Downloaded 11 times












![© 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
response =
ec2_client.describe_spot_price_history(
AvailabilityZone='eu-west-1a',
StartTime='2018-03-01',
EndTime='2018-03-21',
InstanceTypes=['c3.xlarge'],
ProductDescriptions=['Linux/UNIX'],
MaxResults=100
)](https://image.slidesharecdn.com/communitydaynordics-180327095916/85/Make-your-data-fly-Building-data-platform-in-AWS-18-320.jpg)


















![© 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
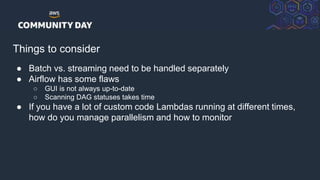
Simple tasks to secure data
● Encrypt
○ S3 buckets
○ RDS & Redshift
○ EBS volumes
● Just block accesses
○ Network ACL
○ Security groups
○ S3 bucket policies
● Setup notifications on changes
● Prevent opening access
{ "Version": "2008-10-17",
"Statement": [
"Effect": "Deny",
"Action": "*",
"Resource": "arn:aws:s3:::my-bucket/*",
"Condition": {
"StringNotEqualsIfExists": {
"aws:SourceVpc": "vpc-abcdefg"
},
"NotIpAddressIfExists": {
"aws:SourceIp": [
"1.1.1.1/32" ]](https://image.slidesharecdn.com/communitydaynordics-180327095916/85/Make-your-data-fly-Building-data-platform-in-AWS-50-320.jpg)
















![© 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
response =
ec2_client.describe_spot_price_history(
AvailabilityZone='eu-west-1a',
StartTime='2018-03-01',
EndTime='2018-03-21',
InstanceTypes=['c3.xlarge'],
ProductDescriptions=['Linux/UNIX'],
MaxResults=100
)](https://image.slidesharecdn.com/communitydaynordics-180327095916/75/Make-your-data-fly-Building-data-platform-in-AWS-18-2048.jpg)













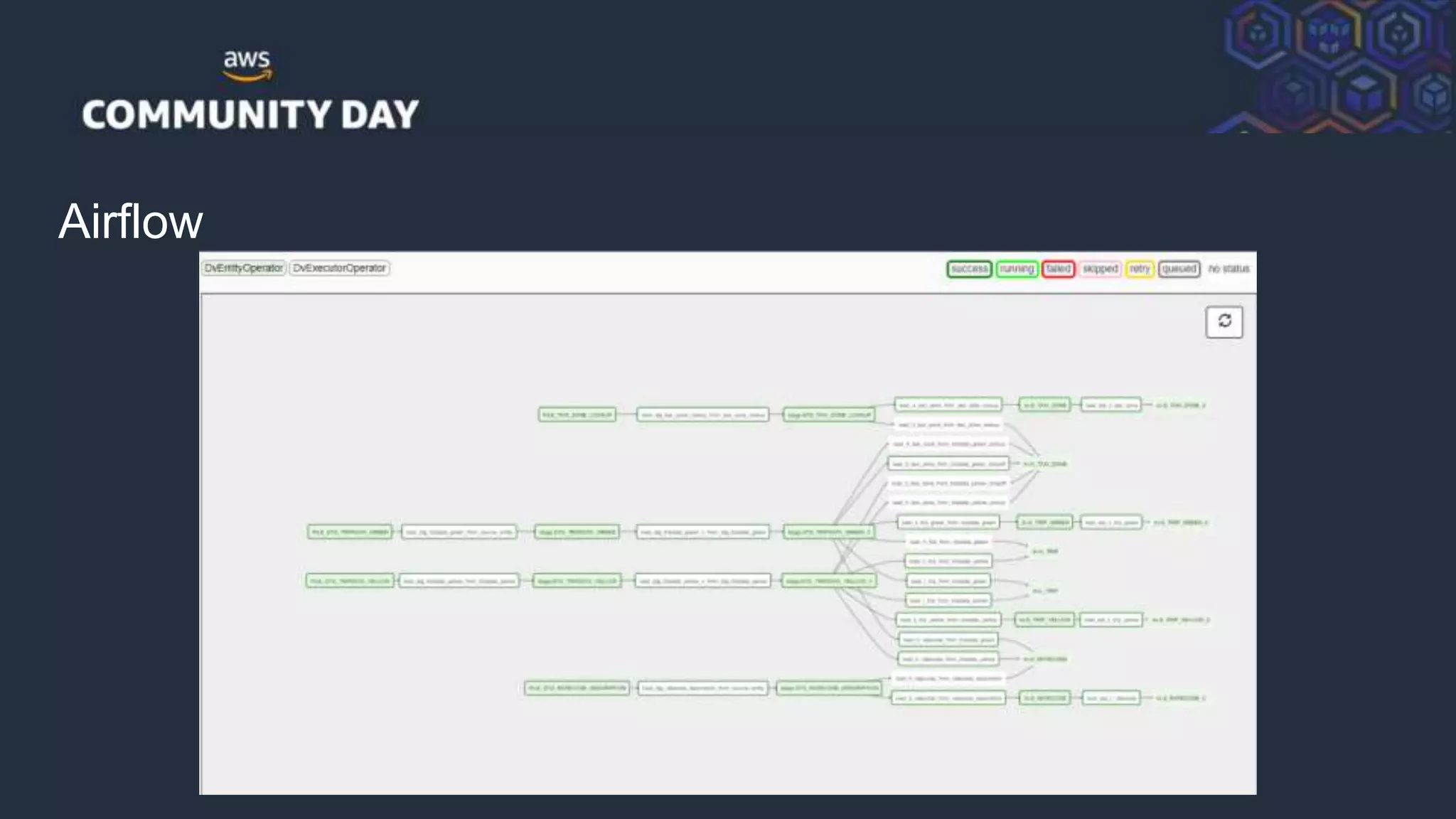
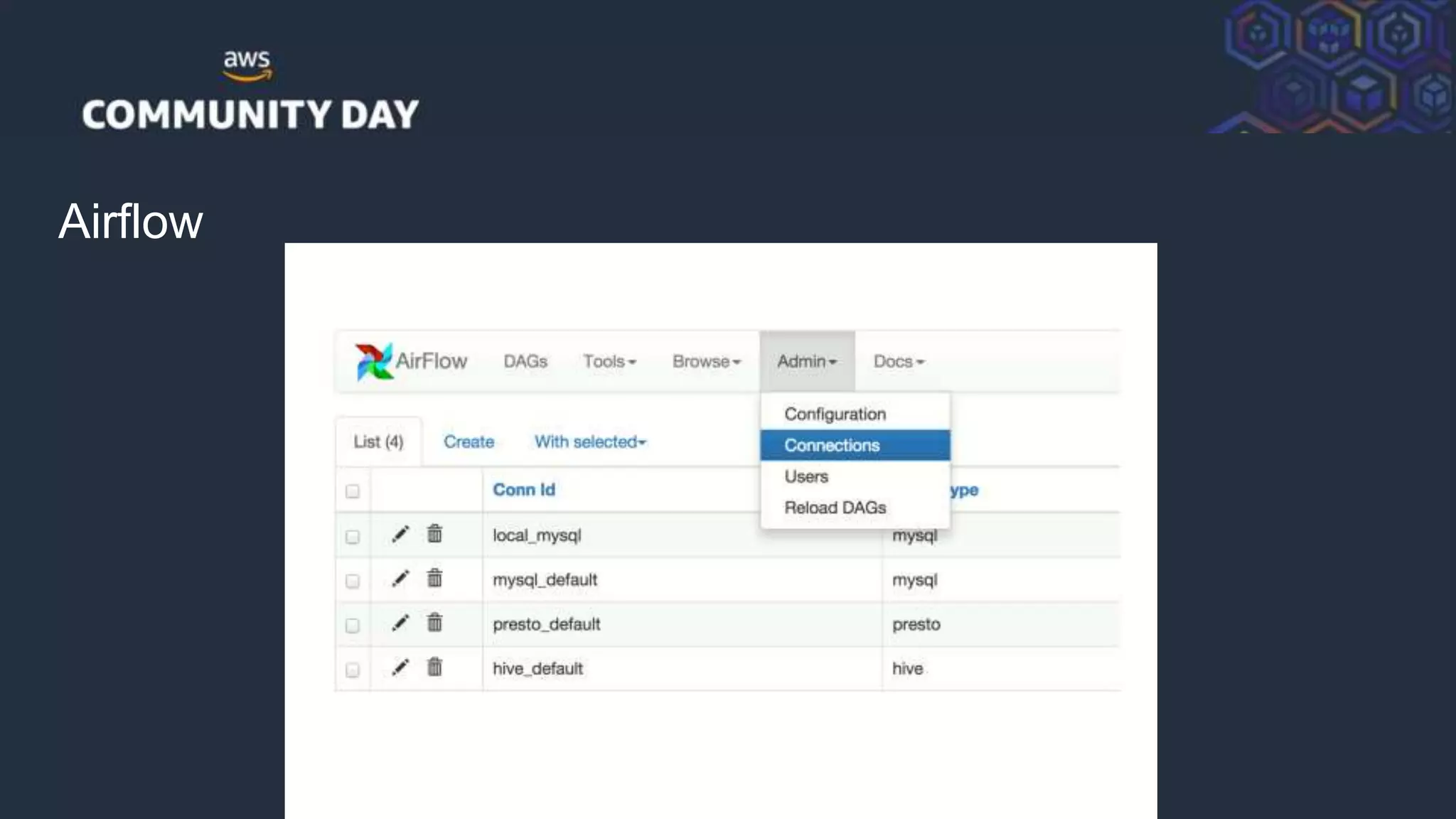


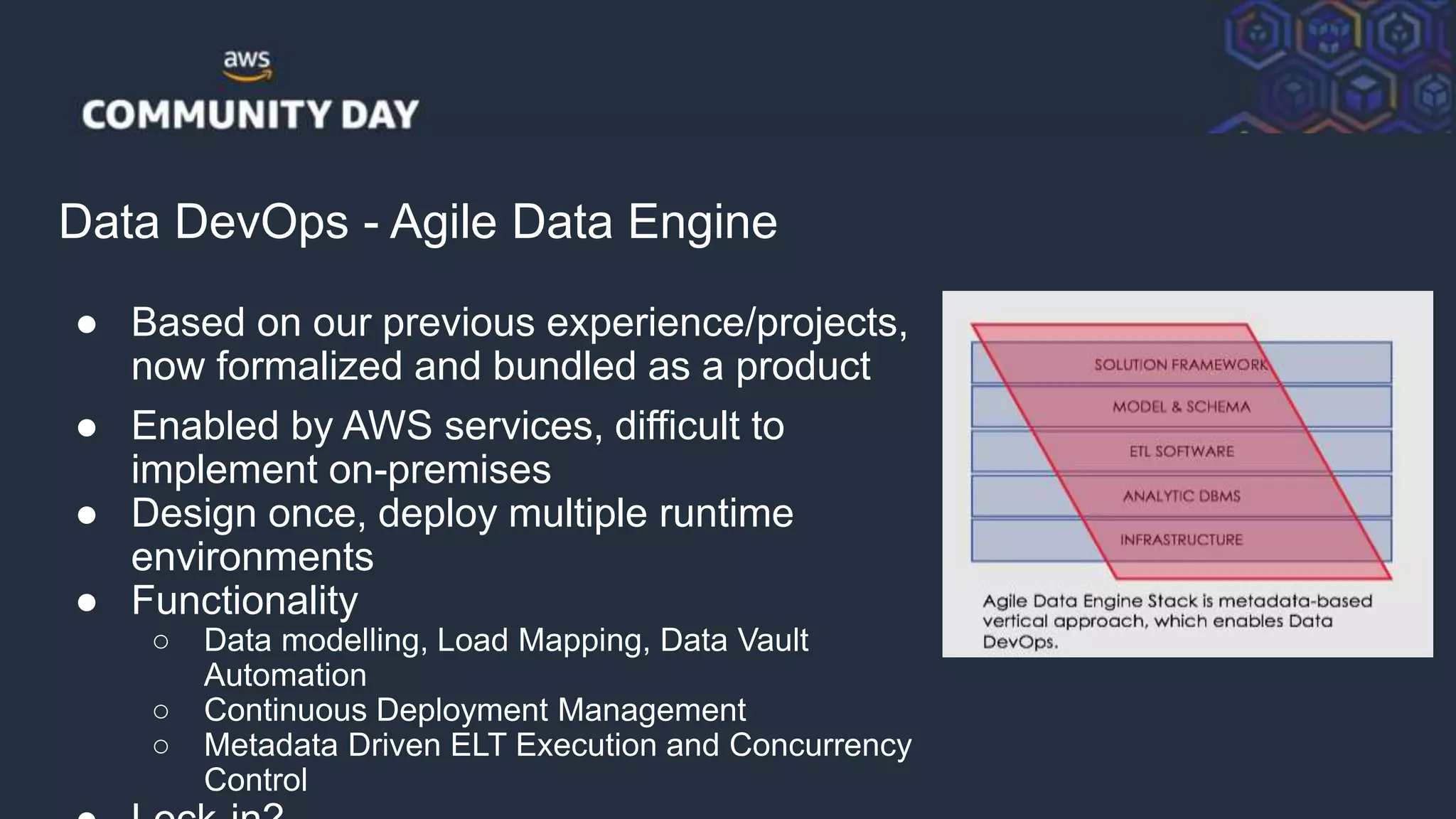






![© 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Simple tasks to secure data
● Encrypt
○ S3 buckets
○ RDS & Redshift
○ EBS volumes
● Just block accesses
○ Network ACL
○ Security groups
○ S3 bucket policies
● Setup notifications on changes
● Prevent opening access
{ "Version": "2008-10-17",
"Statement": [
"Effect": "Deny",
"Action": "*",
"Resource": "arn:aws:s3:::my-bucket/*",
"Condition": {
"StringNotEqualsIfExists": {
"aws:SourceVpc": "vpc-abcdefg"
},
"NotIpAddressIfExists": {
"aws:SourceIp": [
"1.1.1.1/32" ]](https://image.slidesharecdn.com/communitydaynordics-180327095916/75/Make-your-data-fly-Building-data-platform-in-AWS-50-2048.jpg)




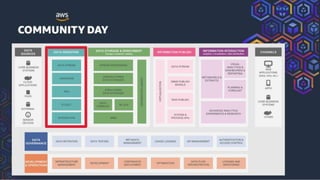
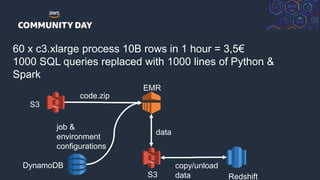
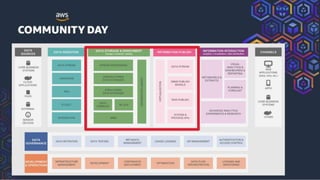
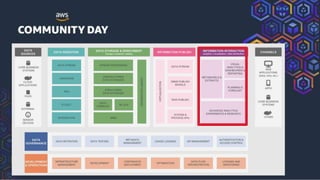
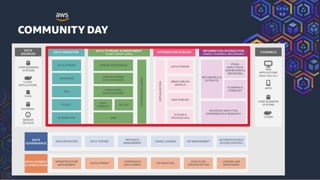
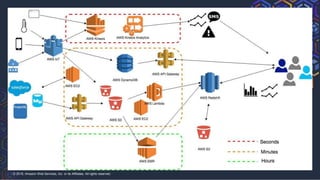
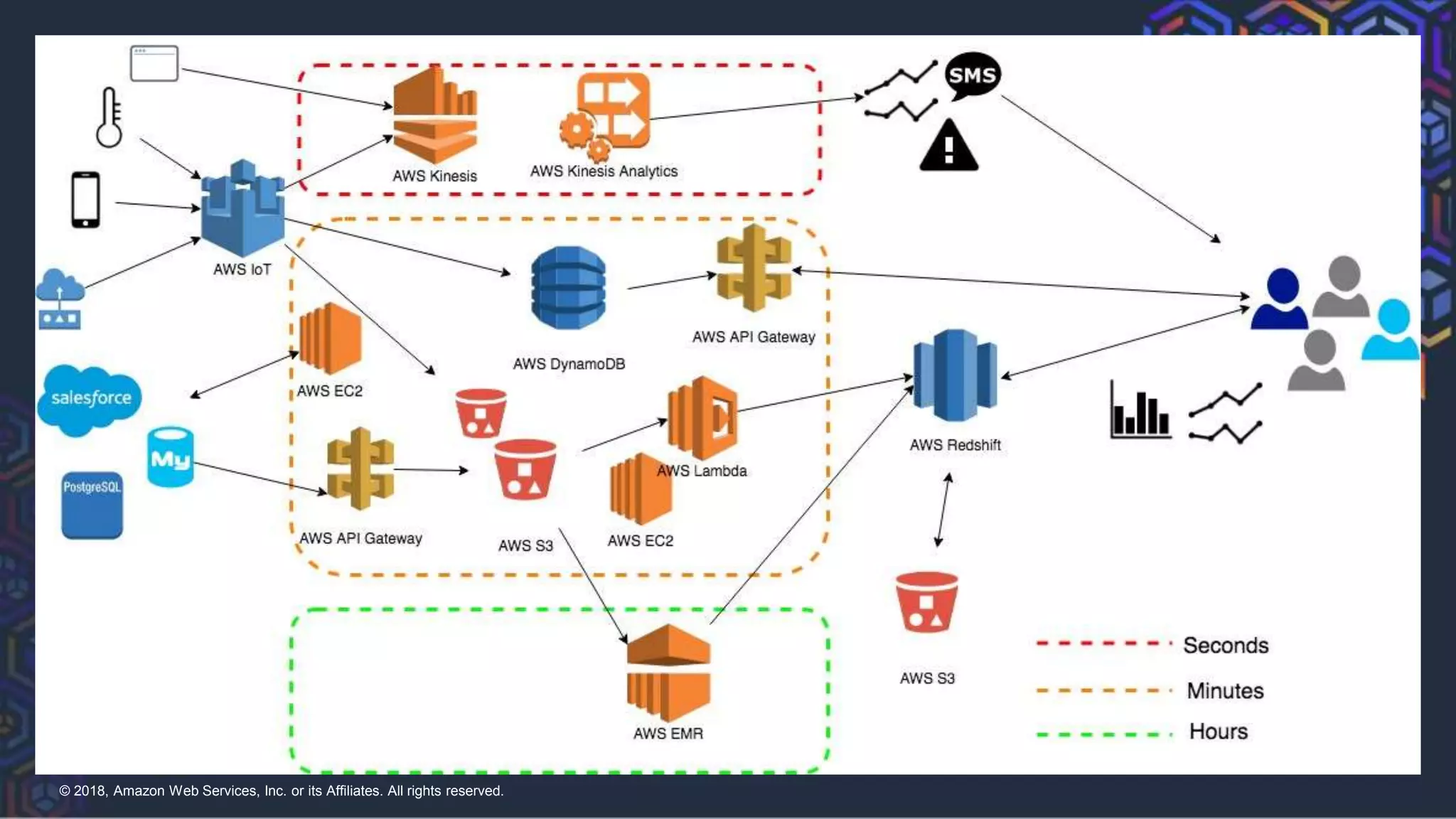
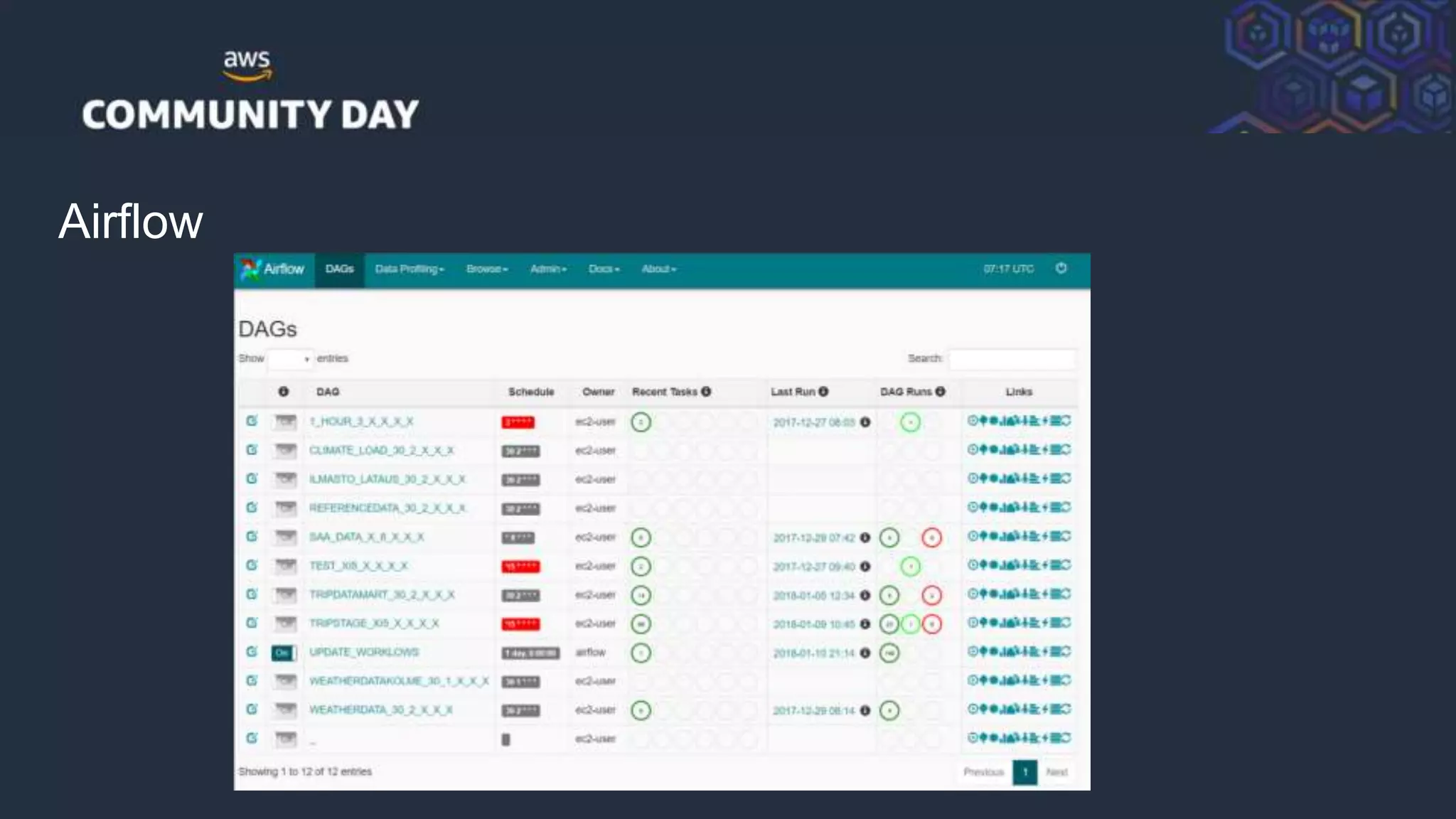
This document summarizes a presentation on building a data platform in AWS. It discusses the architectural evolution from on-premise data warehouses to cloud-based data lakes and platforms. It provides examples of using AWS services like EMR, Redshift, Airflow and visualization tools. It also covers best practices for data modeling, performance optimization, security and DevOps approaches.















































