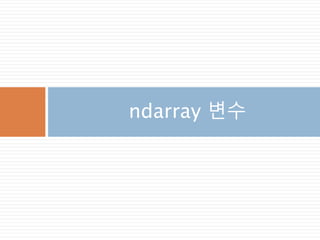
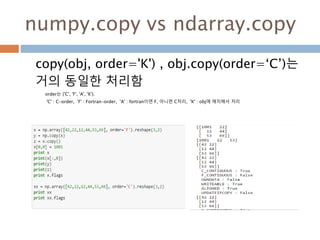
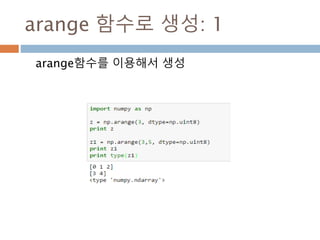
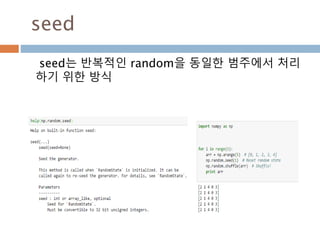
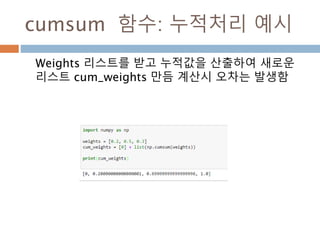
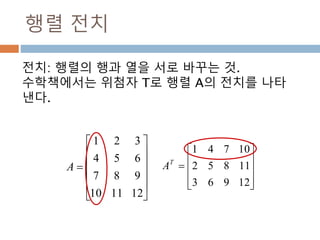
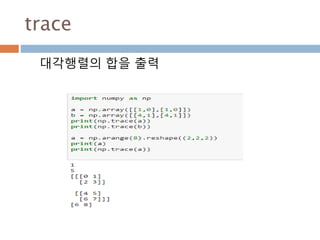
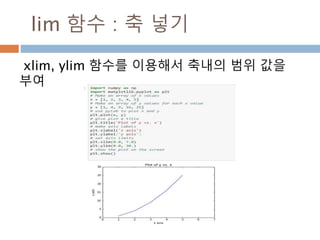
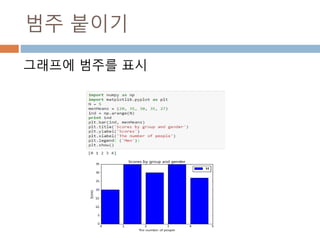
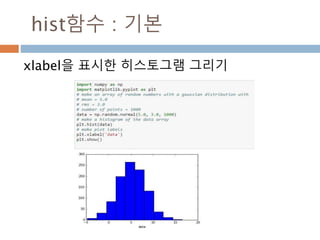
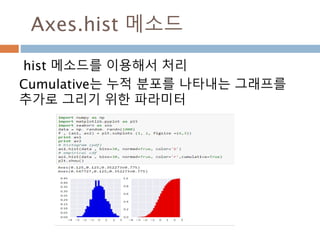
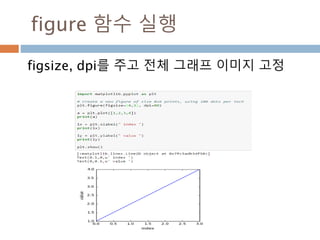
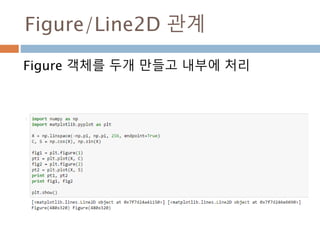
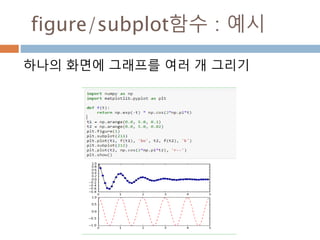
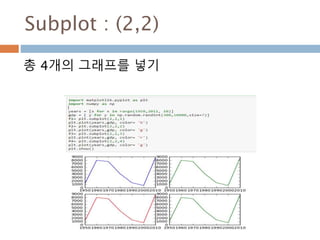
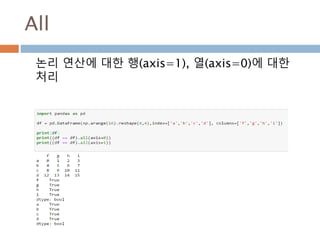
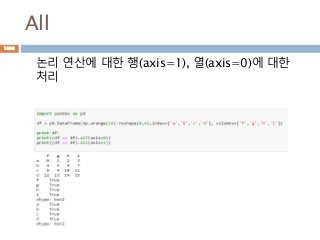
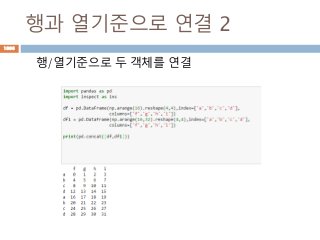
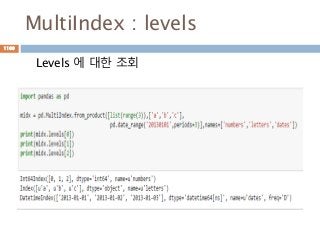
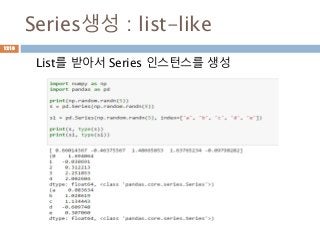
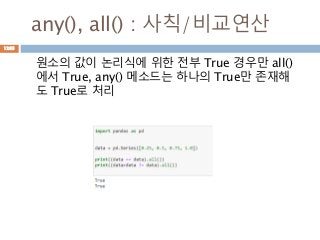
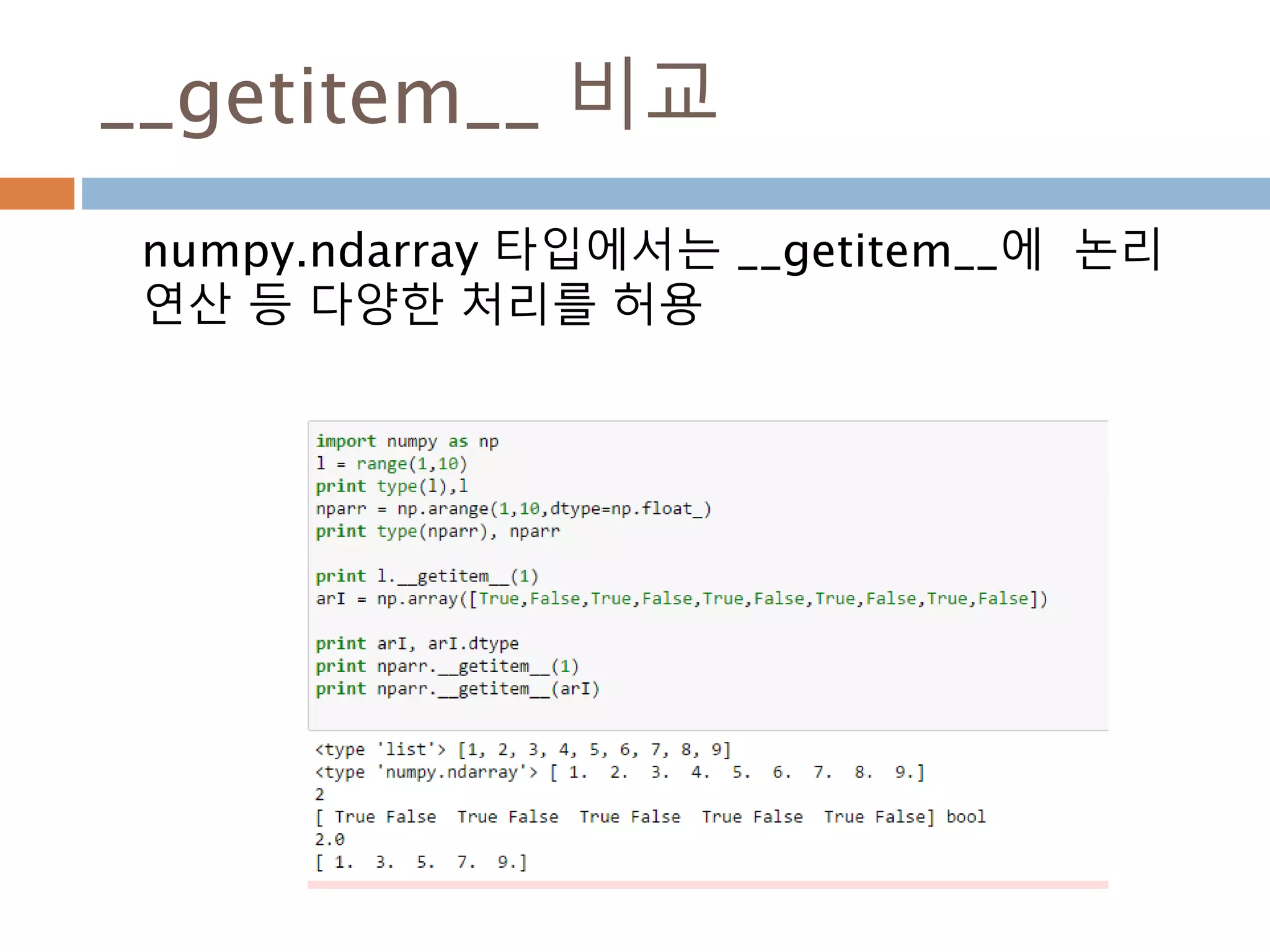
numpy.ndarray 변수 :1
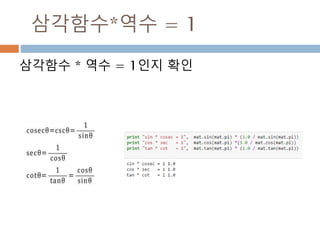
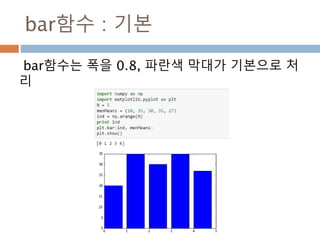
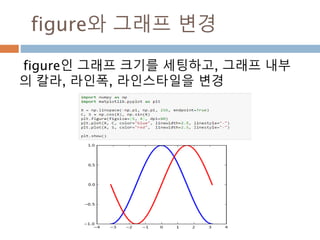
a = numpy.array([1,2,3])
변수 example Description
ndarray.ndim a = numpy.array([1,2,3])
>>> a.ndim
1
ndarray 객체에 대한 차원
ndarray.shape >>> a.shape
(3,)
ndarray 객체에 대한 다차원 모습
ndarray.size >>> a.size
3
ndarray 객체에 대한 원소의 갯수
ndarray.dtype >>> a.dtype
dtype(‘int32’)
ndarray 객체에 대한 원소 타입
ndarray.itemsize >>> a.itemsize
4
ndarray 객체에 대한 원소의 사이즈
ndarray.data >>> type(a.data)
>>> a.data.__str__()
'x01x00x00x00x02x00x
00x00x03x00x00x00'
ndarray 객체에 데이터는 itemsize 크기
의 hex값으로 표현
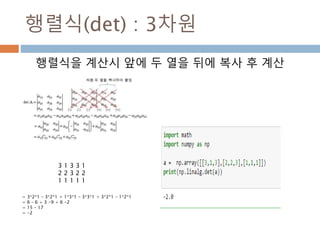
13
14.
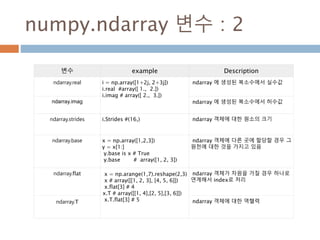
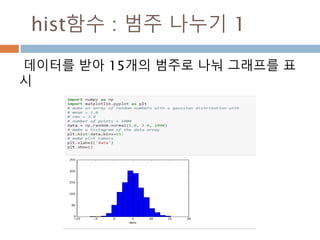
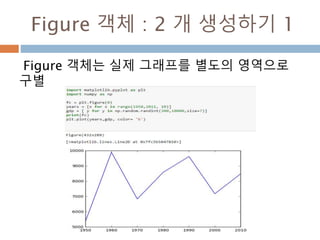
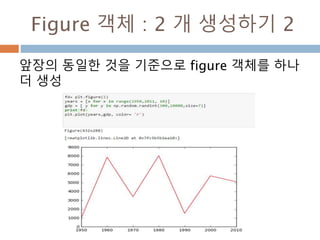
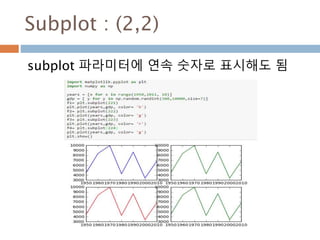
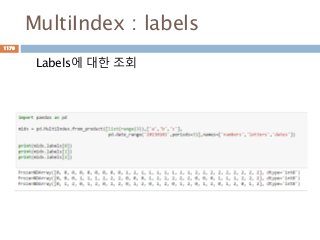
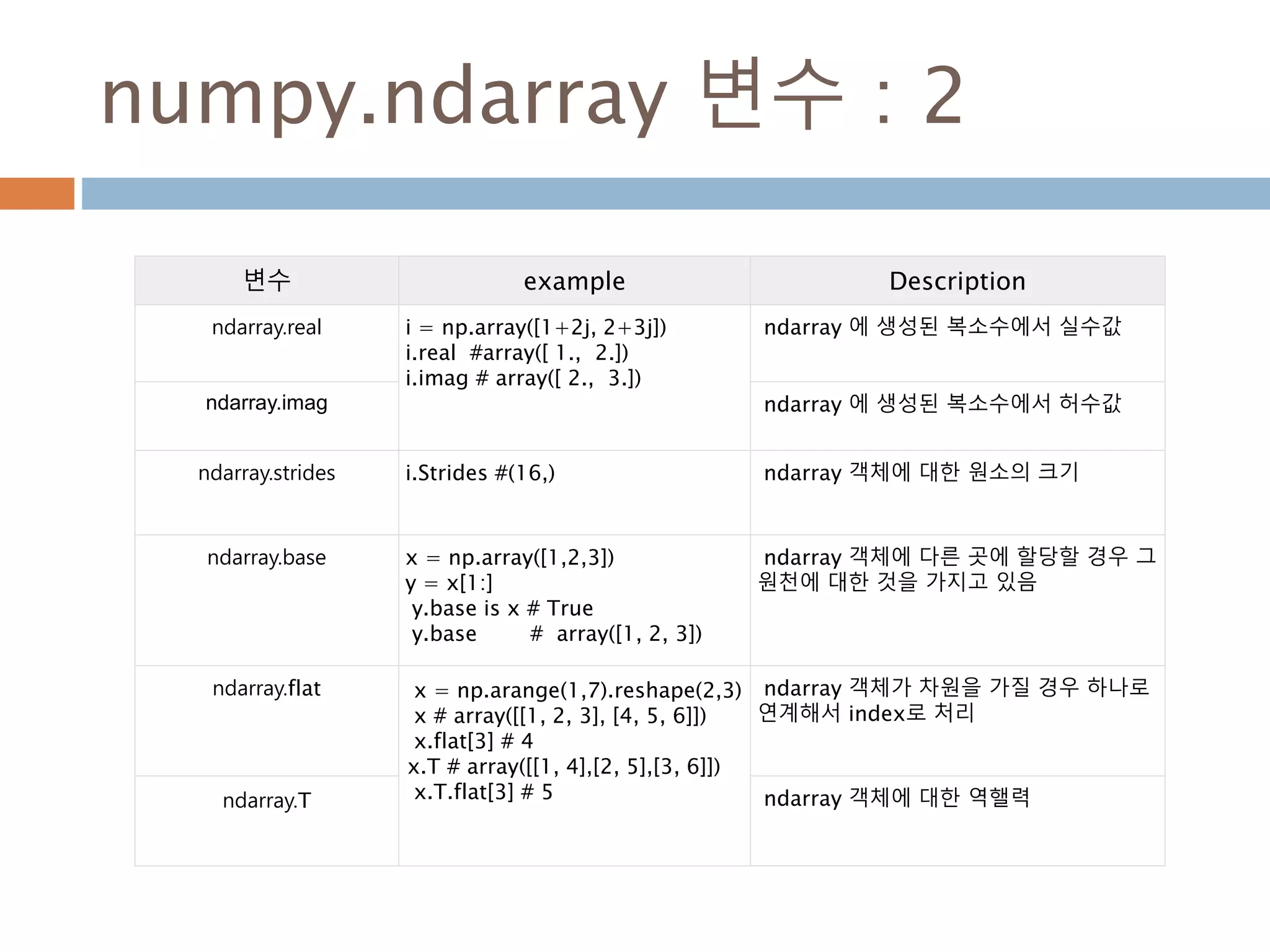
numpy.ndarray 변수 :2
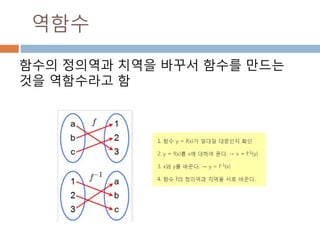
변수 example Description
ndarray.real i = np.array([1+2j, 2+3j])
i.real #array([ 1., 2.])
i.imag # array([ 2., 3.])
ndarray 에 생성된 복소수에서 실수값
ndarray.imag ndarray 에 생성된 복소수에서 허수값
ndarray.strides i.Strides #(16,) ndarray 객체에 대한 원소의 크기
ndarray.base x = np.array([1,2,3])
y = x[1:]
y.base is x # True
y.base # array([1, 2, 3])
ndarray 객체에 다른 곳에 할당할 경우 그
원천에 대한 것을 가지고 있음
ndarray.flat x = np.arange(1,7).reshape(2,3)
x # array([[1, 2, 3], [4, 5, 6]])
x.flat[3] # 4
x.T # array([[1, 4],[2, 5],[3, 6]])
x.T.flat[3] # 5
ndarray 객체가 차원을 가질 경우 하나로
연계해서 index로 처리
ndarray.T ndarray 객체에 대한 역핼력
14
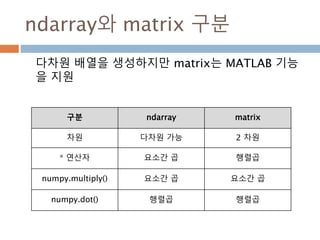
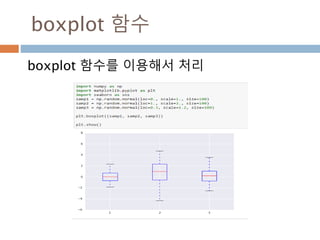
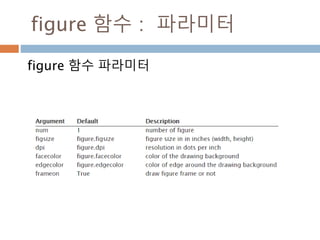
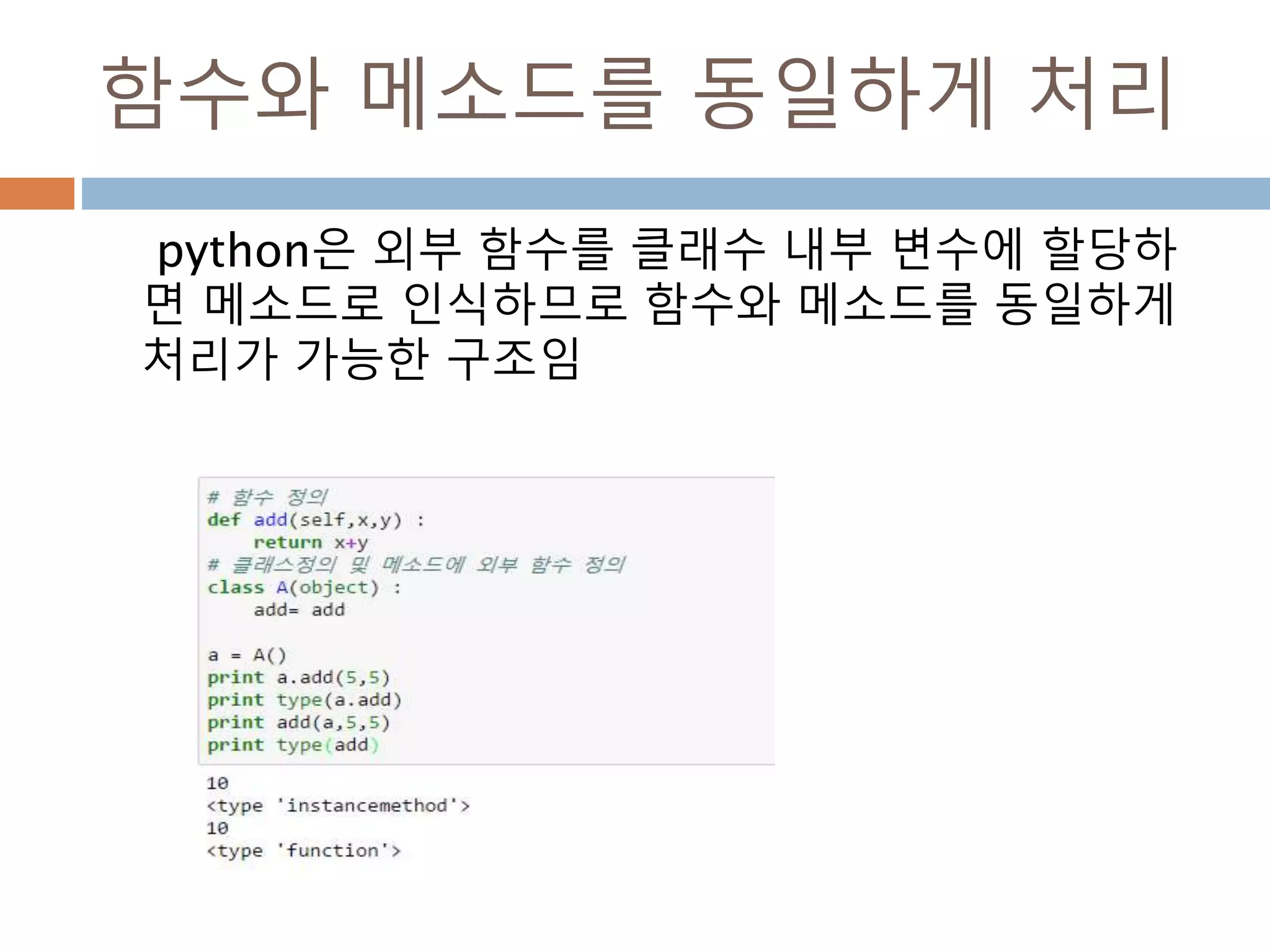
생성함수 : 1
Ndarray를생성하는 함수
함수 설명
array
입력 데이터를 ndarray로 변환하며 dtype이 명시되지 않은 경우
에는 자료형을 추론해 저장
asarray
입력 데이터를 ndarray로 변환하지만 입력 데이터가 ndarray일
경우 그대로 표시
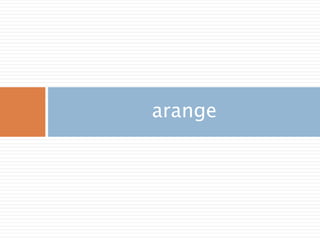
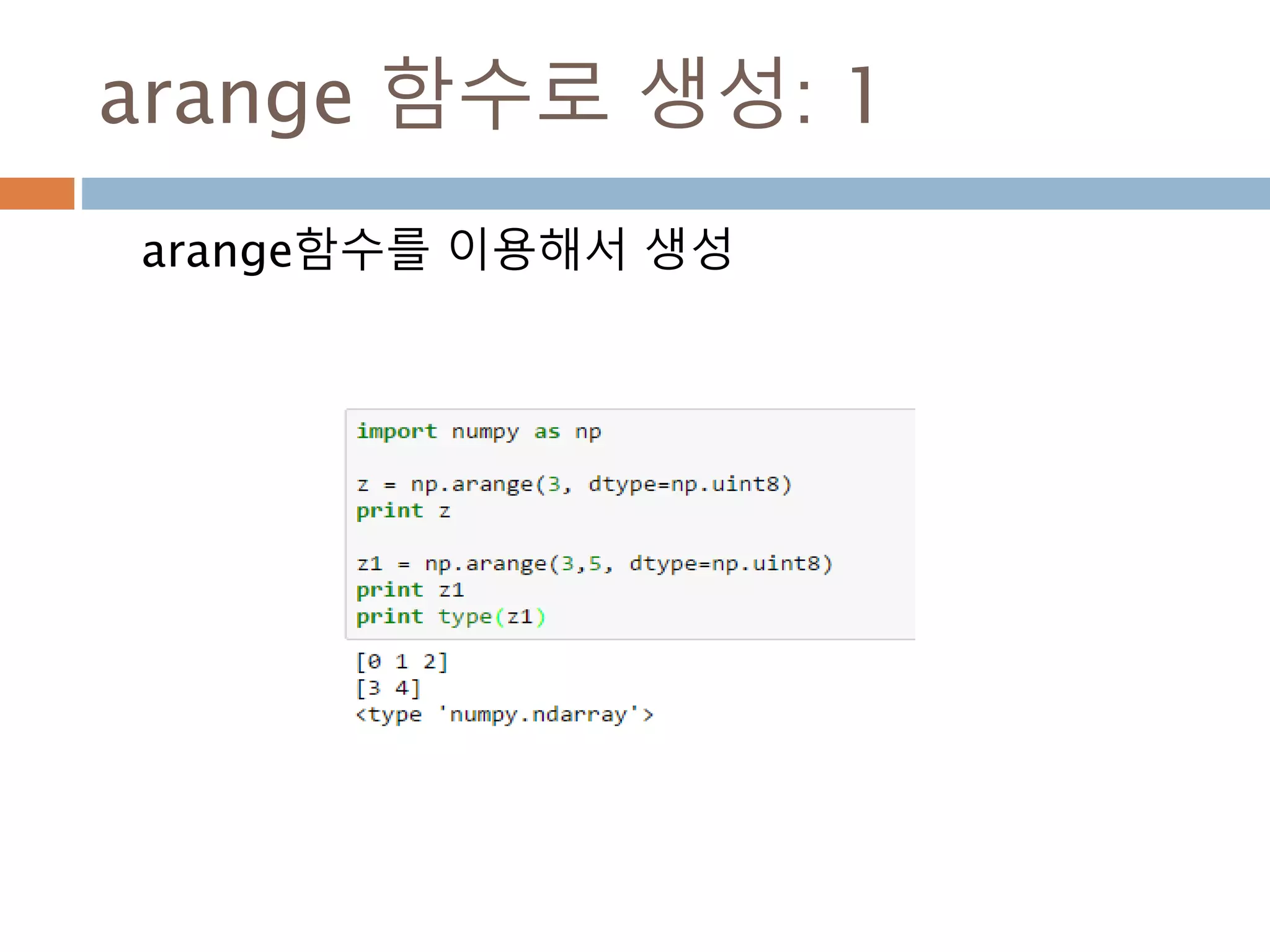
arange
내장range 함수와 유사하지만 리스트 대신 ndarray를 반환
ones
주어진 dtype과 주어진 모양을 가지는 배열을 생성하고 내용을 모
두 1로 초기화
ones_like
주어진 배열과 동일한 모양과 dtype을 가지는 배열을 새로 생성하
여 1로 초기화
zero
ones와 같지만 0으로 채운다
39
40.
생성함수 : 2
Ndarray를생성하는 함수
함수 설명
zeros_like
ones_like와 같지만 0dmfh codnsek
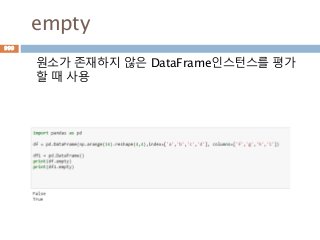
empty
메모리를 할당하지만 초기화가 없음
empty_like
메모리를 할당하지만 초기화가 없음
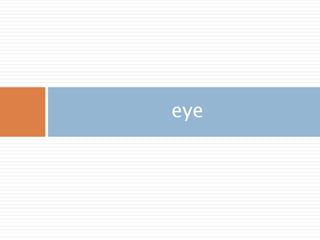
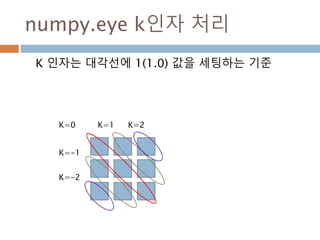
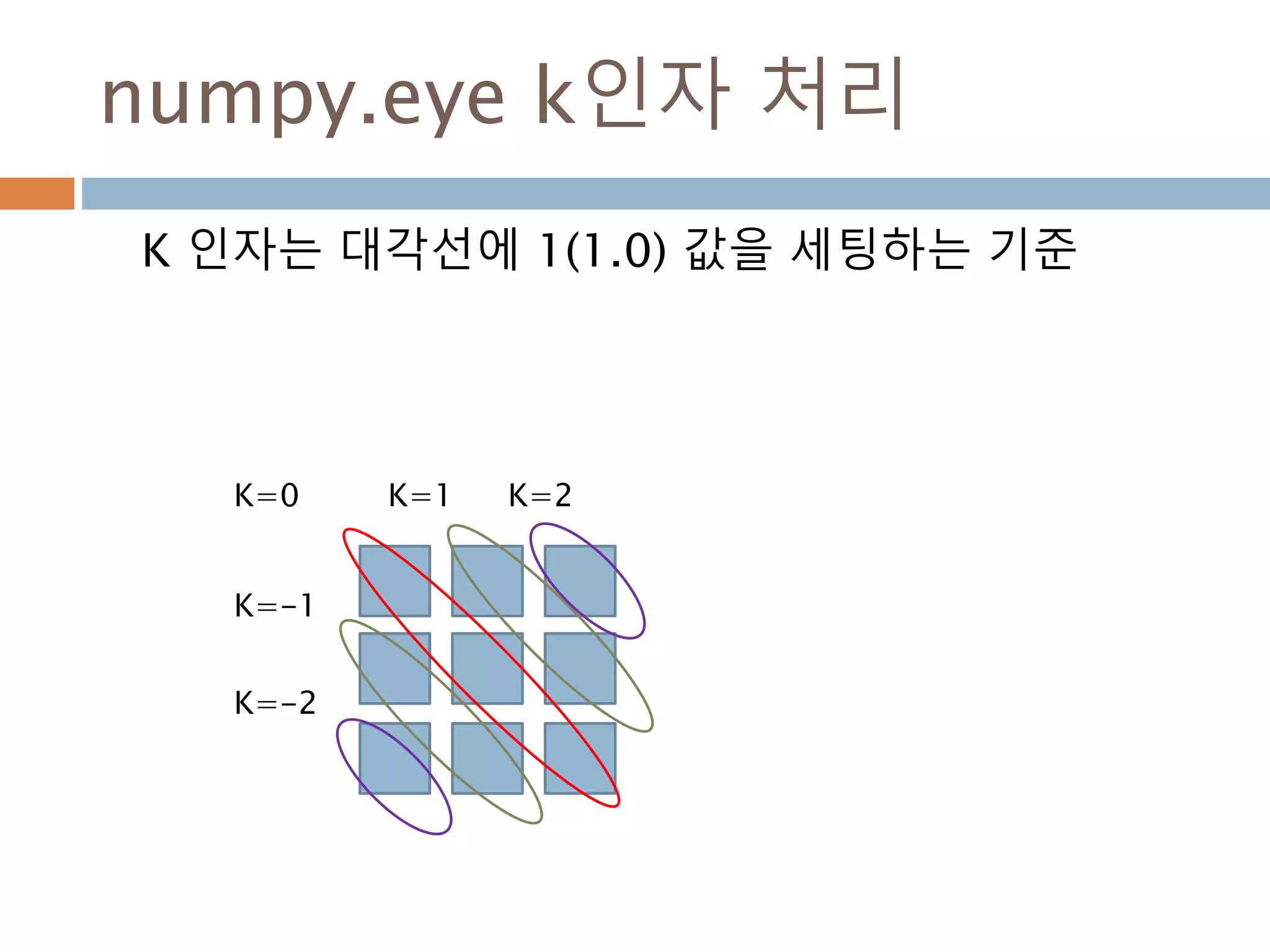
eye
n*n 단위행렬 생성하고 대각선으로 1을 표시하고 나머지는 0
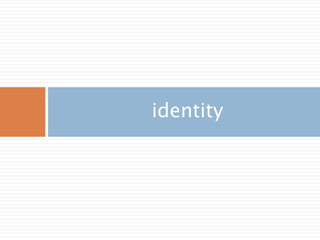
identity
n*n 단위행렬 생성
linspace
시작과 종료 그리고 총갯수 생성을 주면 ndarray로 생성
40
numpy.array 생성함수
numpy.array 함수로생성하면 실제 ndarray 타입
이 생김
numpy.array(object, dtype=None, copy=True, order=None,
subok=False, ndim=0)
42
43.
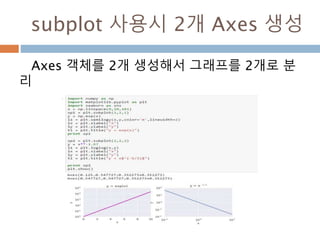
array 생성 :0차원
numpy.array 생성시 단일값(scalar value)를 넣으
면 arrary 타입이 아니 일반 타입을 만듬
43
44.
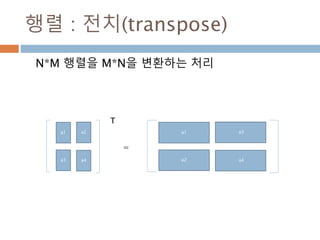
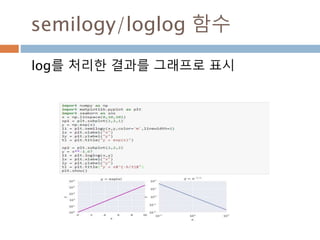
array 생성 :1차원
배열의 특징. 차원, 형태, 요소를 가지고 있음
생성시 데이터와 타입을 넣으면 ndim(차원),
shape(형태), 타입(dtype)
44
45.
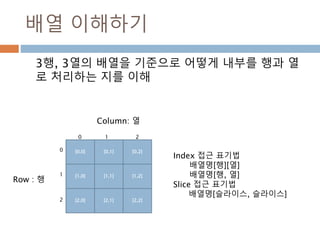
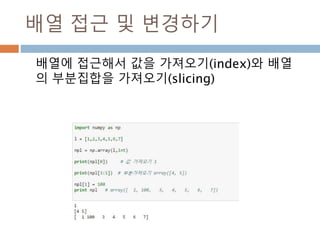
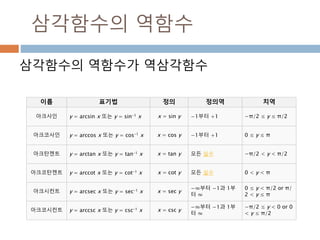
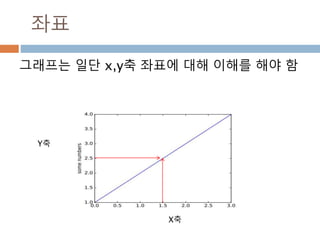
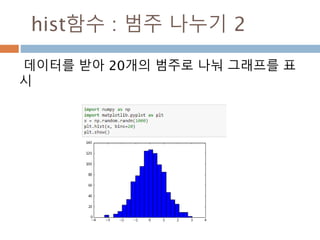
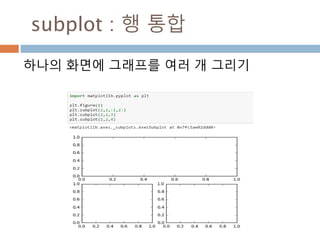
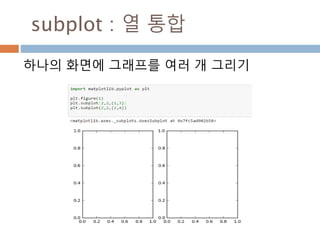
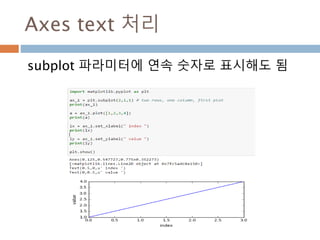
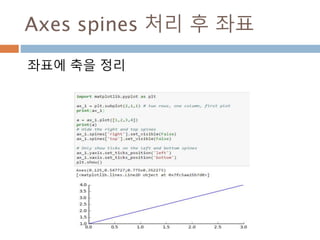
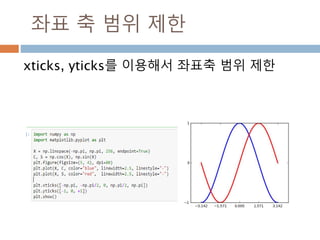
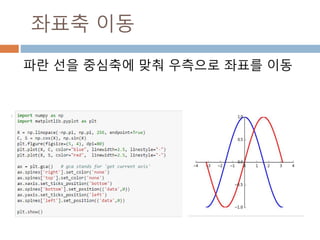
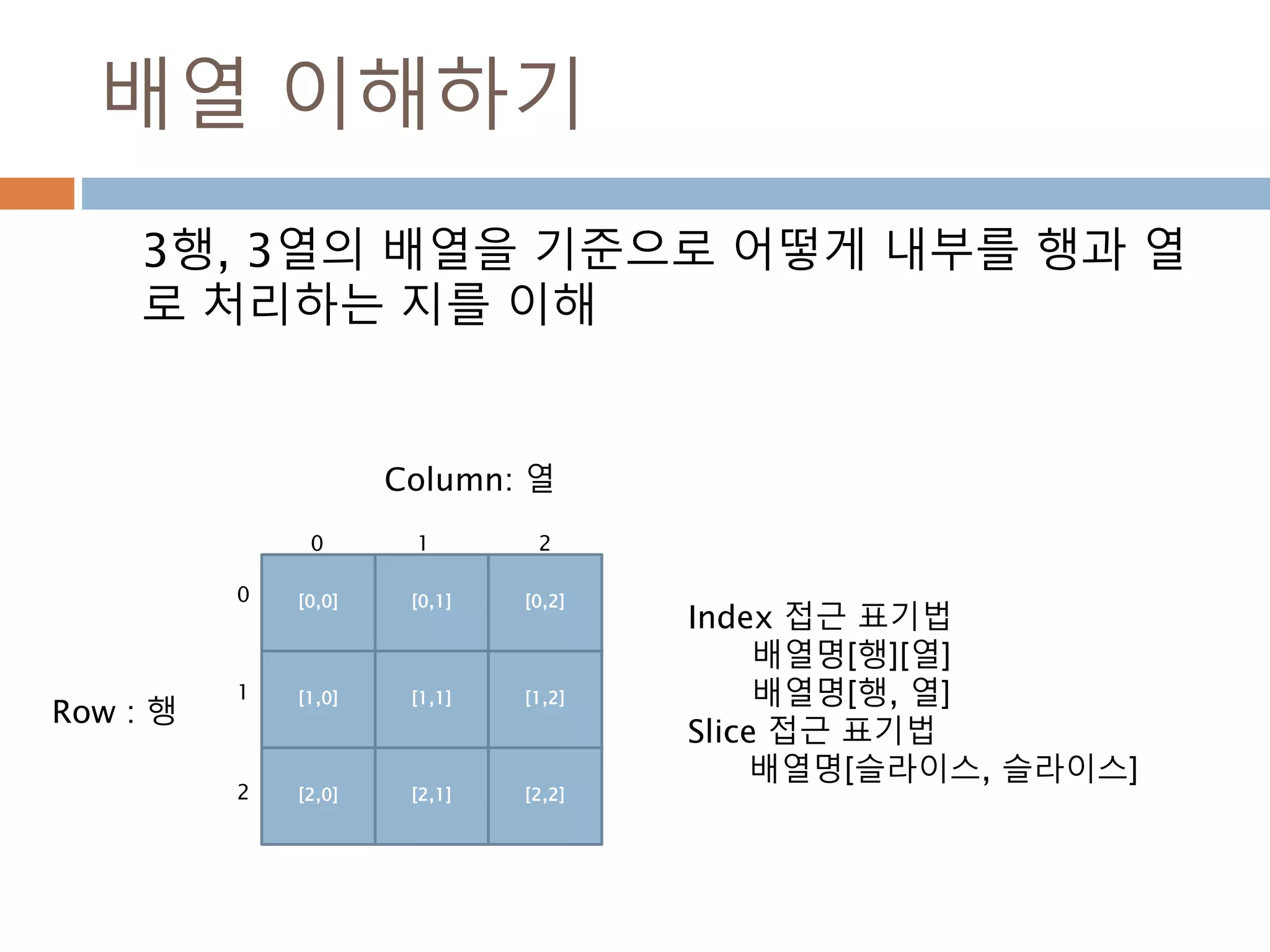
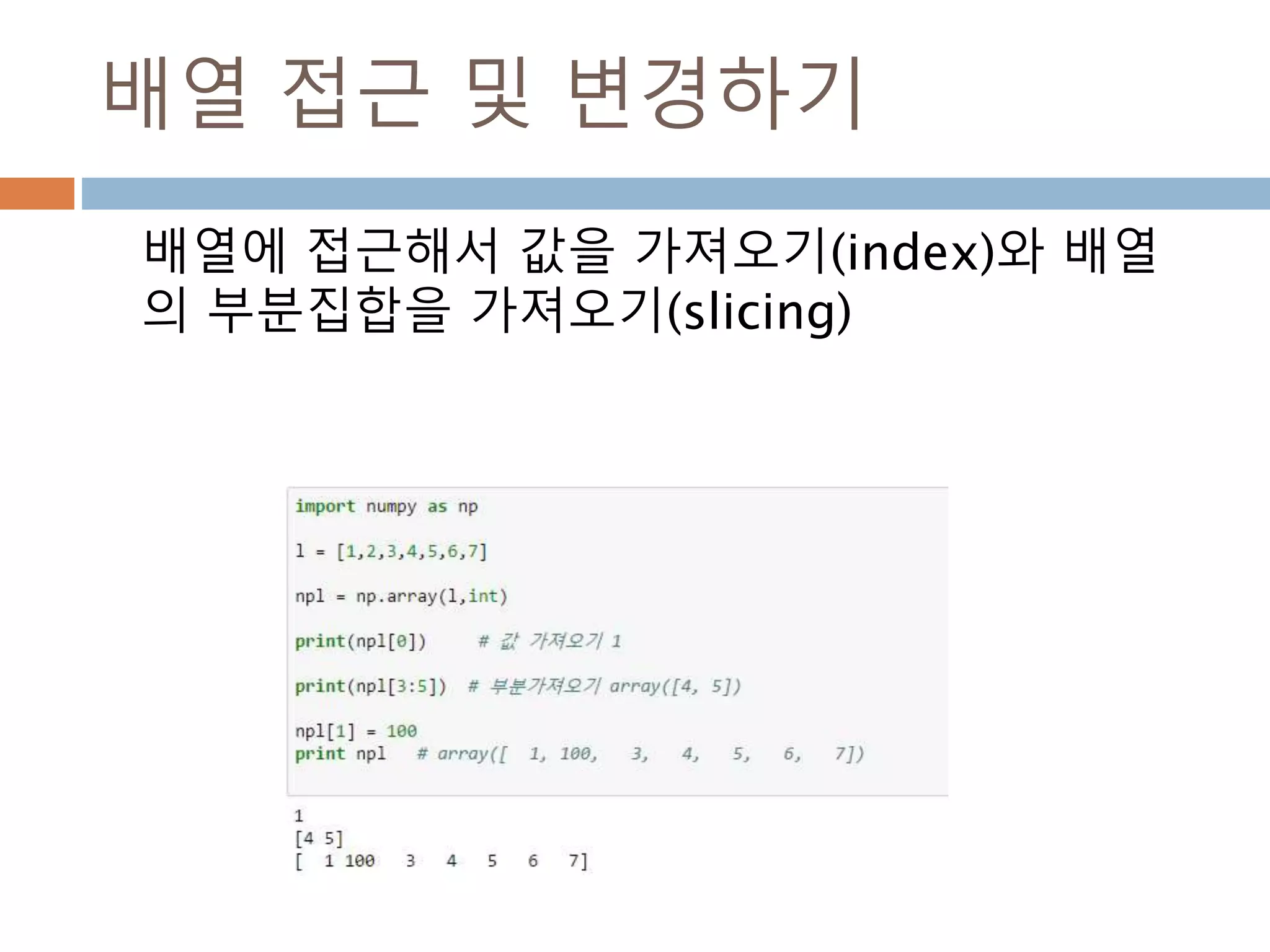
배열 이해하기
3행, 3열의배열을 기준으로 어떻게 내부를 행과 열
로 처리하는 지를 이해
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
Index 접근 표기법
배열명[행][열]
배열명[행, 열]
Slice 접근 표기법
배열명[슬라이스, 슬라이스]
45
46.
배열 만들기
배열의 특징.차원, 형태, 요소를 가지고 있음
생성시 데이터와 타입을 넣으면 ndim(차원),
shape(형태), 타입(dtype)
46
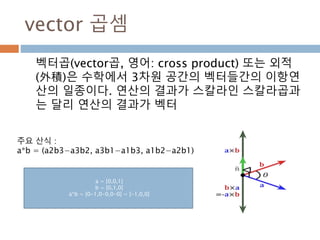
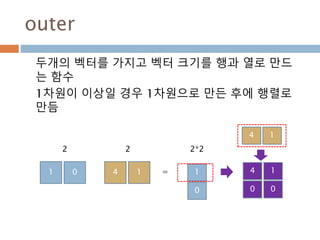
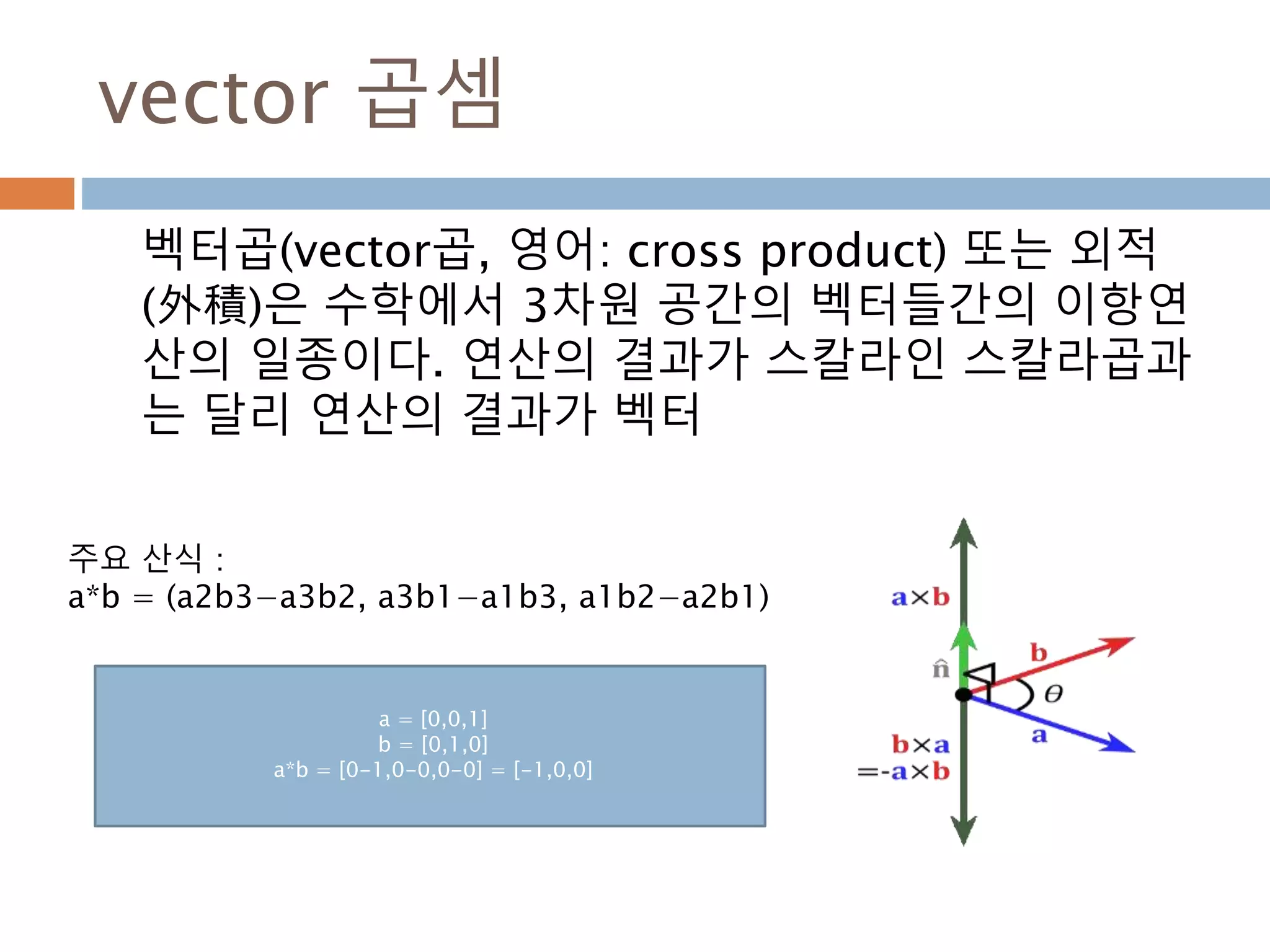
vector 곱셈
벡터곱(vector곱, 영어:cross product) 또는 외적
(外積)은 수학에서 3차원 공간의 벡터들간의 이항연
산의 일종이다. 연산의 결과가 스칼라인 스칼라곱과
는 달리 연산의 결과가 벡터
a = [0,0,1]
b = [0,1,0]
a*b = [0-1,0-0,0-0] = [-1,0,0]
주요 산식 :
a*b = (a2b3−a3b2, a3b1−a1b3, a1b2−a2b1)
88
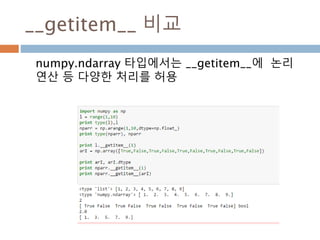
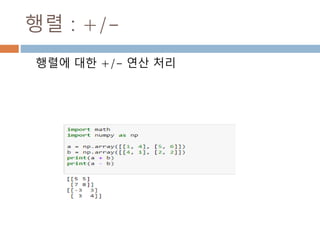
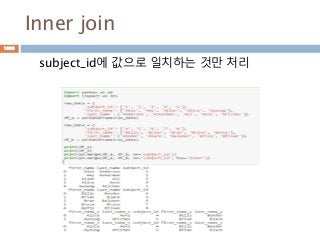
ndarray 와 비교연산처리
ndarray와 ndarray간의 비교연산. Scala 값은
broadcasting하므로 ndarray 동일 모형의 동일값
으로 인지해서 처리된 후 bool값을 가지는 ndarray
가 생성됨
ndarray 비교연산 ndarrayndarray =
104
105.
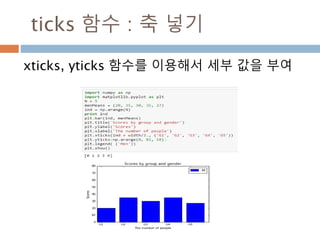
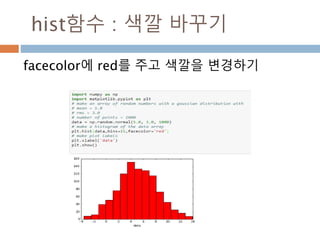
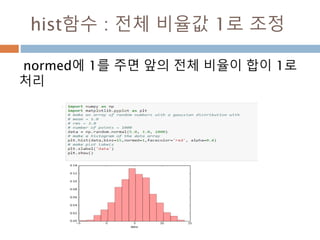
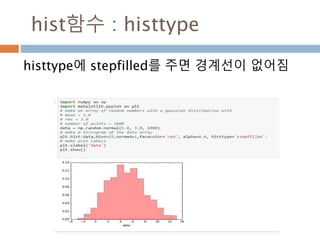
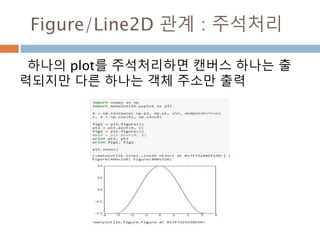
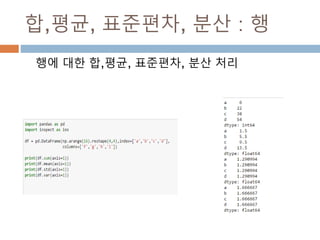
다차원 배열 :열 조회/ 변경
[data1 <0] =0 실제 배열의 원소들 값이 0보다 작
을 경우 0으로 전환
배열명[논리연산]
논리 연산 등 다양한 연산을
이용해서 배열 접근
105
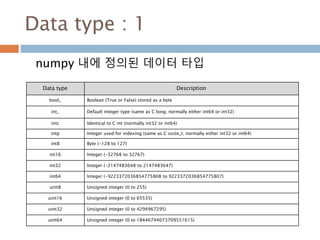
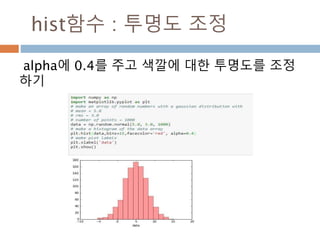
Data type :1
numpy 내에 정의된 데이터 타입
Data type Description
bool_ Boolean (True or False) stored as a byte
int_ Default integer type (same as C long; normally either int64 or int32)
intc Identical to C int (normally int32 or int64)
intp Integer used for indexing (same as C ssize_t; normally either int32 or int64)
int8 Byte (-128 to 127)
int16 Integer (-32768 to 32767)
int32 Integer (-2147483648 to 2147483647)
int64 Integer (-9223372036854775808 to 9223372036854775807)
uint8 Unsigned integer (0 to 255)
uint16 Unsigned integer (0 to 65535)
uint32 Unsigned integer (0 to 4294967295)
uint64 Unsigned integer (0 to 18446744073709551615)
134
135.
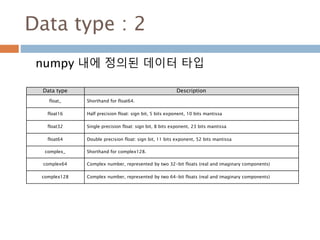
Data type :2
numpy 내에 정의된 데이터 타입
Data type Description
float_ Shorthand for float64.
float16 Half precision float: sign bit, 5 bits exponent, 10 bits mantissa
float32 Single precision float: sign bit, 8 bits exponent, 23 bits mantissa
float64 Double precision float: sign bit, 11 bits exponent, 52 bits mantissa
complex_ Shorthand for complex128.
complex64 Complex number, represented by two 32-bit floats (real and imaginary components)
complex128 Complex number, represented by two 64-bit floats (real and imaginary components)
135
numpy.dtype 생성예시(2)
Array 원소가하나의 타입만 세팅할 수도 있고, 여
러 개의 데이터 타입을 구성할 수 있음
Structured type : two fieldStructured type : one field
140
141.
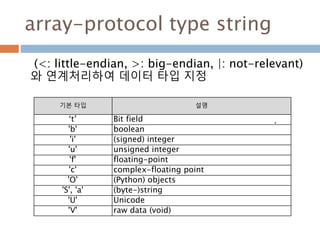
array-protocol type string
(<:little-endian, >: big-endian, |: not-relevant)
와 연계처리하여 데이터 타입 지정
기본 타입 설명
‘t’ Bit field
'b' boolean
'i' (signed) integer
'u' unsigned integer
'f' floating-point
'c' complex-floating point
'O' (Python) objects
'S', 'a' (byte-)string
'U' Unicode
'V' raw data (void)
.
141
142.
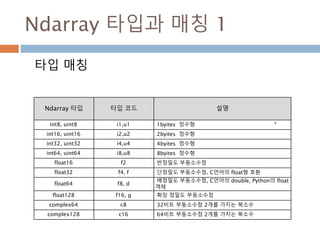
Ndarray 타입과 매칭1
타입 매칭
Ndarray 타입 타입 코드 설명
int8, uint8 i1,u1 1byites 정수형
int16, uint16 i2,u2 2byites 정수형
int32, uint32 i4,u4 4byites 정수형
int64, uint64 i8,u8 8byites 정수형
float16 f2 반정밀도 부동소수점
float32 f4, f 단정밀도 부동소수점. C언어의 float형 호환
float64 f8, d
배정밀도 부동소수점, C언어의 double, Python의 float
객체
float128 f16, g 확장 정밀도 부동소수점
complex64 c8 32비트 부동소수점 2개를 가지는 복소수
complex128 c16 64비트 부동소수점 2개를 가지는 복소수
.
142
143.
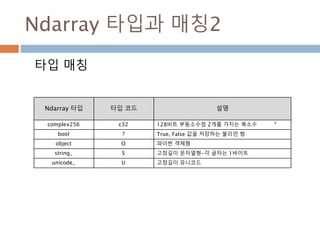
Ndarray 타입과 매칭2
타입매칭
Ndarray 타입 타입 코드 설명
complex256 c32 128비트 부동소수점 2개를 가지는 복소수
bool ? True, False 값을 저장하는 불리언 형
object O 파이썬 객체형
string_ S 고정길이 문자열형-각 글자는 1바이트
unicode_ U 고정길이 유니코드
.
143
Byte 메모리 저장방식
(<:little-endian, >: big-endian, |: not-relevant),
.
<: little-endian
>: big-endian
|: not-relevant
리틀 엔디안은 최하위 비트(LSB)부터 부호화되어 저장된
다. 예를 들면, 숫자 12는 2진수로 나타내면 1100인데
리틀 엔디안은 0011로 각각 저장된다.
이 방식은 데이터의 최상위 비트가 가장 높은 주소에 저장되므로
그냥 보기에는 역으로 보인다. 빅 엔디안은 최상위 비트(MSB)부터
부호화되어 저장되며 예를 들면, 숫자 12는 2진수로 나타내면
1100인데 빅 엔디안은 1100으로 저장된다.
문자를 저장할 때 사용 endian가 상관없이 처리
145
146.
Little-endian
숫자를 저장할때 제일왼쪽부터 저장됨
.
>>> ar = np.array([1,2,3])
>>> ar.tostring()
'x01x00x00x00x00x00x00x00x02x0
0x00x00x00x00x00x00x03x00x00x
00x00x00x00x00'
>>> l = ar.tosting()
>>> ar.itemsize
8
>>> l[0:8]
x01x00x00x00x00x00x00x00
x01x00x00x
00x00x00x00
x00
8bytes씩 저장하고
숫자는 첫번째부터
들어감
146
147.
big-endian
숫자를 저장할때 제일오른쪽부터 저장됨
.
>>> ar = np.array([1,2,3],dtype='>i8')
>>> ar.tostring()
'x00x00x00x00x00x00x00x01x00x0
0x00x00x00x00x00x02x00x00x00x
00x00x00x00x03’
>>> ar.dtype
dtype('>i8')
x00x00x00x00x0
0x00x00x01
8bytes씩 저장하고 숫자
는 마지막째부터 들어감
147
148.
not-relevant
endian에 상관없이 문자를저장할때 제일 왼쪽
부터 저장됨
.
>>> sr = np.array(['a','b',"abc"],dtype='|S10')
>>> sr.tostring()
'ax00x00x00x00x00x00x00x00x00bx00x
00x00x00x00x00x00x00x00abcx00x00x0
0x00x00x00x00’
>>> sr.dtype
dtype('S10')
>>> sr.tostring()[0:10]
'ax00x00x00x00x00x00x00x00x00'
10bytes씩 저장하
고 문자는 첫번째부
터 들어감
148
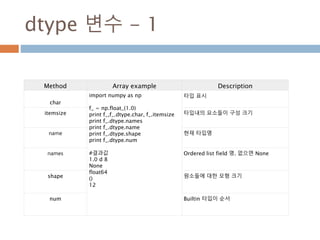
dtype 변수 -1
Method Array example Description
char
import numpy as np
f_ = np.float_(1.0)
print f_,f_.dtype.char, f_.itemsize
print f_.dtype.names
print f_.dtype.name
print f_.dtype.shape
print f_.dtype.num
#결과값
1.0 d 8
None
float64
()
12
타입 표시
itemsize 타입내의 요소들이 구성 크기
name 현재 타입명
names Ordered list field 명. 없으면 None
shape 원소들에 대한 모형 크기
num Builtin 타입이 순서
150
151.
dtype 변수 -2
Method Array example Description
type import numpy as np
f_ = np.float_(1.0)
print f_.dtype.type
print f_.dtype.str
print f_.dtype.isbuiltin
print f_.dtype.byteorder
print f_.dtype.alignment
print f_.dtype.isalignedstruct
#결과값
<type 'numpy.float64'>
<f8
1
=
8
False
numpy 내의 타입으로 표시
str Array-protocol 타입스트링 표시
<: little-endian으로 float 8개 bytes 처리
isbuiltin 0:structure array type
1: numpy 내부 타입
2: 사용자 정의 타입
byteorder = : 기본
< : little
> : big
| : not applicable
alignment 타입내의 요소들이 구성 크기
isalignedstruct ?
151
152.
dtype 변수 -3
Method Array example Description
descr import numpy as np
f_ = np.float_(1.0)
print f_.dtype.descr
print f_.dtype.hasobject
print f_.dtype.subdtype
print f_.dtype.base
print f_.dtype.kind
print f_.dtype.isnative
#결과값
[('', '<f8')]
False
None
Float64
F
True
Array interface 표시
hasobject any reference-counted objects in any
fields or sub-dtypes 가 존재시 True
subdtype
Tuple (item_dtype, shape) if this dtype
describes a sub-array, and None other
wise.
base 기본 정의된 타입
kind array-protocol type
isnative 파이썬 내부 byte order 사용여부
152
153.
dtype 변수 -4
Method Array example Description
flags
import numpy as np
f_ = np.float_(1.0)
print f_.dtype.flags
print f_.dtype.fields
print f_.dtype.metadata
#결과값
0
None
None
Interpret 되어진 bit flags
fields Dtype 정의한 필드들
metadata ?
153
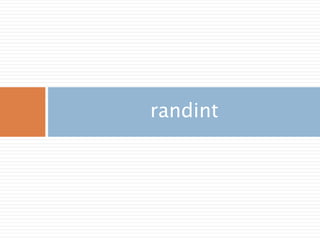
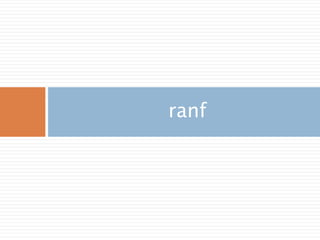
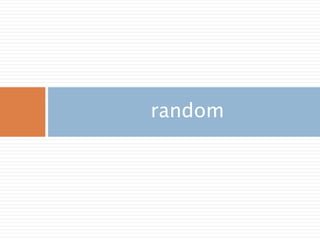
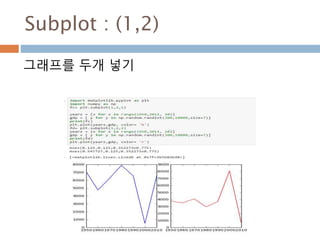
주요 함수
rand(d0, d1,..., dn) 주어진 모양에 대해 0에서 1사이의 균등 분포 생성
randn(d0, d1, ..., dn) 주어진 모양에 대해 정규분포 값을 생성
randint(low[, high, size]) Return random integers from low (inclusive) to high (exclusive).
random_sample([size]) Return random floats in the half-open interval [0.0, 1.0).
random([size]) Return random floats in the half-open interval [0.0, 1.0).
ranf([size]) Return random floats in the half-open interval [0.0, 1.0).
sample([size]) Return random floats in the half-open interval [0.0, 1.0).
choice(a[, size, replace, p]) Generates a random sample from a given 1-D array ..
bytes(length) Return random bytes.
156
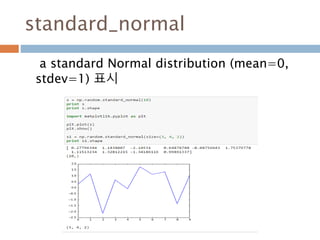
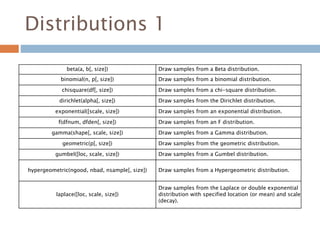
Distributions 1
beta(a, b[,size]) Draw samples from a Beta distribution.
binomial(n, p[, size]) Draw samples from a binomial distribution.
chisquare(df[, size]) Draw samples from a chi-square distribution.
dirichlet(alpha[, size]) Draw samples from the Dirichlet distribution.
exponential([scale, size]) Draw samples from an exponential distribution.
f(dfnum, dfden[, size]) Draw samples from an F distribution.
gamma(shape[, scale, size]) Draw samples from a Gamma distribution.
geometric(p[, size]) Draw samples from the geometric distribution.
gumbel([loc, scale, size]) Draw samples from a Gumbel distribution.
hypergeometric(ngood, nbad, nsample[, size]) Draw samples from a Hypergeometric distribution.
laplace([loc, scale, size])
Draw samples from the Laplace or double exponential
distribution with specified location (or mean) and scale
(decay).
183
184.
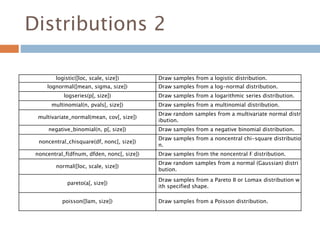
Distributions 2
logistic([loc, scale,size]) Draw samples from a logistic distribution.
lognormal([mean, sigma, size]) Draw samples from a log-normal distribution.
logseries(p[, size]) Draw samples from a logarithmic series distribution.
multinomial(n, pvals[, size]) Draw samples from a multinomial distribution.
multivariate_normal(mean, cov[, size])
Draw random samples from a multivariate normal distr
ibution.
negative_binomial(n, p[, size]) Draw samples from a negative binomial distribution.
noncentral_chisquare(df, nonc[, size])
Draw samples from a noncentral chi-square distributio
n.
noncentral_f(dfnum, dfden, nonc[, size]) Draw samples from the noncentral F distribution.
normal([loc, scale, size])
Draw random samples from a normal (Gaussian) distri
bution.
pareto(a[, size])
Draw samples from a Pareto II or Lomax distribution w
ith specified shape.
poisson([lam, size]) Draw samples from a Poisson distribution.
184
185.
Distributions 3
power(a[, size])
Drawssamples in [0, 1] from a power distribution with positive ex
ponent a - 1.
rayleigh([scale, size]) Draw samples from a Rayleigh distribution.
standard_cauchy([size]) Draw samples from a standard Cauchy distribution with mode = 0.
standard_exponential([size]) Draw samples from the standard exponential distribution.
standard_gamma(shape[, size]) Draw samples from a standard Gamma distribution.
standard_normal([size])
Draw samples from a standard Normal distribution (mean=0, stde
v=1).
standard_t(df[, size])
Draw samples from a standard Student’s t distribution with df deg
rees of freedom.
triangular(left, mode, right[, size]) Draw samples from the triangular distribution.
uniform([low, high, size]) Draw samples from a uniform distribution.
vonmises(mu, kappa[, size]) Draw samples from a von Mises distribution.
wald(mean, scale[, size]) Draw samples from a Wald, or inverse Gaussian, distribution.
weibull(a[, size]) Draw samples from a Weibull distribution.
zipf(a[, size]) Draw samples from a Zipf distribution.
185
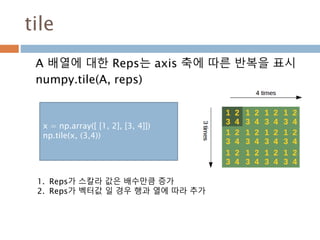
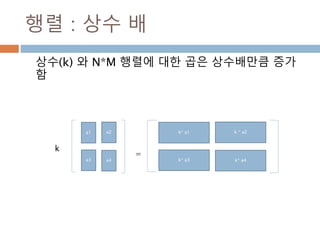
tile
A 배열에 대한Reps는 axis 축에 따른 반복을 표시
numpy.tile(A, reps)
x = np.array([ [1, 2], [3, 4]])
np.tile(x, (3,4))
1. Reps가 스칼라 값은 배수만큼 증가
2. Reps가 벡터값 일 경우 행과 열에 따라 추가
200
201.
Tile 함수를 이용해서array_like를 모형에 따라
ndarray로 변환
Array_like를 ndarray로 변환
201
항등원
항등원(恒等元)은 집합의 어떤원소와 연산을 취
해도, 자기 자신이 되는 원소를 말한다. 쉽게 말해
서, 1개의 양을 전혀 달라 보이는 다른 양과 같게
만드는 수학적 관계를 말한다고 생각하면 된다.
217
218.
역수
어떤 수의 역수(逆數,영어: reciprocal) 또는 곱
셈 역원(-逆元, 영어: multiplicative inverse)은
그 수와 곱해서 1, 즉 곱셈 항등원이 되는 수를 말
한다.
x의 역수는 1/x 또는 x -1로 표기한다.
곱해서 1이 되는 두 수를 서로 역수
218
절댓값은 거리의 개념이므로반드시 0또는 양수이어야하며, 만약
실수 a가 음수라면, a에 (-1)을 곱해 양수화
절대값 absolute value
어떤 실수 a를 수직선에 대응시켰을 때, 수직선의
원점에서 실수 a까지의 거리를 의미한다. 이것을
기호로 |a|로 표시.
220
수학에서, 집합 S에 이항연산 * 이 정의되어 있을 때, S의 임의의
두 원소 a, b 에 대해
a * b = b * a가 성립하면, 이 연산은 교환법칙(交換法則,
commutative law)을 만족한다고 한다
교환법칙을 만족하는 연산의 예를 들어보면 다음과 같다.
유리수, 실수, 복소수에서 덧셈과 곱셈.
행렬, 벡터의 덧셈
집합의 교집합, 합집합 연산
교환법칙
수학에서 순서와 상관없이 다른 항을 바꿔 계산
해도 동일한 값이 나오는 법칙
235
236.
교환법칙 : 덧셈과곱셈
수학에서 순서와 상관없이 다른 항을 바꿔 계산
해도 동일한 값이 나오는 법칙
236
수학에서 결합법칙(結合 法則,associated law)은 한 식에서 연산
이 두 번 이상 연속될 때, 앞쪽의 연산을 먼저 계산한 값과 뒤쪽의
연산을 먼저 계산한 결과가 항상 같을 경우 그 연산은 결합법칙을
만족한다고 한다.
결합법칙을 만족하는 연산의 예를 들어보면 다음과 같다.
실수와 복소수, 사원수의 덧셈과 곱셈은 결합법칙이 성립한
다.
최대공약수와 최소공배수 함수는 결합법칙을 만족한다.
행렬 곱셈은 결합법칙을 만족한다.
결합법칙
연산이 두 번 이상 연속될 때 연산을 묶어서 처리
238
집합 S와 S에대해 닫혀있는 이항 연산 *가 정의되어 있을 때, S의
임의의 원소 a, b, c에 대해 a * (b + c) = (a * b) + (a * c)가 성립
하면 좌분배법칙이, (b + c) * a = (b * a) + (c * a)가 성립하면 우
분배법칙이 성립한다고 하며 양쪽모두 성립할 경우 집합 S에서 연
산 *에 대해 분배법칙이 성립한다고 한다.
분배법칙을 만족하는 연산의 예를 들어보면 다음과 같다.
임의의 자연수, 정수, 유리수, 실수, 복소수의 곱셈 ×은 덧
셈 +에 대해 분배법칙이 성립한다.
합집합 연산 ∪은 교집합 연산 ∩에 대해 분배법칙이 성립하
고, 교집합 연산 ∩은 합집합 연산 ∪에 대해 분배법칙이 성
립한다. 또한, 교집합 연산은 대칭자 연산에 대해 분배법칙
이 성립한다.
분배법칙
수학에서 이항연산 *와 묶음이 있을 경우 분배하
면 동일한 처리값이 나오는 법칙
241
공약수/최대공약수
공약수, 최대공약수, 서로소용어 정의
공약수 두 개 또는 그 이상의 자연수가 있을 때 그 자연수들의 공통인 약수.
최대공약수 공약수들 중에서 가장 큰 수.12의 약수={1,2,3,6,12}
16의 약수={1,2,4,8,16}
18의 약수={1,2,3,6,9,18} 에서
12와 16의 공약수 → 1,2,4 → 최대공약수는 4
12, 16, 18의 공약수 → 1,2 → 최대공약수는 2
서로소 공약수가 1 하나 뿐인 두 자연수 사이의 관계
(예) 8의 약수={1,2,4,8}, 9의 약수={1,3,9}에서 8과 9의 공약수는 1 한 개
뿐이므로 8과 9는 서로소
244
245.
서로소
최대공약수가 1인, 둘이상의 양의 정수들은 서로
소(relatively prime)이라고 불린다.
두 정수가 1 이외에 양의 공약수를 가지지 않으면
서로소이다.
245
이항정리 : 전개
다항식(a+b)3의 전개식에서 각 항의 계수를 조
합의 수를 이용하여 나타내는 방법
(a+b)3=(a+b)(a+b)(a+b)
=aaa+aab+aba+abb+baa+bab+bba+bbb
=a3+3a2b+3ab2+b3
=a3+3C1a2b+3C2ab2+b3
3C1 = 3P1/1! = 3!/2!/1! = 3
3C2 = 3P2/2! = 3!/1!/2! = 3
257
258.
이항정리 : 파스칼방식
다항식 (a+b)3의 전개식에서 각 항의 계수를 조
합의 수를 이용하여 나타내는 방법
258
단사 함수란?
단사(injective) 또는일대일(one-to-one)이라
하고 일대일인 함수를 단사함수(injection) 또는
일대일 함수(one-to-one function)이라 한다
262
263.
전사 함수란?
공역의 모든원소에게 정의역의 적어도 하나의 원소
를 대응시킨다면(즉, 치역이 공역과 같다면) 전사
(surjective) 또는 X에서 Y 로(onto)의 함수라 한다.
전사인 함수를 전사함수(surjection)이라 한다.
263
264.
전단사 함수란?
f:X→Y가 전사이고단사일 때 f를 전단사(bijective)
라 한다. 전단사인 함수를 전단사함수(bijection) 또
는 일대일 대응(one-to-one correspondence)라 한
다. one-to-one & onto라고도 많이 사용한다.
264
함수합성 function composition
함수의합성(函數의合成, function composition)은
한 함수의 공역이 다른 함수의 정의역과 일치하는 경
우 두 함수를 이어 하나의 함수로 만드는 연산이다.
이렇게 얻어진 함수를 합성 함수(合成函數
composite function)라고 한다.
269
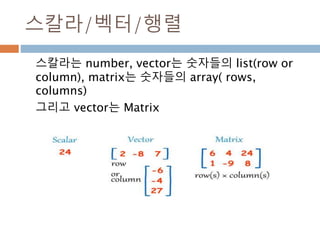
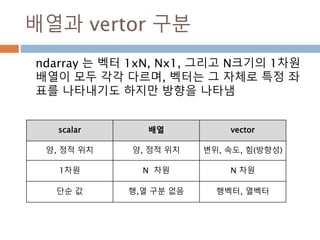
배열과 vertor 구분
ndarray는 벡터 1xN, Nx1, 그리고 N크기의 1차원
배열이 모두 각각 다르며, 벡터는 그 자체로 특정 좌
표를 나타내기도 하지만 방향을 나타냄
scalar 배열 vector
양, 정적 위치 양, 정적 위치 변위, 속도, 힘(방향성)
1차원 N 차원 N 차원
단순 값 행,열 구분 없음 행벡터, 열벡터
281
벡터: +
The vector(8,13) and the vector (26,7) add up to
the vector (34,20)
Example: add the vectors a = (8,13) and b = (26,7)
c = a + b
c = (8,13) + (26,7) = (8+26,13+7) = (34,20)
a
b
a
b
c
291
292.
Vector 연산: +
두벡터 평행 이동해 평행사변형을 만든 후 가운데
벡터가 실제 덧셈한 벡터를 표시
e
d
f
e
d
292
293.
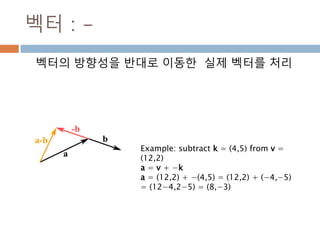
벡터 : -
벡터의방향성을 반대로 이동한 실제 벡터를 처리
Example: subtract k = (4,5) from v =
(12,2)
a = v + −k
a = (12,2) + −(4,5) = (12,2) + (−4,−5)
= (12−4,2−5) = (8,−3)
293
294.
Vector 연산: -
두벡터 반대 방향으로 평행 이동해 평행사변형을
만든 후 가운데 벡터가 실제 덧셈한 벡터를 표시
e
d
g
-e
-e
294
295.
벡터: 스칼라곱
벡터의 각원소에 스칼라값만큼 곱하여 표시
벡터 m = [7,3]
A = 3m= [21,9]
295
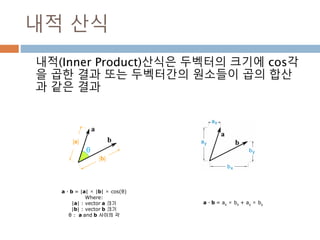
내적 산식
내적(Inner Product)산식은두벡터의 크기에 cos각
을 곱한 결과 또는 두벡터간의 원소들이 곱의 합산
과 같은 결과
a · b = |a| × |b| × cos(θ)
Where:
|a| : vector a 크기
|b| : vector b 크기
θ : a and b 사이의 각
a · b = ax × bx + ay × by
300
301.
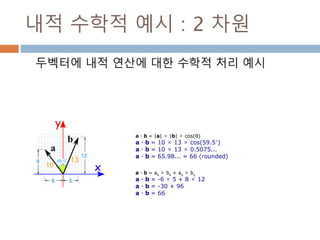
내적 수학적 예시: 2 차원
두벡터에 내적 연산에 대한 수학적 처리 예시
a · b = |a| × |b| × cos(θ)
a · b = 10 × 13 × cos(59.5°)
a · b = 10 × 13 × 0.5075...
a · b = 65.98... = 66 (rounded)
a · b = ax × bx + ay × by
a · b = -6 × 5 + 8 × 12
a · b = -30 + 96
a · b = 66
301
302.
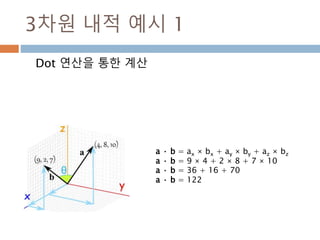
3차원 내적 예시1
Dot 연산을 통한 계산
a · b = ax × bx + ay × by + az × bz
a · b = 9 × 4 + 2 × 8 + 7 × 10
a · b = 36 + 16 + 70
a · b = 122
302
303.
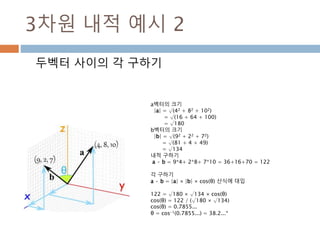
3차원 내적 예시2
두벡터 사이의 각 구하기
a벡터의 크기
|a| = √(42 + 82 + 102)
= √(16 + 64 + 100)
= √180
b벡터의 크기
|b| = √(92 + 22 + 72)
= √(81 + 4 + 49)
= √134
내적 구하기
a · b = 9*4+ 2*8+ 7*10 = 36+16+70 = 122
각 구하기
a · b = |a| × |b| × cos(θ) 산식에 대입
122 = √180 × √134 × cos(θ)
cos(θ) = 122 / (√180 × √134)
cos(θ) = 0.7855...
θ = cos-1(0.7855...) = 38.2...°
303
304.
내적(dot) 예시
두벡터에 대한내적(dot) 연산은 같은 위치의 원
소를 곱해서 합산함
두벡터의 곱셈은 단순히 원소를 곱해서 벡터를
유지
304
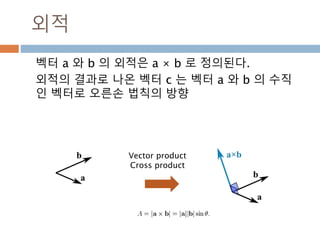
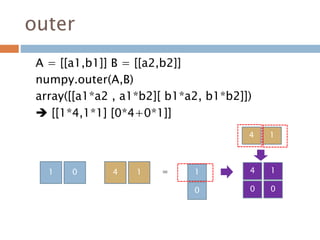
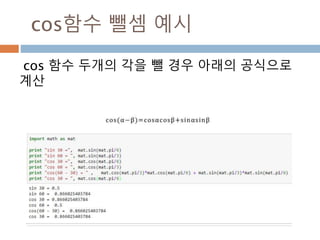
외적
벡터 a 와b 의 외적은 a × b 로 정의된다.
외적의 결과로 나온 벡터 c 는 벡터 a 와 b 의 수직
인 벡터로 오른손 법칙의 방향
Vector product
Cross product
307
308.
외적 산식 :2차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2]
u = [b1,b2]
a1 a2
b1 b2
a1*b2 – a2*b1 Example: The cross product of a = (2,3) and b = (5,6)
c = a1b2 − a2b1 = 2×6− 3×5 = −3
Answer: a × b = -3
308
309.
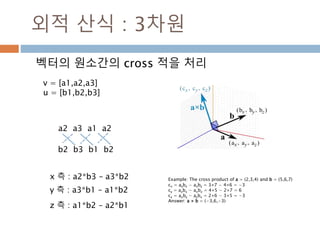
외적 산식 :3차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2,a3]
u = [b1,b2,b3]
a2 a3 a1 a2
b2 b3 b1 b2
x 측 : a2*b3 – a3*b2
y 측 : a3*b1 – a1*b2
z 측 : a1*b2 – a2*b1
Example: The cross product of a = (2,3,4) and b = (5,6,7)
cx = aybz − azby = 3×7 − 4×6 = −3
cy = azbx − axbz = 4×5 − 2×7 = 6
cz = axby − aybx = 2×6 − 3×5 = −3
Answer: a × b = (−3,6,−3)
309
310.
외적 산식예시
두벡터에 대한외적(cross) 연산은 다른 위치의
원소를 곱해서 뺄셈
2차원 벡터는 스칼라 값으로 나옴 3차원 벡터이
상 표시 됨
310
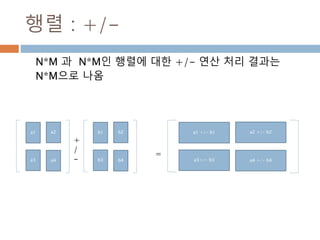
항등행렬
모든 행렬과 닷연산시 자기 자신이 나오게 하는
단위행렬
import numpy as np
a = np.array([[1,0],[0,1]])
b = np.array([[4,1],[3,2]])
print(np.dot(b,a))
print(np.dot(a,b))
[[4 1]
[3 2]]
[[4 1]
[3 2]]
334
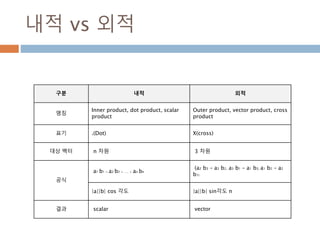
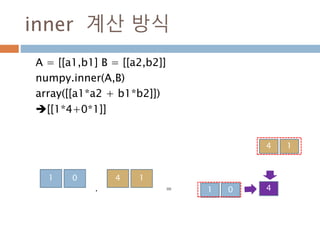
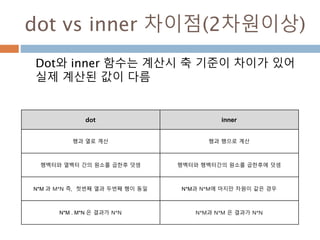
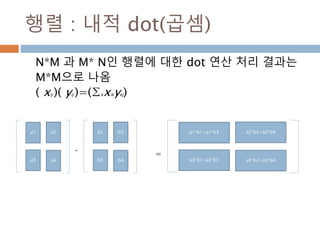
dot vs inner차이점(2차원이상)
Dot와 inner 함수는 계산시 축 기준이 차이가 있어
실제 계산된 값이 다름
dot inner
행과 열로 계산 행과 행으로 계산
행벡터와 열벡터 간의 원소를 곱한후 덧셈 행벡터와 행벡터간의 원소를 곱한후에 덧셈
N*M 과 M*N 즉, 첫번째 열과 두번째 행이 동일 N*M과 N*M에 마지만 차원이 같은 경우
N*M . M*N 은 결과가 N*N N*M과 N*M 은 결과가 N*N
344
345.
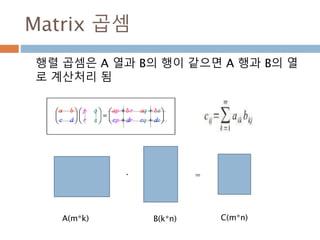
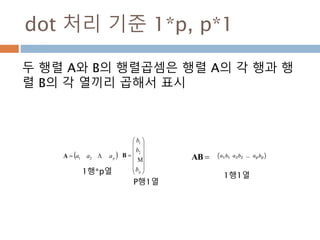
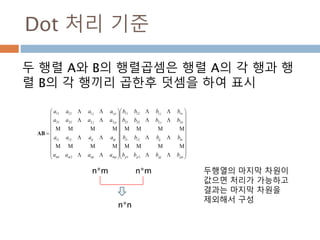
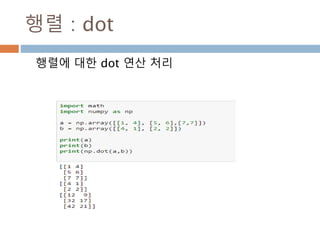
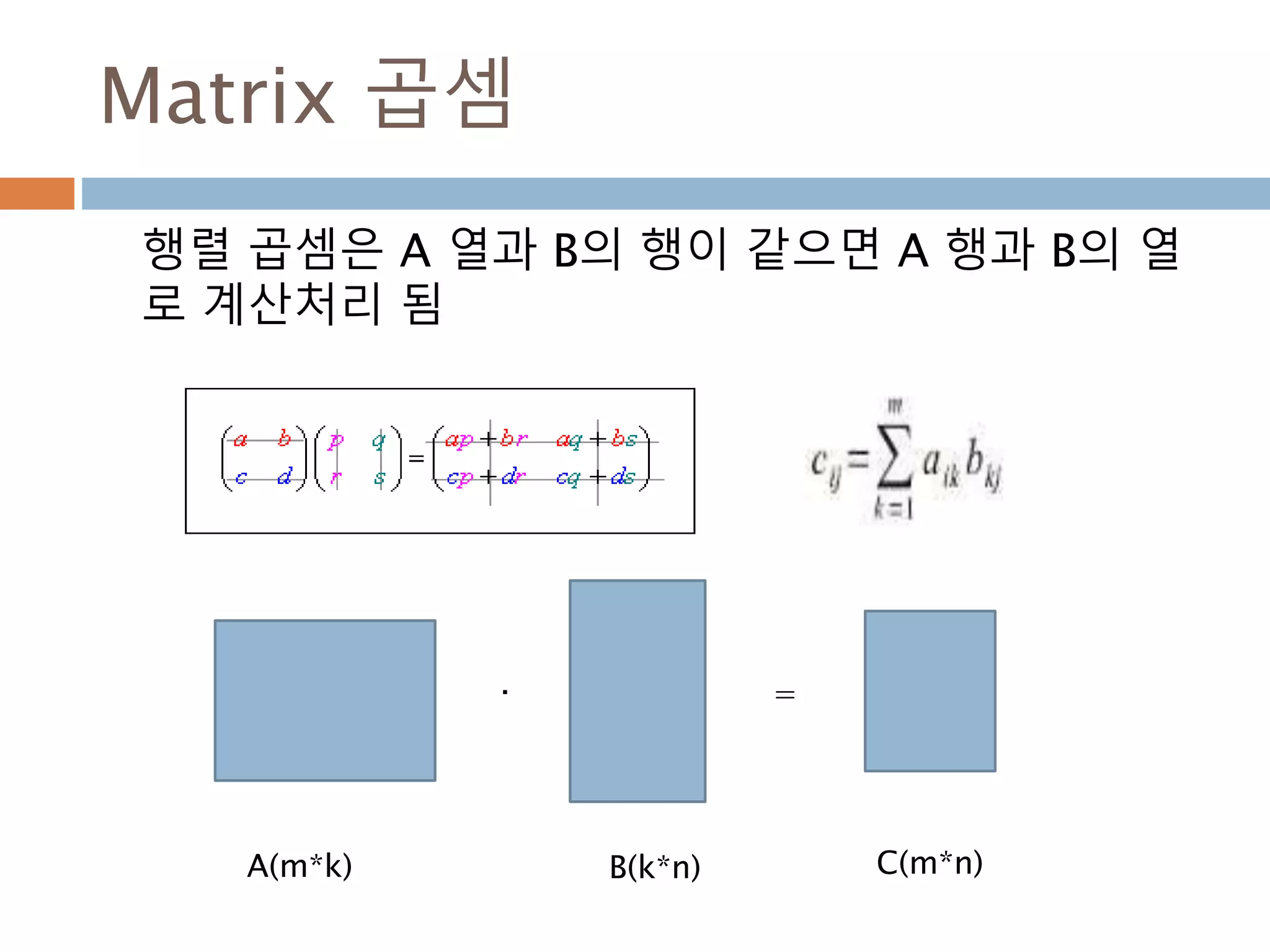
dot 처리 기준1*p, p*1
두 행렬 A와 B의 행렬곱셈은 행렬 A의 각 행과 행
렬 B의 각 열끼리 곱해서 표시
AB 𝑎1 𝑏1 𝑎2 𝑏2 … 𝑎 𝑝 𝑏 𝑝 paaa 21A
pb
b
b
2
1
B
1행*p열
P행1열
1행1열
345
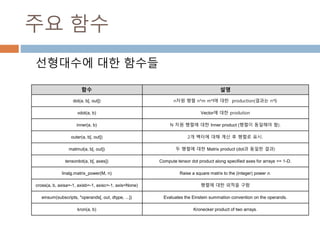
주요 함수
선형대수에 대한함수들
함수 설명
dot(a, b[, out]) n차원 행렬 n*m m*l에 대한 production(결과는 n*l)
vdot(a, b) Vector에 대한 prodution
inner(a, b) N 차원 행렬에 대한 Inner product (행렬이 동일해야 함).
outer(a, b[, out]) 2개 벡터에 대해 계산 후 행렬로 표시.
matmul(a, b[, out]) 두 행렬에 대한 Matrix product (dot과 동일한 결과)
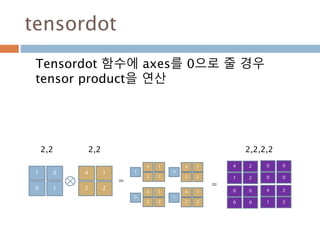
tensordot(a, b[, axes]) Compute tensor dot product along specified axes for arrays >= 1-D.
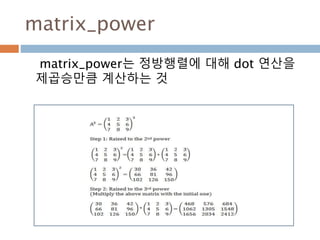
linalg.matrix_power(M, n) Raise a square matrix to the (integer) power n.
cross(a, b, axisa=-1, axisb=-1, axisc=-1, axis=None) 행렬에 대한 외적을 구함
einsum(subscripts, *operands[, out, dtype, ...]) Evaluates the Einstein summation convention on the operands.
kron(a, b) Kronecker product of two arrays.
408
주요 함수
선형대수에 대한함수들
함수 설명
linalg.cholesky(a) Cholesky decomposition.
linalg.qr(a[, mode]) Compute the qr factorization of a matrix.
linalg.svd(a[, full_matrices, compute_uv]) Singular Value Decomposition.
410
주요 함수
선형대수에 대한함수들
함수 설명
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
linalg.eigh(a[, UPLO]) Return the eigenvalues and eigenvectors of a Hermitian or symmetric matrix.
linalg.eigvals(a) Compute the eigenvalues of a general matrix.
linalg.eigvalsh(a[, UPLO]) Compute the eigenvalues of a Hermitian or real symmetric matrix.
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
412
주요 함수
선형대수에 대한함수들
함수 설명
linalg.norm(x[, ord, axis, keepdims]) Matrix or vector norm.
linalg.cond(x[, p]) Compute the condition number of a matrix.
linalg.det(a) Compute the determinant of an array.
linalg.matrix_rank(M[, tol])
Return matrix rank of array using SVD method Rank of the array is the number of SVD sing
ular values of the array that are greater than tol.
linalg.slogdet(a) Compute the sign and (natural) logarithm of the determinant of an array.
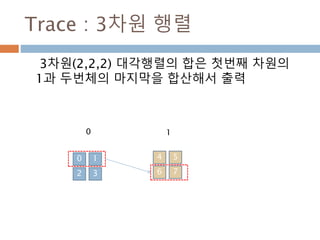
trace(a[, offset, axis1, axis2, dtype, out]) Return the sum along diagonals of the array.
414
주요 함수
선형대수에 대한함수들
함수 설명
linalg.solve(a, b) Solve a linear matrix equation, or system of linear scalar equations.
linalg.tensorsolve(a, b[, axes]) Solve the tensor equation a x = b for x.
linalg.lstsq(a, b[, rcond]) Return the least-squares solution to a linear matrix equation.
linalg.inv(a) Compute the (multiplicative) inverse of a matrix.
linalg.pinv(a[, rcond]) Compute the (Moore-Penrose) pseudo-inverse of a matrix.
linalg.tensorinv(a[, ind]) Compute the ‘inverse’ of an N-dimensional array.
416
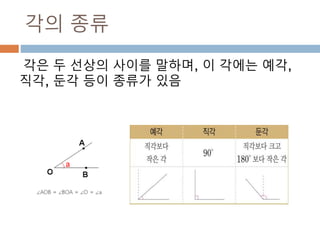
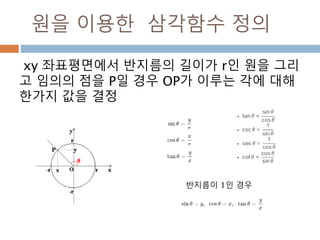
각의 변화를 알아보기
각은n*π/2 + θ 또는 90n + θ으로 변환해서
각의 위치에 따라 삼각함수를 변환
1. 나오는 각을 n*π/2 + θ 또는 90n + θ, 이때 n은
정수 이면 0< θ < π/2 , 0 < θ <90
2. n이 짝수이면 변하지 않지만 홀수이면
sin-> cos, cos-> sin, tan-> cot로 변환
3. 몇 사분면의 각이냐 에 따라 부호가(+,-)로 변환됨
1사분면 2사분면 3사분면 4사분면
sin + + - -
cos + - - +
tan + - + -
462
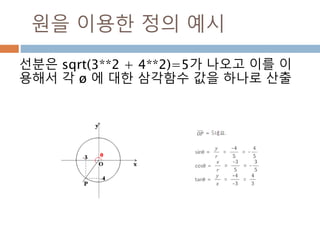
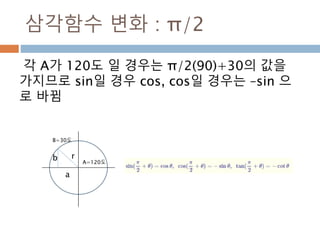
삼각함수 변화 :π/2
각 A가 120도 일 경우는 π/2(90)+30의 값을
가지므로 sin일 경우 cos, cos일 경우는 –sin 으
로 바뀜
r
a
b A=120도
B=30도
469
470.
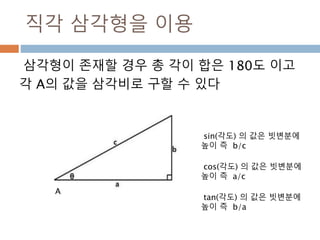
삼각함수의 변형 :90도 이내
직각 삼각형의 성질을 이용하면 직각을 빼면 나머지
각이 90도인 것을 감안하면, 각 B를 기준을 sin 함수
의 결과는 각 A를 기준으로 cos 함수 결과와 동일
A
B
cos(A) = sin(B), sin(B) = cos(A) , tan(B) = cot(A) 와 동일
각 A + 각 B = 90도
각 B로 삼각함수 처리
470
삼각함수의 변형 :180도 이내
180도 이내의 각으로 삼각함수를 계산할 경우
90도 + 나머지 각으로 삼각함수를 계산할 수 있
음
r
a
b A=120도
B=30도
sin(A) = cos(B) = b/r
cos(A) = - sin(B) = - a/r
tan(A) = - cot(B) = -b/a
472
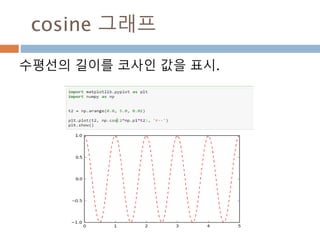
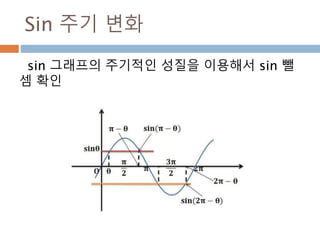
Sin 주기 변화
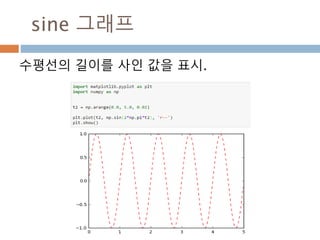
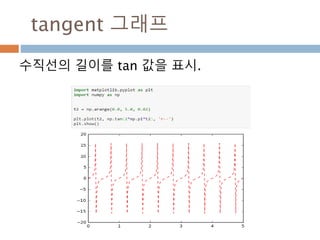
sin그래프의 주기적인 pi 와 2pi 배수 단위로
동일한 값을 처리 성질을 이용
475
476.
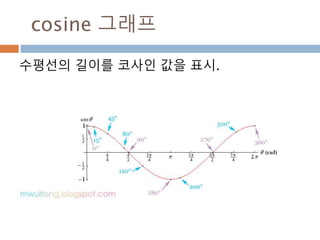
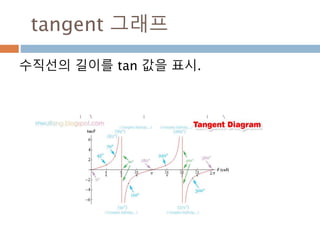
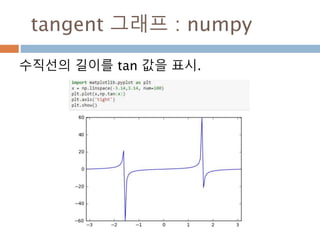
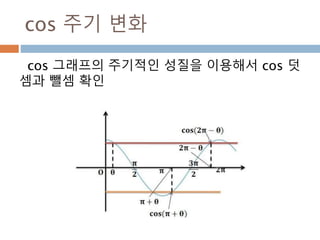
cos 주기 변화
cos그래프의 pi 와 2pi 배수 단위로 동일한 값
을 처리 성질을 이용
476
477.
삼각함수 변화 :π - 예각
180도 이내의 각으로 삼각함수를 계산할 경우
각 B에 대해 계산하는 것과 동일
r
a
b
B=30도
sin(π-B) = sin(B) = b/r
cos(π-B) = - cos(B) = - a/r
tan(π-B) = - tan(B) = -b/a
477
478.
삼각함수 변화 :π + 예각
각 A가 120도 일 경우는 π(180)+30의 값을 가
지므로 sin일 경우 sin, cos일 경우는 –cos 으로
바뀜
r
a
b
A=210도
B=30도
478
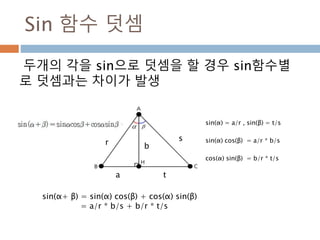
Sin 함수 덧셈
두개의각을 sin으로 덧셈을 할 경우 sin함수별
로 덧셈과는 차이가 발생
r
a
b
t
s
sin(α+ β) = sin(α) cos(β) + cos(α) sin(β)
= a/r * b/s + b/r * t/s
sin(α) cos(β) = a/r * b/s
cos(α) sin(β) = b/r * t/s
sin(α) = a/r , sin(β) = t/s
484
역수
어떤 수의 역수(逆數,영어: reciprocal) 또는 곱셈 역원(-
逆元, 영어: multiplicative inverse)은 그 수와 곱해서 1,
즉 곱셈 항등원이 되는 수를 말한다. x의 역수는 1/x
또는 x -1로 표기한다. 곱해서 1이 되는 두 수를 서로 역
수
493
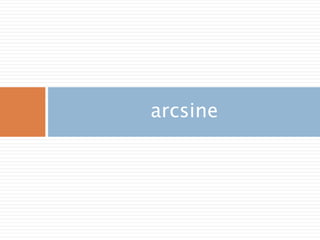
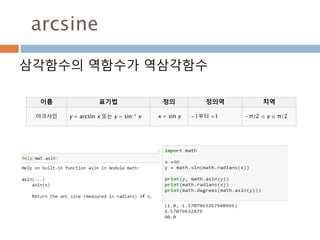
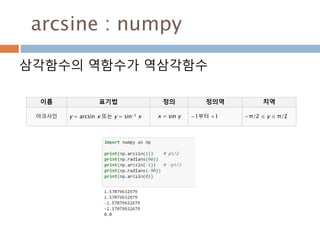
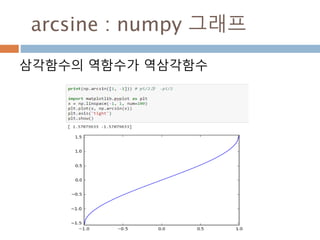
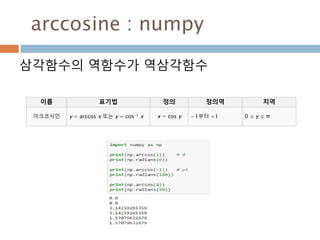
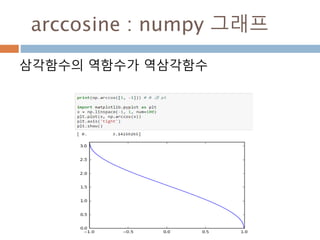
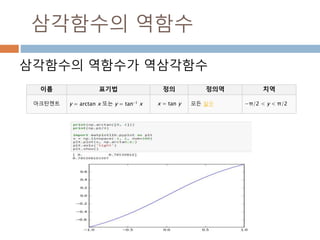
삼각함수의 역함수
삼각함수의 역함수가역삼각함수
이름 표기법 정의 정의역 치역
아크사인 y = arcsin x 또는 y = sin-1 x x = sin y −1부터 +1 −π/2 ≤ y ≤ π/2
아크코사인 y = arccos x 또는 y = cos-1 x x = cos y −1부터 +1 0 ≤ y ≤ π
아크탄젠트 y = arctan x 또는 y = tan-1 x x = tan y 모든 실수 −π/2 < y < π/2
아크코탄젠트 y = arccot x 또는 y = cot-1 x x = cot y 모든 실수 0 < y < π
아크시컨트 y = arcsec x 또는 y = sec-1 x x = sec y
−∞부터 −1과 1부
터 ∞
0 ≤ y < π/2 or π/
2 < y ≤ π
아크코시컨트 y = arccsc x 또는 y = csc-1 x x = csc y
−∞부터 −1과 1부
터 ∞
−π/2 ≤ y < 0 or 0
< y ≤ π/2
500
급수(級數,series, ∑an)
수학에서의 급수는수열 a_1, a_2, a_3, ... ,
a_na1,a2,a3,...,an까지 주어졌을 때 이것들을 다 더
해 a_1+a_2+a_3+...+a_n, a1+a2+a3+...+an로
나타낸 것, 즉 수열의 합을 의미한다.
급수의 예는 등차수열, 등비수열의 합, 자연수의 거
듭제곱의 합 등이 있다
538
539.
급수의 표현 1
Σ는 일반항 식을 가지고 시작항과 마지막 항까
지의 합을 표시하는 수학식
539
등차 수열의 합: 등차급수
등차급수( arithmetic series)는 등차수열의 합이
다. 초항부터 n번째 항까지의 합Sn는 다음과 같은
공식으로 나타난다
554
555.
등차 수열의 합의산식
하나의 등차수열과 이 등차수열을 역으로 변환해
서 더하며 동일한 패턴이 값이 나오고 이를 다시
하나(2로 나눔)로 만들면 합산 값이 됨
등차수열을 역순으로 만들고 합산
하면 동일한 결과를 가진 패턴이
나옴
패턴 찾을 것을 2로 나누면 수열
의 합이 계산됨
555
수열의 극한
수열의 극한(數列-極限,limit of a sequence)
은 수열이 한없이 가까워지는 값이다.
직관적으로, 수열 (an)이 수렴(收斂, convergent)
한다는 것은 n이 커짐에 따라 an이 어떤 고정된
값 a에 한없이 가까워지는 것을 뜻한다. 이때 a를
수열 {an}의 극한이라고 한다.
수열이 수렴하지 않으면 발산(發散, divergent)한
다고 한다.
569
수렴
한 점으로 모인다는뜻. 보통 의견 수렴이라든지
여론 수렴 등등으로 해서 한 점에 모인다는 의미
로 사용하는 경우가 많은데, 이 뜻을 수학으로 빌
려와서 여러 값이 기어코야 한 값으로 모이게 되
었다는 의미로 사용한다.
즉 x가 a에 한없이 가까워지거나 한없이 커지거
나 작아지면 f(x)도 어디로 한없이 가까워진다는
뜻.
573
574.
발산
수렴하지 않으면 발산한다.수열이 계속 커지는
양의 무한대로 발산, 수열이 계속 작아지는 음의
무한대로 발산이 있다.
574
미분가능한 함수 :differentiable function
미분은 함수 f(x)의 순간변화율을 계산하는 과정
이다.
f(x)에서 미분계수 f'(a) 가 존재할 때 미분 가능이
라고 한다.
정의역의 모든 점에서 미분가능한 함수이다.
즉, 모든 곳에서 수직이 아닌 접선을 그릴 수 있다
는 것이다
599
600.
미분가능
함수 f가 점x0에서 미분가능하다는 건 그 점에서
의 미분, 즉 평균변화율의 극한이 존재하는 것으
로 정의된다
600
정적분: definite integral
리만적분에서 다루는 고전적인 정의에 따르면 실수
의 척도를 사용하는 측도 공간에 나타낼 수 있는 연
속인 함수 f(x)에 대하여 그 함수의 정의역의 부분 집
합을 이루는 구간 [a, b] 에 대응하는 치역으로 이루
어진 곡선의 리만 합의 극한을 구하는 것이다. 이를
정적분(定積分, definite integral)이라 한다.
620
경우의 수 (numberof cases)
경우는 수는 사건에서 일어날 수 있는 경우의 가
짓수(원소의 개수)를 말하며, 합의 법칙과 곱의
법칙에 따라 경우의 수를 계산
같은 조건에서 여러 번 할 수 있는 실험이나
관찰로 얻어진 결과를 말한다.
즉, 어떤 실험이나 관찰에서 주어진 경우를
만족하는 경우의 집합
사건
시행 실험이나 관찰을 하는 행위
669
670.
합의 법칙
합의 법칙은두 사건 A,B가 동시에 일어나지 않을 때
각각의 사건이 일어날 경우의 수를 서로 더해서 구하
는 경우
사건 A가 일어나는 경우의 수 : m
사건 B가 일어나는 경우의 수 : n
사건 A 또는 B가 일어날 경우의 수 = m+n
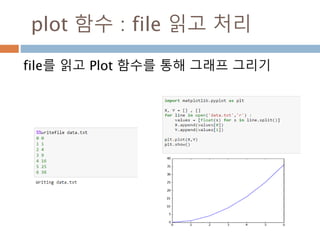
670
671.
곱의 법칙
곱의 법칙은두 사건 A,B가 동시에(연달아서) 일어날
때 각각의 사건이 일어날 경우의 수를 서로 곱해서
구하는 경우
사건 A 가 일어나는 경우의 수 : m
사건 B가 일어나는 경우의 수 : n
사건 A와 사건 b가 동시에 일어날 경우의 수 : m*n
671
672.
곱의 법칙:데카르트 곱
집합A의 원소와 집합 B의 원소인 순서쌍을 만드
는 집합
집합 A={a,b}, B= {1,2} 일때
A*B = {(a,1),(a,2),(b,1),(b,2)}
즉 2*2 = 4
672
673.
합/곱의 법칙 구별
동시에일어나는 사건을 경우 별개의 두 사건이 모두 발
생하는 것(곱의 법칙)이고, 별개의 두 사건이 있는 경우
둘다 일어나지 않아도 상관없는 것(합의 법칙)임
독립사건 A 또는 B가 일어나는 경우의 수를
구할 때에는 합의 법칙이 이용된다.
독립사건 A와 B가 동시에 일어나는 경우의 수
를 구할 때에는 곱의 법칙이 이용된다
673
연속확률분포
연속 확률분포는 확률밀도 함수를 이용해 분포
를 표현할 수 있는 경우를 의미한다. 연속 확률분
포를 가지는 확률변수는 연속 확률변수라고 부른
다.
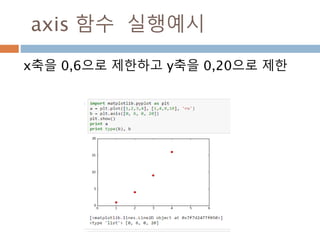
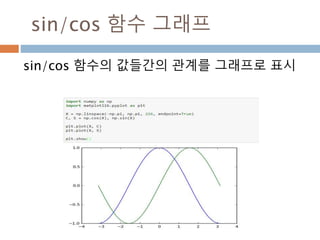
702
703.
확률밀도함수
확률밀도함수(probability density function약
자 PDF )f(x)는 일정한 값들의 범위를 포괄하는
연속확률변수의 확률을 찾는데 사용하고 연속데
이터에서의 확률을 구하기 위해서 확률밀도함수
의 면적을 구함
703
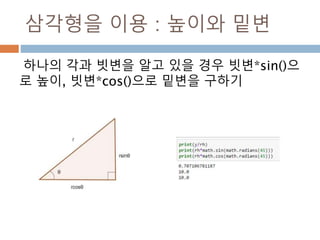
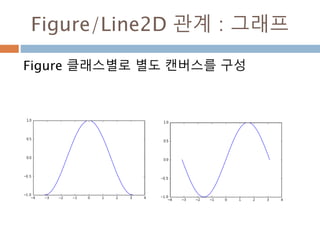
확률 밀도함수 f(x)와 구간[a,b] 에
대해 확률변수 X가 구간에 포함될
확률 P(a<= X<=b)는
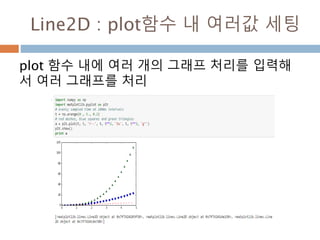
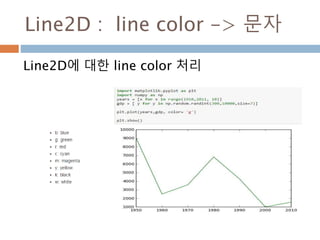
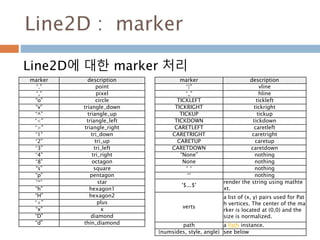
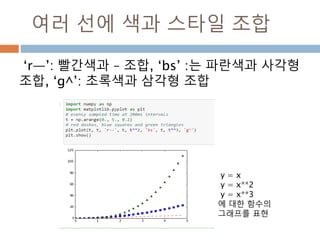
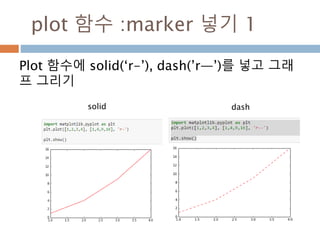
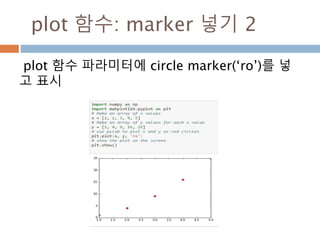
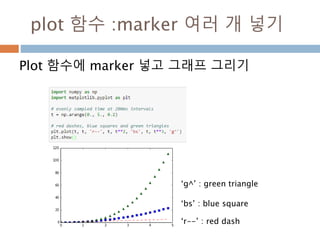
Line2D : marker
Line2D에대한 marker 처리
marker description
”.” point
”,” pixel
“o” circle
“v” triangle_down
“^” triangle_up
“<” triangle_left
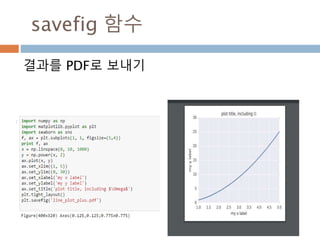
“>” triangle_right
“1” tri_down
“2” tri_up
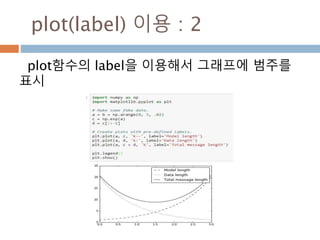
“3” tri_left
“4” tri_right
“8” octagon
“s” square
“p” pentagon
“*” star
“h” hexagon1
“H” hexagon2
“+” plus
“x” x
“D” diamond
“d” thin_diamond
marker description
“|” vline
“_” hline
TICKLEFT tickleft
TICKRIGHT tickright
TICKUP tickup
TICKDOWN tickdown
CARETLEFT caretleft
CARETRIGHT caretright
CARETUP caretup
CARETDOWN caretdown
“None” nothing
None nothing
” “ nothing
“” nothing
'$...$'
render the string using mathte
xt.
verts
a list of (x, y) pairs used for Pat
h vertices. The center of the ma
rker is located at (0,0) and the
size is normalized.
path a Path instance.
(numsides, style, angle) see below
748
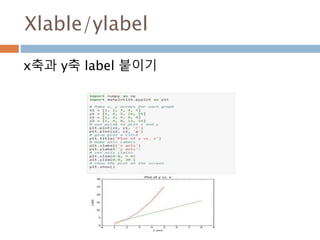
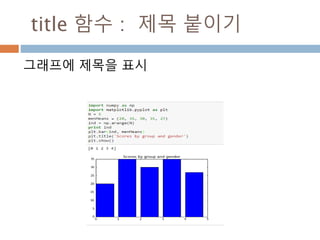
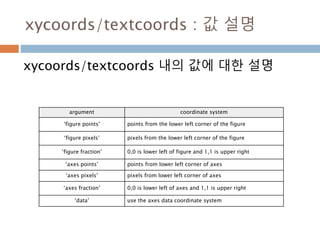
xycoords/textcoords : 값설명
xycoords/textcoords 내의 값에 대한 설명
argument coordinate system
‘figure points’ points from the lower left corner of the figure
‘figure pixels’ pixels from the lower left corner of the figure
‘figure fraction’ 0,0 is lower left of figure and 1,1 is upper right
‘axes points’ points from lower left corner of axes
‘axes pixels’ pixels from lower left corner of axes
‘axes fraction’ 0,0 is lower left of axes and 1,1 is upper right
‘data’ use the axes data coordinate system
814
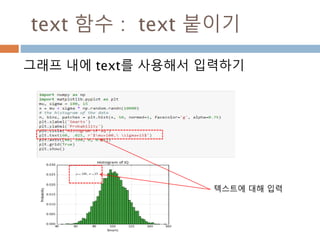
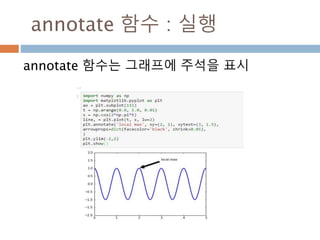
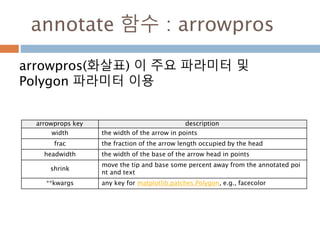
annotate 함수 :arrowpros
arrowpros(화살표) 이 주요 파라미터 및
Polygon 파라미터 이용
arrowprops key description
width the width of the arrow in points
frac the fraction of the arrow length occupied by the head
headwidth the width of the base of the arrow head in points
shrink
move the tip and base some percent away from the annotated poi
nt and text
**kwargs any key for matplotlib.patches.Polygon, e.g., facecolor
816
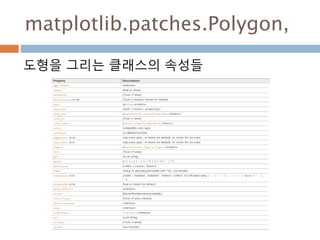
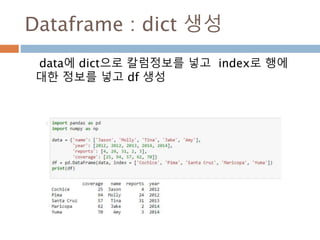
DataFrame 생성
n*m 행렬구조를가지는 데이터 구조 생성
class DataFrame(pandas.core.generic.NDFrame)
| 2차원 행렬
| Parameters
| ----------
| data : numpy.ndarray ,dict, or DataFrame
| dict can contain Series, arrays, constants, or list-like objects
| index : Index or array-like
| 행에 대한 정보 기본은 np.arange(n), 명칭도 부여 가능
| columns : Index or array-like
행에 대한 정보 기본은 np.arange(n), 명칭도 부여 가능
| dtype : dtype, default None
| Data type to force, otherwise infer
| copy : boolean, default False
| Copy data from inputs. Only affects DataFrame / 2d ndarray input
972
973.
DataFrame 구조
n*m 행렬구조를가지는 데이터 구조이고 index와
column이 별도의 명을 가지고, column별로 다른
데이터 타입을 가질 수 있음
Index(행)
Column(열)
col1 col2 col3
row1row2row3
973
974.
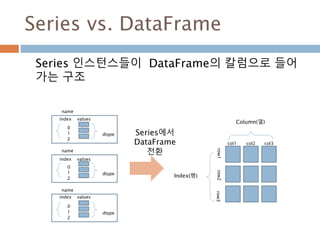
Series vs. DataFrame
Series인스턴스들이 DataFrame의 칼럼으로 들어
가는 구조
Index(행)
Column(열)
col1 col2 col3
row1row2row3
index
0
1
2
values
dtype
name
index
0
1
2
values
dtype
name
index
0
1
2
values
dtype
name
Series에서
DataFrame
전환
974
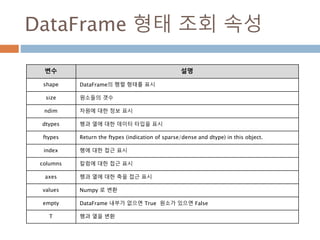
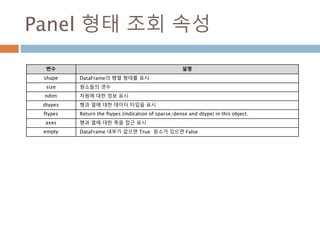
DataFrame 형태 조회속성
변수 설명
shape DataFrame의 행렬 형태를 표시
size 원소들의 갯수
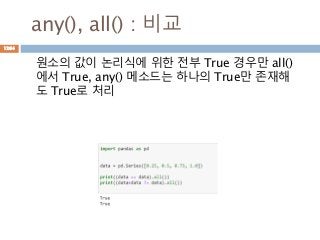
ndim 차원에 대한 정보 표시
dtypes 행과 열에 대한 데이터 타입을 표시
ftypes Return the ftypes (indication of sparse/dense and dtype) in this object.
index 행에 대한 접근 표시
columns 칼럼에 대한 접근 표시
axes 행과 열에 대한 축을 접근 표시
values Numpy 로 변환
empty DataFrame 내부가 없으면 True 원소가 있으면 False
T 행과 열을 변환
992
993.
DataFrame 생성
이름과 생일을한쌍을 만들어서 dataframe으로 생
성
Index(행)
Column(열)
col
1
col
2
row1row2row3
993
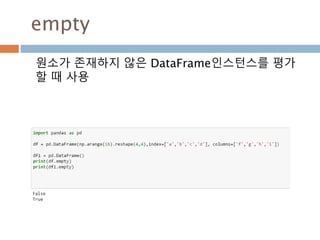
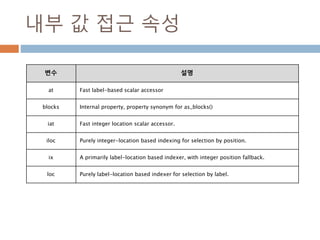
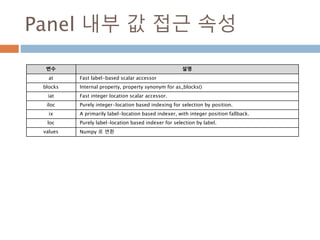
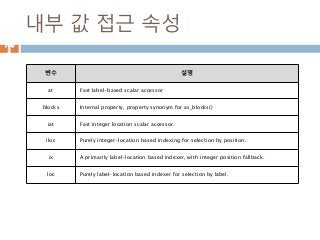
내부 값 접근속성
변수 설명
at Fast label-based scalar accessor
blocks Internal property, property synonym for as_blocks()
iat Fast integer location scalar accessor.
iloc Purely integer-location based indexing for selection by position.
ix A primarily label-location based indexer, with integer position fallback.
loc Purely label-location based indexer for selection by label.
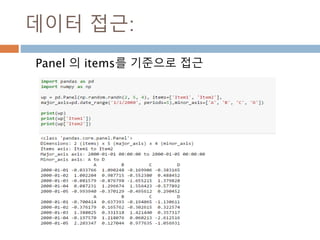
100
2
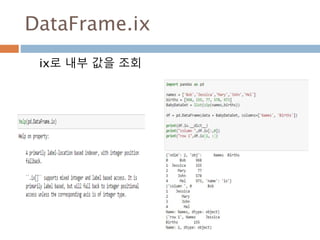
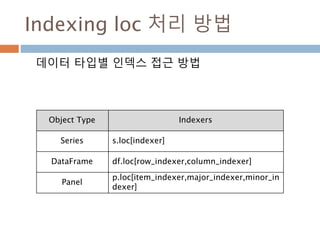
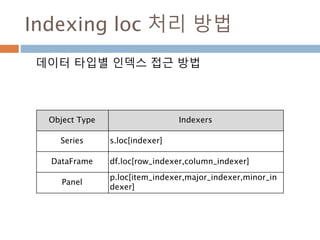
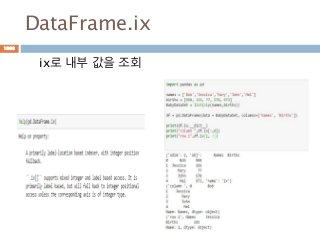
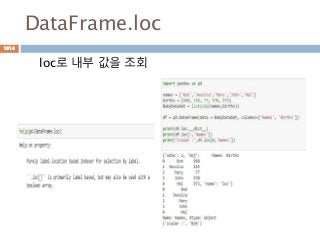
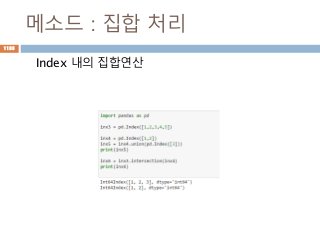
Indexing loc 처리방법
데이터 타입별 인덱스 접근 방법
Object Type Indexers
Series s.loc[indexer]
DataFrame df.loc[row_indexer,column_indexer]
Panel
p.loc[item_indexer,major_indexer,minor_in
dexer]
1013
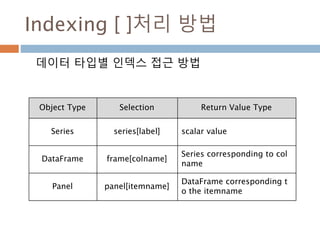
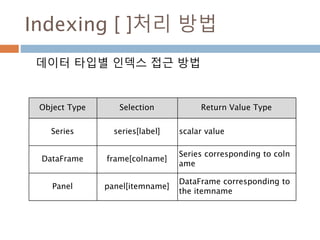
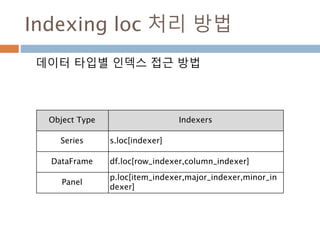
Indexing [ ]처리방법
데이터 타입별 인덱스 접근 방법
Object Type Selection Return Value Type
Series series[label] scalar value
DataFrame frame[colname]
Series corresponding to col
name
Panel panel[itemname]
DataFrame corresponding t
o the itemname
1021
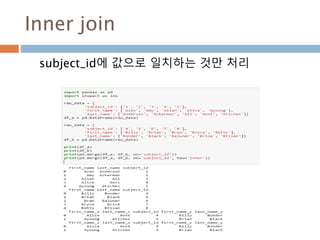
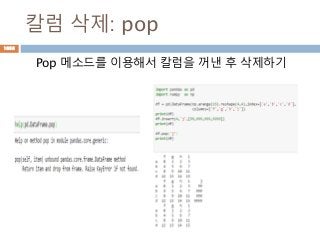
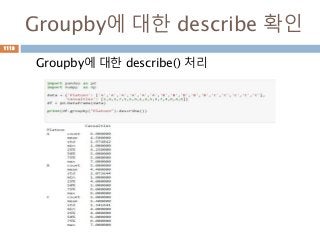
Groupby : 1칼럼
하나의칼럼을 기준으로 group화해서 칼럼들에 대
한 연산 처리
letter one two
0 a 1 2
1 a 1 2
2 b 1 2
3 b 1 2
4 c 1 2
one two
letter
a 2 4
b 2 4
c 1 2
1072
1073.
Groupby : 여러칼럼 1
칼럼기준을 그룹을 연계해서 서비스 진행하지만 인
덱스가 multi index로 변함
letter one two
0 a 1 2
1 a 1 2
2 b 1 2
3 b 1 2
4 c 1 2
two
letter one
a 1 4
b 1 4
c 1 2
1073
1074.
Groupby : 여러칼럼 2
as_index=False로 처리해서 grouby메소드 이후에
도 index구성이 변하지 않도록 처리
letter one two
0 a 1 2
1 a 1 2
2 b 1 2
3 b 1 2
4 c 1 2
letter one two
0 a 1 4
1 b 1 4
2 c 1 2
1074
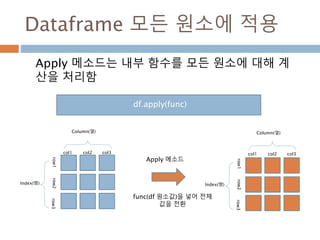
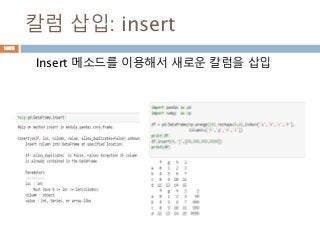
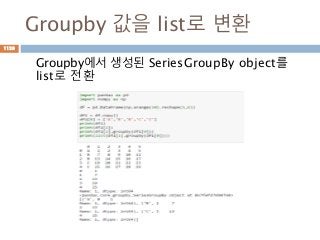
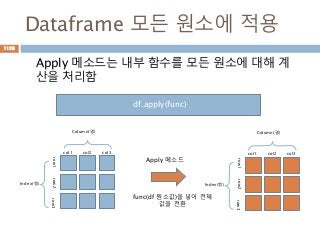
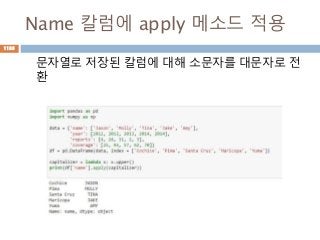
Dataframe 모든 원소에적용
Apply 메소드는 내부 함수를 모든 원소에 대해 계
산을 처리함
Index(행)
Column(열)
col1 col2 col3
row1row2row3
df.apply(func)
Apply 메소드
func(df 원소값)을 넣어 전체
값을 전환
Index(행)
Column(열)
col1 col2 col3
row1row2row3
1126
Index
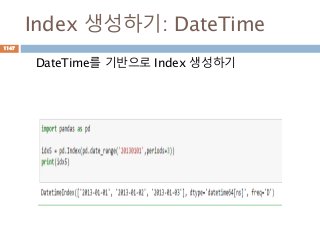
행과 열에 들어갈index 대한 메타데이터 객체화하
는 클래스
class Index(pandas.core.base.IndexOpsMixin, pandas.core.strings.StringAccessorMixin,
pandas.core.base.PandasObject)
| Immutable ndarray implementing an ordered, sliceable set. The basic object
| storing axis labels for all pandas objects
|
| Parameters
| ----------
| data : array-like (1-dimensional)
| dtype : NumPy dtype (default: object)
| copy : bool
| Make a copy of input ndarray
| name : object
| Name to be stored in the index
| tupleize_cols : bool (default: True)
| When True, attempt to create a MultiIndex if possible
1143
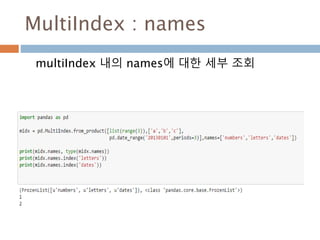
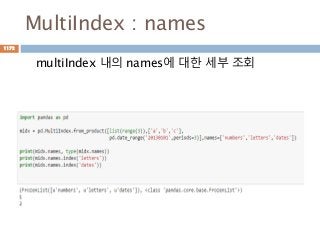
MultiIndex
Index나 column에 대한메타데이터에 대한 객체화
class MultiIndex(pandas.indexes.base.Index)
| A multi-level, or hierarchical, index object for pandas objects
|
| Parameters
| ----------
| levels : sequence of arrays
| The unique labels for each level
| labels : sequence of arrays
| Integers for each level designating which label at each location
| sortorder : optional int
| Level of sortedness (must be lexicographically sorted by that
| level)
| names : optional sequence of objects
| Names for each of the index levels. (name is accepted for compat)
| copy : boolean, default False
| Copy the meta-data
| verify_integrity : boolean, default True
| Check that the levels/labels are consistent and valid
|
1160
1161.
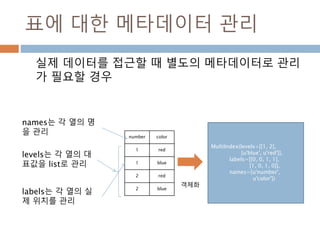
표에 대한 메타데이터관리
실제 데이터를 접근할 때 별도의 메타데이터로 관리
가 필요할 경우
MultiIndex(levels=[[1, 2],
[u'blue', u'red']],
labels=[[0, 0, 1, 1],
[1, 0, 1, 0]],
names=[u'number',
u'color'])
levels는 각 열의 대
표값을 list로 관리
number color
1 red
1 blue
2 red
2 blue
names는 각 열의 명
을 관리
labels는 각 열의 실
제 위치를 관리
객체화
1161
1162.
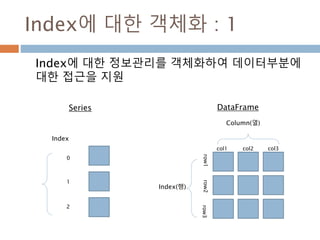
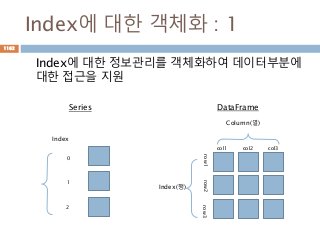
Index에 대한 객체화: 1
Index에 대한 정보관리를 객체화하여 데이터부분에
대한 접근을 지원
Index
0
1
2
Series
Index(행)
Column(열)
col1 col2 col3
row1row2row3
DataFrame
1162
1163.
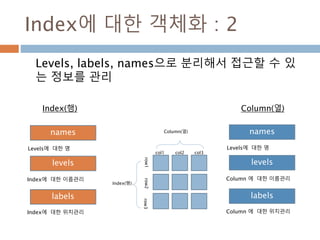
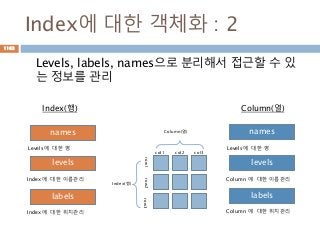
Index에 대한 객체화: 2
Levels, labels, names으로 분리해서 접근할 수 있
는 정보를 관리
Index(행)
Column(열)
col1 col2 col3
row1row2row3
levels
labels
names
Index에 대한 이름관리
Index에 대한 위치관리
Levels에 대한 명
levels
labels
names
Column 에 대한 이름관리
Column 에 대한 위치관리
Levels에 대한 명
Index(행) Column(열)
1163
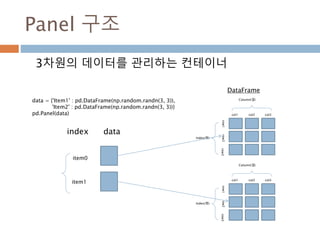
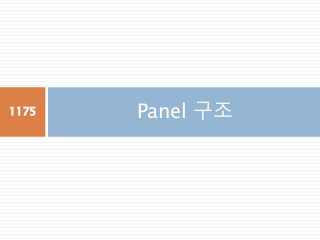
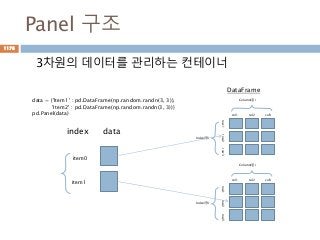
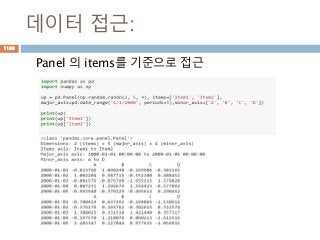
Panel 구조
3차원의 데이터를관리하는 컨테이너
index
item0
item1
data
Index(행)
Column(열)
col1 col2 col3
row1row2row3
DataFrame
Index(행)
Column(열)
col1 col2 col3
row1row2row3
data = {'Item1' : pd.DataFrame(np.random.randn(3, 3)),
'Item2' : pd.DataFrame(np.random.randn(3, 3))}
pd.Panel(data)
1176
1177.
Panel
items: axis 0,item은 dataframe과 매핑
major_axis: axis 1, 행으로 구성된 dataframe
minor_axis: axis 2, 열로 구성된 dataframe
class Panel(pandas.core.generic.NDFrame)
| Represents wide format panel data, stored as 3-dimensional array
|
| Parameters
| ----------
| data : ndarray (items x major x minor), or dict of DataFrames
| items : Index or array-like
| axis=0
| major_axis : Index or array-like
| axis=1
| minor_axis : Index or array-like
| axis=2
| dtype : dtype, default None
| Data type to force, otherwise infer
| copy : boolean, default False
| Copy data from inputs. Only affects DataFrame / 2d ndarray input
1177
1178.
Indexing loc 처리방법
데이터 타입별 인덱스 접근 방법
Object Type Indexers
Series s.loc[indexer]
DataFrame df.loc[row_indexer,column_indexer]
Panel
p.loc[item_indexer,major_indexer,minor_in
dexer]
1178
1179.
Indexing [ ]처리방법
데이터 타입별 인덱스 접근 방법
Object Type Selection Return Value Type
Series series[label] scalar value
DataFrame frame[colname]
Series corresponding to coln
ame
Panel panel[itemname]
DataFrame corresponding to
the itemname
1179
1180.
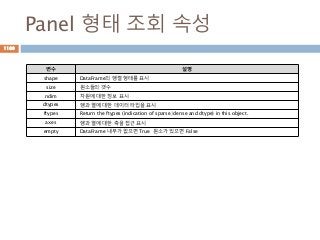
Panel 형태 조회속성
변수 설명
shape DataFrame의 행렬 형태를 표시
size 원소들의 갯수
ndim 차원에 대한 정보 표시
dtypes 행과 열에 대한 데이터 타입을 표시
ftypes Return the ftypes (indication of sparse/dense and dtype) in this object.
axes 행과 열에 대한 축을 접근 표시
empty DataFrame 내부가 없으면 True 원소가 있으면 False
1180
1181.
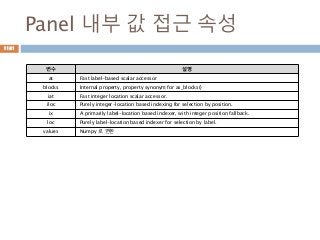
Panel 내부 값접근 속성
변수 설명
at Fast label-based scalar accessor
blocks Internal property, property synonym for as_blocks()
iat Fast integer location scalar accessor.
iloc Purely integer-location based indexing for selection by position.
ix A primarily label-location based indexer, with integer position fallback.
loc Purely label-location based indexer for selection by label.
values Numpy 로 변환
1181
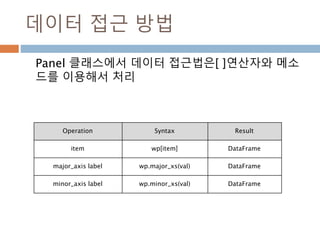
데이터 접근 방법
Panel클래스에서 데이터 접근법은[ ]연산자와 메소
드를 이용해서 처리
Operation Syntax Result
item wp[item] DataFrame
major_axis label wp.major_xs(val) DataFrame
minor_axis label wp.minor_xs(val) DataFrame
1187
Series 구조
1차원의 데이터를관리하는 컨테이너
index
0
1
2
pandas.Series(data,index,dtypes,name,copy)
data: 실제 데이터 값
index : 데이터를 접근할 정보
dtypes : 데이터들의 타입
name : Series 인스턴스의 이름
values
dtypes
1192
Indexing loc 처리방법
데이터 타입별 인덱스 접근 방법
Object Type Indexers
Series s.loc[indexer]
DataFrame df.loc[row_indexer,column_indexer]
Panel
p.loc[item_indexer,major_indexer,minor_in
dexer]
1194
1195.
Indexing [ ]처리방법
데이터 타입별 인덱스 접근 방법
Object Type Selection Return Value Type
Series series[label] scalar value
DataFrame frame[colname]
Series corresponding to coln
ame
Panel panel[itemname]
DataFrame corresponding to
the itemname
1195
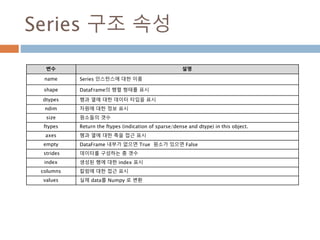
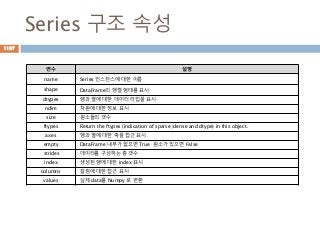
Series 구조 속성
변수설명
name Series 인스턴스에 대한 이름
shape DataFrame의 행렬 형태를 표시
dtypes 행과 열에 대한 데이터 타입을 표시
ndim 차원에 대한 정보 표시
size 원소들의 갯수
ftypes Return the ftypes (indication of sparse/dense and dtype) in this object.
axes 행과 열에 대한 축을 접근 표시
empty DataFrame 내부가 없으면 True 원소가 있으면 False
strides 데이터를 구성하는 총 갯수
index 생성된 행에 대한 index 표시
columns 칼럼에 대한 접근 표시
values 실제 data를 Numpy 로 변환
1197
Series 구조 속성:index,values,dtype
Series의 주요 속성인 values는 데이터를 나태내고
index는 series 인스턴스에 대한 index 정보를 가
짐
1199
1200.
Series 구조 속성: shape, ndim
주요 Series 모형과 차원에 대해 출력
1200
1201.
Series 구조 속성: strides, base
주요 Series 속성에 대해 출력
1201
1202.
Series 변환 속성
변수설명
blocks Internal property, property synonym for as_blocks()
T 행과 열을 변환
1202
1203.
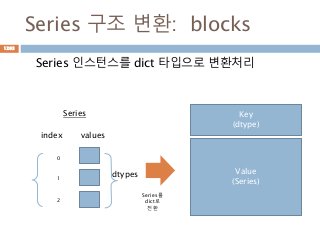
Series 구조 변환:blocks
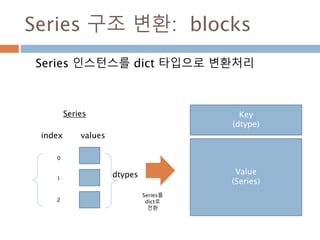
Series 인스턴스를 dict 타입으로 변환처리
dtypes
index
0
1
2
values
Key
(dtype)
Value
(Series)
Series
Series를
dict로
전환
1203
1204.
Series 구조 변환:blocks 예시
Series이 인스턴스에 대해 dict 타입으로 데이터를
표시
1204
1205.
Series 구조 변환:T
주요 Series 속성에 index, values를 교체해서 보여
줌
1205
1206.
Series 접근 속성
변수설명
at Fast label-based scalar accessor
iat Fast integer location scalar accessor.
ix A primarily label-location based indexer, with integer position fallback.
loc Purely label-location based indexer for selection by label.
iloc Purely integer-location based indexing for selection by position.
1206
1207.
Series 접근 속성:at,iat,loc,iloc,ix
주요 Series 인스턴스의 값을 접근하기 위해 at은
원소의 값, loc는 슬라이싱 처리를 포함해서 검색,
ix는 값을 검색
1207











![numpy.ndarray 변수 : 1
a = numpy.array([1,2,3])
변수 example Description
ndarray.ndim a = numpy.array([1,2,3])
>>> a.ndim
1
ndarray 객체에 대한 차원
ndarray.shape >>> a.shape
(3,)
ndarray 객체에 대한 다차원 모습
ndarray.size >>> a.size
3
ndarray 객체에 대한 원소의 갯수
ndarray.dtype >>> a.dtype
dtype(‘int32’)
ndarray 객체에 대한 원소 타입
ndarray.itemsize >>> a.itemsize
4
ndarray 객체에 대한 원소의 사이즈
ndarray.data >>> type(a.data)
>>> a.data.__str__()
'x01x00x00x00x02x00x
00x00x03x00x00x00'
ndarray 객체에 데이터는 itemsize 크기
의 hex값으로 표현
13](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-13-320.jpg)
![numpy.ndarray 변수 : 2
변수 example Description
ndarray.real i = np.array([1+2j, 2+3j])
i.real #array([ 1., 2.])
i.imag # array([ 2., 3.])
ndarray 에 생성된 복소수에서 실수값
ndarray.imag ndarray 에 생성된 복소수에서 허수값
ndarray.strides i.Strides #(16,) ndarray 객체에 대한 원소의 크기
ndarray.base x = np.array([1,2,3])
y = x[1:]
y.base is x # True
y.base # array([1, 2, 3])
ndarray 객체에 다른 곳에 할당할 경우 그
원천에 대한 것을 가지고 있음
ndarray.flat x = np.arange(1,7).reshape(2,3)
x # array([[1, 2, 3], [4, 5, 6]])
x.flat[3] # 4
x.T # array([[1, 4],[2, 5],[3, 6]])
x.T.flat[3] # 5
ndarray 객체가 차원을 가질 경우 하나로
연계해서 index로 처리
ndarray.T ndarray 객체에 대한 역핼력
14](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-14-320.jpg)














![ndarray 클래스 이해하기 1
ndarray는 각 원소별로 동일한 데이터 타입으로 처
리
원소 원소 원소array( [ ]), ,
33](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-33-320.jpg)
![ndarray 클래스 이해하기 2
ndarray는 각 원소내의 데이터 타입을 다양하게 구
성할 수 있음
원소 원소 원소
numpy.int_ numpy.float_ numpy.bool_
array( [ ]), ,( )
34](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-34-320.jpg)








![배열 이해하기
3행, 3열의 배열을 기준으로 어떻게 내부를 행과 열
로 처리하는 지를 이해
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
Index 접근 표기법
배열명[행][열]
배열명[행, 열]
Slice 접근 표기법
배열명[슬라이스, 슬라이스]
45](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-45-320.jpg)

















![배열 값 바꾸기 : Broadcasting
배열계산시 scalar 값과 계산시 크기가 작은 것을
동일한 크기로 계산되도록 확산이 발생
npl[2:5]는 원소가 3개에 스칼
라 값인 42를 할당했지만
[42,42,42]로 인식하여 처리
69](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-69-320.jpg)
















![vector 곱셈
벡터곱(vector곱, 영어: cross product) 또는 외적
(外積)은 수학에서 3차원 공간의 벡터들간의 이항연
산의 일종이다. 연산의 결과가 스칼라인 스칼라곱과
는 달리 연산의 결과가 벡터
a = [0,0,1]
b = [0,1,0]
a*b = [0-1,0-0,0-0] = [-1,0,0]
주요 산식 :
a*b = (a2b3−a3b2, a3b1−a1b3, a1b2−a2b1)
88](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-88-320.jpg)



![axis 이해하기 : 2차원
Axis는 배열의 축을 나타내며 0은 열이고, 1은
행을 표시
92
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
Row : 행
Column: 열
0
1
2
0 1 2](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-92-320.jpg)


![배열 접근하기
행과 열의 인덱스를 지정하면 실제 값에 접근해서
보여줌
배열명[ 행 범위, 열 범위]
96](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-96-320.jpg)
![배열 접근하기 : 행과 열구분
행으로 접근, 열로 접근
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
첫번째 행 접근
첫번째 열 접근
97](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-97-320.jpg)
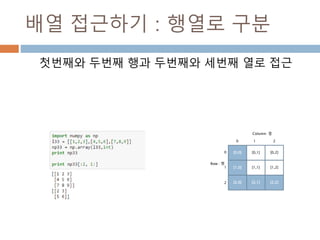
![배열 접근하기 : 행렬로 구분
첫번째와 두번째 행과 두번째와 세번째 열로 접근
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
98](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-98-320.jpg)
![배열 접근하기 : 값
행과 열의 인덱스를 지정하면 실제 값에 접근해서
보여줌
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
99](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-99-320.jpg)

![다차원 배열 : 열 조회/ 변경
7*4배열을 정의하고 첫번째 열의 값을 99으로
변경
배열명[행접근, 열접근]
Slicing도 행접근과 열접근으
로 별도로 할 수 있음
배열명[ 행 슬라이싱, 열 슬라
이싱] 으로 배열을 접근 가능
101](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-101-320.jpg)
![argmax/argmin
배열 내부의 최대값과 최소값에 대한 인덱스를 검
색 가능하고 [ ] 내부에 표시하면 값을 검색
102](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-102-320.jpg)


![다차원 배열 : 열 조회/ 변경
[data1 <0] =0 실제 배열의 원소들 값이 0보다 작
을 경우 0으로 전환
배열명[논리연산]
논리 연산 등 다양한 연산을
이용해서 배열 접근
105](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-105-320.jpg)






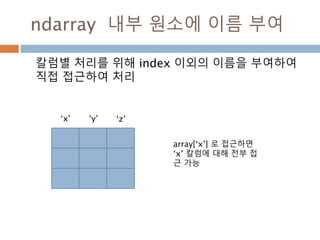




![ndarray 내부 원소에 이름 부여
칼럼별 처리를 위해 index 이외의 이름을 부여하여
직접 접근하여 처리
‘x’ ‘y’ ‘z’
array[‘x’] 로 접근하면
‘x’ 칼럼에 대해 전부 접
근 가능
117](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-117-320.jpg)






















![Little-endian
숫자를 저장할때 제일 왼쪽부터 저장됨
.
>>> ar = np.array([1,2,3])
>>> ar.tostring()
'x01x00x00x00x00x00x00x00x02x0
0x00x00x00x00x00x00x03x00x00x
00x00x00x00x00'
>>> l = ar.tosting()
>>> ar.itemsize
8
>>> l[0:8]
x01x00x00x00x00x00x00x00
x01x00x00x
00x00x00x00
x00
8bytes씩 저장하고
숫자는 첫번째부터
들어감
146](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-146-320.jpg)
![big-endian
숫자를 저장할때 제일 오른쪽부터 저장됨
.
>>> ar = np.array([1,2,3],dtype='>i8')
>>> ar.tostring()
'x00x00x00x00x00x00x00x01x00x0
0x00x00x00x00x00x02x00x00x00x
00x00x00x00x03’
>>> ar.dtype
dtype('>i8')
x00x00x00x00x0
0x00x00x01
8bytes씩 저장하고 숫자
는 마지막째부터 들어감
147](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-147-320.jpg)
![not-relevant
endian에 상관없이 문자를 저장할때 제일 왼쪽
부터 저장됨
.
>>> sr = np.array(['a','b',"abc"],dtype='|S10')
>>> sr.tostring()
'ax00x00x00x00x00x00x00x00x00bx00x
00x00x00x00x00x00x00x00abcx00x00x0
0x00x00x00x00’
>>> sr.dtype
dtype('S10')
>>> sr.tostring()[0:10]
'ax00x00x00x00x00x00x00x00x00'
10bytes씩 저장하
고 문자는 첫번째부
터 들어감
148](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-148-320.jpg)



![dtype 변수 - 3
Method Array example Description
descr import numpy as np
f_ = np.float_(1.0)
print f_.dtype.descr
print f_.dtype.hasobject
print f_.dtype.subdtype
print f_.dtype.base
print f_.dtype.kind
print f_.dtype.isnative
#결과값
[('', '<f8')]
False
None
Float64
F
True
Array interface 표시
hasobject any reference-counted objects in any
fields or sub-dtypes 가 존재시 True
subdtype
Tuple (item_dtype, shape) if this dtype
describes a sub-array, and None other
wise.
base 기본 정의된 타입
kind array-protocol type
isnative 파이썬 내부 byte order 사용여부
152](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-152-320.jpg)


![주요 함수
rand(d0, d1, ..., dn) 주어진 모양에 대해 0에서 1사이의 균등 분포 생성
randn(d0, d1, ..., dn) 주어진 모양에 대해 정규분포 값을 생성
randint(low[, high, size]) Return random integers from low (inclusive) to high (exclusive).
random_sample([size]) Return random floats in the half-open interval [0.0, 1.0).
random([size]) Return random floats in the half-open interval [0.0, 1.0).
ranf([size]) Return random floats in the half-open interval [0.0, 1.0).
sample([size]) Return random floats in the half-open interval [0.0, 1.0).
choice(a[, size, replace, p]) Generates a random sample from a given 1-D array ..
bytes(length) Return random bytes.
156](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-156-320.jpg)













![Binomial : 이항분포
n은 trial , p는 구간 [0,1]에 성공 P는 확률
이항 분포에서 작성한 것임
180](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-180-320.jpg)

![Distributions 1
beta(a, b[, size]) Draw samples from a Beta distribution.
binomial(n, p[, size]) Draw samples from a binomial distribution.
chisquare(df[, size]) Draw samples from a chi-square distribution.
dirichlet(alpha[, size]) Draw samples from the Dirichlet distribution.
exponential([scale, size]) Draw samples from an exponential distribution.
f(dfnum, dfden[, size]) Draw samples from an F distribution.
gamma(shape[, scale, size]) Draw samples from a Gamma distribution.
geometric(p[, size]) Draw samples from the geometric distribution.
gumbel([loc, scale, size]) Draw samples from a Gumbel distribution.
hypergeometric(ngood, nbad, nsample[, size]) Draw samples from a Hypergeometric distribution.
laplace([loc, scale, size])
Draw samples from the Laplace or double exponential
distribution with specified location (or mean) and scale
(decay).
183](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-183-320.jpg)
![Distributions 2
logistic([loc, scale, size]) Draw samples from a logistic distribution.
lognormal([mean, sigma, size]) Draw samples from a log-normal distribution.
logseries(p[, size]) Draw samples from a logarithmic series distribution.
multinomial(n, pvals[, size]) Draw samples from a multinomial distribution.
multivariate_normal(mean, cov[, size])
Draw random samples from a multivariate normal distr
ibution.
negative_binomial(n, p[, size]) Draw samples from a negative binomial distribution.
noncentral_chisquare(df, nonc[, size])
Draw samples from a noncentral chi-square distributio
n.
noncentral_f(dfnum, dfden, nonc[, size]) Draw samples from the noncentral F distribution.
normal([loc, scale, size])
Draw random samples from a normal (Gaussian) distri
bution.
pareto(a[, size])
Draw samples from a Pareto II or Lomax distribution w
ith specified shape.
poisson([lam, size]) Draw samples from a Poisson distribution.
184](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-184-320.jpg)
![Distributions 3
power(a[, size])
Draws samples in [0, 1] from a power distribution with positive ex
ponent a - 1.
rayleigh([scale, size]) Draw samples from a Rayleigh distribution.
standard_cauchy([size]) Draw samples from a standard Cauchy distribution with mode = 0.
standard_exponential([size]) Draw samples from the standard exponential distribution.
standard_gamma(shape[, size]) Draw samples from a standard Gamma distribution.
standard_normal([size])
Draw samples from a standard Normal distribution (mean=0, stde
v=1).
standard_t(df[, size])
Draw samples from a standard Student’s t distribution with df deg
rees of freedom.
triangular(left, mode, right[, size]) Draw samples from the triangular distribution.
uniform([low, high, size]) Draw samples from a uniform distribution.
vonmises(mu, kappa[, size]) Draw samples from a von Mises distribution.
wald(mean, scale[, size]) Draw samples from a Wald, or inverse Gaussian, distribution.
weibull(a[, size]) Draw samples from a Weibull distribution.
zipf(a[, size]) Draw samples from a Zipf distribution.
185](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-185-320.jpg)








![tile
A 배열에 대한 Reps는 axis 축에 따른 반복을 표시
numpy.tile(A, reps)
x = np.array([ [1, 2], [3, 4]])
np.tile(x, (3,4))
1. Reps가 스칼라 값은 배수만큼 증가
2. Reps가 벡터값 일 경우 행과 열에 따라 추가
200](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-200-320.jpg)

























































![벡터: 스칼라곱
벡터의 각 원소에 스칼라값만큼 곱하여 표시
벡터 m = [7,3]
A = 3m= [21,9]
295](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-295-320.jpg)








![외적 산식 : 2차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2]
u = [b1,b2]
a1 a2
b1 b2
a1*b2 – a2*b1 Example: The cross product of a = (2,3) and b = (5,6)
c = a1b2 − a2b1 = 2×6− 3×5 = −3
Answer: a × b = -3
308](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-308-320.jpg)
![외적 산식 : 3차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2,a3]
u = [b1,b2,b3]
a2 a3 a1 a2
b2 b3 b1 b2
x 측 : a2*b3 – a3*b2
y 측 : a3*b1 – a1*b2
z 측 : a1*b2 – a2*b1
Example: The cross product of a = (2,3,4) and b = (5,6,7)
cx = aybz − azby = 3×7 − 4×6 = −3
cy = azbx − axbz = 4×5 − 2×7 = 6
cz = axby − aybx = 2×6 − 3×5 = −3
Answer: a × b = (−3,6,−3)
309](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-309-320.jpg)
![inner 계산 방식
A = [[a1,b1] B = [[a2,b2]]
numpy.inner(A,B)
array([[a1*a2 + b1*b2]])
[[1*4+0*1]]
1 0 4 1
1 0
4 1
4=.
312](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-312-320.jpg)


![outer
A = [[a1,b1]] B = [[a2,b2]]
numpy.outer(A,B)
array([[a1*a2 , a1*b2][ b1*a2, b1*b2]])
[[1*4,1*1] [0*4+0*1]]
1 0 4 1 1
0
4 1
4 1
0 0
=
315](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-315-320.jpg)









![항등행렬
모든 행렬과 닷 연산시 자기 자신이 나오게 하는
단위행렬
import numpy as np
a = np.array([[1,0],[0,1]])
b = np.array([[4,1],[3,2]])
print(np.dot(b,a))
print(np.dot(a,b))
[[4 1]
[3 2]]
[[4 1]
[3 2]]
334](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-334-320.jpg)









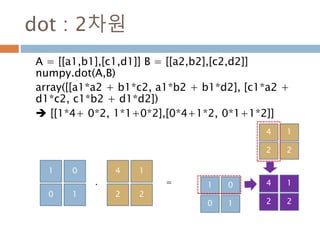
![dot : 2차원
A = [[a1,b1],[c1,d1]] B = [[a2,b2],[c2,d2]]
numpy.dot(A,B)
array([[a1*a2 + b1*c2, a1*b2 + b1*d2], [c1*a2 +
d1*c2, c1*b2 + d1*d2])
[[1*4+ 0*2, 1*1+0*2],[0*4+1*2, 0*1+1*2]]
1 0
0 1
4 1
2 2
1 0
0 1
4 1
2 2
4 1
2 2
=.
347](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-347-320.jpg)










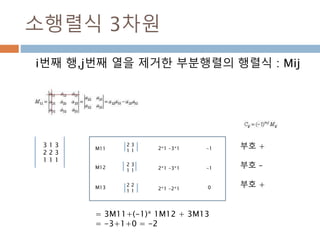
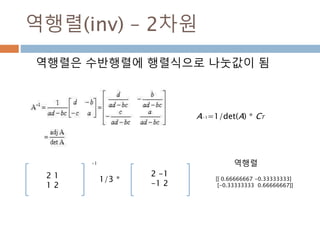
![역행렬(inv) – 2차원
역행렬은 수반행렬에 행렬식으로 나눗값이 됨
[[ 0.66666667 -0.33333333]
[-0.33333333 0.66666667]]
1/3 *
2 -1
-1 2
역행렬
2 1
1 2
-1
A−1=1/det(A) * CT
361](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-361-320.jpg)
![역행렬(inv) – 3차원
역행렬은 수반행렬에 행렬식으로 나눗값이 됨
[[ 0.5 -1. 1.5]
[-0.5 0. 1.5]
[ 0. 1. -2. ]]
- 0.5 *
-1 2 -3
1 0 -3
0 -2 4
역행렬3 1 3
2 2 3
1 1 1
-1
A−1=1/det(A) * CT
362](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-362-320.jpg)




![cross 계산 방식
A = [[a1,b1],[c1,d1]] B = [[a2,b2],[c2,d2]]
numpy.cross(A,B) = A.T * B
array([[a1*b2 - c1*a2 , b1*d2 – d1*c2])
[[1*1- 0*4,0*2-1*2]]
1 0
0 1
4 2
1 2
1 -2=
369](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-369-320.jpg)


![inner 계산 방식
A = [[a1,b1],[c1,d1]] B = [[a2,b2],[c2,d2]]
numpy.inner(A,B)
array([[a1*a2 + b1*b2, a1*c2 + b1*d2], [c1*a2 +
d1*b2, c1*c2 + d1*d2])
[[1*4+0*1,1*2+0*2],[0*4+1*1, 0*2+1*2]]
1 0
0 1
4 1
2 2
1 0
0 1
4 1
2 2
4 2
1 2
=.
372](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-372-320.jpg)
![Inner 예시 : 2차원
a(2,2) 행렬과 b(2,2)행렬의 마지막 차수가 같으
므로 계산결과는 out.shape = a.shape[:-1] +
b.shape[:-1]
373](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-373-320.jpg)
![Inner 예시 : 3차원
a(2,3,2) 행렬과 b(2,2)행렬의 마지막 차수가 같
으므로 계산결과는 out.shape = a.shape[:-1] +
b.shape[:-1]
374](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-374-320.jpg)


![outer: 1
Out는 두개의 벡터에 대한 행렬로 구성
out[i, j] = a[i] * b[j]
377](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-377-320.jpg)




![행렬
n개의 실수의 순서쌍에 성분별로 덧셈과 실수상수
곱을 주면[2] 이는 "nn차원" 벡터공간이라 할 수 있
고(, 벡터공간에서 벡터공간으로 가는 함수 중 덧셈
과 상수배를 보존하는 함수를 선형사상을 행렬이라
함
390](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-390-320.jpg)










![주요 함수
선형대수에 대한 함수들
함수 설명
dot(a, b[, out]) n차원 행렬 n*m m*l에 대한 production(결과는 n*l)
vdot(a, b) Vector에 대한 prodution
inner(a, b) N 차원 행렬에 대한 Inner product (행렬이 동일해야 함).
outer(a, b[, out]) 2개 벡터에 대해 계산 후 행렬로 표시.
matmul(a, b[, out]) 두 행렬에 대한 Matrix product (dot과 동일한 결과)
tensordot(a, b[, axes]) Compute tensor dot product along specified axes for arrays >= 1-D.
linalg.matrix_power(M, n) Raise a square matrix to the (integer) power n.
cross(a, b, axisa=-1, axisb=-1, axisc=-1, axis=None) 행렬에 대한 외적을 구함
einsum(subscripts, *operands[, out, dtype, ...]) Evaluates the Einstein summation convention on the operands.
kron(a, b) Kronecker product of two arrays.
408](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-408-320.jpg)
![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.cholesky(a) Cholesky decomposition.
linalg.qr(a[, mode]) Compute the qr factorization of a matrix.
linalg.svd(a[, full_matrices, compute_uv]) Singular Value Decomposition.
410](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-410-320.jpg)

![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
linalg.eigh(a[, UPLO]) Return the eigenvalues and eigenvectors of a Hermitian or symmetric matrix.
linalg.eigvals(a) Compute the eigenvalues of a general matrix.
linalg.eigvalsh(a[, UPLO]) Compute the eigenvalues of a Hermitian or real symmetric matrix.
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
412](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-412-320.jpg)

![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.norm(x[, ord, axis, keepdims]) Matrix or vector norm.
linalg.cond(x[, p]) Compute the condition number of a matrix.
linalg.det(a) Compute the determinant of an array.
linalg.matrix_rank(M[, tol])
Return matrix rank of array using SVD method Rank of the array is the number of SVD sing
ular values of the array that are greater than tol.
linalg.slogdet(a) Compute the sign and (natural) logarithm of the determinant of an array.
trace(a[, offset, axis1, axis2, dtype, out]) Return the sum along diagonals of the array.
414](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-414-320.jpg)
![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.solve(a, b) Solve a linear matrix equation, or system of linear scalar equations.
linalg.tensorsolve(a, b[, axes]) Solve the tensor equation a x = b for x.
linalg.lstsq(a, b[, rcond]) Return the least-squares solution to a linear matrix equation.
linalg.inv(a) Compute the (multiplicative) inverse of a matrix.
linalg.pinv(a[, rcond]) Compute the (Moore-Penrose) pseudo-inverse of a matrix.
linalg.tensorinv(a[, ind]) Compute the ‘inverse’ of an N-dimensional array.
416](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-416-320.jpg)



















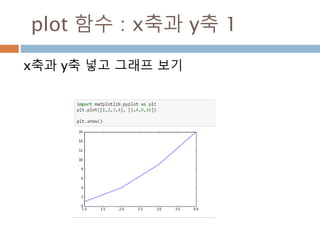











































![등차급수
등차급수[ arithmetic series , 等差級數 ]
산술급수(算術級數)라고도 한다. 등차수열을 이
루고 있는 것을 말 함
급수 a1+a2+a3+…+an+…에서
an=an-1+d(n=2,3,…) 인 관계식
급수로 표시
546](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-546-320.jpg)











































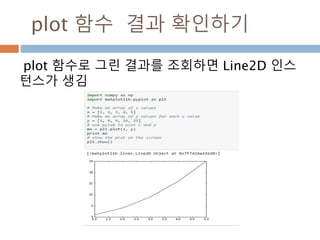
![정적분: definite integral
리만 적분에서 다루는 고전적인 정의에 따르면 실수
의 척도를 사용하는 측도 공간에 나타낼 수 있는 연
속인 함수 f(x)에 대하여 그 함수의 정의역의 부분 집
합을 이루는 구간 [a, b] 에 대응하는 치역으로 이루
어진 곡선의 리만 합의 극한을 구하는 것이다. 이를
정적분(定積分, definite integral)이라 한다.
620](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-620-320.jpg)





















































![확률밀도함수
확률밀도함수(probability density function 약
자 PDF )f(x)는 일정한 값들의 범위를 포괄하는
연속확률변수의 확률을 찾는데 사용하고 연속데
이터에서의 확률을 구하기 위해서 확률밀도함수
의 면적을 구함
703
확률 밀도함수 f(x)와 구간[a,b] 에
대해 확률변수 X가 구간에 포함될
확률 P(a<= X<=b)는](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-703-320.jpg)
![연속균등분포
연속균등분포(continuous uniform distribution)은
연속 확률 분포로, 분포가 특정 범위 내에서 균등하
게 나타나 있을 경우를 가리킨다. 이 분포는 두 개의
매개변수 a,b를 받으며, 이때 [a,b] 범위에서 균등한
확률을 가진다.
705](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-705-320.jpg)






























































































































































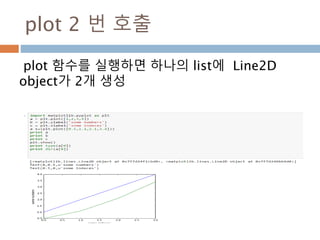
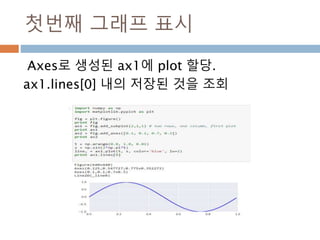
![첫번째 그래프 표시
Axes로 생성된 ax1에 plot 할당.
ax1.lines[0] 내의 저장된 것을 조회
893](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-893-320.jpg)

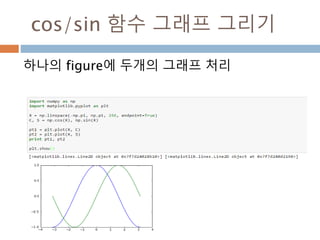
![첫번째 그래프 지우려면
del ax1.lines[0], ax1.lines.remove(line)으로
그래프 삭제
895](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-895-320.jpg)





























































































![DataFrame 행과열 검색 1
DataFrame은 ix 속성을 이용해서 행과 열을 동시
에 검색 ([ 행(슬라이싱 : ), 칼럼(명) ])
행
열
col1
row1row2row3
col2
1009](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1009-320.jpg)
![DataFrame 행과열 검색 2
DataFrame은 ix 속성을 이용해서 행과 복수의 열
을 동시에 검색 ([ 행(슬라이싱 : ), [칼럼명,칼럼명 ])
행
열
col1
row1row2row3
col2
1010](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1010-320.jpg)

![Indexing loc 처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Indexers
Series s.loc[indexer]
DataFrame df.loc[row_indexer,column_indexer]
Panel
p.loc[item_indexer,major_indexer,minor_in
dexer]
1013](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1013-320.jpg)

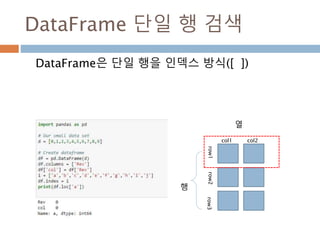
![DataFrame 단일 행 검색
DataFrame은 단일 행을 인덱스 방식([ ])
행
열
col1
row1row2row3
col2
1016](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1016-320.jpg)
![DataFrame 멀티 행 검색
DataFrame은 멀티행을 슬라이싱 방식([ : ])을 사용
하지만 이름으로 검색시에는 해당 이름까지 포함해
서 처리
행
열
col1
row1row2row3
col2
1017](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1017-320.jpg)



![Indexing [ ]처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Selection Return Value Type
Series series[label] scalar value
DataFrame frame[colname]
Series corresponding to col
name
Panel panel[itemname]
DataFrame corresponding t
o the itemname
1021](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1021-320.jpg)







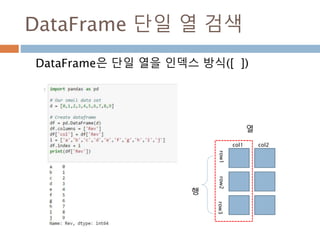
![DataFrame 단일 열 검색
DataFrame은 단일 열을 인덱스 방식([ ])
행
열
col1
row1row2row3
col2
1029](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1029-320.jpg)
![DataFrame 멀티 열 검색
DataFrame은 멀티 열은 슬라이스 방식([ [ , ] ])
을 사용하지만 칼럼명을 리스트로 작성해서 검색
행
열
col1
row1row2row3
col2
1030](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1030-320.jpg)
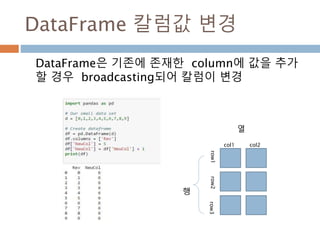
![DataFrame 접근: 사전형식
[“칼럼명”]으로 조회하면 칼럼 기준으로 접근해서
데이터 검색
1031](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1031-320.jpg)



![DataFrame 접근: swap처리
칼럼별 swap 처리를 하려면 indexinf[ ]처리하기
위해 리스트에 칼럼명을 사용해서 처리
1035](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1035-320.jpg)






































































![Groupby + mean: 2개 그룹
Groupby + mean 메소드를 사용해서 2개 그룹에
대한 평균값을 계산 groupby 내의 파라미터를
칼럼구분([ , ]) 처리
1123](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1123-320.jpg)





























![표에 대한 메타데이터 관리
실제 데이터를 접근할 때 별도의 메타데이터로 관리
가 필요할 경우
MultiIndex(levels=[[1, 2],
[u'blue', u'red']],
labels=[[0, 0, 1, 1],
[1, 0, 1, 0]],
names=[u'number',
u'color'])
levels는 각 열의 대
표값을 list로 관리
number color
1 red
1 blue
2 red
2 blue
names는 각 열의 명
을 관리
labels는 각 열의 실
제 위치를 관리
객체화
1161](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1161-320.jpg)









![Indexing loc 처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Indexers
Series s.loc[indexer]
DataFrame df.loc[row_indexer,column_indexer]
Panel
p.loc[item_indexer,major_indexer,minor_in
dexer]
1178](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1178-320.jpg)
![Indexing [ ]처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Selection Return Value Type
Series series[label] scalar value
DataFrame frame[colname]
Series corresponding to coln
ame
Panel panel[itemname]
DataFrame corresponding to
the itemname
1179](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1179-320.jpg)




![데이터 접근 방법
Panel 클래스에서 데이터 접근법은[ ]연산자와 메소
드를 이용해서 처리
Operation Syntax Result
item wp[item] DataFrame
major_axis label wp.major_xs(val) DataFrame
minor_axis label wp.minor_xs(val) DataFrame
1187](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1187-320.jpg)





![Indexing loc 처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Indexers
Series s.loc[indexer]
DataFrame df.loc[row_indexer,column_indexer]
Panel
p.loc[item_indexer,major_indexer,minor_in
dexer]
1194](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1194-320.jpg)
![Indexing [ ]처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Selection Return Value Type
Series series[label] scalar value
DataFrame frame[colname]
Series corresponding to coln
ame
Panel panel[itemname]
DataFrame corresponding to
the itemname
1195](https://image.slidesharecdn.com/pythonnumpy-160804042235/85/Python_numpy_pandas_matplotlib-_20160815-1195-320.jpg)











































































![numpy.ndarray 변수 : 1
a = numpy.array([1,2,3])
변수 example Description
ndarray.ndim a = numpy.array([1,2,3])
>>> a.ndim
1
ndarray 객체에 대한 차원
ndarray.shape >>> a.shape
(3,)
ndarray 객체에 대한 다차원 모습
ndarray.size >>> a.size
3
ndarray 객체에 대한 원소의 갯수
ndarray.dtype >>> a.dtype
dtype(‘int32’)
ndarray 객체에 대한 원소 타입
ndarray.itemsize >>> a.itemsize
4
ndarray 객체에 대한 원소의 사이즈
ndarray.data >>> type(a.data)
>>> a.data.__str__()
'x01x00x00x00x02x00x
00x00x03x00x00x00'
ndarray 객체에 데이터는 itemsize 크기
의 hex값으로 표현
13](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-13-2048.jpg)
![numpy.ndarray 변수 : 2
변수 example Description
ndarray.real i = np.array([1+2j, 2+3j])
i.real #array([ 1., 2.])
i.imag # array([ 2., 3.])
ndarray 에 생성된 복소수에서 실수값
ndarray.imag ndarray 에 생성된 복소수에서 허수값
ndarray.strides i.Strides #(16,) ndarray 객체에 대한 원소의 크기
ndarray.base x = np.array([1,2,3])
y = x[1:]
y.base is x # True
y.base # array([1, 2, 3])
ndarray 객체에 다른 곳에 할당할 경우 그
원천에 대한 것을 가지고 있음
ndarray.flat x = np.arange(1,7).reshape(2,3)
x # array([[1, 2, 3], [4, 5, 6]])
x.flat[3] # 4
x.T # array([[1, 4],[2, 5],[3, 6]])
x.T.flat[3] # 5
ndarray 객체가 차원을 가질 경우 하나로
연계해서 index로 처리
ndarray.T ndarray 객체에 대한 역핼력
14](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-14-2048.jpg)















![ndarray 클래스 이해하기 1
ndarray는 각 원소별로 동일한 데이터 타입으로 처
리
원소 원소 원소array( [ ]), ,
33](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-33-2048.jpg)
![ndarray 클래스 이해하기 2
ndarray는 각 원소내의 데이터 타입을 다양하게 구
성할 수 있음
원소 원소 원소
numpy.int_ numpy.float_ numpy.bool_
array( [ ]), ,( )
34](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-34-2048.jpg)








![배열 이해하기
3행, 3열의 배열을 기준으로 어떻게 내부를 행과 열
로 처리하는 지를 이해
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
Index 접근 표기법
배열명[행][열]
배열명[행, 열]
Slice 접근 표기법
배열명[슬라이스, 슬라이스]
45](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-45-2048.jpg)

















![배열 값 바꾸기 : Broadcasting
배열계산시 scalar 값과 계산시 크기가 작은 것을
동일한 크기로 계산되도록 확산이 발생
npl[2:5]는 원소가 3개에 스칼
라 값인 42를 할당했지만
[42,42,42]로 인식하여 처리
69](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-69-2048.jpg)
















![vector 곱셈
벡터곱(vector곱, 영어: cross product) 또는 외적
(外積)은 수학에서 3차원 공간의 벡터들간의 이항연
산의 일종이다. 연산의 결과가 스칼라인 스칼라곱과
는 달리 연산의 결과가 벡터
a = [0,0,1]
b = [0,1,0]
a*b = [0-1,0-0,0-0] = [-1,0,0]
주요 산식 :
a*b = (a2b3−a3b2, a3b1−a1b3, a1b2−a2b1)
88](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-88-2048.jpg)



![axis 이해하기 : 2차원
Axis는 배열의 축을 나타내며 0은 열이고, 1은
행을 표시
92
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
Row : 행
Column: 열
0
1
2
0 1 2](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-92-2048.jpg)



![배열 접근하기
행과 열의 인덱스를 지정하면 실제 값에 접근해서
보여줌
배열명[ 행 범위, 열 범위]
96](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-96-2048.jpg)
![배열 접근하기 : 행과 열구분
행으로 접근, 열로 접근
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
첫번째 행 접근
첫번째 열 접근
97](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-97-2048.jpg)
![배열 접근하기 : 행렬로 구분
첫번째와 두번째 행과 두번째와 세번째 열로 접근
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
98](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-98-2048.jpg)
![배열 접근하기 : 값
행과 열의 인덱스를 지정하면 실제 값에 접근해서
보여줌
[0,0] [0,1] [0,2]
[1,0] [1,1] [1,2]
[2,0] [2,1] [2,2]
Row : 행
Column: 열
0
1
2
0 1 2
99](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-99-2048.jpg)

![다차원 배열 : 열 조회/ 변경
7*4배열을 정의하고 첫번째 열의 값을 99으로
변경
배열명[행접근, 열접근]
Slicing도 행접근과 열접근으
로 별도로 할 수 있음
배열명[ 행 슬라이싱, 열 슬라
이싱] 으로 배열을 접근 가능
101](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-101-2048.jpg)
![argmax/argmin
배열 내부의 최대값과 최소값에 대한 인덱스를 검
색 가능하고 [ ] 내부에 표시하면 값을 검색
102](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-102-2048.jpg)


![다차원 배열 : 열 조회/ 변경
[data1 <0] =0 실제 배열의 원소들 값이 0보다 작
을 경우 0으로 전환
배열명[논리연산]
논리 연산 등 다양한 연산을
이용해서 배열 접근
105](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-105-2048.jpg)






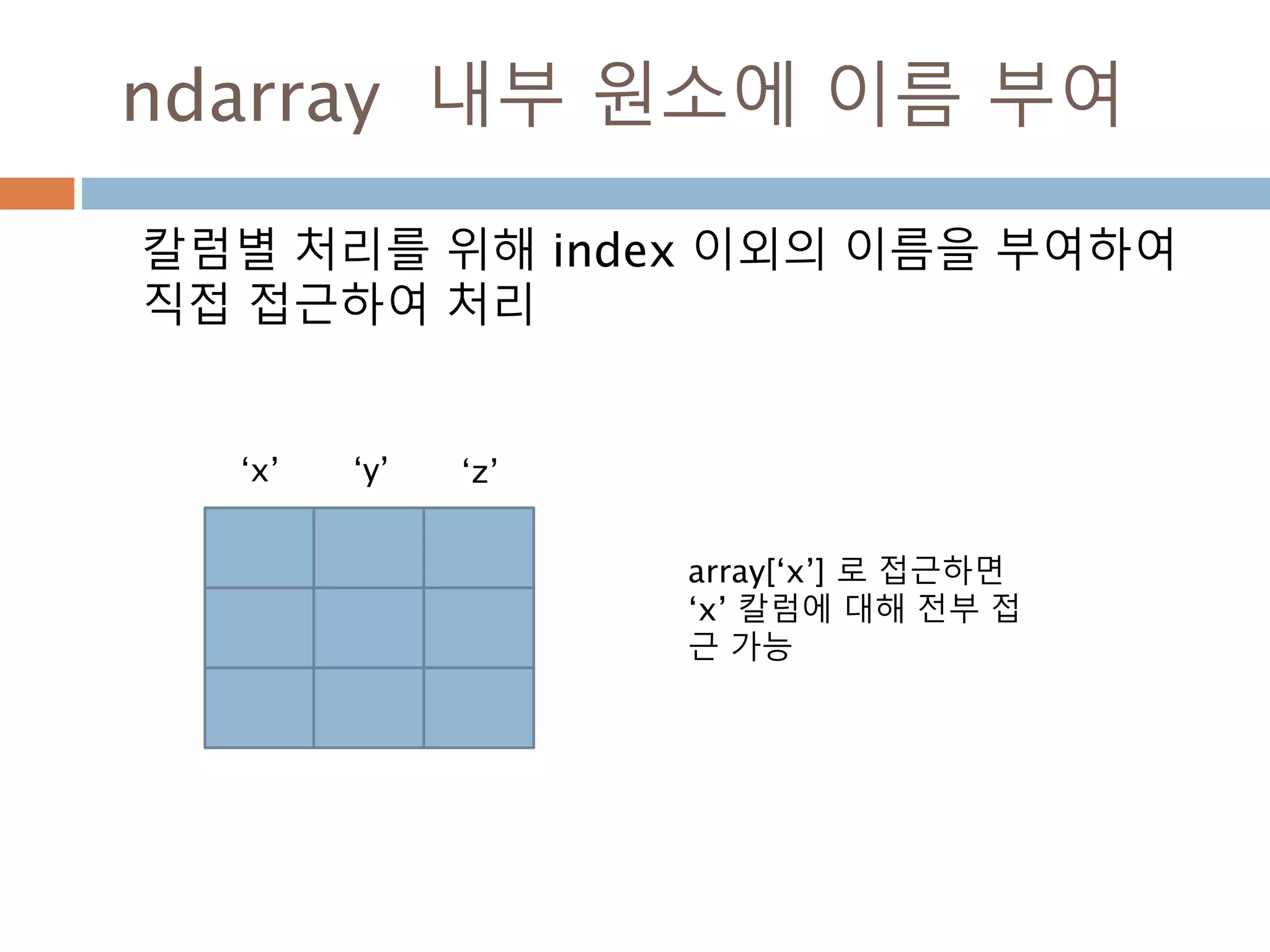




![ndarray 내부 원소에 이름 부여
칼럼별 처리를 위해 index 이외의 이름을 부여하여
직접 접근하여 처리
‘x’ ‘y’ ‘z’
array[‘x’] 로 접근하면
‘x’ 칼럼에 대해 전부 접
근 가능
117](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-117-2048.jpg)











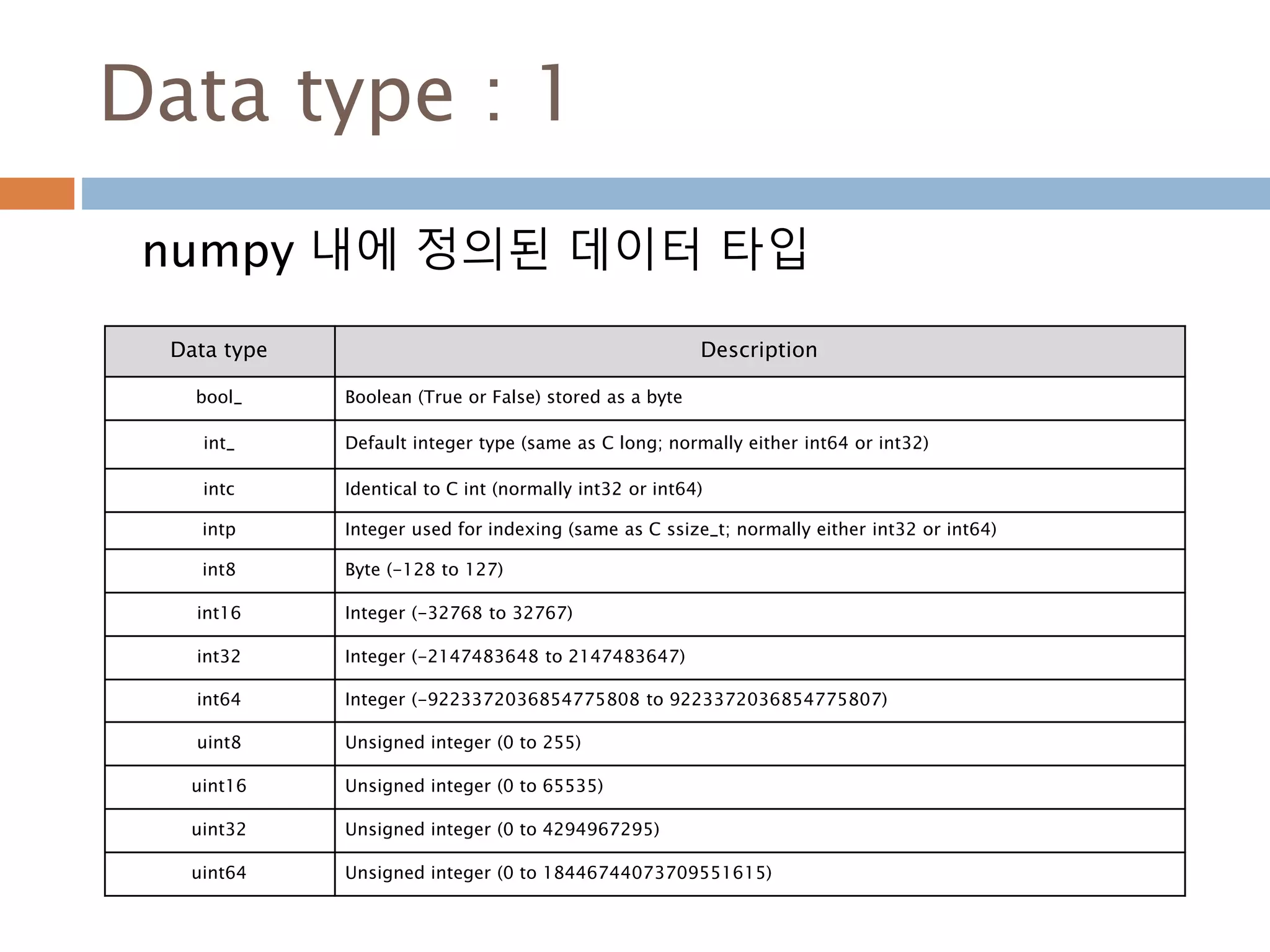
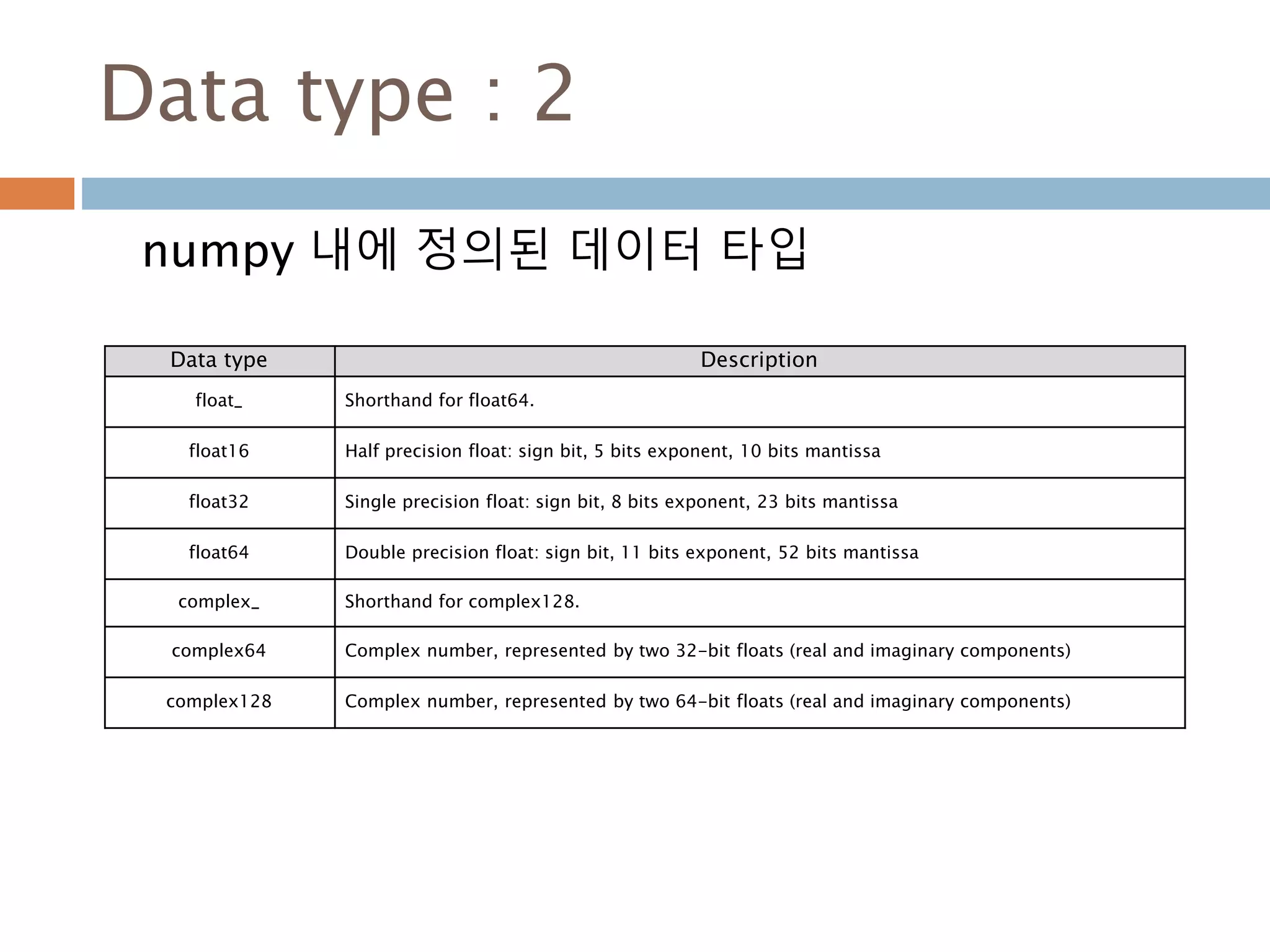





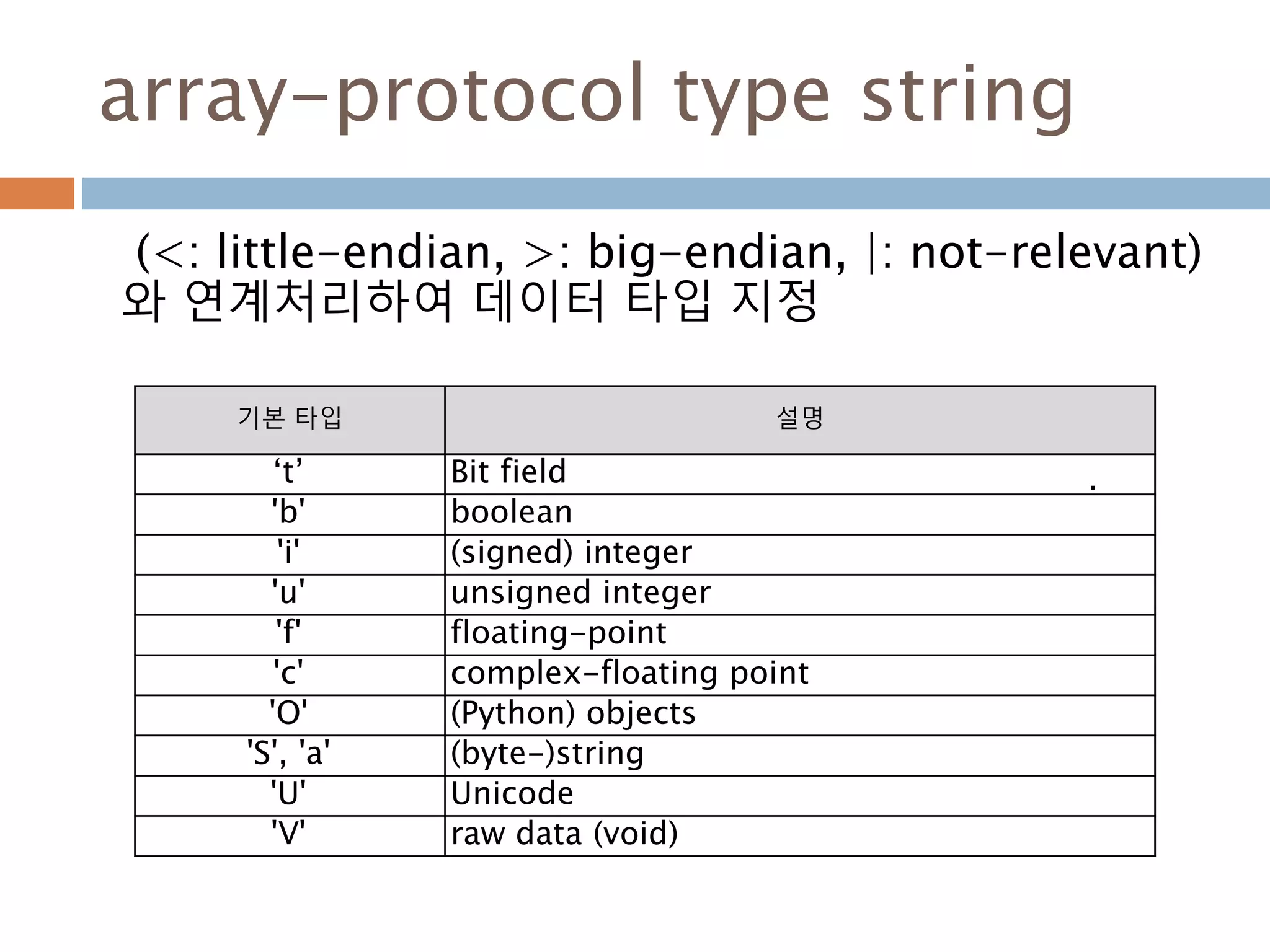
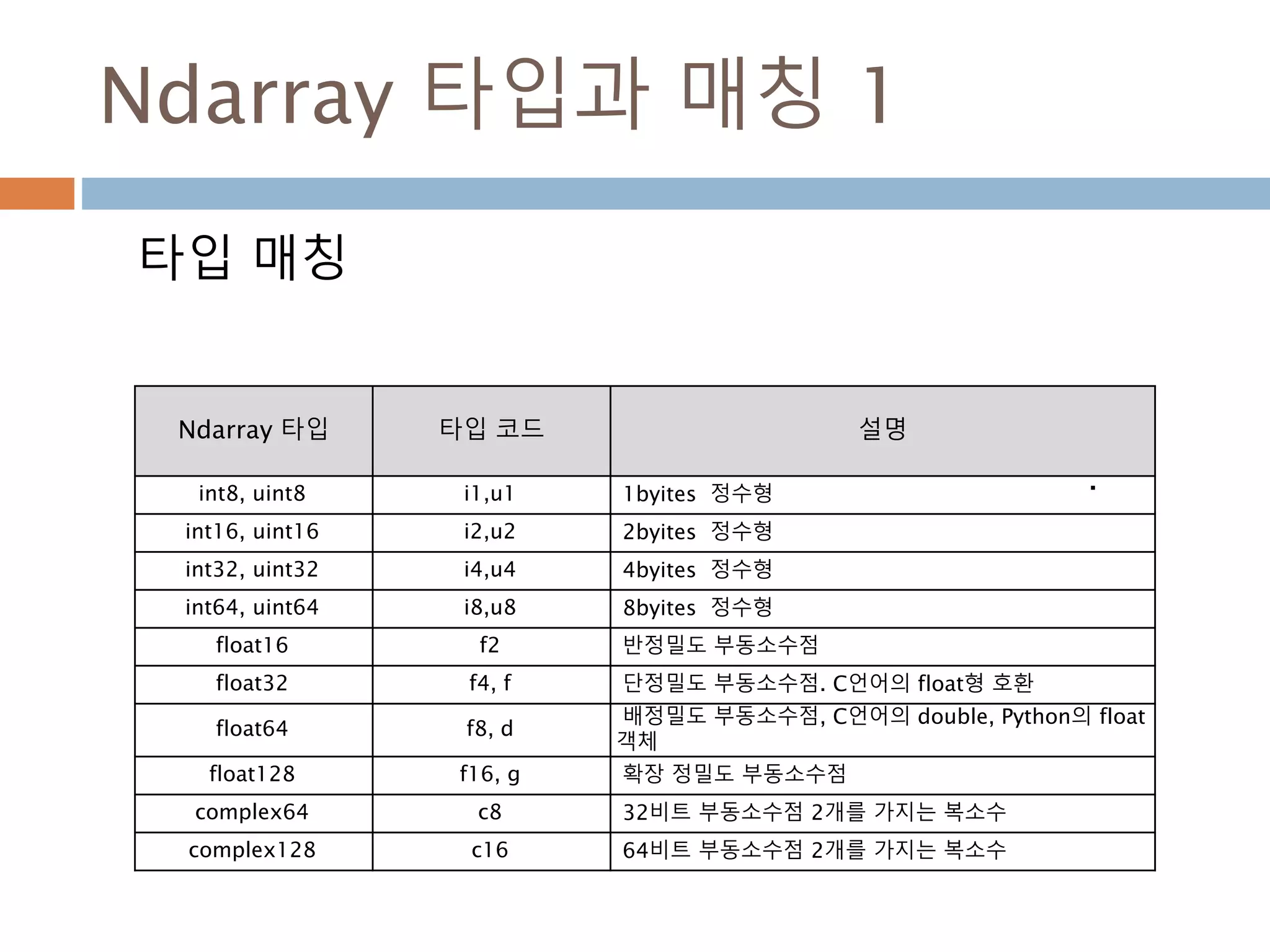
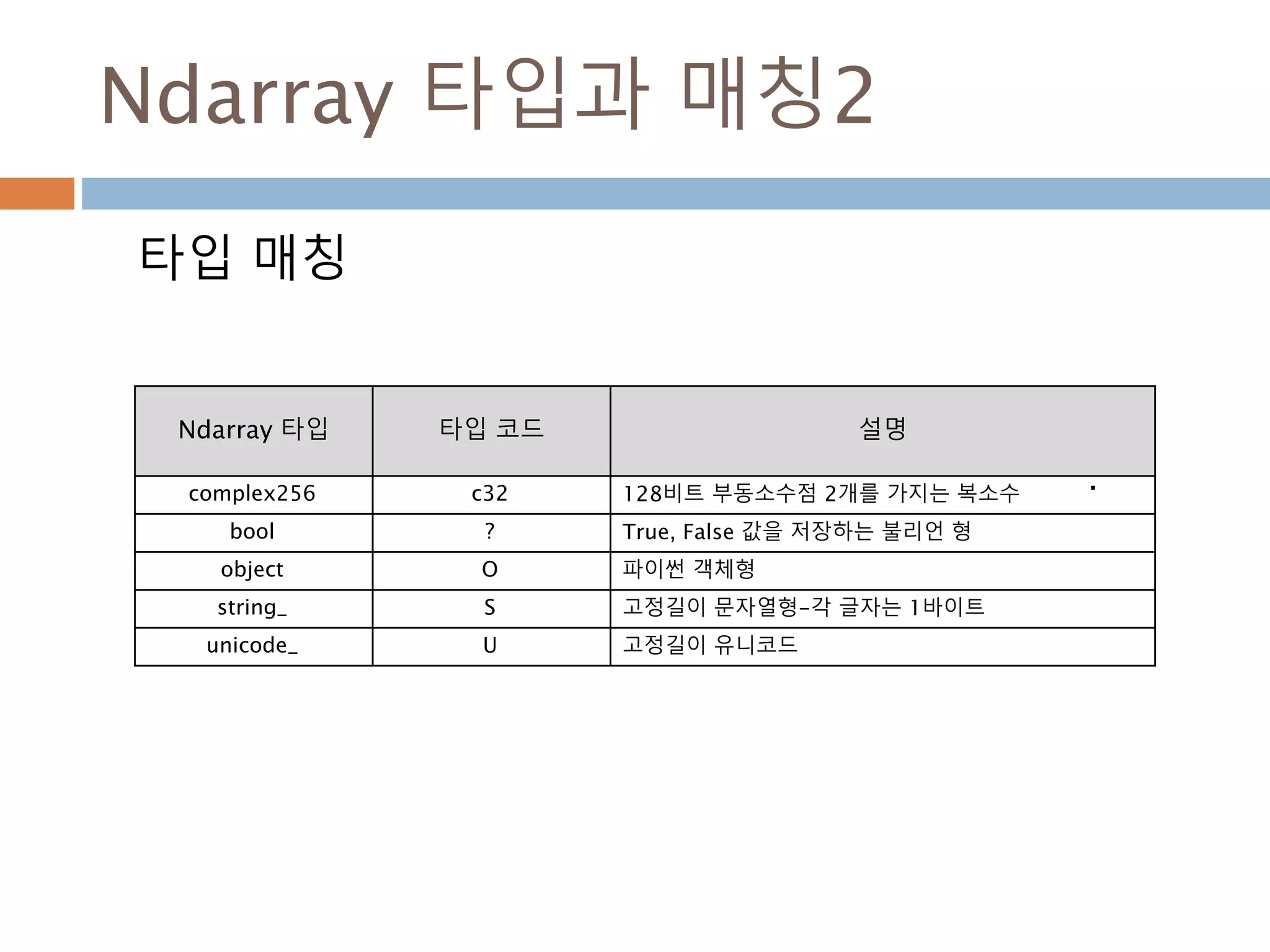






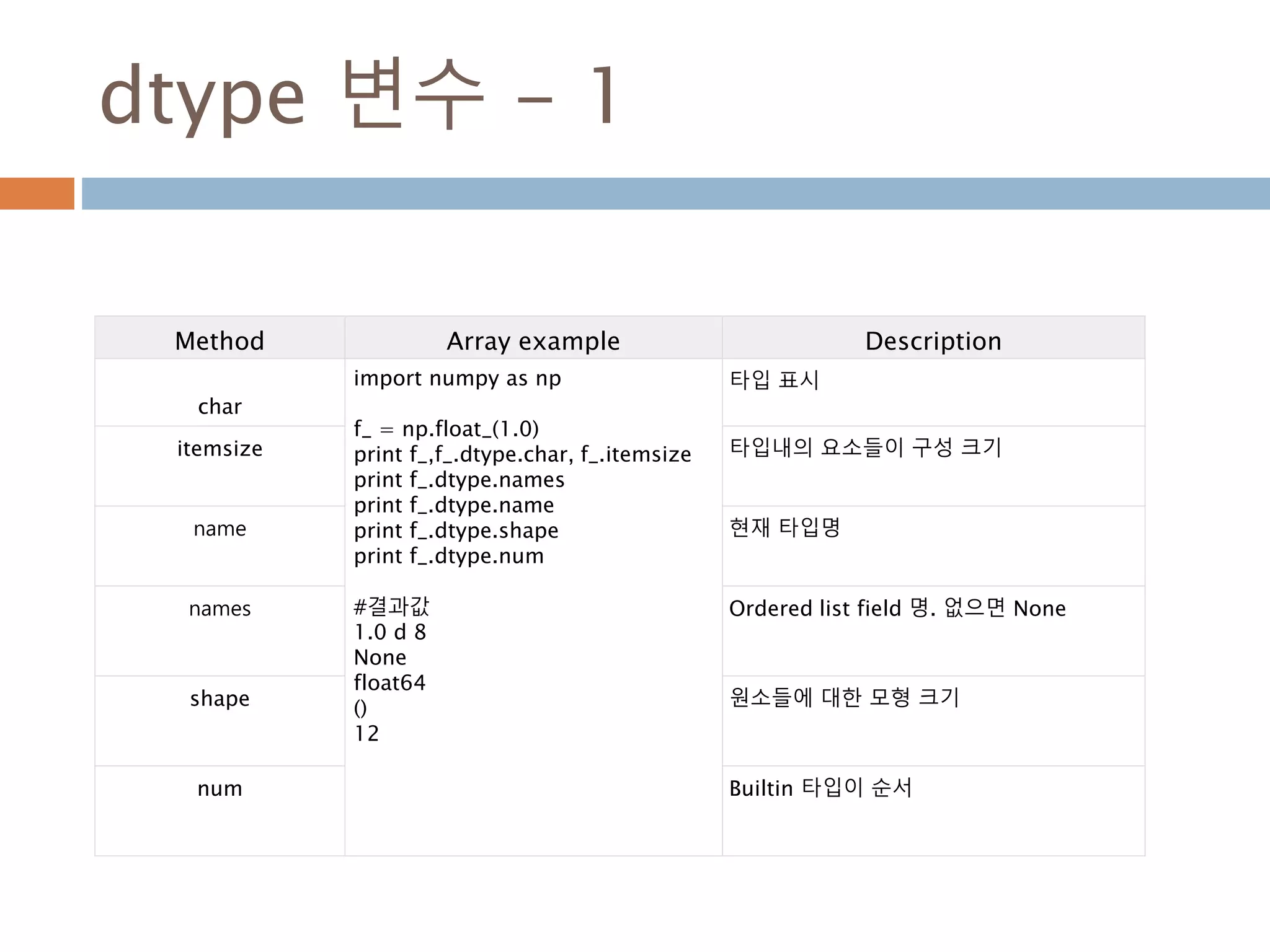
![Little-endian
숫자를 저장할때 제일 왼쪽부터 저장됨
.
>>> ar = np.array([1,2,3])
>>> ar.tostring()
'x01x00x00x00x00x00x00x00x02x0
0x00x00x00x00x00x00x03x00x00x
00x00x00x00x00'
>>> l = ar.tosting()
>>> ar.itemsize
8
>>> l[0:8]
x01x00x00x00x00x00x00x00
x01x00x00x
00x00x00x00
x00
8bytes씩 저장하고
숫자는 첫번째부터
들어감
146](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-146-2048.jpg)
![big-endian
숫자를 저장할때 제일 오른쪽부터 저장됨
.
>>> ar = np.array([1,2,3],dtype='>i8')
>>> ar.tostring()
'x00x00x00x00x00x00x00x01x00x0
0x00x00x00x00x00x02x00x00x00x
00x00x00x00x03’
>>> ar.dtype
dtype('>i8')
x00x00x00x00x0
0x00x00x01
8bytes씩 저장하고 숫자
는 마지막째부터 들어감
147](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-147-2048.jpg)
![not-relevant
endian에 상관없이 문자를 저장할때 제일 왼쪽
부터 저장됨
.
>>> sr = np.array(['a','b',"abc"],dtype='|S10')
>>> sr.tostring()
'ax00x00x00x00x00x00x00x00x00bx00x
00x00x00x00x00x00x00x00abcx00x00x0
0x00x00x00x00’
>>> sr.dtype
dtype('S10')
>>> sr.tostring()[0:10]
'ax00x00x00x00x00x00x00x00x00'
10bytes씩 저장하
고 문자는 첫번째부
터 들어감
148](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-148-2048.jpg)



![dtype 변수 - 3
Method Array example Description
descr import numpy as np
f_ = np.float_(1.0)
print f_.dtype.descr
print f_.dtype.hasobject
print f_.dtype.subdtype
print f_.dtype.base
print f_.dtype.kind
print f_.dtype.isnative
#결과값
[('', '<f8')]
False
None
Float64
F
True
Array interface 표시
hasobject any reference-counted objects in any
fields or sub-dtypes 가 존재시 True
subdtype
Tuple (item_dtype, shape) if this dtype
describes a sub-array, and None other
wise.
base 기본 정의된 타입
kind array-protocol type
isnative 파이썬 내부 byte order 사용여부
152](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-152-2048.jpg)


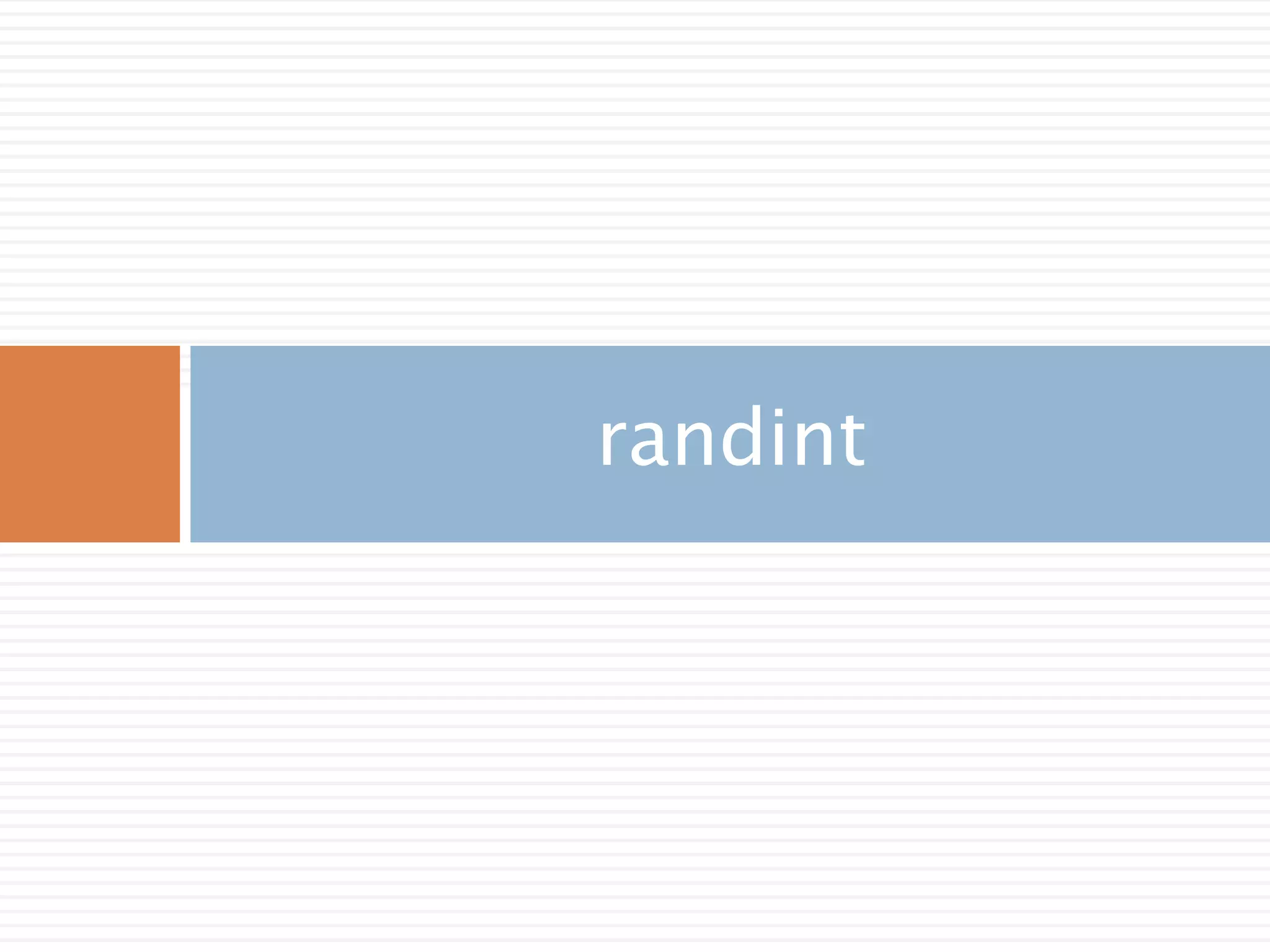
![주요 함수
rand(d0, d1, ..., dn) 주어진 모양에 대해 0에서 1사이의 균등 분포 생성
randn(d0, d1, ..., dn) 주어진 모양에 대해 정규분포 값을 생성
randint(low[, high, size]) Return random integers from low (inclusive) to high (exclusive).
random_sample([size]) Return random floats in the half-open interval [0.0, 1.0).
random([size]) Return random floats in the half-open interval [0.0, 1.0).
ranf([size]) Return random floats in the half-open interval [0.0, 1.0).
sample([size]) Return random floats in the half-open interval [0.0, 1.0).
choice(a[, size, replace, p]) Generates a random sample from a given 1-D array ..
bytes(length) Return random bytes.
156](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-156-2048.jpg)


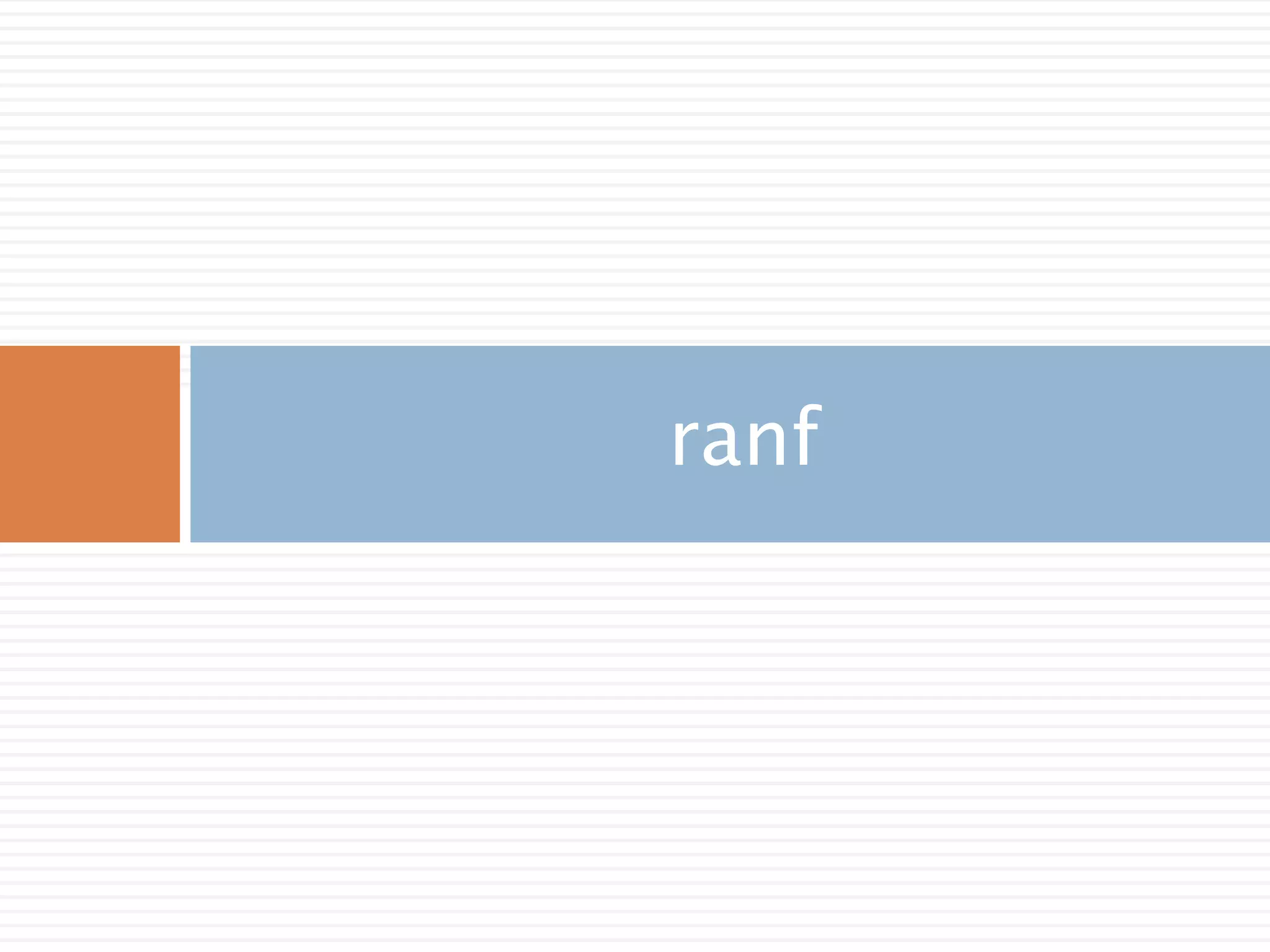

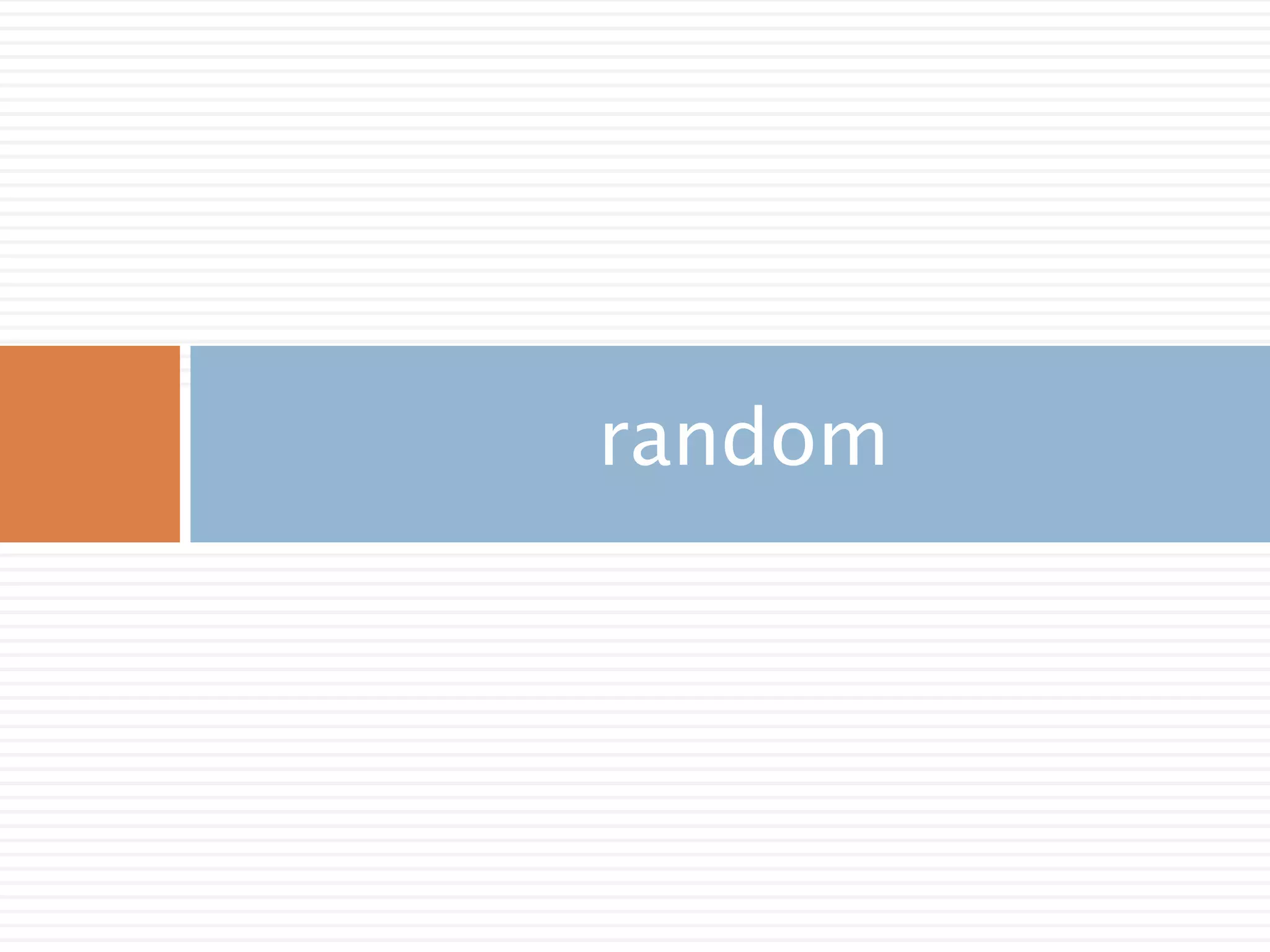


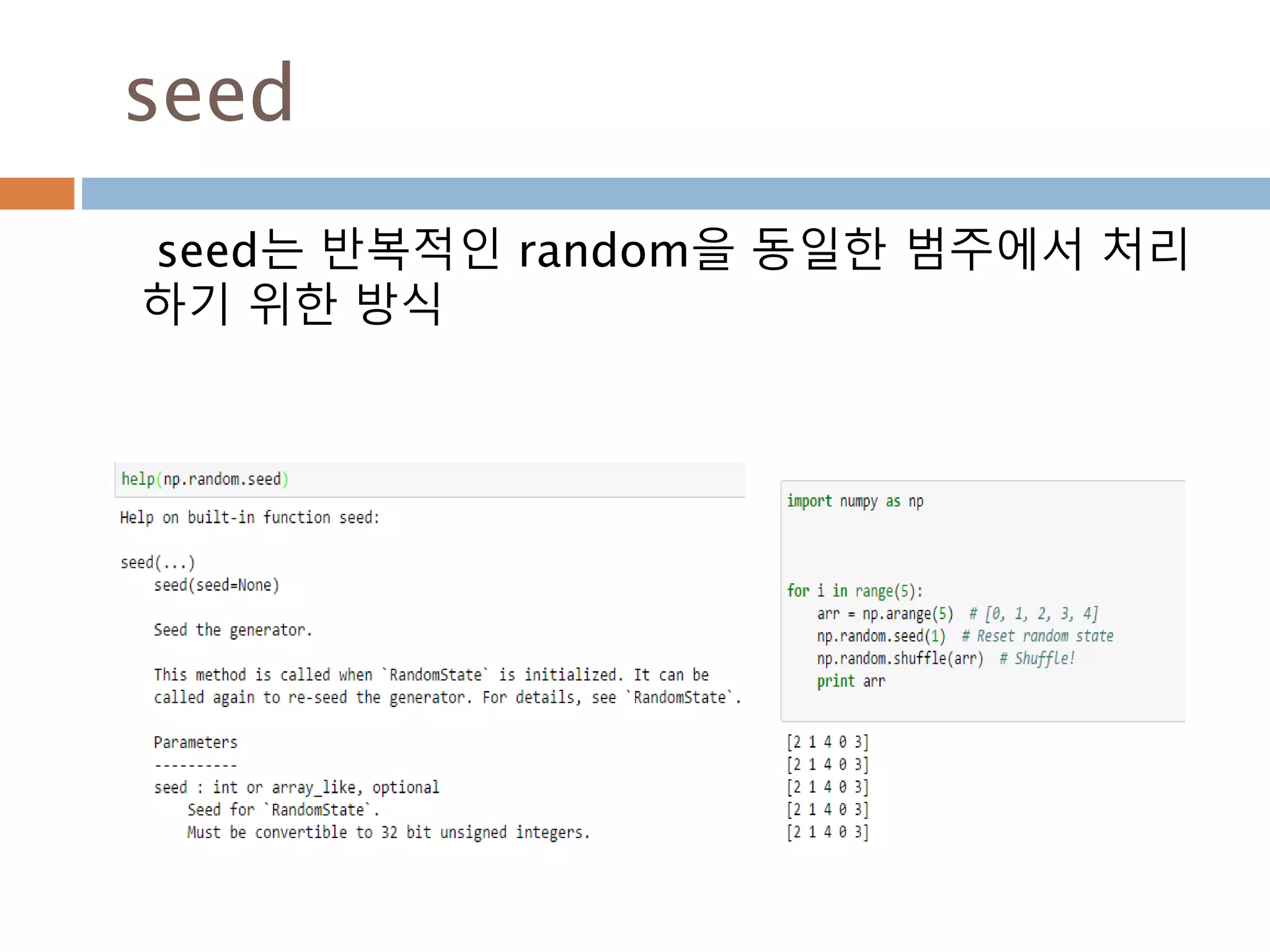









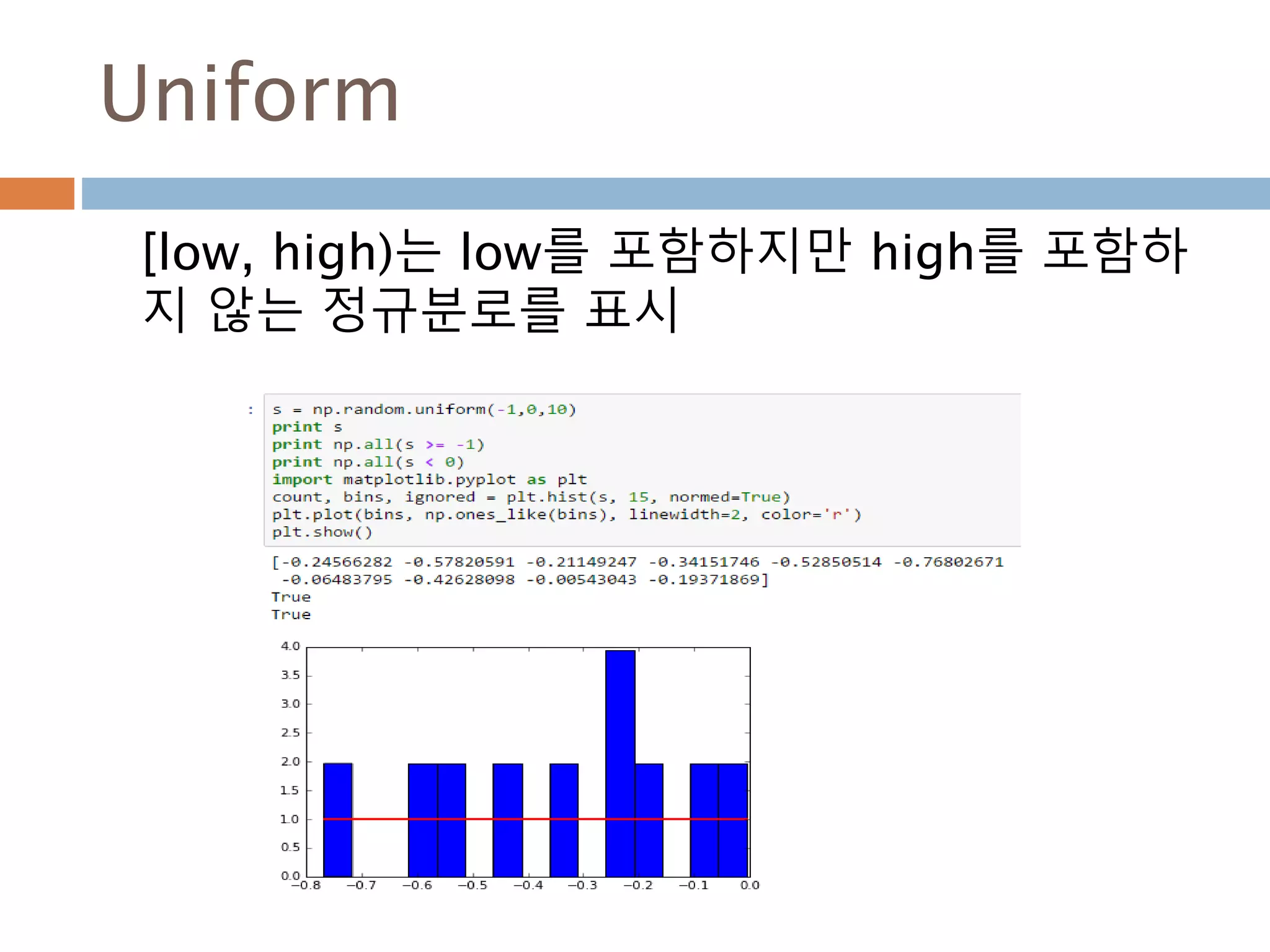
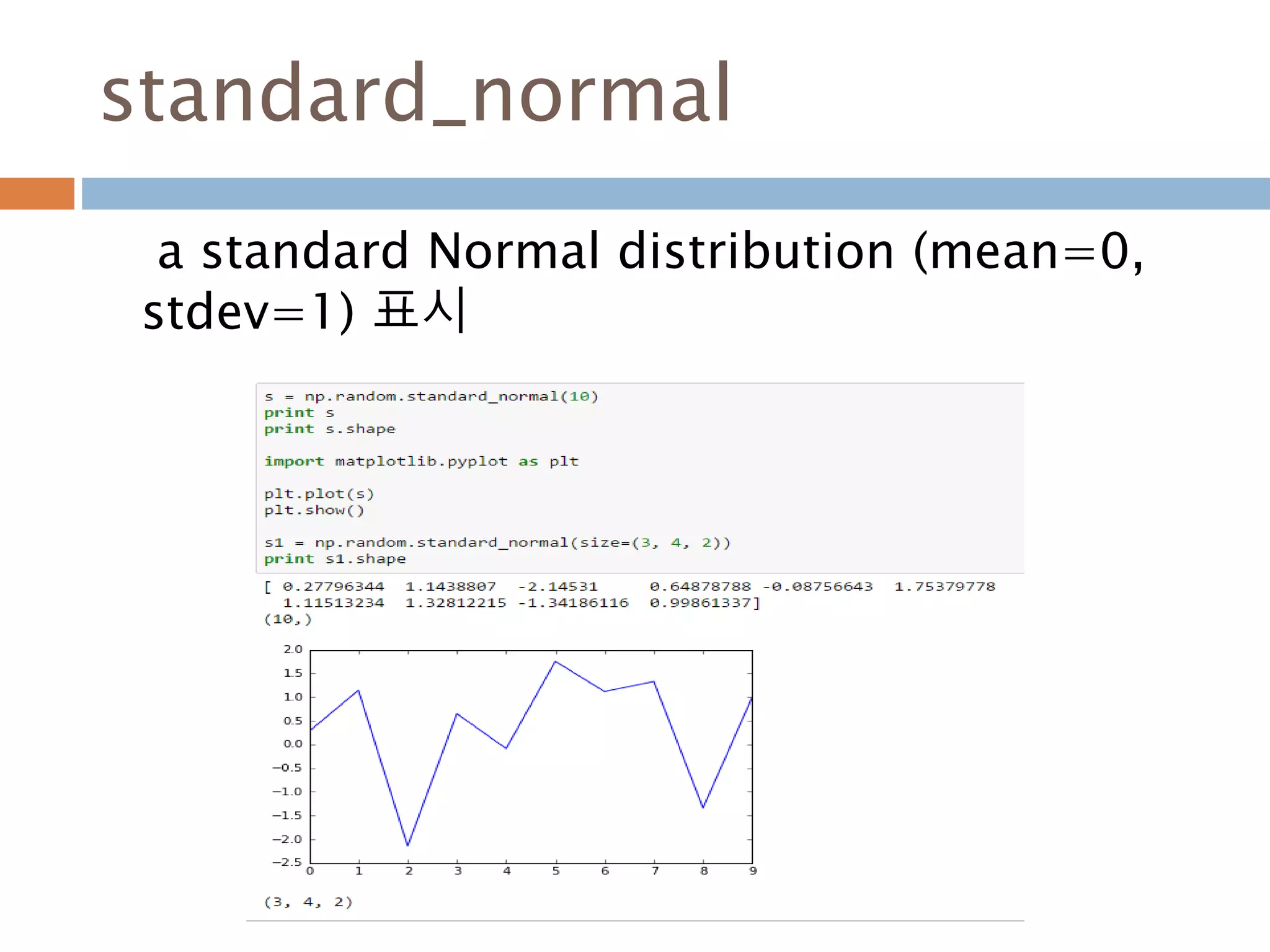
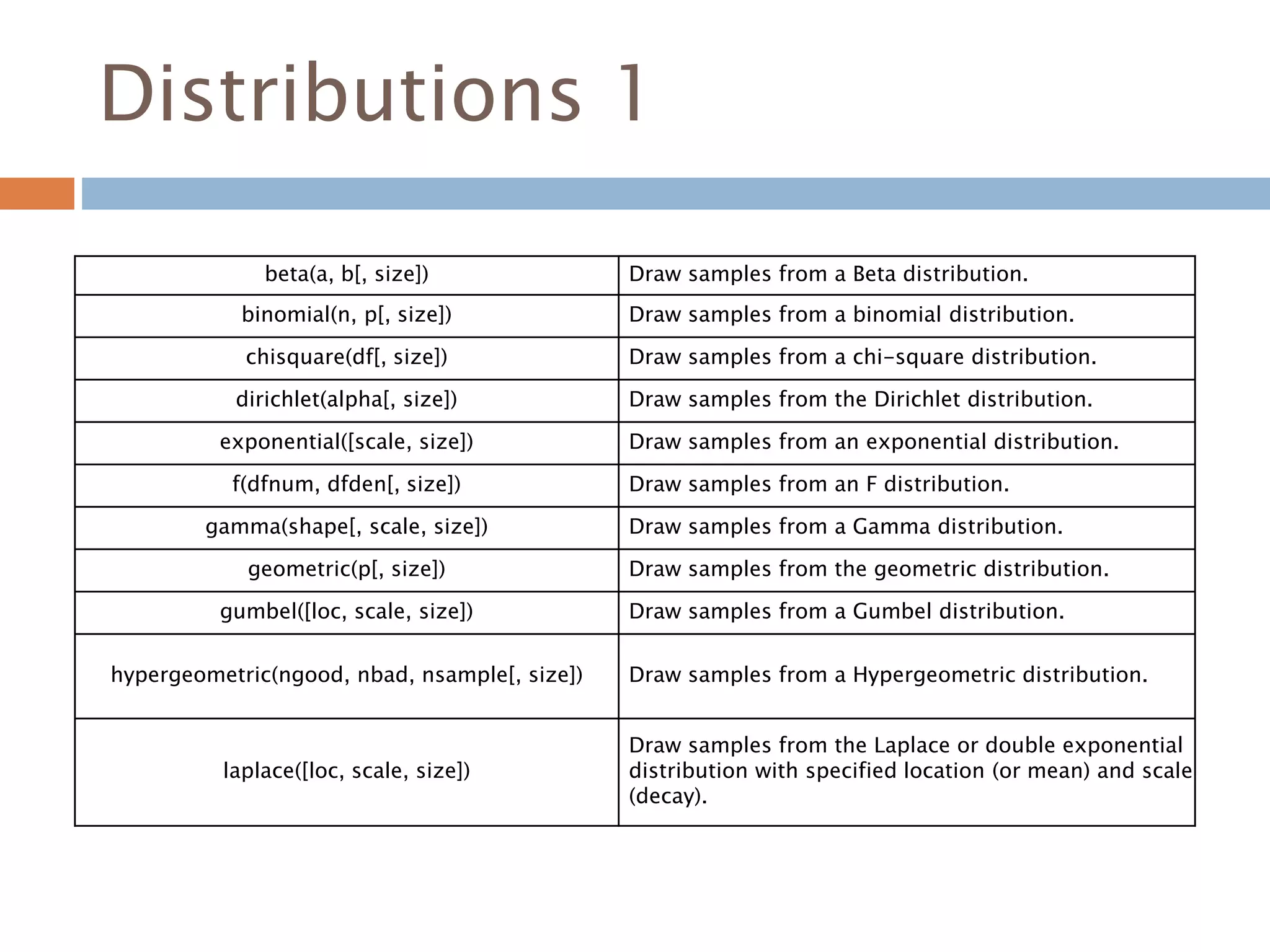
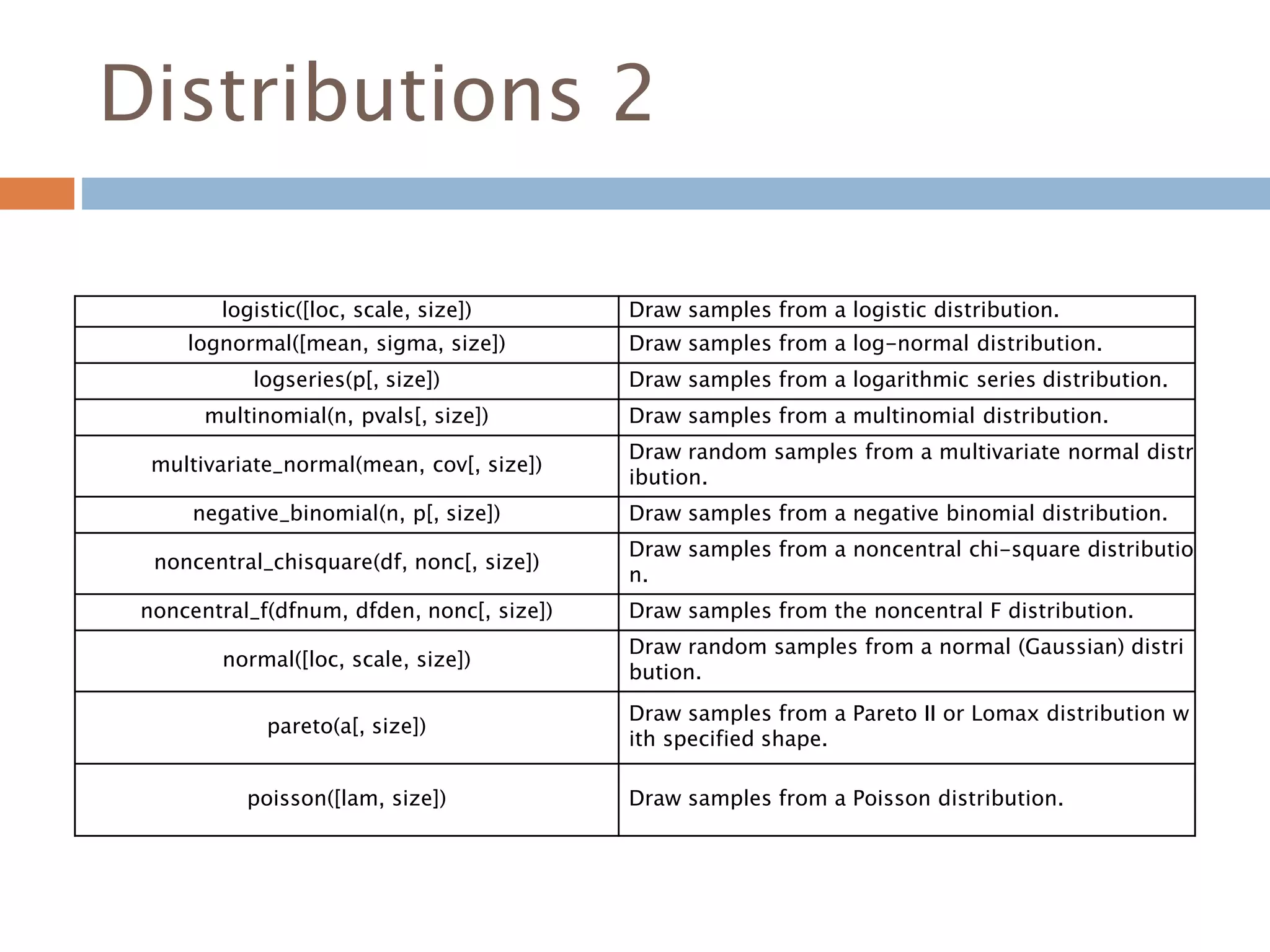
![Binomial : 이항분포
n은 trial , p는 구간 [0,1]에 성공 P는 확률
이항 분포에서 작성한 것임
180](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-180-2048.jpg)

![Distributions 1
beta(a, b[, size]) Draw samples from a Beta distribution.
binomial(n, p[, size]) Draw samples from a binomial distribution.
chisquare(df[, size]) Draw samples from a chi-square distribution.
dirichlet(alpha[, size]) Draw samples from the Dirichlet distribution.
exponential([scale, size]) Draw samples from an exponential distribution.
f(dfnum, dfden[, size]) Draw samples from an F distribution.
gamma(shape[, scale, size]) Draw samples from a Gamma distribution.
geometric(p[, size]) Draw samples from the geometric distribution.
gumbel([loc, scale, size]) Draw samples from a Gumbel distribution.
hypergeometric(ngood, nbad, nsample[, size]) Draw samples from a Hypergeometric distribution.
laplace([loc, scale, size])
Draw samples from the Laplace or double exponential
distribution with specified location (or mean) and scale
(decay).
183](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-183-2048.jpg)
![Distributions 2
logistic([loc, scale, size]) Draw samples from a logistic distribution.
lognormal([mean, sigma, size]) Draw samples from a log-normal distribution.
logseries(p[, size]) Draw samples from a logarithmic series distribution.
multinomial(n, pvals[, size]) Draw samples from a multinomial distribution.
multivariate_normal(mean, cov[, size])
Draw random samples from a multivariate normal distr
ibution.
negative_binomial(n, p[, size]) Draw samples from a negative binomial distribution.
noncentral_chisquare(df, nonc[, size])
Draw samples from a noncentral chi-square distributio
n.
noncentral_f(dfnum, dfden, nonc[, size]) Draw samples from the noncentral F distribution.
normal([loc, scale, size])
Draw random samples from a normal (Gaussian) distri
bution.
pareto(a[, size])
Draw samples from a Pareto II or Lomax distribution w
ith specified shape.
poisson([lam, size]) Draw samples from a Poisson distribution.
184](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-184-2048.jpg)
![Distributions 3
power(a[, size])
Draws samples in [0, 1] from a power distribution with positive ex
ponent a - 1.
rayleigh([scale, size]) Draw samples from a Rayleigh distribution.
standard_cauchy([size]) Draw samples from a standard Cauchy distribution with mode = 0.
standard_exponential([size]) Draw samples from the standard exponential distribution.
standard_gamma(shape[, size]) Draw samples from a standard Gamma distribution.
standard_normal([size])
Draw samples from a standard Normal distribution (mean=0, stde
v=1).
standard_t(df[, size])
Draw samples from a standard Student’s t distribution with df deg
rees of freedom.
triangular(left, mode, right[, size]) Draw samples from the triangular distribution.
uniform([low, high, size]) Draw samples from a uniform distribution.
vonmises(mu, kappa[, size]) Draw samples from a von Mises distribution.
wald(mean, scale[, size]) Draw samples from a Wald, or inverse Gaussian, distribution.
weibull(a[, size]) Draw samples from a Weibull distribution.
zipf(a[, size]) Draw samples from a Zipf distribution.
185](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-185-2048.jpg)











![tile
A 배열에 대한 Reps는 axis 축에 따른 반복을 표시
numpy.tile(A, reps)
x = np.array([ [1, 2], [3, 4]])
np.tile(x, (3,4))
1. Reps가 스칼라 값은 배수만큼 증가
2. Reps가 벡터값 일 경우 행과 열에 따라 추가
200](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-200-2048.jpg)




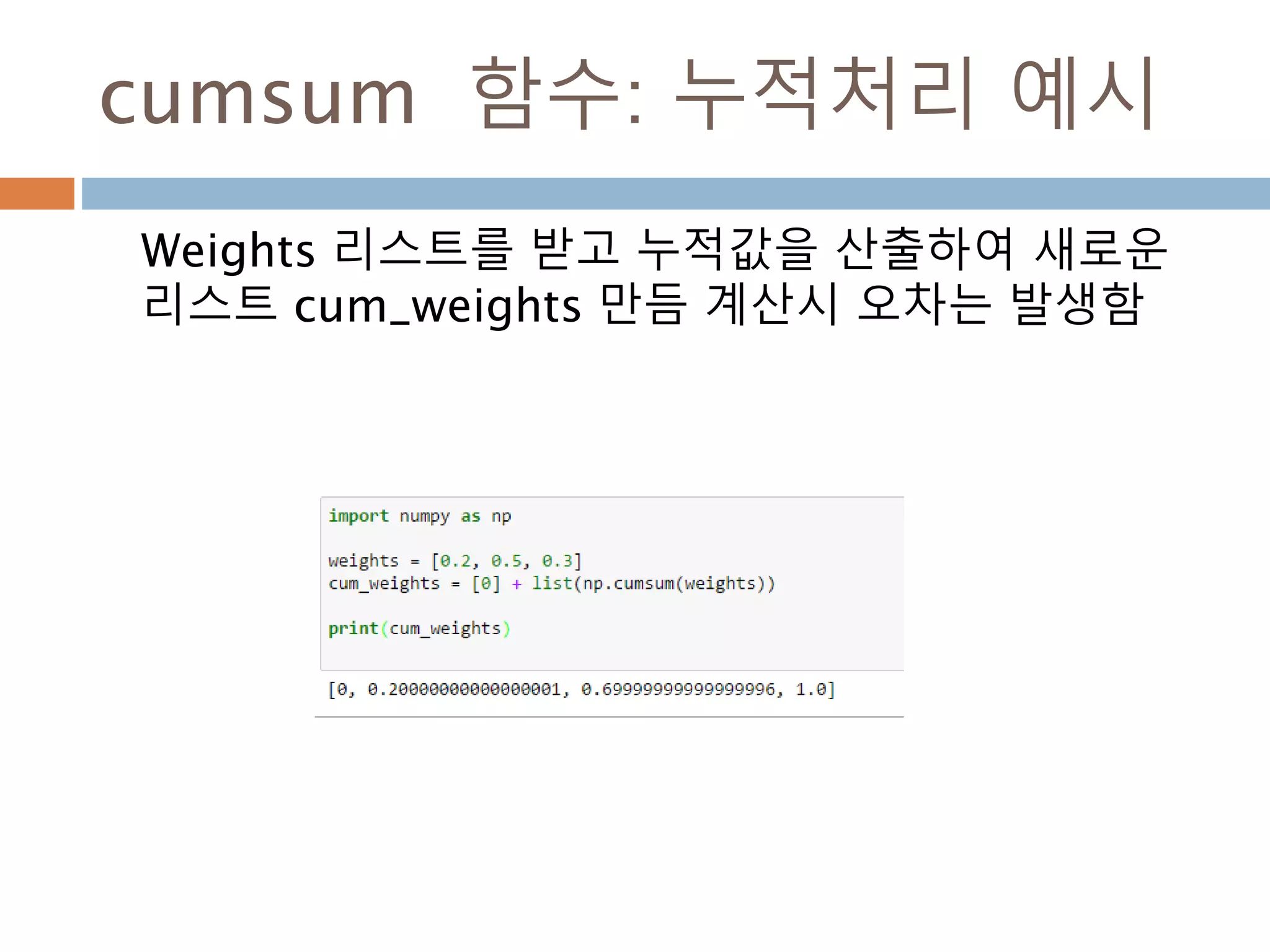



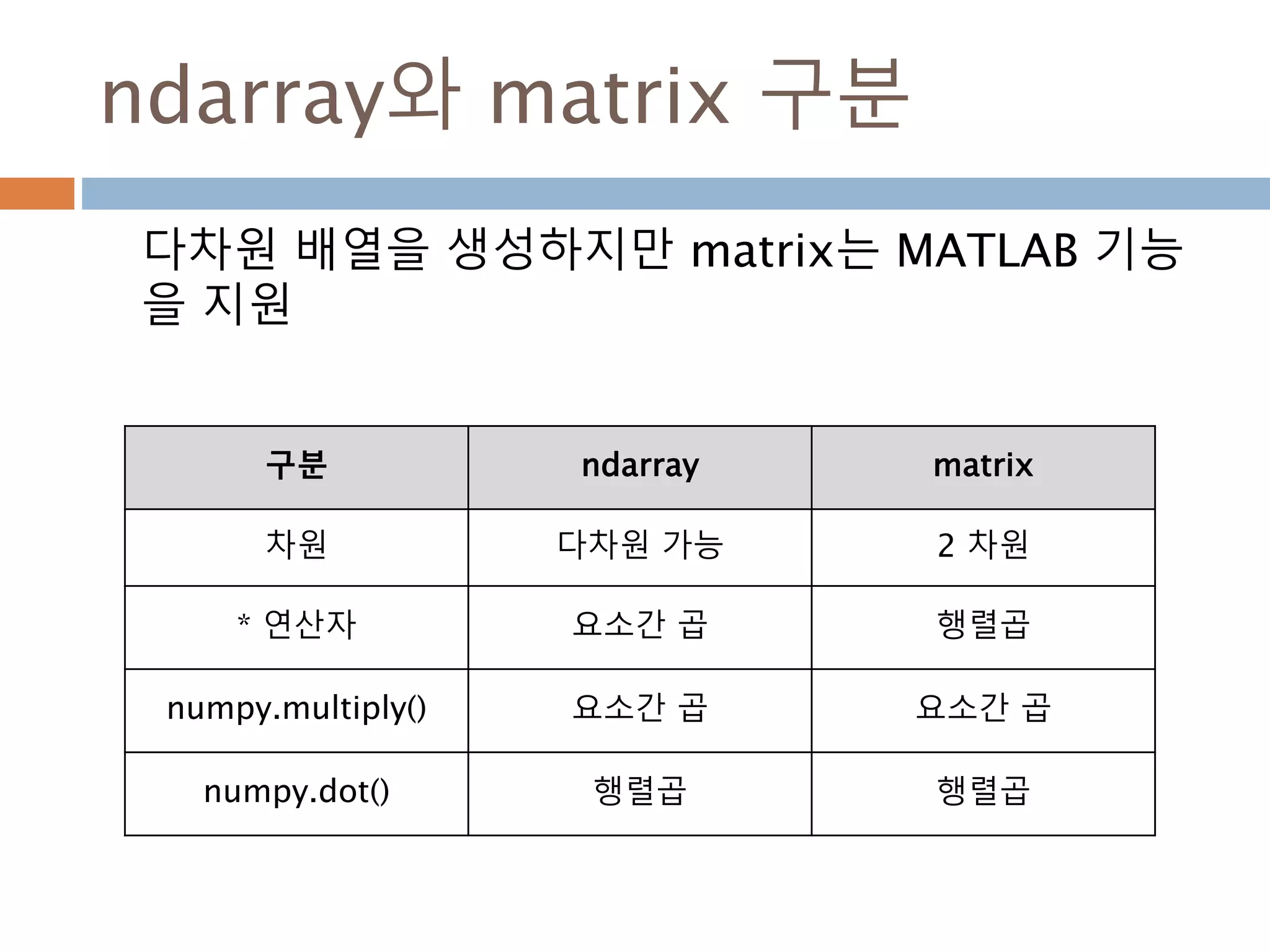




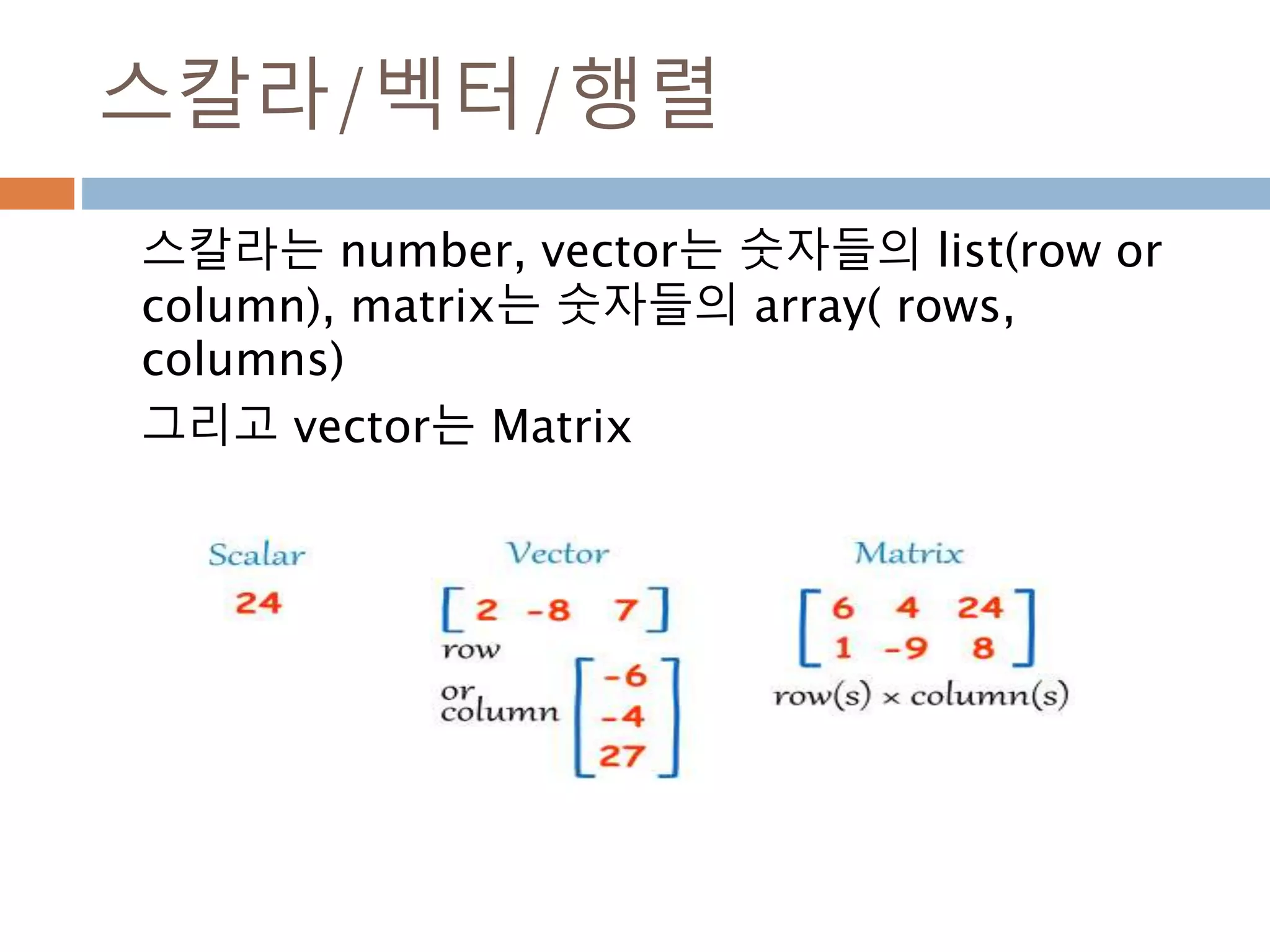
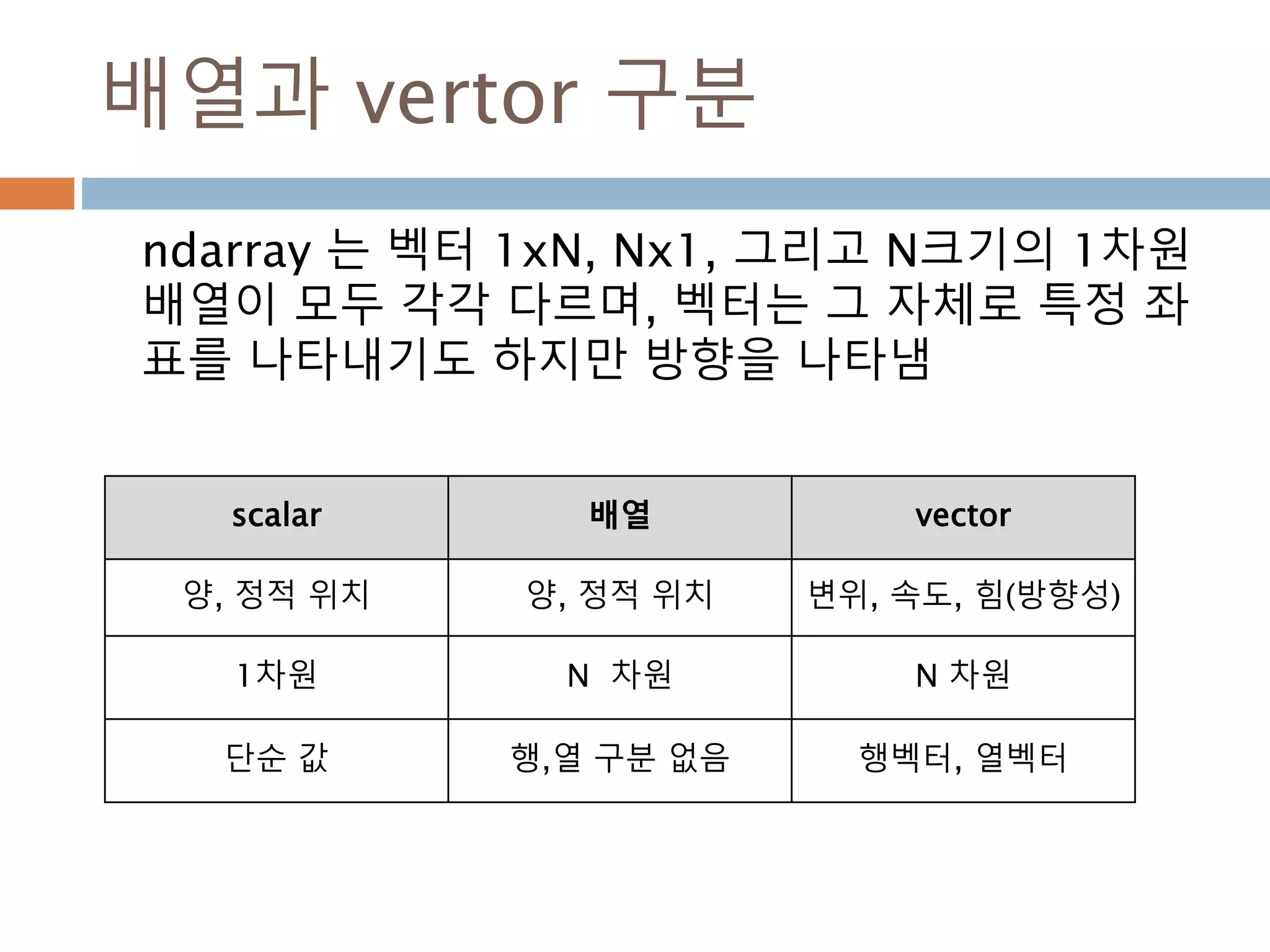



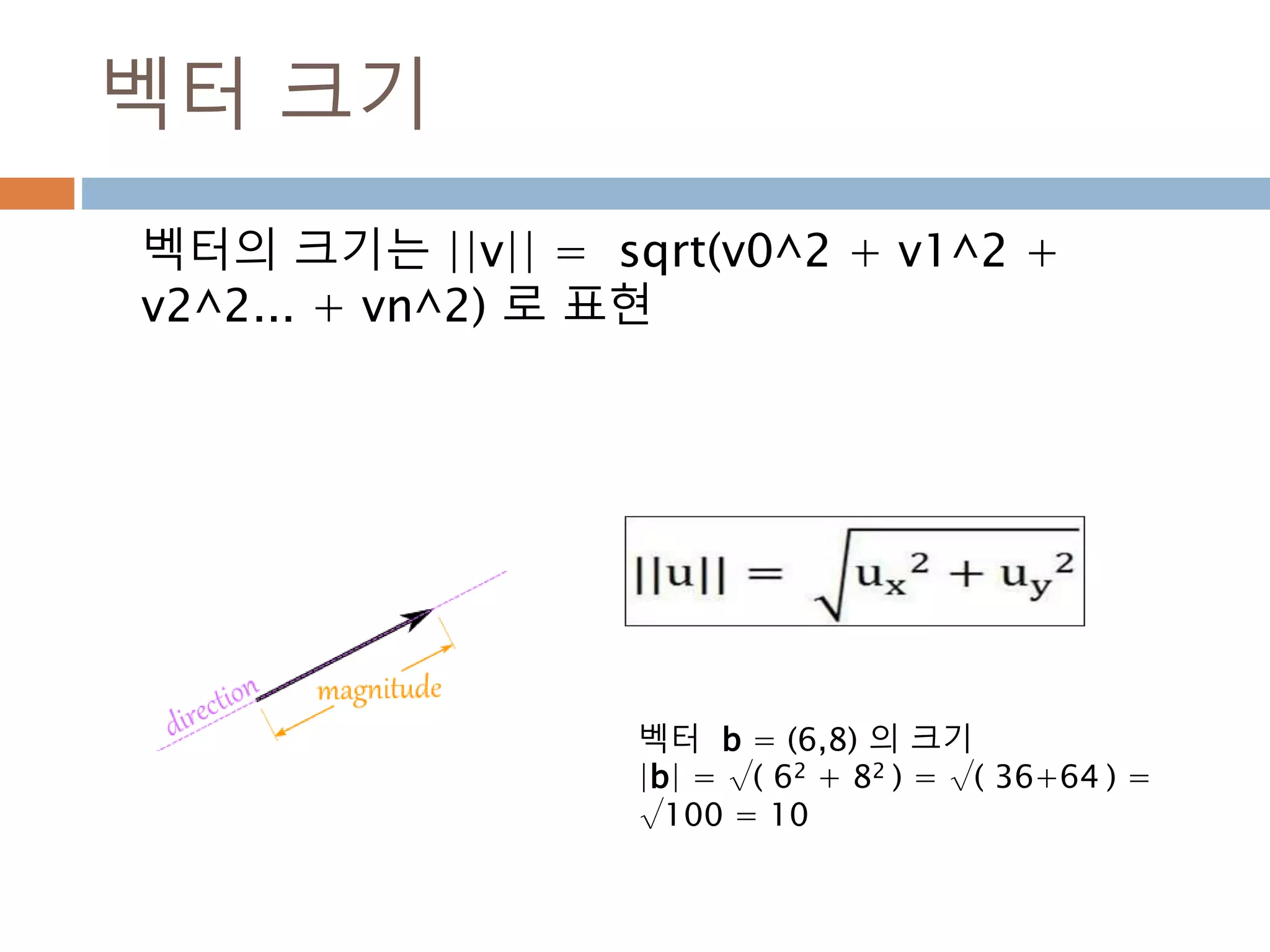
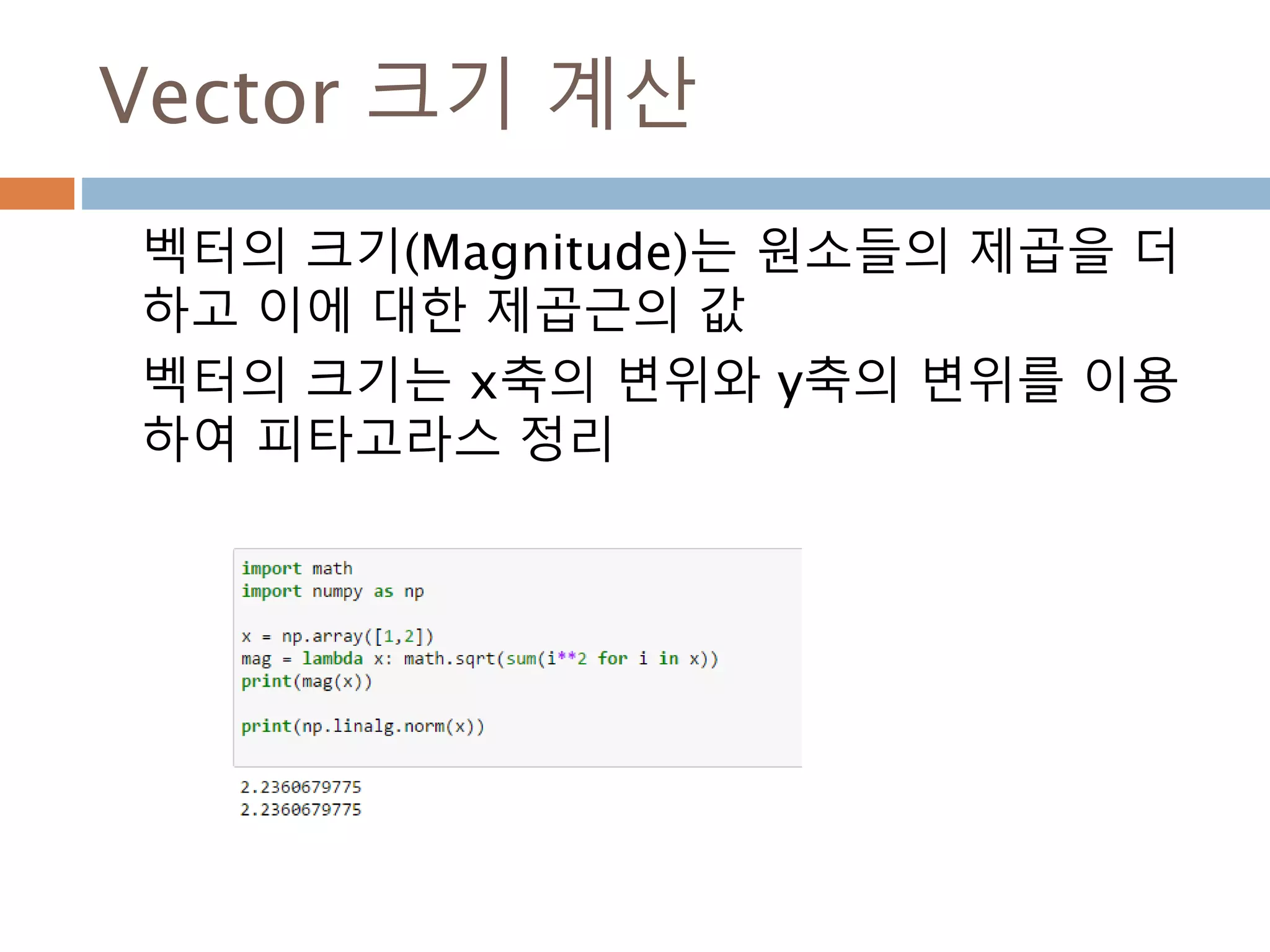

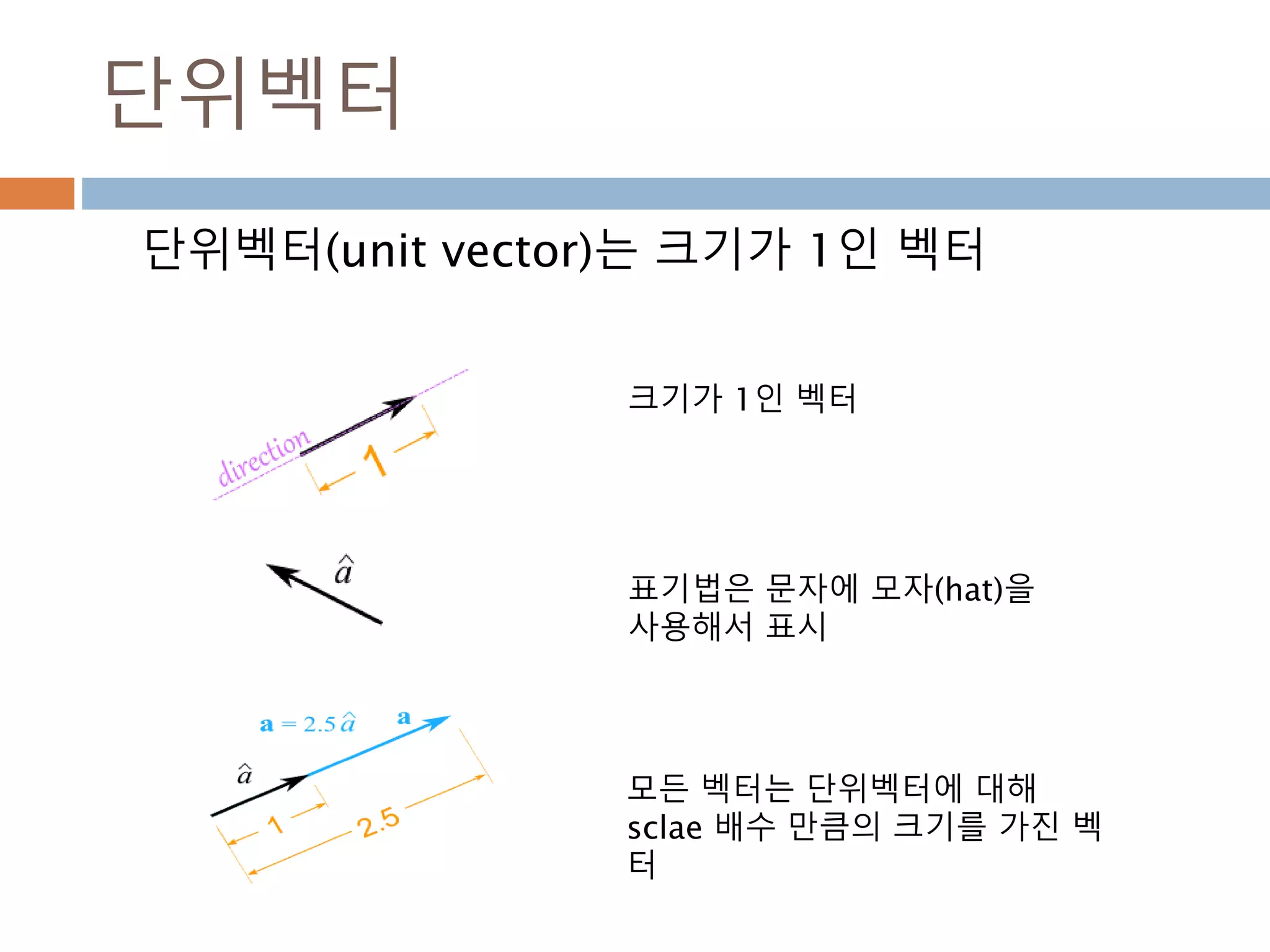




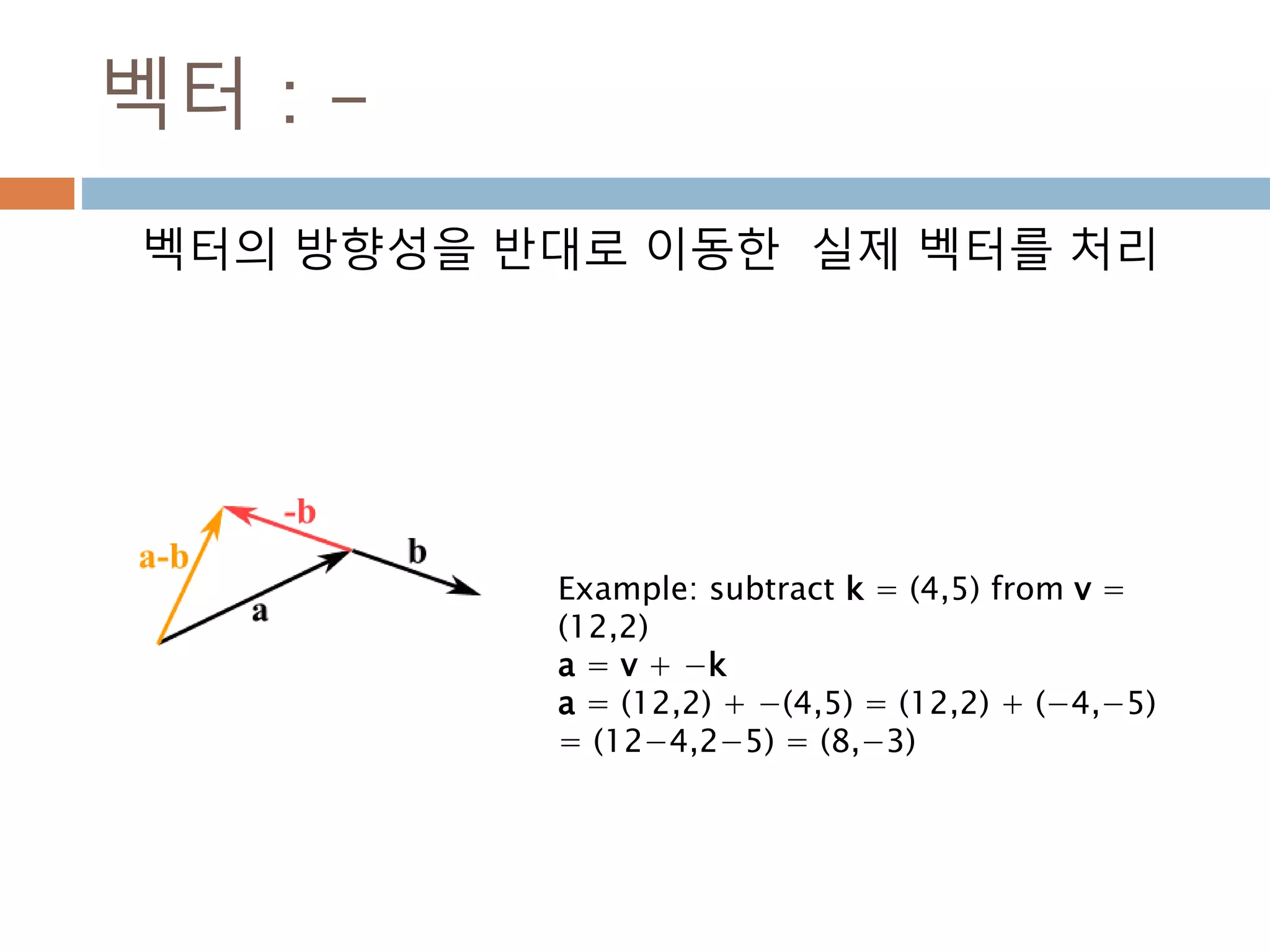

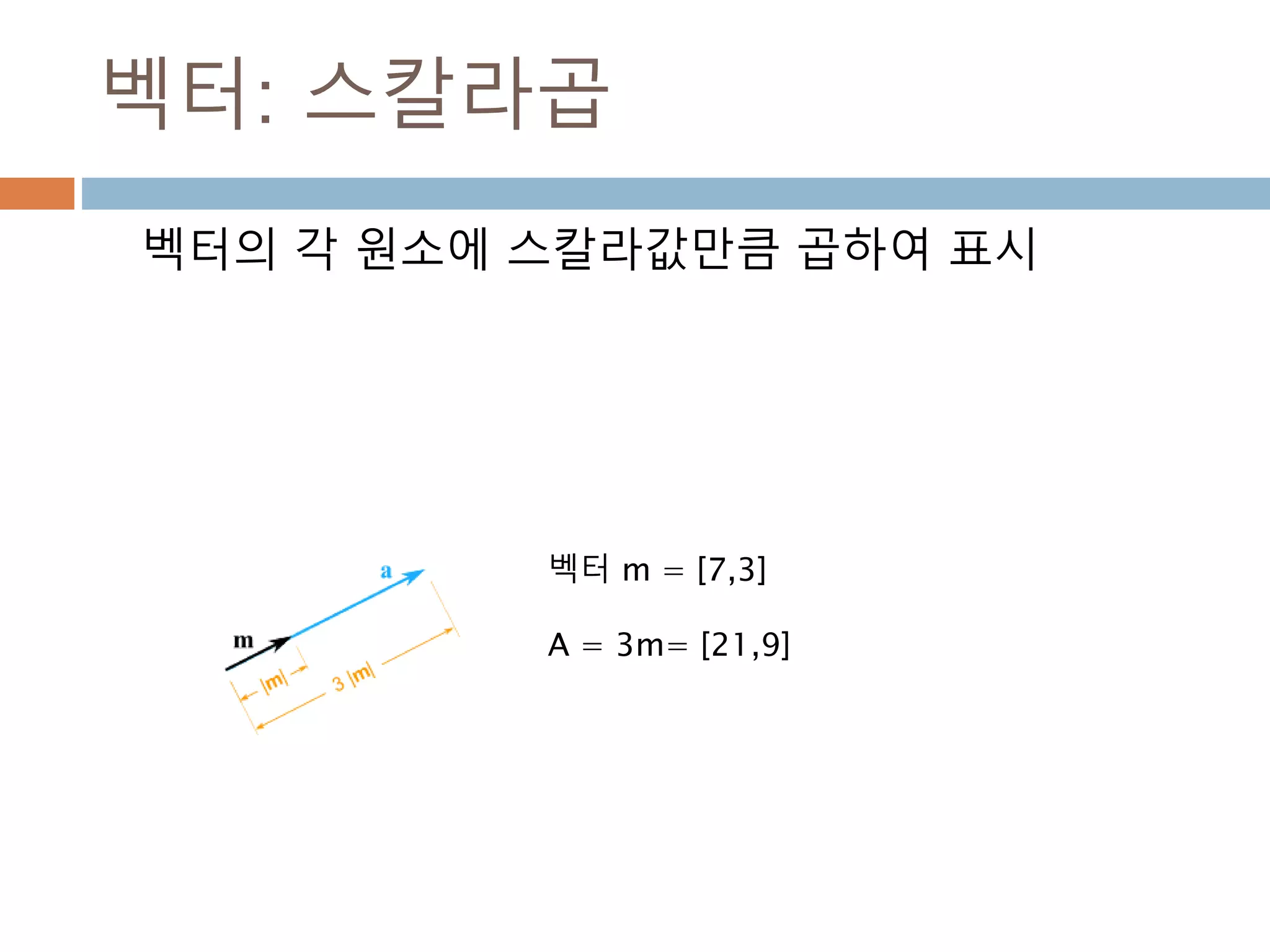


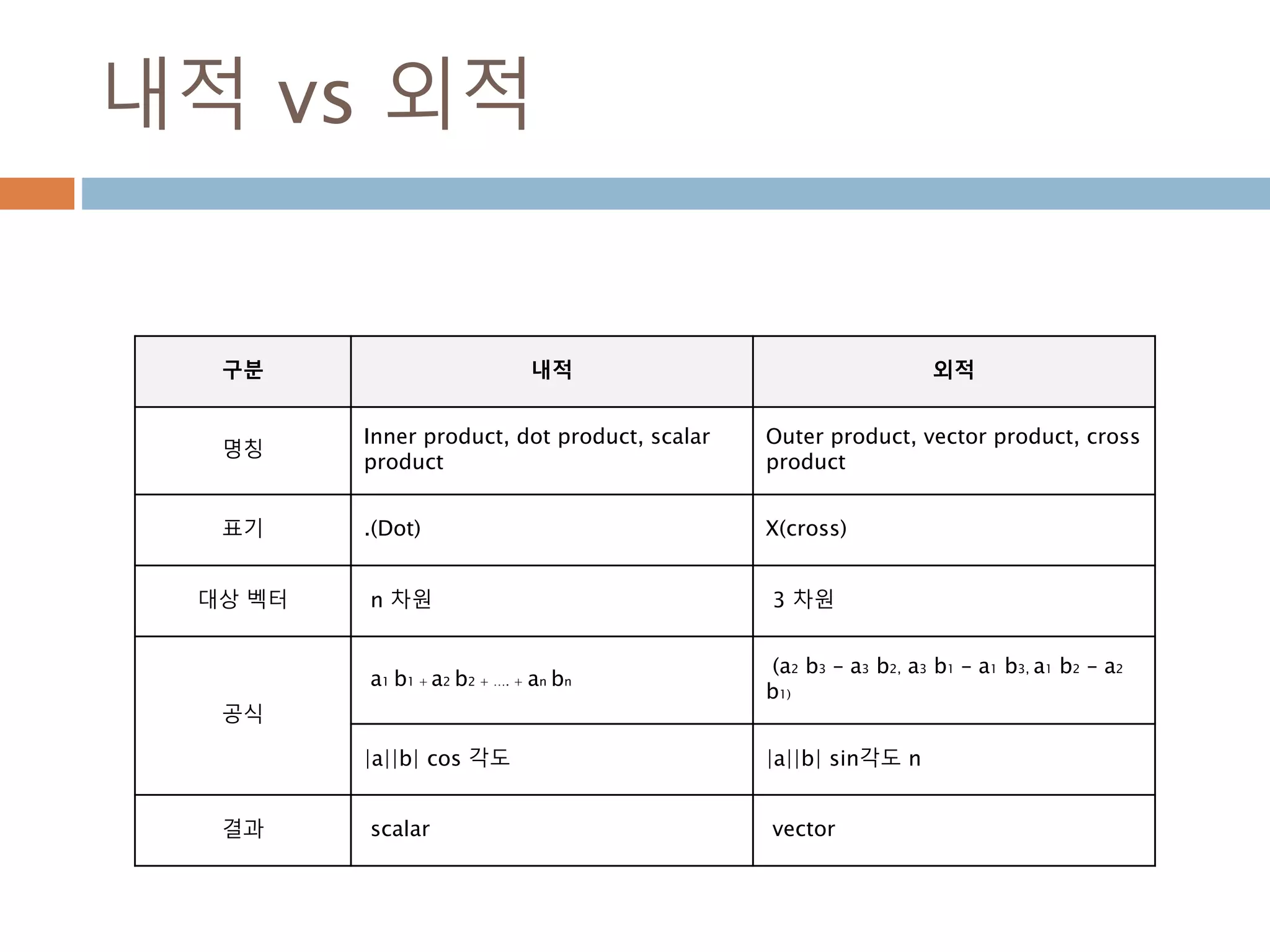

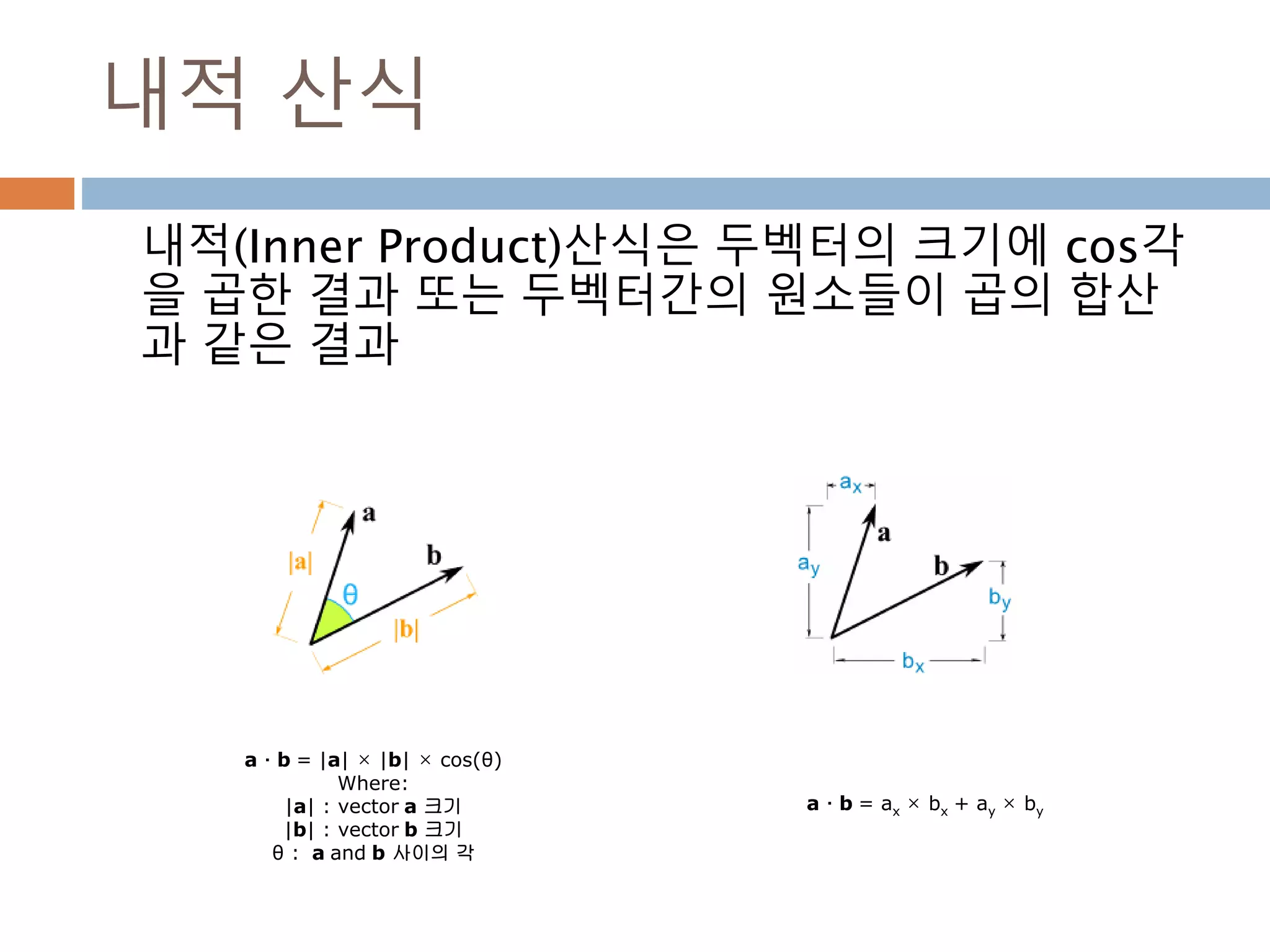
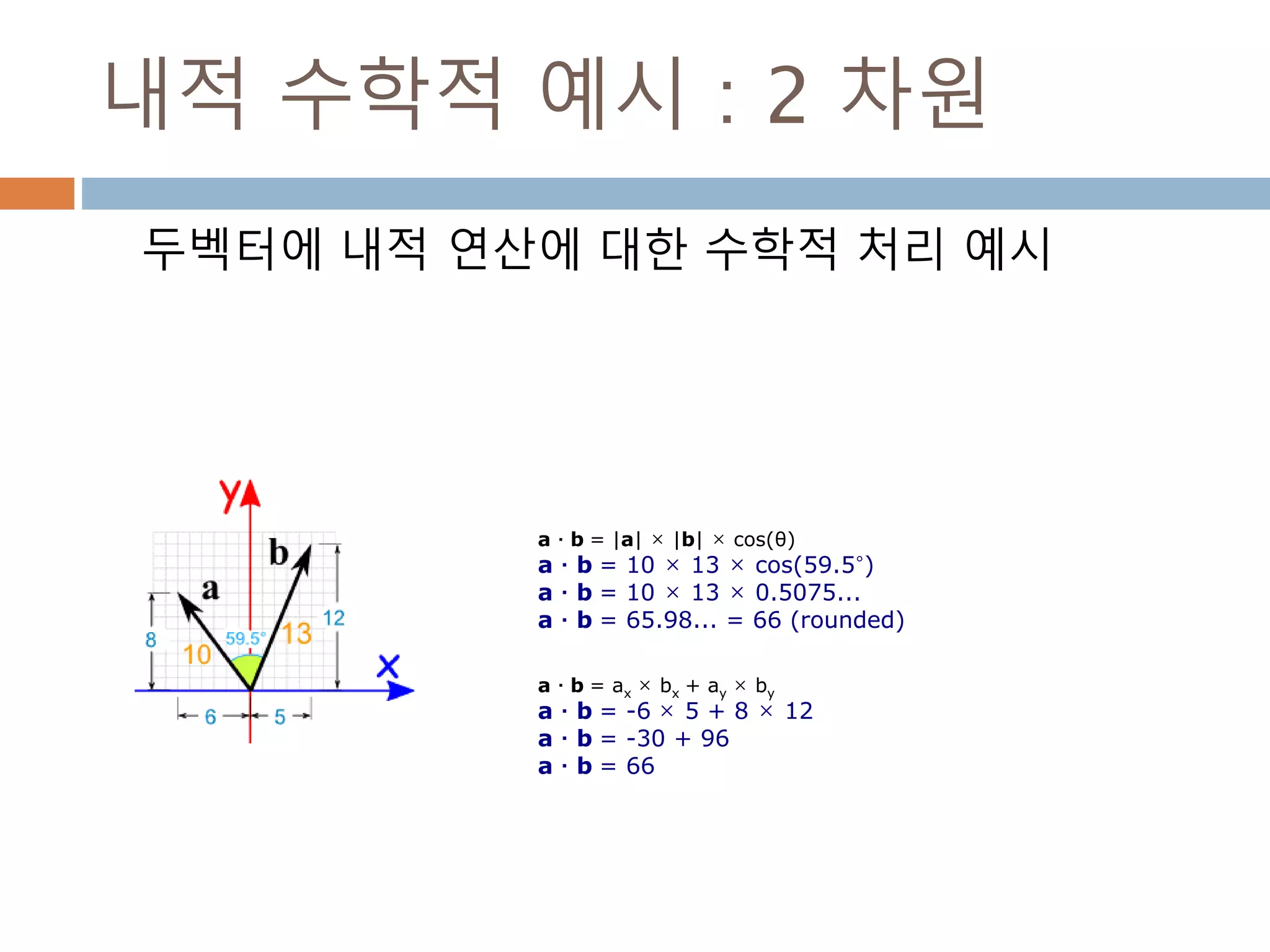
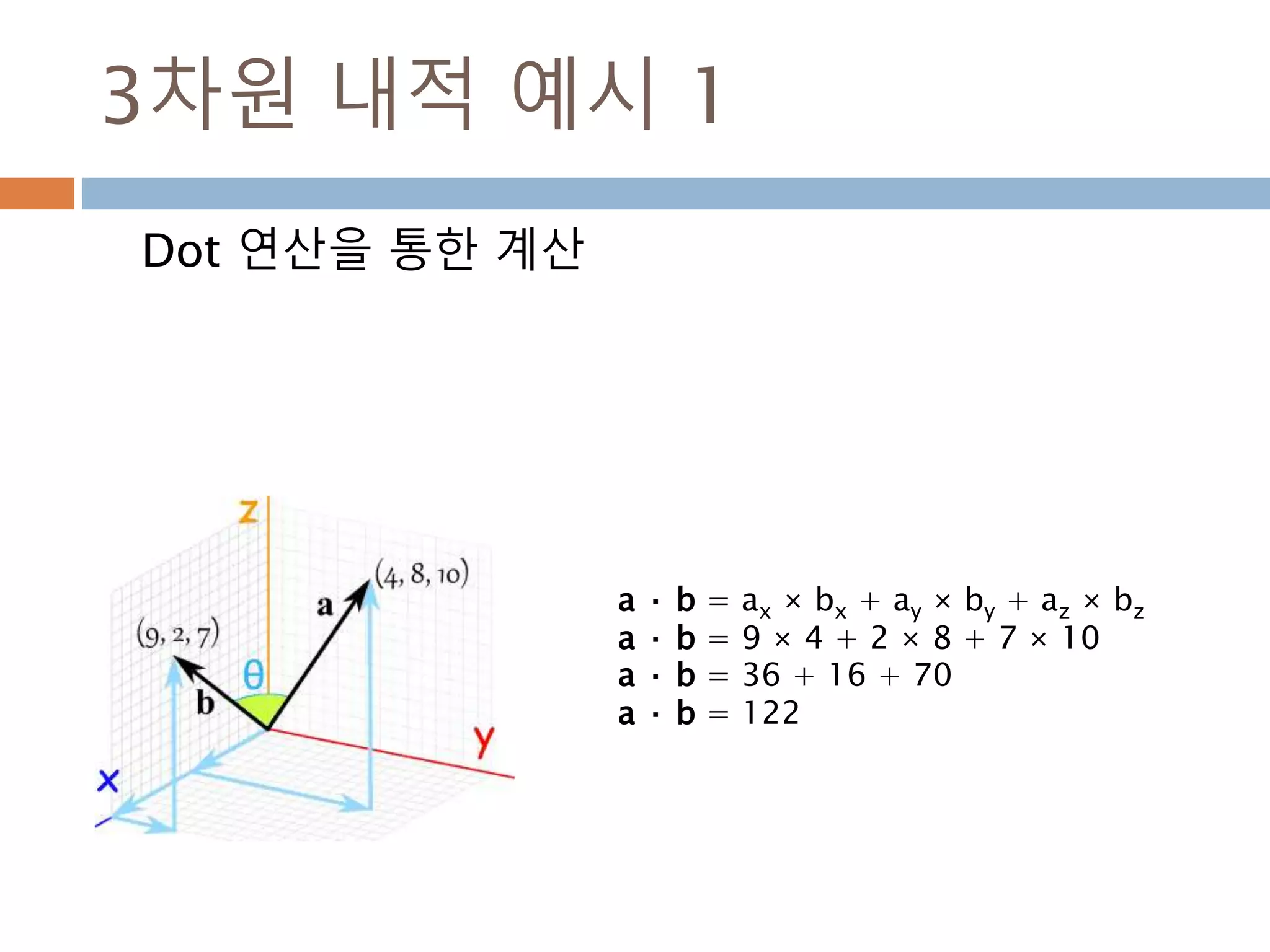
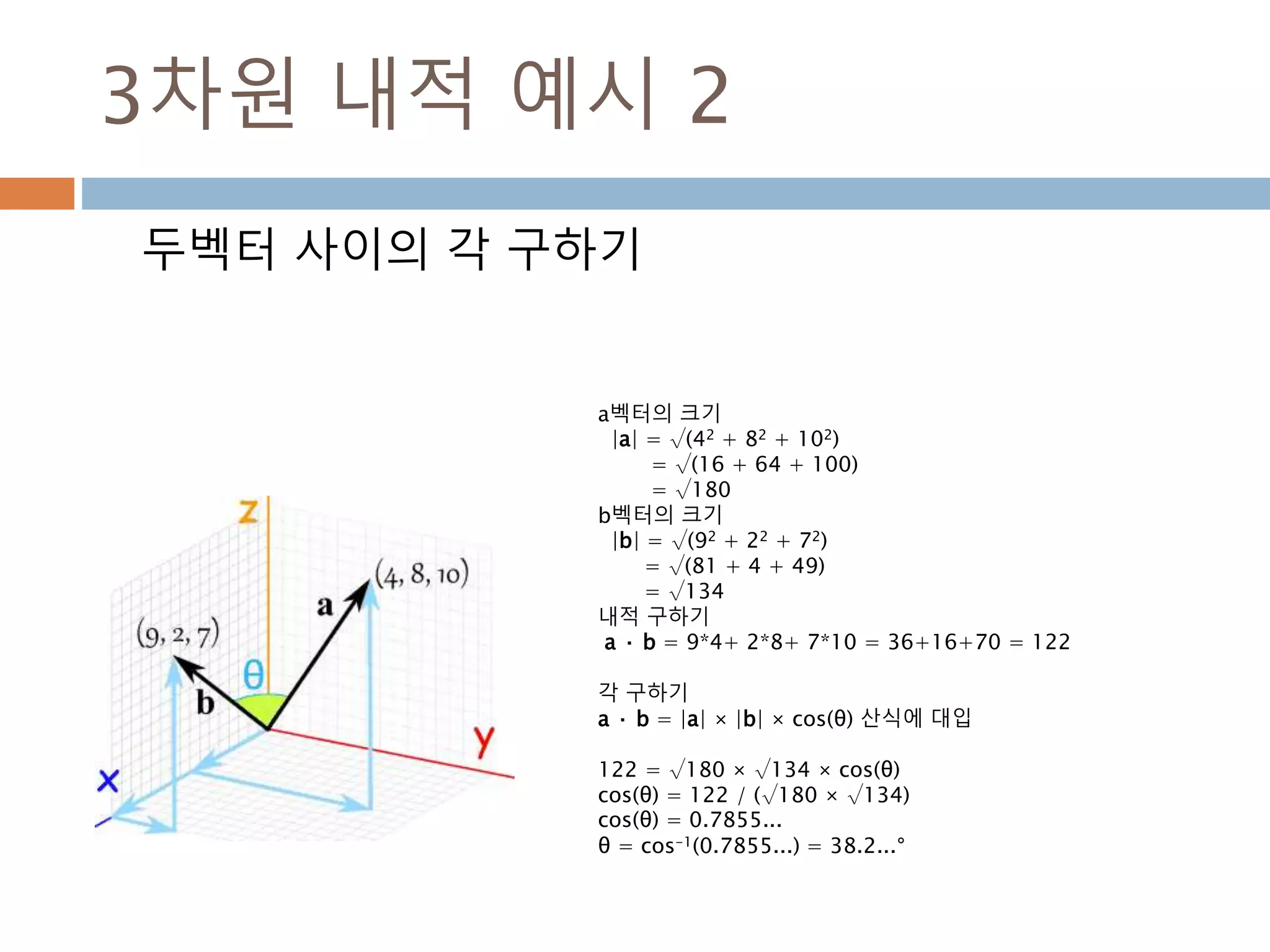



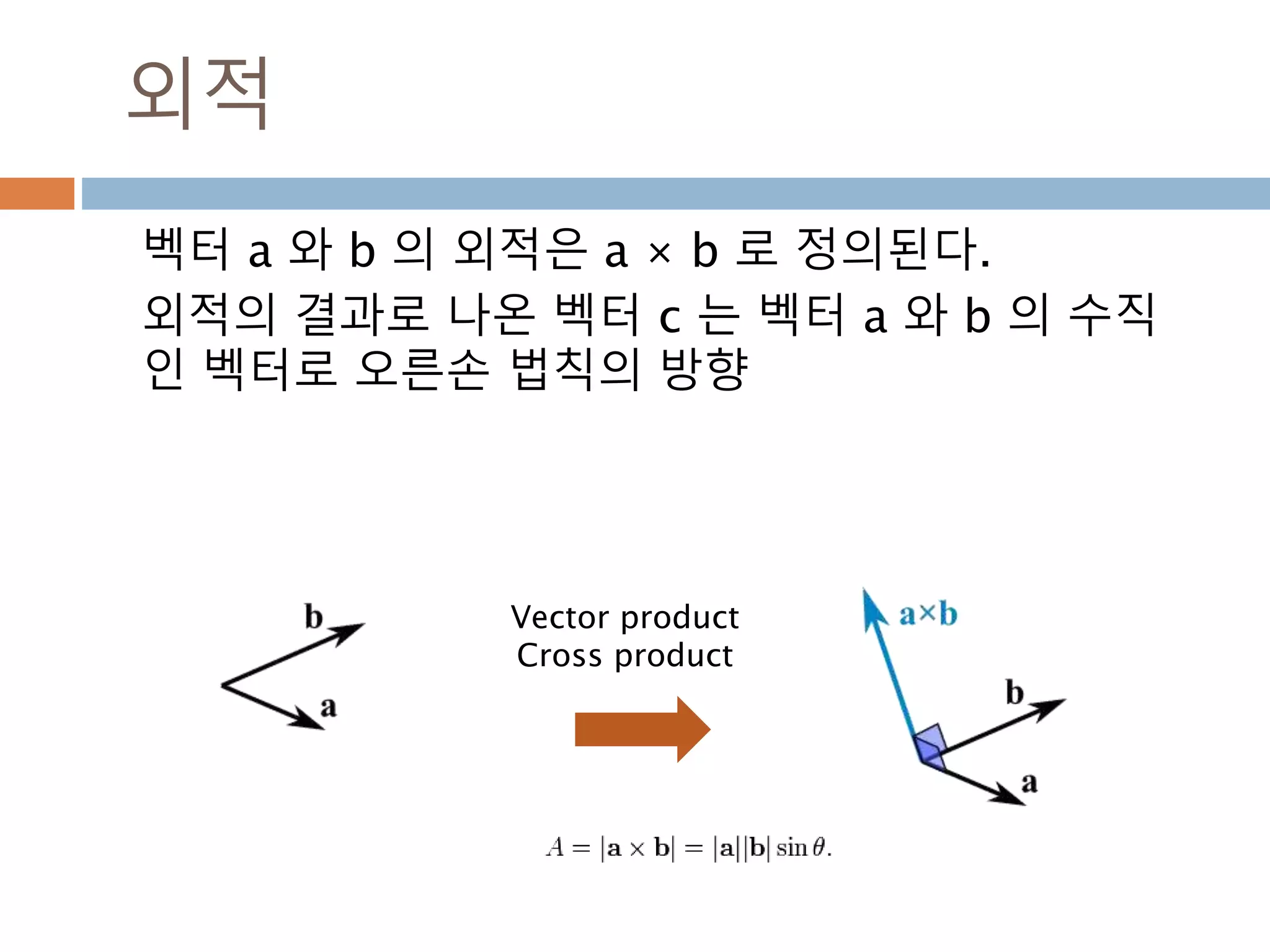




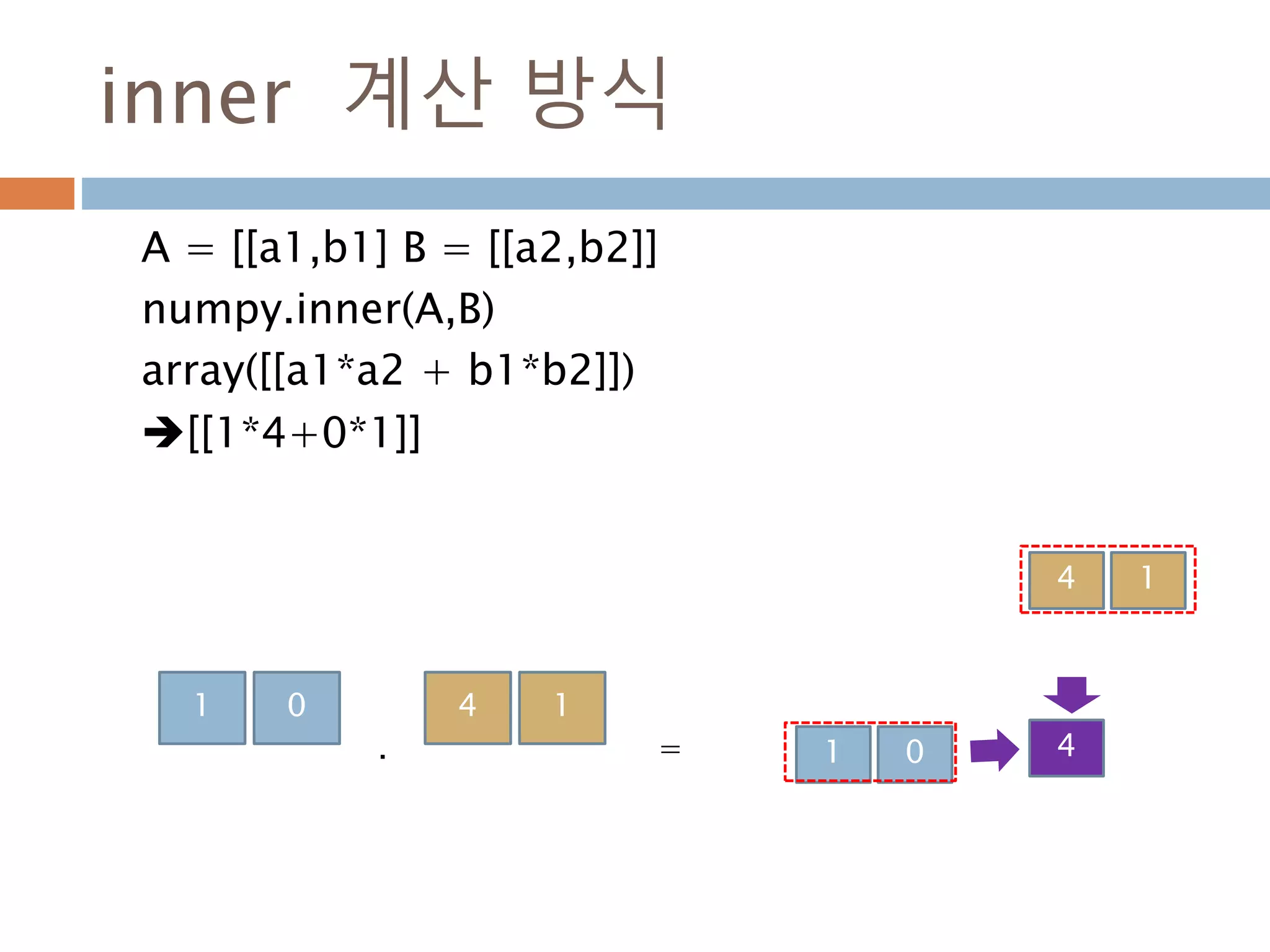


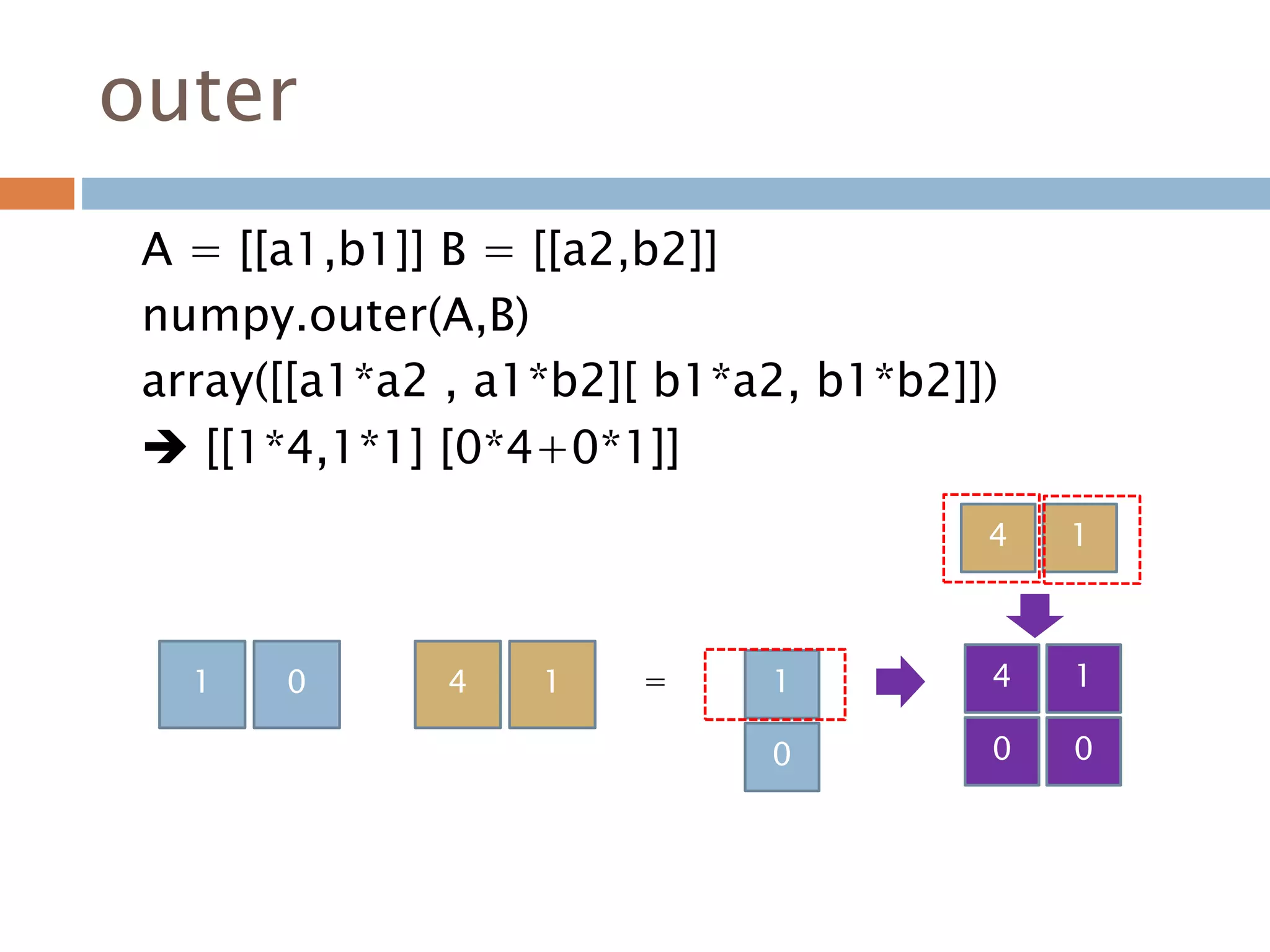



















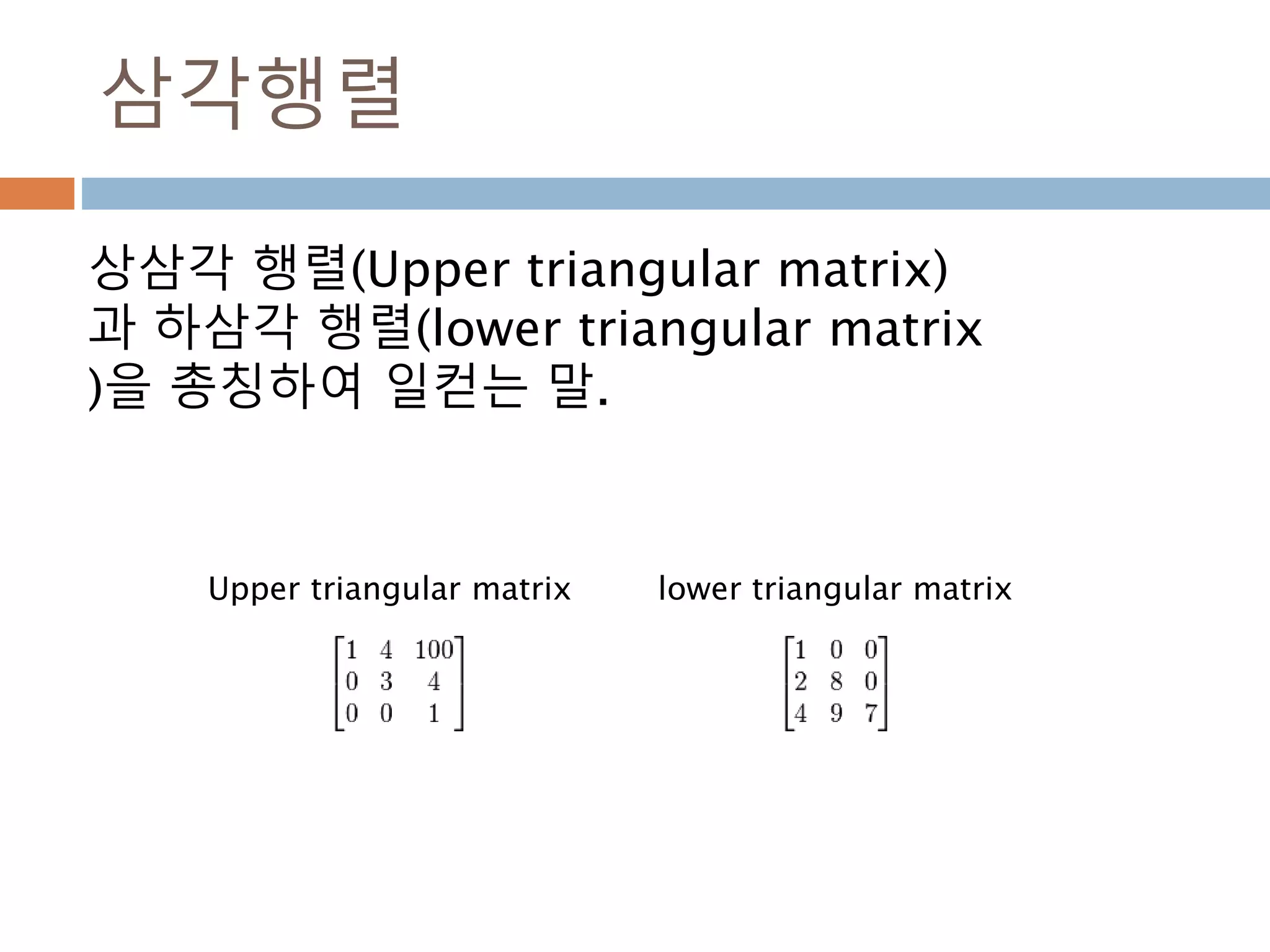

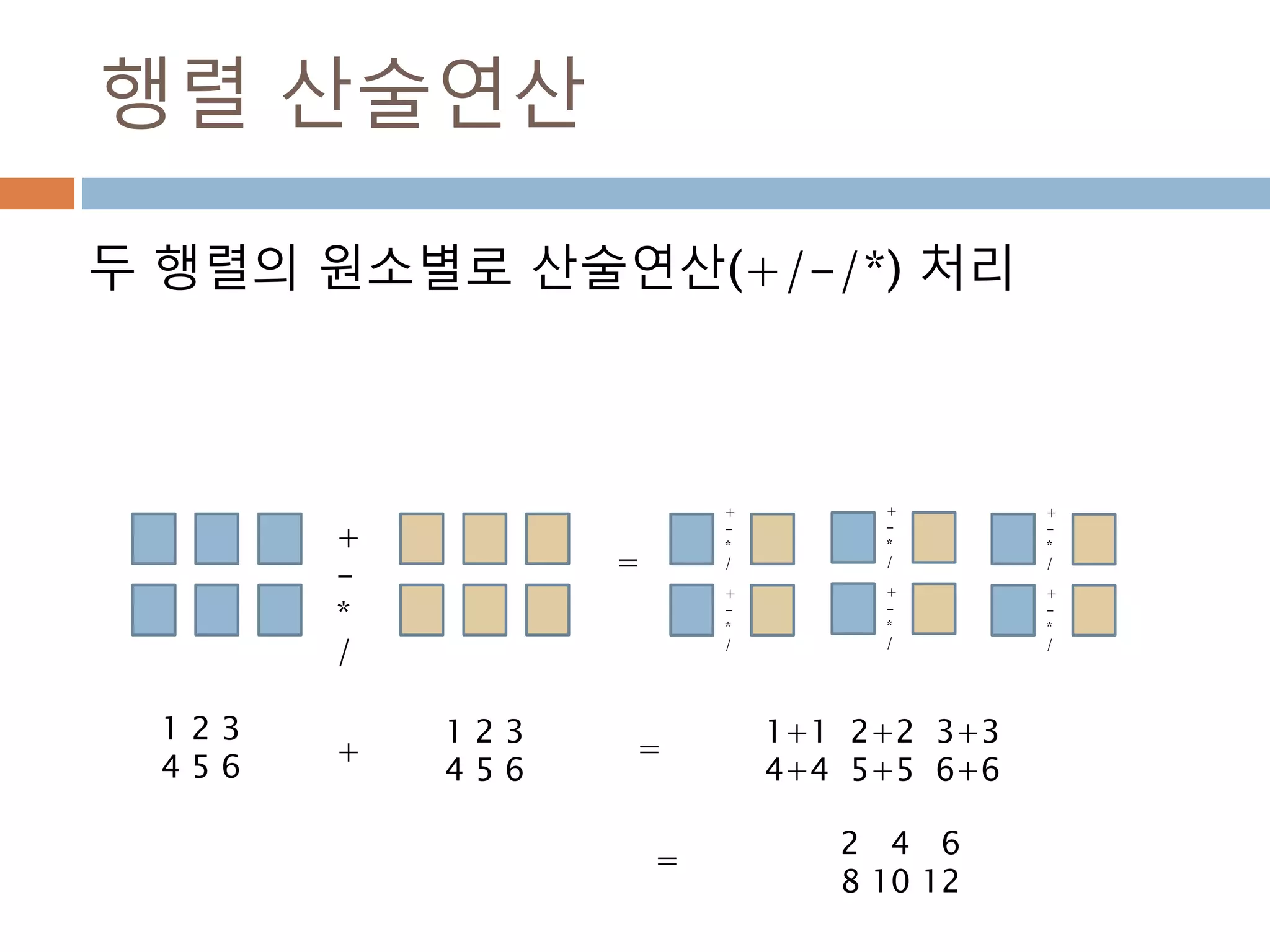


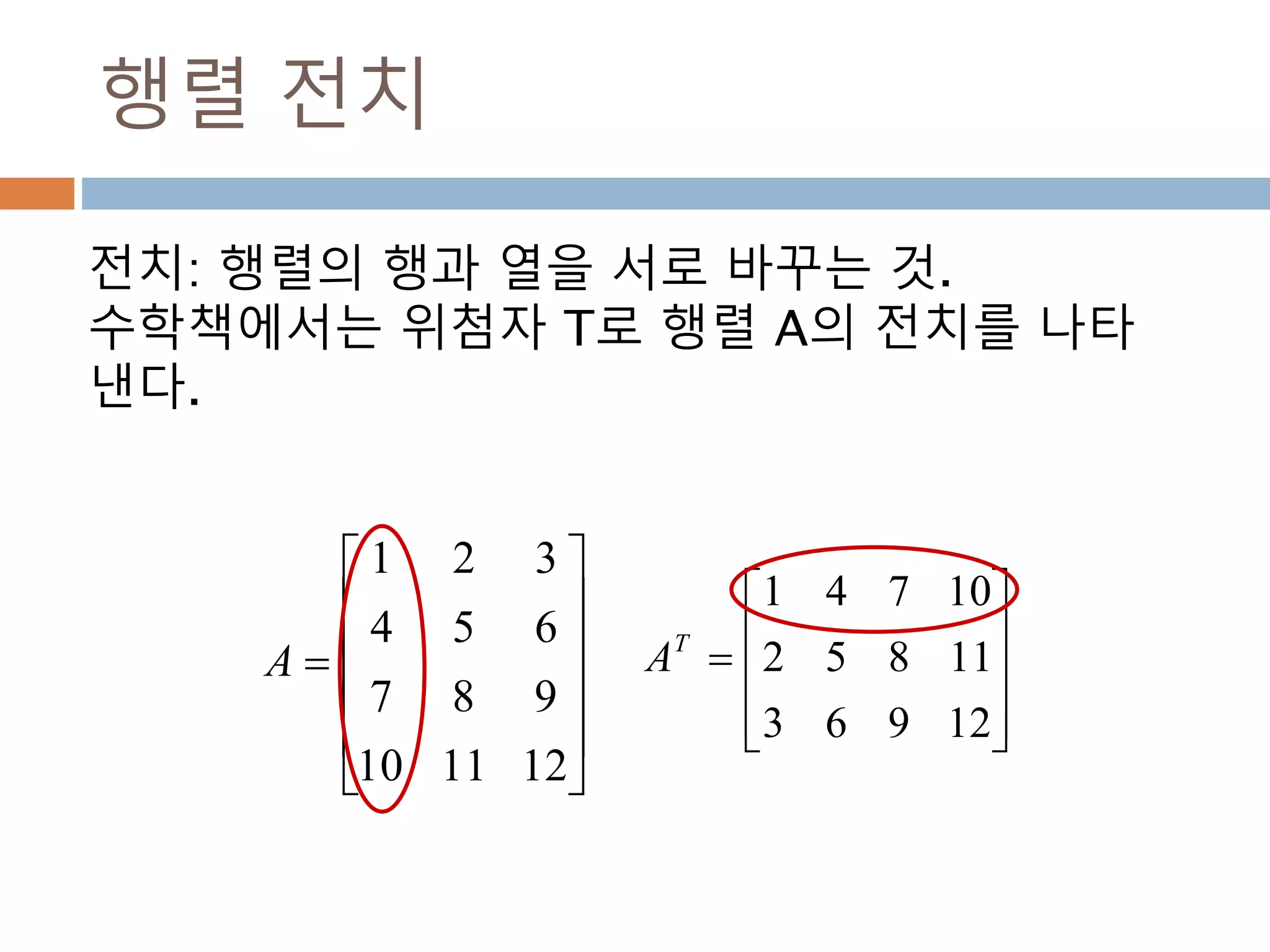


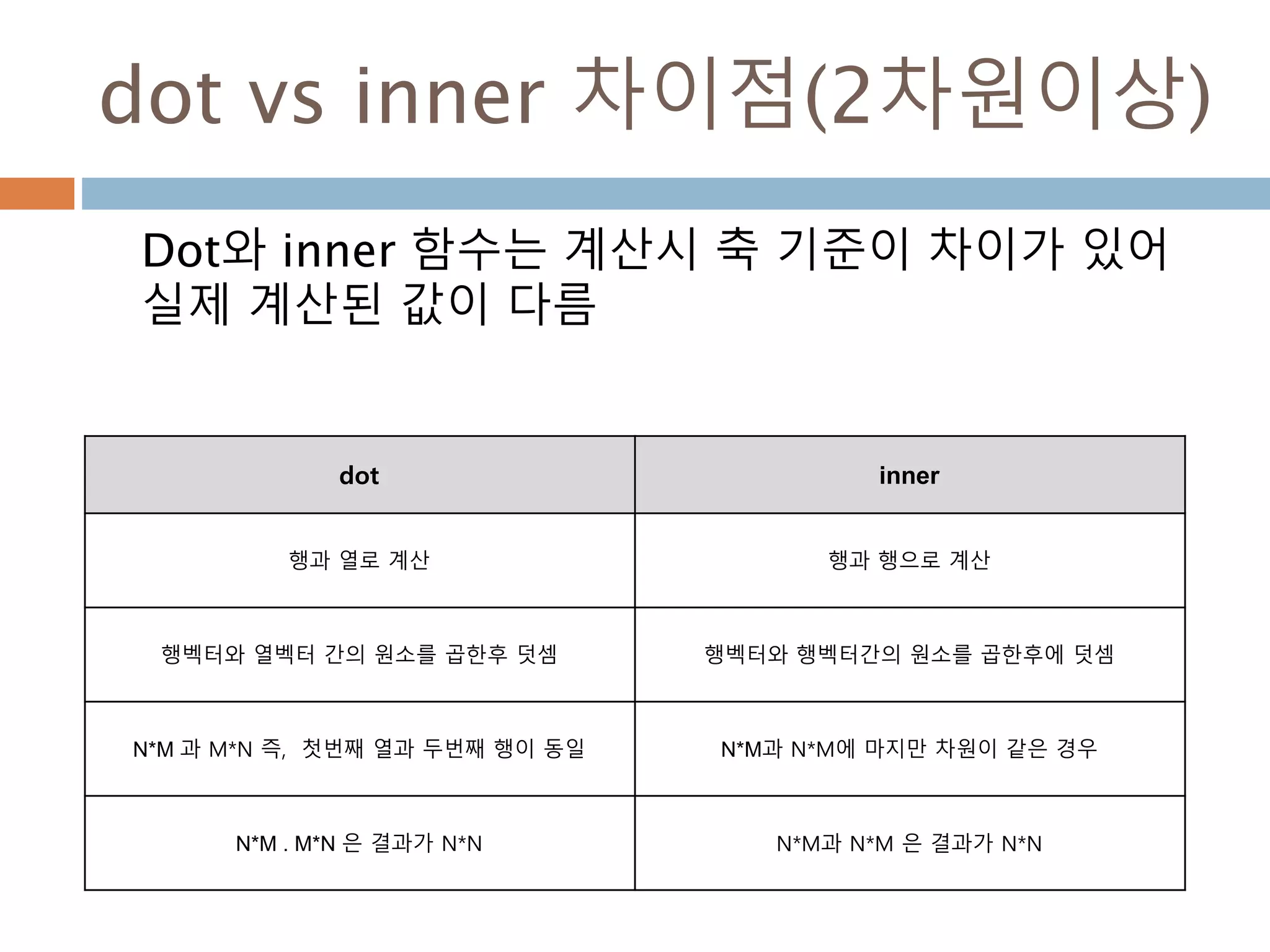
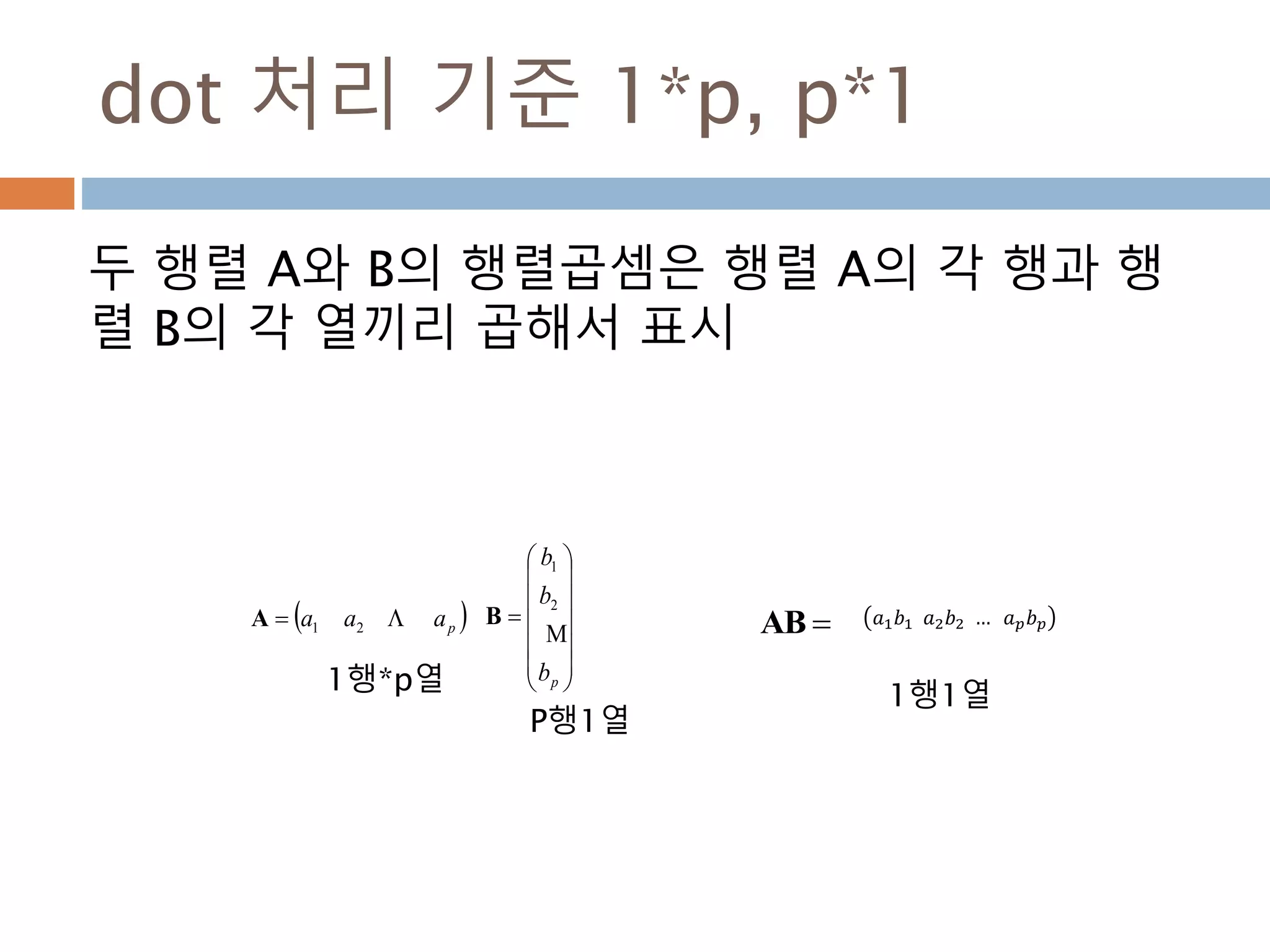

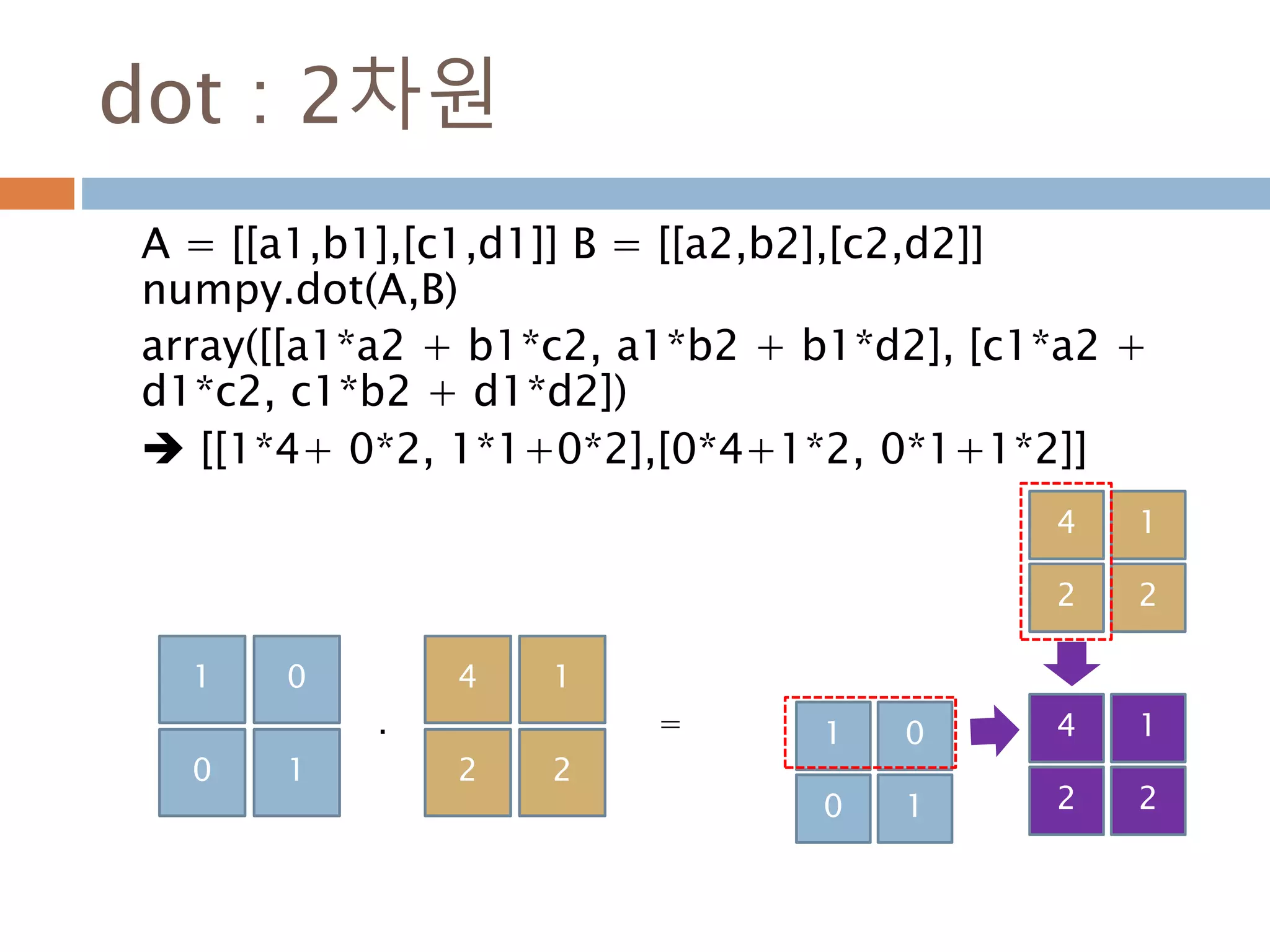




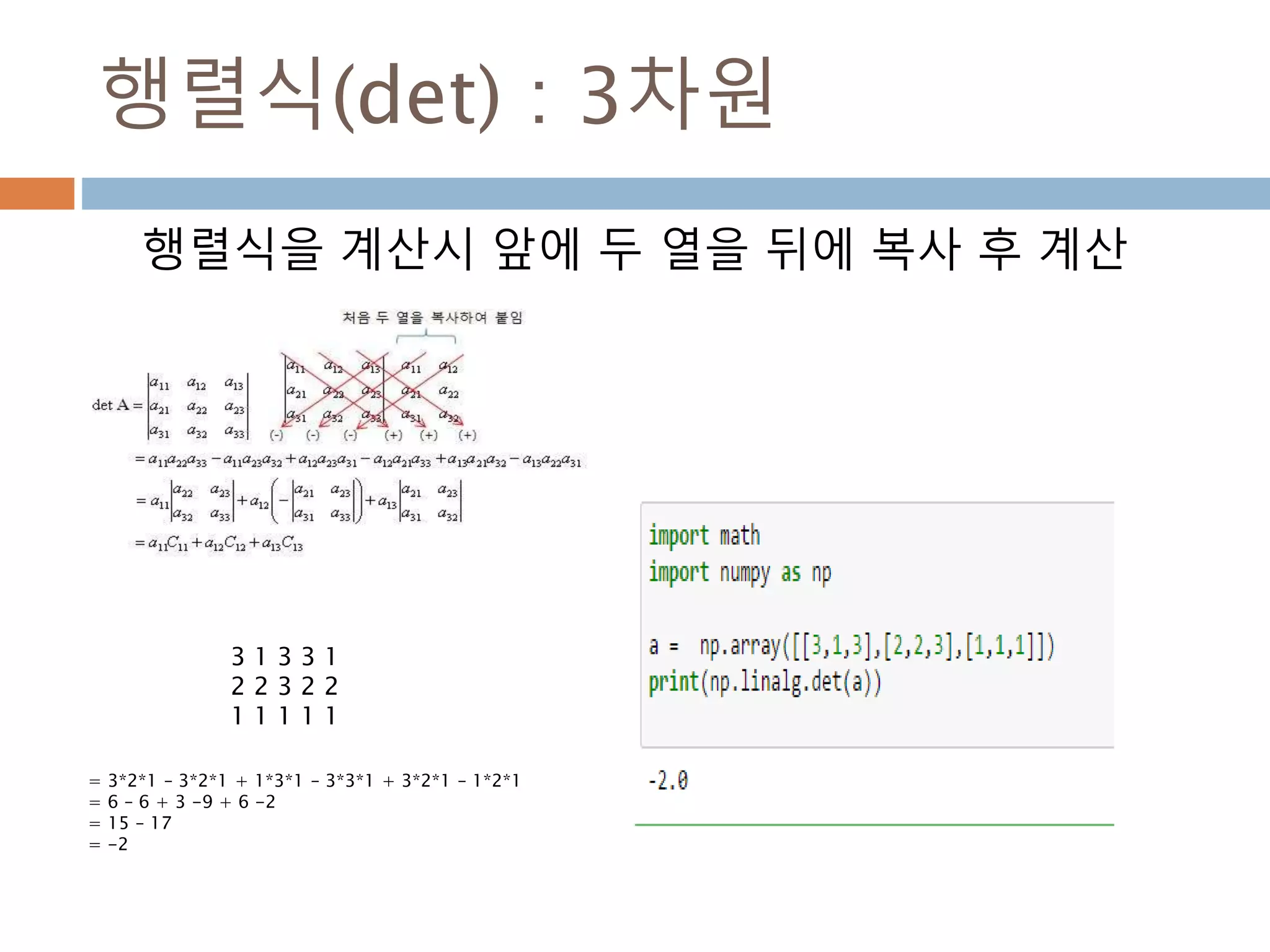



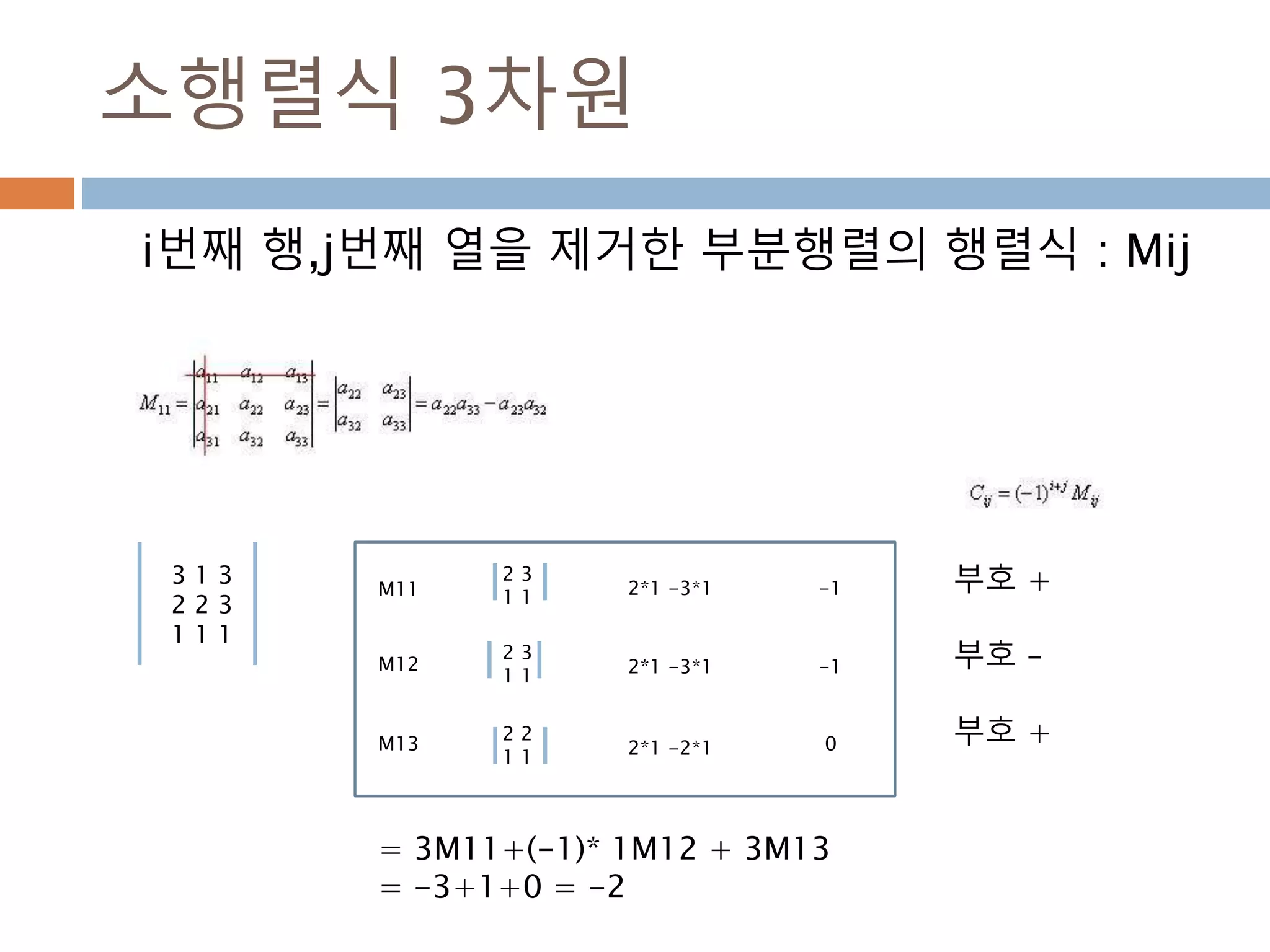


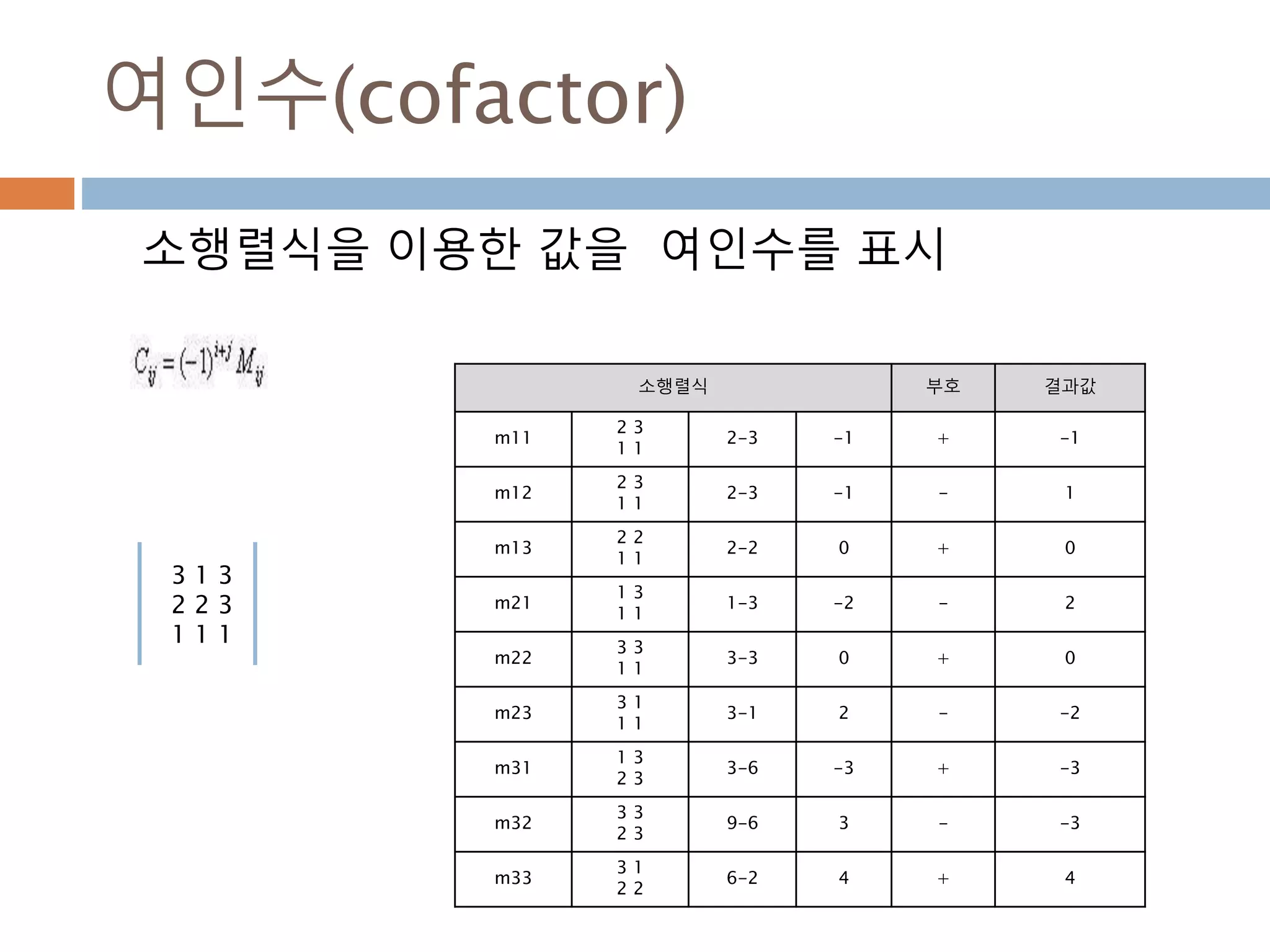
![벡터: 스칼라곱
벡터의 각 원소에 스칼라값만큼 곱하여 표시
벡터 m = [7,3]
A = 3m= [21,9]
295](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-295-2048.jpg)
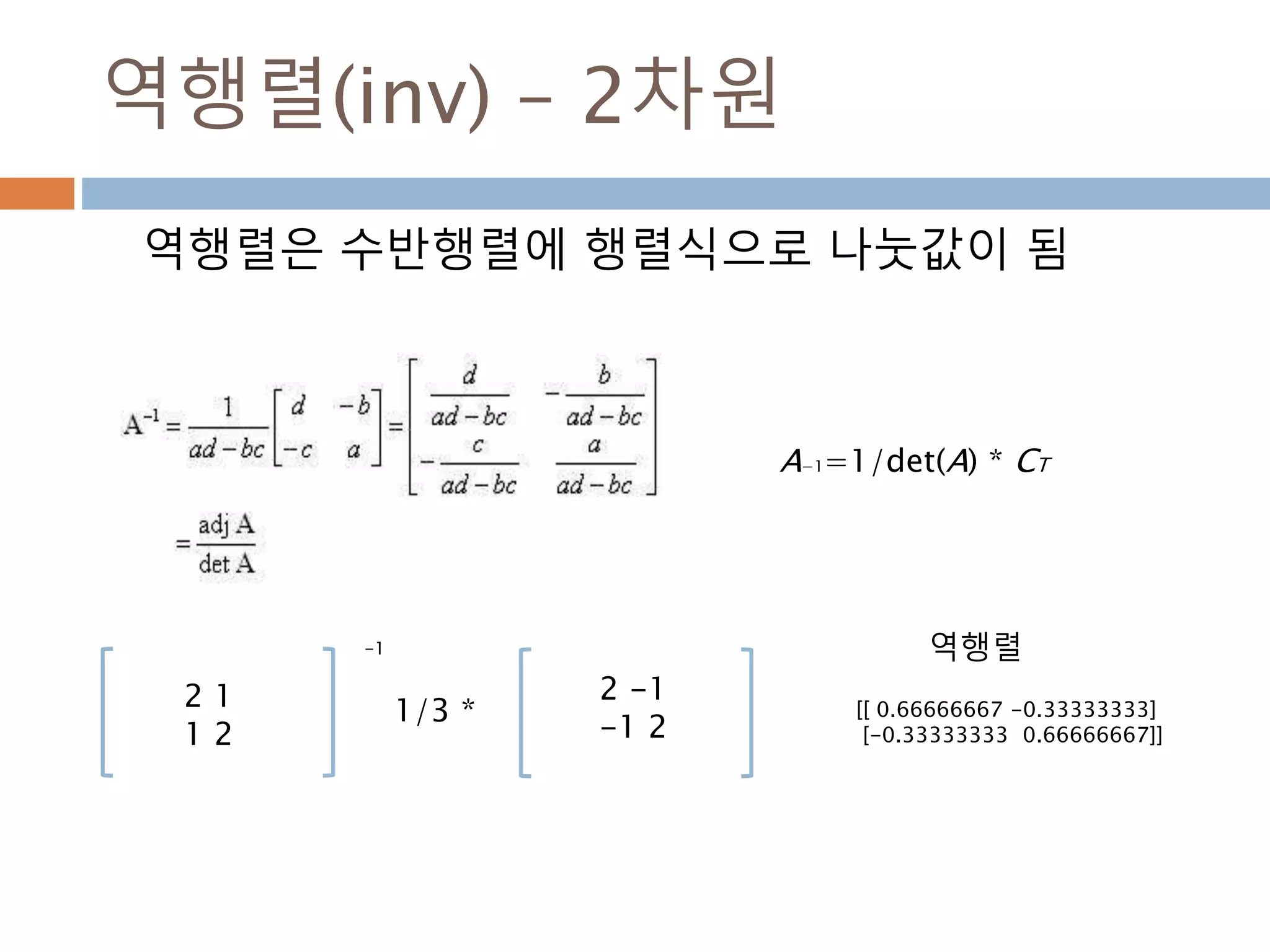



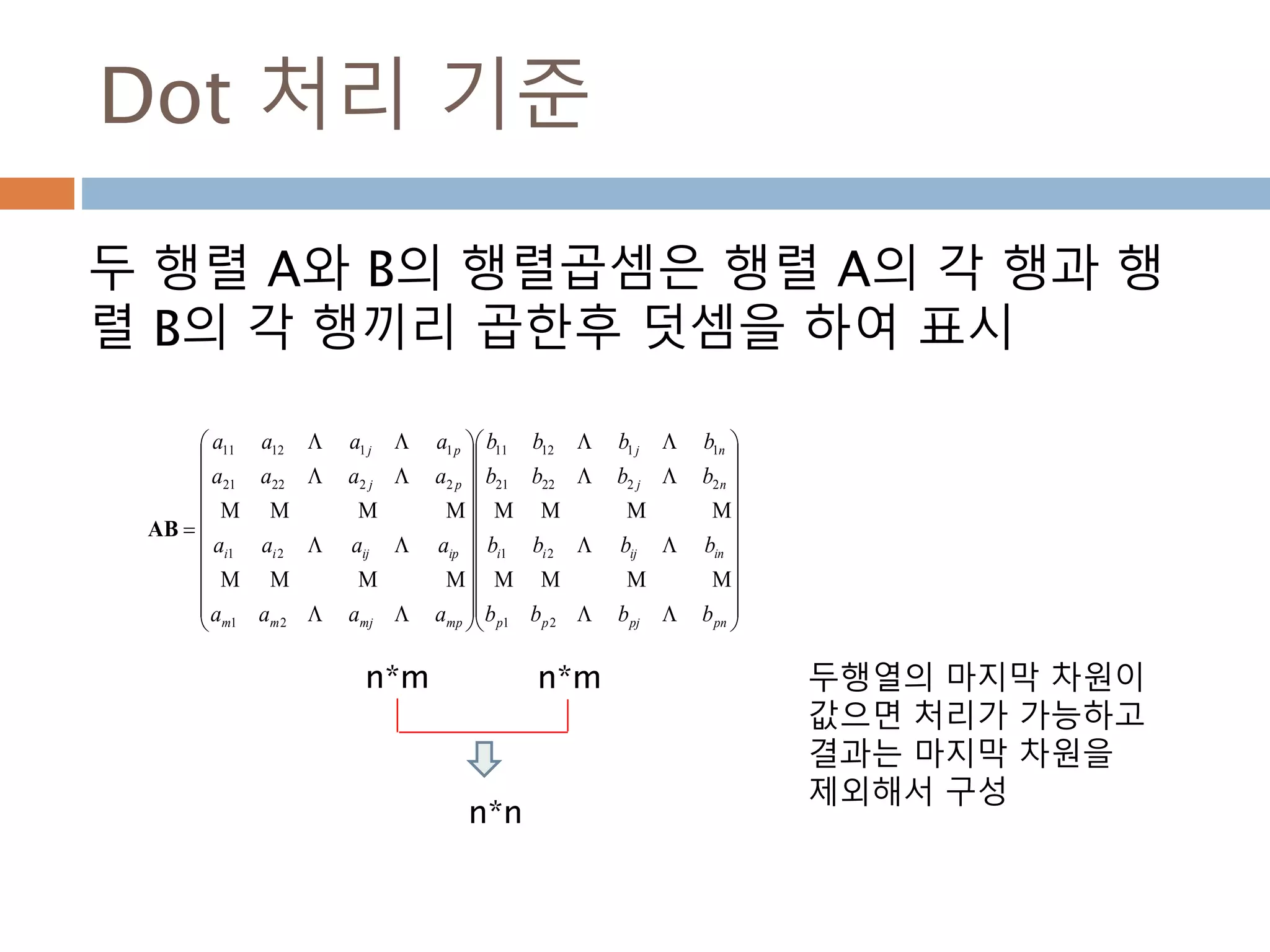

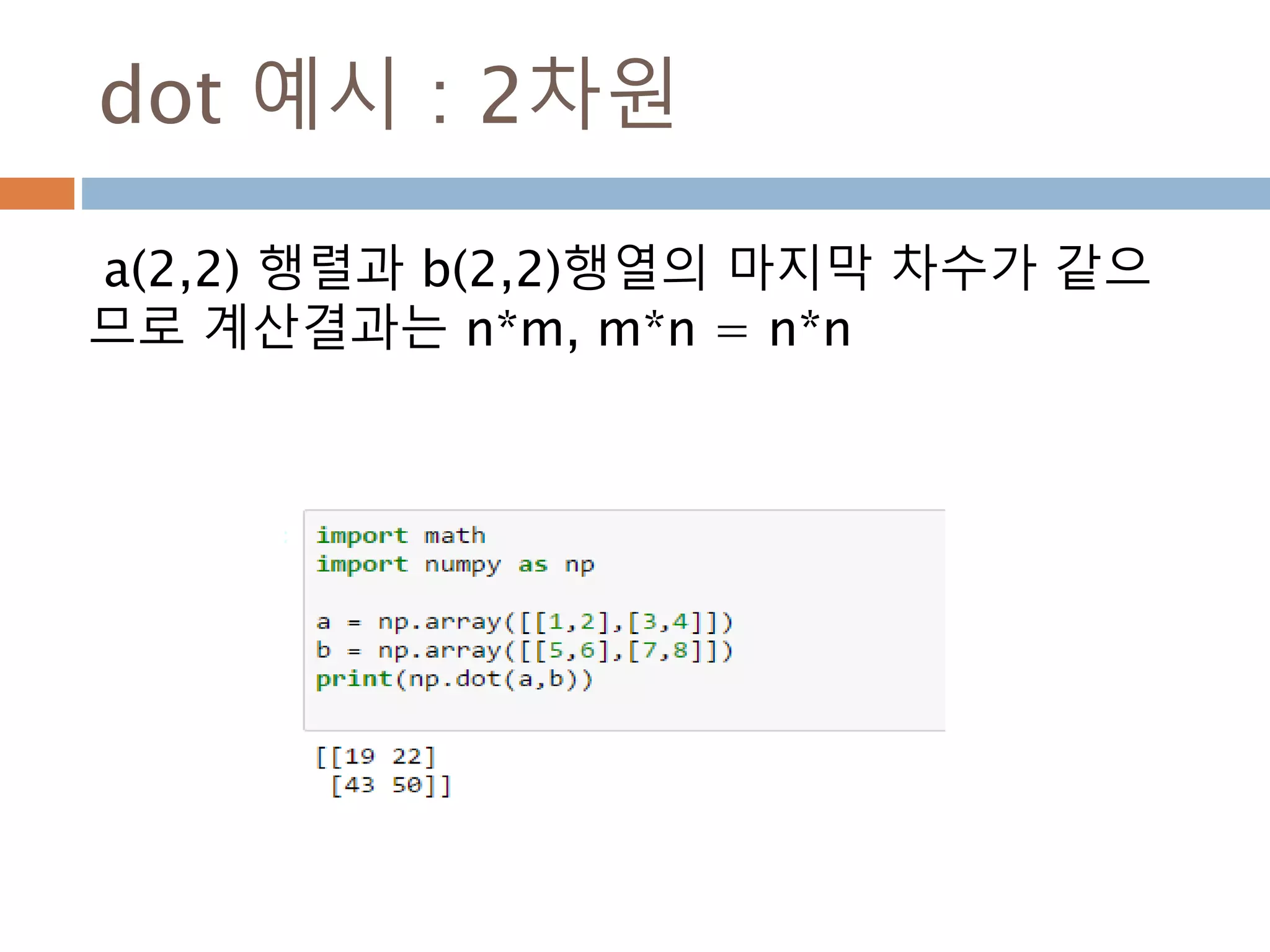



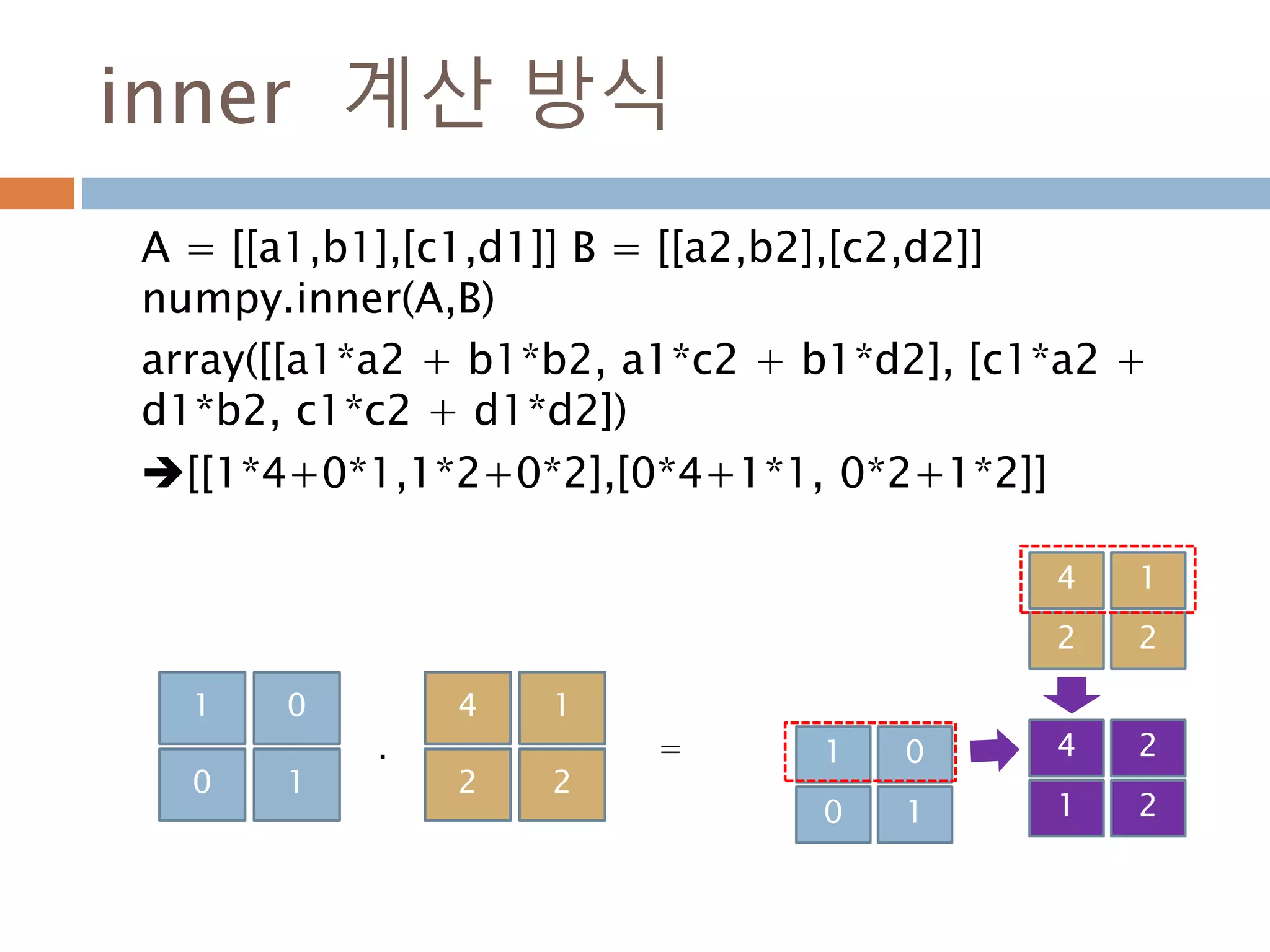
![외적 산식 : 2차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2]
u = [b1,b2]
a1 a2
b1 b2
a1*b2 – a2*b1 Example: The cross product of a = (2,3) and b = (5,6)
c = a1b2 − a2b1 = 2×6− 3×5 = −3
Answer: a × b = -3
308](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-308-2048.jpg)
![외적 산식 : 3차원
벡터의 원소간의 cross 적을 처리
v = [a1,a2,a3]
u = [b1,b2,b3]
a2 a3 a1 a2
b2 b3 b1 b2
x 측 : a2*b3 – a3*b2
y 측 : a3*b1 – a1*b2
z 측 : a1*b2 – a2*b1
Example: The cross product of a = (2,3,4) and b = (5,6,7)
cx = aybz − azby = 3×7 − 4×6 = −3
cy = azbx − axbz = 4×5 − 2×7 = 6
cz = axby − aybx = 2×6 − 3×5 = −3
Answer: a × b = (−3,6,−3)
309](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-309-2048.jpg)
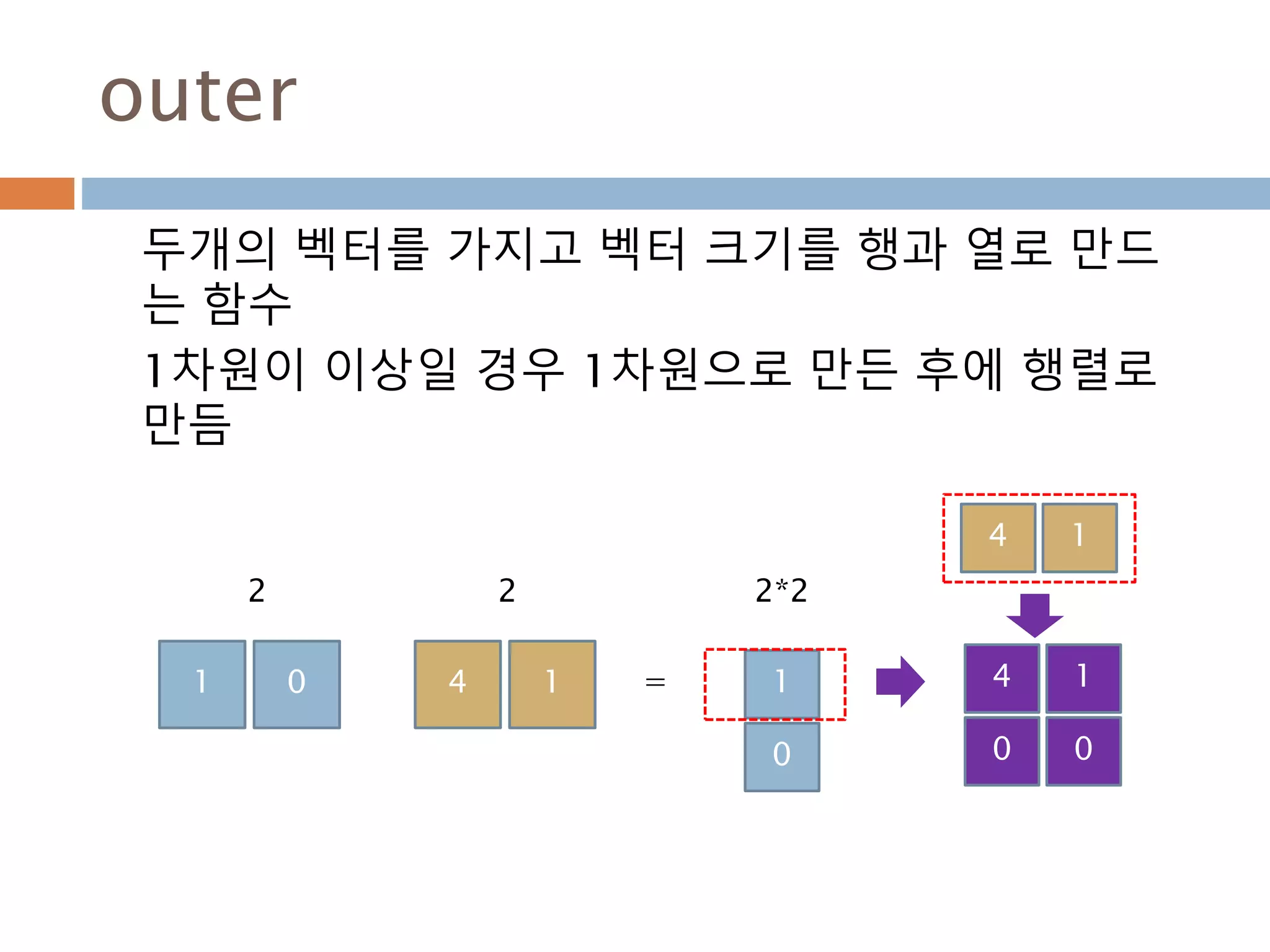
![inner 계산 방식
A = [[a1,b1] B = [[a2,b2]]
numpy.inner(A,B)
array([[a1*a2 + b1*b2]])
[[1*4+0*1]]
1 0 4 1
1 0
4 1
4=.
312](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-312-2048.jpg)


![outer
A = [[a1,b1]] B = [[a2,b2]]
numpy.outer(A,B)
array([[a1*a2 , a1*b2][ b1*a2, b1*b2]])
[[1*4,1*1] [0*4+0*1]]
1 0 4 1 1
0
4 1
4 1
0 0
=
315](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-315-2048.jpg)

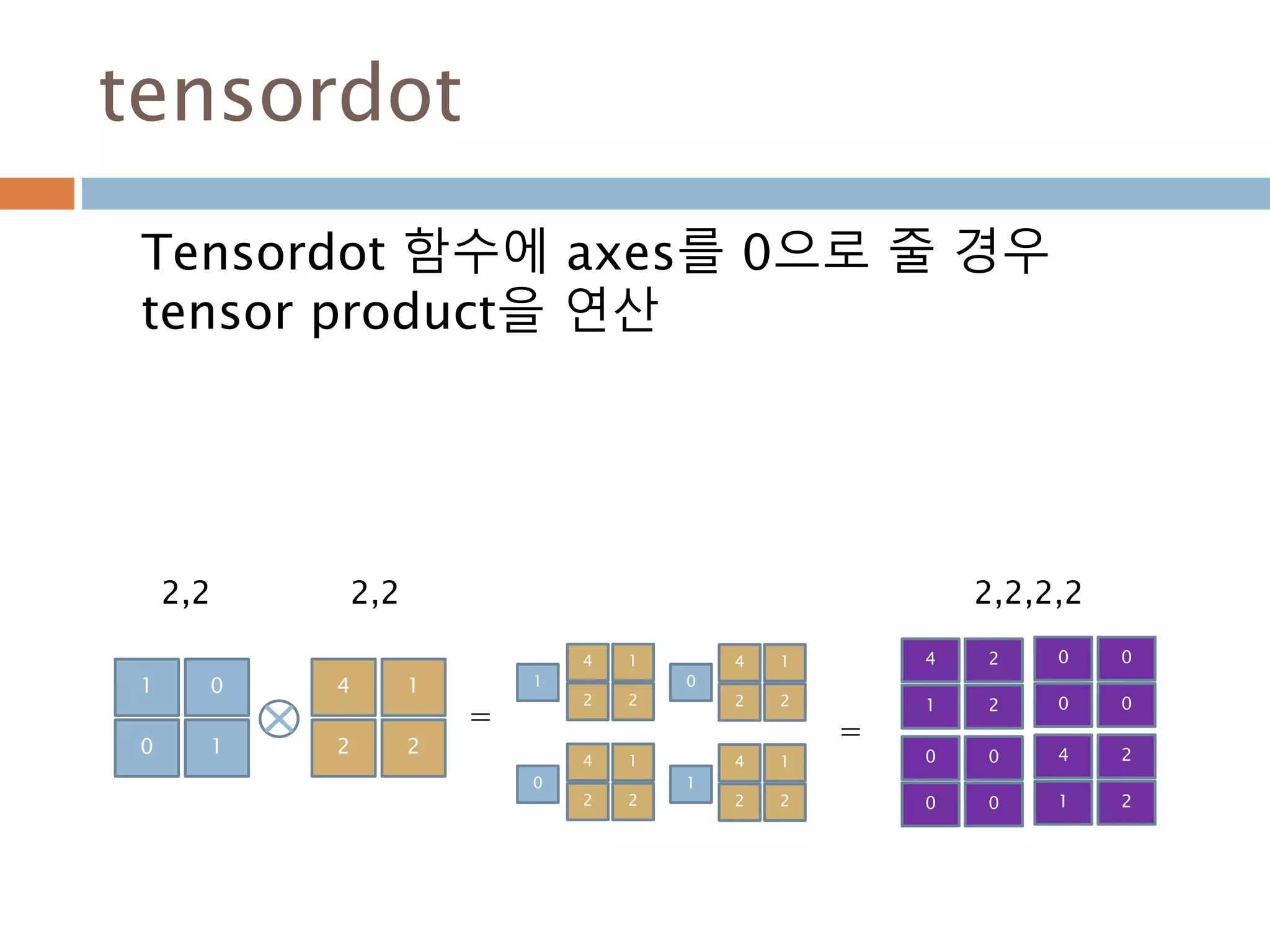



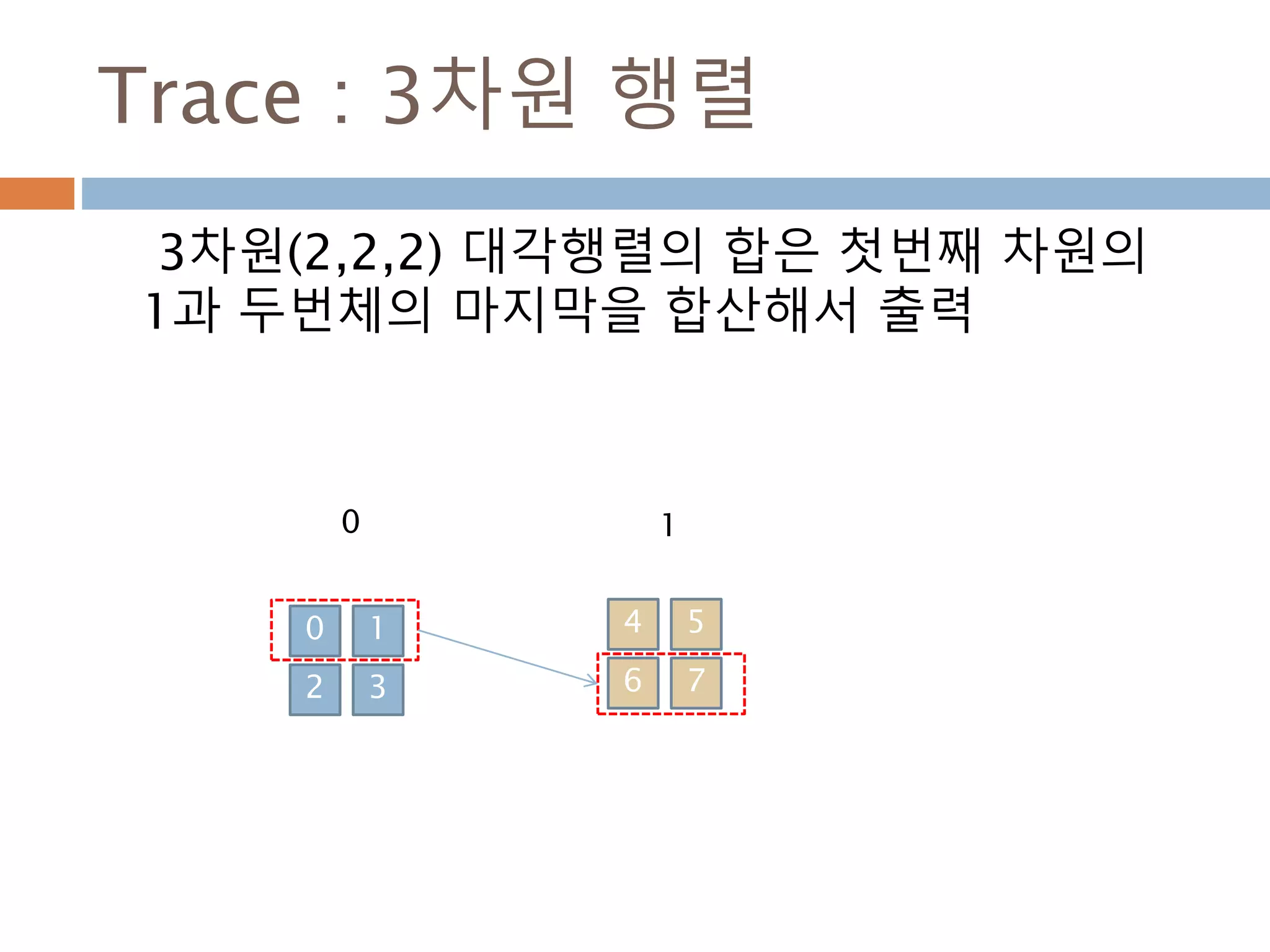






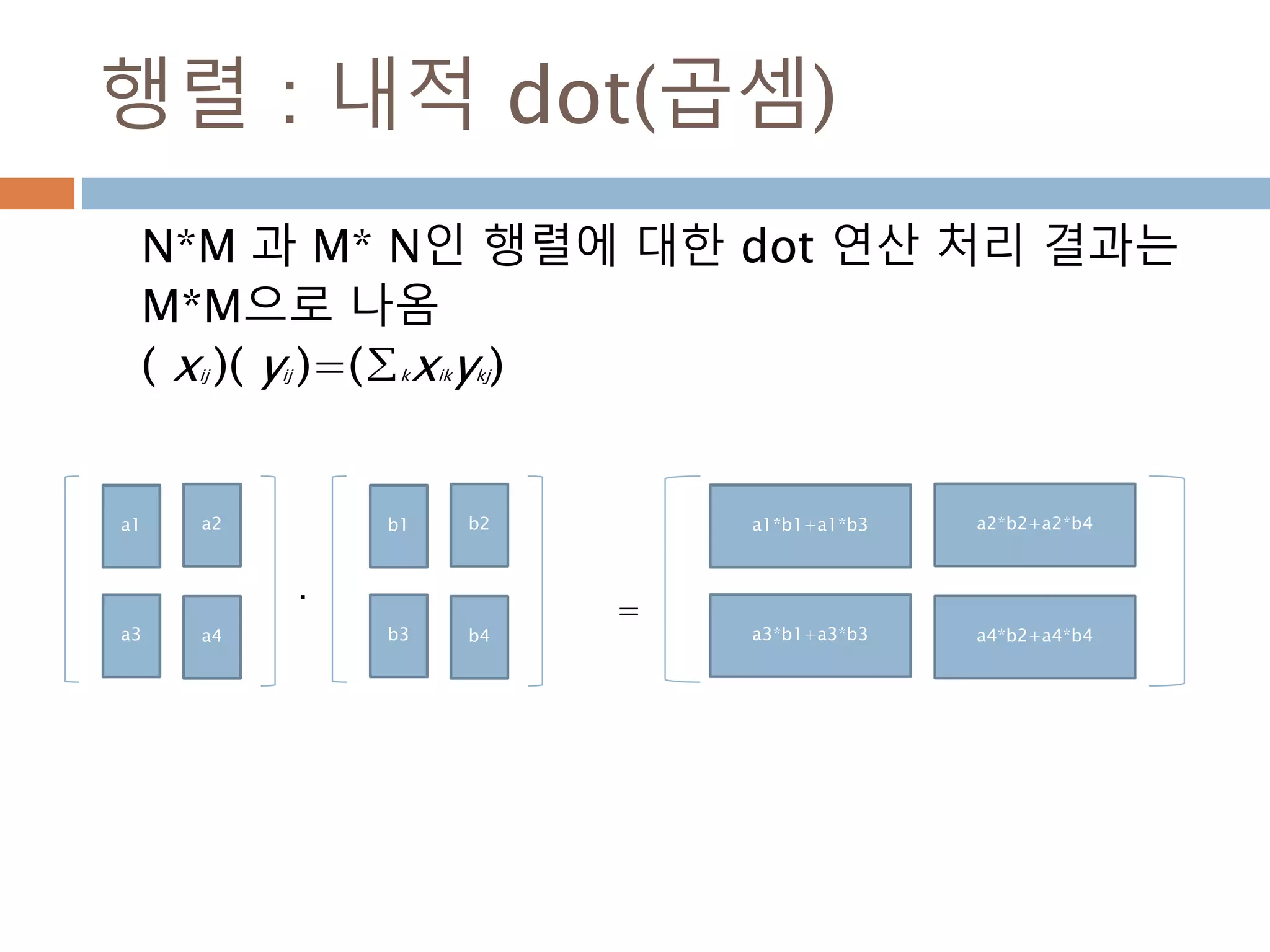


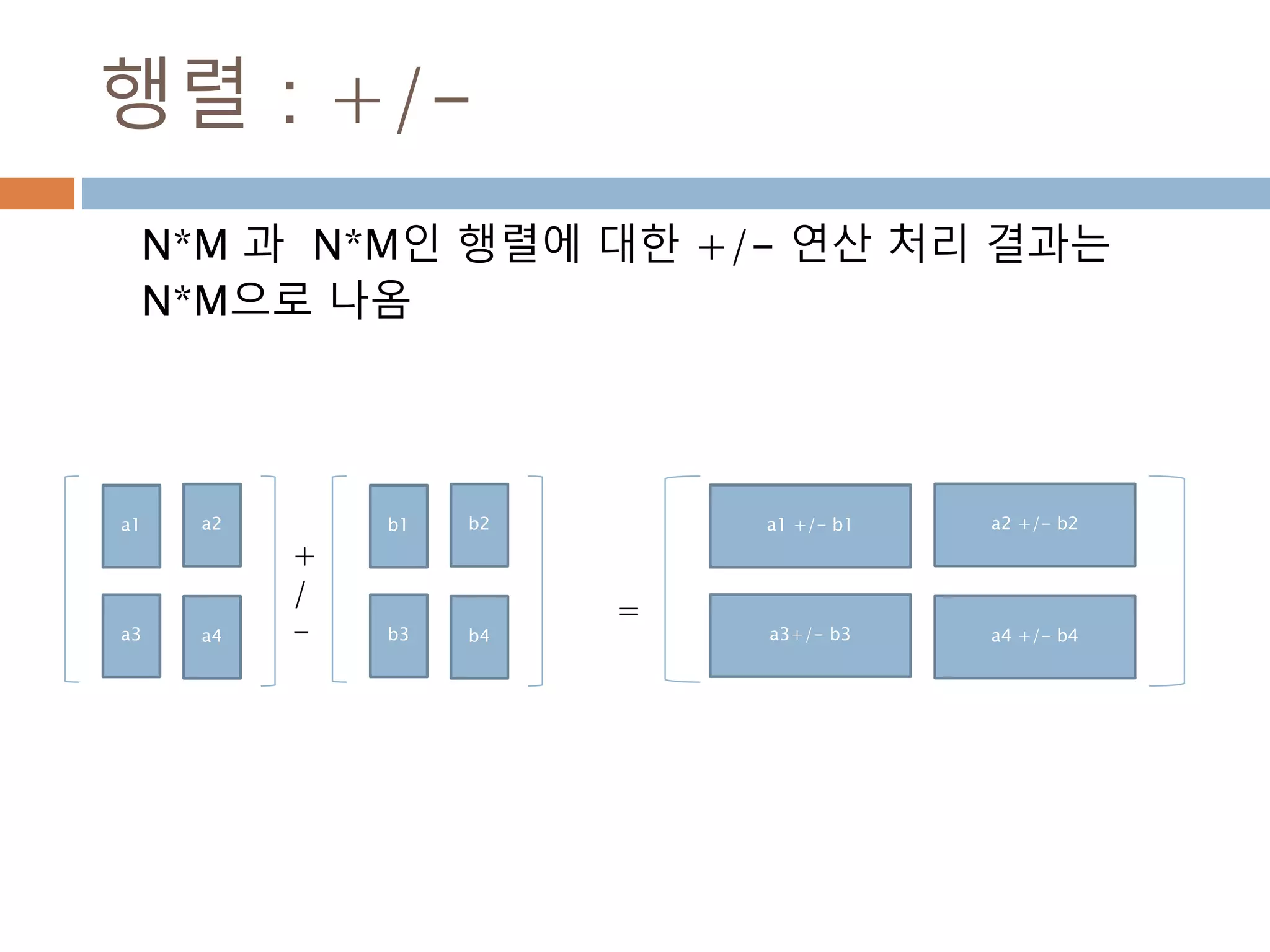

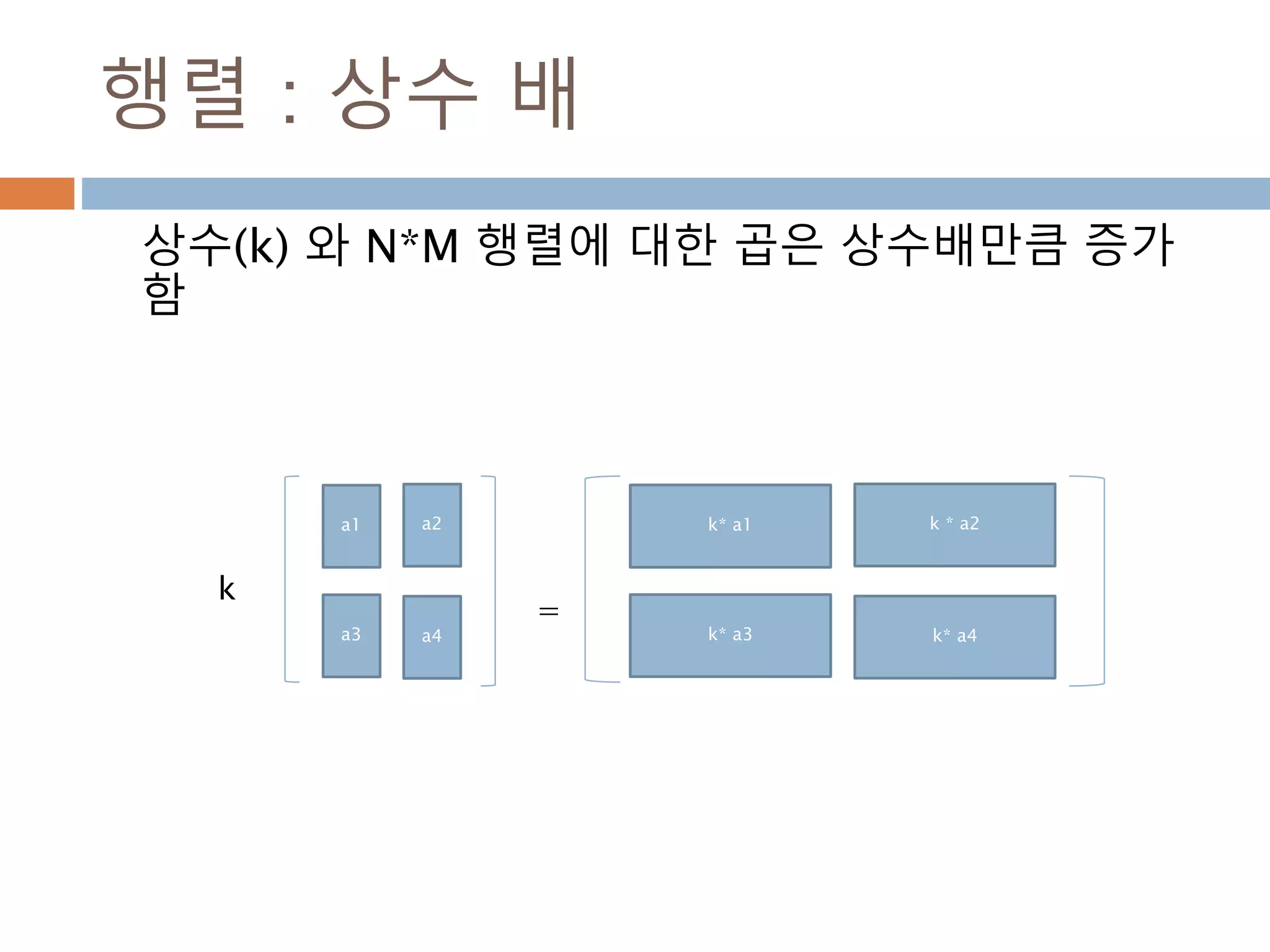
![항등행렬
모든 행렬과 닷 연산시 자기 자신이 나오게 하는
단위행렬
import numpy as np
a = np.array([[1,0],[0,1]])
b = np.array([[4,1],[3,2]])
print(np.dot(b,a))
print(np.dot(a,b))
[[4 1]
[3 2]]
[[4 1]
[3 2]]
334](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-334-2048.jpg)
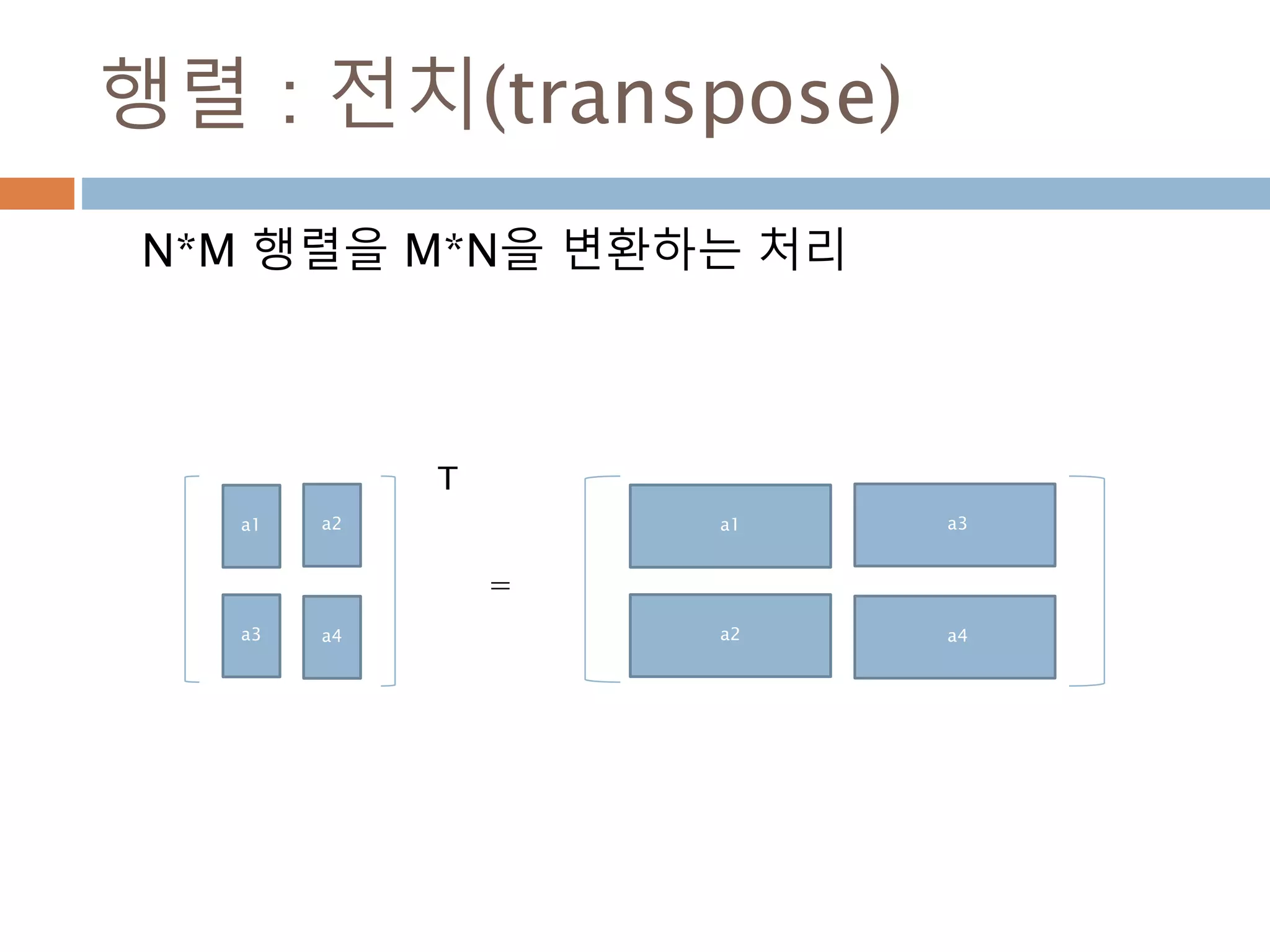







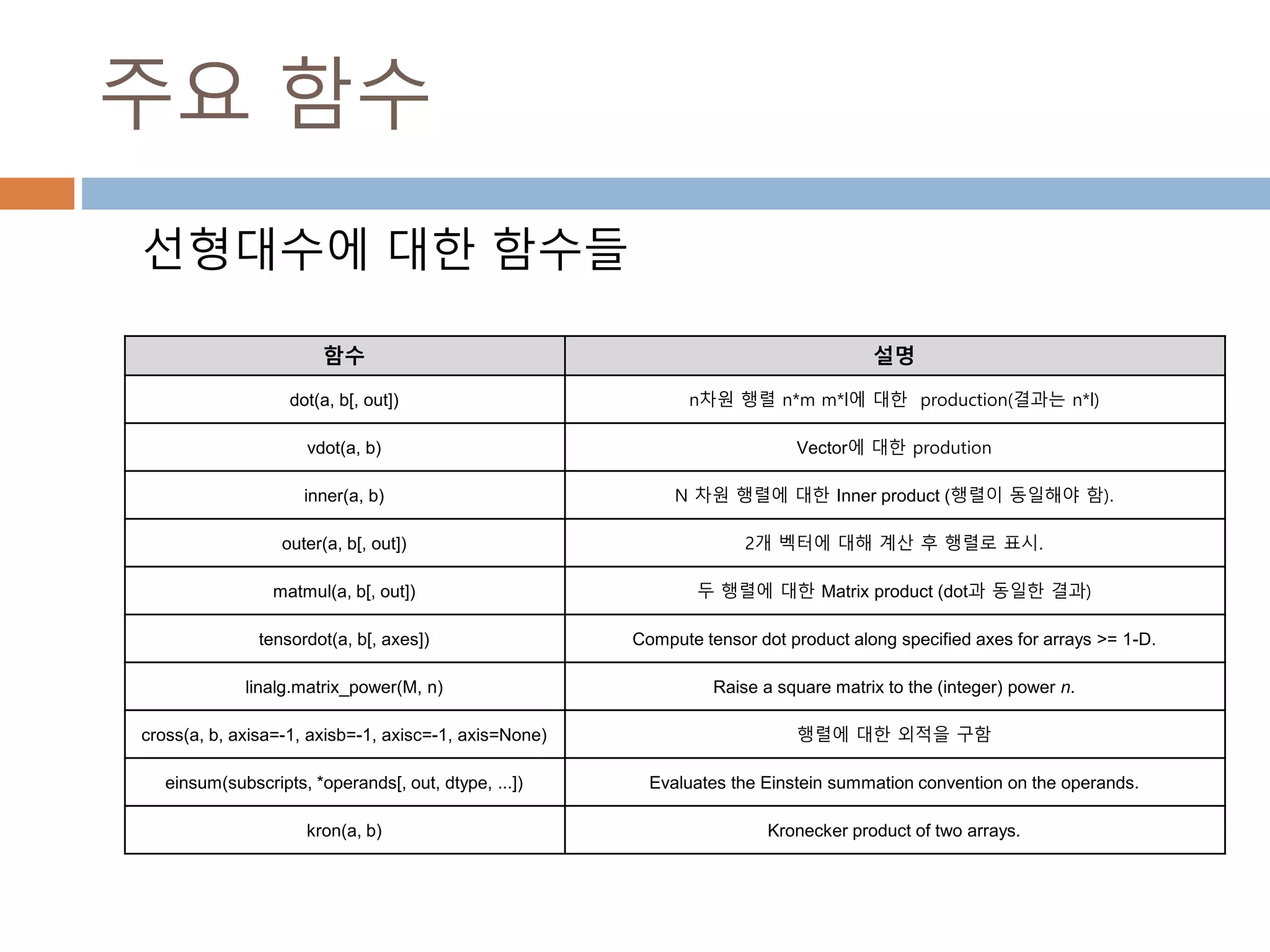



![dot : 2차원
A = [[a1,b1],[c1,d1]] B = [[a2,b2],[c2,d2]]
numpy.dot(A,B)
array([[a1*a2 + b1*c2, a1*b2 + b1*d2], [c1*a2 +
d1*c2, c1*b2 + d1*d2])
[[1*4+ 0*2, 1*1+0*2],[0*4+1*2, 0*1+1*2]]
1 0
0 1
4 1
2 2
1 0
0 1
4 1
2 2
4 1
2 2
=.
347](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-347-2048.jpg)







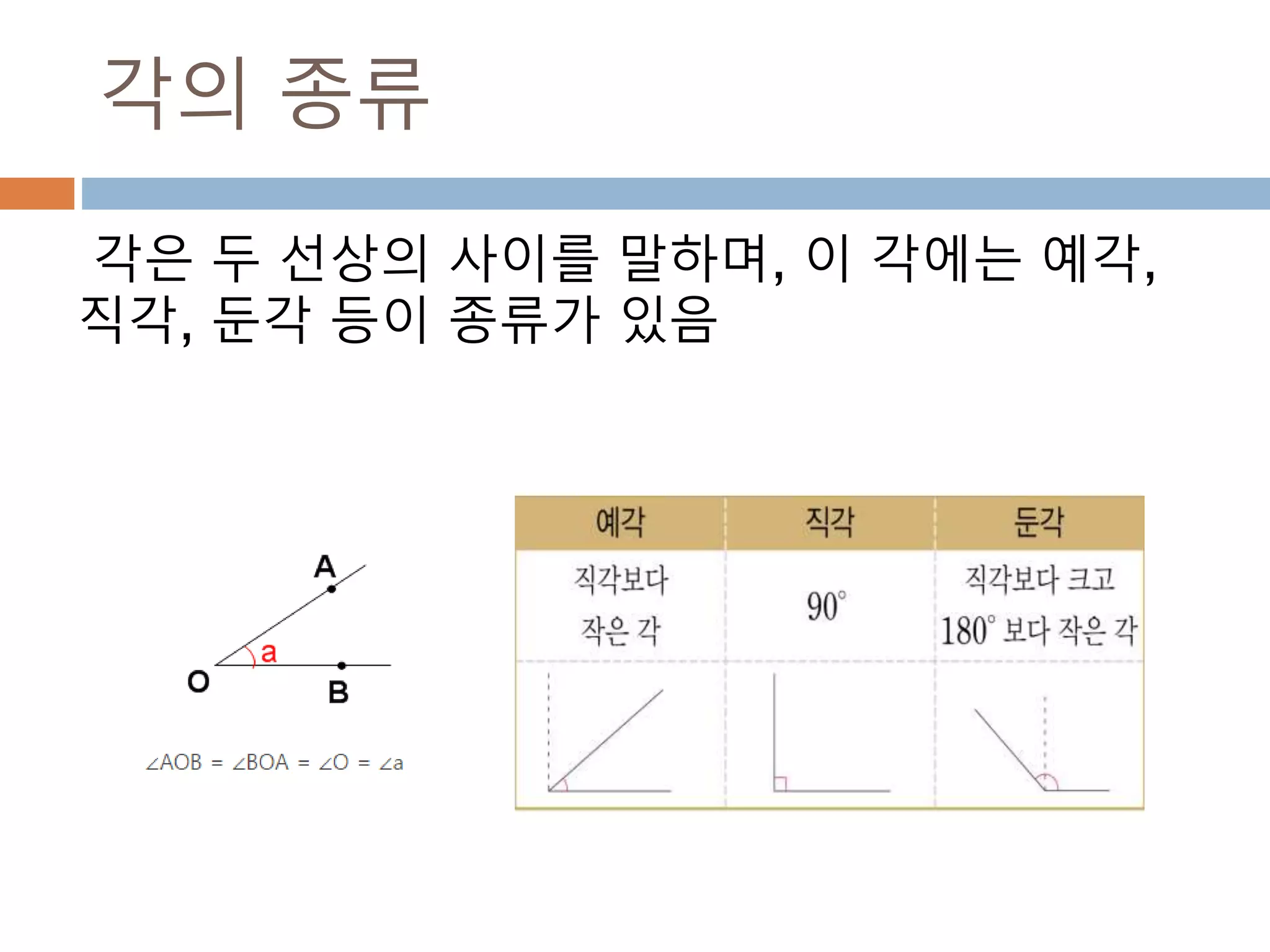

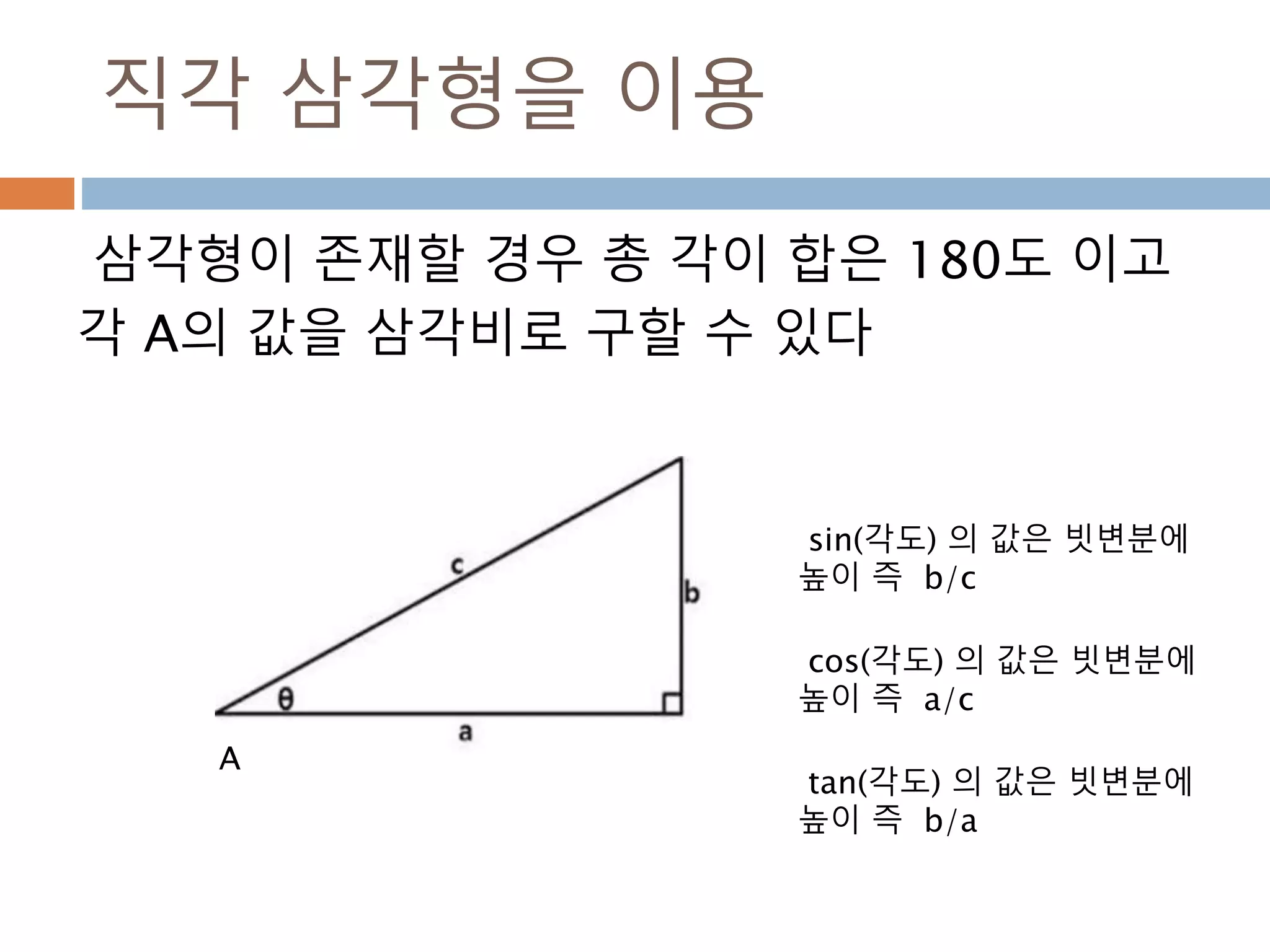


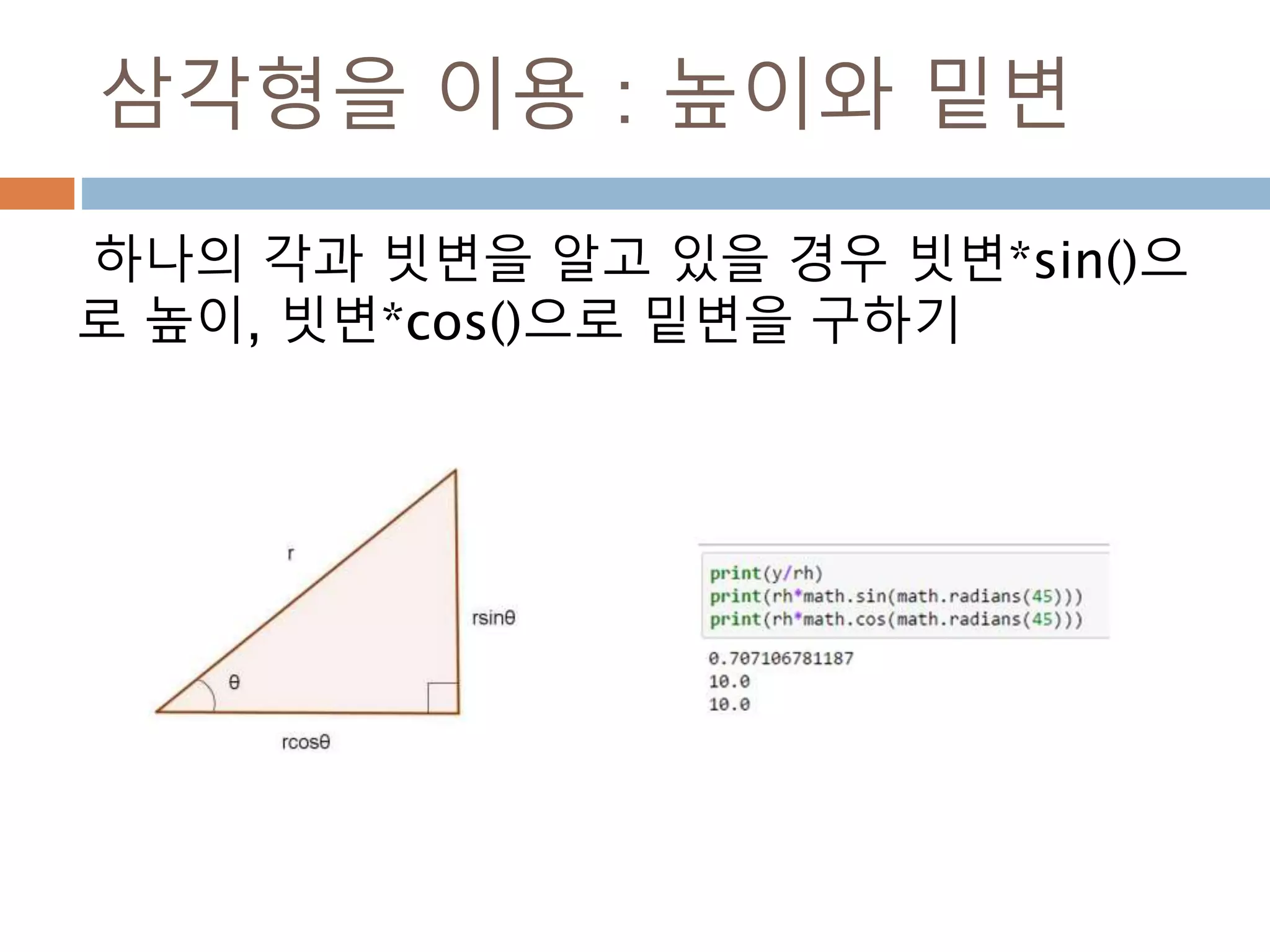
![역행렬(inv) – 2차원
역행렬은 수반행렬에 행렬식으로 나눗값이 됨
[[ 0.66666667 -0.33333333]
[-0.33333333 0.66666667]]
1/3 *
2 -1
-1 2
역행렬
2 1
1 2
-1
A−1=1/det(A) * CT
361](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-361-2048.jpg)
![역행렬(inv) – 3차원
역행렬은 수반행렬에 행렬식으로 나눗값이 됨
[[ 0.5 -1. 1.5]
[-0.5 0. 1.5]
[ 0. 1. -2. ]]
- 0.5 *
-1 2 -3
1 0 -3
0 -2 4
역행렬3 1 3
2 2 3
1 1 1
-1
A−1=1/det(A) * CT
362](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-362-2048.jpg)



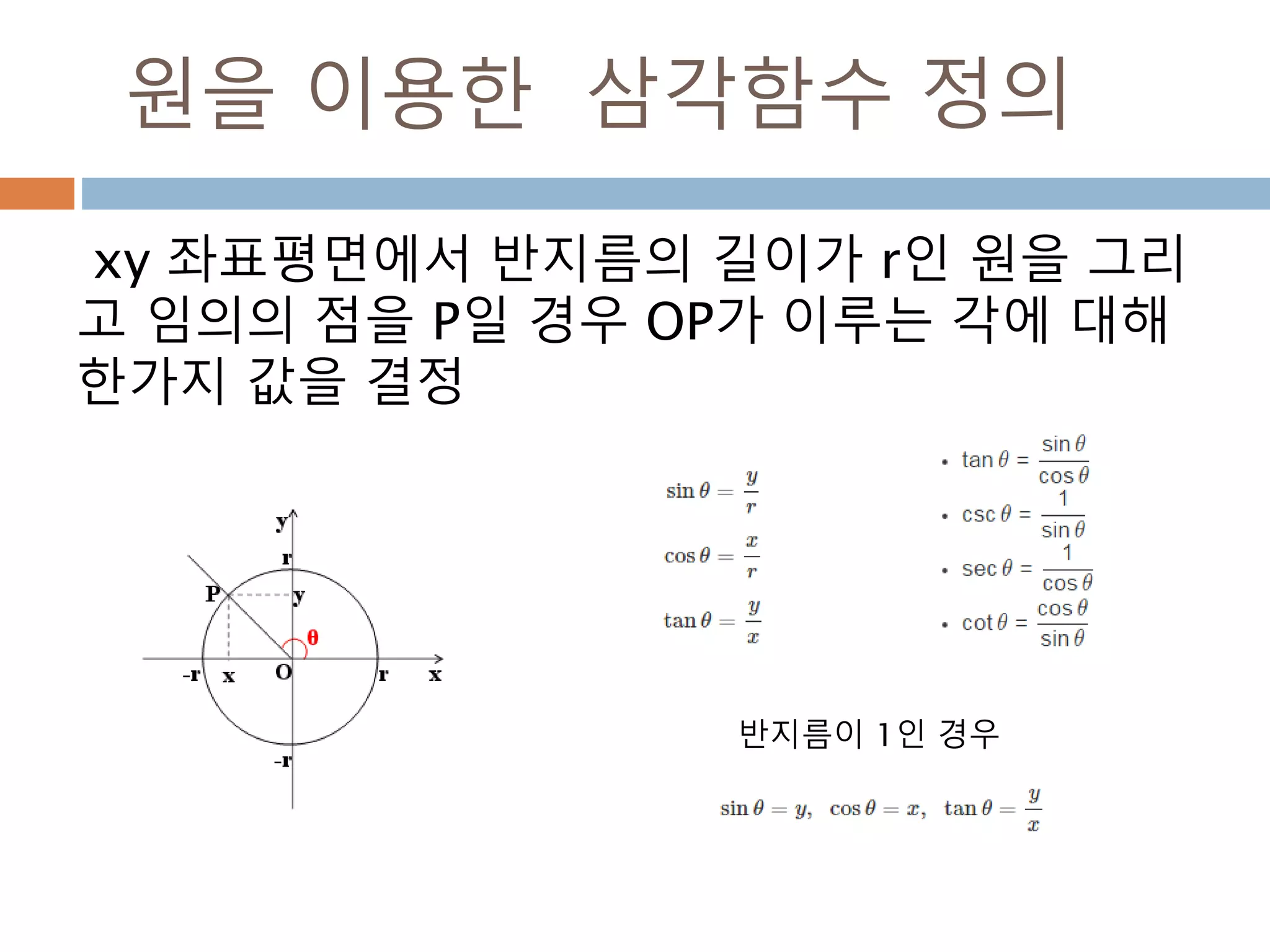
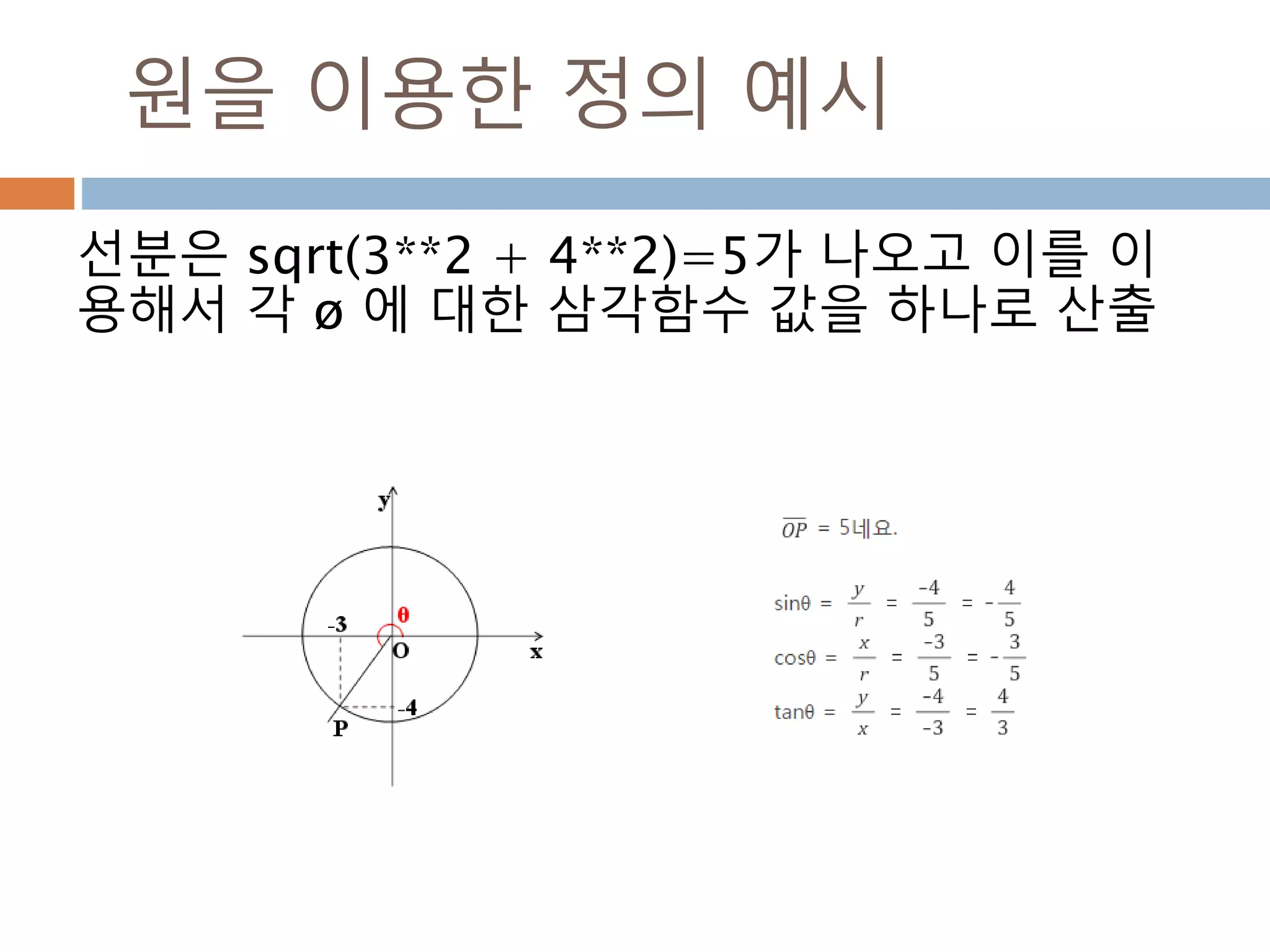

![cross 계산 방식
A = [[a1,b1],[c1,d1]] B = [[a2,b2],[c2,d2]]
numpy.cross(A,B) = A.T * B
array([[a1*b2 - c1*a2 , b1*d2 – d1*c2])
[[1*1- 0*4,0*2-1*2]]
1 0
0 1
4 2
1 2
1 -2=
369](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-369-2048.jpg)


![inner 계산 방식
A = [[a1,b1],[c1,d1]] B = [[a2,b2],[c2,d2]]
numpy.inner(A,B)
array([[a1*a2 + b1*b2, a1*c2 + b1*d2], [c1*a2 +
d1*b2, c1*c2 + d1*d2])
[[1*4+0*1,1*2+0*2],[0*4+1*1, 0*2+1*2]]
1 0
0 1
4 1
2 2
1 0
0 1
4 1
2 2
4 2
1 2
=.
372](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-372-2048.jpg)
![Inner 예시 : 2차원
a(2,2) 행렬과 b(2,2)행렬의 마지막 차수가 같으
므로 계산결과는 out.shape = a.shape[:-1] +
b.shape[:-1]
373](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-373-2048.jpg)
![Inner 예시 : 3차원
a(2,3,2) 행렬과 b(2,2)행렬의 마지막 차수가 같
으므로 계산결과는 out.shape = a.shape[:-1] +
b.shape[:-1]
374](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-374-2048.jpg)


![outer: 1
Out는 두개의 벡터에 대한 행렬로 구성
out[i, j] = a[i] * b[j]
377](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-377-2048.jpg)

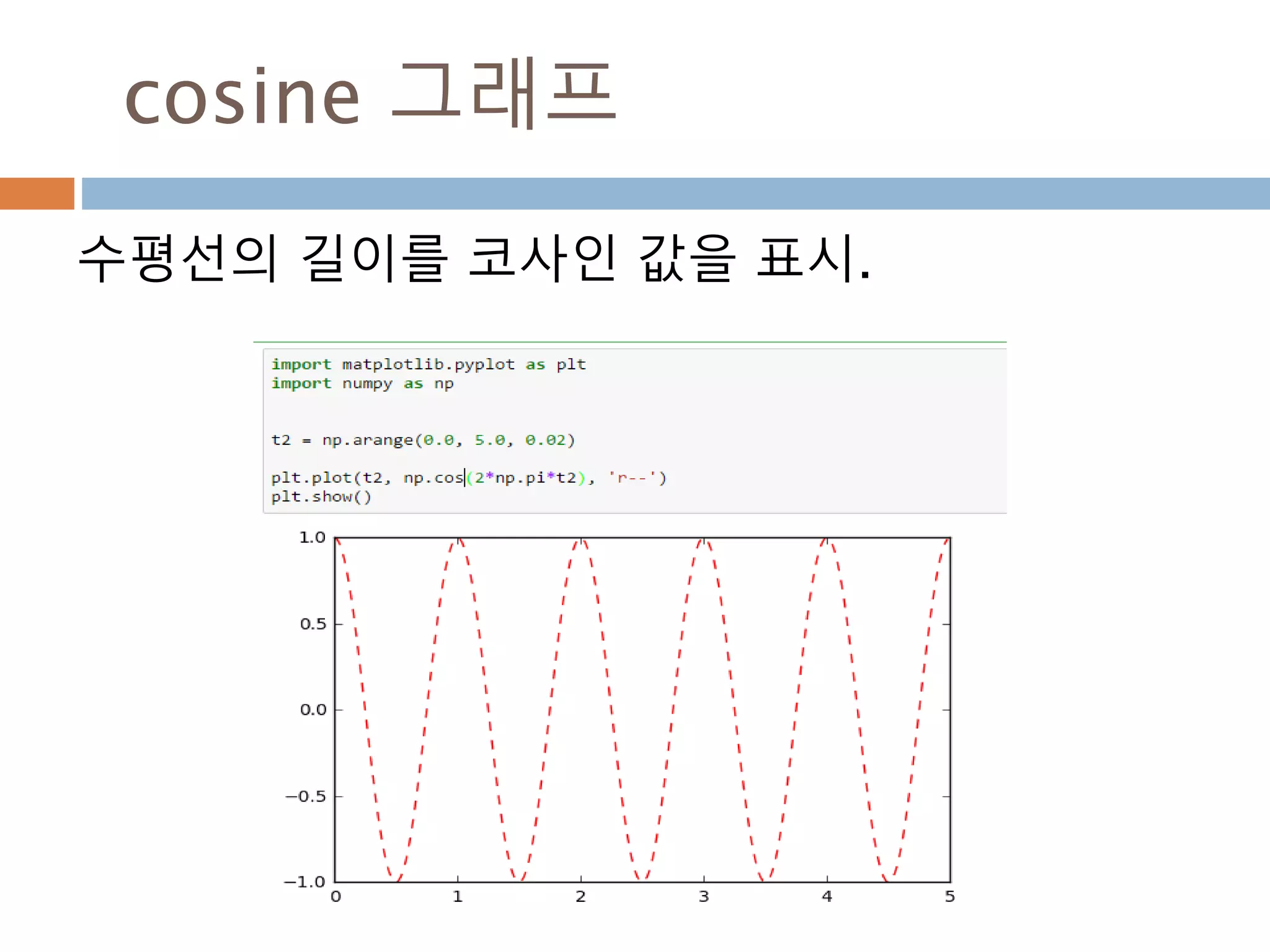
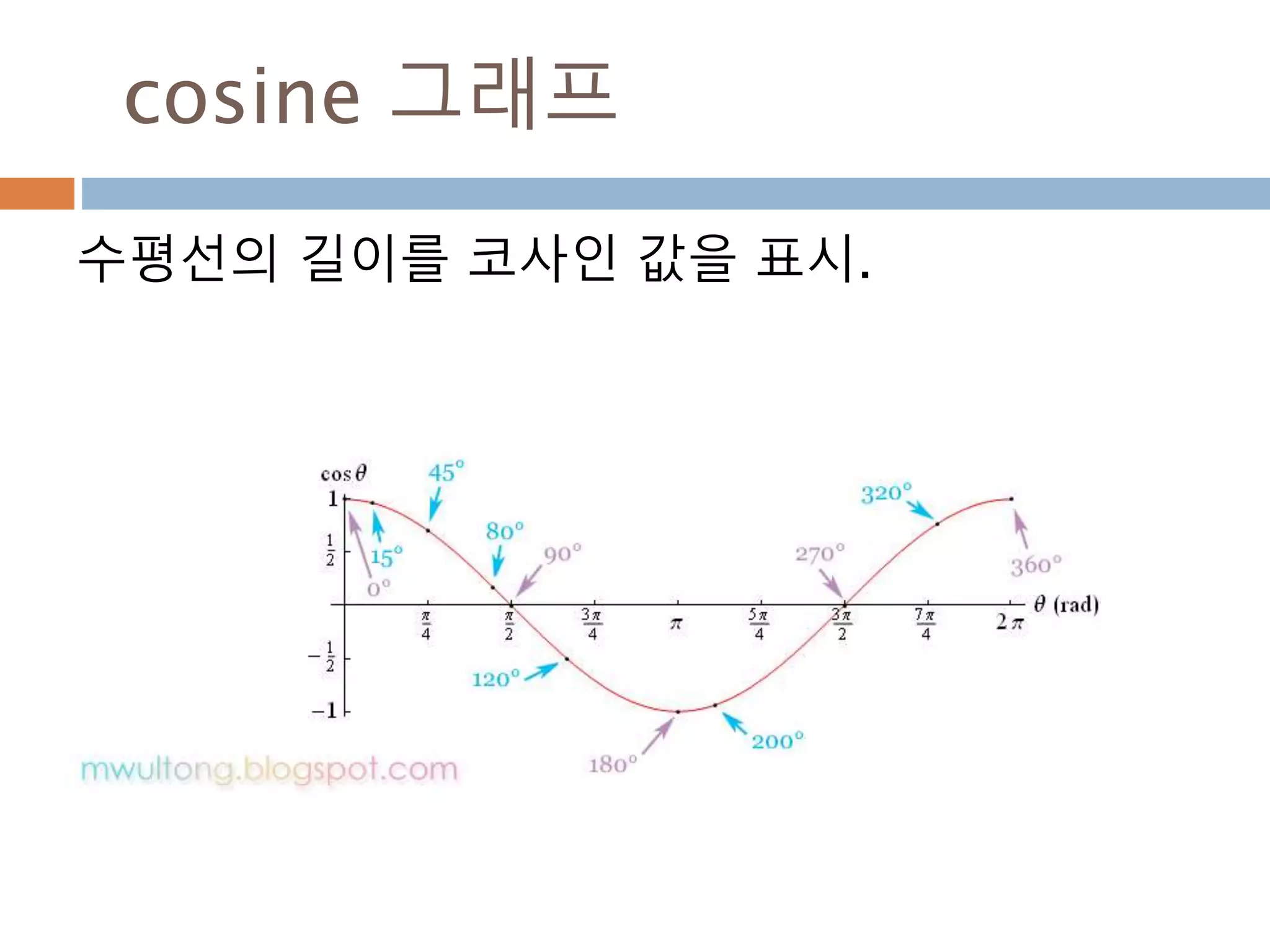
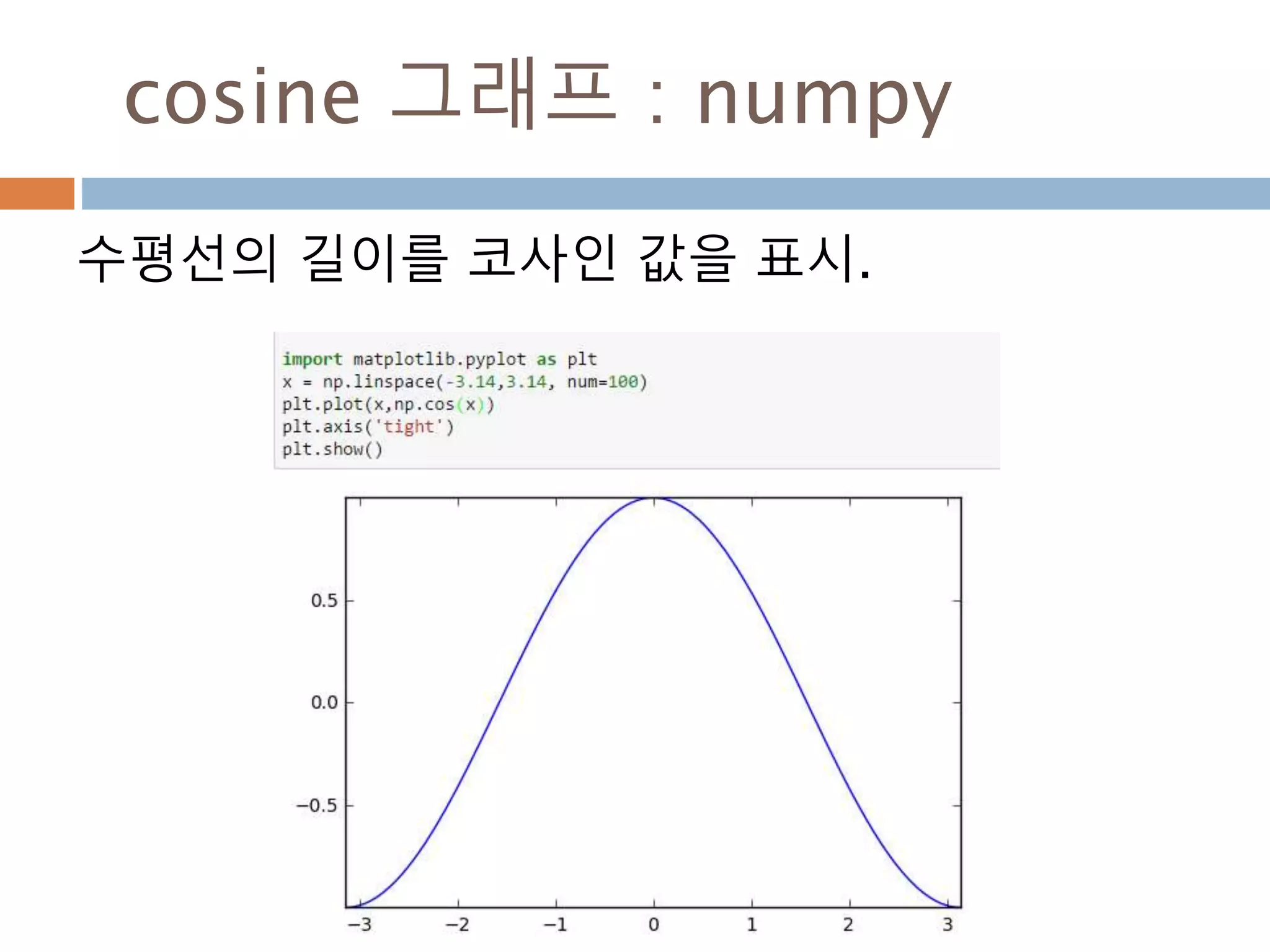
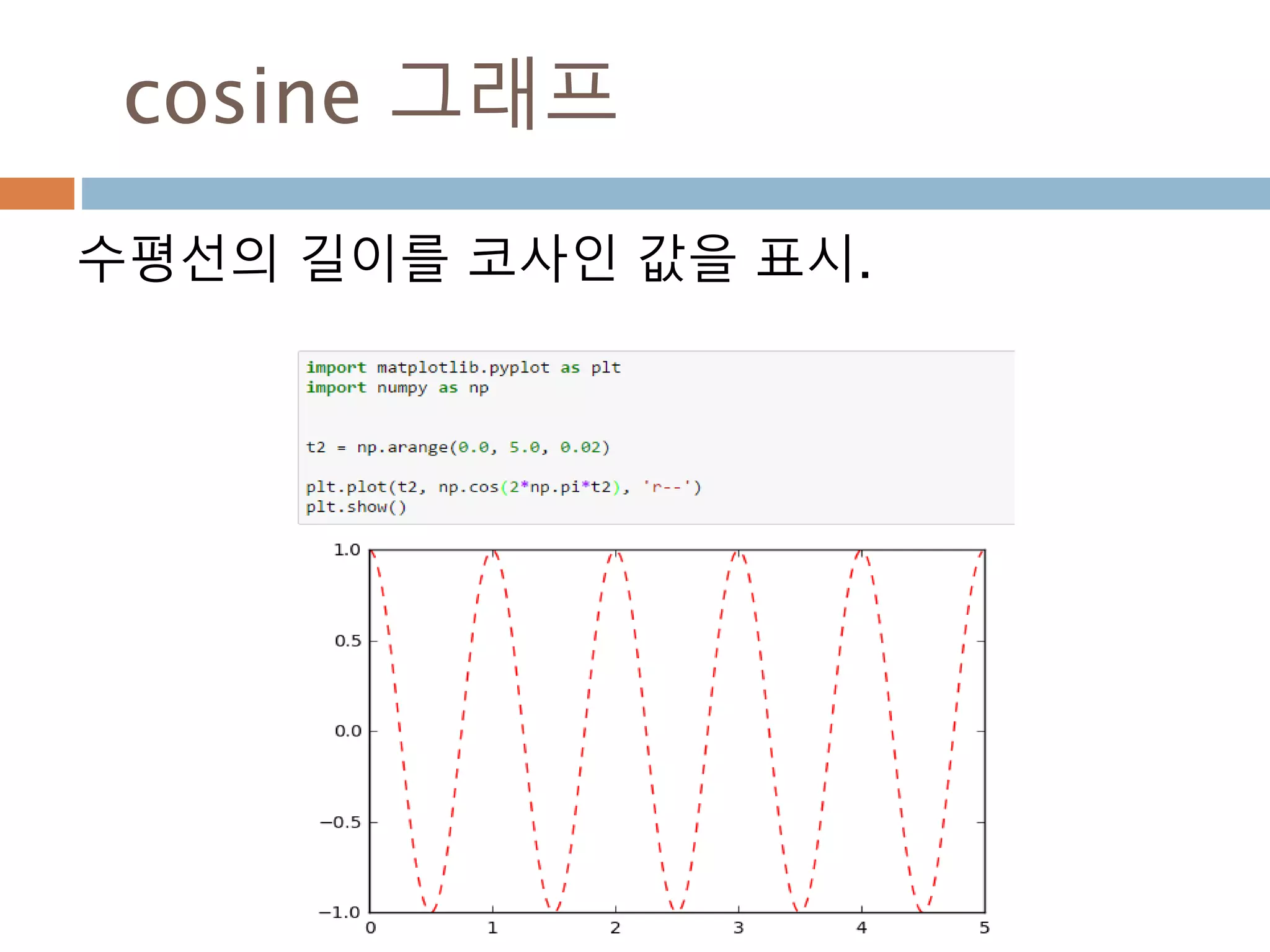

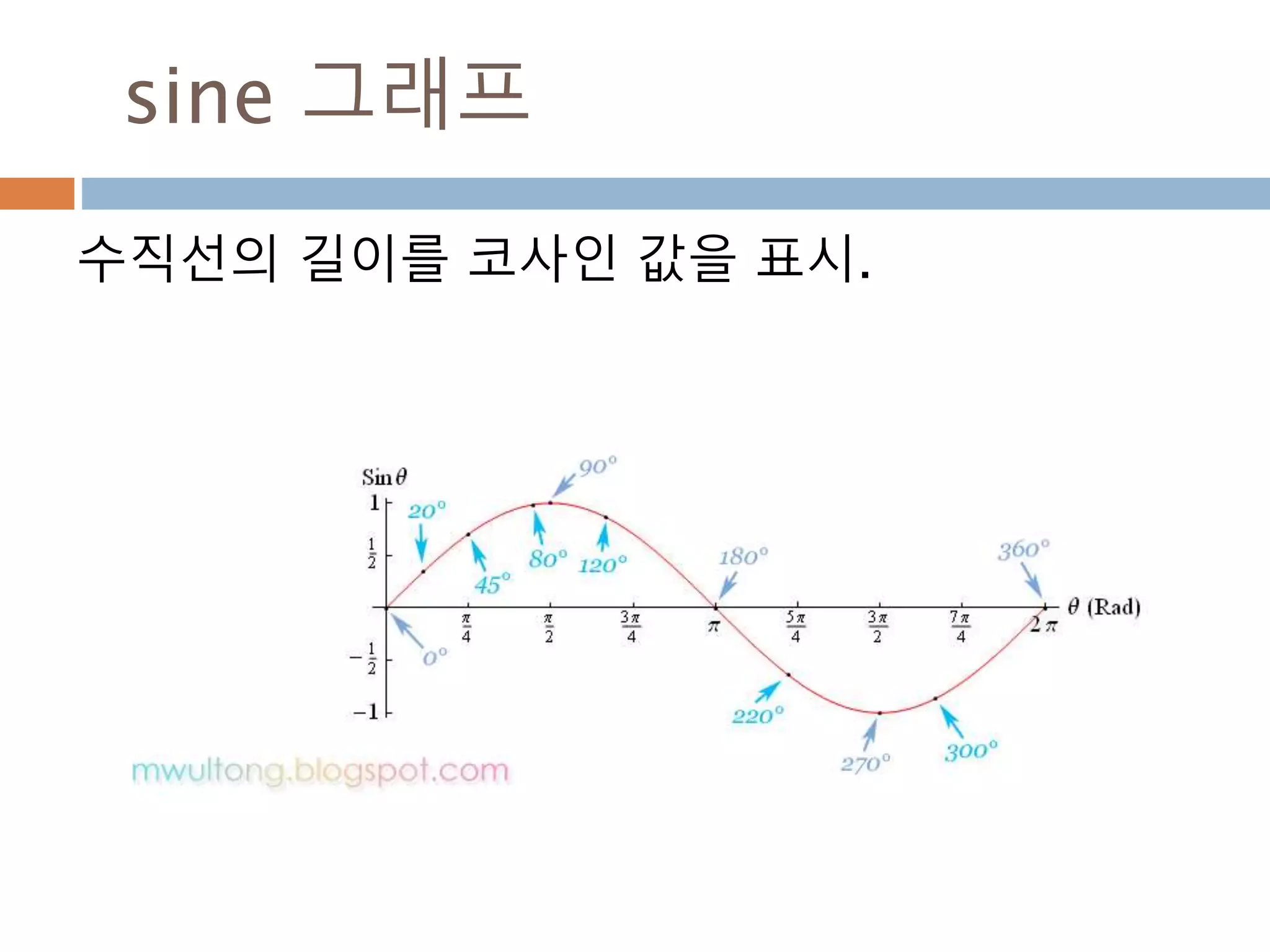
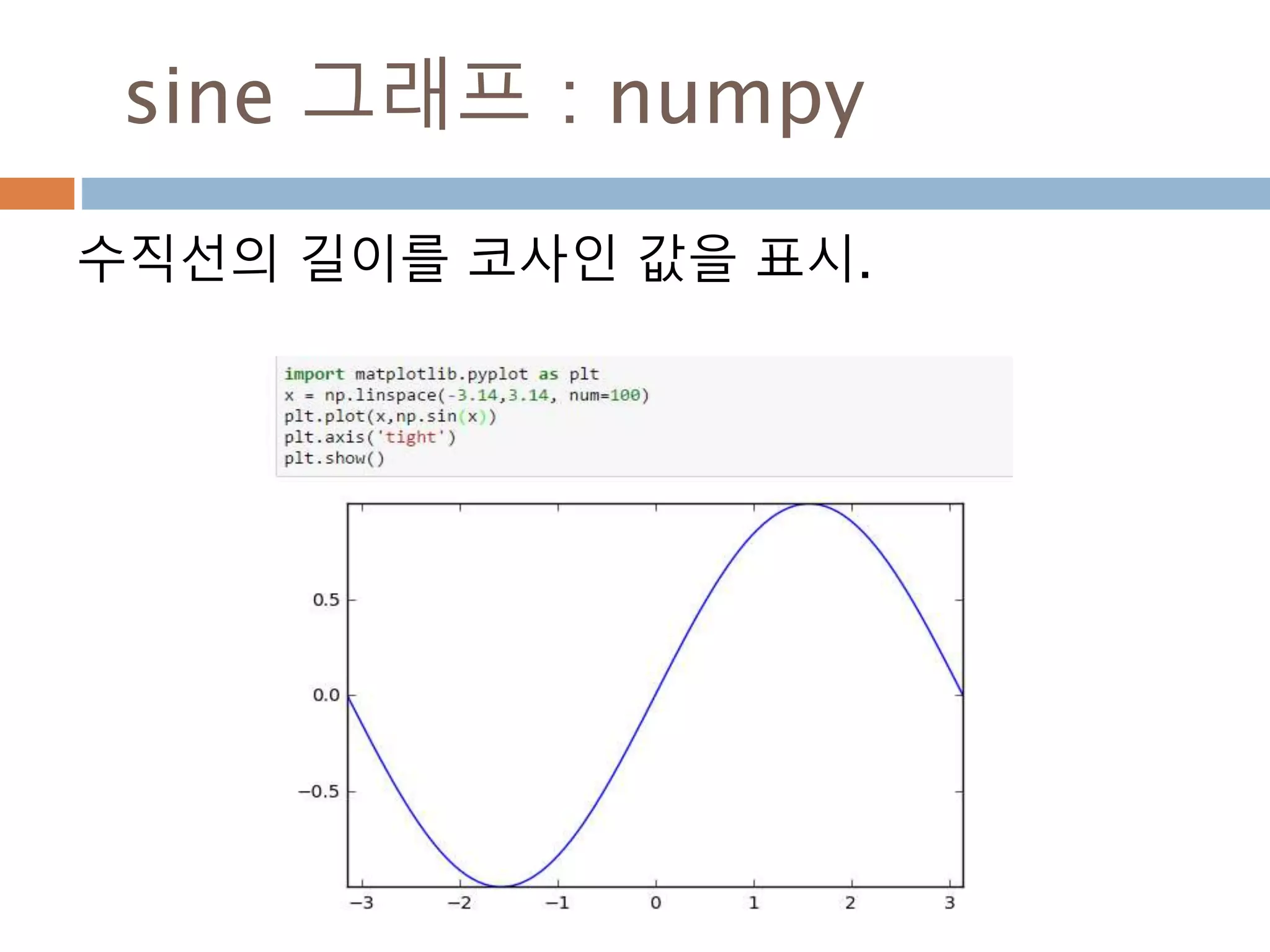
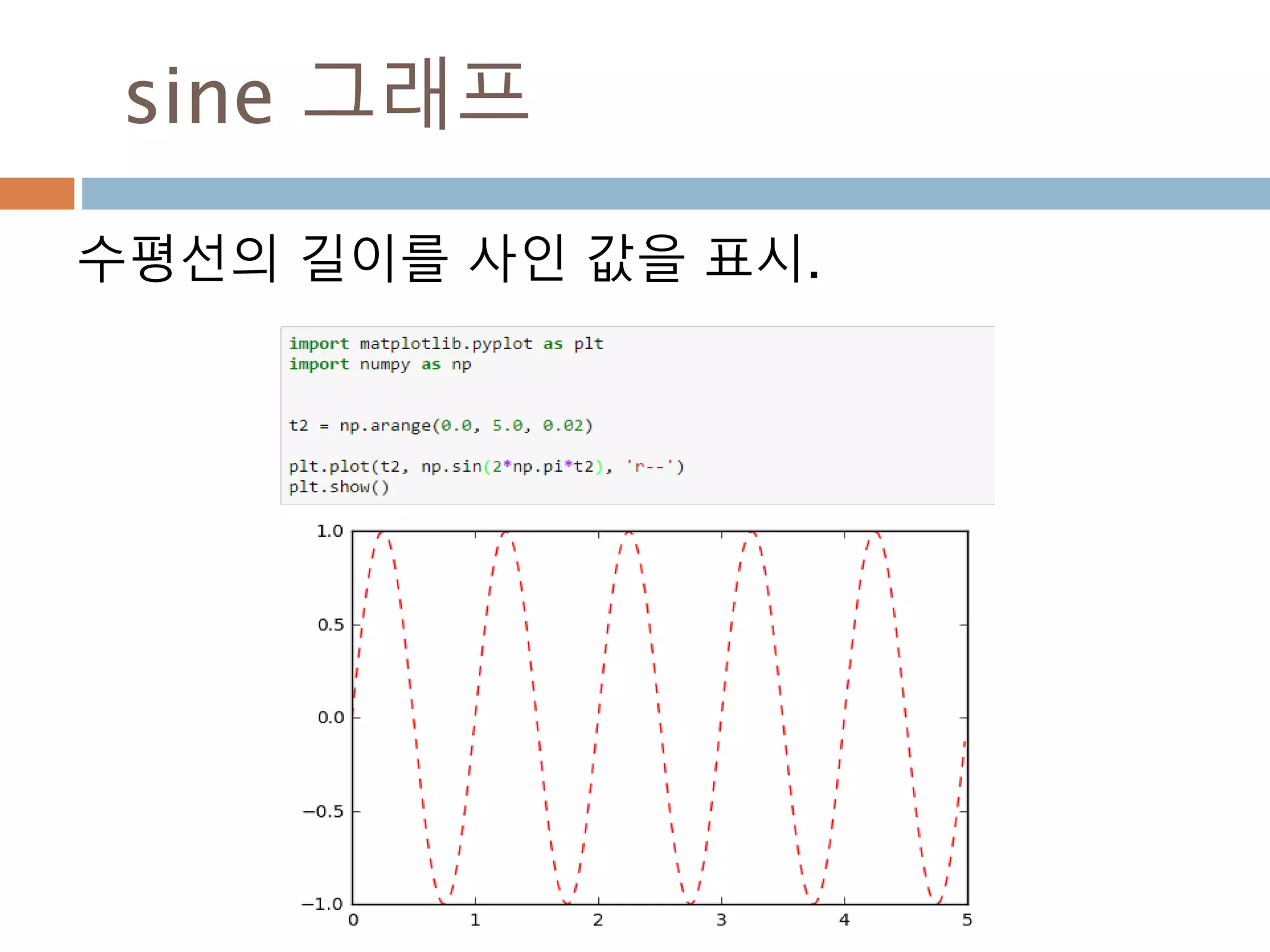
![행렬
n개의 실수의 순서쌍에 성분별로 덧셈과 실수상수
곱을 주면[2] 이는 "nn차원" 벡터공간이라 할 수 있
고(, 벡터공간에서 벡터공간으로 가는 함수 중 덧셈
과 상수배를 보존하는 함수를 선형사상을 행렬이라
함
390](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-390-2048.jpg)
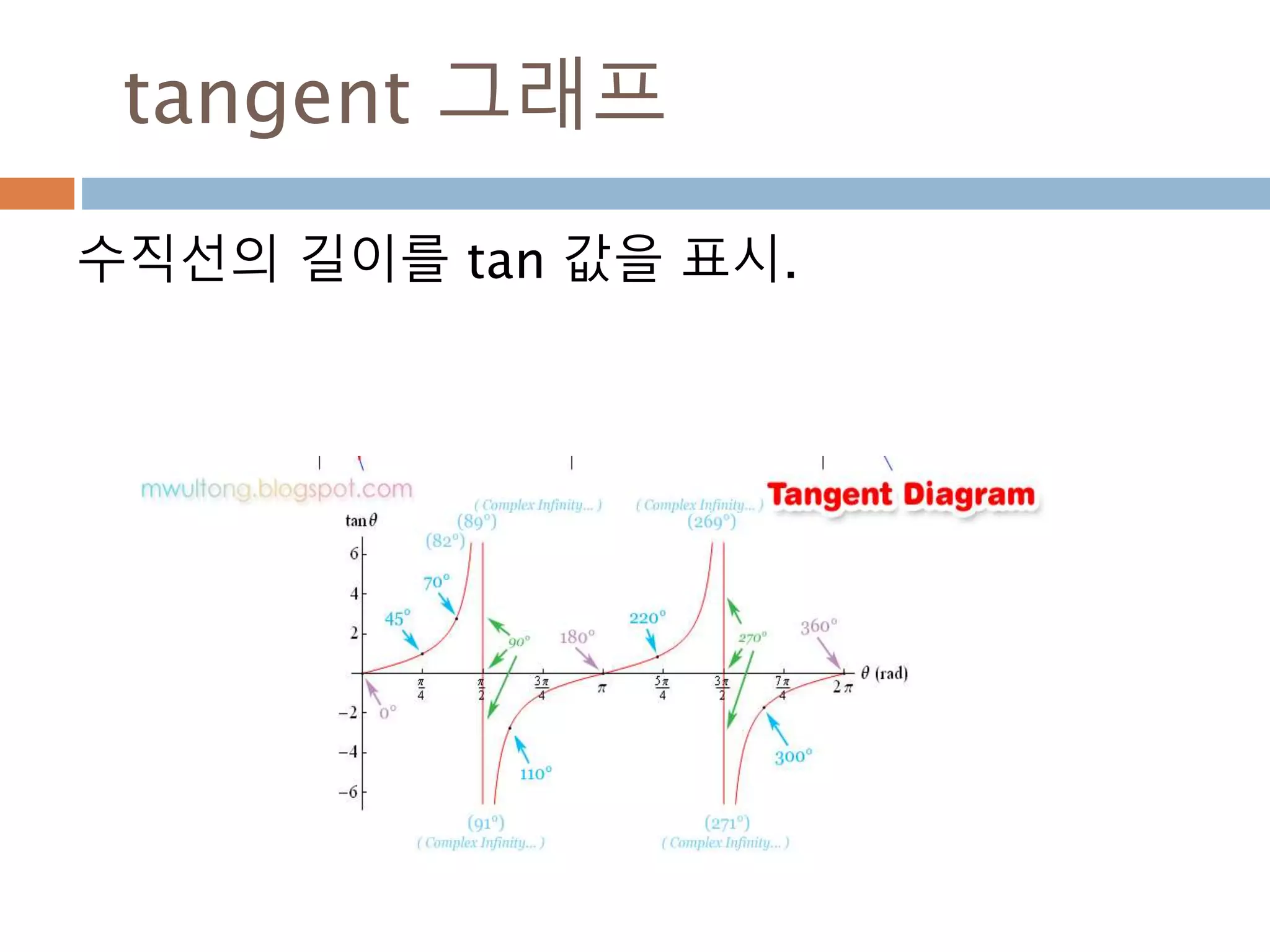
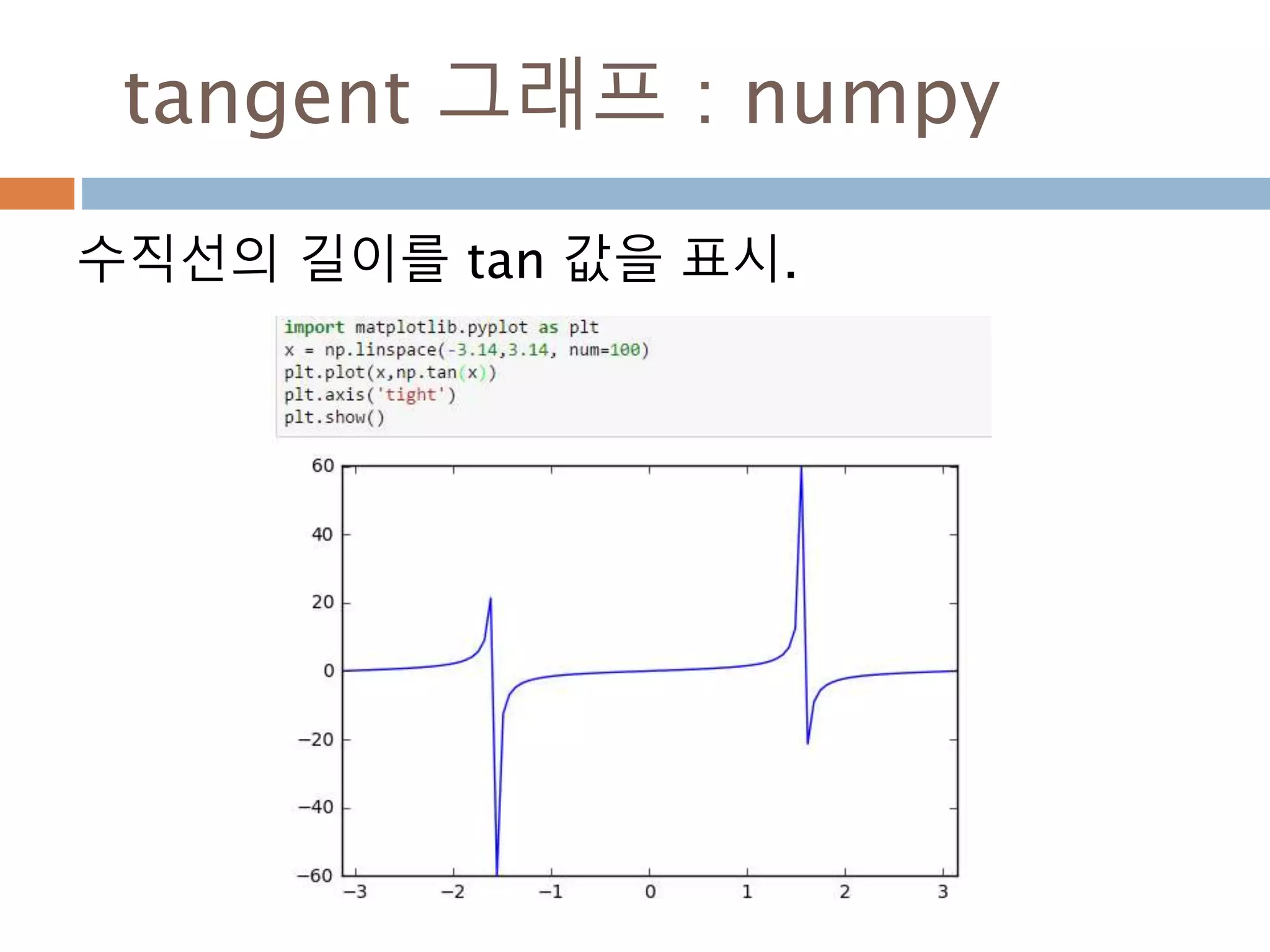
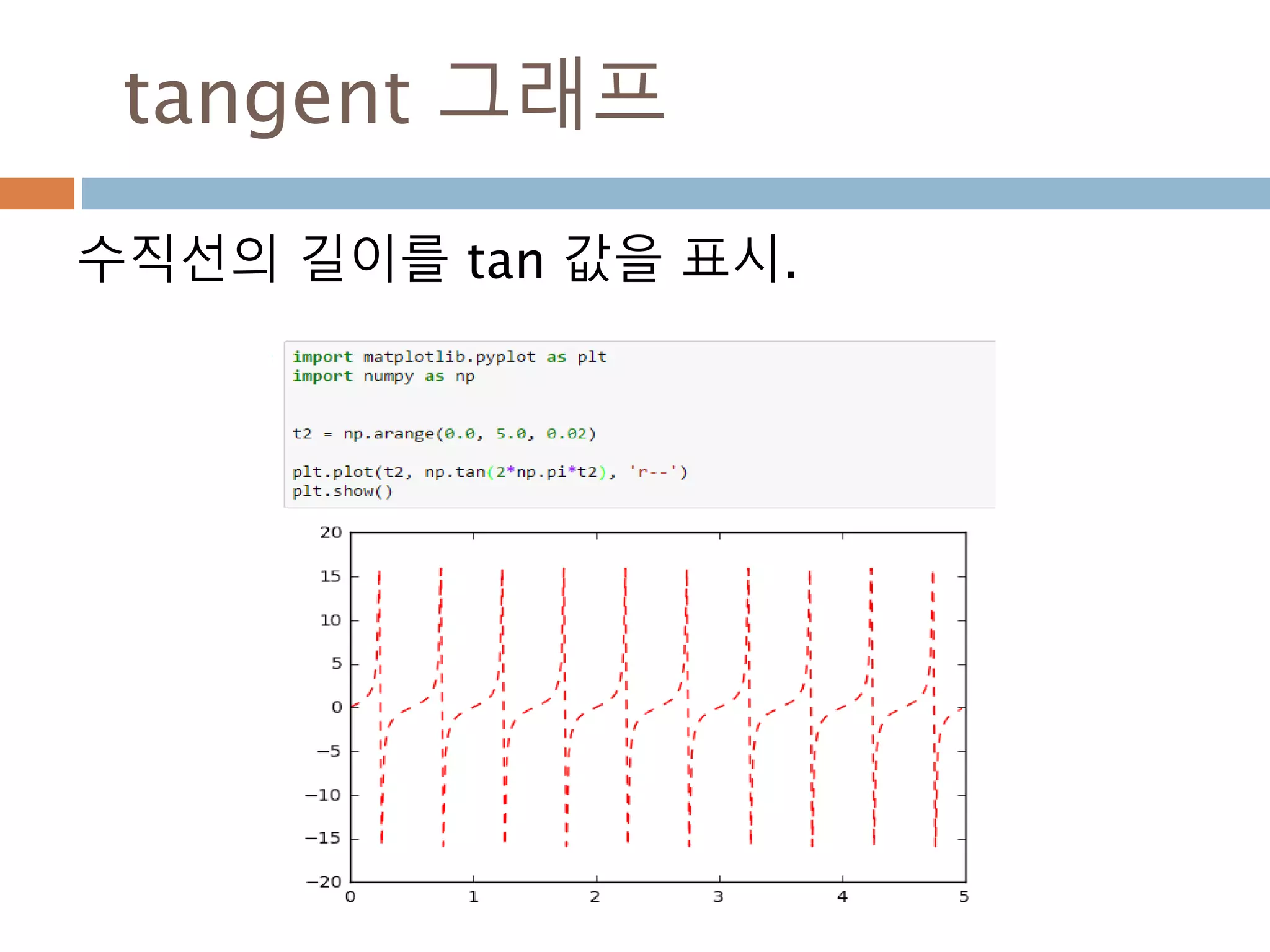

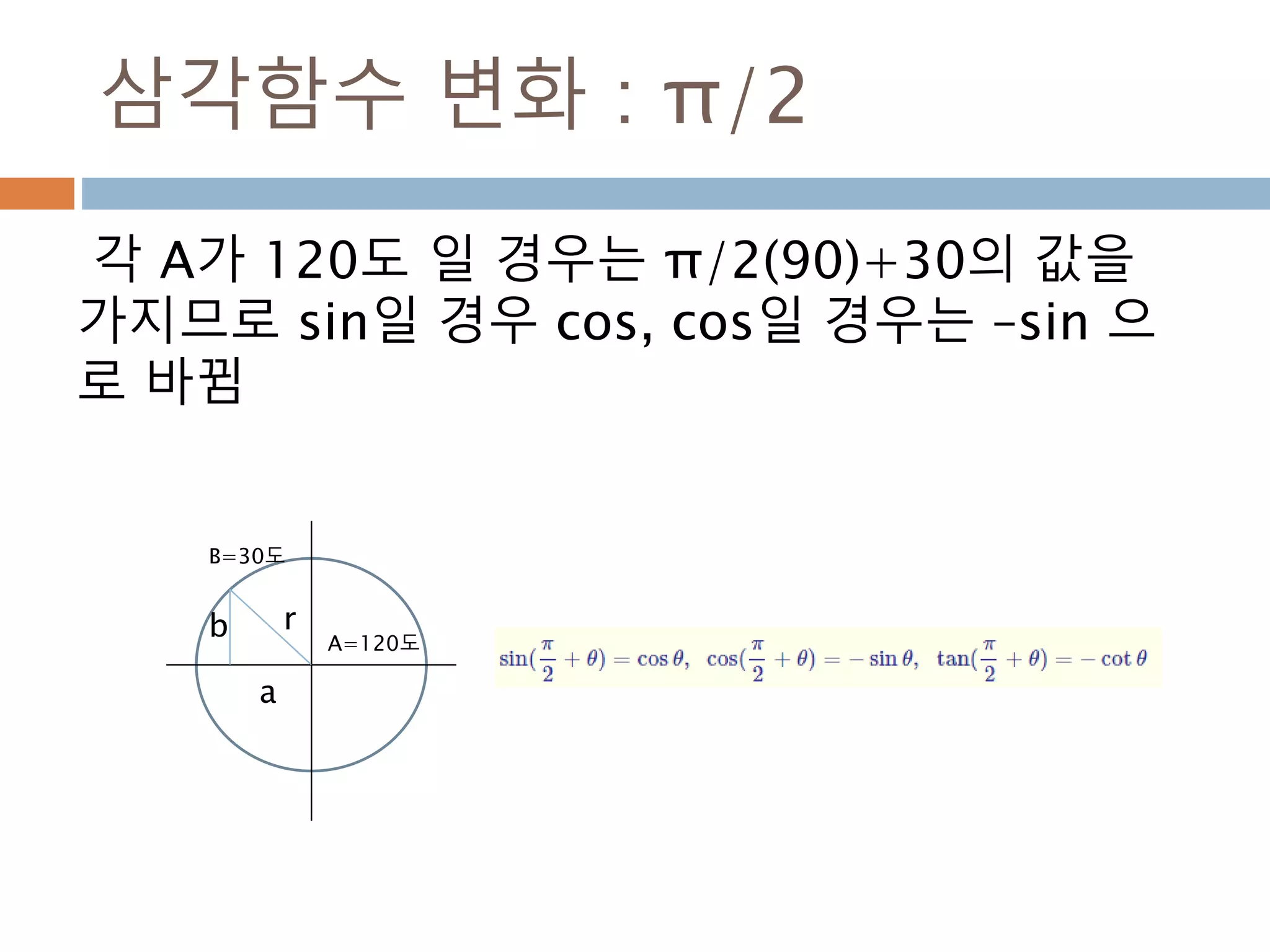



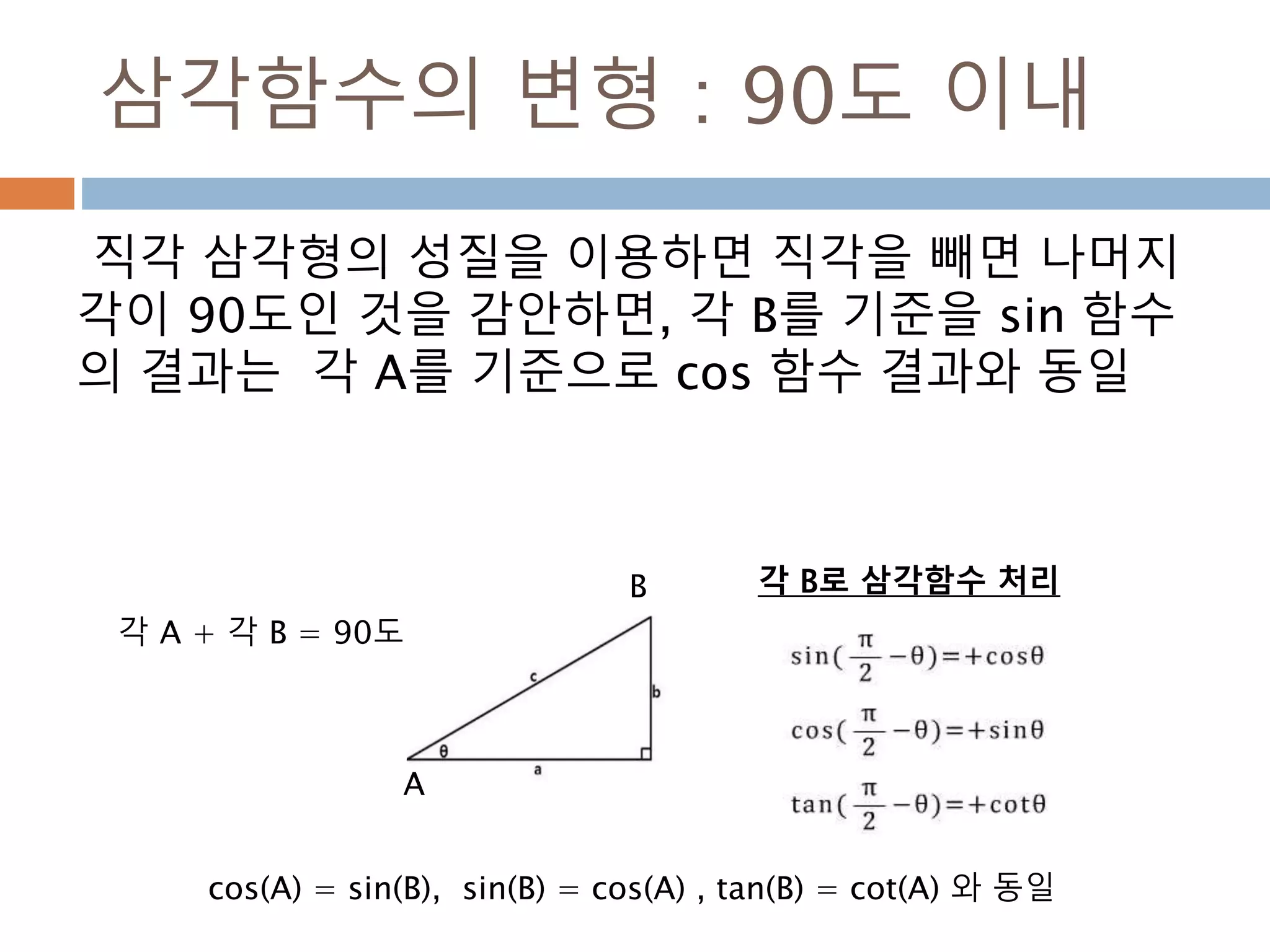


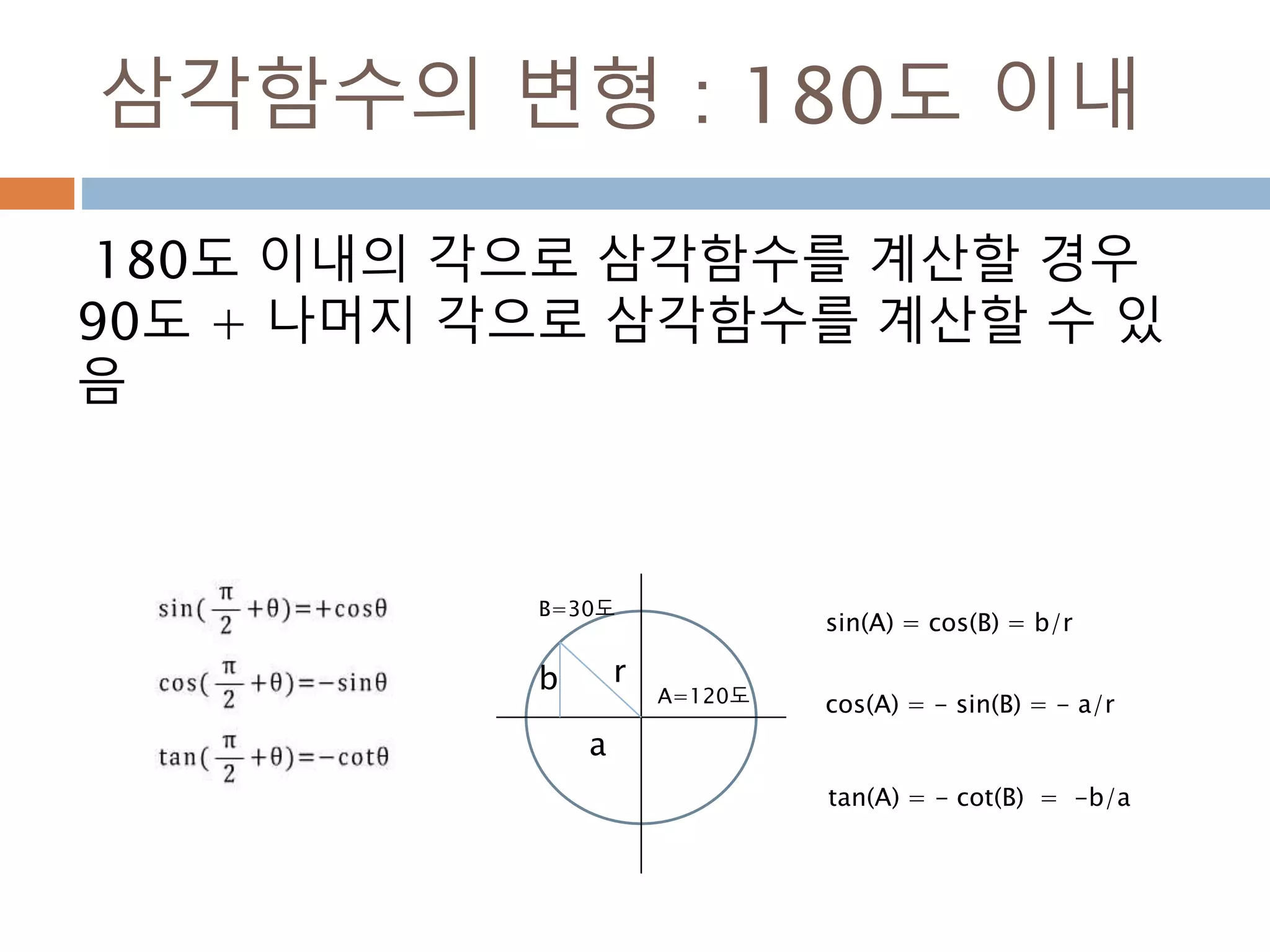


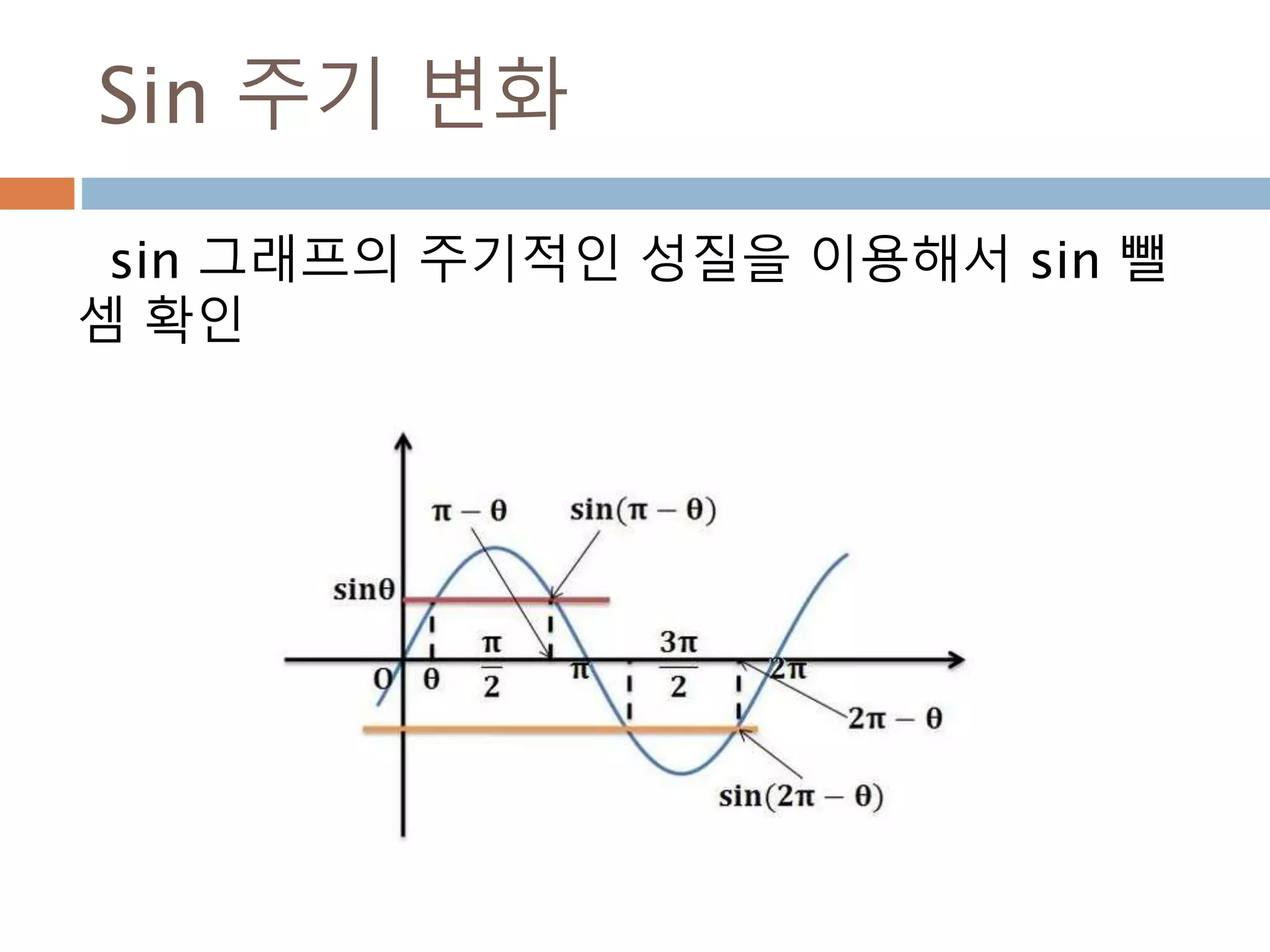
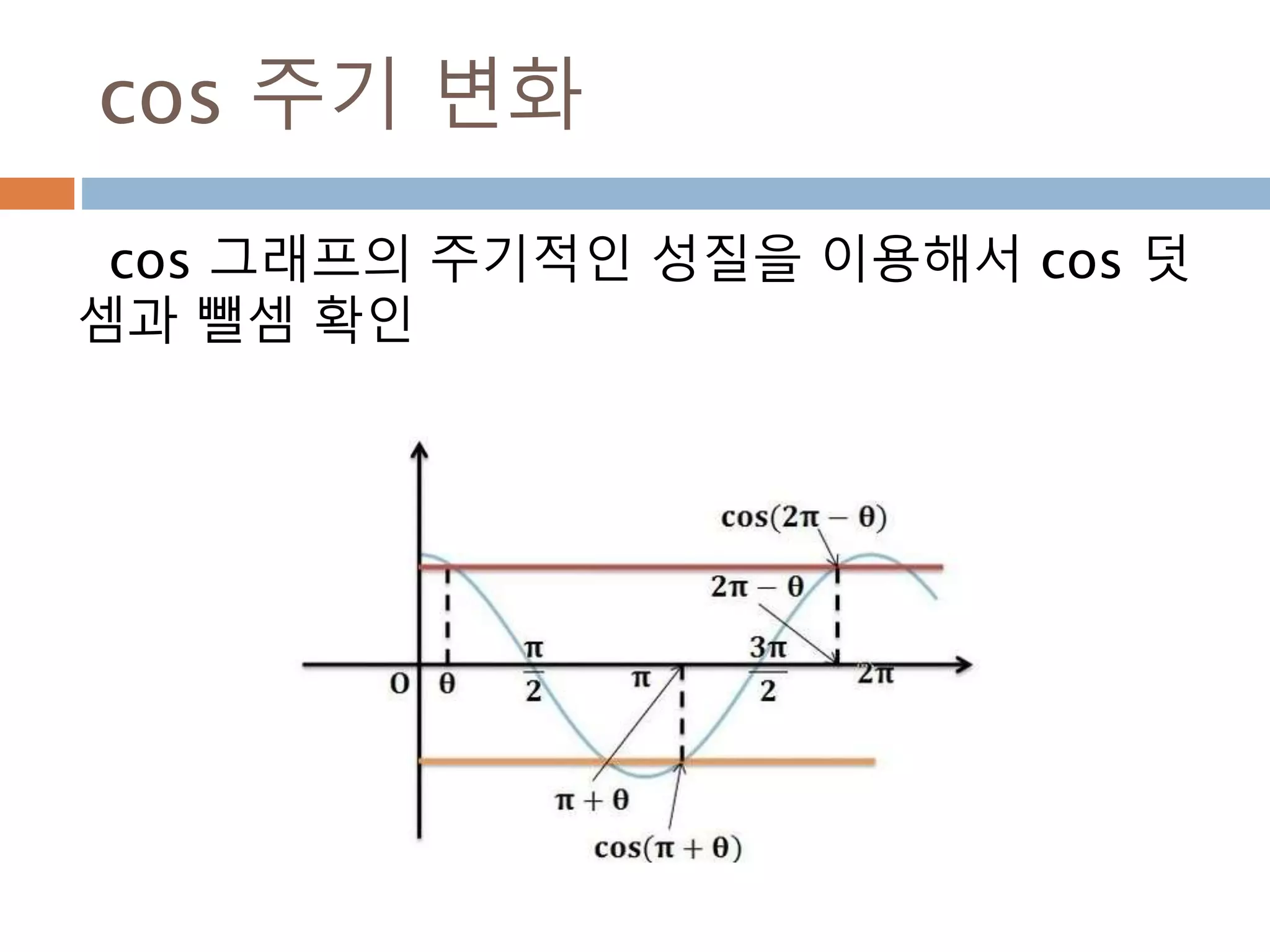

![주요 함수
선형대수에 대한 함수들
함수 설명
dot(a, b[, out]) n차원 행렬 n*m m*l에 대한 production(결과는 n*l)
vdot(a, b) Vector에 대한 prodution
inner(a, b) N 차원 행렬에 대한 Inner product (행렬이 동일해야 함).
outer(a, b[, out]) 2개 벡터에 대해 계산 후 행렬로 표시.
matmul(a, b[, out]) 두 행렬에 대한 Matrix product (dot과 동일한 결과)
tensordot(a, b[, axes]) Compute tensor dot product along specified axes for arrays >= 1-D.
linalg.matrix_power(M, n) Raise a square matrix to the (integer) power n.
cross(a, b, axisa=-1, axisb=-1, axisc=-1, axis=None) 행렬에 대한 외적을 구함
einsum(subscripts, *operands[, out, dtype, ...]) Evaluates the Einstein summation convention on the operands.
kron(a, b) Kronecker product of two arrays.
408](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-408-2048.jpg)
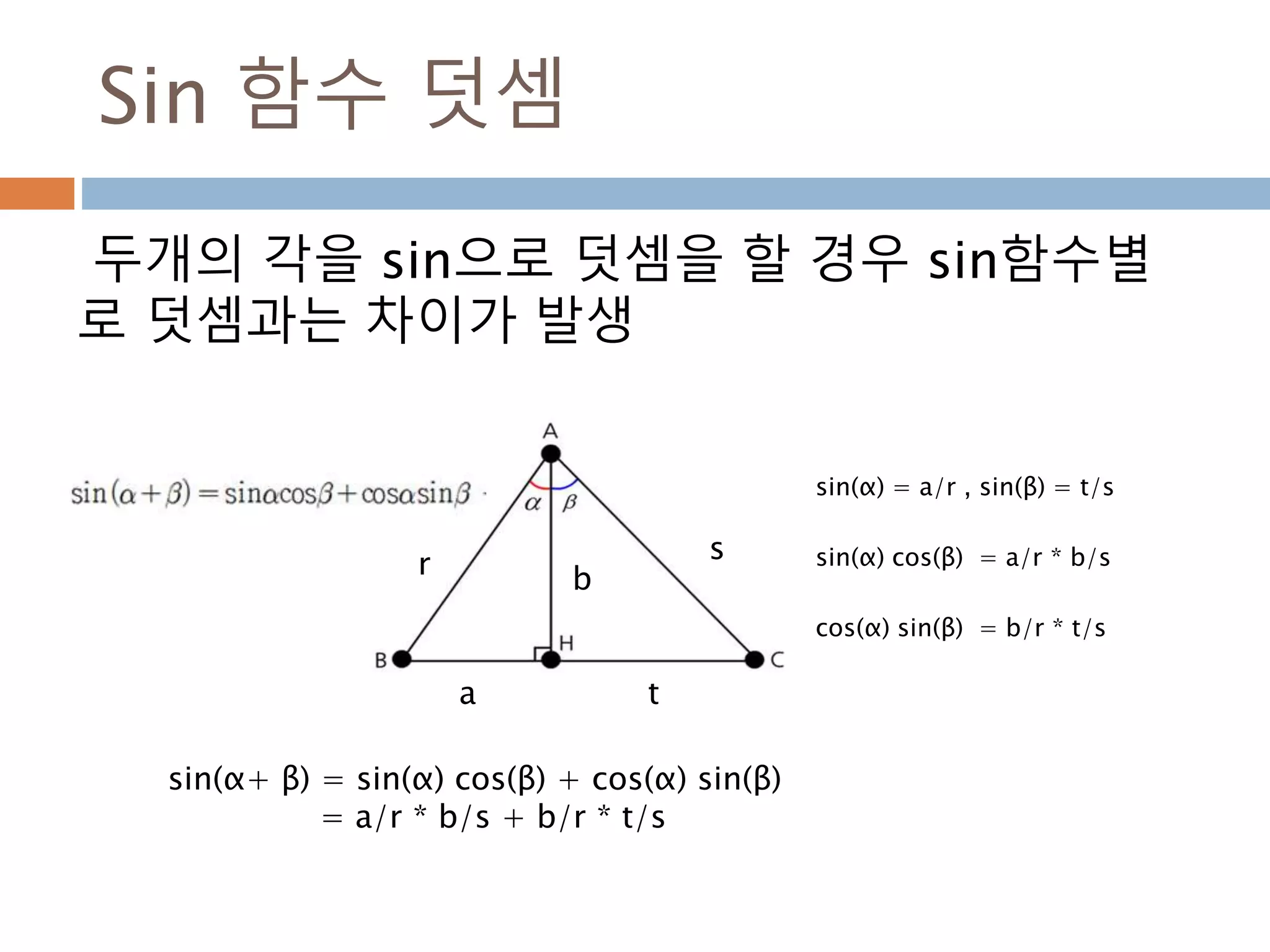
![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.cholesky(a) Cholesky decomposition.
linalg.qr(a[, mode]) Compute the qr factorization of a matrix.
linalg.svd(a[, full_matrices, compute_uv]) Singular Value Decomposition.
410](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-410-2048.jpg)

![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
linalg.eigh(a[, UPLO]) Return the eigenvalues and eigenvectors of a Hermitian or symmetric matrix.
linalg.eigvals(a) Compute the eigenvalues of a general matrix.
linalg.eigvalsh(a[, UPLO]) Compute the eigenvalues of a Hermitian or real symmetric matrix.
linalg.eig(a) Compute the eigenvalues and right eigenvectors of a square array.
412](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-412-2048.jpg)

![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.norm(x[, ord, axis, keepdims]) Matrix or vector norm.
linalg.cond(x[, p]) Compute the condition number of a matrix.
linalg.det(a) Compute the determinant of an array.
linalg.matrix_rank(M[, tol])
Return matrix rank of array using SVD method Rank of the array is the number of SVD sing
ular values of the array that are greater than tol.
linalg.slogdet(a) Compute the sign and (natural) logarithm of the determinant of an array.
trace(a[, offset, axis1, axis2, dtype, out]) Return the sum along diagonals of the array.
414](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-414-2048.jpg)
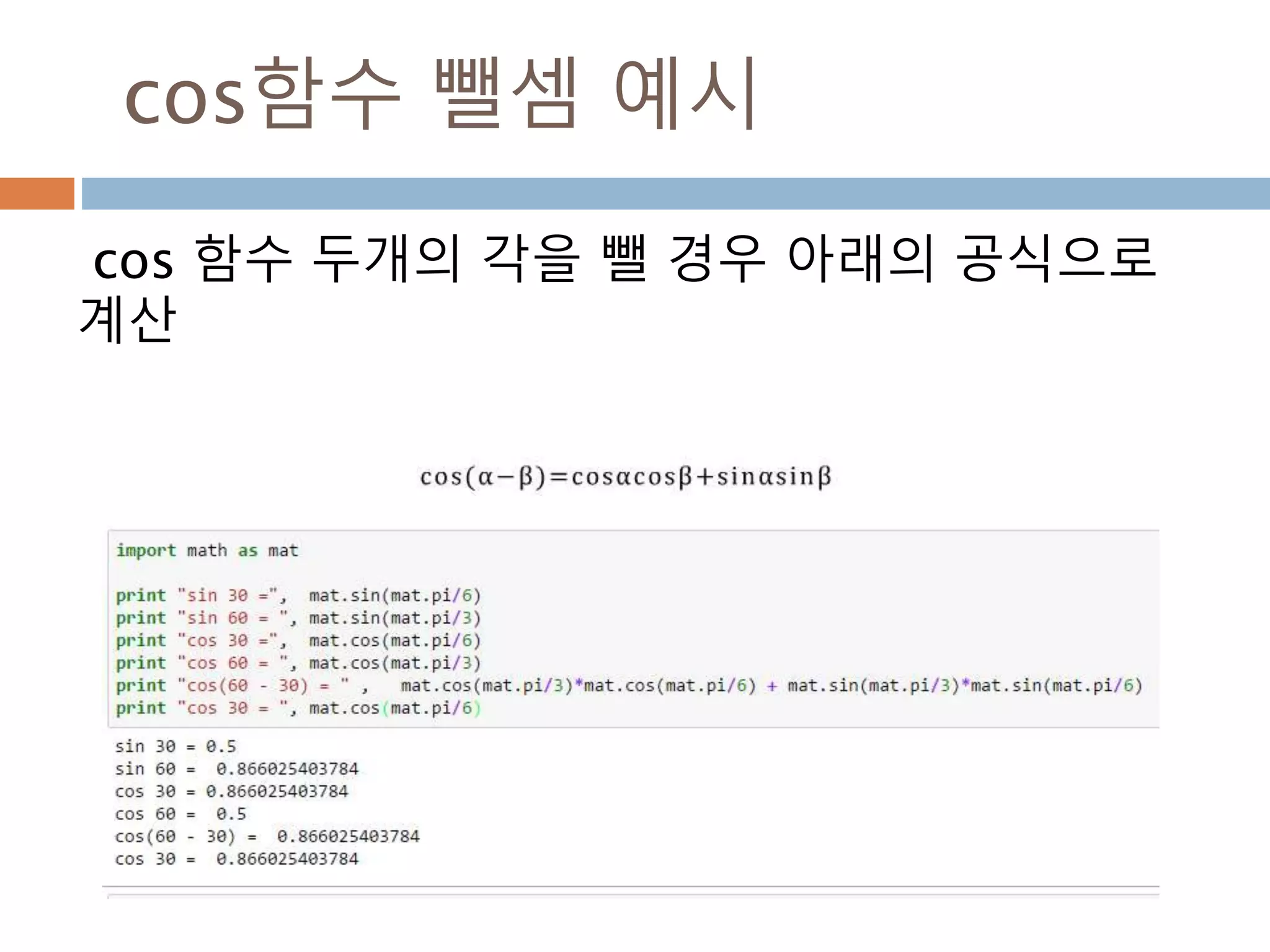
![주요 함수
선형대수에 대한 함수들
함수 설명
linalg.solve(a, b) Solve a linear matrix equation, or system of linear scalar equations.
linalg.tensorsolve(a, b[, axes]) Solve the tensor equation a x = b for x.
linalg.lstsq(a, b[, rcond]) Return the least-squares solution to a linear matrix equation.
linalg.inv(a) Compute the (multiplicative) inverse of a matrix.
linalg.pinv(a[, rcond]) Compute the (Moore-Penrose) pseudo-inverse of a matrix.
linalg.tensorinv(a[, ind]) Compute the ‘inverse’ of an N-dimensional array.
416](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-416-2048.jpg)




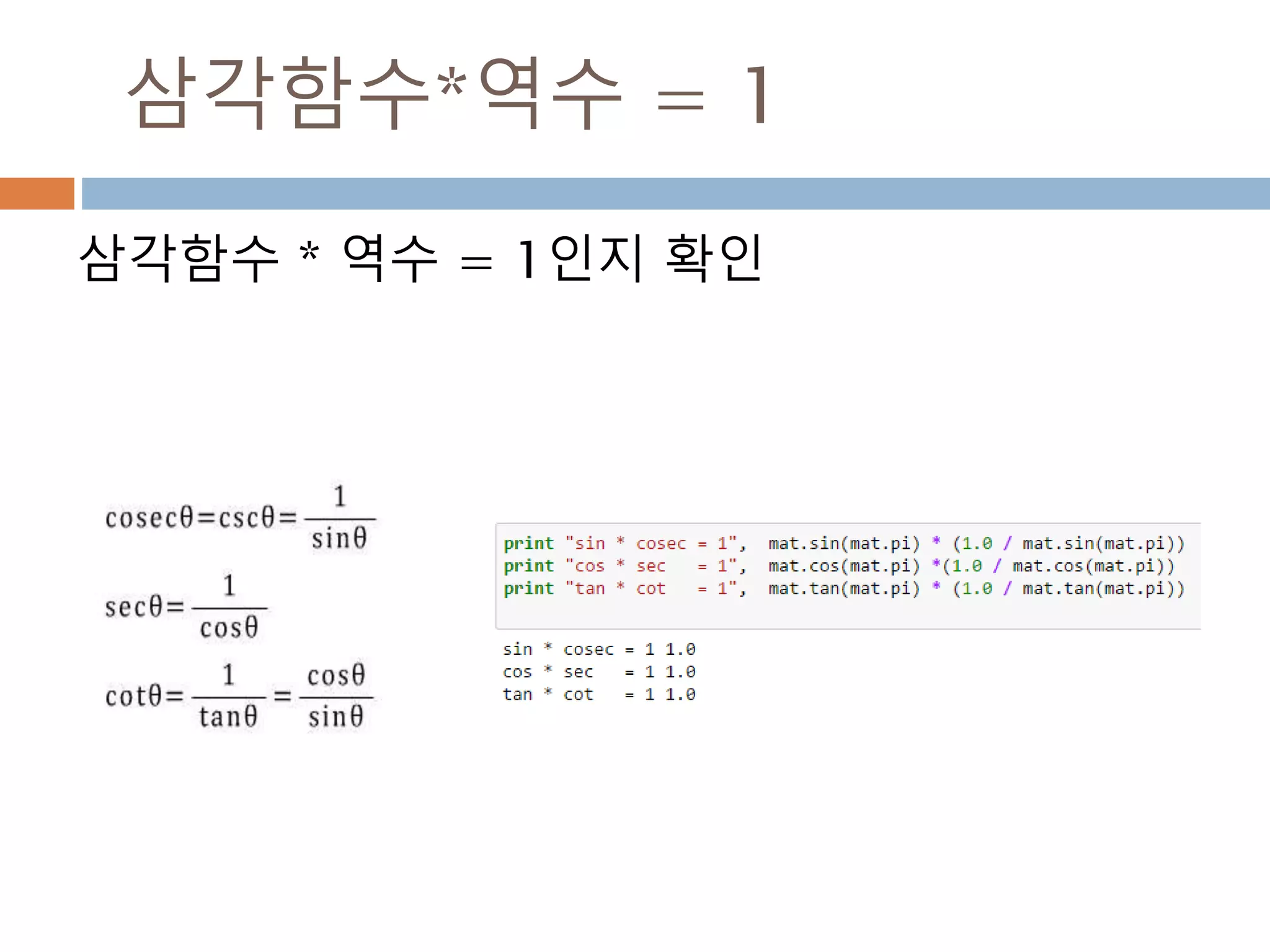


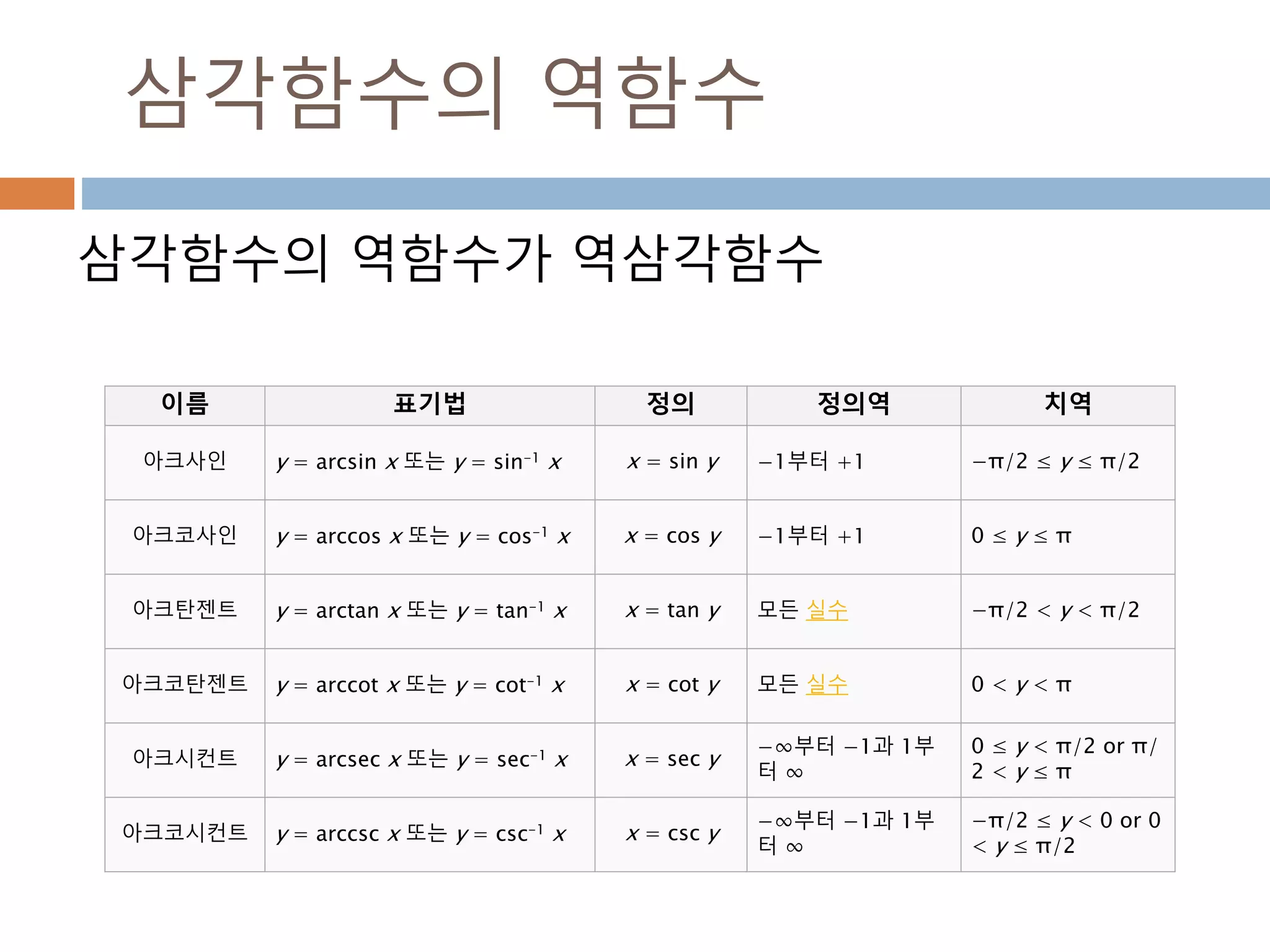
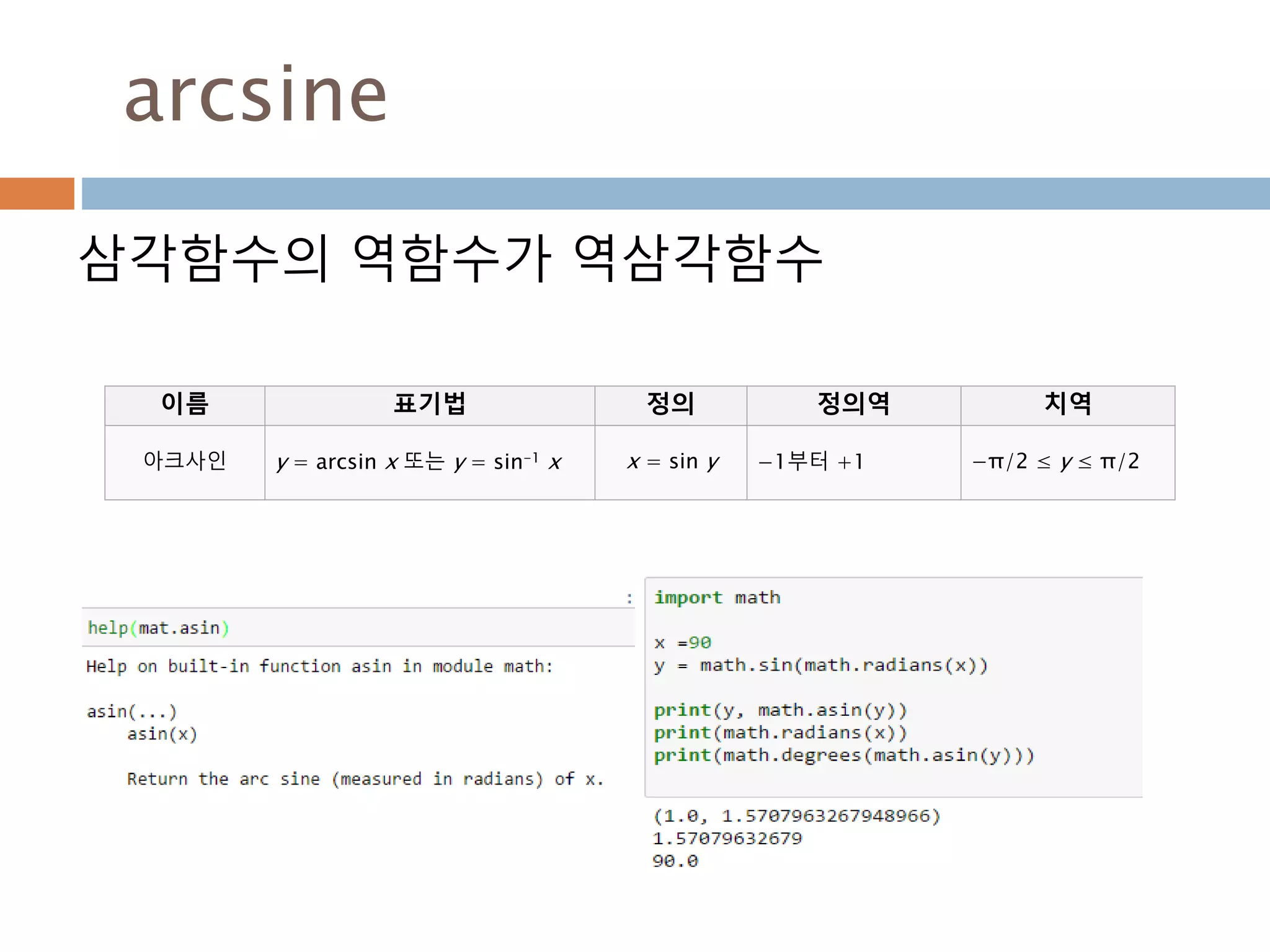

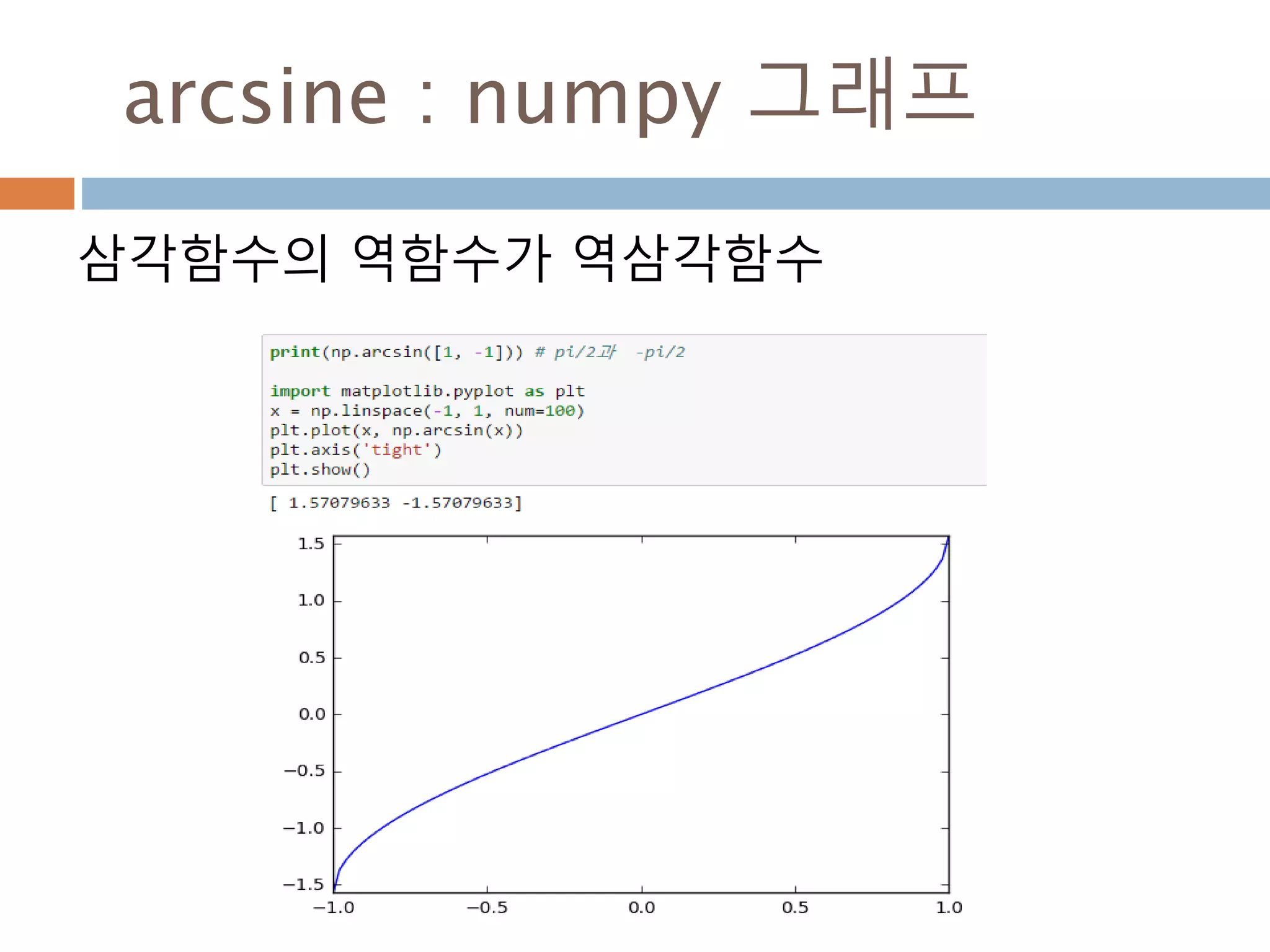

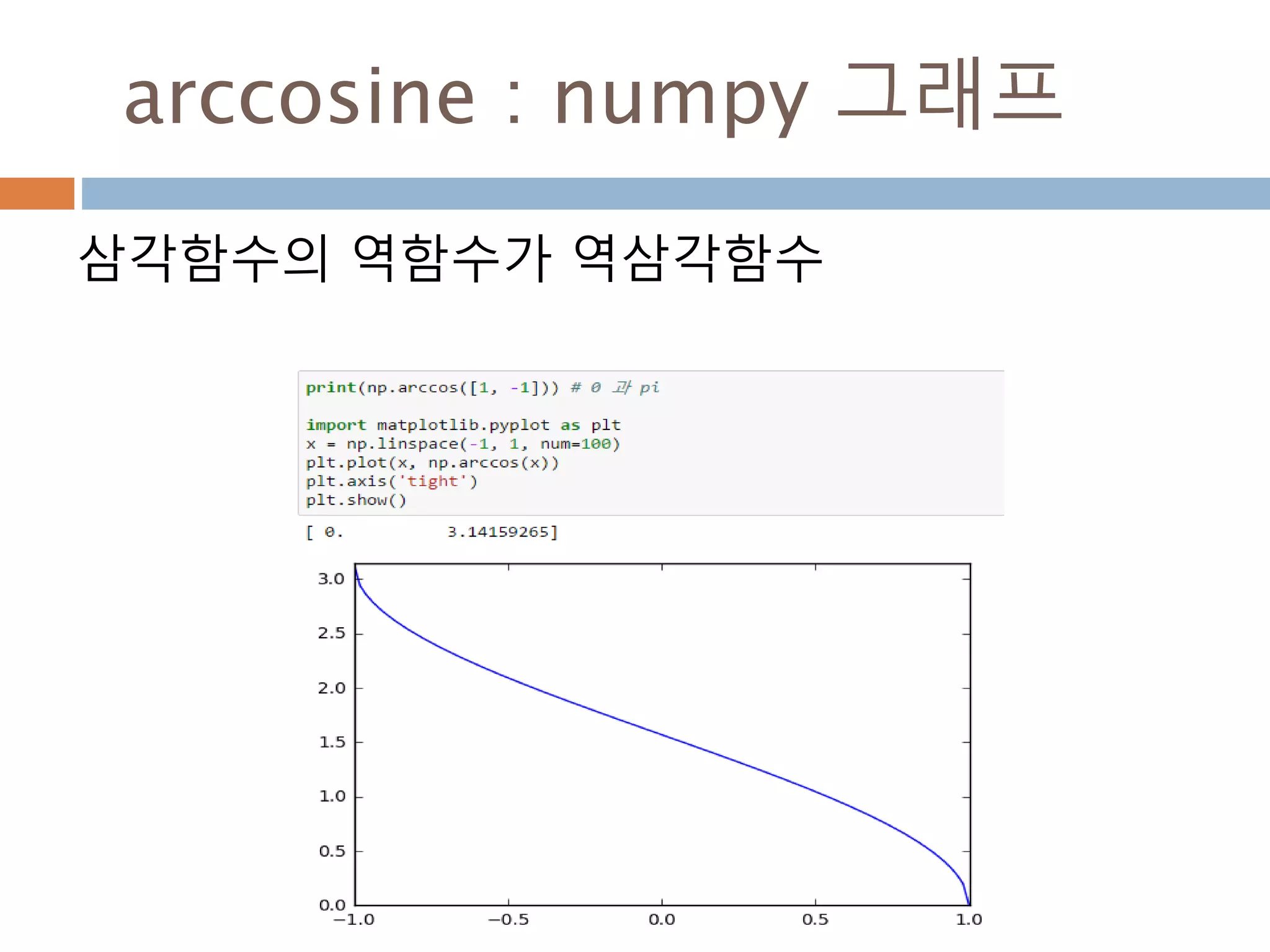
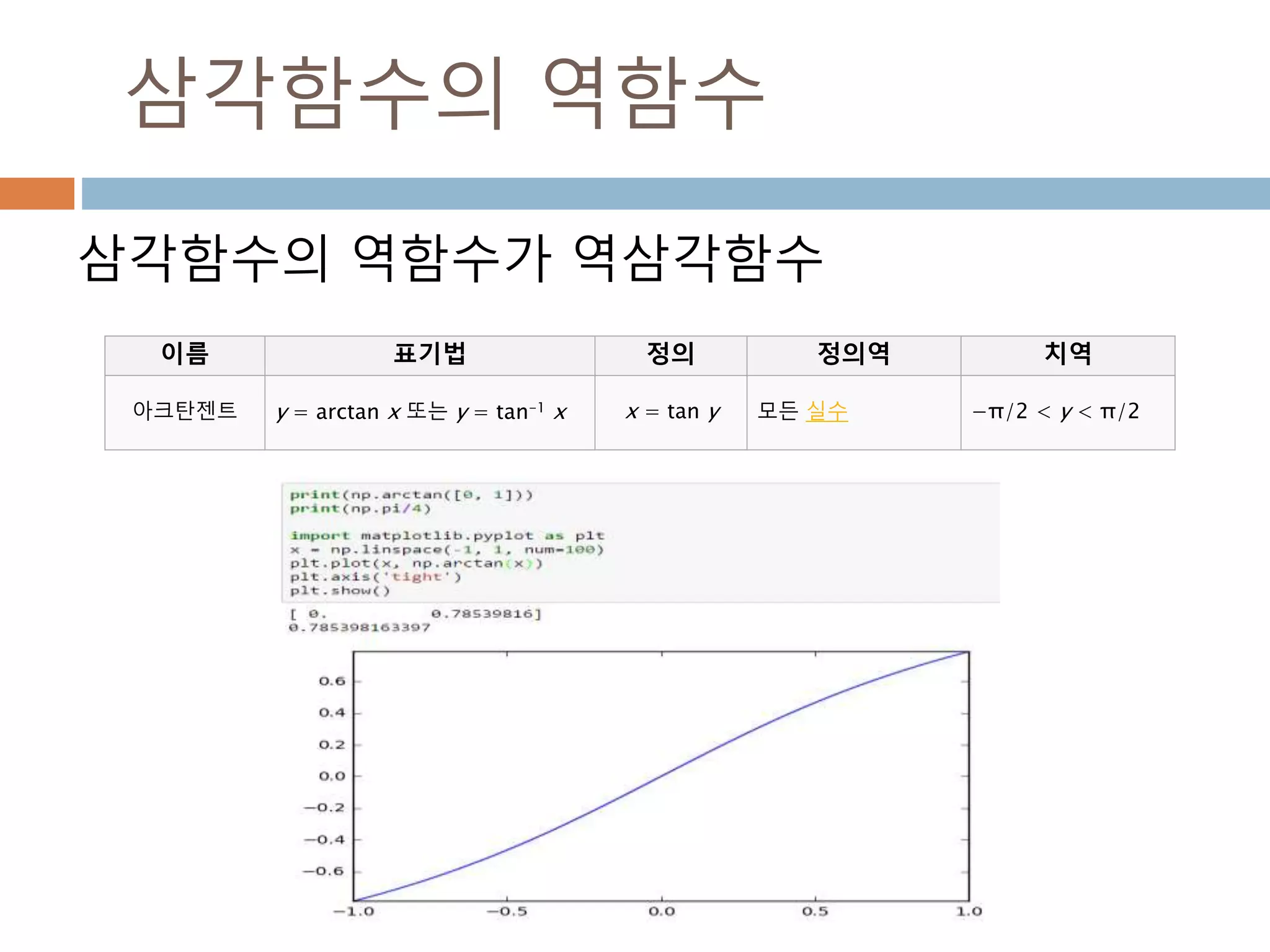




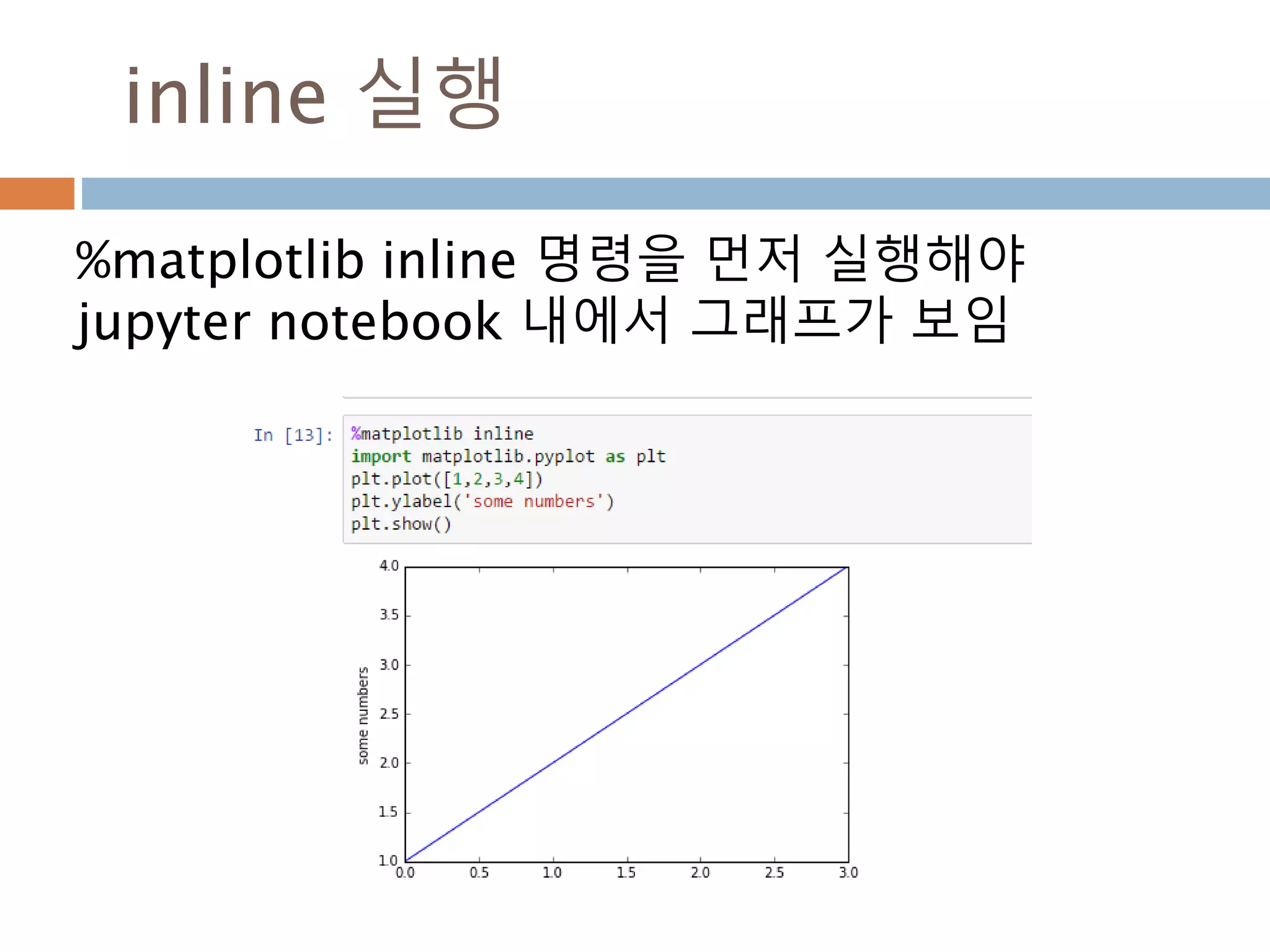
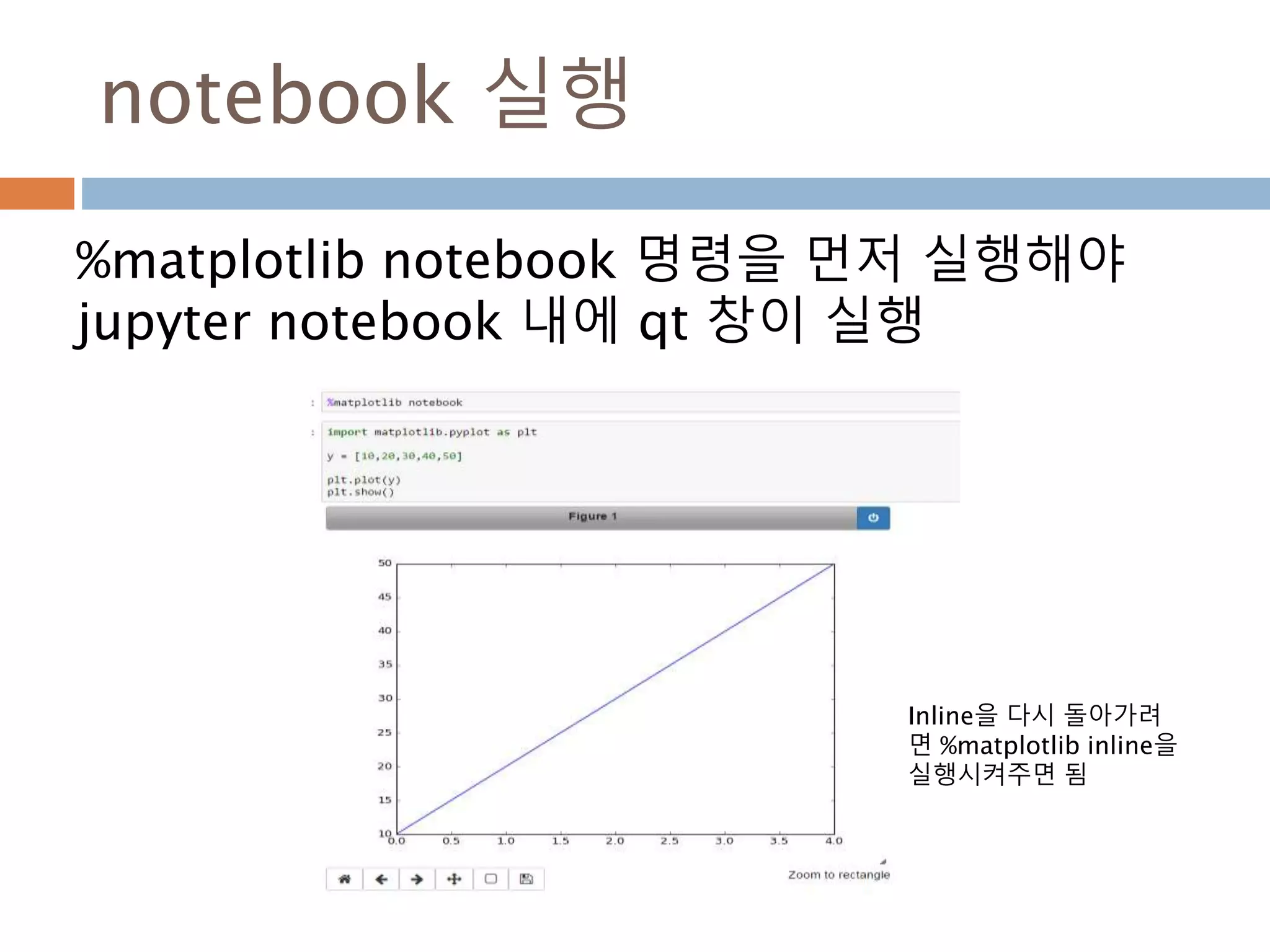

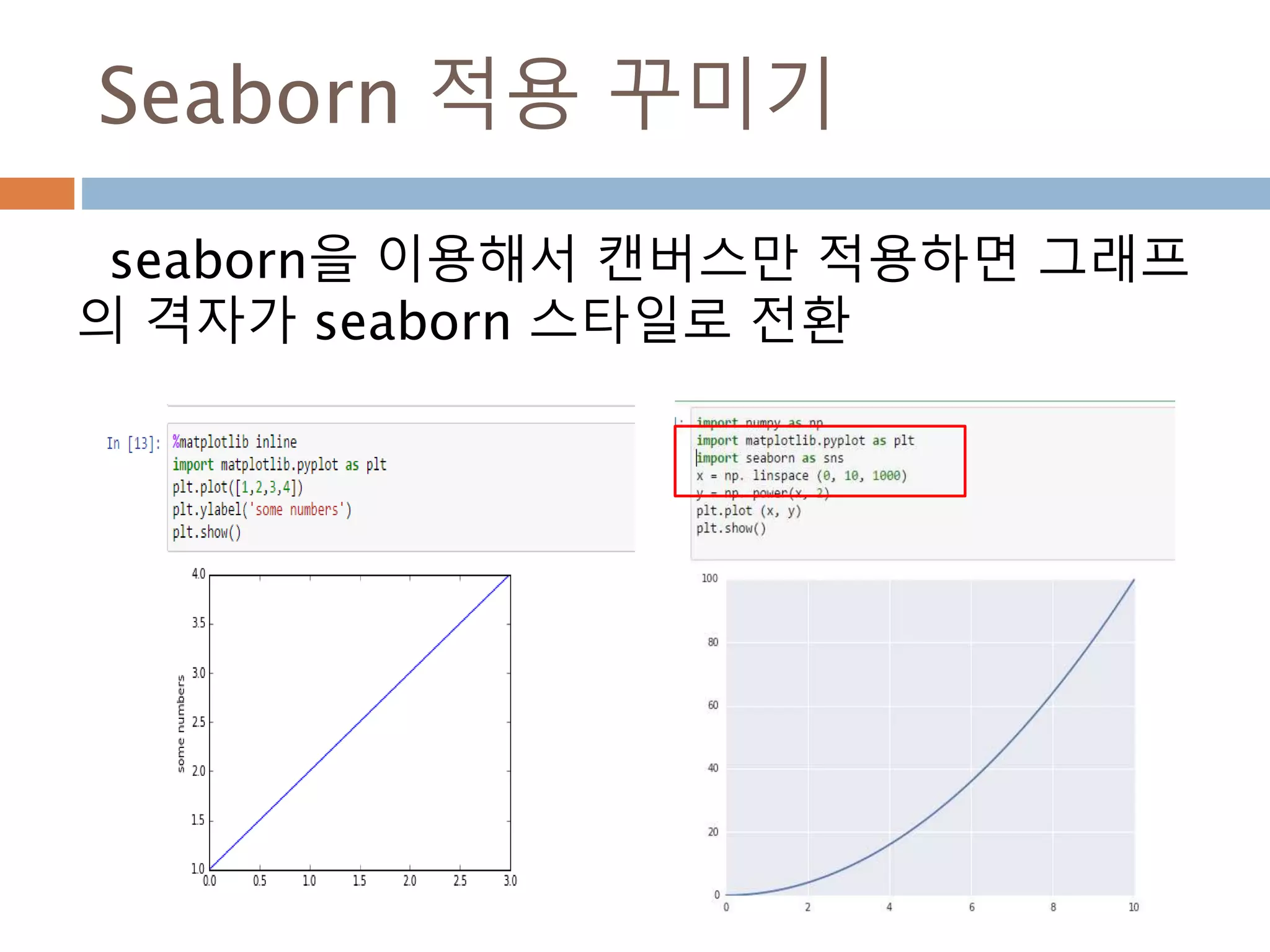


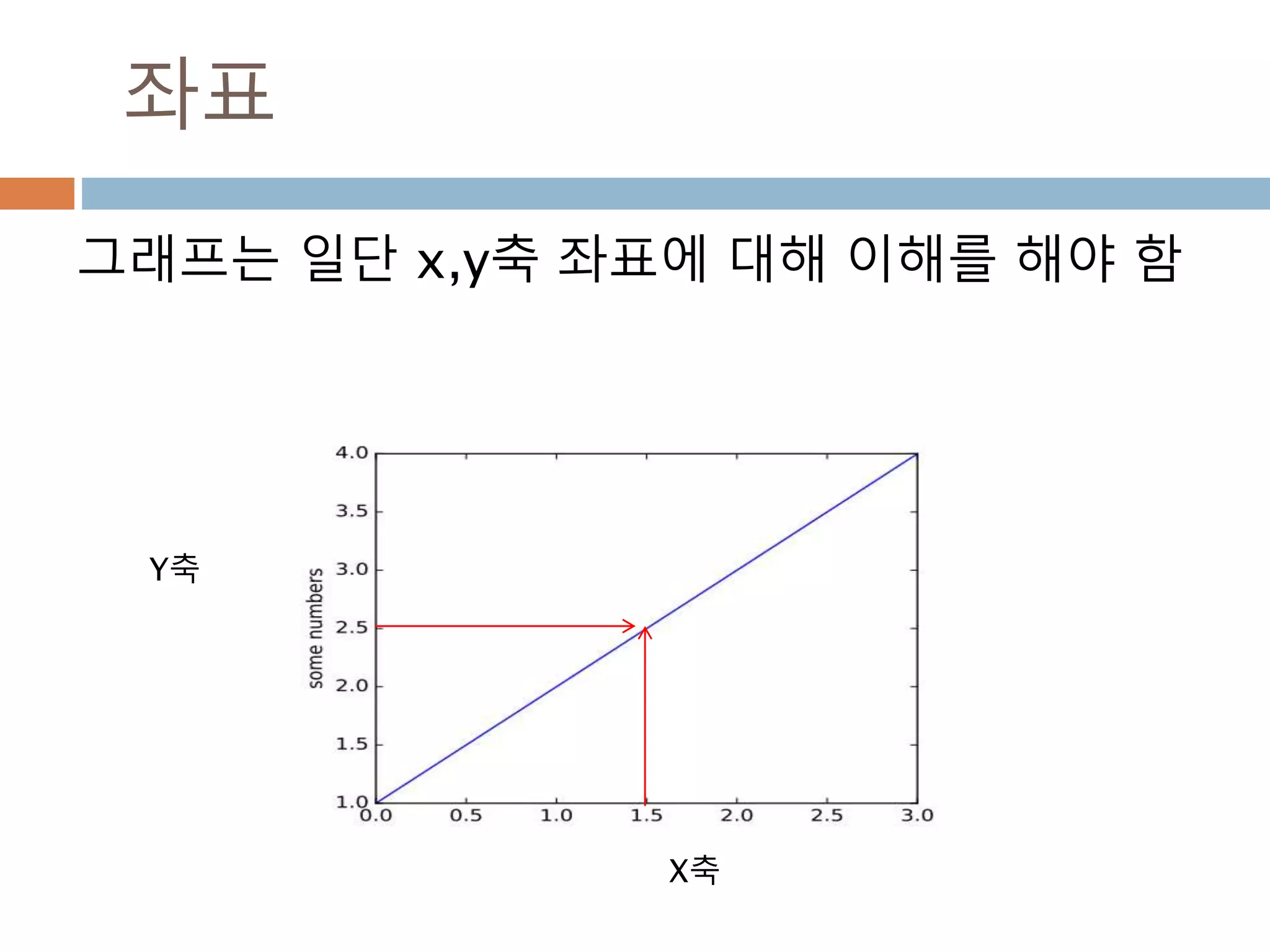

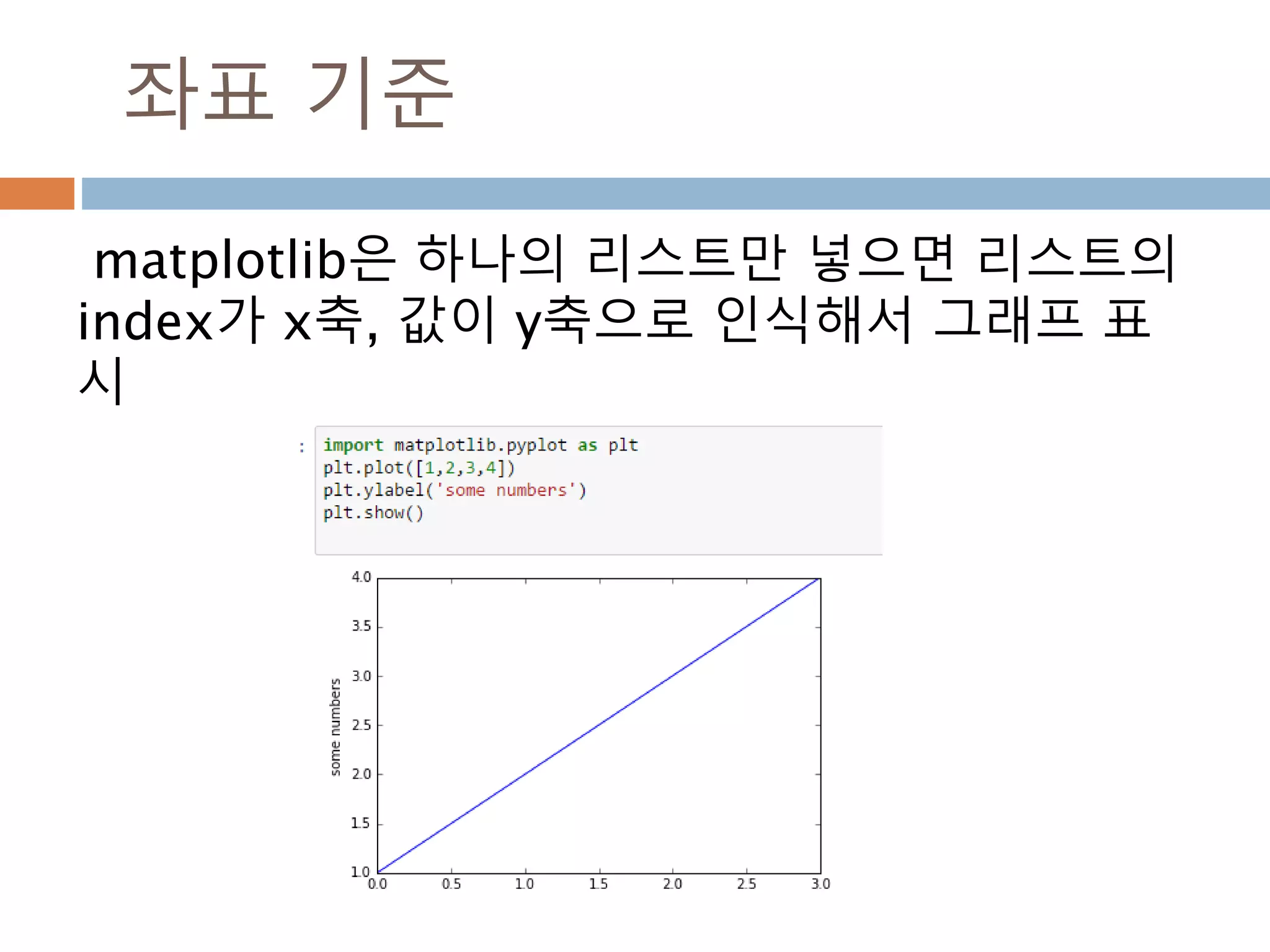






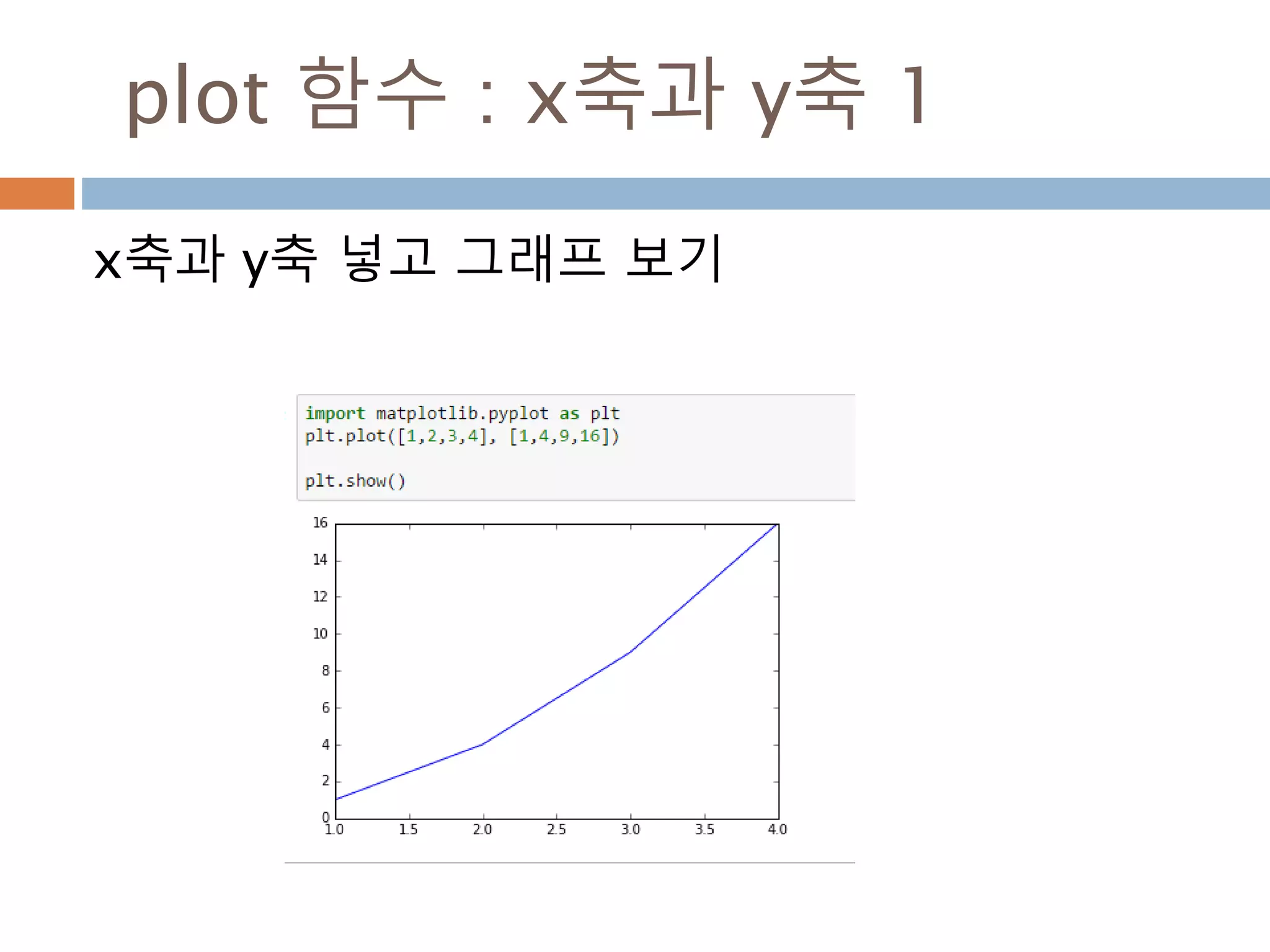
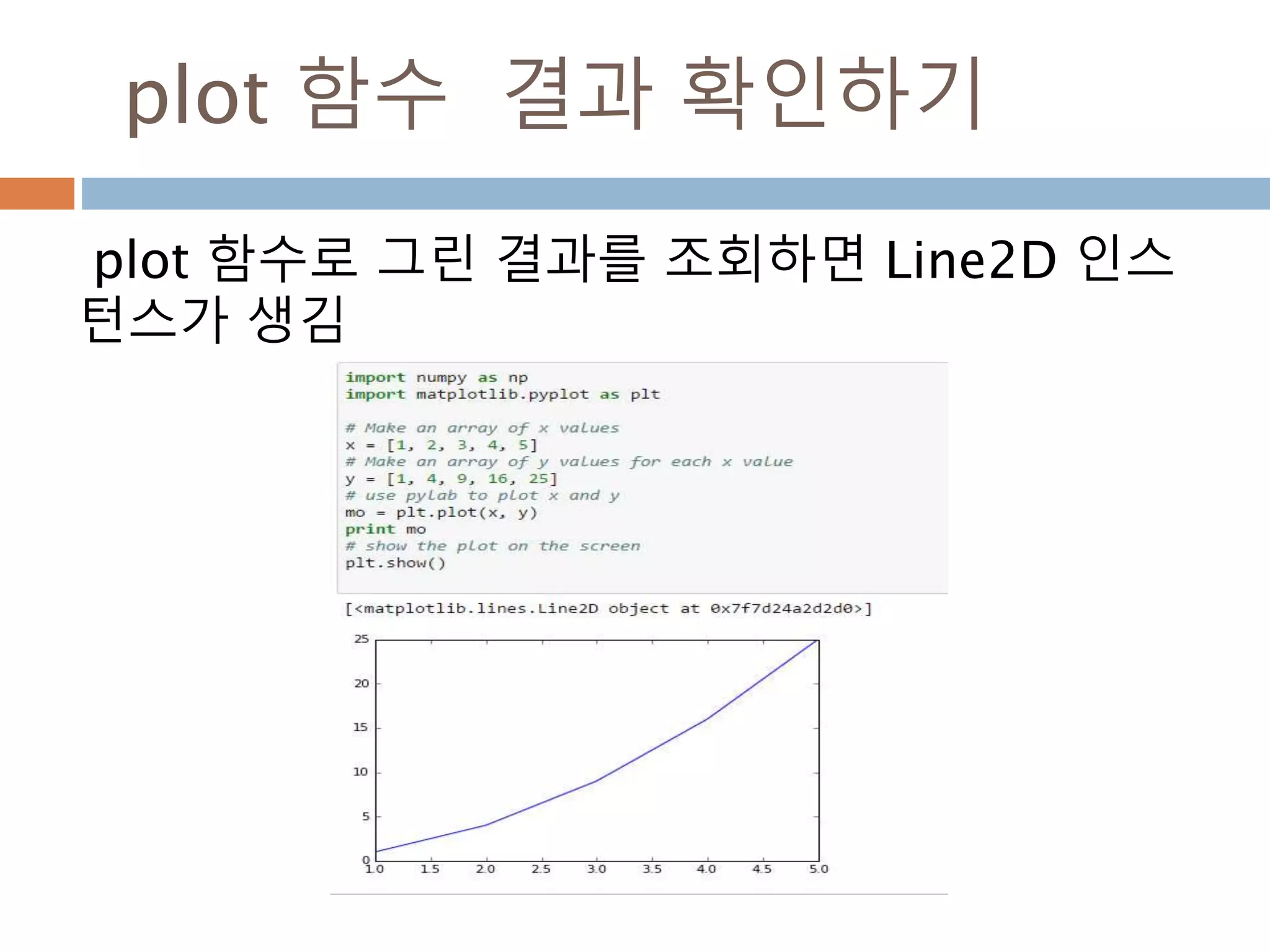

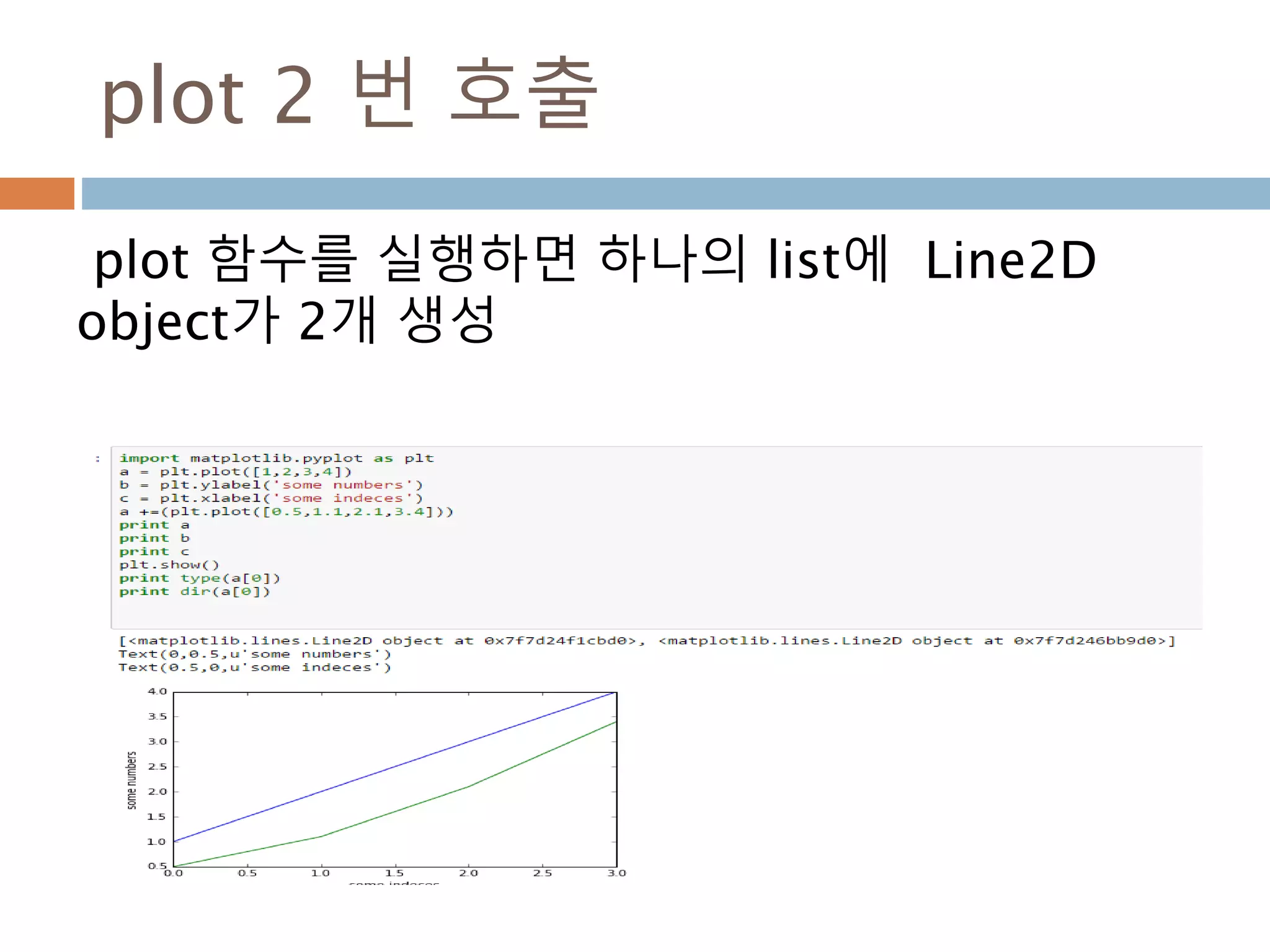
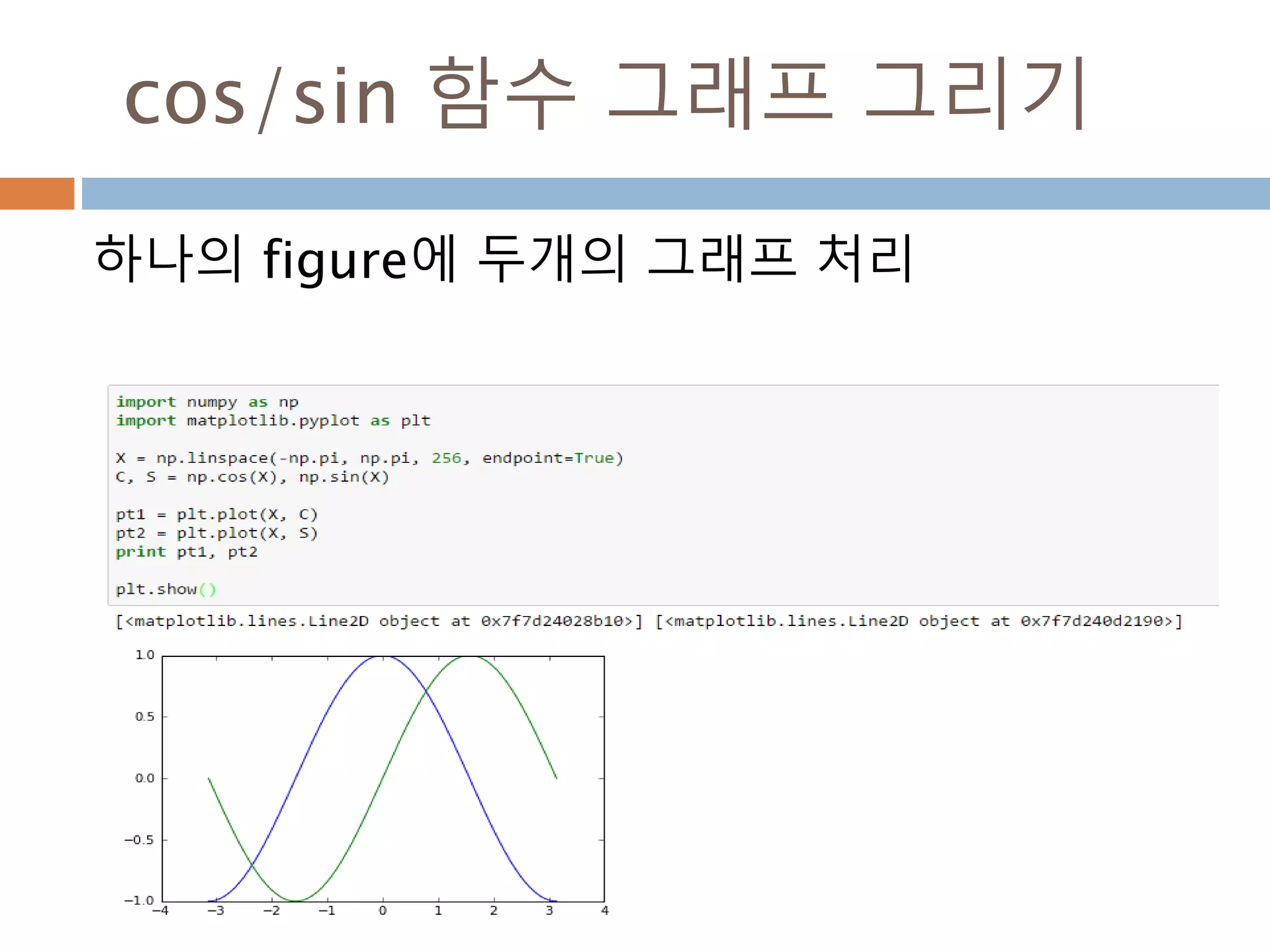

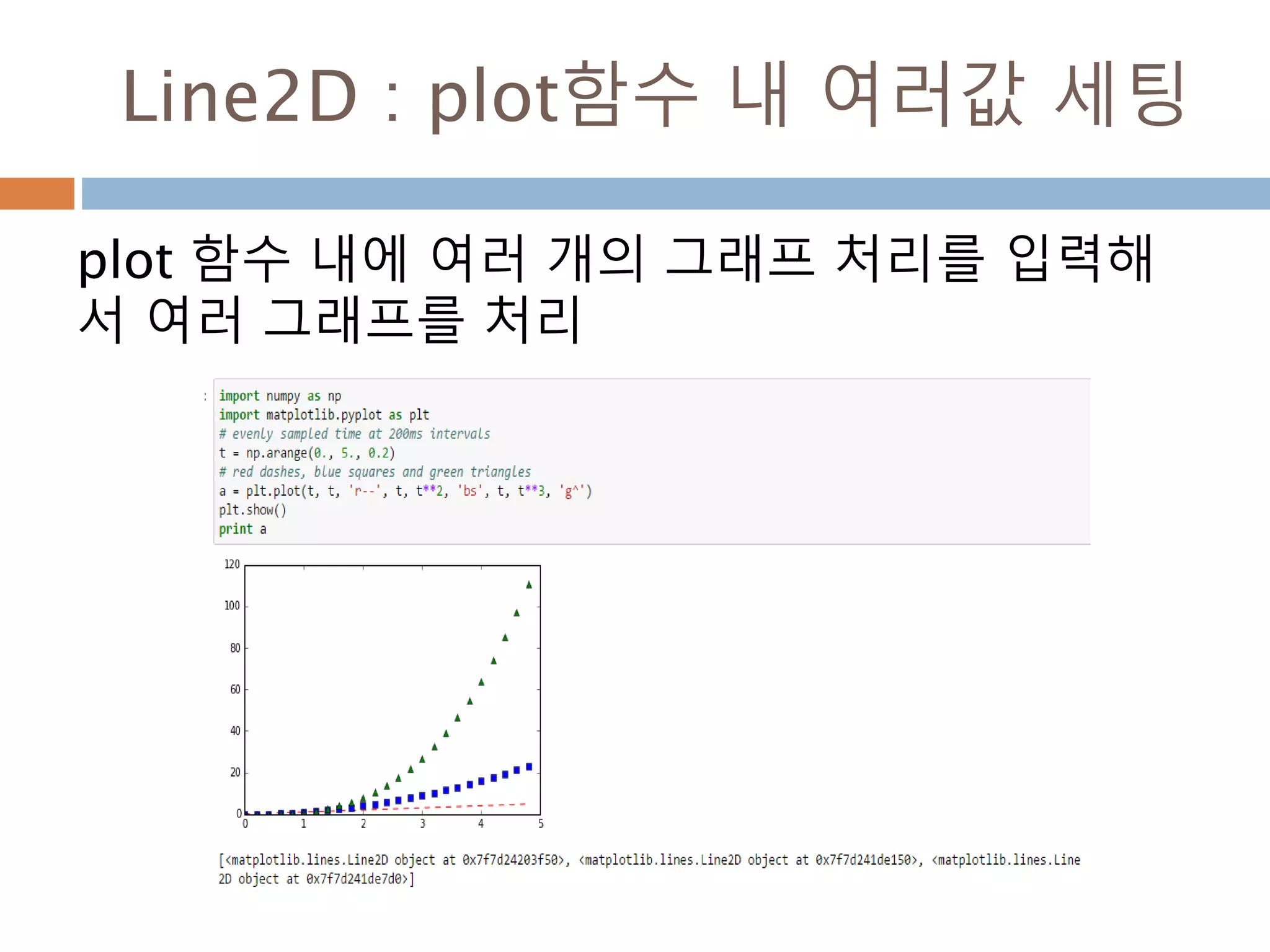


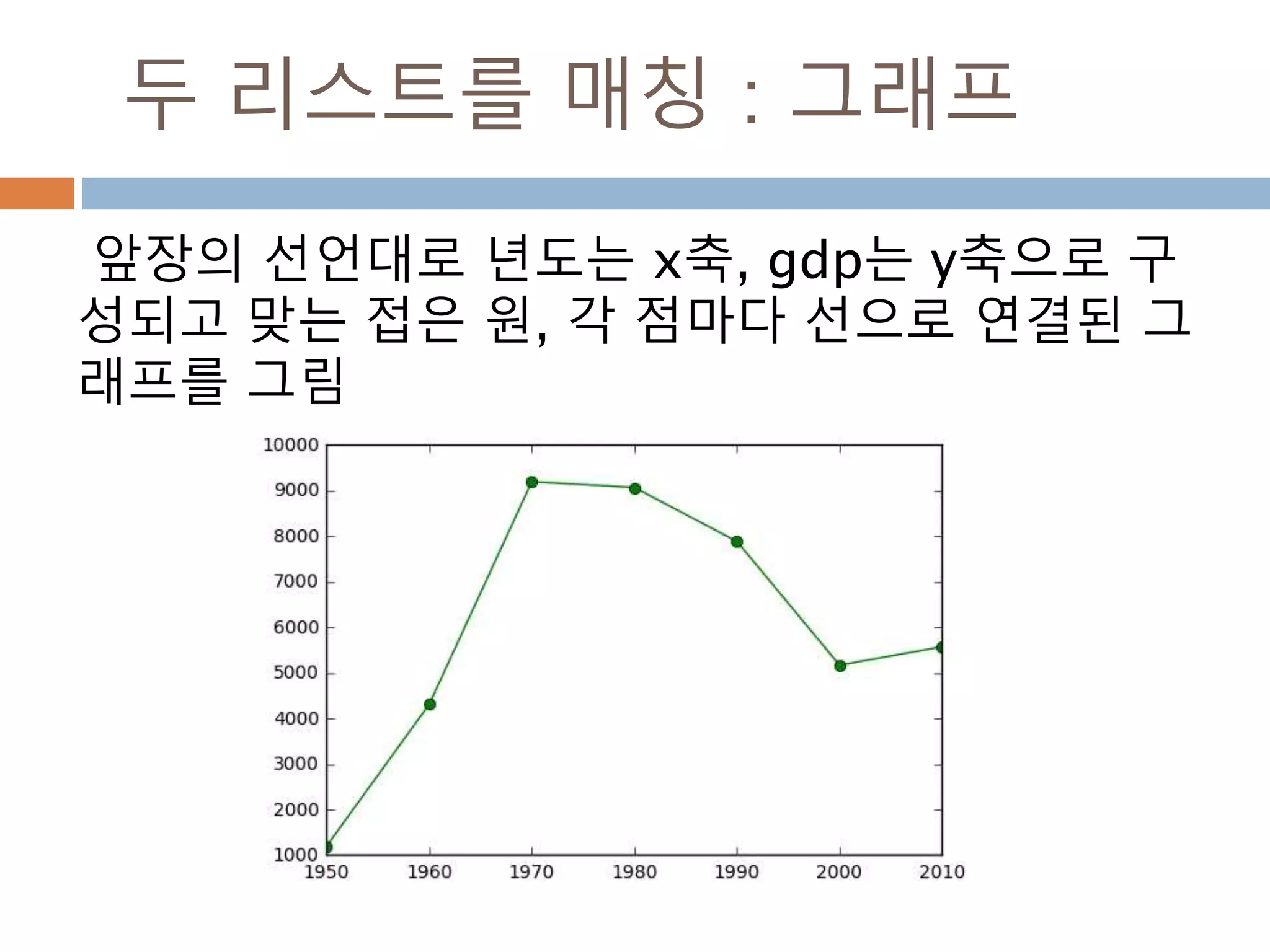
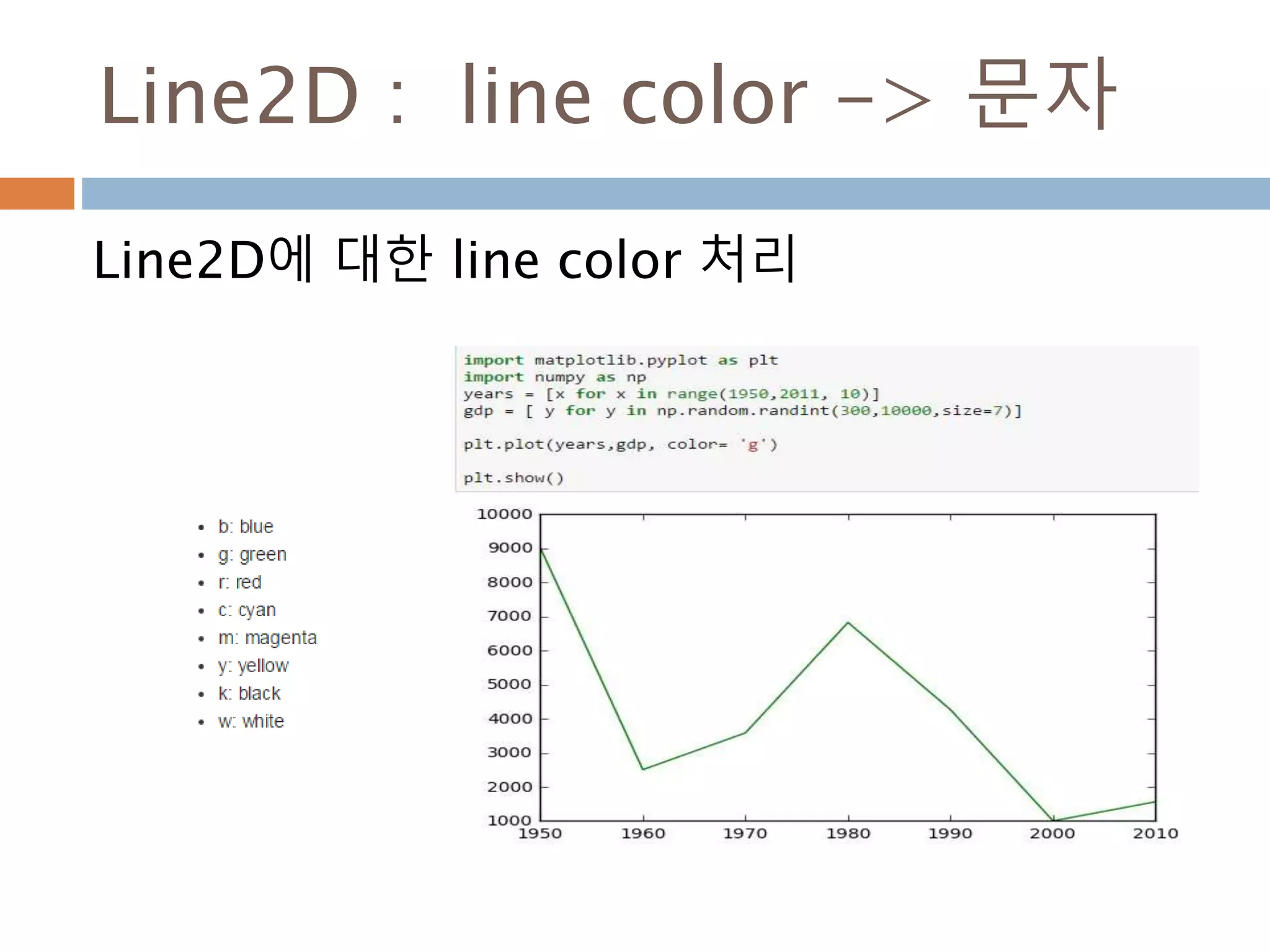

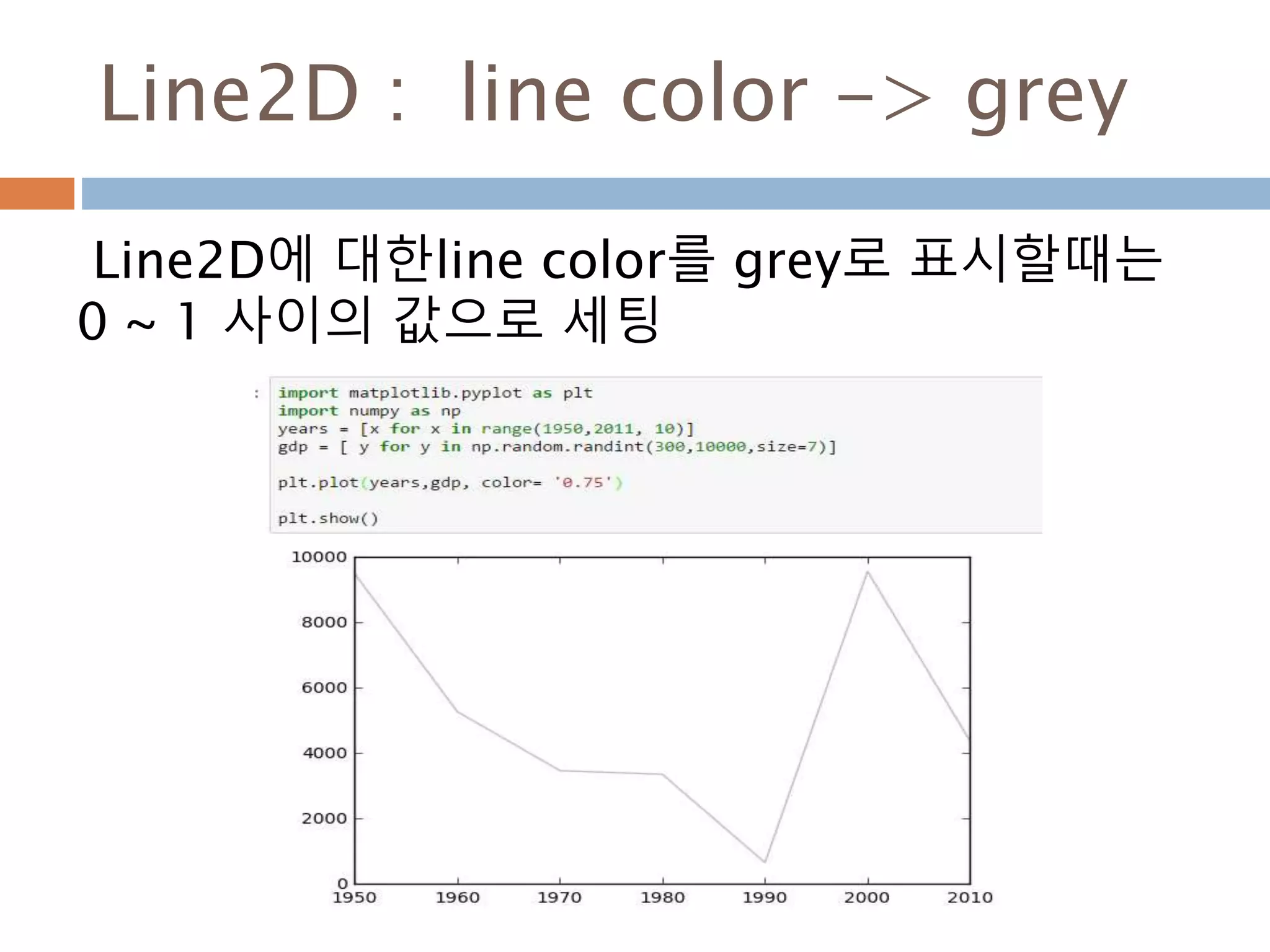
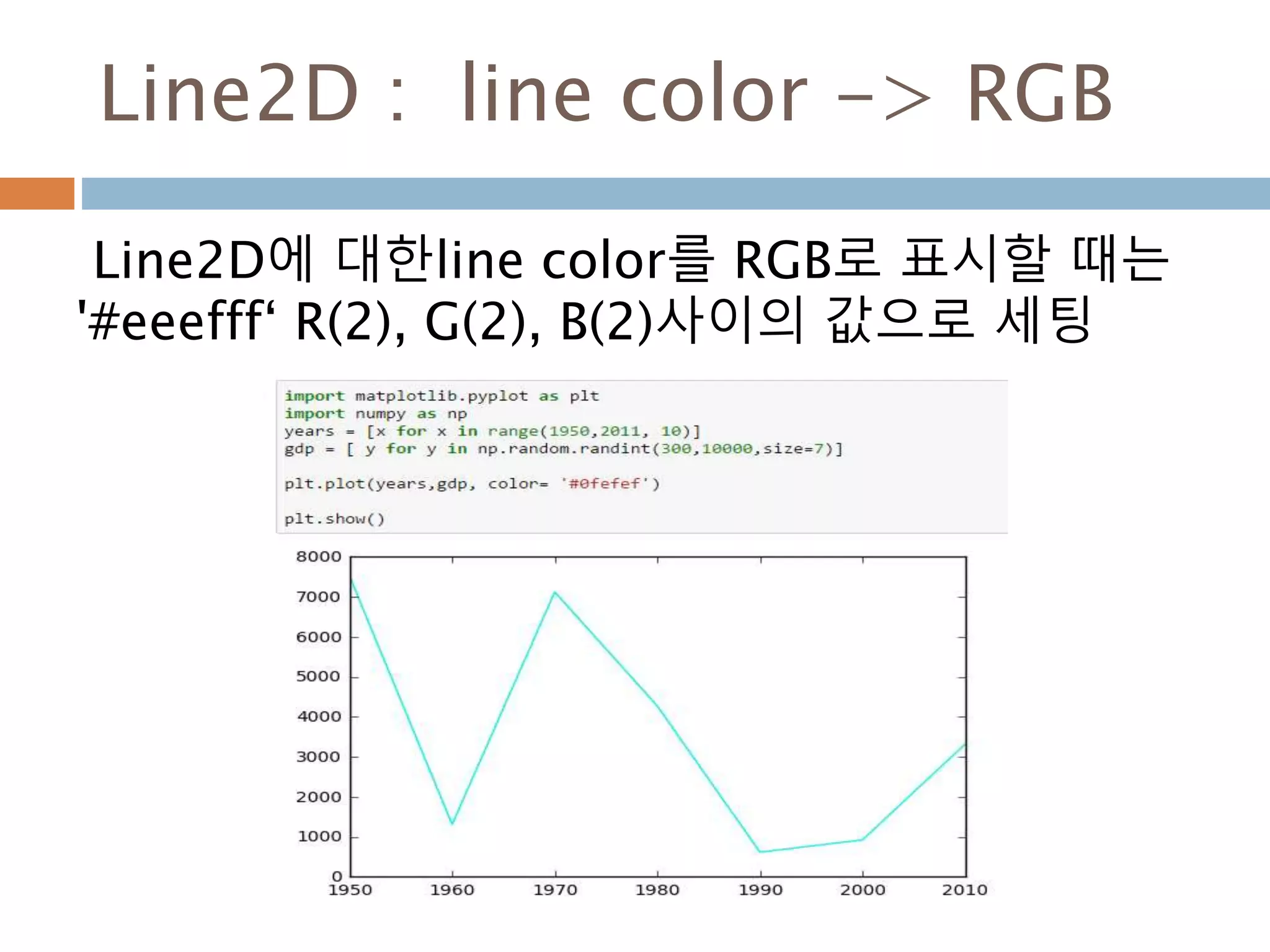
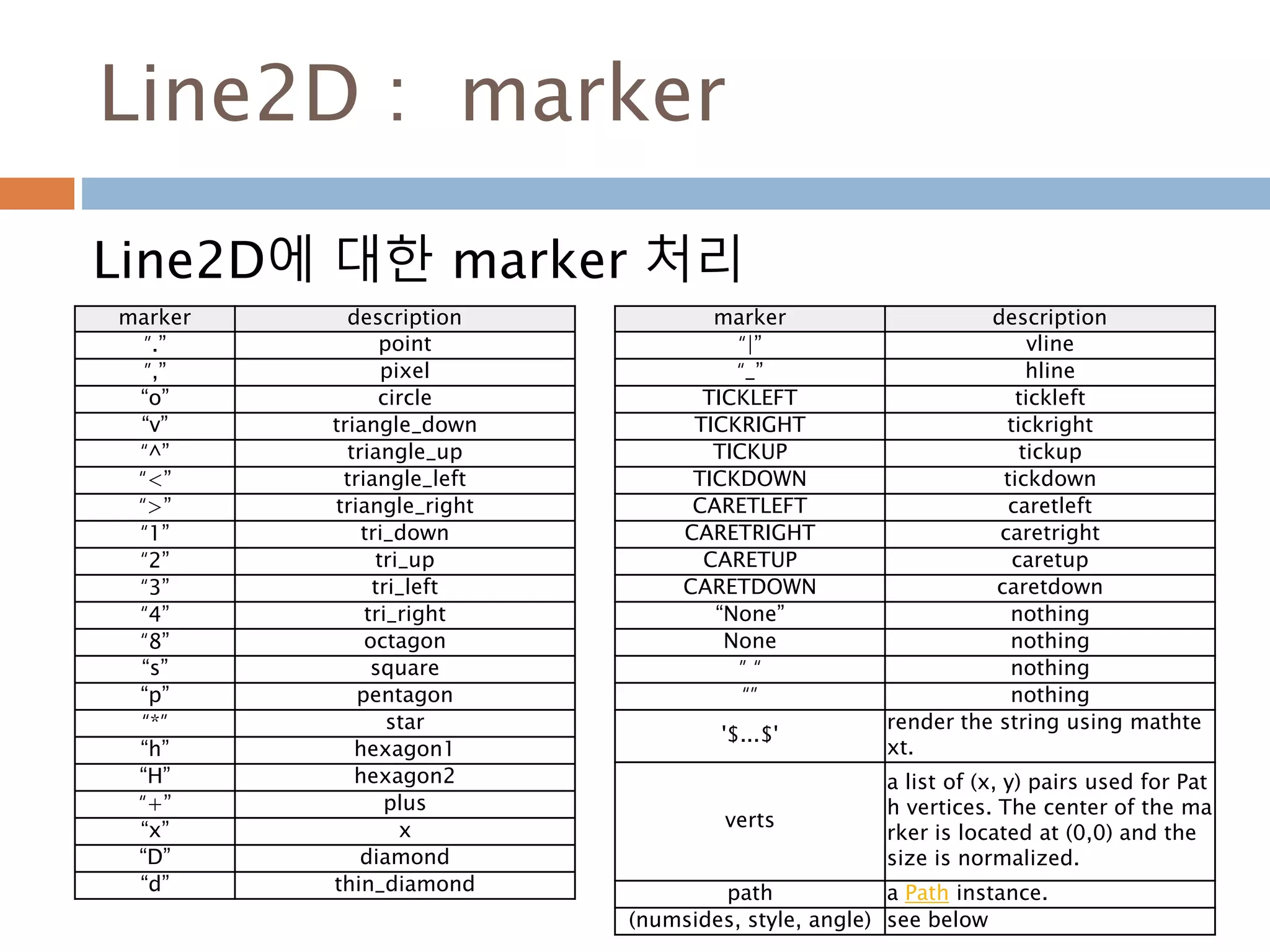
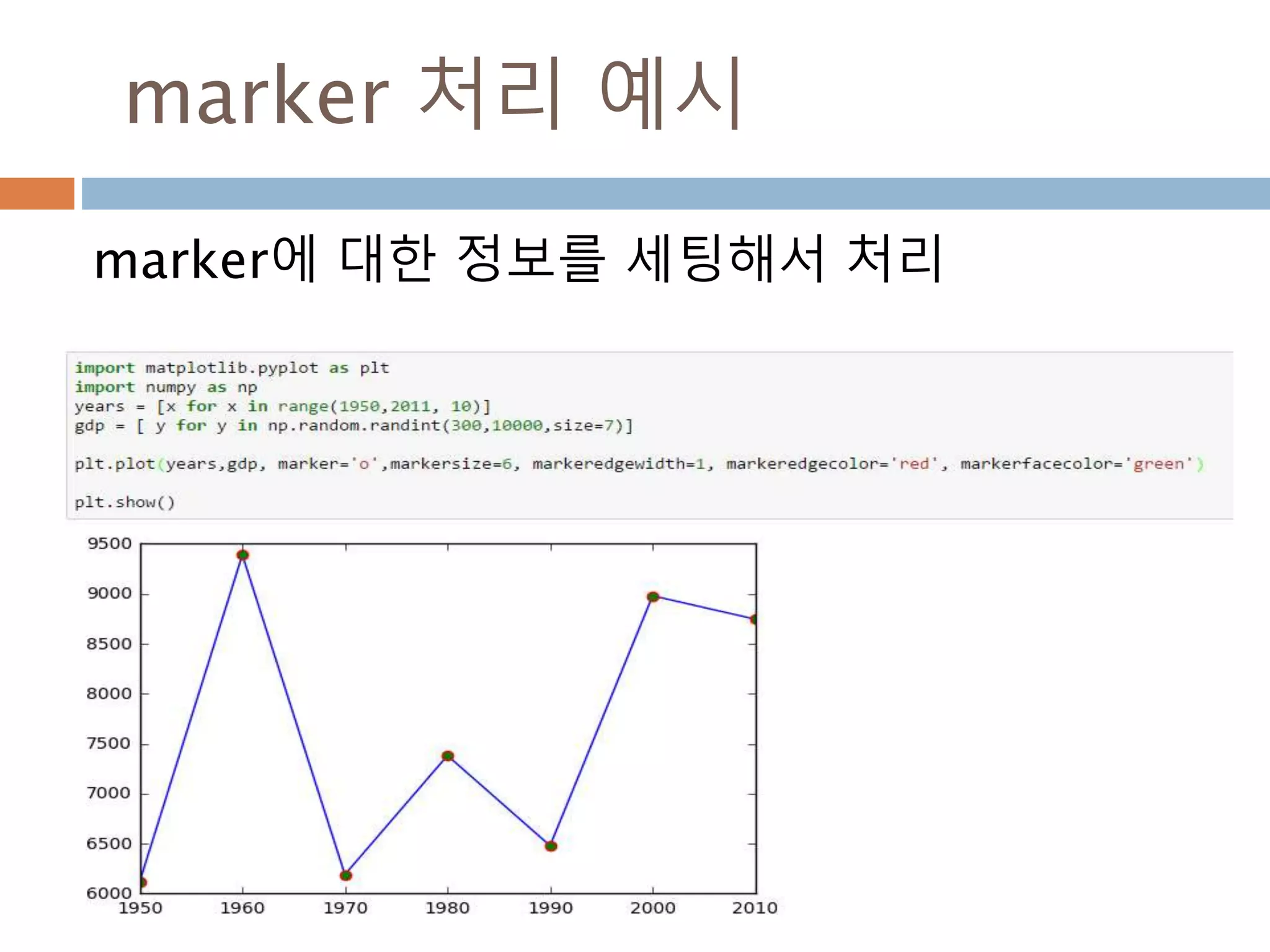
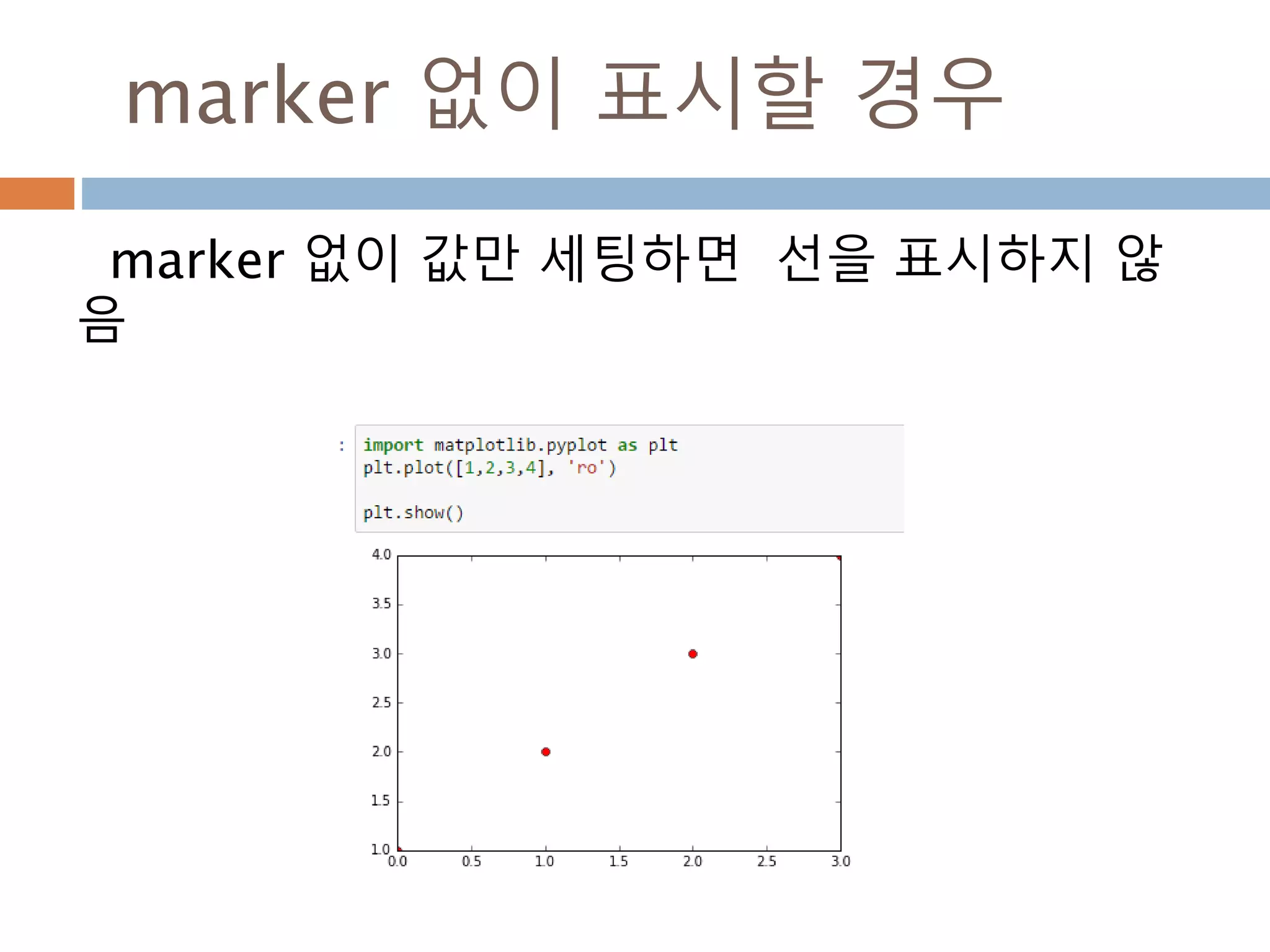
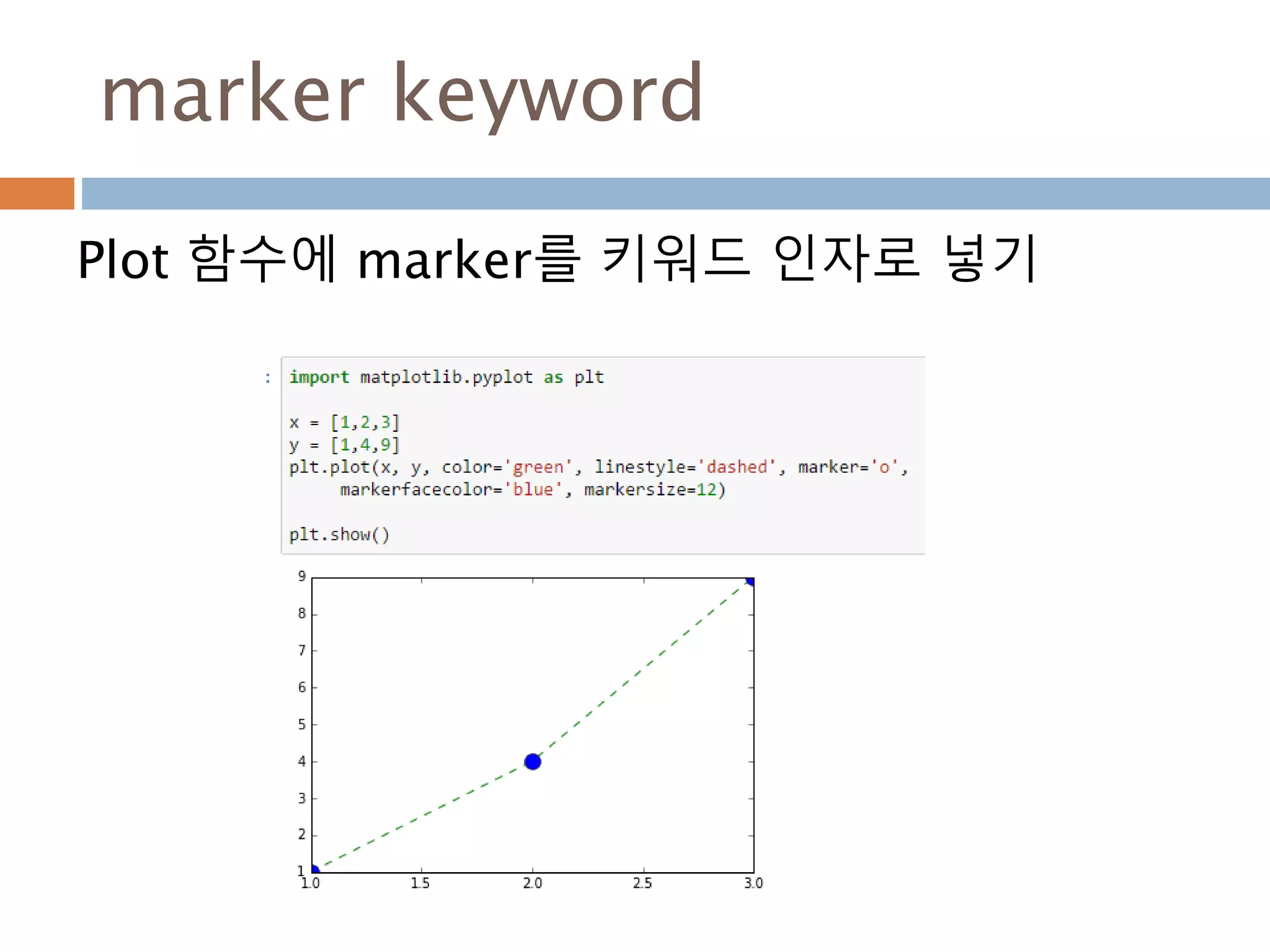


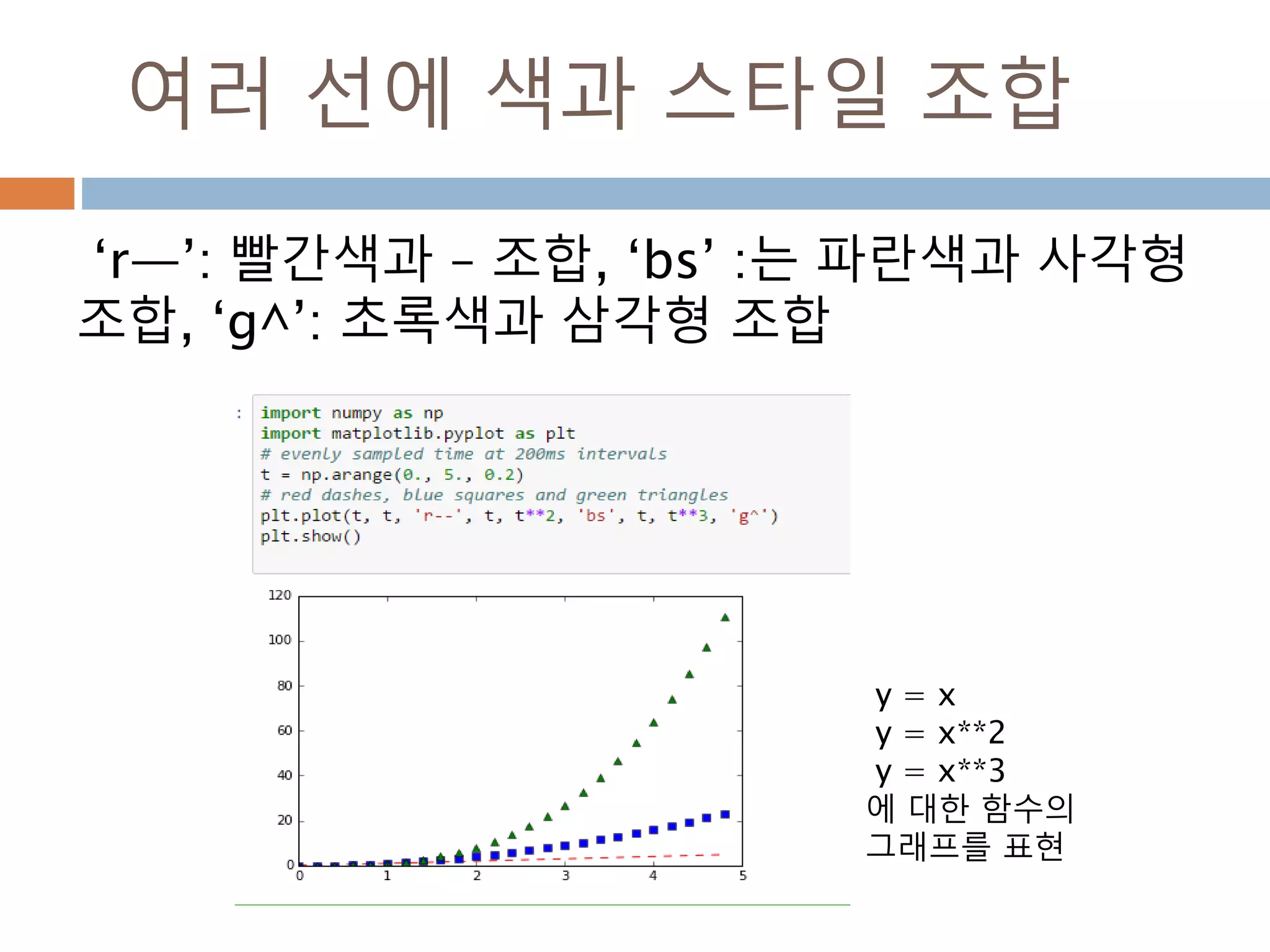
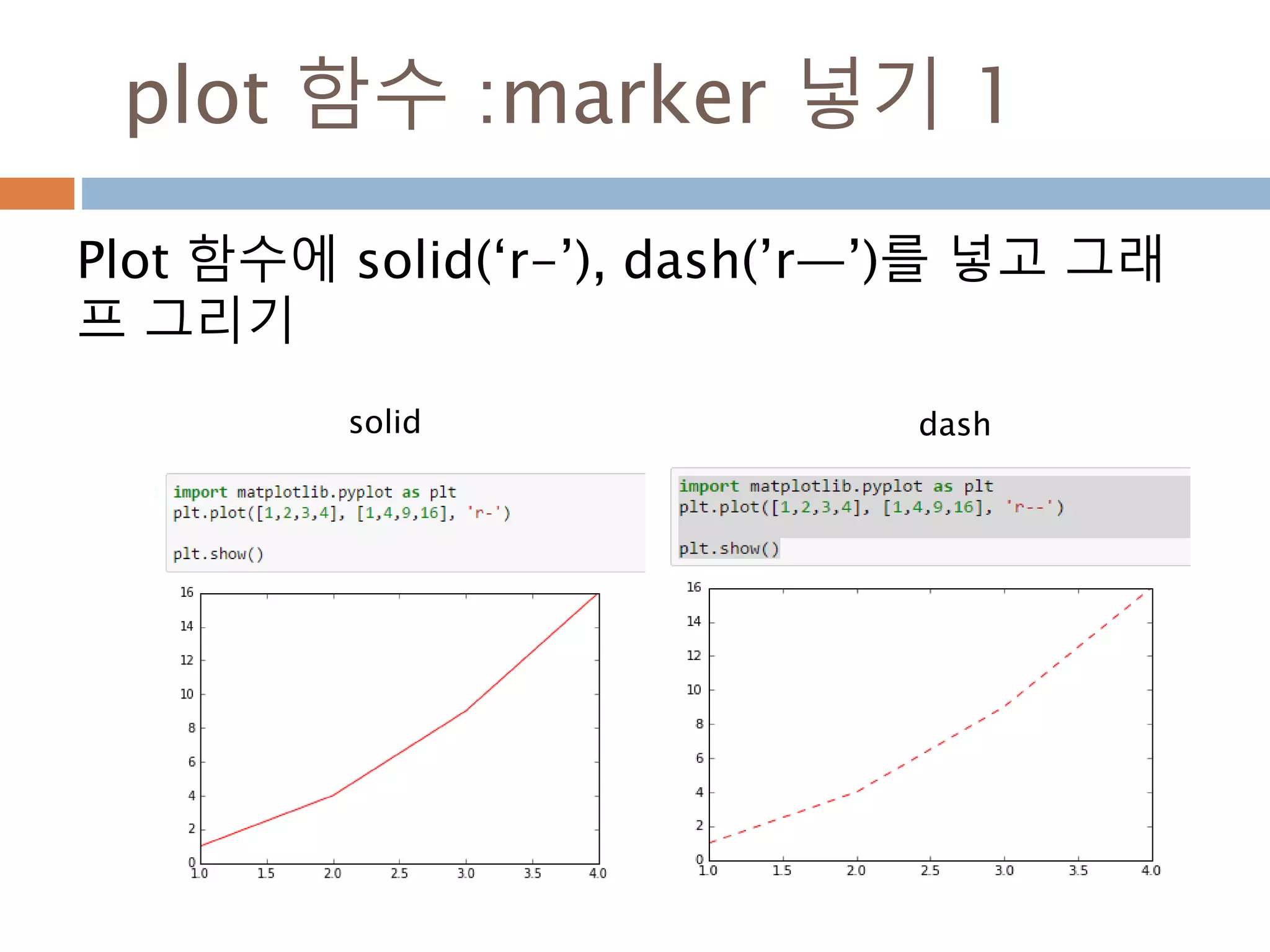
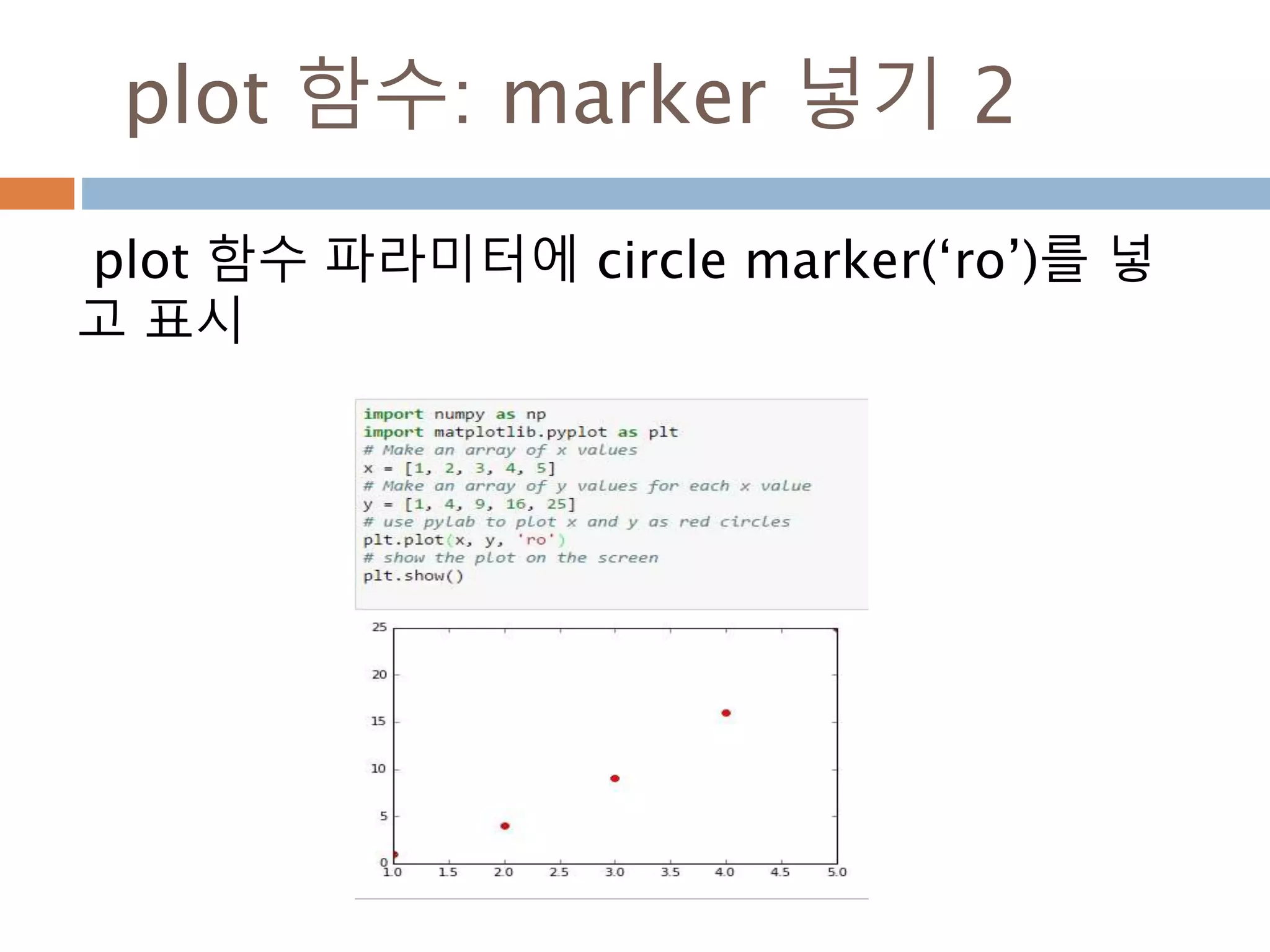
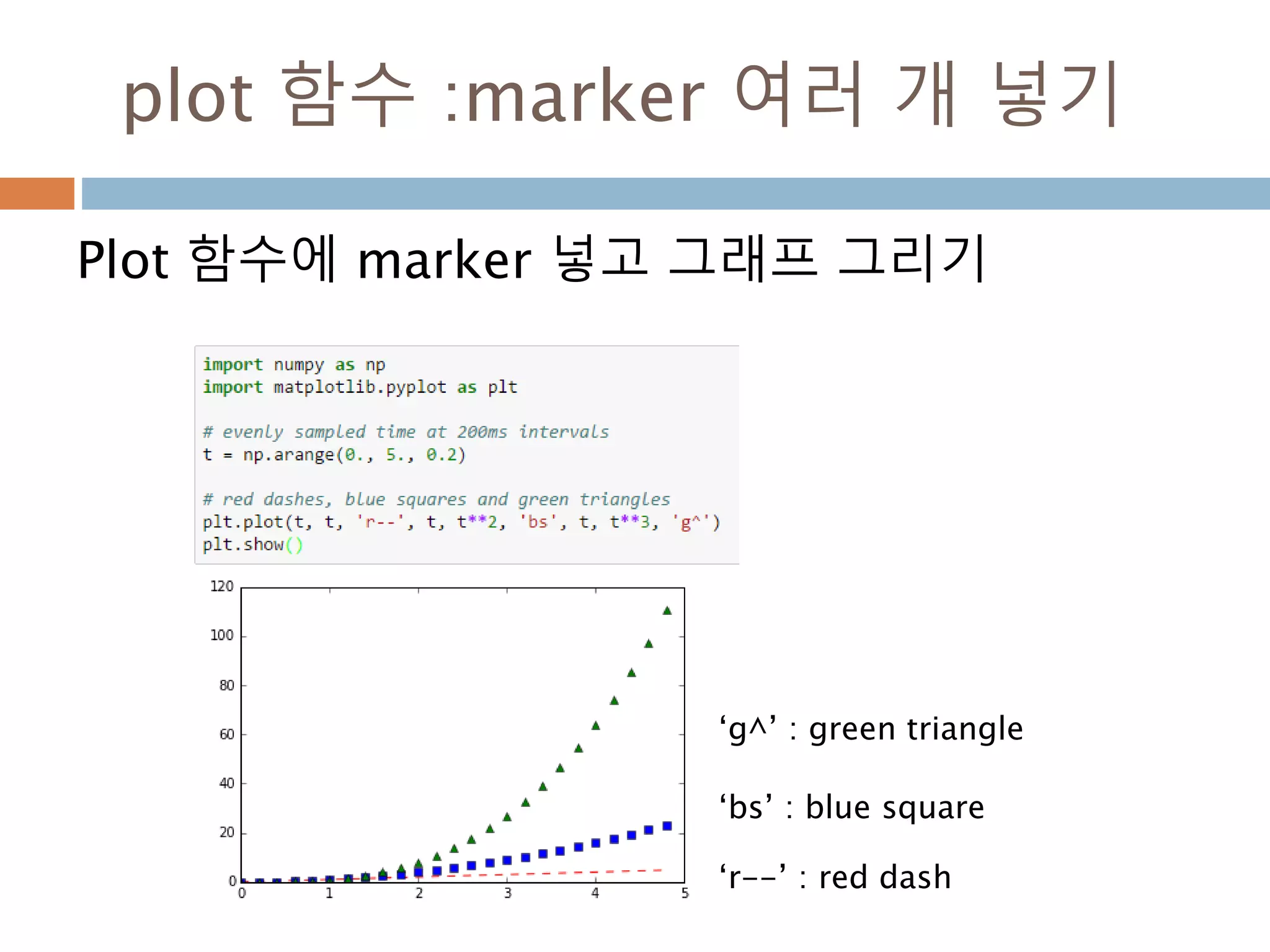

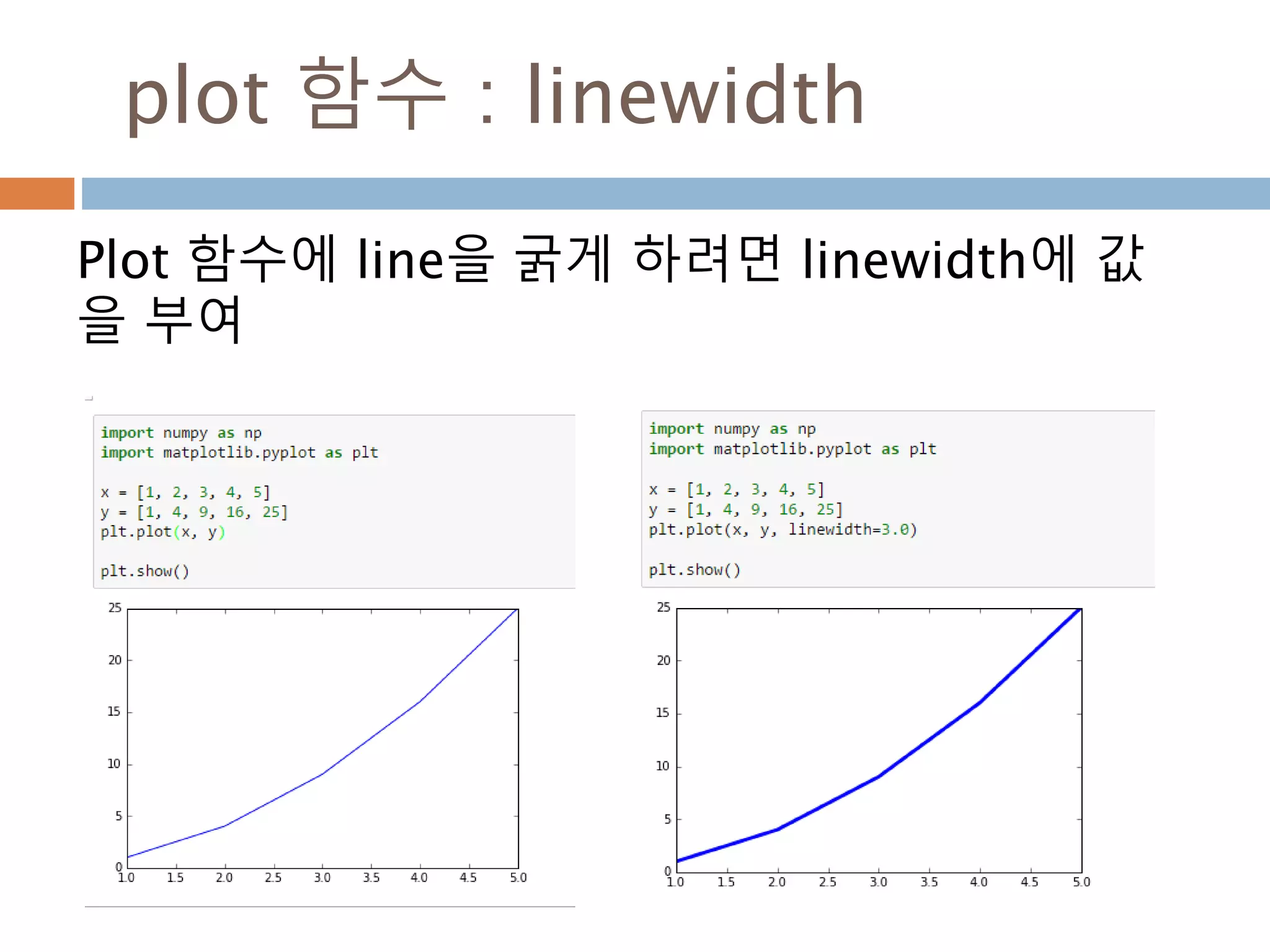



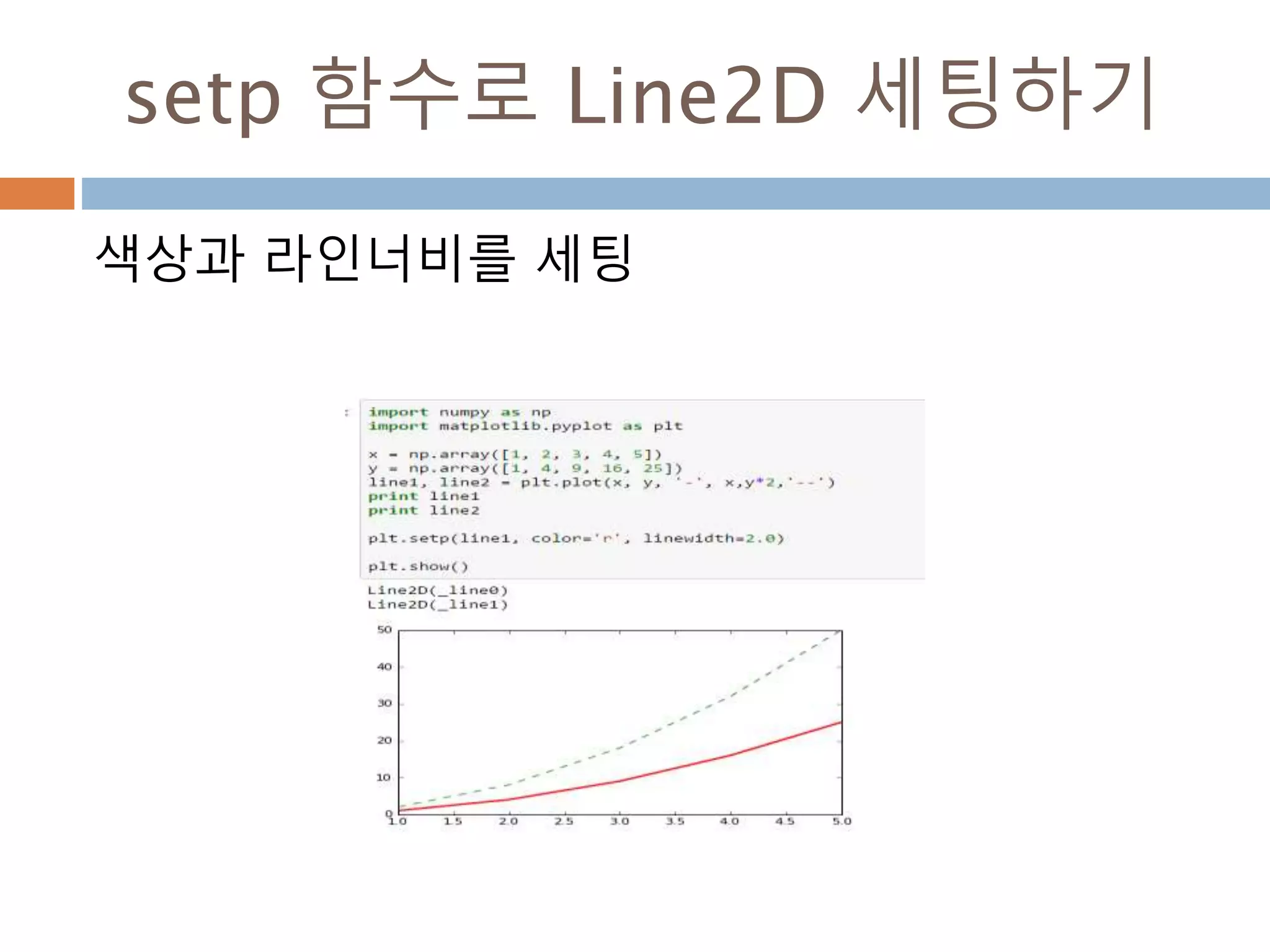



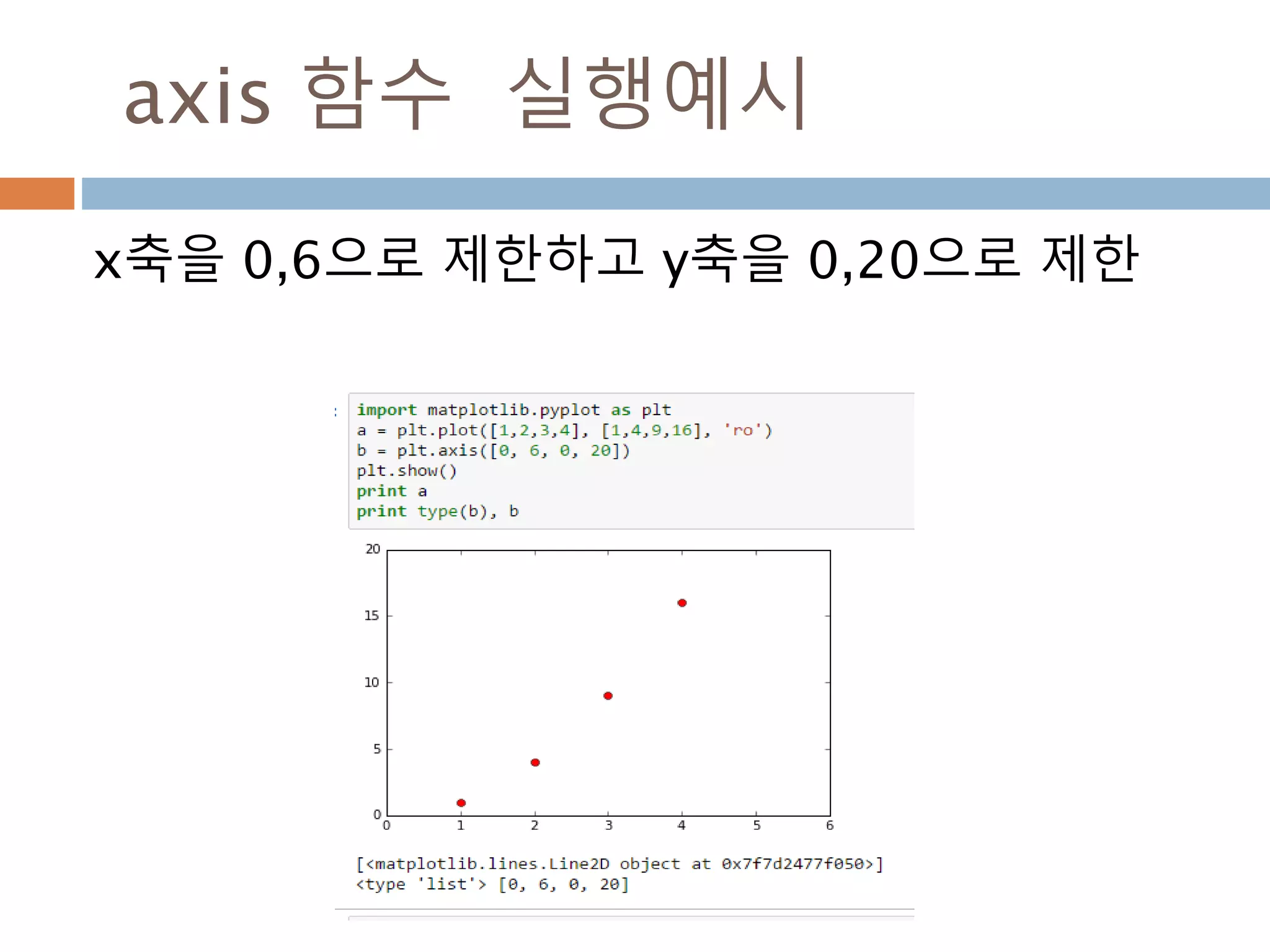



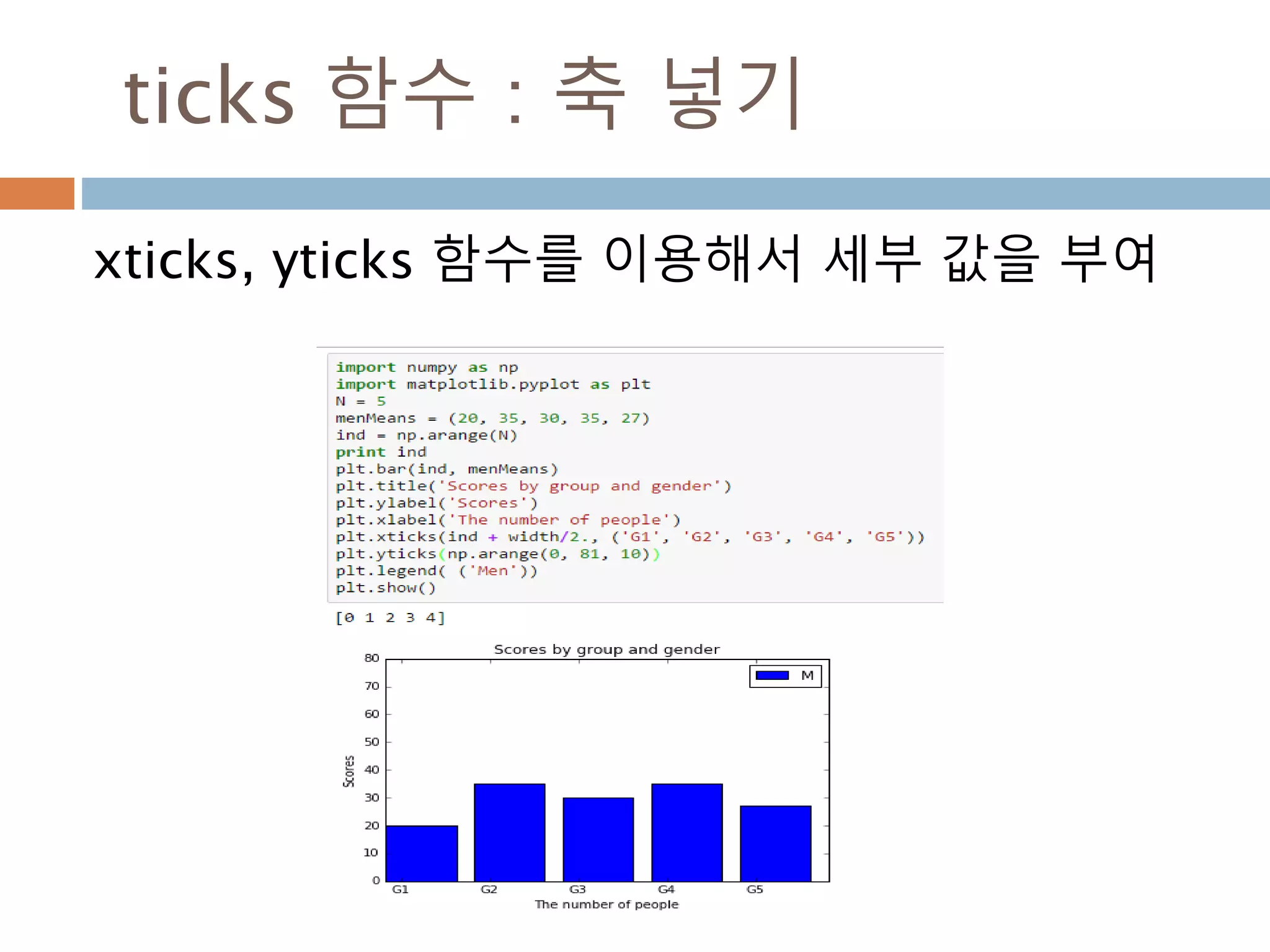

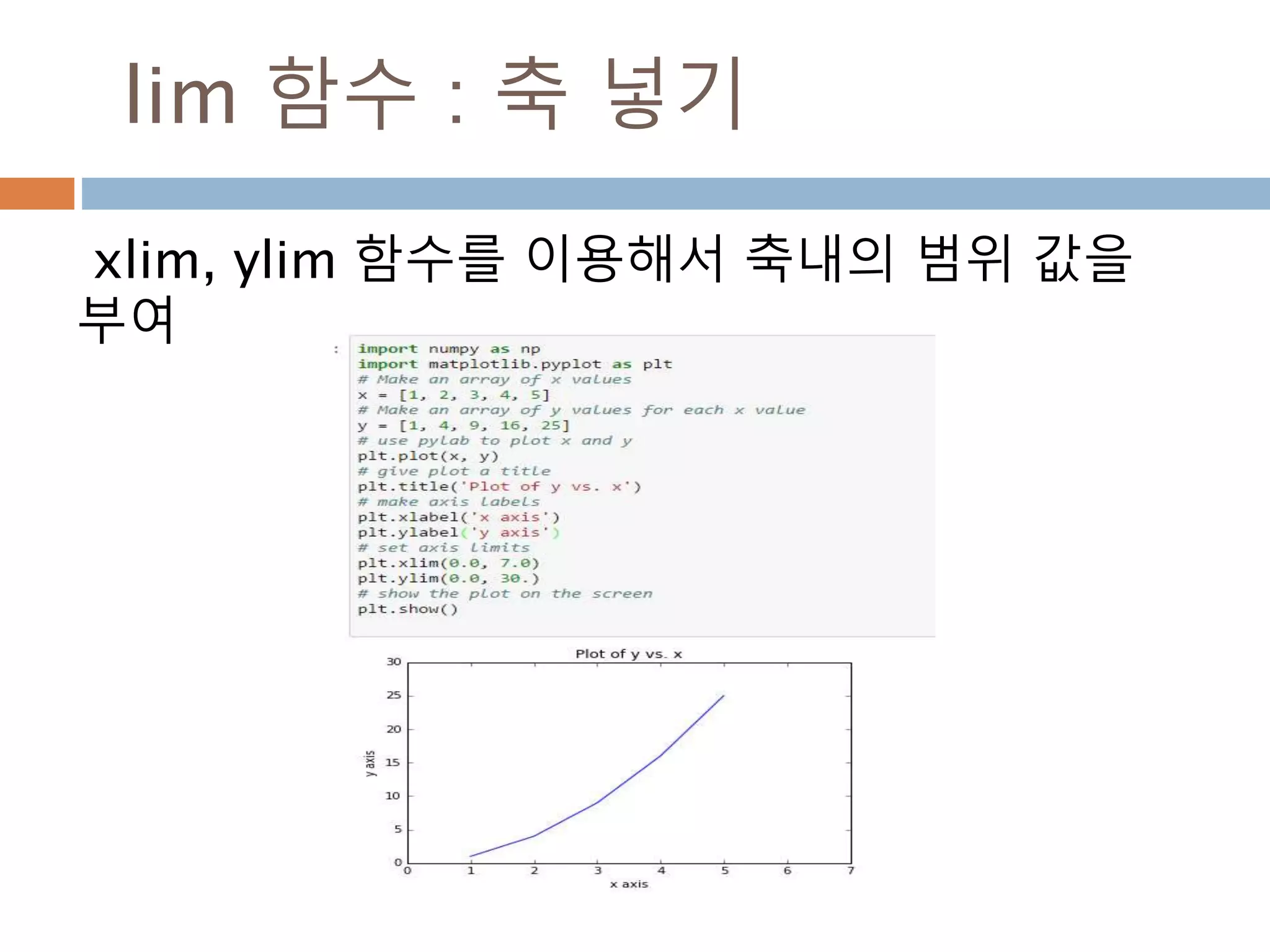




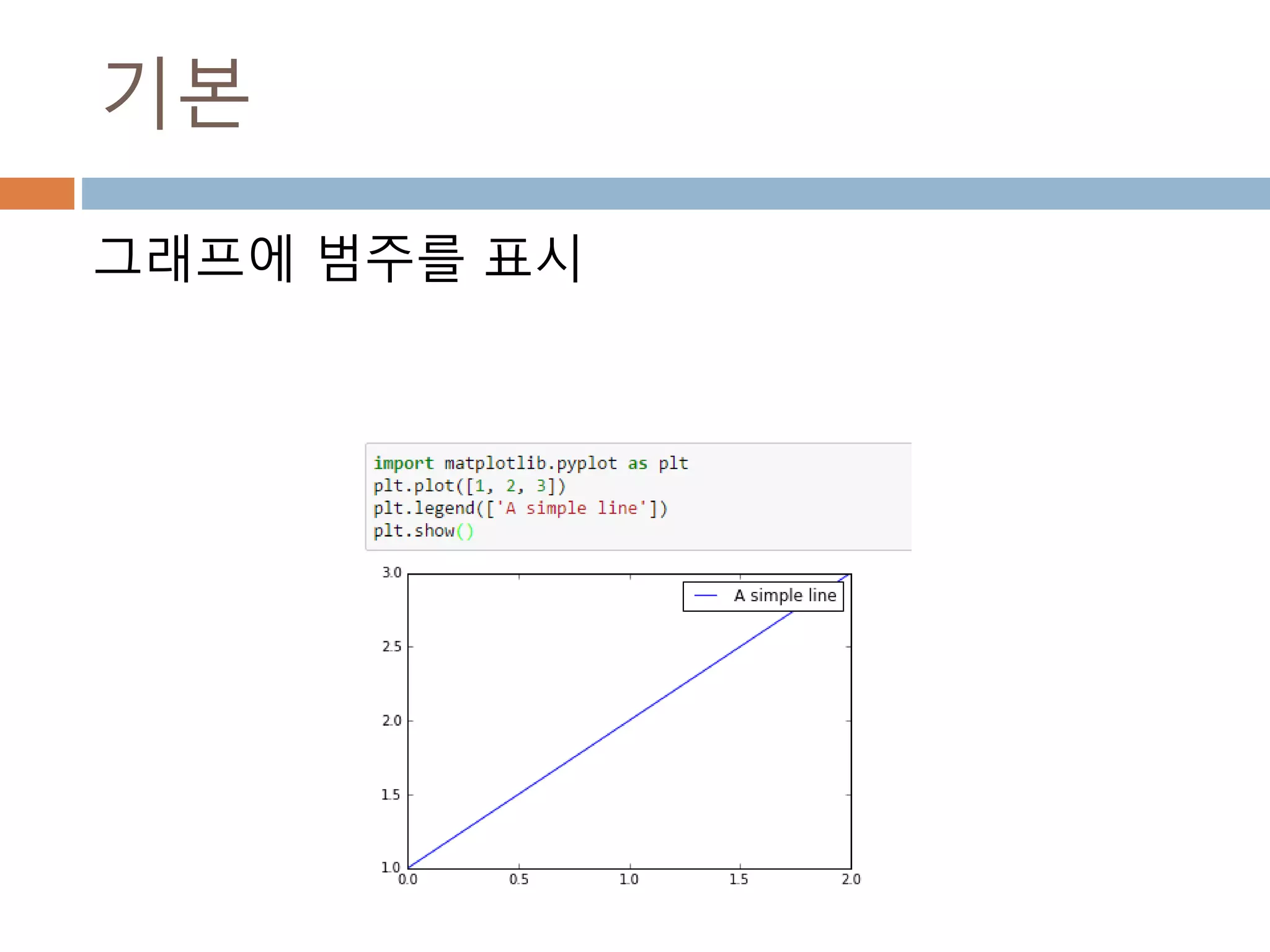
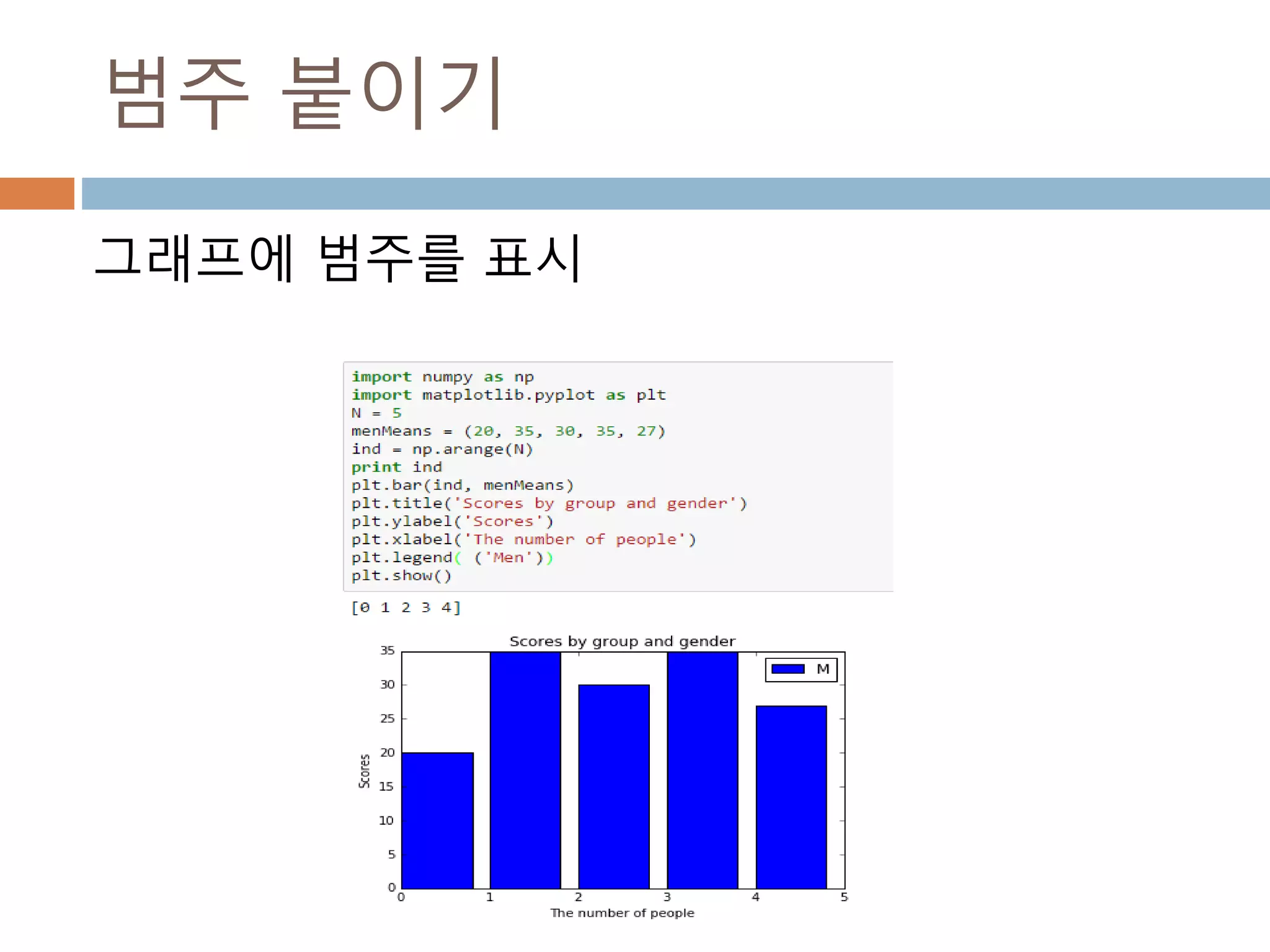
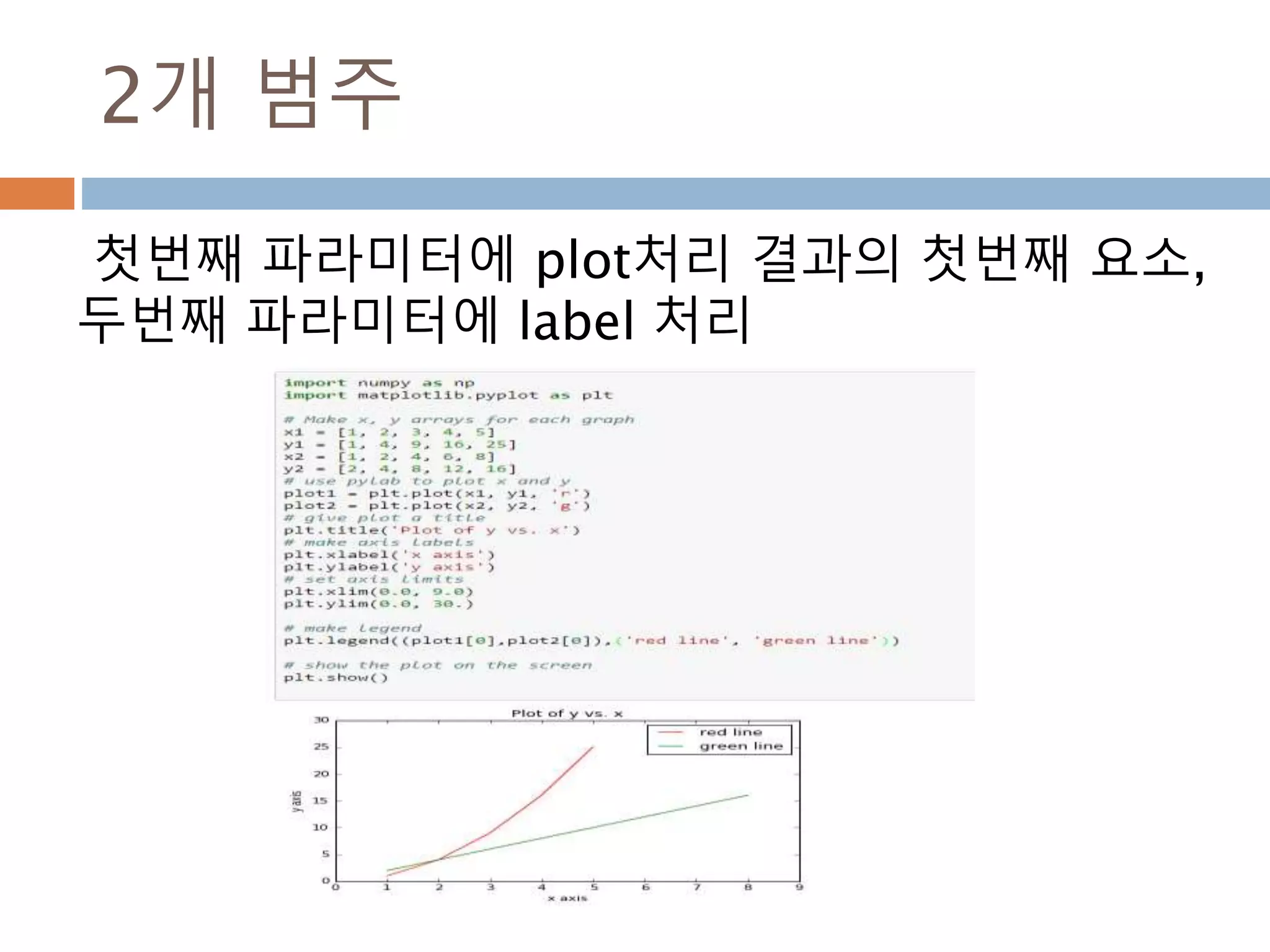

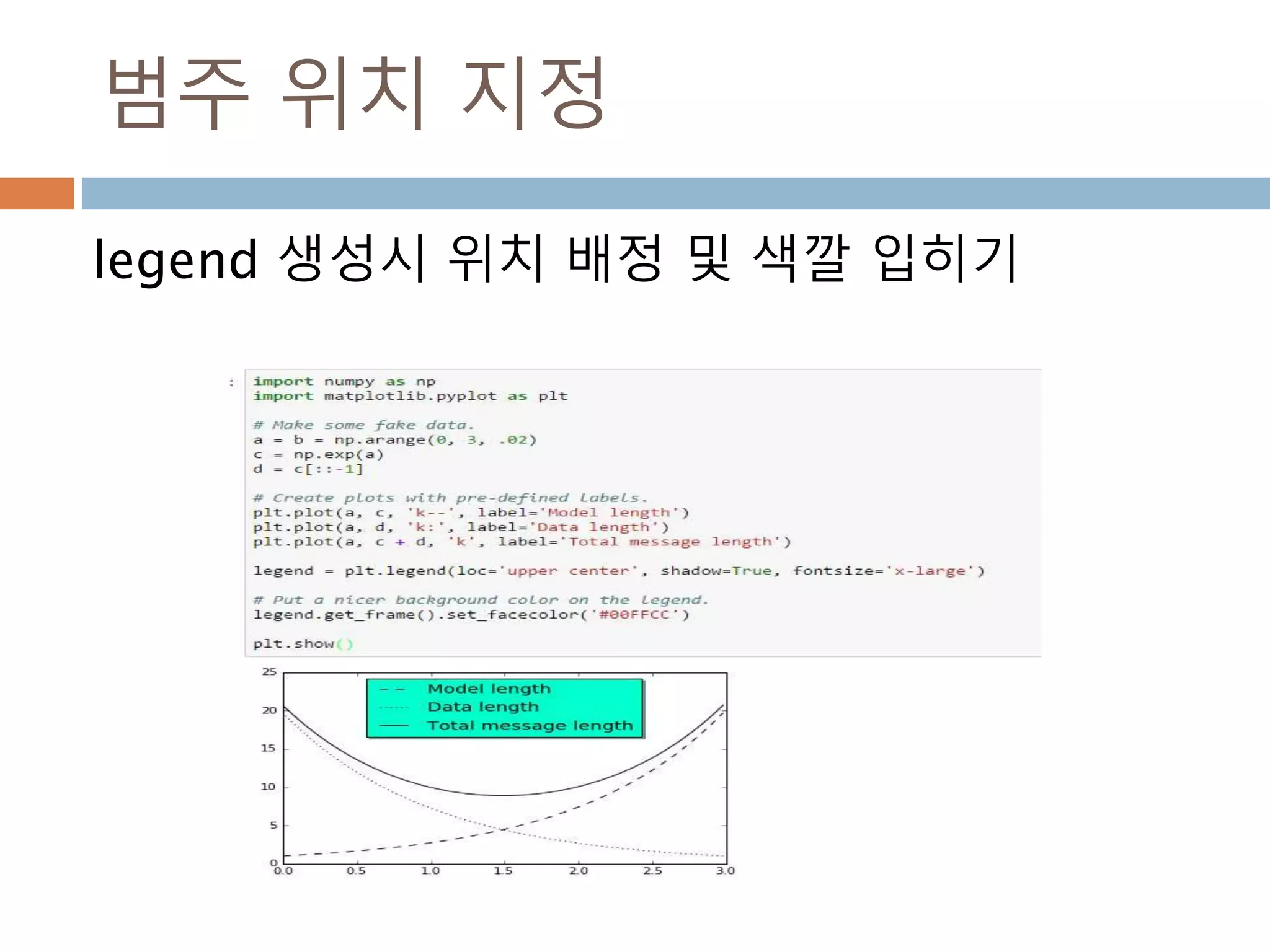

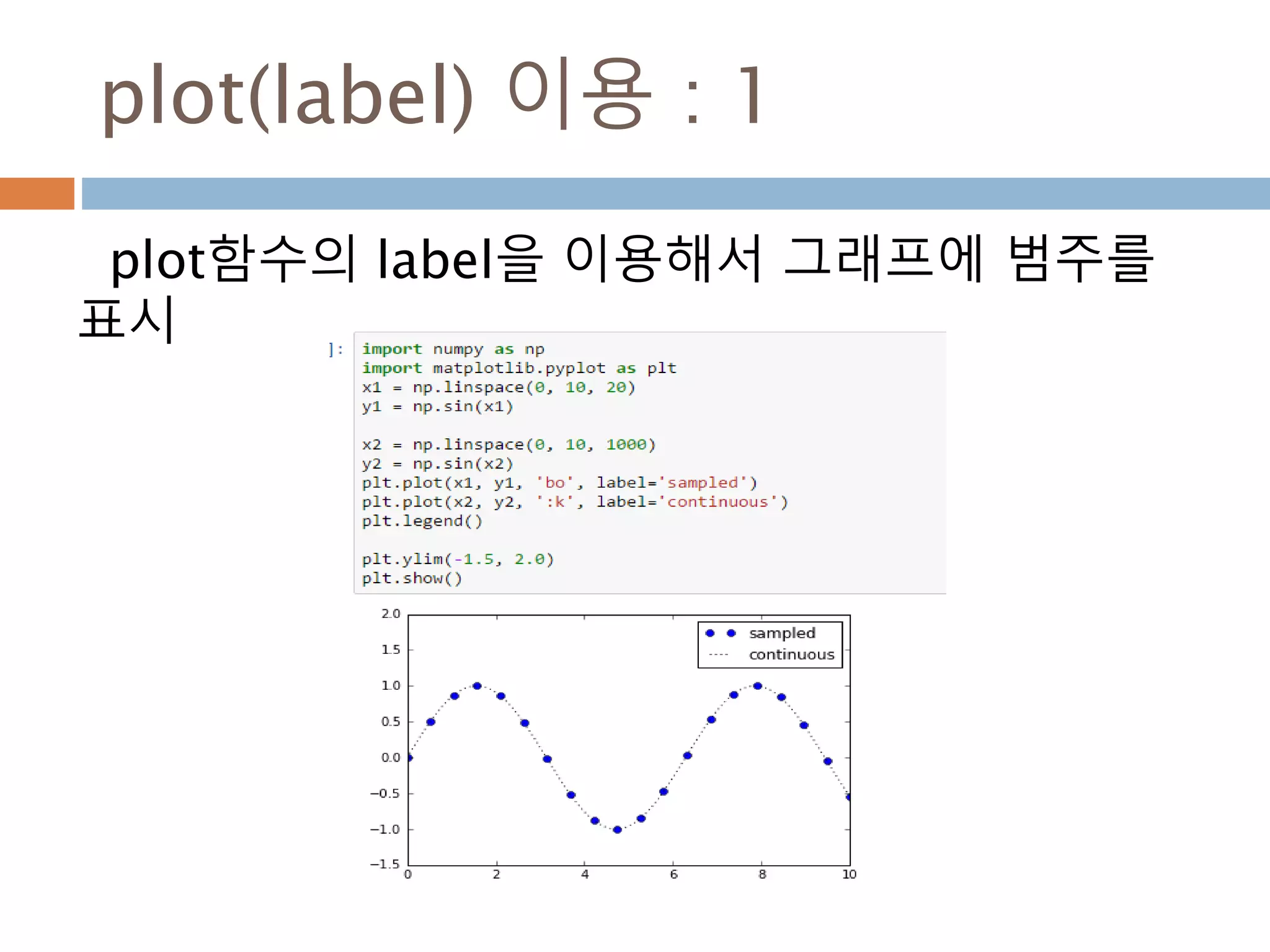
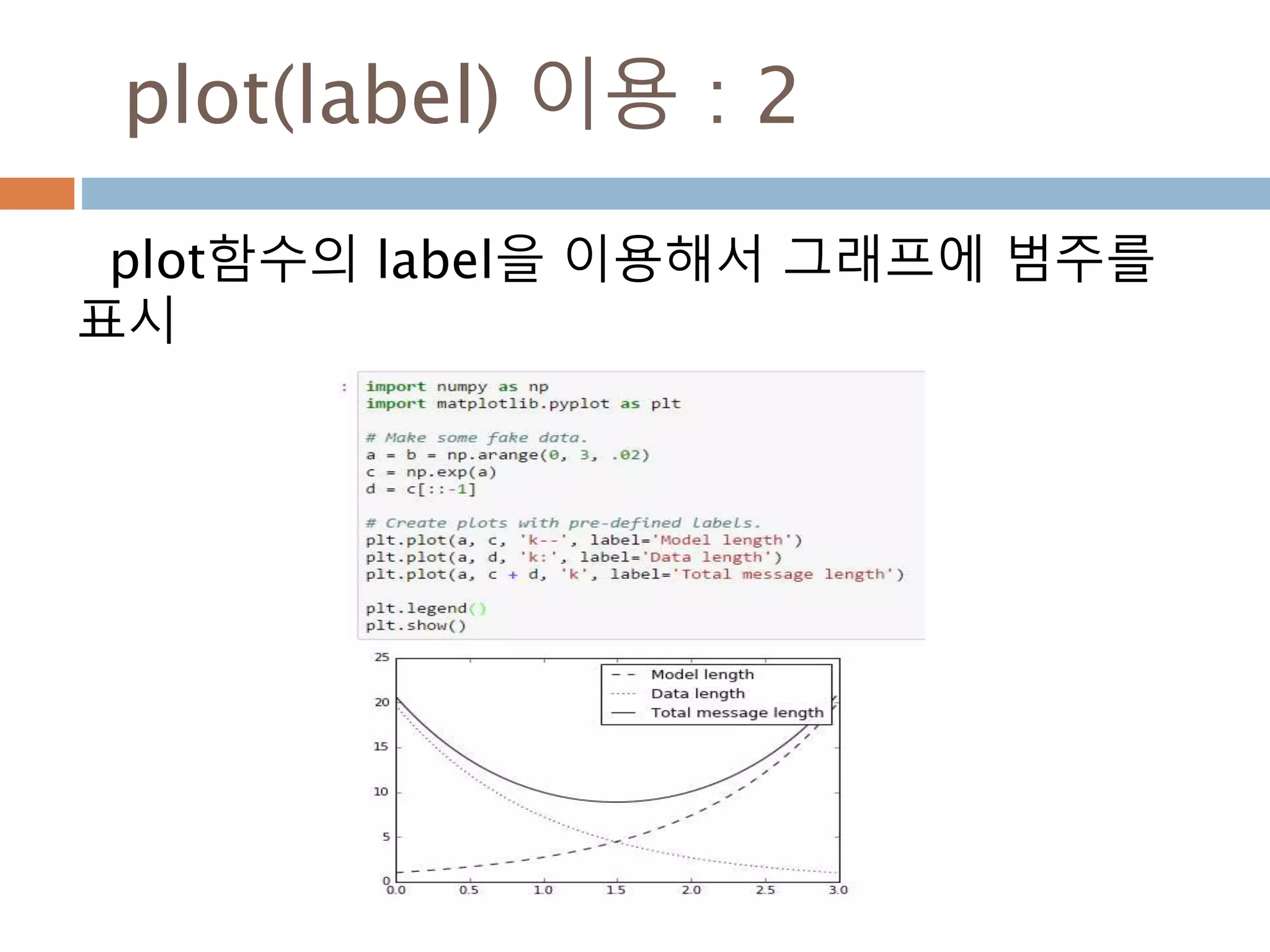






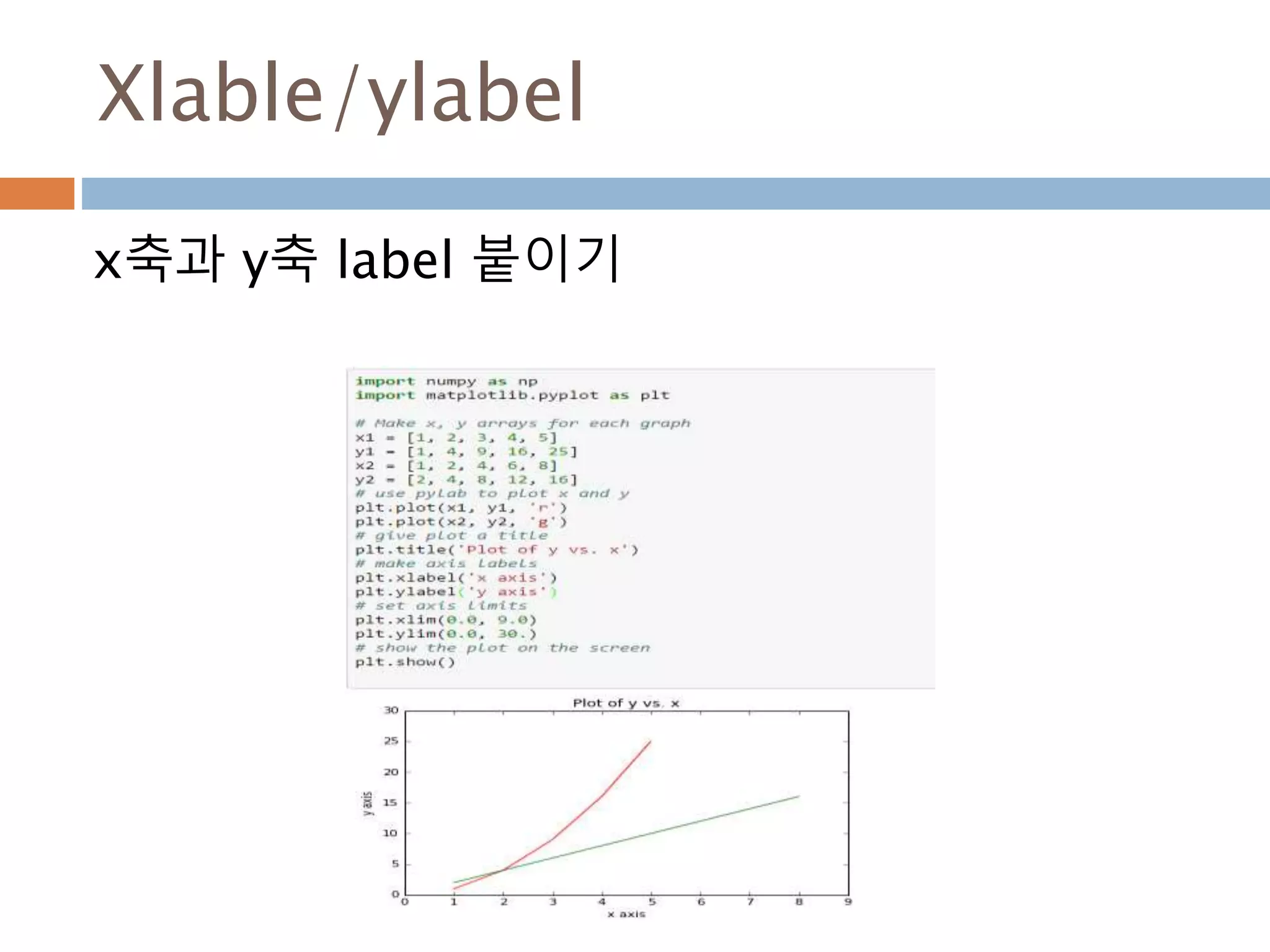









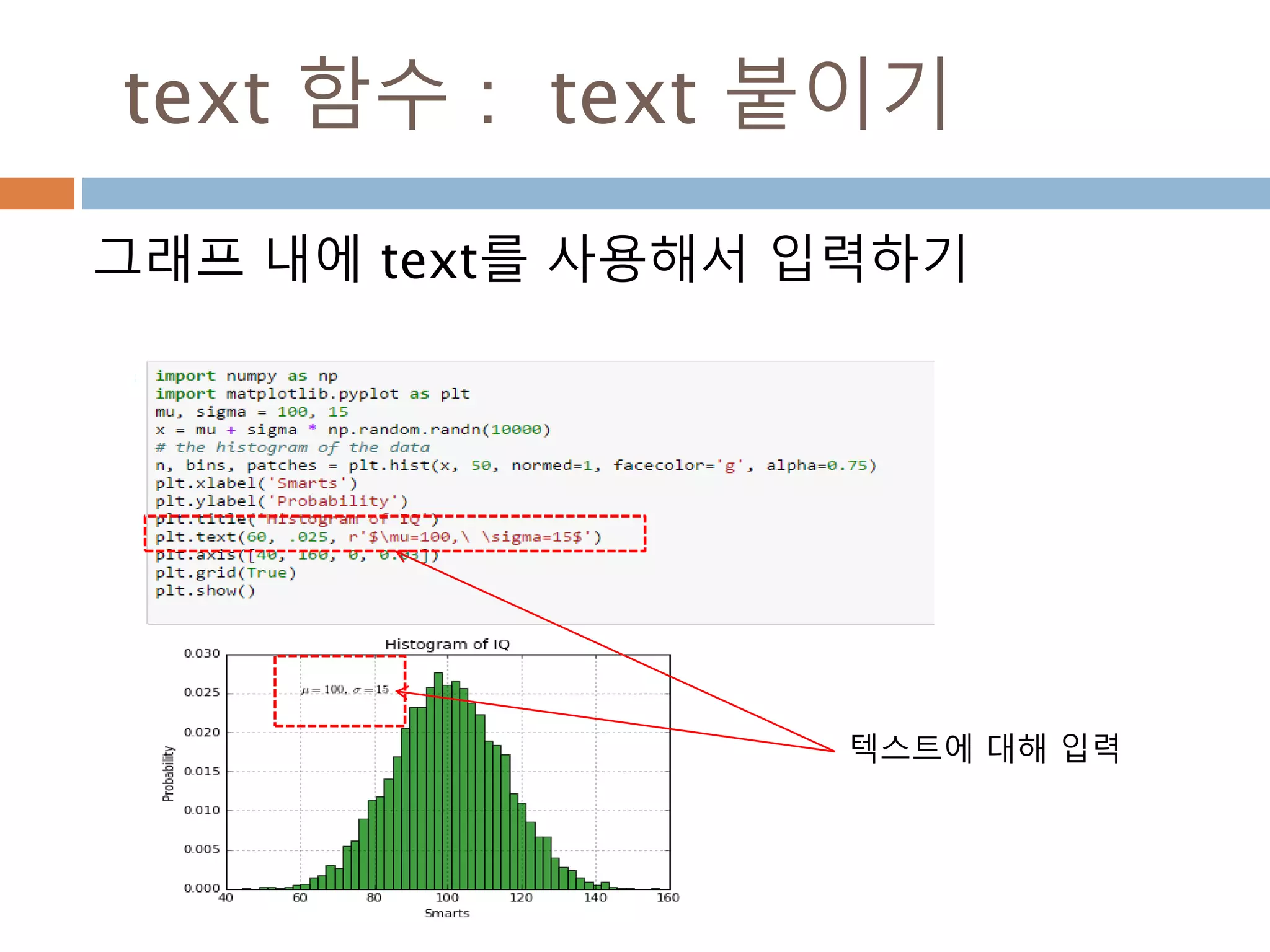

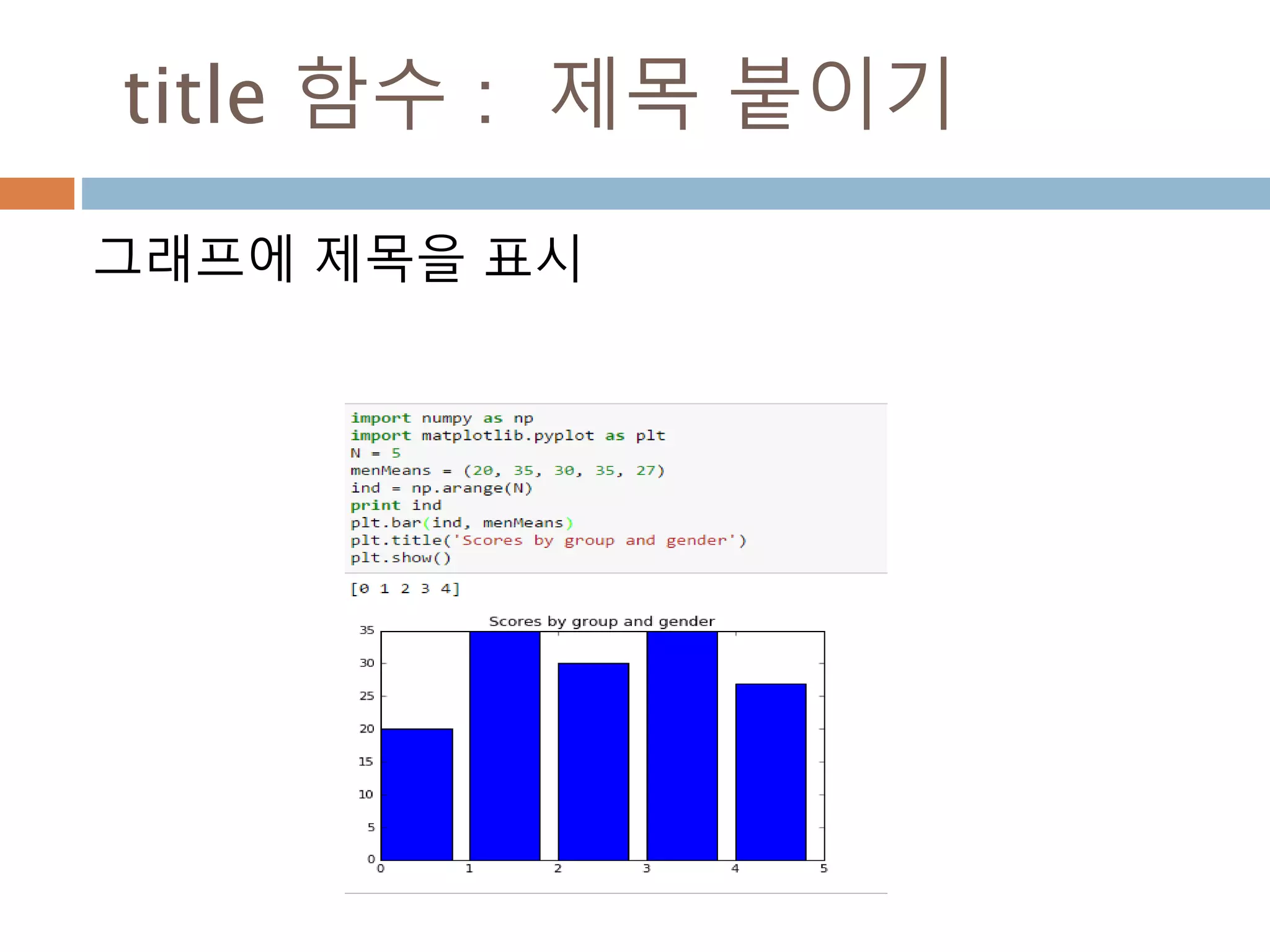

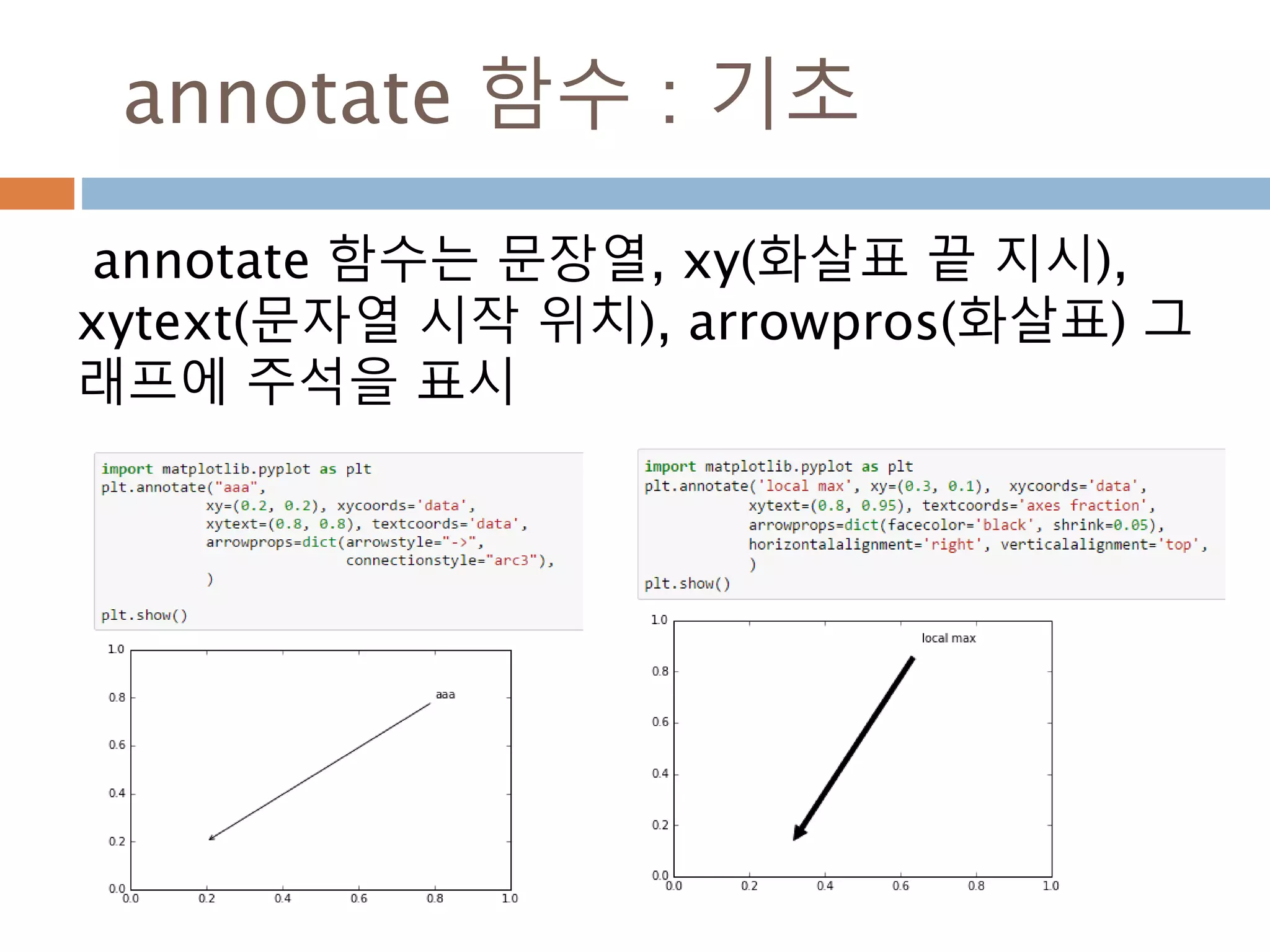
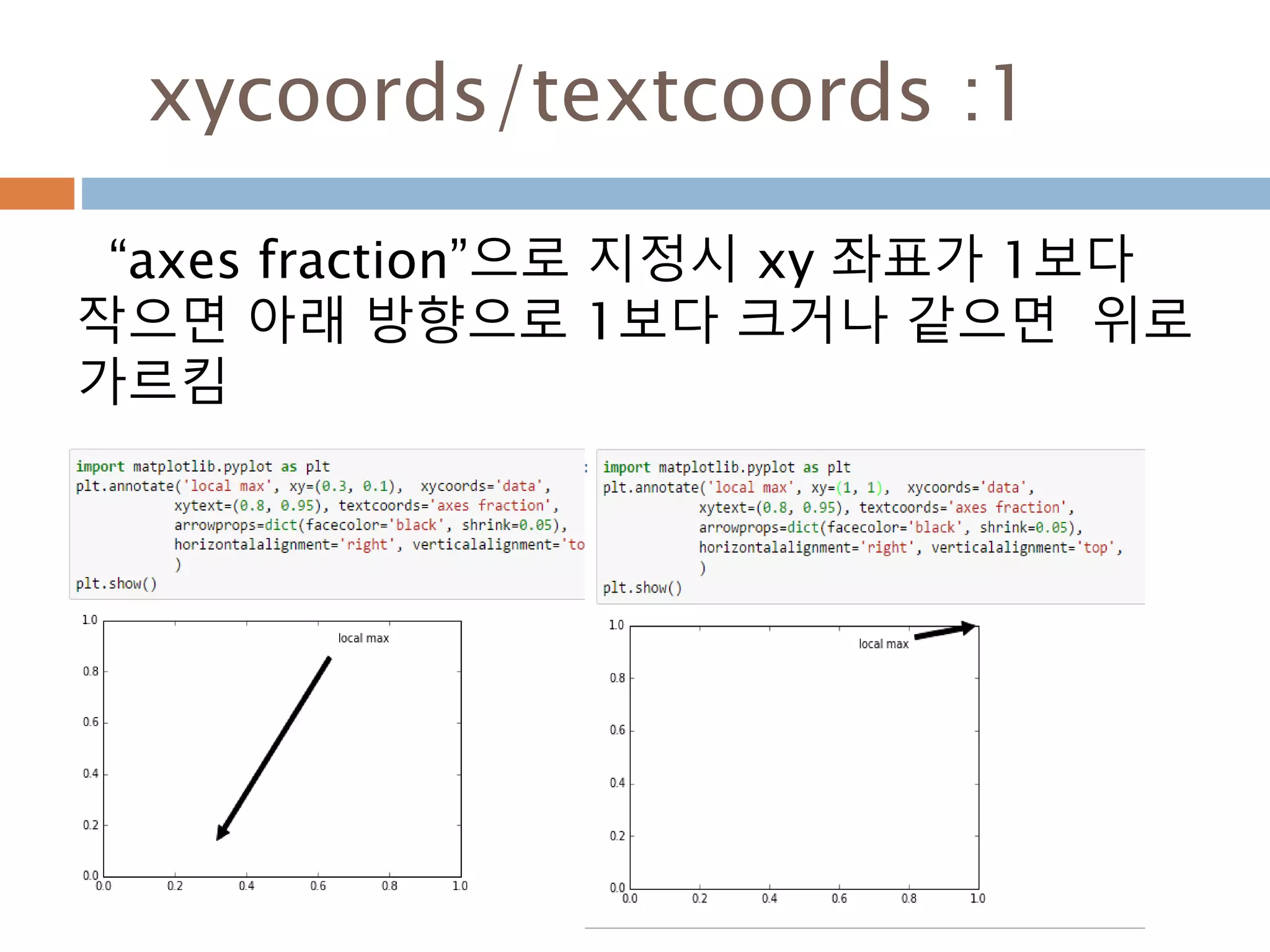
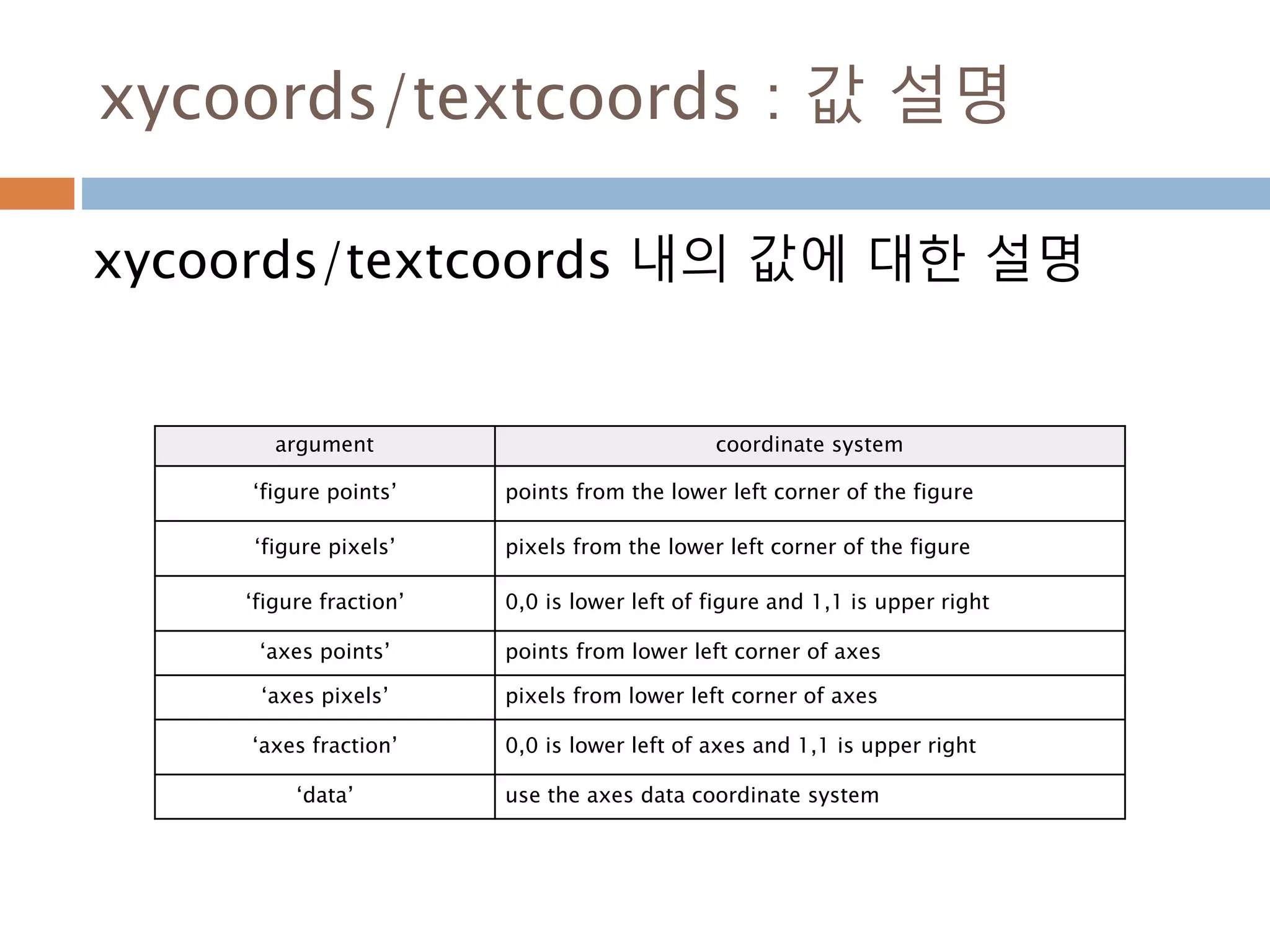
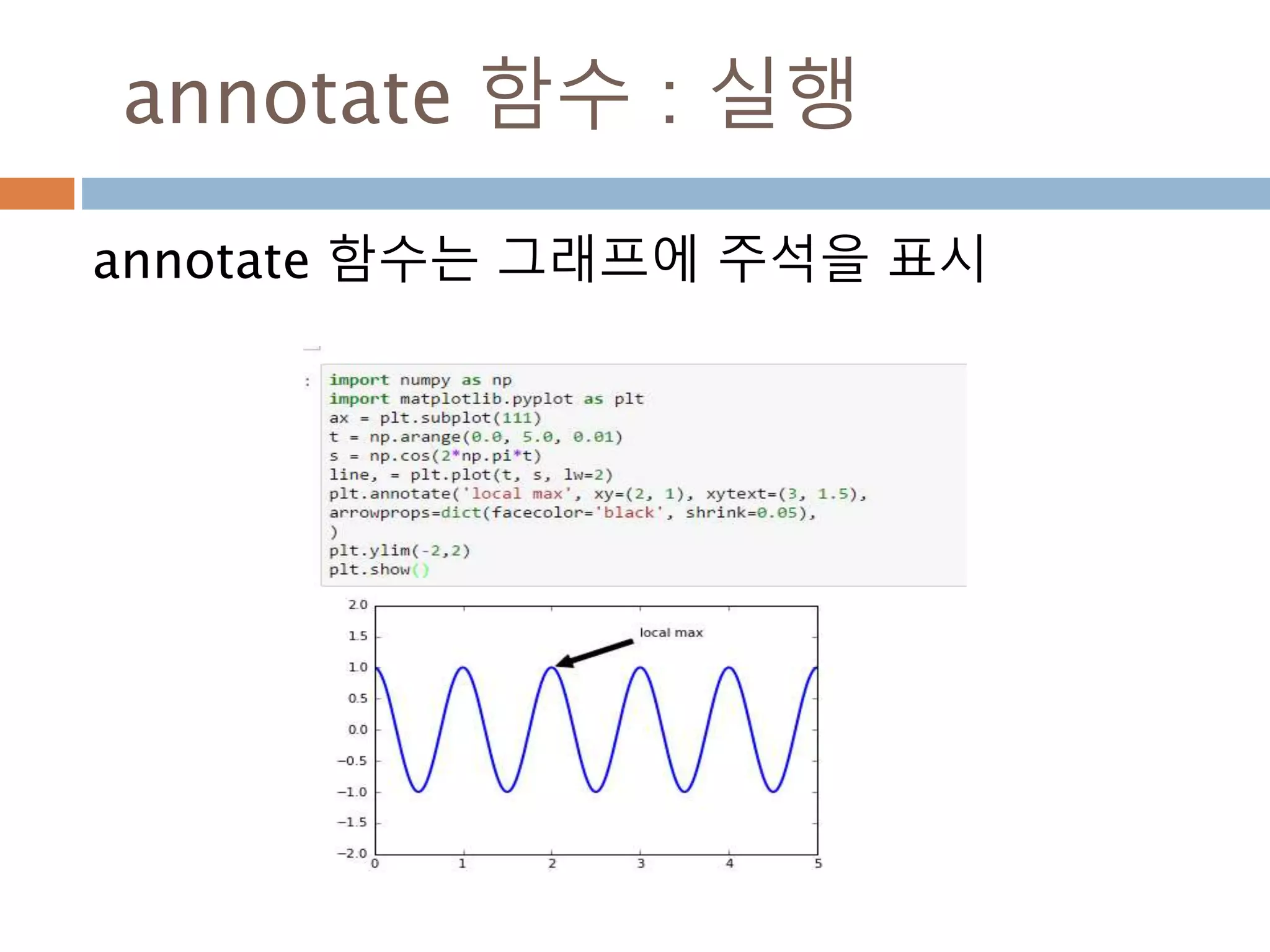
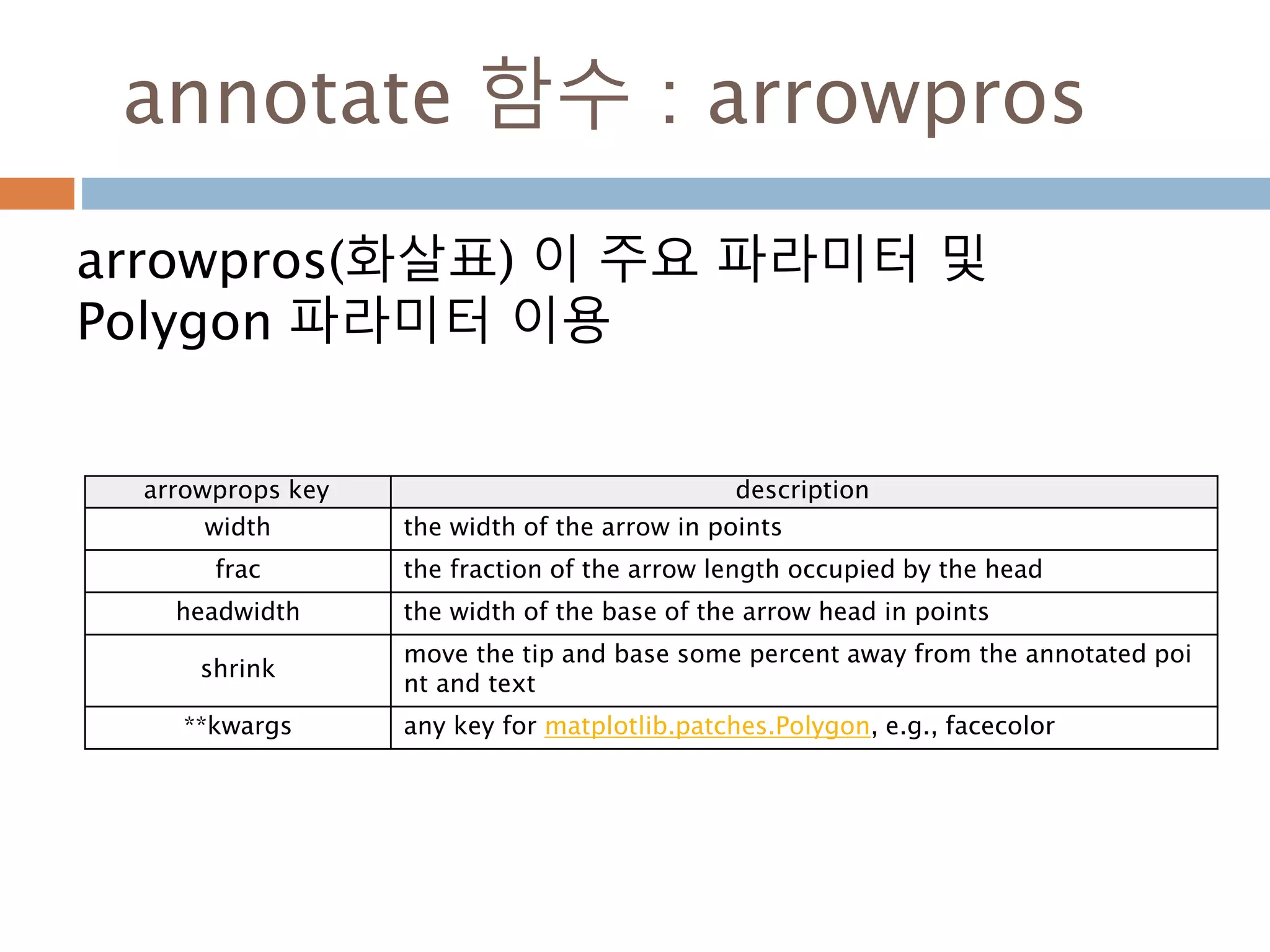
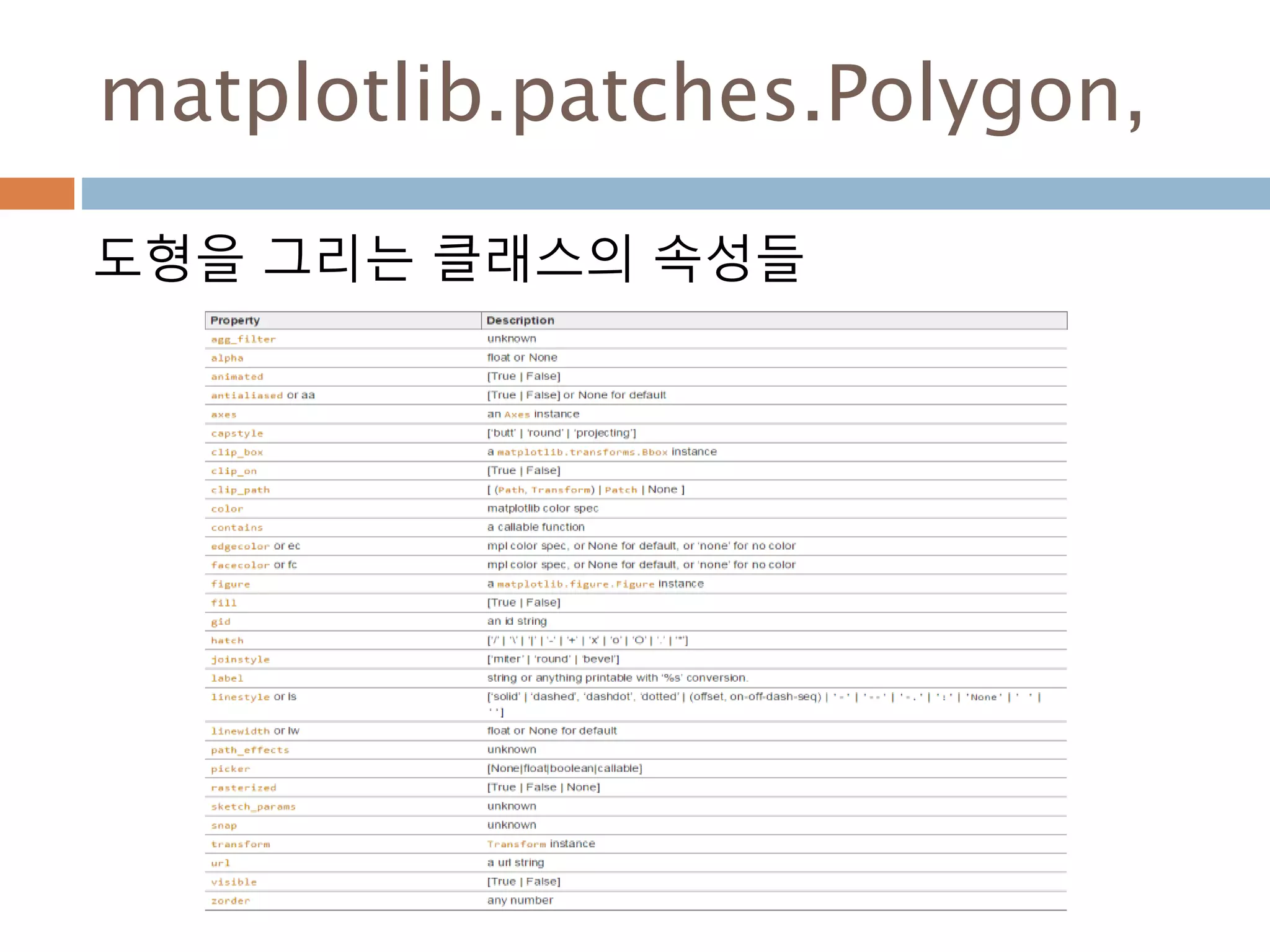


![등차급수
등차급수[ arithmetic series , 等差級數 ]
산술급수(算術級數)라고도 한다. 등차수열을 이
루고 있는 것을 말 함
급수 a1+a2+a3+…+an+…에서
an=an-1+d(n=2,3,…) 인 관계식
급수로 표시
546](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-546-2048.jpg)




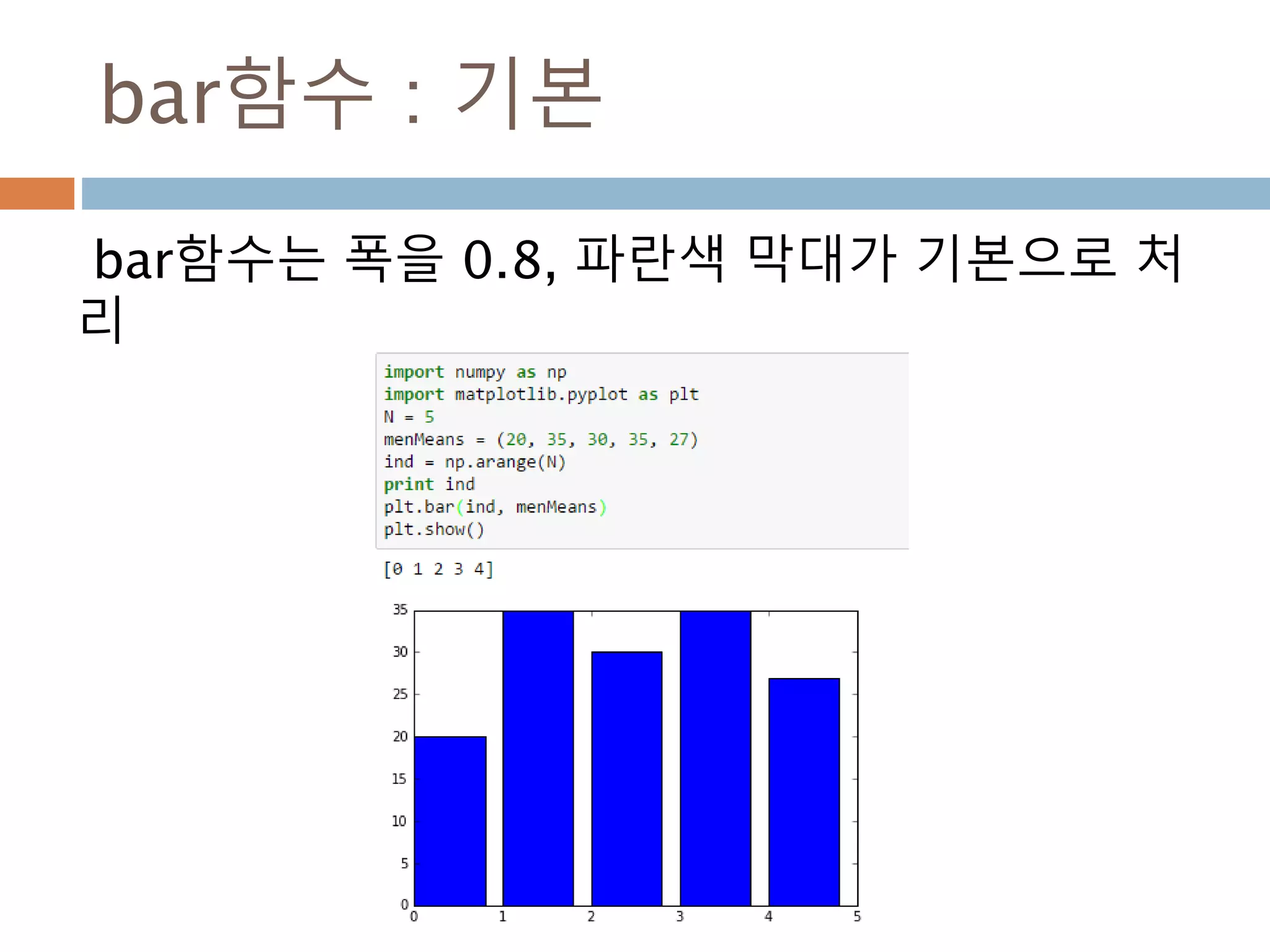
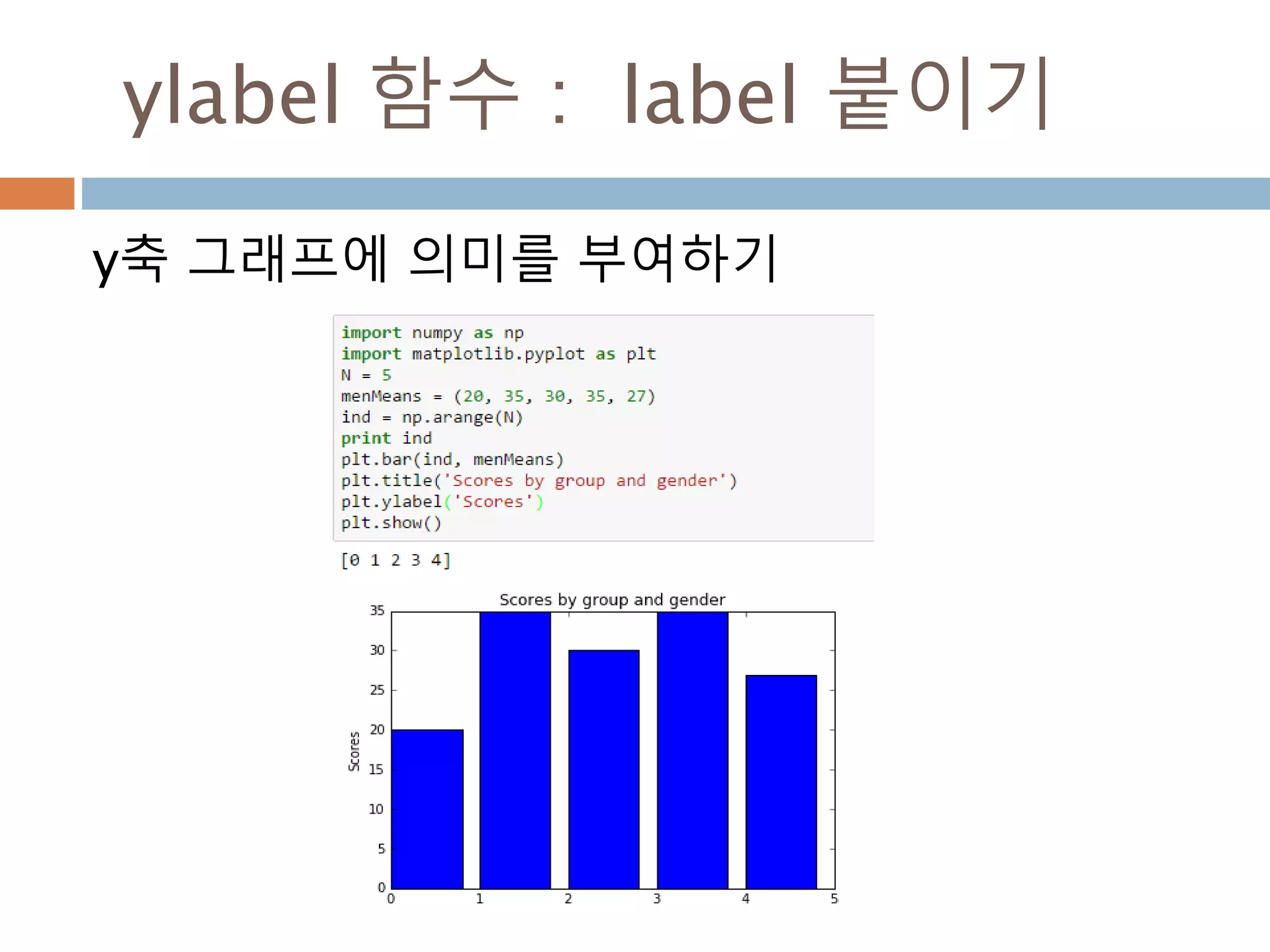
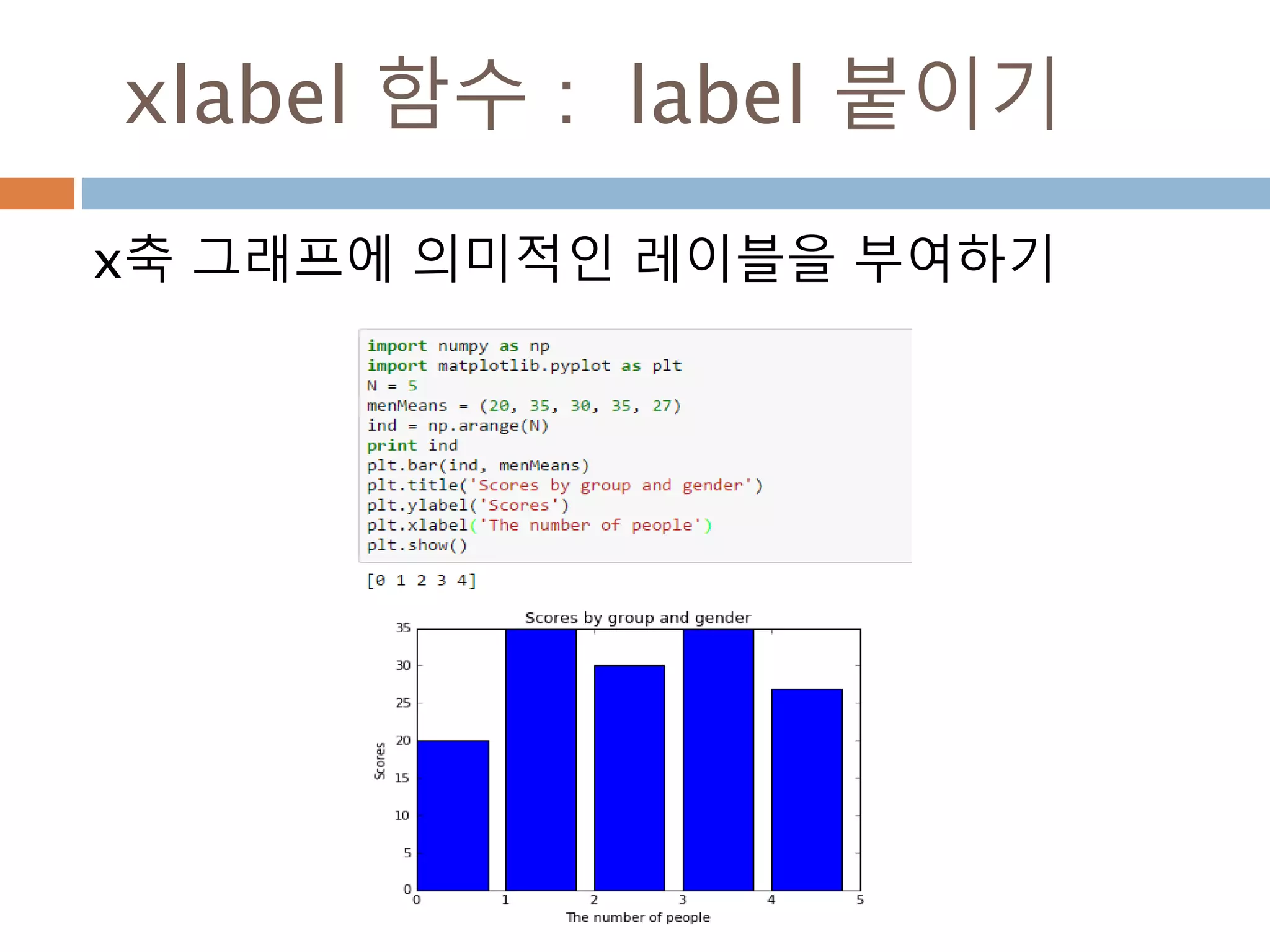

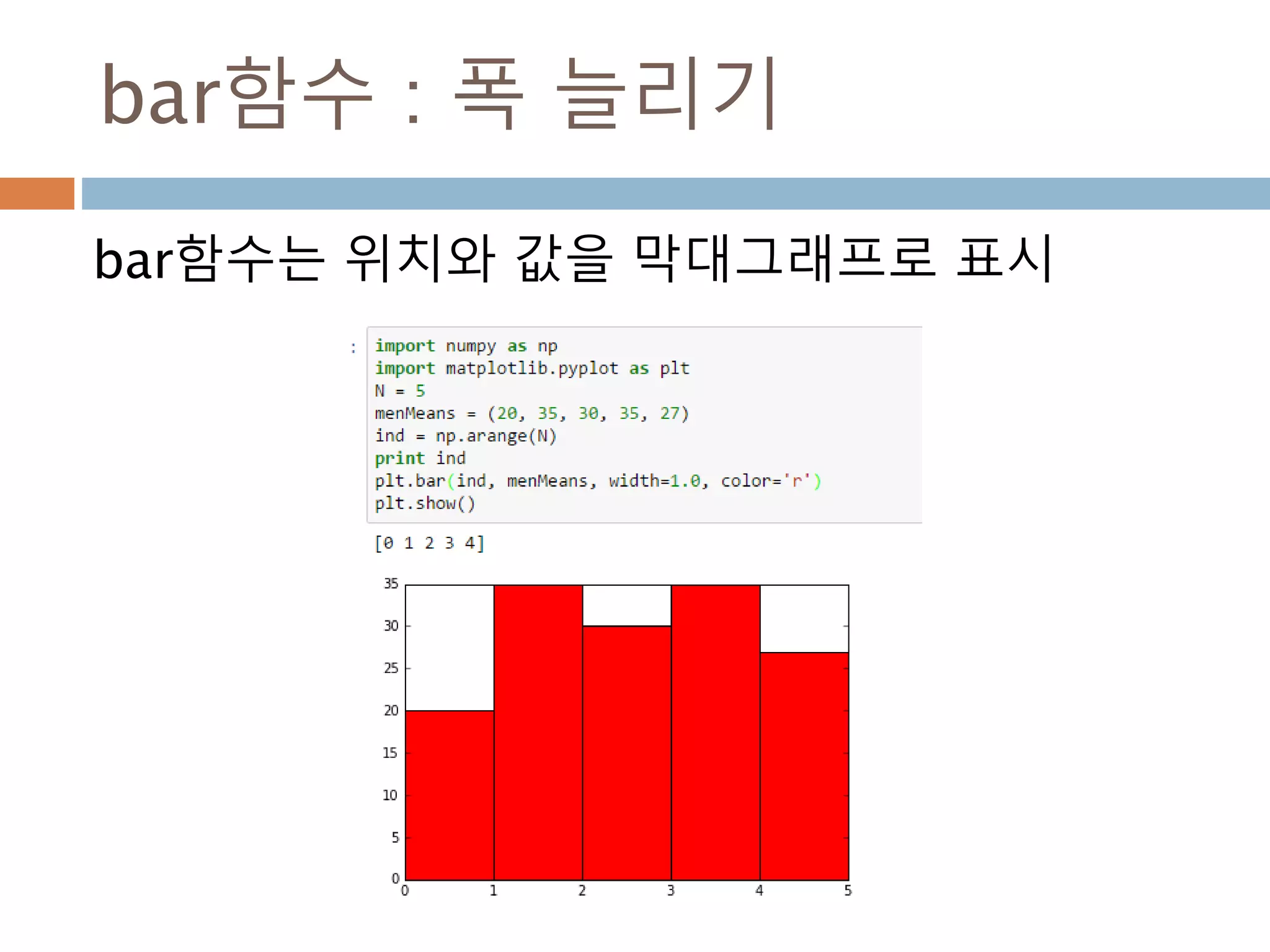
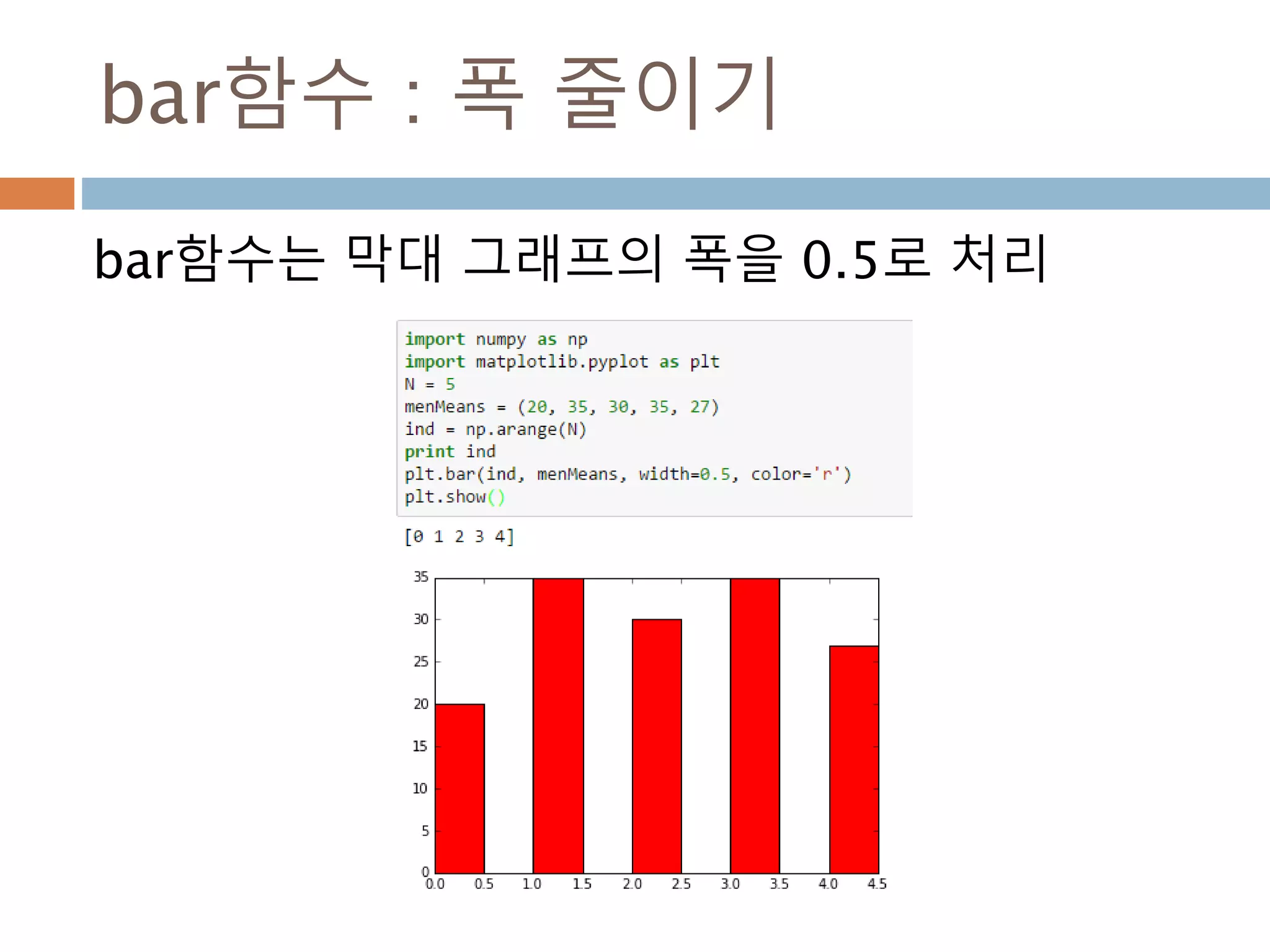

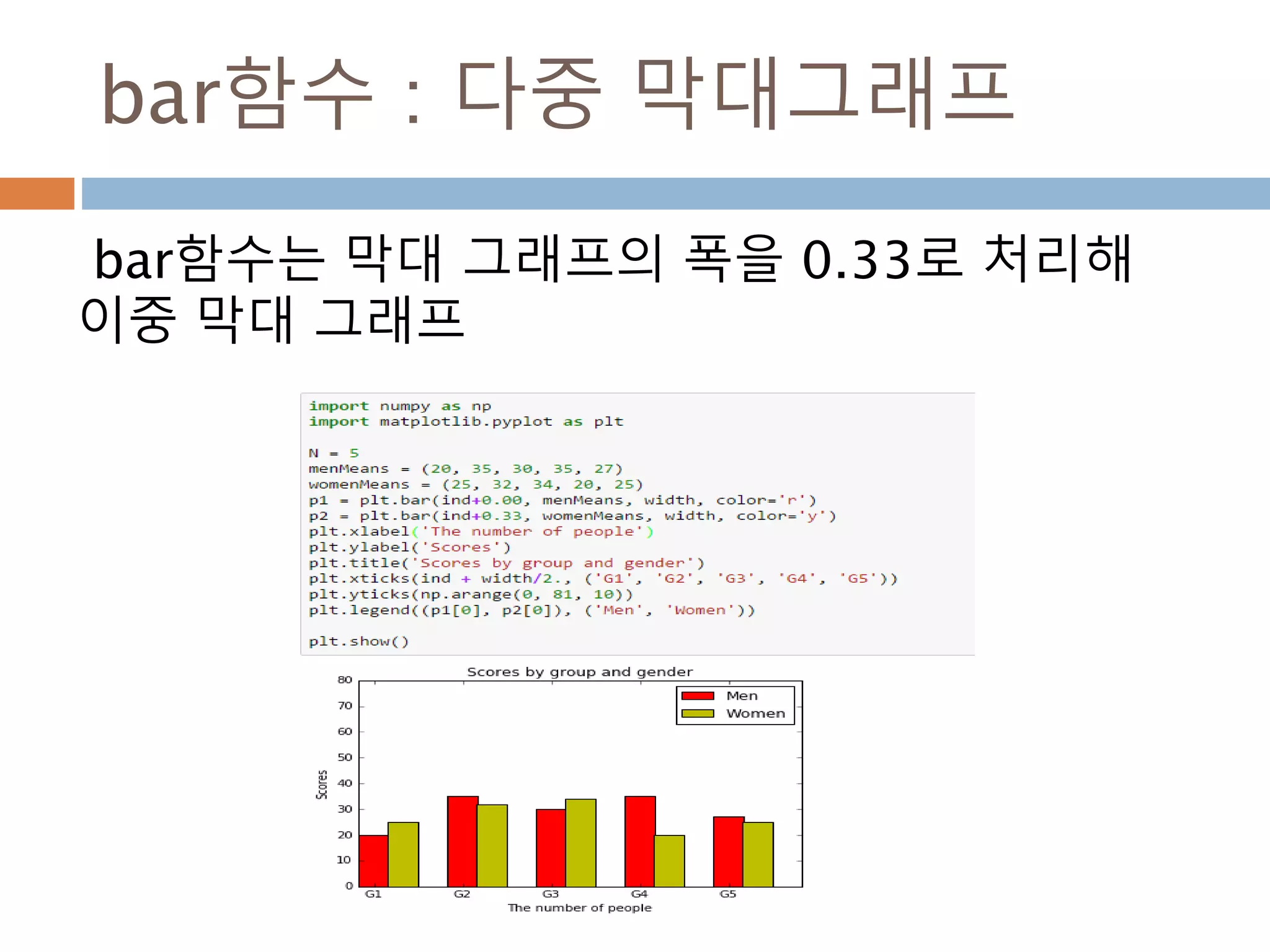


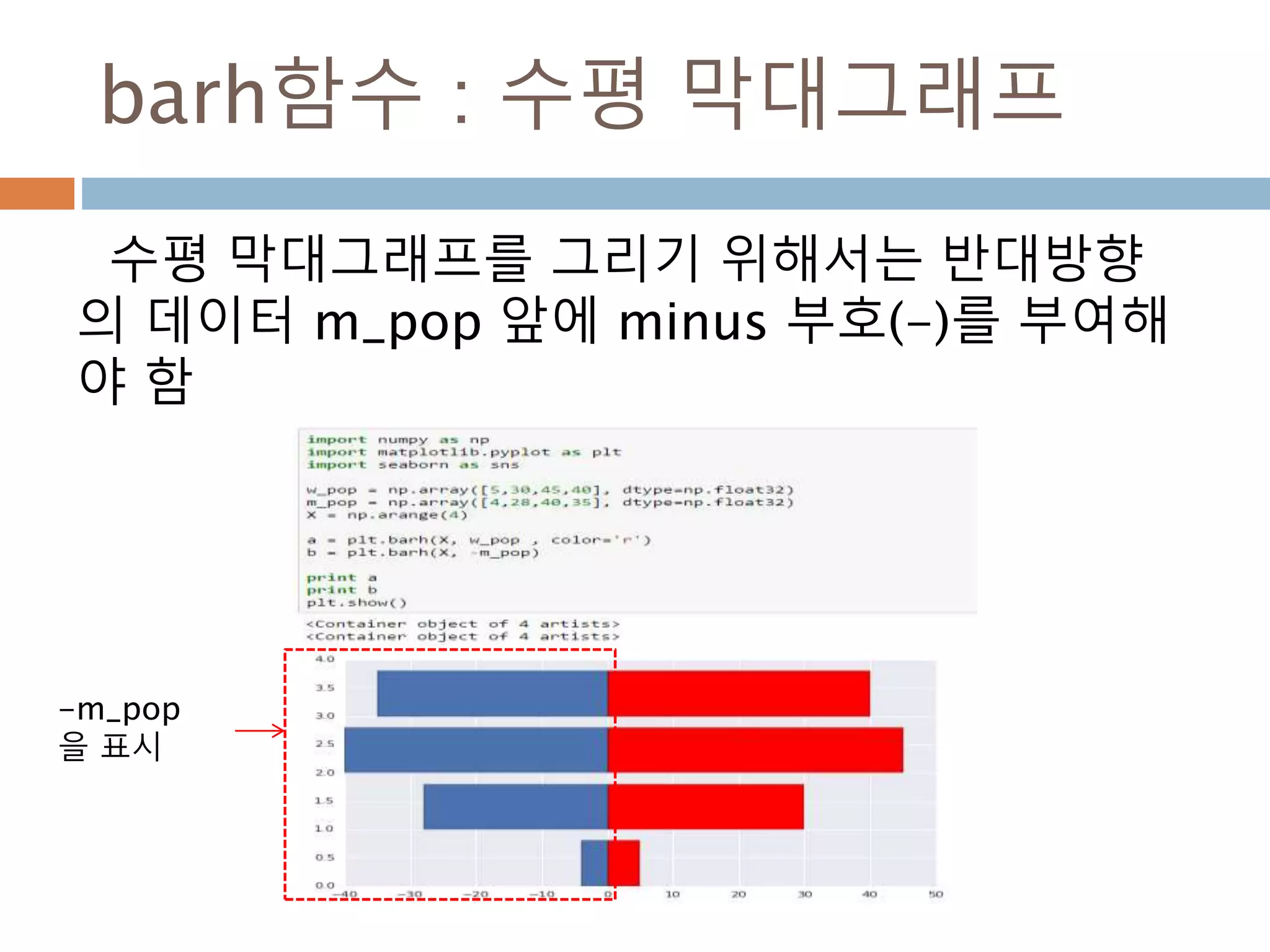






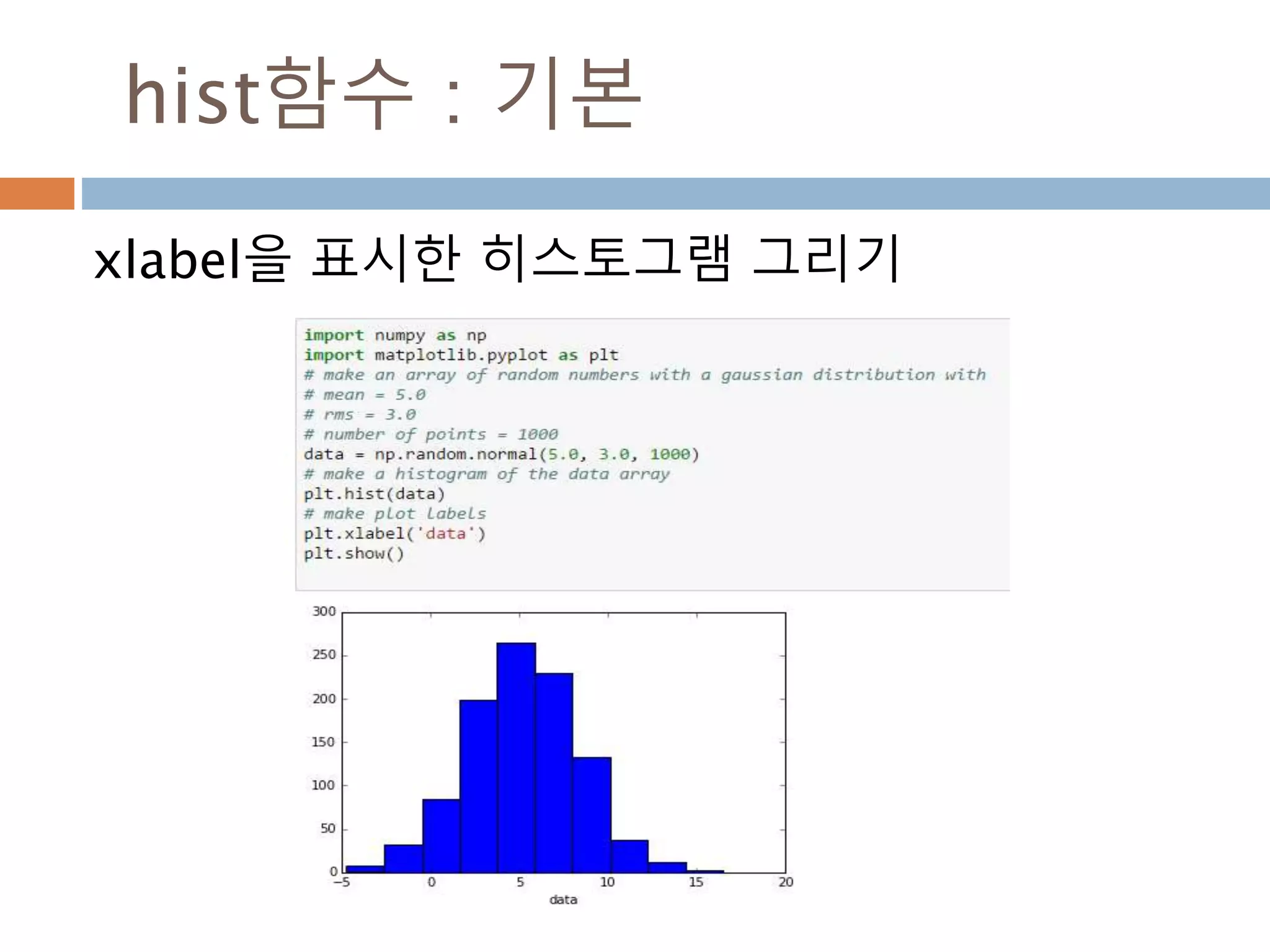

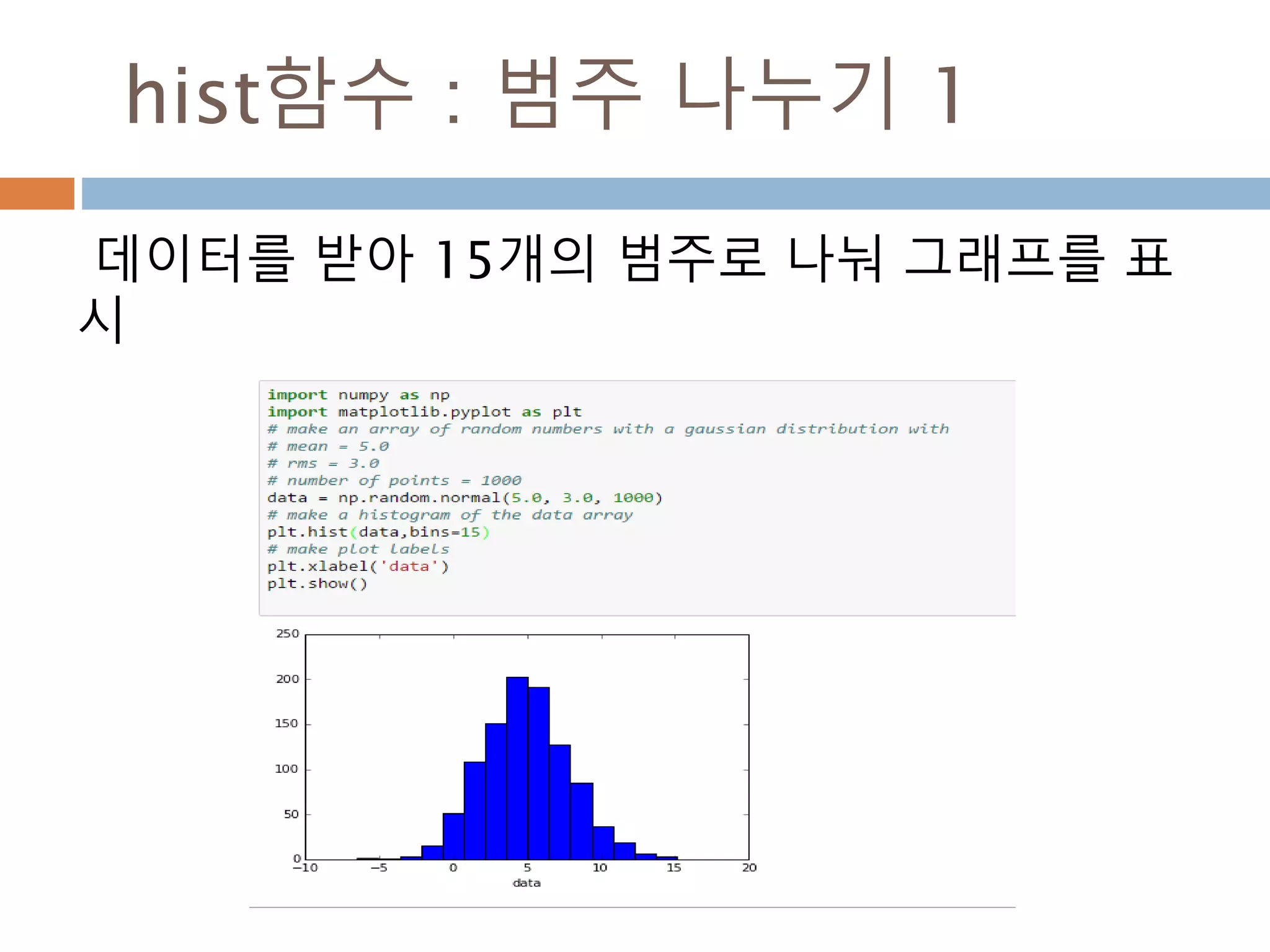
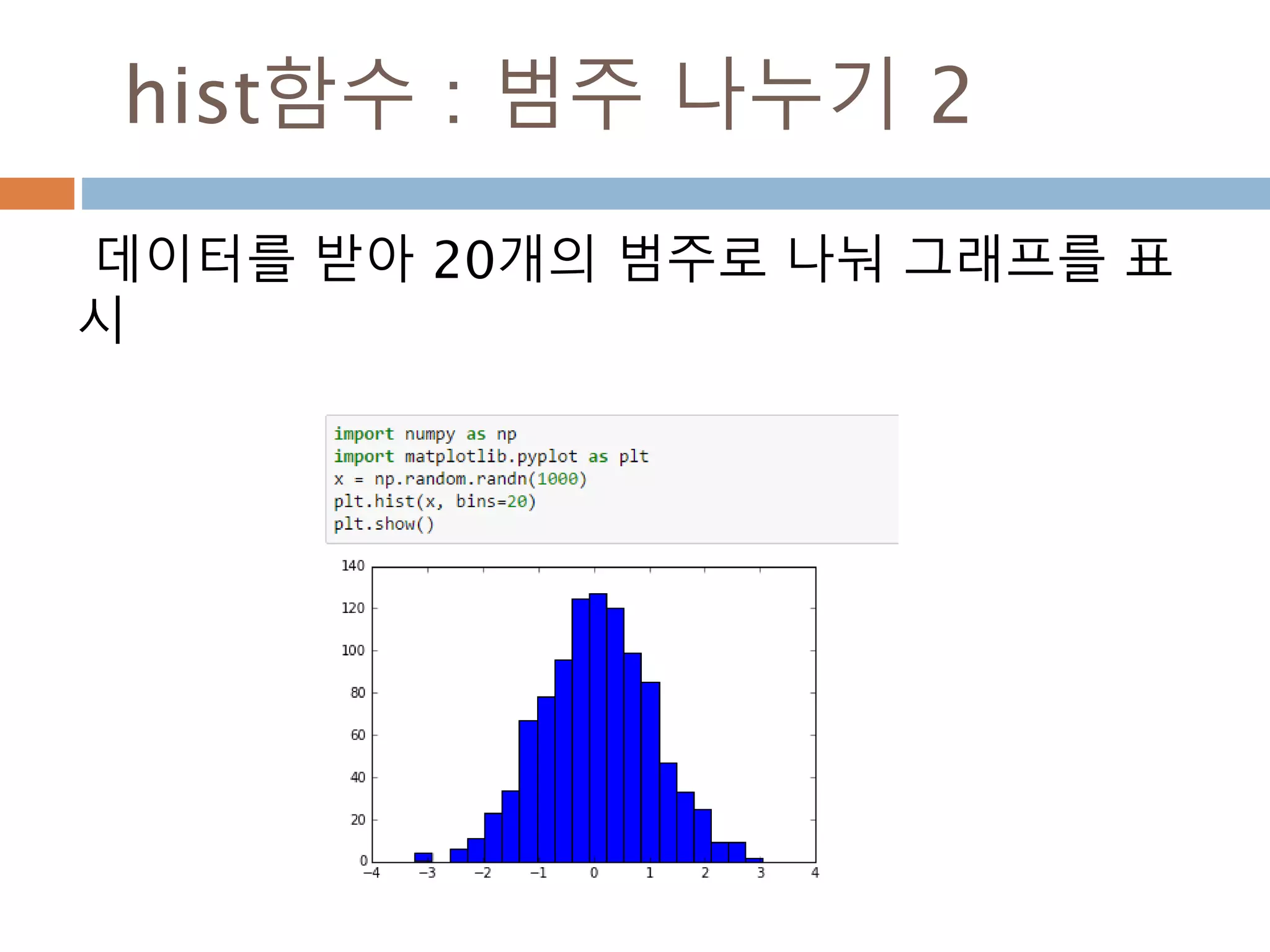

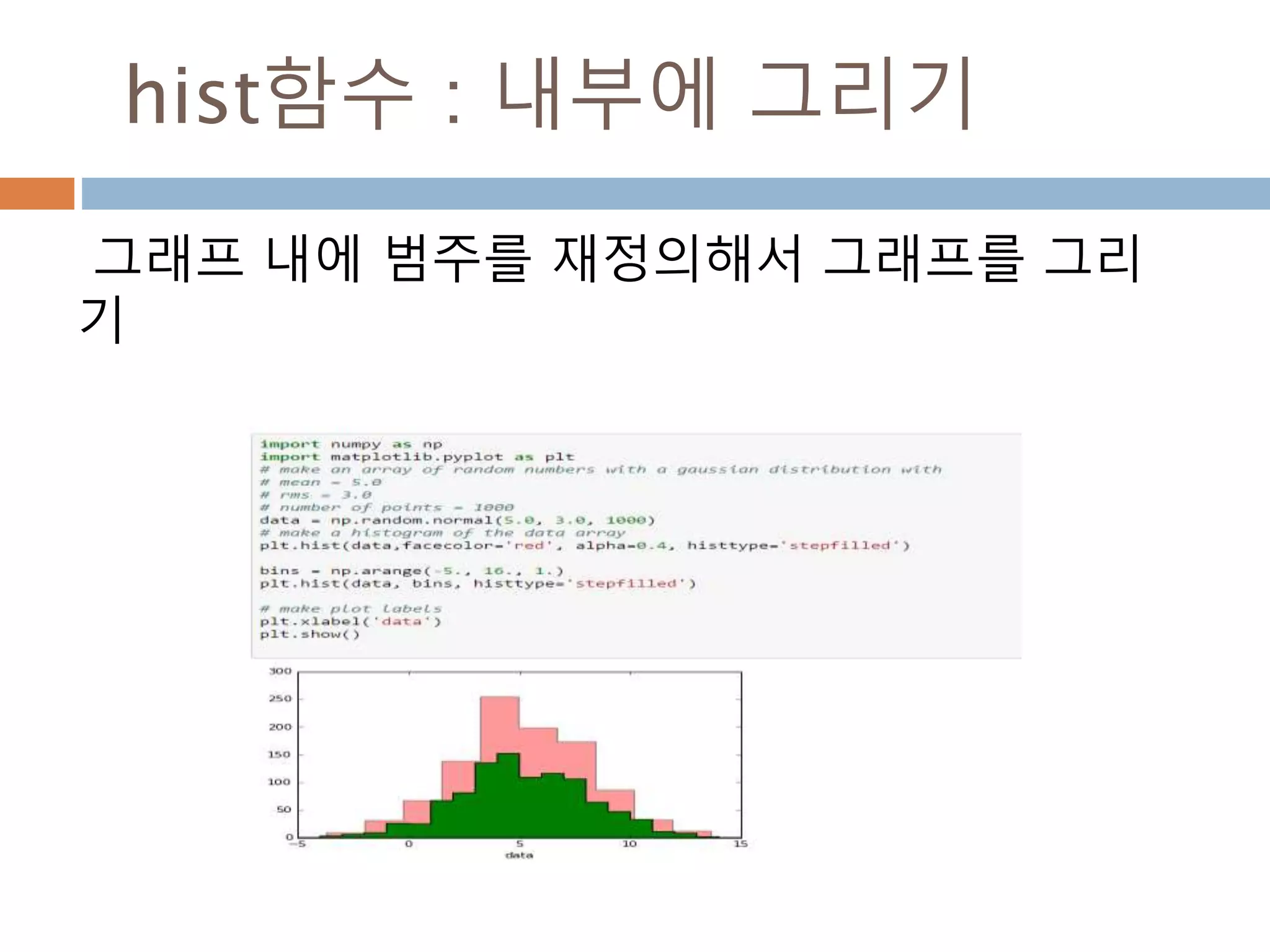

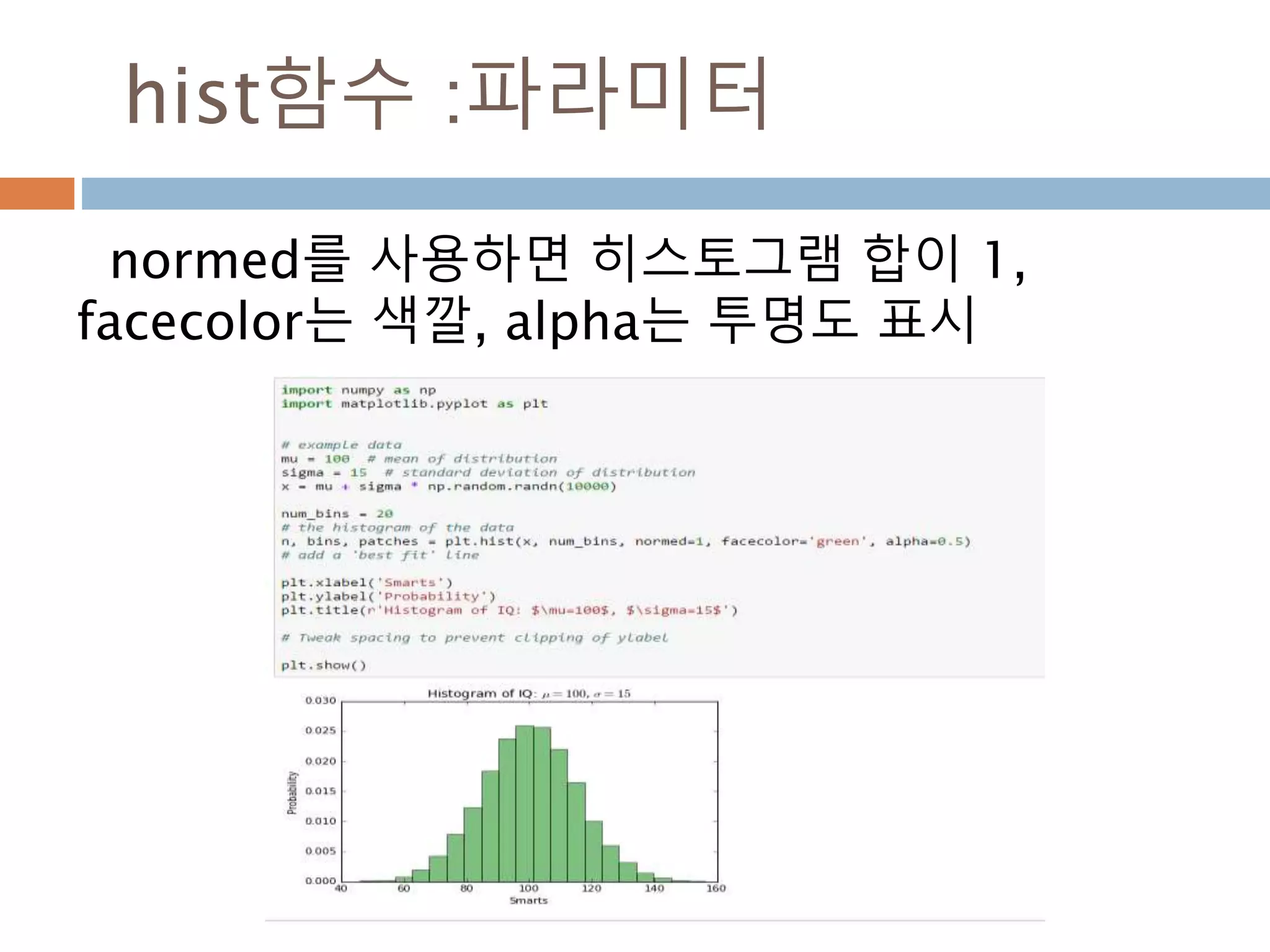
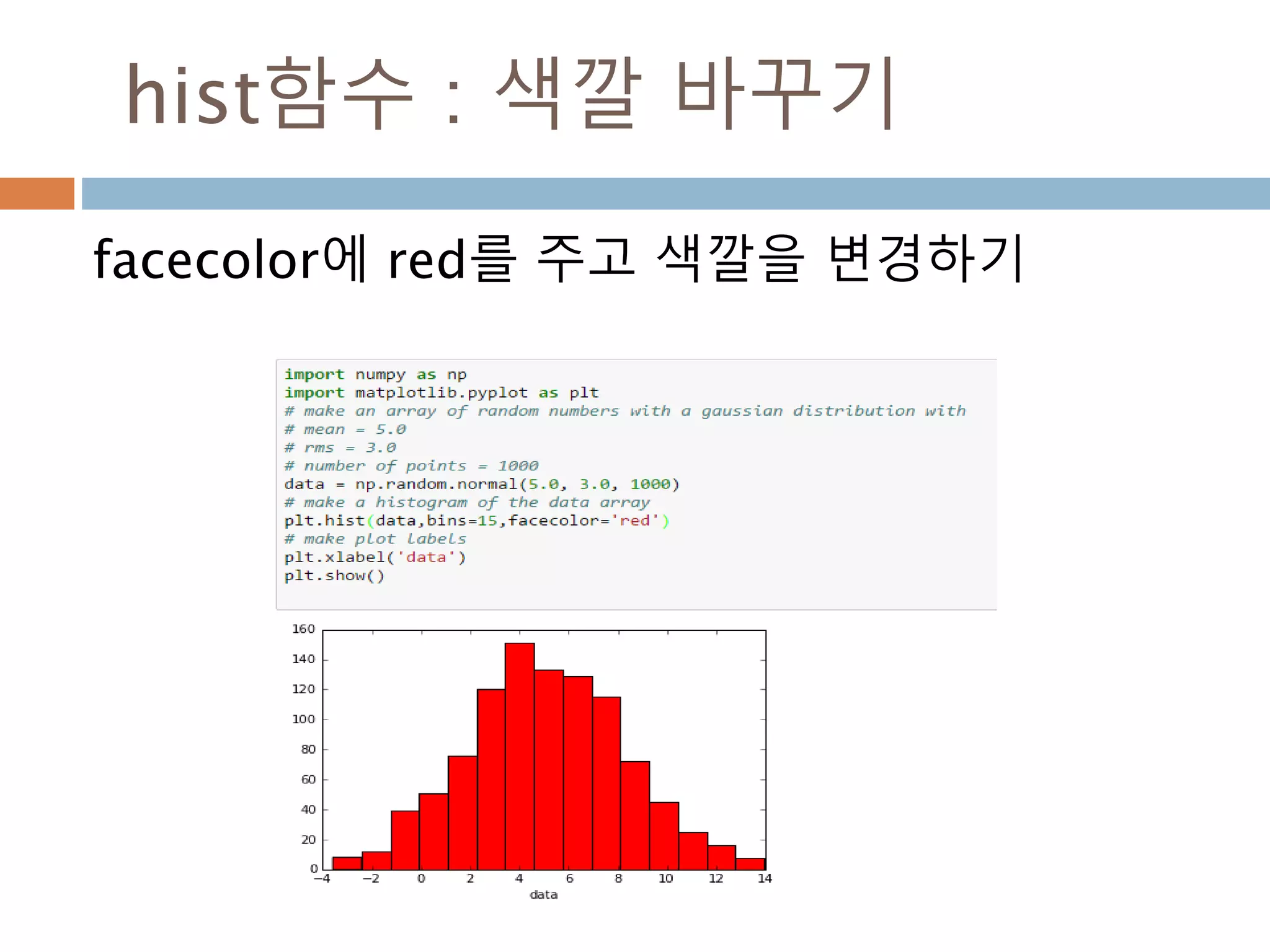
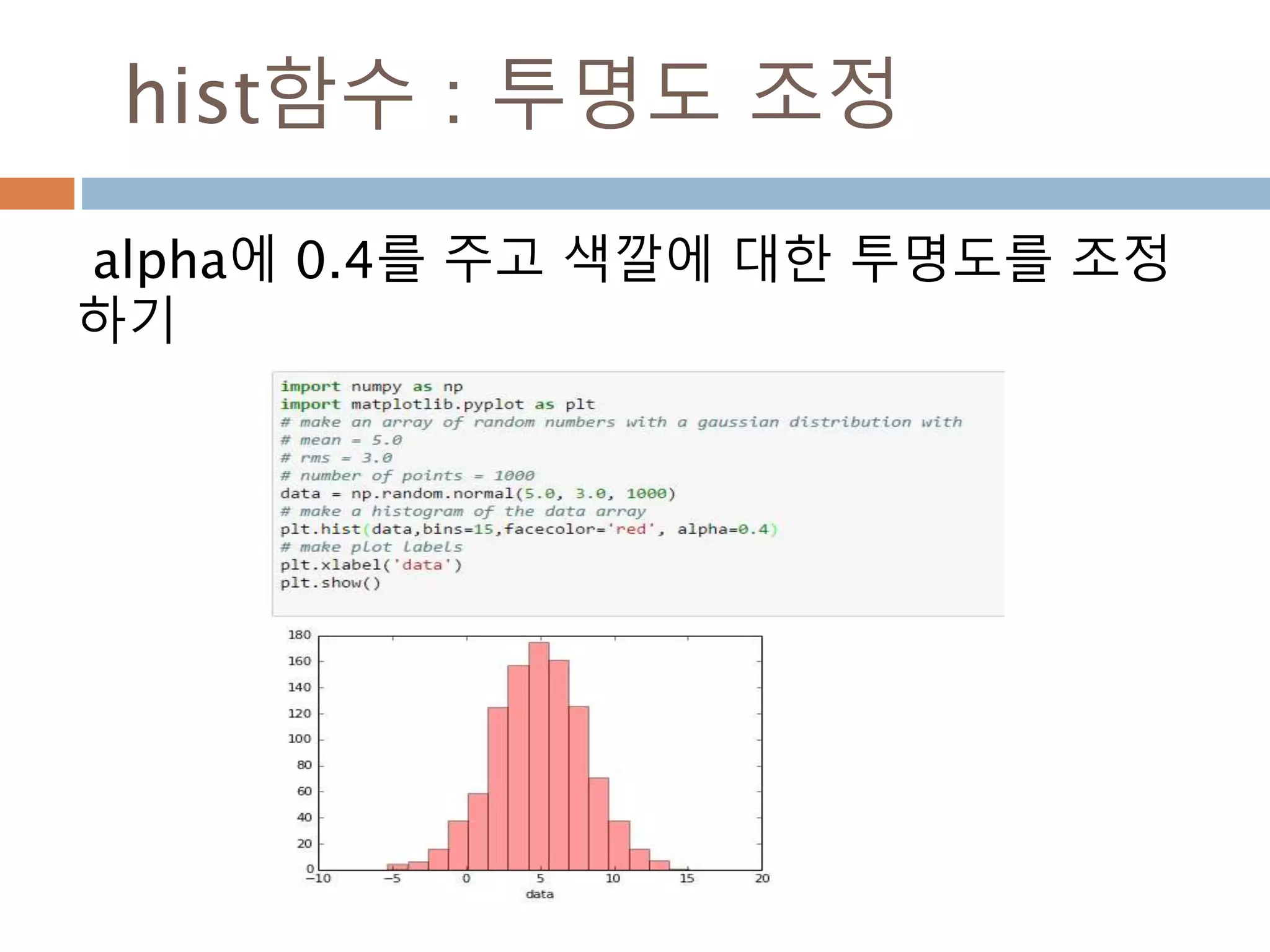
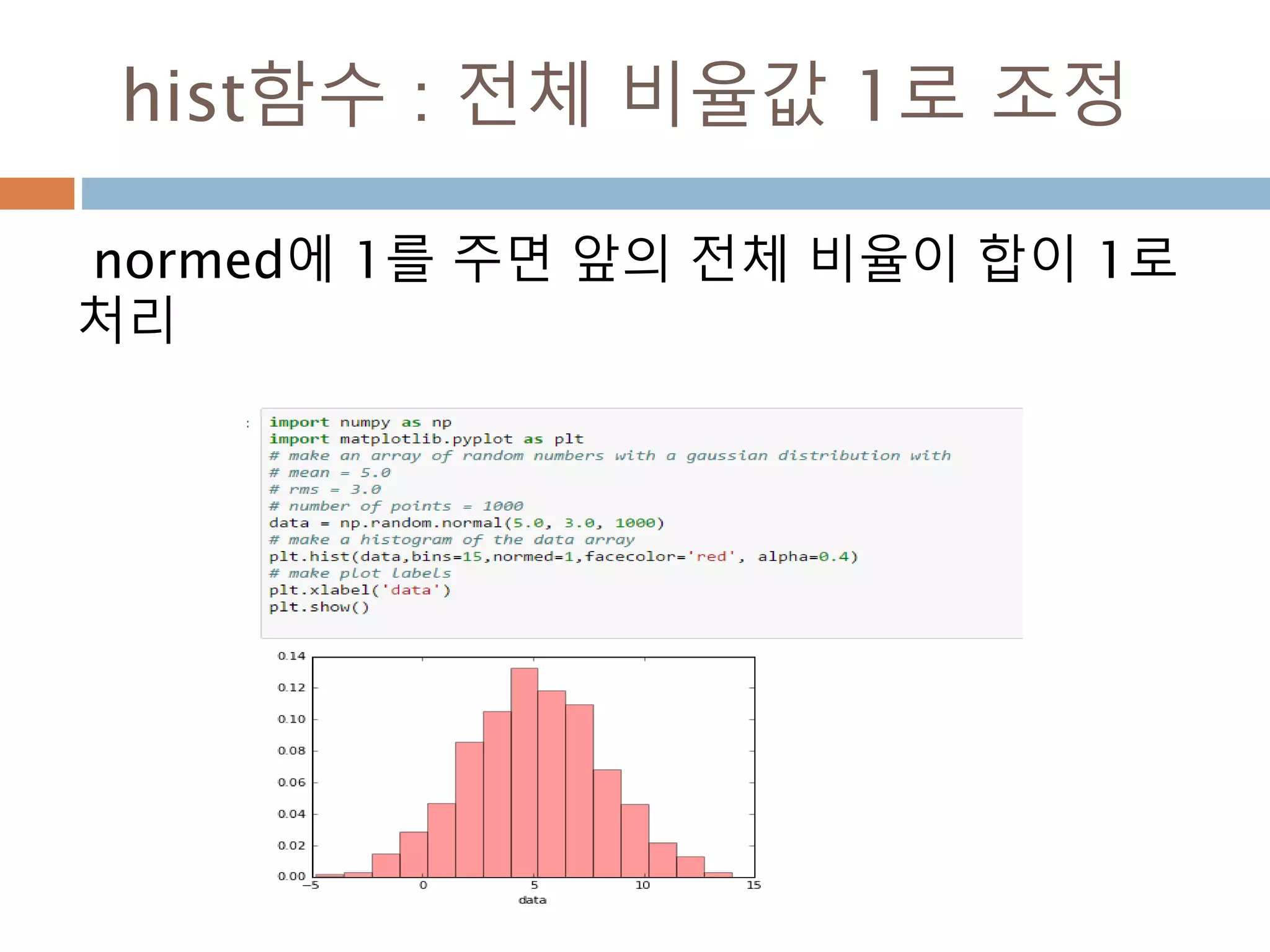
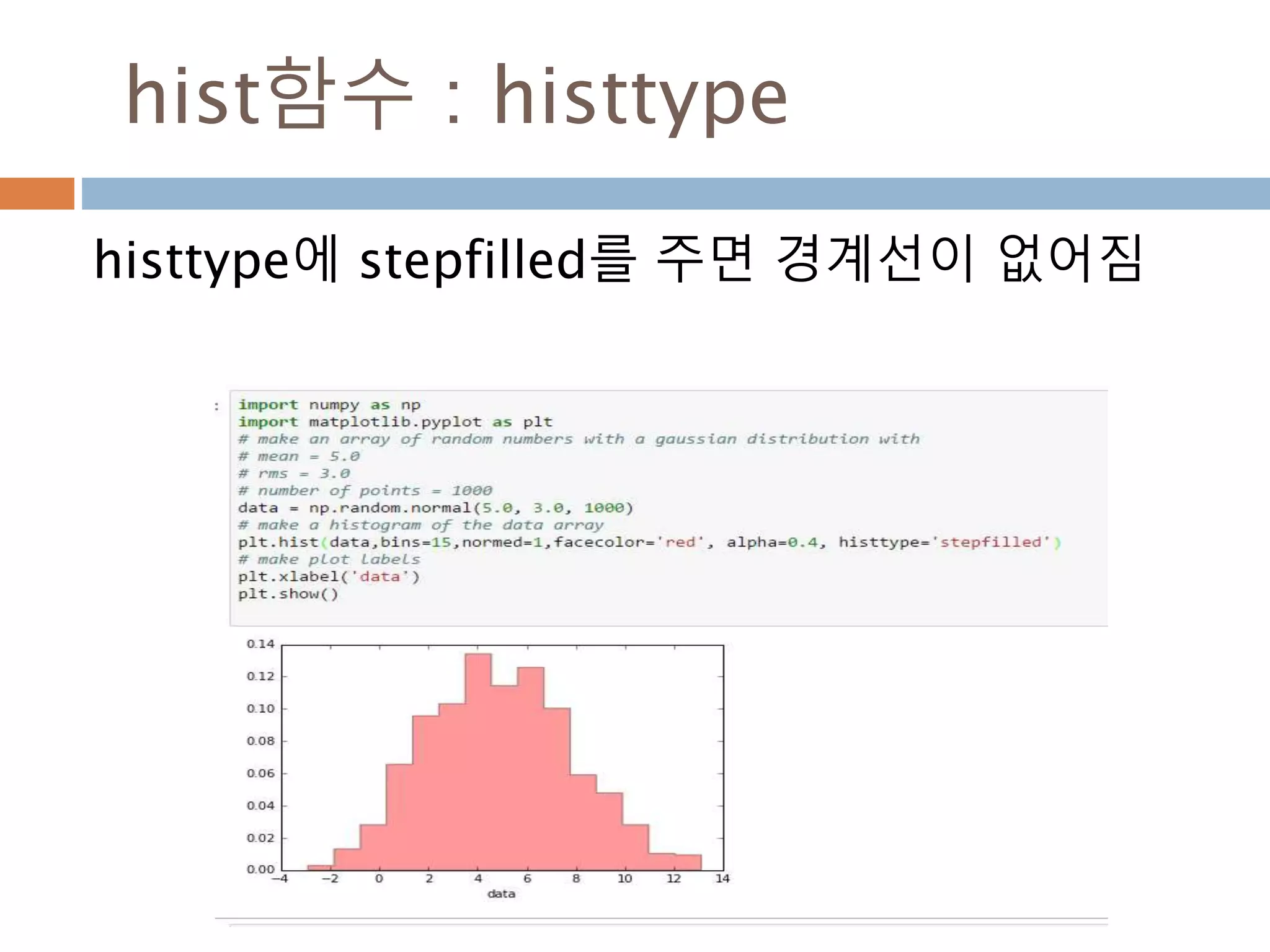

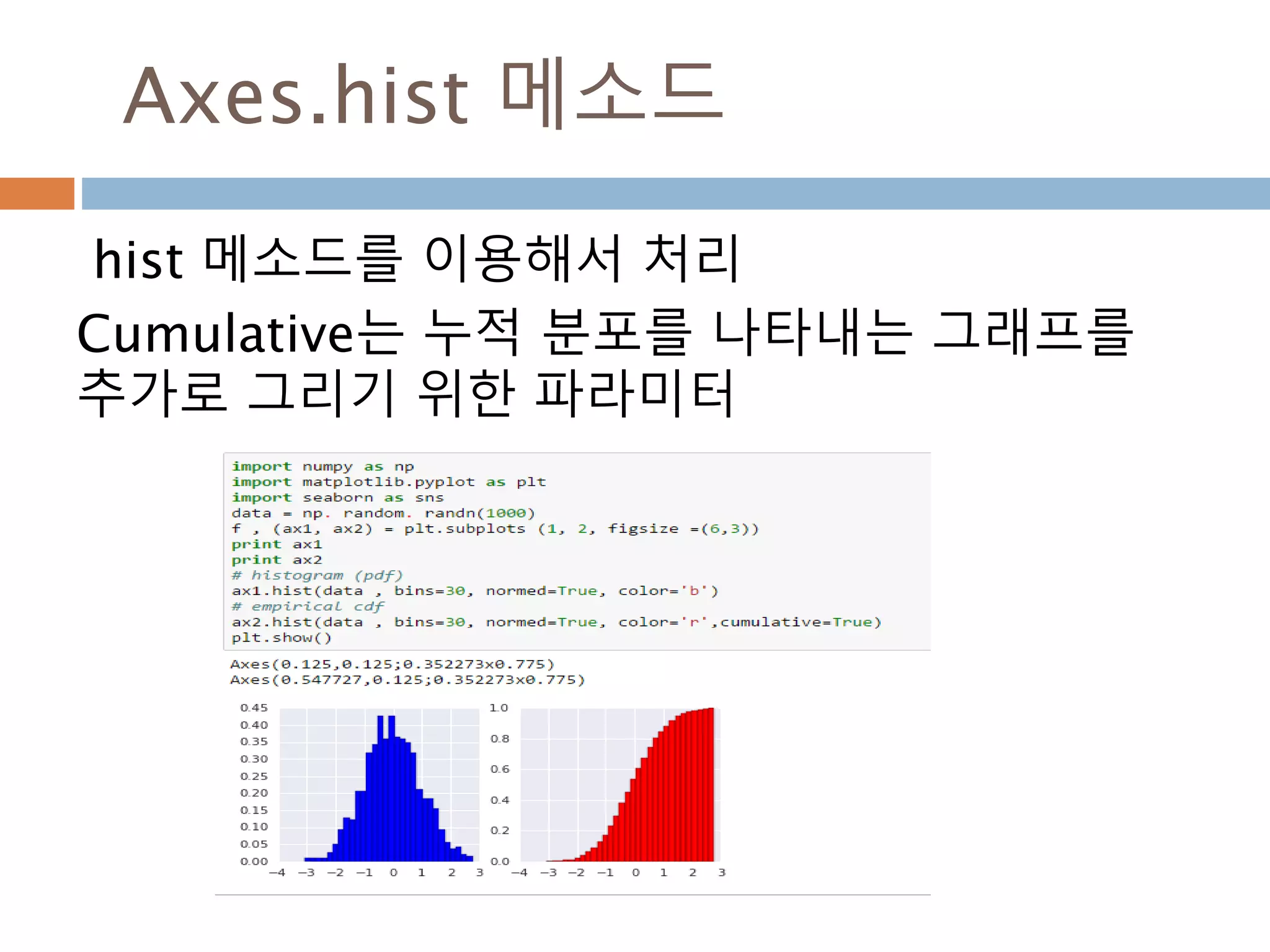



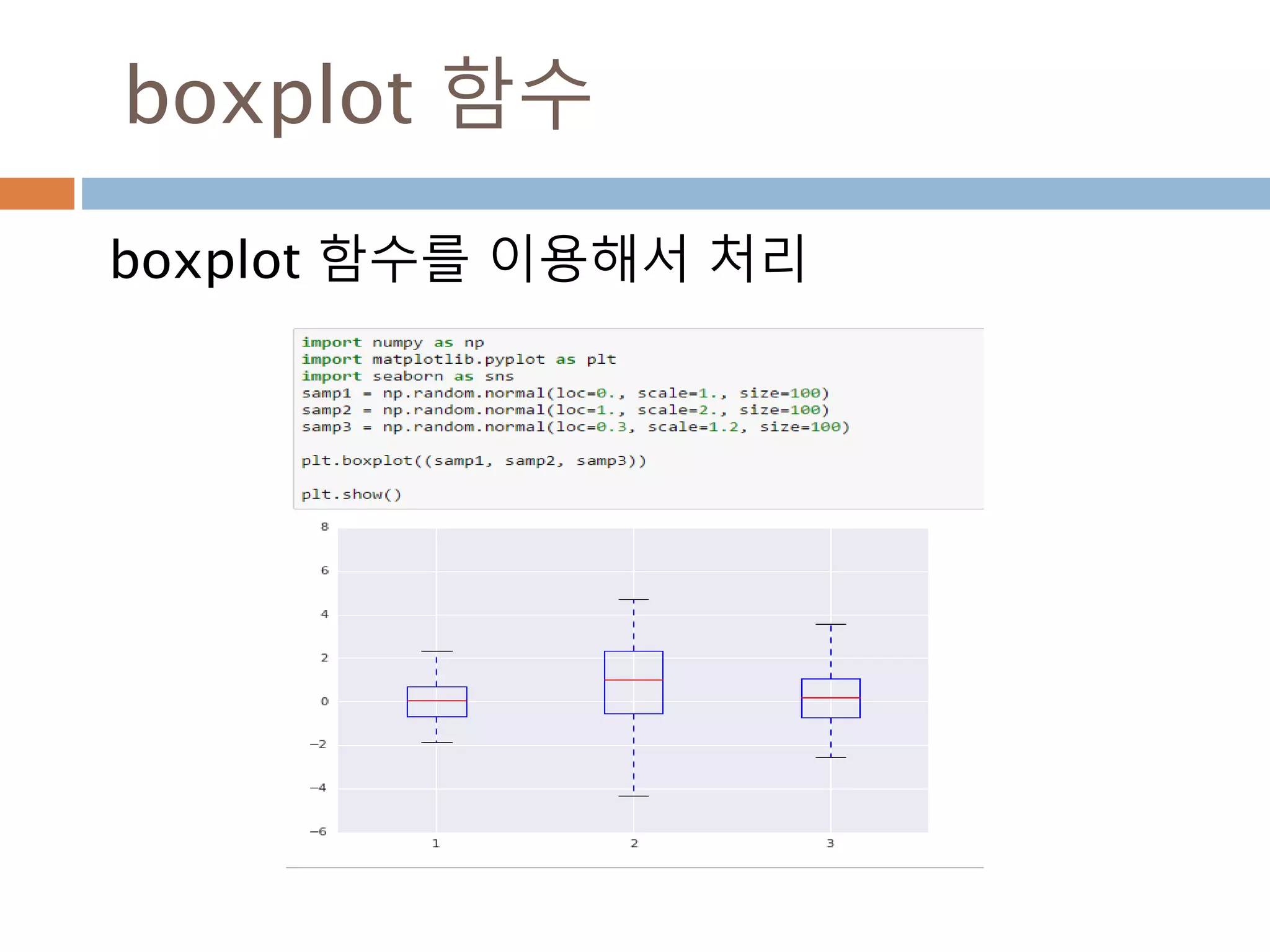









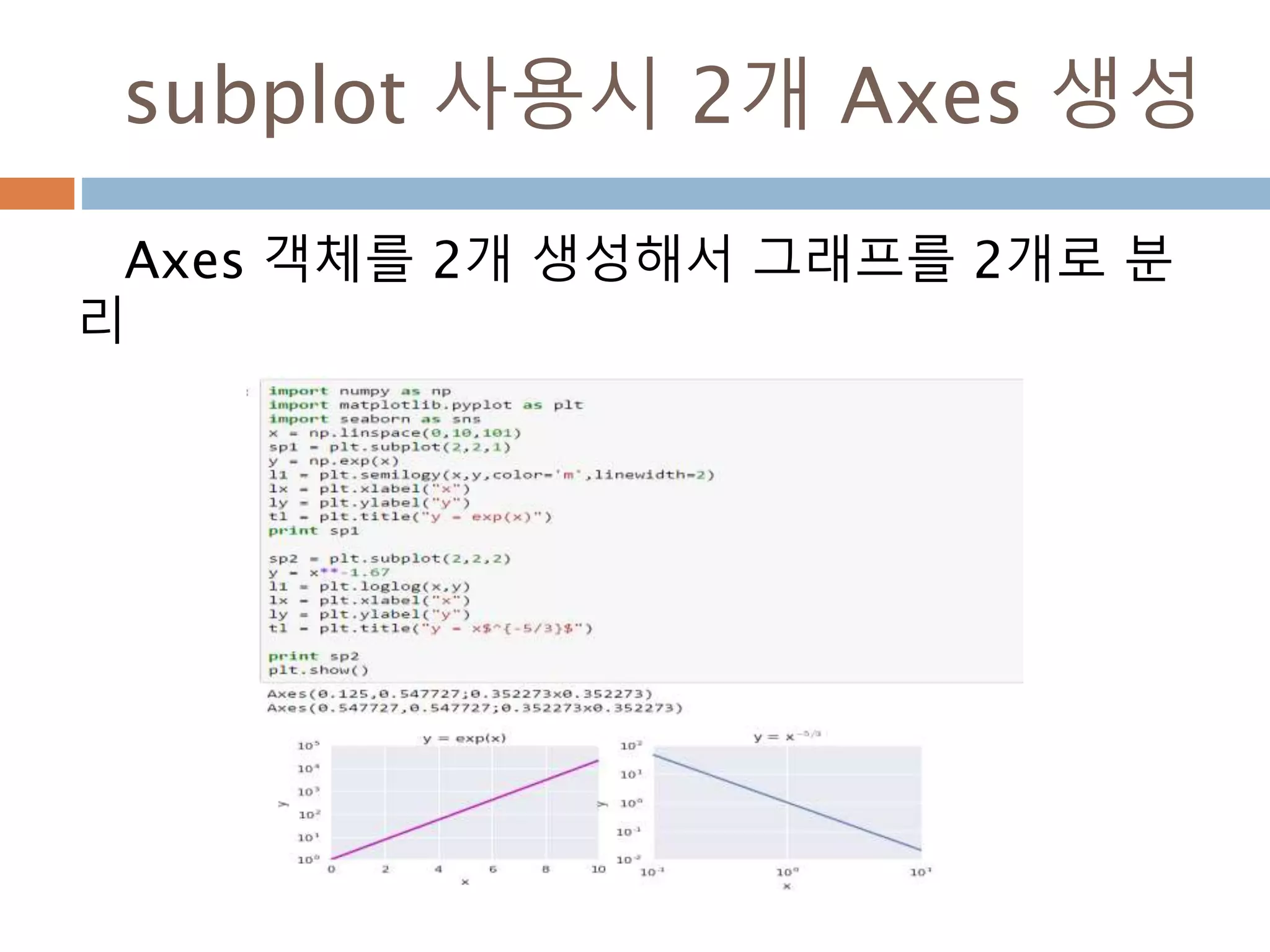
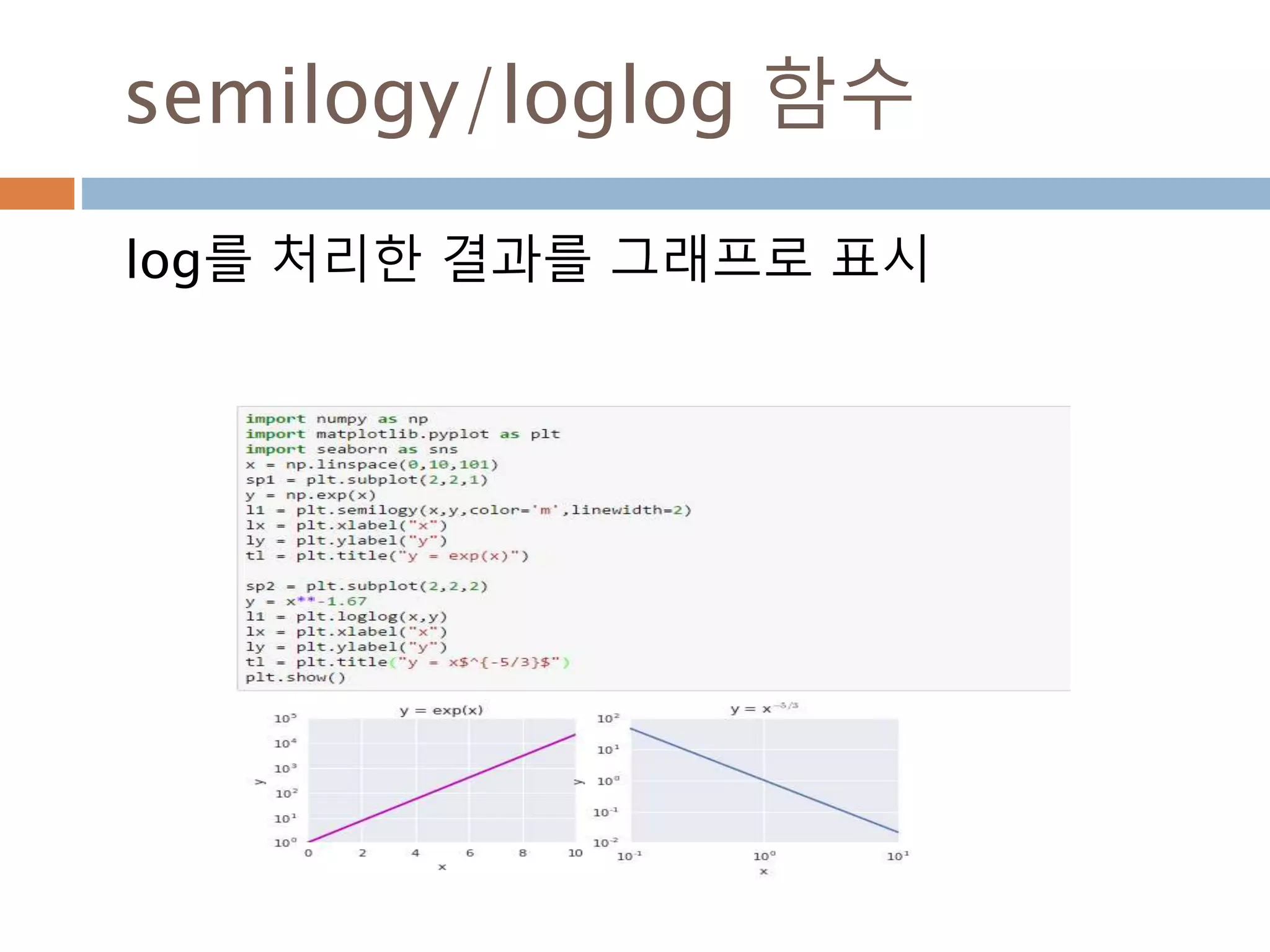










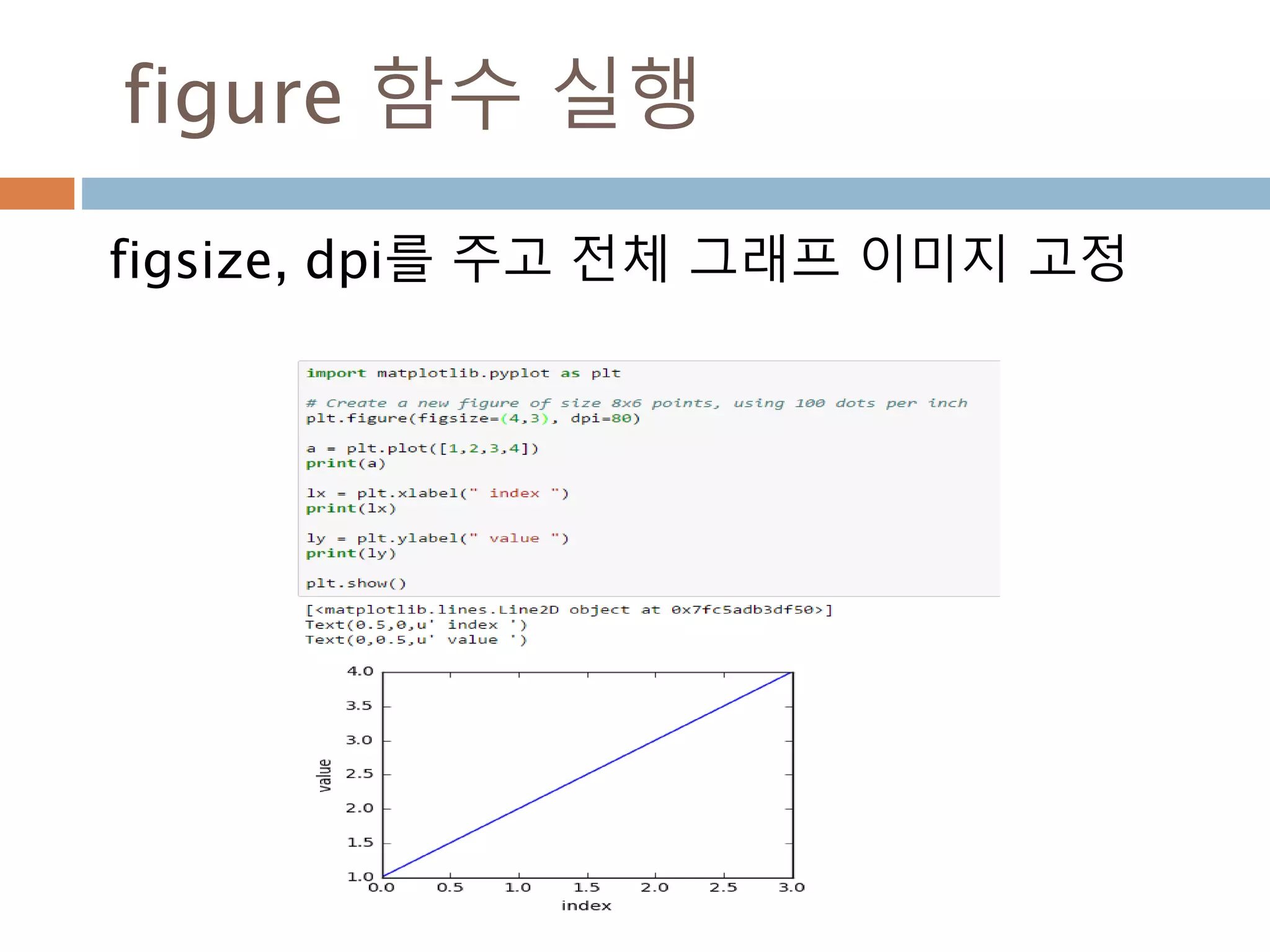

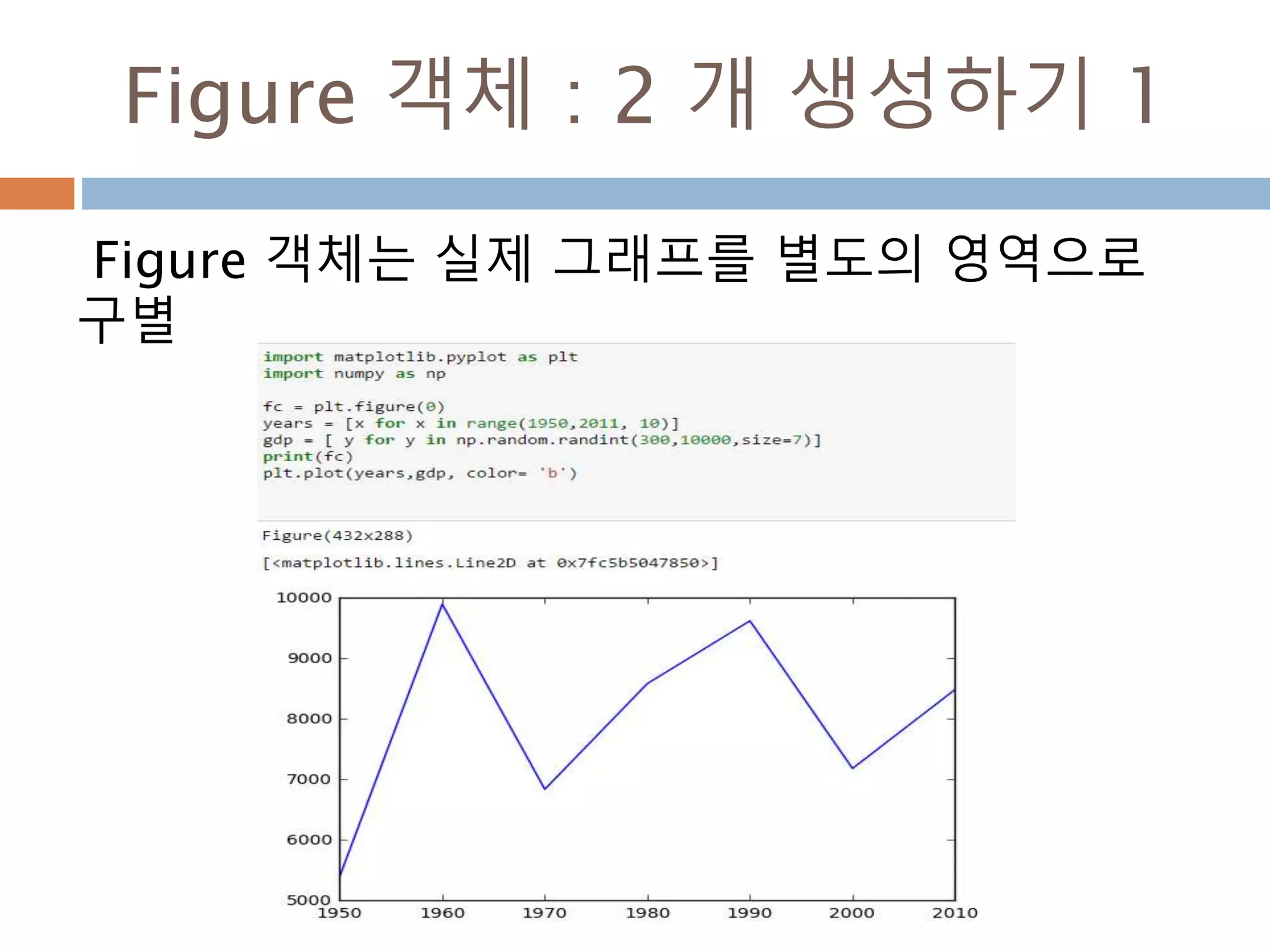
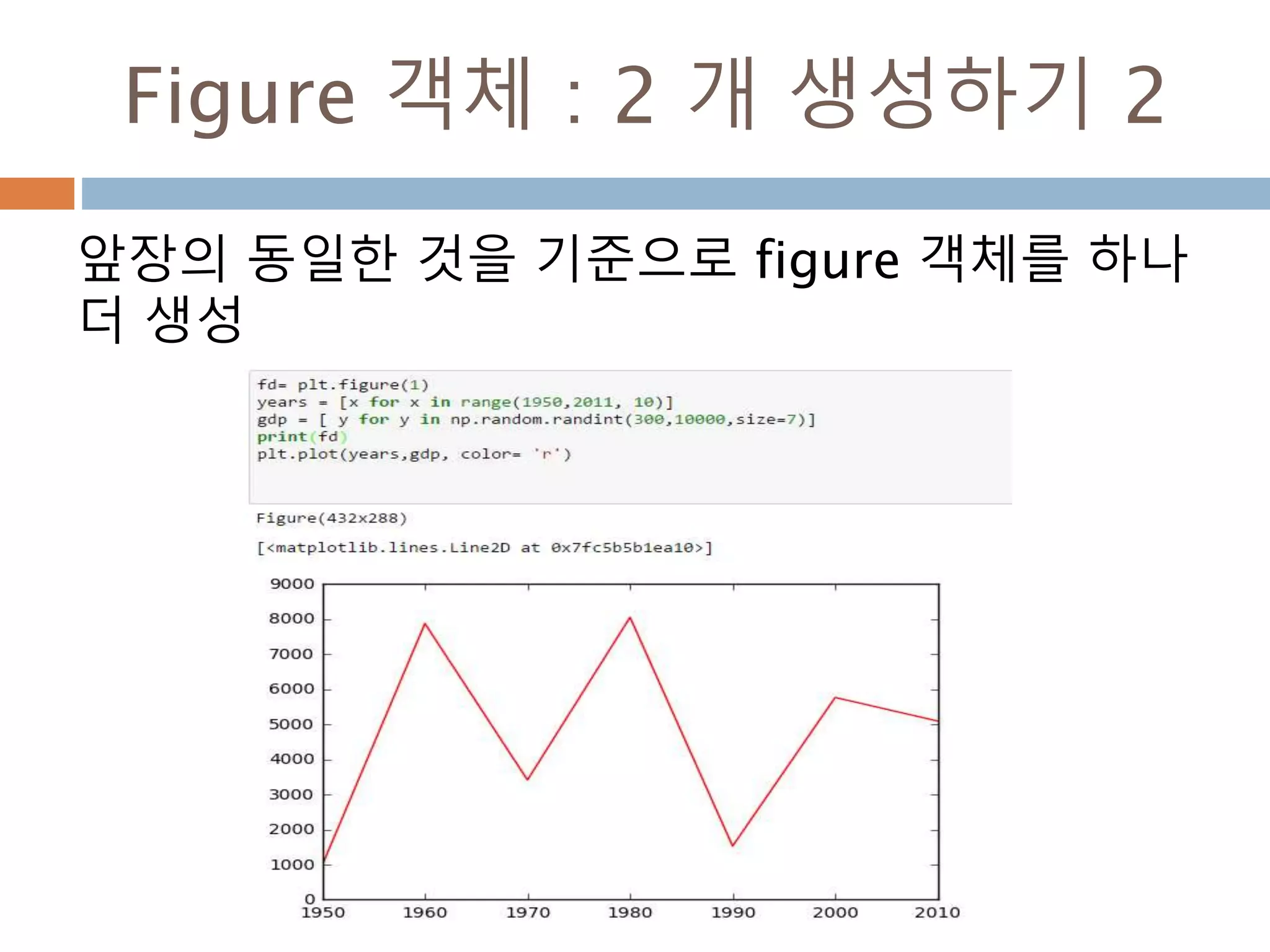

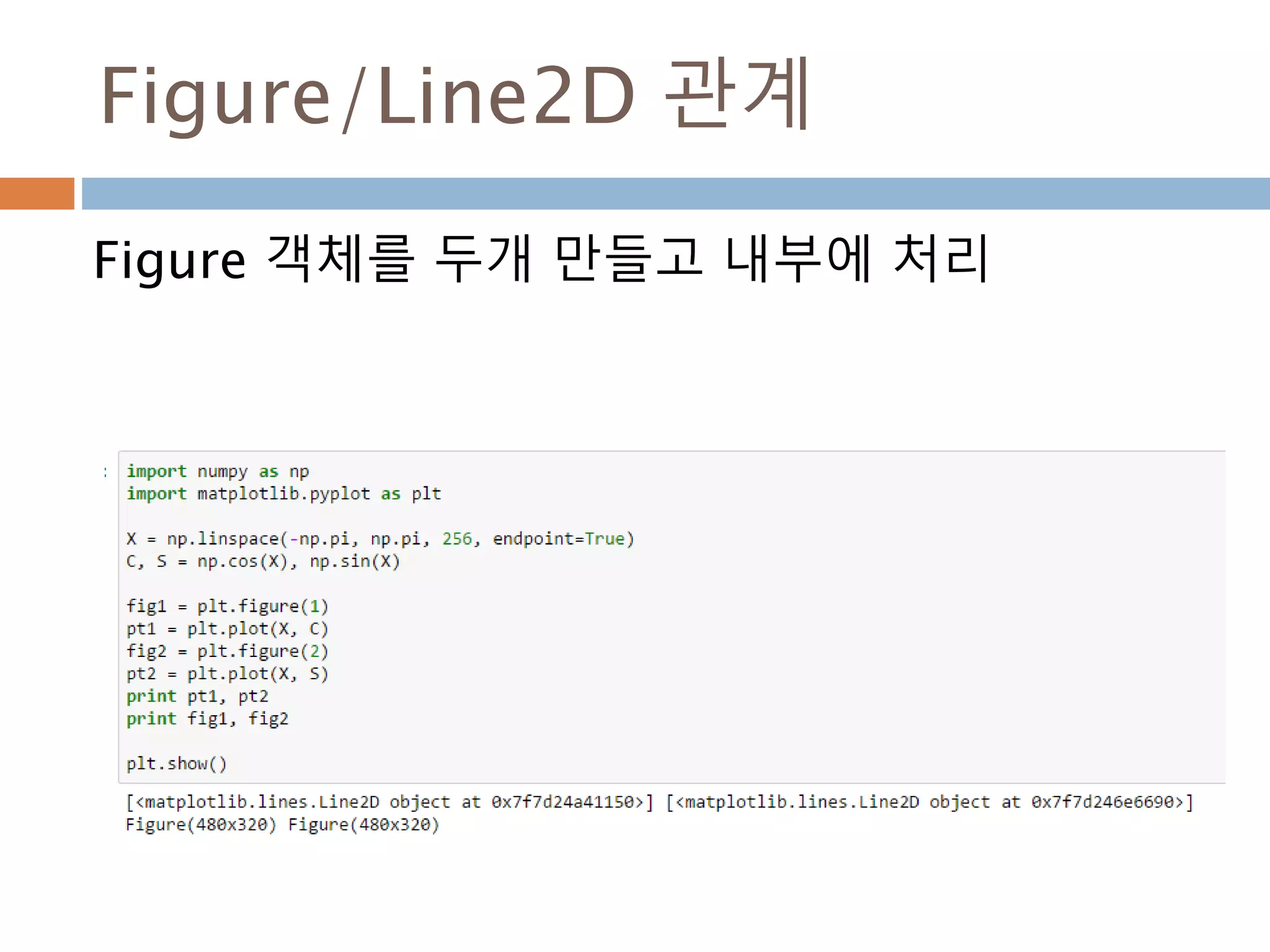
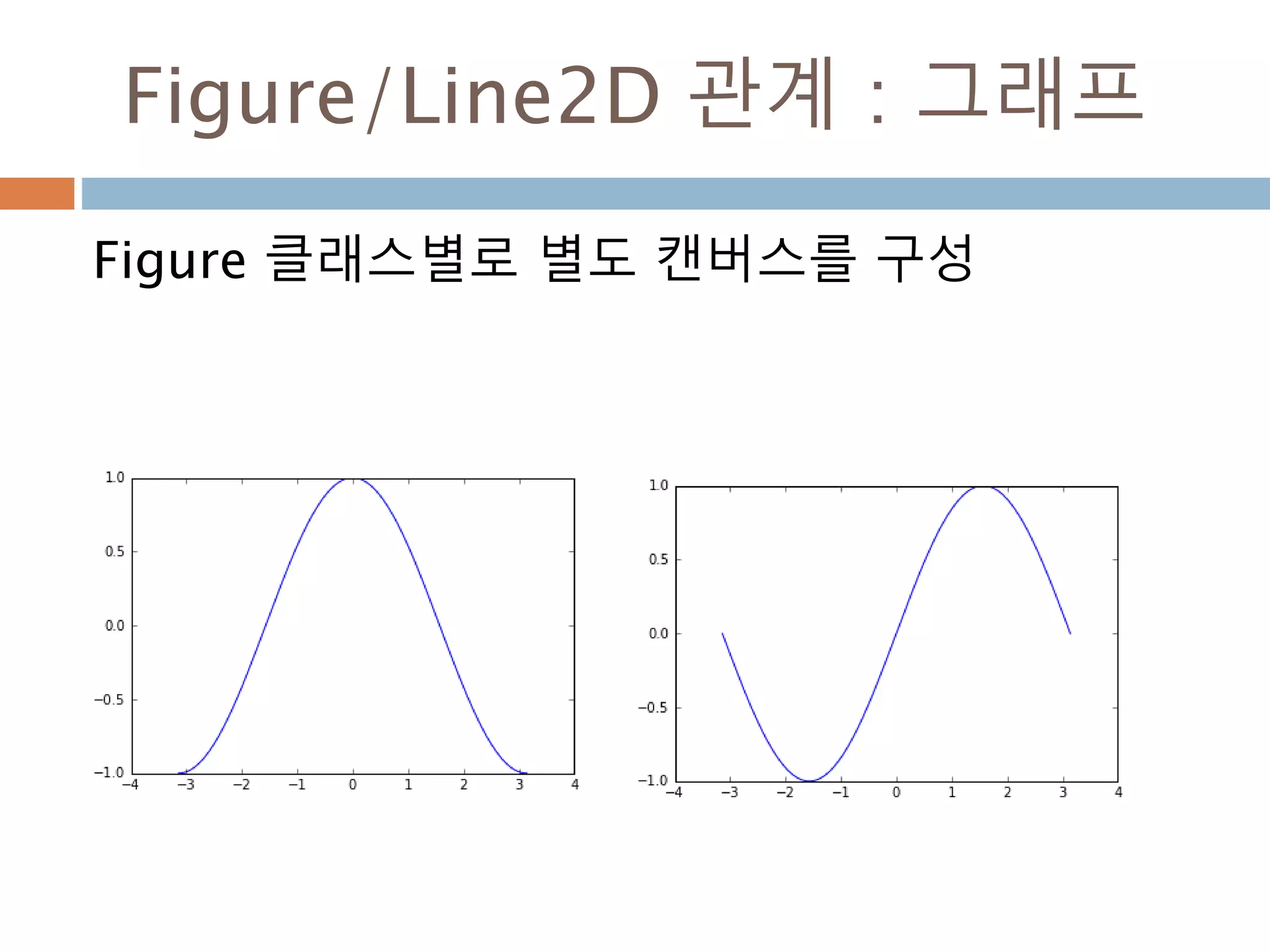
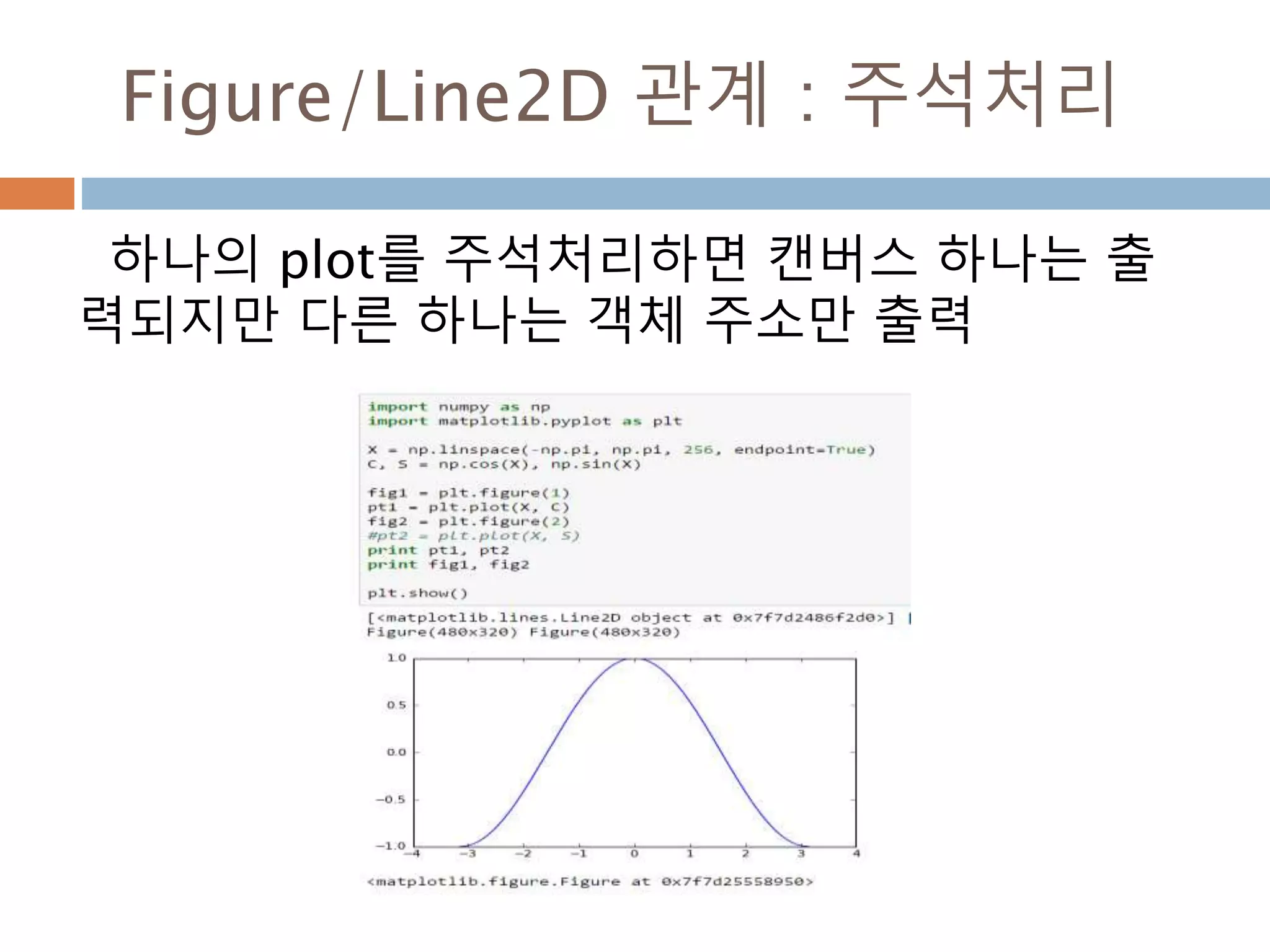


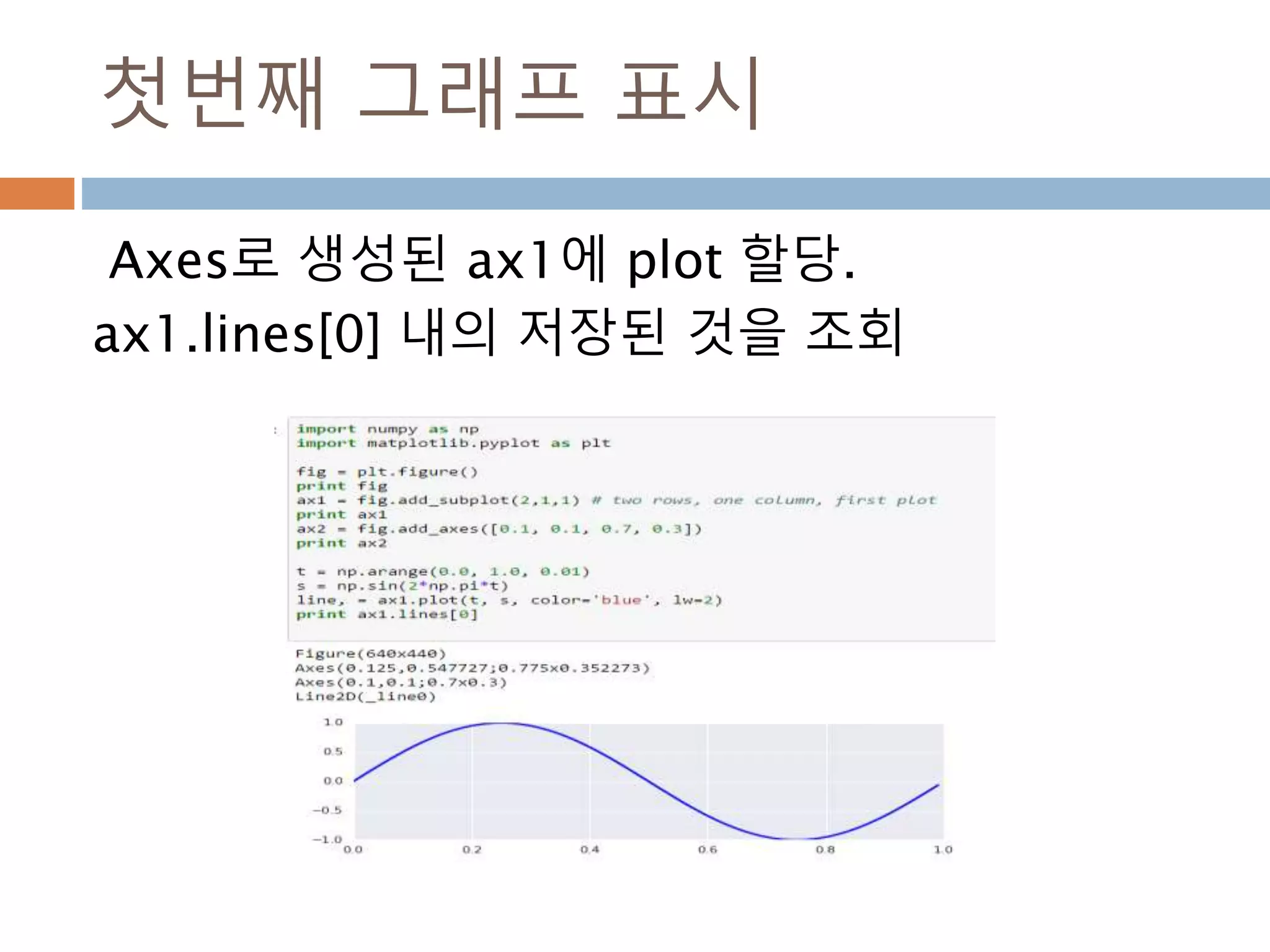
![정적분: definite integral
리만 적분에서 다루는 고전적인 정의에 따르면 실수
의 척도를 사용하는 측도 공간에 나타낼 수 있는 연
속인 함수 f(x)에 대하여 그 함수의 정의역의 부분 집
합을 이루는 구간 [a, b] 에 대응하는 치역으로 이루
어진 곡선의 리만 합의 극한을 구하는 것이다. 이를
정적분(定積分, definite integral)이라 한다.
620](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-620-2048.jpg)



















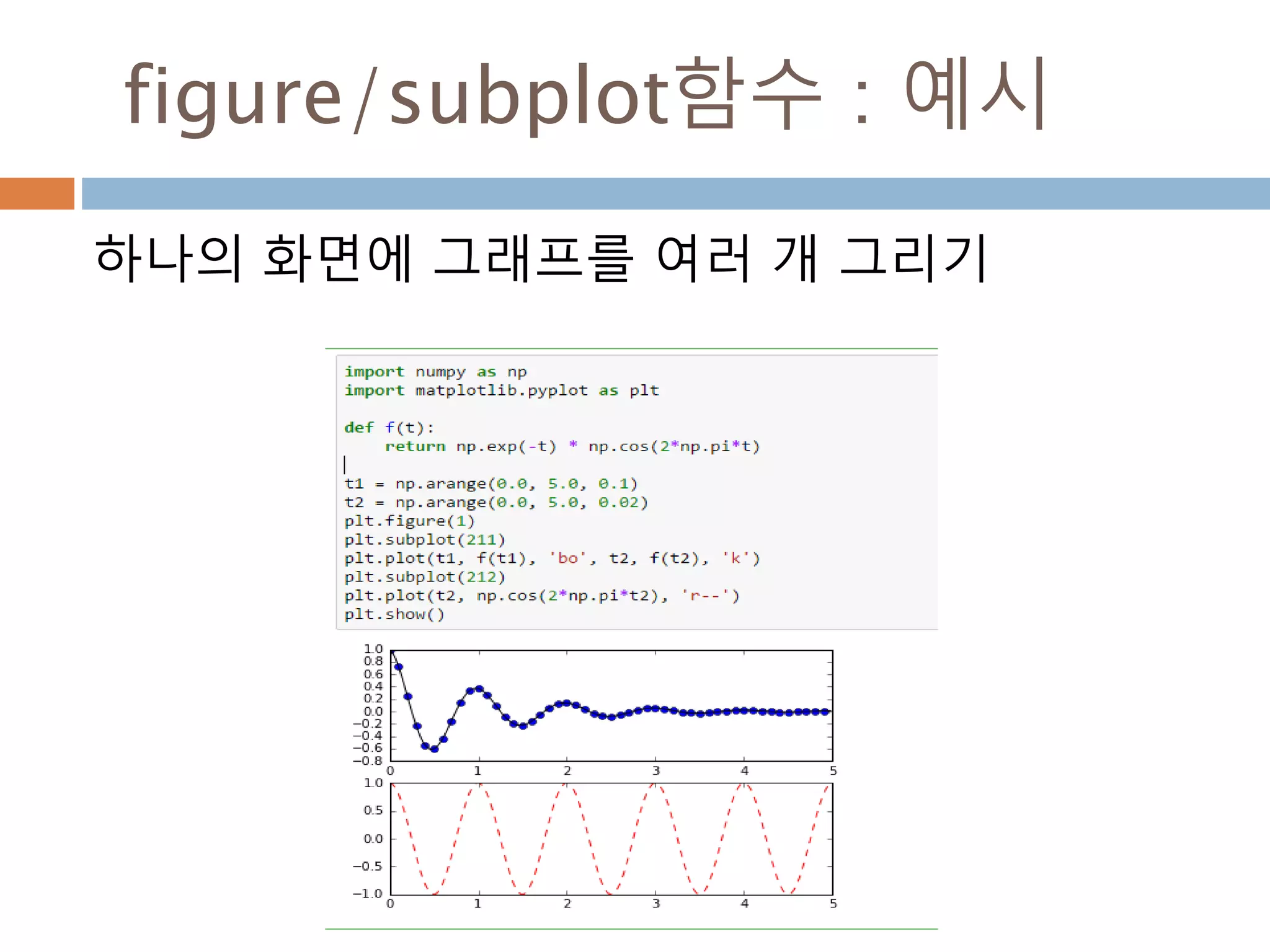






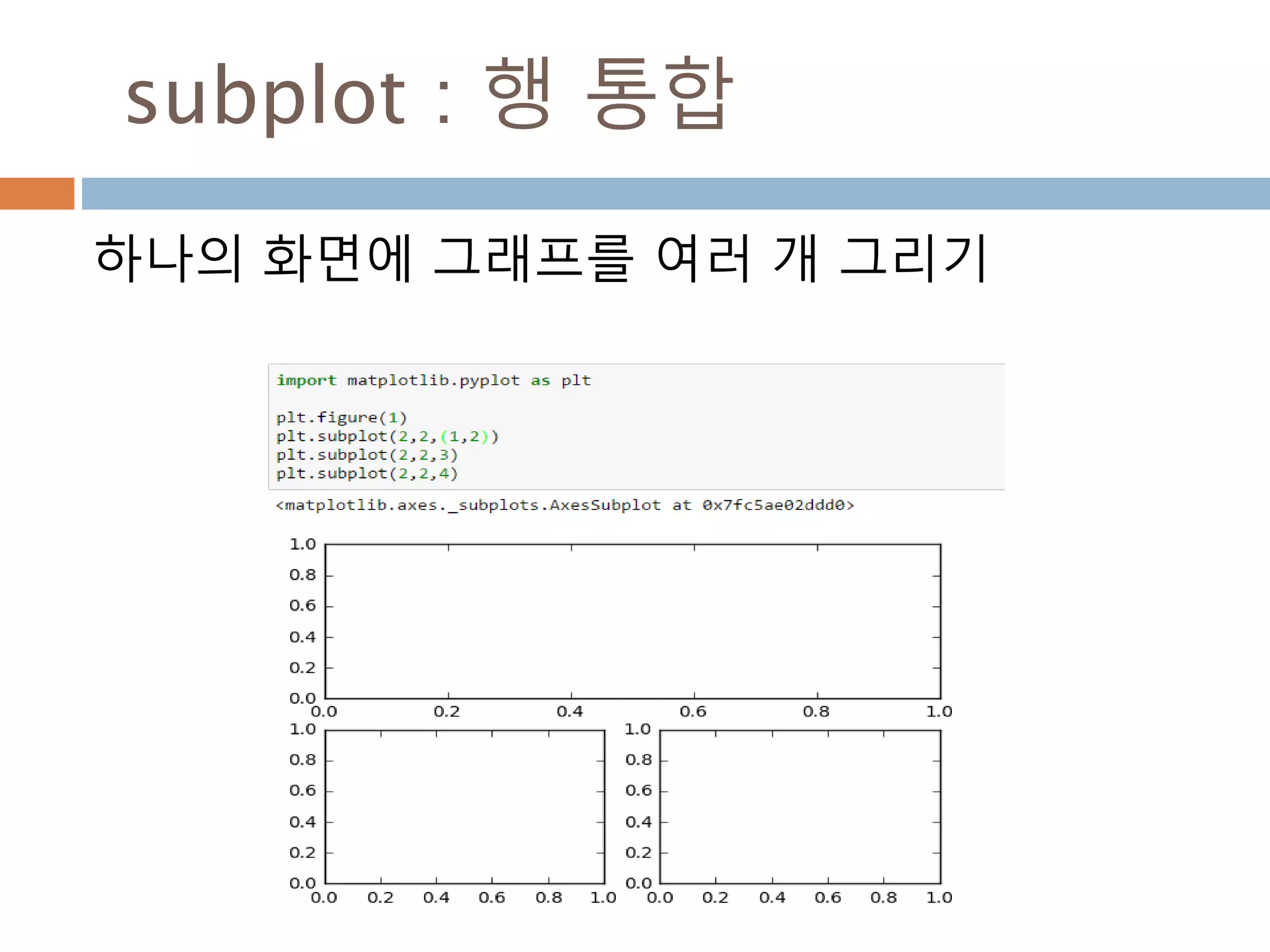
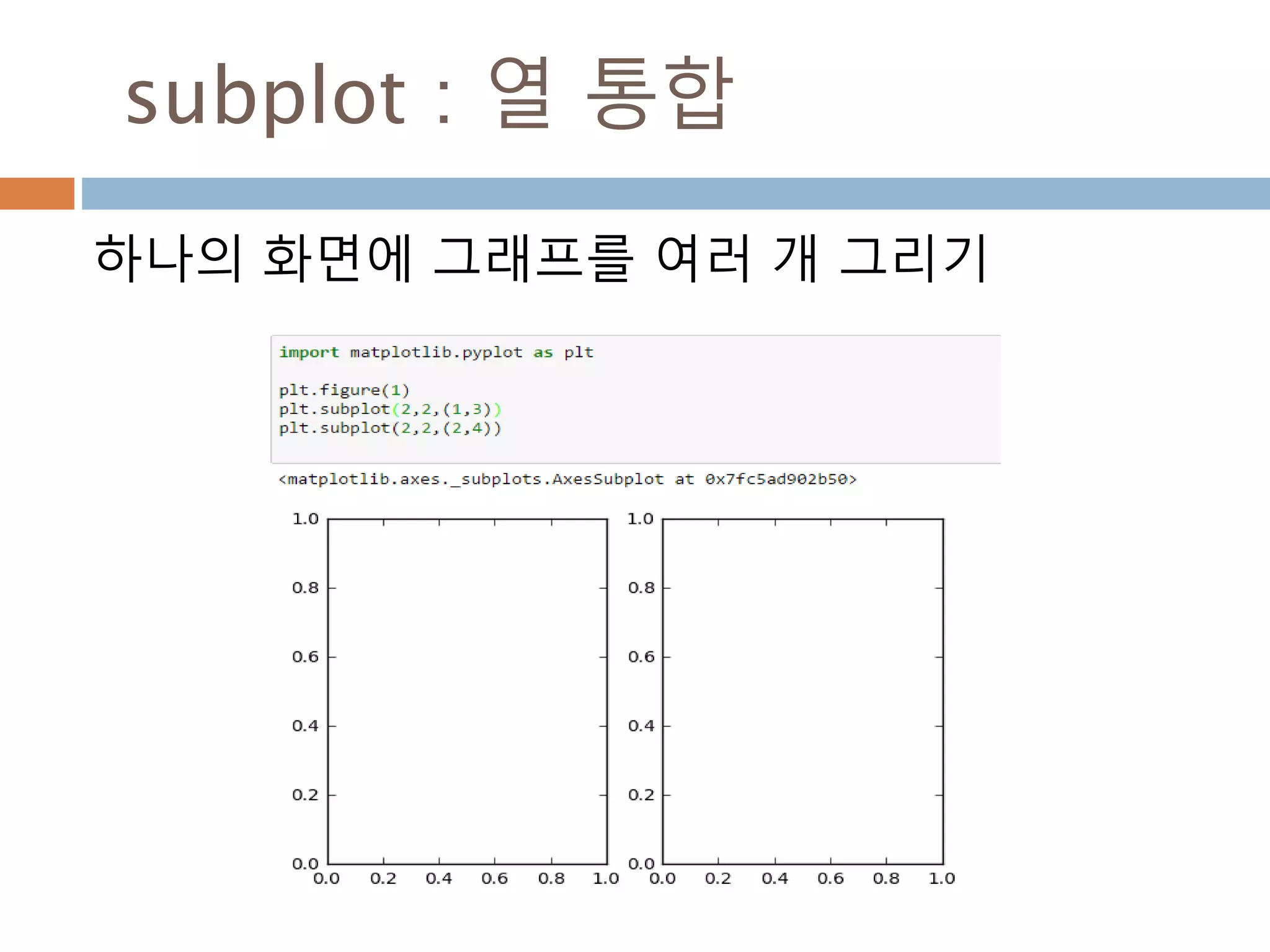

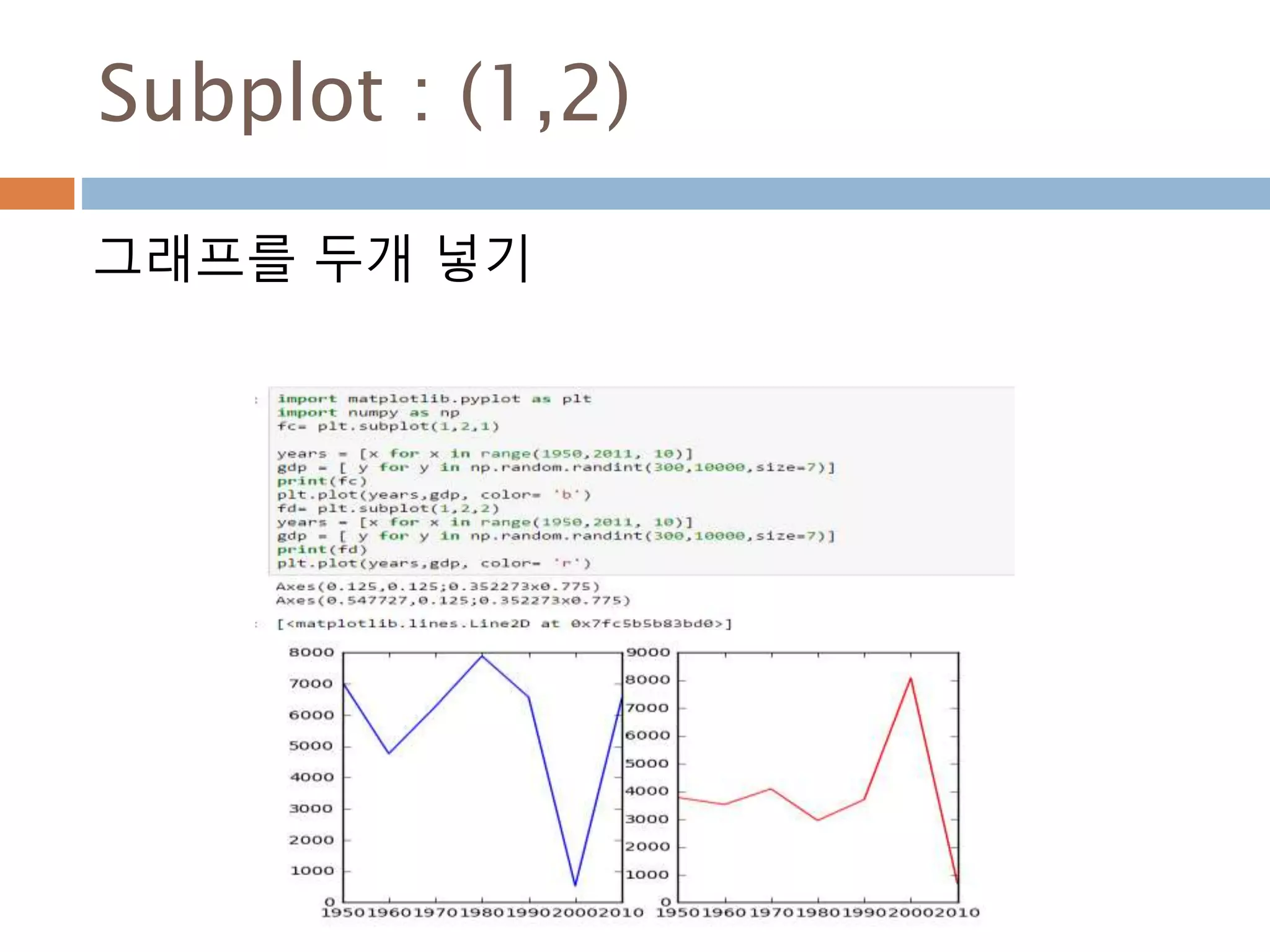
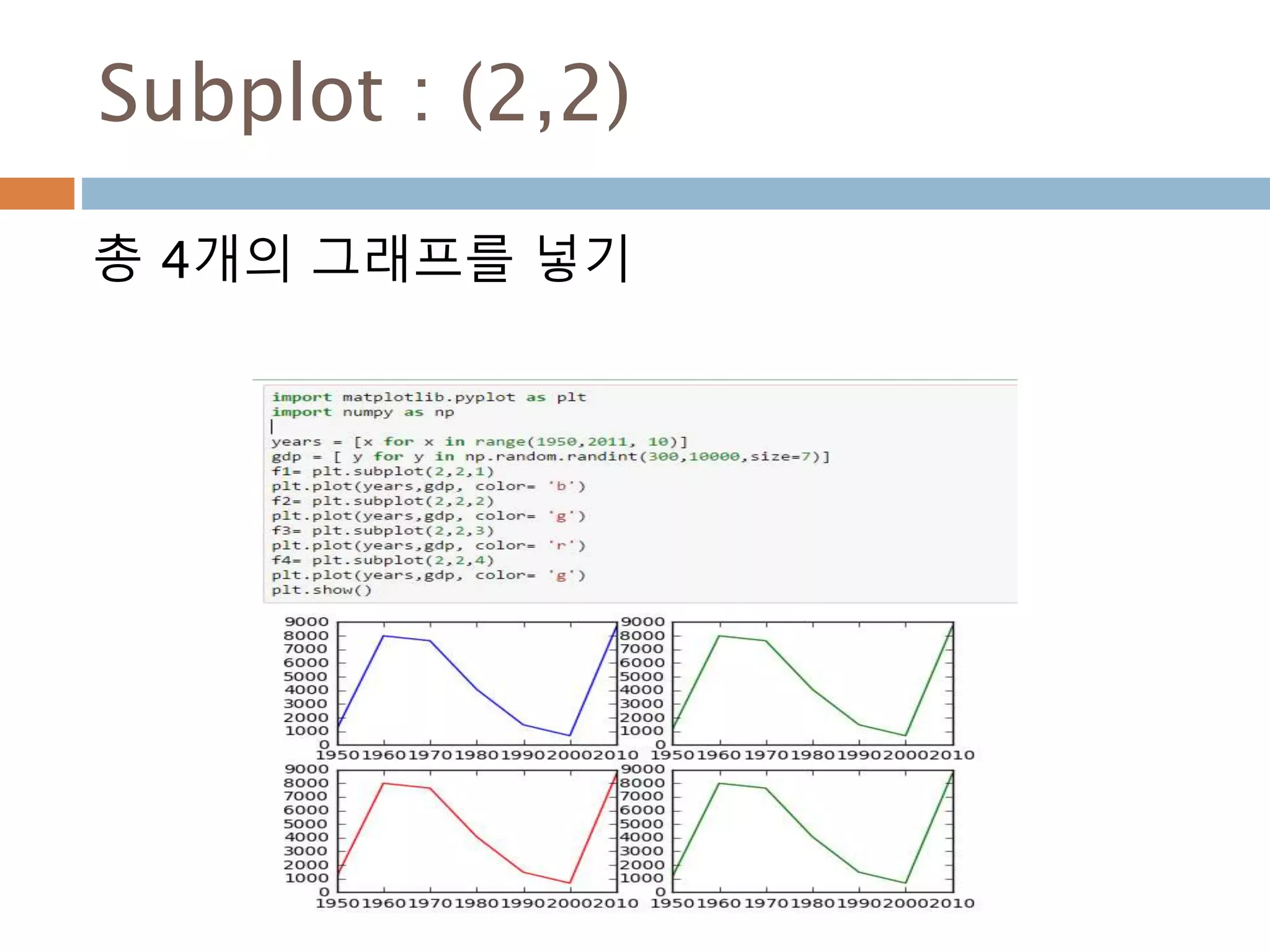

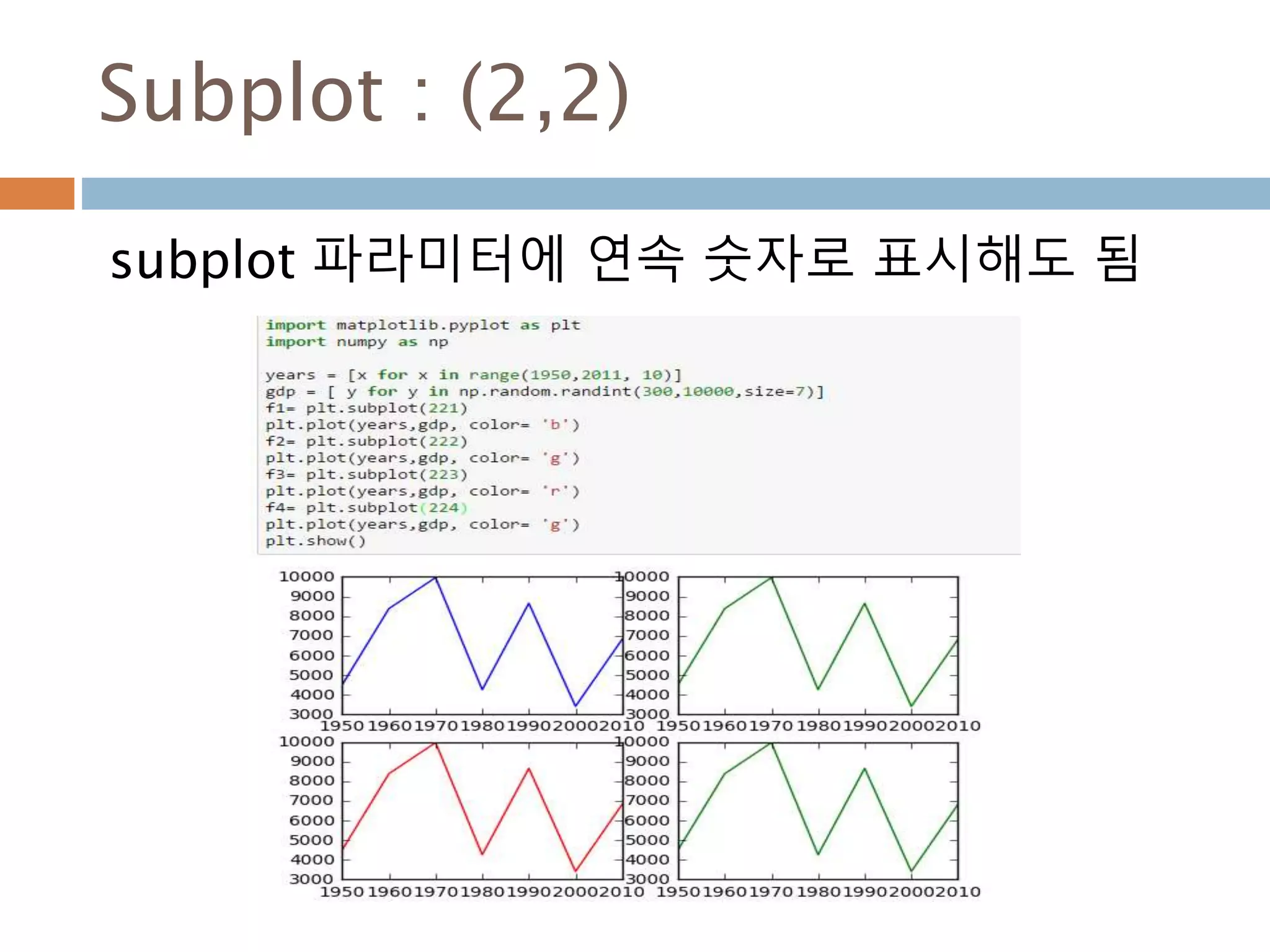

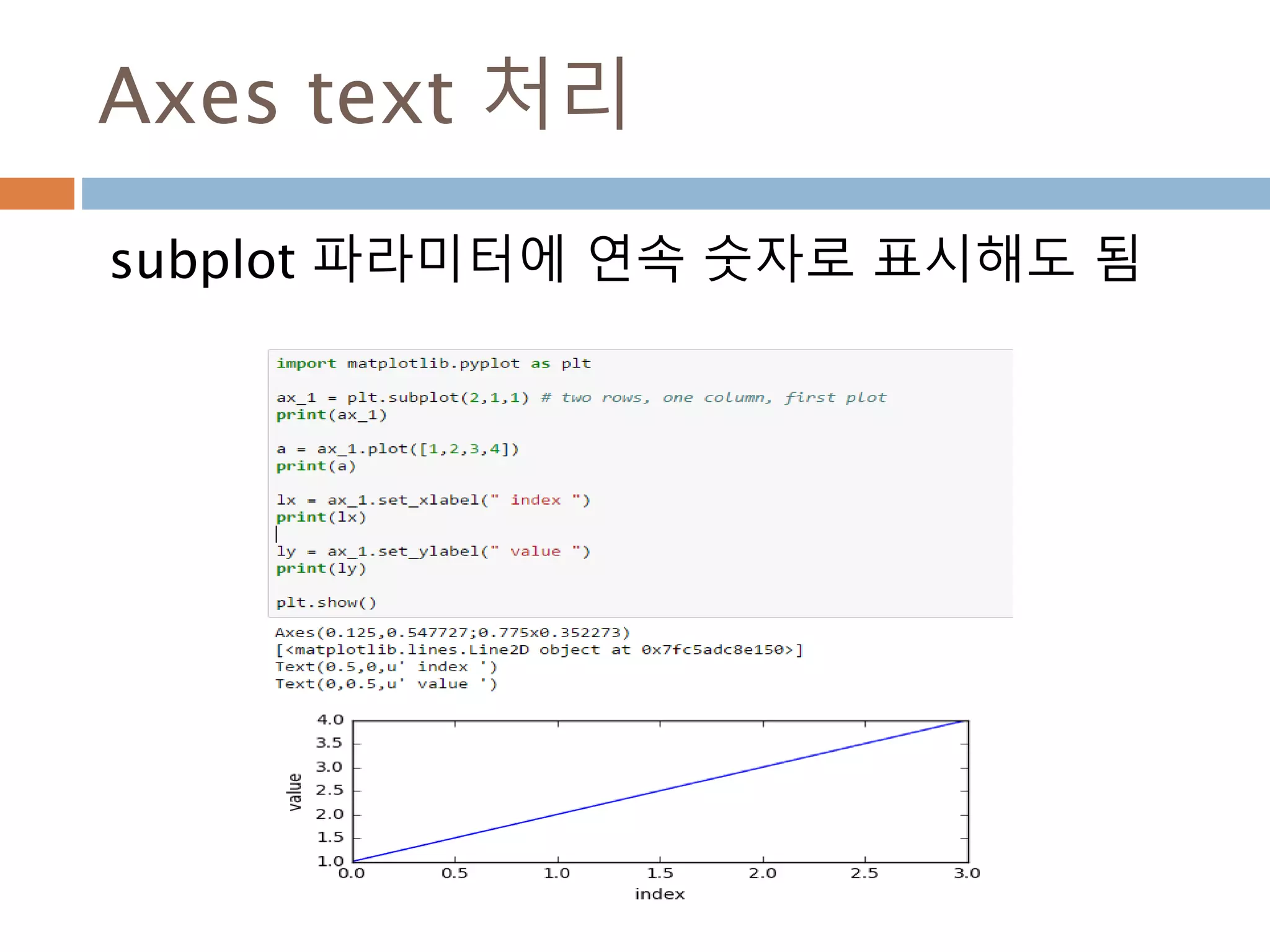


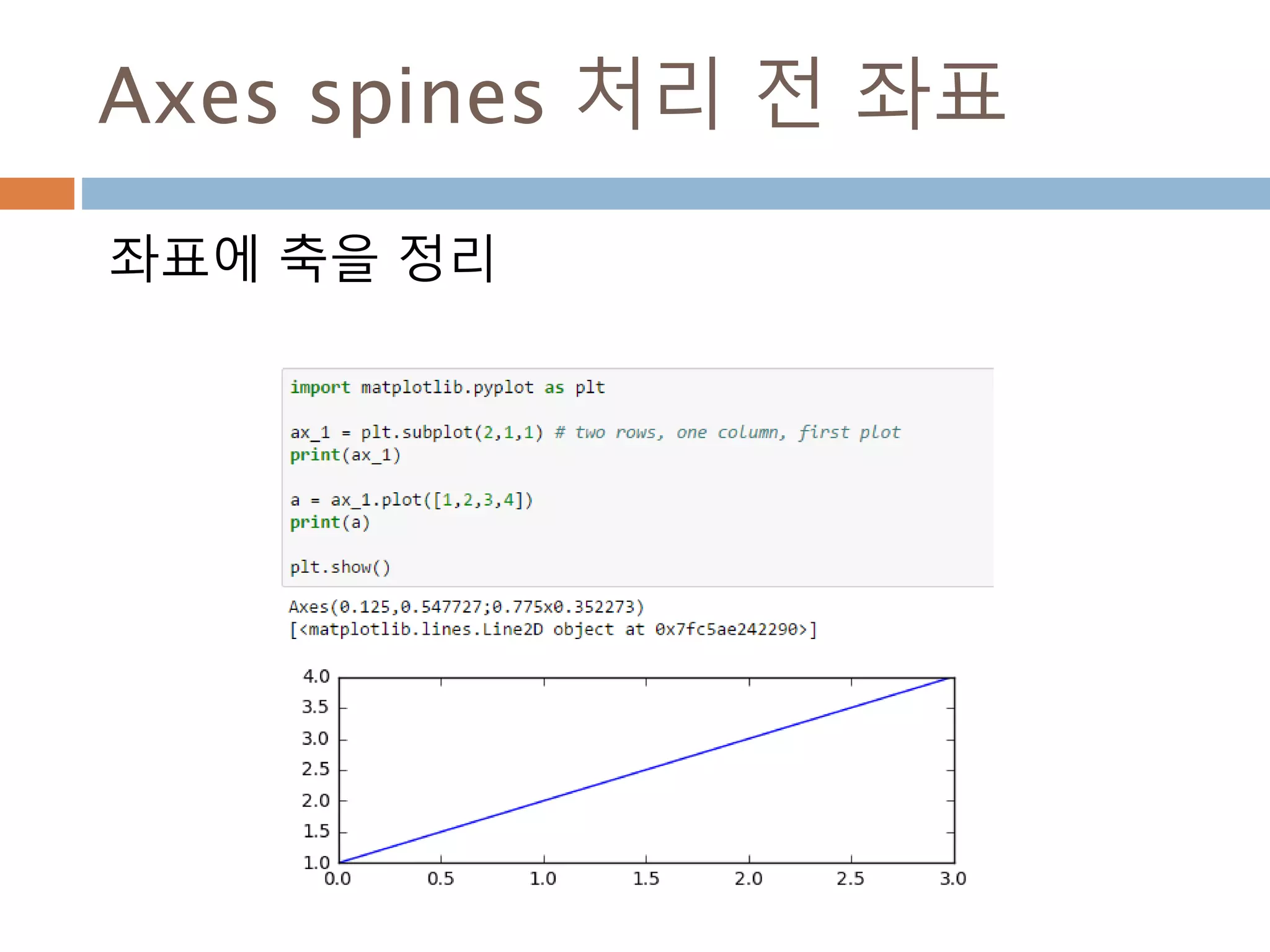
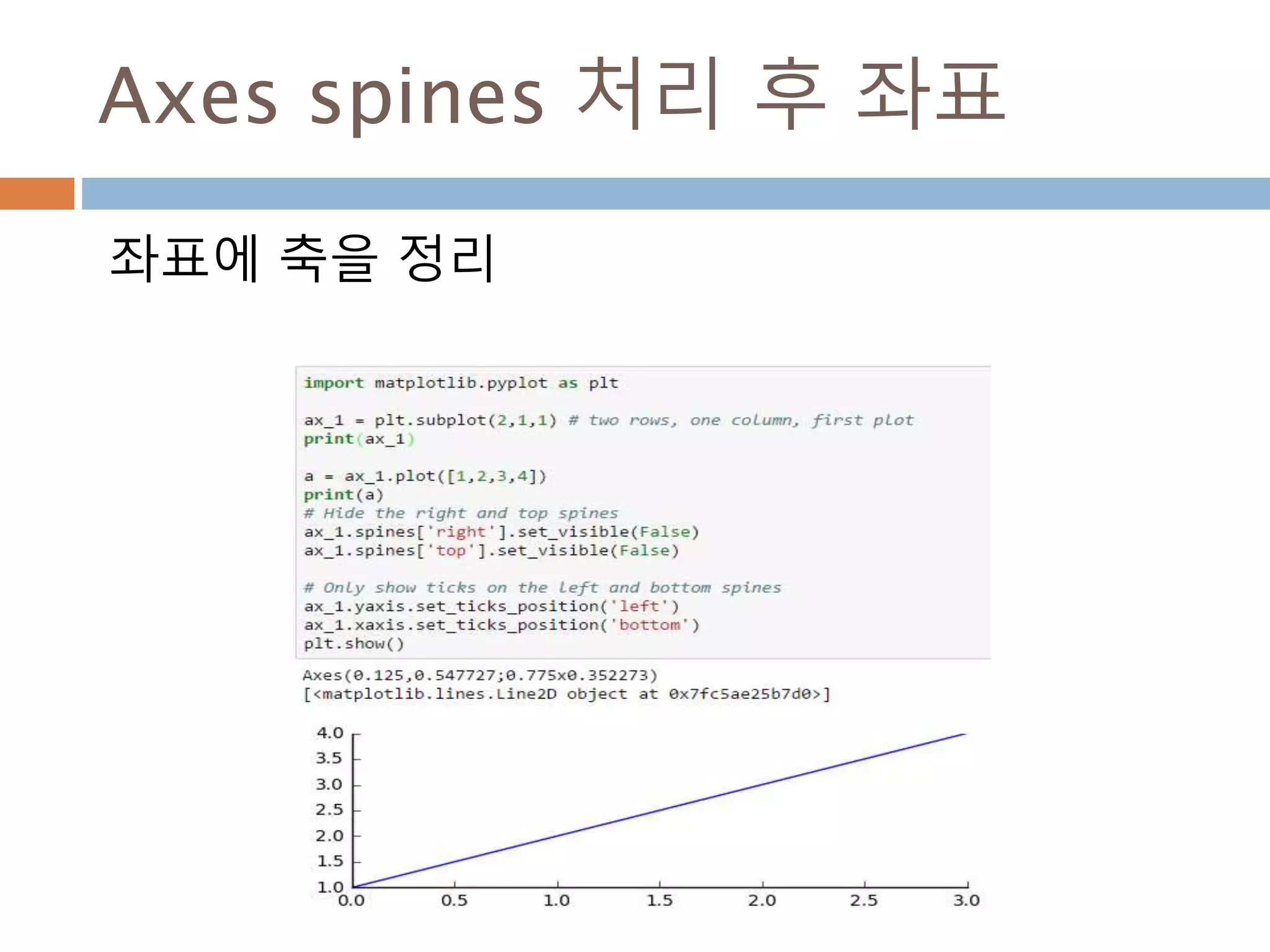


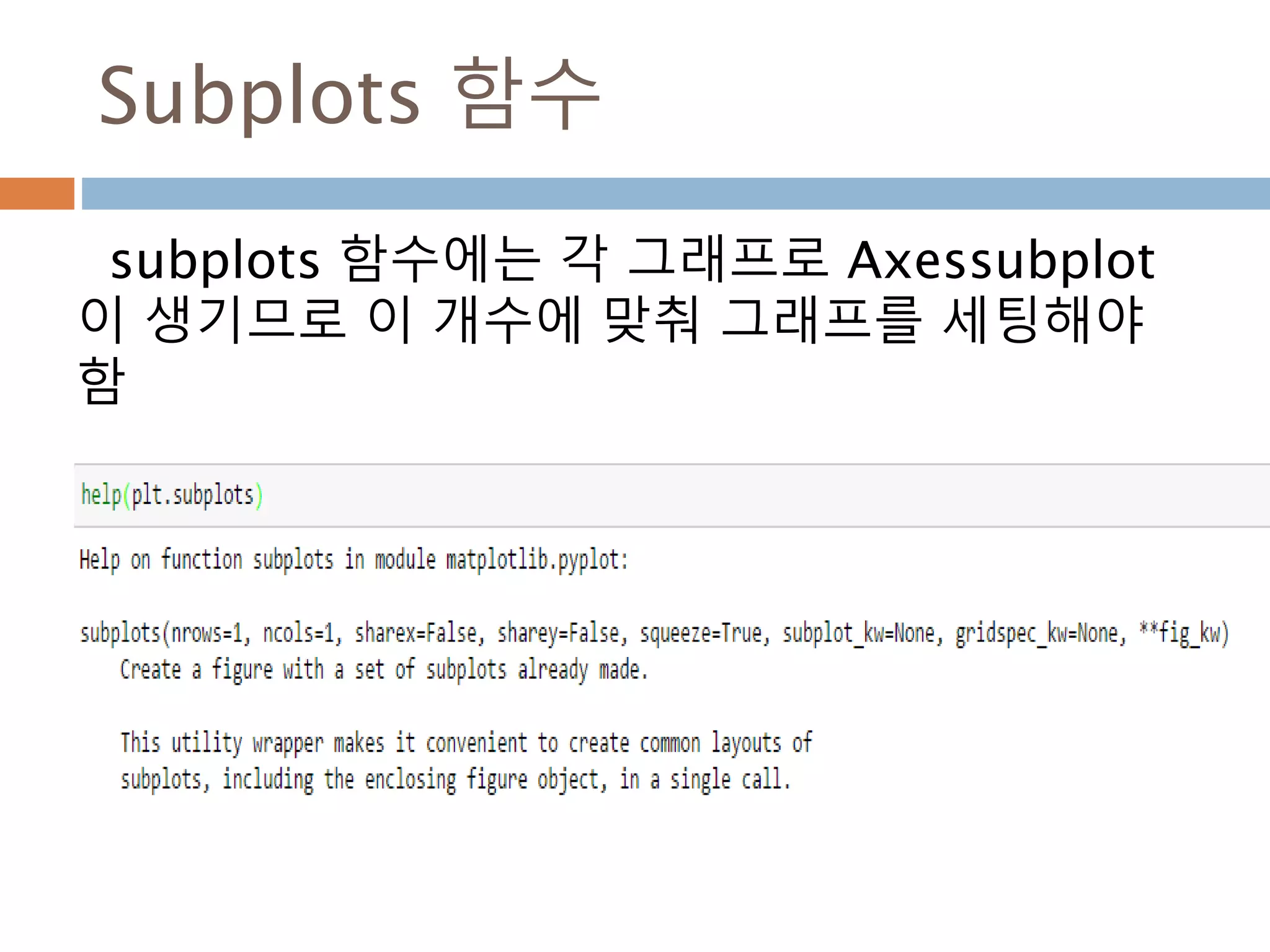



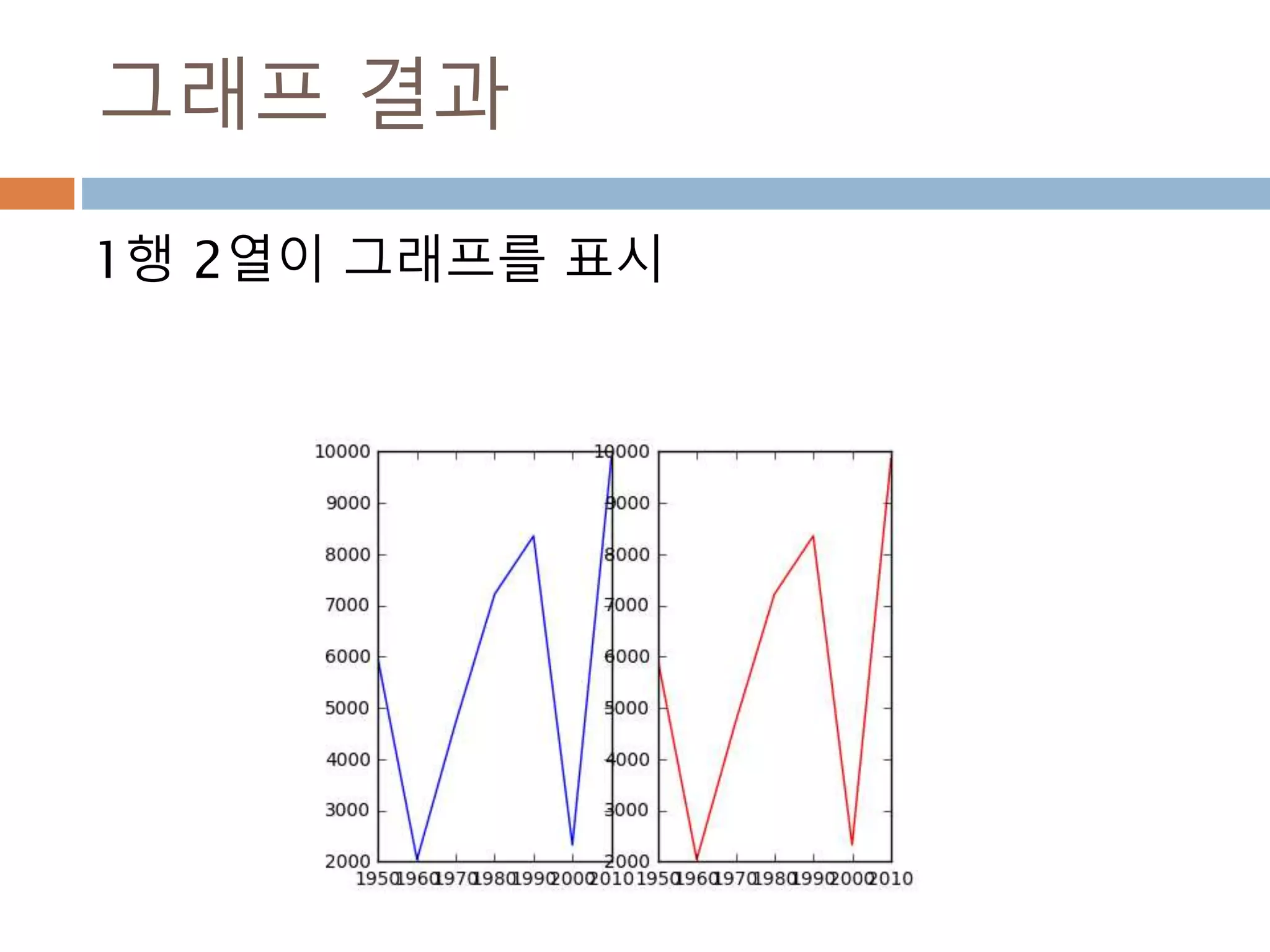





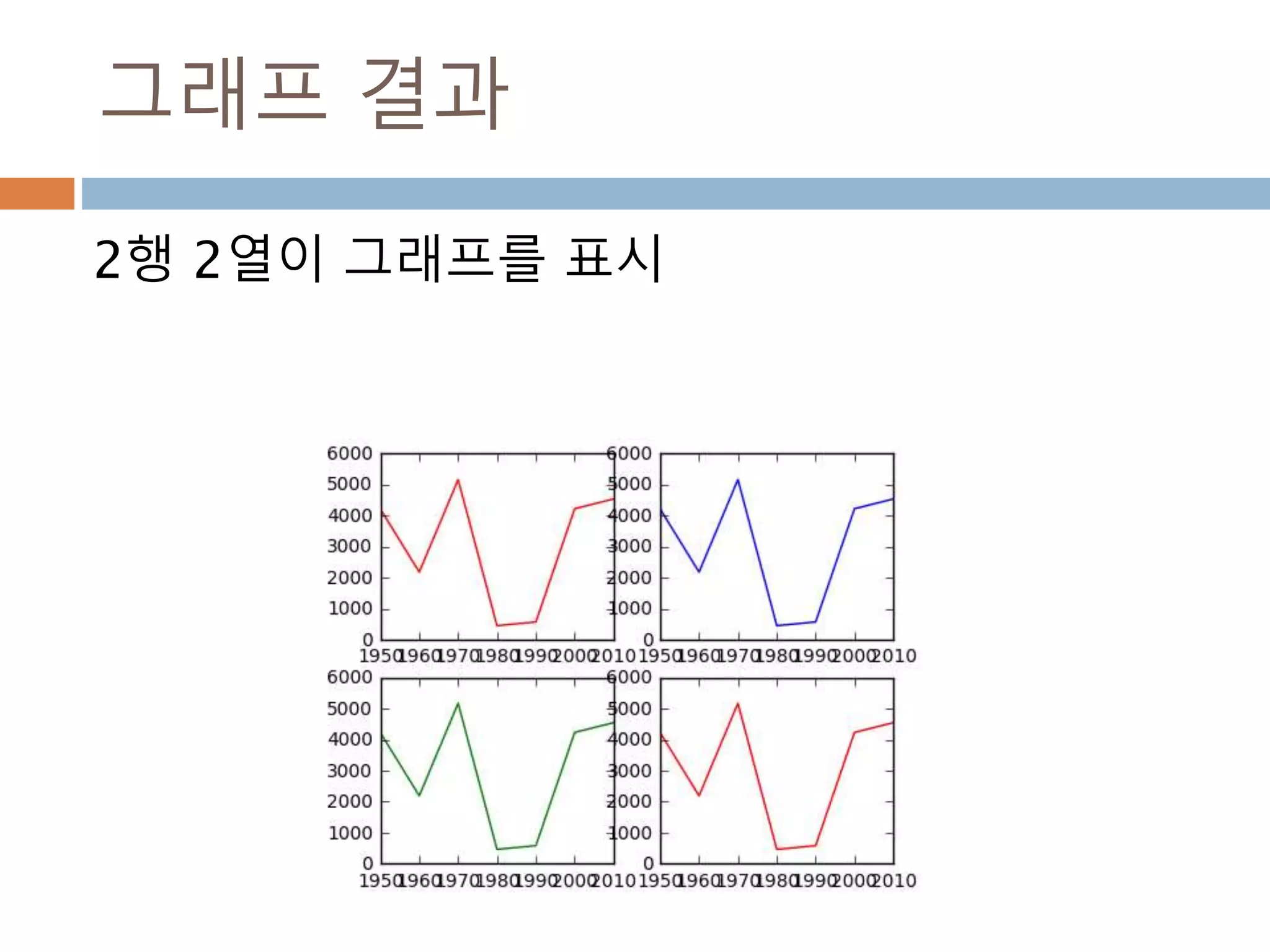


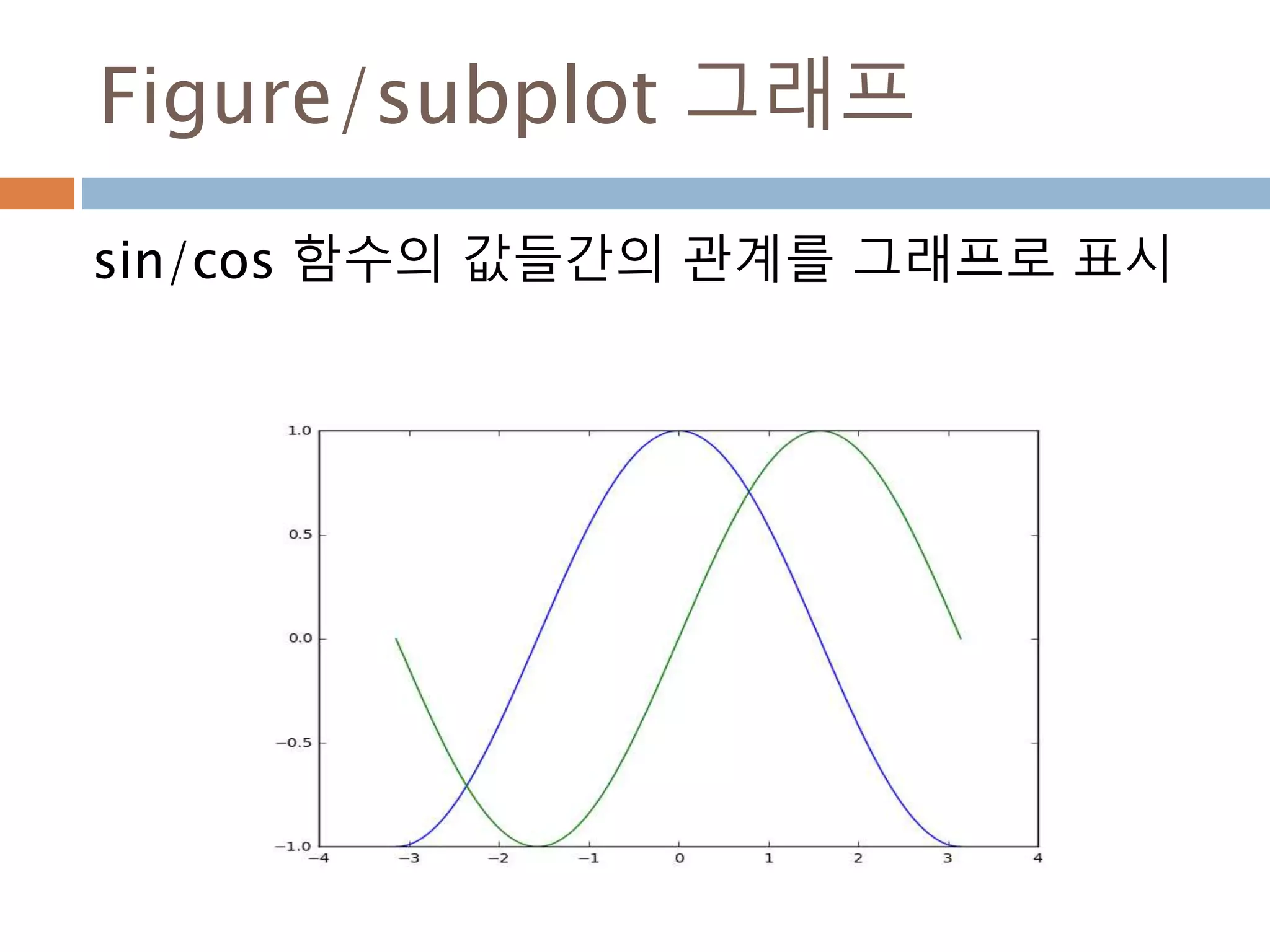


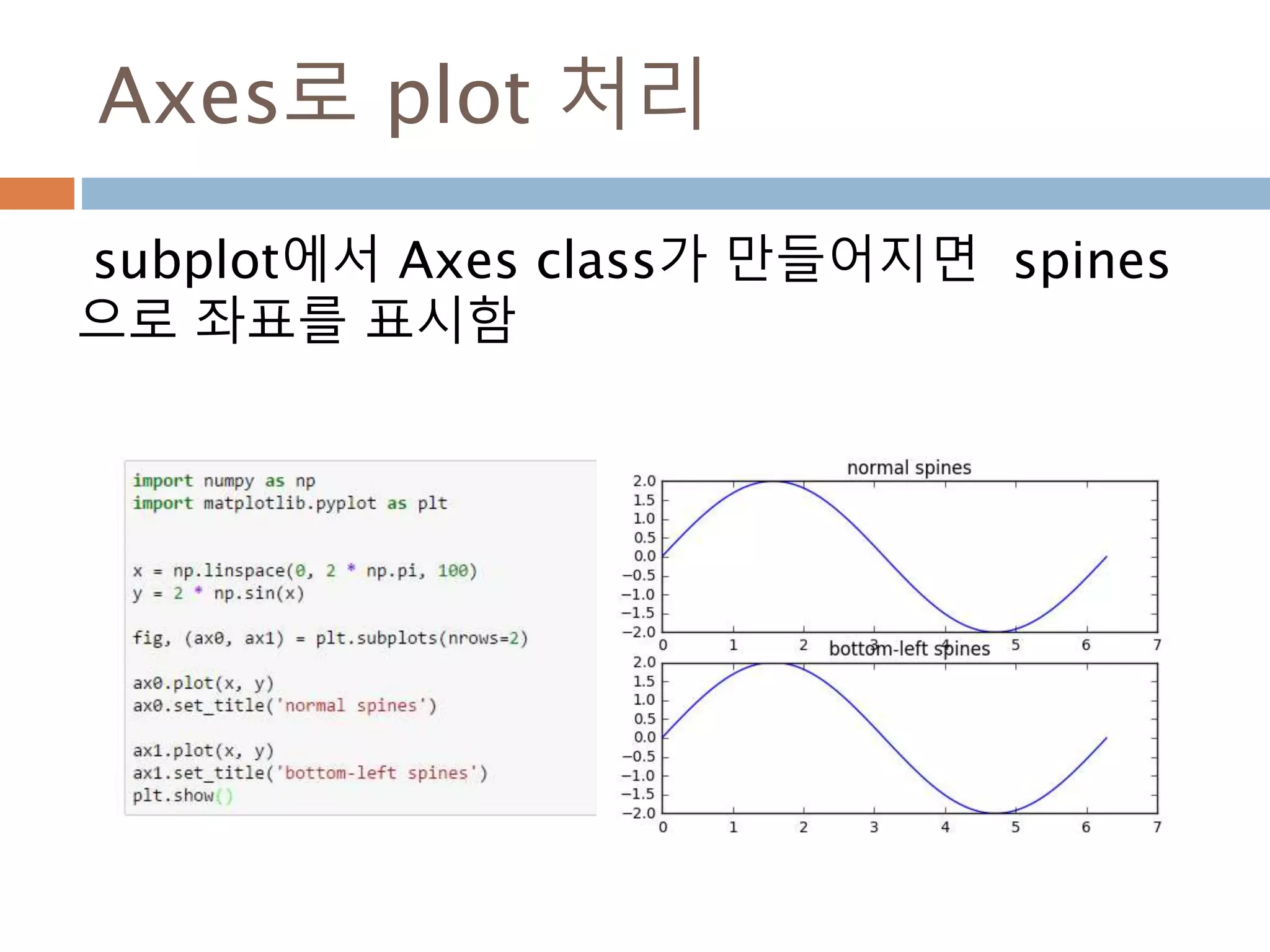
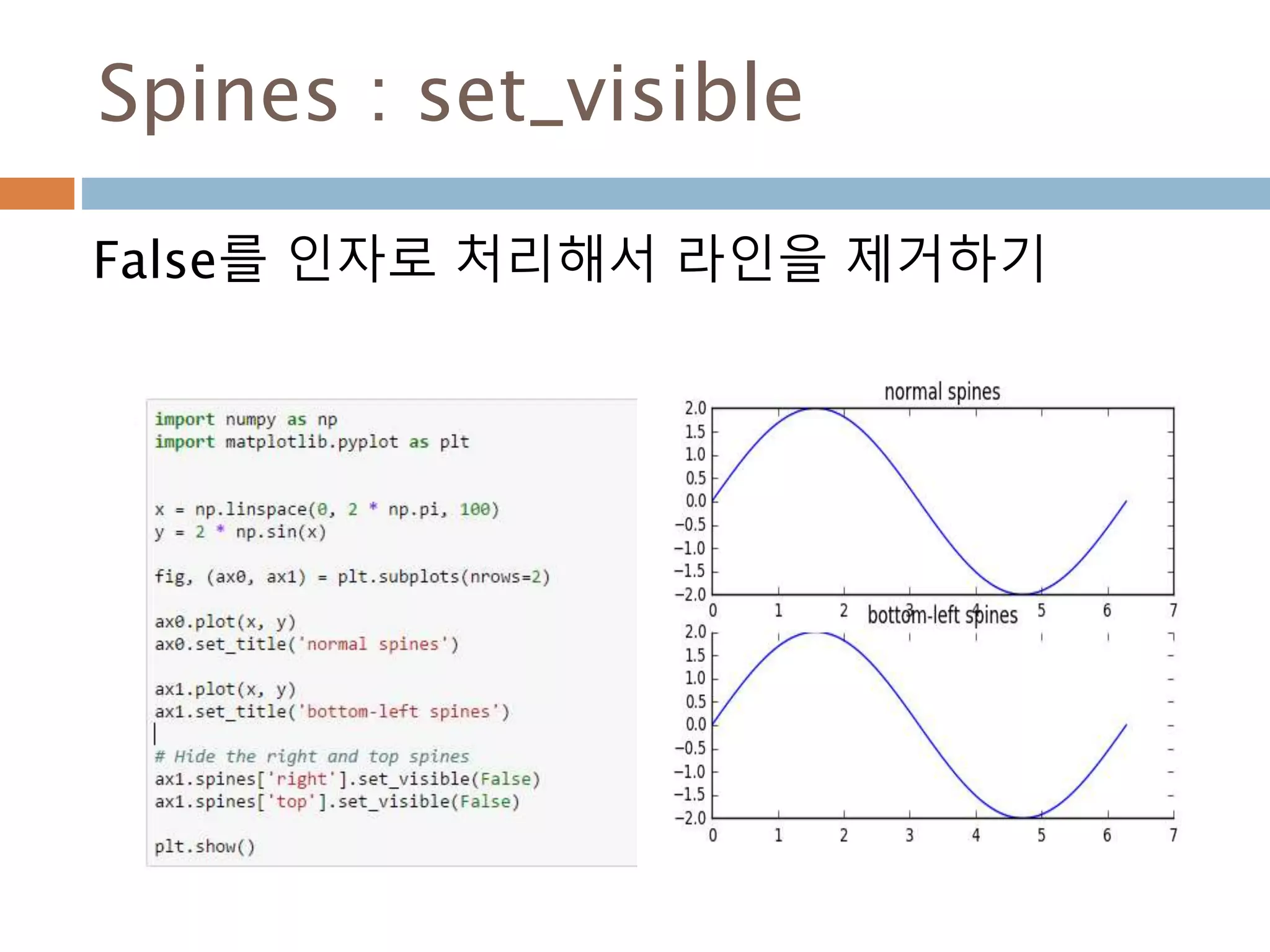
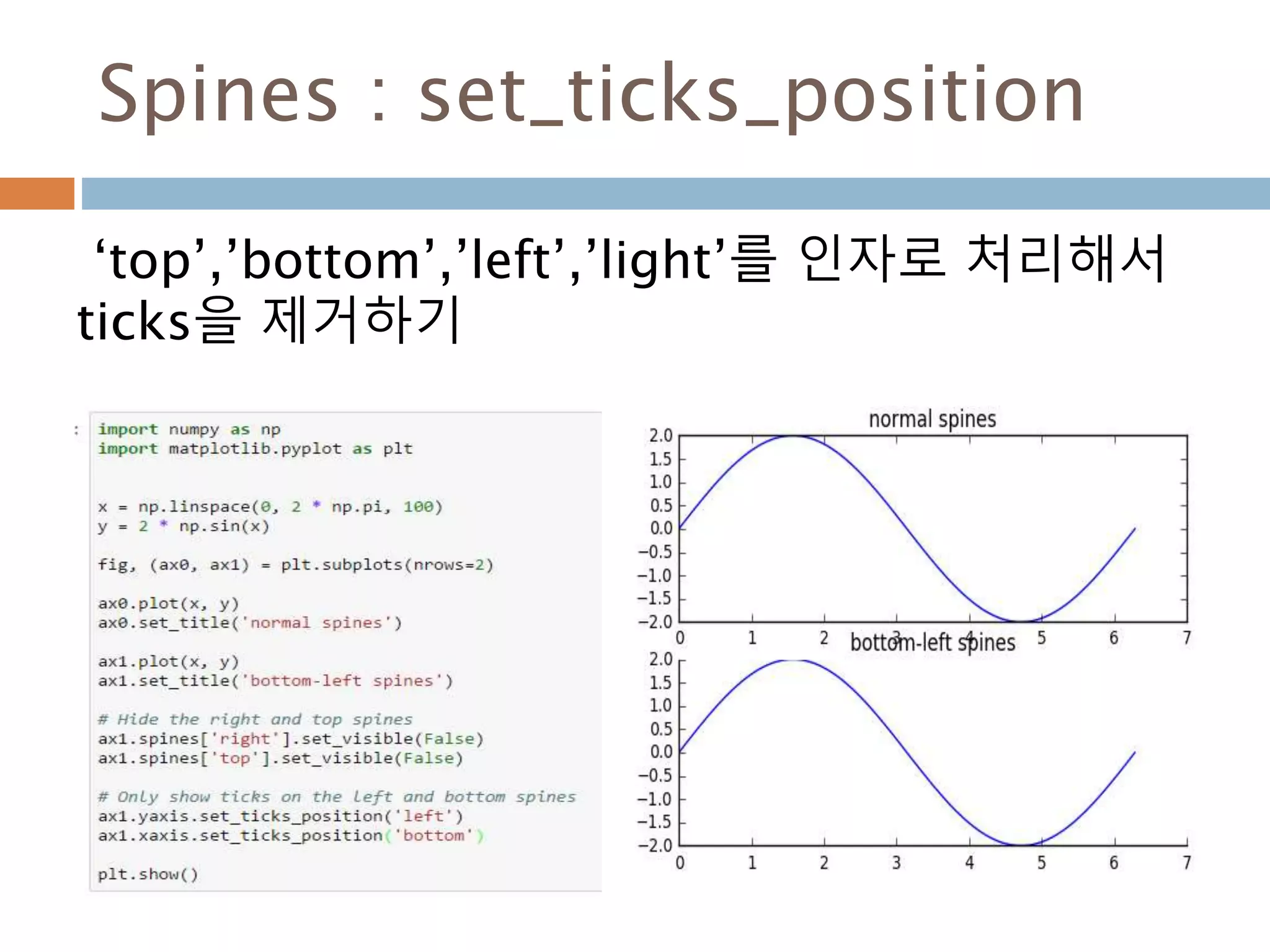

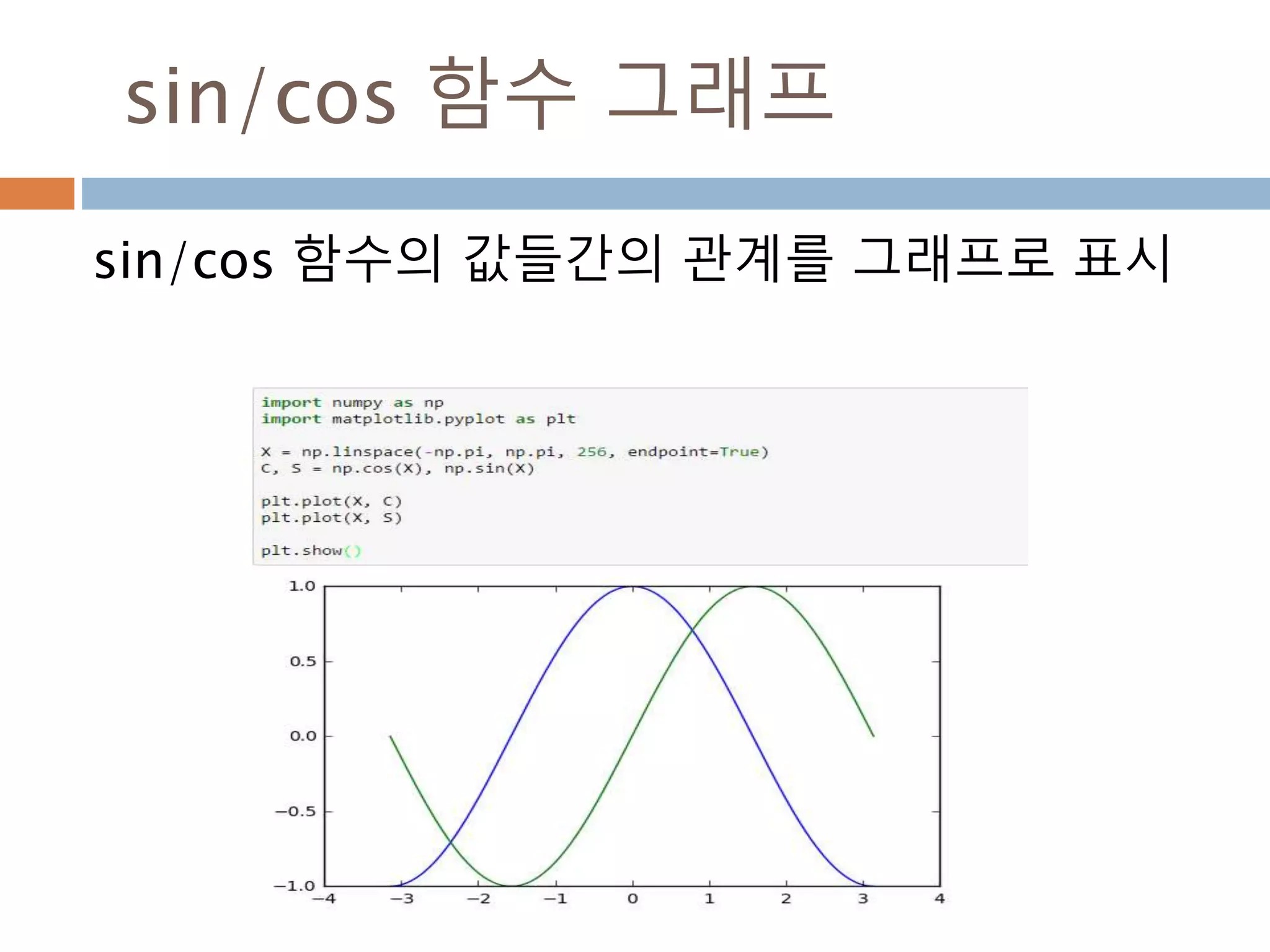
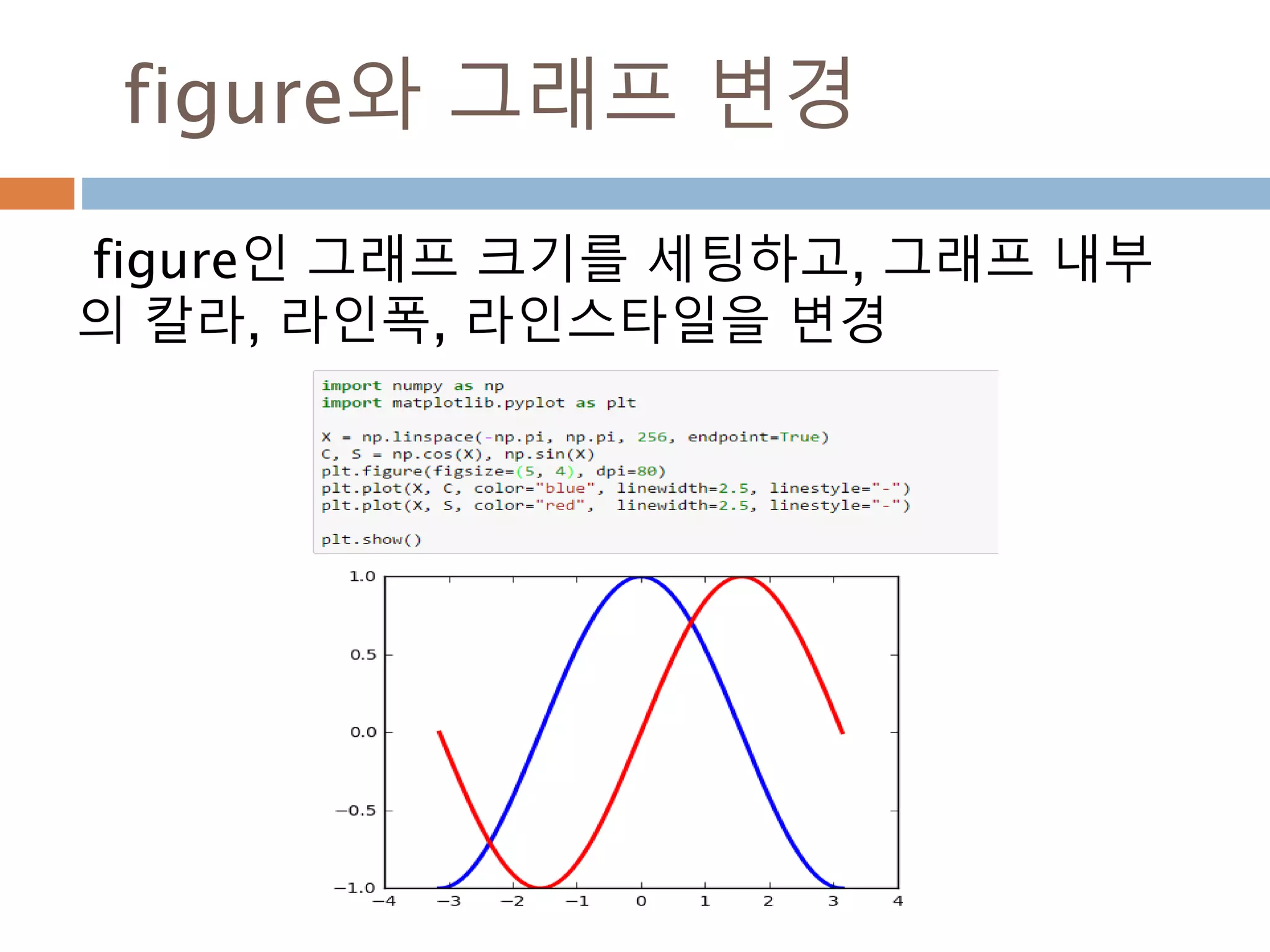
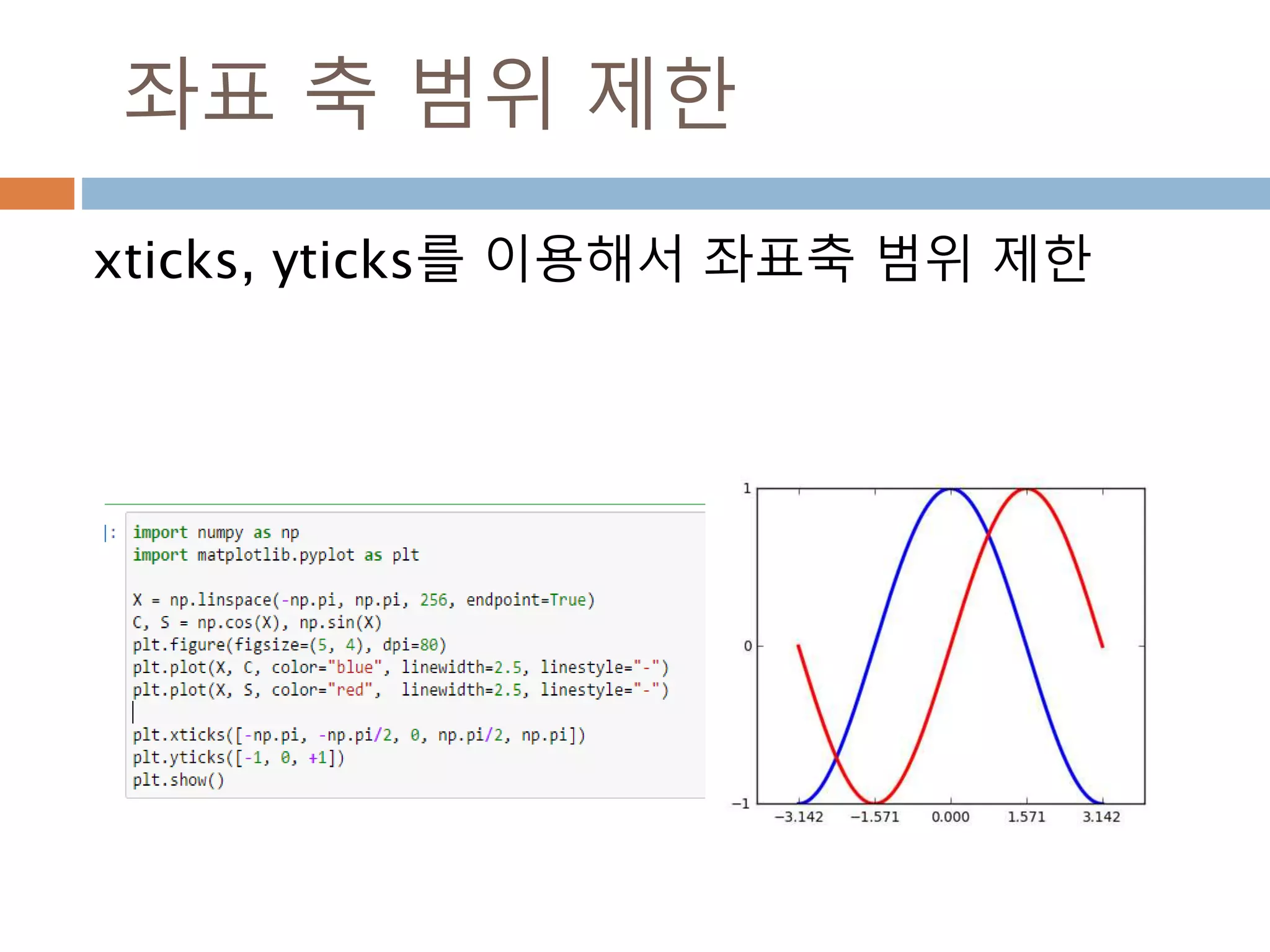
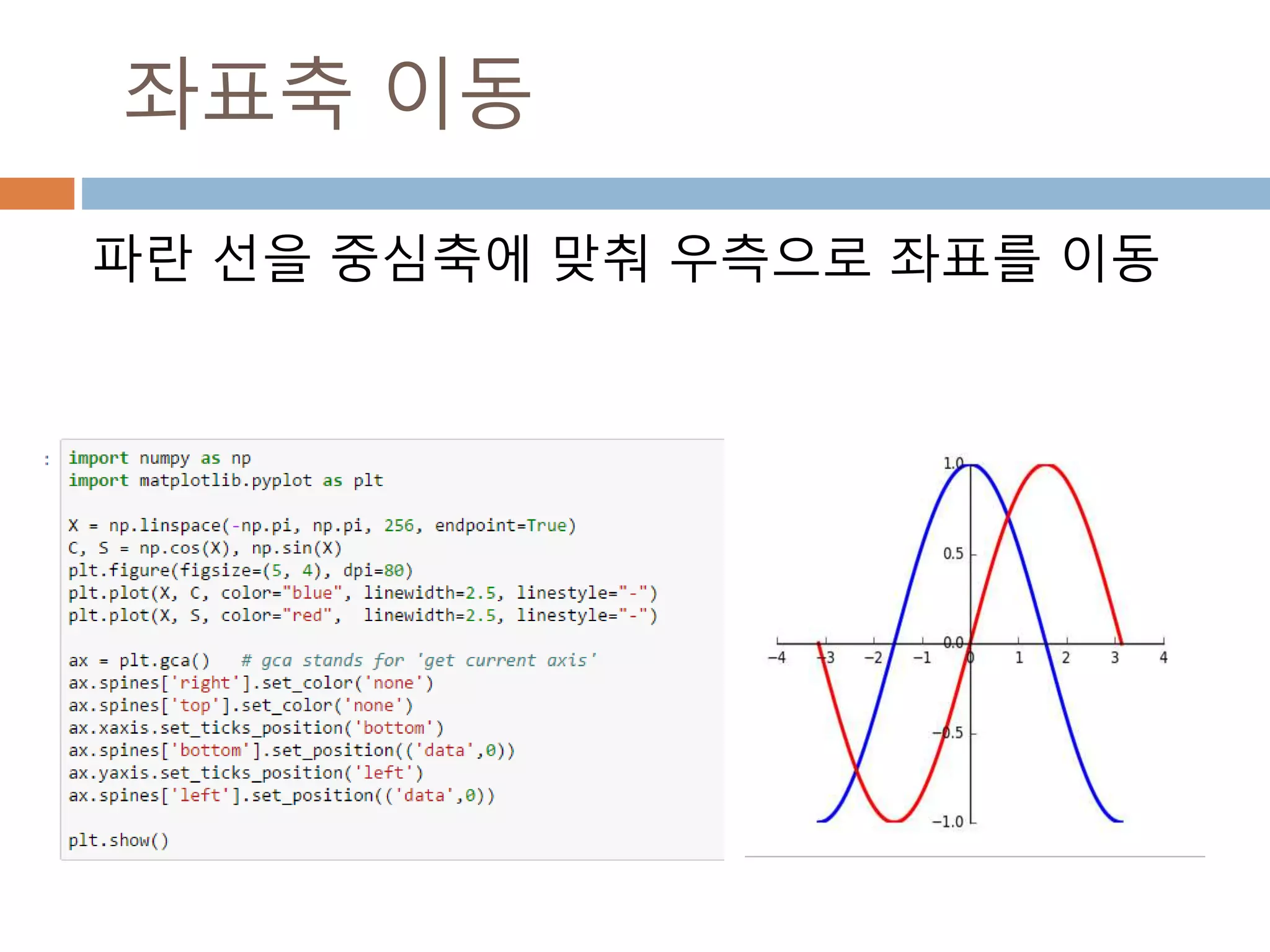


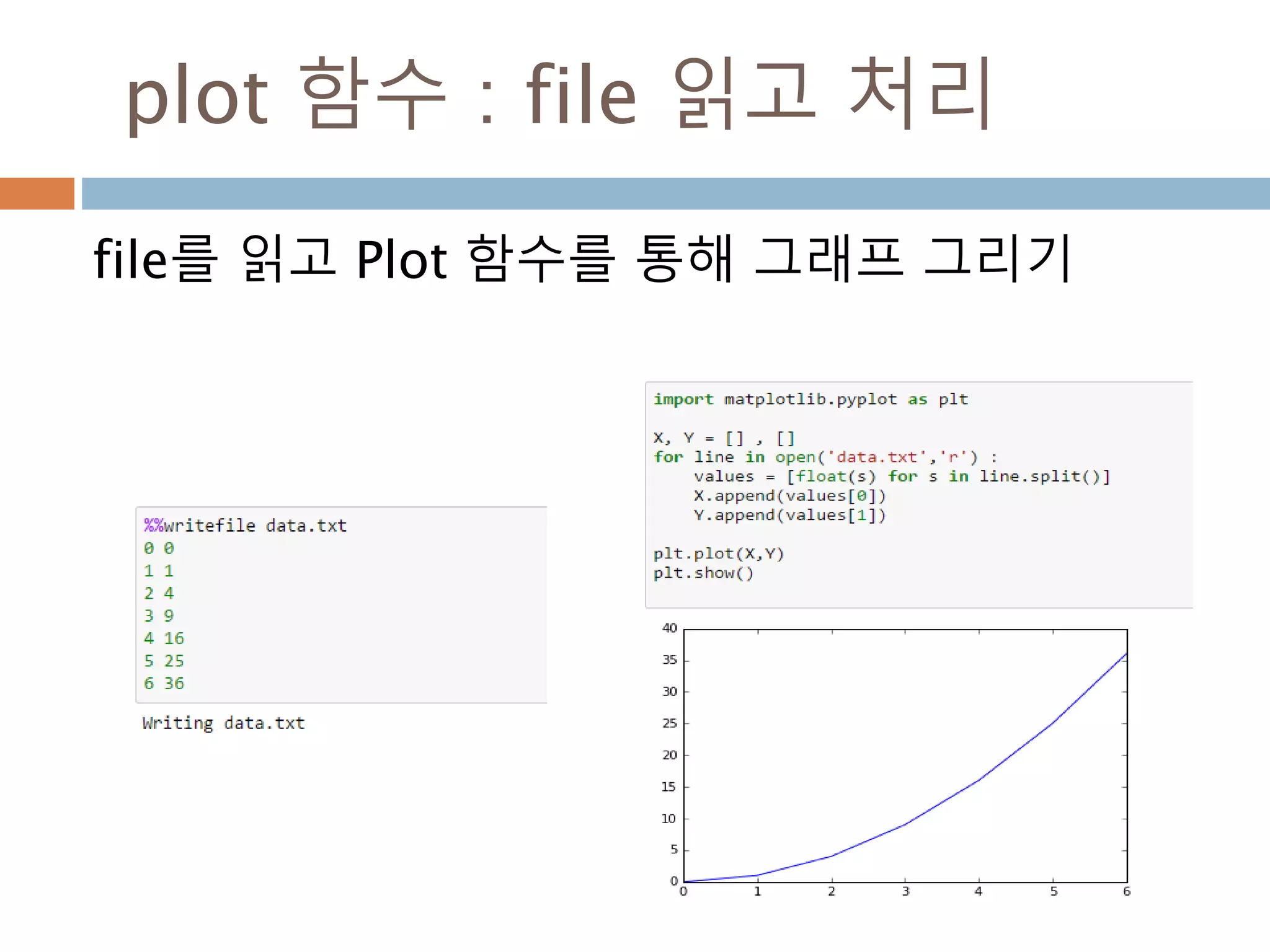

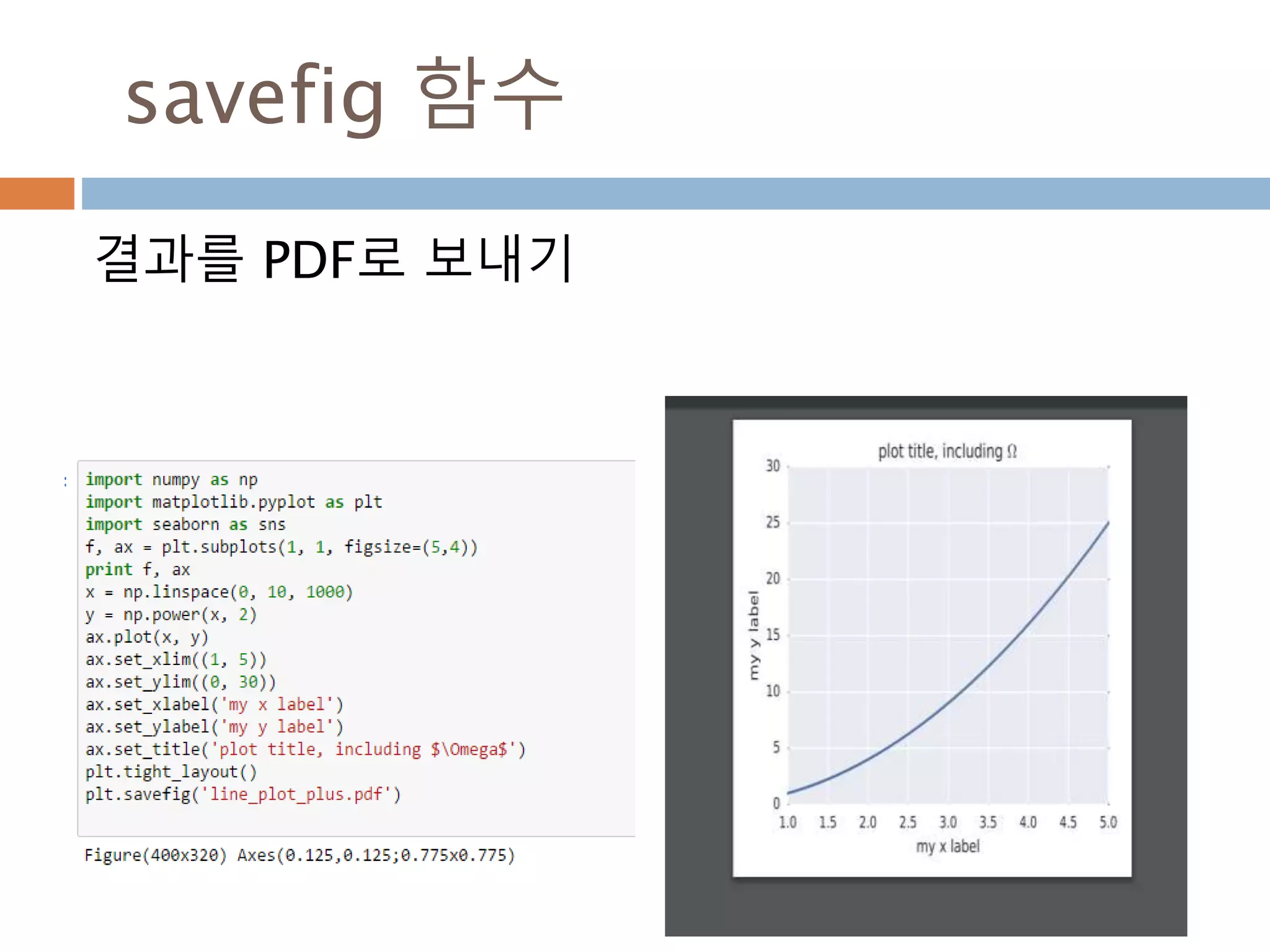




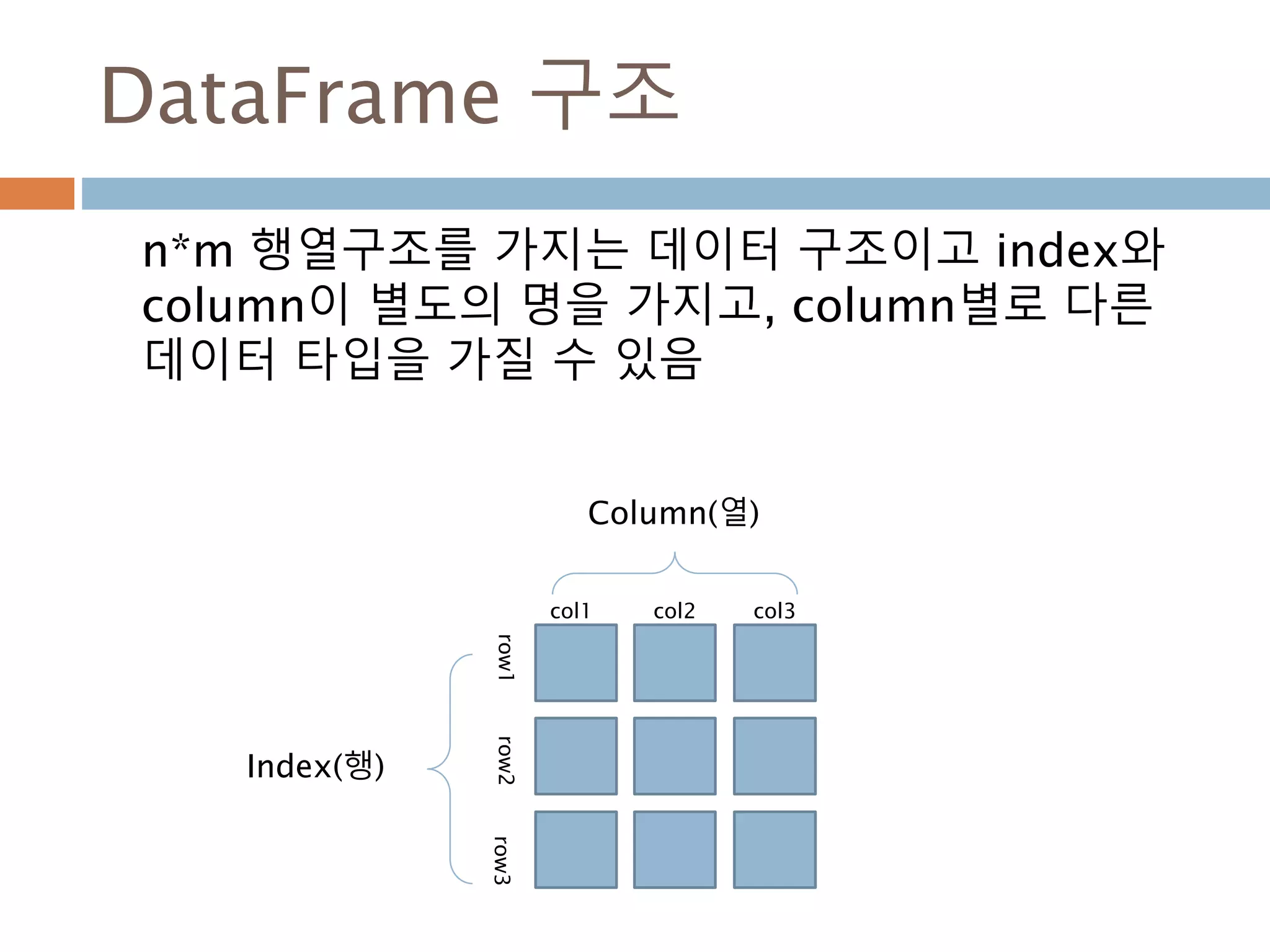
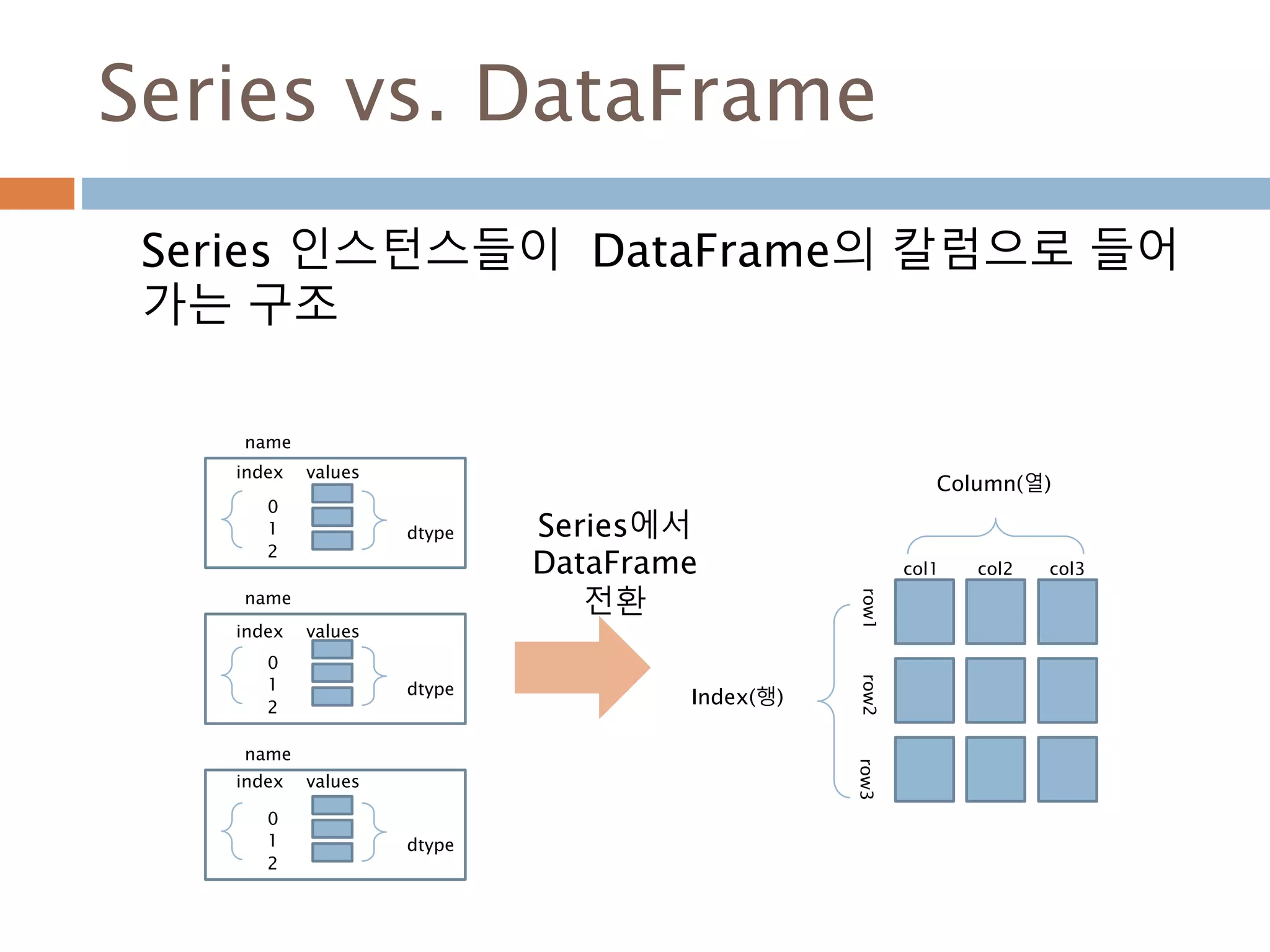


![확률밀도함수
확률밀도함수(probability density function 약
자 PDF )f(x)는 일정한 값들의 범위를 포괄하는
연속확률변수의 확률을 찾는데 사용하고 연속데
이터에서의 확률을 구하기 위해서 확률밀도함수
의 면적을 구함
703
확률 밀도함수 f(x)와 구간[a,b] 에
대해 확률변수 X가 구간에 포함될
확률 P(a<= X<=b)는](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-703-2048.jpg)
![연속균등분포
연속균등분포(continuous uniform distribution)은
연속 확률 분포로, 분포가 특정 범위 내에서 균등하
게 나타나 있을 경우를 가리킨다. 이 분포는 두 개의
매개변수 a,b를 받으며, 이때 [a,b] 범위에서 균등한
확률을 가진다.
705](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-705-2048.jpg)







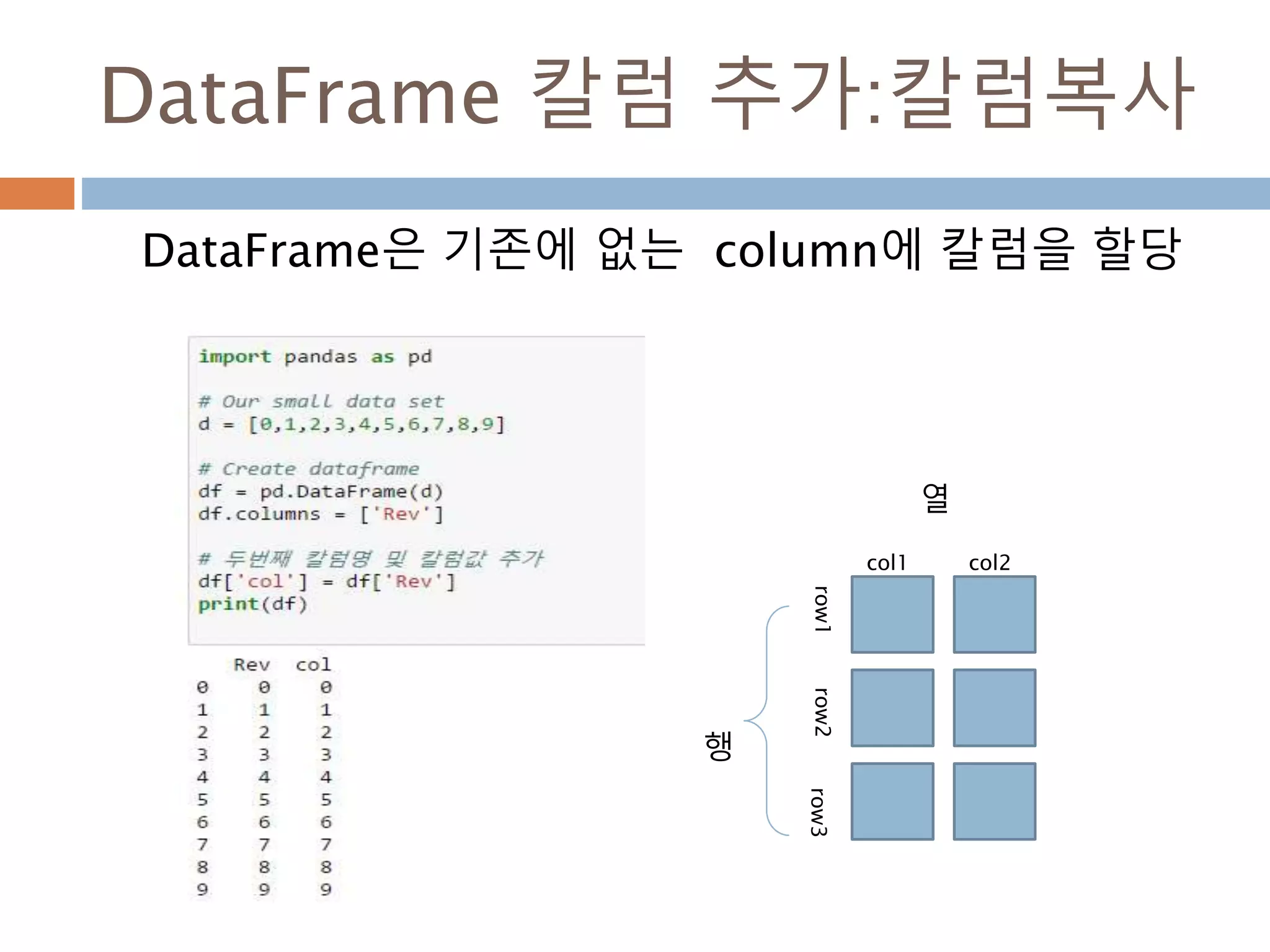




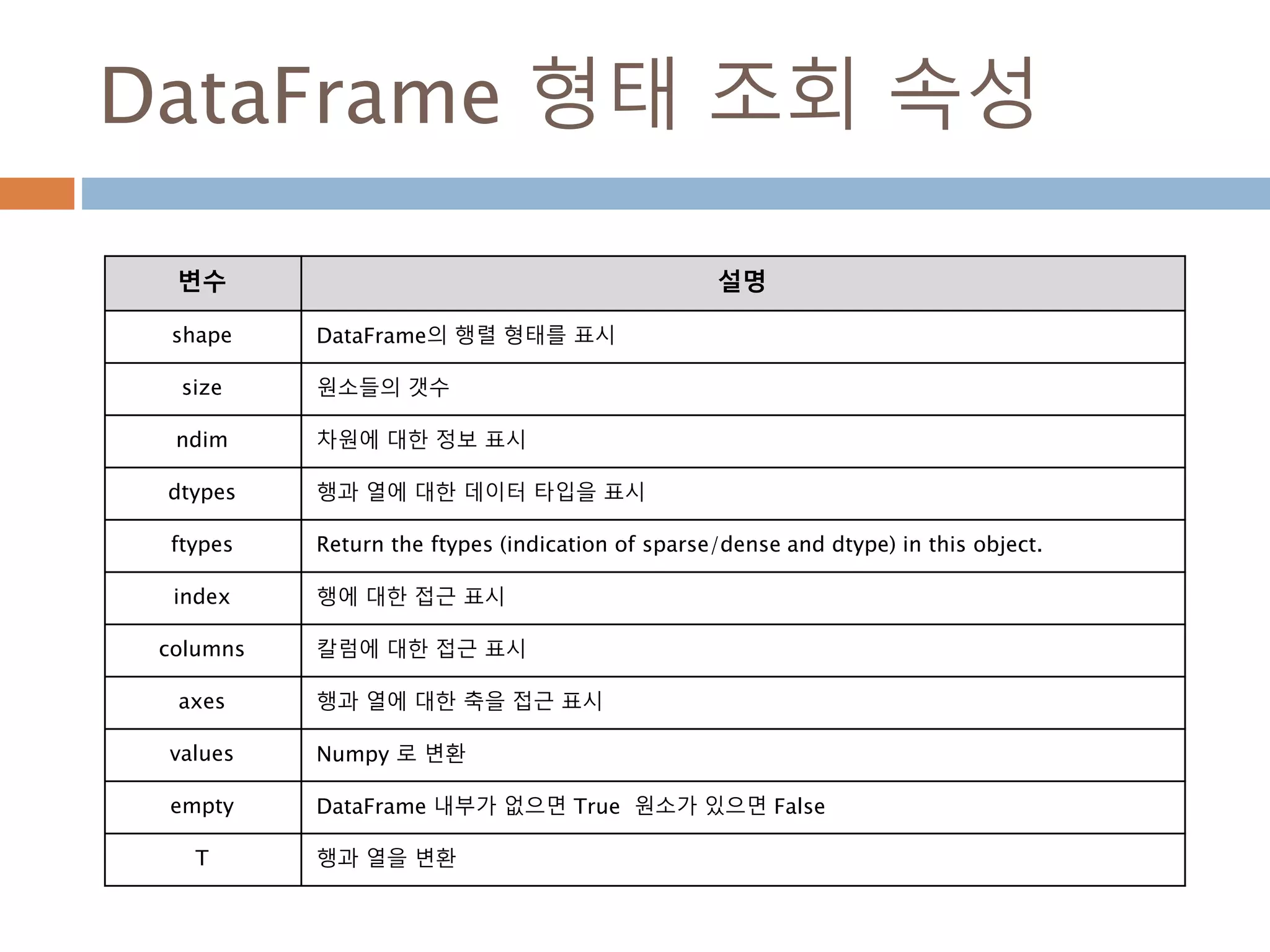






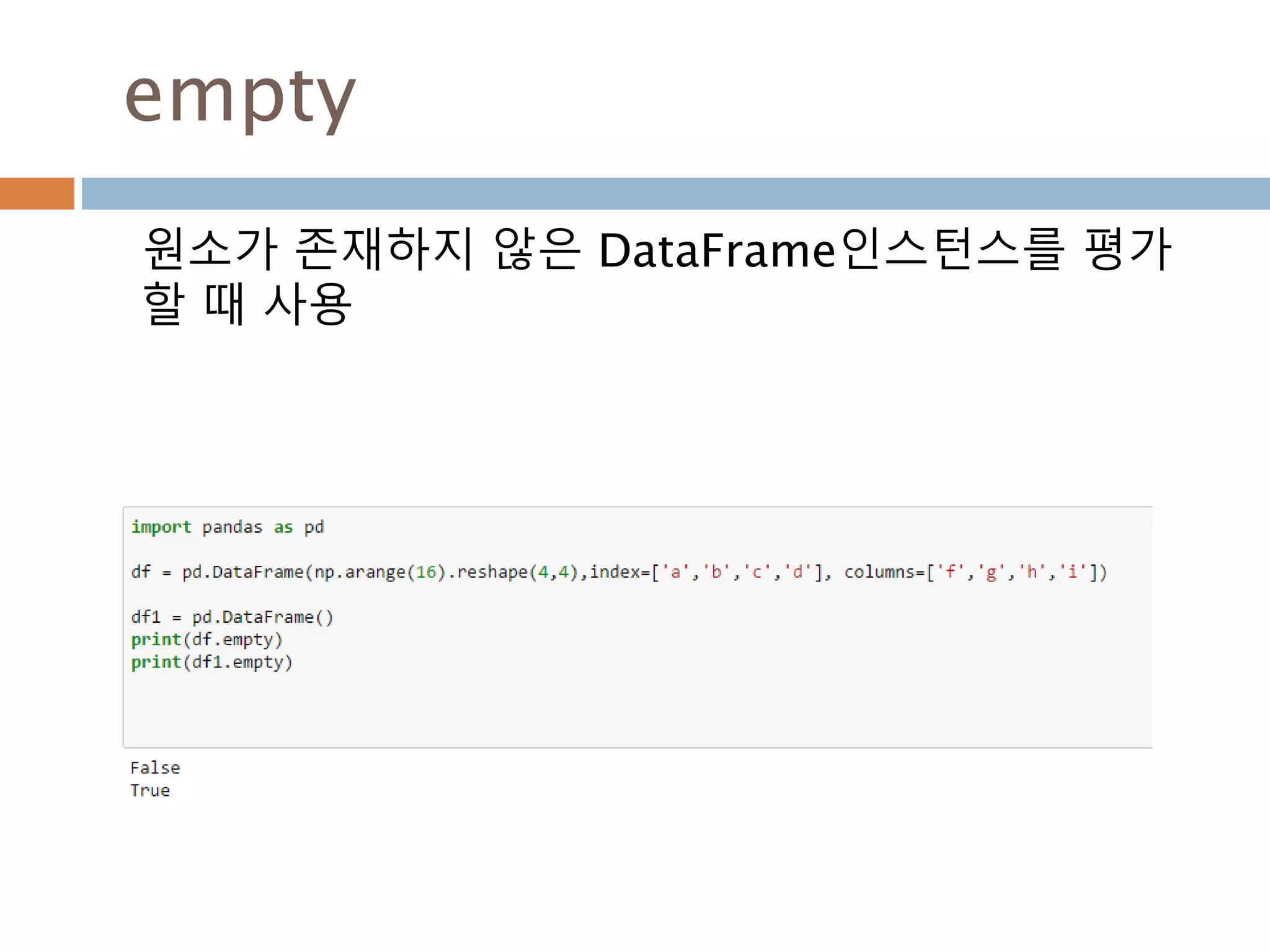


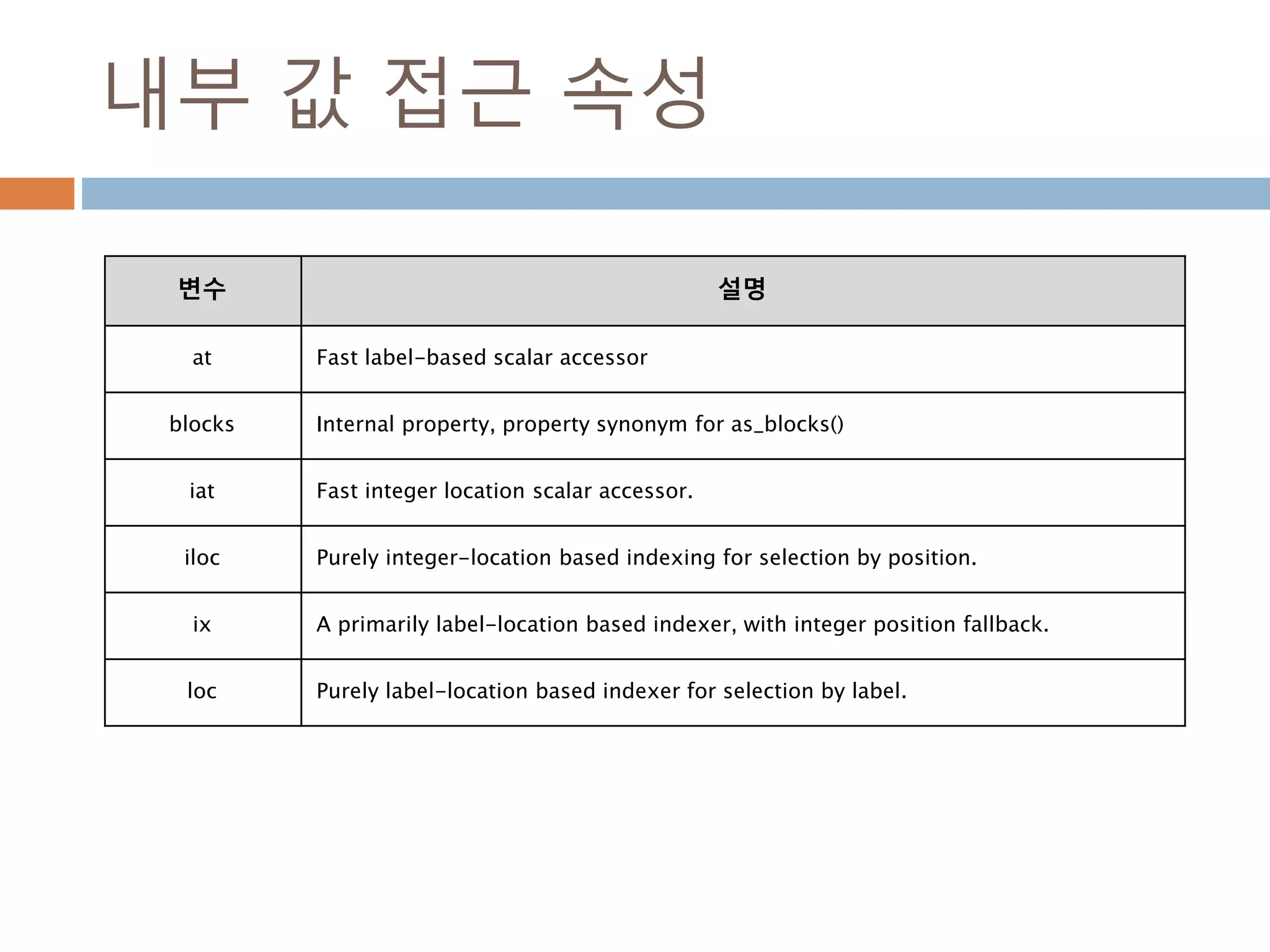





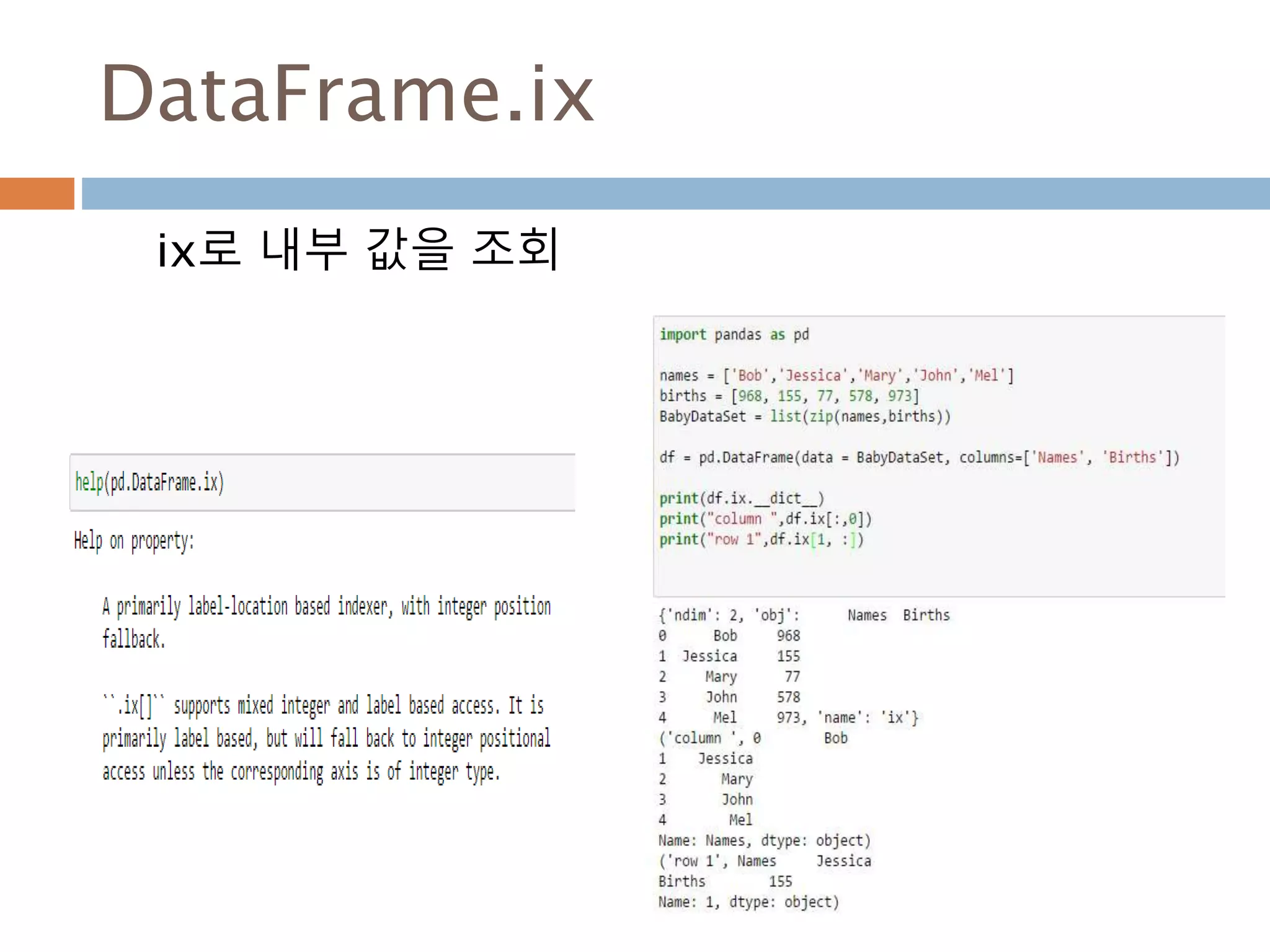
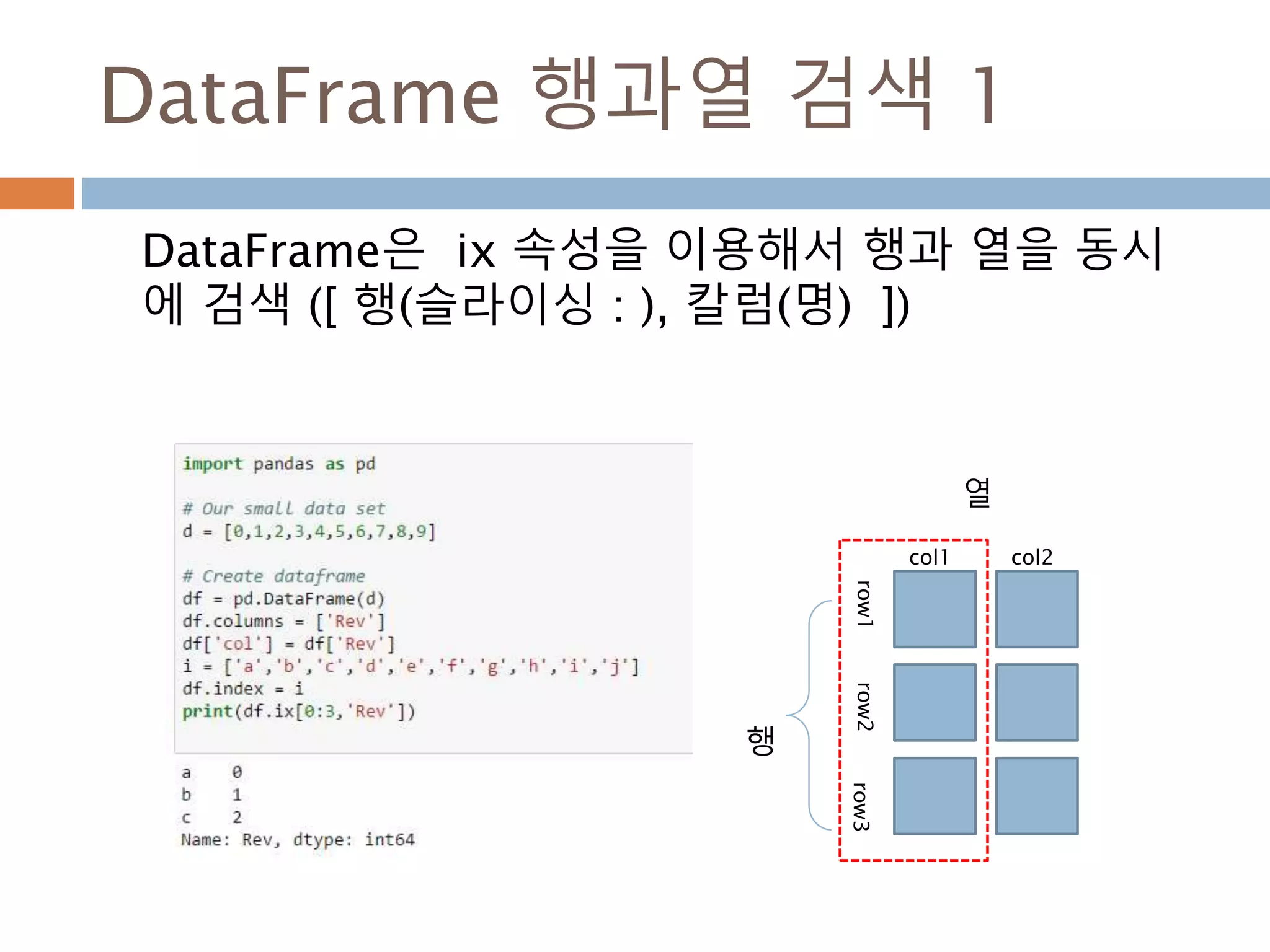
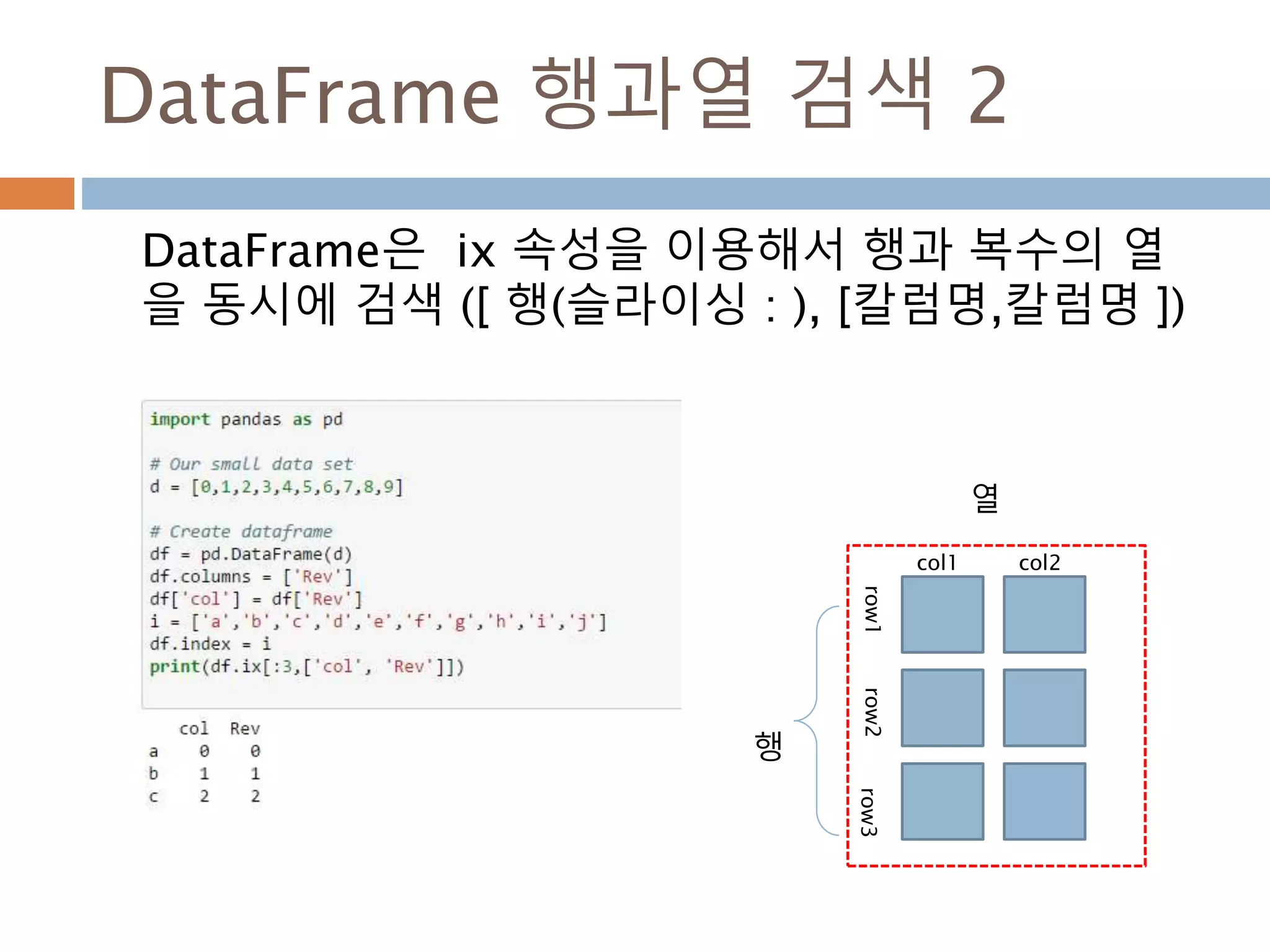

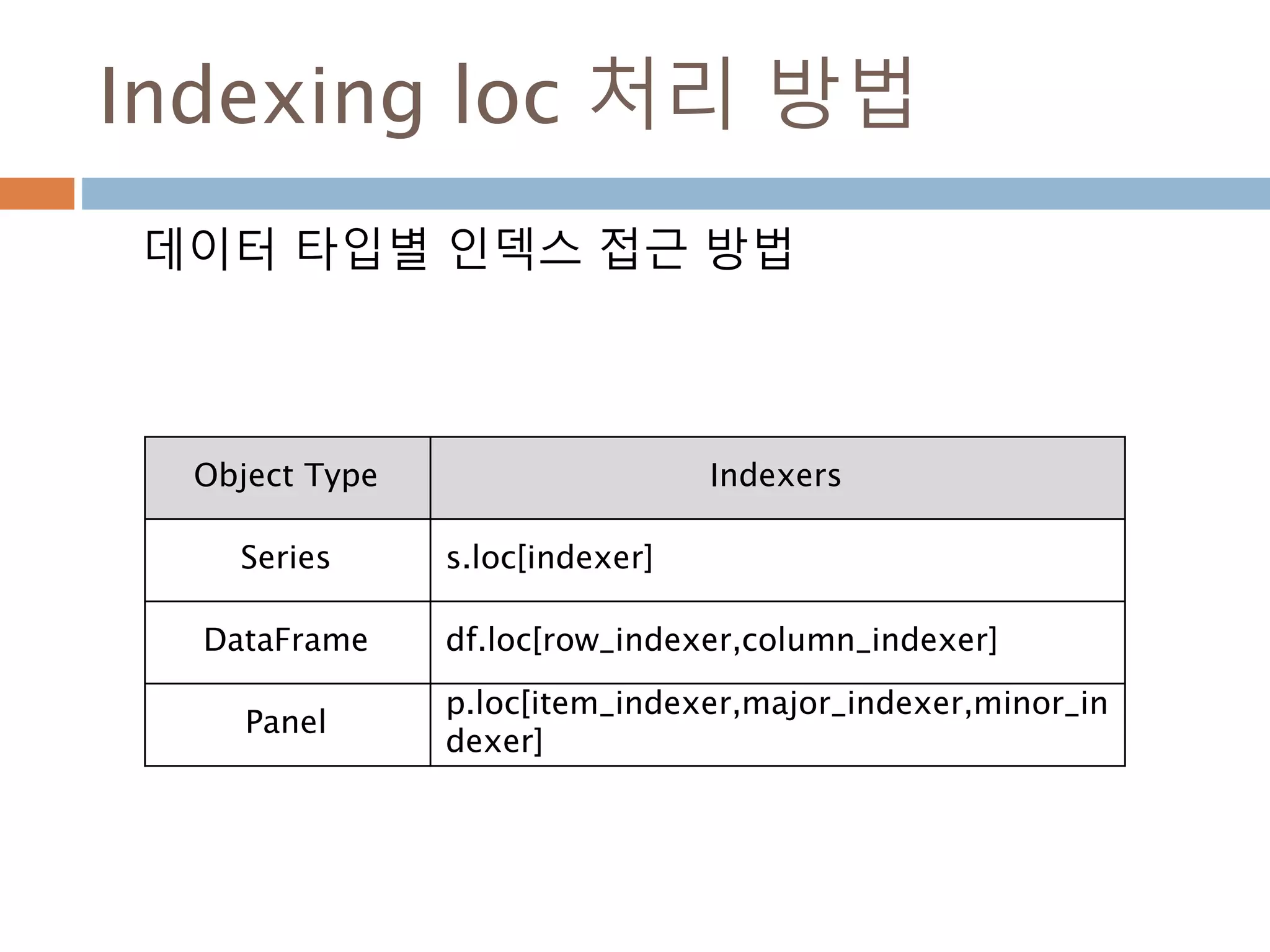
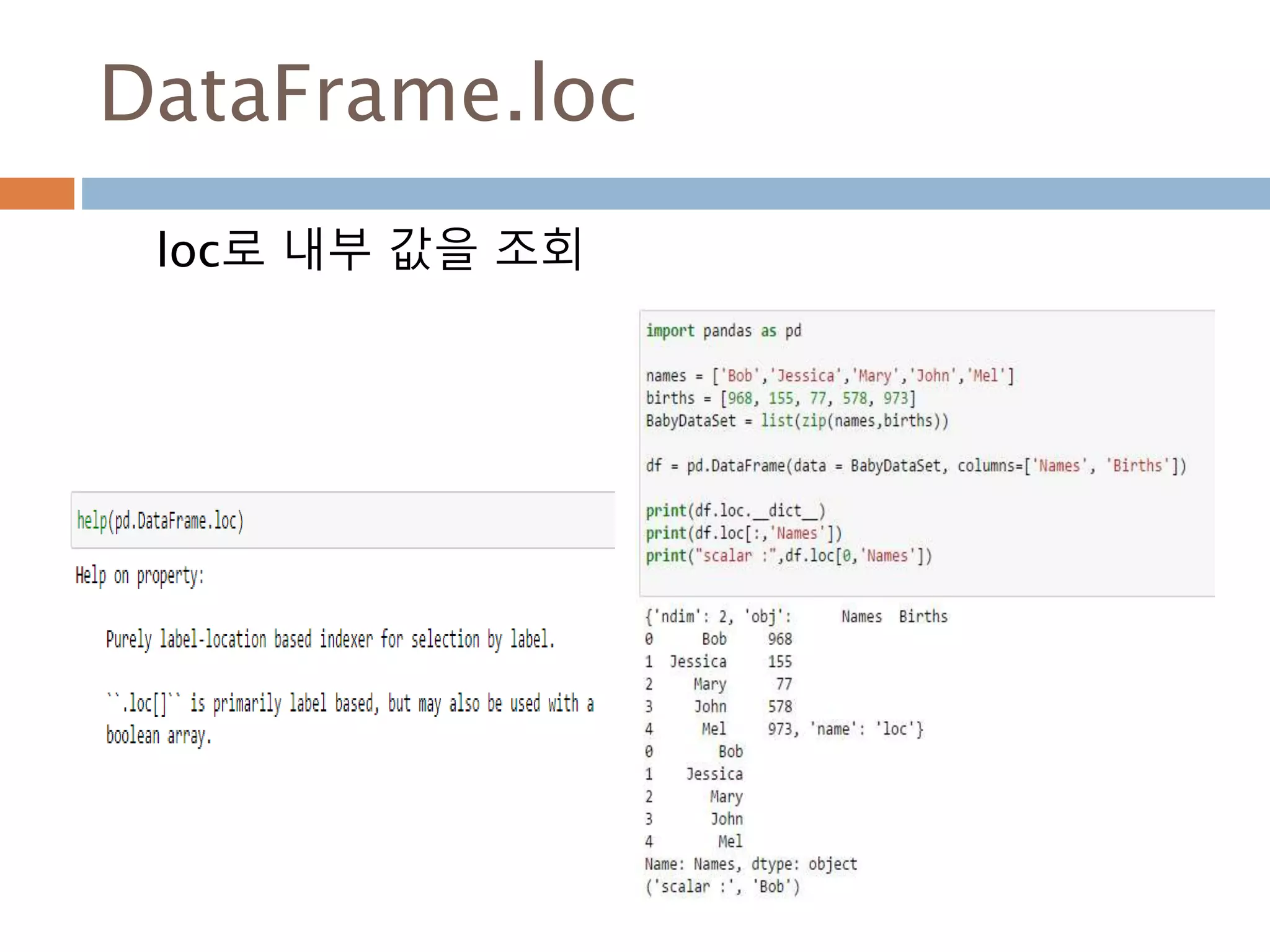

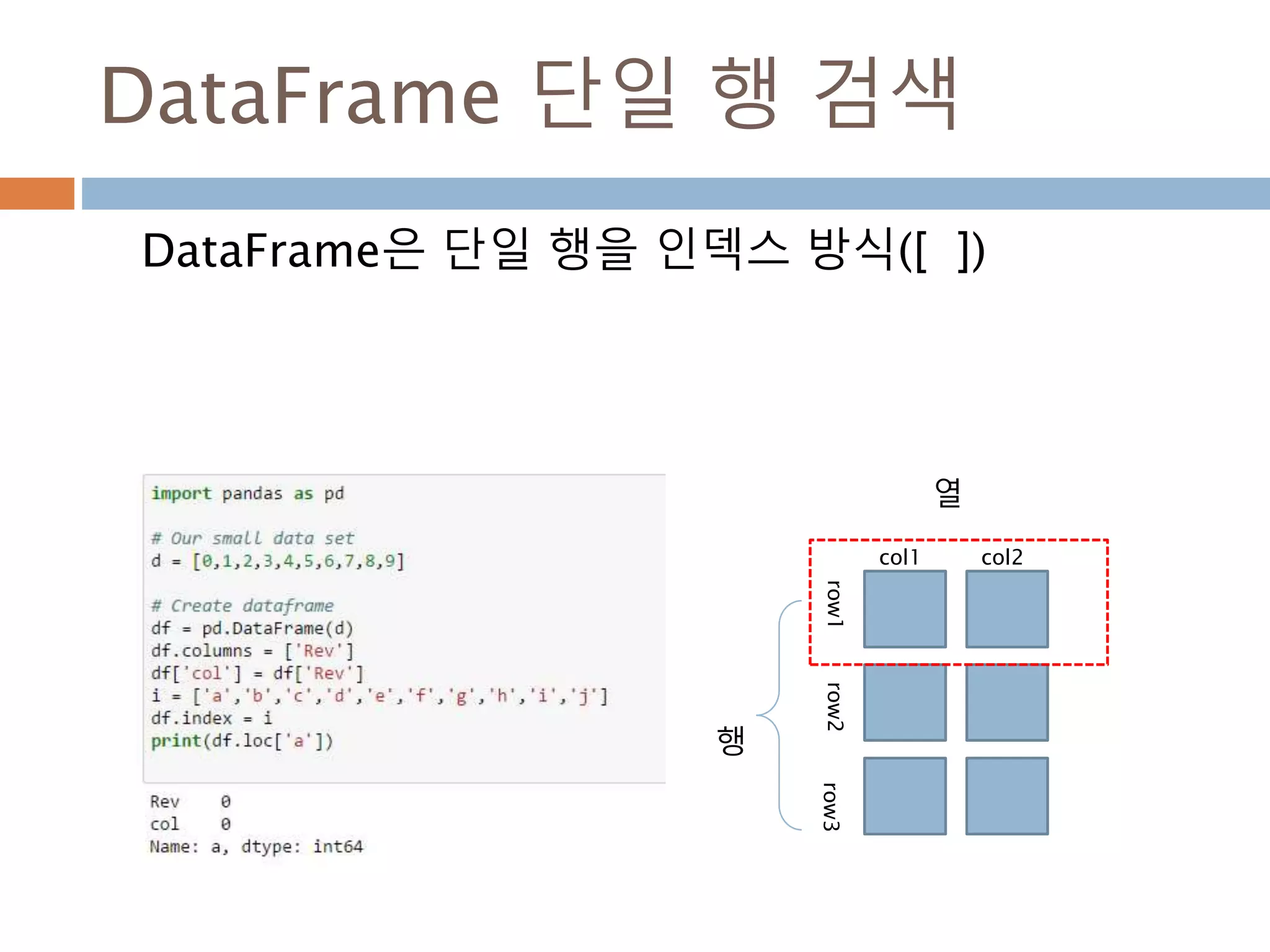




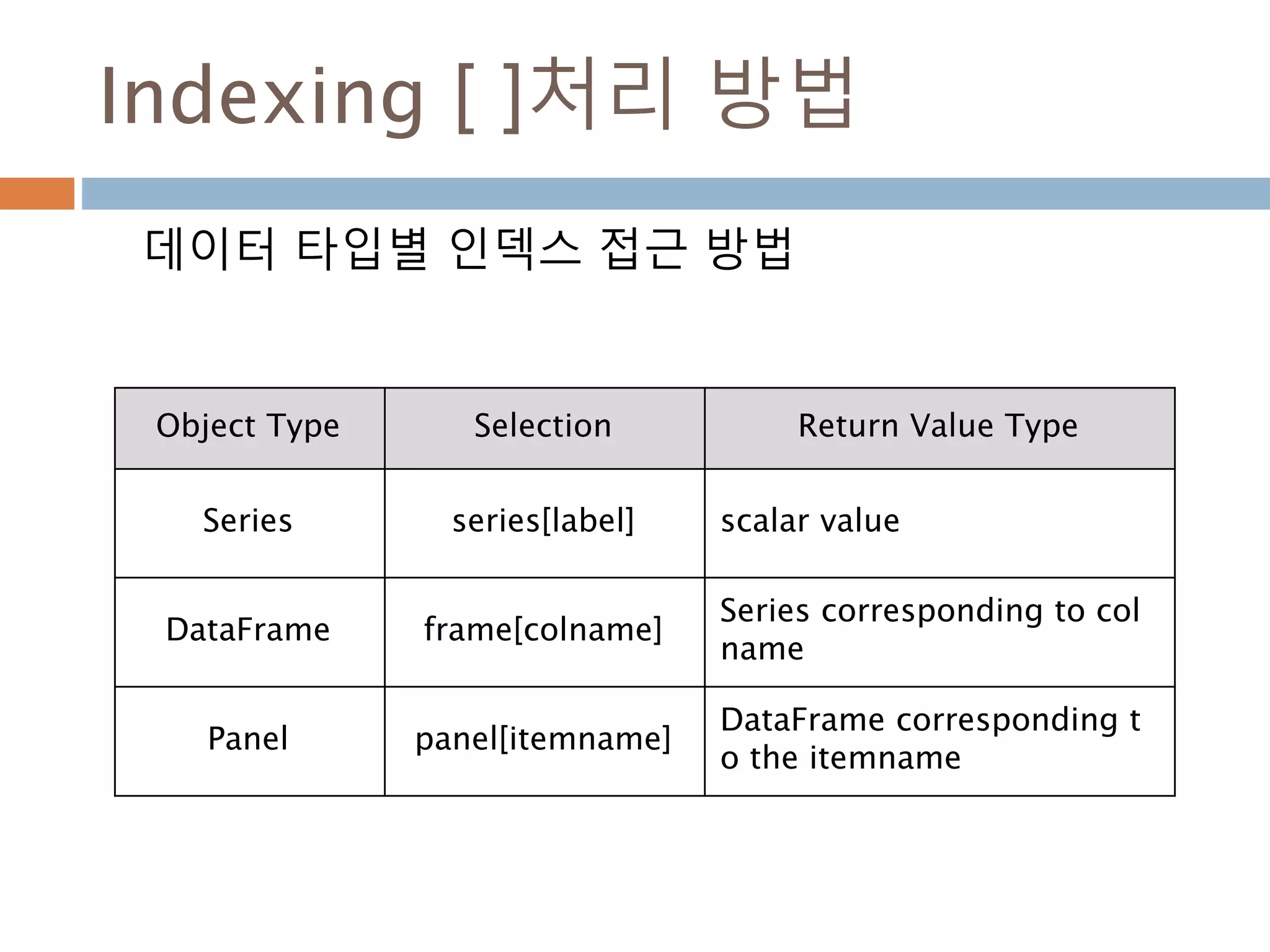

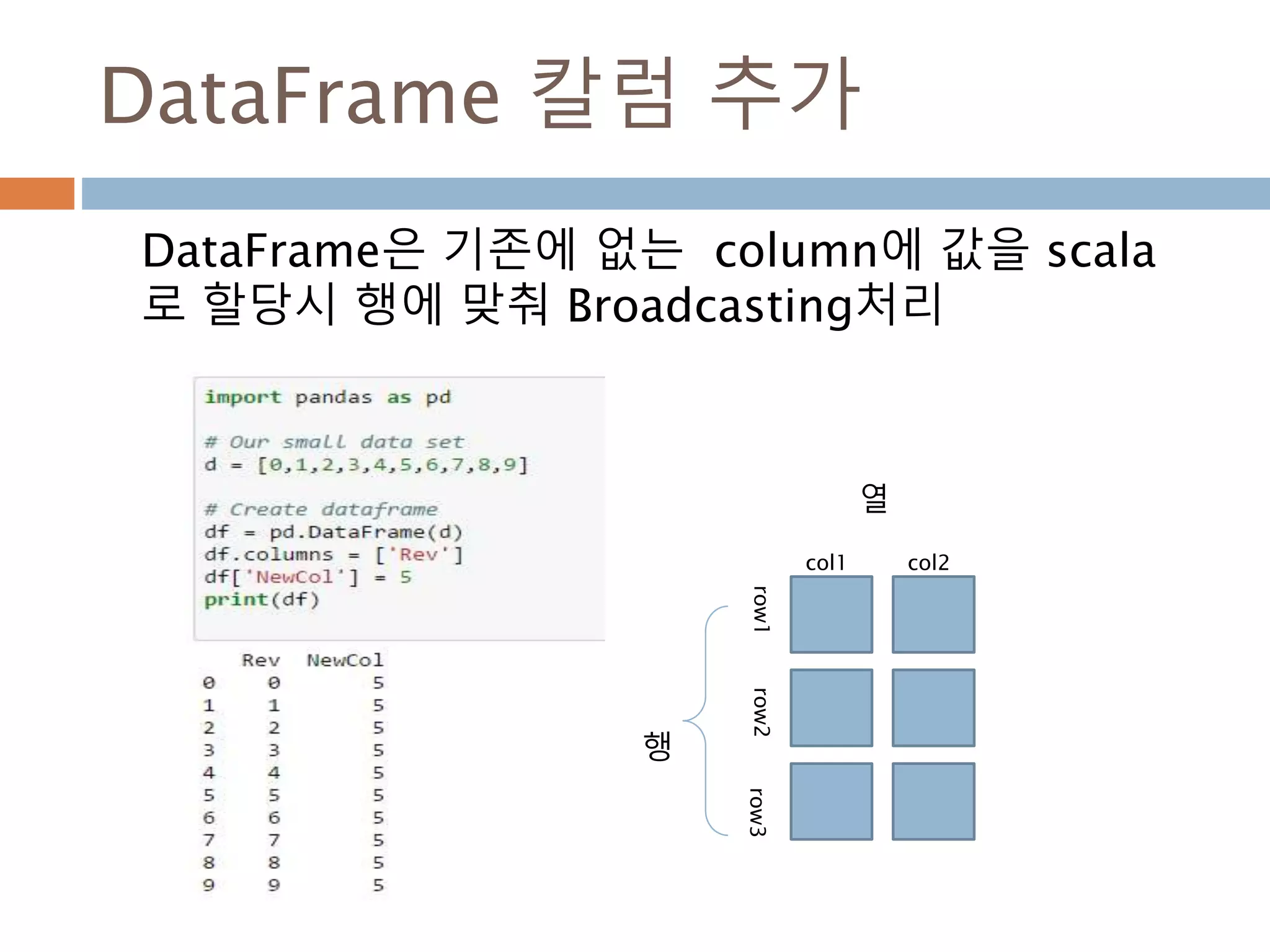



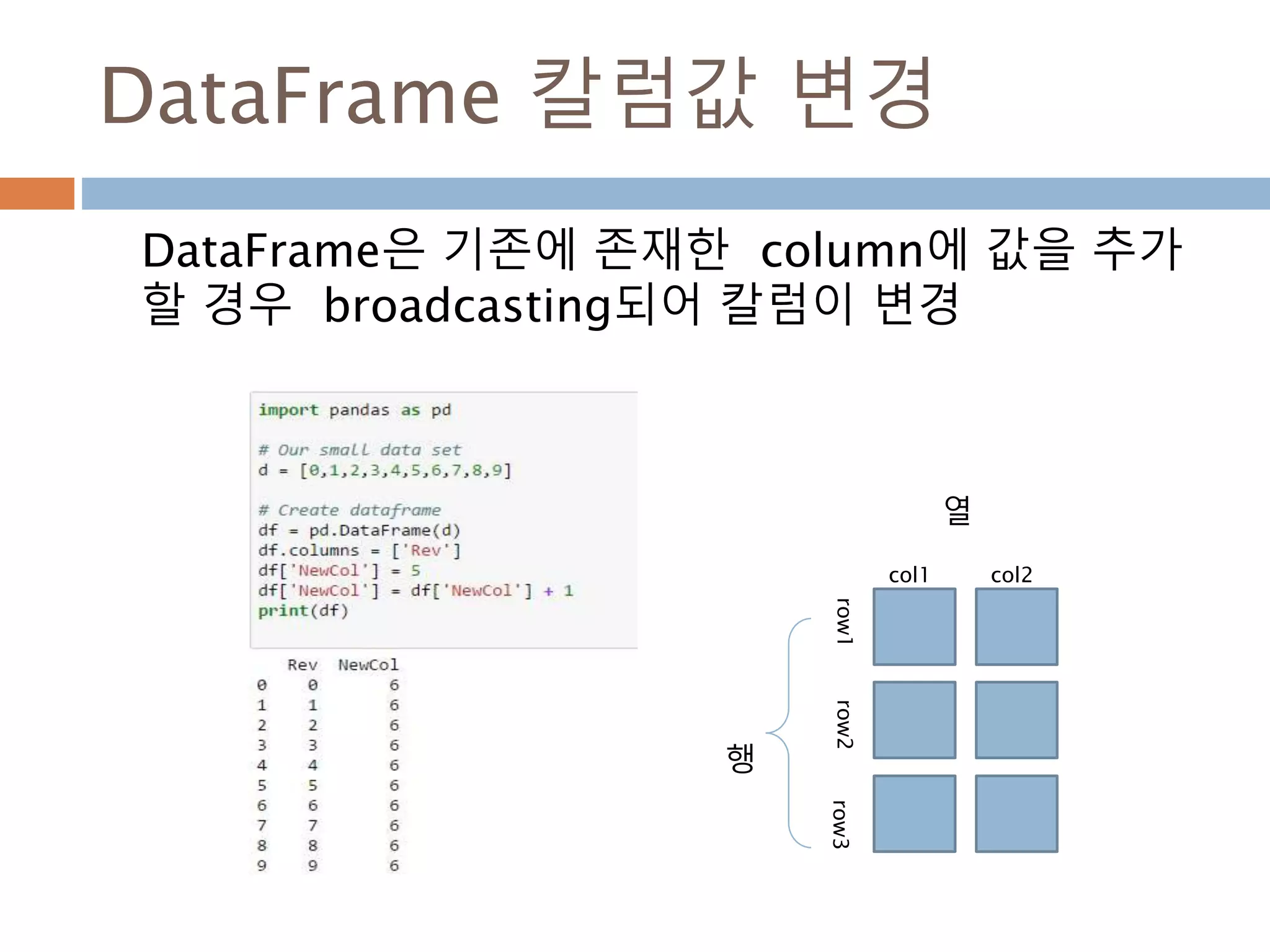

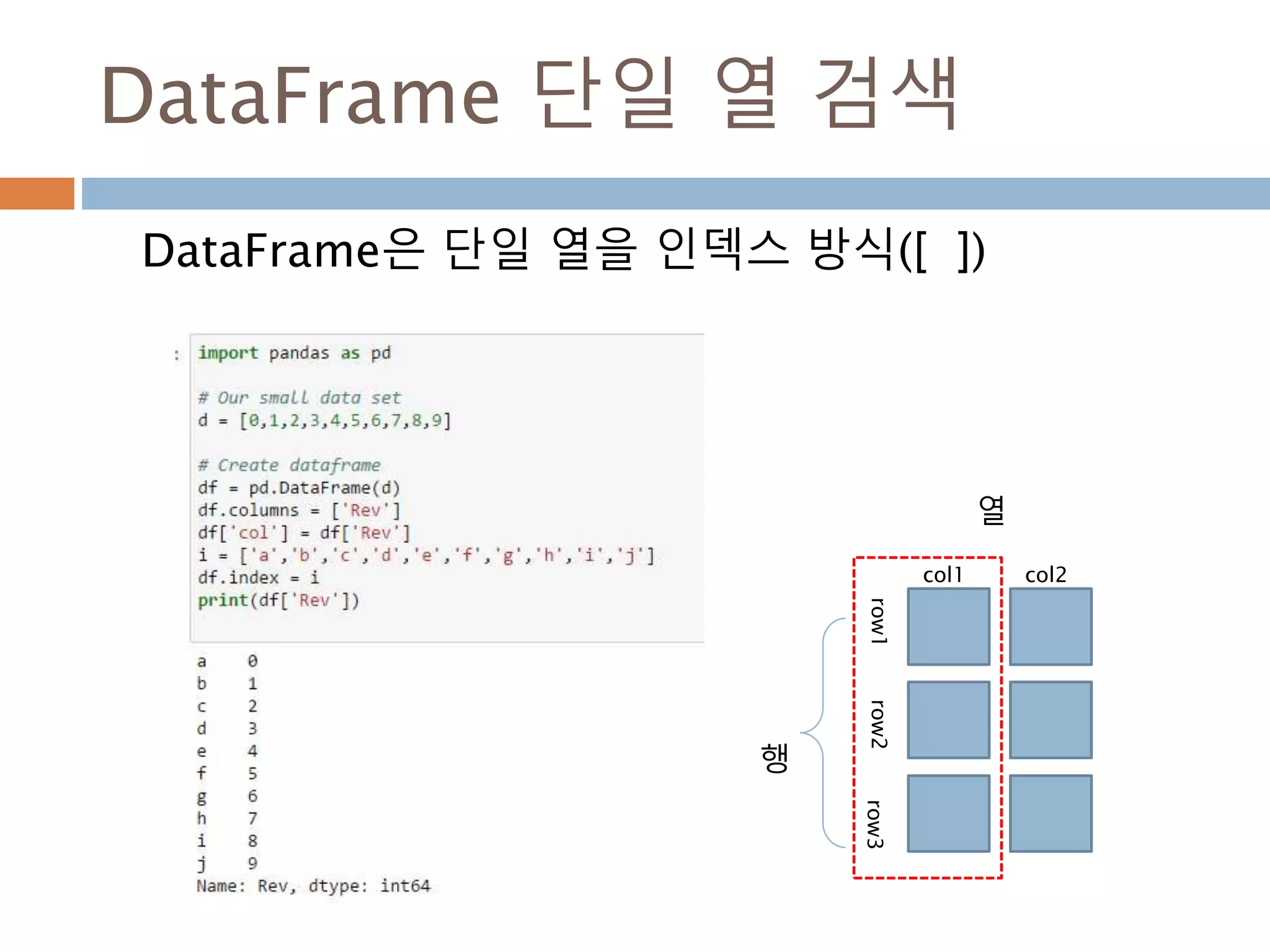
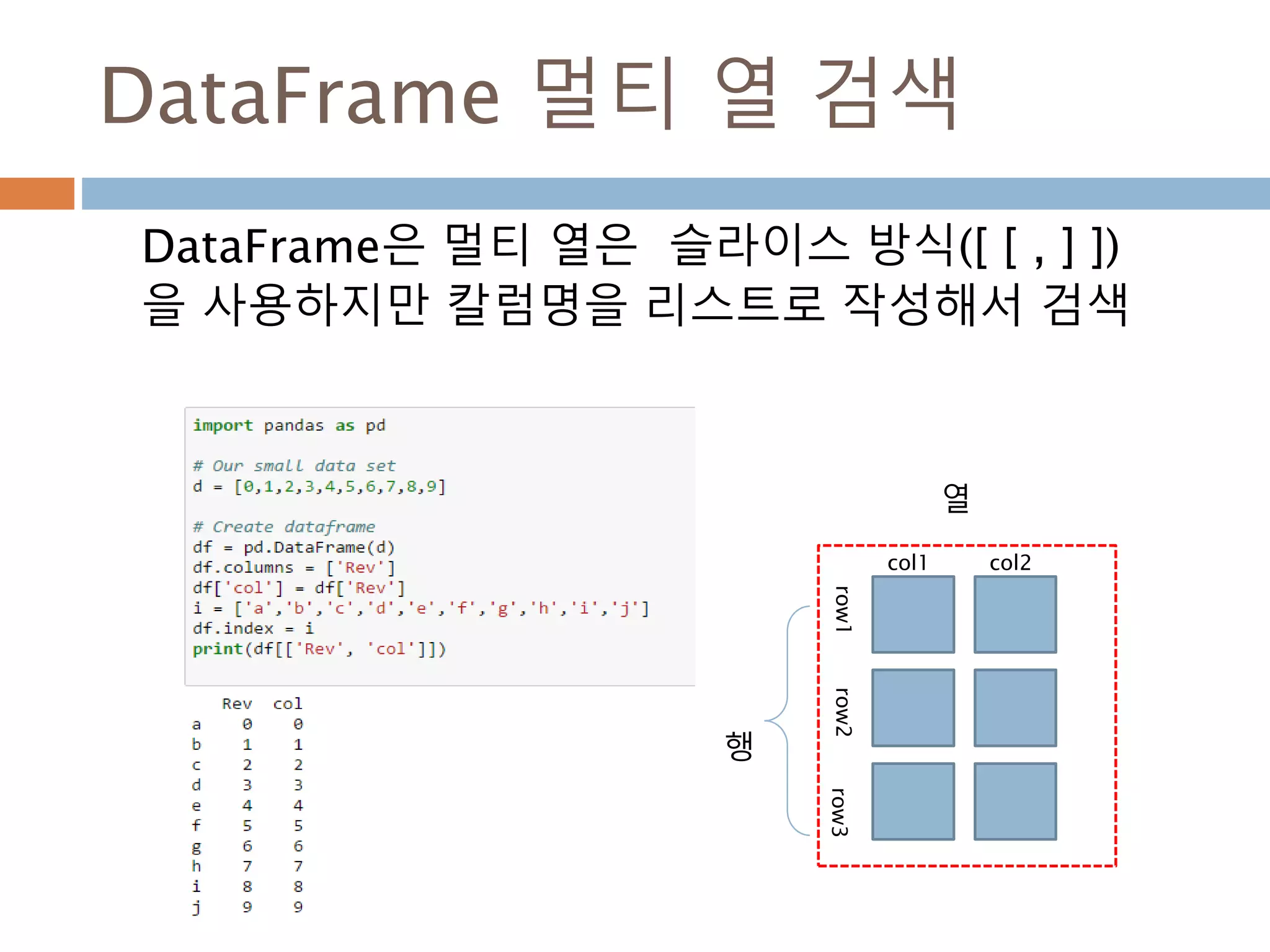


























































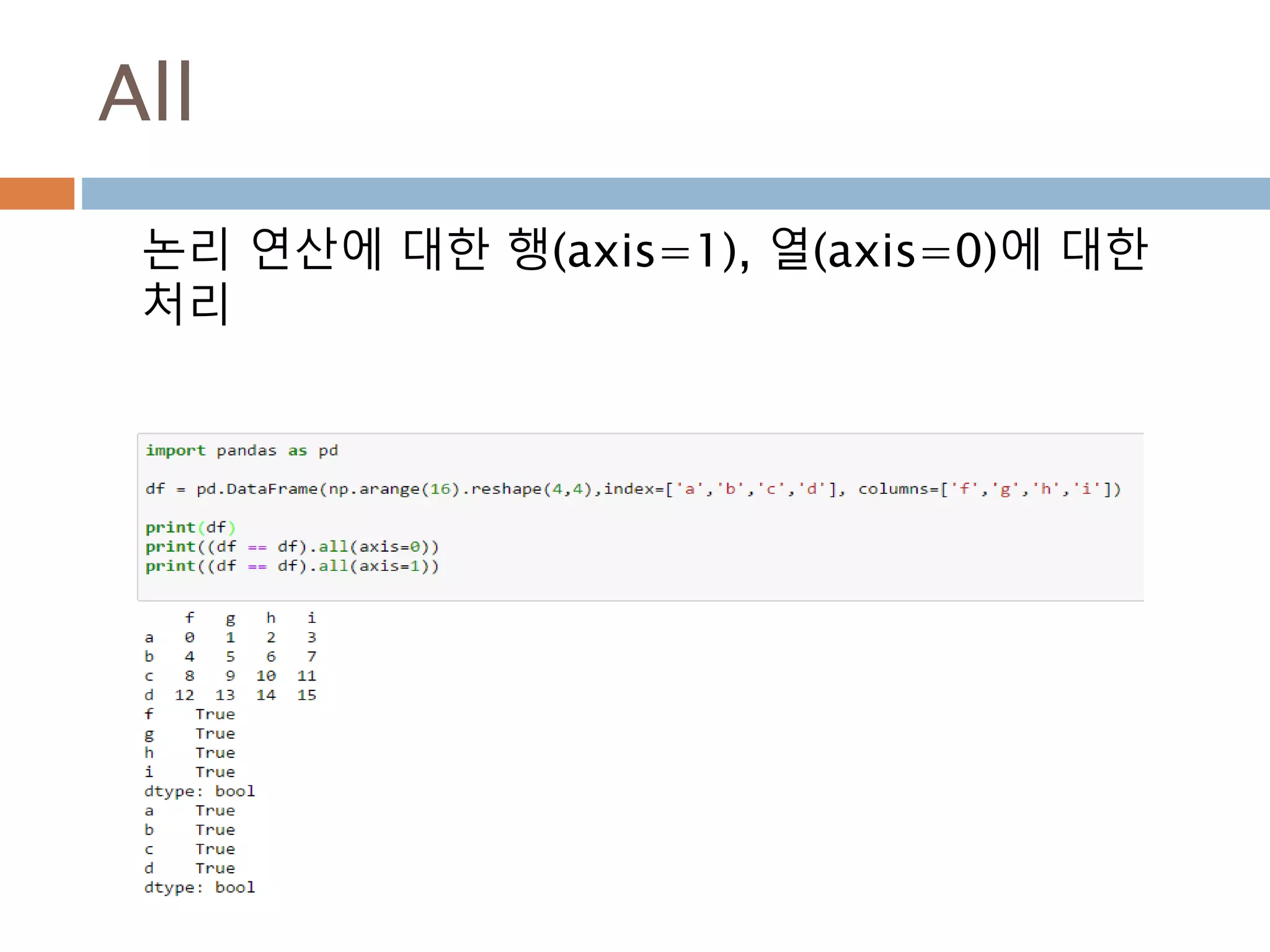
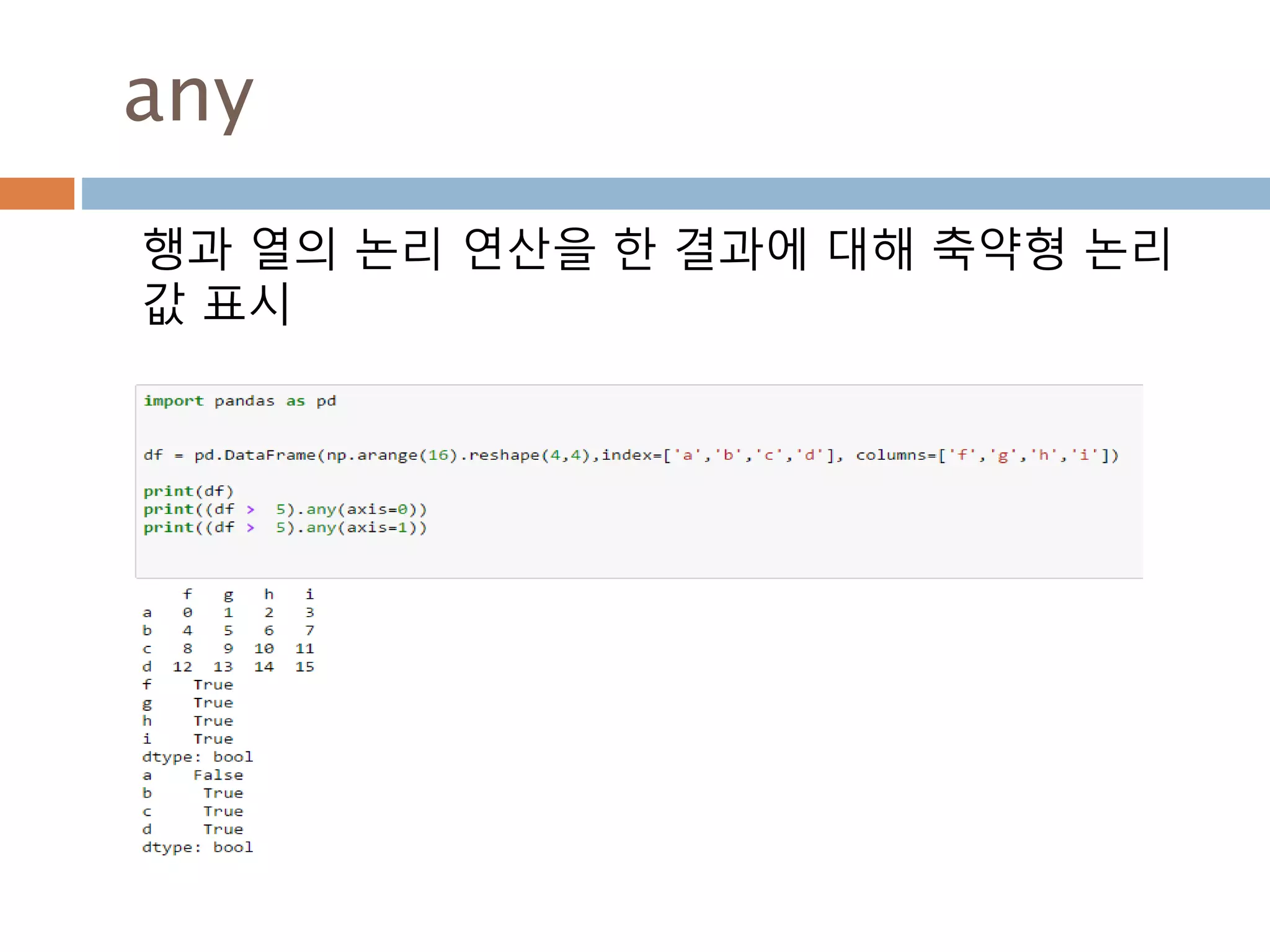
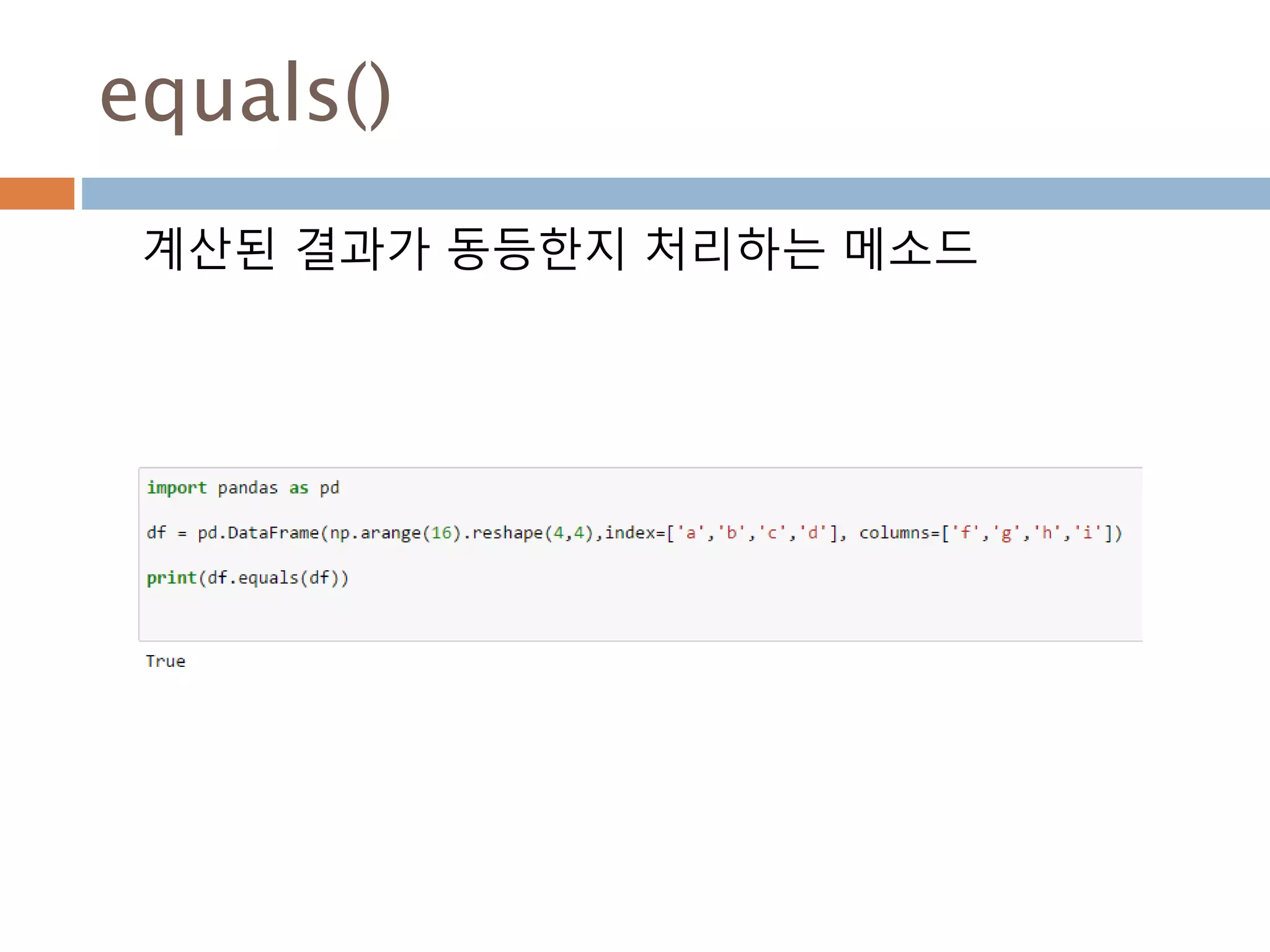





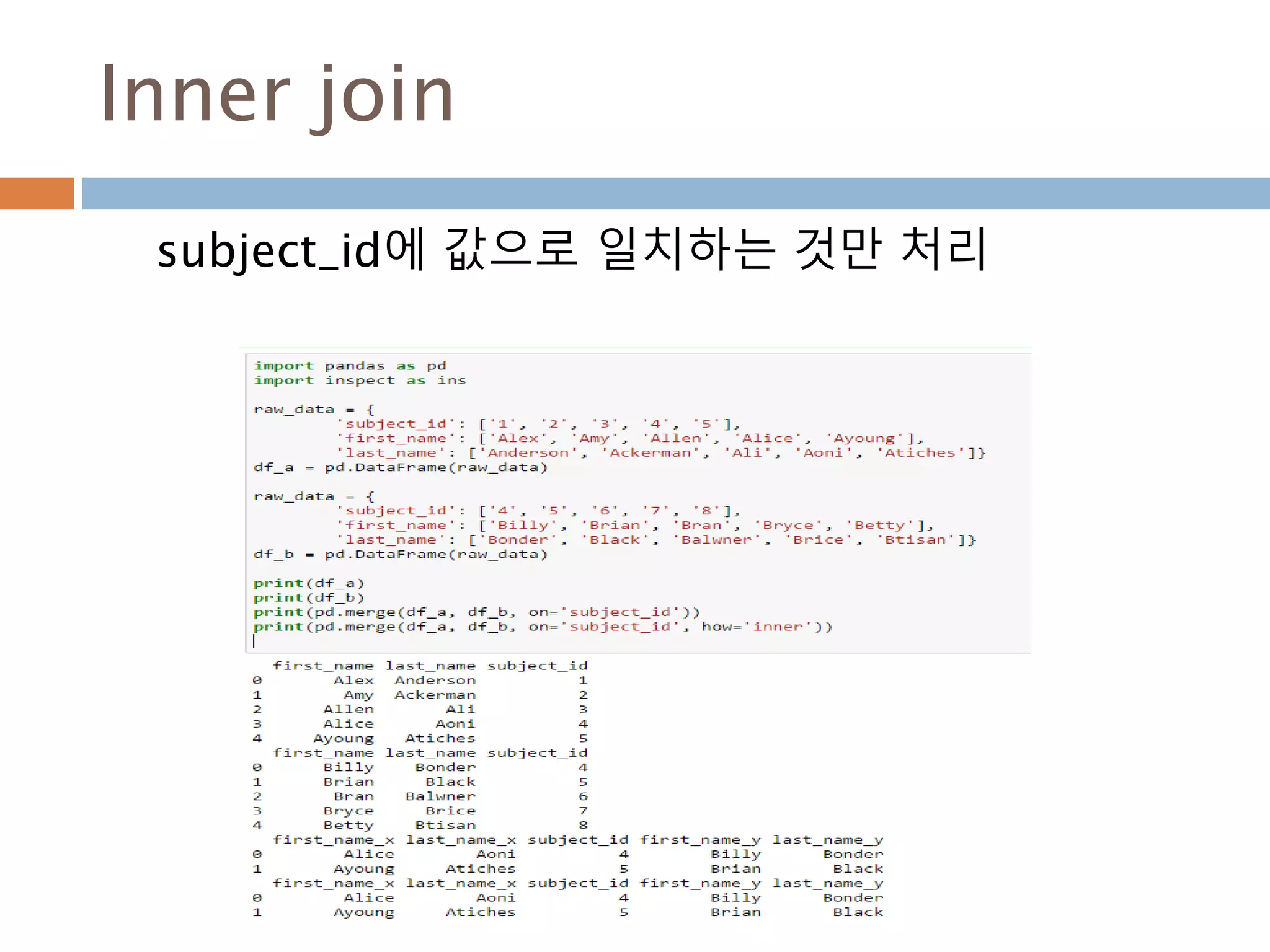



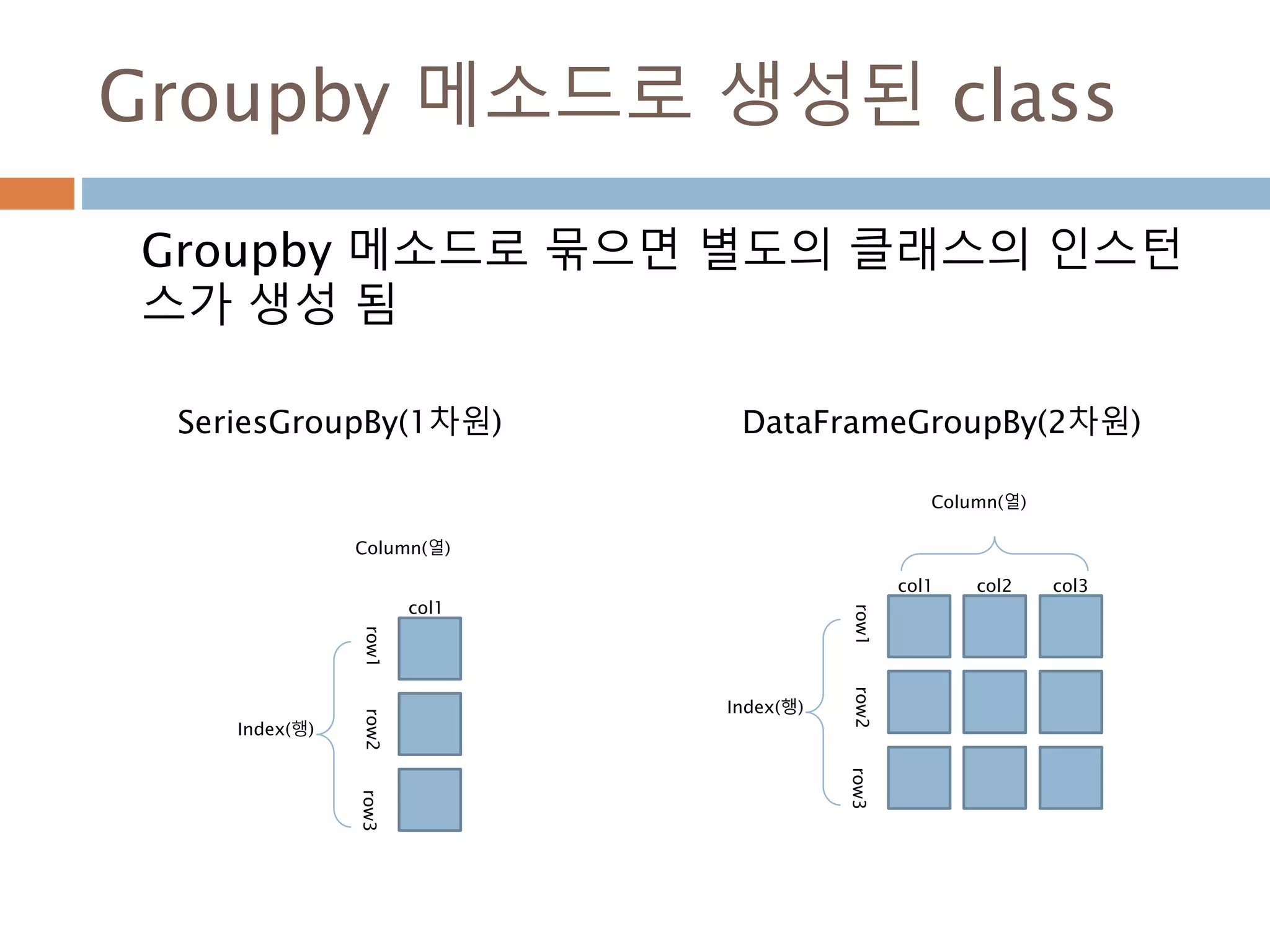





















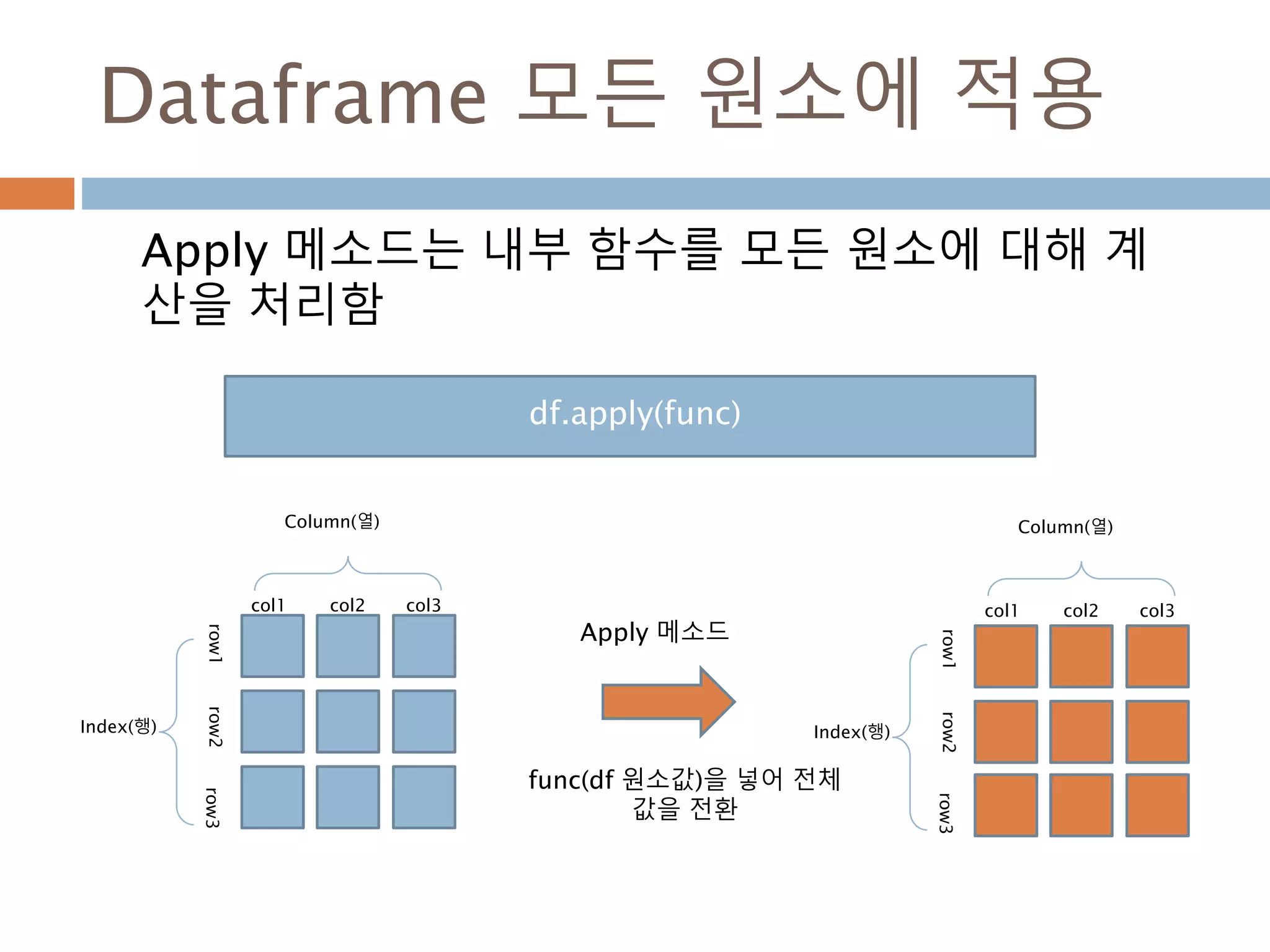




















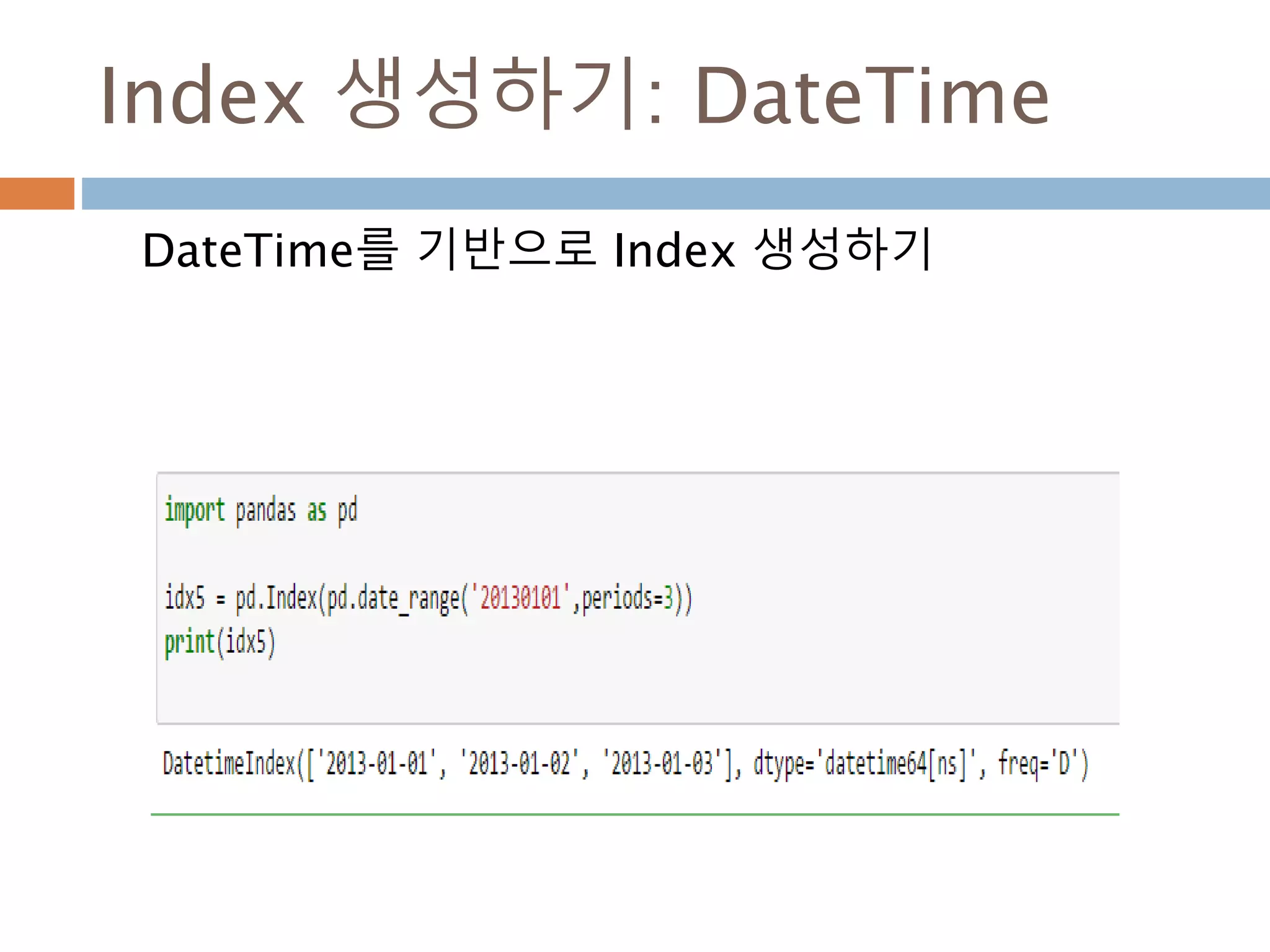













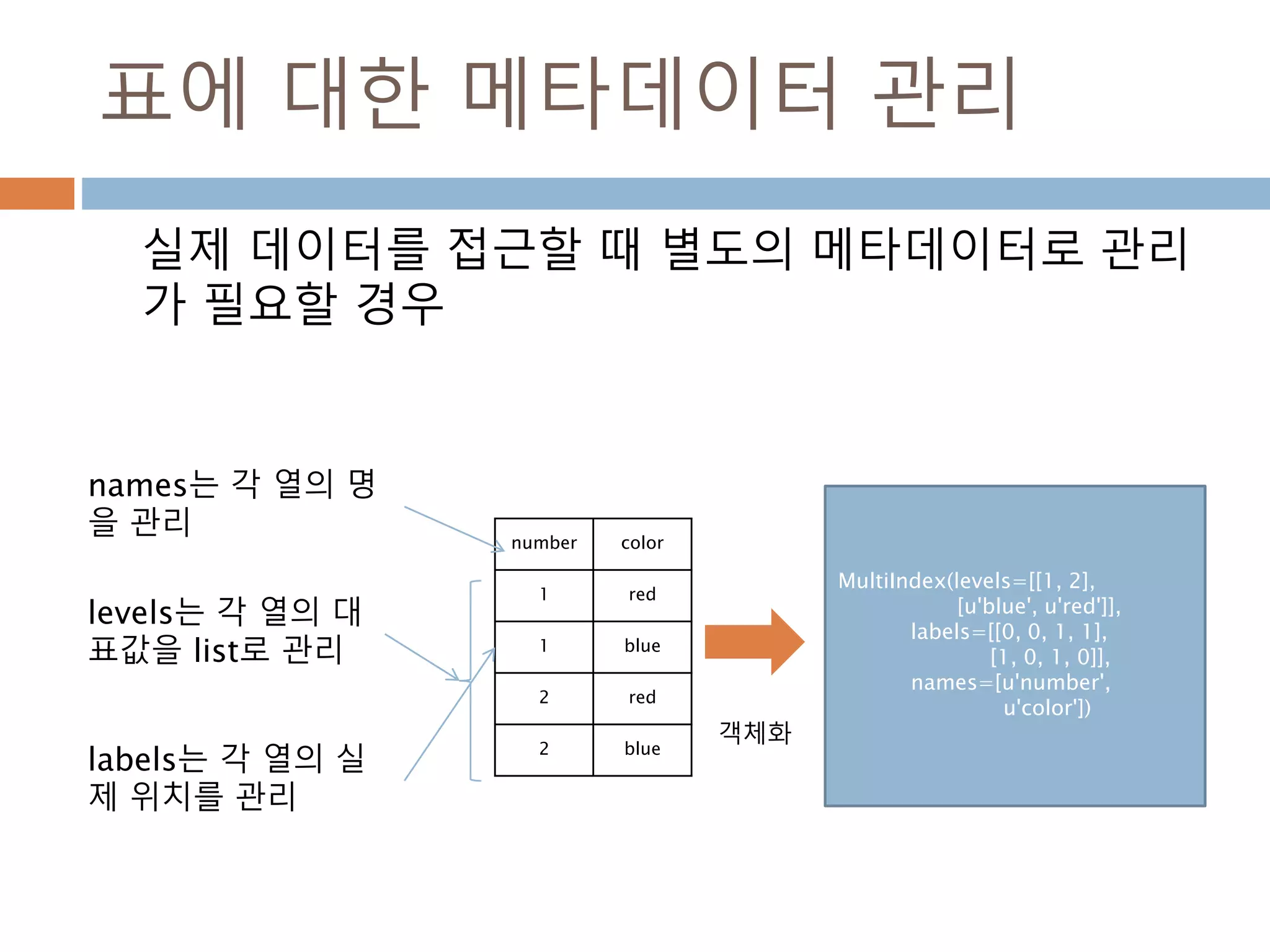
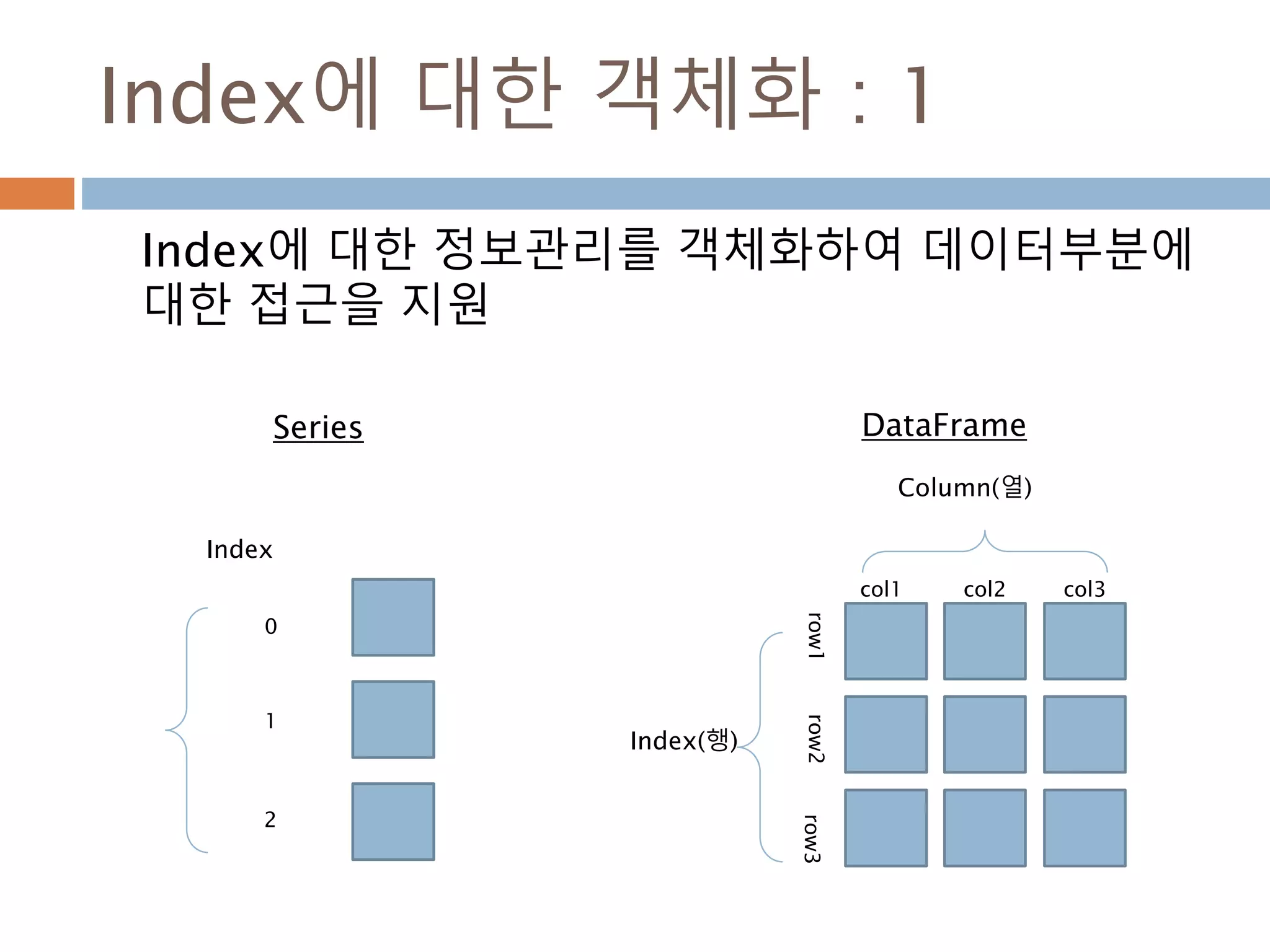




![첫번째 그래프 표시
Axes로 생성된 ax1에 plot 할당.
ax1.lines[0] 내의 저장된 것을 조회
893](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-893-2048.jpg)

![첫번째 그래프 지우려면
del ax1.lines[0], ax1.lines.remove(line)으로
그래프 삭제
895](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-895-2048.jpg)
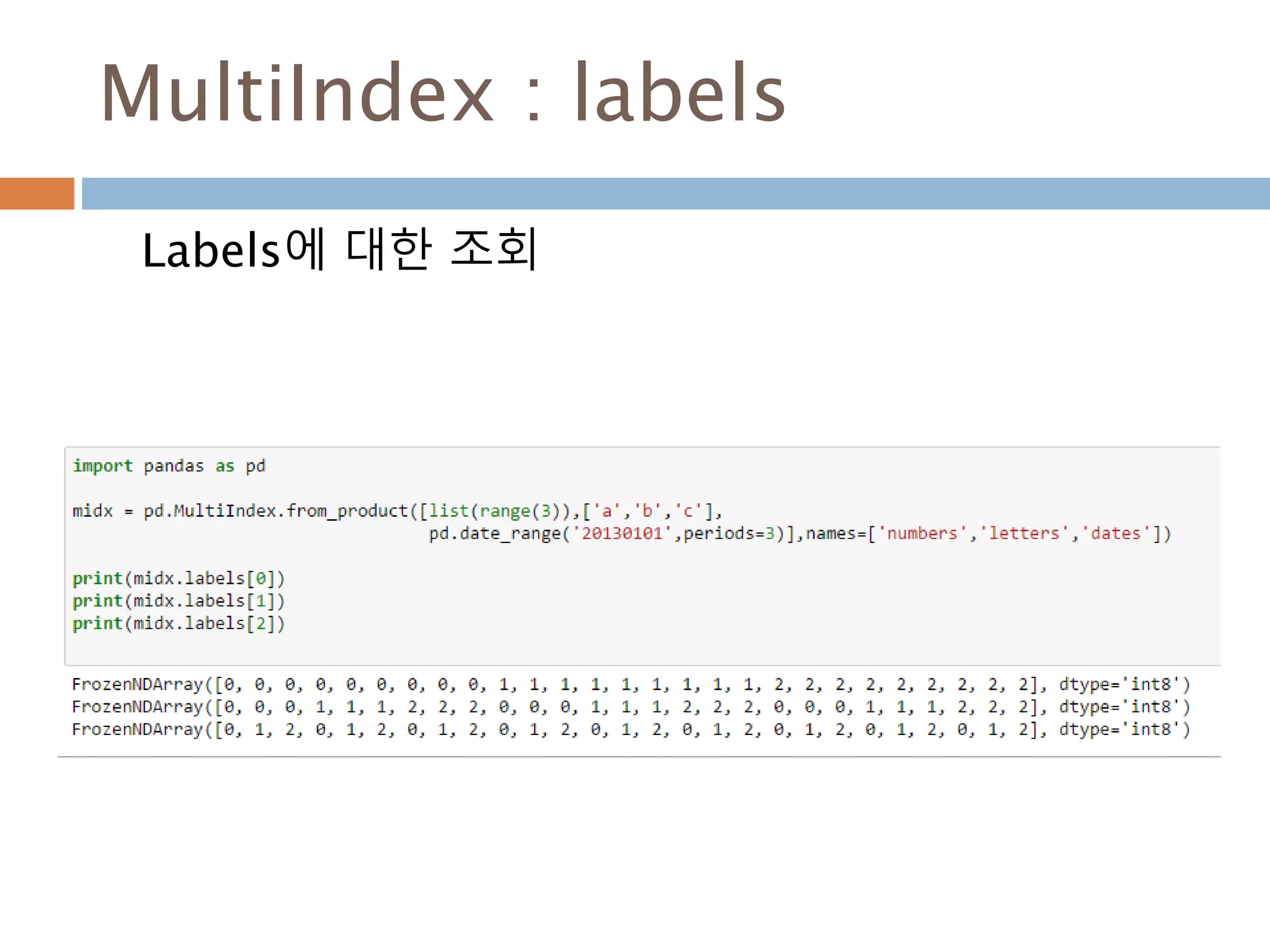

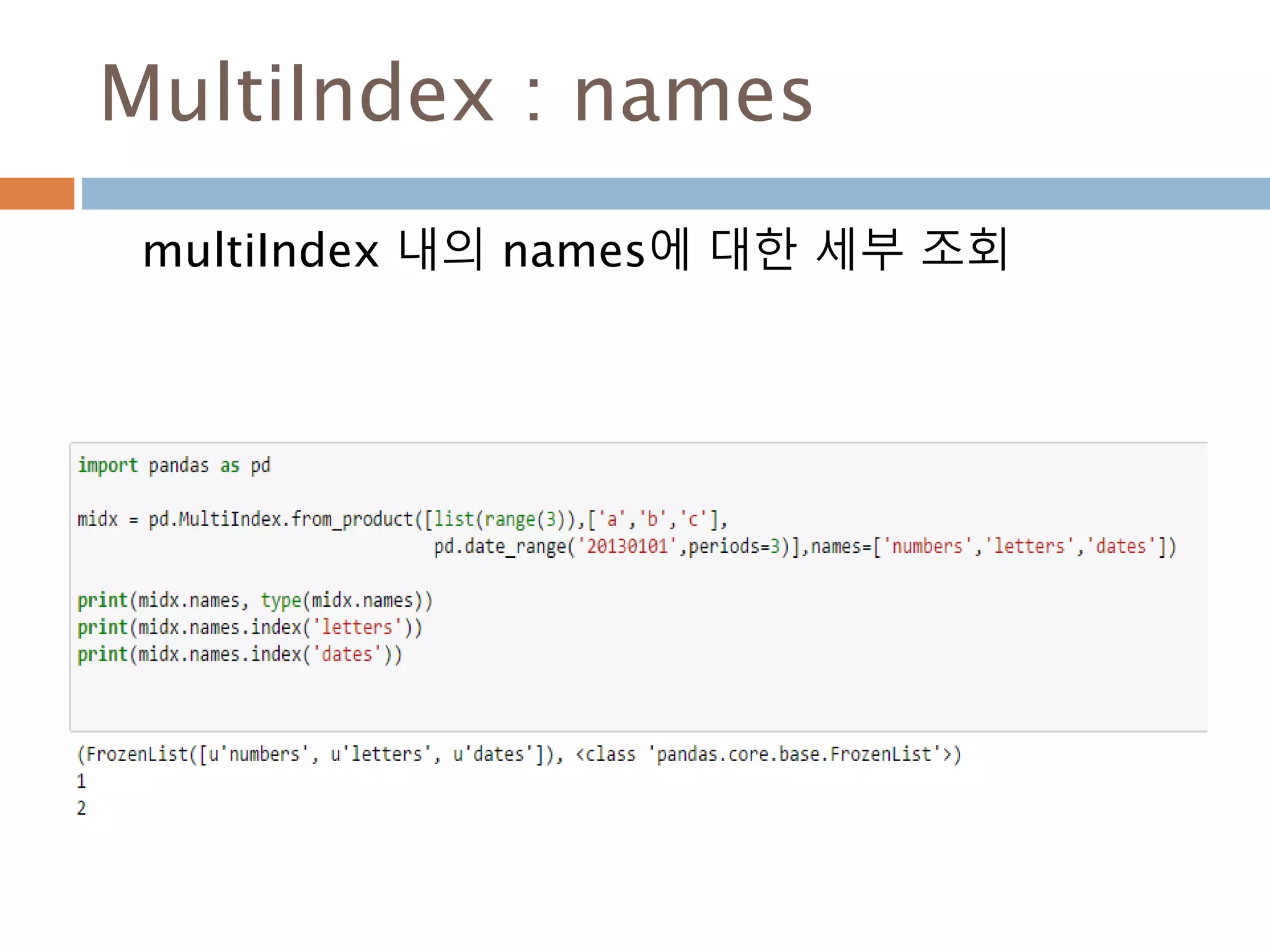



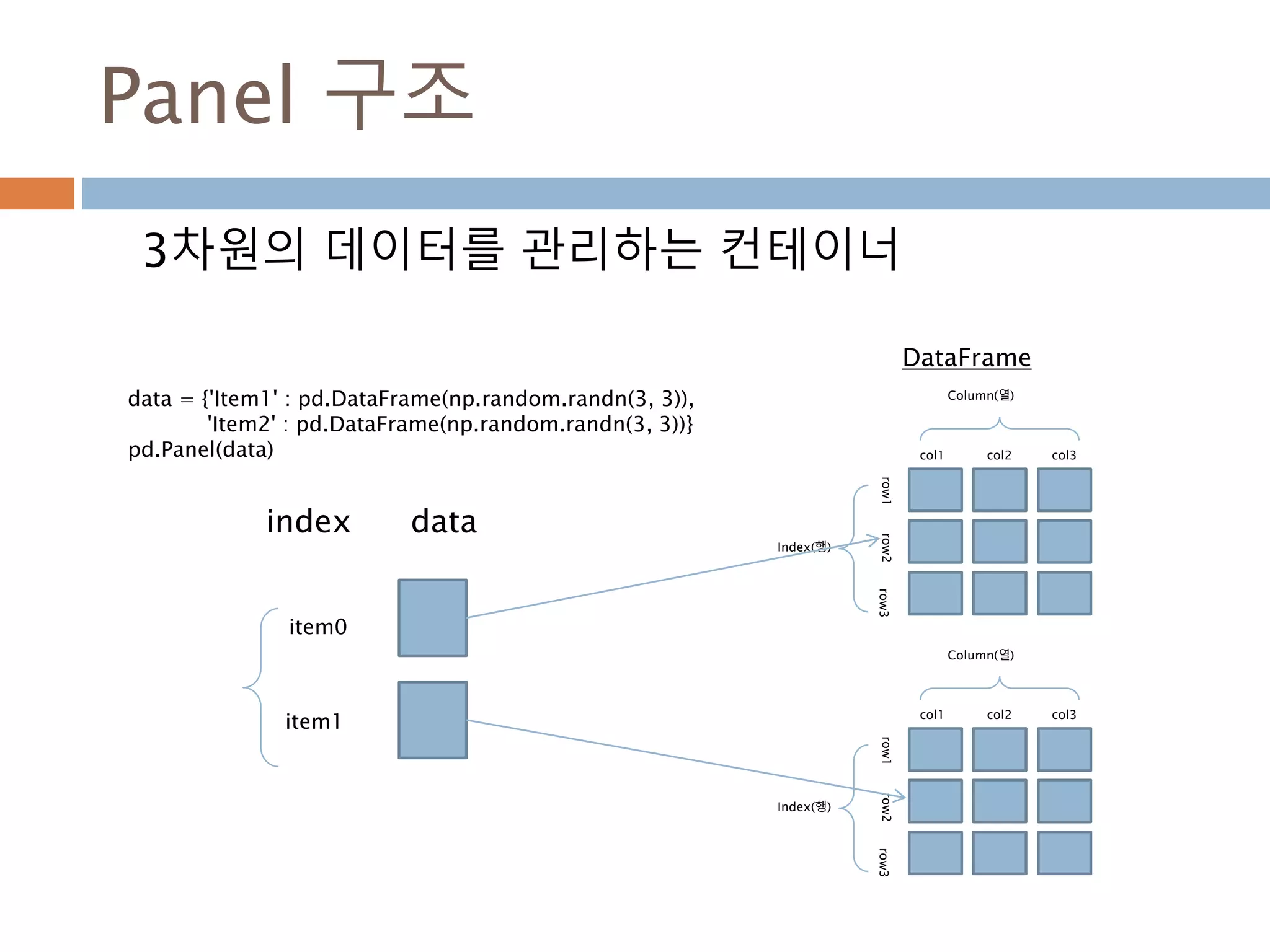

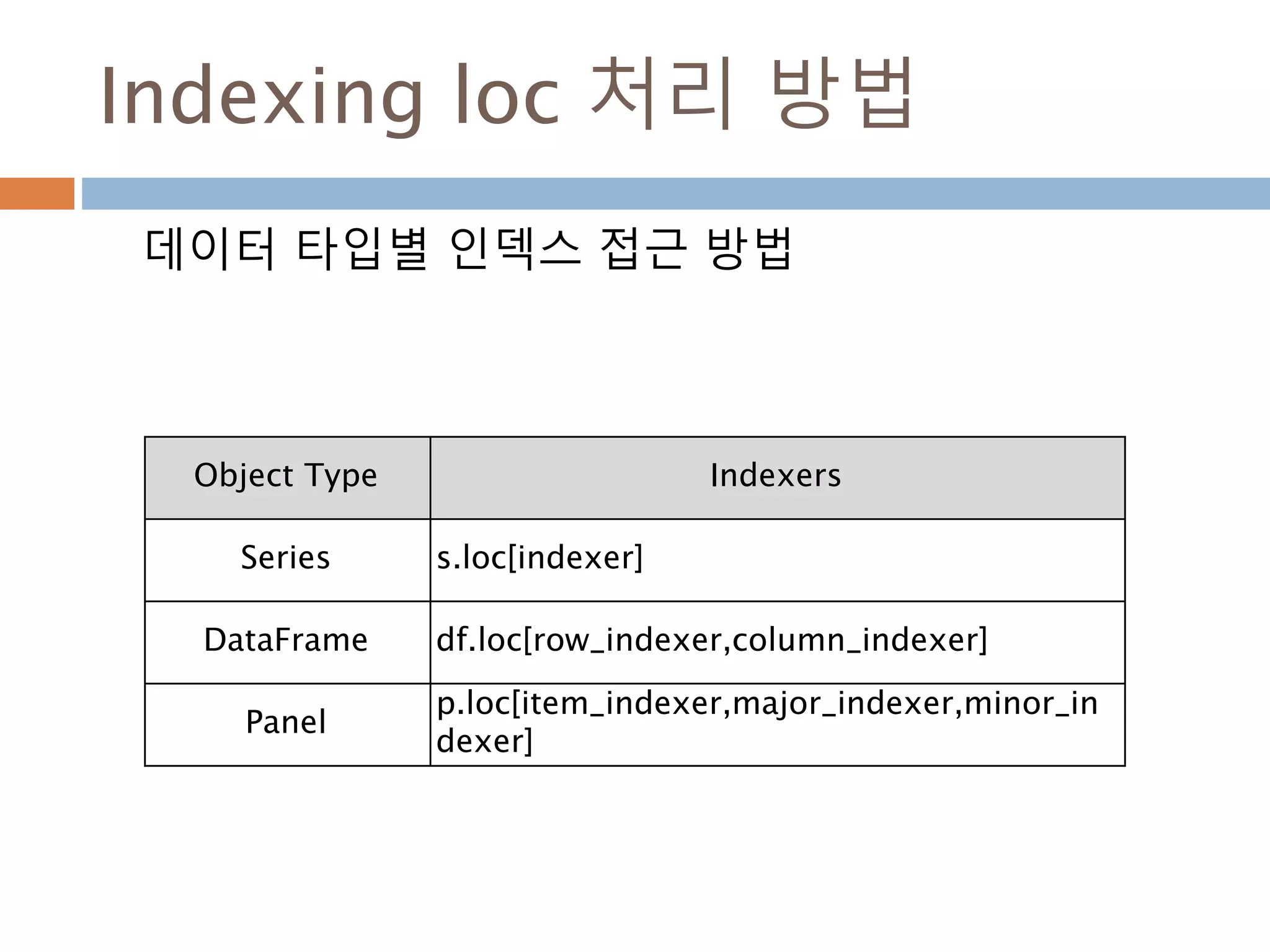
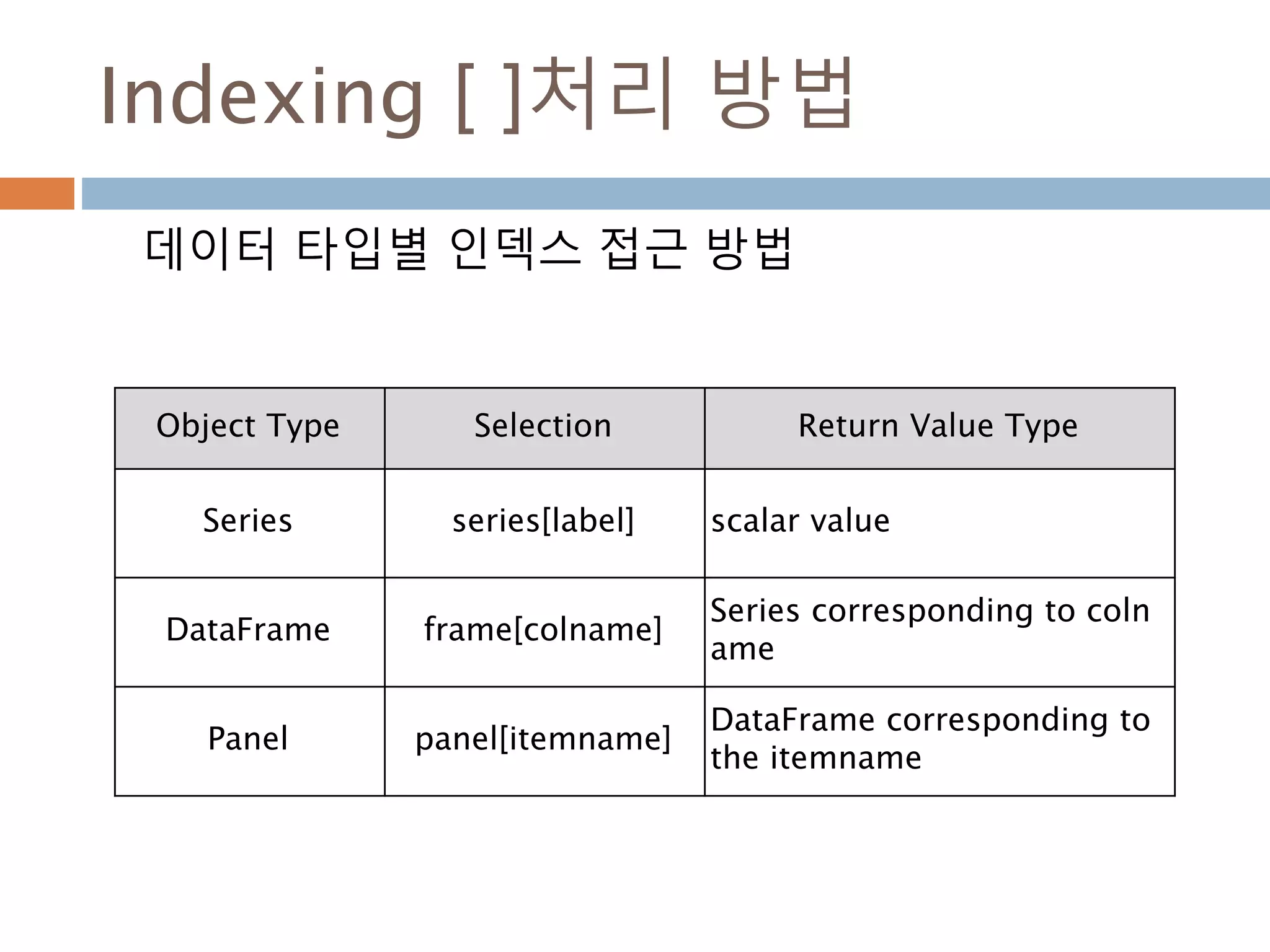
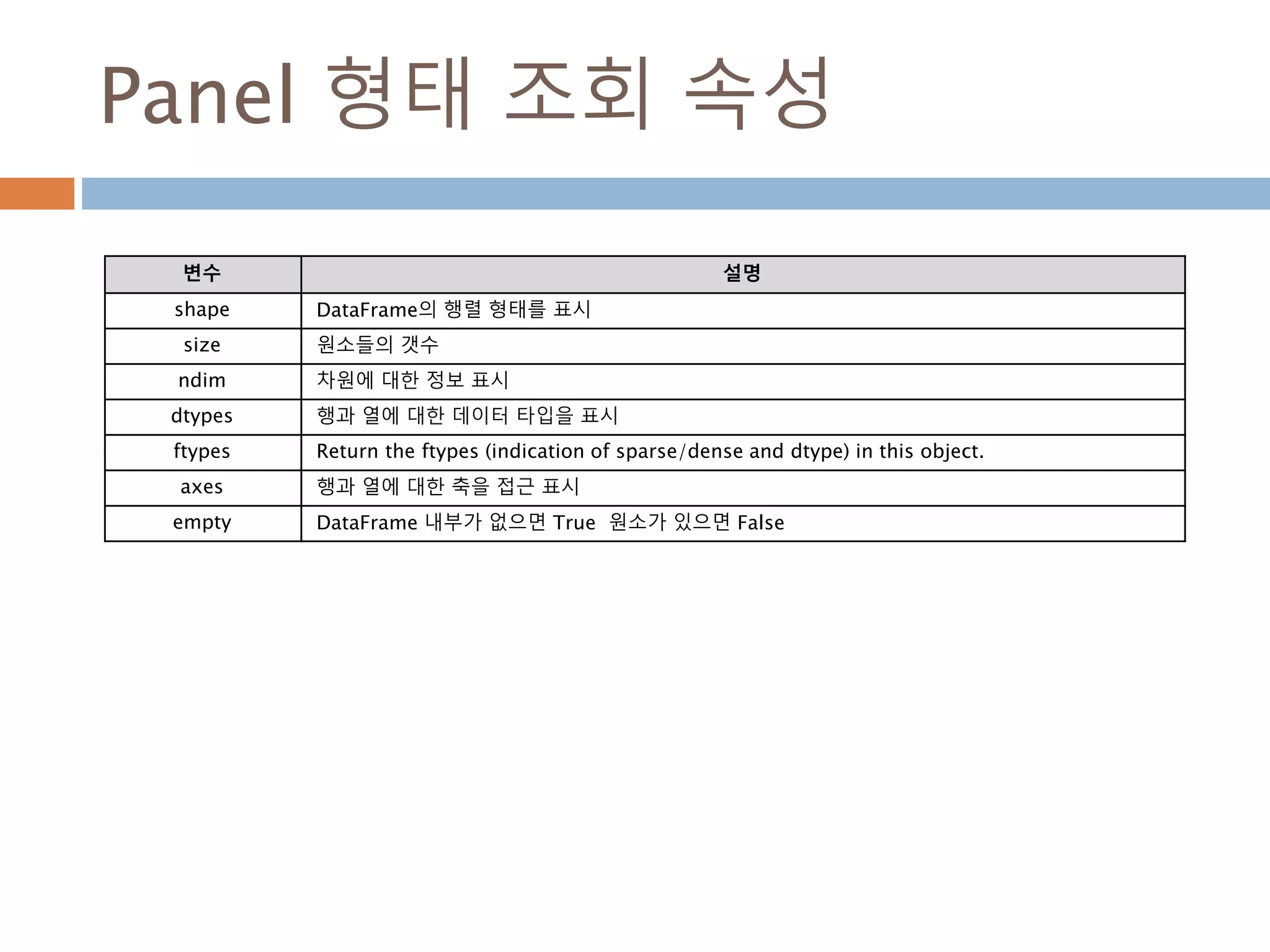
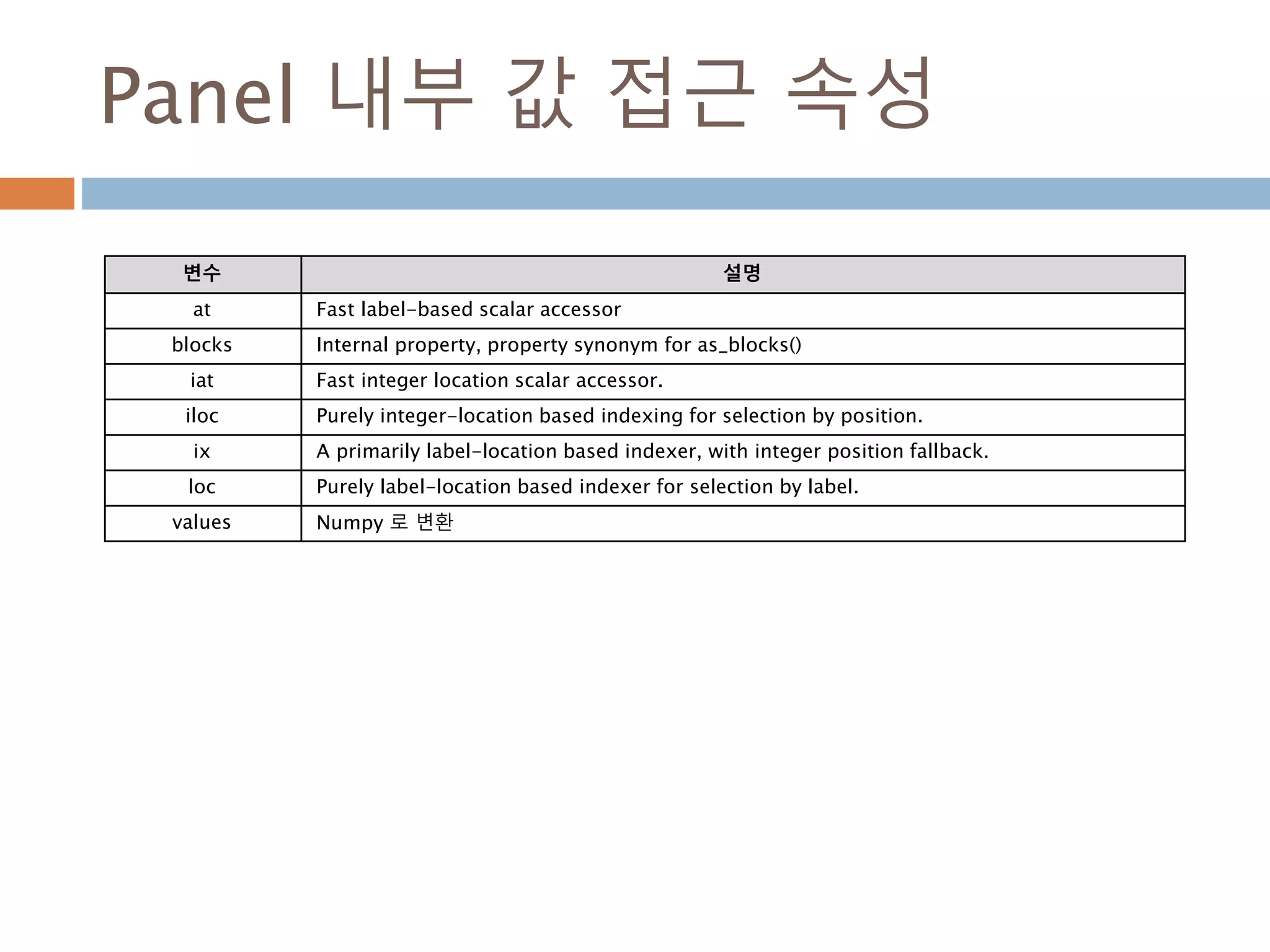





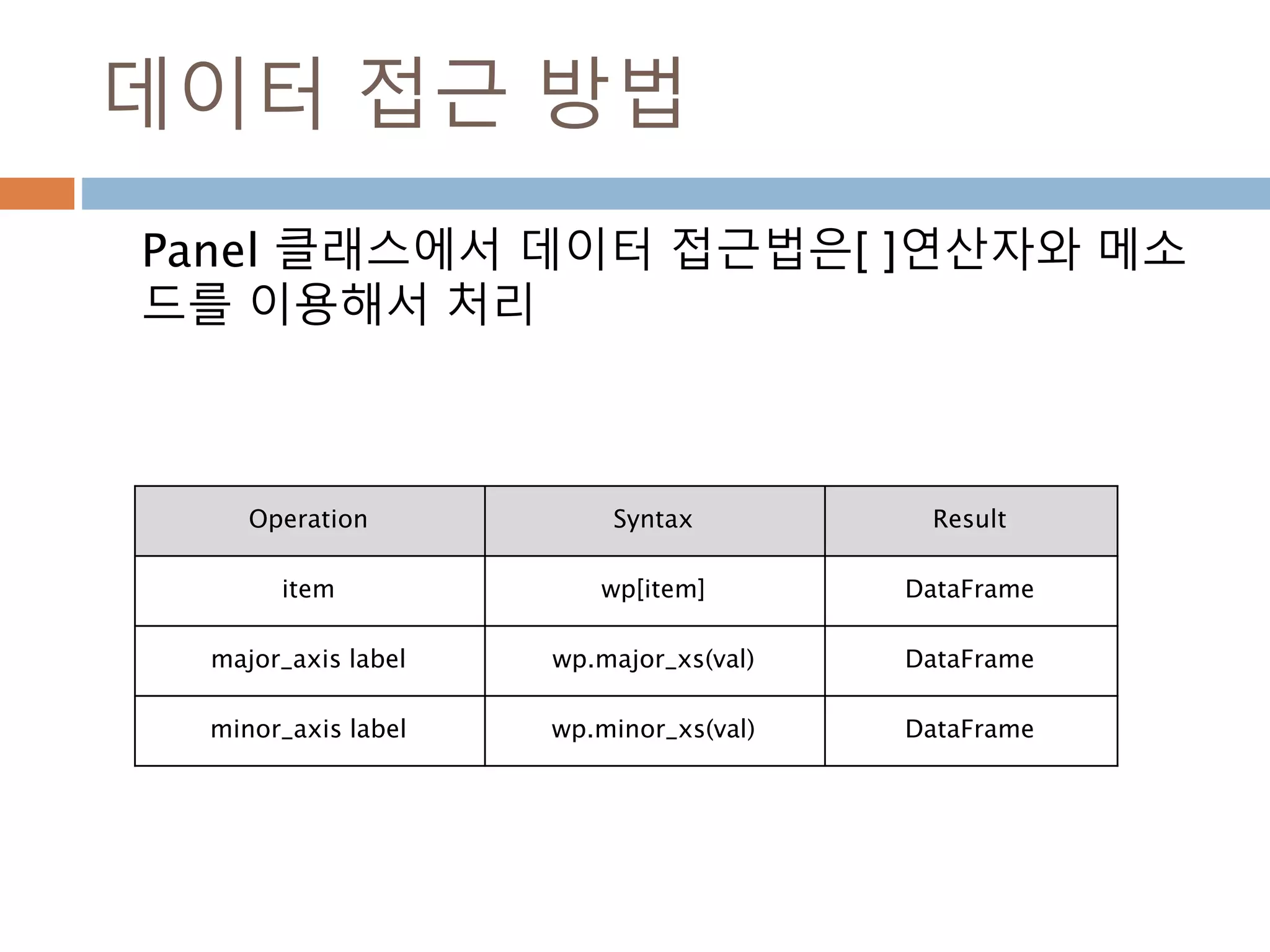
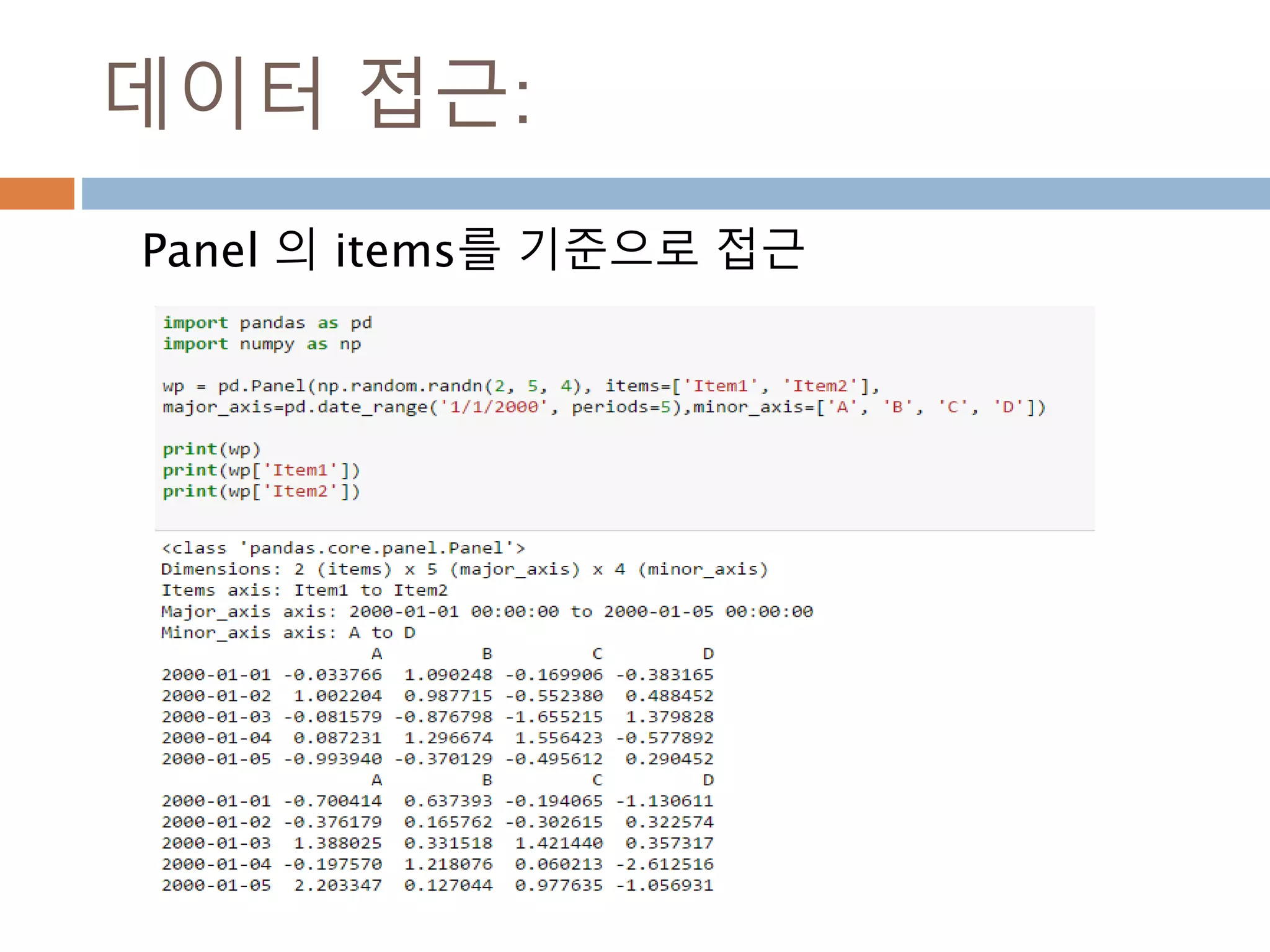





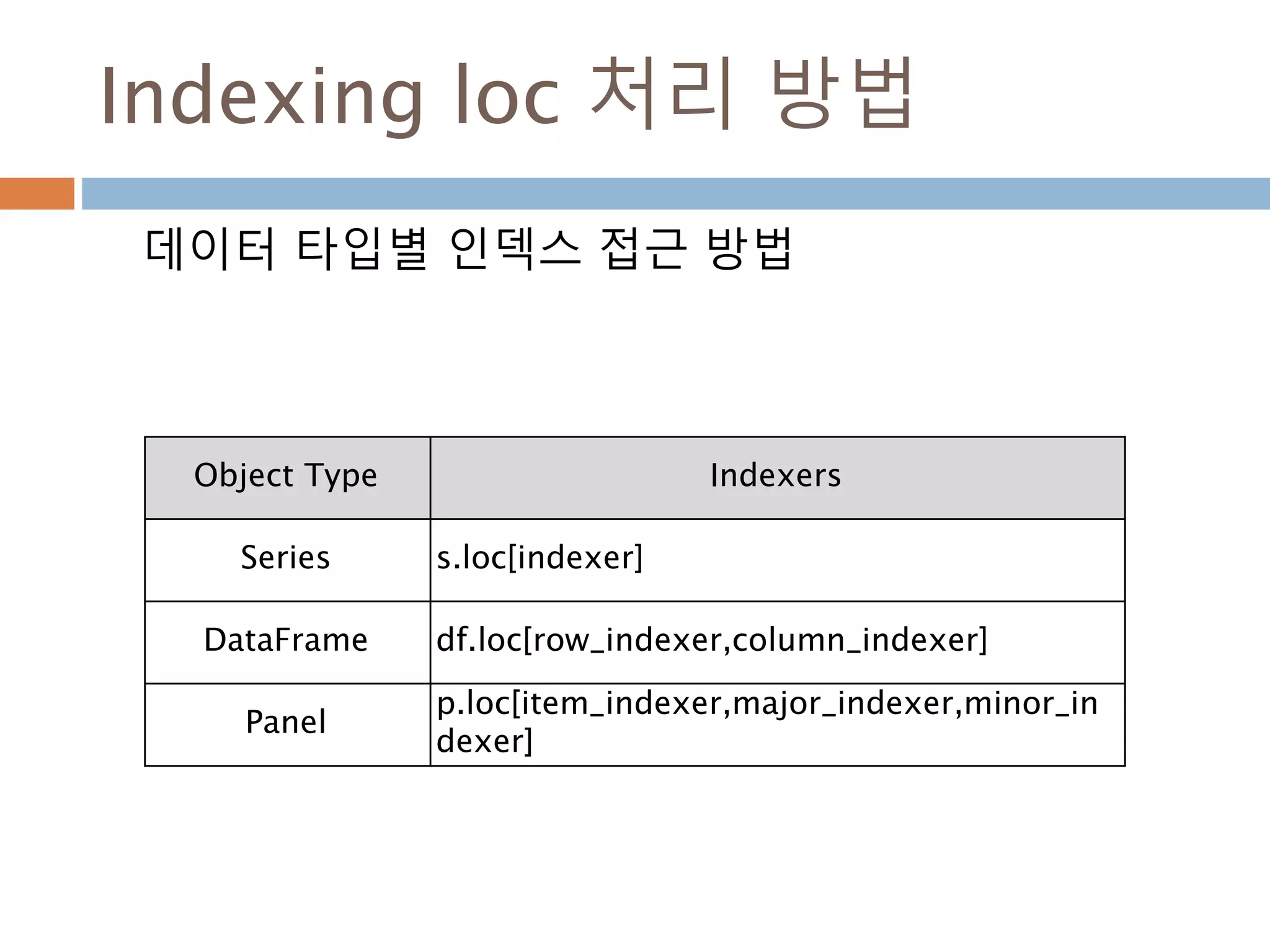
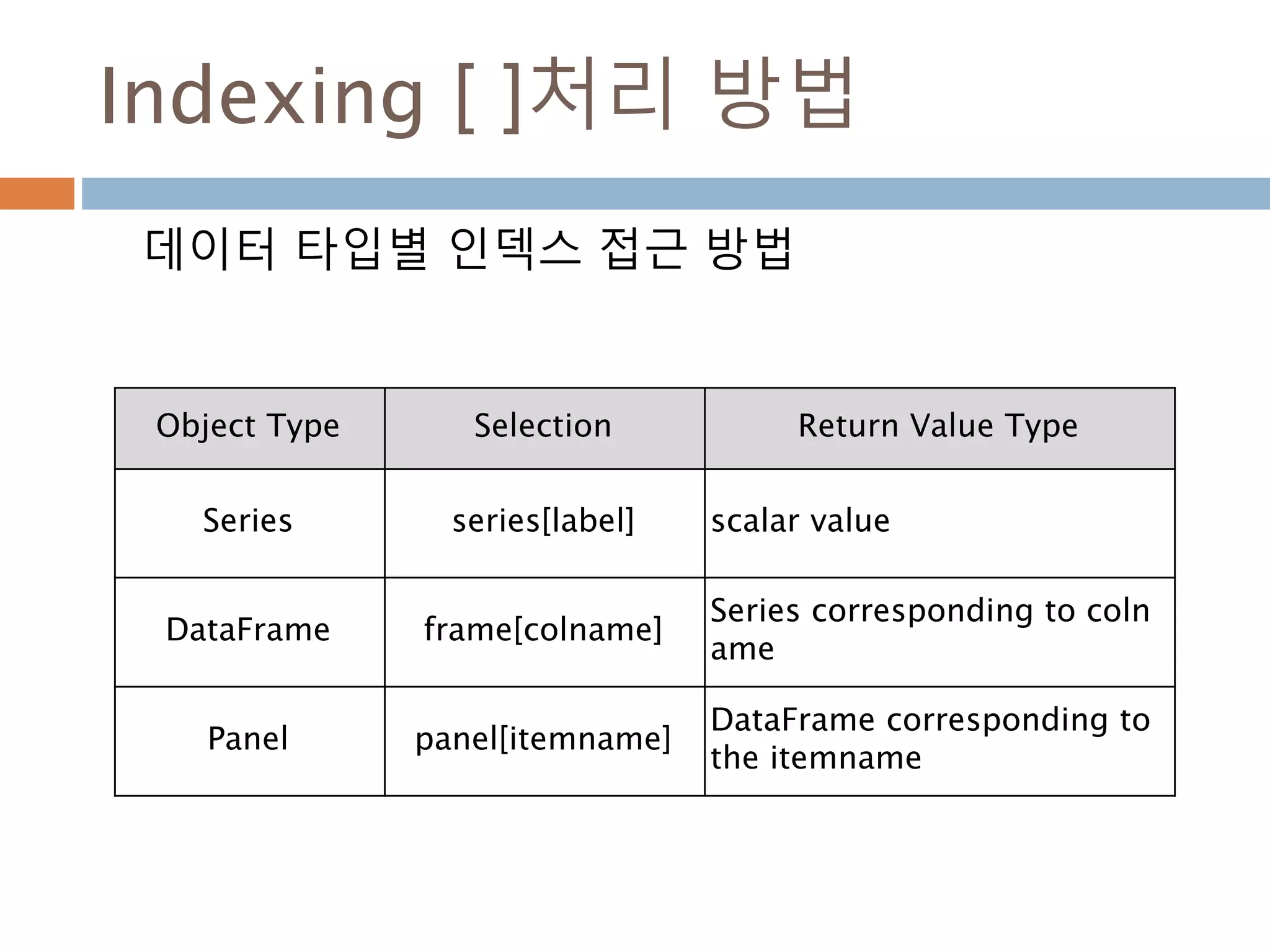

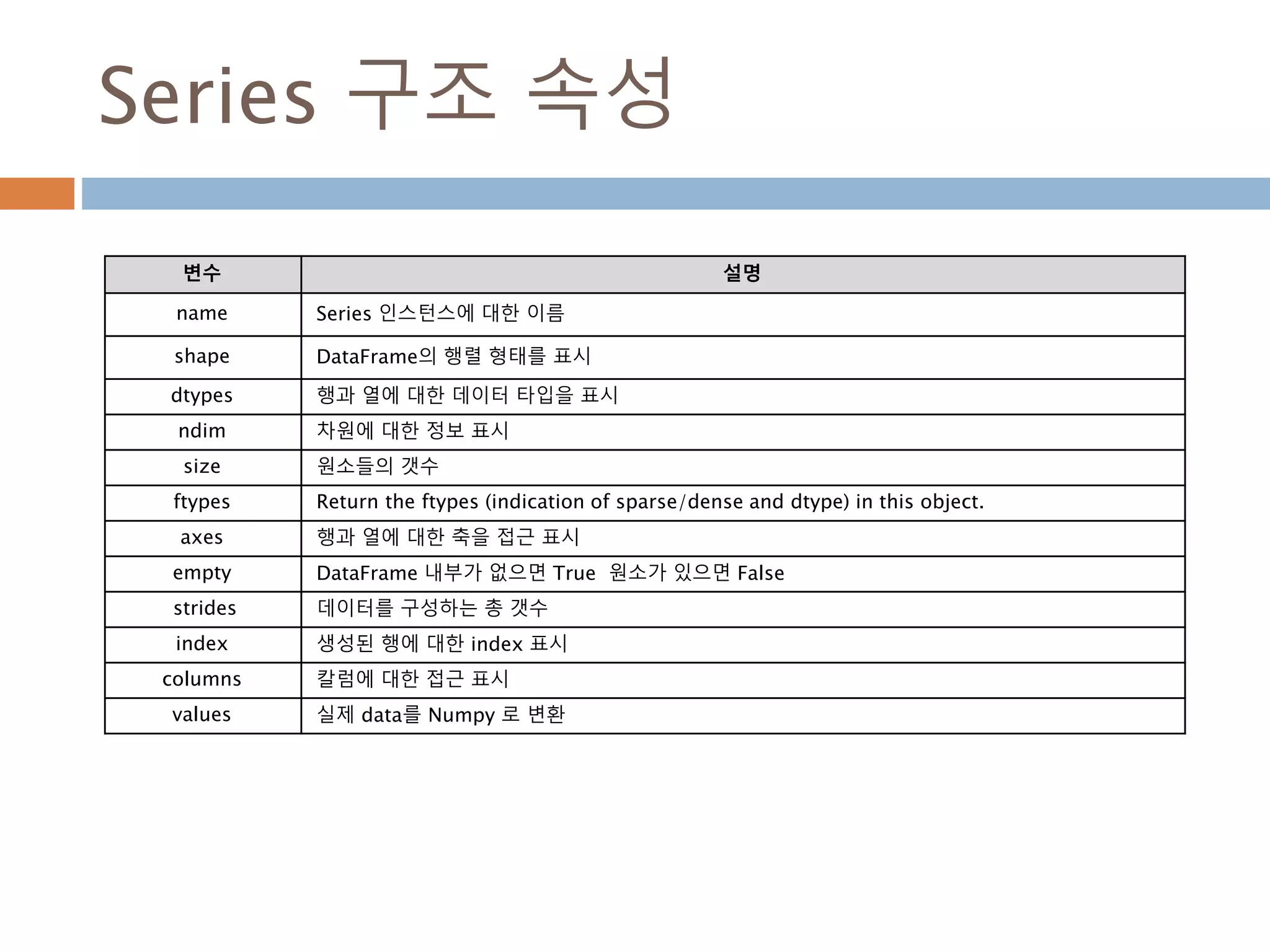




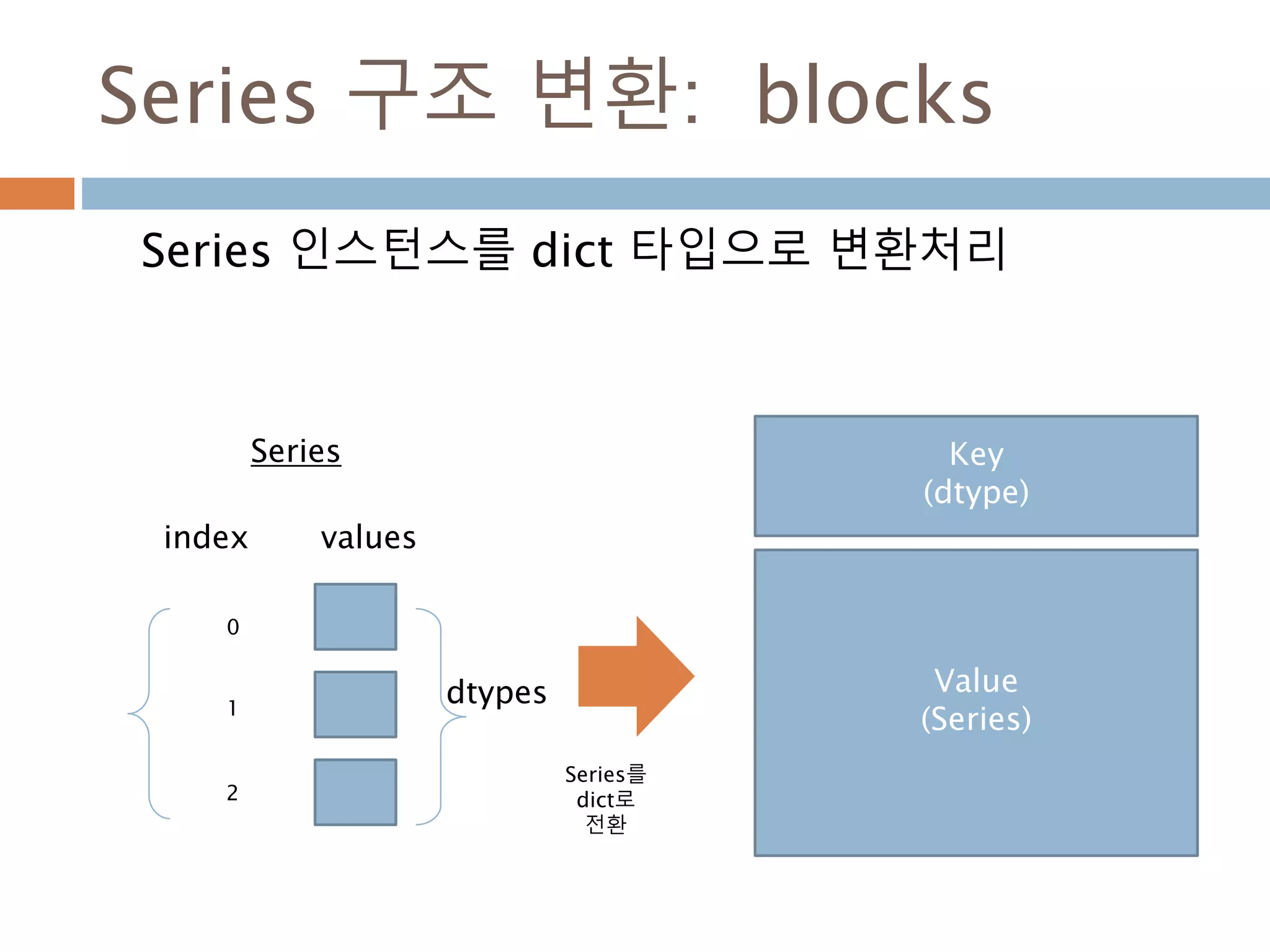


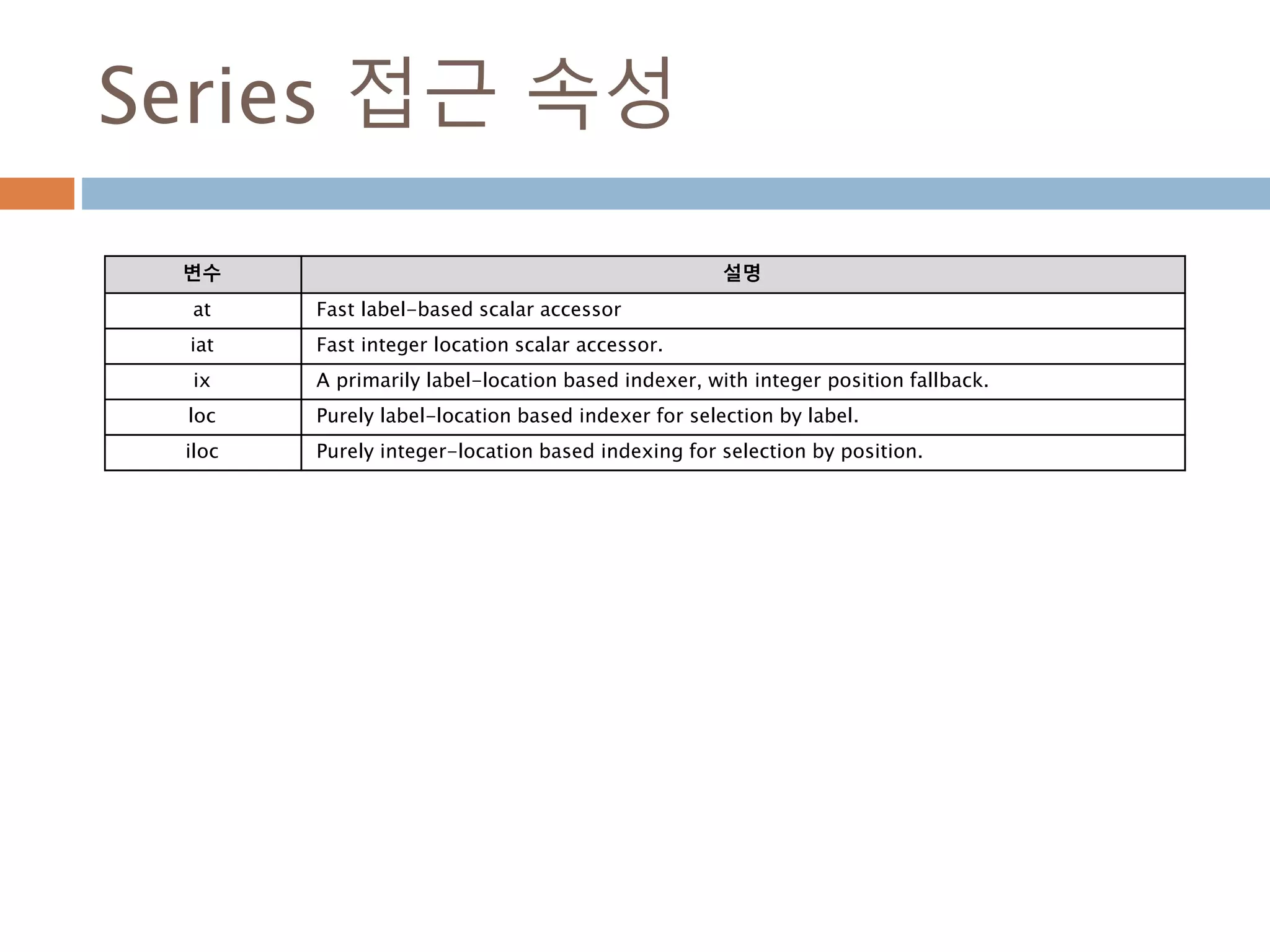























































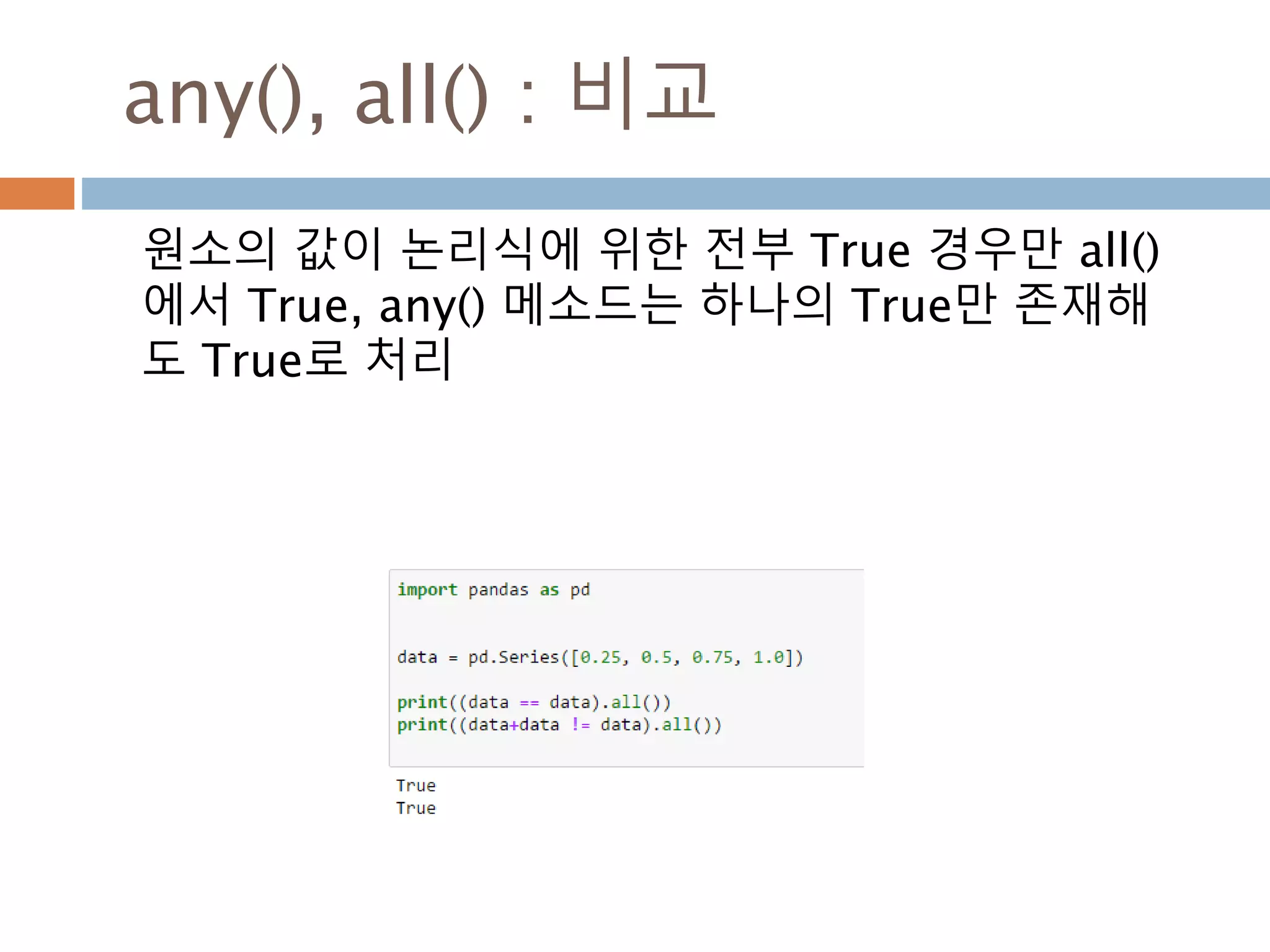
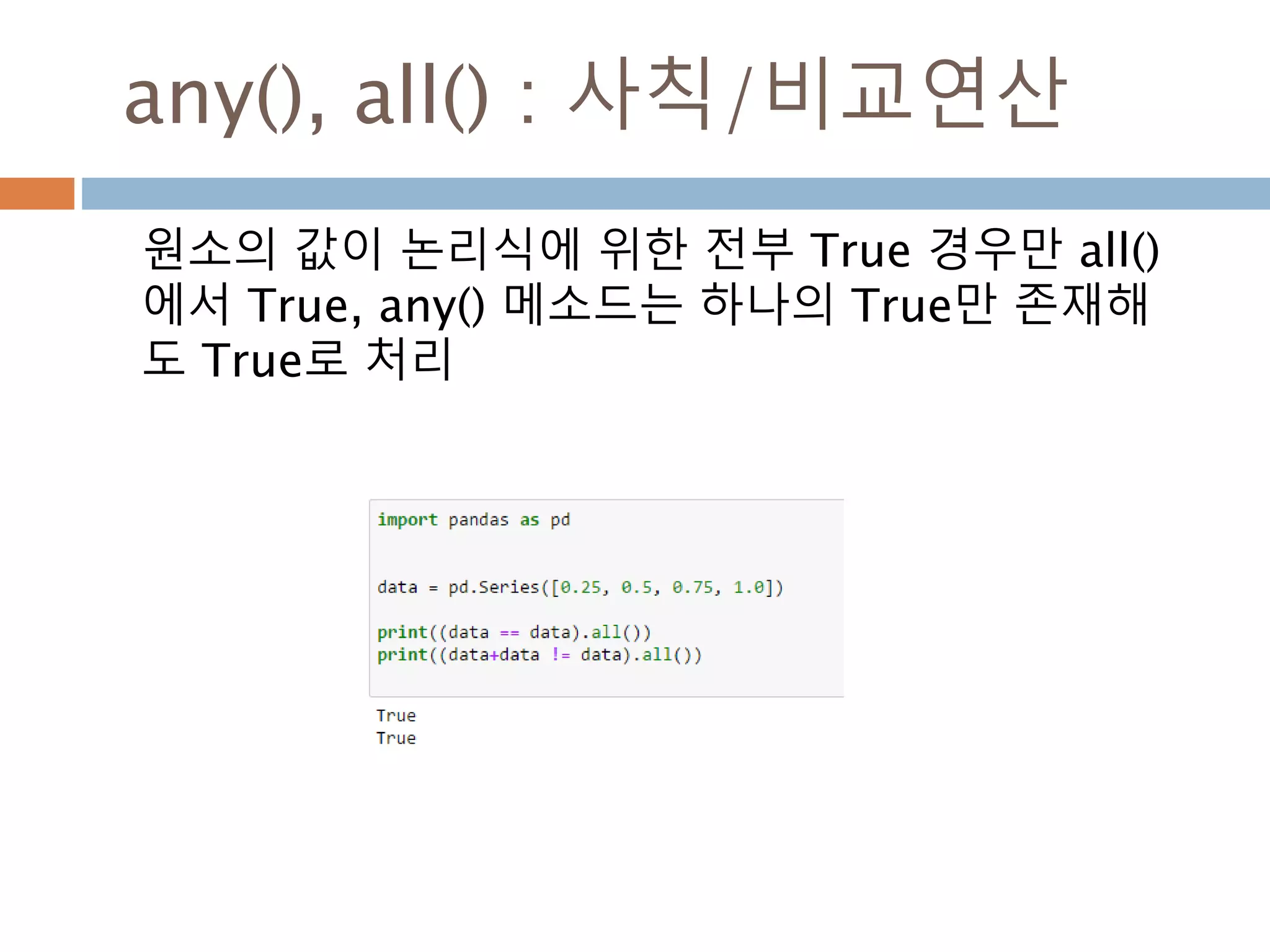

















![DataFrame 행과열 검색 1
DataFrame은 ix 속성을 이용해서 행과 열을 동시
에 검색 ([ 행(슬라이싱 : ), 칼럼(명) ])
행
열
col1
row1row2row3
col2
1009](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1009-2048.jpg)
![DataFrame 행과열 검색 2
DataFrame은 ix 속성을 이용해서 행과 복수의 열
을 동시에 검색 ([ 행(슬라이싱 : ), [칼럼명,칼럼명 ])
행
열
col1
row1row2row3
col2
1010](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1010-2048.jpg)


![Indexing loc 처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Indexers
Series s.loc[indexer]
DataFrame df.loc[row_indexer,column_indexer]
Panel
p.loc[item_indexer,major_indexer,minor_in
dexer]
1013](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1013-2048.jpg)


![DataFrame 단일 행 검색
DataFrame은 단일 행을 인덱스 방식([ ])
행
열
col1
row1row2row3
col2
1016](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1016-2048.jpg)
![DataFrame 멀티 행 검색
DataFrame은 멀티행을 슬라이싱 방식([ : ])을 사용
하지만 이름으로 검색시에는 해당 이름까지 포함해
서 처리
행
열
col1
row1row2row3
col2
1017](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1017-2048.jpg)



![Indexing [ ]처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Selection Return Value Type
Series series[label] scalar value
DataFrame frame[colname]
Series corresponding to col
name
Panel panel[itemname]
DataFrame corresponding t
o the itemname
1021](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1021-2048.jpg)







![DataFrame 단일 열 검색
DataFrame은 단일 열을 인덱스 방식([ ])
행
열
col1
row1row2row3
col2
1029](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1029-2048.jpg)
![DataFrame 멀티 열 검색
DataFrame은 멀티 열은 슬라이스 방식([ [ , ] ])
을 사용하지만 칼럼명을 리스트로 작성해서 검색
행
열
col1
row1row2row3
col2
1030](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1030-2048.jpg)
![DataFrame 접근: 사전형식
[“칼럼명”]으로 조회하면 칼럼 기준으로 접근해서
데이터 검색
1031](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1031-2048.jpg)



![DataFrame 접근: swap처리
칼럼별 swap 처리를 하려면 indexinf[ ]처리하기
위해 리스트에 칼럼명을 사용해서 처리
1035](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1035-2048.jpg)























































































![Groupby + mean: 2개 그룹
Groupby + mean 메소드를 사용해서 2개 그룹에
대한 평균값을 계산 groupby 내의 파라미터를
칼럼구분([ , ]) 처리
1123](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1123-2048.jpg)





































![표에 대한 메타데이터 관리
실제 데이터를 접근할 때 별도의 메타데이터로 관리
가 필요할 경우
MultiIndex(levels=[[1, 2],
[u'blue', u'red']],
labels=[[0, 0, 1, 1],
[1, 0, 1, 0]],
names=[u'number',
u'color'])
levels는 각 열의 대
표값을 list로 관리
number color
1 red
1 blue
2 red
2 blue
names는 각 열의 명
을 관리
labels는 각 열의 실
제 위치를 관리
객체화
1161](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1161-2048.jpg)
















![Indexing loc 처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Indexers
Series s.loc[indexer]
DataFrame df.loc[row_indexer,column_indexer]
Panel
p.loc[item_indexer,major_indexer,minor_in
dexer]
1178](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1178-2048.jpg)
![Indexing [ ]처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Selection Return Value Type
Series series[label] scalar value
DataFrame frame[colname]
Series corresponding to coln
ame
Panel panel[itemname]
DataFrame corresponding to
the itemname
1179](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1179-2048.jpg)







![데이터 접근 방법
Panel 클래스에서 데이터 접근법은[ ]연산자와 메소
드를 이용해서 처리
Operation Syntax Result
item wp[item] DataFrame
major_axis label wp.major_xs(val) DataFrame
minor_axis label wp.minor_xs(val) DataFrame
1187](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1187-2048.jpg)






![Indexing loc 처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Indexers
Series s.loc[indexer]
DataFrame df.loc[row_indexer,column_indexer]
Panel
p.loc[item_indexer,major_indexer,minor_in
dexer]
1194](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1194-2048.jpg)
![Indexing [ ]처리 방법
데이터 타입별 인덱스 접근 방법
Object Type Selection Return Value Type
Series series[label] scalar value
DataFrame frame[colname]
Series corresponding to coln
ame
Panel panel[itemname]
DataFrame corresponding to
the itemname
1195](https://image.slidesharecdn.com/pythonnumpy-160804042235/75/Python_numpy_pandas_matplotlib-_20160815-1195-2048.jpg)













































































































































