Defining the Problemas a State Space Search
Defining Problem & Search
A problem is described formally as:
1. Define a state space that contains all the possible configurations of relevant objects.
2. Specify one or more states within that space that describe possible situations from
which the problem-solving process may start. These states are called initial states.
3. Specify one or more states that would be acceptable as solutions to the problem.
These states are called goal states.
4. Specify a set of rules that describe the actions available.
3.
The problemcan then be solved by using the rules, in combination with an appropriate
control strategy, to move through the problem space until a path from an initial state to a
goal state is found.
This process is known as search.
Search is fundamental to the problem-solving process.
Search is a general mechanism that can be used when more direct method is not known.
Search also provides the framework into which more direct methods for solving
subparts of a problem can be embedded.
4.
Defining State &State Space
A state is a representation of problem elements at a given moment.
A State space is the set of all states reachable from the initial state.
A state space forms a graph in which the nodes are states and the arcs between nodes are
actions.
In state space, a path is a sequence of states connected by a sequence of actions.
The solution of a problem is part of the graph formed by the state space.
The state space representation forms the basis of most of the AI methods.
Its structure corresponds to the structure of problem solving in two important ways:
1. It allows for a formal definition of a problem as per the need to convert some given situation
into some desired situation using a set of permissible operations.
2. It permits the problem to be solved with the help of known techniques and control
strategies to move through the problem space until goal state is found.
•
5.
Ex.:- Consider WaterJug problem
A Water Jug Problem: You are given two jugs, a 4-gallon one and a 3-gallon one, a pump
which has unlimited water which you can use to fill the jug, and the ground on which water
may be poured. Neither jug has any measuring markings on it. How can you get exactly 2
gallons of water in the 4-gallon jug?
Here the initial state is (0, 0). The goal state is (2, n) for any value of n.
State Space Representation: we will represent a state of the problem as a tuple (x, y) where
x represents the amount of water in the 4-gallon jug and y represents the amount of water in
the 3-gallon jug. Note that 0 ≤ x ≤ 4, and 0 ≤ y ≤ 3.
To solve this we have to make some assumptions not mentioned in the problem. They are:
o We can fill a jug from the pump.
o We can pour water out of a jug to the ground.
o We can pour water from one jug to another.
o There is no measuring device available.
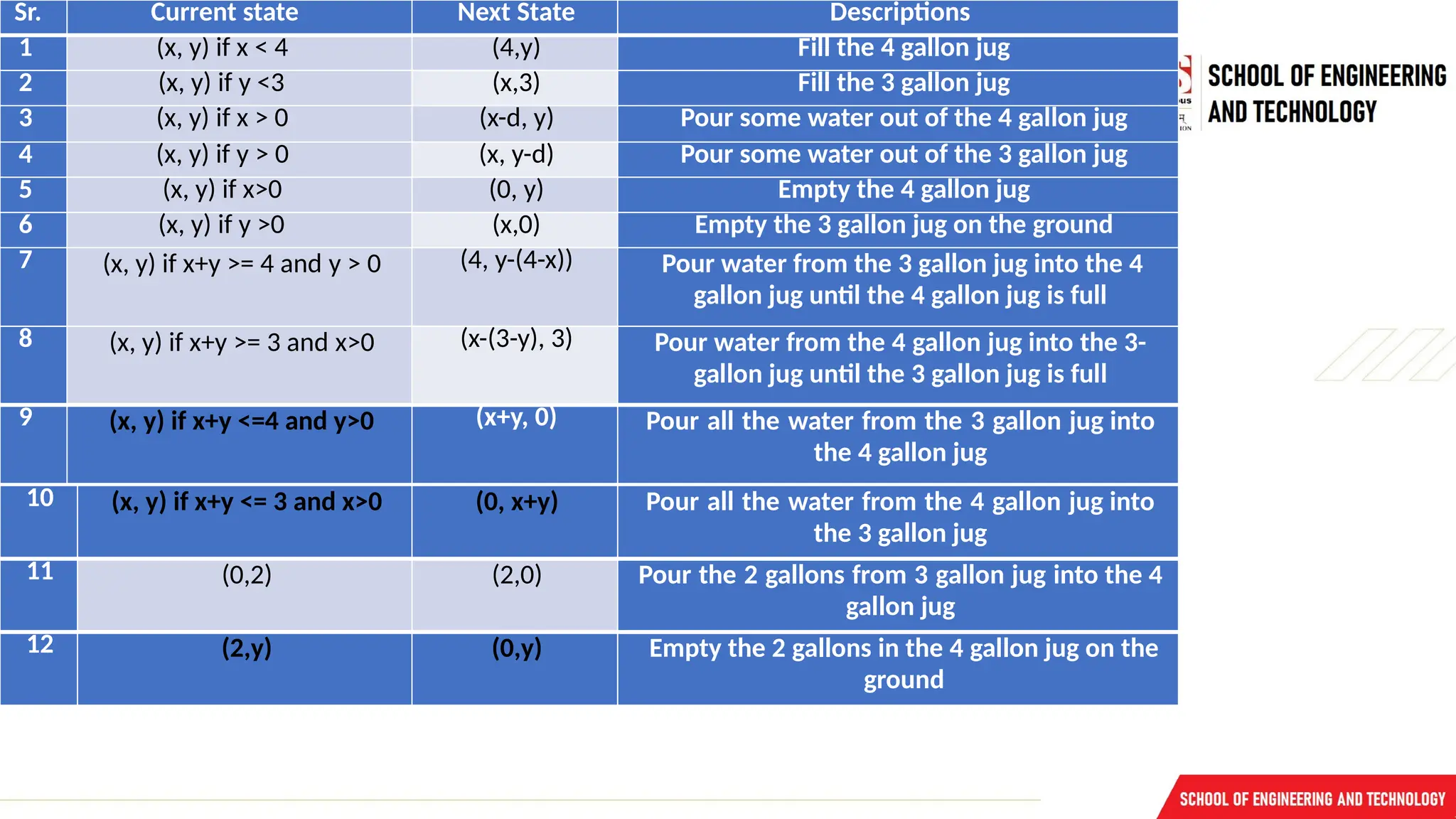
Operators – we must define a set of operators that will take us from one state to another.
6.
Sr. Current stateNext State Descriptions
1 (x, y) if x < 4 (4,y) Fill the 4 gallon jug
2 (x, y) if y <3 (x,3) Fill the 3 gallon jug
3 (x, y) if x > 0 (x-d, y) Pour some water out of the 4 gallon jug
4 (x, y) if y > 0 (x, y-d) Pour some water out of the 3 gallon jug
5 (x, y) if x>0 (0, y) Empty the 4 gallon jug
6 (x, y) if y >0 (x,0) Empty the 3 gallon jug on the ground
7 (x, y) if x+y >= 4 and y > 0 (4, y-(4-x)) Pour water from the 3 gallon jug into the 4
gallon jug until the 4 gallon jug is full
8 (x, y) if x+y >= 3 and x>0 (x-(3-y), 3) Pour water from the 4 gallon jug into the 3-
gallon jug until the 3 gallon jug is full
9 (x, y) if x+y <=4 and y>0 (x+y, 0) Pour all the water from the 3 gallon jug into
the 4 gallon jug
10 (x, y) if x+y <= 3 and x>0 (0, x+y) Pour all the water from the 4 gallon jug into
the 3 gallon jug
11 (0,2) (2,0) Pour the 2 gallons from 3 gallon jug into the 4
gallon jug
12 (2,y) (0,y) Empty the 2 gallons in the 4 gallon jug on the
ground
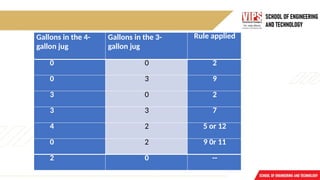
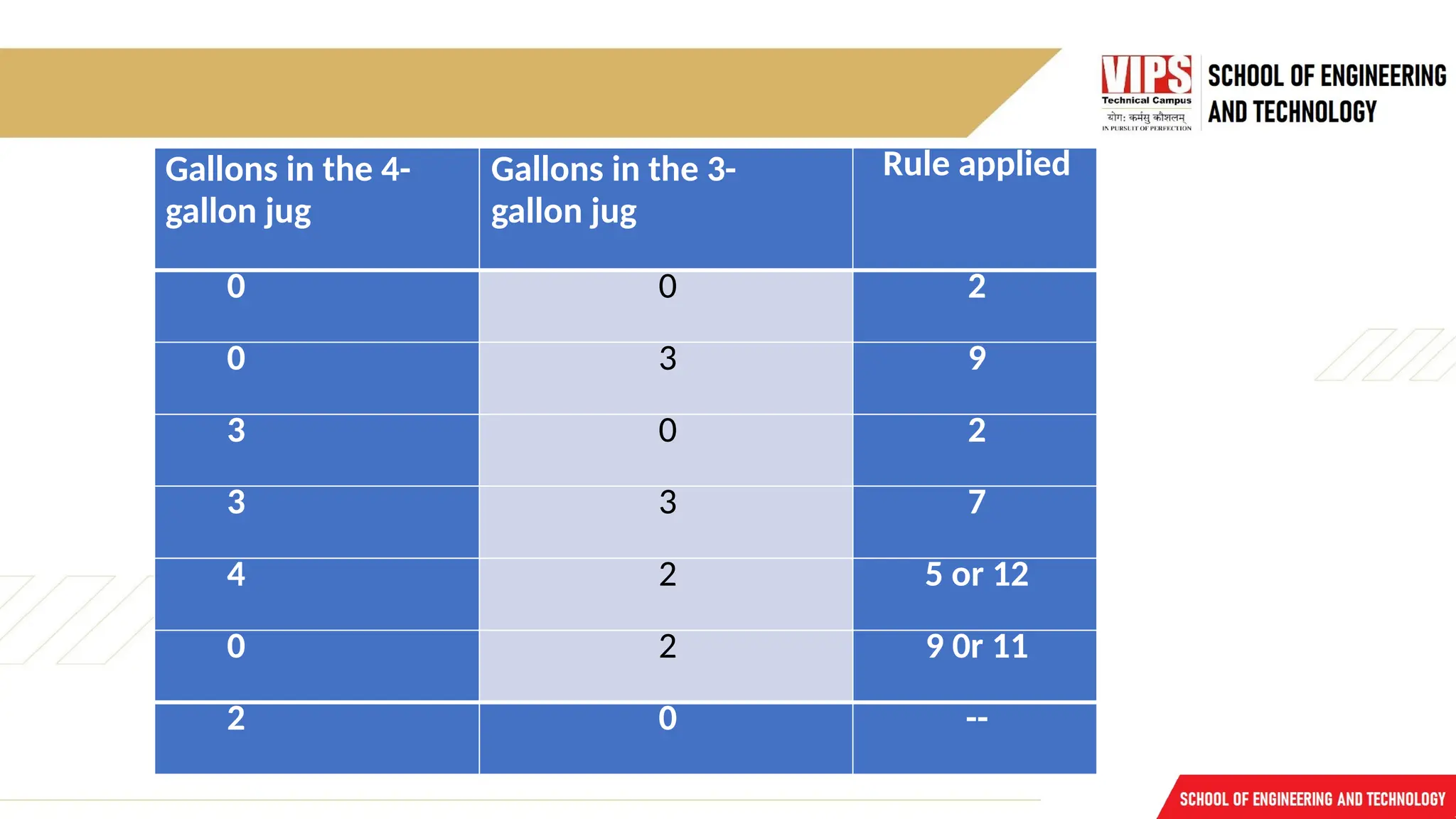
7.
Gallons in the4-
gallon jug
Gallons in the 3-
gallon jug
Rule applied
0 0 2
0 3 9
3 0 2
3 3 7
4 2 5 or 12
0 2 9 0r 11
2 0 --
8.
Production System
Searchprocess forms the core of many intelligence processes.
So, it is useful to structure AI programs in a way that facilitates describing and performing the
search process.
Production system provides such structures.
A production system consists of:
1.A set of rules, each consisting of a left side that determines the applicability of the rule
and a right side that describes the operation to be performed if that rule is applied.
2.One or more knowledge/databases that contain whatever information is appropriate
for the particular task. Some parts of the database may be permanent, while other parts
of it may pertain only to the solution of the current problem.
3.A control strategy that specifies the order in which the rules will be compared to the
database and a way of resolving the conflicts that arise when several rules match at once.
4.A rule applier which is the computational system that implements the control strategy
and applies the rules.
9.
Benefits of ProductionSystem
1. Production systems provide an excellent tool for structuring AI programs.
2. Production Systems are highly modular because the individual rules can be added,
removed or modified independently.
3. The production rules are expressed in a natural form, so the statements contained in the
knowledge base should be easily understandable.
• Production System Characteristics
1. Monotonic Production System: the application of a rule never prevents the later
application of another rule that could also have been applied at the time the first rule
was selected. i.e., rules are independent.
2. Non-Monotonic Production system is one in which this is not true.
10.
3. Partially commutativeProduction system: a production system with the property that if
application of a particular sequence of rules transforms state x to state y, then allowable
permutation of those rules, also transforms state x into state y.
4. Commutative Production system: A Commutative production system is a production
system that is both monotonic and partially commutative.
11.
Control Strategies
Controlstrategies help us decide which rule to apply next during the process of
searching for a solution to a problem.
Good control strategy should:
1. It should cause motion
2. It should be Systematic
Control strategies are classified as:
1. Uninformed/blind search control strategy:
o Do not have additional information about states beyond problem definition.
o Total search space is looked for solution.
o Example: Breadth First Search (BFS), Depth First Search (DFS), Depth Limited
Search (DLS).
2. Informed/Directed Search Control Strategy:
o Some information about problem space is used to compute preference among the
various possibilities for exploration and expansion.
o Examples: Best First Search, Problem Decomposition, A*, Mean end Analysis
12.
o So therevised probability formula is,
• 𝑃′
( )
𝛿𝐸 = (−
𝑒𝑥𝑝 𝛿𝐸 / )
𝑇
o 𝐸 is the positive change in the objective function and T is the current
temperature.
o The probability of accepting a worse state is a function of both the temperature
of the system and the change in the cost function.
o As the temperature decreases, the probability of accepting worse moves
decreases.
o If t=0, no worse moves are accepted (i.e. hill climbing).
13.
Simulated Annealing (SA)
Motivated by the physical annealing process.
Material is heated and slowly cooled into a uniform structure. Simulated annealing
mimics this process.
Compared to hill climbing the main difference is that SA allows downwards steps.
Simulated annealing also differs from hill climbing in that a move is selected at
random and then decides whether to accept it.
To accept or not to accept?
o The law of thermodynamics states that at temperature, t, the probability of an
increase in energy of magnitude, 𝐸, is given by,
• 𝑃()
𝐸 = (−
𝑒𝑥𝑝 𝐸 / )
𝑘𝑡
o Where k is a constant known as Boltzmann’s constant and it is
incorporated into T.
14.
Algorithm
1. Evaluate theinitial state. If it is also a goal state, then return it and quit. Otherwise, continue with the
initial state as the current state.
2. Initialize BEST-SO-FAR to the current state.
3. Initialize T according to the annealing schedule.
4. Loop until a solution is found or until there are no new operators left to be applied in the current state.
a. Select an operator that has not yet been applied to the current state and apply it to produce a new state.
b. Evaluate the new state. Compute
• 𝛿𝐸 = (value of current) – (value of new state)
o If the new state is a goal state, then return it and quit.
o If it is not a goal state but is better than the current state, then make it the current state. Also set
BEST-SO-FAR to this new state.
o If it is not better than the current state, then make it the current state with probability 𝑃′
as defined
above. This step is usually implemented by generating a random number between [0, 1]. If the
number is less than
• 𝑃′
, then the move is accepted otherwise do nothing.
c. Revise T as necessary according to the annealing schedule.
15.
In orderto solve a problem:
o We must first reduce it to the form for which a precise statement can be given. This can
be done by defining the problem’s state space (start and goal states) and a set of
operators for moving that space.
o The problem can then be solved by searching for a path through the space from an
initial state to a goal state.
o The process of solving the problem can usefully be modeled as a production system.
16.
Best First Search
•Uses evaluation algo fun. To decide which adj node is most promising
and then explore
• Category of heuristic search
• Priority Q is used to store cost of nodes
Means-Ends Analysis
Collectionof strategies presented so far can reason either forward or backward, but for a
given problem, one direction or the other must be chosen.
A mixture of the two directions is appropriate. Such a mixed strategy would make it possible
to solve the major parts of a problem first and then go back and solve the small problems
that arise in “gluing” the big pieces together.
The technique of Means-Ends Analysis (MEA) allows us to do that.
MEA process centers around the detection of differences between the current state and the
goal state.
Once such a difference is isolated, an operator that can reduce the difference must be
found.
If the operator cannot be applied to the current state, we set up a sub-problem of getting
to a state in which it can be applied.
The kind of backward chaining in which operators are selected and then sub-goals are set
up to establish the preconditions of the operators is called operator sub-goaling
19.
Algorithm: Means-Ends Analysis
1.Compare CURRENT to GOAL. If there are no differences between them then return.
2. Otherwise, select the most important difference and reduce it by doing the following until success or
failure is signaled:
a. Select an as yet untried operator O that is applicable to the current difference. If there are no such
operators, then signal failure.
b. Attempt to apply O to CURRENT. Generate descriptions of two states: O- START, a state in which
O’s preconditions are satisfied and O-RESULT, the state that would result if O were applied in O-
START.
c. If
(FIRST-PART MEA( CURRENT, O-START))
and
(LAST-PART MEA(O-RESULT, GOAL))
are successful, then signal success and return the result of concatenating FIRST-PART, O, and LAST-
PART.
A* Algorithm
In best-firstsearch, we take heuristic value called evaluation function
value.
It is a value that estimates how far a particular node is from the goal.
Apart from the evaluation function values, one can also bring in cost
functions.
Cost functions indicate how much resources like time, energy, money
etc. have been spent in reaching a particular node from the start.
22.
A*
While evaluation functionvalues deal with the future, cost function values
deal with the past.
Since cost function values are really expanded, they are more concrete
than evaluation function values.
If it is possible for one to obtain the evaluation function values
and the cost function values then A* algorithm can be used.
The sum of these two functions is called fitness number.
Fitness number = all cost function + evaluation function
f(n)=g(n)+h(n)
23.
A*
1. f: Heuristicfunction that estimates the merits of each node we
generate. f = g + h’. f represents an estimate of the cost of getting
from the initial state to a goal state along with the path that generated
the current node.
2. g: The function g is a measure of the cost of getting from initial state
to the current node.
3. h: The function h’ is an estimate of the additional cost of getting
from the current node to a goal state.
24.
Algorithm
• Enter startingnode in open list
• If open list empty FAIL
• Select node from the open list with smallest (g+h), if node is goal
return success
• Expand node n and generate all successor (compute g+h for all)
• If node n is already in open/close, attach to back pointer
• Go to iii
25.
Algorithm
1. Start withOPEN containing only initial node. Set that node’s g value to 0, its h’ value to whatever it is, and its f’ value to h’+0 or h’. Set
CLOSED to empty list.
2. Until a goal node is found, repeat the following procedure: If there are no nodes on OPEN, report failure. Otherwise select the node on
OPEN with the lowest f’ value. Call it BESTNODE. Remove it from OPEN. Place it in CLOSED. See if the BESTNODE is a goal state. If so exit
and report a solution. Otherwise, generate the successors of BESTNODE but do not set the BESTNODE to point to them yet. For each of the
SUCCESSOR, do the following:
a. Set SUCCESSOR to point back to BESTNODE. These backwards links will make it possible to recover the path once a solution is found.
b. Compute g(SUCCESSOR) = g(BESTNODE) + the cost of getting from BESTNODE to SUCCESSOR
c. See if SUCCESSOR is the same as any node on OPEN. If so call the node OLD.
i. Check whether it is cheaper to get to OLD via its current parent or to SUCESSOR via BESTNODE by comparing their g values.
ii. If OLD is cheaper, then do nothing. If SUCCESSOR is cheaper then reset
• OLD’s parent link to point to BESTNODE.
i. Record the new cheaper path in g(OLD) and update f ‘(OLD).
a. If SUCCESSOR was not on OPEN, see if it is on CLOSED. If so, call the node on CLOSED OLD and add OLD to the list of BESTNODE’s
successors.
b. If SUCCESSOR was not already on either OPEN or CLOSED, then put it on OPEN and add it to the list of BESTNODE’s successors.
Compute f’(SUCCESSOR) = g(SUCCESSOR) + h’(SUCCESSOR).
•
26.
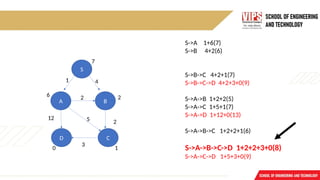
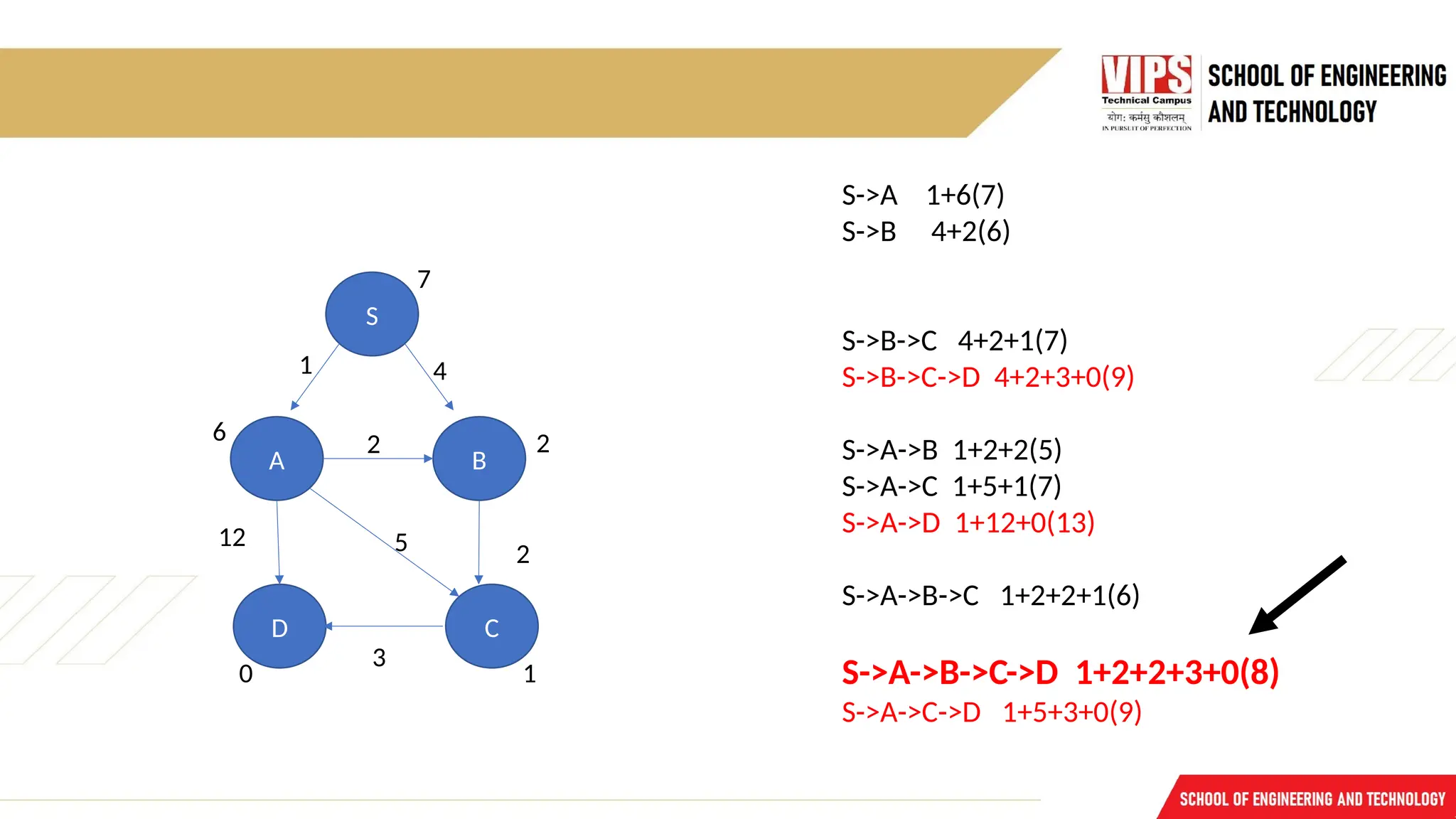
S
B
A
D C
3
4
2
2
12 5
1
7
62
1
0
S->A 1+6(7)
S->B 4+2(6)
S->B->C 4+2+1(7)
S->B->C->D 4+2+3+0(9)
S->A->B 1+2+2(5)
S->A->C 1+5+1(7)
S->A->D 1+12+0(13)
S->A->B->C 1+2+2+1(6)
S->A->B->C->D 1+2+2+3+0(8)
S->A->C->D 1+5+3+0(9)
27.
Adv/Disadv
Advantages:
• Best searchingalgo
• Optimal and complete
• Solve complex problems
Disadvantage
• Doesn’t always produce shortest
• Complexity issue
• Requires m/m
28.
Observations
• Observations aboutA*
o Role of g function: This lets us choose which node to expand next on the basis of not only of how
good the node itself looks, but also on the basis of how good the path to the node was.
o h’, the distance of a node to the goal. If h’ is a perfect estimator of h, then A* will converge
immediately to the goal with no search.
• Admissibility of A*
o A heuristic function h’(n) is said to be admissible if it never overestimates the cost of getting to a
goal state.
o i.e. if the true minimum cost of getting from node n to a goal state is C then h must satisfy: h’(n)
≤ C
o If h’ is a perfect estimator of h, then A* will converge immediately to the goal state with no search.
o If h’ never overestimates h, then A* algorithm is guaranteed to find an optimal path if one exists.
30.
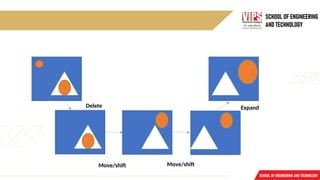
AO* AND-OR GRAPHS
ProblemReduction
o AND-OR graph (or tree) is useful for representing the solution of problems that can be solved
by decomposing them into a set of smaller problems, all of which must then be solved.
o This decomposition or reduction generates arcs that we call AND arcs.
o One AND arc may point to any numbers of successor nodes. All of which must then be solved in
order for the arc to point solution.
o In order to find solution in an AND-OR graph we need an algorithm similar to best –first search
but with the ability to handle the AND arcs appropriately.
o We define FUTILITY, if the estimated cost of solution becomes greater than the value of
FUTILITY then we abandon the search, FUTILITY should be chosen to correspond to a
threshold.
o In following figure AND arcs are indicated with a line connecting all the components.
32.
The AO* Algorithm
Rather than the two lists, OPEN and CLOSED, that were used in the A* algorithm, the AO*
algorithm will use a single structure GRAPH, representing the part of the search graph that
has been explicitly generated so far.
Each node in the graph will point both down to its immediate successors and up to its
immediate predecessors.
Each node in the graph will also have associated with it an h' value, an estimate of the cost
of a path from itself to a set of solution nodes.
We will not store g (the cost of getting from the start node to the current node) as we did in
the A* algorithm.
And such a value is not necessary because of the top-down traversing of the edge which
guarantees that only nodes that are on the best path will ever be considered for expansion.
33.
AO*
1. Let GRAPHconsist only of the node representing the initial state. Call this node INIT, Compute VINIT.
2. Until INIT is labeled SOLVED or until INIT's h' value becomes greater than FUTILITY, repeat the following procedure:
a. Trace the labeled arcs from INIT and select for expansion one of the as yet unexpanded nodes that occurs on this path. Call the selected node NODE.
b. Generate the successors of NODE. If there are none, then assign FUTILITY as the h' value of NODE. This is equivalent to saying that NODE is not solvable.
If there are successors, then for each one (called SUCCESSOR) that is not also an ancestor of NODE do the following:
i. Add SUCCESSOR to GRAPH
ii. If SUCCESSOR is a terminal node, label it SOLVED and assign it an h' value of 0
iii. If SUCCESSOR is not a terminal node, compute its h' value
c. Propagate the newly discovered information up the graph by doing the following: Let S be a set of nodes that have been labeled SOLVED or whose h'
values have been changed and so need to have values propagated back to their parents. Initialize S to NODE. Until S is empty, repeat the, following
procedure:
i. If possible, select from S a node none of whose descendants in GRAPH occurs in S. If there is no such node, select any node from S. Call this node
CURRENT, and remove it from S.
ii. Compute the cost of each of the arcs emerging from CURRENT. The cost of each arc is equal to the sum of the h' values of each of the nodes at the
end of the arc plus whatever the cost of the arc itself is. Assign as CURRENT'S new h' value the minimum of the costs just computed for the arcs
emerging from it.
iii. Mark the best path out of CURRENT by marking the arc that had the minimum cost as computed in the previous step.
iv. Mark CURRENT SOLVED if all of the nodes connected to it through the new labeled arc have been labeled SOLVED.
v. If CURRENT has been labeled SOLVED or if the cost of CURRENT was just changed, then its new status must be propagated back up the graph. So
add all of the ancestors of CURRENT to S.
35.
Knowledge Representation
Inorder to solve complex problems encountered in artificial intelligence, one needs both a
large amount of knowledge and some mechanism for manipulating that knowledge to create
solutions.
Knowledge and Representation are two distinct entities. They play central but
distinguishable roles in intelligent system.
Knowledge is a description of the world. It determines a system's competence by what it
knows.
Representation is the way knowledge is encoded. It defines a system's performance in
doing something.
Different types of knowledge require different kinds of representation.
The Knowledge Representation models/mechanisms are often based on:
o Logic
o Rules
o Frames
o Semantic Net
36.
Types
1. Tacit correspondsto "informal" or "implicit“
Exists within a human being;
It is embodied.
Difficult to articulate formally.
Difficult to communicate or share.
Hard to steal or copy.
Drawn from experience, action, subjective insight
2. Explicit formal type of knowledge, Explicit
Explicit knowledge
Exists outside a human being;
It is embedded.
Can be articulated formally.
Can be shared, copied, processed and stored.
Easy to steal or copy
Drawn from artifact of some type as principle, procedure, process, concepts.
37.
Contd.
There aretwo different kinds of entities, we are dealing with.
1. Facts: Truth in some relevant world. Things we want to represent.
2. Representation of facts in some chosen formalism. Things we will actually be
able to manipulate.
These entities are structured at two levels:
1. The knowledge level, at which facts are described.
2. The symbol level, at which representation of objects are defined in terms of
symbols that can be manipulated by programs
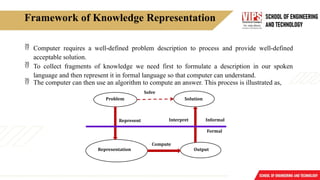
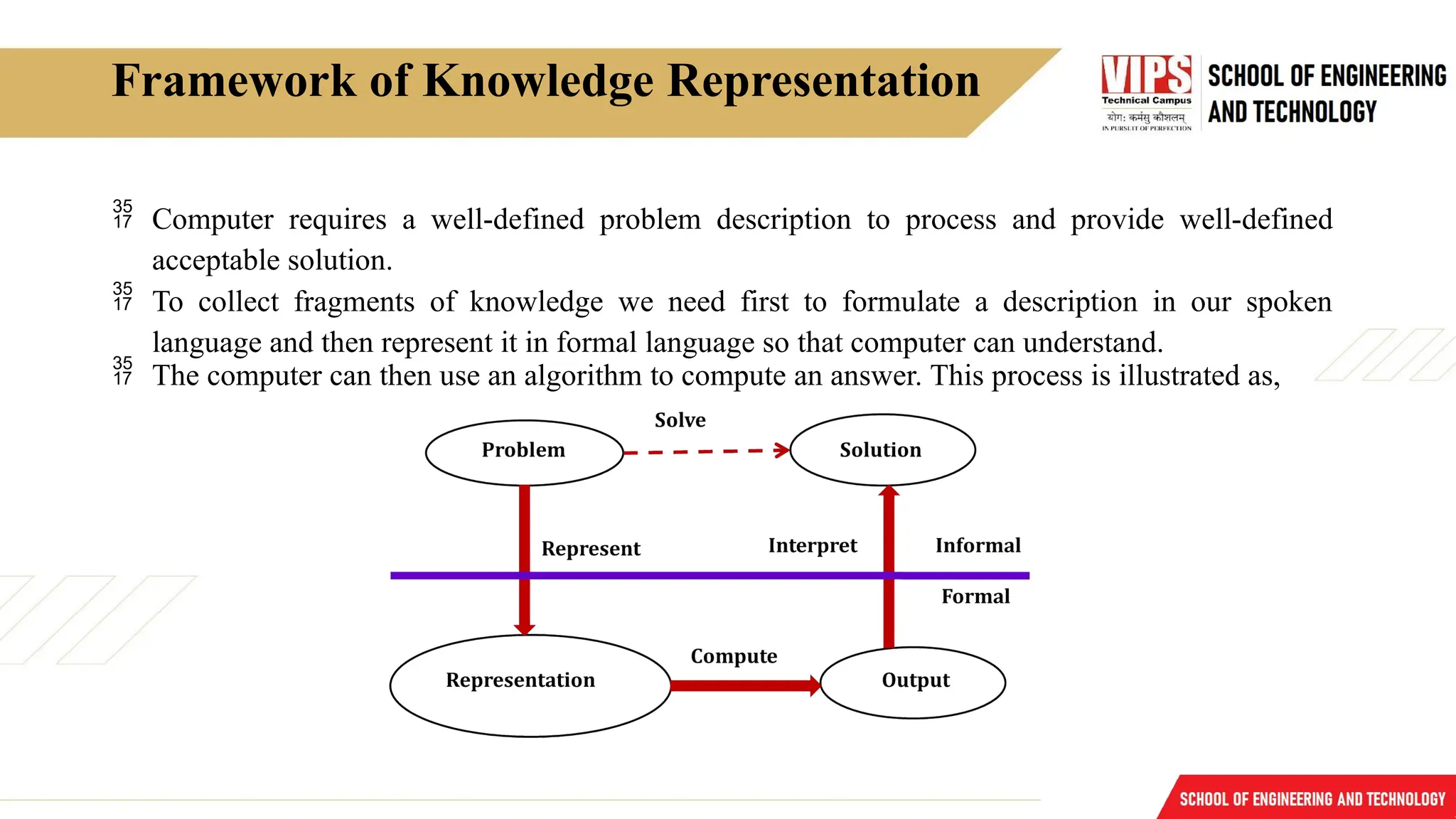
Framework of KnowledgeRepresentation
Computer requires a well-defined problem description to process and provide well-defined
acceptable solution.
To collect fragments of knowledge we need first to formulate a description in our spoken
language and then represent it in formal language so that computer can understand.
The computer can then use an algorithm to compute an answer. This process is illustrated as,
40.
The steps are:
oThe informal formalism of the problem takes place first.
o It is then represented formally, and the computer produces an output.
o This output can then be represented in an informally described solution that user
understands or checks for consistency.
The Problem solving requires,
o Formal knowledge representation, and
o Conversion of informal knowledge to formal knowledge that is conversion of implicit
knowledge to explicit knowledge.
41.
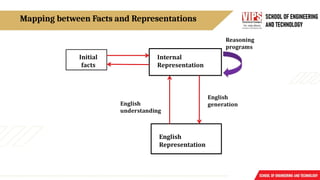
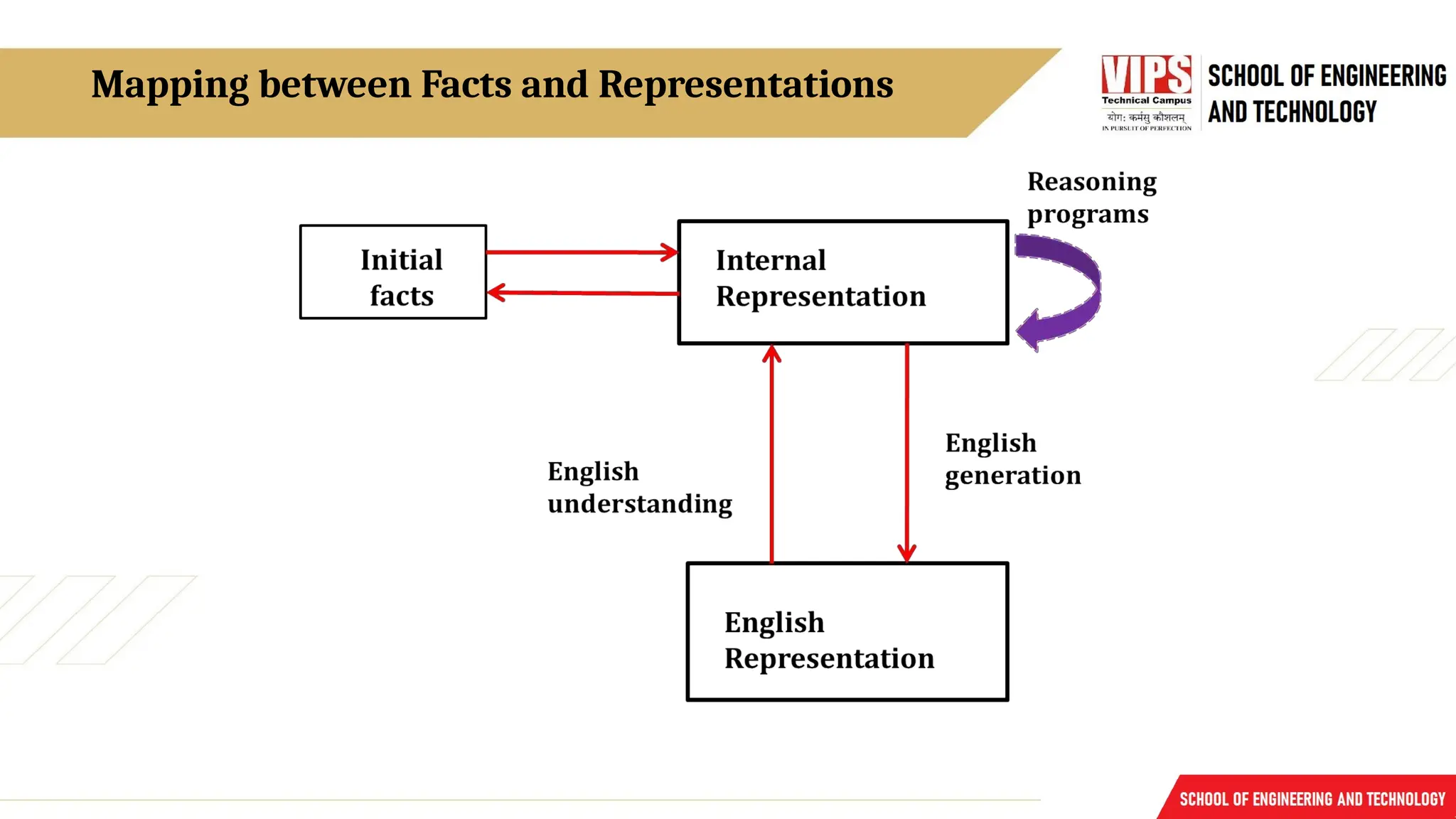
Mapping between Factsand Representation
Knowledge is a collection of facts from some domain.
We need a representation of "facts“ that can be manipulated by a program.
Normal English is insufficient, too hard currently for a computer program to draw
inferences in natural languages.
Thus some symbolic representation is necessary
42.
Approaches to knowledgeRepresentation
A good knowledge representation enables fast and accurate access to knowledge and
understanding of the content.
A knowledge representation system should have following properties.
1. Representational Adequacy
o The ability to represent all kinds of knowledge that are needed in that domain.
2. Inferential Adequacy
o The ability to manipulate the representational structures to derive new structures
corresponding to new knowledge inferred from old.
3. Inferential Efficiency
o The ability to incorporate additional information into the knowledge structure that can
be used to focus the attention of the inference mechanisms in the most promising
direction.
4. Acquisitional Efficiency
o The ability to acquire new knowledge using automatic methods wherever possible
rather than reliance on human intervention.
43.
Knowledge Representation Schemes
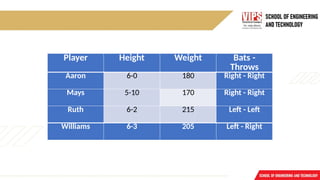
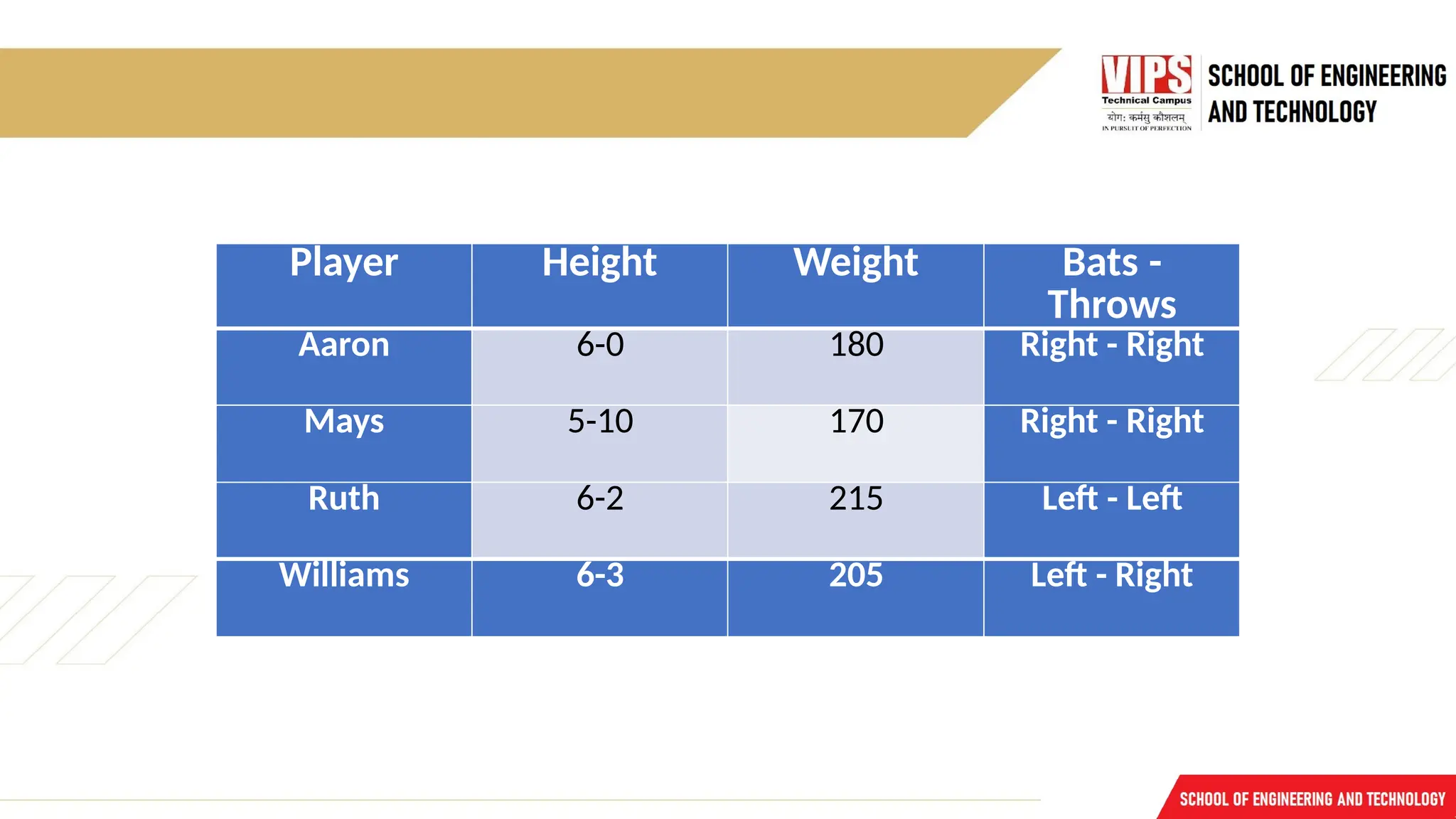
1.Relational Knowledge :
o The simplest way to represent declarative facts is as a set of relations of the same
sort used in the database system.
o Provides a framework to compare two objects based on equivalent attributes.
o Any instance in which two different objects are compared is a relational type of
knowledge.
o The table below shows a simple way to store facts.
The facts about a set of objects are put systematically in columns.
This representation provides little opportunity for inference.
Given the facts it is not possible to answer simple question such as :
• “Who is the heaviest player?”
But if a procedure for finding heaviest player is provided, then these facts will
enable that procedure to compute an answer.
We can ask things like who "bats – left" and "throws – right".
44.
Player Height WeightBats -
Throws
Aaron 6-0 180 Right - Right
Mays 5-10 170 Right - Right
Ruth 6-2 215 Left - Left
Williams 6-3 205 Left - Right
45.
Inheritable Knowledge
o Herethe knowledge elements inherit attributes from their parents.
o The knowledge is embodied in the design hierarchies found in the functional,
physical and process domains.
o Within the hierarchy, elements inherit attributes from their parents, but in many
cases not all attributes of the parent elements be prescribed to the child elements.
o The inheritance is a powerful form of inference, but not adequate.
o The basic KR (Knowledge Representation) needs to be augmented with inference
mechanism.
o Property inheritance: The objects or elements of specific classes inherit attributes
and values from more general classes.
o The classes are organized in a generalized hierarchy.
46.
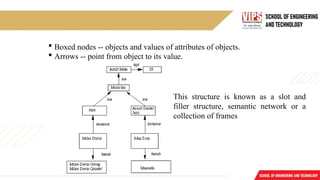
Boxed nodes-- objects and values of attributes of objects.
Arrows -- point from object to its value.
This structure is known as a slot and
filler structure, semantic network or a
collection of frames
47.
o The stepsto retrieve a value for an attribute of an instance object:
i. Find the object in the knowledge base
ii. If there is a value for the attribute report it
iii.Otherwise look for a value of an instance, if none fail
iv. Otherwise go to that node and find a value for the attribute and then report it
v. Otherwise search through using isa until a value is found for the attribute.
48.
Inferential Knowledge
o Thisknowledge generates new information from the given information.
o This new information does not require further data gathering form source, but does require
analysis of the given information to generate new knowledge.
o Example: given a set of relations and values, one may infer other values or relations. A
predicate logic (a mathematical deduction) is used to infer from a set of attributes. Inference
through predicate logic uses a set of logical operations to relate individual data.
o Represent knowledge as formal logic:
• All dogs have tails x
∀ : dog(x) → hastail(x)
o Advantages:
A set of strict rules.
Can be used to derive more facts.
Truths of new statements can be verified.
Guaranteed correctness.
49.
Procedural Knowledge
o Arepresentation in which the control information, to use the knowledge, is embedded in
the knowledge itself. For example, computer programs, directions, and recipes; these
indicate specific use or implementation;
o Knowledge is encoded in some procedures, small programs that know how to do specific
things, how to proceed.
o Advantages:
Heuristic or domain specific knowledge can be represented.
Extended logical inferences, such as default reasoning facilitated.
Side effects of actions may be modeled. Some rules may become false in time. Keeping
track of this in large systems may be tricky.
o Disadvantages:
Completeness -- not all cases may be represented.
Consistency -- not all deductions may be correct. e.g If we know that Fred is a bird we
might deduce that Fred can fly. Later we might discover that Fred is an emu.
Modularity is sacrificed. Changes in knowledge base might have far-reaching effects.
Cumbersome control information.
50.
Propositional Calculus
• Systemthat deals with method used for manipulation of symbol acc. to some rules
• Proposition
A proposition is a statement, or a simple declarative
sentence.
For example, “the book is expensive” is a proposition.
A proposition can be either true or false.
• Propositional logic
Logical constants: true, false
Propositional symbols: P, Q, S,... (atomic sentences)
Propositions are combined by connectives:
∧ and [conjunction]
/ or [disjunction]
implies [implication]
¬ not [negation]
∀ For all
∃ There exists
51.
Example
X: It ishot
Y: It is humid
Z: It is raining
1. If it is humid, then it is hot
YX
2. If it if hot and humid, then it is not raining
(X ∧ Y) ¬ Z
Truth Table
A: Itis humid
B: It will rain
If it is humid then it will rain and since it is humid today it will rain
(AB/A)B
Truth Table???
55.
Tautology/Contradiction
A proposition thatis true under all circumstances: TAUTOLOGY
A proposition that is not true under all circumstances: CONTRADICTION
A proposition that is neighter TAUTOLOGY nor CONTRADICTION: CONTINGENCY
56.
Rules of Inference
•Modus Ponens: if P and PQ are True, Q is True
• Modus Tollens: If ¬ Q and ¬ P ¬ Q are True, ¬ P is True
• P: It is holiday
• Q: School is closed
• PQ : If it’s a holiday, the school is closed.
57.
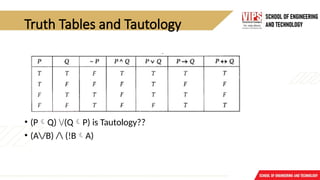
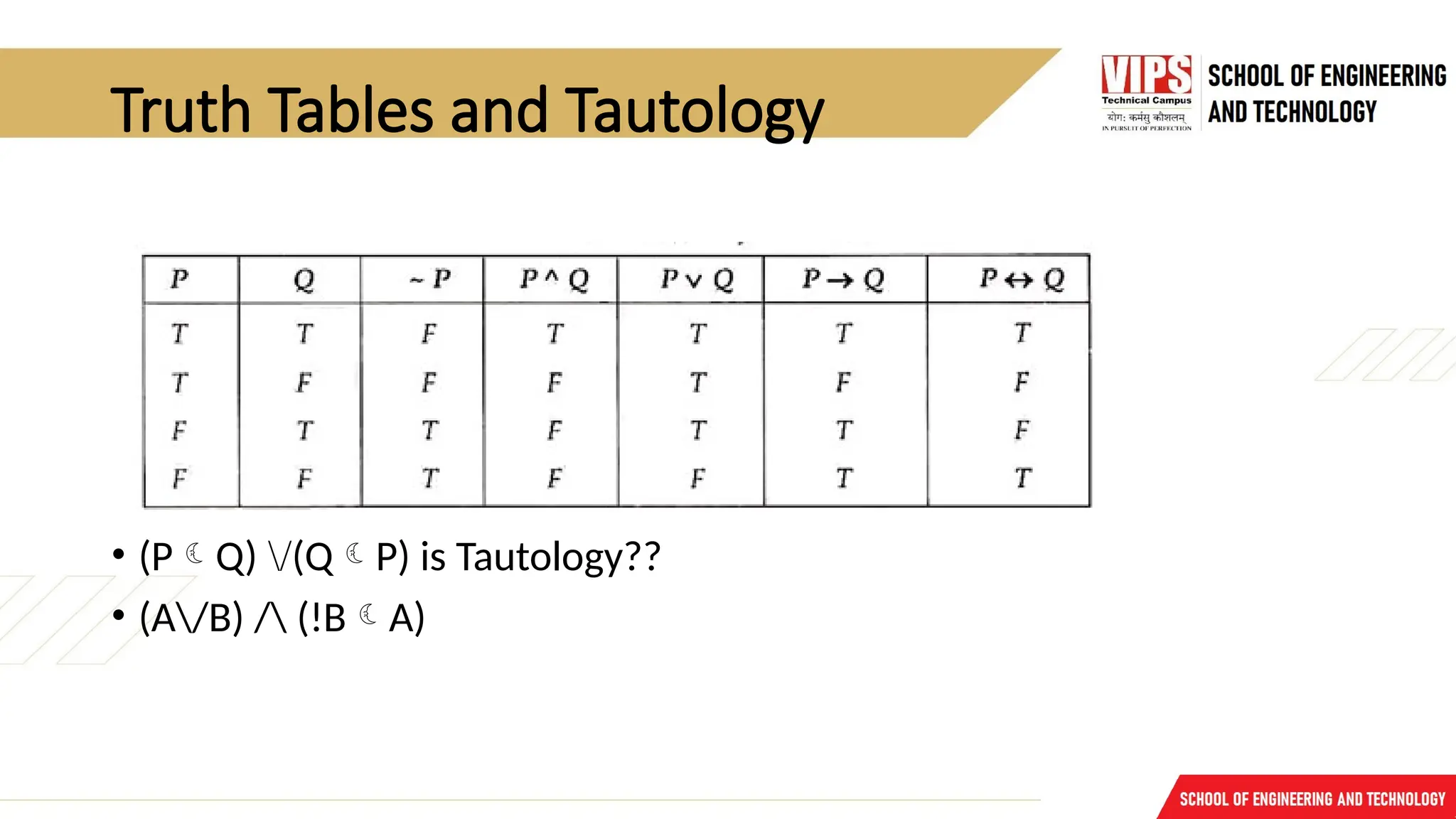
Truth Tables andTautology
• (PQ) /(QP) is Tautology??
• (A/B) / (!BA)
58.
Truth Tables andTautology
A sentence (well-formed formula) is defined as follows:
A symbol is a sentence.
If S is a sentence, then ¬ S is a sentence.
If S is a sentence, then (S) is a sentence.
If S and T are sentences, then (S ∧ T), (S ∨ T), (S T), and (ST) are
sentences
A sentence results from a finite number of applications of the above rules.
59.
Properties of Statement
•Valid: if it is true for all input values (tautology)
• Satisfiable: statements having atleast one instance for which it is true
• Unsatisfiable: if it is not true for any interpretation (contradiction)
• Equivalence: two statements s1 and s2 are equivalent if both have same truth value
First Order Logic
•Propositional logic is useful because it is simple to deal with and a decision procedure for it
exists.
• In order to draw conclusions, facts are represented in a more convenient way as,
1. Marcus is a man. man(Marcus)
2. Plato is a man. man(Plato)
3. All men are mortal. mortal(men)
• But propositional logic fails to capture the relationship between any individual being a man and
that individual being a mortal.
How can these sentences be represented so that we can infer the third sentence from the
first two?
Propositional logic commits only to the existence of facts that may or may not be the case in
the world being represented.
It has a simple syntax and simple semantics. It suffices to illustrate the process of inference.
Propositional logic quickly becomes impractical, even for very small worlds.
70.
Predicate logic
First-order Predicatelogic (FOPL) models the world in terms of
o Objects, which are things with individual identities
o Properties of objects that distinguish them from other objects
o Relations that hold among sets of objects
o Functions, which are a subset of relations where there is only one “value” for any given “input”
• First-order Predicate logic (FOPL) provides
o Constants: a, b, dog33. Name a specific object.
o Variables: X, Y. Refer to an object without naming it.
o Functions: Mapping from objects to objects.
o Terms: Refer to objects
o Atomic Sentences: in(dad-of(X), food6) Can be true or false, Correspond to propositional
symbols P, Q.
o A well-formed formula (wff) is a sentence containing no “free” variables. That is, all variables
are “bound” by universal or existential quantifiers.
71.
• Quantifiers
Universalquantification
• (∀x)P(x) means that P holds for all values of x in the domain associated with that
variable
• E.g., (∀x) dolphin(x) mammal(x)
Existential quantification
• (∃x)P(x) means that P holds for some value of x in the domain associated with that
variable
• E.g., (∃x) mammal(x) ∧ lays-eggs(x)
72.
Consider the followingexample that shows the use of predicate logic as a
way of representing knowledge.
1. Marcus was a man.
2. Marcus was a Pompeian.
3. All Pompeians were Romans.
4. Caesar was a ruler.
5. All Pompeians were either loyal to Caesar or hated him.
6. Everyone is loyal to someone.
7. People only try to assassinate rulers they are not loyal to.
8. Marcus tried to assassinate Caesar.
73.
The facts describedby these sentences can be represented as a set of well-formed formulas (wffs) as
follows:
Marcus was a man. man(Marcus)
Marcus was a Pompeian. Pompeian(Marcus)
All Pompeians were Romans. x
∀ : Pompeian(x)
Roman(x)
Caesar was a ruler. ruler(Caesar)
All Pompeians/Romans were either loyal to Caesar or hated him.
• inclusive-or
• ∀x : Romans(x) loyalto(x, Caesar) ∨ hate(x, Caesar)
• exclusive-or
∀x : Romans(x) (loyalto(x, Caesar) ∨ ¬ hate(x,
Caesar)) ∨ (¬ loyalto(x, Caesar) ∨ hate(x, Caesar))
74.
Every-one is loyalto someone.
∀x : ∃ y: loyalto(x, y)
People only try to assassinate rulers they are not loyal to.
∀x : ∃ y : person(x) ∧ ruler(y) ∧ tryassassinate(x, y) ¬ loyalto(x, y)
Marcus tried to assassinate Caesar.
tryassassinate(Marcus, Caesar)
75.
Now supposeif we want to use these statements to answer the question
• Was Marcus loyal to Caesar?
Now let's try to produce a formal proof, reasoning backward from the desired goal:
• ¬ Ioyalto(Marcus, Caesar)
In order to prove the goal, we need to use the rules of inference to transform it into another
goal (or possibly a set of goals) that can in turn be transformed, and so on, until there are no
unsatisfied goals remaining.
7. x
∀ : ∃ y : person(x) ∧ ruler(y) ∧ tryassassinate(x, y) ¬ loyalto(x,
y)
4. ruler(Caesar)
8. tryassassinate(Marcus, Caesar)
76.
The problemis that, although we know that Marcus was a man, we do not have any way
to conclude from that that Marcus was a person. We need to add the representation of
another fact to our system, namely:
• ∀x : man(x) → person(x)
Now we can satisfy the last goal and produce a proof that Marcus was not loyal to
Caesar.
From this simple example, we see that three important issues must be addressed in the
process of converting English sentences into logical statements and then using those
statements to deduce new ones:
1. Many English sentences are ambiguous (for example, 5, 6, and 7 above). Choosing
the correct interpretation may be difficult.
2. There is often a choice of how to represent the knowledge. Simple representations
are desirable, but they may exclude certain kinds of reasoning.
77.
• Even invery simple situations, a set of sentences is unlikely to contain all the information
necessary to reason about the topic at hand. In order to be able to use a set of statements
effectively, it is usually necessary to have access to another set of statements that
represent facts that people consider too obvious to mention.
• The problem was how to start
¬ Ioyalto(Marcus, Caesar) OR Ioyalto(Marcus, Caesar)
Try to prove both simultaneously and stop when one efforts is successful
Try both to Prove one and disprove it and use the info. Gained in one of the processes to
guide other
78.
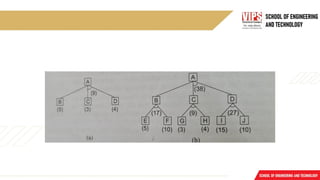
Instance and ISA
•Representing INSTANCE and ISA Relationships
Specific attributes instance and isa play important role particularly in a useful form of
reasoning called property inheritance.
The predicates instance and isa explicitly captured the relationships they are used to
express, namely class membership and class inclusion.
Fig. shows the first five sentences of the last section represented in logic in three different
ways.
The first part of the figure contains the representations we have already discussed. In these
representations, class membership is represented with unary predicates (such as Roman),
each of which corresponds to a class.
Asserting that P(x) is true is equivalent to asserting that x is an instance (or element) of P.
The second part of the figure contains representations that use the instance predicate
explicitly.
80.
The predicateinstance is a binary one, whose first argument is an object and whose second
argument is a class to which the object belongs.
But these representations do not use an explicit isa predicate.
Instead, subclass relationships, such as that between Pompeians and Romans, are described
as shown in sentence 3.
The implication rule states that if an object is an instance of the subclass Pompeian then it is
an instance of the superclass Roman.
Note that this rule is equivalent to the standard set-theoretic definition of the subclass-
superclass relationship.
The third part contains representations that use both the instance and isa predicates
explicitly.
The use of the isa predicate simplifies the representation of sentence 3, but it requires that
one additional axiom (shown here as number 6) be provided.
81.
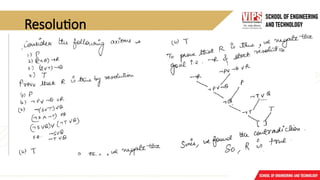
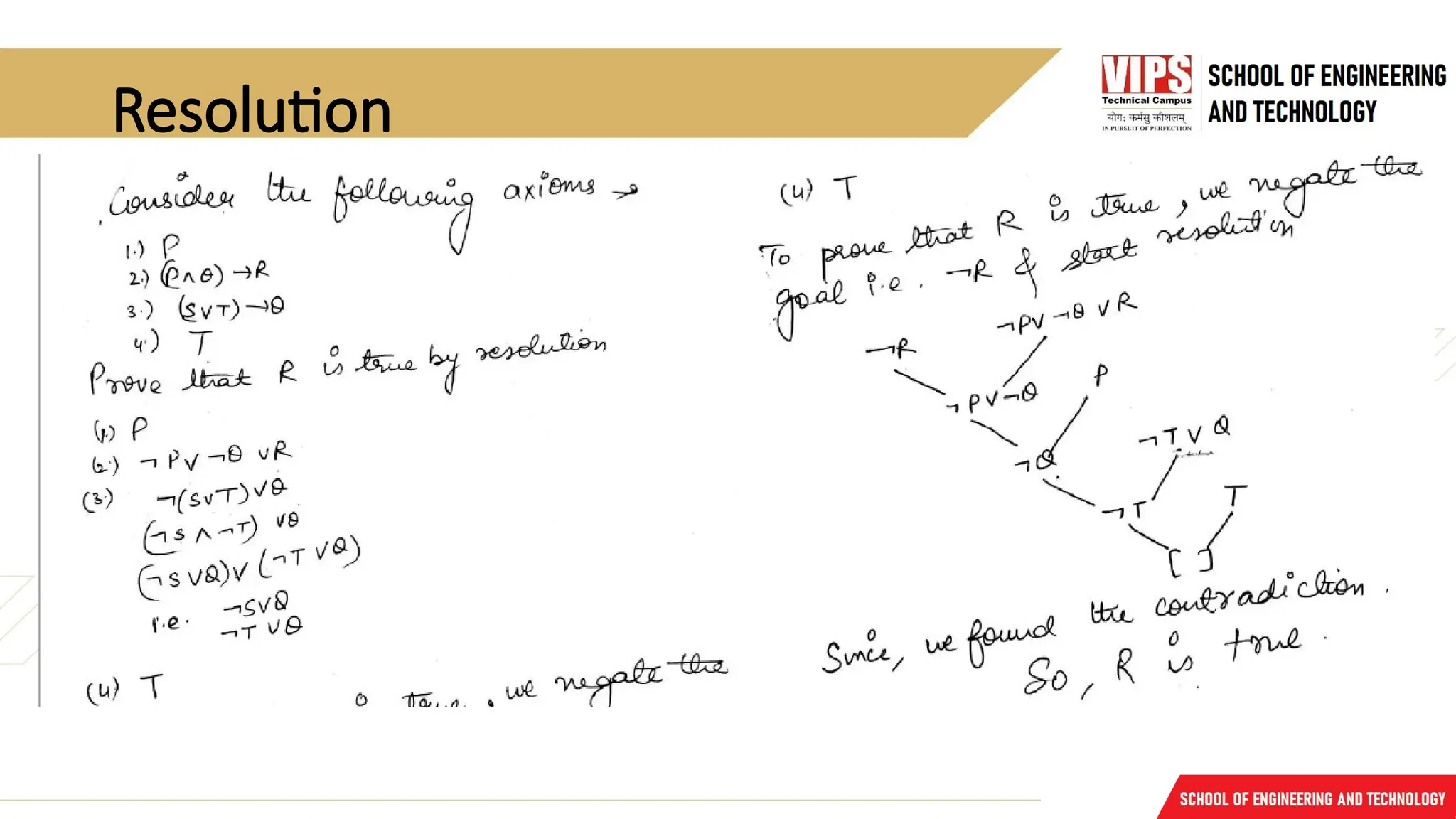
Resolution
Resolution isa procedure, which gains its efficiency from the fact that it operates on statements that have
been converted to a very convenient standard form.
Resolution produces proofs by refutation.
In other words, to prove a statement (i.e., to show that it is valid), resolution attempts to show that the
negation of the statement produces a contradiction with the known statements (i.e., that it is unsatisfiable).
The resolution procedure is a simple iterative process: at each step, two clauses, called the parent clauses,
are compared (resolved), resulting into a new clause that has been inferred from them. The new clause
represents ways that the two parent clauses interact with each other. Suppose that there are two clauses in
the system:
winter V summer ¬ winter V cold
Now we observe that precisely one of winter and ¬ winter will be true at any point.
If winter is true, then cold must be true to guarantee the truth of the second clause. If ¬ winter is true, then
summer must be true to guarantee the truth of the first clause.
82.
Thus wesee that from these two clauses we can deduce
• summer V cold
This is the deduction that the resolution procedure will make.
Resolution operates by taking two clauses that each contains the same literal, in this example,
winter.
The literal must occur in positive form in one clause and in negative form in the other. The
resolvent is obtained by combining all of the literals of the two parent clauses except the ones
that cancel.
If the clause that is produced is the empty clause, then a contradiction has been found.
• For example, the two clauses winter, ¬ winter will
produce the empty clause.
83.
Steps
• Negate thestatement to be proved
• Covert given facts into FOL
• Convert FOL into CNF
• Draw Resolution Graph
84.
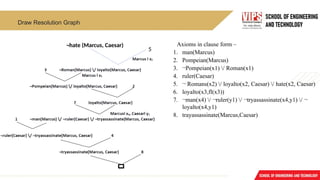
Convert given factsinto FOL
1. Marcus was a man. man(Marcus)
2. Marcus was a Pompeian. Pompeian(Marcus)
3. All Pompeians were Romans. x
∀ : Pompeian(x)
Roman(x)
4. Caesar was a ruler ruler(Caesar)
5. All Romans were either loyal to Caesar or hated him.
inclusive-or x
∀ : Romans(x) loyalto(x, Caesar) ∨
hate(x, Caesar)
exclusive-or x :
∀ Romans(x) (loyalto(x, Caesar) ∨ ¬
hate(x, Caesar)) ∨
(¬ loyalto(x, Caesar) ∨ hate(x, Caesar))
85.
6. Every-one isloyal to someone. x
∀ : ∃ y: loyalto(x, y)
7. People only try to assassinate rulers they are not loyal to.
∀x : ∃ y : person(x) ∧ ruler(y) ∧ tryassassinate(x, y) ¬ loyalto(x, y)
8. Marcus tried to assassinate Caesar.
Tryassassinate(Marcus, Caesar)
• Now suppose if we want to use these statements to
answer the question
• Was Marcus loyal to Caesar?
Now let's try to produce a formal proof, reasoning
backward from the desired goal:
• ¬ Ioyalto(Marcus, Caesar)
86.
Convert FOL intoCNF
• Eliminate →, using the fact that a → b is equivalent to ¬ a V b.
• ab b
∧ a
• Reduce the scope of each ¬ to a single term, using the fact that ¬ (¬ p) = p, move negation inward
• Eliminate existential quantifiers. So, for example, the formula
• ∃y : President(y)
• can be transformed into the formula
• President(S1)
• For example, in the formula
• ∀x: ∃y: father-of(y, x)
• would be transformed into
• ∀x: father-of(S2(x), x)
• These generated functions are called Skolem functions. Sometimes ones with no arguments are
called Skolem constants.
• Drop Universal quantifiers
Algorithm: Propositional Resolution
1.Convert all the propositions of F to clause form.
2. Negate P and convert the result to clause form. Add it to the set of clauses obtained in step
1.
3. Repeat until either a contradiction is found or no progress can be made:
a. Select two clauses. Call these the parent clauses.
b.Resolve them together. The resulting clause, called the resolvent, will be the disjunction
of all of the literals of both of the parent clauses with the following exception: If there
are any pairs of literals L and ¬ L such that one of the parent clauses contains L and the
other contains ¬L, then select one such pair and eliminate both L and ¬ L from the
resolvent.
c. If the resolvent is the empty clause, then a contradiction has been found. If it is not, then
add it to the set of clauses available to the procedure.
90.
Unification
In propositionallogic, it is easy to determine that two literals cannot both be true at the
same time.
Simply look for L and ¬L in predicate logic, this matching process is more
complicated since the arguments of the predicates must be considered.
For example, man(John) and ¬man(John) is a contradiction, while man(John) and
¬man(Spot) is not.
Thus, in order to determine contradictions, we need a matching procedure that
compares two literals and discovers whether there exists a set of substitutions that
makes them identical.
There is a straightforward recursive procedure, called the unification algorithm, that
does it.
91.
Algorithm: Unify(L1, L2)
1.If L1 or L2 are both variables or constants, then:
a. If L1 and L2 are identical, then return NIL.
b. Else if L1 is a variable, then if L1 occurs in L2 then return {FAIL}, else return (L2/L1).
c. Else if L2 is a variable, then if L2 occurs in L1 then return {FAIL}, else return (L1/L2).
d. Else return {FAIL}.
2. If the initial predicate symbols in L1 and L2 are not identical, then return {FAIL}.
3. If LI and L2 have a different number of arguments, then return {FAIL}.
4. Set SUBST to NIL. (At the end of this procedure, SUBST will contain all the substitutions used to unify L1
and L2.)
5. For i ← 1 to number of arguments in L1 :
a. Call Unify with the ith
argument of L1 and the ith
argument of L2, putting result in S.
b. If S contains FAIL then return {FAIL}.
c. If S is not equal to NIL then:
i. Apply S to the remainder of both L1 and L2.
ii. SUBST: = APPEND(S, SUBST).
6. Return SUBST.
Natural Deduction
• Whileconverting to clause form we often loose valuable heuristic info.
• Ex. All judges who are not crooked are well educated
• ∀ x: judges(x)^ ¬ crooked(x)educated(x)
• Reduced to ¬ judges(x) / crooked(x) / educated(x) (Not a precise way)
• Leads to Natural deduction
• Arrange the knowledge not by predicated but with the objects associated with them
95.
Procedural versus DeclarativeKnowledge
• Procedural Knowledge
A representation in which the control information that is necessary to use the
knowledge is embedded in the knowledge itself for e.g. computer programs,
directions, and recipes; these indicate specific use or implementation;
The real difference between declarative and procedural views of knowledge lies in
where control information reside.
For example, consider the following
Man (Marcus)
Man (Caesar)
Person (Cleopatra)
∀ x: Man(x)Person(x)
Now, try to answer the question. ∃y:Person(y)
The knowledge base justifies any of the following answers.
• Y=Marcus Y=Caesar Y=Cleopatra
96.
Procedural versus DeclarativeKnowledge
We get more than one value that satisfies the predicate.
If only one value is needed, then the answer to the question will depend on the order
in which the assertions are examined during the search for a response.
If the assertions are declarative then they do not themselves say anything about how
they will be examined. In case of procedural representation, they say how they will
be examined.
97.
Procedural versus DeclarativeKnowledge
• Declarative Knowledge
A statement in which knowledge is specified, but the use to which that knowledge is to
be put is not given.
For example, laws, people's name; these are the facts which can stand alone, not
dependent on other knowledge;
So to use declarative representation, we must have a program that explains what is to be
done to the knowledge and how.
For example, a set of logical assertions can be combined with a resolution theorem
prover to give a complete program for solving problems but in some cases the logical
assertions can be viewed as a program rather than data to a program.
Hence the implication statements define the legitimate reasoning paths and automatic
assertions provide the starting points of those paths.
These paths define the execution paths which is similar to the ‘if then else “in
traditional programming.
So logical assertions can be viewed as a procedural representation of knowledge.
98.
Procedural versus DeclarativeKnowledge
• Man (Marcus)
• Man (Caesar)
• ∀ x: Man(x)Person(x)
• Person (Cleopatra)
• Now the answer will be Marcus, earlier it was Cleopatra
• Can caesar be the answer??
99.
Procedural versus DeclarativeKnowledge
Procedural knowledge Declarative knowledge
High efficiency Higher level of abstraction
Low modifiability Good modifiability and
Good readability
Low perceptive adequacy (better For
knowledge engineers)
Suitable for independent facts
Produces creative, reflective
thought and promoters critical thinking
and independent decision making
Good cognitive matching (better
for domain experts and end-
users) and low computational
efficiency.
100.
• Logic Programming
Logic programming is a programming paradigm in which logical assertions are
viewed as programs.
These are several logic programming systems, PROLOG is one of them.
A PROLOG program consists of several logical assertions where each is a horn
clause i.e. a clause with at most one positive literal.
• Ex : P, P V Q, P Q
The facts are represented on Horn Clause for two reasons.
i. Because of a uniform representation, a simple and efficient interpreter can be
written.
ii.The logic of Horn Clause is decidable.
The first two differences are from the fact that PROLOG programs are actually sets
of Horn clause that have been transformed as follows:-
101.
1. If theHorn Clause contains no negative literal then leave it as it is.
2. Otherwise rewrite the Horn clauses as an implication, combining all of the negative
literals in to the antecedent of the implications and the single positive literal into the
consequent.
This procedure causes a clause which originally consisted of a disjunction of literals
(one of them was positive) to be transformed into a single implication whose
antecedent is a conjunction universally quantified.
But when we apply this transformation, any variables that occurred in negative
literals and so now occur in the antecedent become existentially quantified, while
the variables in the consequent are still universally quantified.
For example the PROLOG clause P(x): - Q(x, y) is equal to logical expression
∀ x: ∃ y: Q (x, y) P(x).
102.
Procedural versus DeclarativeKnowledge
The difference between the logic and PROLOG representation is that the PROLOG
interpretation has a fixed control strategy and so the assertions in the PROLOG
program define a particular search path to answer to any question.
But, the logical assertions define only the set of answers but not about how to
choose among those answers if there is more than one.
103.
Assignment
SNO. Question CO
1Explain the terms State, State Space, Goal State, Production
System and Control Strategy
[1]
2 Give an Example of a problem for which BFS would work
better than DFS
[1]
3 Show how means-end analysis can be used to solve the
problem of getting from one place to another
[1]
4 Solve 8 puzzle problem using Heuristic values [1]












![Algorithm
1. Evaluate the initial state. If it is also a goal state, then return it and quit. Otherwise, continue with the
initial state as the current state.
2. Initialize BEST-SO-FAR to the current state.
3. Initialize T according to the annealing schedule.
4. Loop until a solution is found or until there are no new operators left to be applied in the current state.
a. Select an operator that has not yet been applied to the current state and apply it to produce a new state.
b. Evaluate the new state. Compute
• 𝛿𝐸 = (value of current) – (value of new state)
o If the new state is a goal state, then return it and quit.
o If it is not a goal state but is better than the current state, then make it the current state. Also set
BEST-SO-FAR to this new state.
o If it is not better than the current state, then make it the current state with probability 𝑃′
as defined
above. This step is usually implemented by generating a random number between [0, 1]. If the
number is less than
• 𝑃′
, then the move is accepted otherwise do nothing.
c. Revise T as necessary according to the annealing schedule.](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/85/PPT-FOPL-first-order-predicate-logic-pptx-14-320.jpg)


![A
C
D
F
B
E
H
G
25
7
18
10
8
11
9
10
20
15
14
A->G 40
B->G 32
C->G 25
D->G 35
E->G 19
F->G 17
G->G 0
H->G 10
OPEN CLOSE
[A] []
[CBD] [A]
[FEBD] [AC]
[GEBD] [ACF]
[EBD] [ACFG]
A->C->F->G
14+10+20=44
MIGHT NOT BE THE MIN. COST
TC/SC=O(b^d)
Branching factor
depth](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/85/PPT-FOPL-first-order-predicate-logic-pptx-17-320.jpg)
























![Propositional Calculus
• System that deals with method used for manipulation of symbol acc. to some rules
• Proposition
A proposition is a statement, or a simple declarative
sentence.
For example, “the book is expensive” is a proposition.
A proposition can be either true or false.
• Propositional logic
Logical constants: true, false
Propositional symbols: P, Q, S,... (atomic sentences)
Propositions are combined by connectives:
∧ and [conjunction]
/ or [disjunction]
implies [implication]
¬ not [negation]
∀ For all
∃ There exists](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/85/PPT-FOPL-first-order-predicate-logic-pptx-50-320.jpg)






































![• P(x,F(y)) (1)
• P(a,F(g(z)) (2)
Substituting
• xa
• yg(z)
Eq 1 becomes
• P(a,F(g(z)) [a/x, g(z)/y]substitution set](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/85/PPT-FOPL-first-order-predicate-logic-pptx-92-320.jpg)
![• Q(a, g(x,a), f(y))
• Q(a, g(f(b),a), x)
• [f(b)/x, b/y]](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/85/PPT-FOPL-first-order-predicate-logic-pptx-93-320.jpg)









![Assignment
SNO. Question CO
1 Explain the terms State, State Space, Goal State, Production
System and Control Strategy
[1]
2 Give an Example of a problem for which BFS would work
better than DFS
[1]
3 Show how means-end analysis can be used to solve the
problem of getting from one place to another
[1]
4 Solve 8 puzzle problem using Heuristic values [1]](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/85/PPT-FOPL-first-order-predicate-logic-pptx-103-320.jpg)
















![Algorithm
1. Evaluate the initial state. If it is also a goal state, then return it and quit. Otherwise, continue with the
initial state as the current state.
2. Initialize BEST-SO-FAR to the current state.
3. Initialize T according to the annealing schedule.
4. Loop until a solution is found or until there are no new operators left to be applied in the current state.
a. Select an operator that has not yet been applied to the current state and apply it to produce a new state.
b. Evaluate the new state. Compute
• 𝛿𝐸 = (value of current) – (value of new state)
o If the new state is a goal state, then return it and quit.
o If it is not a goal state but is better than the current state, then make it the current state. Also set
BEST-SO-FAR to this new state.
o If it is not better than the current state, then make it the current state with probability 𝑃′
as defined
above. This step is usually implemented by generating a random number between [0, 1]. If the
number is less than
• 𝑃′
, then the move is accepted otherwise do nothing.
c. Revise T as necessary according to the annealing schedule.](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/75/PPT-FOPL-first-order-predicate-logic-pptx-14-2048.jpg)


![A
C
D
F
B
E
H
G
25
7
18
10
8
11
9
10
20
15
14
A->G 40
B->G 32
C->G 25
D->G 35
E->G 19
F->G 17
G->G 0
H->G 10
OPEN CLOSE
[A] []
[CBD] [A]
[FEBD] [AC]
[GEBD] [ACF]
[EBD] [ACFG]
A->C->F->G
14+10+20=44
MIGHT NOT BE THE MIN. COST
TC/SC=O(b^d)
Branching factor
depth](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/75/PPT-FOPL-first-order-predicate-logic-pptx-17-2048.jpg)



























![Propositional Calculus
• System that deals with method used for manipulation of symbol acc. to some rules
• Proposition
A proposition is a statement, or a simple declarative
sentence.
For example, “the book is expensive” is a proposition.
A proposition can be either true or false.
• Propositional logic
Logical constants: true, false
Propositional symbols: P, Q, S,... (atomic sentences)
Propositions are combined by connectives:
∧ and [conjunction]
/ or [disjunction]
implies [implication]
¬ not [negation]
∀ For all
∃ There exists](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/75/PPT-FOPL-first-order-predicate-logic-pptx-50-2048.jpg)







































![• P(x,F(y)) (1)
• P(a,F(g(z)) (2)
Substituting
• xa
• yg(z)
Eq 1 becomes
• P(a,F(g(z)) [a/x, g(z)/y]substitution set](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/75/PPT-FOPL-first-order-predicate-logic-pptx-92-2048.jpg)
![• Q(a, g(x,a), f(y))
• Q(a, g(f(b),a), x)
• [f(b)/x, b/y]](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/75/PPT-FOPL-first-order-predicate-logic-pptx-93-2048.jpg)









![Assignment
SNO. Question CO
1 Explain the terms State, State Space, Goal State, Production
System and Control Strategy
[1]
2 Give an Example of a problem for which BFS would work
better than DFS
[1]
3 Show how means-end analysis can be used to solve the
problem of getting from one place to another
[1]
4 Solve 8 puzzle problem using Heuristic values [1]](https://image.slidesharecdn.com/pptfopl-250511060729-d593750c/75/PPT-FOPL-first-order-predicate-logic-pptx-103-2048.jpg)




















































