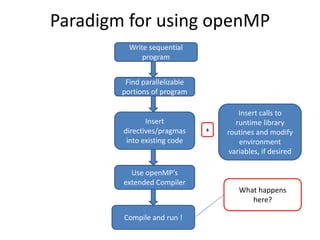
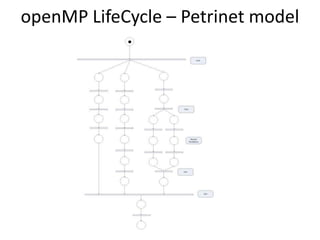
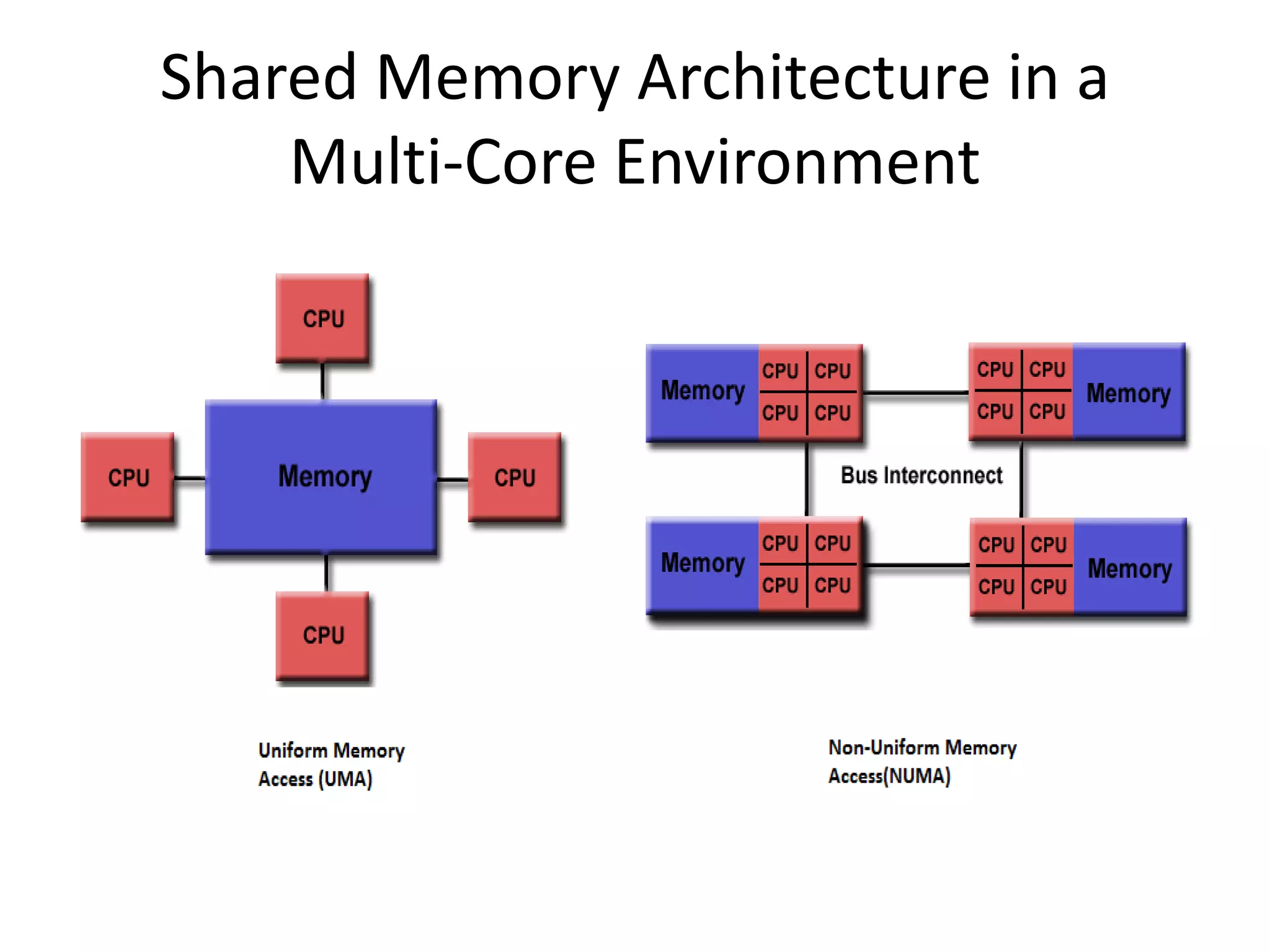
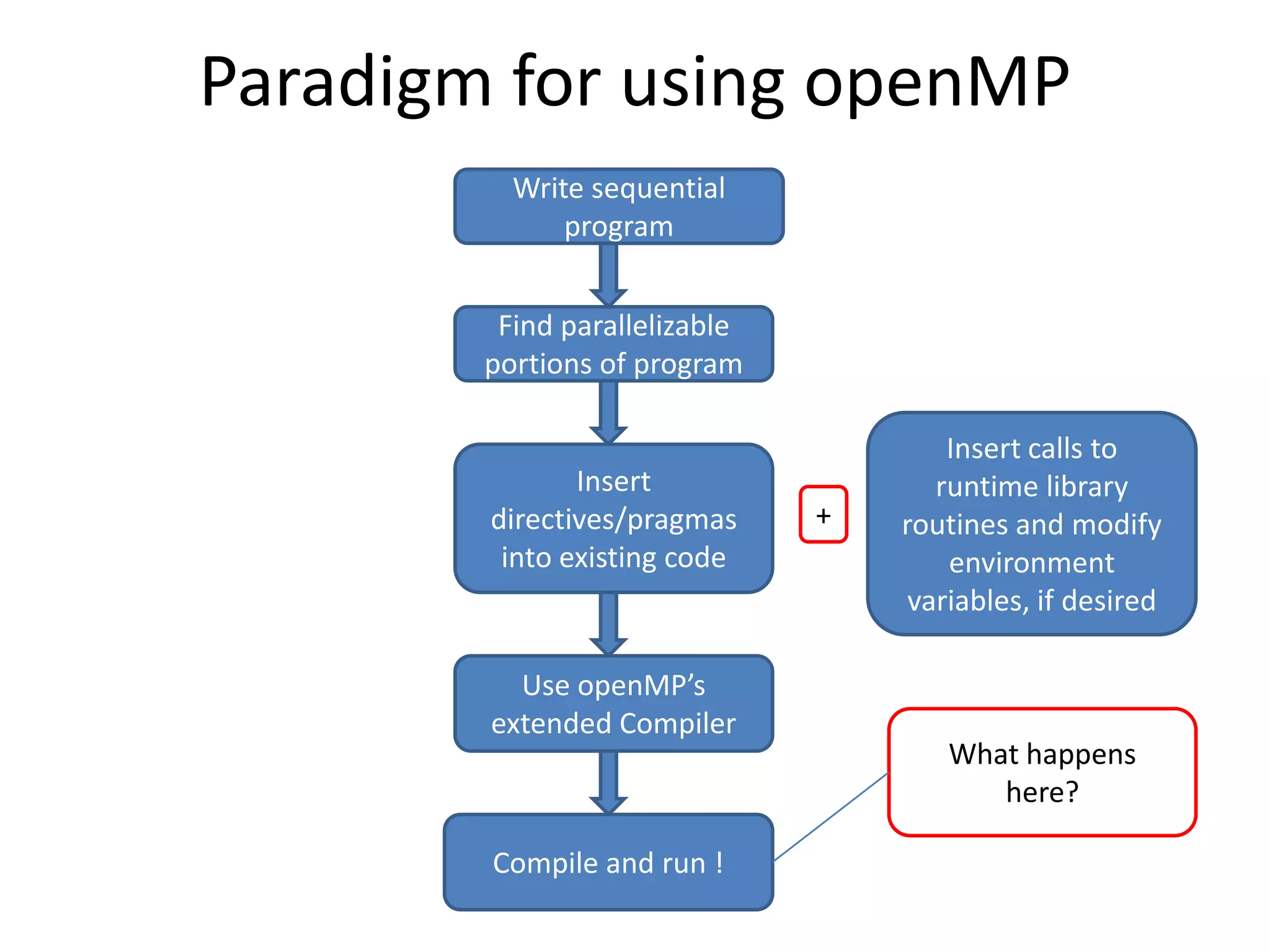
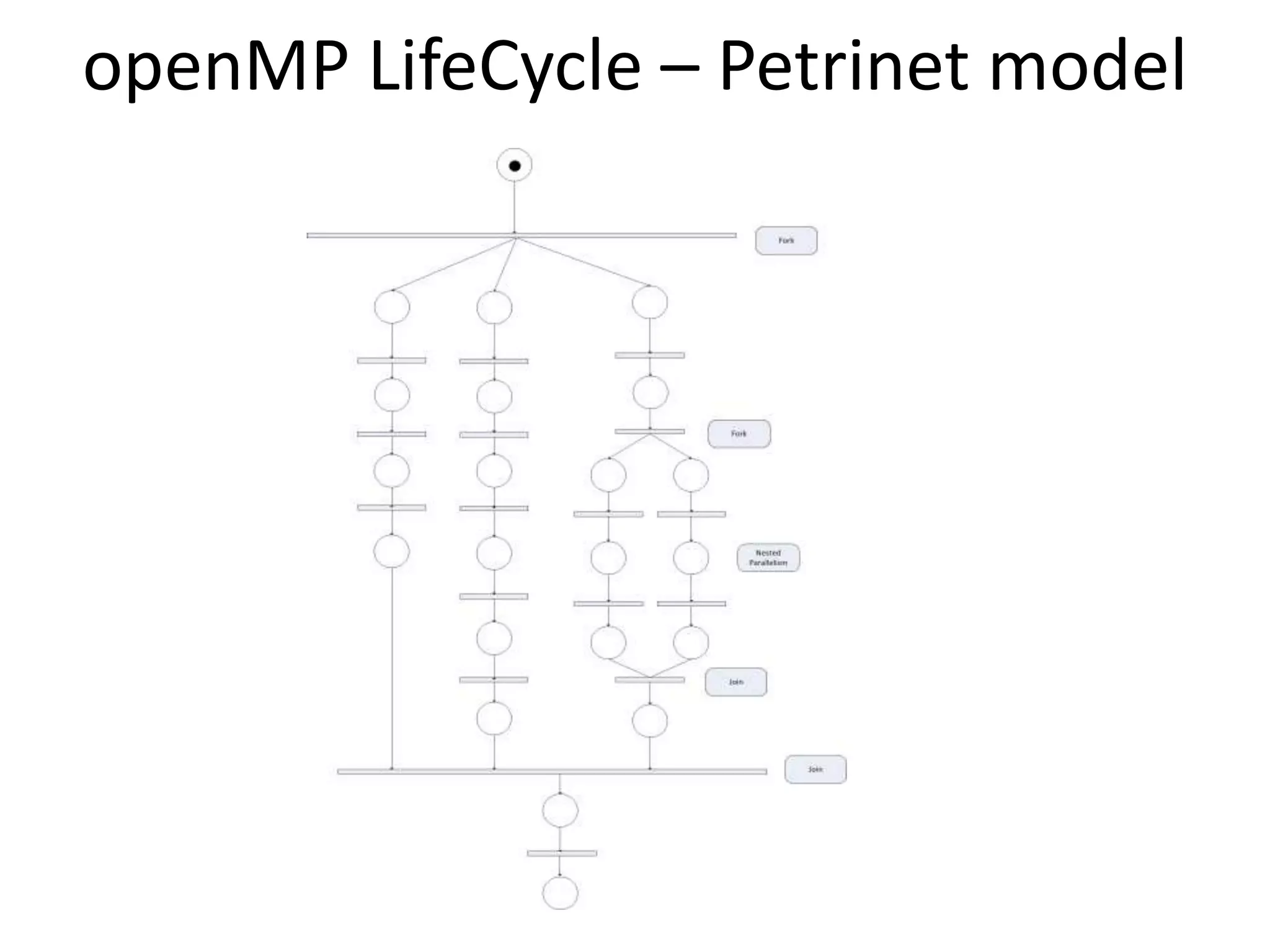
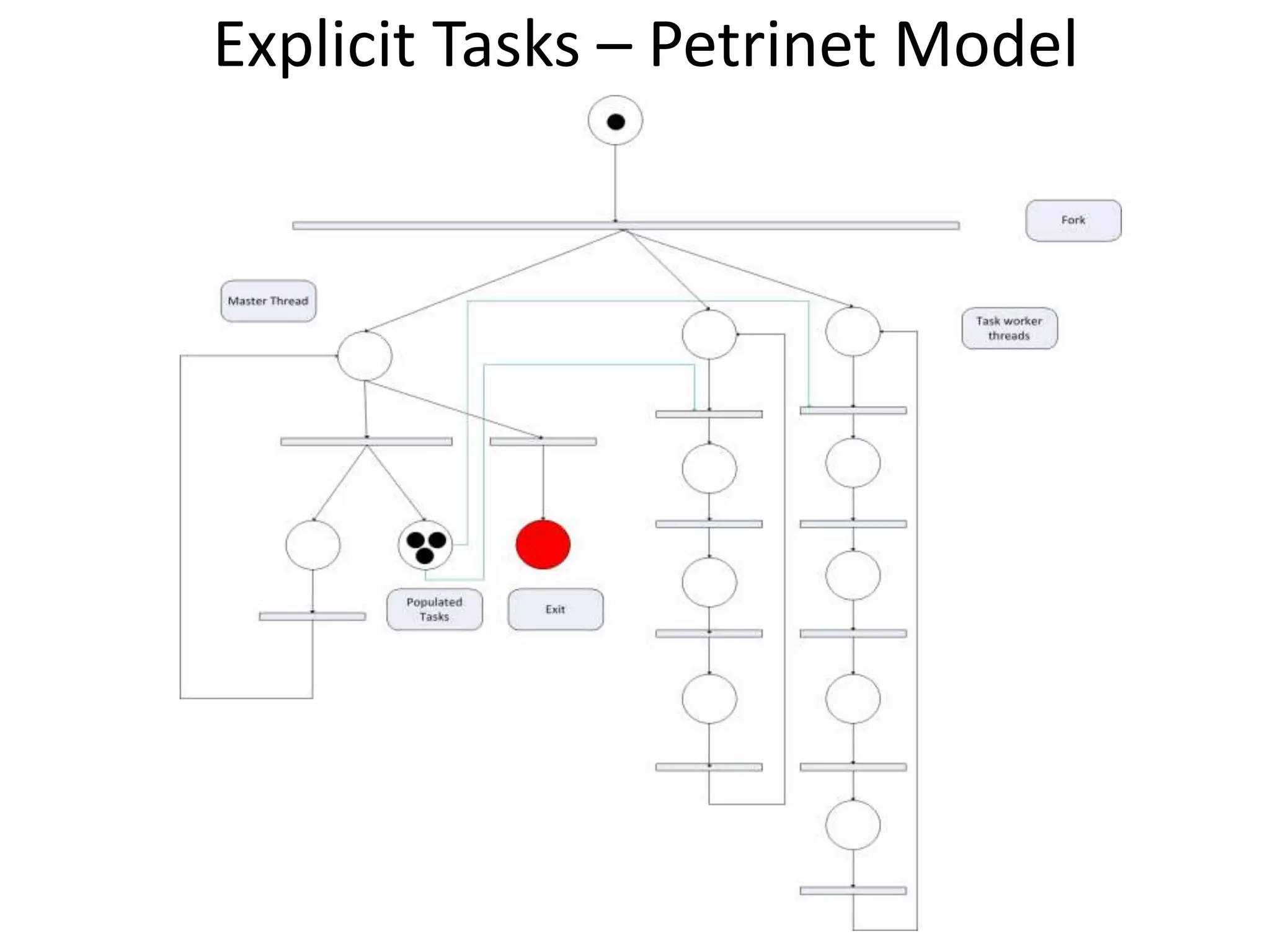
The document provides an introduction to OpenMP, an open standard for shared memory multiprocessing aimed at leveraging multicore hardware. It details the primary components of the OpenMP API, including compiler directives, runtime library routines, and environment variables, along with their functions and usage in parallel programming. Key concepts such as parallel regions, synchronization, and scheduling of parallel loops are also discussed to facilitate effective programming practices.


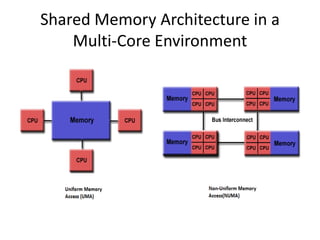








![Compiler directives – The Multi Core
Magic Spells !
• Types of workshare directives
for Countable iteration[static]
sections One or more sequential
sections of code, executed
by a single thread
single Serializes a section of code](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-14-320.jpg)



![Matrix Multiplication using loop
directive
#pragma omp parallel private(i,j,k)
{
#pragma omp for
for(i=0;i<N;i++)
for(k=0;k<K;k++)
for(j=0;j<M;j++)
C[i][j]=C[i][j]+A[i][k]*B[k][j];
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-18-320.jpg)




![Matrix Multiplication using loop
directive – with a schedule
#pragma omp parallel private(i,j,k)
{
#pragma omp for schedule(static)
for(i=0;i<N;i++)
for(k=0;k<K;k++)
for(j=0;j<M;j++)
C[i][j]=C[i][j]+A[i][k]*B[k][j];
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-23-320.jpg)

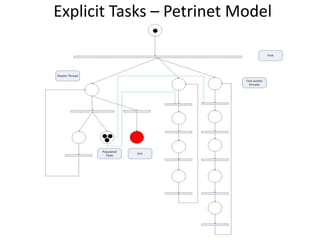
![Parallelizing when the no.of Iterations
is unknown[dynamic] !
• openMP has a directive called task](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-25-320.jpg)



![Without using reduction
#pragma omp parallel shared(array,sum)
firstprivate(local_sum)
{
#pragma omp for private(i,j)
for(i=0;i<max_i;i++)
{
for(j=0;j<max_j;++j)
local_sum+=array[i][j];
}
}
#pragma omp critical
sum+=local_sum;
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-30-320.jpg)
![Using Reductions in openMP
sum=0;
#pragma omp parallel shared(array)
{
#pragma omp for reduction(+:sum) private(i,j)
for(i=0;i<max_i;i++)
{
for(j=0;j<max_j;++j)
sum+=array[i][j];
}
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/85/Presentation-on-Shared-Memory-Parallel-Programming-31-320.jpg)













![Compiler directives – The Multi Core
Magic Spells !
• Types of workshare directives
for Countable iteration[static]
sections One or more sequential
sections of code, executed
by a single thread
single Serializes a section of code](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/75/Presentation-on-Shared-Memory-Parallel-Programming-14-2048.jpg)



![Matrix Multiplication using loop
directive
#pragma omp parallel private(i,j,k)
{
#pragma omp for
for(i=0;i<N;i++)
for(k=0;k<K;k++)
for(j=0;j<M;j++)
C[i][j]=C[i][j]+A[i][k]*B[k][j];
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/75/Presentation-on-Shared-Memory-Parallel-Programming-18-2048.jpg)




![Matrix Multiplication using loop
directive – with a schedule
#pragma omp parallel private(i,j,k)
{
#pragma omp for schedule(static)
for(i=0;i<N;i++)
for(k=0;k<K;k++)
for(j=0;j<M;j++)
C[i][j]=C[i][j]+A[i][k]*B[k][j];
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/75/Presentation-on-Shared-Memory-Parallel-Programming-23-2048.jpg)

![Parallelizing when the no.of Iterations
is unknown[dynamic] !
• openMP has a directive called task](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/75/Presentation-on-Shared-Memory-Parallel-Programming-25-2048.jpg)



![Without using reduction
#pragma omp parallel shared(array,sum)
firstprivate(local_sum)
{
#pragma omp for private(i,j)
for(i=0;i<max_i;i++)
{
for(j=0;j<max_j;++j)
local_sum+=array[i][j];
}
}
#pragma omp critical
sum+=local_sum;
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/75/Presentation-on-Shared-Memory-Parallel-Programming-30-2048.jpg)
![Using Reductions in openMP
sum=0;
#pragma omp parallel shared(array)
{
#pragma omp for reduction(+:sum) private(i,j)
for(i=0;i<max_i;i++)
{
for(j=0;j<max_j;++j)
sum+=array[i][j];
}
}](https://image.slidesharecdn.com/openmppresentationfinal-130214173826-phpapp02/75/Presentation-on-Shared-Memory-Parallel-Programming-31-2048.jpg)




















































































