Download as PDF, PPTX










![urllib & BeautifulSoup
>>> import urllib, BeautifulSoup
>>> fd = urllib.urlopen('http://mobile.example.org/
foo.html')
>>> soup = BeautifulSoup.BeautifulSoup(fd.read())
>>> print soup.prettify()
...
<table>
<tr><td>23</td></tr>
<tr><td>24</td></tr>
<tr><td>25</td></tr>
<tr><td>22</td></tr>
<tr><td>23</td></tr>
</table>
...
>>> values = [elem.text for elem in soup.find('table').findChildren('td')]
>>>> values
[u'23', u'24', u'25', u'22', u'23']
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/85/Python-for-Data-Science-12-320.jpg)








![NumPy + SciPy +
Matplotlib + IPython
• Provides Matlab ”-ish” environment
• ipython provides extended interactive
interpreter (tab completion, magic
functions for object querying, debugging, ...)
ipython --pylab
In [1]: x = linspace(1, 10, 42)
In [2]: y = randn(42)
In [3]: plot(x, y, 'r--.', markersize=15)
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/85/Python-for-Data-Science-22-320.jpg)


![NetworkX
>>> import networkx
>>> g = networkx.Graph()
>>> data = {'Turku': [('Helsinki', 165), ('Tampere', 157)],
'Helsinki': [('Kotka', 133), ('Kajaani', 557)],
'Tampere': [('Jyväskylä', 149)],
'Jyväskylä': [('Kajaani', 307)] }
>>> for k,v in data.items():
... for dest, dist in v:
... g.add_edge(k, dest, weight=dist)
>>> networkx.astar_path_length(g, 'Turku', 'Kajaani')
613
>>> networkx.astar_path(g, 'Kajaani', 'Turku')
['Kajaani', 'Jyväskylä', 'Tampere', 'Turku']
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/85/Python-for-Data-Science-25-320.jpg)

![NetworkX
>>> import networkx
>>> g = networkx.Graph()
>>> data = {'Turku': [('Helsinki', 165), ('Tampere', 157)],
'Helsinki': [('Kotka', 133), ('Kajaani', 557)],
'Tampere': [('Jyväskylä', 149)],
'Jyväskylä': [('Kajaani', 307)] }
>>> for k,v in data.items():
... for dest, dist in v:
... g.add_edge(k, dest, weight=dist)
>>> networkx.astar_path_length(g, 'Turku', 'Kajaani')
613
>>> networkx.astar_path(g, 'Kajaani', 'Turku')
['Kajaani', 'Jyväskylä', 'Tampere', 'Turku']
>>> networkx.draw(g)
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/85/Python-for-Data-Science-27-320.jpg)







![from SPARQLWrapper import SPARQLWrapper, JSON
QUERY = """
Prefix lgd:<http://linkedgeodata.org/>
Prefix lgdo:<http://linkedgeodata.org/ontology/>
Prefix rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
Select distinct ?label ?g From <http://linkedgeodata.org> {
?s rdf:type <http://linkedgeodata.org/ontology/Library> .
?s <http://www.w3.org/2000/01/rdf-schema#label> ?label.
?s geo:geometry ?g .
Filter(bif:st_intersects (?g, bif:st_point (24.9375, 60.170833), 1)) .
}"""
sparql = SPARQLWrapper("http://linkedgeodata.org/sparql")
sparql.setQuery(QUERY)
sparql.setReturnFormat(JSON)
results = sparql.query().convert()['results']['bindings']
for result in results:
print result['label']['value'].encode('utf-8'), result['g']['value']
German library POINT(24.9495 60.1657)
Query for libraries in Metsätalo POINT(24.9497 60.1729)
Opiskelijakirjasto POINT(24.9489 60.1715)
Helsinki located within Topelia POINT(24.9493 60.1713)
1 kilometer radius from Eduskunnan kirjasto POINT(24.9316 60.1725)
the city centre Rikhardinkadun kirjasto POINT(24.9467 60.1662)
Helsinki 10 POINT(24.9386 60.1713)
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/85/Python-for-Data-Science-37-320.jpg)












![urllib & BeautifulSoup
>>> import urllib, BeautifulSoup
>>> fd = urllib.urlopen('http://mobile.example.org/
foo.html')
>>> soup = BeautifulSoup.BeautifulSoup(fd.read())
>>> print soup.prettify()
...
<table>
<tr><td>23</td></tr>
<tr><td>24</td></tr>
<tr><td>25</td></tr>
<tr><td>22</td></tr>
<tr><td>23</td></tr>
</table>
...
>>> values = [elem.text for elem in soup.find('table').findChildren('td')]
>>>> values
[u'23', u'24', u'25', u'22', u'23']
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/75/Python-for-Data-Science-12-2048.jpg)








![NumPy + SciPy +
Matplotlib + IPython
• Provides Matlab ”-ish” environment
• ipython provides extended interactive
interpreter (tab completion, magic
functions for object querying, debugging, ...)
ipython --pylab
In [1]: x = linspace(1, 10, 42)
In [2]: y = randn(42)
In [3]: plot(x, y, 'r--.', markersize=15)
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/75/Python-for-Data-Science-22-2048.jpg)


![NetworkX
>>> import networkx
>>> g = networkx.Graph()
>>> data = {'Turku': [('Helsinki', 165), ('Tampere', 157)],
'Helsinki': [('Kotka', 133), ('Kajaani', 557)],
'Tampere': [('Jyväskylä', 149)],
'Jyväskylä': [('Kajaani', 307)] }
>>> for k,v in data.items():
... for dest, dist in v:
... g.add_edge(k, dest, weight=dist)
>>> networkx.astar_path_length(g, 'Turku', 'Kajaani')
613
>>> networkx.astar_path(g, 'Kajaani', 'Turku')
['Kajaani', 'Jyväskylä', 'Tampere', 'Turku']
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/75/Python-for-Data-Science-25-2048.jpg)

![NetworkX
>>> import networkx
>>> g = networkx.Graph()
>>> data = {'Turku': [('Helsinki', 165), ('Tampere', 157)],
'Helsinki': [('Kotka', 133), ('Kajaani', 557)],
'Tampere': [('Jyväskylä', 149)],
'Jyväskylä': [('Kajaani', 307)] }
>>> for k,v in data.items():
... for dest, dist in v:
... g.add_edge(k, dest, weight=dist)
>>> networkx.astar_path_length(g, 'Turku', 'Kajaani')
613
>>> networkx.astar_path(g, 'Kajaani', 'Turku')
['Kajaani', 'Jyväskylä', 'Tampere', 'Turku']
>>> networkx.draw(g)
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/75/Python-for-Data-Science-27-2048.jpg)







![from SPARQLWrapper import SPARQLWrapper, JSON
QUERY = """
Prefix lgd:<http://linkedgeodata.org/>
Prefix lgdo:<http://linkedgeodata.org/ontology/>
Prefix rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
Select distinct ?label ?g From <http://linkedgeodata.org> {
?s rdf:type <http://linkedgeodata.org/ontology/Library> .
?s <http://www.w3.org/2000/01/rdf-schema#label> ?label.
?s geo:geometry ?g .
Filter(bif:st_intersects (?g, bif:st_point (24.9375, 60.170833), 1)) .
}"""
sparql = SPARQLWrapper("http://linkedgeodata.org/sparql")
sparql.setQuery(QUERY)
sparql.setReturnFormat(JSON)
results = sparql.query().convert()['results']['bindings']
for result in results:
print result['label']['value'].encode('utf-8'), result['g']['value']
German library POINT(24.9495 60.1657)
Query for libraries in Metsätalo POINT(24.9497 60.1729)
Opiskelijakirjasto POINT(24.9489 60.1715)
Helsinki located within Topelia POINT(24.9493 60.1713)
1 kilometer radius from Eduskunnan kirjasto POINT(24.9316 60.1725)
the city centre Rikhardinkadun kirjasto POINT(24.9467 60.1662)
Helsinki 10 POINT(24.9386 60.1713)
Wednesday, October 19, 11](https://image.slidesharecdn.com/pythonfordatascience-111019072221-phpapp01/75/Python-for-Data-Science-37-2048.jpg)



This document presents a comprehensive overview of using Python for data science, highlighting tools and techniques for data harvesting, cleansing, analysis, and visualization. It emphasizes the importance of ethical considerations when dealing with data and discusses various Python libraries suitable for different tasks, such as Scrapy, Numpy, and NetworkX. The latter part focuses on data publishing and sharing, advocating for the open data movement and providing examples of data formats and sources.
Introduction to Data Science, its components: computer science, mathematics/statistics, and visualization. Covers the scope of the talk and the outline.
Discusses data harvesting techniques including sources of data, web APIs, crawling, web scraping, and relevant libraries like urllib and BeautifulSoup.
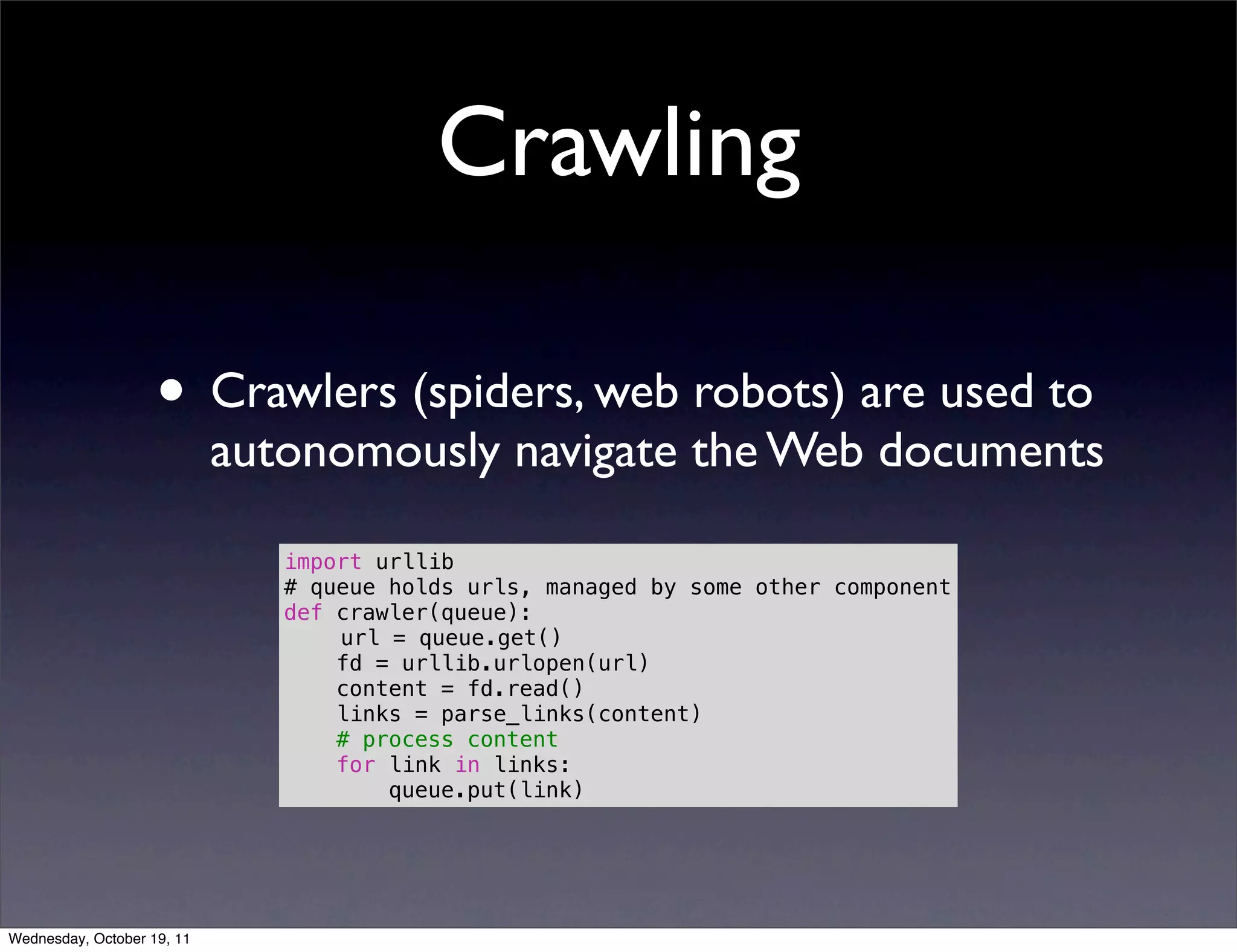
Covers the use of crawlers to navigate web documents, tools for scraping like BeautifulSoup, Scrapy, and ethics in data collection.
Describes data cleansing, preprocessing techniques, detection of noise and anomalies, and preparing data for structured analysis.
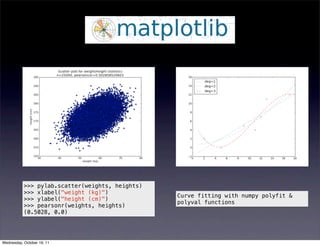
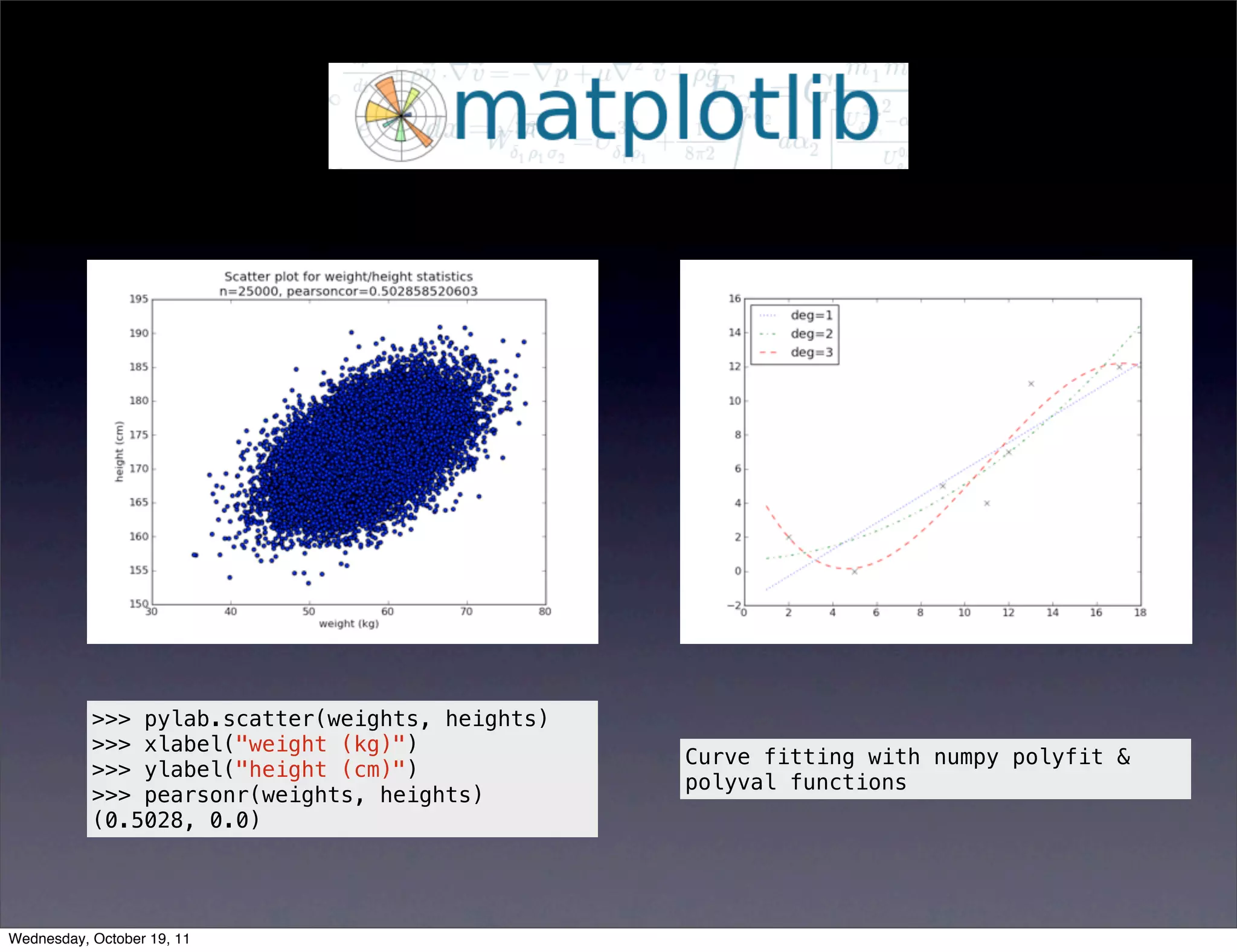
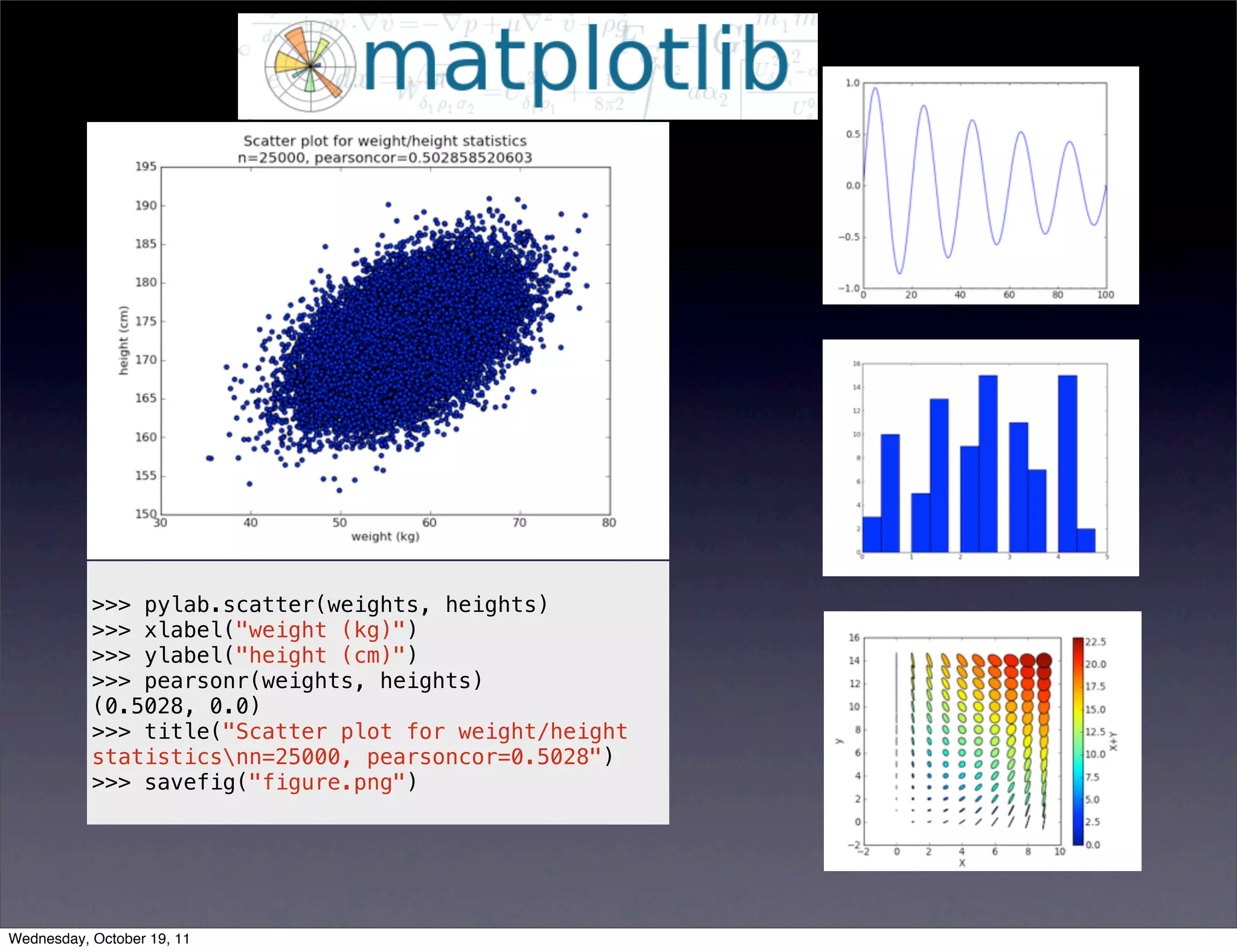
Discusses various analysis methods, basic operations with NumPy and SciPy, analyzing networks with NetworkX, and visualizing data.Focuses on visualizing data with tools like Matplotlib and techniques for creating scatter and 3D plots.
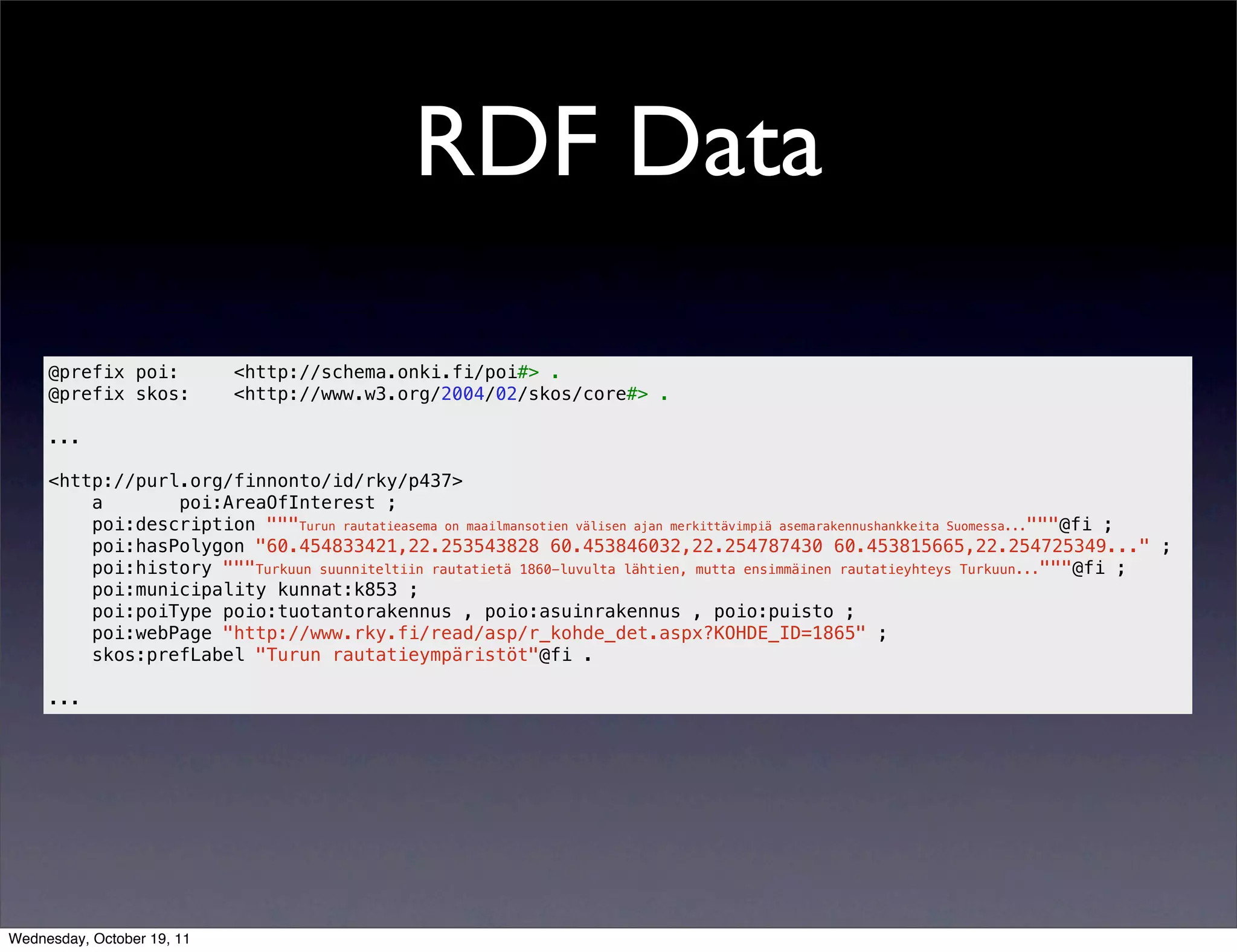
Discusses the importance of open data, sharing formats like JSON and XML, RDF standards, and querying data sources with SPARQL.



































































