The document provides an overview of the numpy and pandas libraries in Python, focusing on their capabilities for handling multidimensional arrays and tabular data, respectively. It includes details on various array operations, data types, and how to create and manipulate Series and DataFrames using pandas. Key functionalities such as reshaping, indexing, and performing mathematical operations on data structures are also discussed.

![Array
An array is a collection of items stored at contiguous memory
locations.
The idea is to store multiple items of the same type together.
This makes it easier to calculate the position of each element by
simply adding an offset to a base value, i.e., the memory location of
the first element of the array (generally denoted by the name of the
array).
cars = ["Ford", "Volvo", "BMW"]
x = cars[0]
Cars[1](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-2-320.jpg)








![ndarray.shape
This array attribute returns a tuple consisting of array dimensions. It can also
be used to resize the array.
import numpy as np
B=np.array([]) c=np.array([[1,2],[3,4]]])
a = np.array([[1,2,3],[4,5,6]])
print a.shape
The output is as follows −
(2, 3)](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-11-320.jpg)
![NumPy also provides a reshape function to resize an
array.
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = a.reshape(3,2)
print b
The output is as follows −
[[1, 2]
[3, 4]
[5, 6]]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-12-320.jpg)
![ndarray.ndim
This array attribute returns the number of array dimensions.
# an array of evenly spaced numbers
import numpy as np
a = np.arange(24)
print a
The output is as follows −
[0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-13-320.jpg)
![NumPy - Array Creation Routines
numpy.empty
It creates an uninitialized array of specified shape and dtype. It uses the following
constructor −
numpy.empty(shape, dtype = float, order = 'C')
import numpy as np
x = np.empty([3,2], dtype = int)
print x
The output is as follows −
[[22649312 1701344351]
[1818321759 1885959276]
[16779776 156368896]]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-14-320.jpg)
![ numpy.zeros
Returns a new array of specified size, filled with zeros.
numpy.zeros(shape, dtype = float, order = 'C')
The constructor takes the following parameters.
# array of five zeros. Default dtype is float
import numpy as np
x = np.zeros(5)
print x
The output is as follows −
[ 0. 0. 0. 0. 0.]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-15-320.jpg)

![# numpy.random.randn() method --generates
samples from the normal distribution---any
number can be generated
import numpy as np
# 1D Array
array = np.random.randn(5)
print("1D Array filled with random values : n", array);
Output----
1D Array filled with randnom values :
[-0.51733692 0.48813676 -0.88147002 1.12901958 0.68026197]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-17-320.jpg)

![2D Array filled with random values :
output
[[ 1.33262386 -0.88922967 -0.07056098 0.27340112]
[ 1.00664965 -0.68443807 0.43801295 -0.35874714]
[-0.19289416 -0.42746963 -1.80435223 0.02751727]]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-19-320.jpg)




![Create a Series from ndarray
#import the pandas library and
aliasing as pd
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data)
print s
Its output is as follows −
0 a
1 b
2 c
3 d
dtype: object](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-24-320.jpg)
![Pandas Series with index
#import the pandas library and
aliasing as pd
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s =
pd.Series(data,index=[100,101,102,103
])
print s
Its output is as follows −
100 a
101 b
102 c
103 d
dtype: object](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-25-320.jpg)
![Accessing Data from Series with
Position
import pandas as pd
s = pd.Series([1,2,3,4,5])
#retrieve the first element
print s[0]
Output
1](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-26-320.jpg)
![Retrieve the first three elements in
the Series.
import pandas as pd
s = pd.Series([1,2,3,4,5],index =
['a','b','c','d','e'])
#retrieve the first three element
print s[:3]
Its output is as follows −
a 1
b 2
c 3
dtype: int64](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-27-320.jpg)
![Retrieve the last three elements.
import pandas as pd
s = pd.Series([1,2,3,4,5])
#retrieve the last three element
print s[-3:]
Its output is as follows −
3
4
5
dtype: int64](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-28-320.jpg)




![Create a DataFrame from Lists
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print df
Its output is as follows −
0
0 1
1 2
2 3
3 4
4 5](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-33-320.jpg)
![import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df =
pd.DataFrame(data,columns=['Name','Ag
e'])
print df
Its output is as follows −
Name Age
0 Alex 10
1 Bob 12
2 Clarke 13](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-34-320.jpg)
![Create a DataFrame from Dict of ndarrays / Lists
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print df
Its output is as follows −
Age Name
0 28 Tom
1 34 Jack
2 29 Steve
3 42 Ricky](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-35-320.jpg)
![Missing data
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print df
Its output is as follows −
a b c
0 1 2 NaN
1 5 10 20.0
2 Note − Observe, NaN (Not a Number) is appended in missing areas.](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-36-320.jpg)

![mean()
Returns the average value
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
#Create a DataFrame
df = pd.DataFrame(d)
print df.mean()](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-38-320.jpg)

![std()
Returns the standard deviation of the
numerical columns.
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
#Create a DataFrame
df = pd.DataFrame(d)
print df.std()](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-40-320.jpg)

![Summarizing Data
The describe() function computes a summary of statistics
pertaining to the DataFrame columns.
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
#Create a DataFrame
df = pd.DataFrame(d)
print df.describe()](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-42-320.jpg)



![#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4),
index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D'])
print(df)](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-46-320.jpg)

![By adding .loc in the code
#select all rows for a specific column
print df.loc[:,'A']](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-48-320.jpg)


![import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D'])
# select all rows for a specific column
print df.iloc[:4]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/85/Numpy_Pandas_for-beginners_________-pptx-51-320.jpg)




![Array
An array is a collection of items stored at contiguous memory
locations.
The idea is to store multiple items of the same type together.
This makes it easier to calculate the position of each element by
simply adding an offset to a base value, i.e., the memory location of
the first element of the array (generally denoted by the name of the
array).
cars = ["Ford", "Volvo", "BMW"]
x = cars[0]
Cars[1](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-2-2048.jpg)




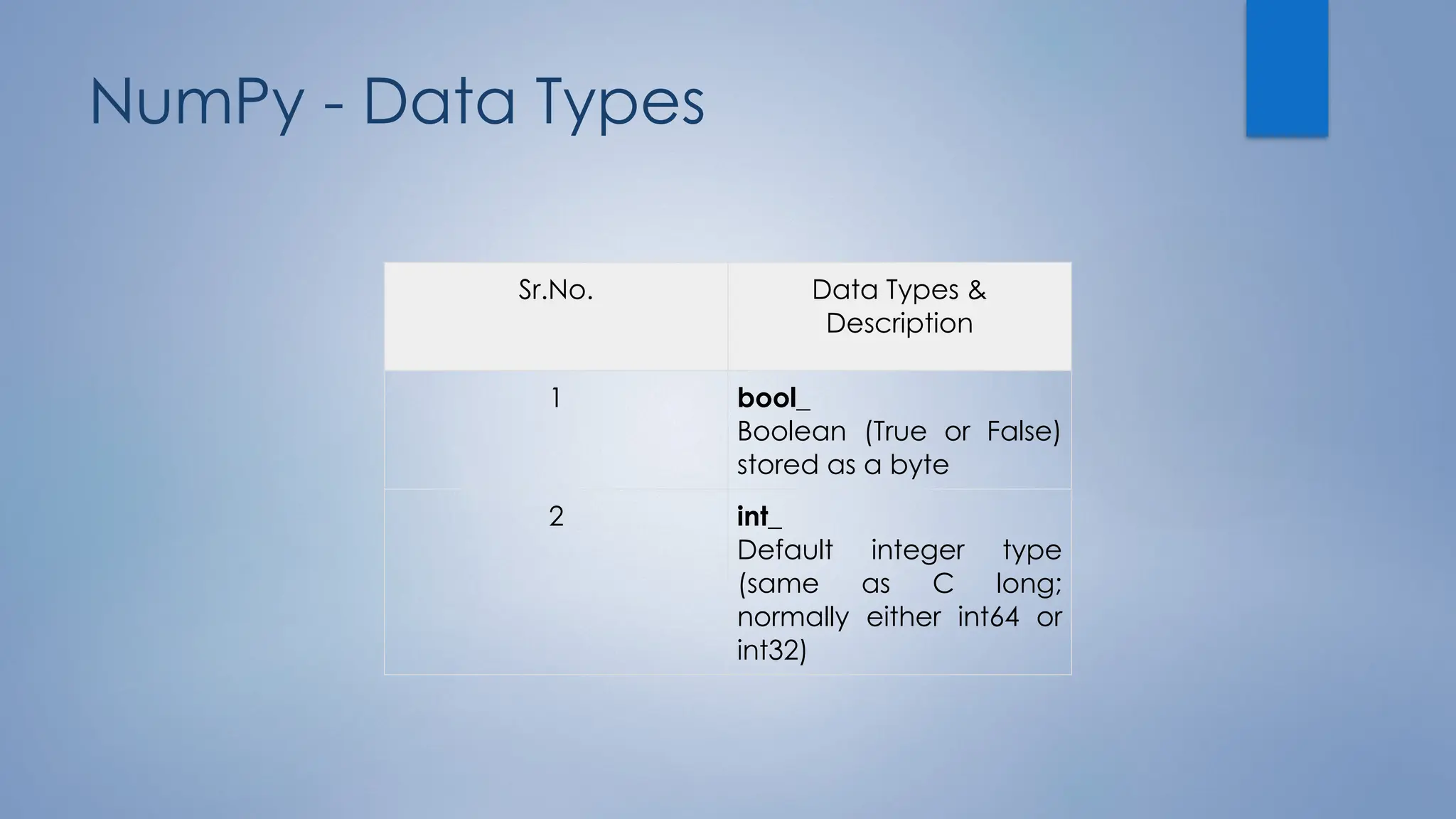



![ndarray.shape
This array attribute returns a tuple consisting of array dimensions. It can also
be used to resize the array.
import numpy as np
B=np.array([]) c=np.array([[1,2],[3,4]]])
a = np.array([[1,2,3],[4,5,6]])
print a.shape
The output is as follows −
(2, 3)](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-11-2048.jpg)
![NumPy also provides a reshape function to resize an
array.
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = a.reshape(3,2)
print b
The output is as follows −
[[1, 2]
[3, 4]
[5, 6]]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-12-2048.jpg)
![ndarray.ndim
This array attribute returns the number of array dimensions.
# an array of evenly spaced numbers
import numpy as np
a = np.arange(24)
print a
The output is as follows −
[0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-13-2048.jpg)
![NumPy - Array Creation Routines
numpy.empty
It creates an uninitialized array of specified shape and dtype. It uses the following
constructor −
numpy.empty(shape, dtype = float, order = 'C')
import numpy as np
x = np.empty([3,2], dtype = int)
print x
The output is as follows −
[[22649312 1701344351]
[1818321759 1885959276]
[16779776 156368896]]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-14-2048.jpg)
![ numpy.zeros
Returns a new array of specified size, filled with zeros.
numpy.zeros(shape, dtype = float, order = 'C')
The constructor takes the following parameters.
# array of five zeros. Default dtype is float
import numpy as np
x = np.zeros(5)
print x
The output is as follows −
[ 0. 0. 0. 0. 0.]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-15-2048.jpg)

![# numpy.random.randn() method --generates
samples from the normal distribution---any
number can be generated
import numpy as np
# 1D Array
array = np.random.randn(5)
print("1D Array filled with random values : n", array);
Output----
1D Array filled with randnom values :
[-0.51733692 0.48813676 -0.88147002 1.12901958 0.68026197]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-17-2048.jpg)

![2D Array filled with random values :
output
[[ 1.33262386 -0.88922967 -0.07056098 0.27340112]
[ 1.00664965 -0.68443807 0.43801295 -0.35874714]
[-0.19289416 -0.42746963 -1.80435223 0.02751727]]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-19-2048.jpg)




![Create a Series from ndarray
#import the pandas library and
aliasing as pd
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data)
print s
Its output is as follows −
0 a
1 b
2 c
3 d
dtype: object](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-24-2048.jpg)
![Pandas Series with index
#import the pandas library and
aliasing as pd
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s =
pd.Series(data,index=[100,101,102,103
])
print s
Its output is as follows −
100 a
101 b
102 c
103 d
dtype: object](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-25-2048.jpg)
![Accessing Data from Series with
Position
import pandas as pd
s = pd.Series([1,2,3,4,5])
#retrieve the first element
print s[0]
Output
1](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-26-2048.jpg)
![Retrieve the first three elements in
the Series.
import pandas as pd
s = pd.Series([1,2,3,4,5],index =
['a','b','c','d','e'])
#retrieve the first three element
print s[:3]
Its output is as follows −
a 1
b 2
c 3
dtype: int64](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-27-2048.jpg)
![Retrieve the last three elements.
import pandas as pd
s = pd.Series([1,2,3,4,5])
#retrieve the last three element
print s[-3:]
Its output is as follows −
3
4
5
dtype: int64](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-28-2048.jpg)




![Create a DataFrame from Lists
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print df
Its output is as follows −
0
0 1
1 2
2 3
3 4
4 5](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-33-2048.jpg)
![import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df =
pd.DataFrame(data,columns=['Name','Ag
e'])
print df
Its output is as follows −
Name Age
0 Alex 10
1 Bob 12
2 Clarke 13](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-34-2048.jpg)
![Create a DataFrame from Dict of ndarrays / Lists
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print df
Its output is as follows −
Age Name
0 28 Tom
1 34 Jack
2 29 Steve
3 42 Ricky](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-35-2048.jpg)
![Missing data
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print df
Its output is as follows −
a b c
0 1 2 NaN
1 5 10 20.0
2 Note − Observe, NaN (Not a Number) is appended in missing areas.](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-36-2048.jpg)

![mean()
Returns the average value
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
#Create a DataFrame
df = pd.DataFrame(d)
print df.mean()](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-38-2048.jpg)

![std()
Returns the standard deviation of the
numerical columns.
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
#Create a DataFrame
df = pd.DataFrame(d)
print df.std()](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-40-2048.jpg)

![Summarizing Data
The describe() function computes a summary of statistics
pertaining to the DataFrame columns.
import pandas as pd
import numpy as np
#Create a Dictionary of series
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
#Create a DataFrame
df = pd.DataFrame(d)
print df.describe()](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-42-2048.jpg)



![#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4),
index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D'])
print(df)](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-46-2048.jpg)

![By adding .loc in the code
#select all rows for a specific column
print df.loc[:,'A']](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-48-2048.jpg)


![import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D'])
# select all rows for a specific column
print df.iloc[:4]](https://image.slidesharecdn.com/numpypandas-241107165043-b5a04185/75/Numpy_Pandas_for-beginners_________-pptx-51-2048.jpg)









































![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








