Downloaded 361 times







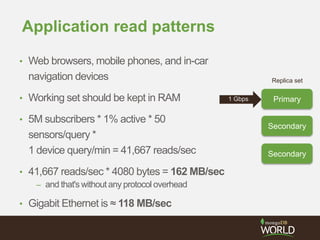

![Replica Set Tags
• app servers in different data centers use
replica set tags plus read preferencenearest
• db.collection.find().readPref( { mode: 'nearest',
tags: [ {'datacenter': 'east'} ] } )
east
Secondary
Secondary
Primary
>rs.conf()
{"_id":"rs0",
"version":2,
"members":[
{"_id":0,
"host":"node0.example.net:27017",
"tags":{"datacenter":"east"}
},
{"_id":1,
"host":"node1.example.net:27017",
"tags":{"datacenter":"east"}
},
{"_id":2,
"host":"node2.example.net:27017",
"tags":{"datacenter":"east"}
},
}](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/85/MongoDB-for-Time-Series-Data-Part-3-Sharding-15-320.jpg)










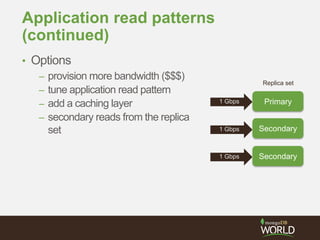
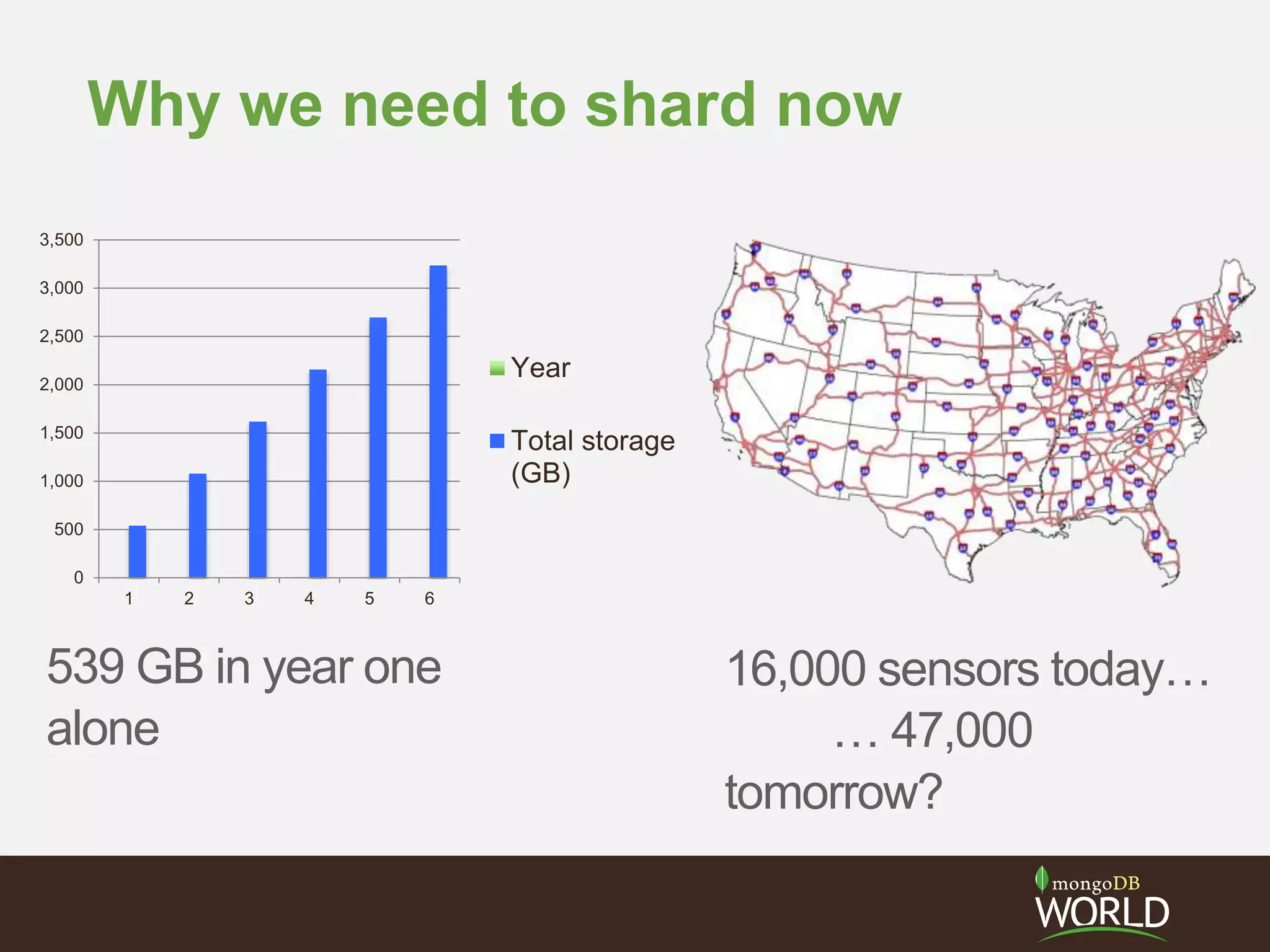
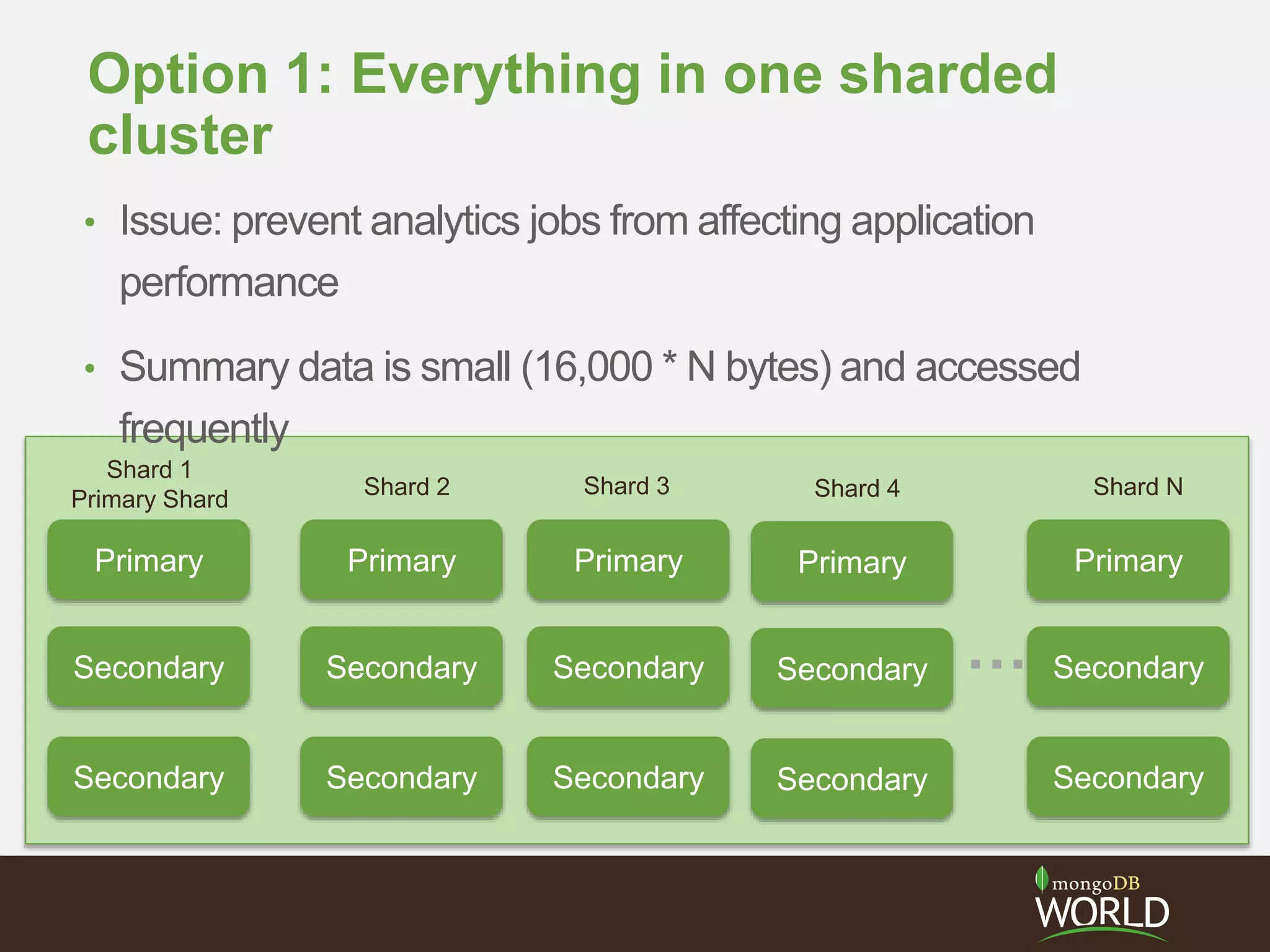
![I decided to shard from the outset
• Sensor summary
documents can all fit in
RAM
– 16,000 sensors * N bytes
• Velocity of sensor events
is only 267 writes/sec
• Volume of sensor events
is what dictates sharding
{ _id:<linkID>,
update:ISODate(“2013-10-10T23:06:37.000Z”),
last10:{
avgSpeed:<int>,
avgTime:<int>
},
lastHour:{
avgSpeed:<int>,
avgTime:<int>
},
speeds:[52,49,45,51,...],
times:[237,224,246,233,...],
pavement:"WetSpots",
status:"WetConditions",
weather:"LightRain"
}](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/85/MongoDB-for-Time-Series-Data-Part-3-Sharding-32-320.jpg)
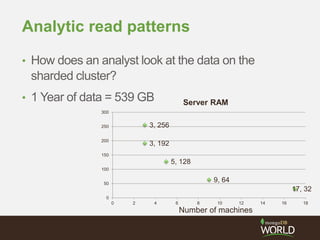
![> this_is_for_replica_sets_not_sharding = {
_id : "mySet",
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C"},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)
Configuring Sharding](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/85/MongoDB-for-Time-Series-Data-Part-3-Sharding-33-320.jpg)

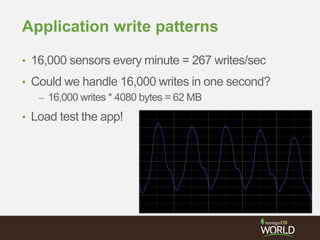
![> conf = {
_id : "mySet",
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C"},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)
Configuration Options](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/85/MongoDB-for-Time-Series-Data-Part-3-Sharding-36-320.jpg)

![> conf = {
_id : "mySet”,
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C"},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)
Configuration Options
Primary DC](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/85/MongoDB-for-Time-Series-Data-Part-3-Sharding-38-320.jpg)









![Replica Set Tags
• app servers in different data centers use
replica set tags plus read preferencenearest
• db.collection.find().readPref( { mode: 'nearest',
tags: [ {'datacenter': 'east'} ] } )
east
Secondary
Secondary
Primary
>rs.conf()
{"_id":"rs0",
"version":2,
"members":[
{"_id":0,
"host":"node0.example.net:27017",
"tags":{"datacenter":"east"}
},
{"_id":1,
"host":"node1.example.net:27017",
"tags":{"datacenter":"east"}
},
{"_id":2,
"host":"node2.example.net:27017",
"tags":{"datacenter":"east"}
},
}](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/75/MongoDB-for-Time-Series-Data-Part-3-Sharding-15-2048.jpg)










![I decided to shard from the outset
• Sensor summary
documents can all fit in
RAM
– 16,000 sensors * N bytes
• Velocity of sensor events
is only 267 writes/sec
• Volume of sensor events
is what dictates sharding
{ _id:<linkID>,
update:ISODate(“2013-10-10T23:06:37.000Z”),
last10:{
avgSpeed:<int>,
avgTime:<int>
},
lastHour:{
avgSpeed:<int>,
avgTime:<int>
},
speeds:[52,49,45,51,...],
times:[237,224,246,233,...],
pavement:"WetSpots",
status:"WetConditions",
weather:"LightRain"
}](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/75/MongoDB-for-Time-Series-Data-Part-3-Sharding-32-2048.jpg)
![> this_is_for_replica_sets_not_sharding = {
_id : "mySet",
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C"},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)
Configuring Sharding](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/75/MongoDB-for-Time-Series-Data-Part-3-Sharding-33-2048.jpg)

![> conf = {
_id : "mySet",
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C"},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)
Configuration Options](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/75/MongoDB-for-Time-Series-Data-Part-3-Sharding-36-2048.jpg)

![> conf = {
_id : "mySet”,
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C"},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)
Configuration Options
Primary DC](https://image.slidesharecdn.com/28zakvfsimqlkctfd2w4-signature-41934cbc7379ca067d76322c42d073c0dc50c41dfb1c7e975c9c0301f0bb145e-poli-140707140950-phpapp01/75/MongoDB-for-Time-Series-Data-Part-3-Sharding-38-2048.jpg)


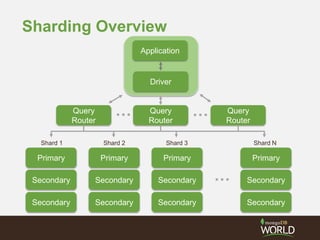
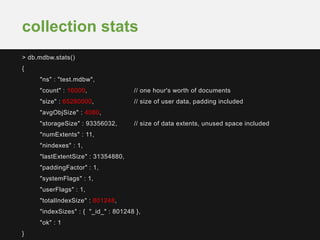
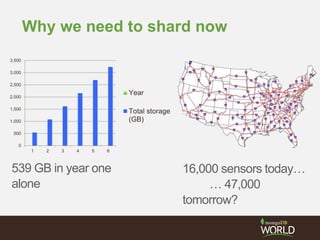
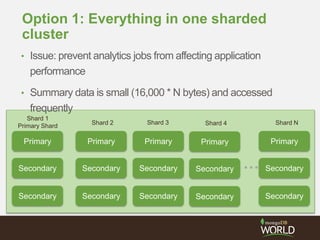
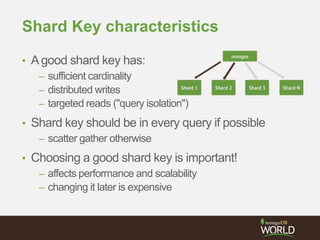
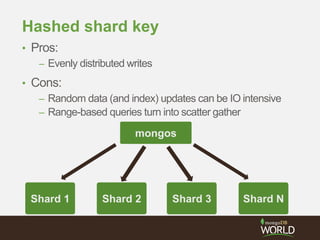
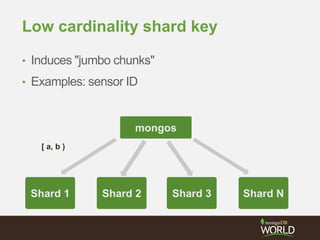
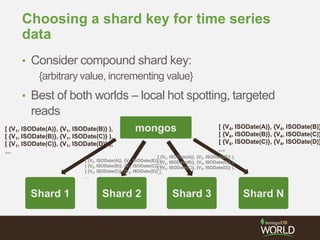
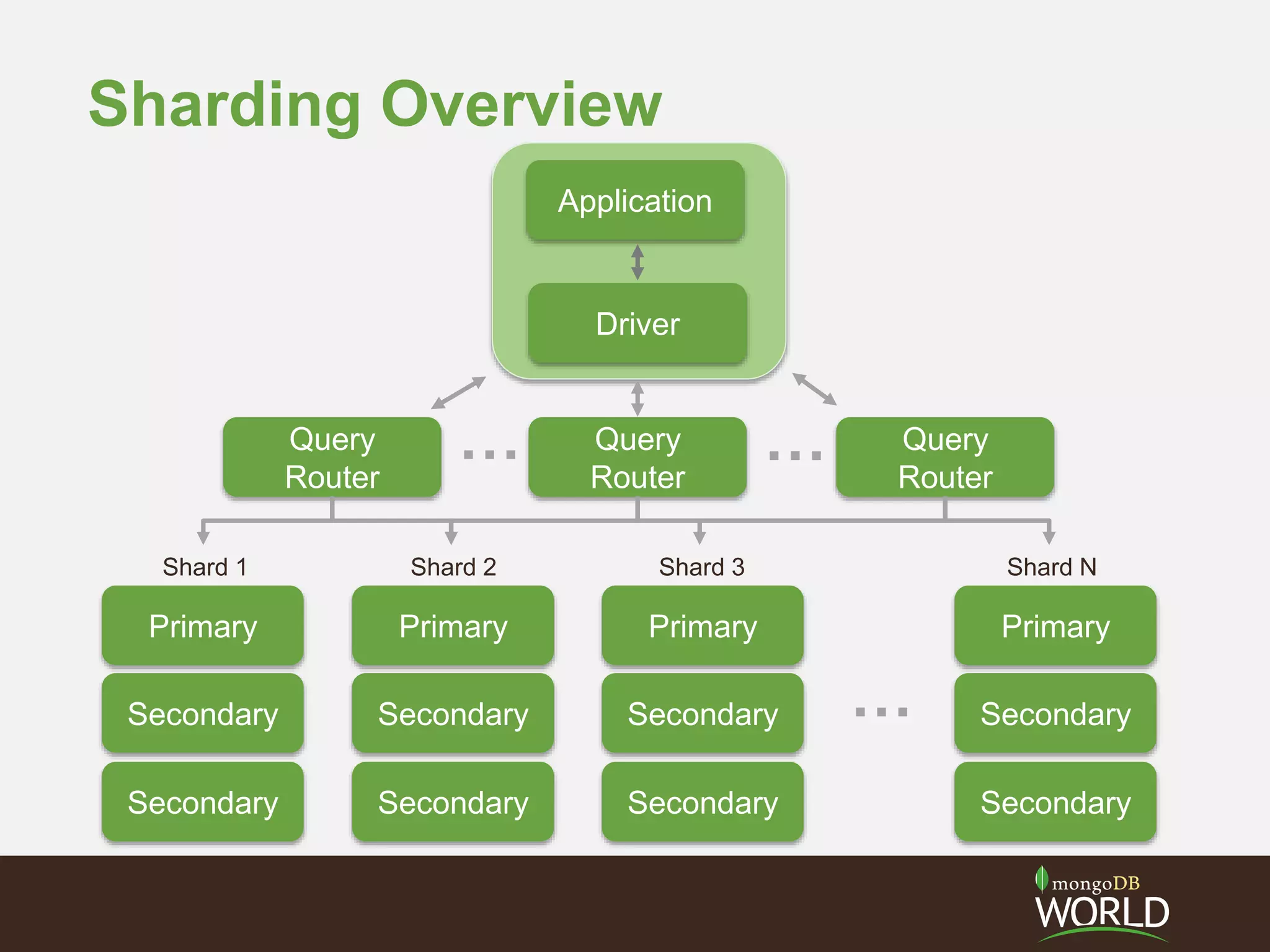
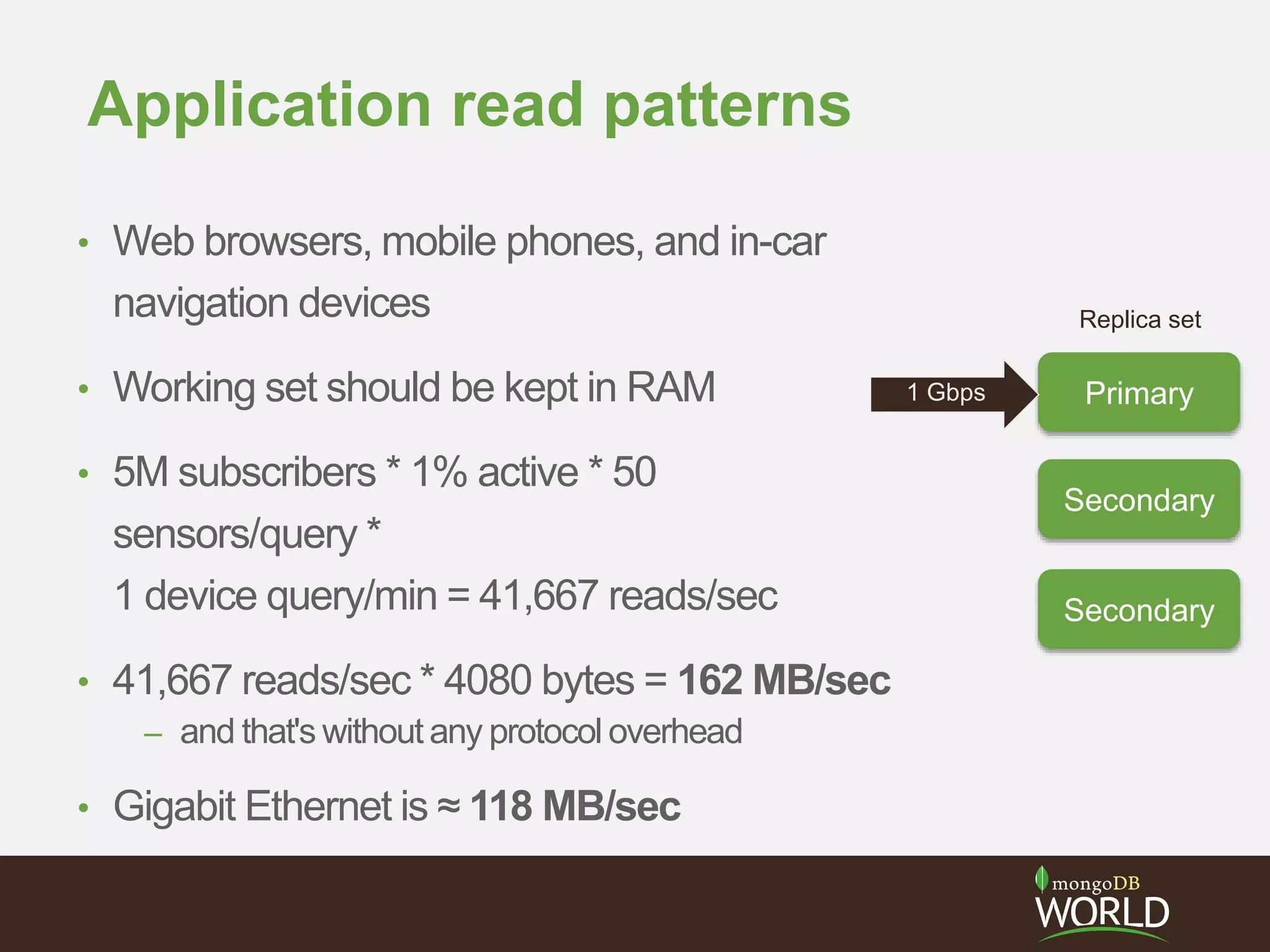
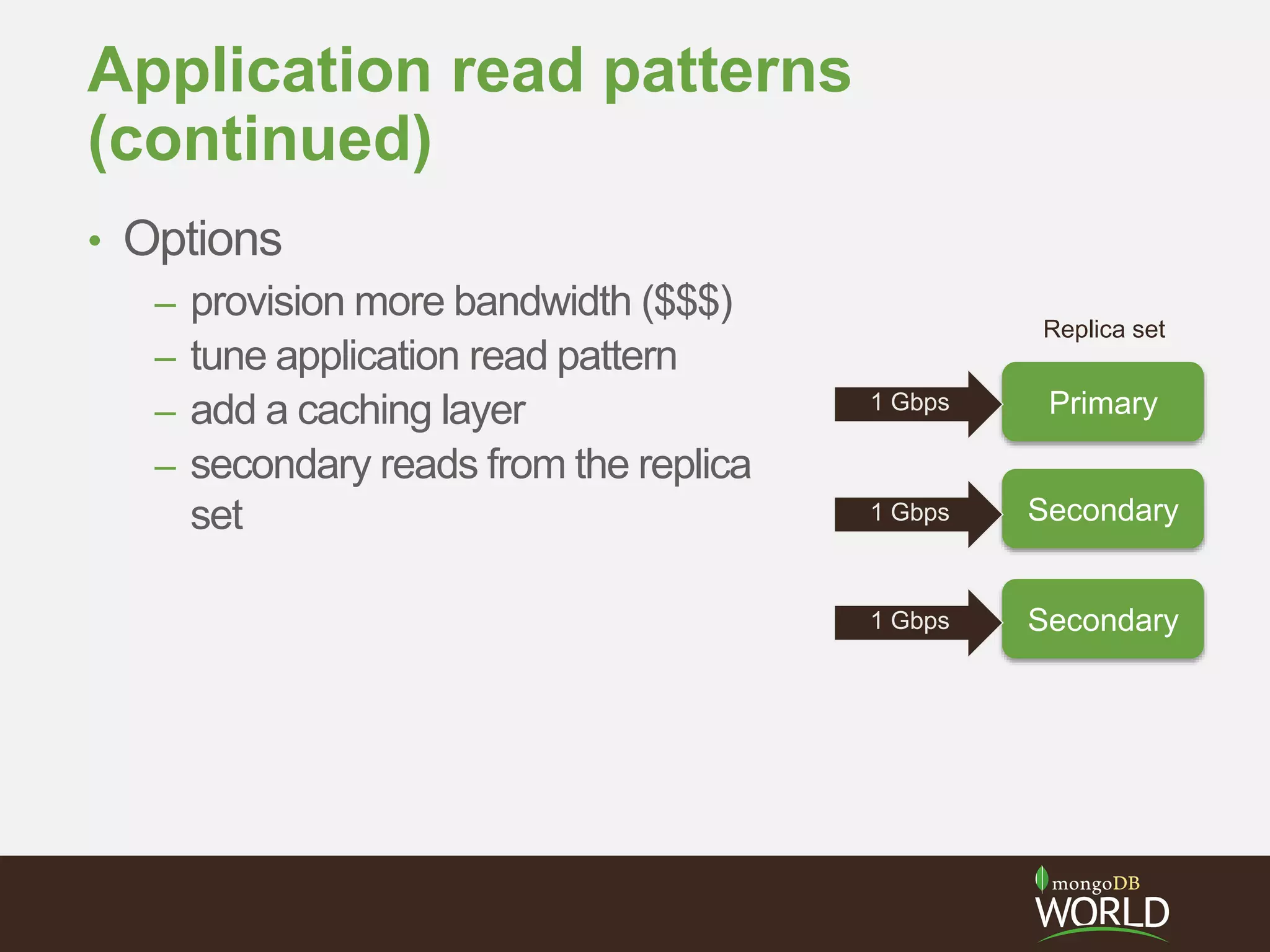
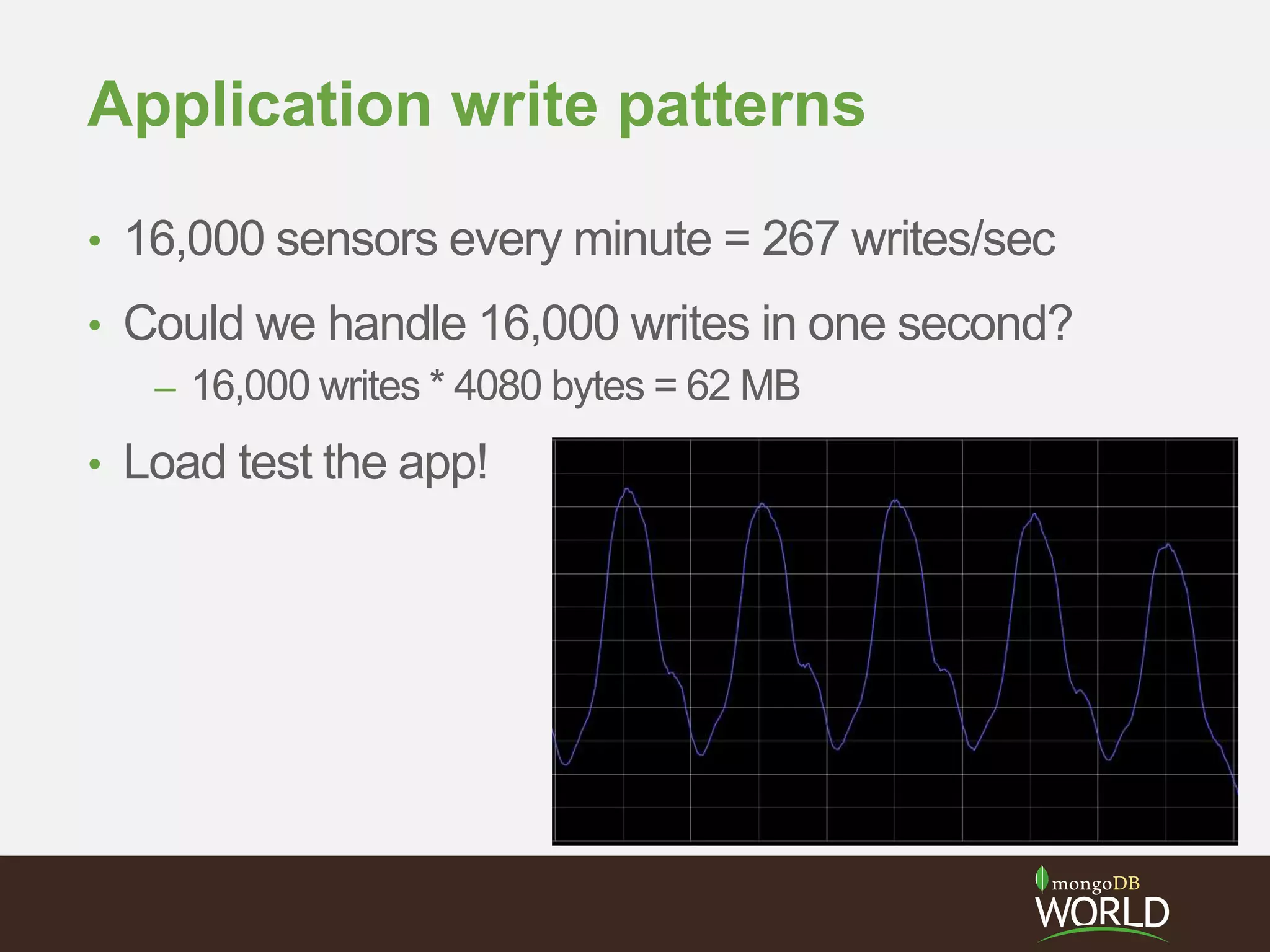
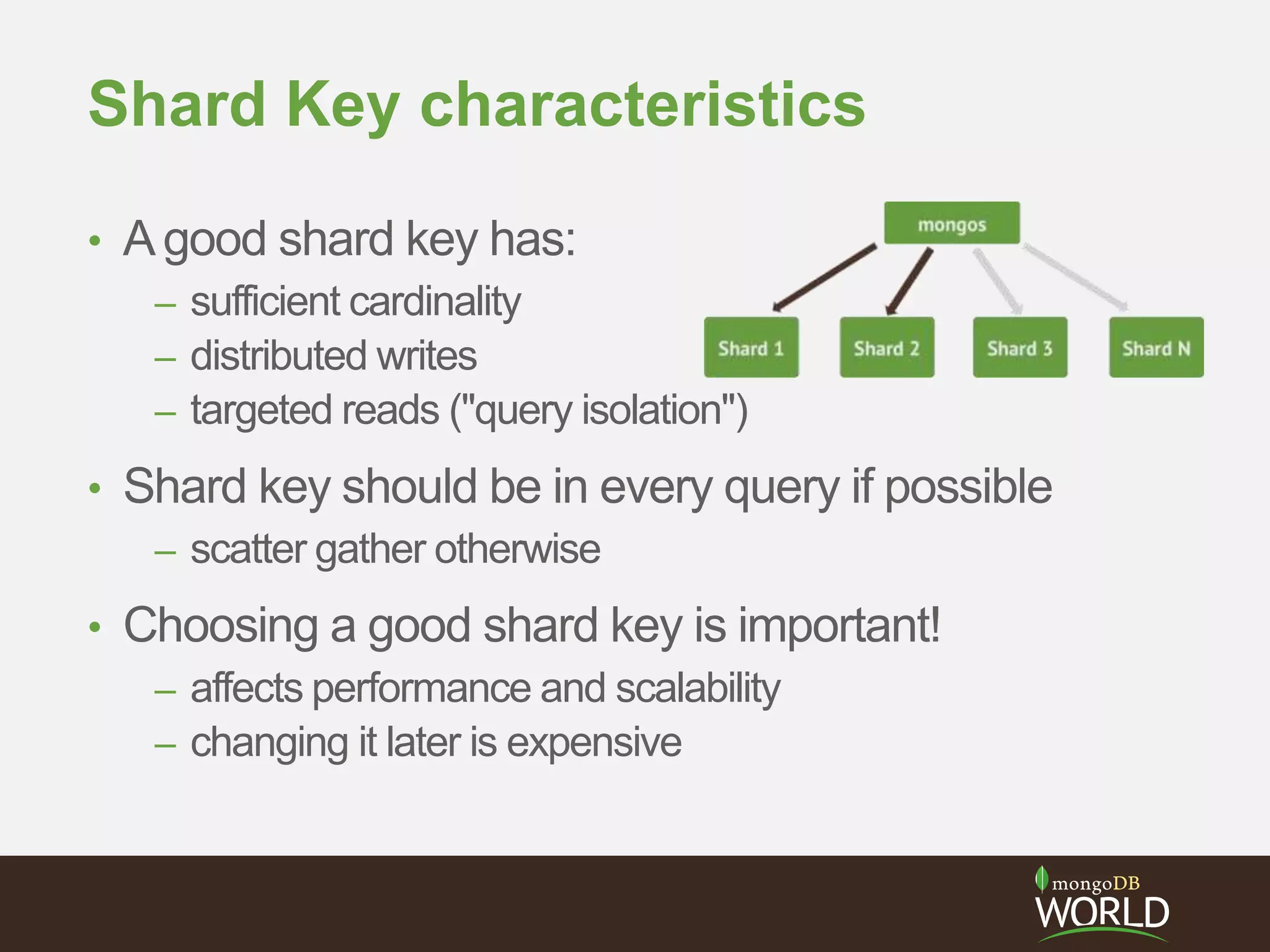
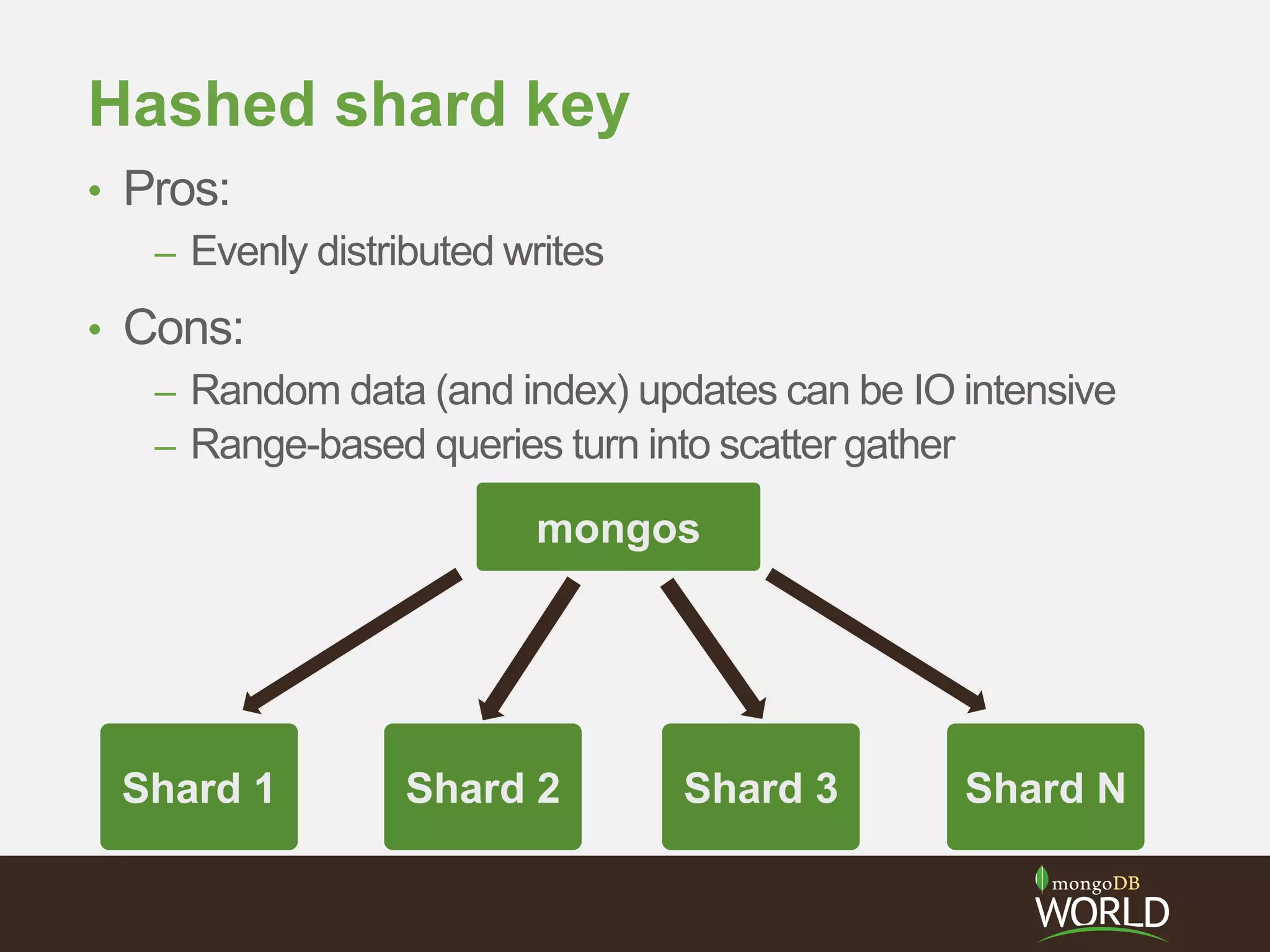
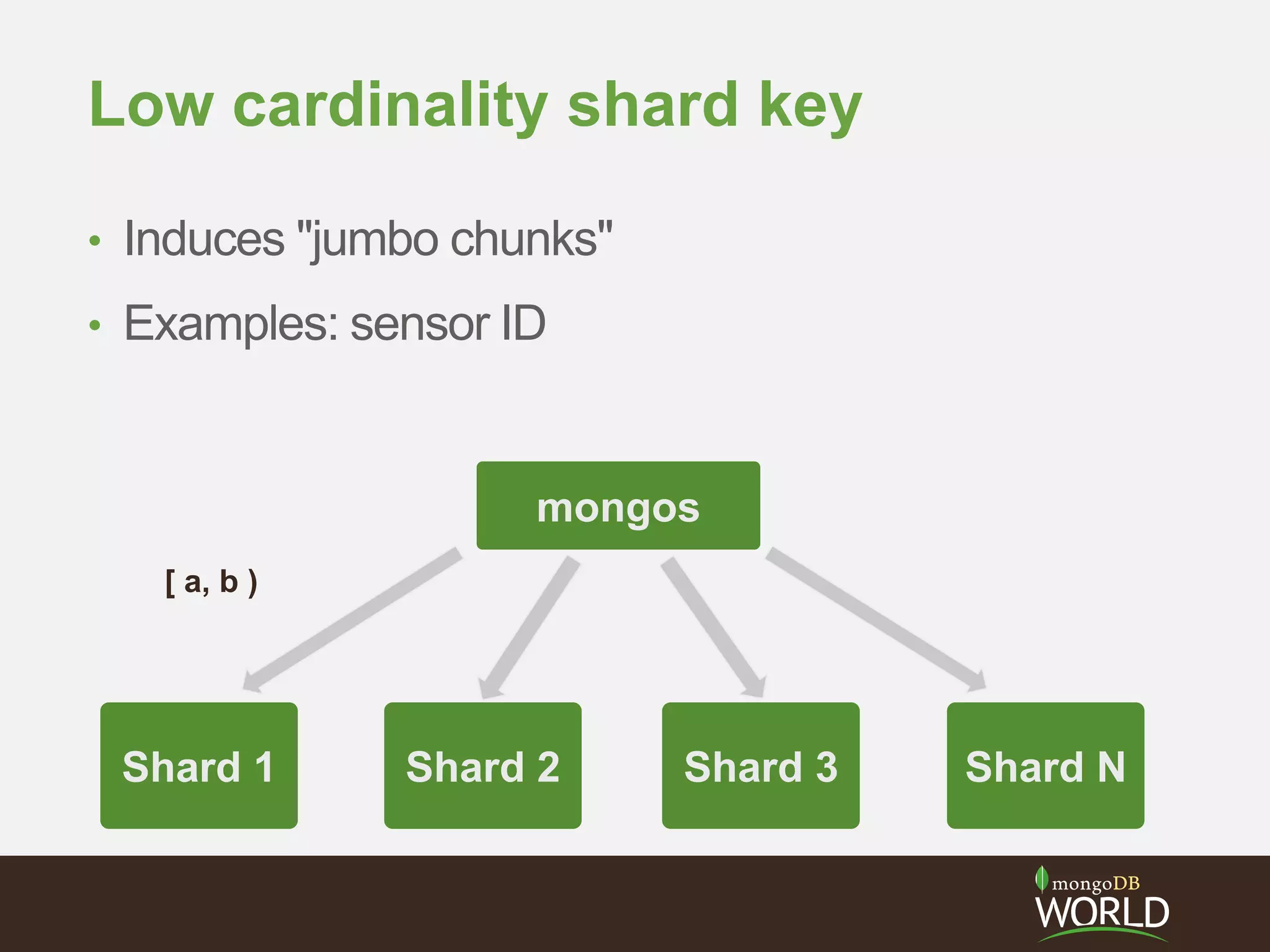
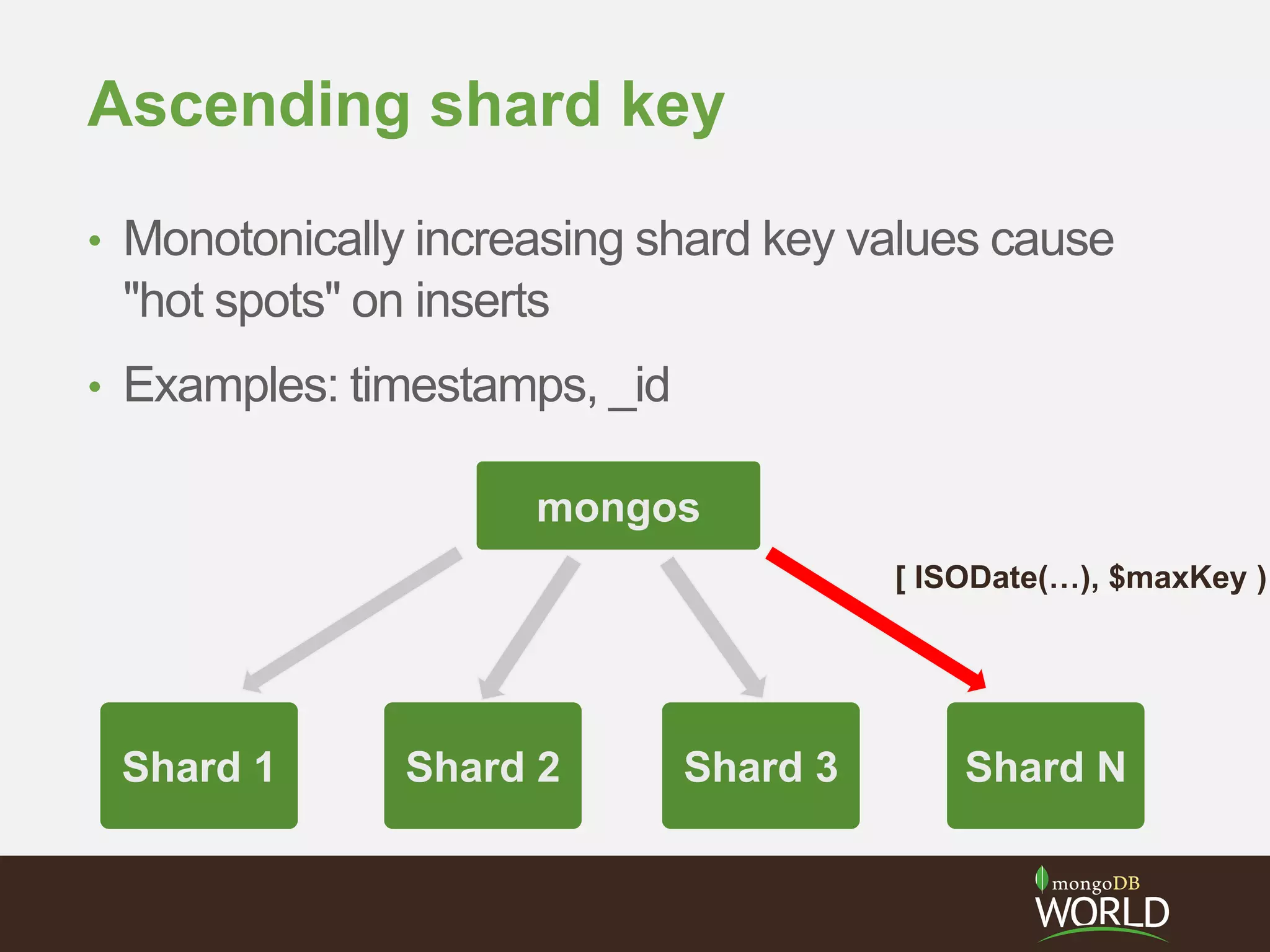
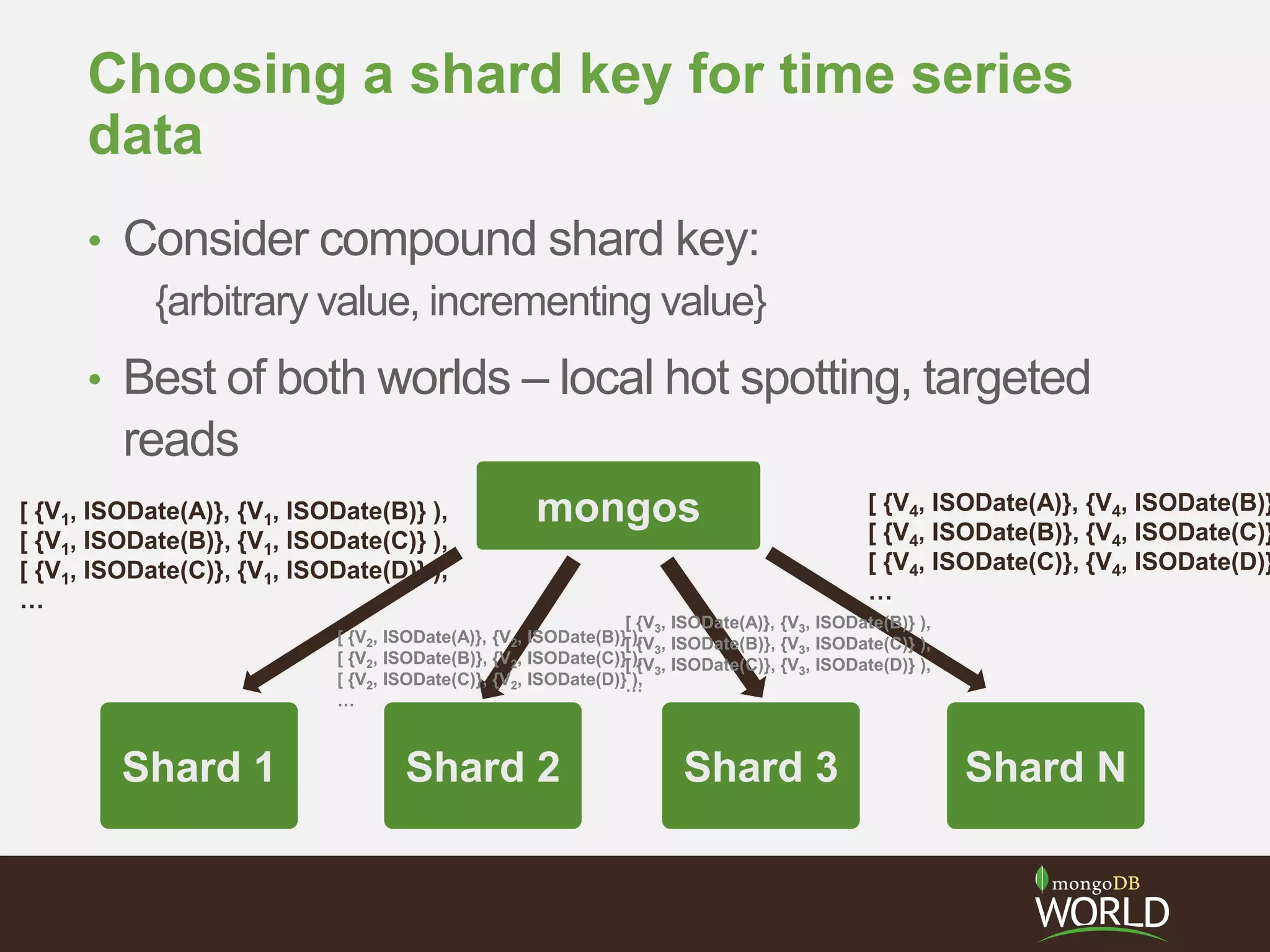
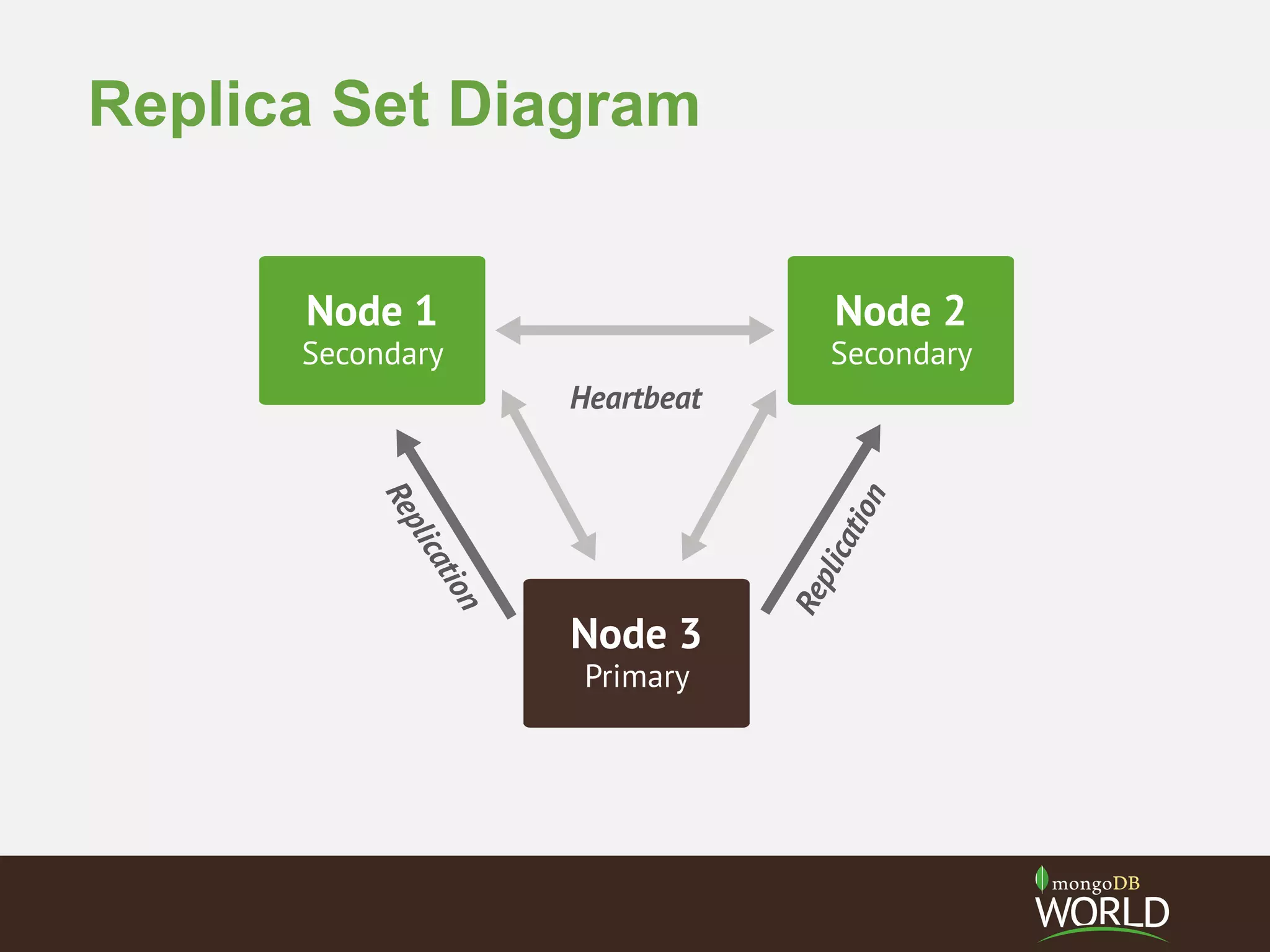
The document discusses sharding time series sensor data in MongoDB. It recommends modeling the application's read, write and storage patterns to determine the optimal sharding strategy. A good shard key has sufficient cardinality, distributes writes evenly and enables targeted reads. For time series data, a compound shard key of an arbitrary value and incrementing timestamp is suggested to balance hot spots and targeted queries. The document also covers configuring a sharded cluster and replica sets with tags to control data distribution.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=600ounds&width=560&fit=bounds)































