Downloaded 93 times









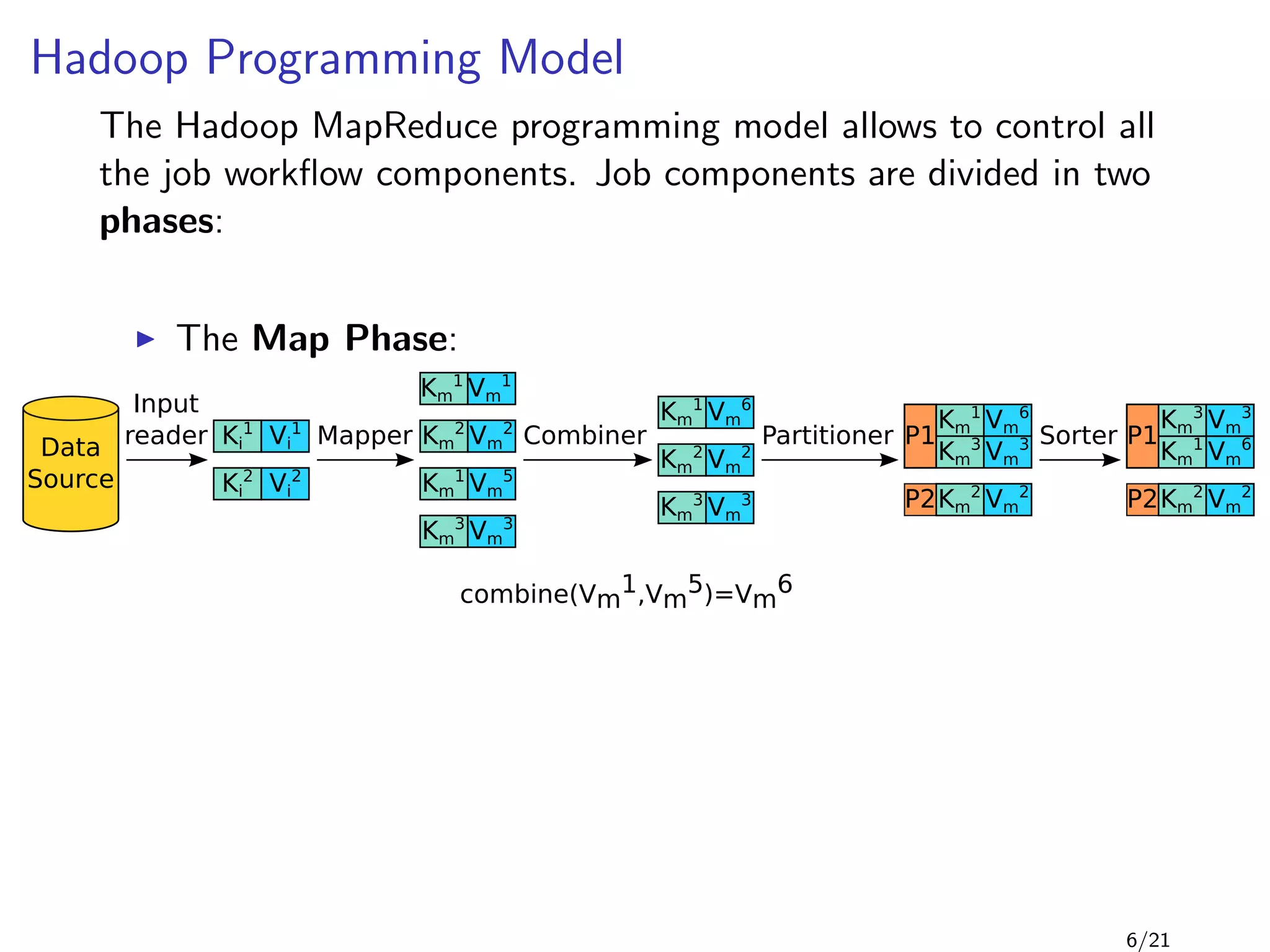
![Example: Word Count 2/2
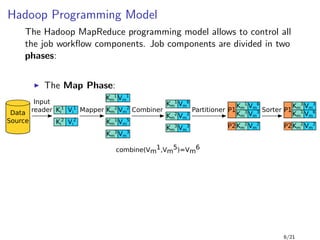
1 public class WordCount {
2
3 public static void main(String[] args) throws Exception {
4 Job job = new Job(conf, "word count");
5 job.setMapperClass(TokenizerMapper.class);
6
7
8
9 job.setReducerClass(IntSumReducer.class);
10 job.setOutputKeyClass(Text.class);
11 job.setOutputValueClass(IntWritable.class);
12 FileInputFormat.addInputPath(job, new Path(args[0]));
13 FileOutputFormat.setOutputPath(job, new Path(args[1]));
14 System.exit(job.waitForCompletion(true) ? 0 : 1);
15 }
16 }
8/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/85/Scalding-12-320.jpg)
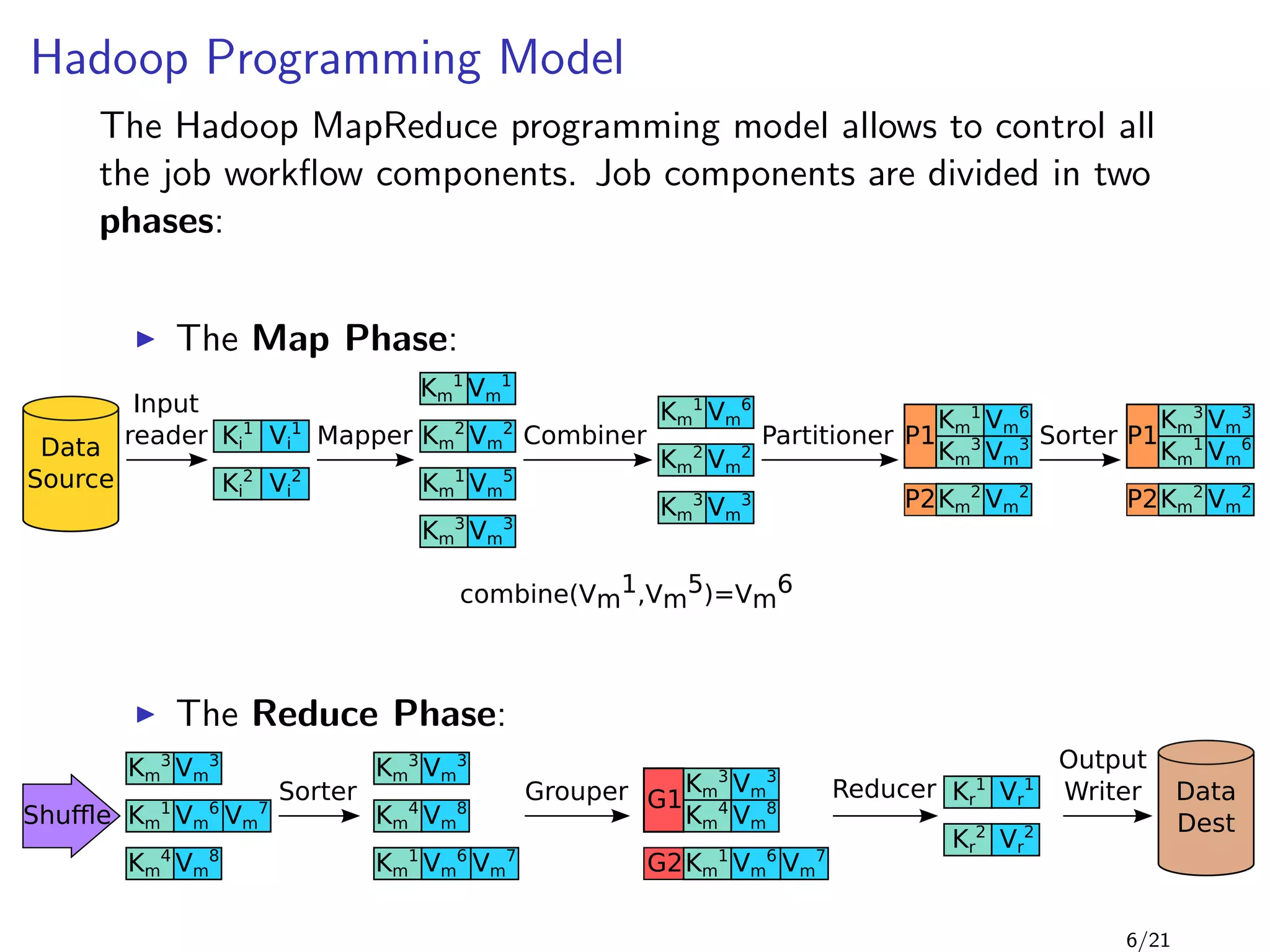
![Example: Word Count 2/2
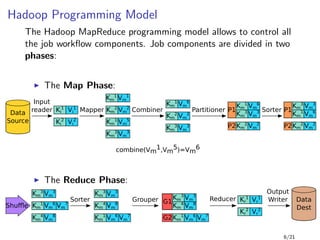
1 public class WordCount {
2
3 public static void main(String[] args) throws Exception {
4 Job job = new Job(conf, "word count");
5 job.setMapperClass(TokenizerMapper.class);
6
7 job.setCombinerClass(IntSumReducer.class);
8
9 job.setReducerClass(IntSumReducer.class);
10 job.setOutputKeyClass(Text.class);
11 job.setOutputValueClass(IntWritable.class);
12 FileInputFormat.addInputPath(job, new Path(args[0]));
13 FileOutputFormat.setOutputPath(job, new Path(args[1]));
14 System.exit(job.waitForCompletion(true) ? 0 : 1);
15 }
16 }
Sending the integer 1 for each instance of a word is very
inefficient (1TB of data yields 1TB+ of data)
Hadoop doesn’t know if it can use the reducer as combiner. A
manual set is needed
8/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/85/Scalding-13-320.jpg)




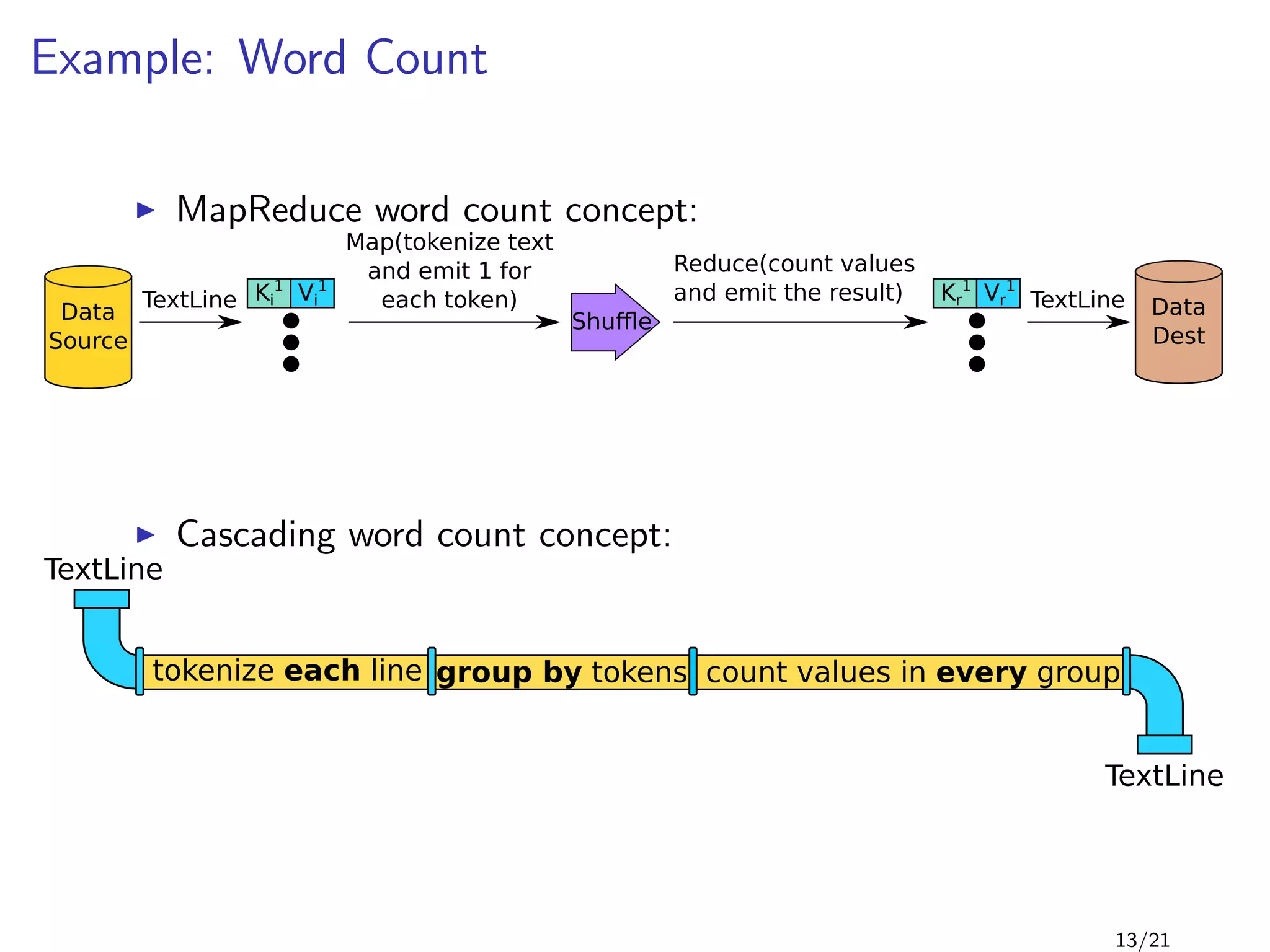
![Example: Word Count
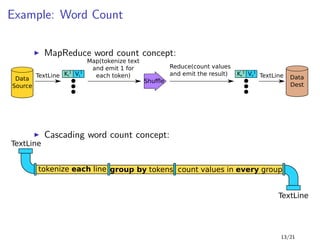
1 public class WordCount {
2 public static void main( String[] args ) {
3 Tap docTap = new Hfs( new TextDelimited( true, "t" ), args[0] );
4 Tap wcTap = new Hfs( new TextDelimited( true, "t" ), args[1] );
5
6 RegexSplitGenerator s = new RegexSplitGenerator(
7 new Fields("token"),
8 "[ [](),.]" );
9 Pipe docPipe = new Each( "token", new Fields( "text" ), s,
10 Fields.RESULTS ); // text -> token
11
12 Pipe wcPipe = new Pipe( "wc", docPipe );
13 wcPipe = new GroupBy( wcPipe, new Fields( "token" ) );
14 wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );
15
16 // connect the taps and pipes to create a flow definition
17 FlowDef flowDef = FlowDef.flowDef().setName( "wc" )
18 .addSource( docPipe, docTap )
19 .addTailSink( wcPipe, wcTap );
20
21 getFlowConnector().connect( flowDef ).complete();
22 }
23 }
14/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/85/Scalding-19-320.jpg)








![Example: Word Count
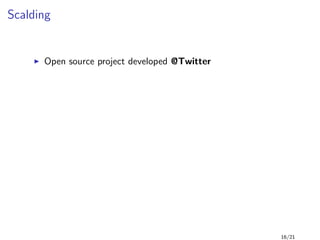
1 class WordCount(args : Args) extends Job(args) {
2
3 /* TextLine reads each line of the given file */
4 val input = TypedPipe.from( TextLine( args( "input" ) ) )
5
6 /* tokenize every line and flat the result into a list of words */
7 val words = input.flatMap{ tokenize(_) }
8
9 /* group by words and add a new field size that is the group size */
10 val wordGroups = words.groupBy{ identity(_) }.size
11
12 /* write each pair (word,count) as line using TextLine */
13 wordGroups.write((0,1), TextLine( args( "output" ) ) )
14
15 /* Split a piece of text into individual words */
16 def tokenize(text : String) : Array[String] = {
17 // Lowercase each word and remove punctuation.
18 text.trim.toLowerCase.replaceAll("[ˆa-zA-Z0-9s]", "")
19 .split("s+")
20 }
21 }
18/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/85/Scalding-29-320.jpg)

![Scalding TypeSafe API
Two main concepts:
TypedPipe[T]: class whose instances are distributed
objects that wrap a cascading Pipe object, and holds the
transformation done up until that point. Its interface is similar
to Scala’s Iterator[T] (map, flatMap, groupBy,
filter,. . . )
19/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/85/Scalding-31-320.jpg)
![Scalding TypeSafe API
Two main concepts:
TypedPipe[T]: class whose instances are distributed
objects that wrap a cascading Pipe object, and holds the
transformation done up until that point. Its interface is similar
to Scala’s Iterator[T] (map, flatMap, groupBy,
filter,. . . )
KeyedList[K,V]: trait that represents a sharded lists of
items. Two implementations:
Grouped[K,V]: represents a grouping on keys of type K
CoGrouped2[K,V,W,Result]: represents a cogroup over
two grouped pipes. Used for joins
19/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/85/Scalding-32-320.jpg)













![Example: Word Count 2/2
1 public class WordCount {
2
3 public static void main(String[] args) throws Exception {
4 Job job = new Job(conf, "word count");
5 job.setMapperClass(TokenizerMapper.class);
6
7
8
9 job.setReducerClass(IntSumReducer.class);
10 job.setOutputKeyClass(Text.class);
11 job.setOutputValueClass(IntWritable.class);
12 FileInputFormat.addInputPath(job, new Path(args[0]));
13 FileOutputFormat.setOutputPath(job, new Path(args[1]));
14 System.exit(job.waitForCompletion(true) ? 0 : 1);
15 }
16 }
8/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/75/Scalding-12-2048.jpg)
![Example: Word Count 2/2
1 public class WordCount {
2
3 public static void main(String[] args) throws Exception {
4 Job job = new Job(conf, "word count");
5 job.setMapperClass(TokenizerMapper.class);
6
7 job.setCombinerClass(IntSumReducer.class);
8
9 job.setReducerClass(IntSumReducer.class);
10 job.setOutputKeyClass(Text.class);
11 job.setOutputValueClass(IntWritable.class);
12 FileInputFormat.addInputPath(job, new Path(args[0]));
13 FileOutputFormat.setOutputPath(job, new Path(args[1]));
14 System.exit(job.waitForCompletion(true) ? 0 : 1);
15 }
16 }
Sending the integer 1 for each instance of a word is very
inefficient (1TB of data yields 1TB+ of data)
Hadoop doesn’t know if it can use the reducer as combiner. A
manual set is needed
8/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/75/Scalding-13-2048.jpg)




![Example: Word Count
1 public class WordCount {
2 public static void main( String[] args ) {
3 Tap docTap = new Hfs( new TextDelimited( true, "t" ), args[0] );
4 Tap wcTap = new Hfs( new TextDelimited( true, "t" ), args[1] );
5
6 RegexSplitGenerator s = new RegexSplitGenerator(
7 new Fields("token"),
8 "[ [](),.]" );
9 Pipe docPipe = new Each( "token", new Fields( "text" ), s,
10 Fields.RESULTS ); // text -> token
11
12 Pipe wcPipe = new Pipe( "wc", docPipe );
13 wcPipe = new GroupBy( wcPipe, new Fields( "token" ) );
14 wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );
15
16 // connect the taps and pipes to create a flow definition
17 FlowDef flowDef = FlowDef.flowDef().setName( "wc" )
18 .addSource( docPipe, docTap )
19 .addTailSink( wcPipe, wcTap );
20
21 getFlowConnector().connect( flowDef ).complete();
22 }
23 }
14/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/75/Scalding-19-2048.jpg)








![Example: Word Count
1 class WordCount(args : Args) extends Job(args) {
2
3 /* TextLine reads each line of the given file */
4 val input = TypedPipe.from( TextLine( args( "input" ) ) )
5
6 /* tokenize every line and flat the result into a list of words */
7 val words = input.flatMap{ tokenize(_) }
8
9 /* group by words and add a new field size that is the group size */
10 val wordGroups = words.groupBy{ identity(_) }.size
11
12 /* write each pair (word,count) as line using TextLine */
13 wordGroups.write((0,1), TextLine( args( "output" ) ) )
14
15 /* Split a piece of text into individual words */
16 def tokenize(text : String) : Array[String] = {
17 // Lowercase each word and remove punctuation.
18 text.trim.toLowerCase.replaceAll("[ˆa-zA-Z0-9s]", "")
19 .split("s+")
20 }
21 }
18/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/75/Scalding-29-2048.jpg)

![Scalding TypeSafe API
Two main concepts:
TypedPipe[T]: class whose instances are distributed
objects that wrap a cascading Pipe object, and holds the
transformation done up until that point. Its interface is similar
to Scala’s Iterator[T] (map, flatMap, groupBy,
filter,. . . )
19/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/75/Scalding-31-2048.jpg)
![Scalding TypeSafe API
Two main concepts:
TypedPipe[T]: class whose instances are distributed
objects that wrap a cascading Pipe object, and holds the
transformation done up until that point. Its interface is similar
to Scala’s Iterator[T] (map, flatMap, groupBy,
filter,. . . )
KeyedList[K,V]: trait that represents a sharded lists of
items. Two implementations:
Grouped[K,V]: represents a grouping on keys of type K
CoGrouped2[K,V,W,Result]: represents a cogroup over
two grouped pipes. Used for joins
19/21](https://image.slidesharecdn.com/main-120927132352-phpapp01/75/Scalding-32-2048.jpg)





Scalding is a Scala library built on top of Cascading that simplifies the process of defining MapReduce programs. It uses a functional programming approach where data flows are represented as chained transformations on TypedPipes, similar to operations on Scala iterators. This avoids some limitations of the traditional Hadoop MapReduce model by allowing for more flexible multi-step jobs and features like joins. The Scalding TypeSafe API also provides compile-time type safety compared to Cascading's runtime type checking.



































































