Downloaded 20 times


















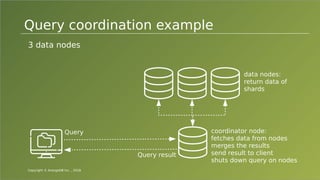



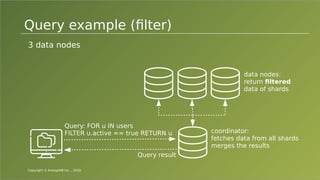

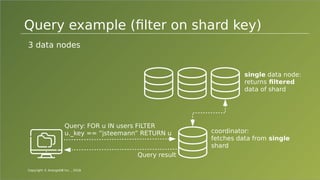

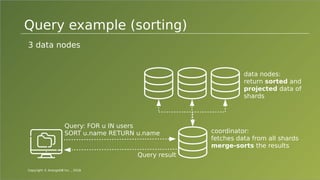

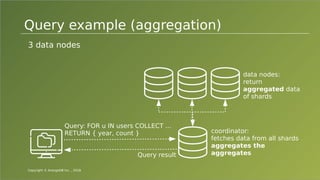

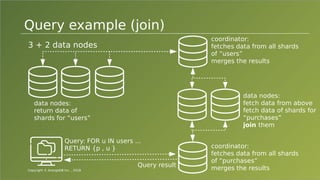




























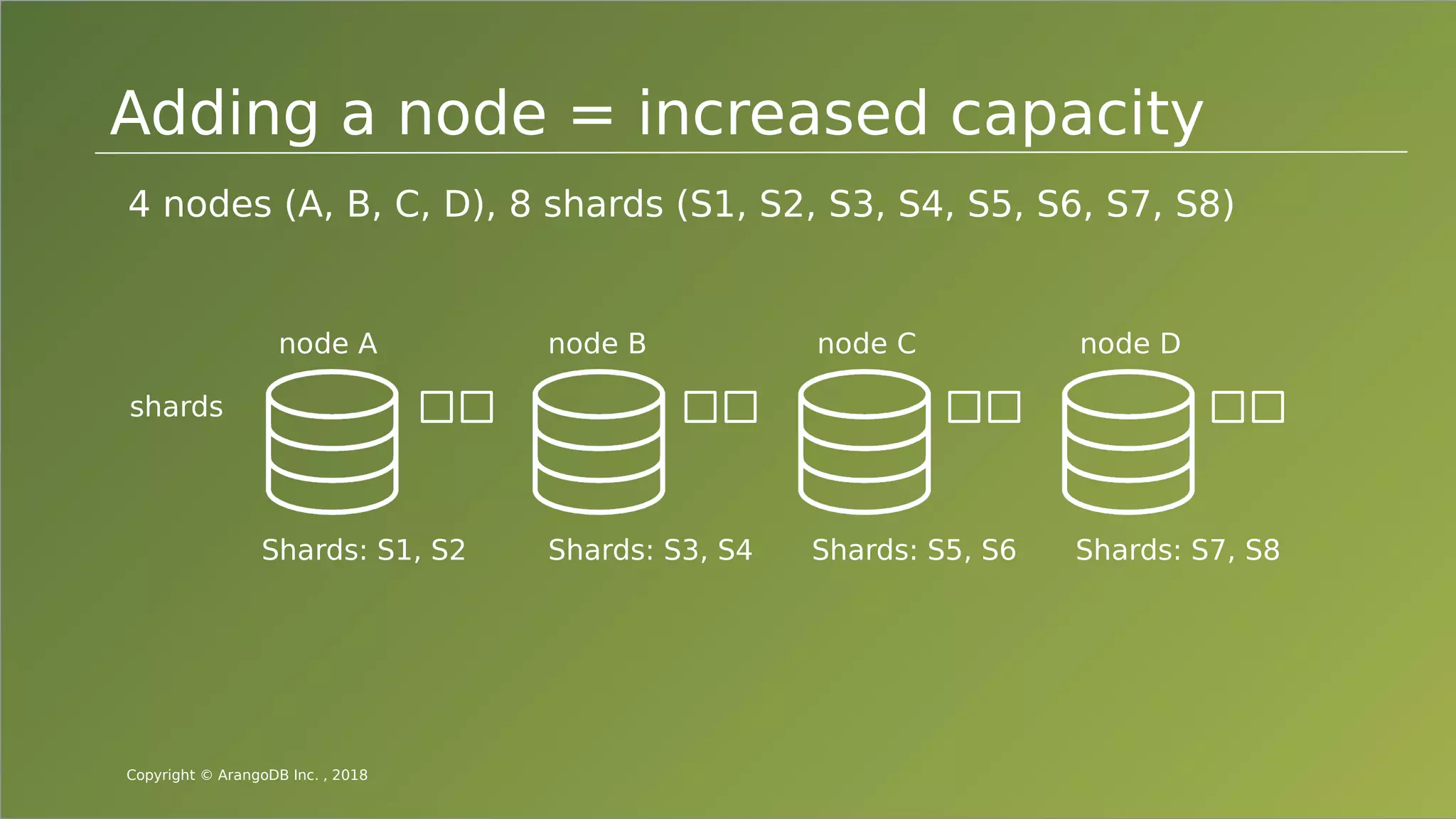



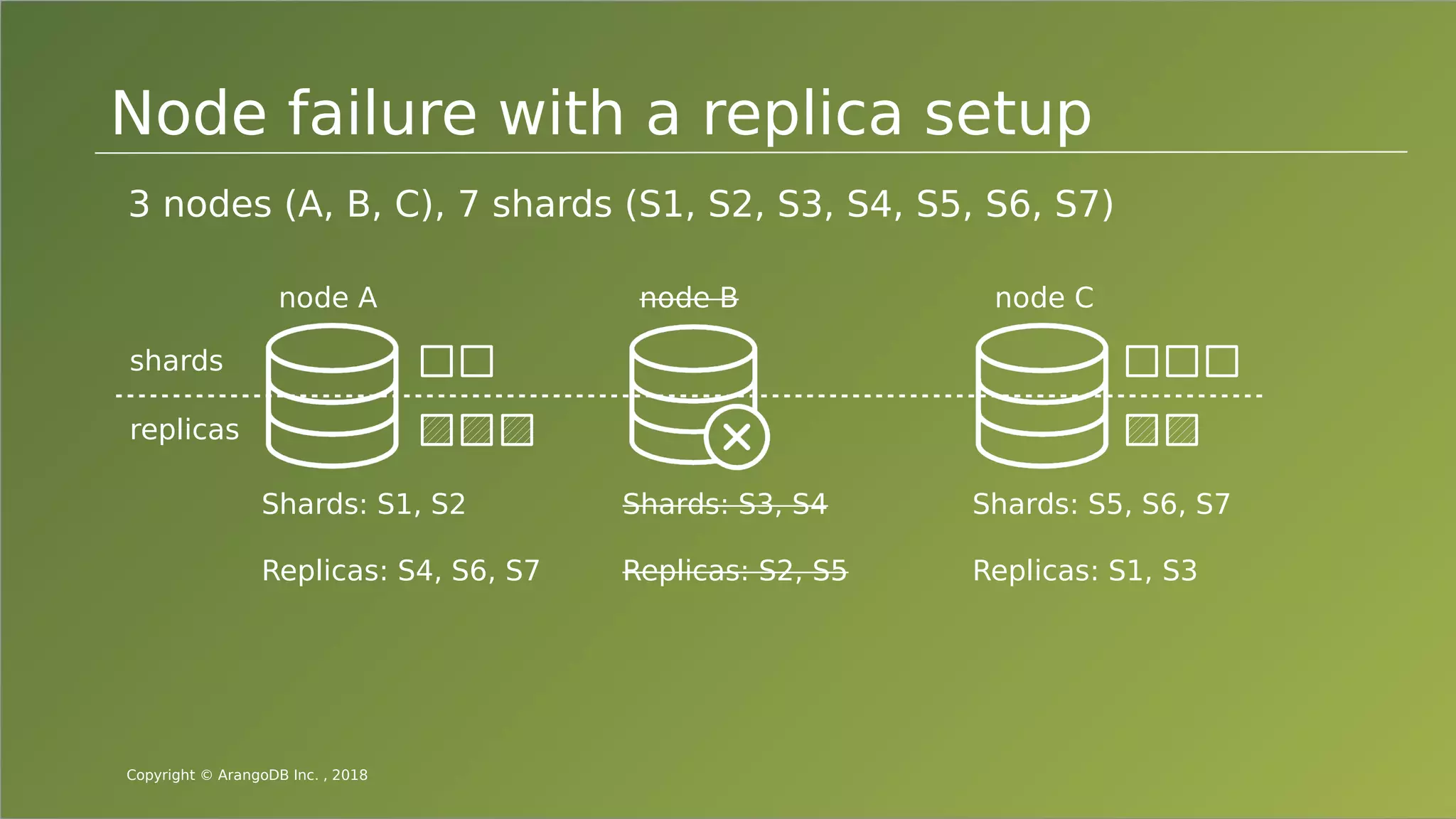
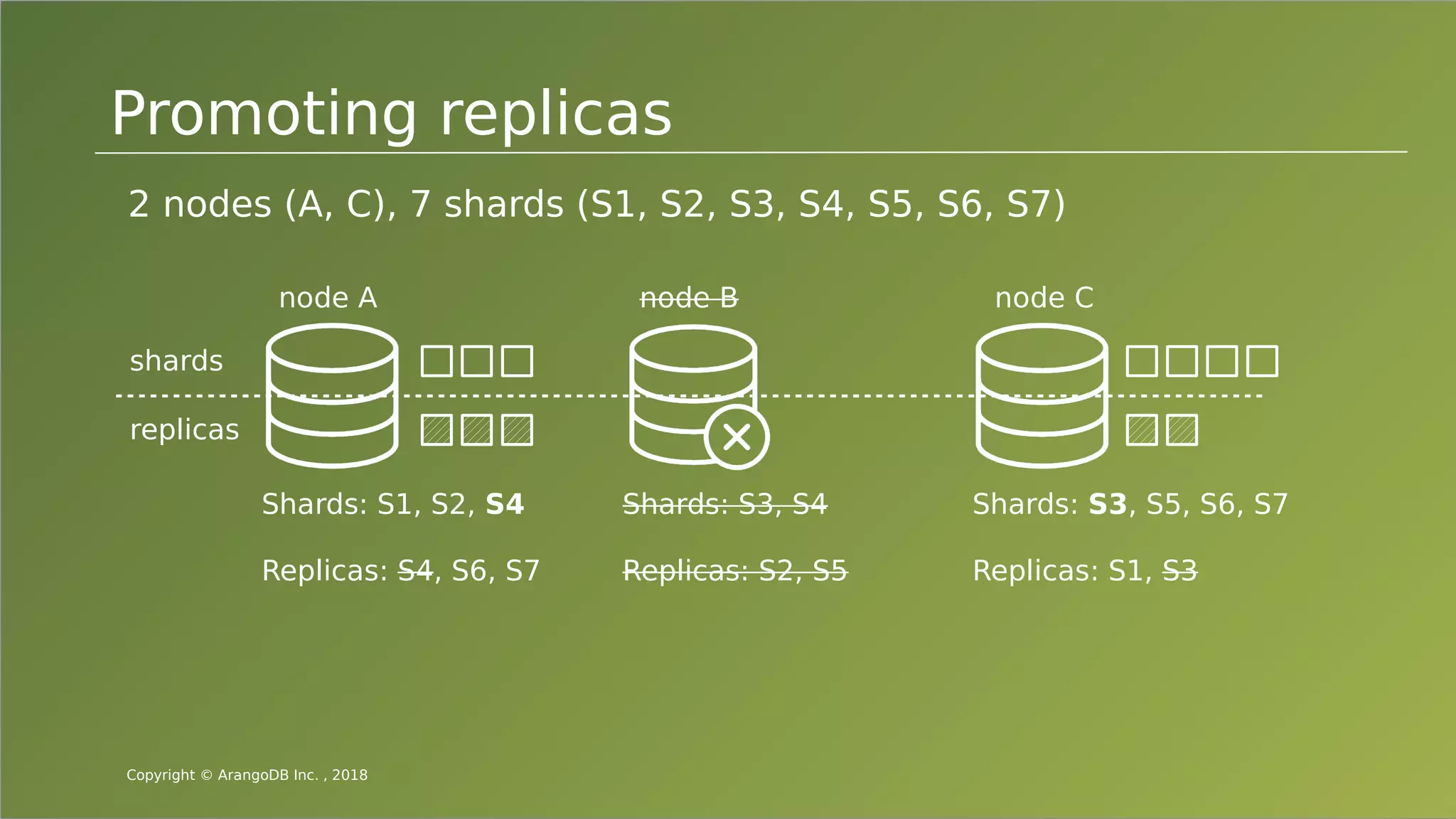
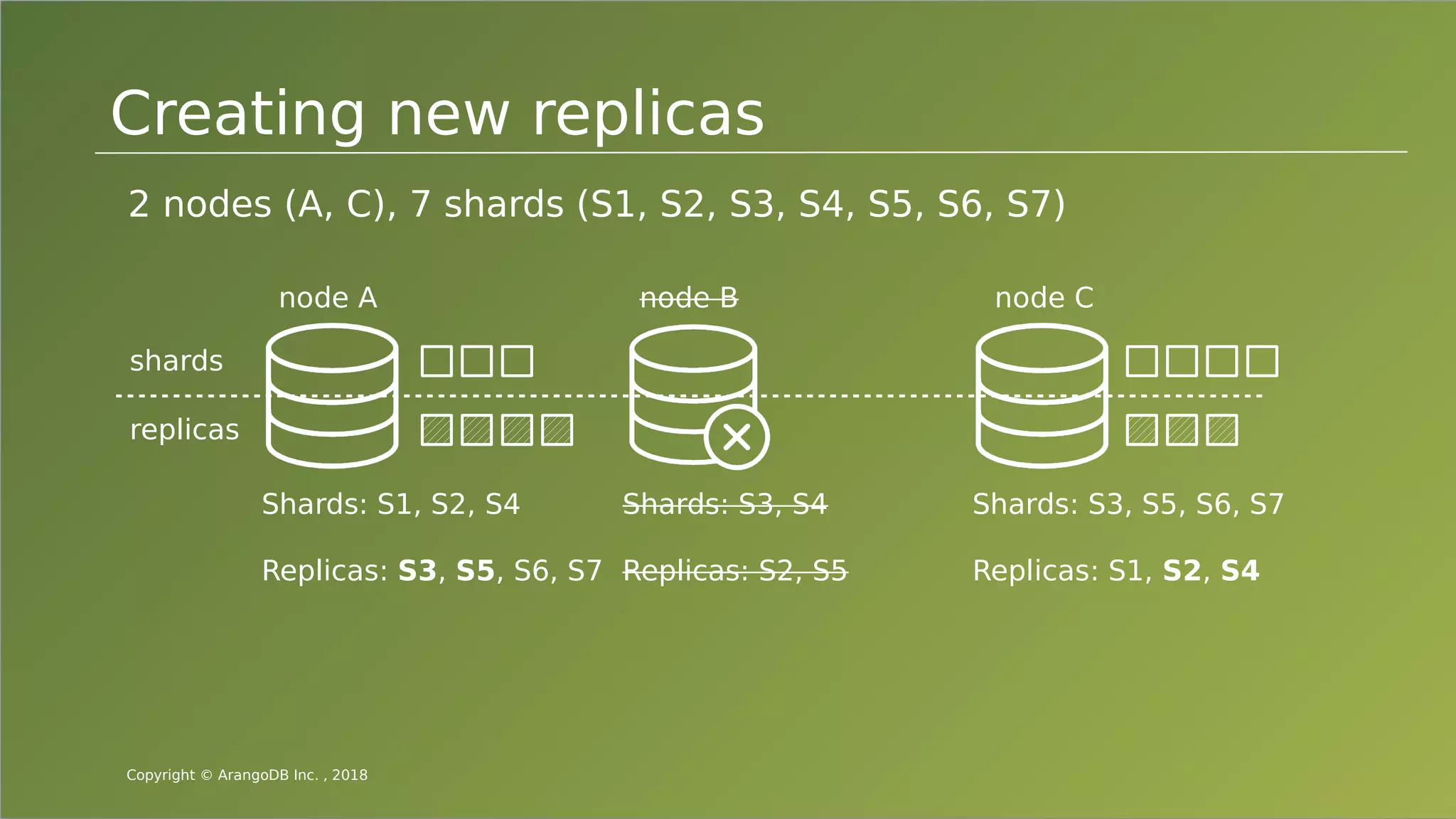


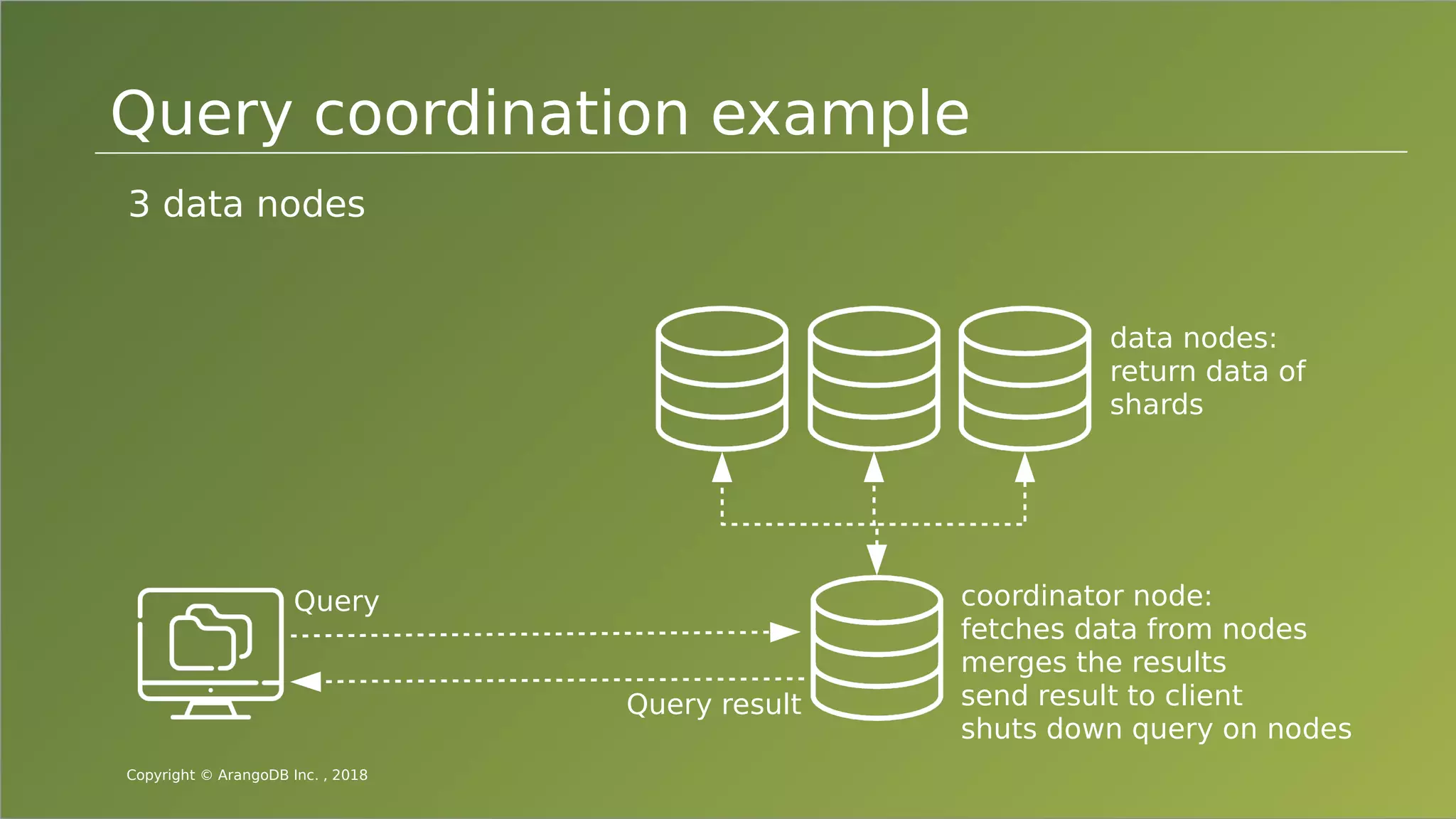



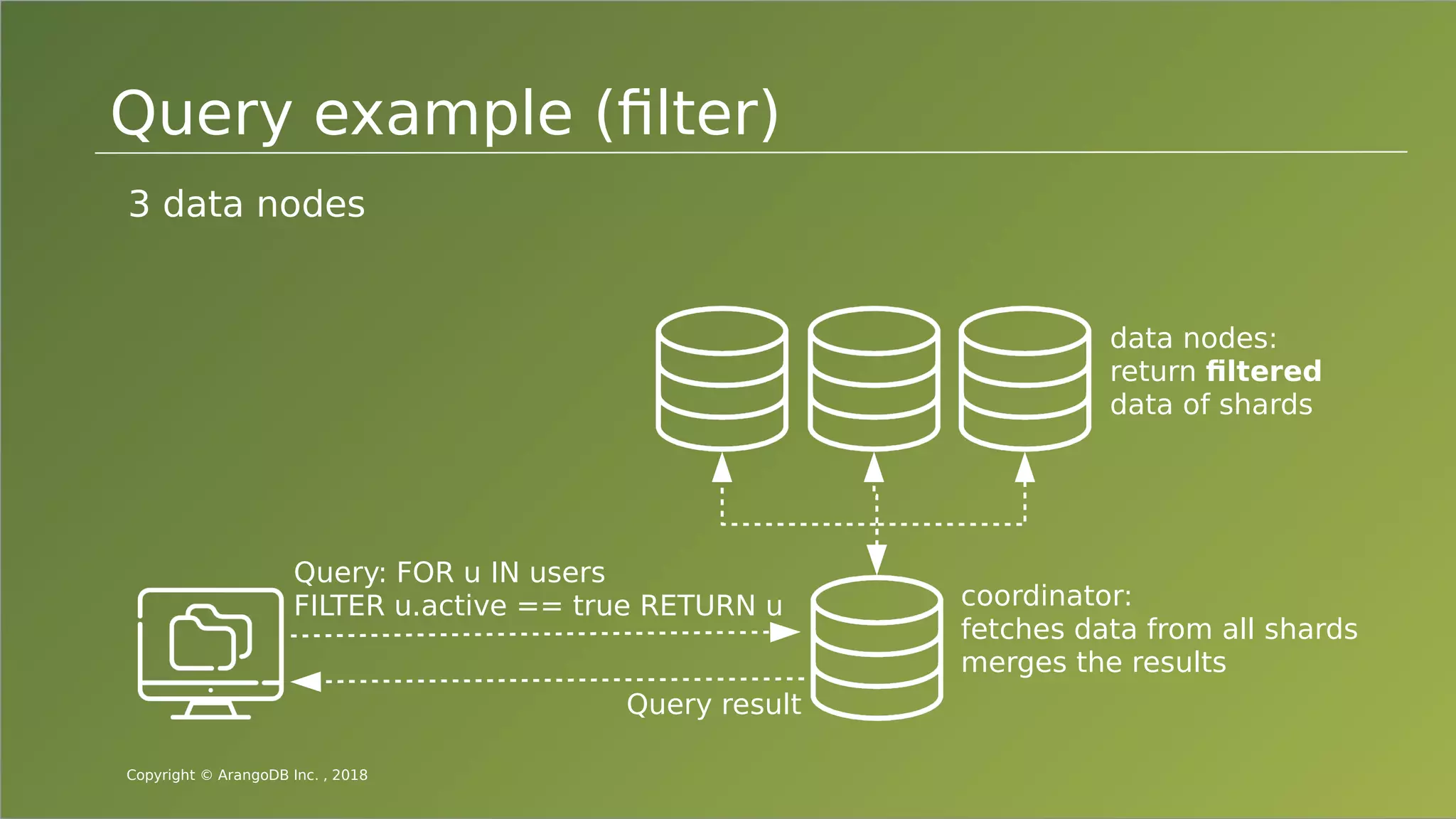

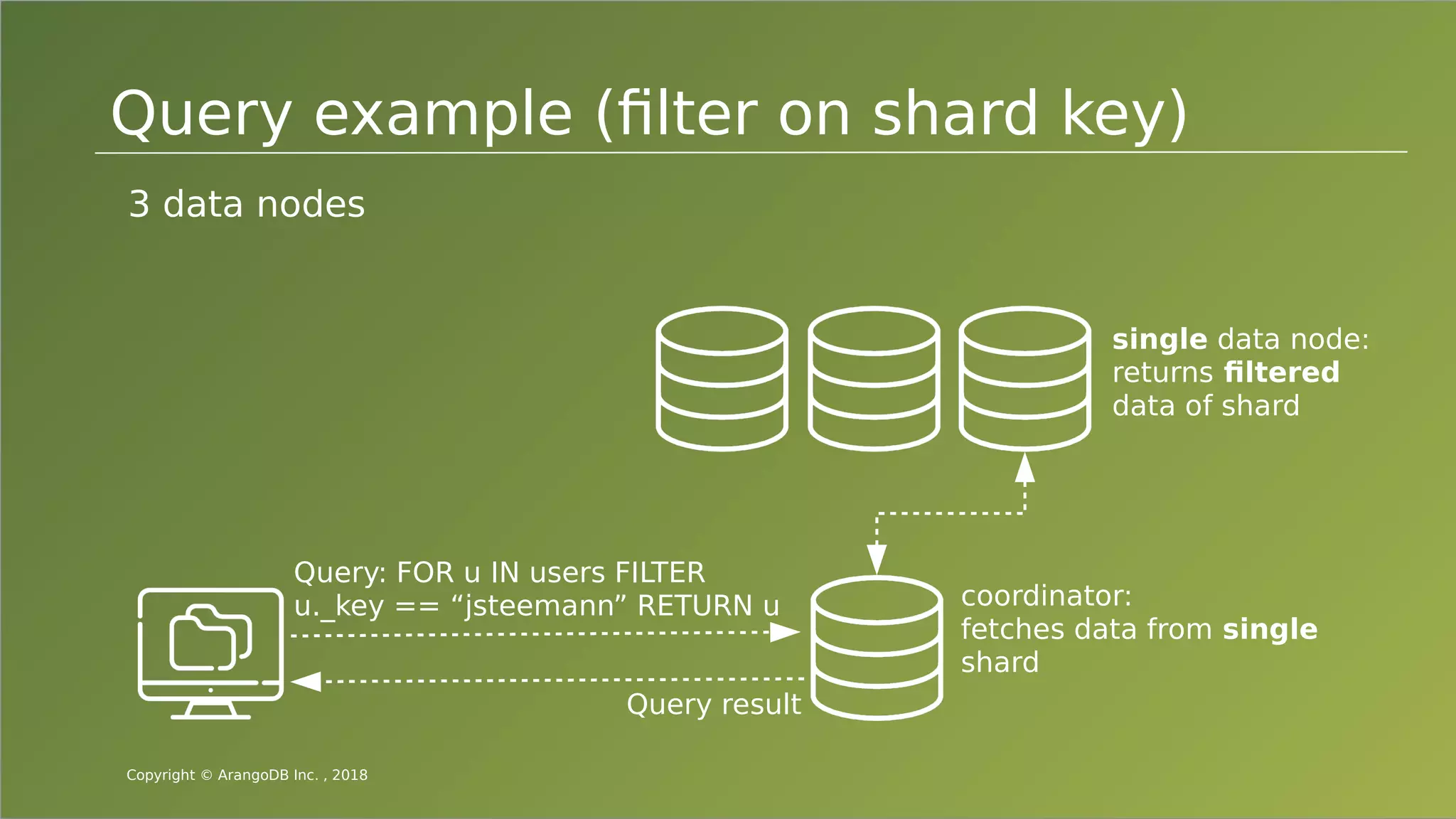

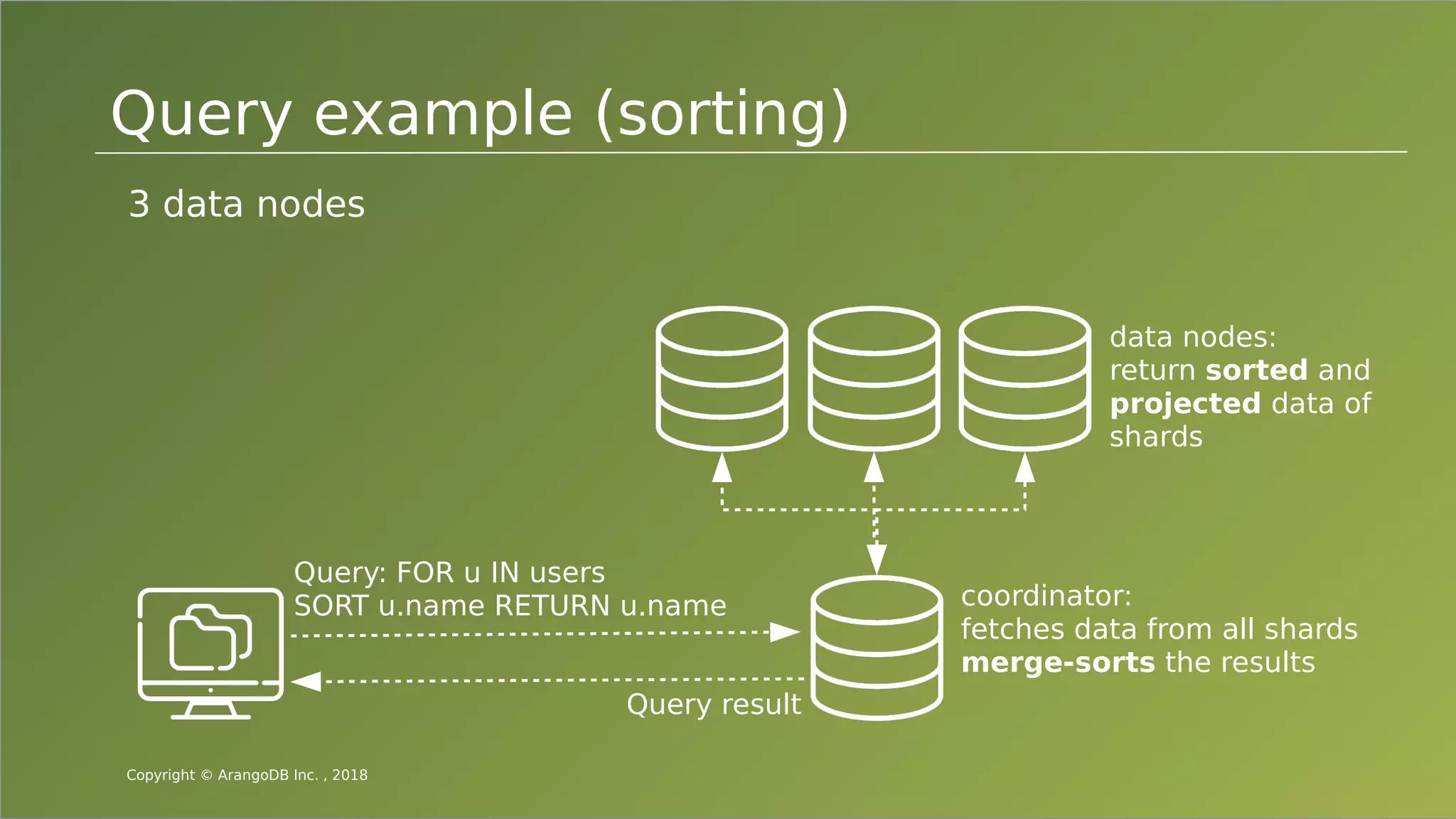

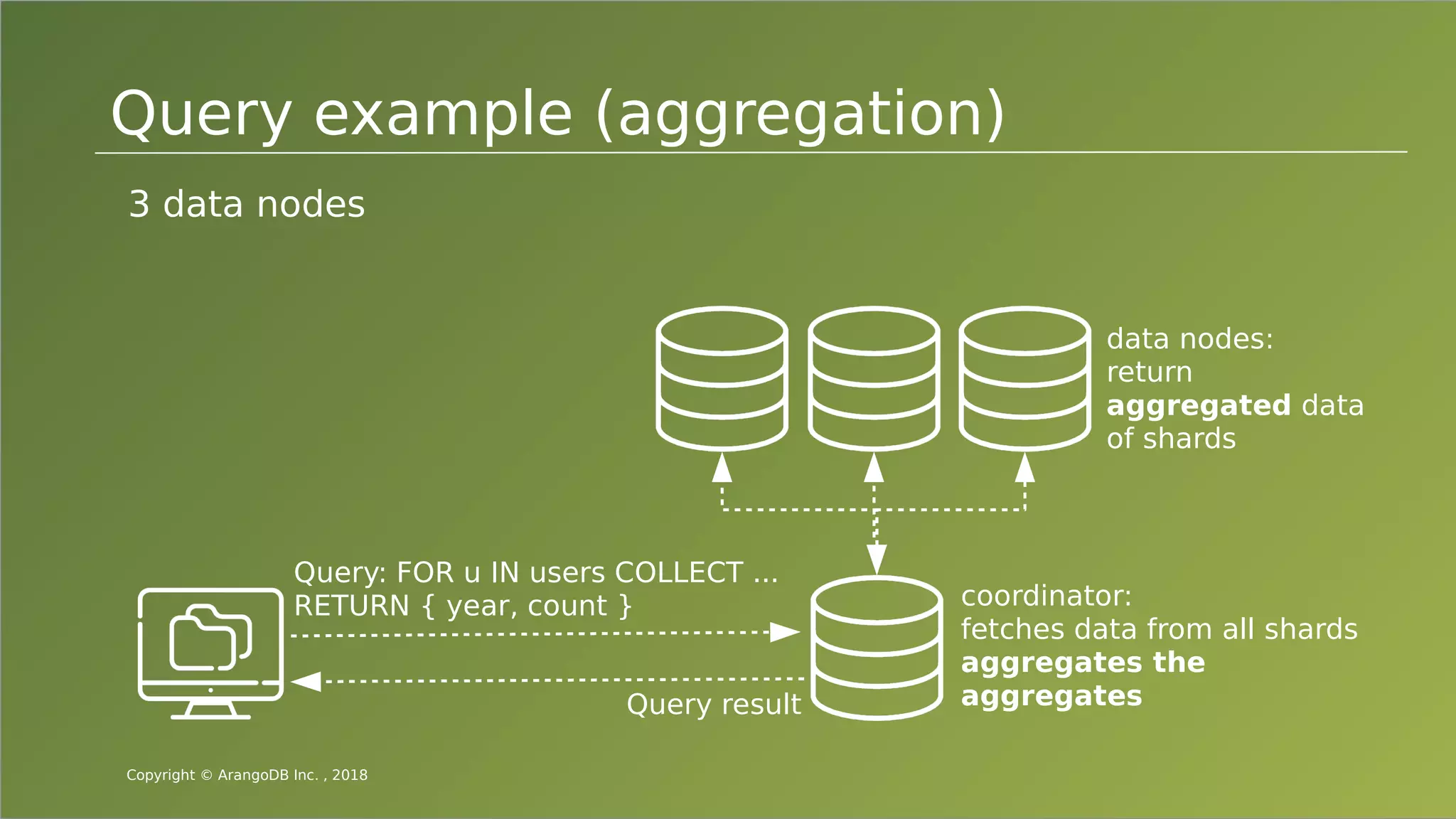

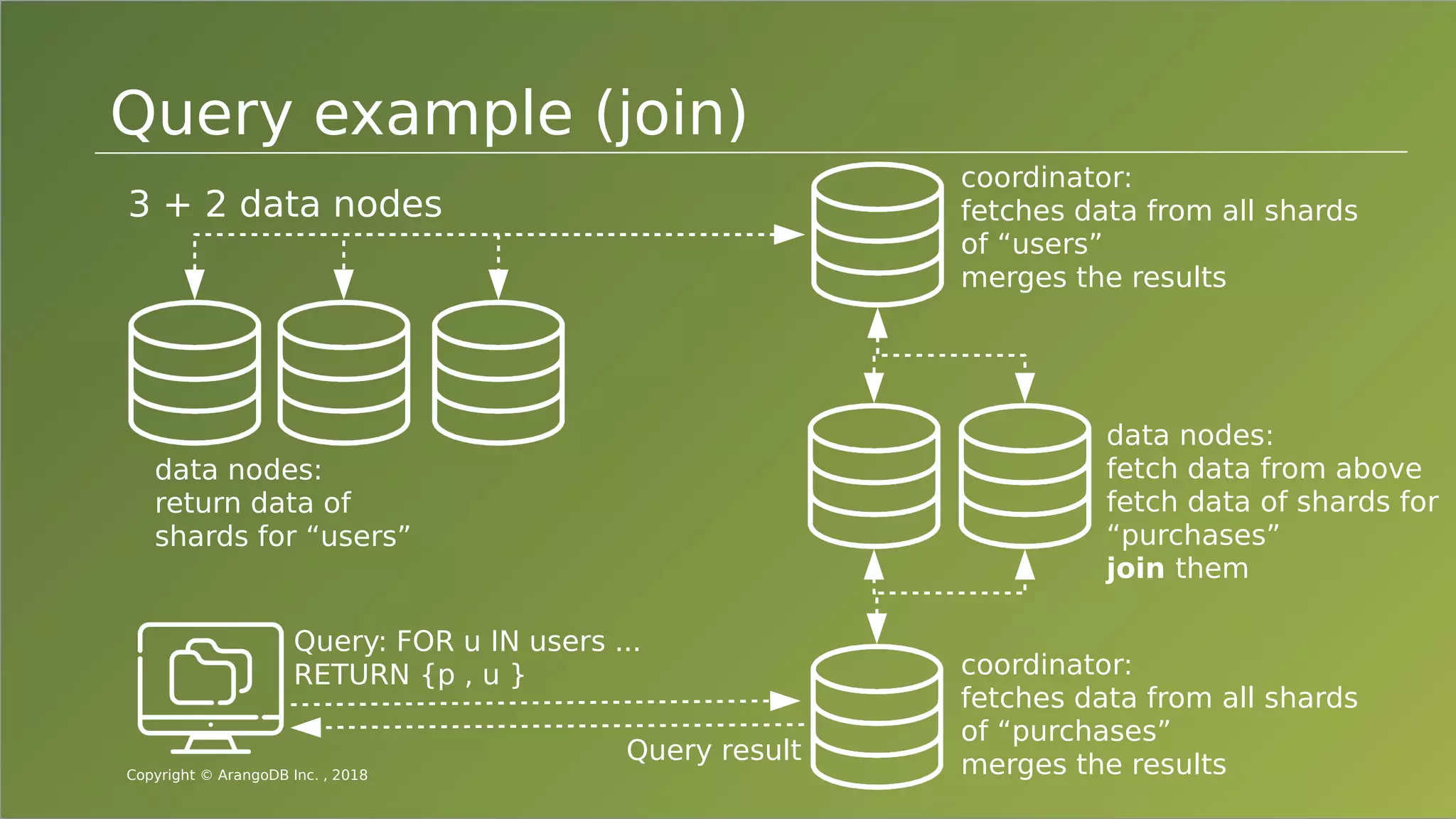






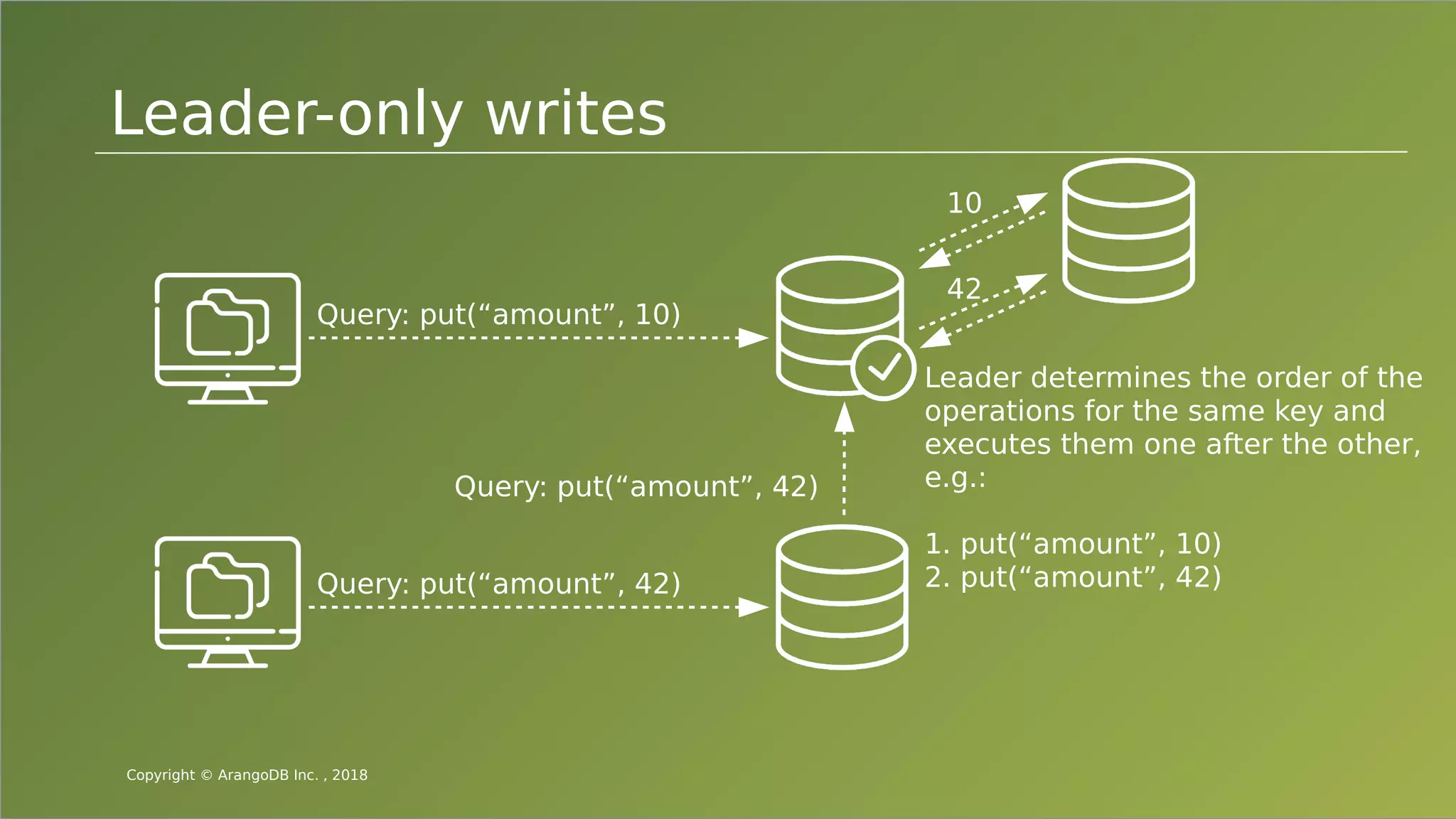













The document provides an overview of ArangoDB, a distributed, multi-model database designed for complex queries and transactions. It discusses the architecture of distributed databases, the coordination of queries across multiple nodes, and the implementation of ACID transactions. Additionally, it includes examples of query syntax in ArangoDB's query language, AQL, and outlines recent trends in the database landscape towards enhanced query functionality and scalability.




















































































