Download to read offline
















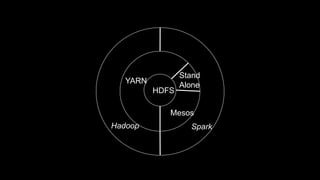
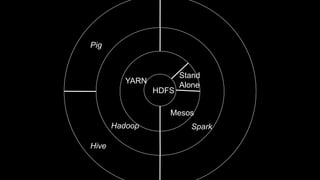
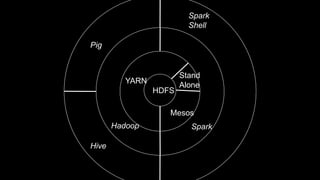
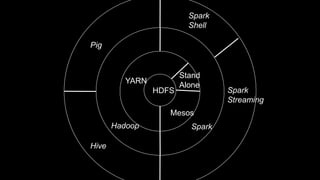
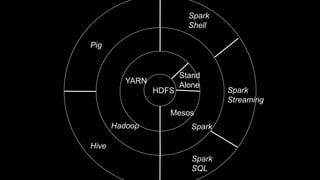
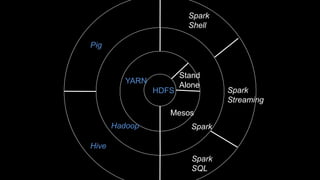

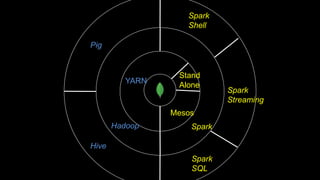

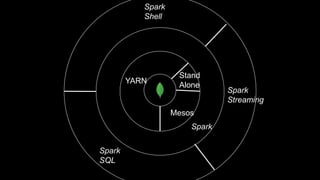
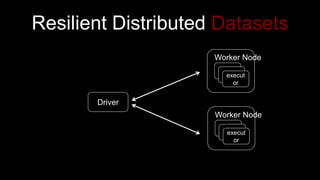









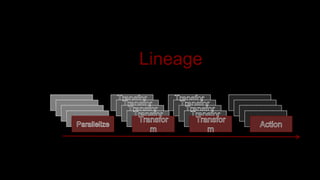
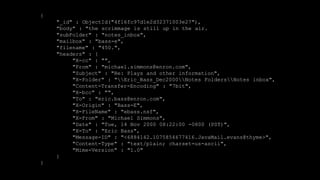
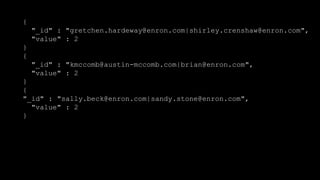
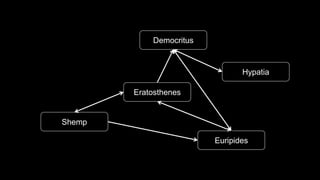
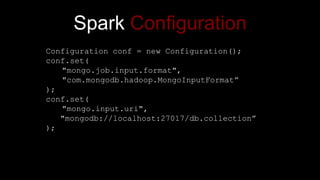





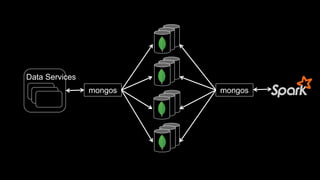
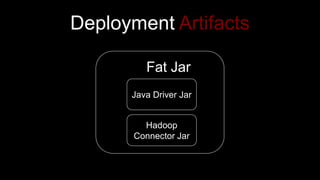
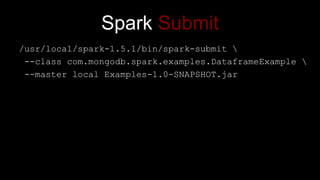
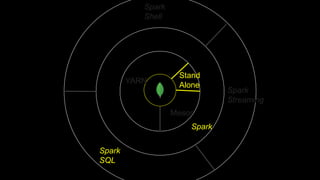
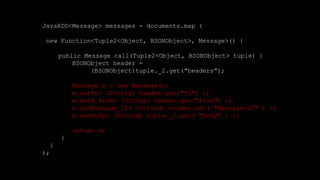


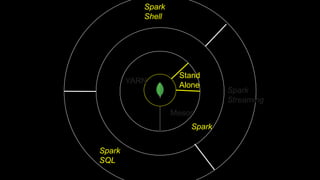
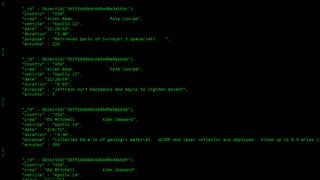
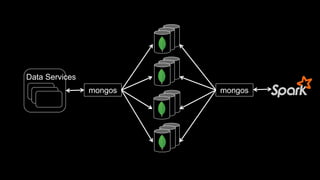
















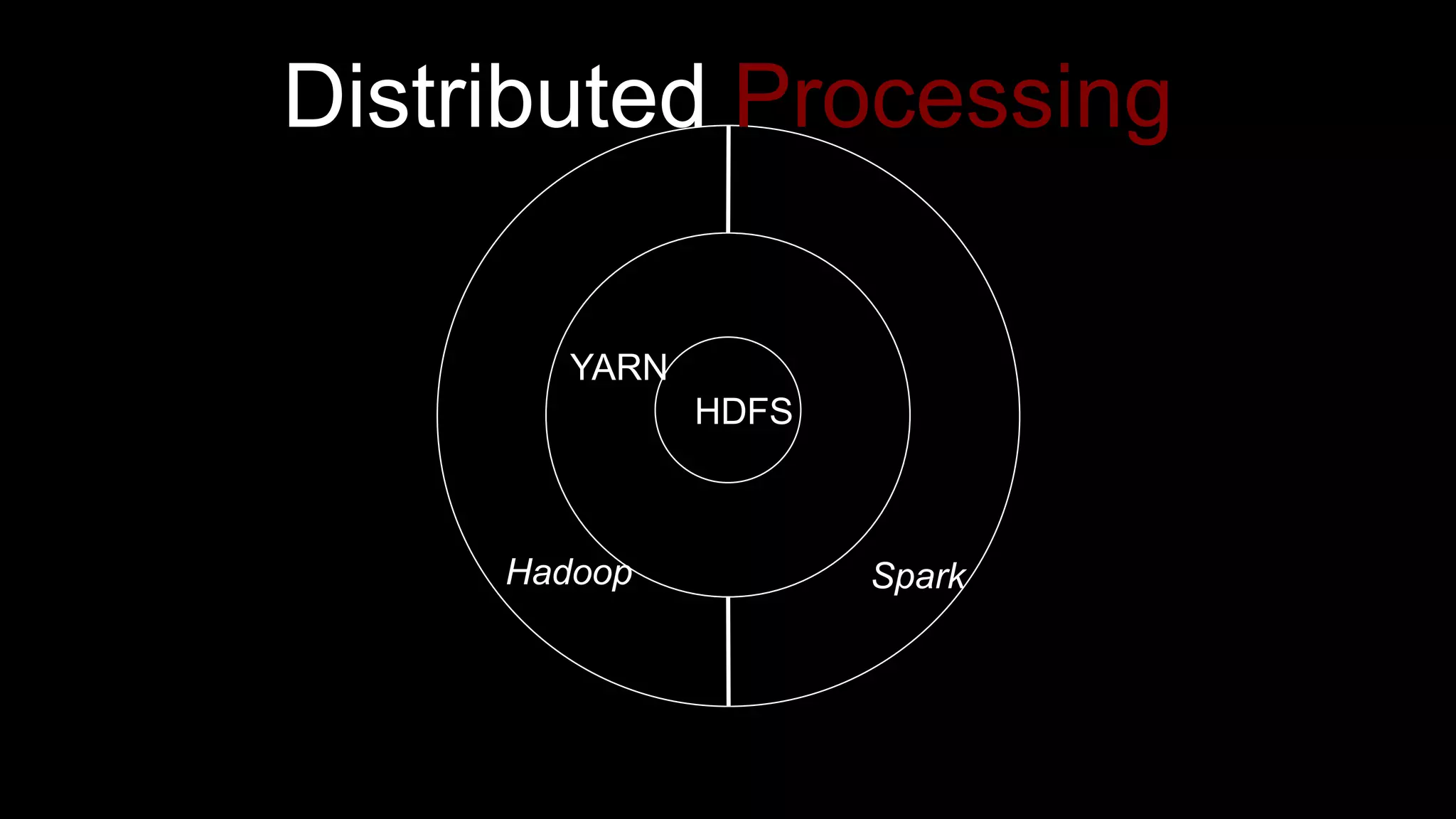
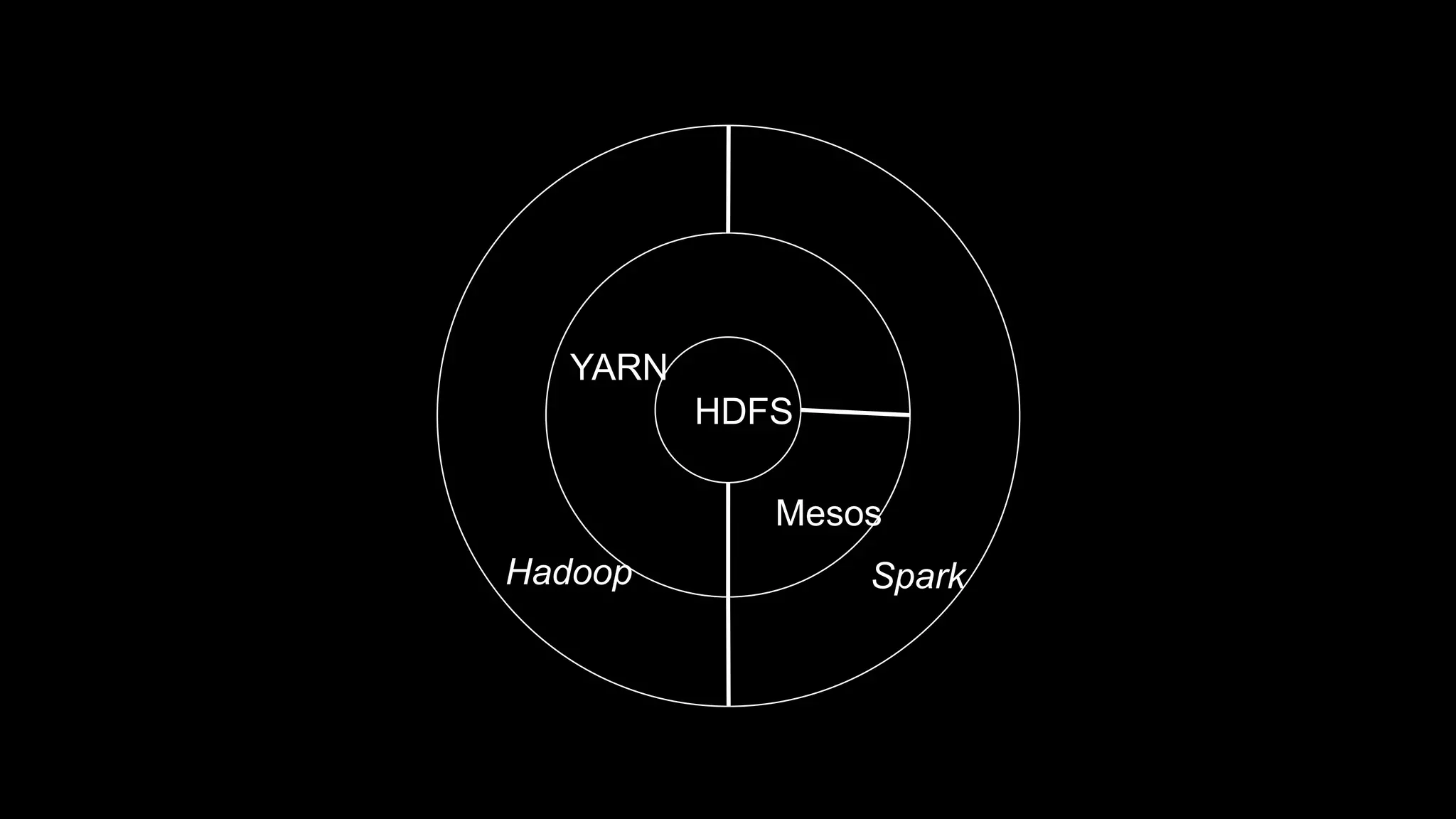
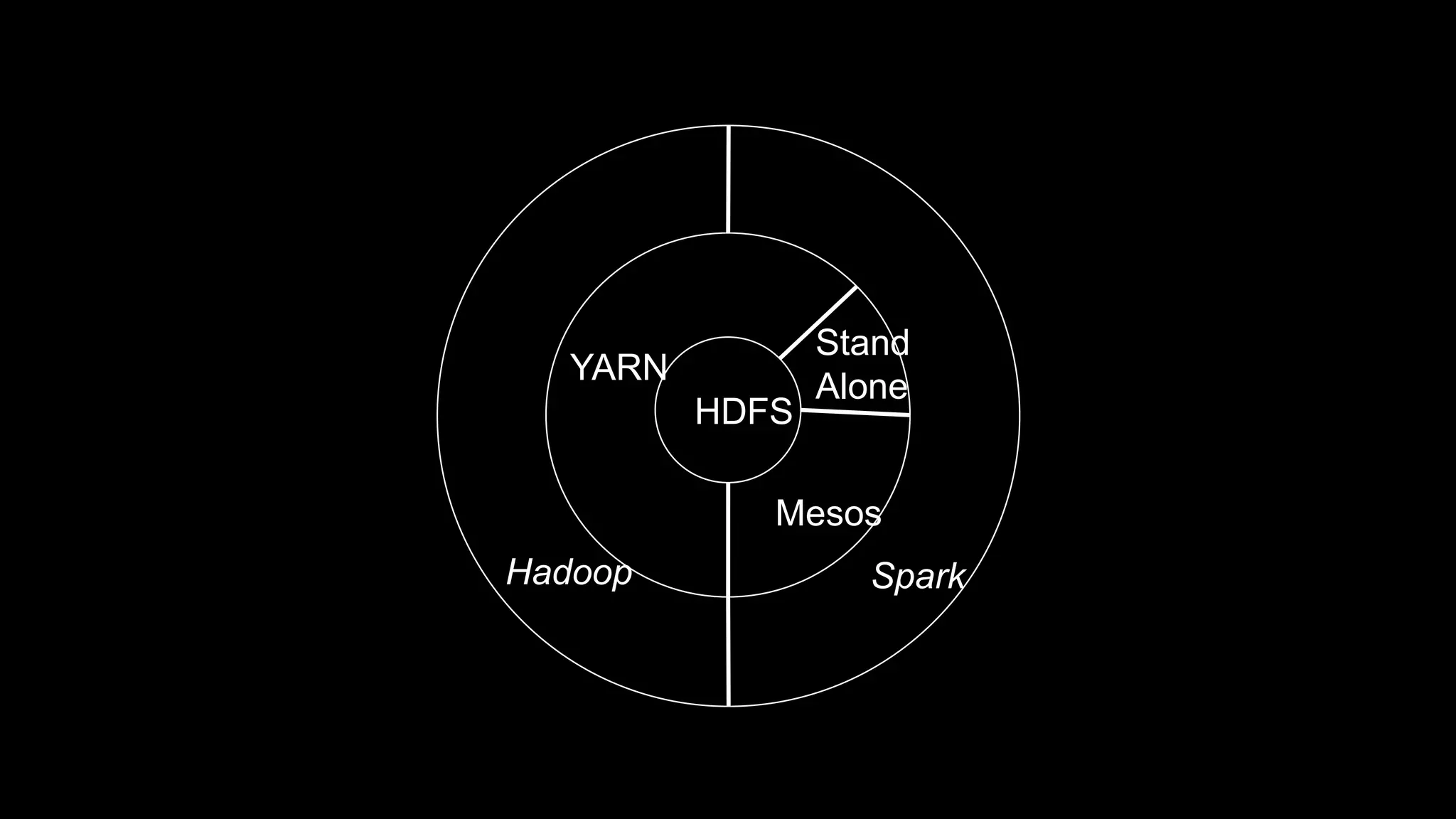
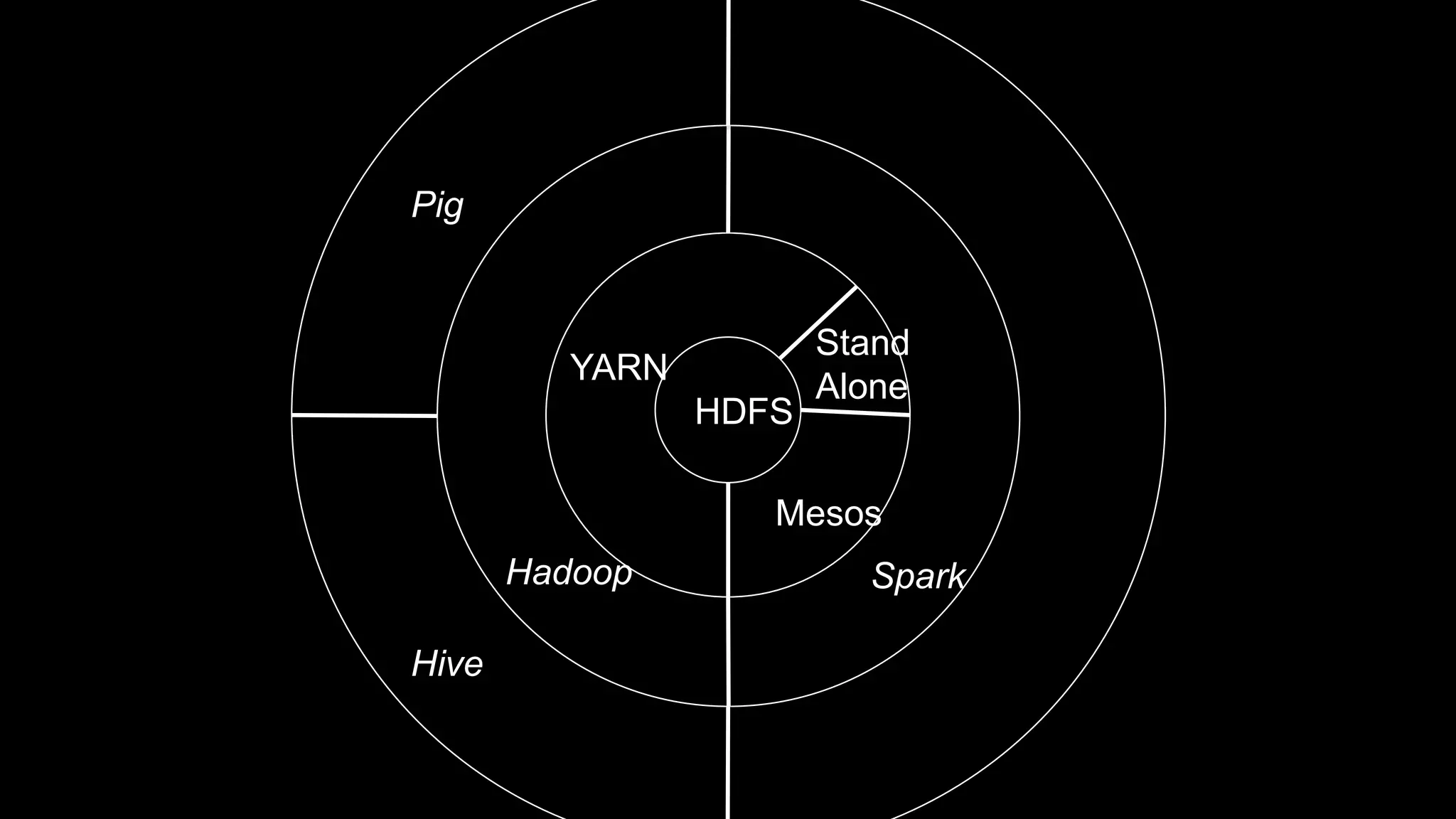

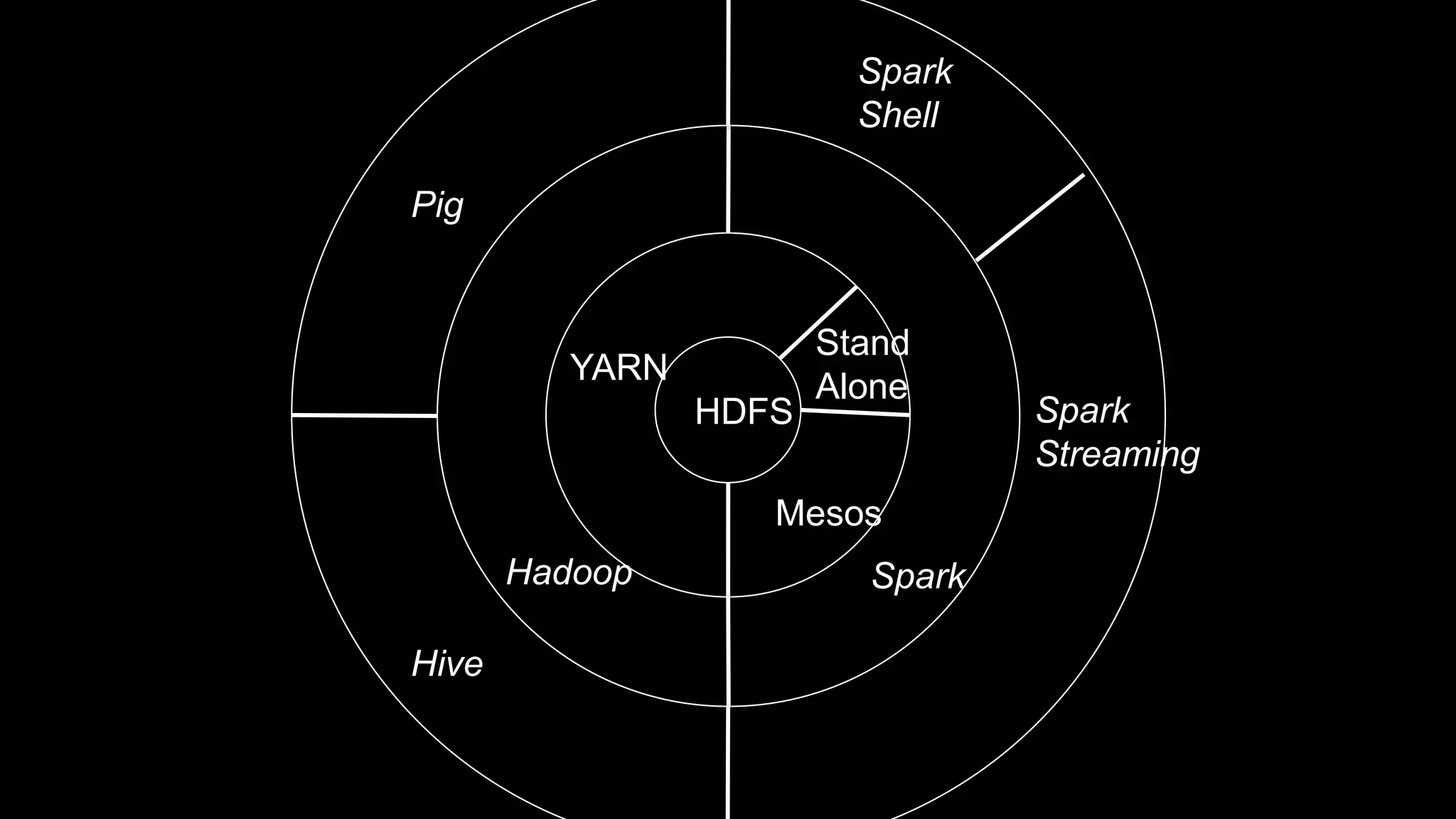

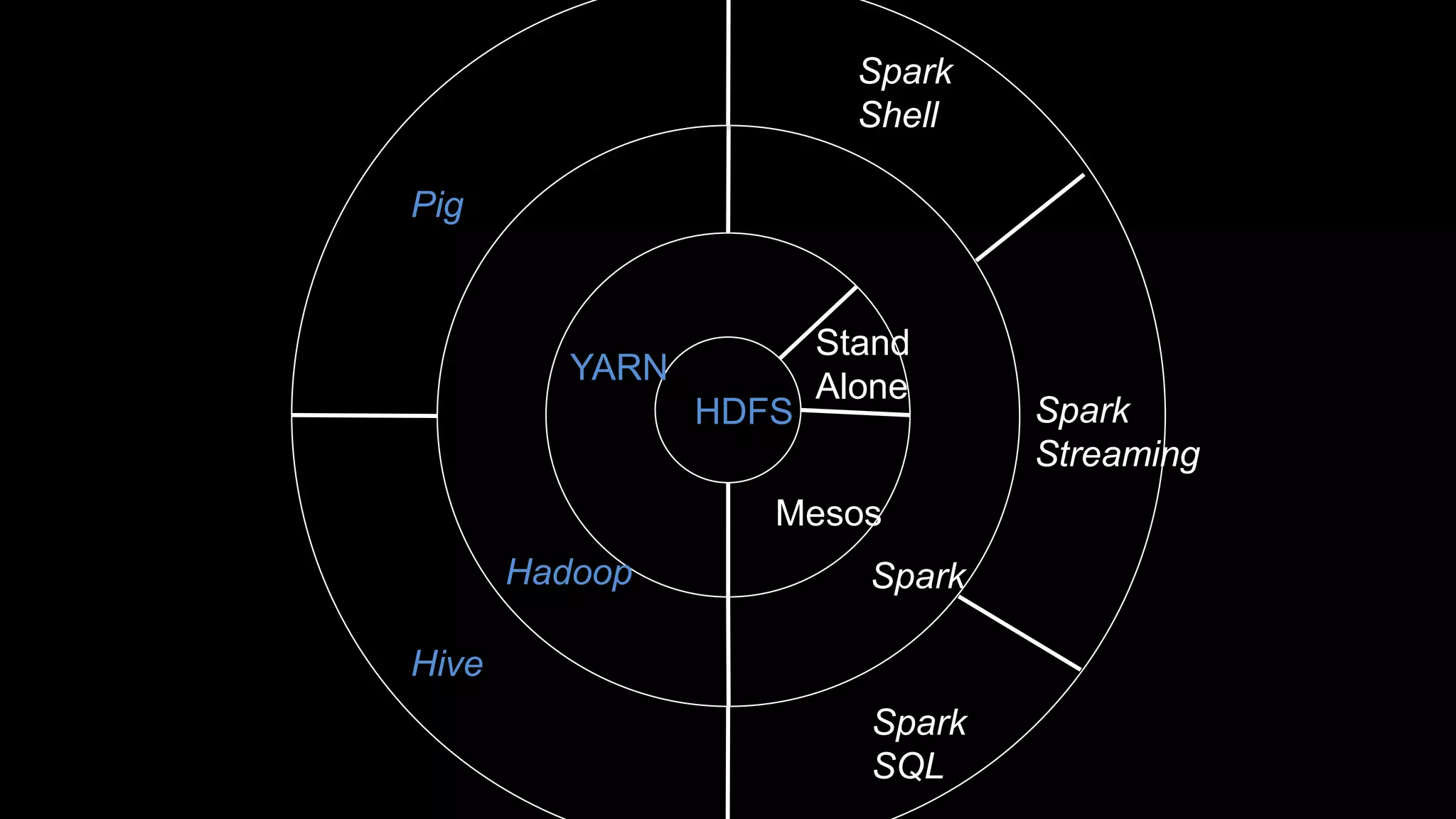
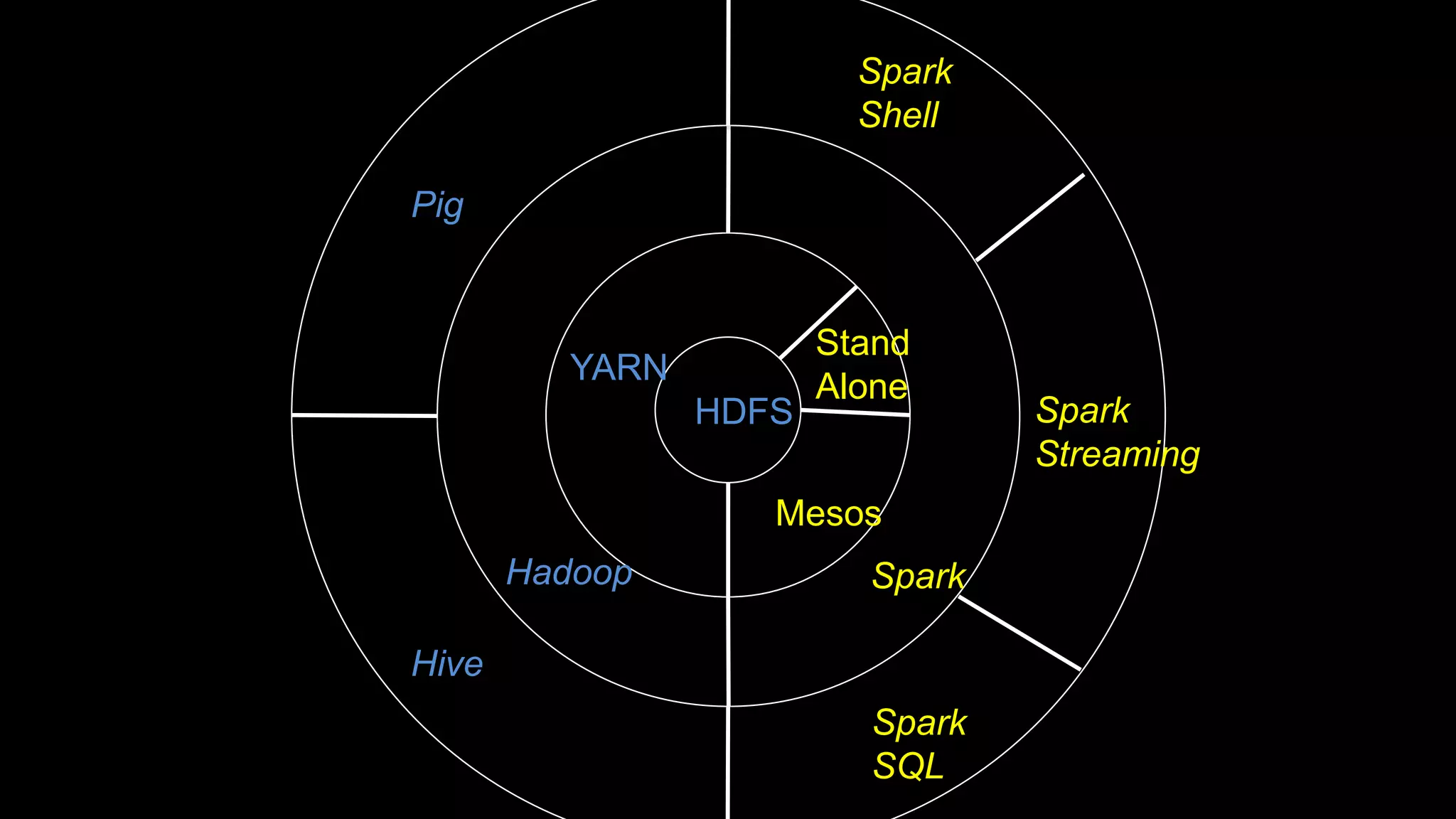
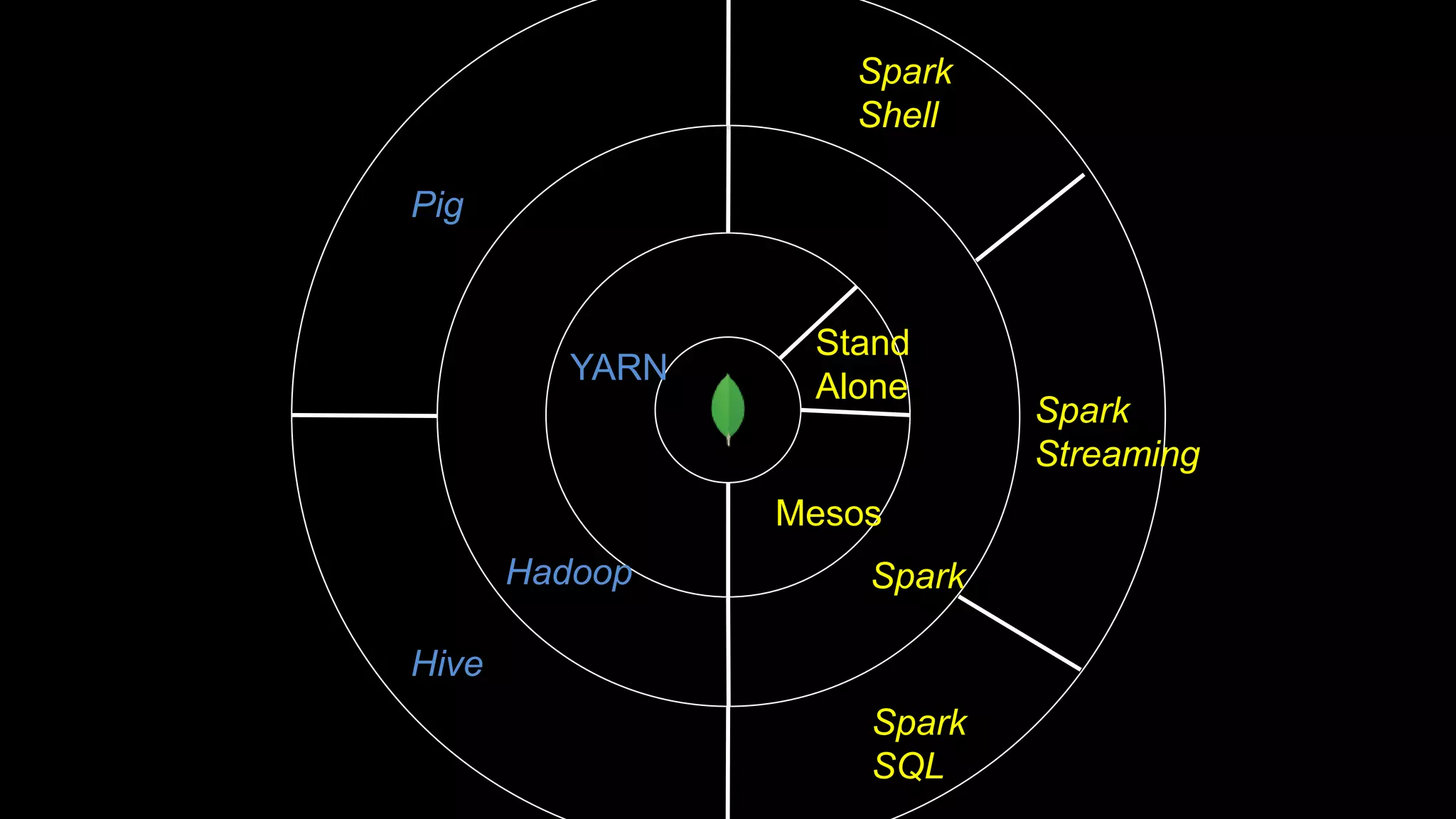
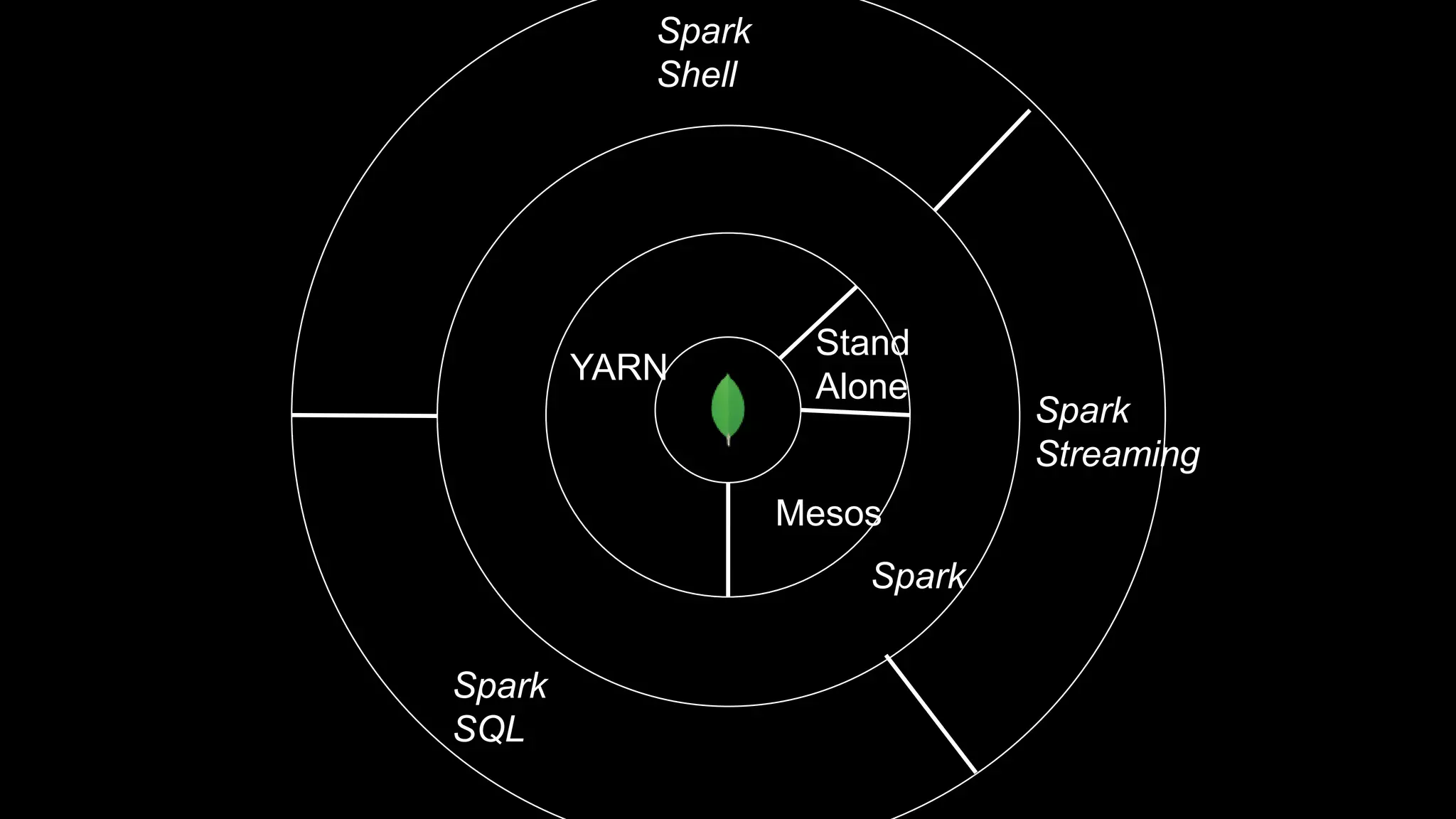
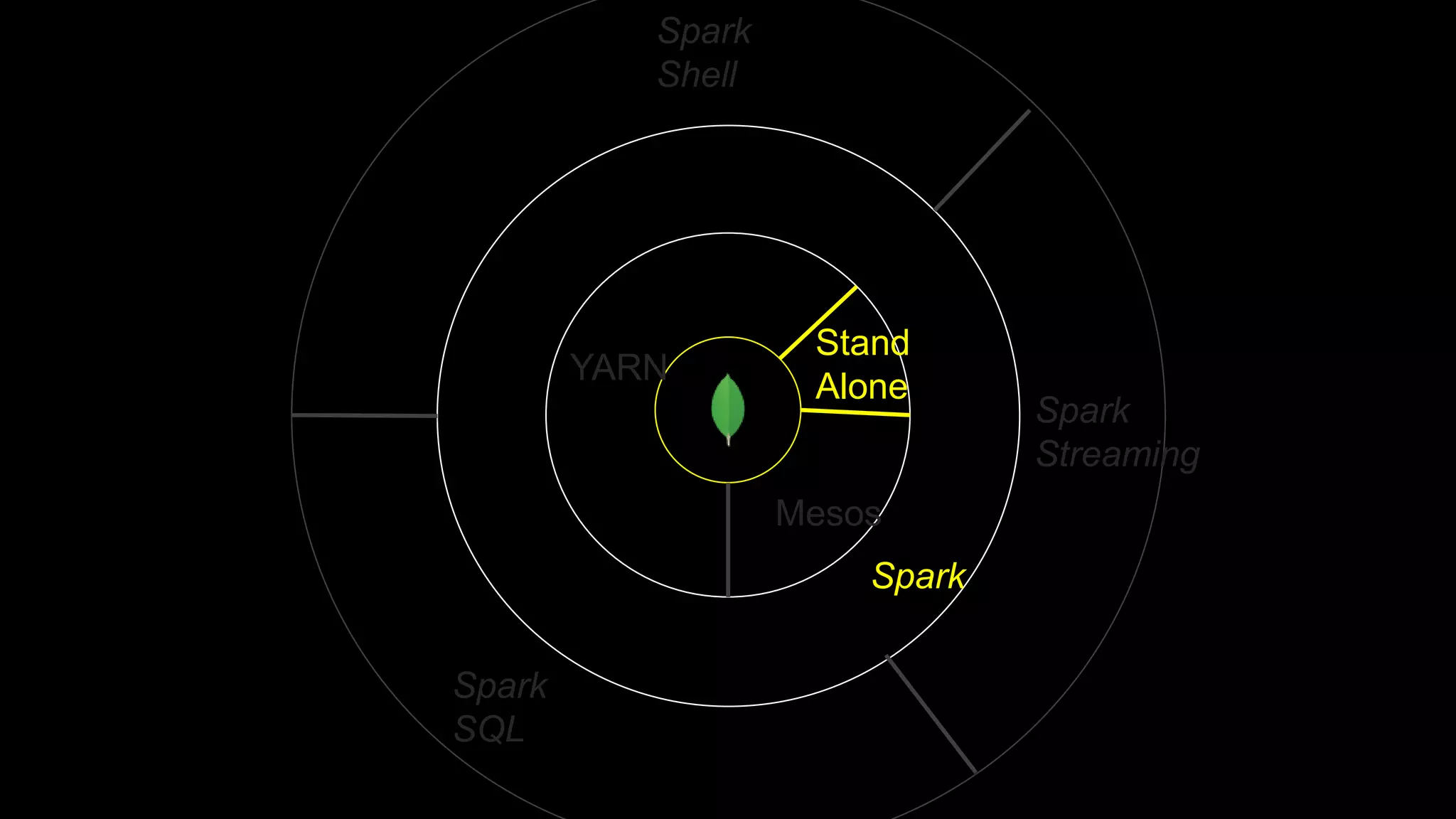
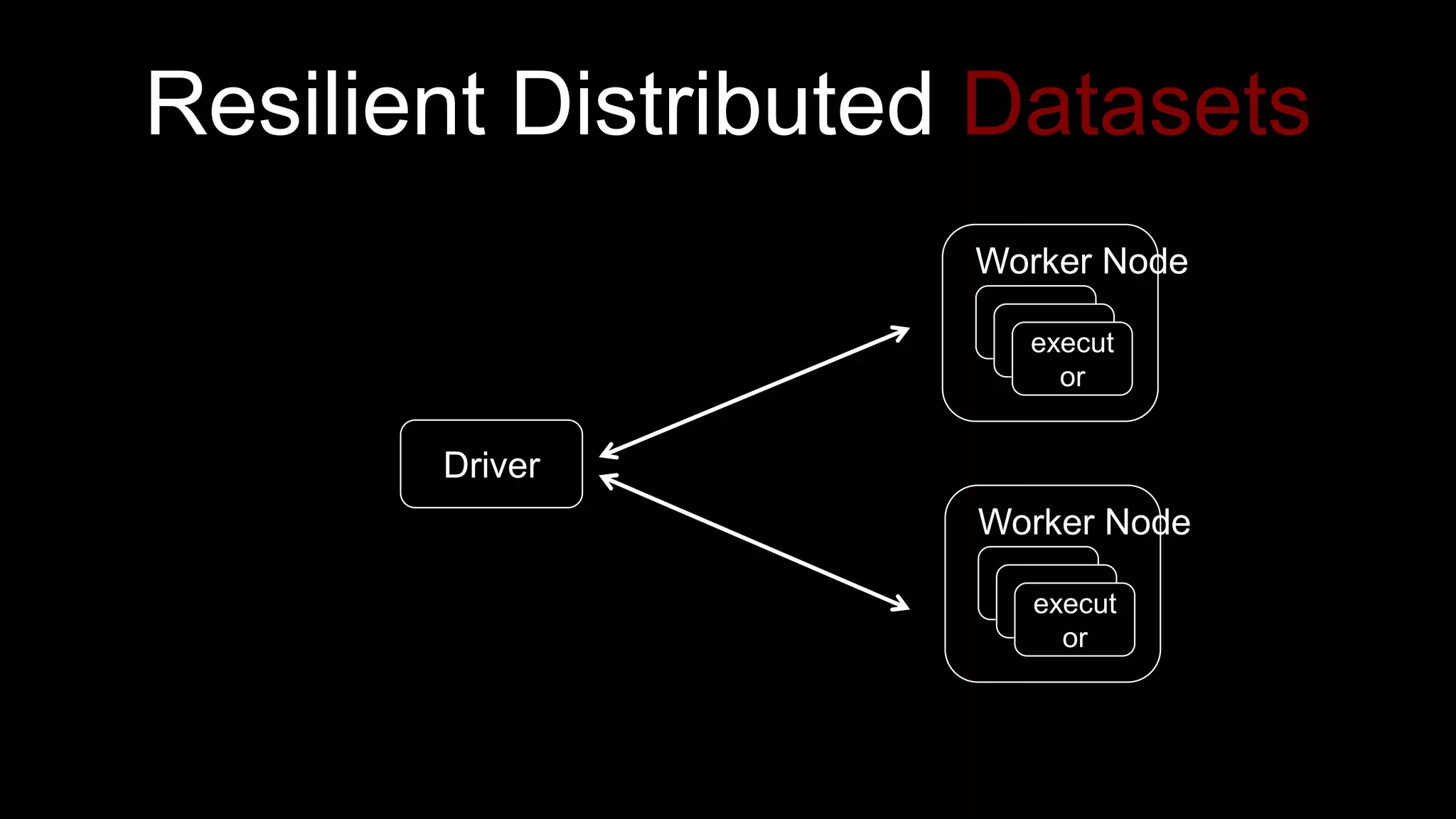








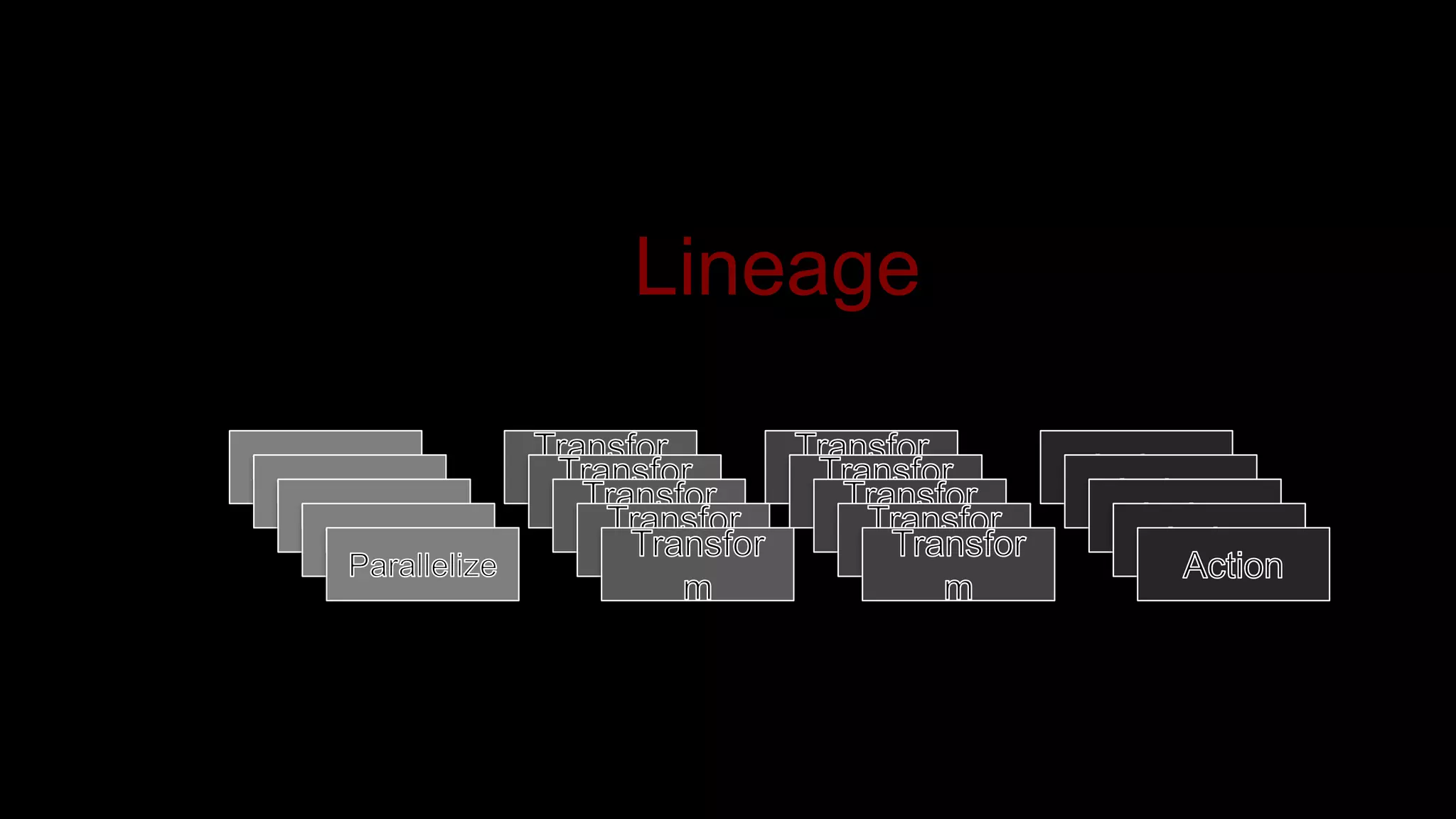
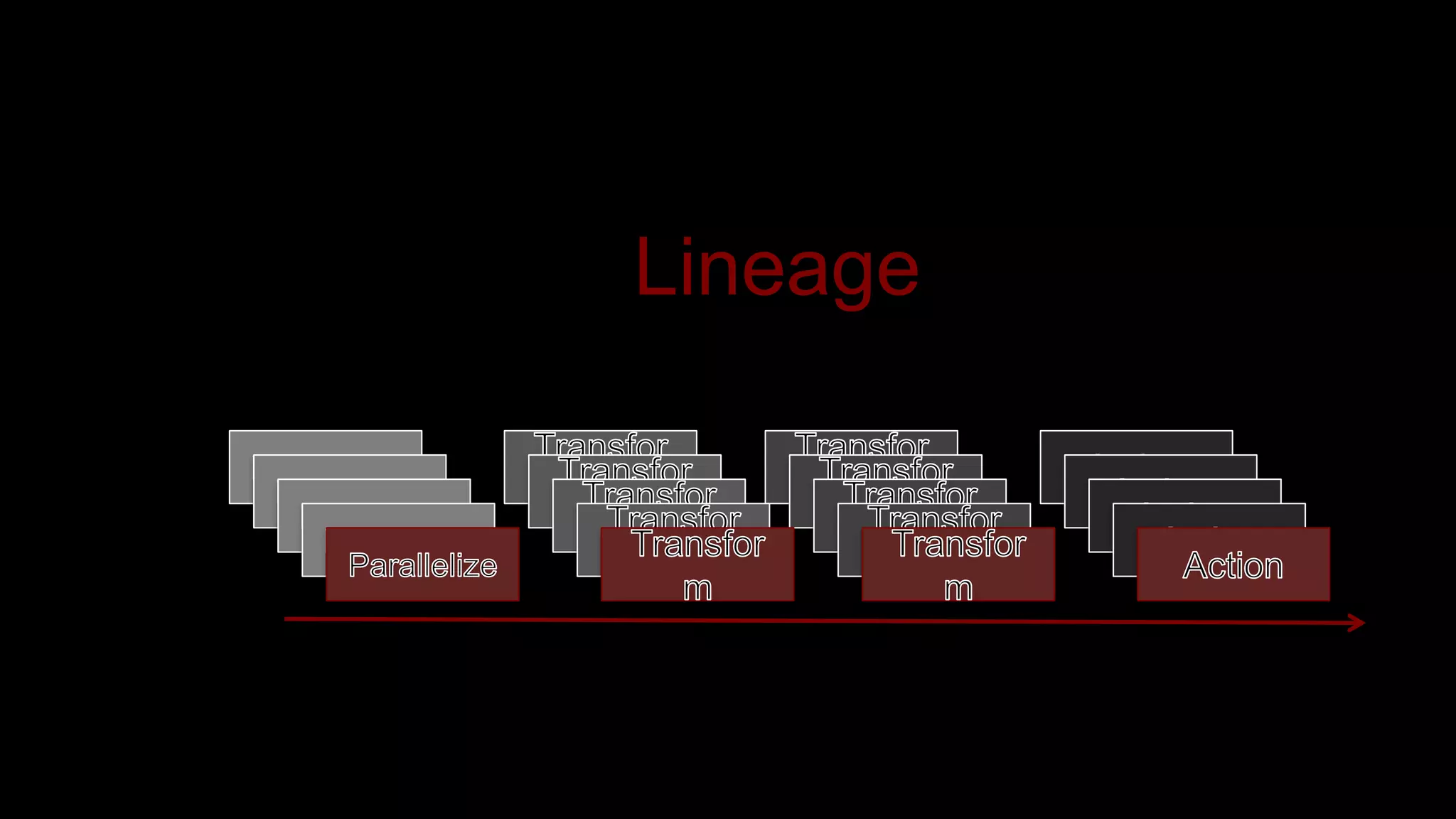
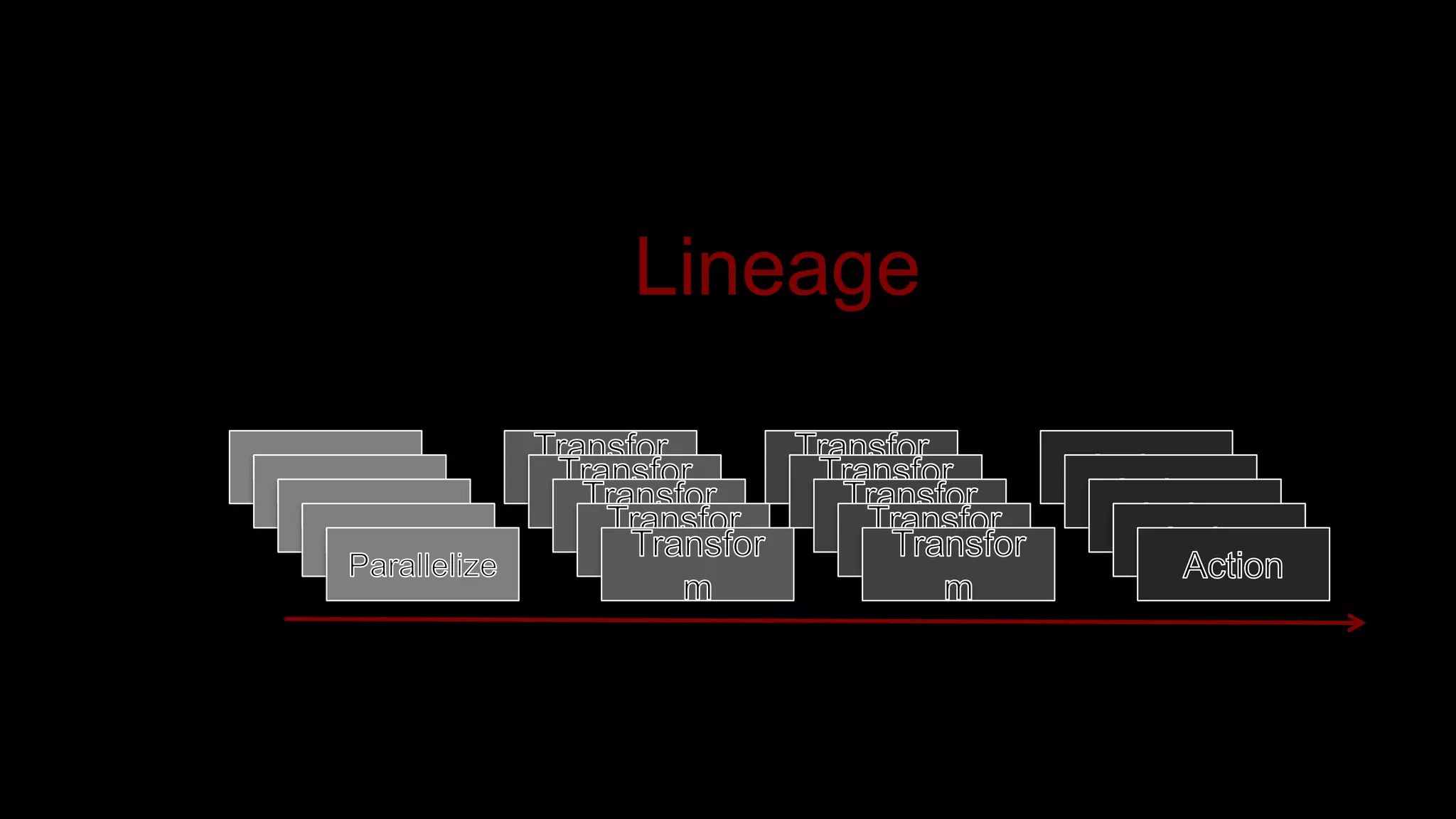
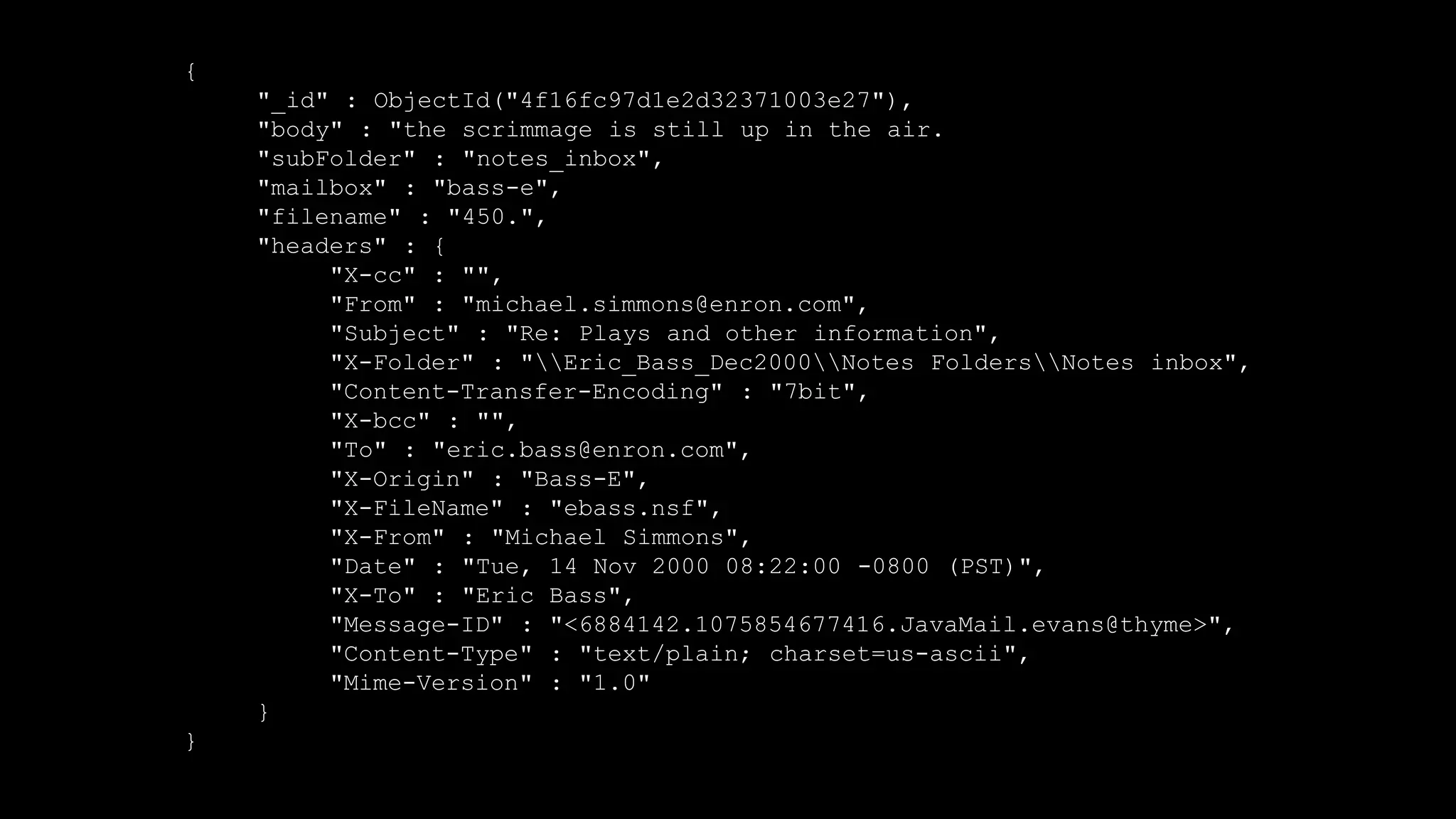
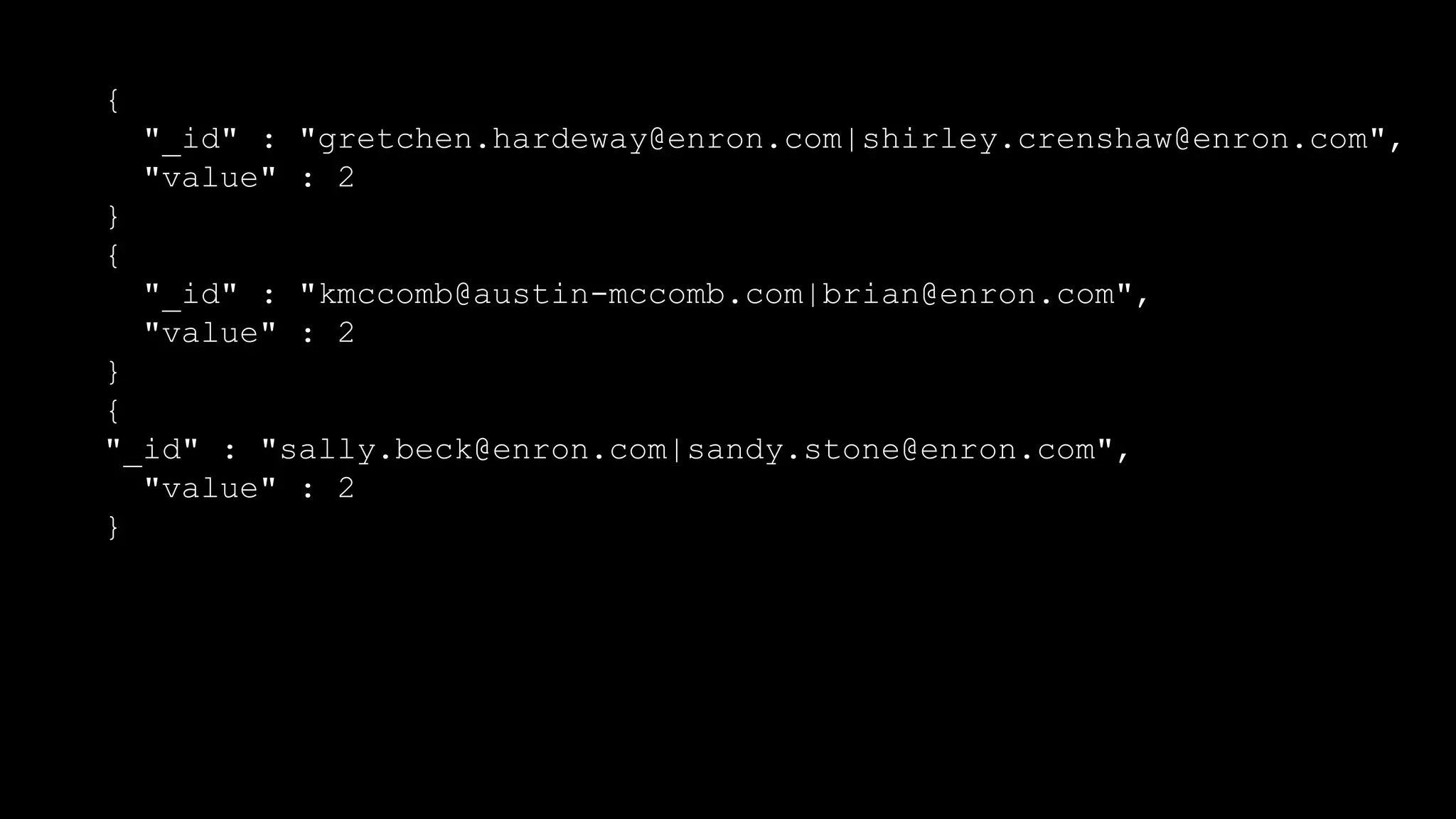
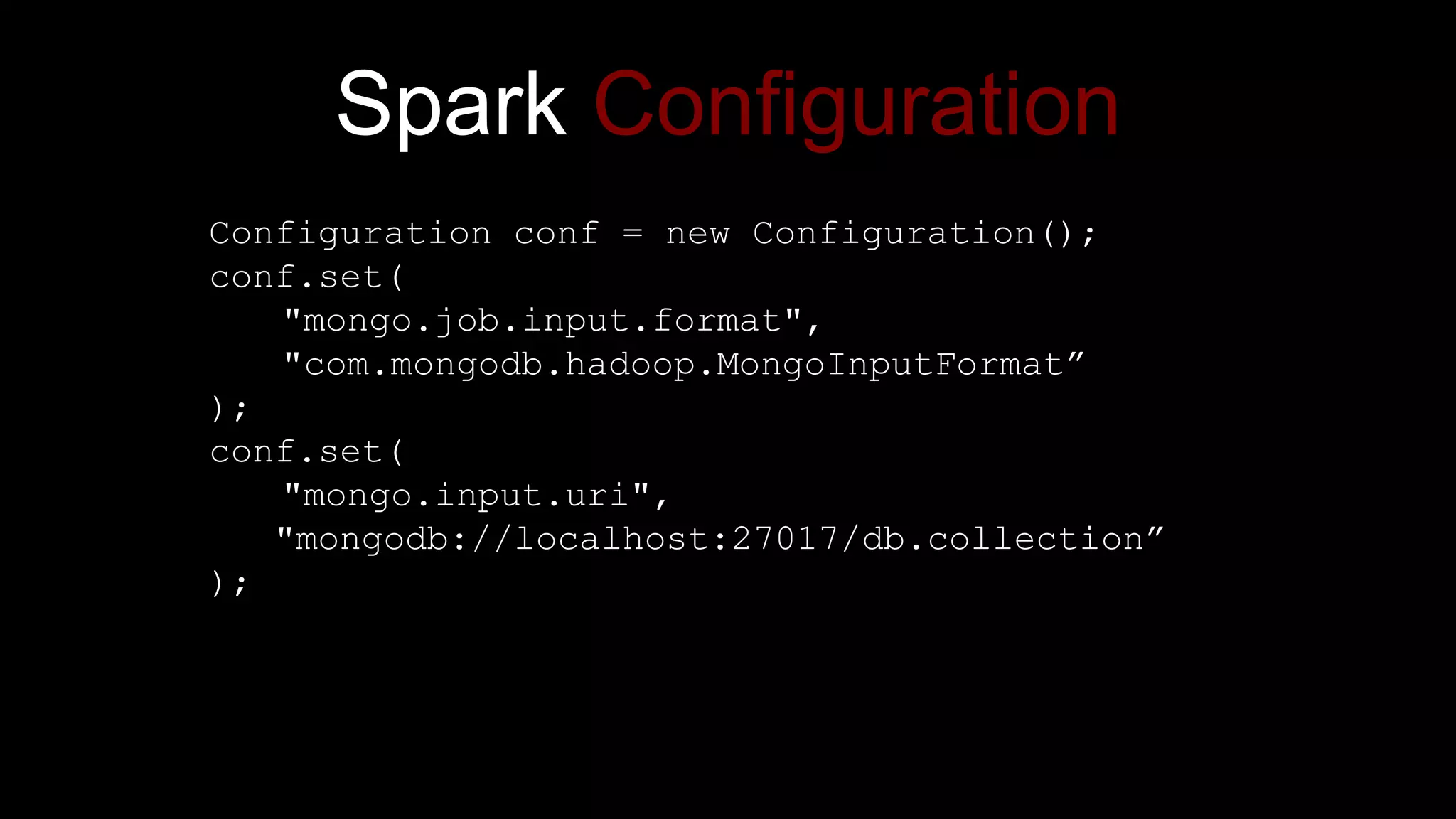





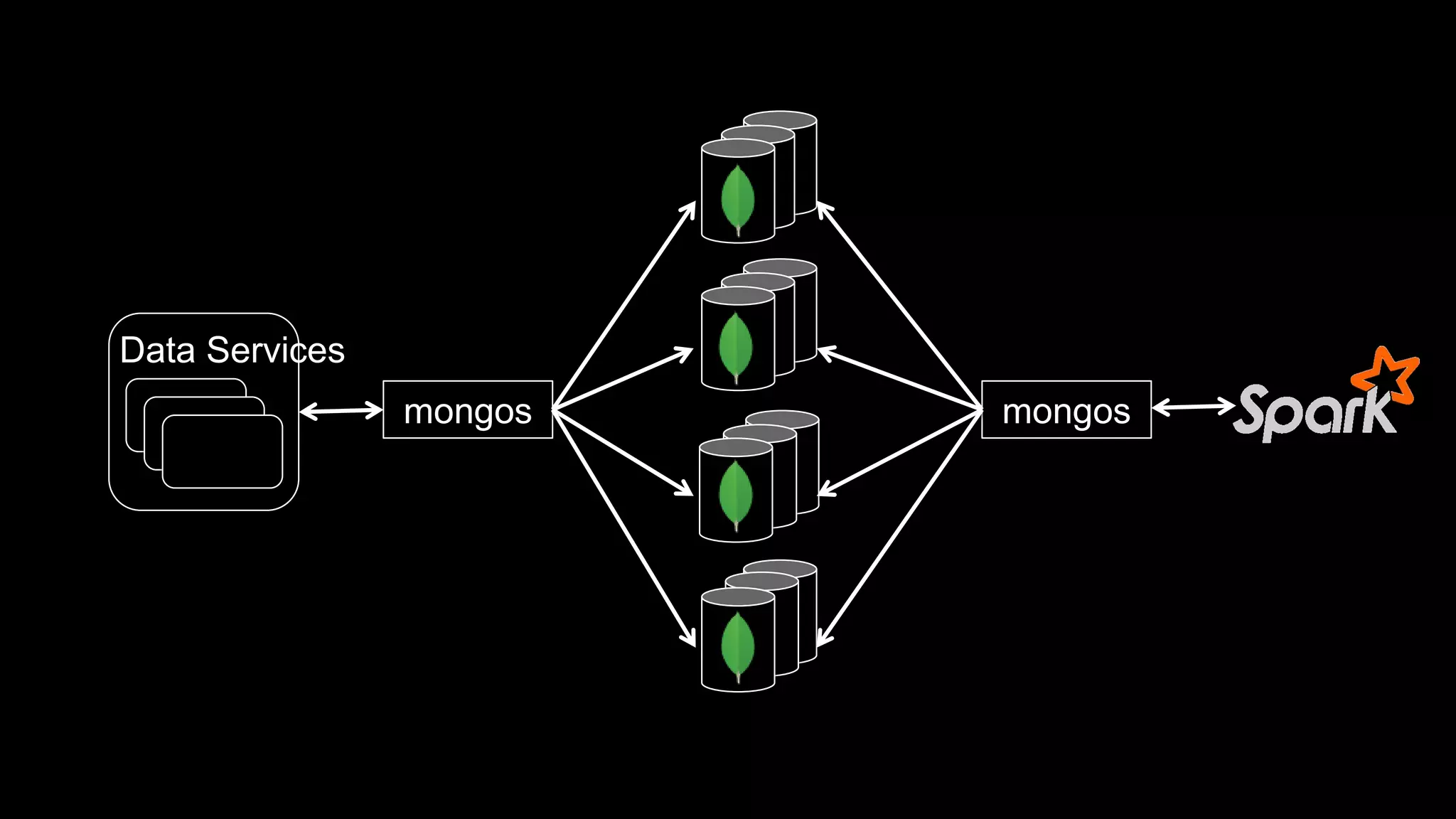

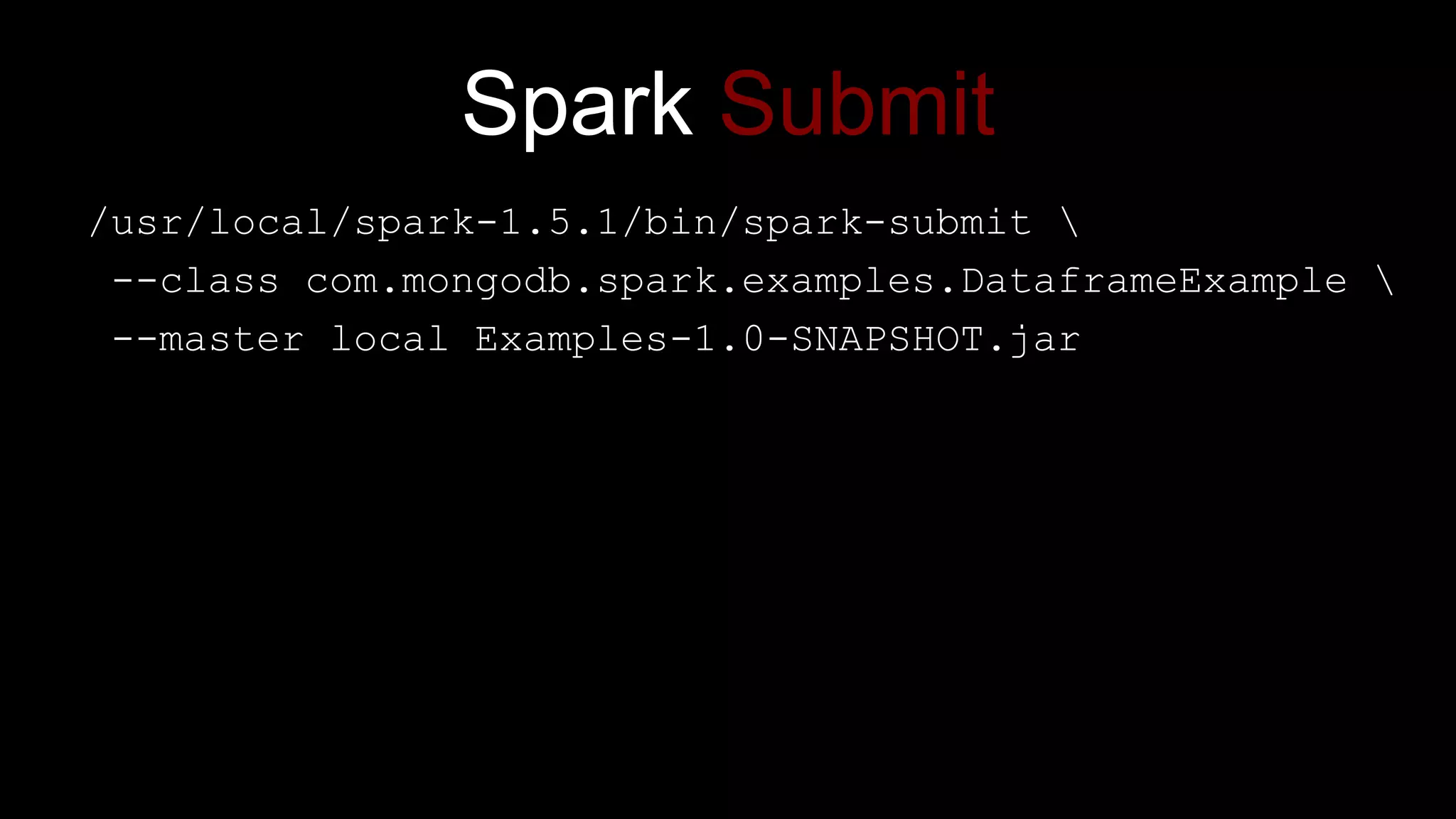
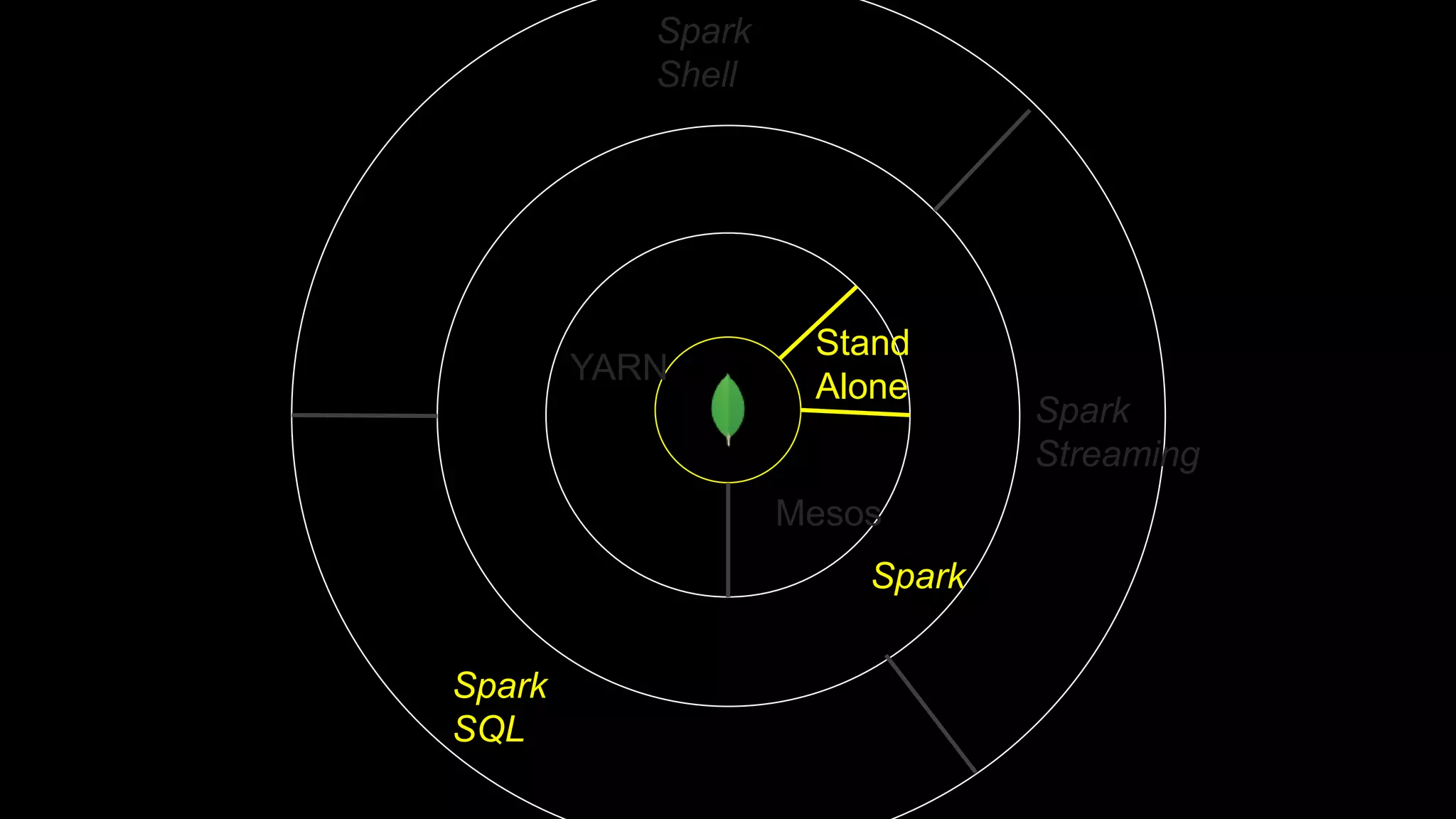
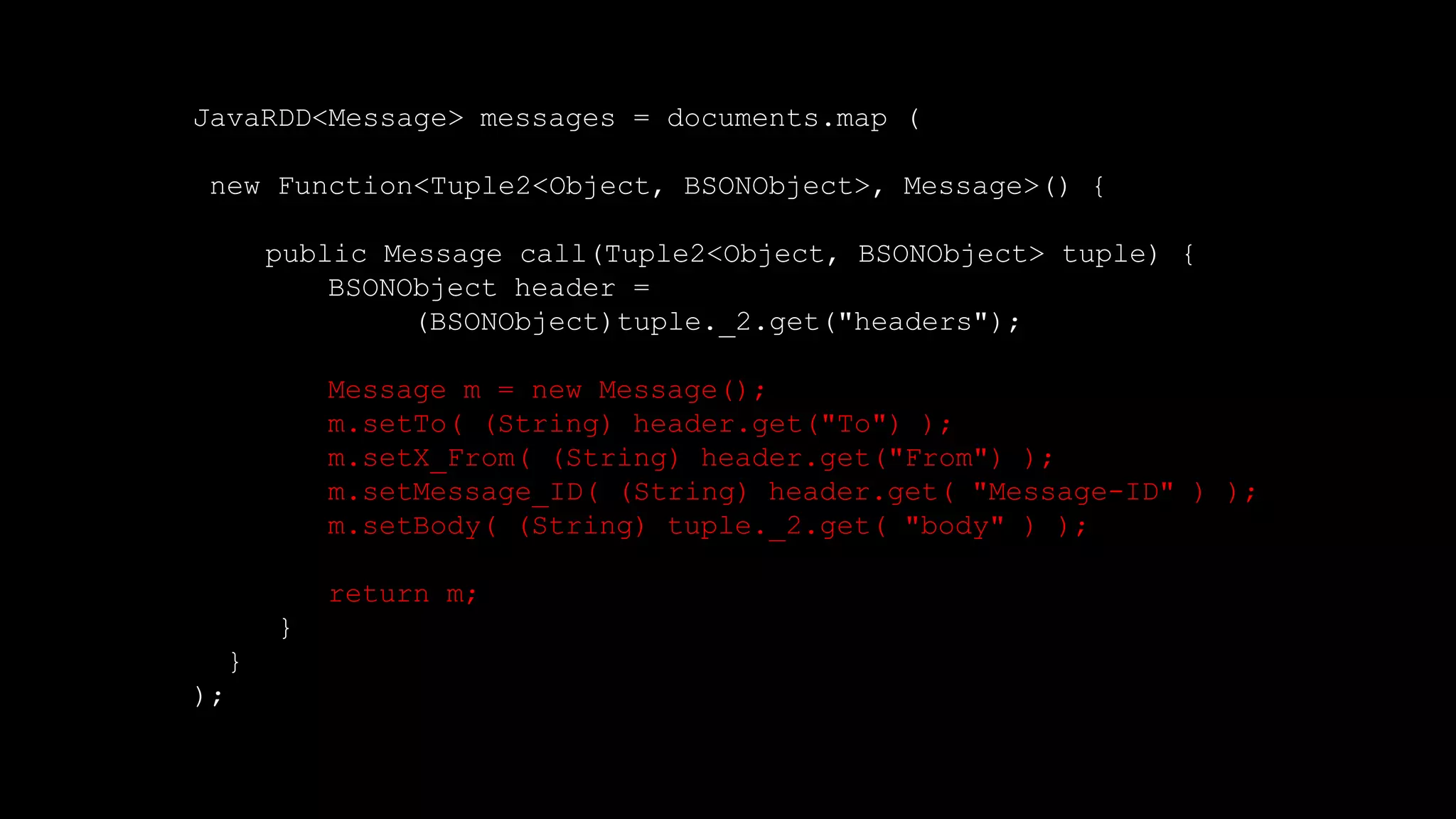


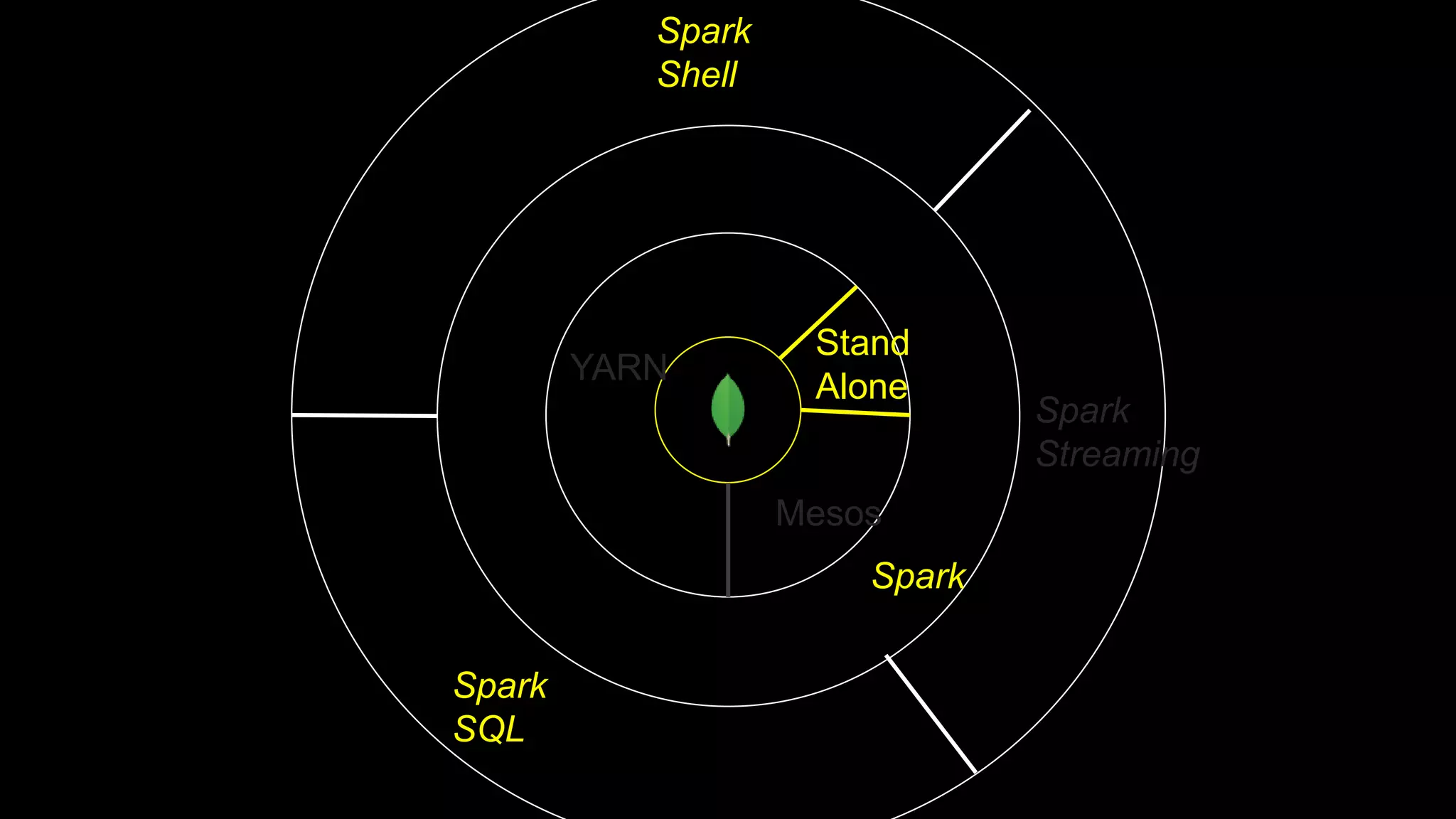
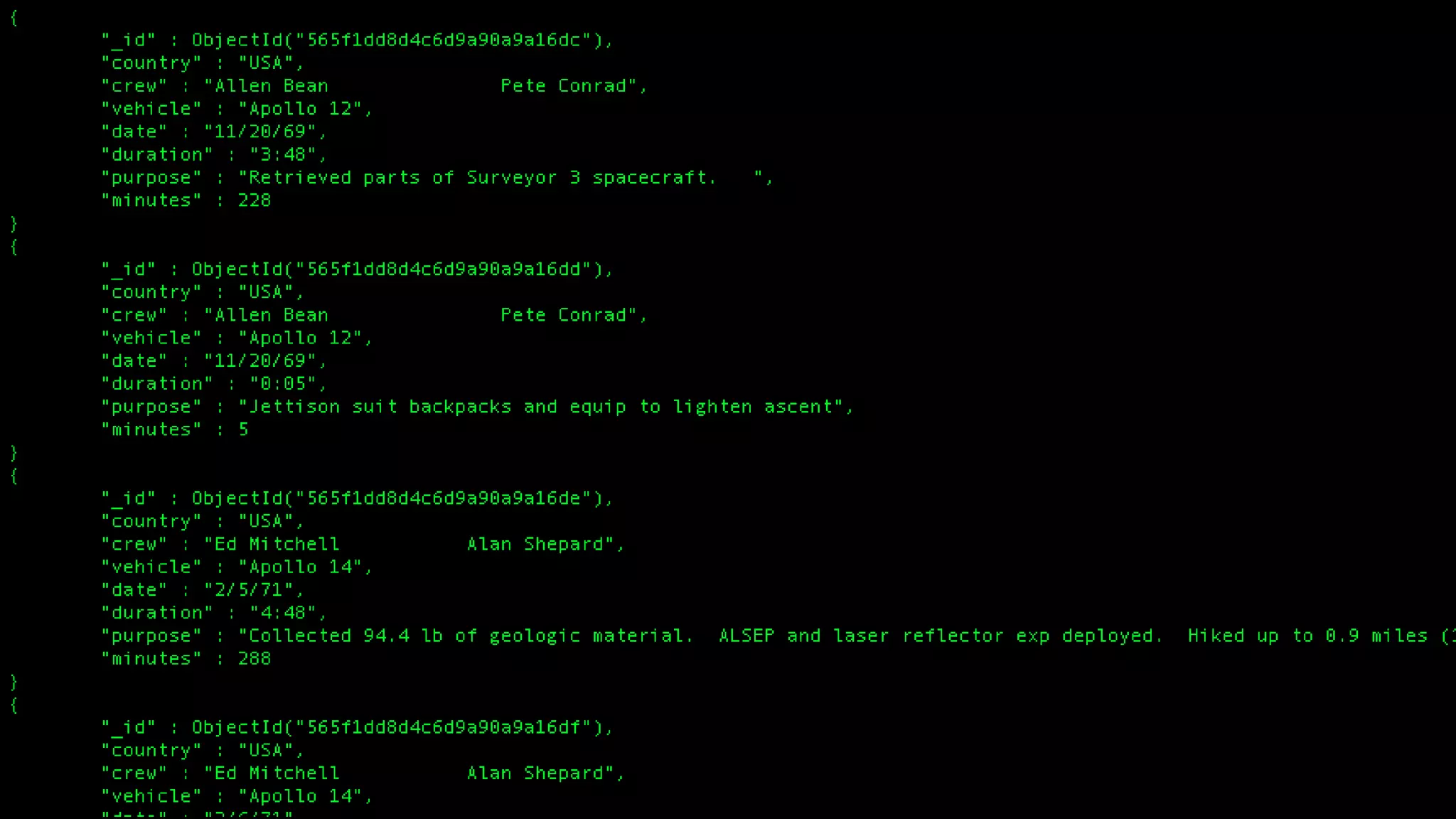
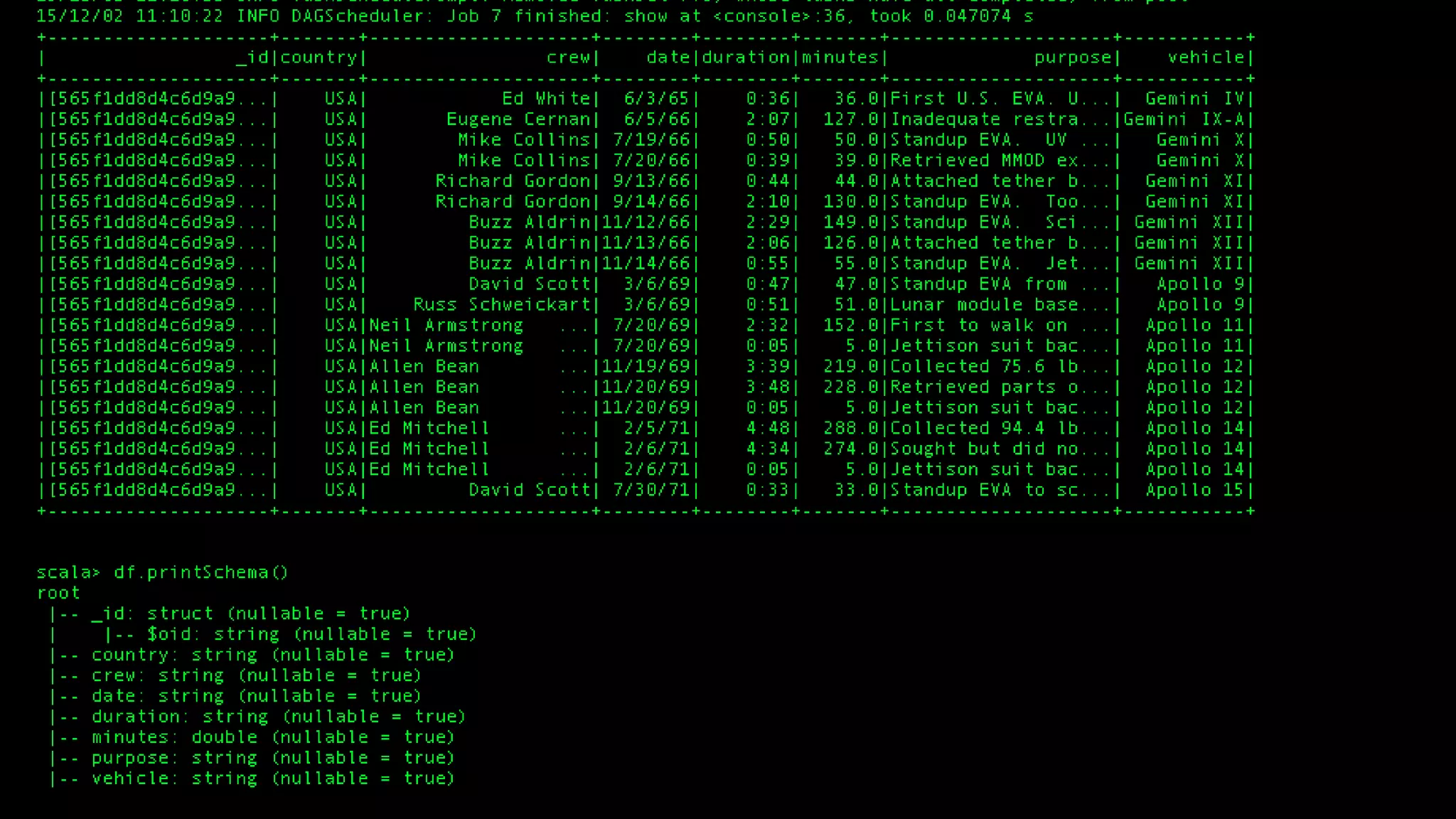
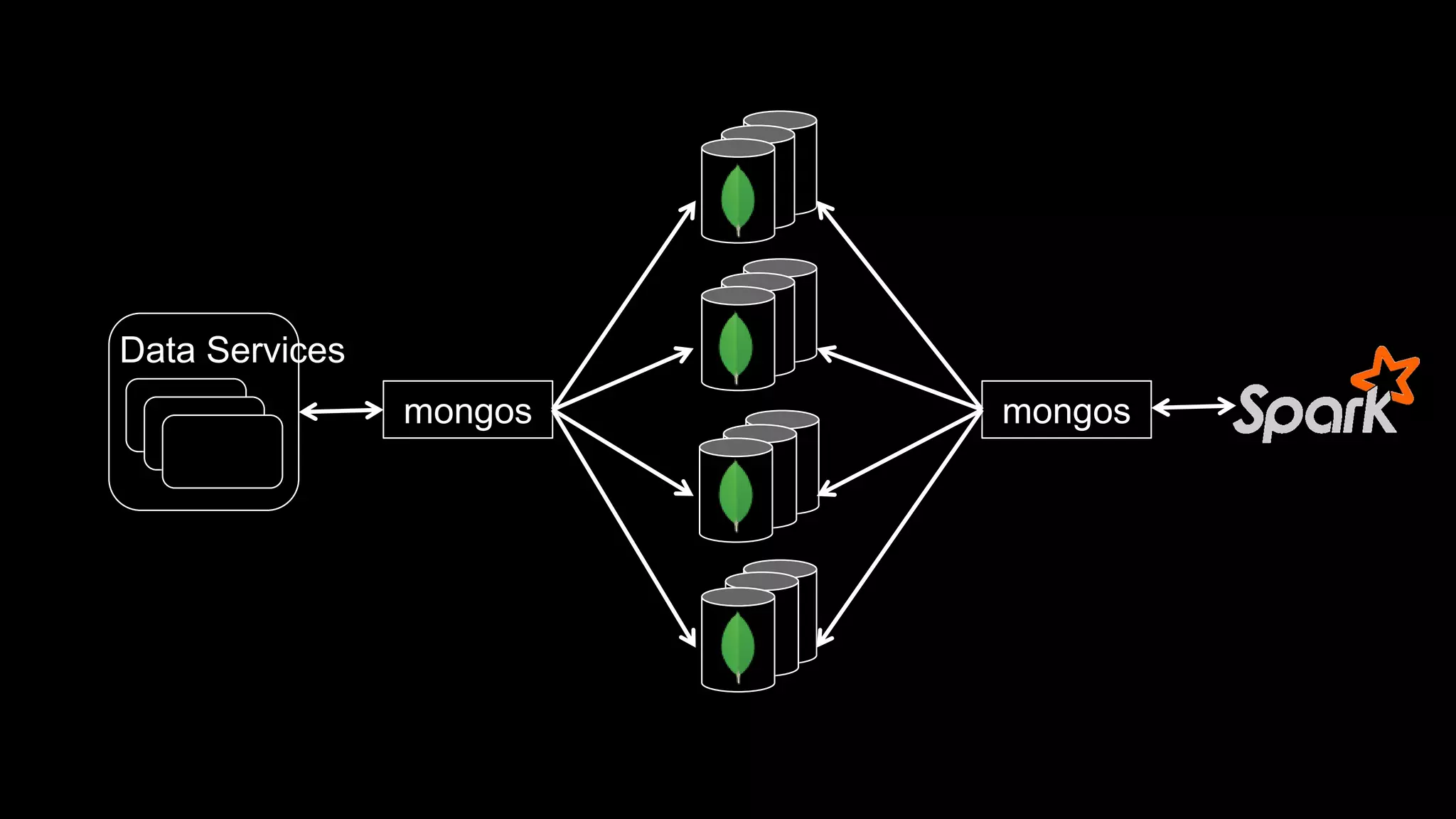



The document describes Spark and how it relates to other big data technologies like HDFS, YARN, and Mesos. It shows how Spark can be used both with these technologies or on its own. Key Spark concepts discussed include Resilient Distributed Datasets (RDDs), transformations, actions, and lineage. It also provides examples of using Spark with MongoDB to read data from a MongoDB collection into an RDD.











































































