Downloaded 60 times














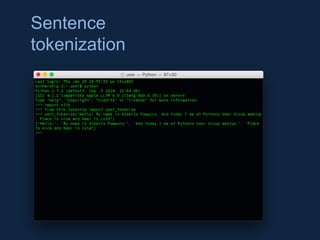
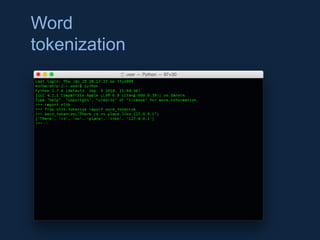
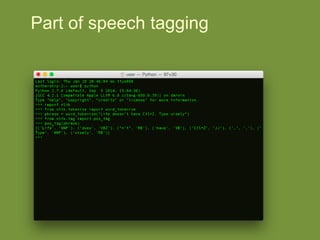

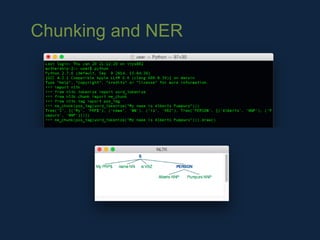

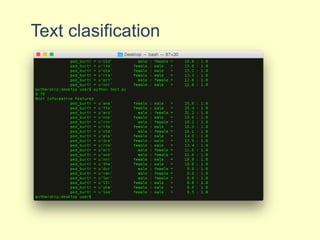
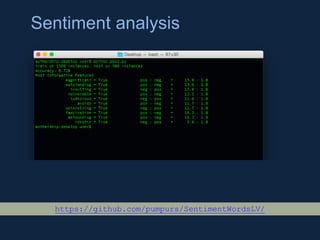

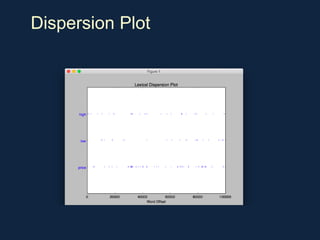

















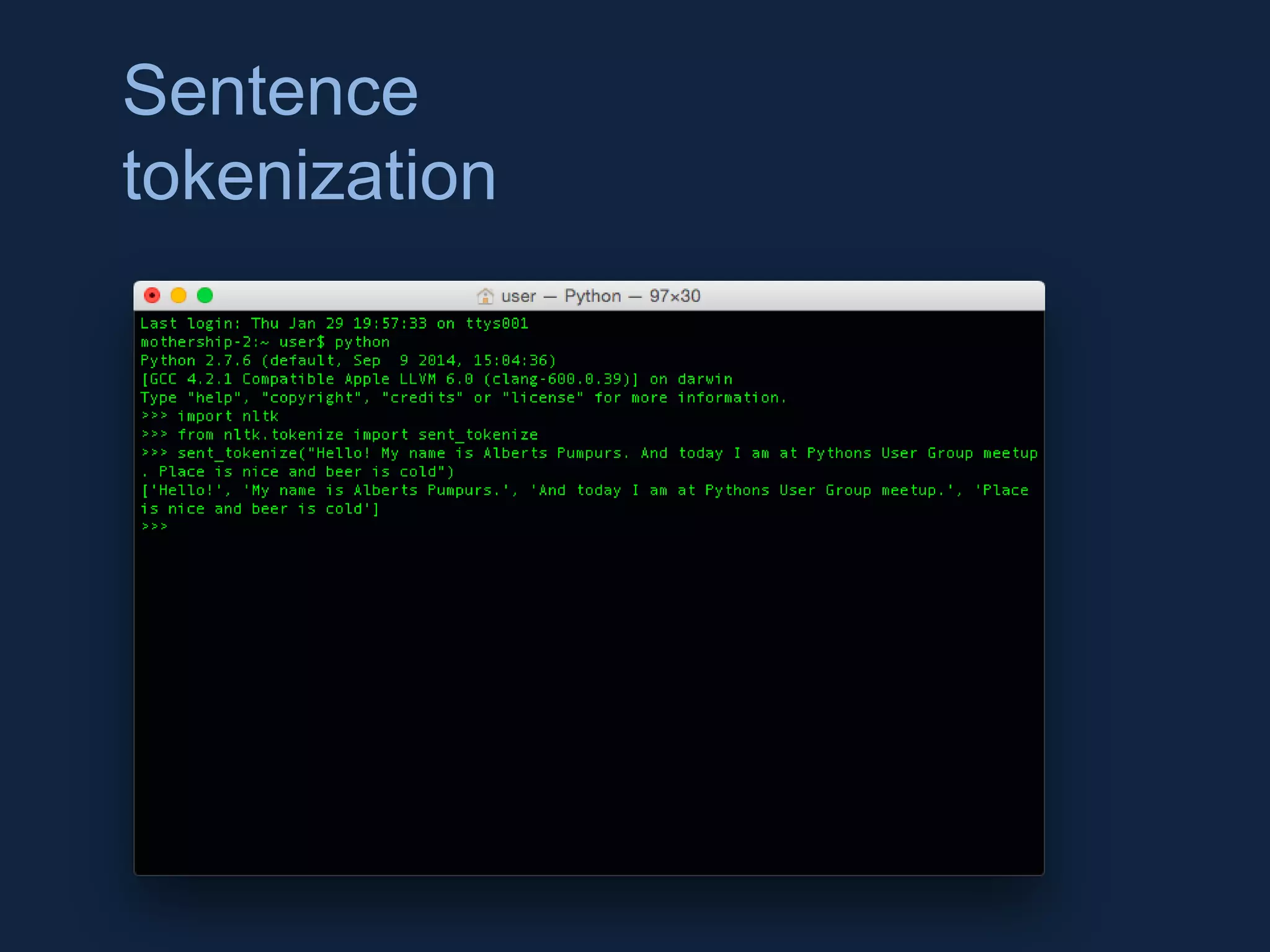
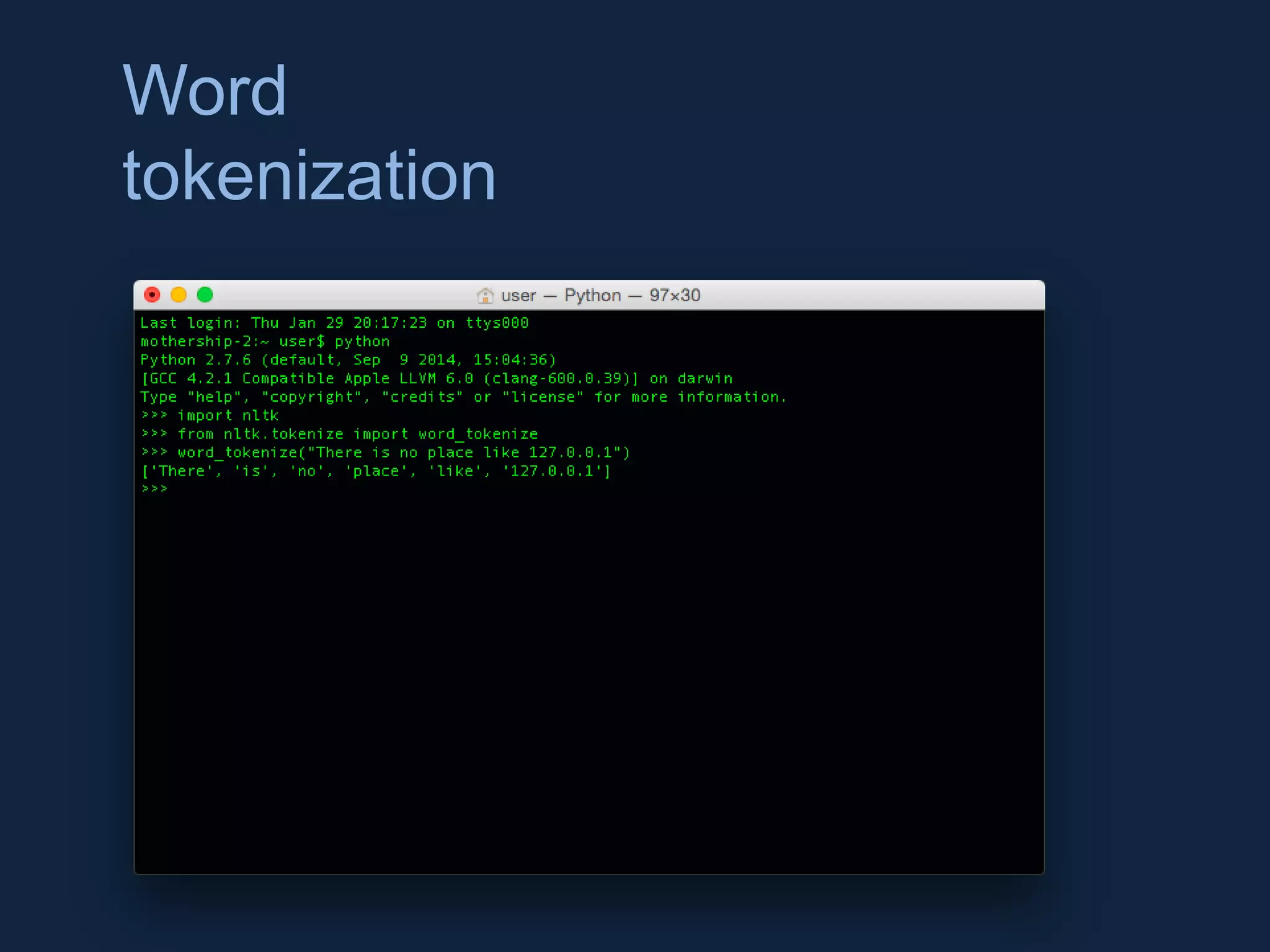
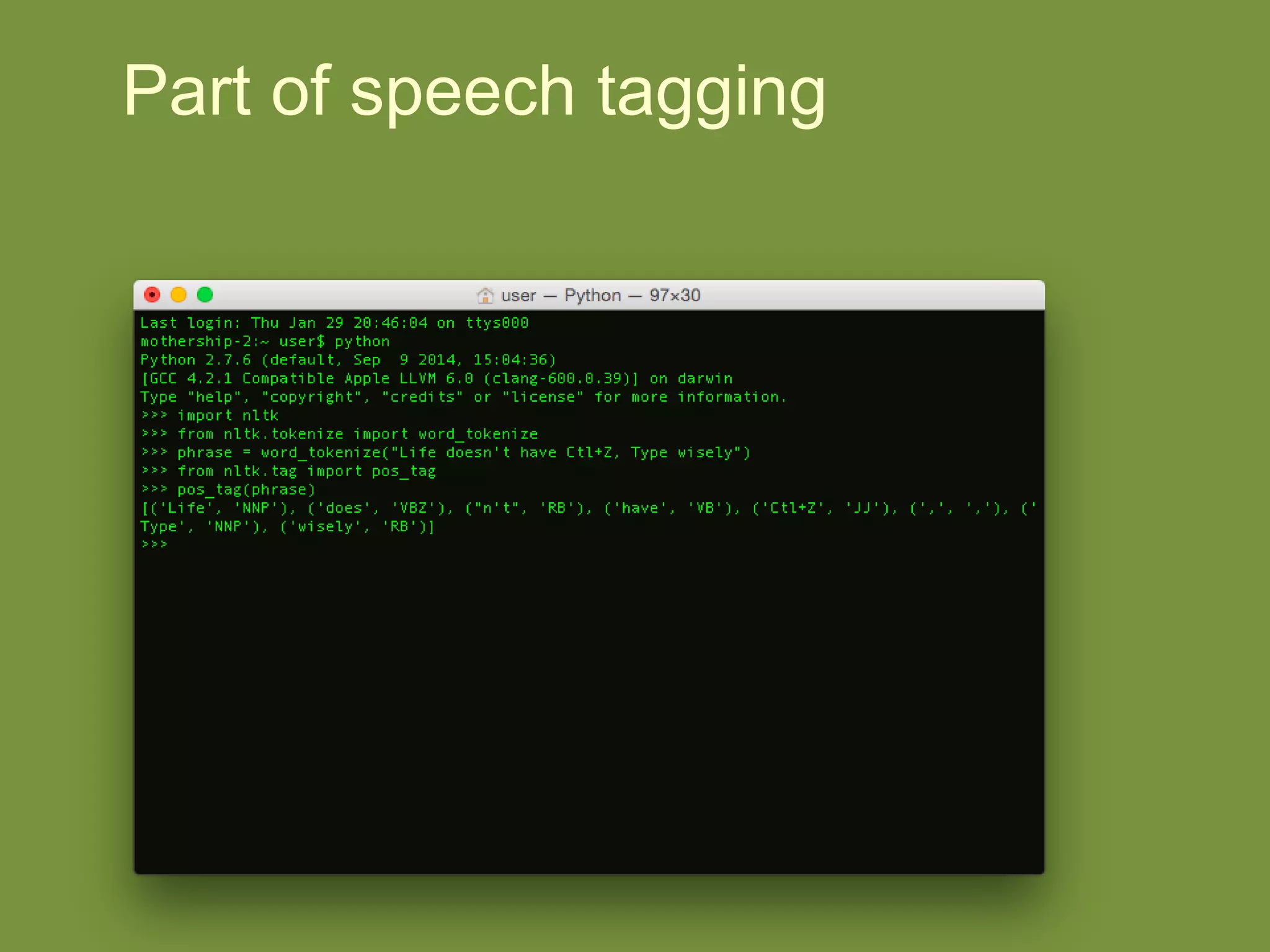

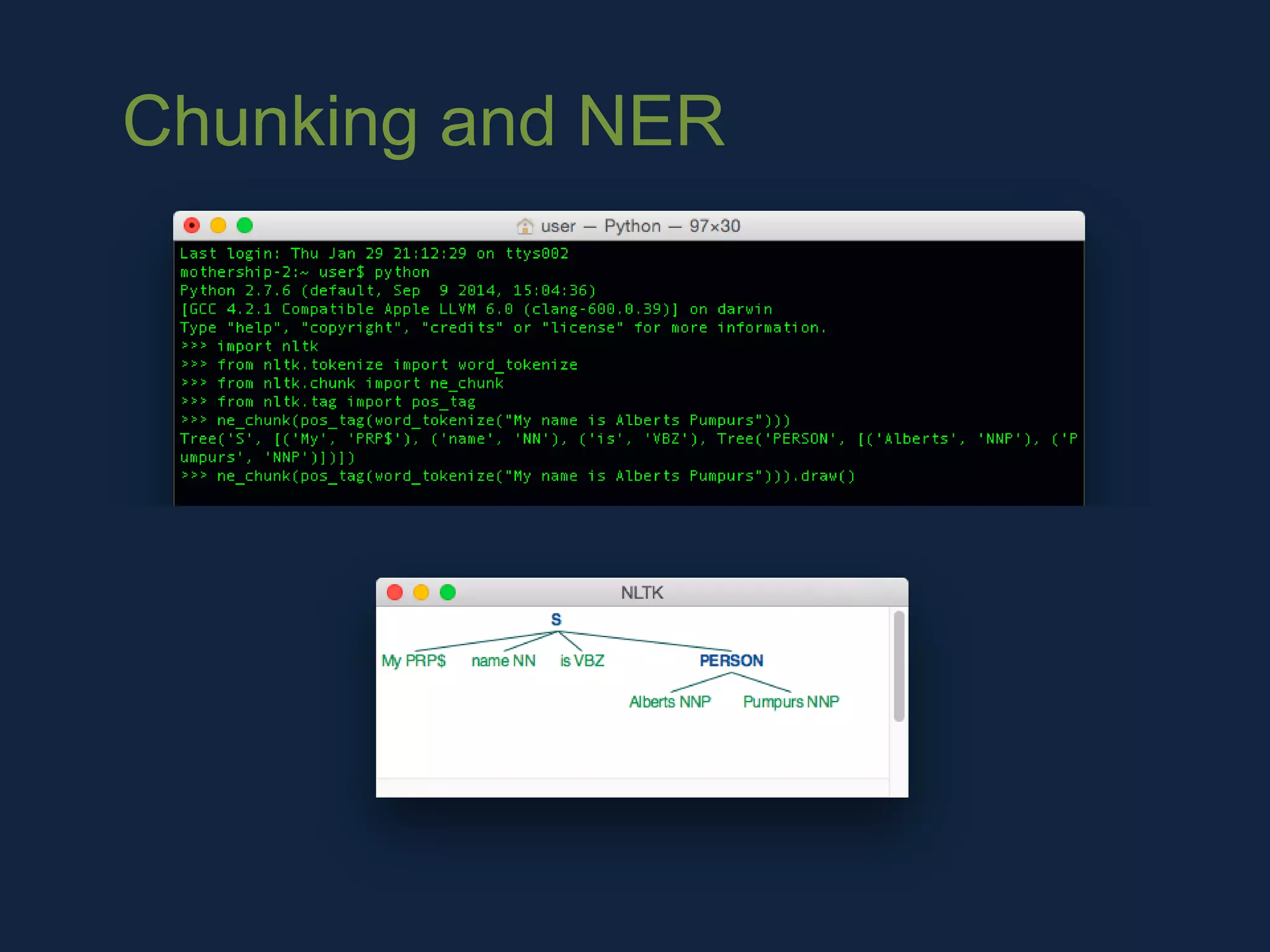

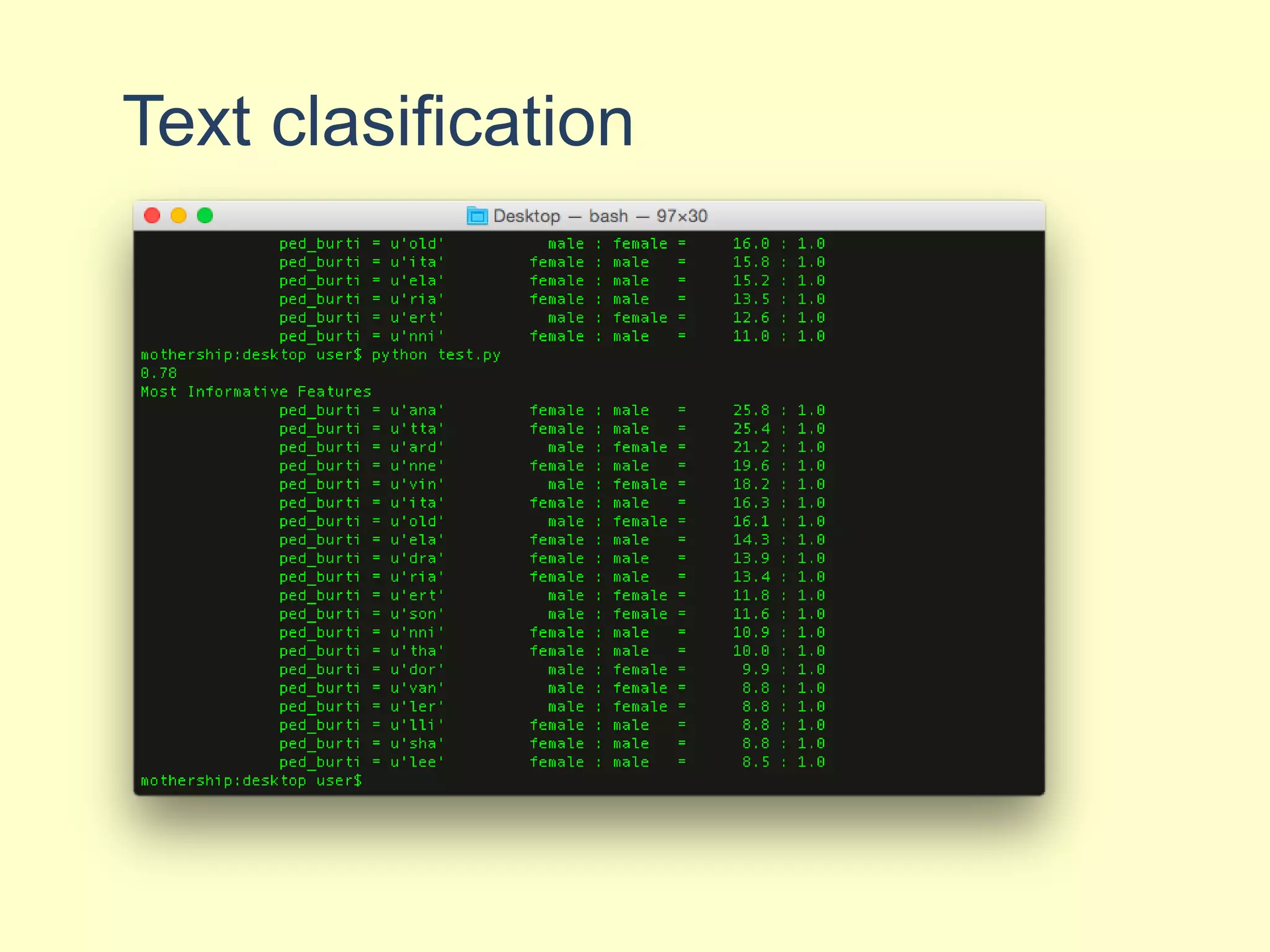
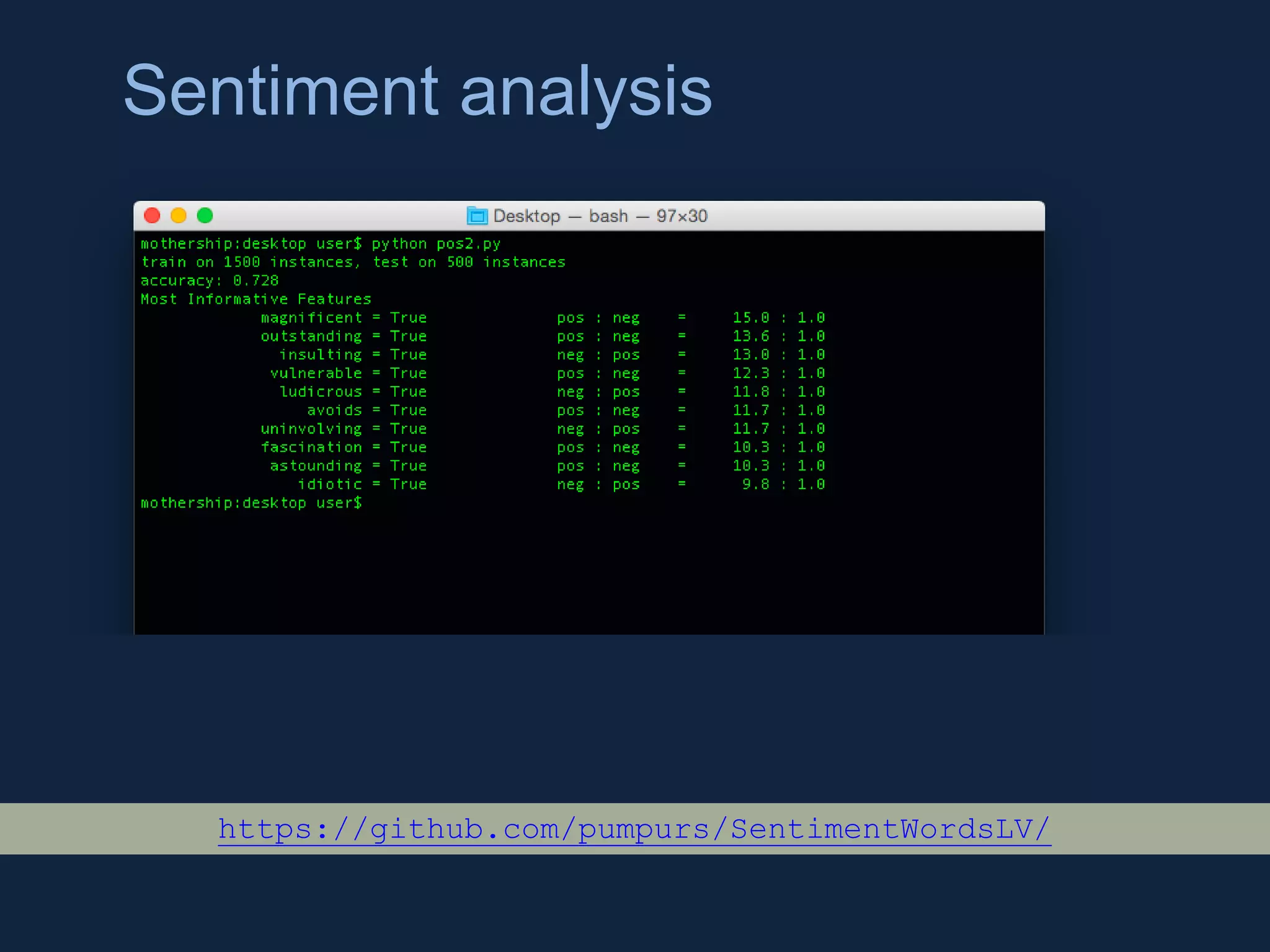
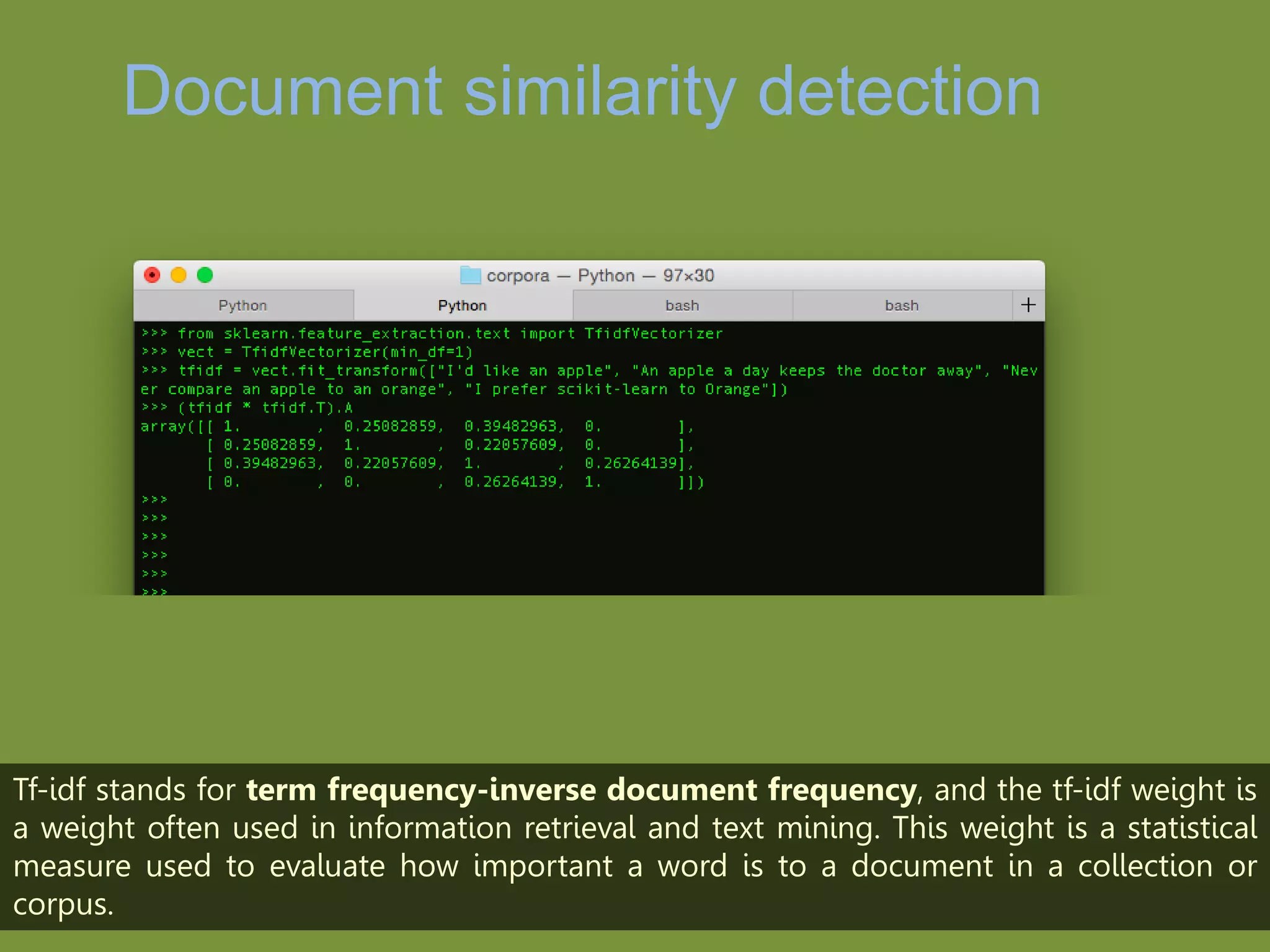

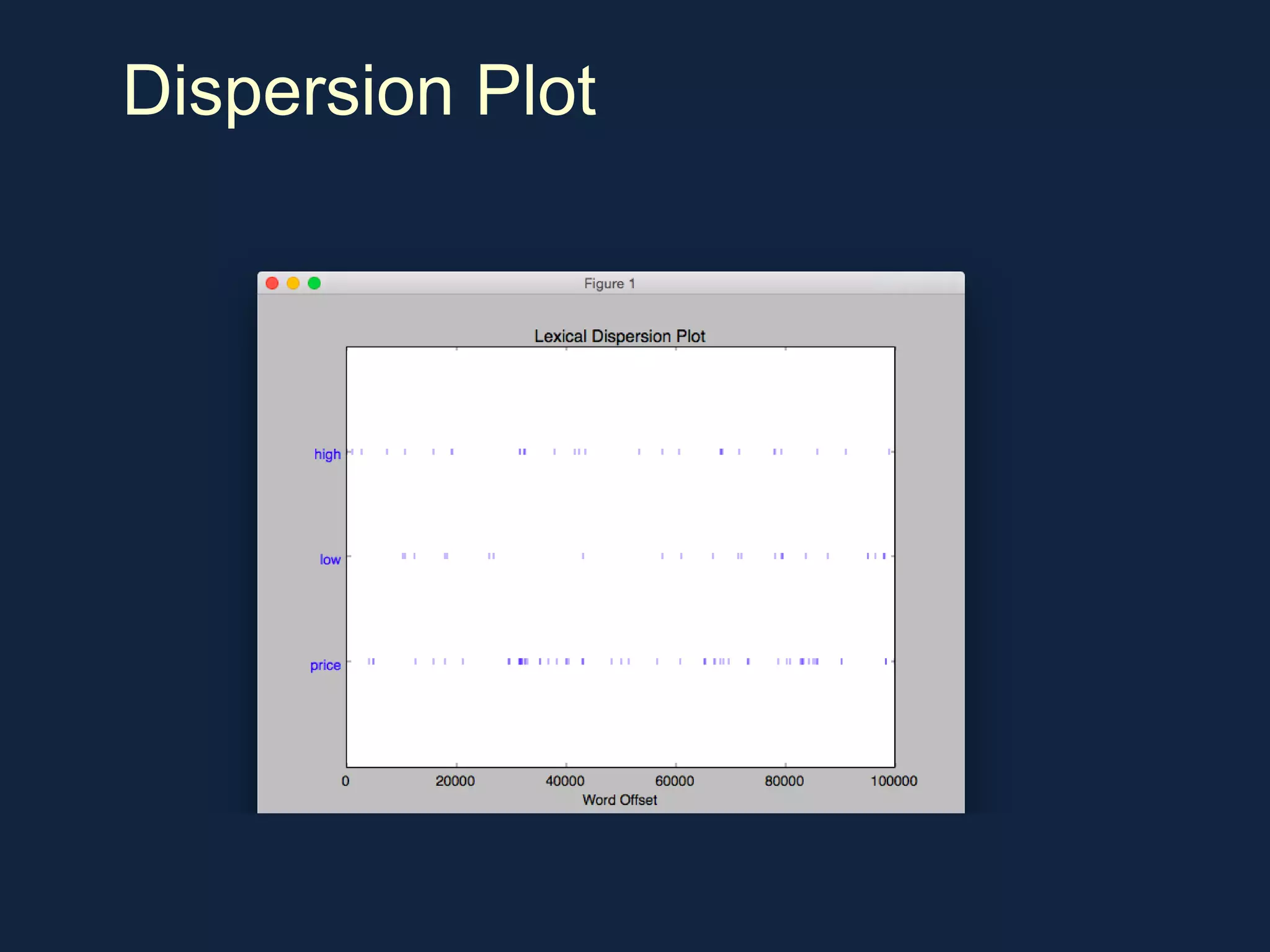




NLTK is a leading platform for building Python programs to analyze human language data. It provides tools for tasks like tokenization, part-of-speech tagging, parsing, classification, and more. As the amount of unstructured data grows exponentially, tools like NLTK help organizations analyze text data from sources like emails, reviews, social media to discover hidden patterns and insights. NLTK features include preprocessing texts, classifying documents, clustering texts, and extracting keywords to help understand large amounts of complex unstructured data.















































