








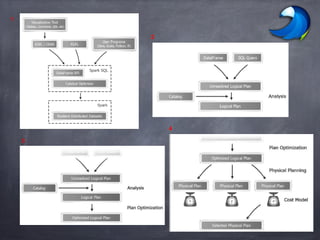





![Write Less Code: Compute an Average
Using RDDs
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
Using DataFrames
sqlCtx.table("people")
.groupBy("name")
.agg("name", avg("age"))
.collect()
Using SQL
SELECT name, avg(age)
FROM people
GROUP BY name
Using Pig
P = load '/people' as (name, name);
G = group P by name;
R = foreach G generate … AVG G.age ;](https://image.slidesharecdn.com/sparksqlsyedacademyv1-170801134417/85/Spark-SQL-In-Depth-www-syedacademy-com-28-320.jpg)


















![Write Less Code: Compute an Average
Using RDDs
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
Using DataFrames
sqlCtx.table("people")
.groupBy("name")
.agg("name", avg("age"))
.collect()
Using SQL
SELECT name, avg(age)
FROM people
GROUP BY name
Using Pig
P = load '/people' as (name, name);
G = group P by name;
R = foreach G generate … AVG G.age ;](https://image.slidesharecdn.com/sparksqlsyedacademyv1-170801134417/75/Spark-SQL-In-Depth-www-syedacademy-com-28-2048.jpg)
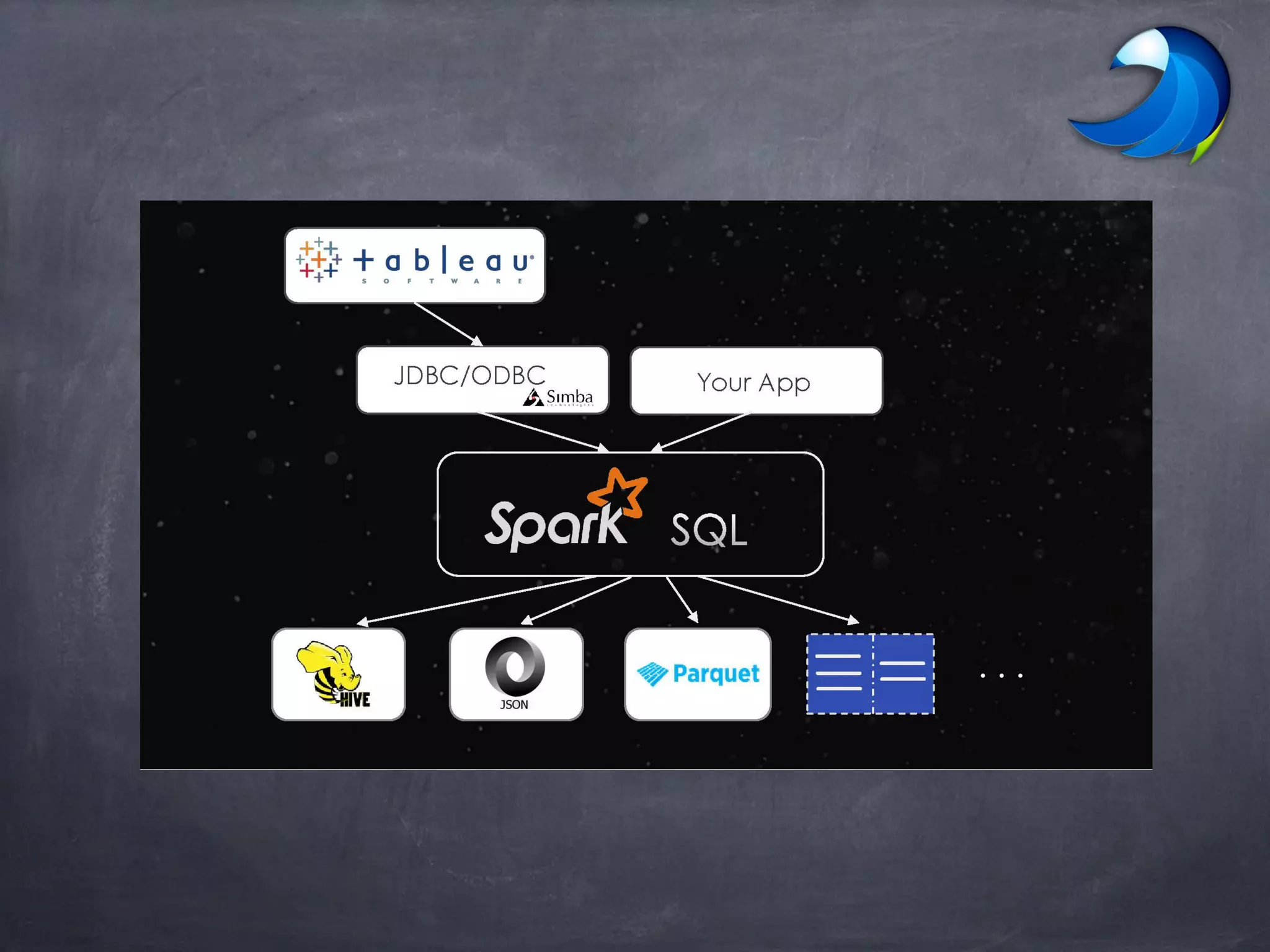


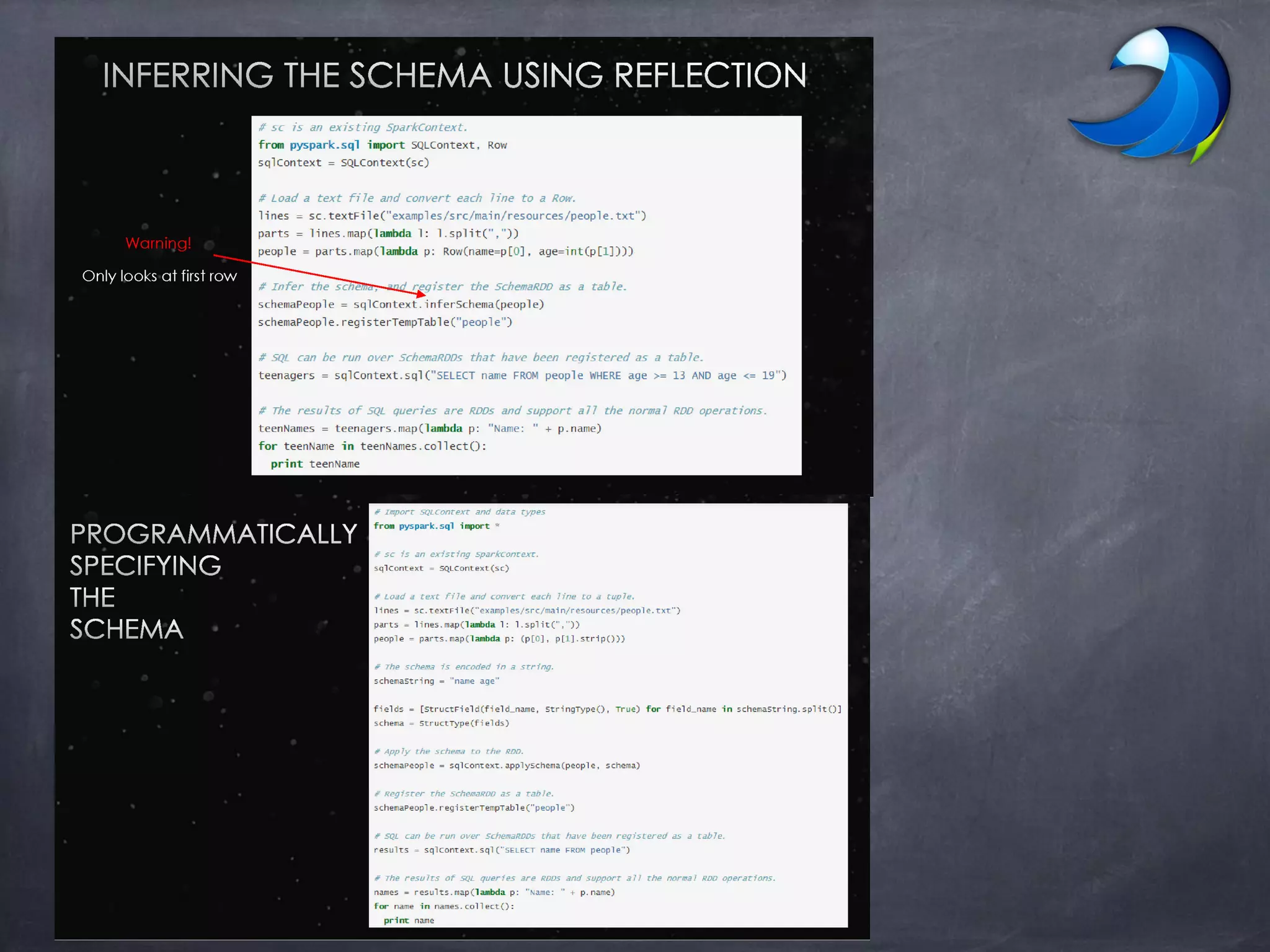
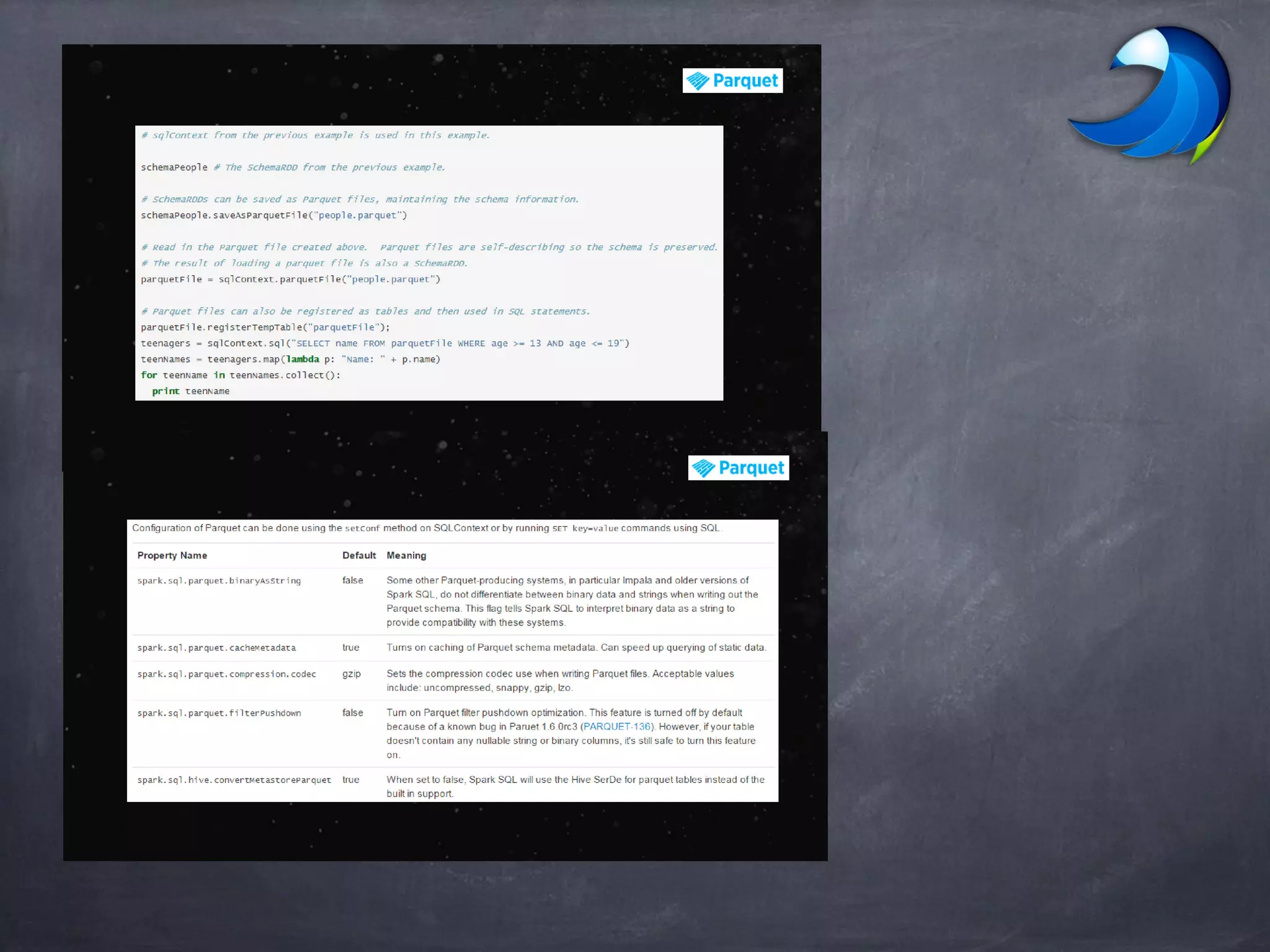



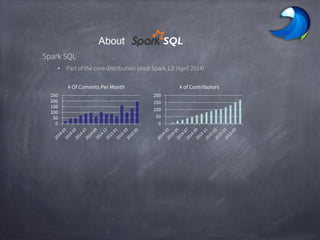
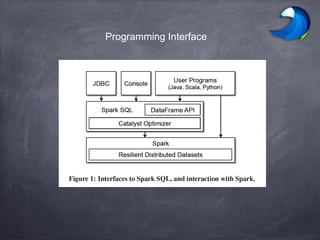
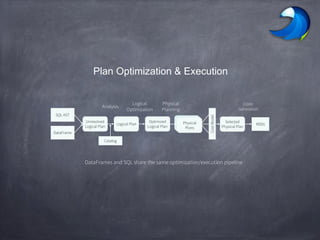
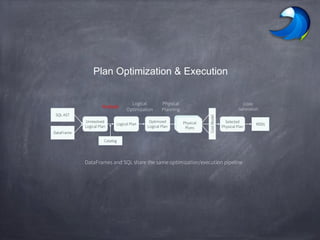
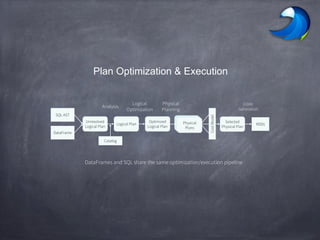
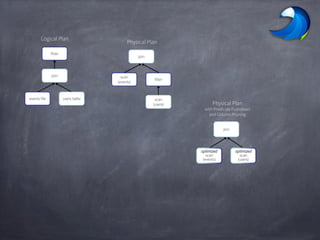
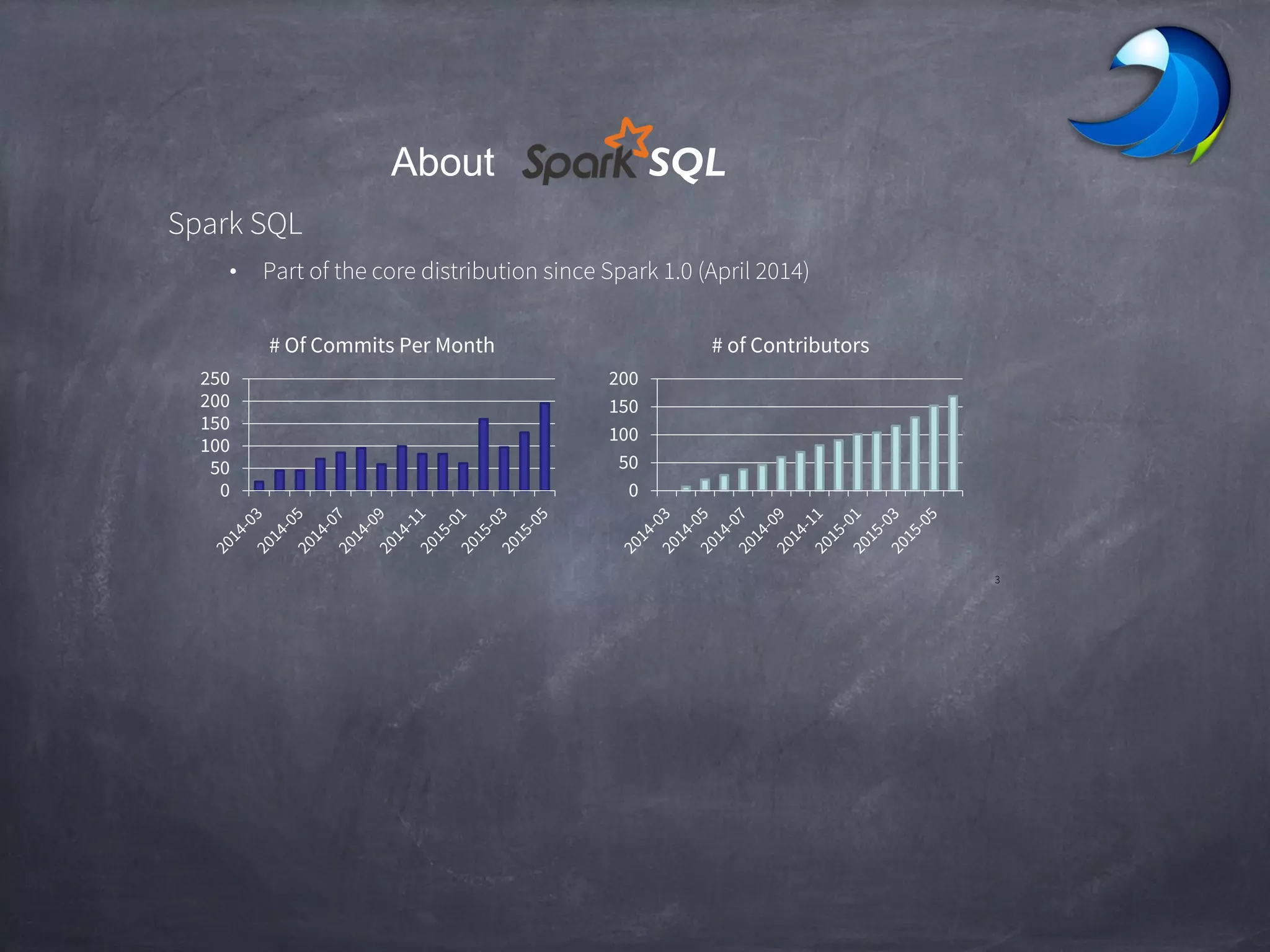
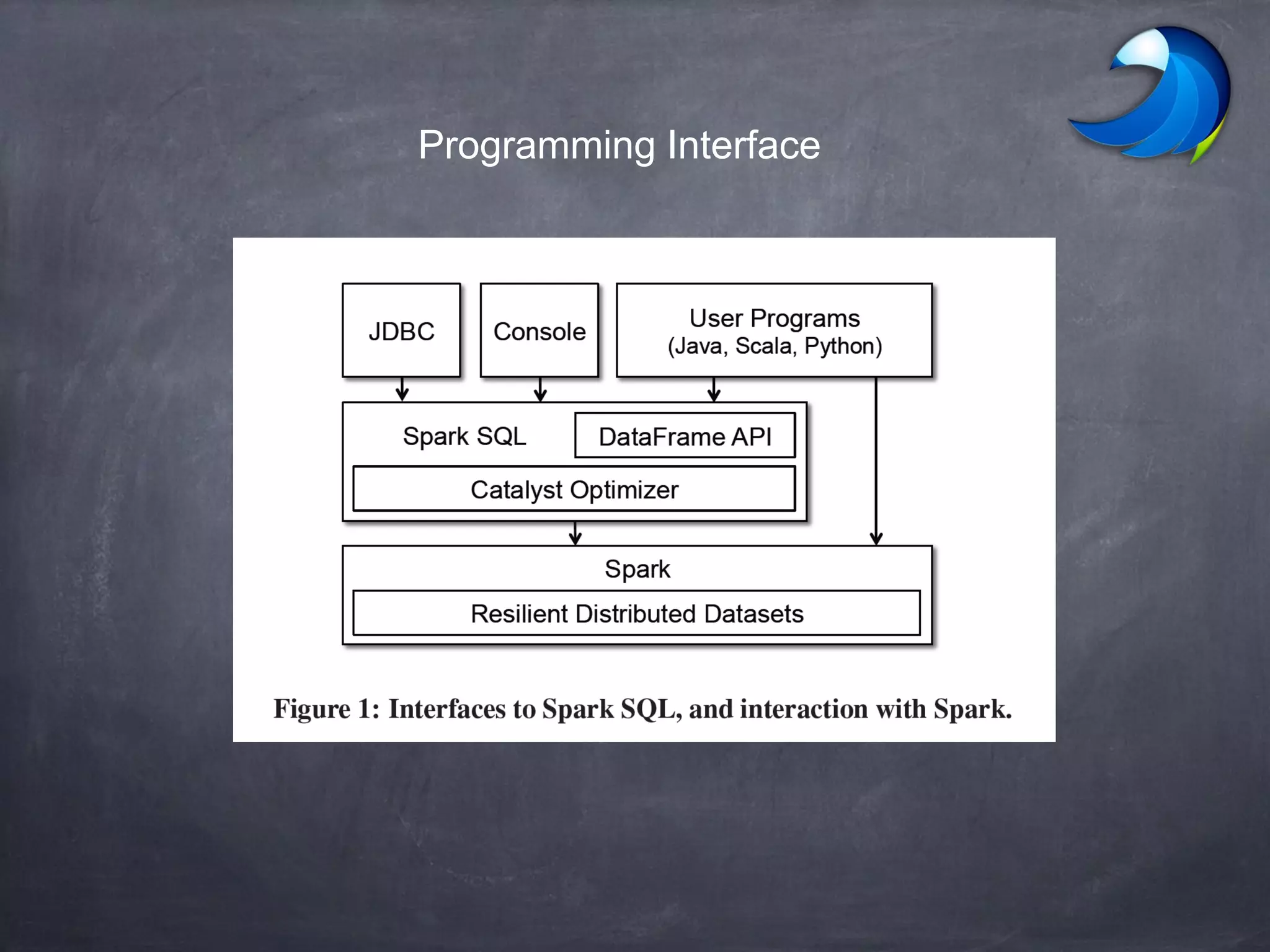
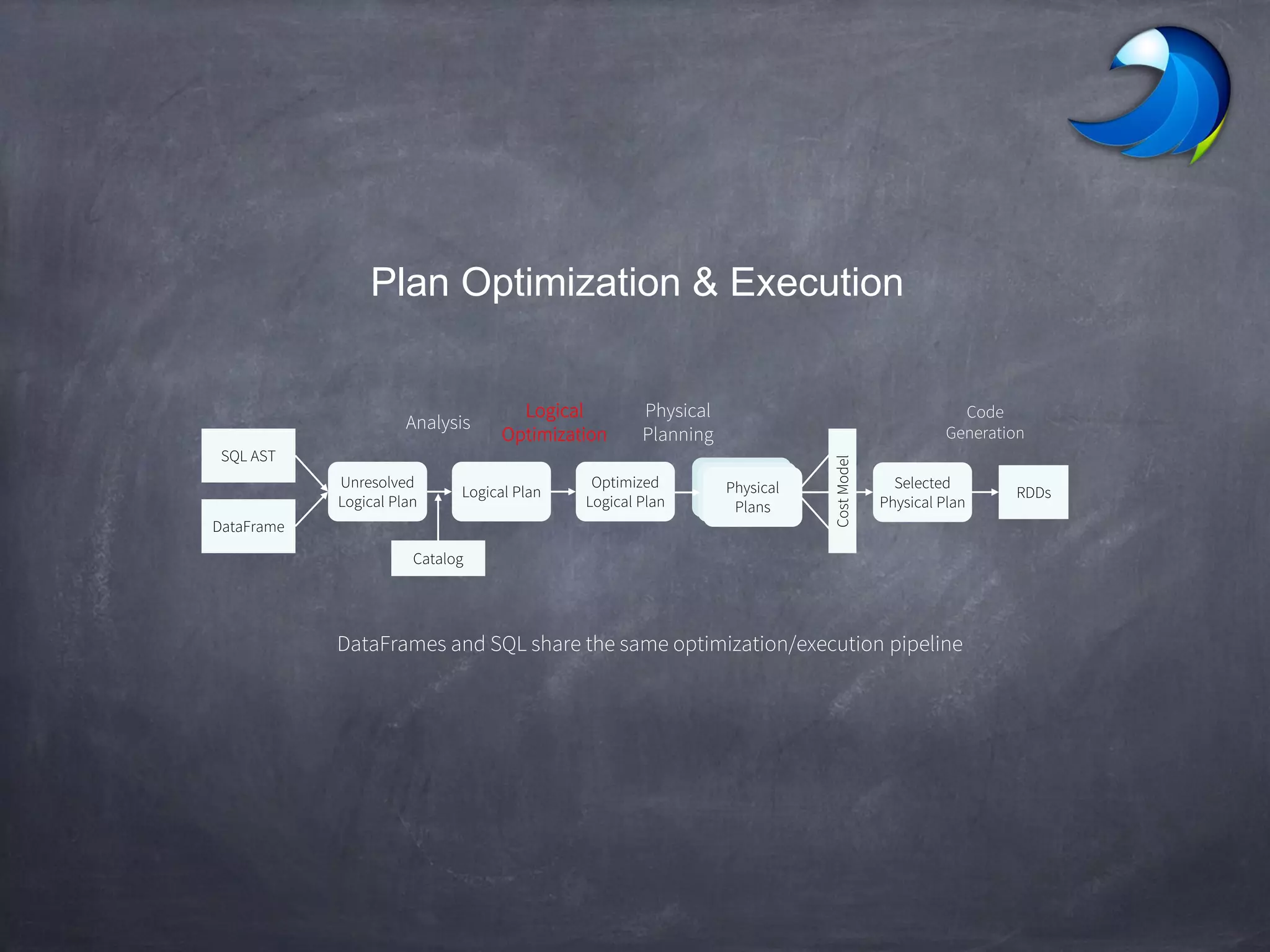
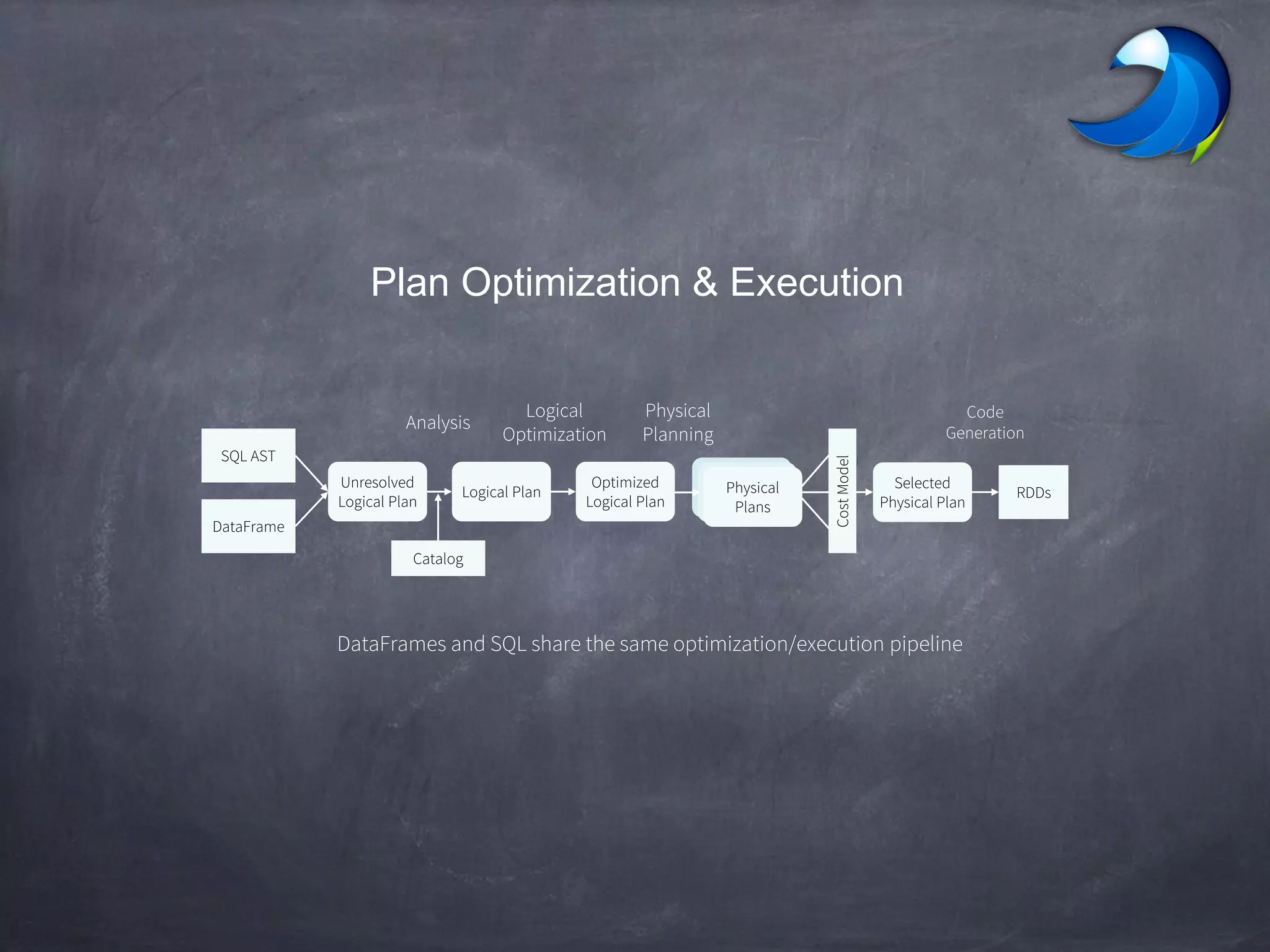
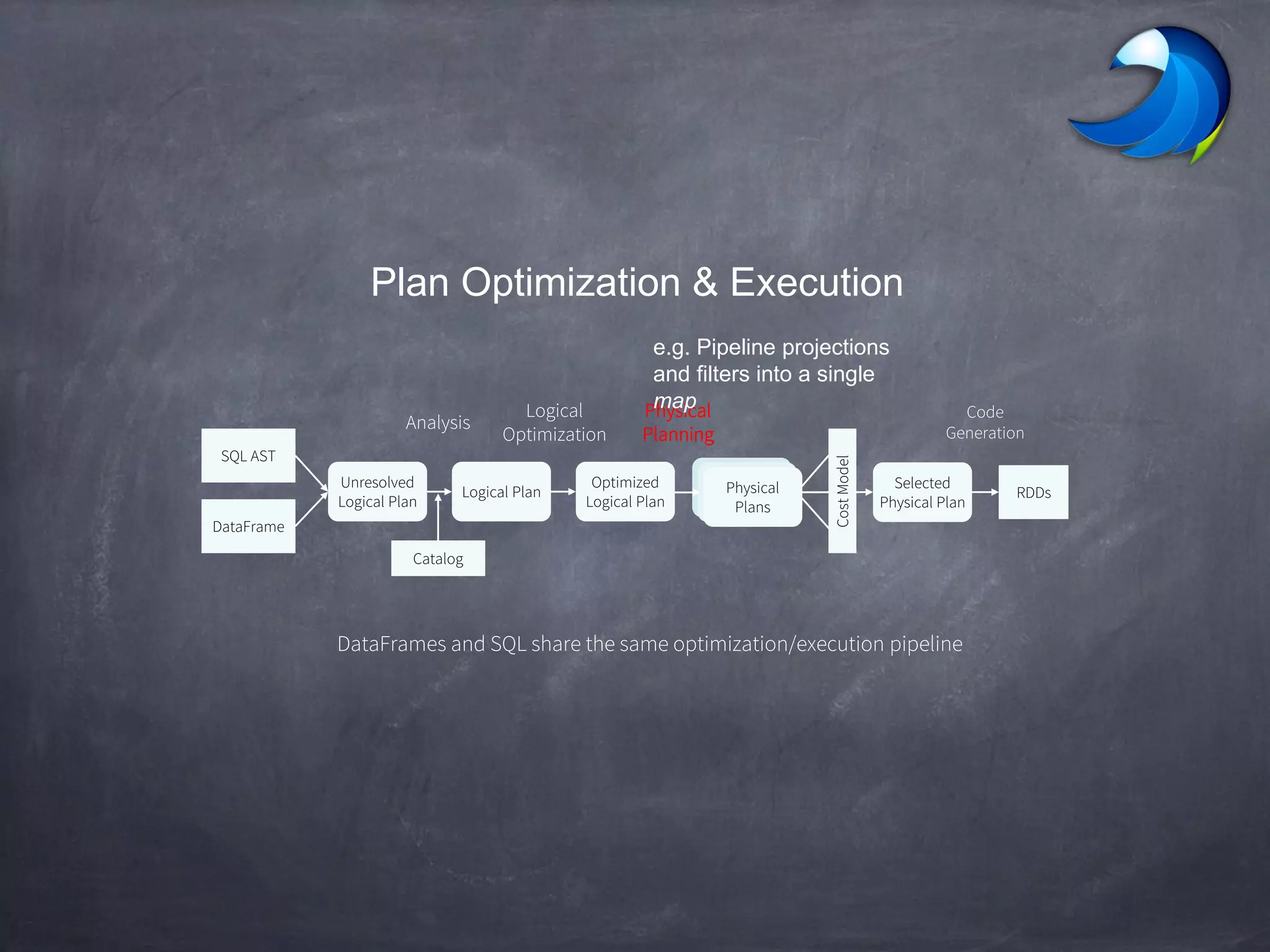
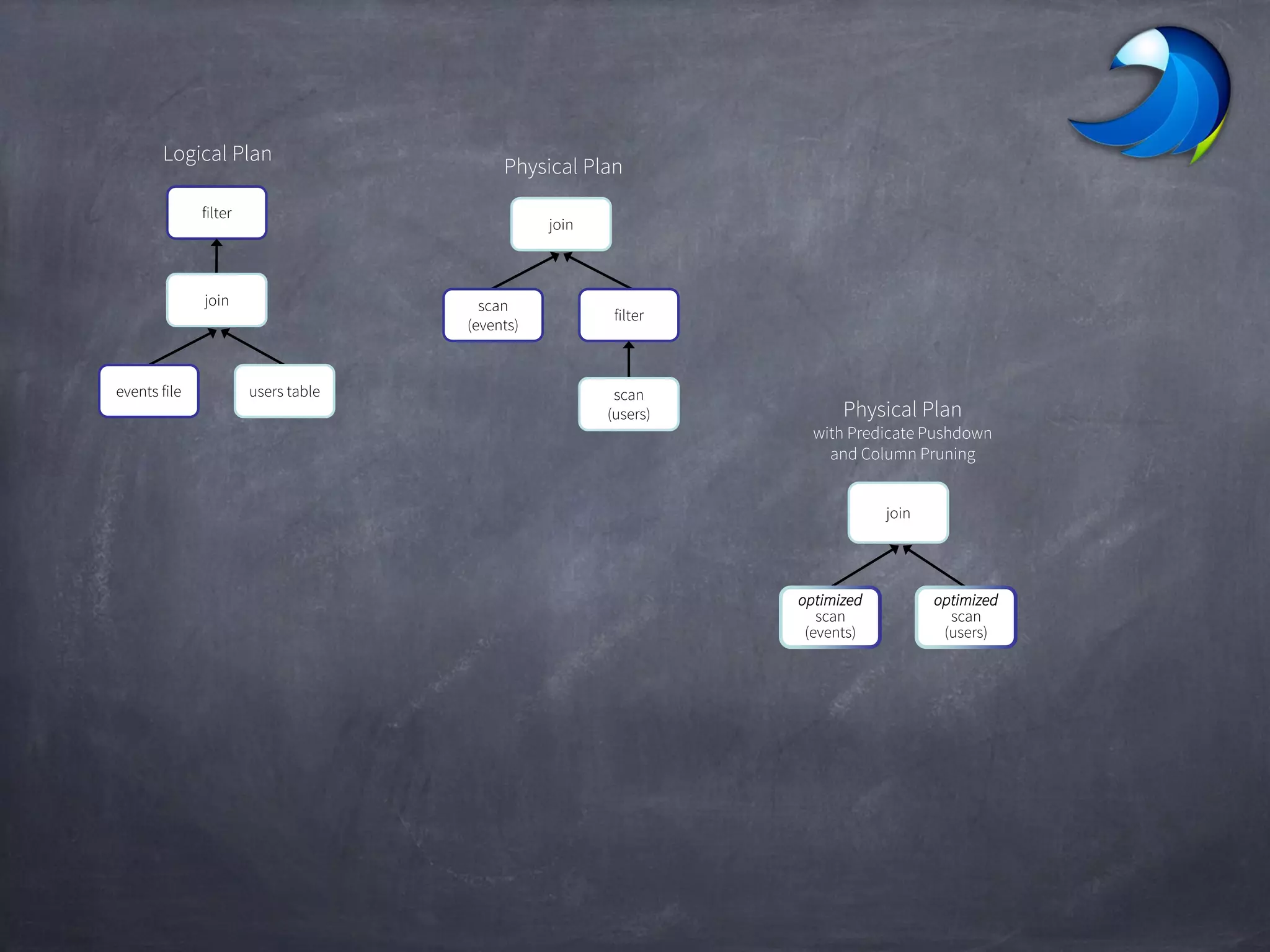
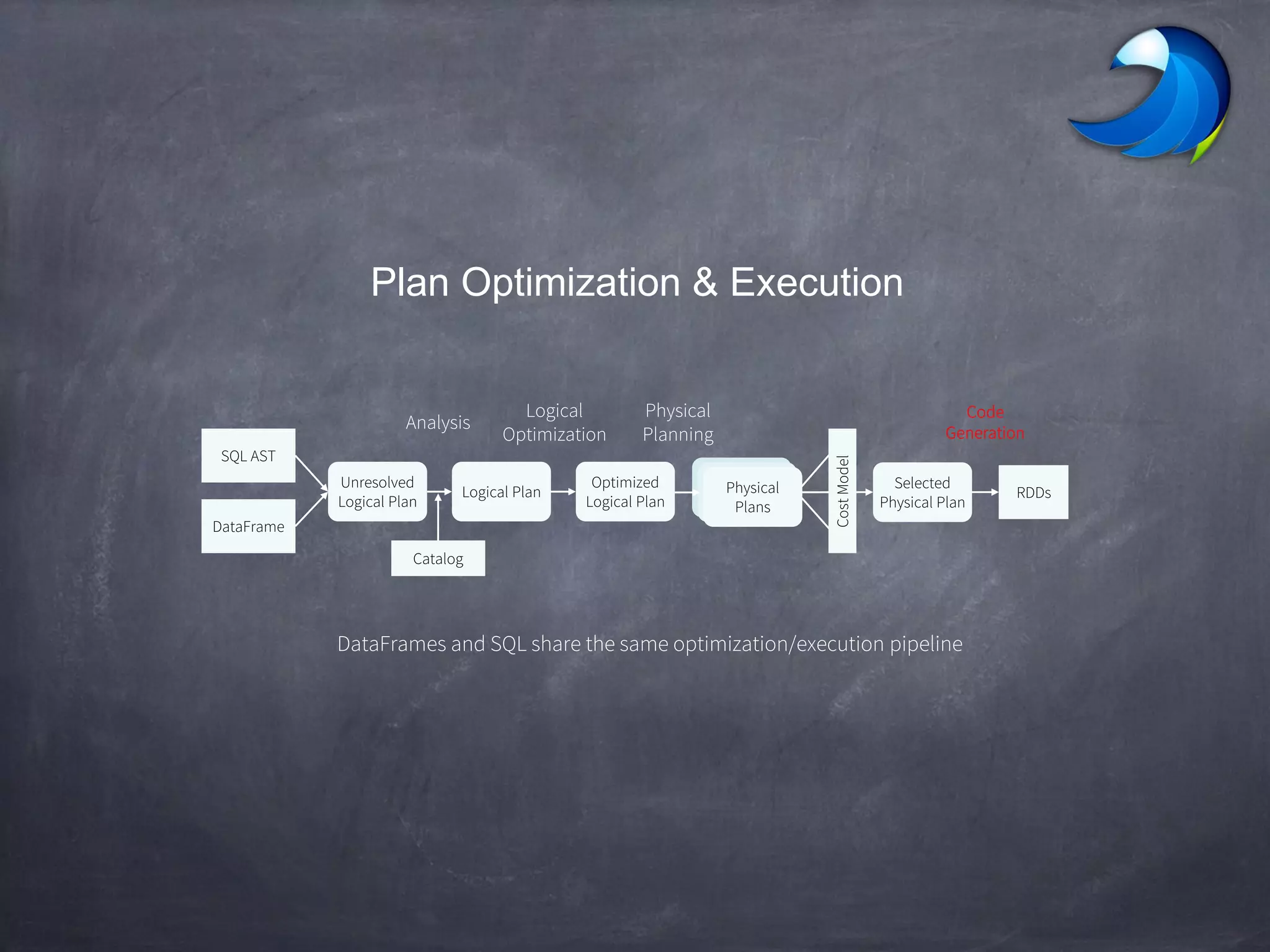
Spark SQL allows users to perform relational operations on Spark's RDDs using a DataFrame API. It addresses challenges in existing systems like limited optimization and data sources by providing a DataFrame API that can query both external data and RDDs. Spark SQL leverages a highly extensible optimizer called Catalyst to optimize logical query plans into efficient physical query plans using features of Scala. It has been part of the Spark core distribution since version 1.0 in 2014.









































































