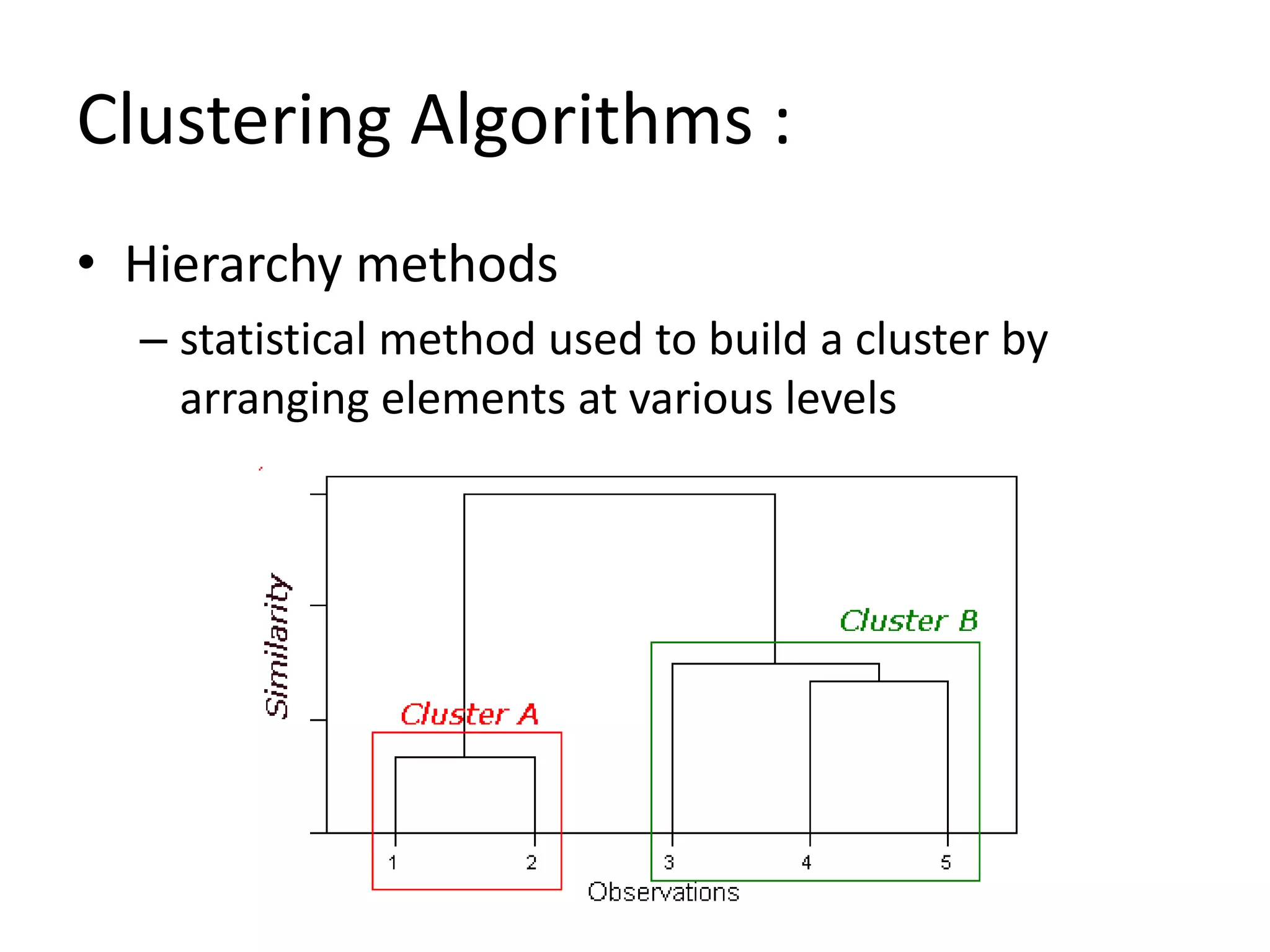

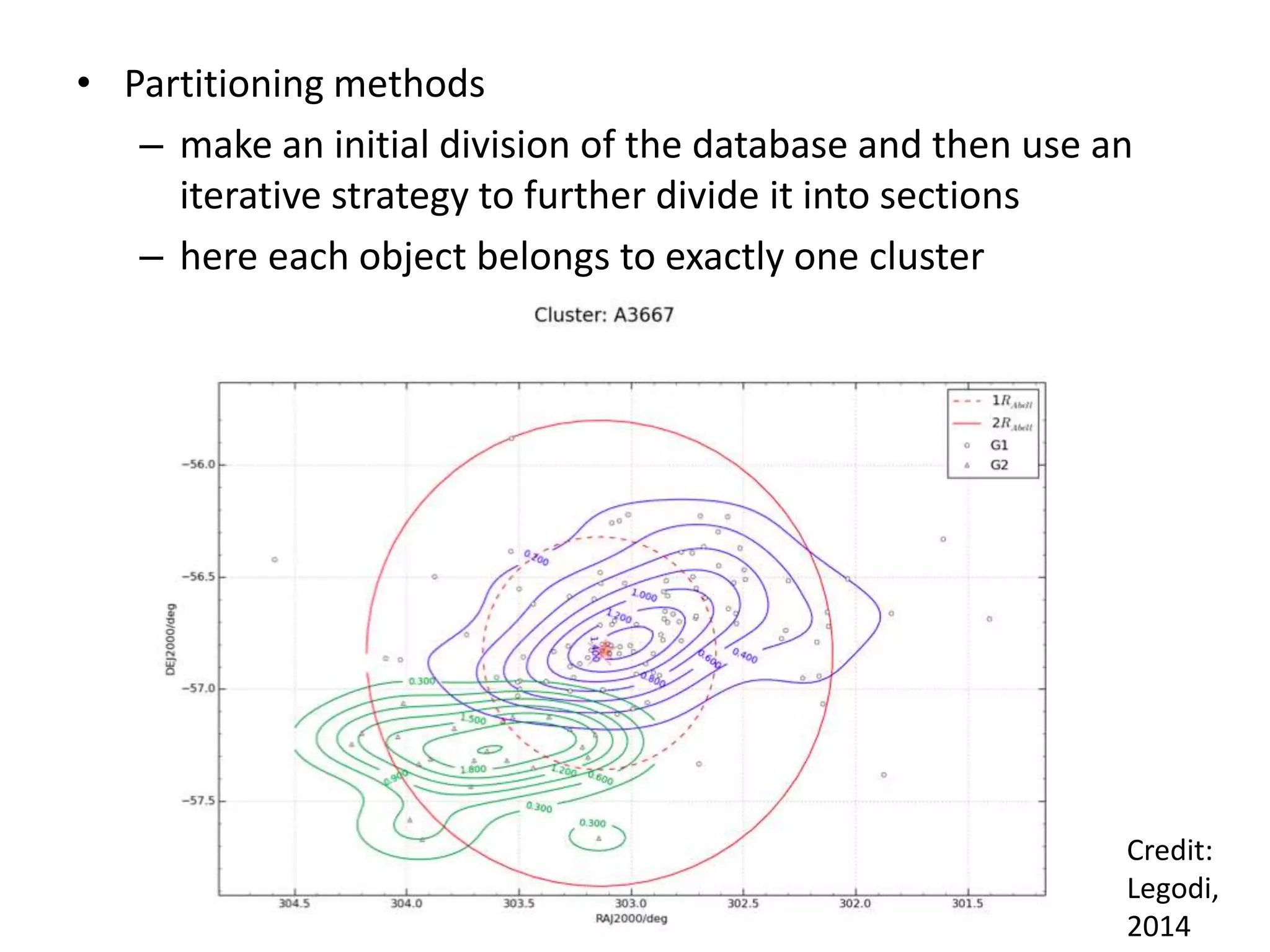
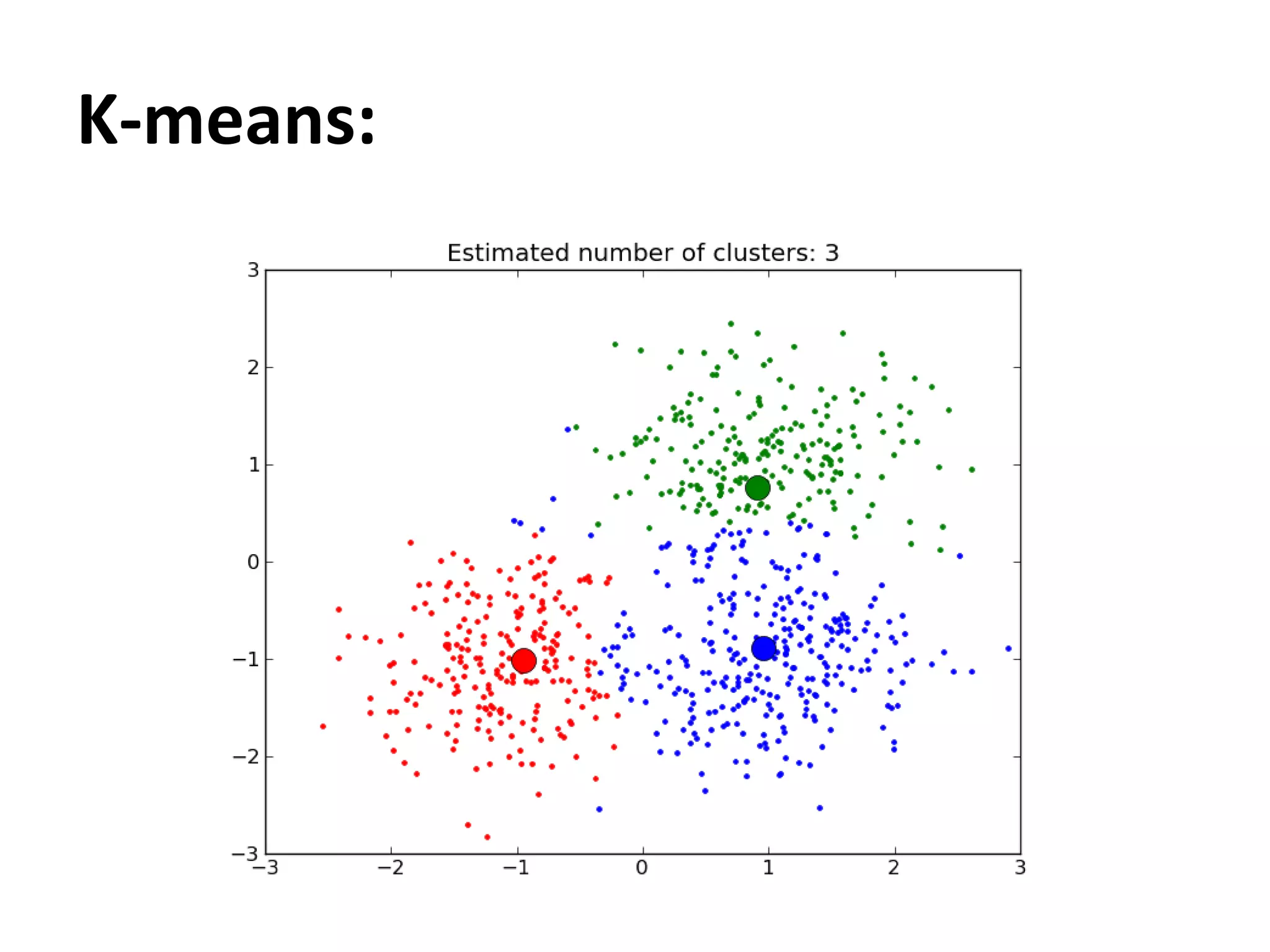


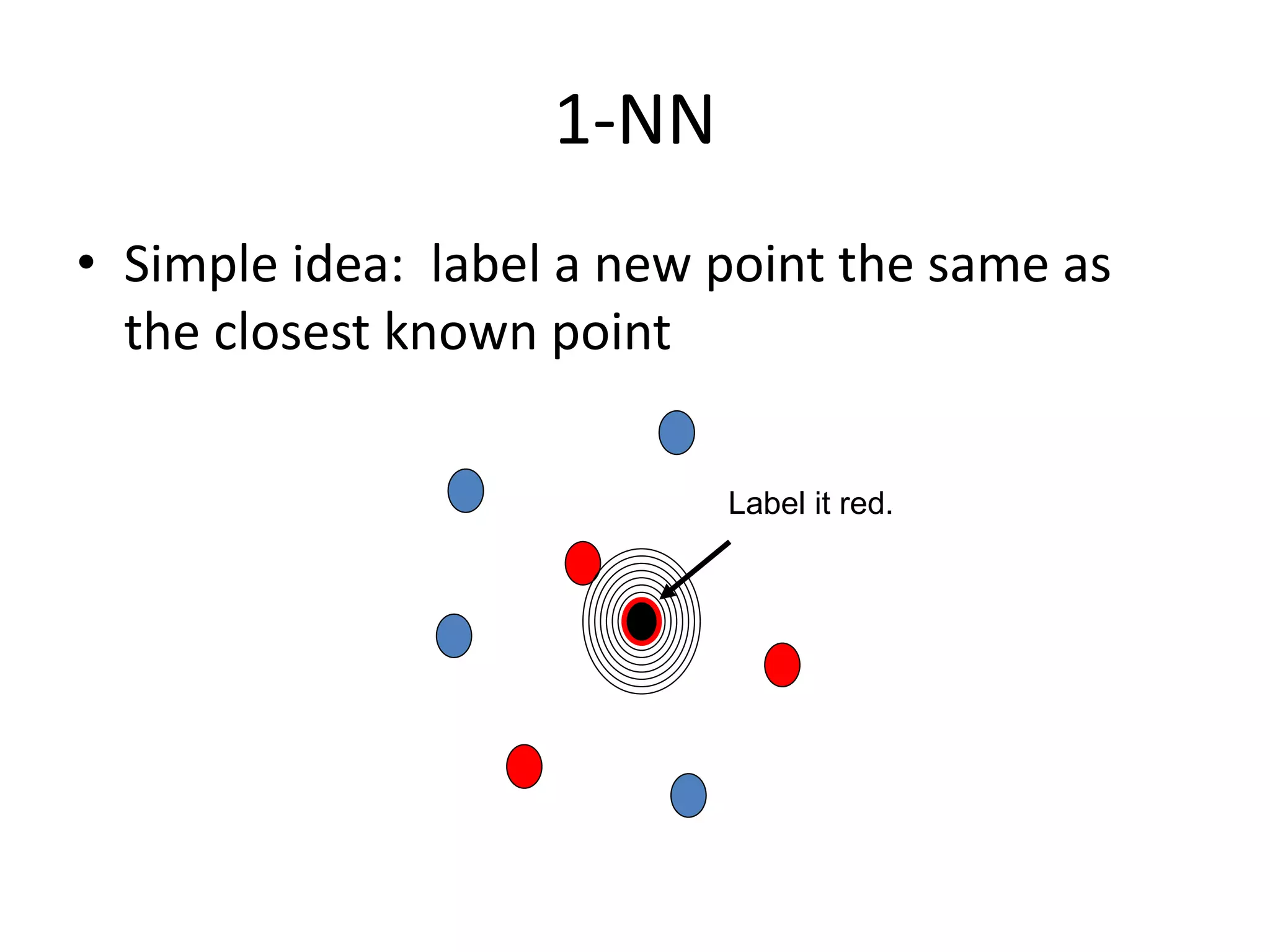

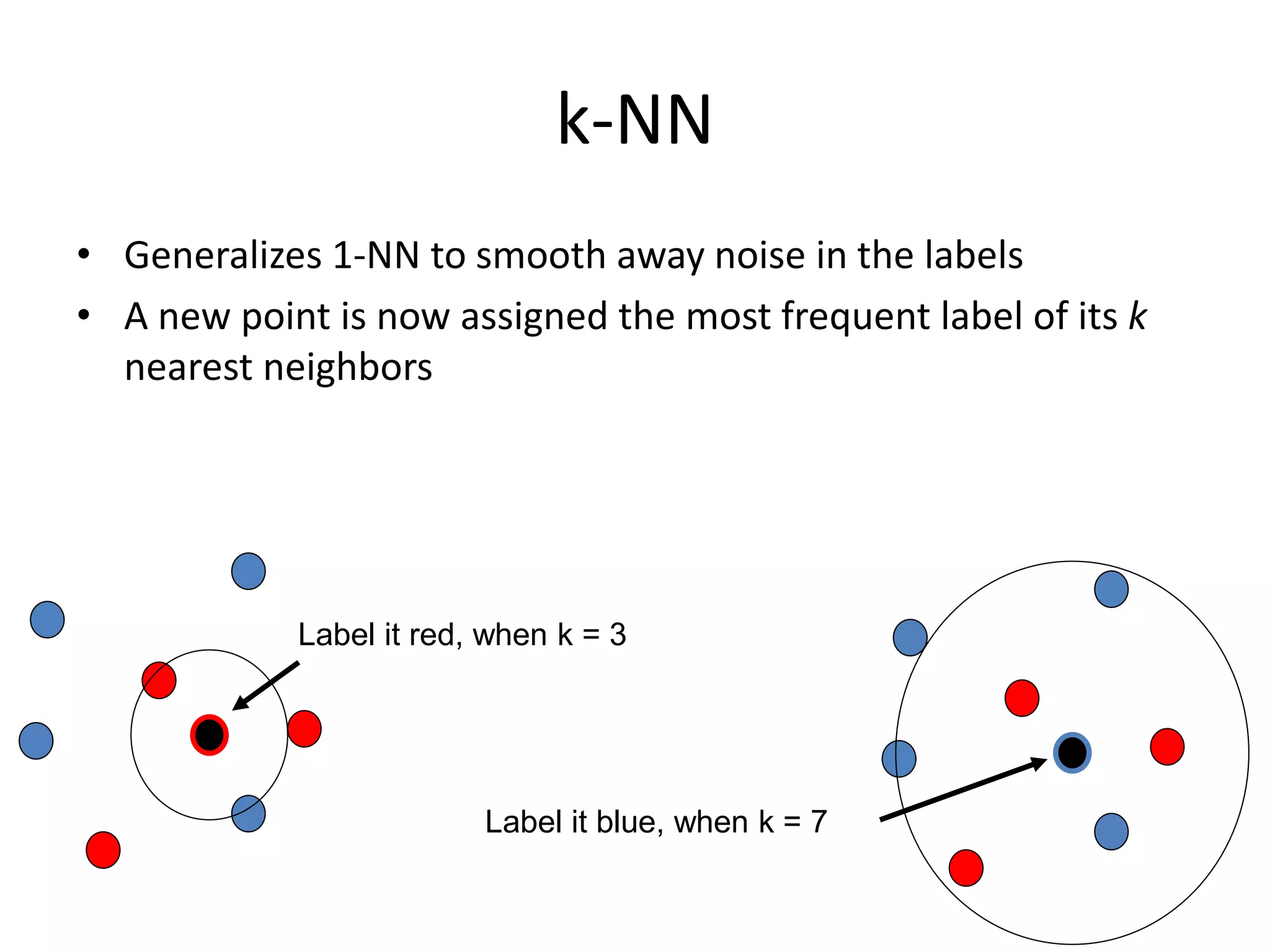

This document discusses machine learning concepts including supervised vs. unsupervised learning, clustering algorithms, and specific clustering methods like k-means and k-nearest neighbors. It provides examples of how clustering can be used for applications such as market segmentation and astronomical data analysis. Key clustering algorithms covered are hierarchy methods, partitioning methods, k-means which groups data by assigning objects to the closest cluster center, and k-nearest neighbors which classifies new data based on its closest training examples.










































![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
























