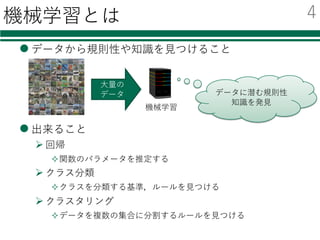
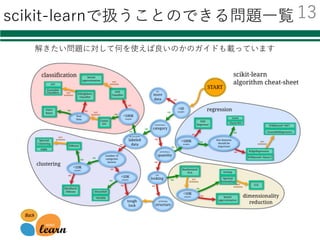
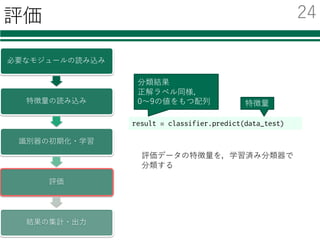
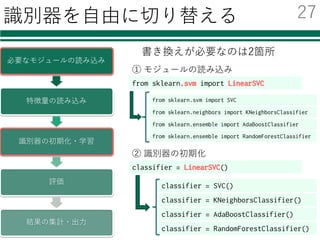
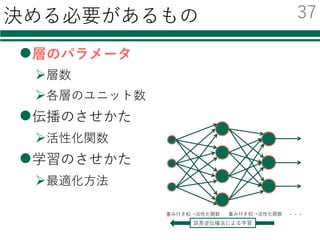
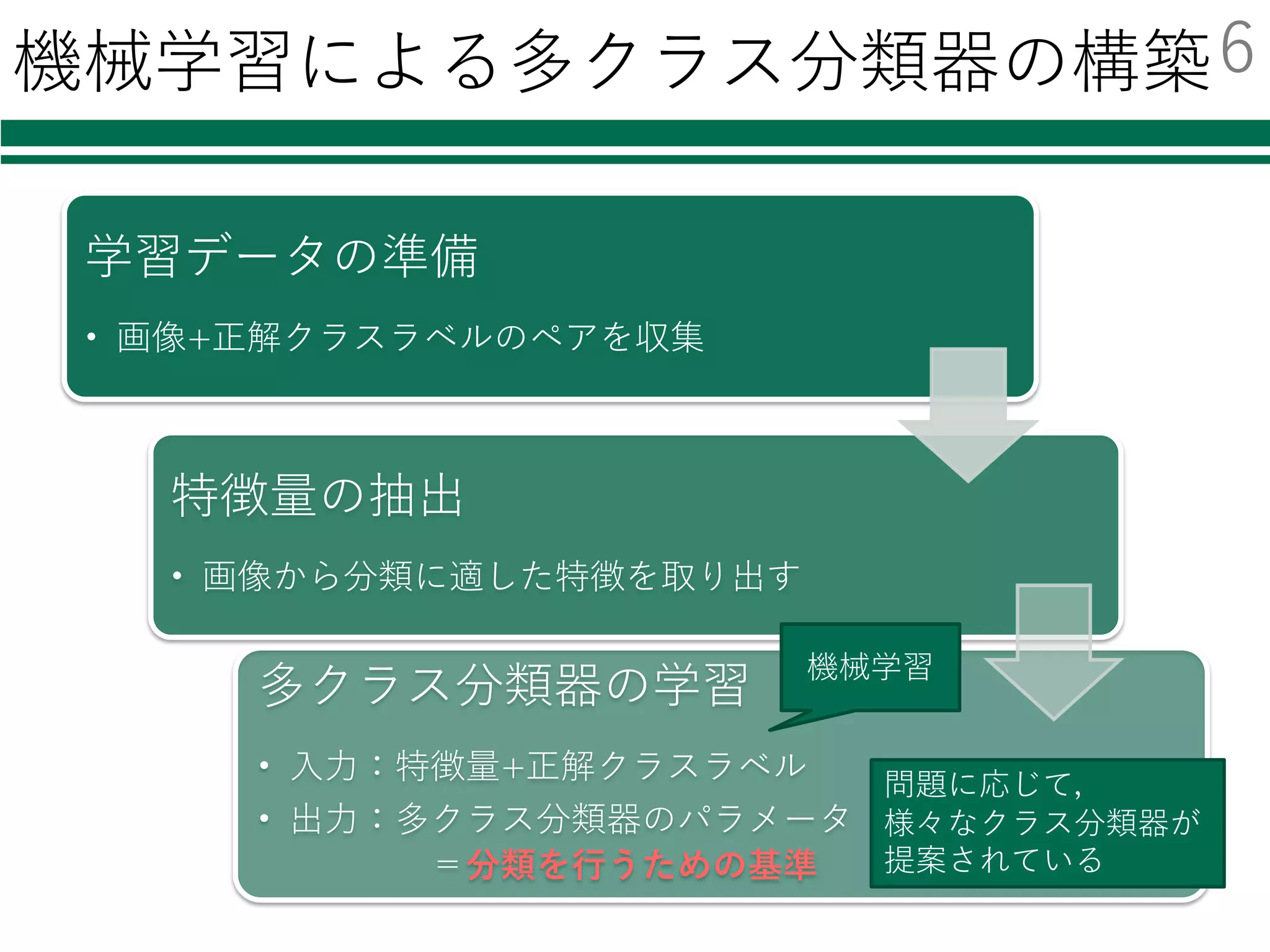
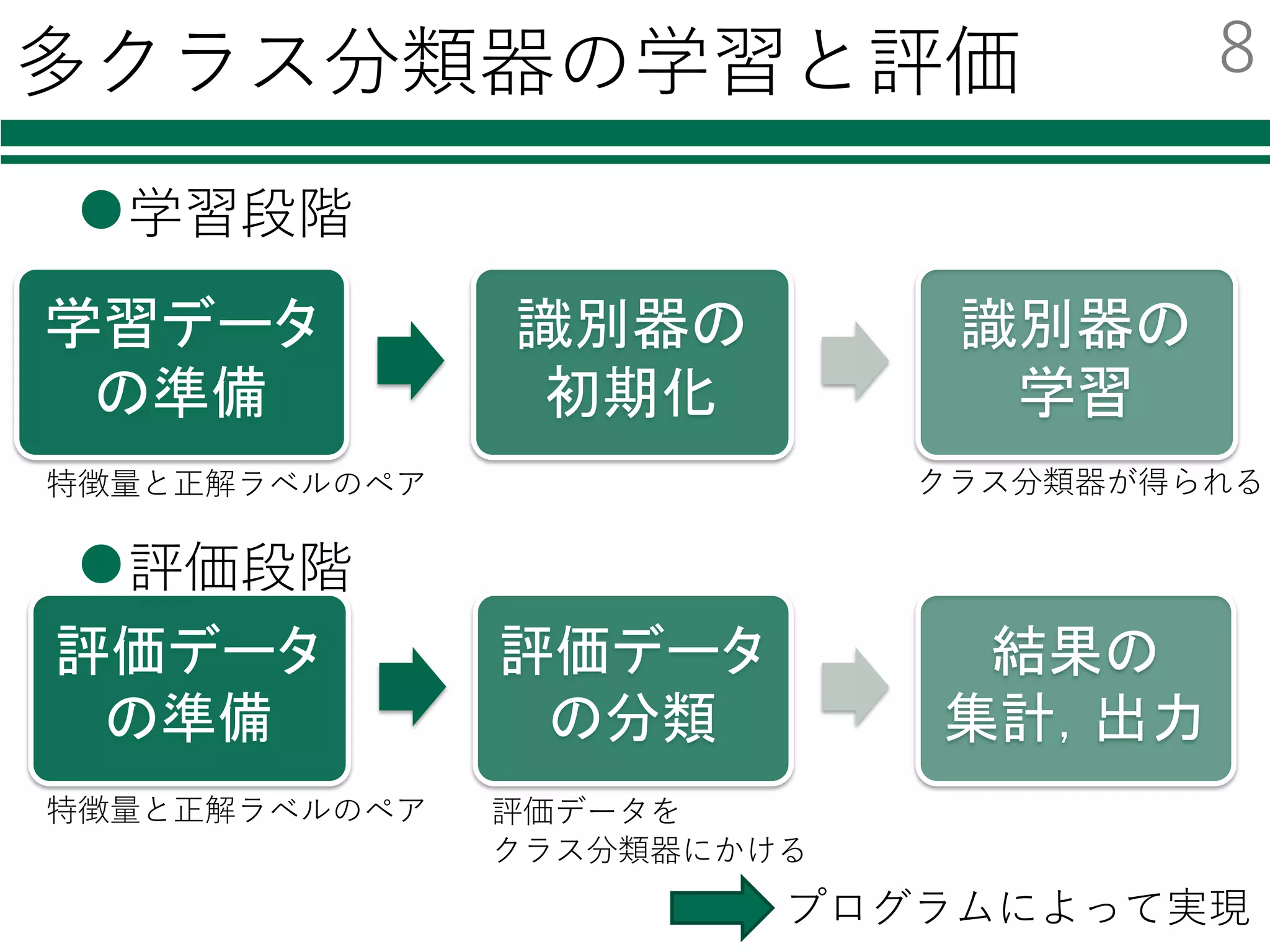
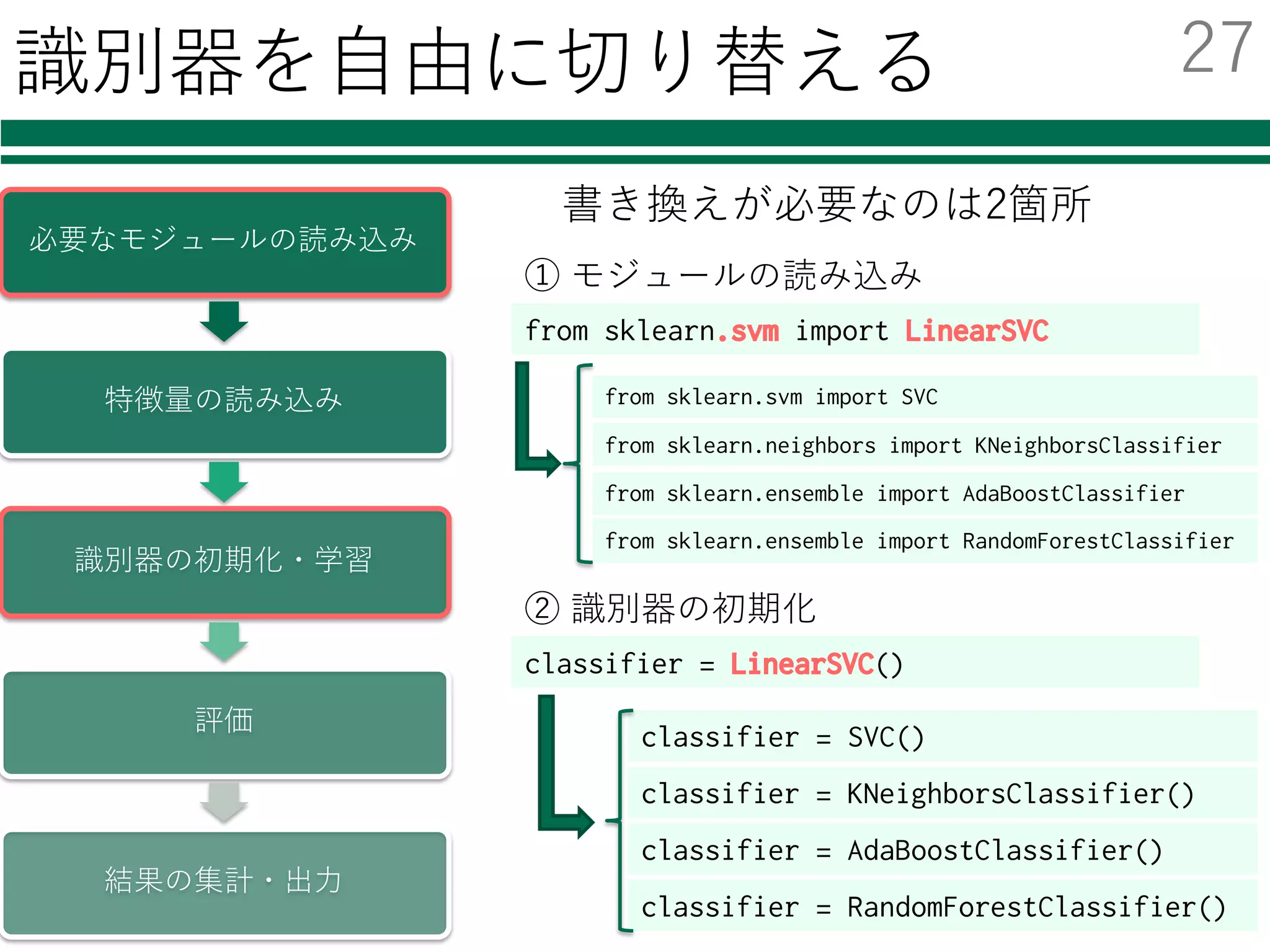
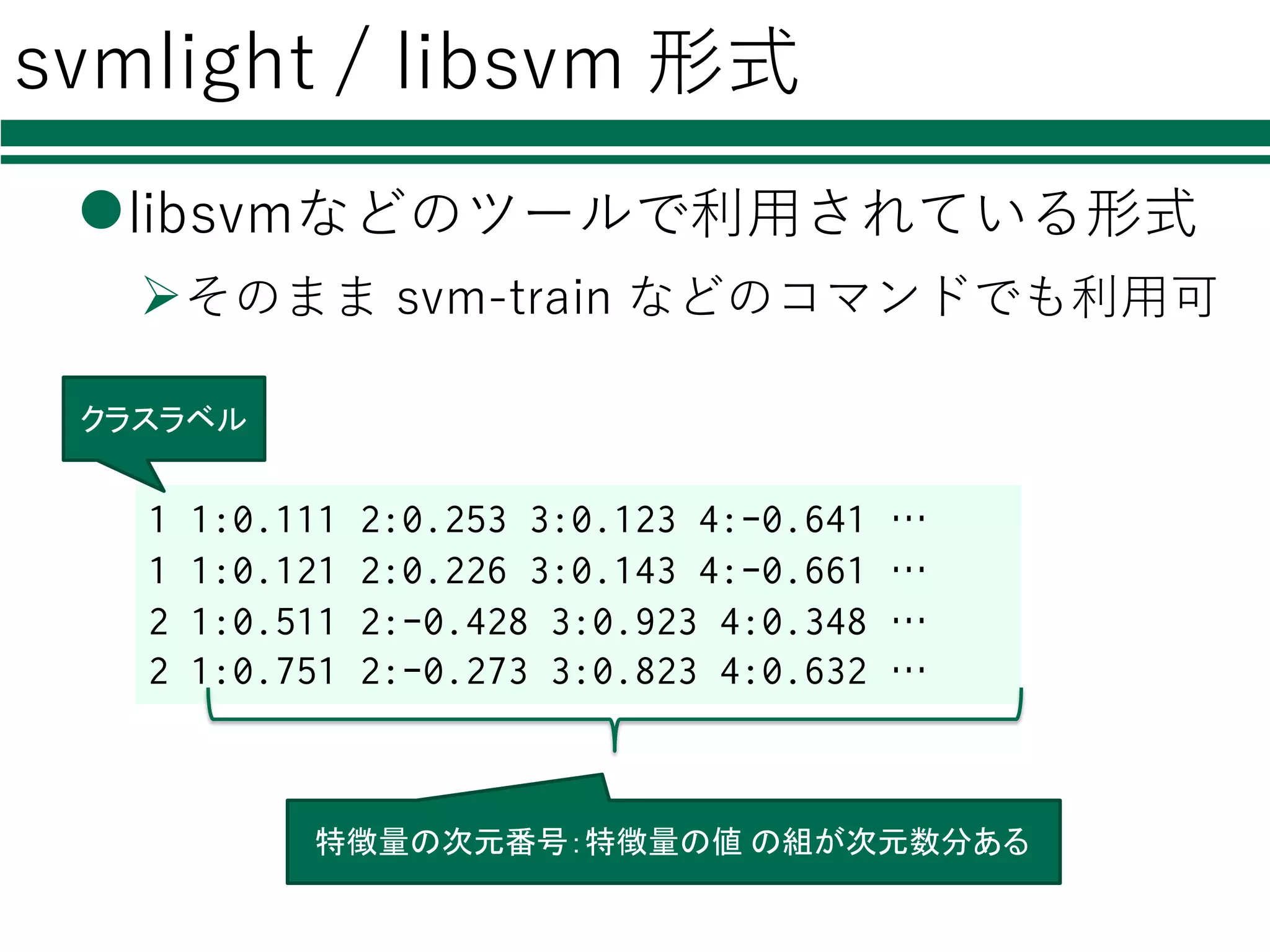
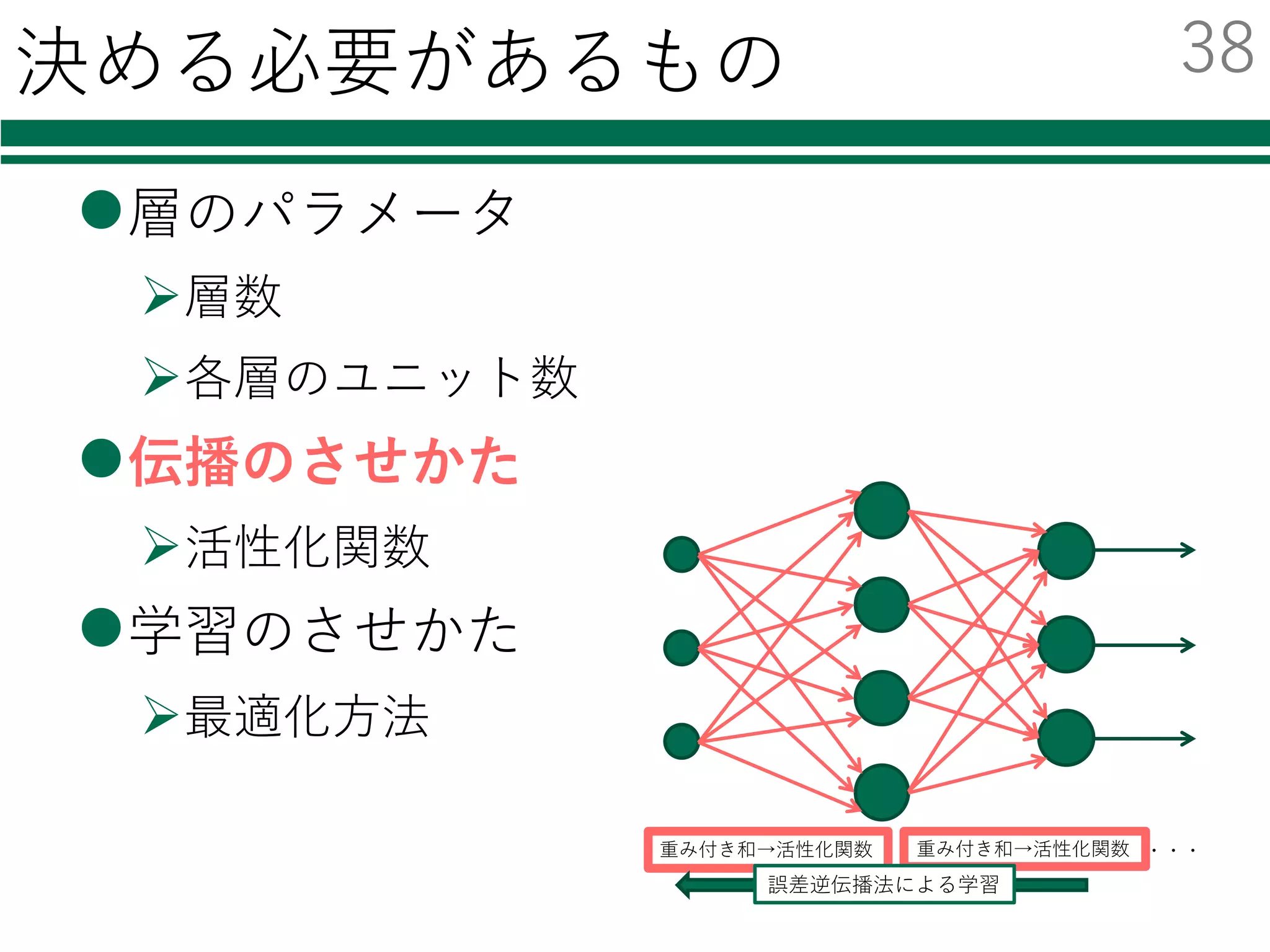
識別器を⾃由に切り替える
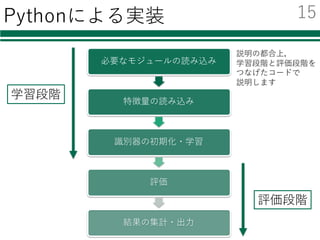
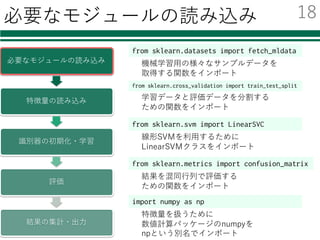
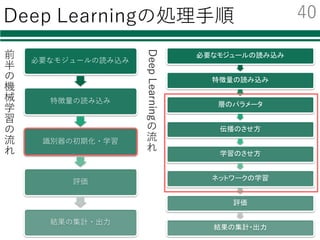
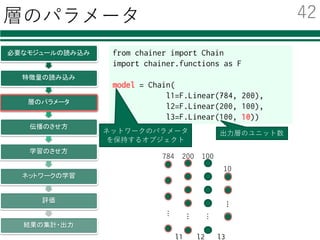
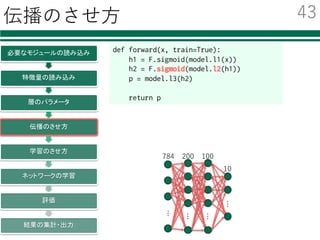
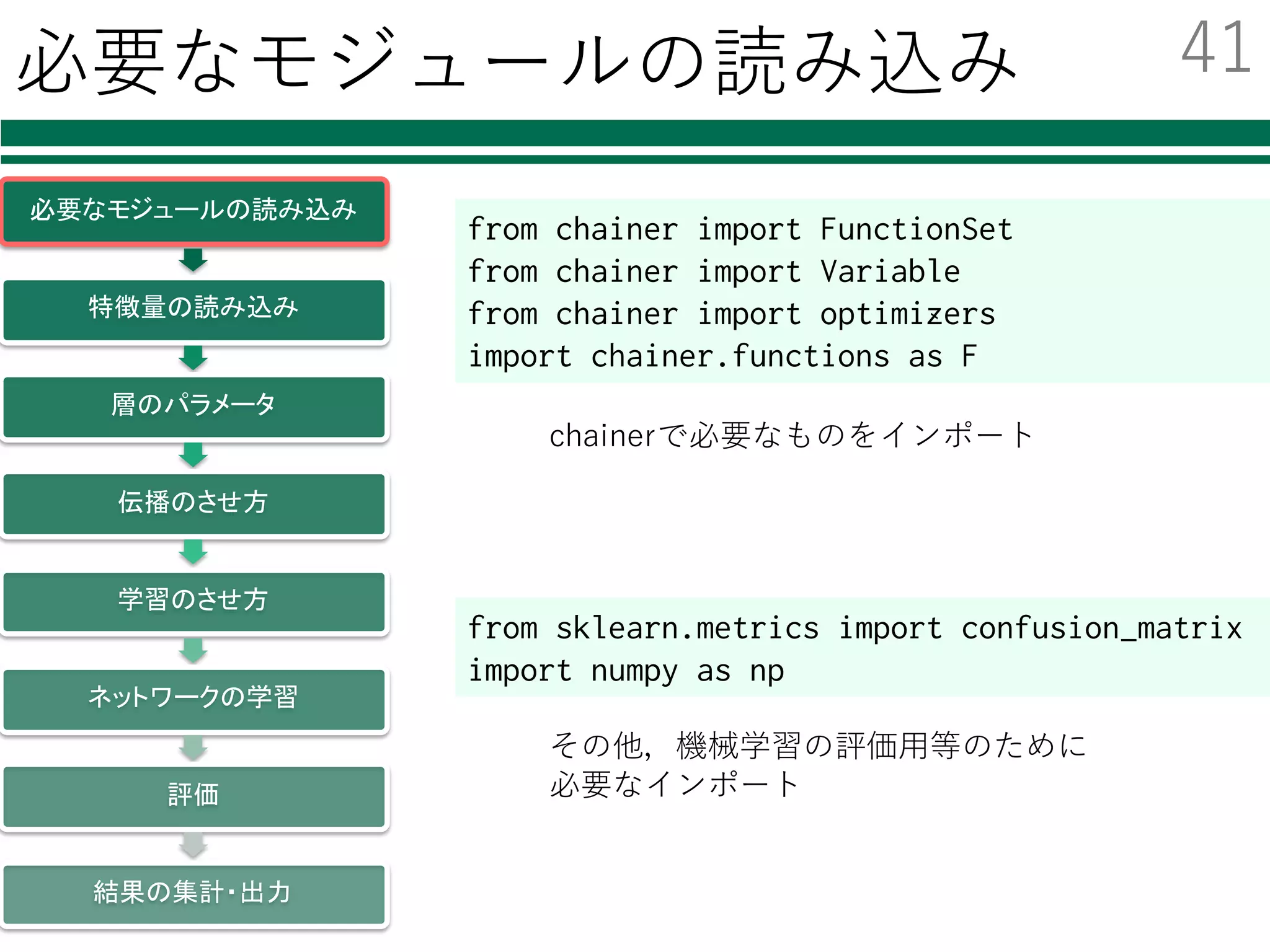
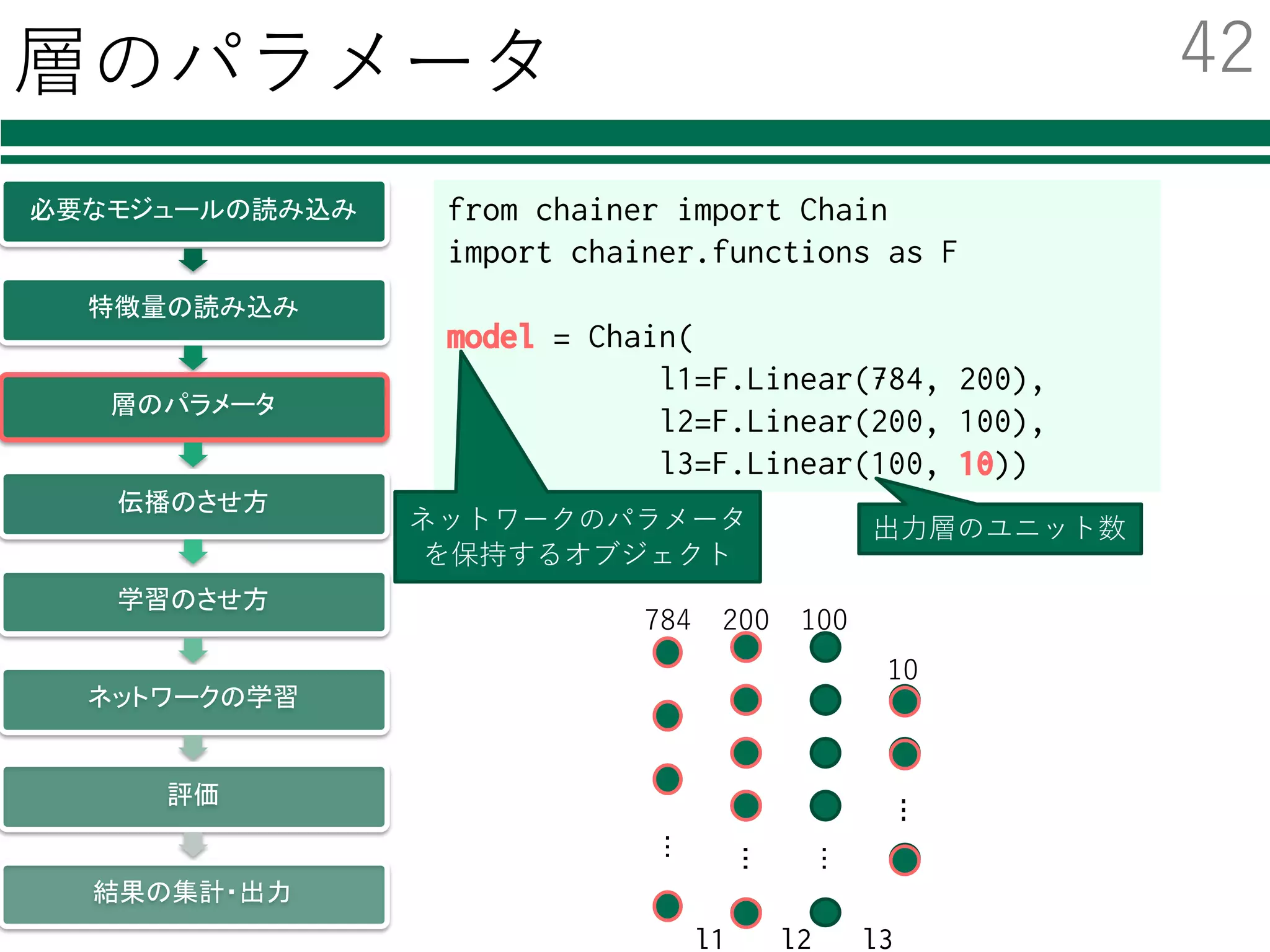
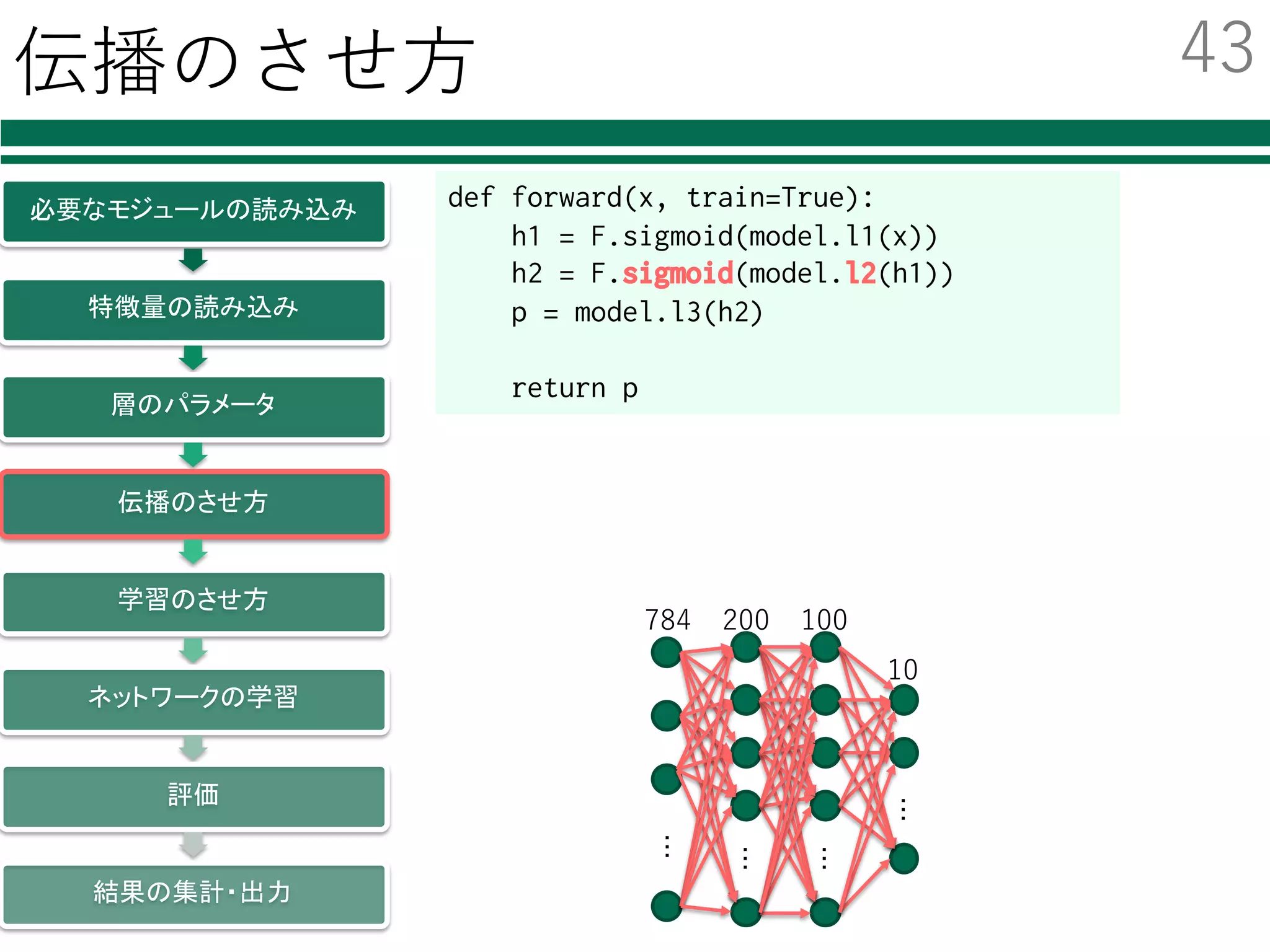
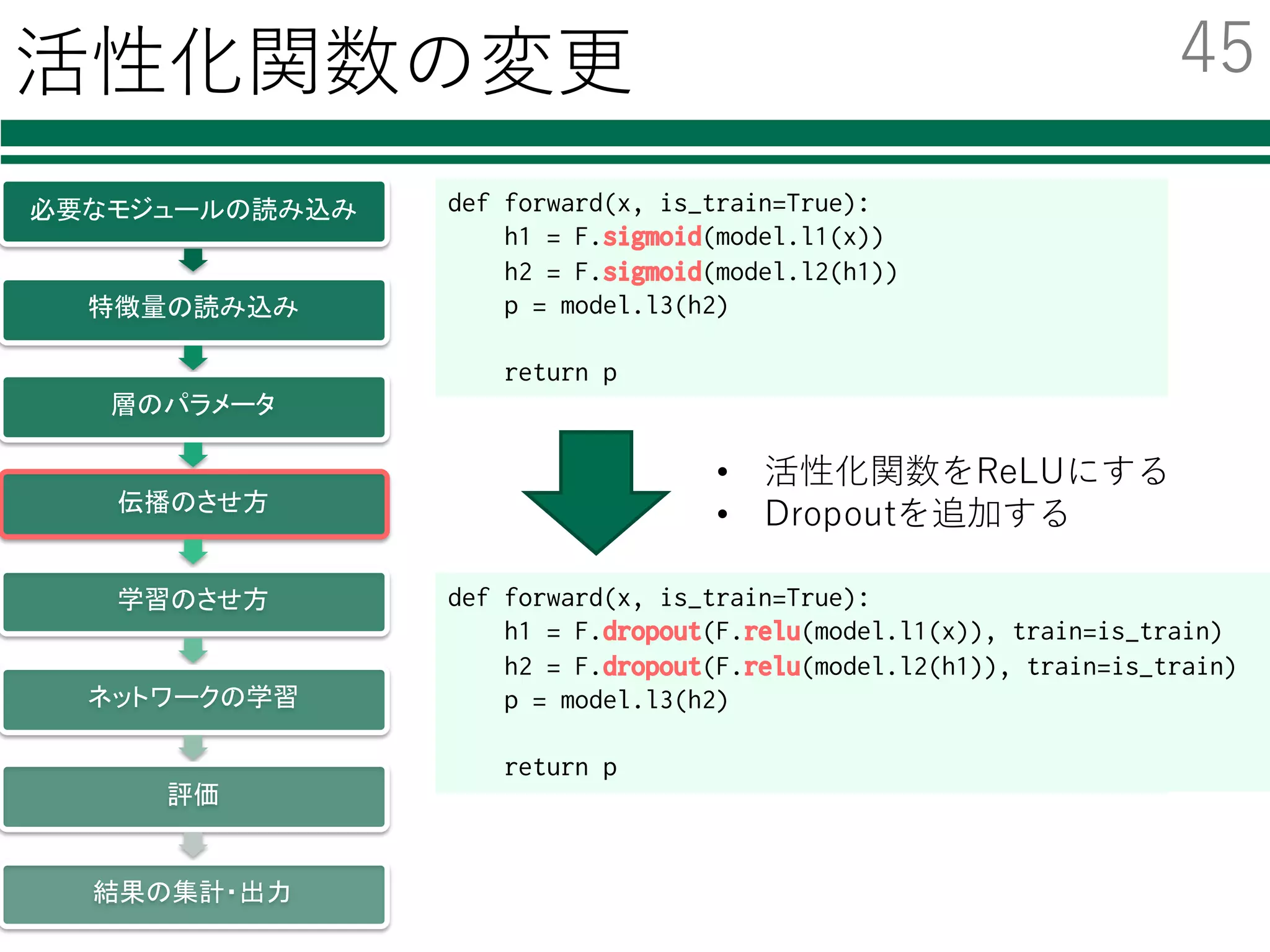
必要なモジュールの読み込み
特徴量の読み込み
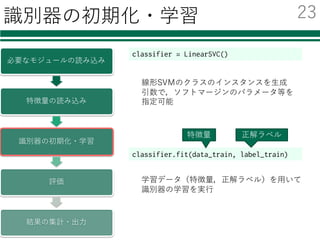
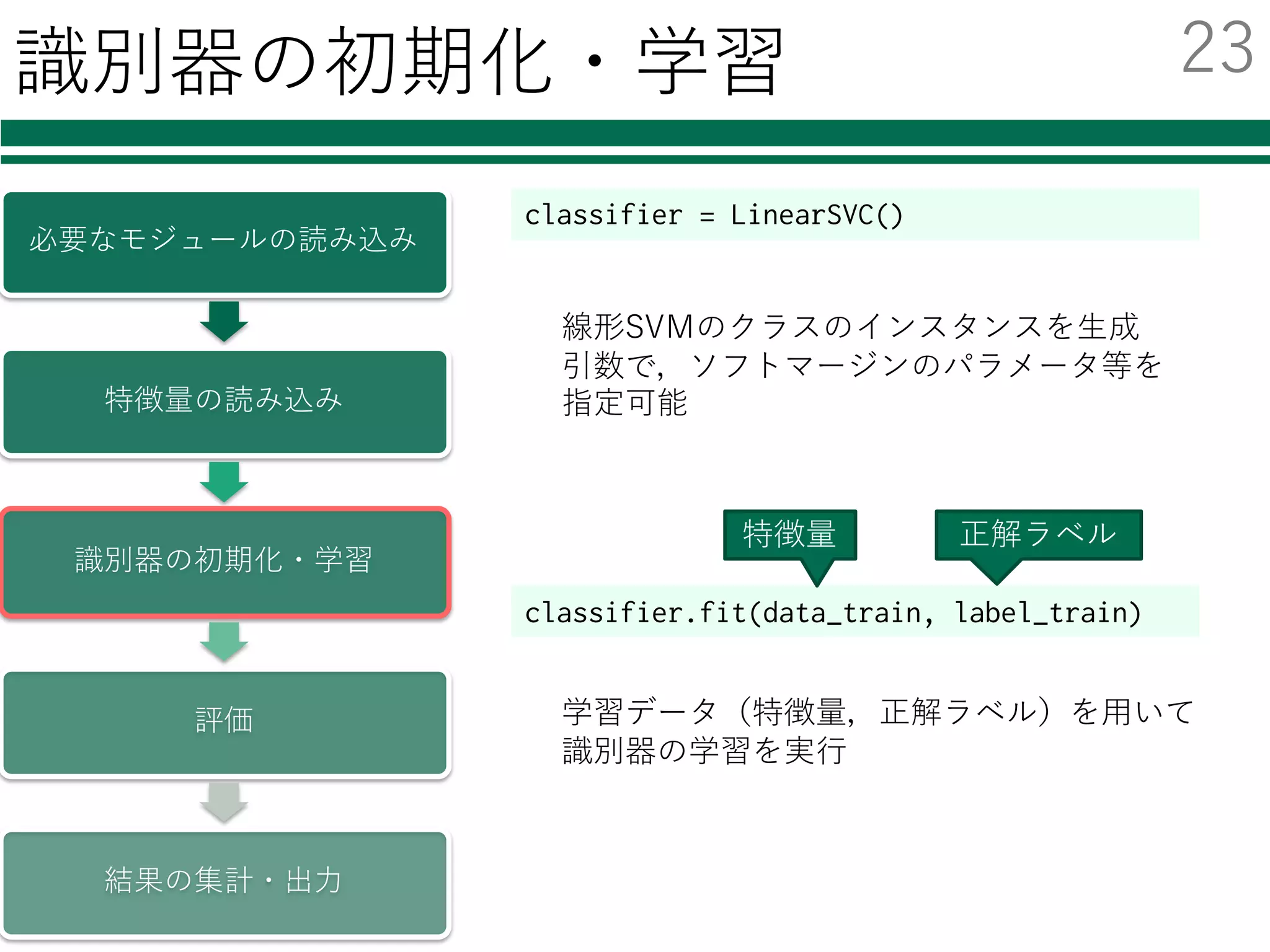
識別器の初期化・学習
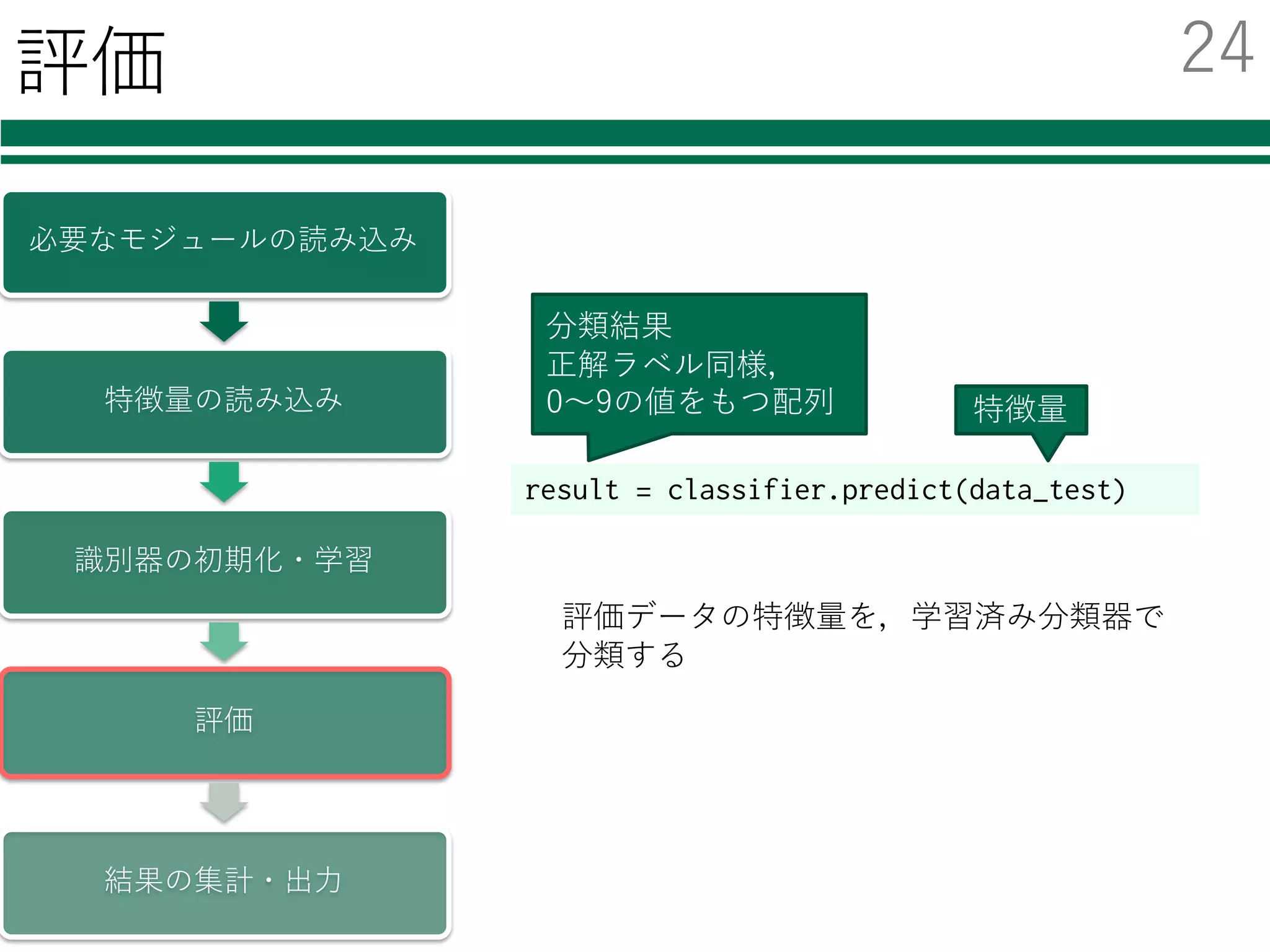
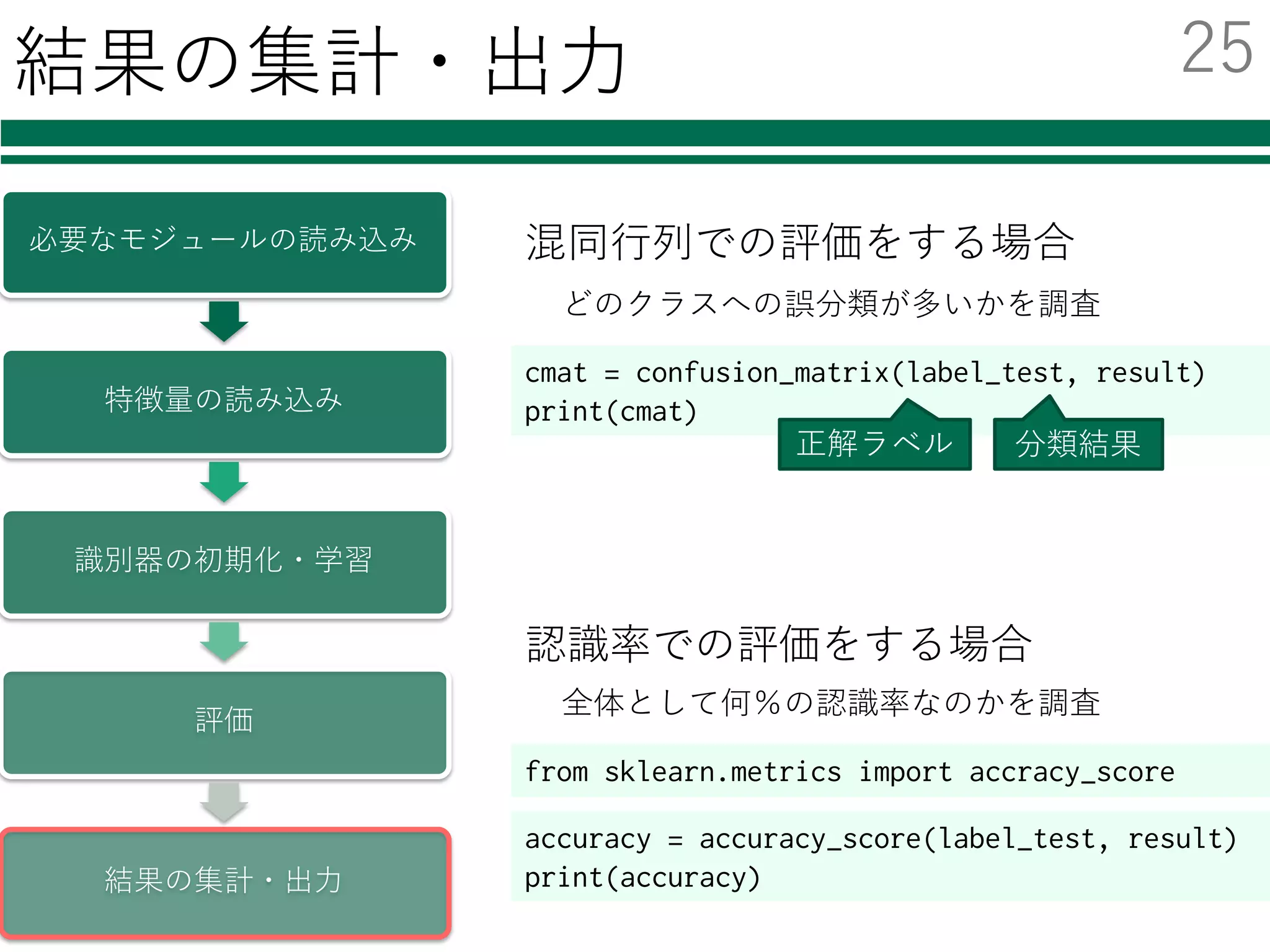
評価
結果の集計・出⼒
classifier = LinearSVC()
書き換えが必要なのは2箇所
classifier= SVC()
classifier = KNeighborsClassifier()
classifier = AdaBoostClassifier()
classifier = RandomForestClassifier()
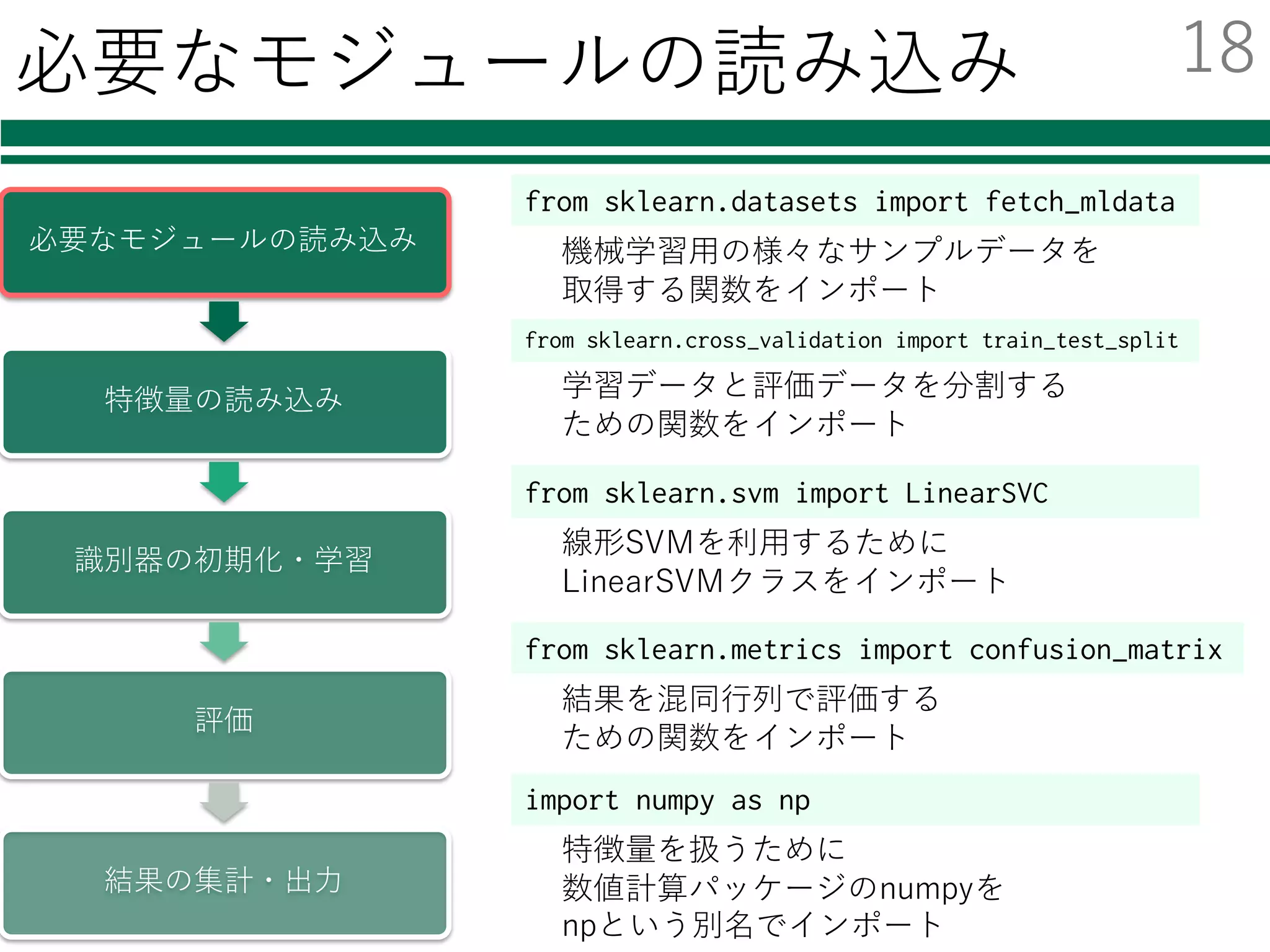
from sklearn.svm import LinearSVC
① モジュールの読み込み
② 識別器の初期化
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import RandomForestClassifier
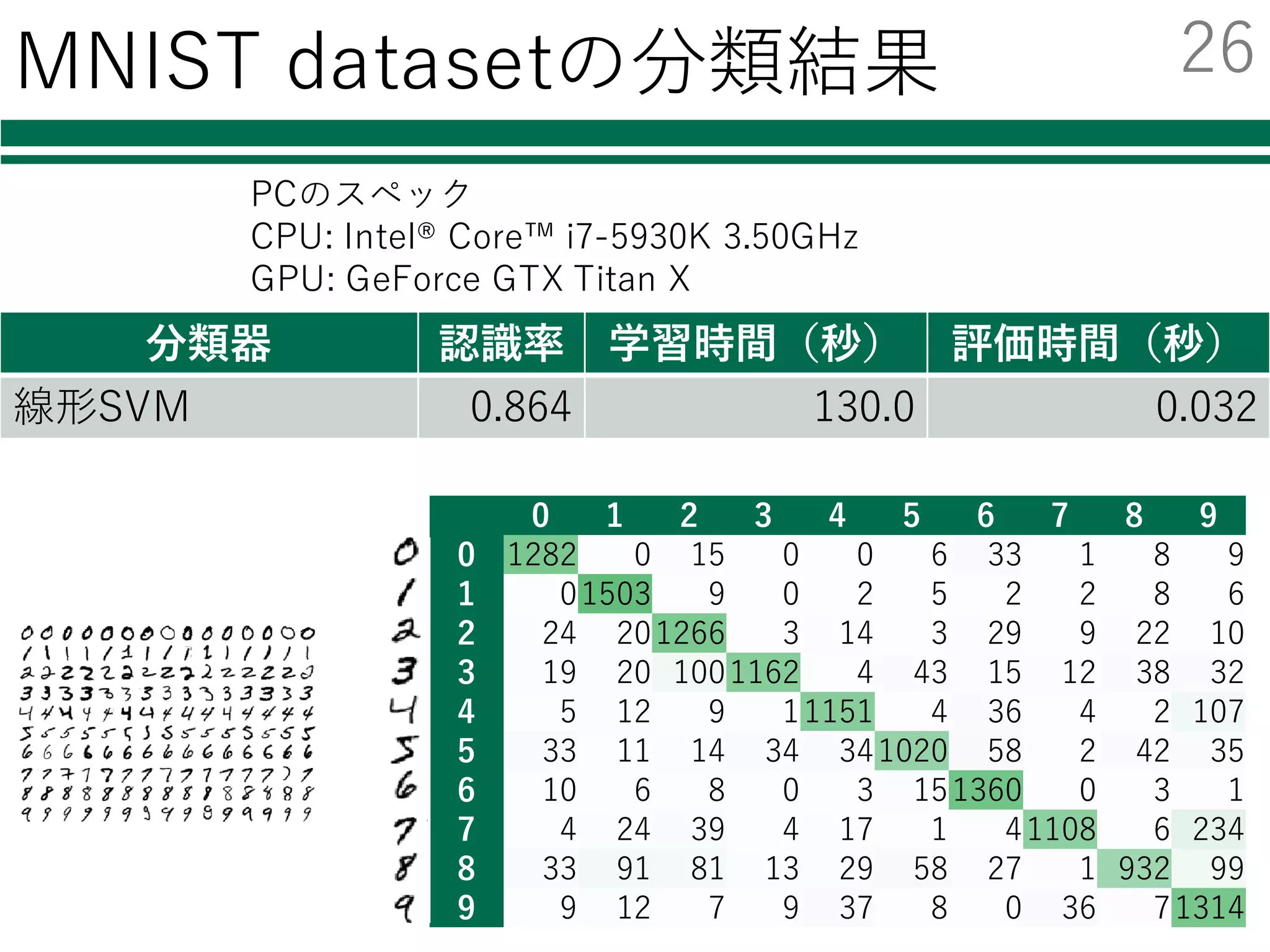
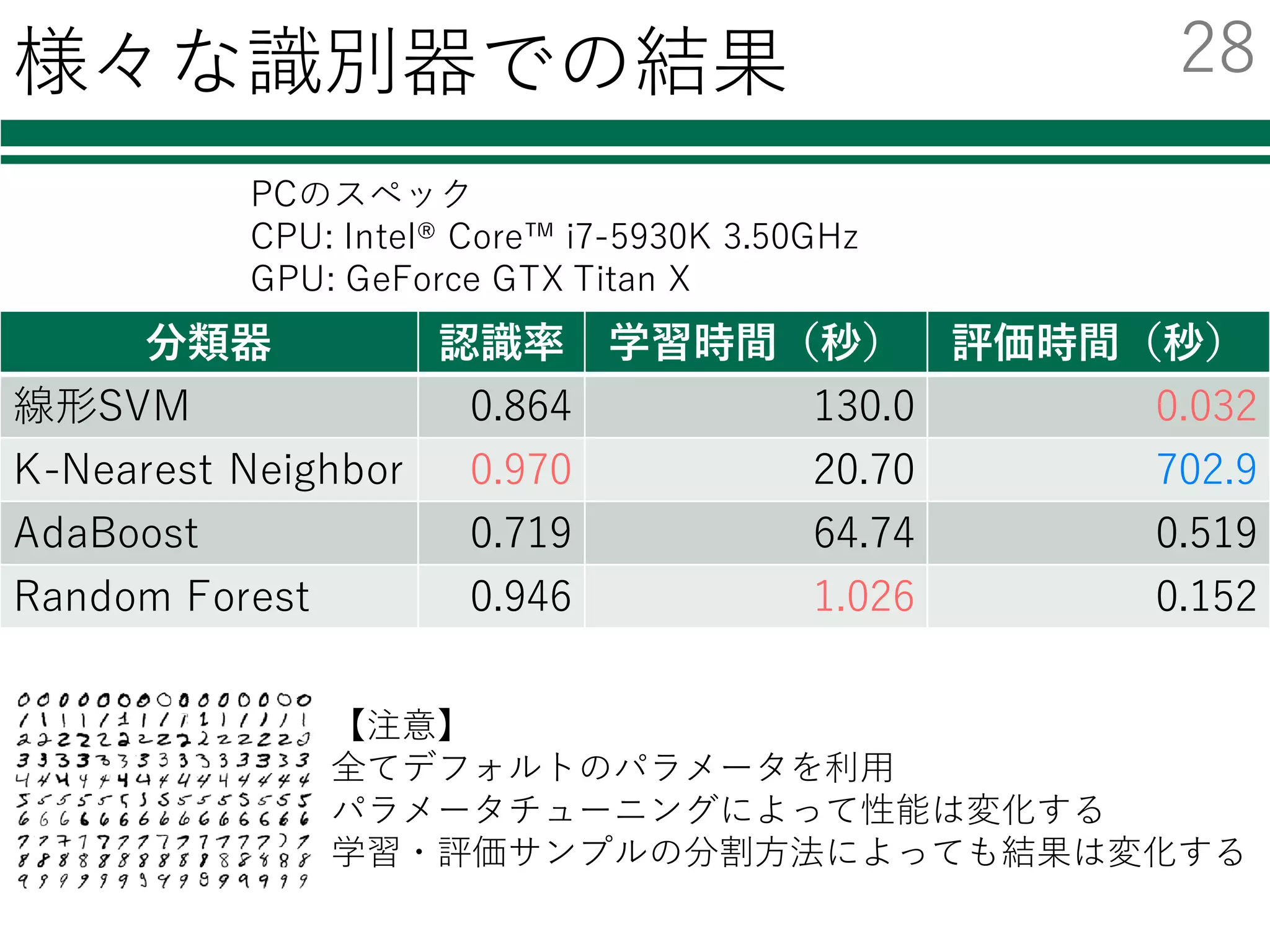
27
29.
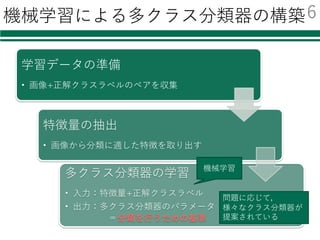
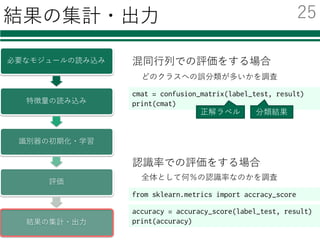
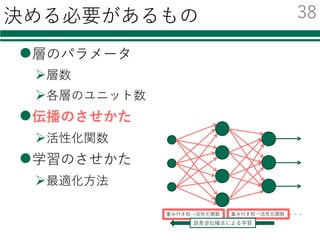
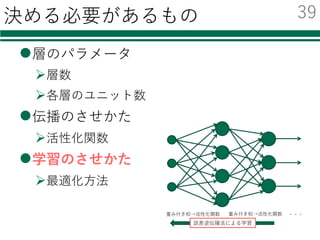
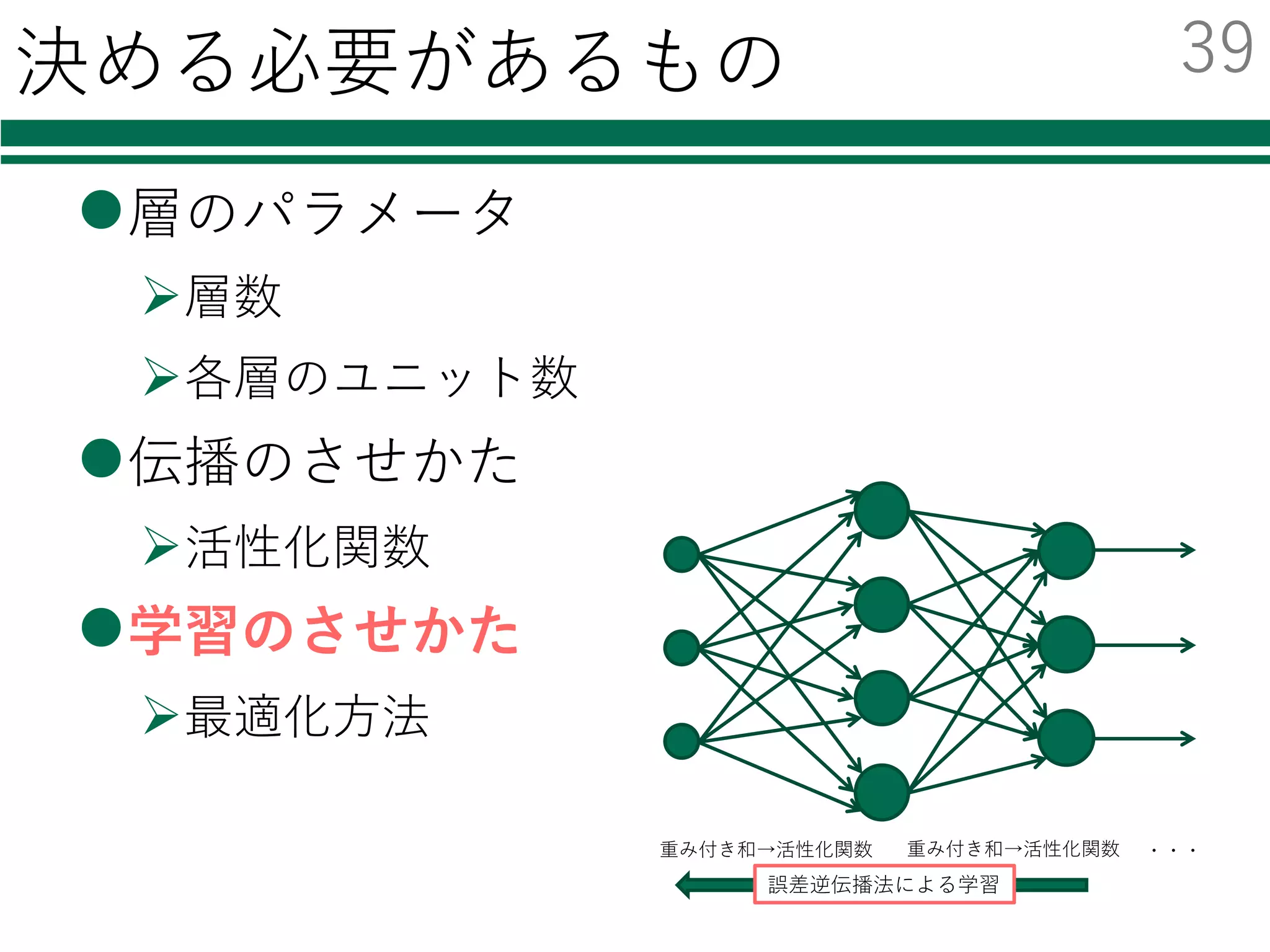
識別器を⾃由に切り替える
必要なモジュールの読み込み
特徴量の読み込み
識別器の初期化・学習
評価
結果の集計・出⼒
classifier = CLF()
インポート時に名前を付けておくと
fromsklearn.svm import LinearSVC as CLF
① モジュールの読み込み
② 識別器の初期化
from sklearn.svm import SVC as CLF
from sklearn.neighbors import KNeighborsClassifier as CLF
from sklearn.ensemble import AdaBoostClassifier as CLF
from sklearn.ensemble import RandomForestClassifier as CLF
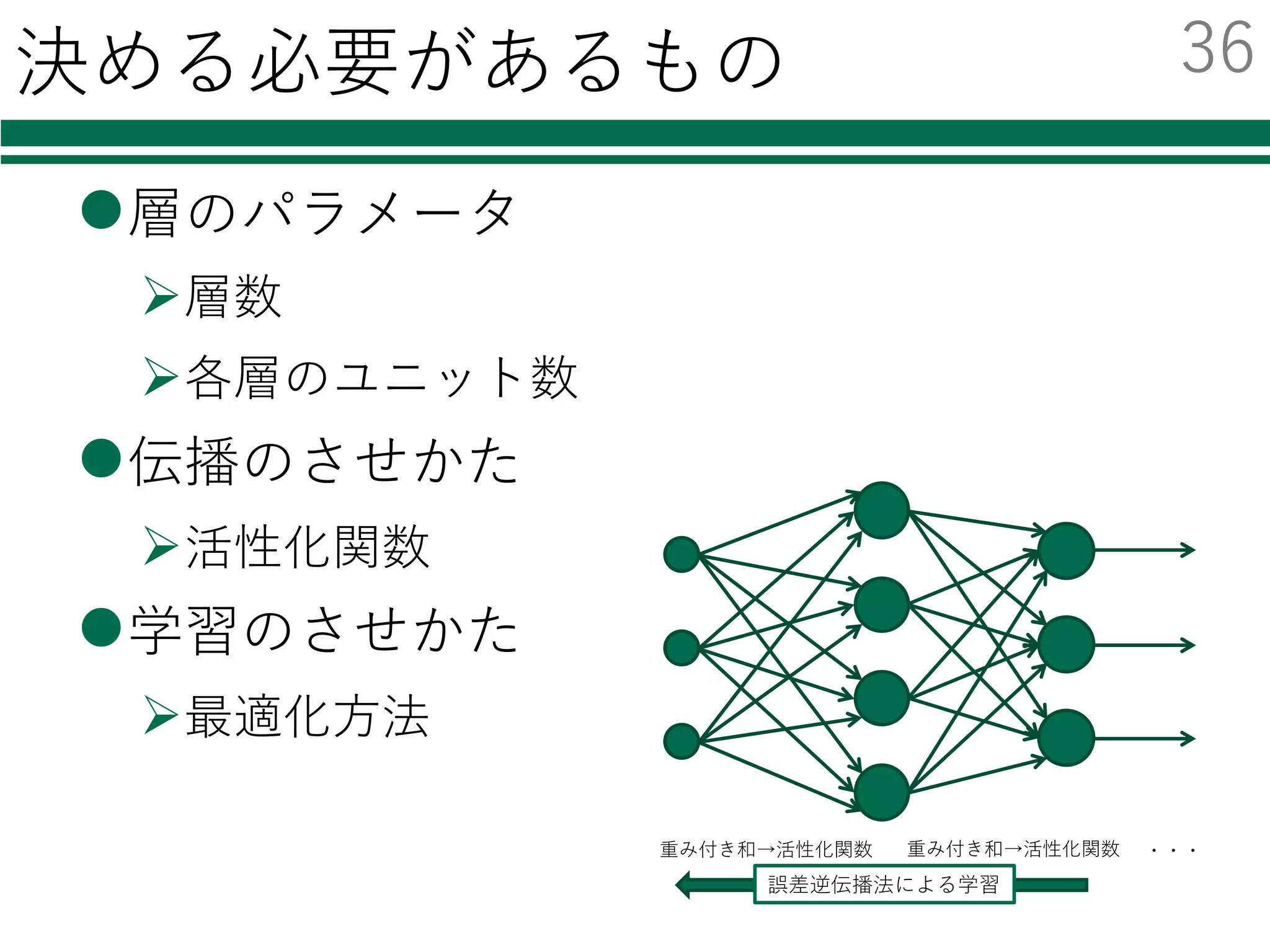
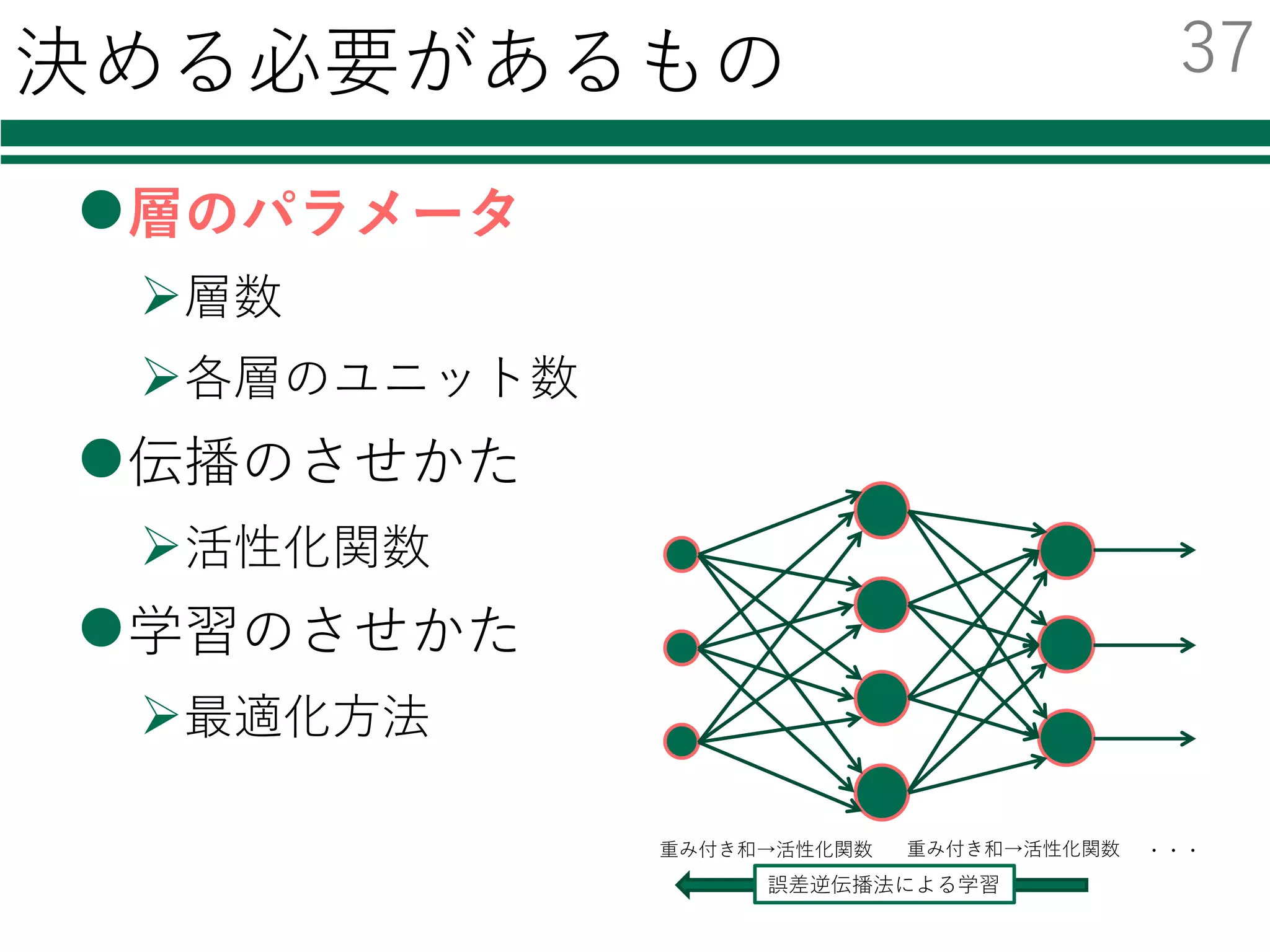
この部分を書き換える必要がなくなる
この場合1⾏書き換えるだけで,各種分類器を
切り替えて利⽤・⽐較することが可能!
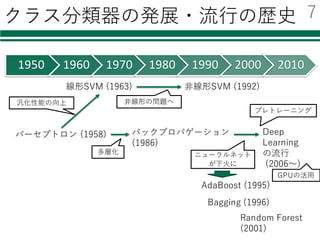
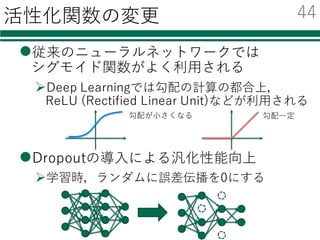
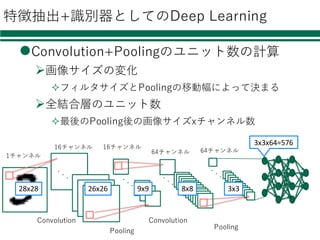
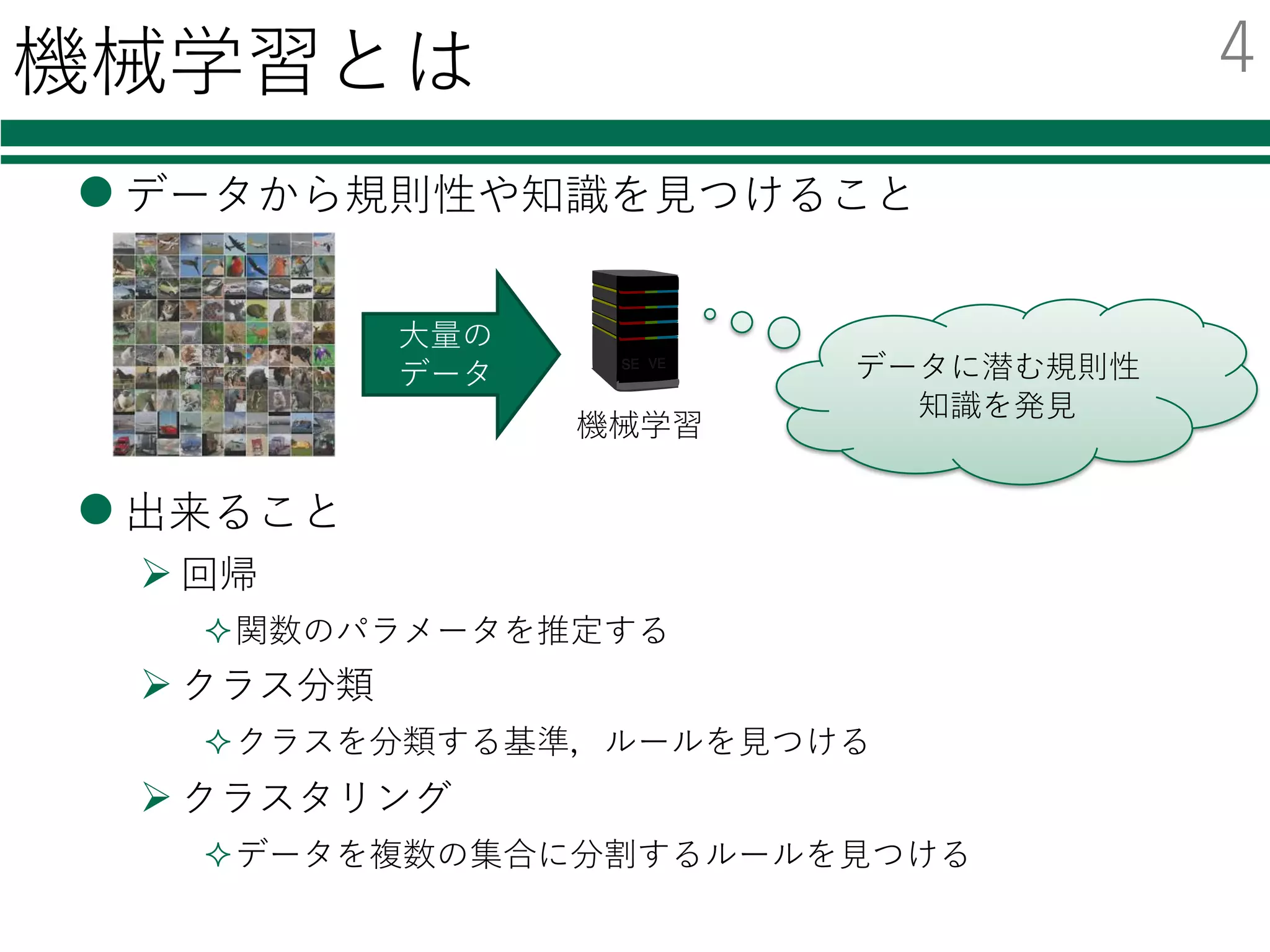
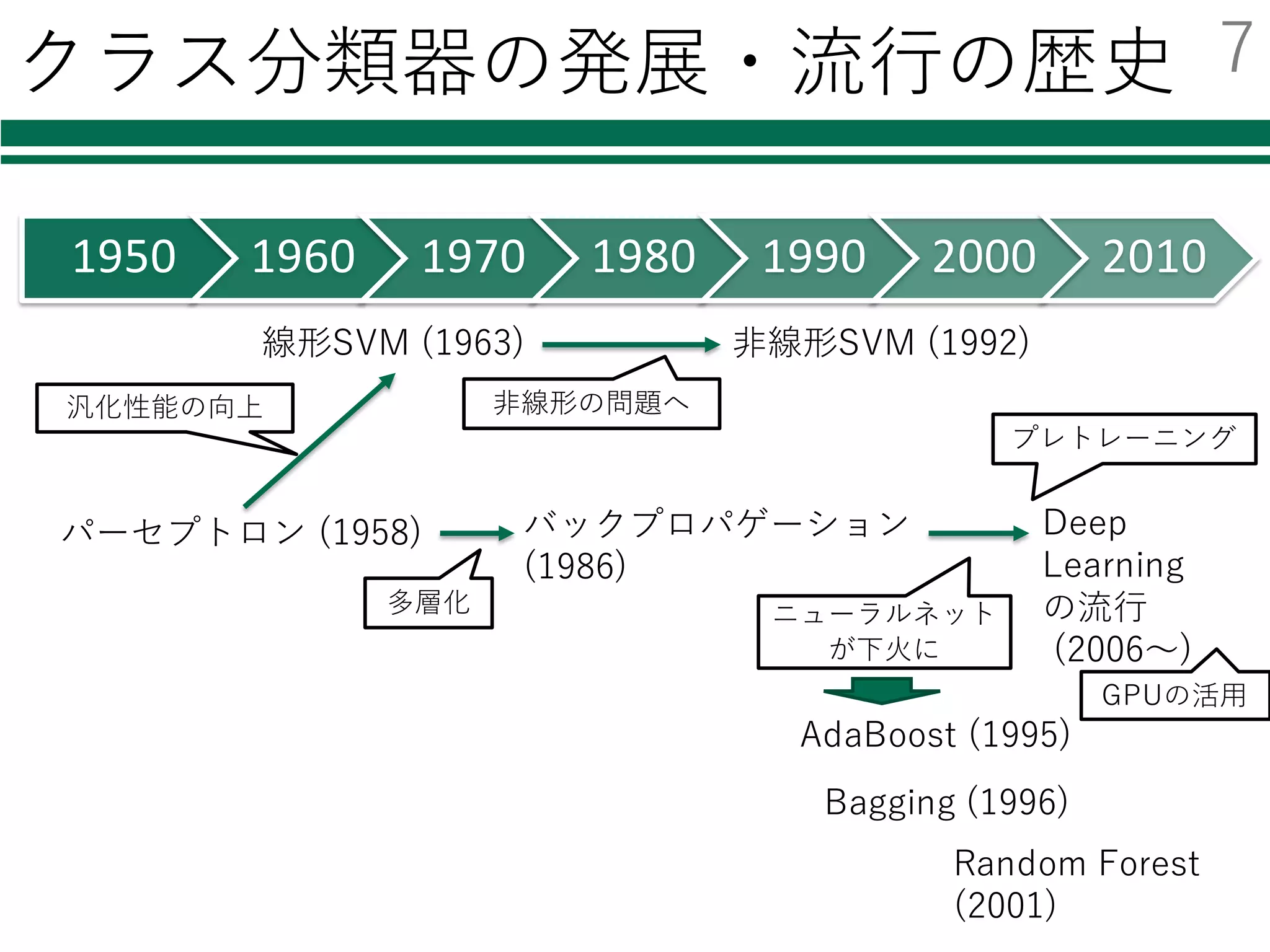
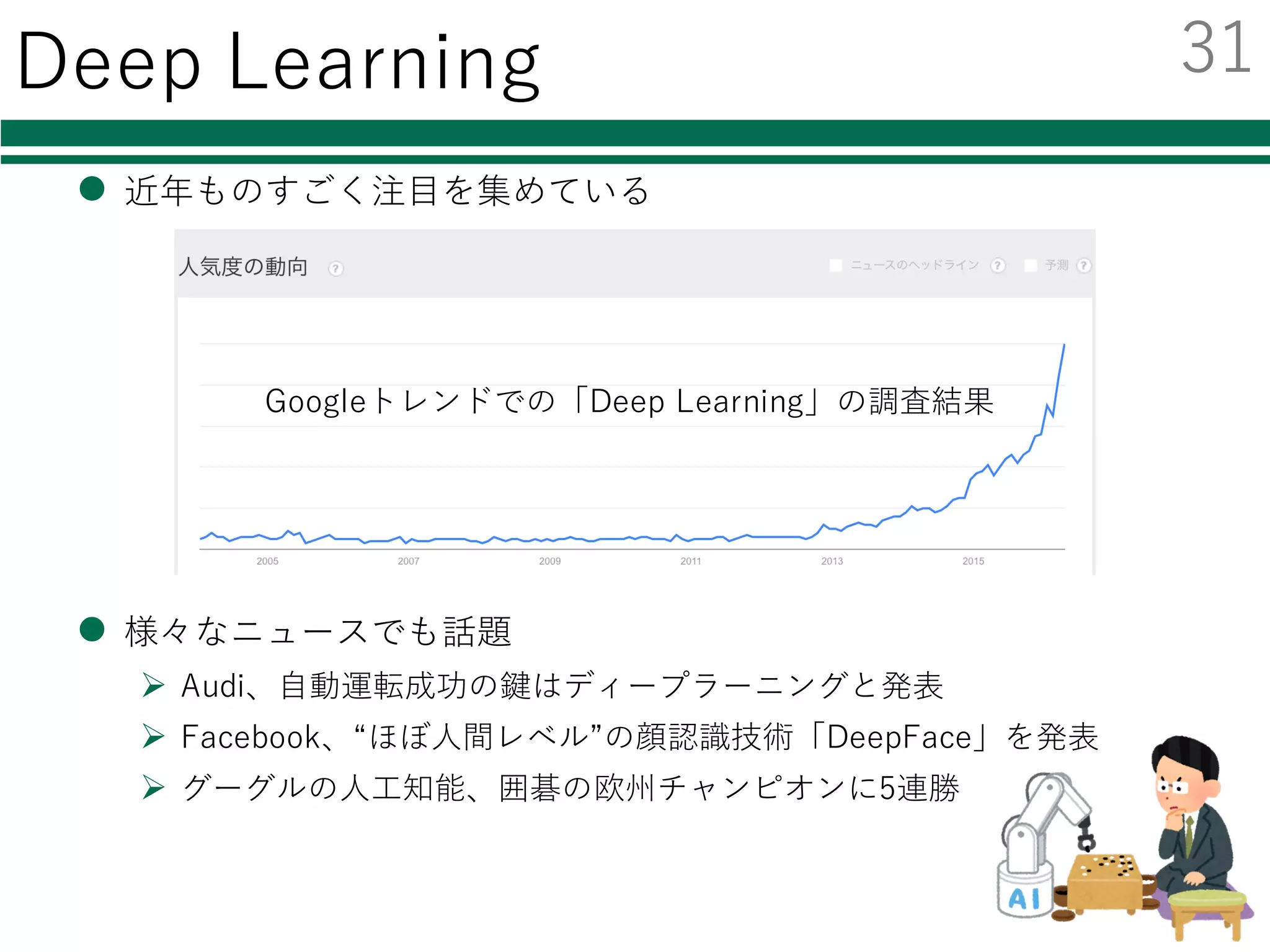
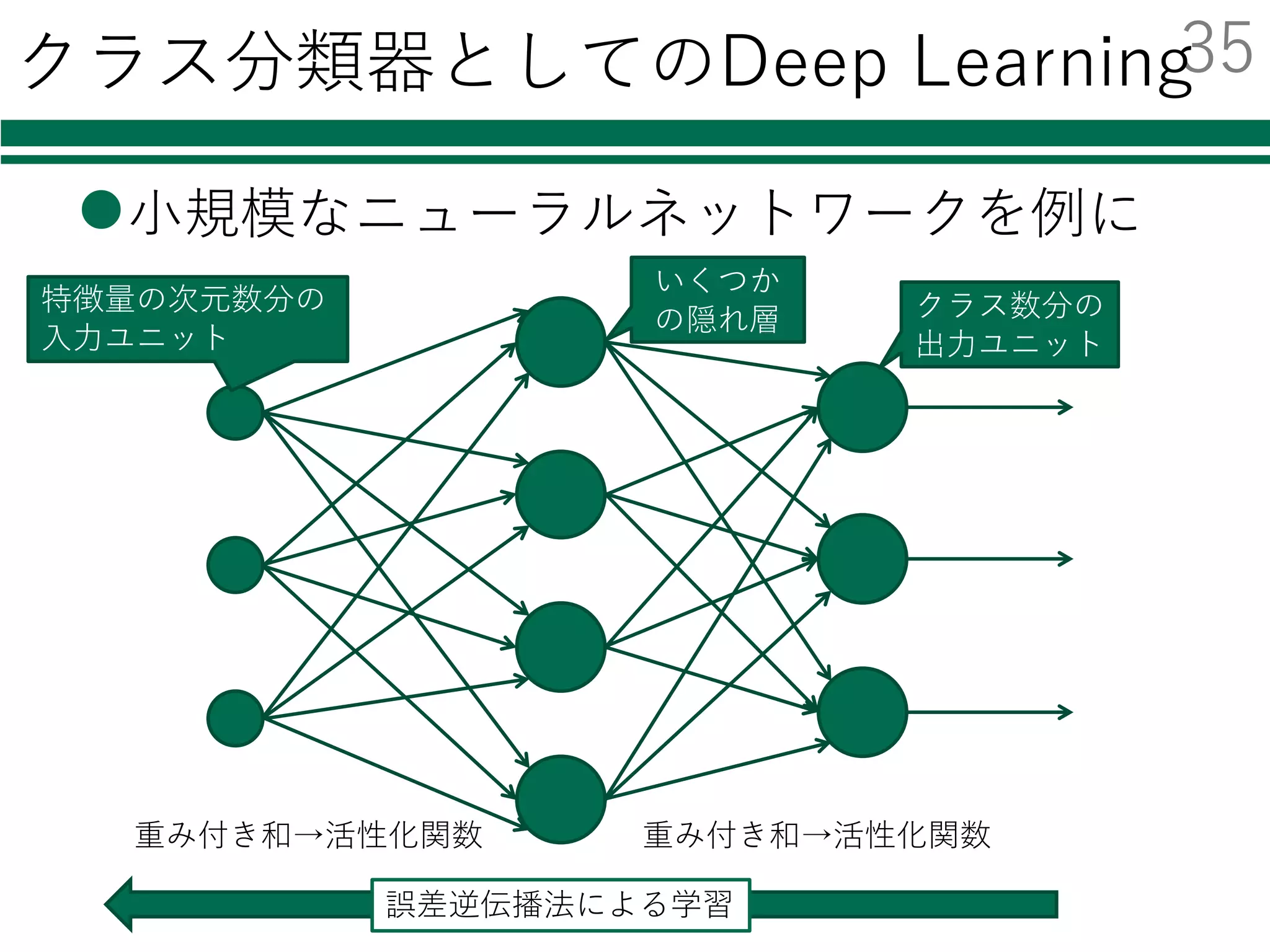
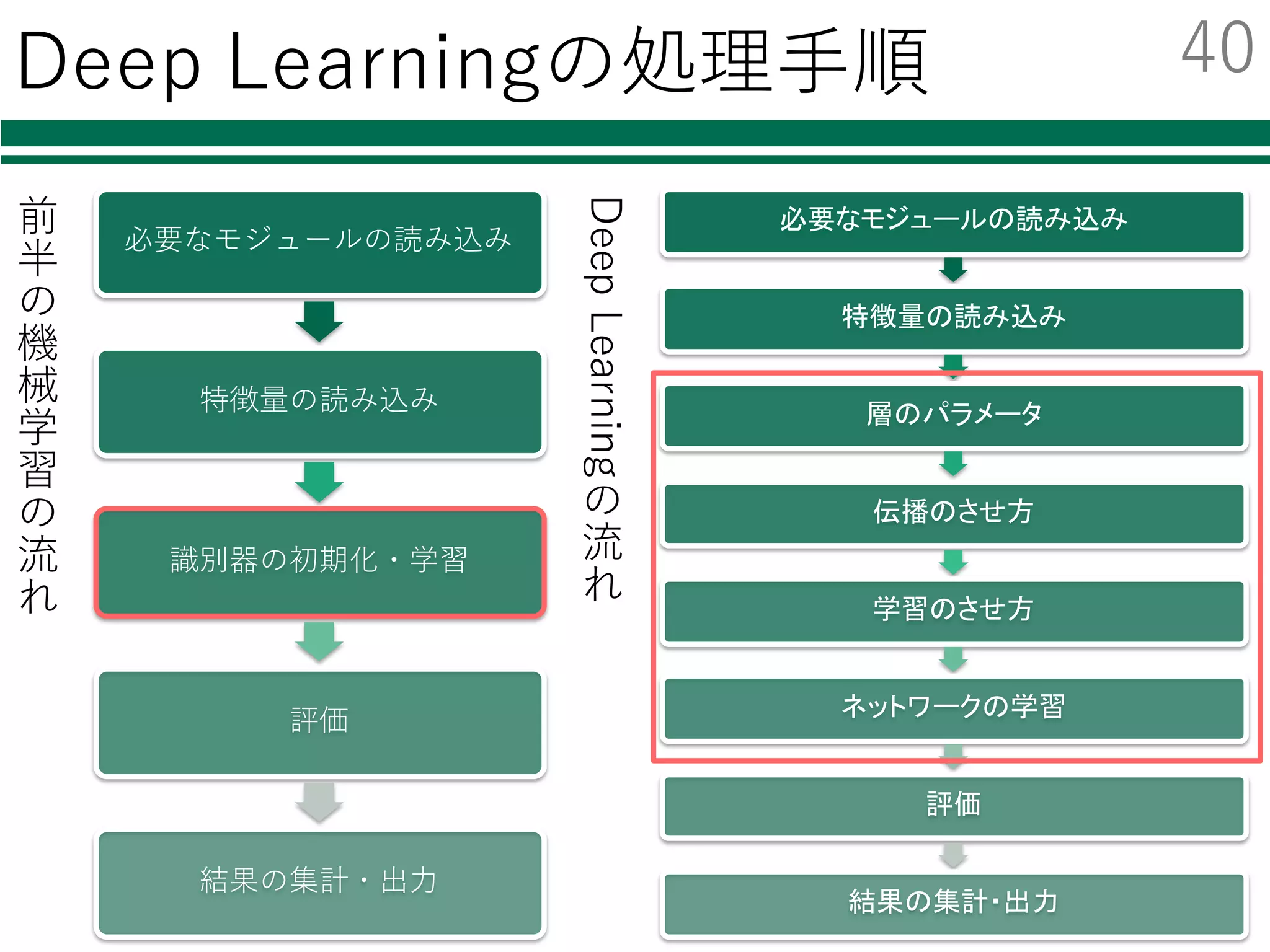
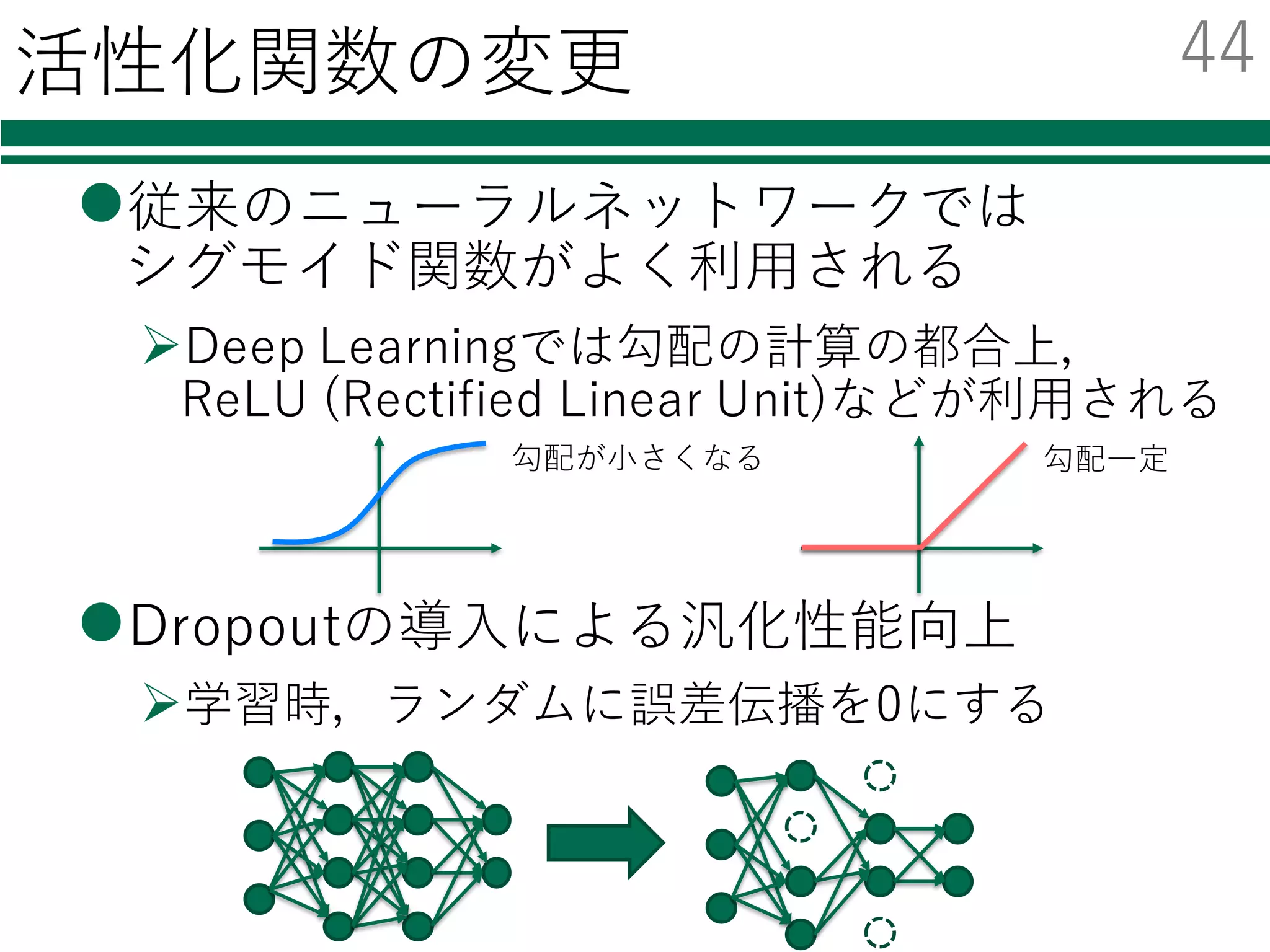
Deep Learning
l 近年ものすごく注⽬を集めている
l様々なニュースでも話題
Ø Audi、⾃動運転成功の鍵はディープラーニングと発表
Ø Facebook、“ほぼ⼈間レベル”の顔認識技術「DeepFace」を発表
Ø グーグルの⼈⼯知能、囲碁の欧州チャンピオンに5連勝
Googleトレンドでの「Deep Learning」の調査結果
31
35.
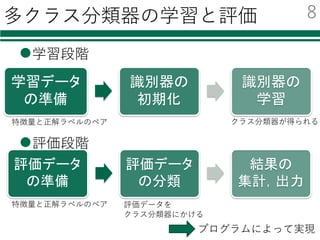
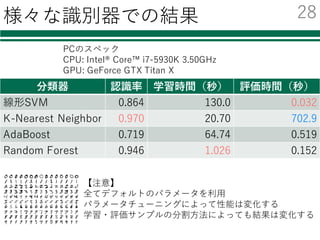
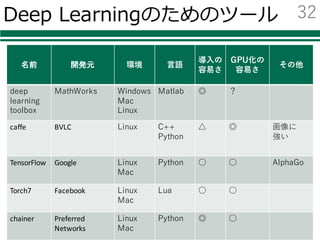
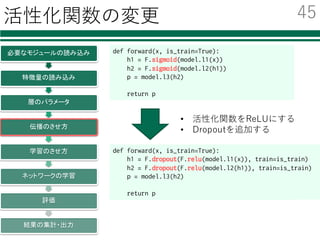
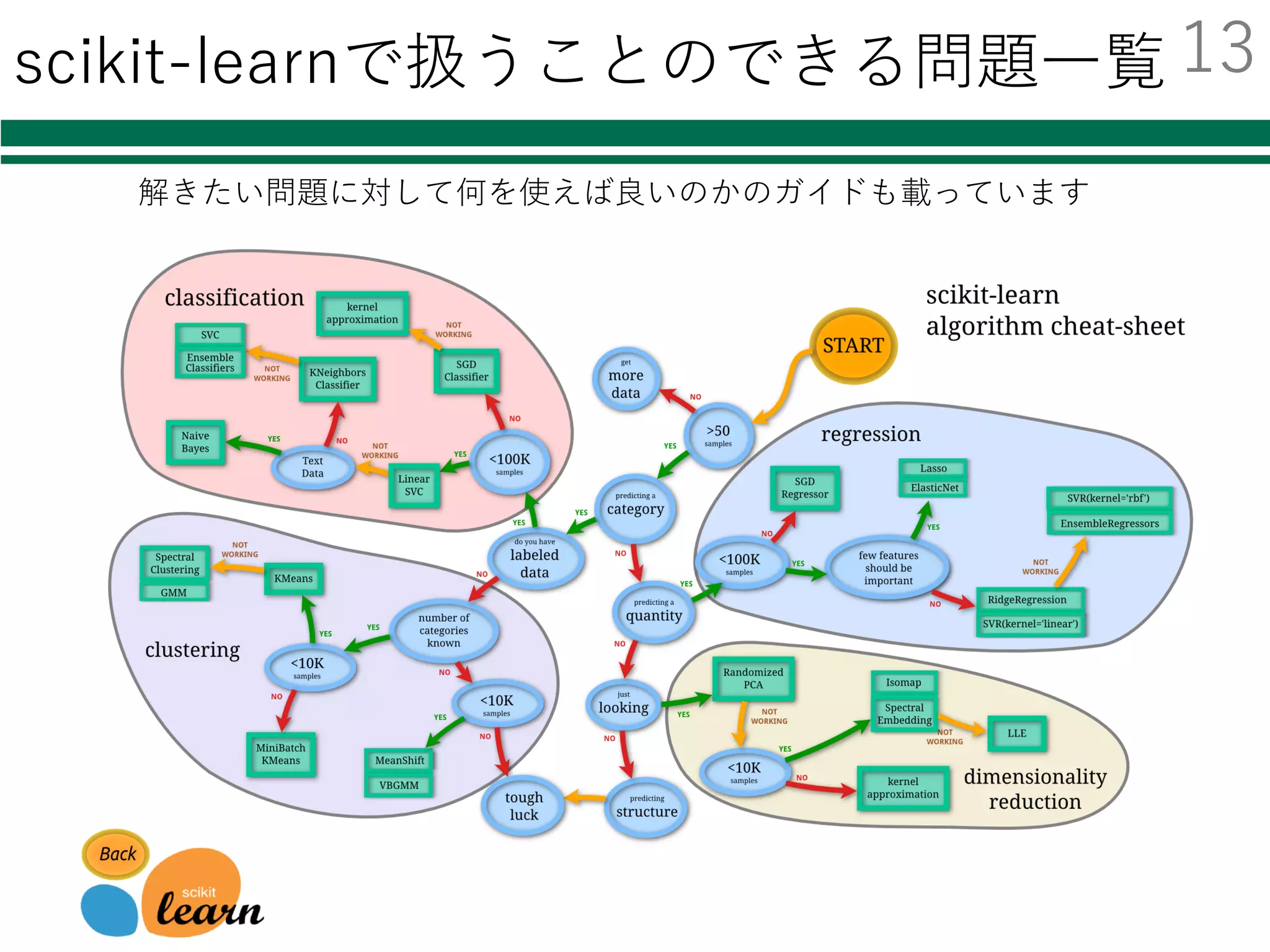
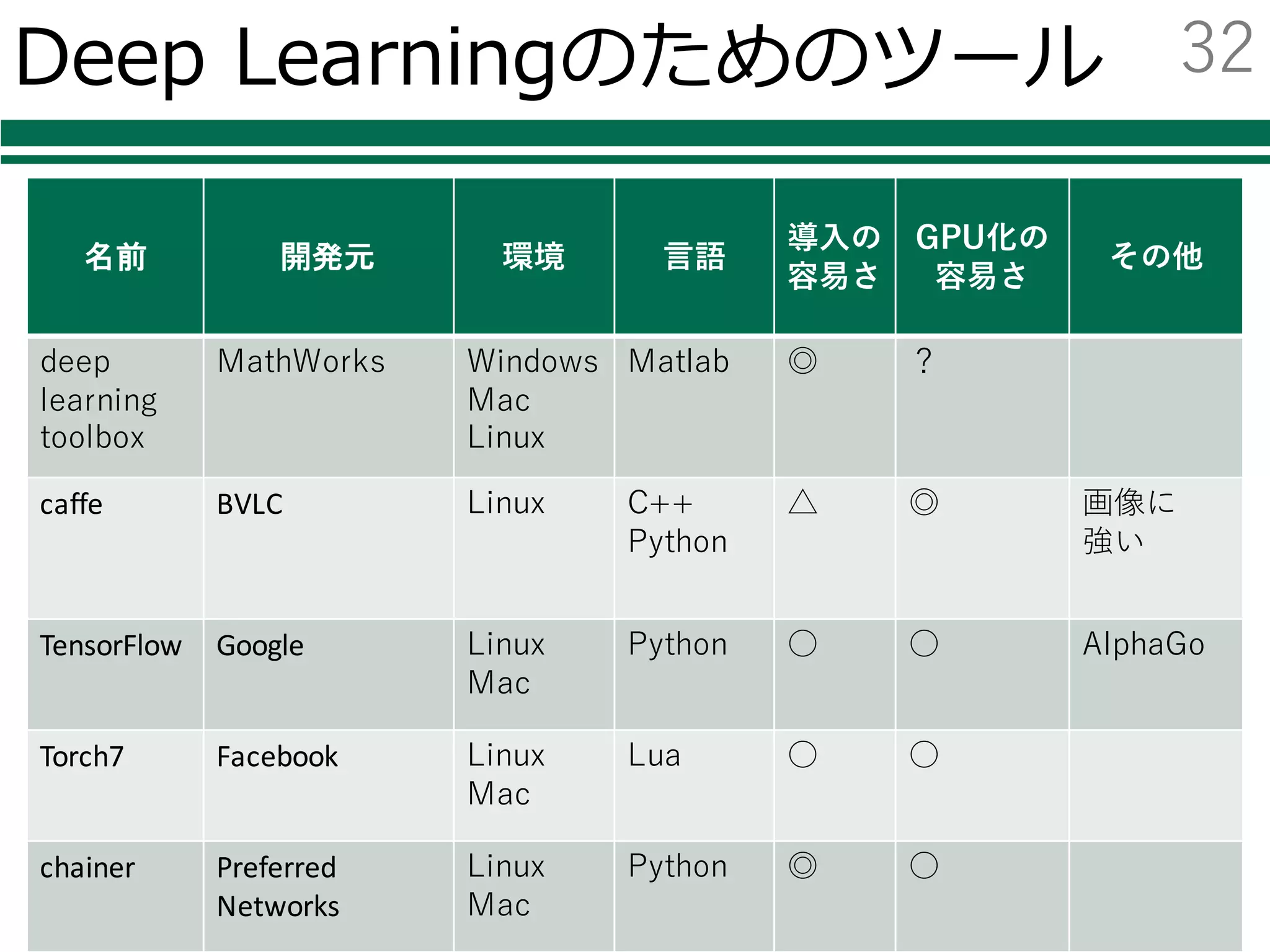
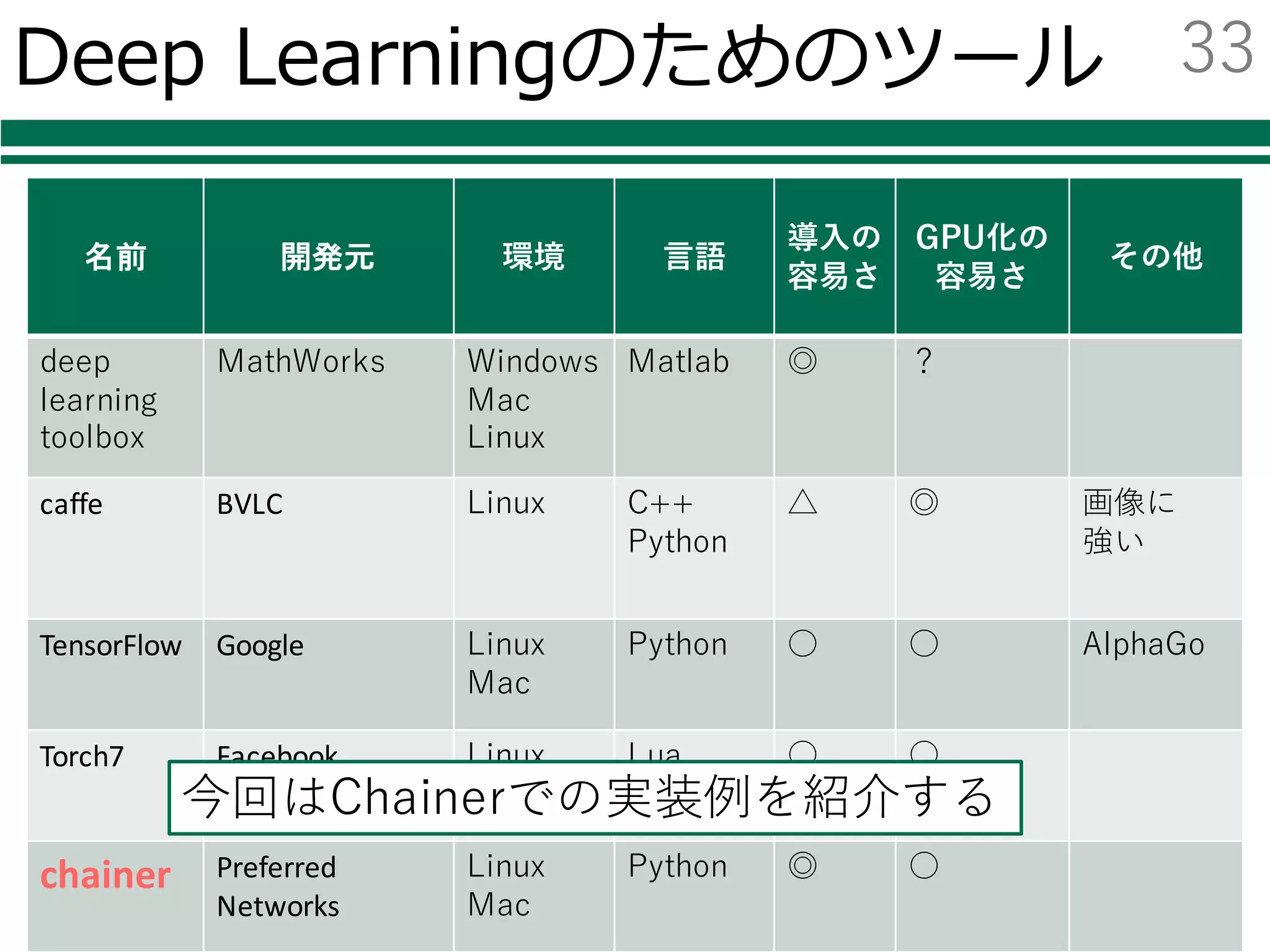
Deep Learningのためのツール
名前 開発元環境 ⾔語
導⼊の
容易さ
GPU化の
容易さ
その他
neural
network
toolbox
MathWorks Windows
Mac
Linux
Matlab ◎ ?
caffe BVLC Linux C++
Python
△ ◎ 画像に
強い
TensorFlow Google Linux
Mac
Python ○ ○ AlphaGo
Torch7 Facebook Linux
Mac
Lua ○ ○
chainer Preferred
Networks
Linux
Mac
Windows
Python ◎ ○
32
36.
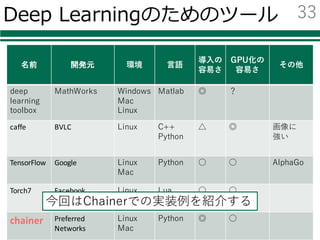
Deep Learningのためのツール
名前 開発元環境 ⾔語
導⼊の
容易さ
GPU化の
容易さ
その他
neural
network
toolbox
MathWorks Windows
Mac
Linux
Matlab ◎ ?
caffe BVLC Linux C++
Python
△ ◎ 画像に
強い
TensorFlow Google Linux
Mac
Python ○ ○ AlphaGo
Torch7 Facebook Linux
Mac
Lua ○ ○
chainer Preferred
Networks
Linux
Mac
Windows
Python ◎ ○
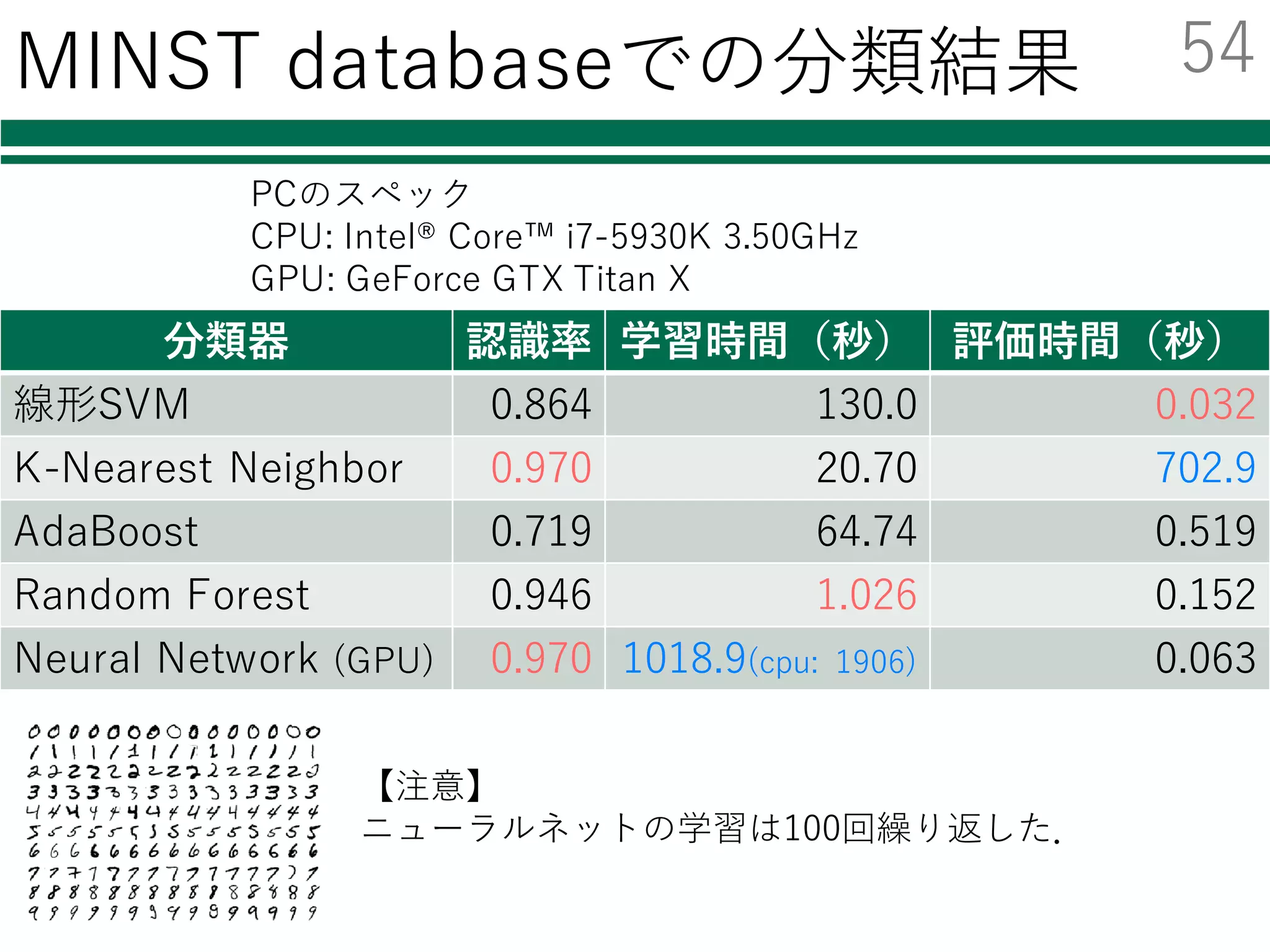
今回はChainerでの実装例を紹介する
33














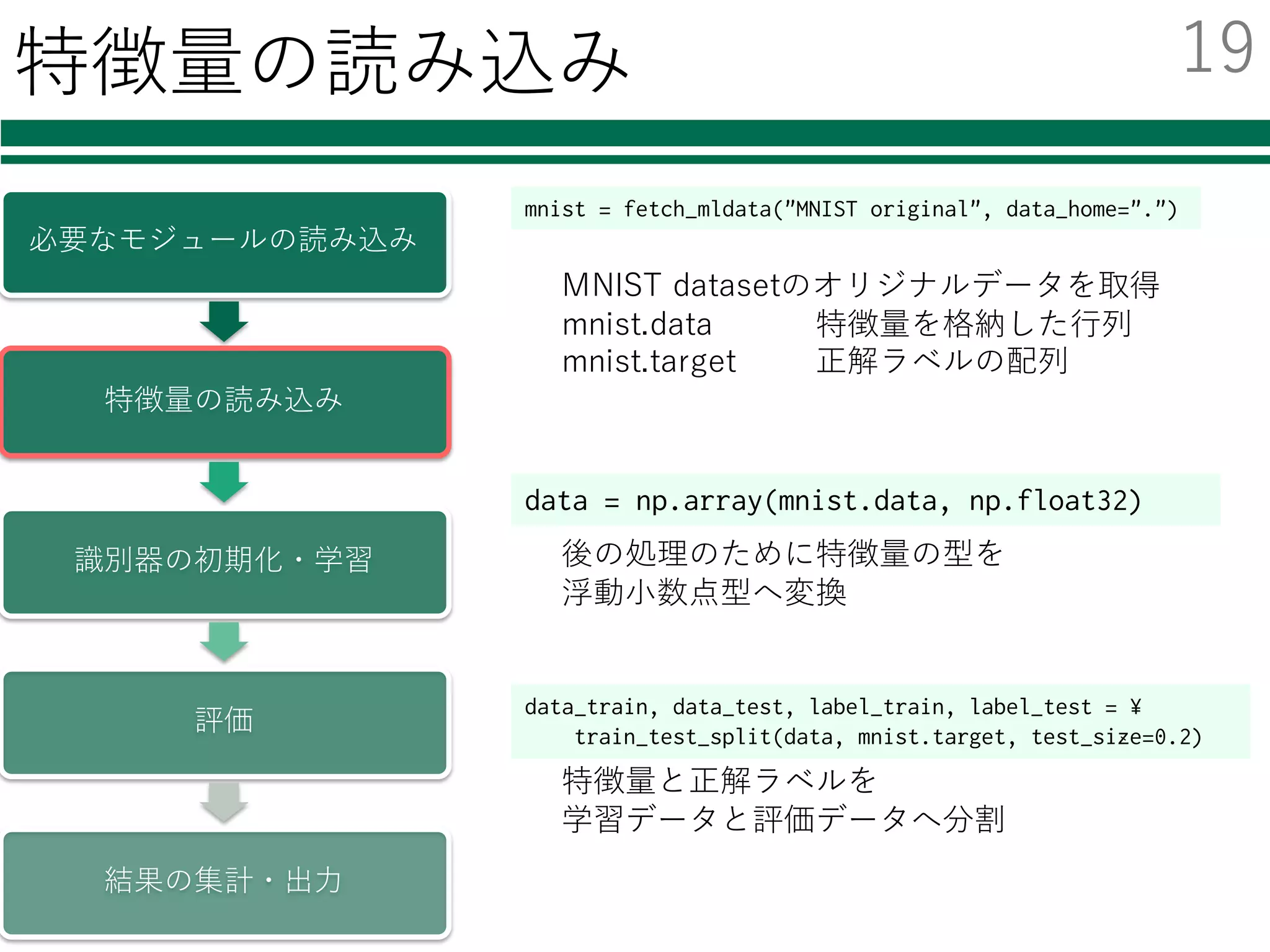
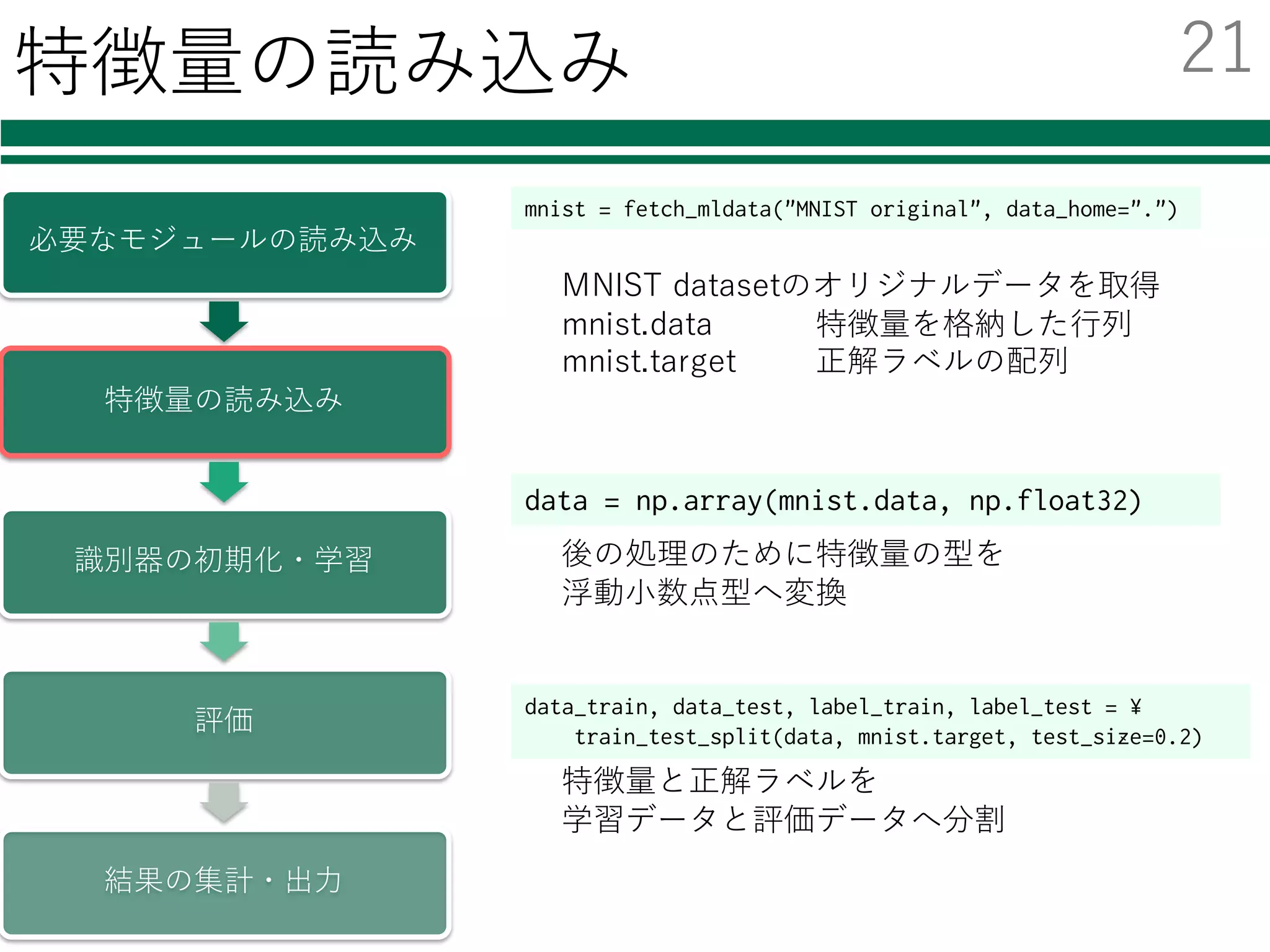
![mnist = fetch_mldata("MNIST original", data_home=".")
特徴量の読み込み
必要なモジュールの読み込み
特徴量の読み込み
識別器の初期化・学習
評価
結果の集計・出⼒
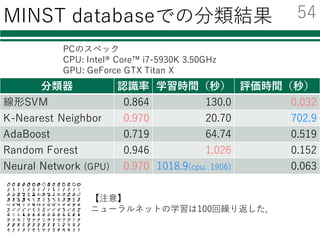
MNIST datasetのオリジナルデータを取得
mnist.data 特徴量を格納した⾏列
mnist.target 正解ラベルの配列
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0]] [ 0., 0., ..., 9., 9.]
mnist.data mnist.target
各⾏には,1枚の画像を
1⾏に伸ばしたもの(画素値)
が格納されている
正解値の配列
0~9の値をもつ
20](https://image.slidesharecdn.com/tutorialpublic-160607132749/85/Python-SVM-Deep-Learning-21-320.jpg)

![特徴量の読み込み
必要なモジュールの読み込み
特徴量の読み込み
識別器の初期化・学習
評価
結果の集計・出⼒
data_train, data_test, label_train, label_test = ¥
train_test_split(data, mnist.target, test_size=0.2)
特徴量と正解ラベルを
学習データと評価データへ分割
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0]] [ 0., 0., ..., 9., 9.]
mnist.data mnist.target
data_test label_testdata_train label_train
学習データ 評価データ
2割を評価用
にする
22](https://image.slidesharecdn.com/tutorialpublic-160607132749/85/Python-SVM-Deep-Learning-23-320.jpg)








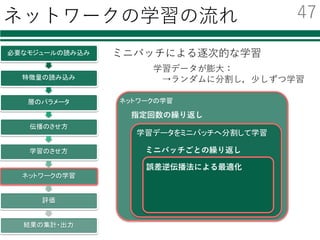

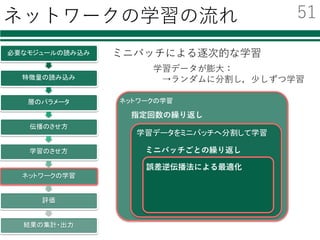
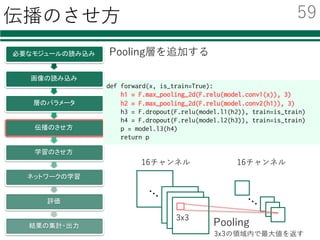
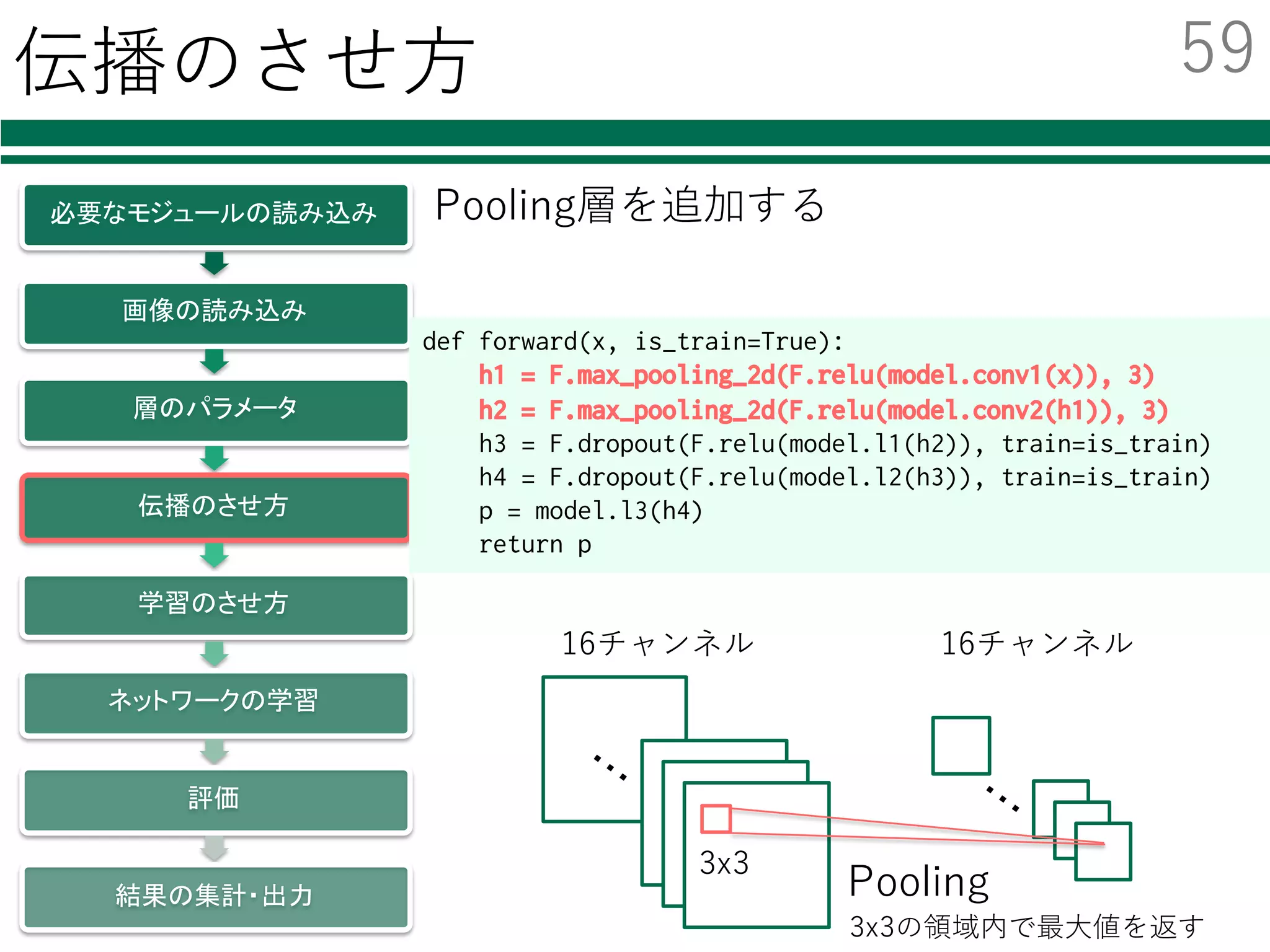
![ネットワークの学習 1/2
必要なモジュールの読み込み
特徴量の読み込み
層のパラメータ
伝播のさせ方
学習のさせ方
ネットワークの学習
評価
結果の集計・出力
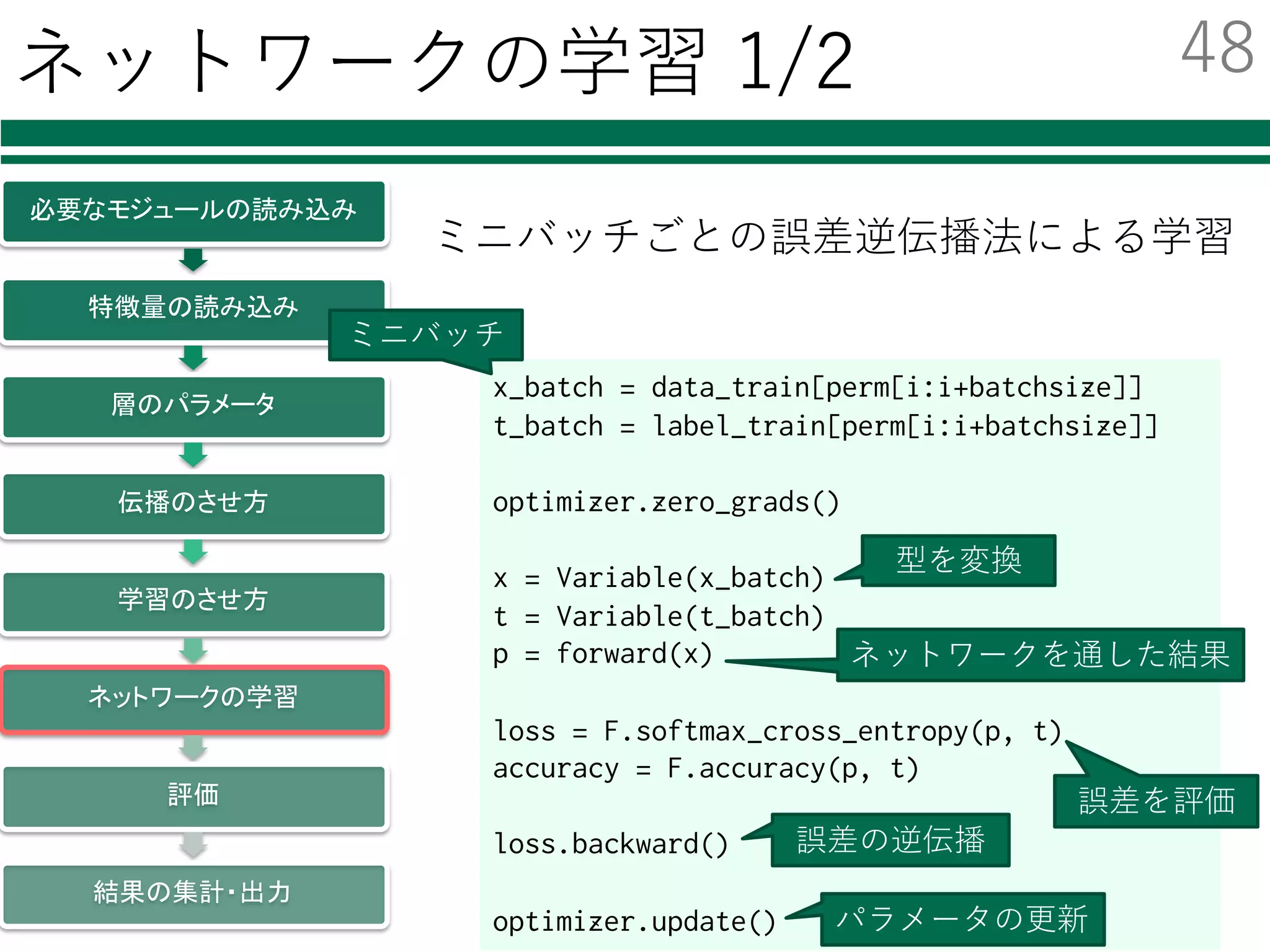
x_batch = data_train[perm[i:i+batchsize]]
t_batch = label_train[perm[i:i+batchsize]]
optimizer.zero_grads()
x = Variable(x_batch)
t = Variable(t_batch)
p = forward(x)
loss = F.softmax_cross_entropy(p, t)
accuracy = F.accuracy(p, t)
loss.backward()
optimizer.update()
ミニバッチごとの誤差逆伝播法による学習
ミニバッチ
型を変換
ネットワークを通した結果
誤差を評価
誤差の逆伝播
パラメータの更新
48](https://image.slidesharecdn.com/tutorialpublic-160607132749/85/Python-SVM-Deep-Learning-51-320.jpg)




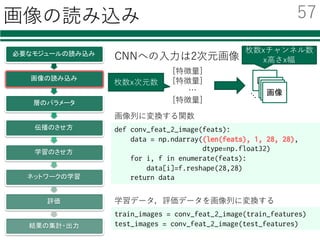
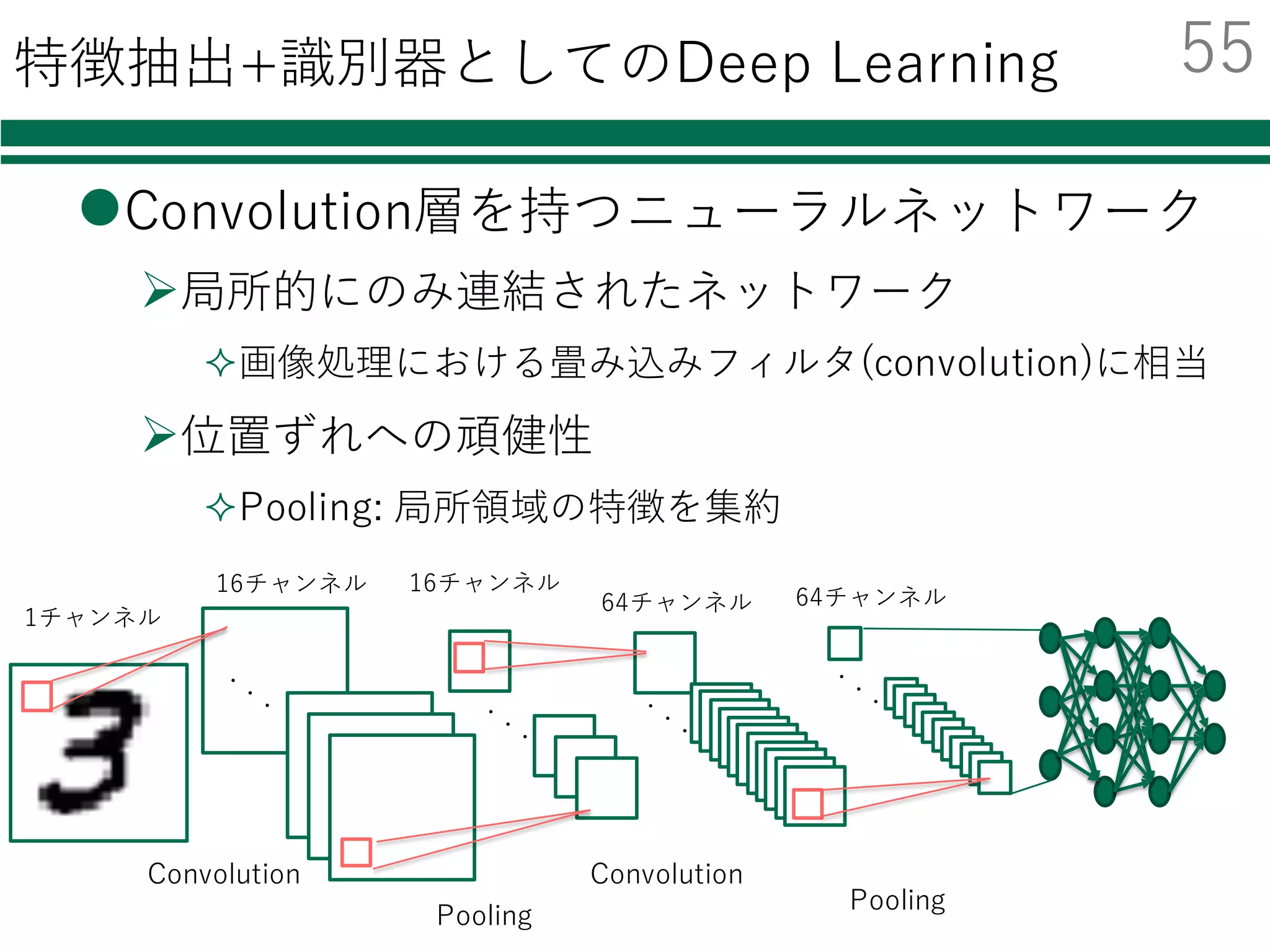
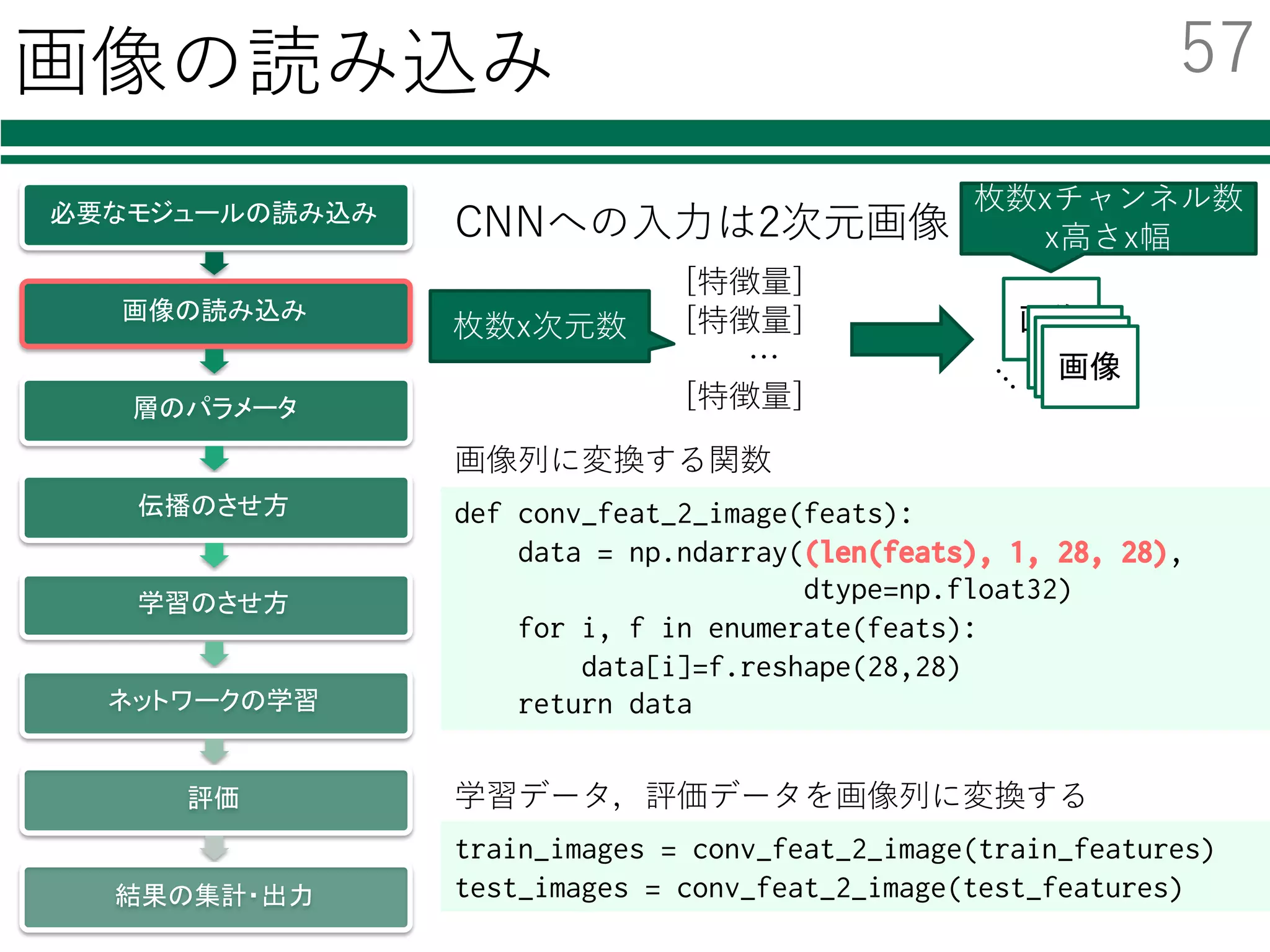
![画像の読み込み
必要なモジュールの読み込み
画像の読み込み
層のパラメータ
伝播のさせ方
学習のさせ方
ネットワークの学習
評価
結果の集計・出力
def conv_feat_2_image(feats):
data = np.ndarray((len(feats), 1, 28, 28),
dtype=np.float32)
for i, f in enumerate(feats):
data[i]=f.reshape(28,28)
return data
train_images = conv_feat_2_image(train_features)
test_images = conv_feat_2_image(test_features)
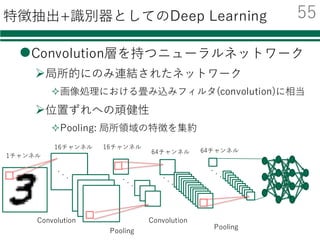
学習データ,評価データを画像列に変換する
画像列に変換する関数
CNNへの⼊⼒は2次元画像
[特徴量]
[特徴量]
…
[特徴量]
画像
画像画像画像
枚数xチャンネル数
x⾼さx幅
枚数x次元数
57](https://image.slidesharecdn.com/tutorialpublic-160607132749/85/Python-SVM-Deep-Learning-60-320.jpg)















![mnist = fetch_mldata("MNIST original", data_home=".")
特徴量の読み込み
必要なモジュールの読み込み
特徴量の読み込み
識別器の初期化・学習
評価
結果の集計・出⼒
MNIST datasetのオリジナルデータを取得
mnist.data 特徴量を格納した⾏列
mnist.target 正解ラベルの配列
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0]] [ 0., 0., ..., 9., 9.]
mnist.data mnist.target
各⾏には,1枚の画像を
1⾏に伸ばしたもの(画素値)
が格納されている
正解値の配列
0~9の値をもつ
20](https://image.slidesharecdn.com/tutorialpublic-160607132749/75/Python-SVM-Deep-Learning-21-2048.jpg)
![特徴量の読み込み
必要なモジュールの読み込み
特徴量の読み込み
識別器の初期化・学習
評価
結果の集計・出⼒
data_train, data_test, label_train, label_test = ¥
train_test_split(data, mnist.target, test_size=0.2)
特徴量と正解ラベルを
学習データと評価データへ分割
[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0]] [ 0., 0., ..., 9., 9.]
mnist.data mnist.target
data_test label_testdata_train label_train
学習データ 評価データ
2割を評価用
にする
22](https://image.slidesharecdn.com/tutorialpublic-160607132749/75/Python-SVM-Deep-Learning-23-2048.jpg)




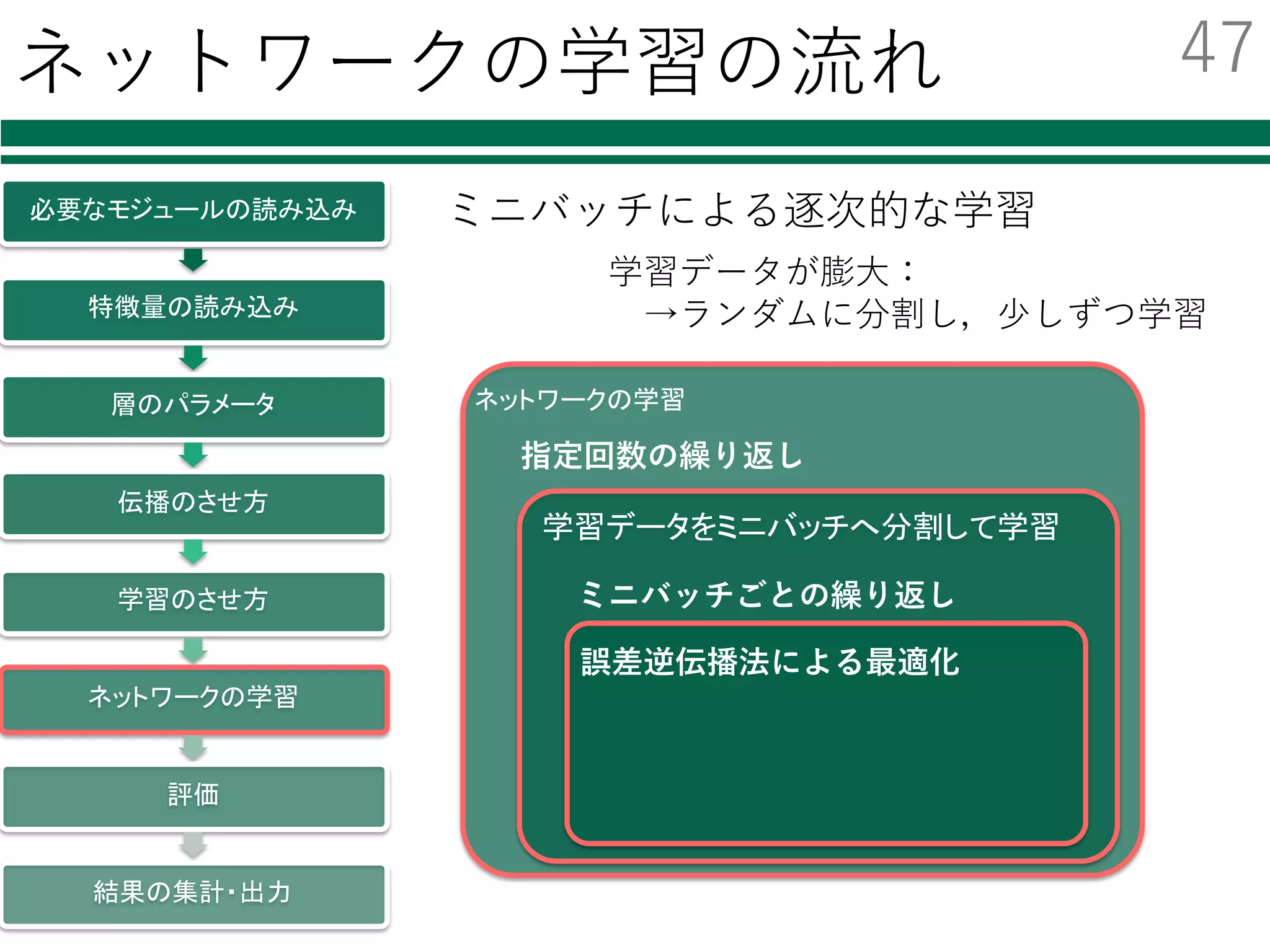
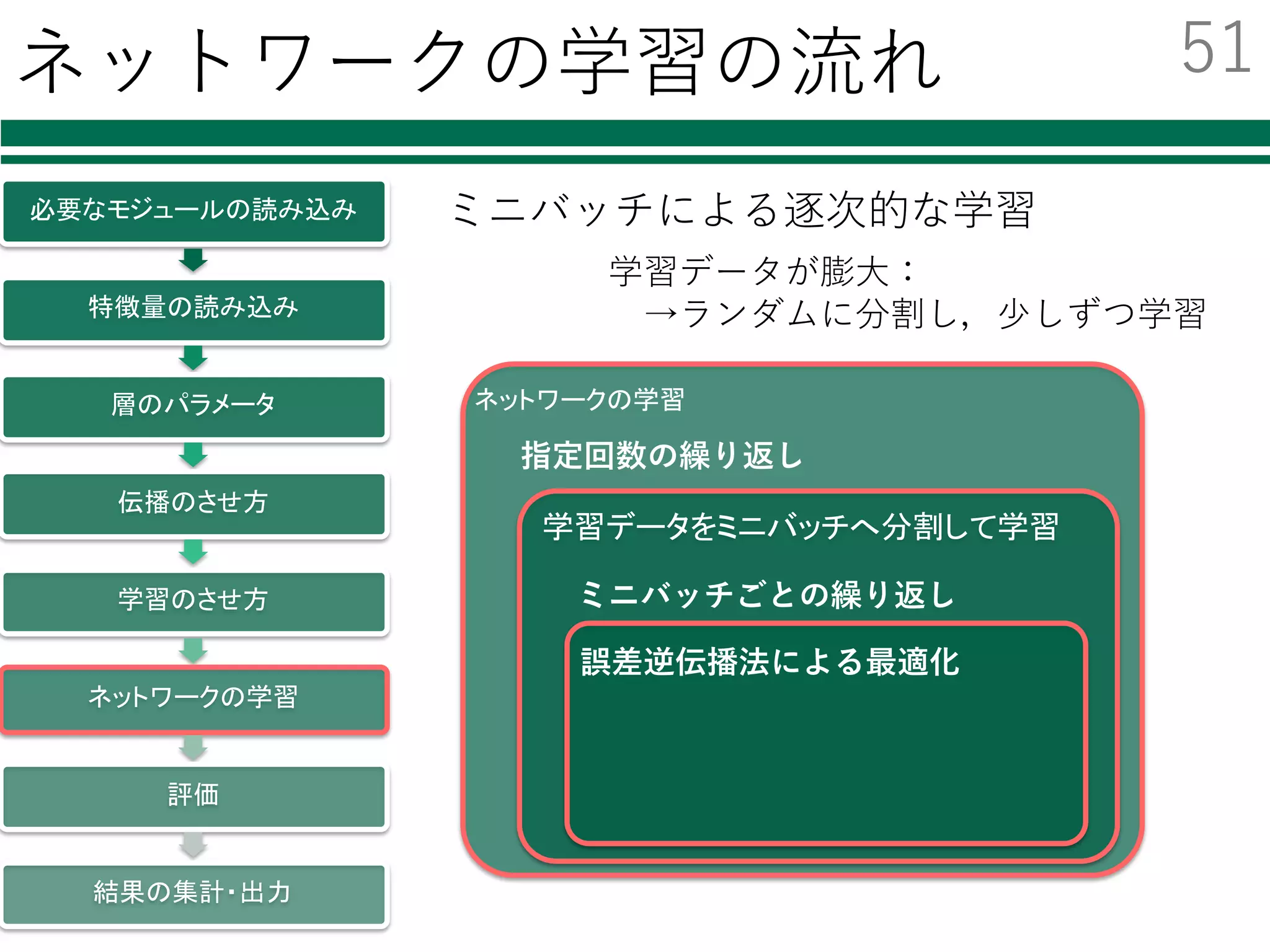
![ネットワークの学習 1/2
必要なモジュールの読み込み
特徴量の読み込み
層のパラメータ
伝播のさせ方
学習のさせ方
ネットワークの学習
評価
結果の集計・出力
x_batch = data_train[perm[i:i+batchsize]]
t_batch = label_train[perm[i:i+batchsize]]
optimizer.zero_grads()
x = Variable(x_batch)
t = Variable(t_batch)
p = forward(x)
loss = F.softmax_cross_entropy(p, t)
accuracy = F.accuracy(p, t)
loss.backward()
optimizer.update()
ミニバッチごとの誤差逆伝播法による学習
ミニバッチ
型を変換
ネットワークを通した結果
誤差を評価
誤差の逆伝播
パラメータの更新
48](https://image.slidesharecdn.com/tutorialpublic-160607132749/75/Python-SVM-Deep-Learning-51-2048.jpg)




![画像の読み込み
必要なモジュールの読み込み
画像の読み込み
層のパラメータ
伝播のさせ方
学習のさせ方
ネットワークの学習
評価
結果の集計・出力
def conv_feat_2_image(feats):
data = np.ndarray((len(feats), 1, 28, 28),
dtype=np.float32)
for i, f in enumerate(feats):
data[i]=f.reshape(28,28)
return data
train_images = conv_feat_2_image(train_features)
test_images = conv_feat_2_image(test_features)
学習データ,評価データを画像列に変換する
画像列に変換する関数
CNNへの⼊⼒は2次元画像
[特徴量]
[特徴量]
…
[特徴量]
画像
画像画像画像
枚数xチャンネル数
x⾼さx幅
枚数x次元数
57](https://image.slidesharecdn.com/tutorialpublic-160607132749/75/Python-SVM-Deep-Learning-60-2048.jpg)

































































![[機械学習]文章のクラス分類](https://cdn.slidesharecdn.com/ss_thumbnails/ss-160218112331-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






















