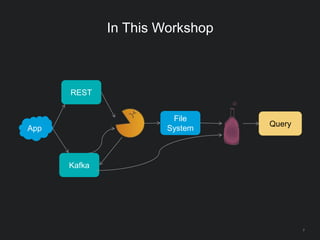
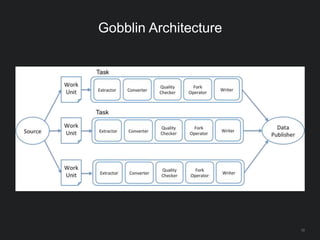
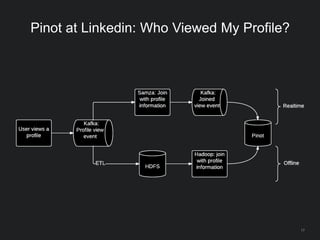
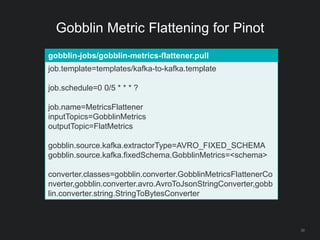
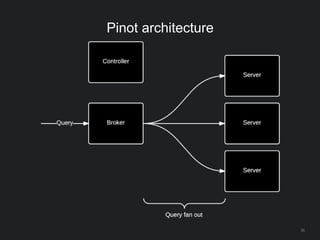
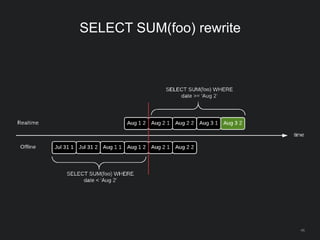
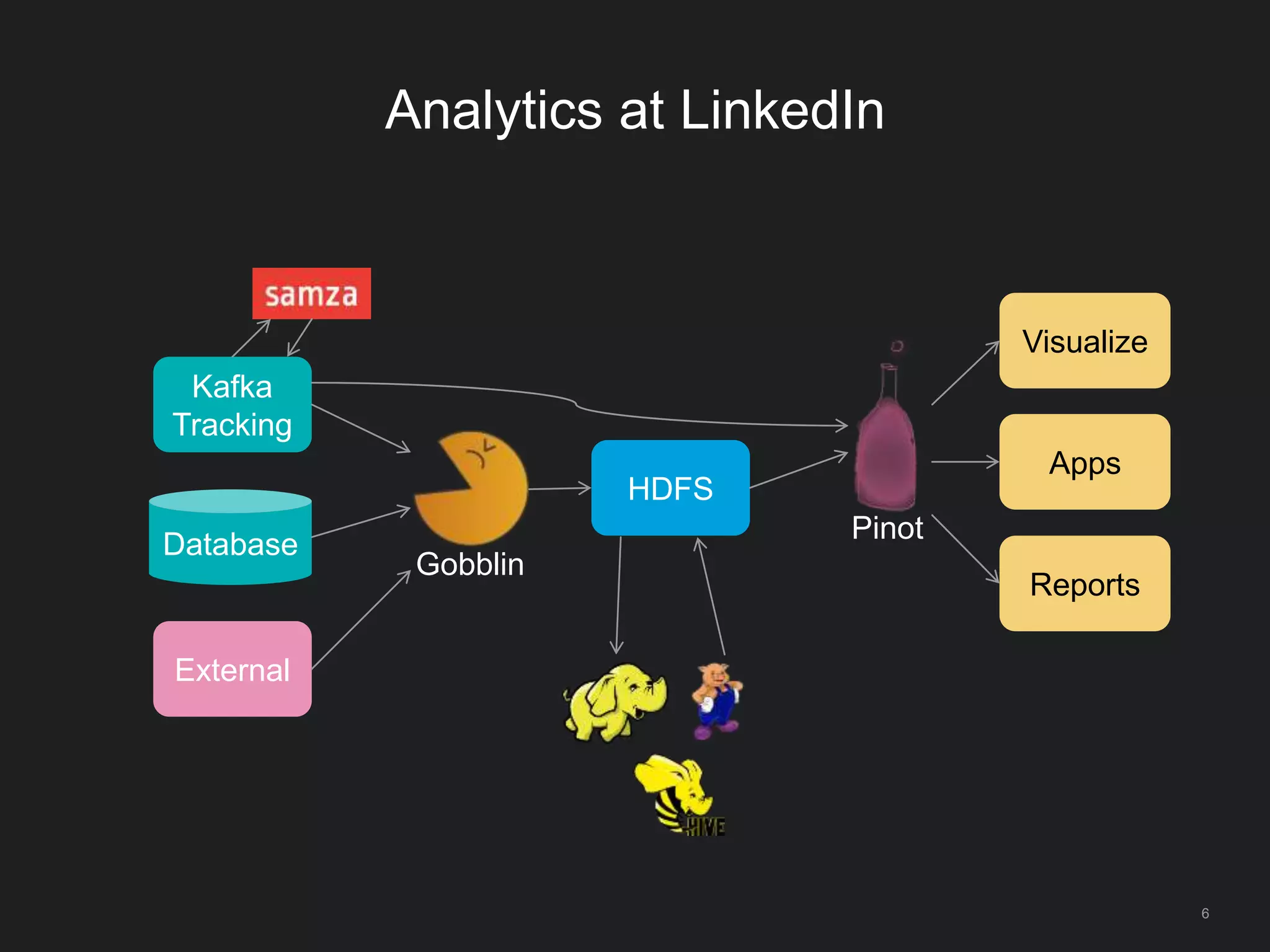
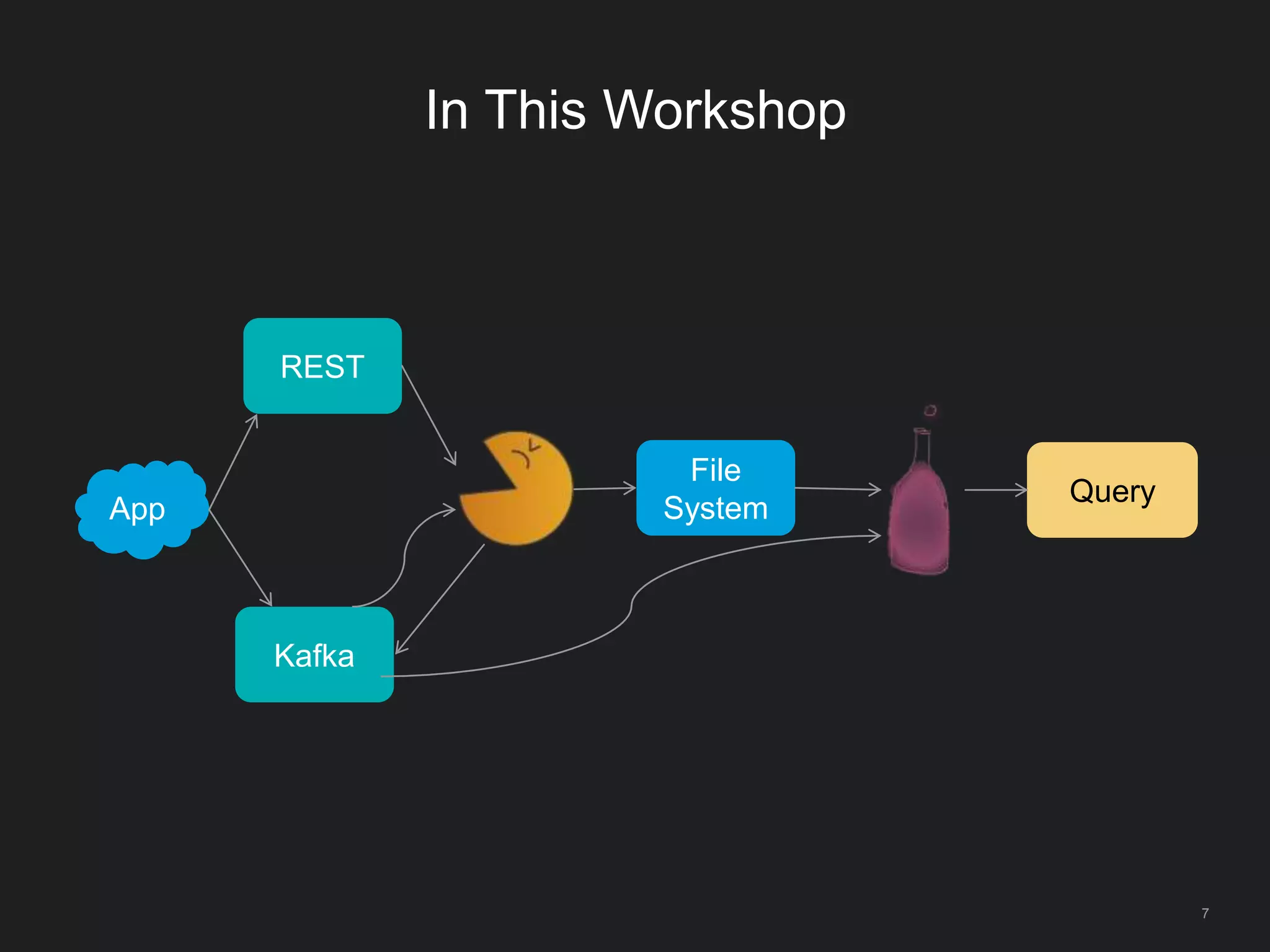
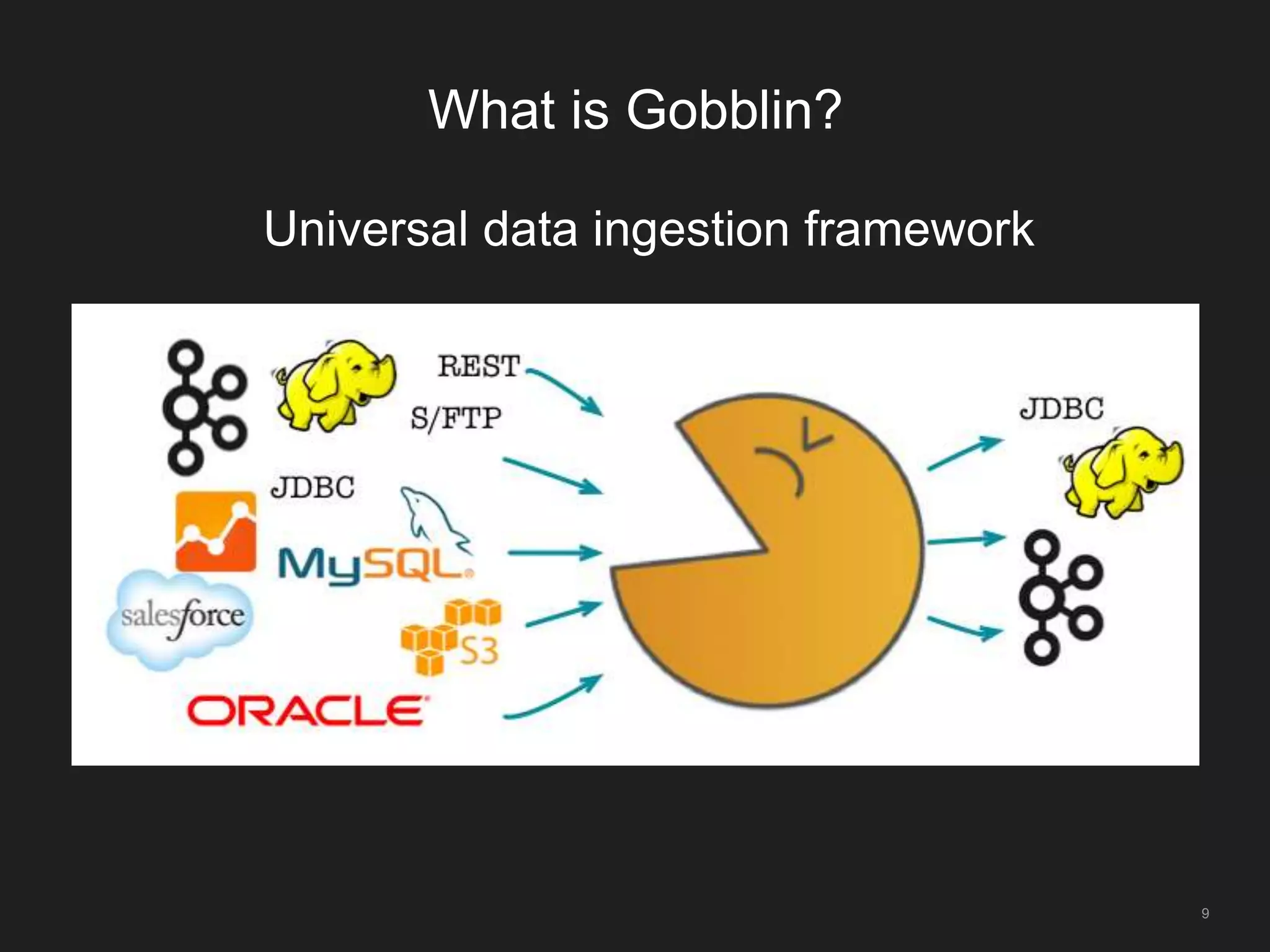
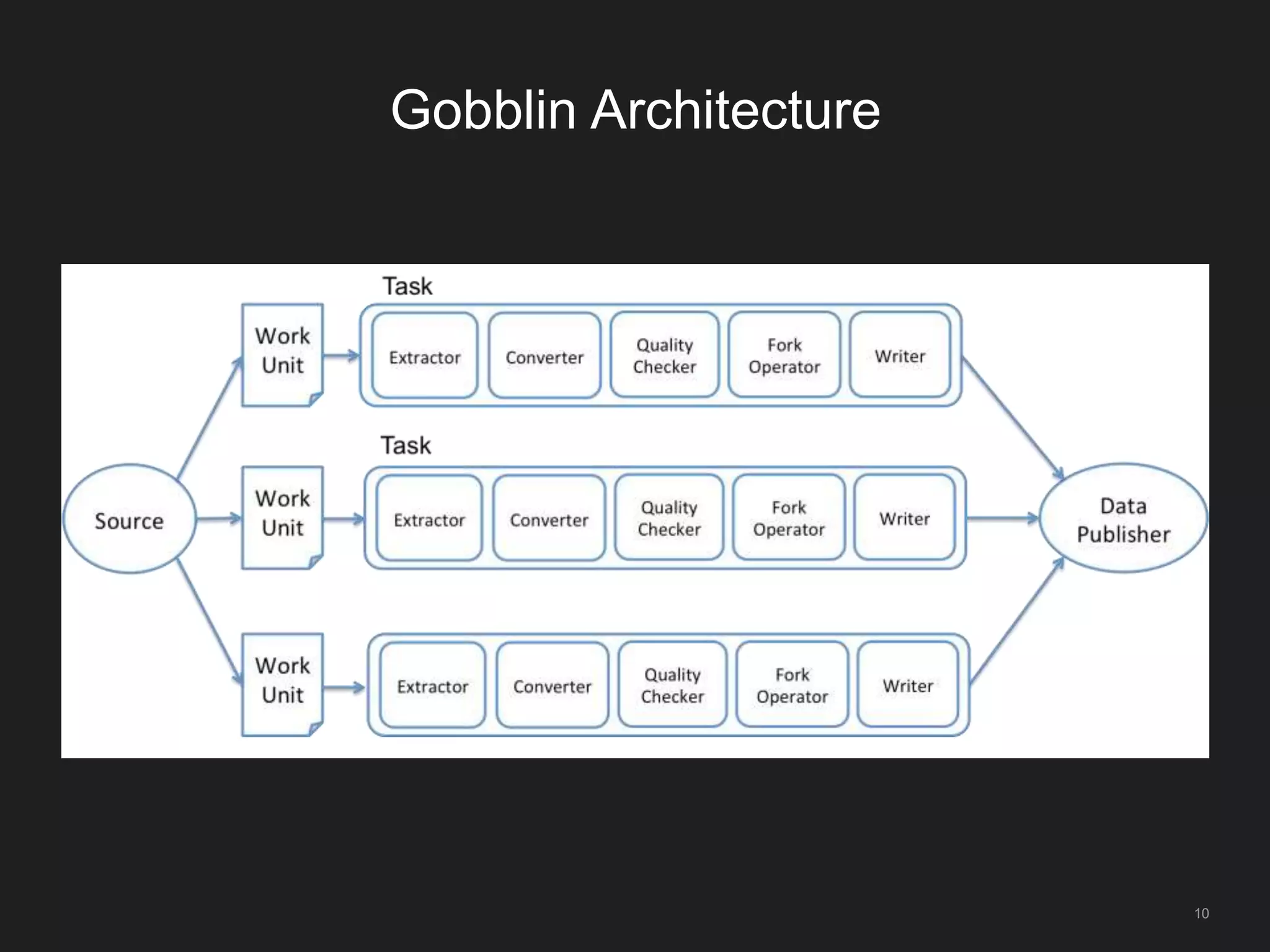
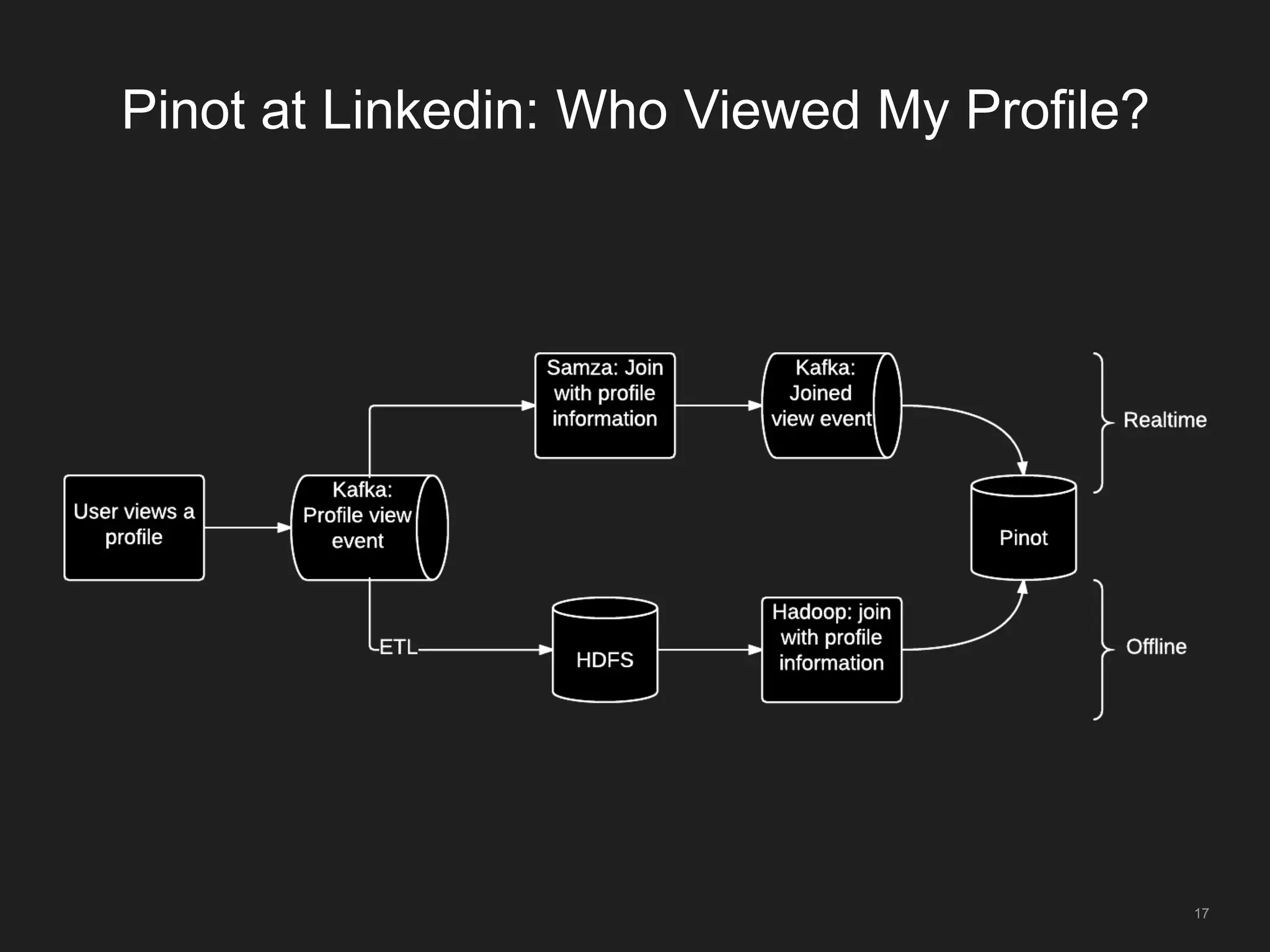
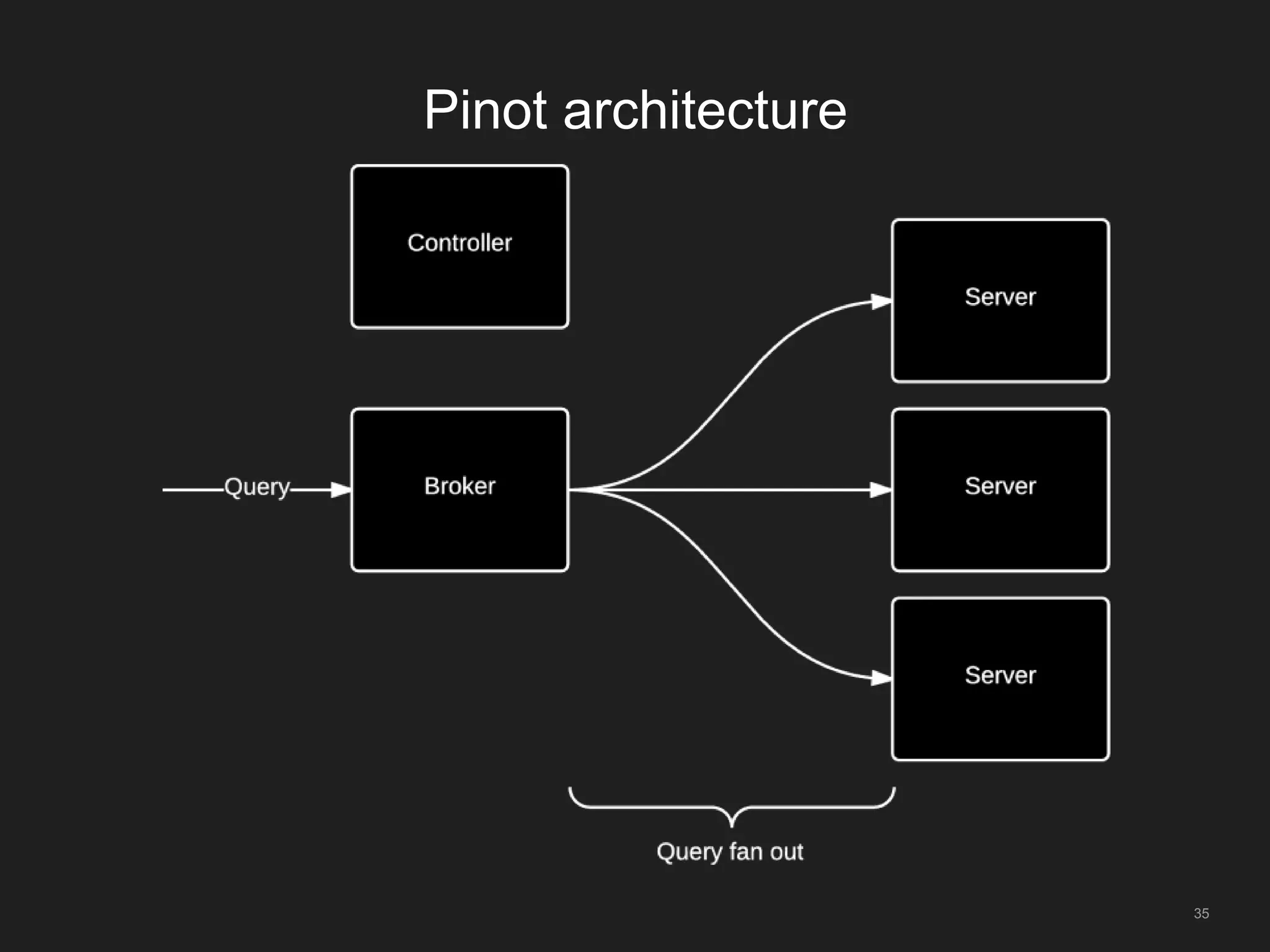
The document outlines LinkedIn's open-source analytics pipeline, focusing on Gobblin and Pinot frameworks for data ingestion and analytics, respectively. Gobblin handles large-scale data processing (over 100 TB/day) from diverse sources, while Pinot provides a distributed near-real-time OLAP datastore for querying data efficiently. The workshop includes demos on setting up and running both Gobblin and Pinot, addressing key operational considerations such as fault tolerance, performance, and data retention.




























![37
{
"tableIndexConfig": {
"invertedIndexColumns":[], "loadMode":"MMAP”,
"lazyLoad":"false”
},
"tenants":{"server":"airline","broker":"airline_broker"},
"tableType":"OFFLINE","metadata":{},
"segmentsConfig":{
"retentionTimeValue":"700”,
"retentionTimeUnit":"DAYS“,
"segmentPushFrequency":"daily“,
"replication":1,
"timeColumnName":"DaysSinceEpoch”,
"timeType":"DAYS”,
"segmentPushType":"APPEND”,
"schemaName":"airlineStats”,
"segmentAssignmentStrategy":
"BalanceNumSegmentAssignmentStrategy”
},
"tableName":"airlineStats“
}](https://image.slidesharecdn.com/vdlb16gobblin-final-v1-160909034518/85/Open-Source-LinkedIn-Analytics-Pipeline-BOSS-2016-VLDB-37-320.jpg)



![Querying Pinot
42
bin/pinot-admin.sh PostQuery -query "select
count(*) from flights"
{
"numDocsScanned":844482,
"aggregationResults”:
[{"function":"count_star","value":"844482"}],
"timeUsedMs":16,
"segmentStatistics":[],
"exceptions":[],
"totalDocs":844482
}](https://image.slidesharecdn.com/vdlb16gobblin-final-v1-160909034518/85/Open-Source-LinkedIn-Analytics-Pipeline-BOSS-2016-VLDB-42-320.jpg)



![Configuring realtime ingestion
47
{
"schemaName" : "flights",
"timeFieldSpec" : {
"incomingGranularitySpec" : {
"timeType" : "DAYS”, "dataType" : "INT”, "name" : "DaysSinceEpoch"
}
},
"metricFieldSpecs" : [
{ "name" : "Delayed”, "dataType" : "INT”, "singleValueField" : true },
...
],
"dimensionFieldSpecs" : [
{ "name": "Year”, "dataType" : "INT”, "singleValueField" : true },
{ "name": "DivAirports”, "dataType" : "STRING”, "singleValueField" : false },
...
],
}](https://image.slidesharecdn.com/vdlb16gobblin-final-v1-160909034518/85/Open-Source-LinkedIn-Analytics-Pipeline-BOSS-2016-VLDB-47-320.jpg)







































![37
{
"tableIndexConfig": {
"invertedIndexColumns":[], "loadMode":"MMAP”,
"lazyLoad":"false”
},
"tenants":{"server":"airline","broker":"airline_broker"},
"tableType":"OFFLINE","metadata":{},
"segmentsConfig":{
"retentionTimeValue":"700”,
"retentionTimeUnit":"DAYS“,
"segmentPushFrequency":"daily“,
"replication":1,
"timeColumnName":"DaysSinceEpoch”,
"timeType":"DAYS”,
"segmentPushType":"APPEND”,
"schemaName":"airlineStats”,
"segmentAssignmentStrategy":
"BalanceNumSegmentAssignmentStrategy”
},
"tableName":"airlineStats“
}](https://image.slidesharecdn.com/vdlb16gobblin-final-v1-160909034518/75/Open-Source-LinkedIn-Analytics-Pipeline-BOSS-2016-VLDB-37-2048.jpg)


![Querying Pinot
42
bin/pinot-admin.sh PostQuery -query "select
count(*) from flights"
{
"numDocsScanned":844482,
"aggregationResults”:
[{"function":"count_star","value":"844482"}],
"timeUsedMs":16,
"segmentStatistics":[],
"exceptions":[],
"totalDocs":844482
}](https://image.slidesharecdn.com/vdlb16gobblin-final-v1-160909034518/75/Open-Source-LinkedIn-Analytics-Pipeline-BOSS-2016-VLDB-42-2048.jpg)




![Configuring realtime ingestion
47
{
"schemaName" : "flights",
"timeFieldSpec" : {
"incomingGranularitySpec" : {
"timeType" : "DAYS”, "dataType" : "INT”, "name" : "DaysSinceEpoch"
}
},
"metricFieldSpecs" : [
{ "name" : "Delayed”, "dataType" : "INT”, "singleValueField" : true },
...
],
"dimensionFieldSpecs" : [
{ "name": "Year”, "dataType" : "INT”, "singleValueField" : true },
{ "name": "DivAirports”, "dataType" : "STRING”, "singleValueField" : false },
...
],
}](https://image.slidesharecdn.com/vdlb16gobblin-final-v1-160909034518/75/Open-Source-LinkedIn-Analytics-Pipeline-BOSS-2016-VLDB-47-2048.jpg)






















































![[ODSC EUROPE 2022] Eagleeye - Data Pipeline for Anomaly Detection in Cyber Se...](https://cdn.slidesharecdn.com/ss_thumbnails/odsceurope2022eagleeye-datapipelineforanomalydetectionincybersecurity-250320161155-77fa6dd8-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
























