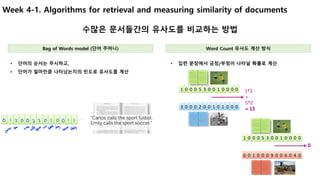
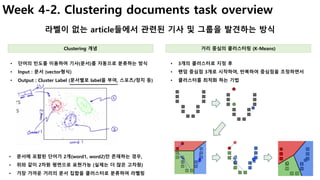
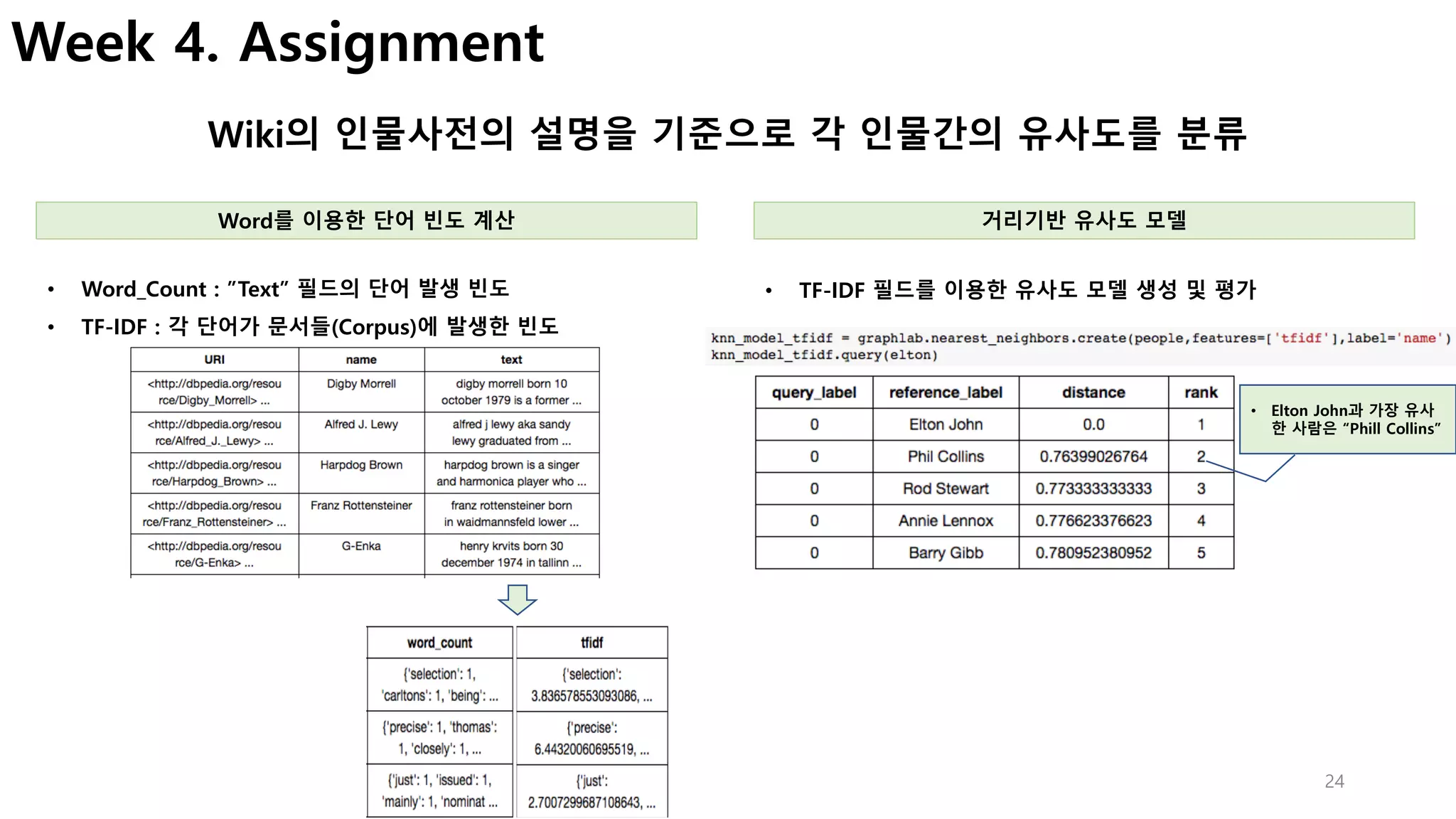
실제 비즈니스에서 많이 활용되는 사례를 중심으로 어떻게 기존 데이터를 이용하여 알고리즘을 선택하고, 학습하여, 예측모델을 구축 하는지 jupyter notebook을 이용하여 실제 코드를 이용하여 실습할 수 있다.
강의 초반에 강조하는 것 처럼, 머신러닝 알고리즘은 나중에 자세히 설명하는 과정이 따로 있고, 이번 강의는 실제 어떻게 활용하는지에 완전히 초점이 맞추어져 있어서, 알고리즘은 아주 간략한 수준으로 설명해 준다. (좀 더 구체적인 내용은 심화과정이 따로 있음)
http://blog.naver.com/freepsw/221113685916 참고
https://github.com/freepsw/coursera/tree/master/ML_Foundations/A_Case_Study 코드 샘플



![4
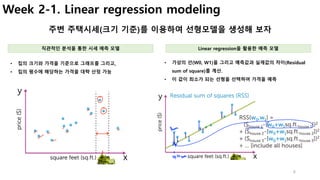
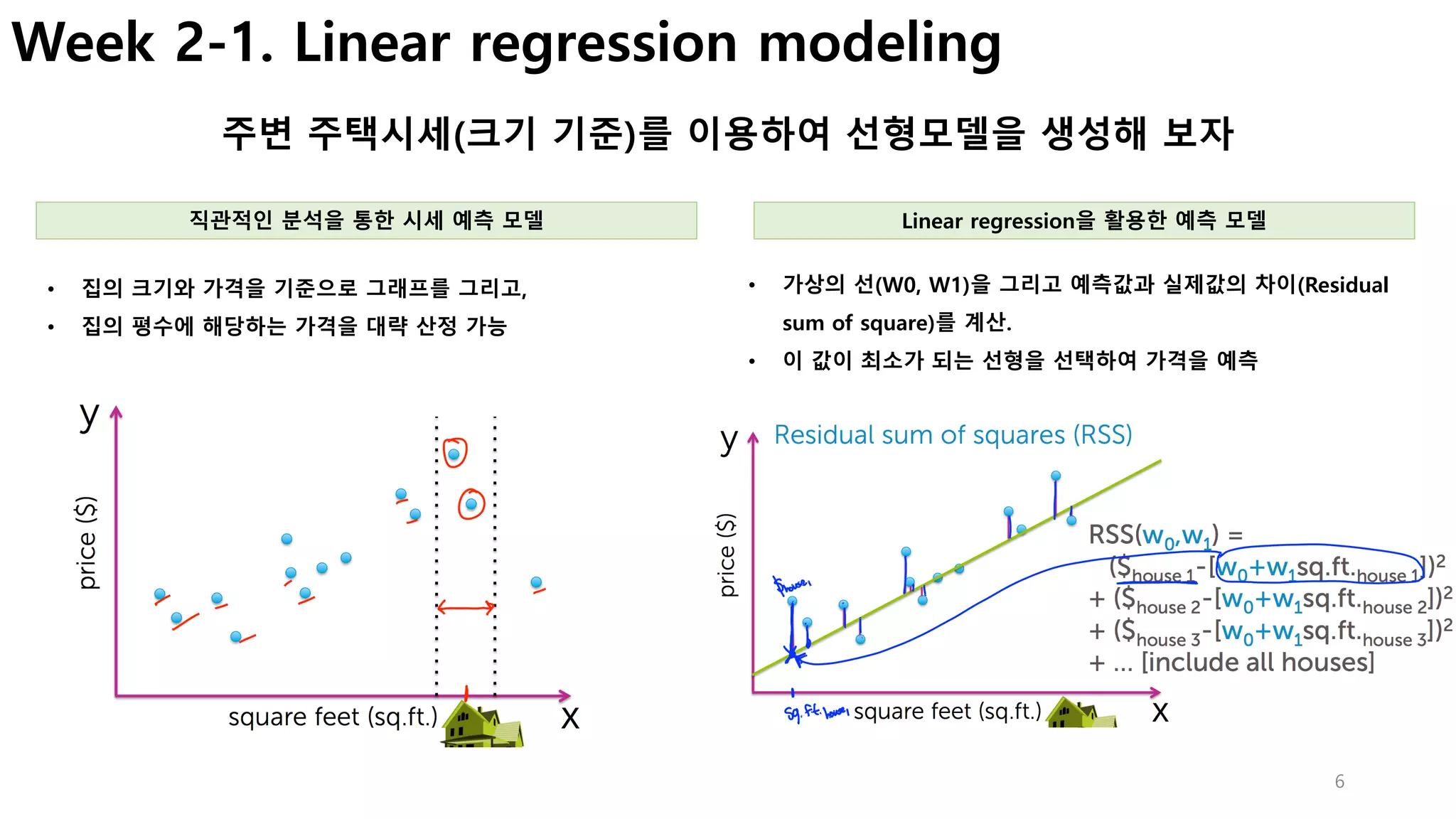
Week1. Canvas for data visualization
GraphLab Create를 이용하여 시각화한 웹서버 접근방법 (sf.show() 실행시)
로컬 환경인 경우 원격서버 환경
• 원격서버(AWS, GCE, 개발서버 등)에 실습환경 구축한 경우
• [문제] Link 클릭시 접속 오류 발생
• [해결] SSH Port Forwarding을 통하여 접속
• 실습환경을 local PC에 설치한 경우 매뉴얼 대로 동작
# local PC에서 실행 (port forwarding 연결)
> ssh -L 37025:localhost:37025 rts@192.168.X.X (원격서버 ip)
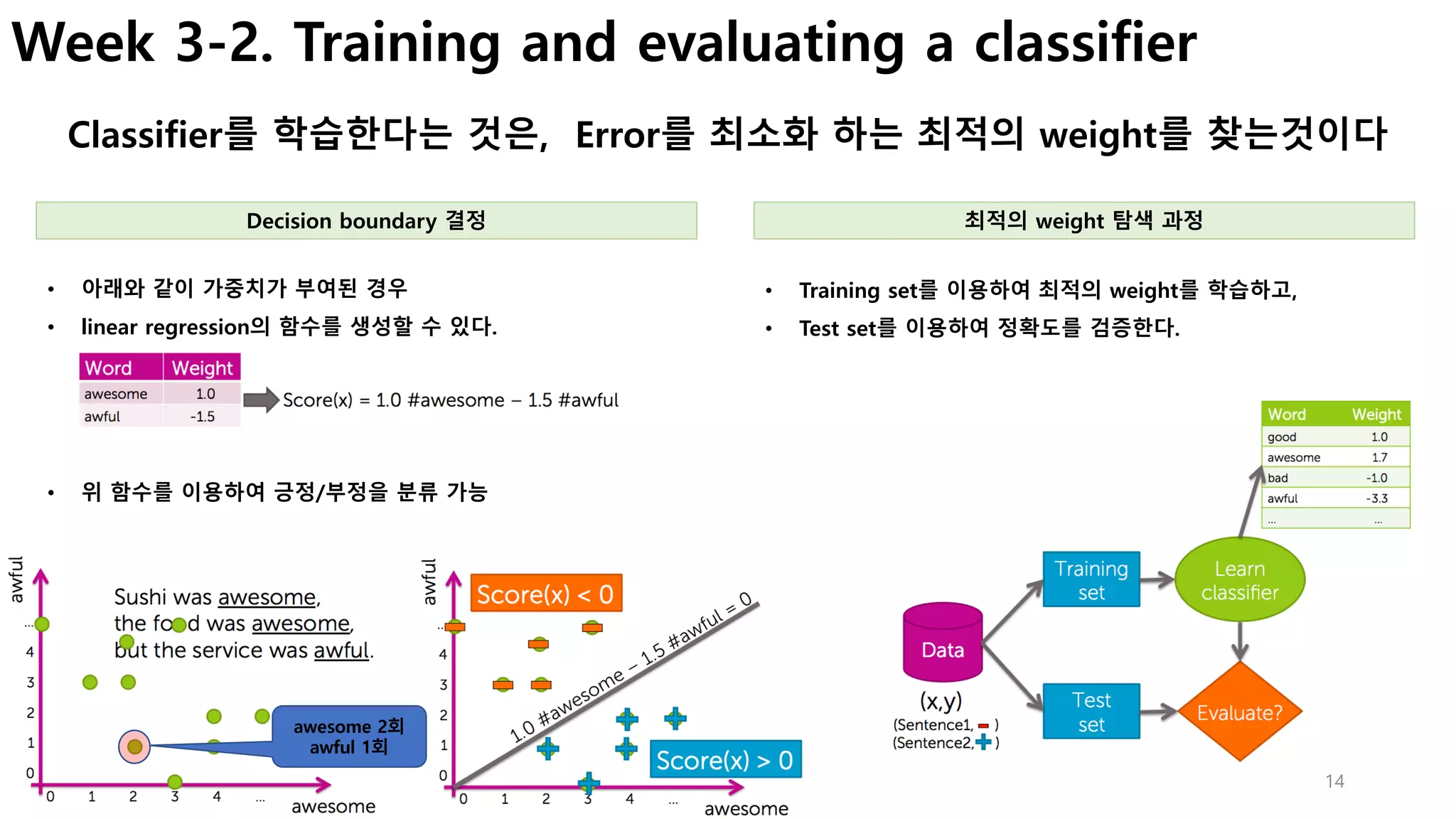
• 출력된 link를 통해 graphlab creat 화면 접속
참고 : http://blog.naver.com/freepsw/220892098919
# local PC Browser
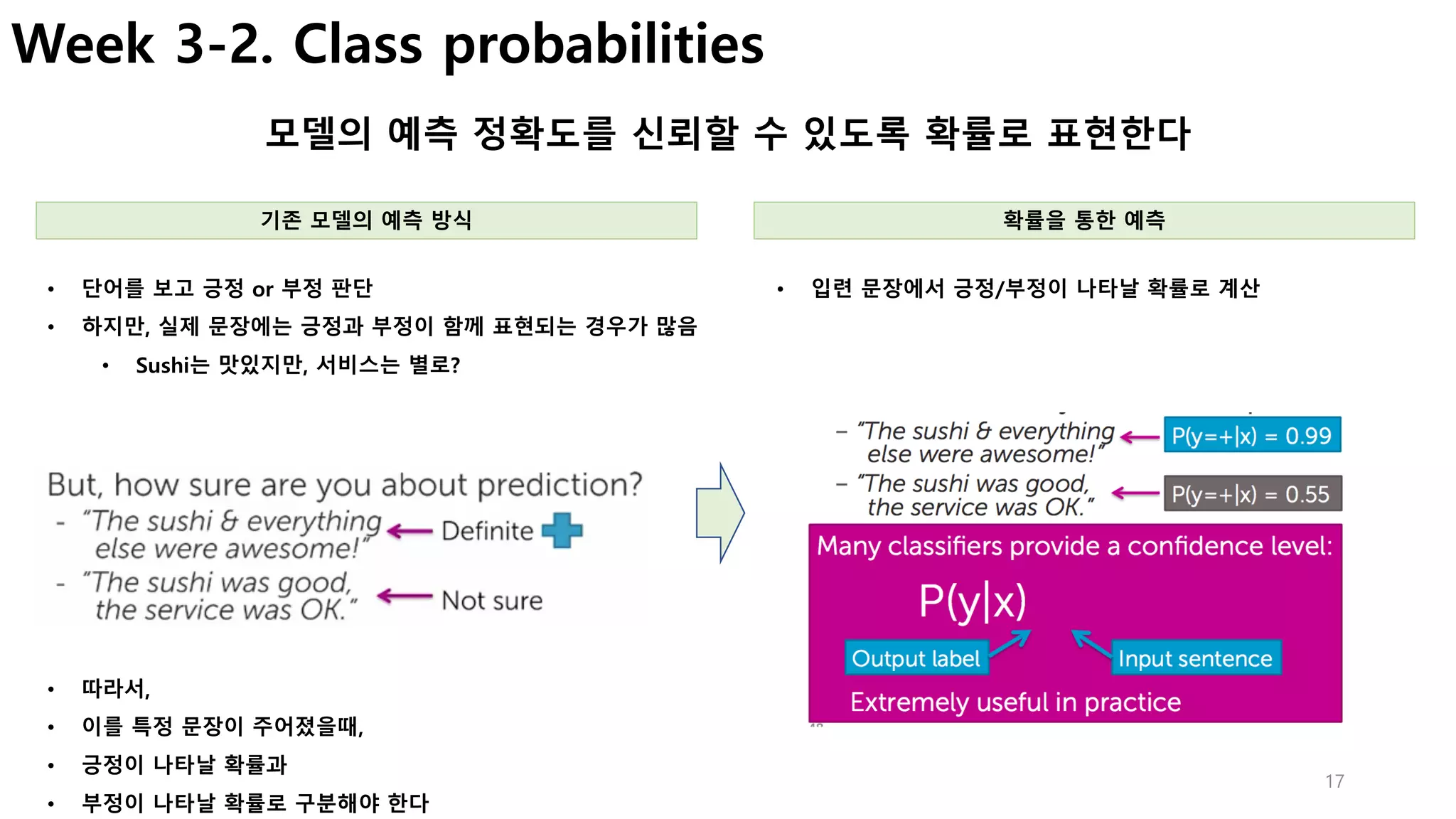
http://localhost:37025/index.html 접속](https://image.slidesharecdn.com/couseramlspecializationv0-171010005508/85/Machine-Learning-Foundations-a-case-study-approach-4-320.jpg)






![15
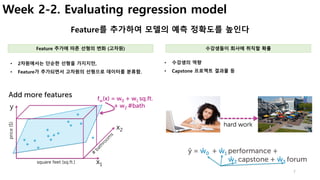
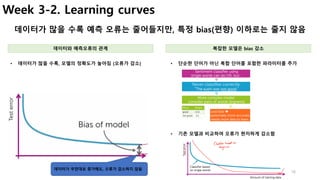
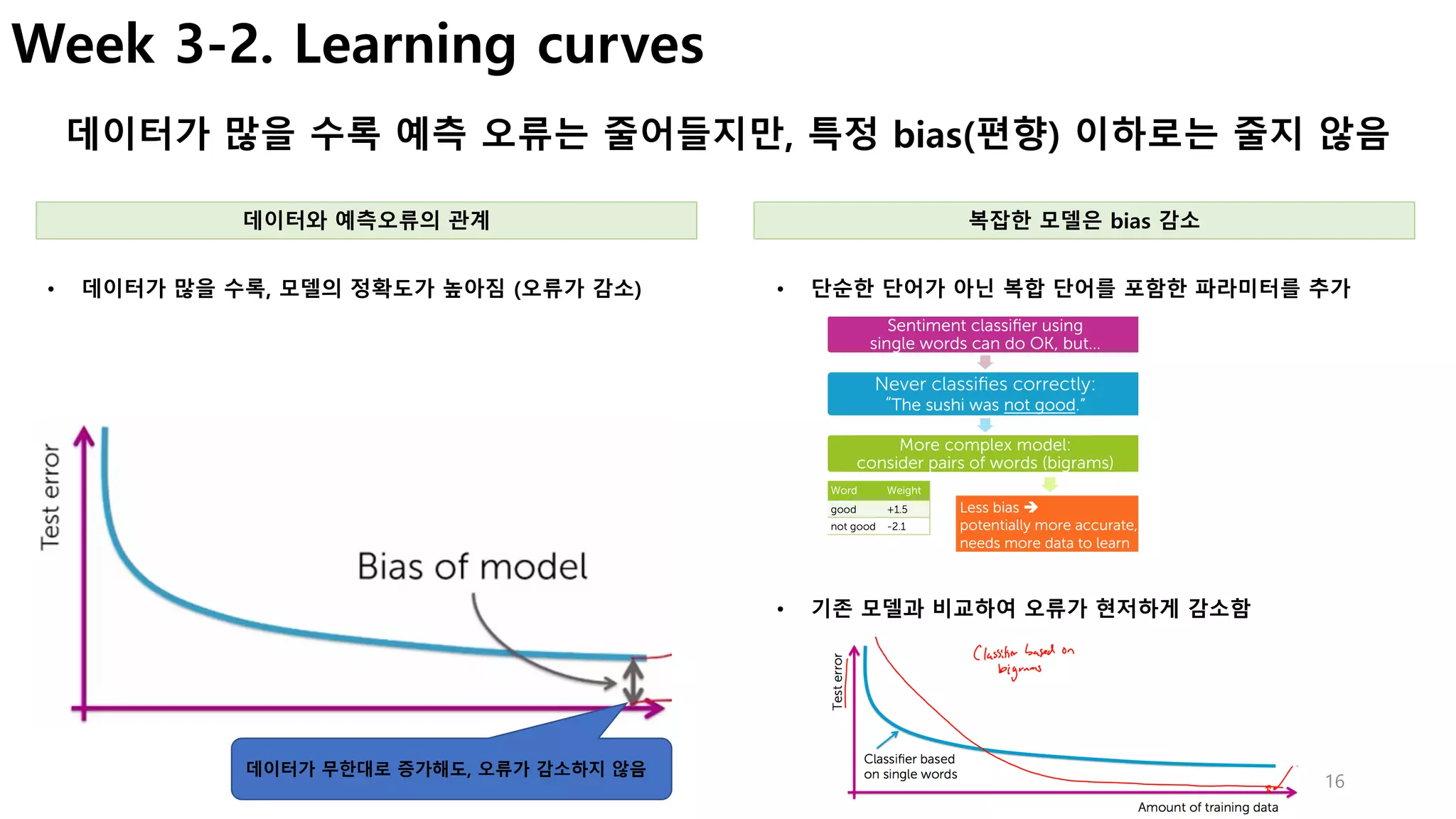
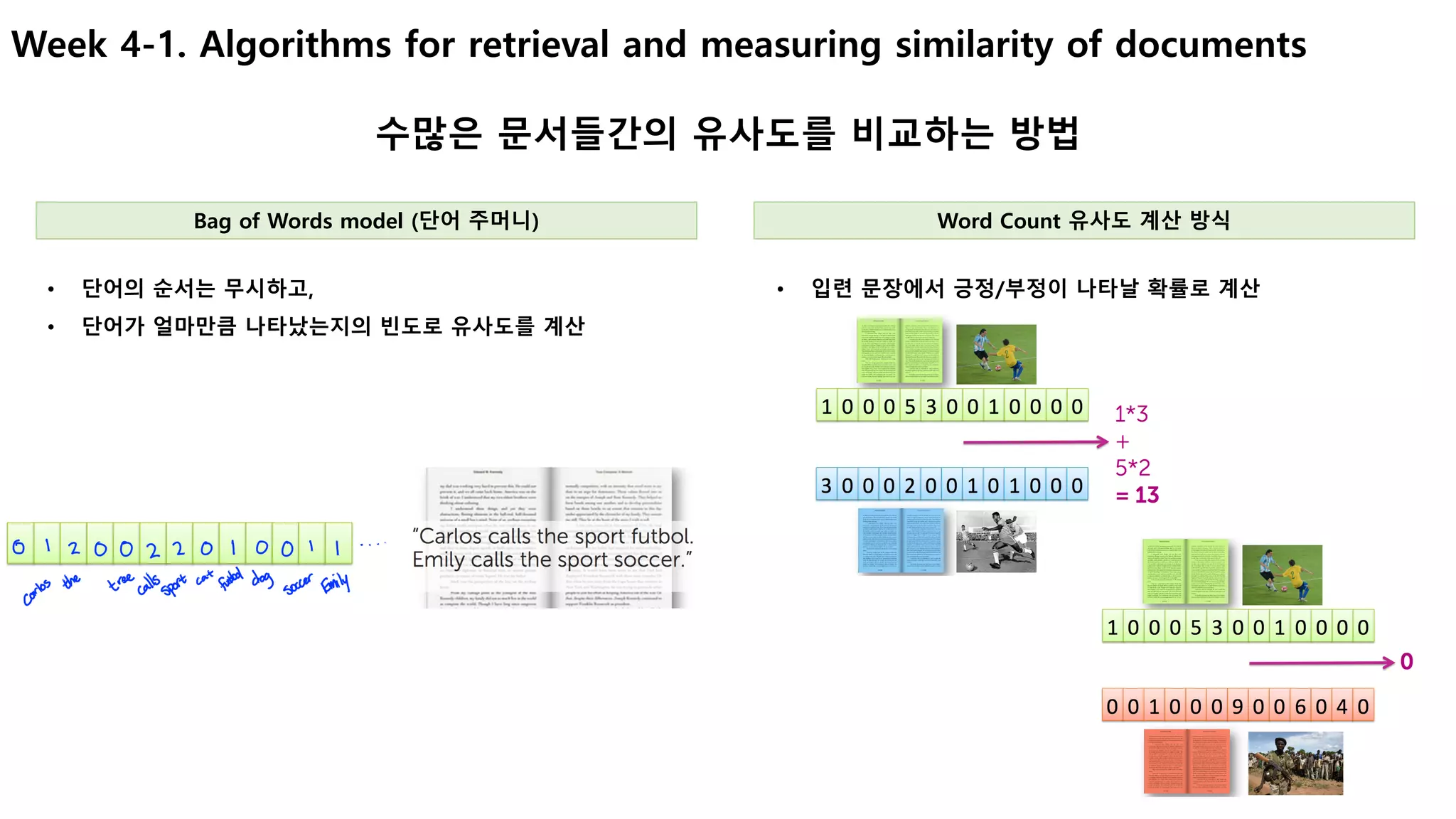
Week 3-2. False positives, false negatives
학습된 모델이 예측을 실패하는 유형 이해
• [Spam Filtering]
• FP : 정상 메일을 spam으로 판단하면, 중요한 메일을 읽지
못함.
• [병/질환 진단]
• FN : 실제 병이 있는데, 없는 것으로 판단 à 치료시기 놓침
• FP : 병이 없는데 있다고 판단 à 불필요한 치료비용/독한 약
• False Negative : 부정(Negative)으로 예측한 것이 틀렸다(False)
• False Positive : 긍정(Positive)으로 예측한 것이 틀렸다(False)
모델의 예측 실패 유형 예측 실패의 영향](https://image.slidesharecdn.com/couseramlspecializationv0-171010005508/85/Machine-Learning-Foundations-a-case-study-approach-15-320.jpg)









![29
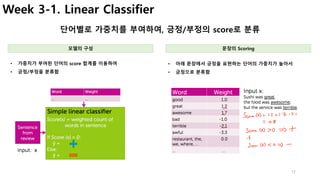
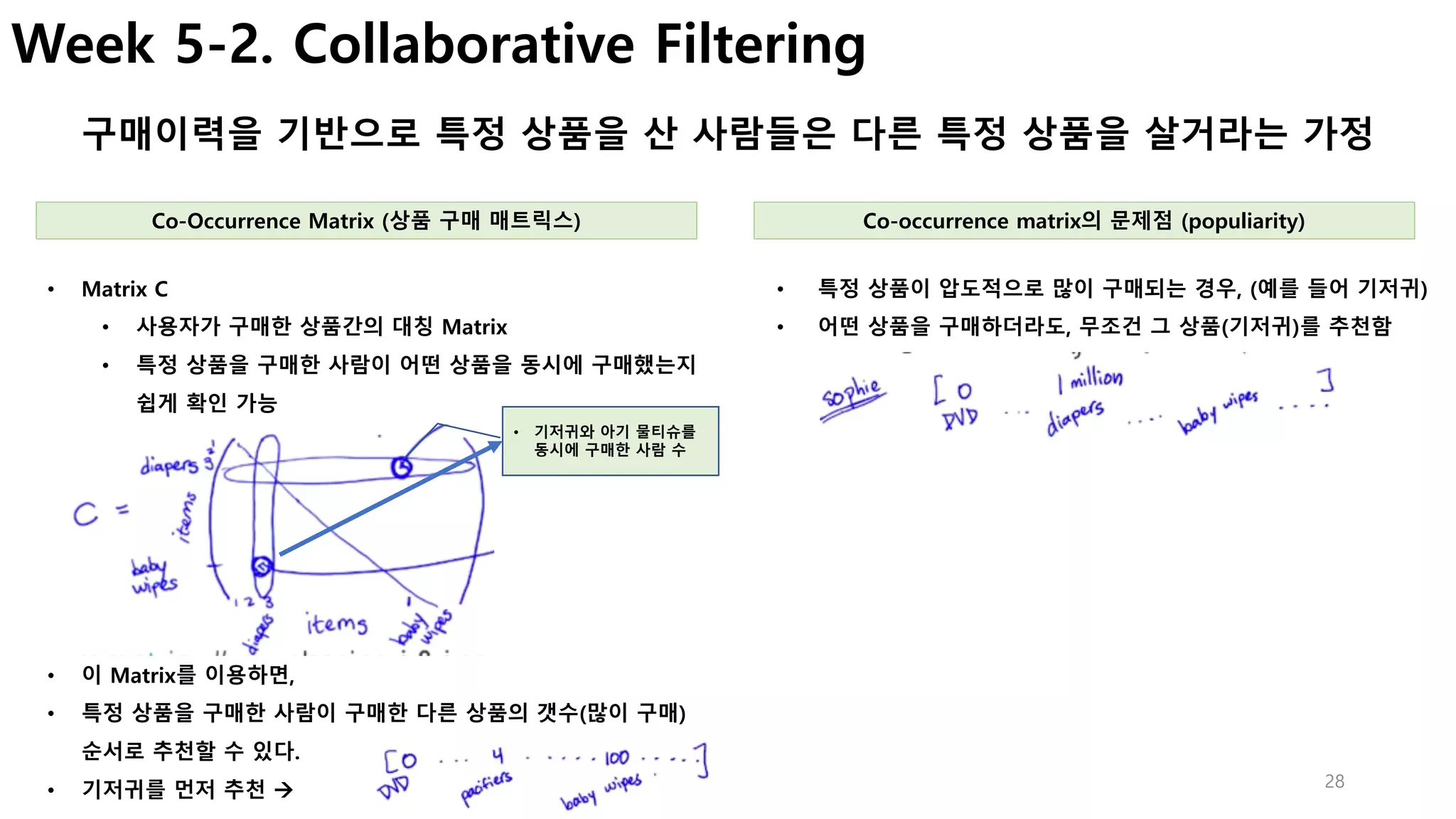
Week 5-2. Normalizing co-occurrence matrix
Popularity를 기준으로 유사도를 가지도록 데이터를 정규화
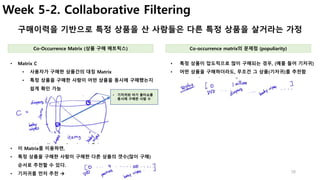
• 구매 이력에 있는 각 상품에 대하여,
• 추천할 상품과의 점수를 구하고, (Co-occurrecne matrix 사용)
• 이를 평균으로 나누어서 가중 점수를 계산
• 내가 구매한 이력이 (diaper, milk)만 있고,
• 나머지 상품에 대한 추천점수를 계산해야 한다면,
• Diaper와 milk와 다른 상품간의 점수를 각각 계산하고,
• 이를 평균으로 계산
• 상품 i와 j를 동시에 구매한 사람의 수를
• 상품 I 또는 j를 구매한 전체 사용자 수로 나누어 유사도를 구한다.
• 이 공식을 이용해 전체 Matrix를 정규화
Jaccard similarity Weighted Average of purchased items
[ Co-occurrence Matrix의 문제점]
• 현재 상태(특정 상품]만 추천이 가능
• 즉, 과거의 구매이력을 이용하여 추천하지 못함.
• 왜냐하면, matrix에서 전체 이력을 계산한 값이 없기 때문…
• 이 점수가 가장 높은 순으로 추천한다
• Baby wipes 추천 점수
• (가중 평균점수)
[ 한계점]
• 문맥(시간 등), 사용자 개인정보, 제품정보를 반영하지 못함.
• Cold Start Problem (신규 사용자 또는 신규제품은?)](https://image.slidesharecdn.com/couseramlspecializationv0-171010005508/85/Machine-Learning-Foundations-a-case-study-approach-29-320.jpg)
![30
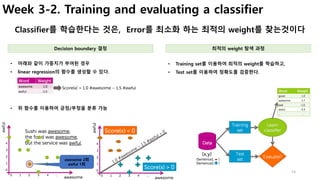
Week 5-3. Matrix Factorization
데이터를 통하여 사용자 또는 상품의 특징을 학습하는 방법 (행렬 분해)
(예를 들어, 영화 평점데이터를 통해 사용자 및 영화의 특징 추출)
• Feature : X1, X2 (영화의 특징)
• 가중치 : 𝜽(𝒖𝒔𝒆𝒓)
• 예측평점 : 𝒚 = 𝜽 𝒋 𝑻
(𝒙 𝒊
)
• 즉, 사용자가 영화를 평가했던 이력이 있고,
• 사용자 및 영화의 feature을 가지고 있다면,
• 여기서는 romance, action 등의 선호도
• 실제는 사용자(나이, 성별, 거주지역 등), 영화(감독, 배우, 장르 등)
• 이를 통해서 가중치를 학습하여 최적의 값을 찾는다. (cost 최적화)
• Feature(특징)이 정의되지 않은 경우, 이를 데이터를 통해 학습
• 먼저, 사용자(U)와 영화(V)의 feature matrix를 이용하여 점수
(rating)을 예측해 보자.
데이터를 통해 특징을 찾아서 분해(Matrix Factorization) Feature를 통해 학습하여 가중치 추출
• Andrew NG 강의
• Week 9 참고 (더 자세함)
• 학습을 통해 𝜽를 최소화
가중치를 통해서 Feature(유형)를 추출
• 가중치를 알면, 평가점수를 기반으로 feature를 추출 가능
• 즉, 사용자 및 영화의 feature를 추출
• 이를 통해 사용자의 유형을 분류할 수 있음
• 사용자 1(Allice)의 3번째 영화(Cute pupple of love)의 평점을 예측해 보자
• 이때 𝜽(𝟏)
은 사전에 학습되었다고 가정한다. [0, 5, 0]](https://image.slidesharecdn.com/couseramlspecializationv0-171010005508/85/Machine-Learning-Foundations-a-case-study-approach-30-320.jpg)








![4
Week1. Canvas for data visualization
GraphLab Create를 이용하여 시각화한 웹서버 접근방법 (sf.show() 실행시)
로컬 환경인 경우 원격서버 환경
• 원격서버(AWS, GCE, 개발서버 등)에 실습환경 구축한 경우
• [문제] Link 클릭시 접속 오류 발생
• [해결] SSH Port Forwarding을 통하여 접속
• 실습환경을 local PC에 설치한 경우 매뉴얼 대로 동작
# local PC에서 실행 (port forwarding 연결)
> ssh -L 37025:localhost:37025 rts@192.168.X.X (원격서버 ip)
• 출력된 link를 통해 graphlab creat 화면 접속
참고 : http://blog.naver.com/freepsw/220892098919
# local PC Browser
http://localhost:37025/index.html 접속](https://image.slidesharecdn.com/couseramlspecializationv0-171010005508/75/Machine-Learning-Foundations-a-case-study-approach-4-2048.jpg)





![15
Week 3-2. False positives, false negatives
학습된 모델이 예측을 실패하는 유형 이해
• [Spam Filtering]
• FP : 정상 메일을 spam으로 판단하면, 중요한 메일을 읽지
못함.
• [병/질환 진단]
• FN : 실제 병이 있는데, 없는 것으로 판단 à 치료시기 놓침
• FP : 병이 없는데 있다고 판단 à 불필요한 치료비용/독한 약
• False Negative : 부정(Negative)으로 예측한 것이 틀렸다(False)
• False Positive : 긍정(Positive)으로 예측한 것이 틀렸다(False)
모델의 예측 실패 유형 예측 실패의 영향](https://image.slidesharecdn.com/couseramlspecializationv0-171010005508/75/Machine-Learning-Foundations-a-case-study-approach-15-2048.jpg)








![29
Week 5-2. Normalizing co-occurrence matrix
Popularity를 기준으로 유사도를 가지도록 데이터를 정규화
• 구매 이력에 있는 각 상품에 대하여,
• 추천할 상품과의 점수를 구하고, (Co-occurrecne matrix 사용)
• 이를 평균으로 나누어서 가중 점수를 계산
• 내가 구매한 이력이 (diaper, milk)만 있고,
• 나머지 상품에 대한 추천점수를 계산해야 한다면,
• Diaper와 milk와 다른 상품간의 점수를 각각 계산하고,
• 이를 평균으로 계산
• 상품 i와 j를 동시에 구매한 사람의 수를
• 상품 I 또는 j를 구매한 전체 사용자 수로 나누어 유사도를 구한다.
• 이 공식을 이용해 전체 Matrix를 정규화
Jaccard similarity Weighted Average of purchased items
[ Co-occurrence Matrix의 문제점]
• 현재 상태(특정 상품]만 추천이 가능
• 즉, 과거의 구매이력을 이용하여 추천하지 못함.
• 왜냐하면, matrix에서 전체 이력을 계산한 값이 없기 때문…
• 이 점수가 가장 높은 순으로 추천한다
• Baby wipes 추천 점수
• (가중 평균점수)
[ 한계점]
• 문맥(시간 등), 사용자 개인정보, 제품정보를 반영하지 못함.
• Cold Start Problem (신규 사용자 또는 신규제품은?)](https://image.slidesharecdn.com/couseramlspecializationv0-171010005508/75/Machine-Learning-Foundations-a-case-study-approach-29-2048.jpg)
![30
Week 5-3. Matrix Factorization
데이터를 통하여 사용자 또는 상품의 특징을 학습하는 방법 (행렬 분해)
(예를 들어, 영화 평점데이터를 통해 사용자 및 영화의 특징 추출)
• Feature : X1, X2 (영화의 특징)
• 가중치 : 𝜽(𝒖𝒔𝒆𝒓)
• 예측평점 : 𝒚 = 𝜽 𝒋 𝑻
(𝒙 𝒊
)
• 즉, 사용자가 영화를 평가했던 이력이 있고,
• 사용자 및 영화의 feature을 가지고 있다면,
• 여기서는 romance, action 등의 선호도
• 실제는 사용자(나이, 성별, 거주지역 등), 영화(감독, 배우, 장르 등)
• 이를 통해서 가중치를 학습하여 최적의 값을 찾는다. (cost 최적화)
• Feature(특징)이 정의되지 않은 경우, 이를 데이터를 통해 학습
• 먼저, 사용자(U)와 영화(V)의 feature matrix를 이용하여 점수
(rating)을 예측해 보자.
데이터를 통해 특징을 찾아서 분해(Matrix Factorization) Feature를 통해 학습하여 가중치 추출
• Andrew NG 강의
• Week 9 참고 (더 자세함)
• 학습을 통해 𝜽를 최소화
가중치를 통해서 Feature(유형)를 추출
• 가중치를 알면, 평가점수를 기반으로 feature를 추출 가능
• 즉, 사용자 및 영화의 feature를 추출
• 이를 통해 사용자의 유형을 분류할 수 있음
• 사용자 1(Allice)의 3번째 영화(Cute pupple of love)의 평점을 예측해 보자
• 이때 𝜽(𝟏)
은 사전에 학습되었다고 가정한다. [0, 5, 0]](https://image.slidesharecdn.com/couseramlspecializationv0-171010005508/75/Machine-Learning-Foundations-a-case-study-approach-30-2048.jpg)







![Random Forest Intro [랜덤포레스트 설명]](https://cdn.slidesharecdn.com/ss_thumbnails/theforestslideshare-170924111713-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








![[한국어] Multiagent Bidirectional- Coordinated Nets for Learning to Play StarCra...](https://cdn.slidesharecdn.com/ss_thumbnails/multiagentbidirectional-coordinatednetsforlearningtoplaystarcraftcombatgames-170623022918-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




![[BIZ+005 스타트업 투자/법률 기초편] 첫 투자를 위한 스타트업 기초상식 | 비즈업 조가연님](https://cdn.slidesharecdn.com/ss_thumbnails/5ckl-170317080235-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






![[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2018joeunparksweat-180820041651-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


































