Download to read offline








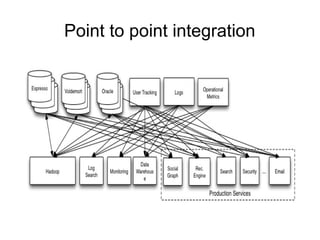
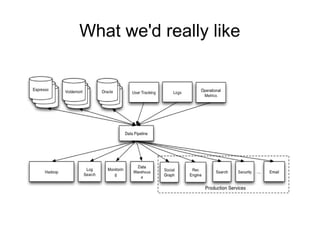

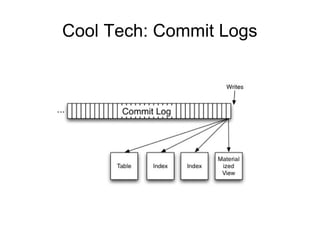

























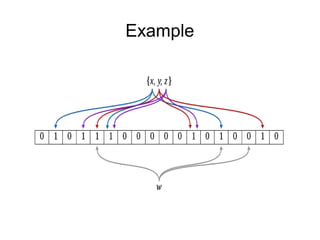














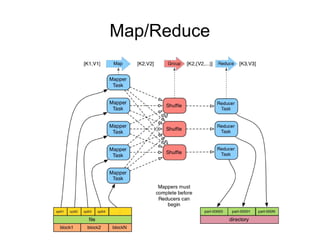































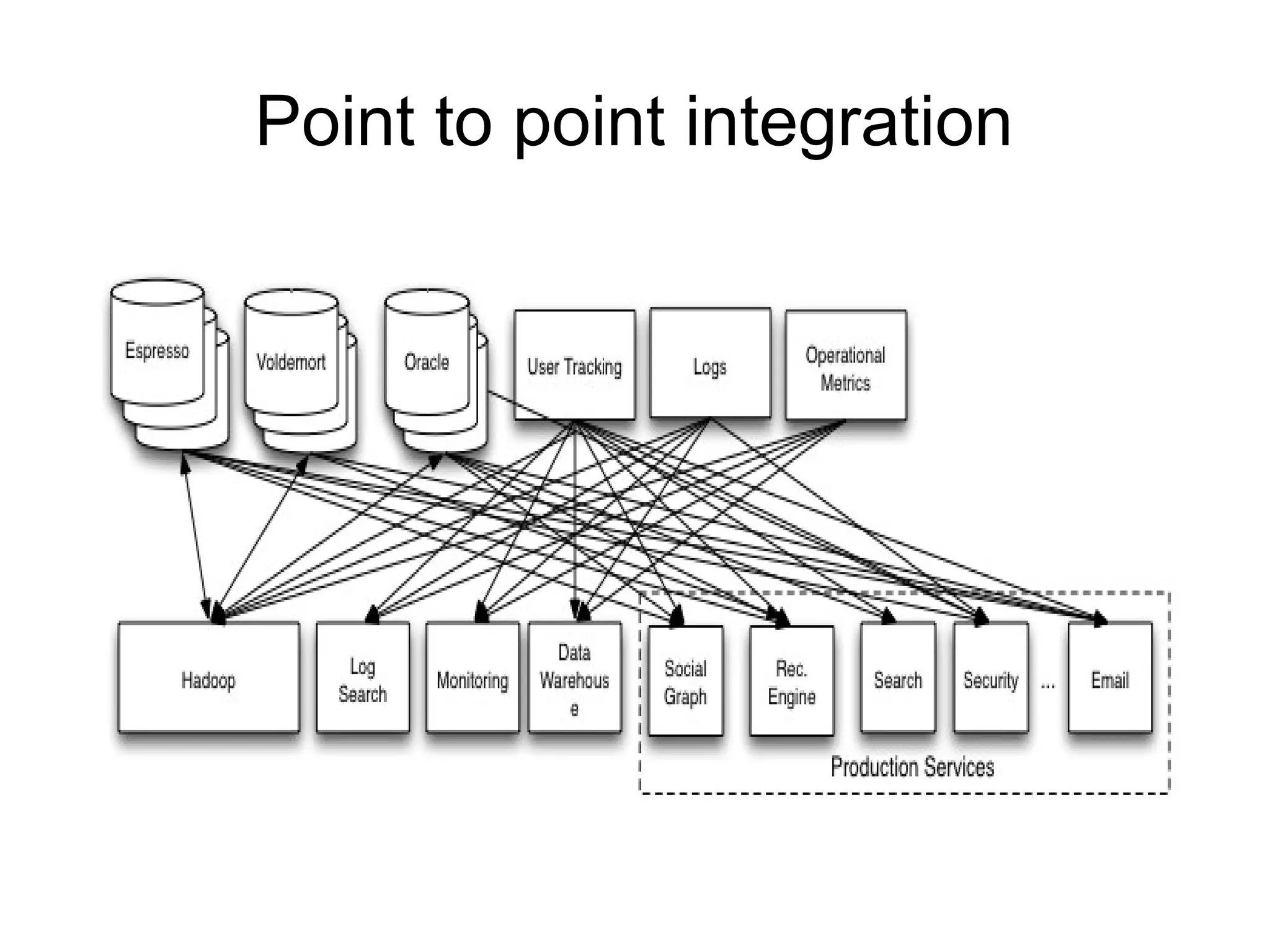


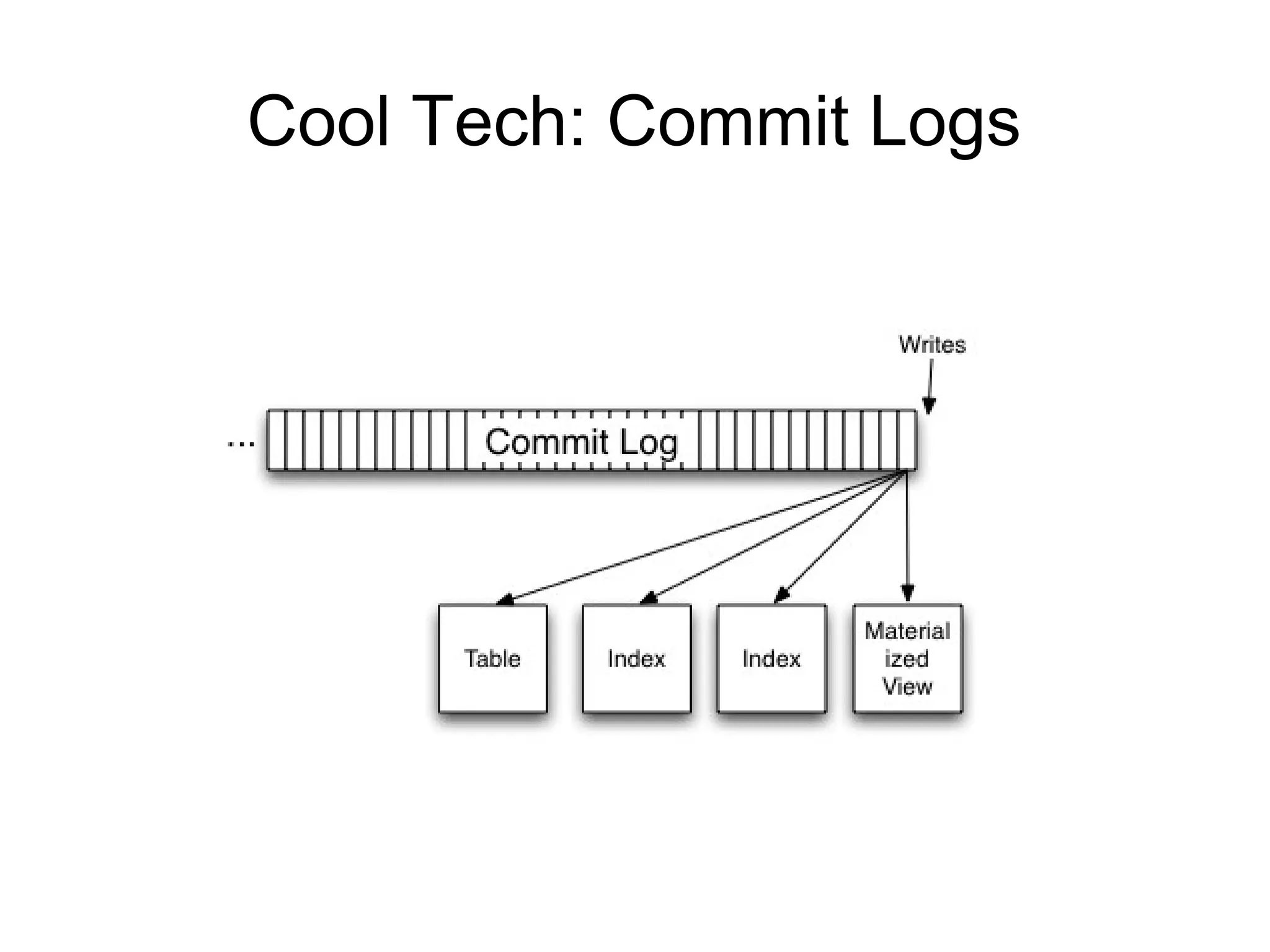

























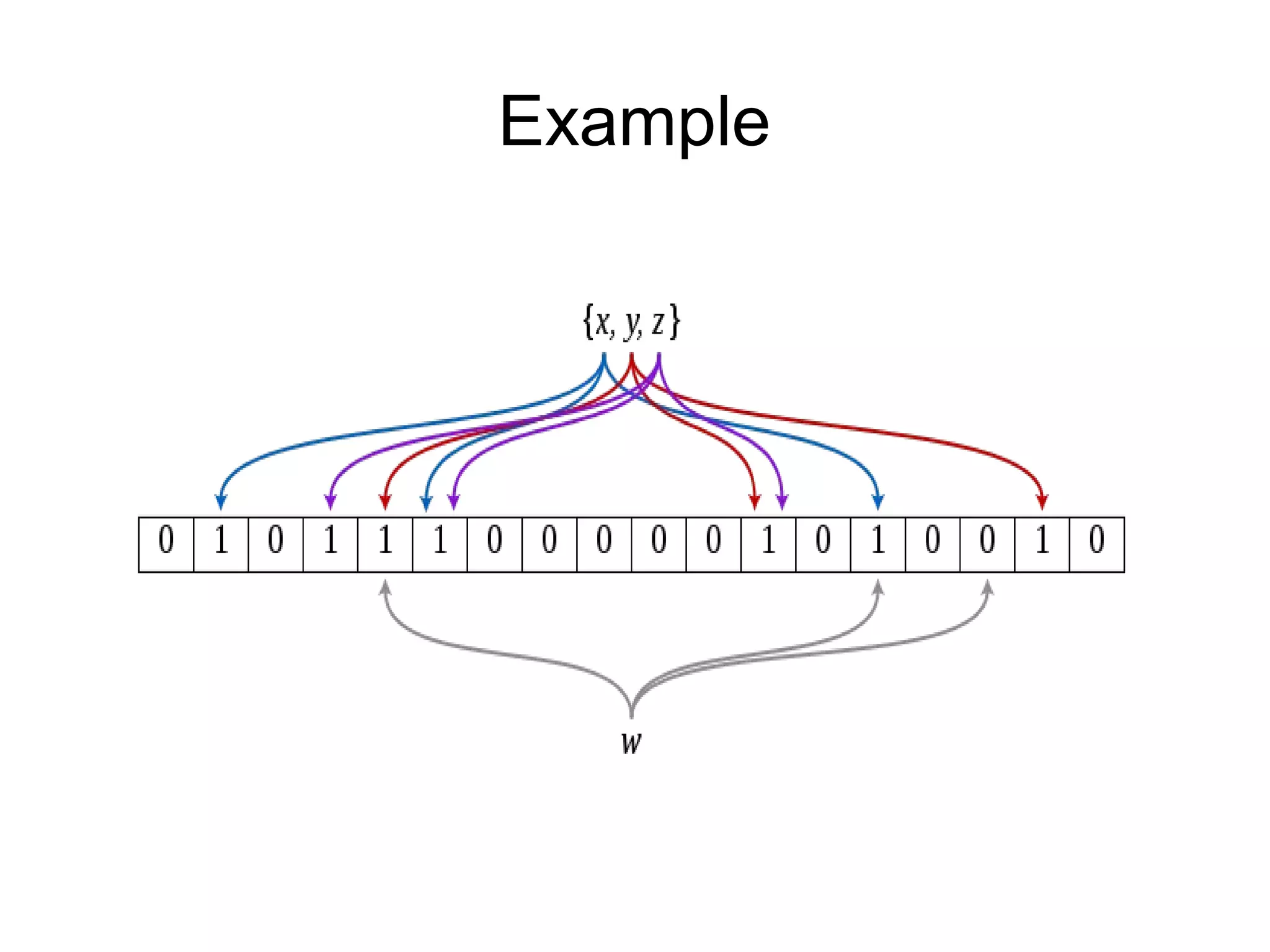














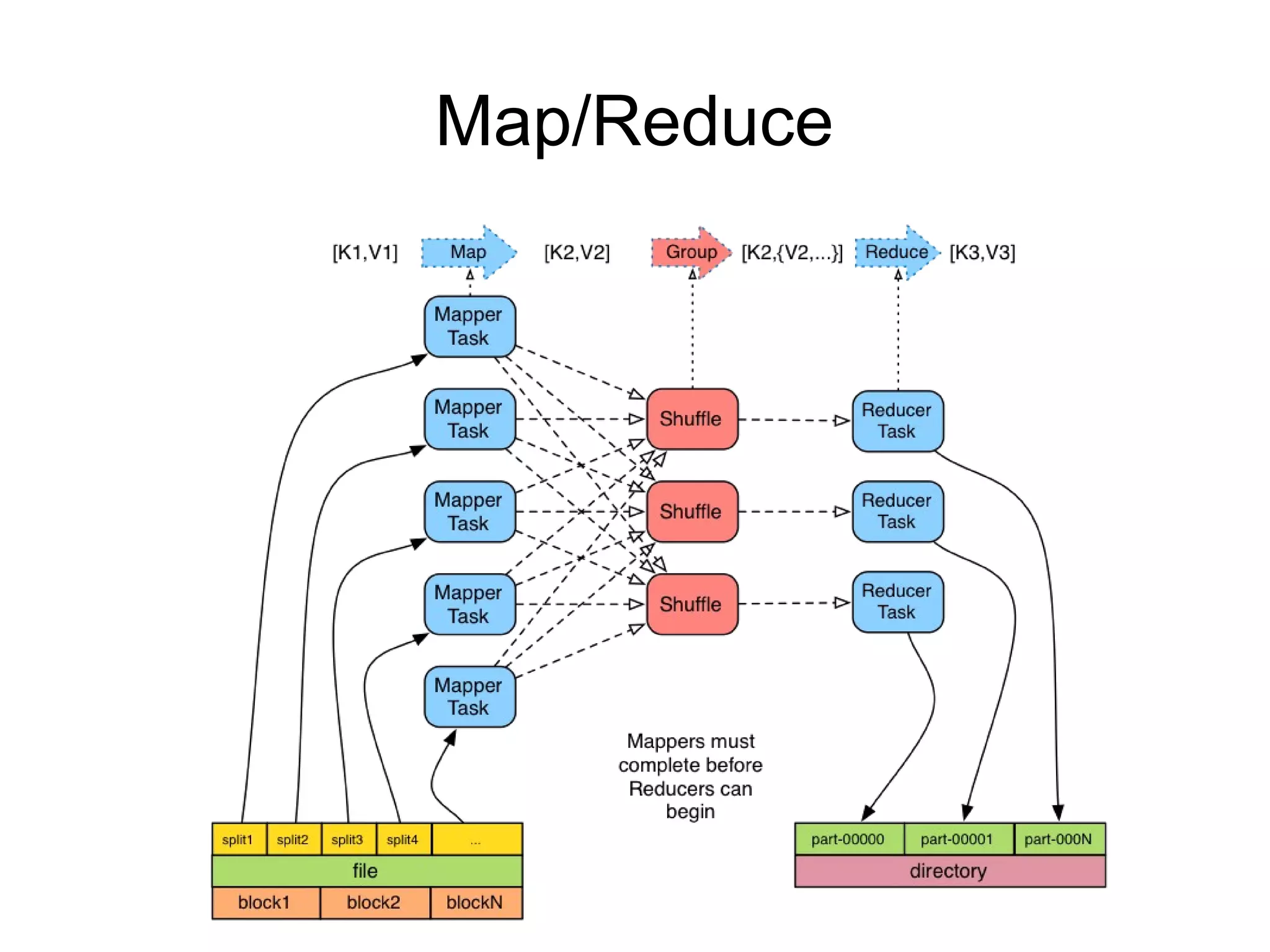























The document discusses a variety of topics related to modern software development practices, including agile methodologies, DevOps, and the use of NoSQL databases like MongoDB and Redis. It emphasizes the importance of scaling technologies, big data processing, actor systems for managing concurrency, and the evolving landscape of cloud computing. Additionally, it offers career advice for aspiring professionals in the tech industry, touching on open source projects, internships, networking, and continuous learning.



































































