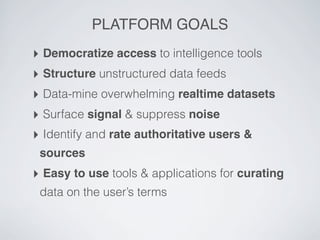
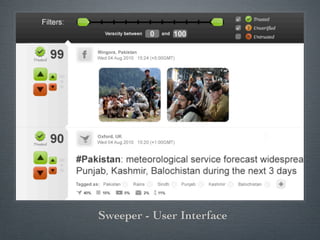
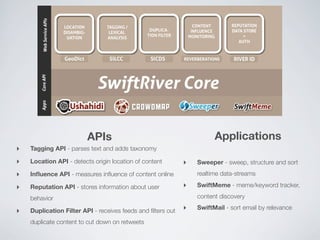
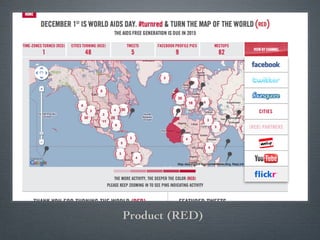
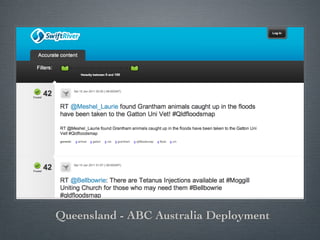
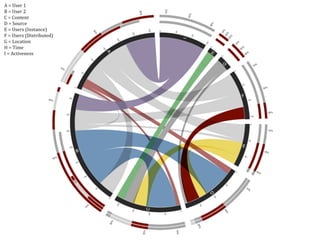
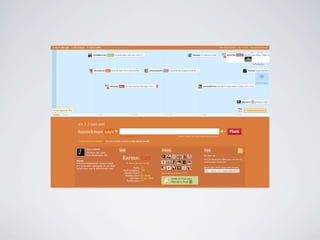
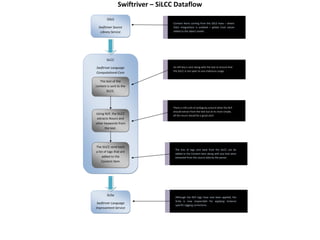
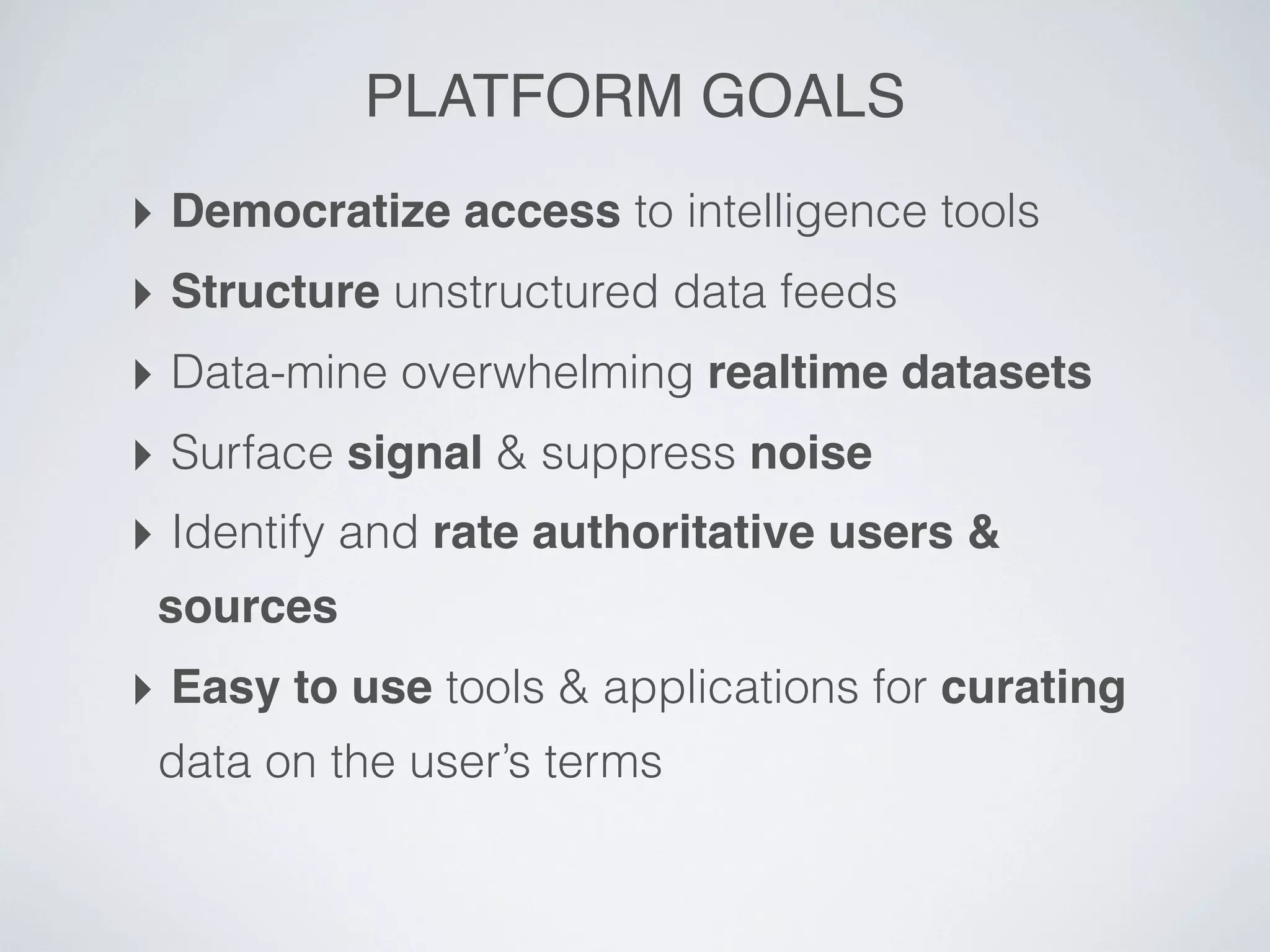
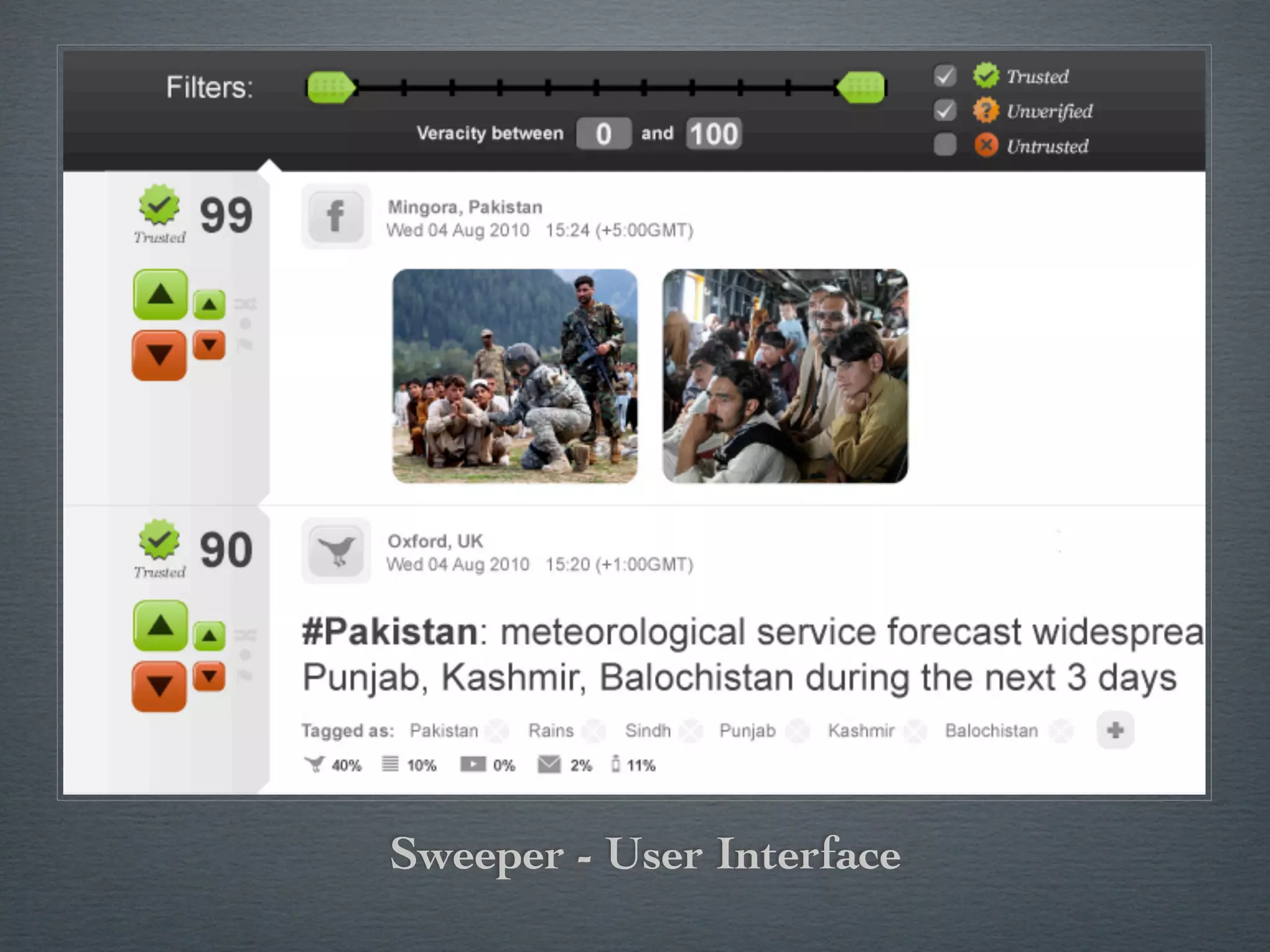
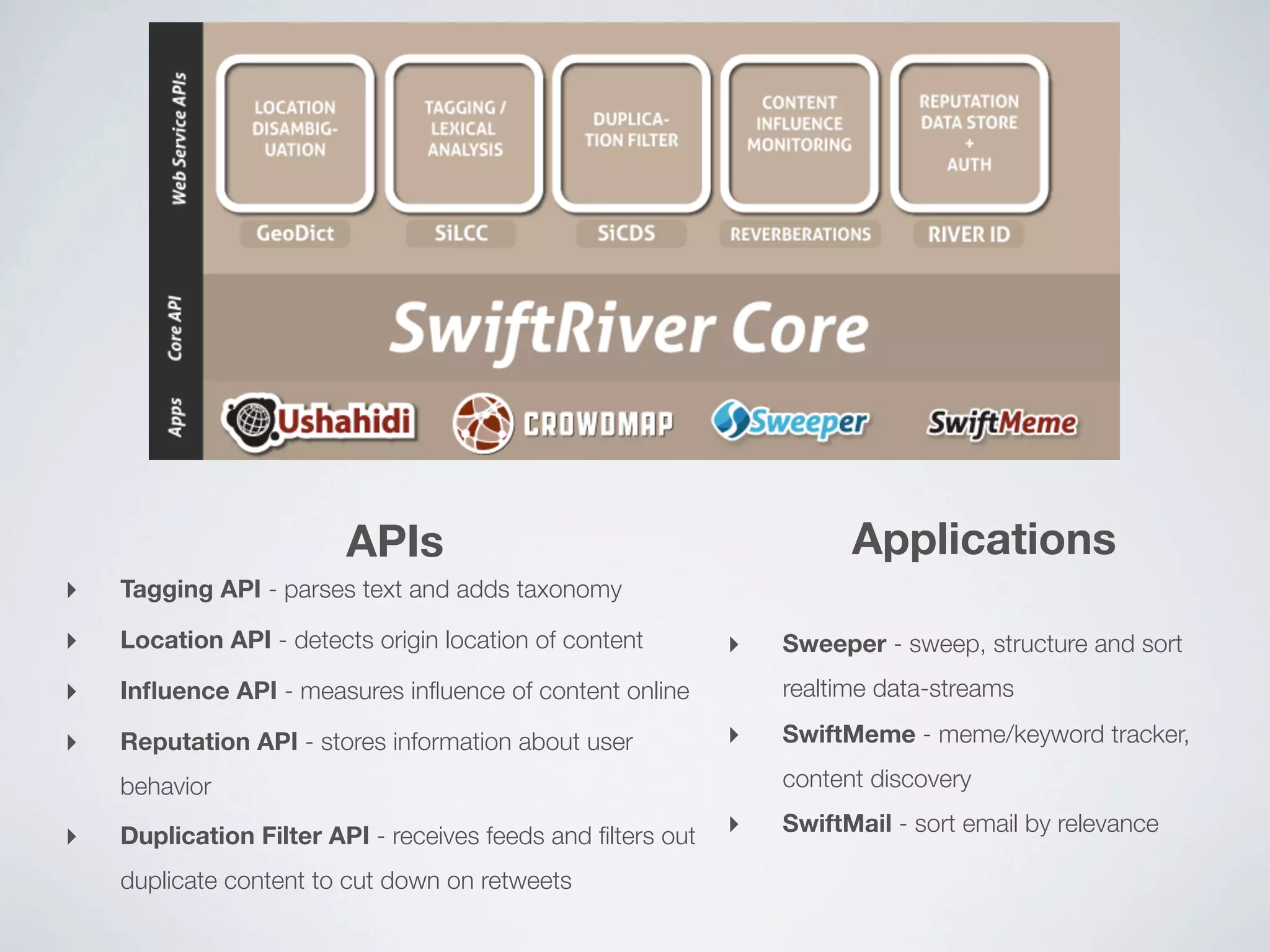
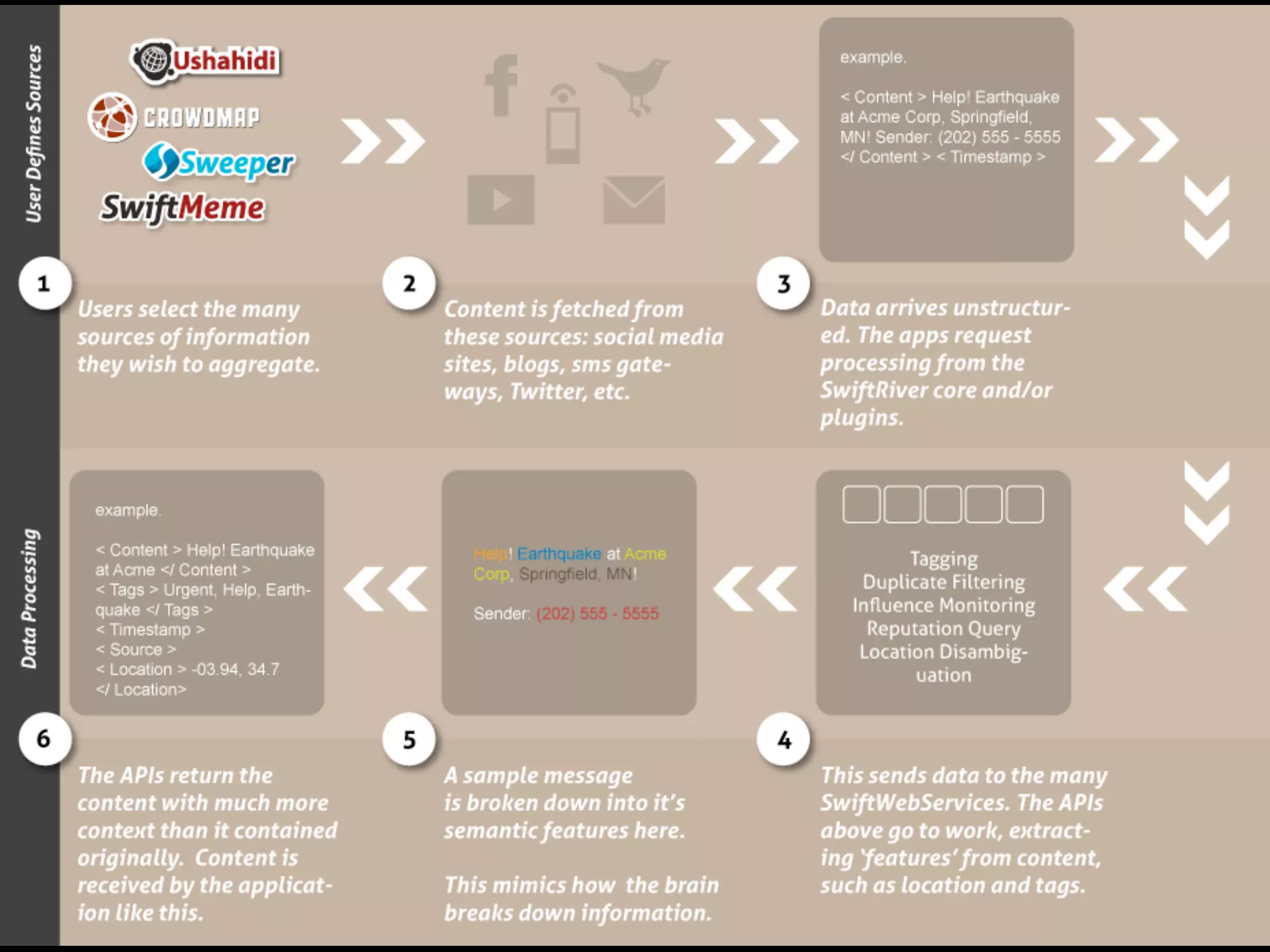
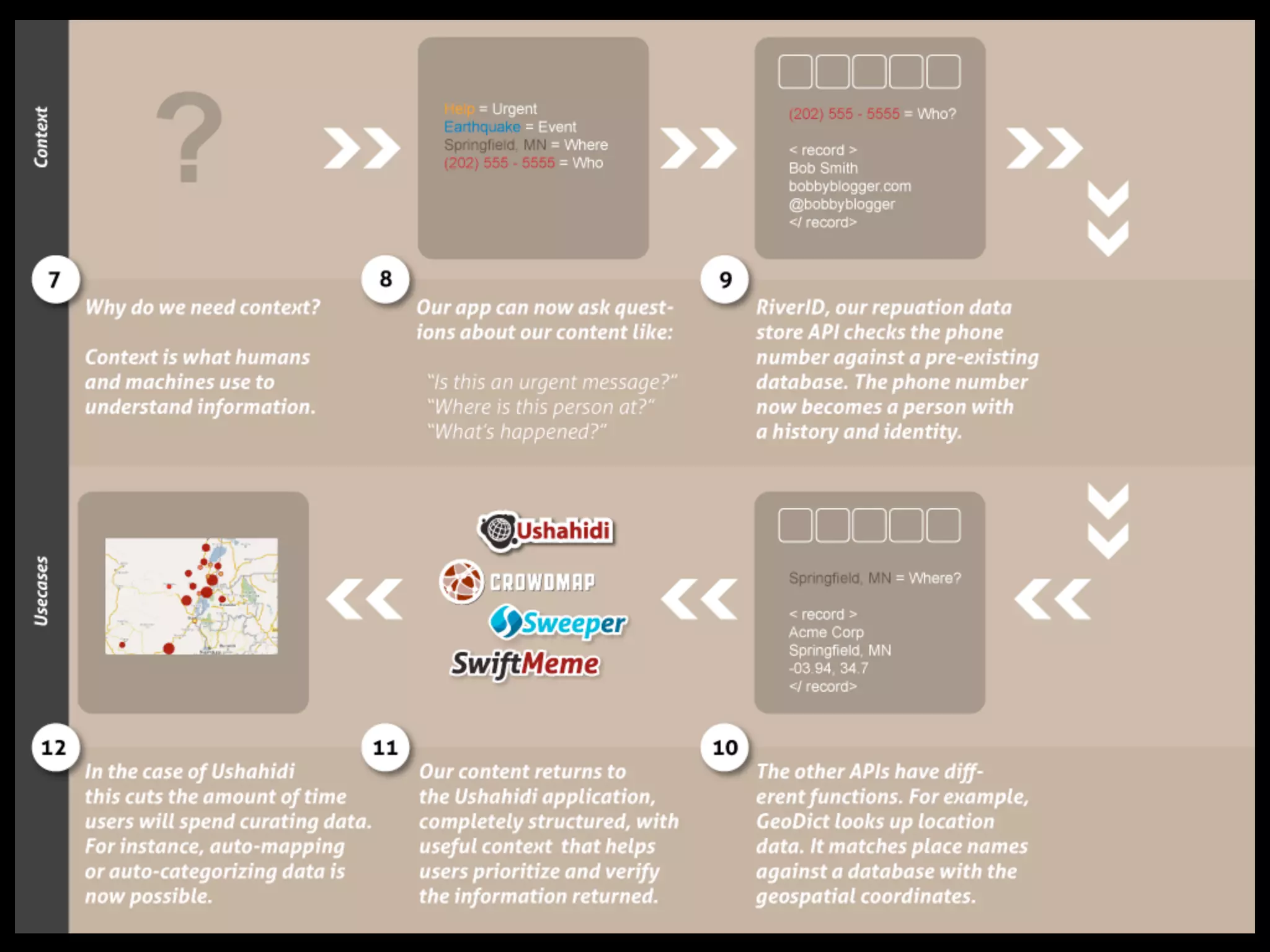
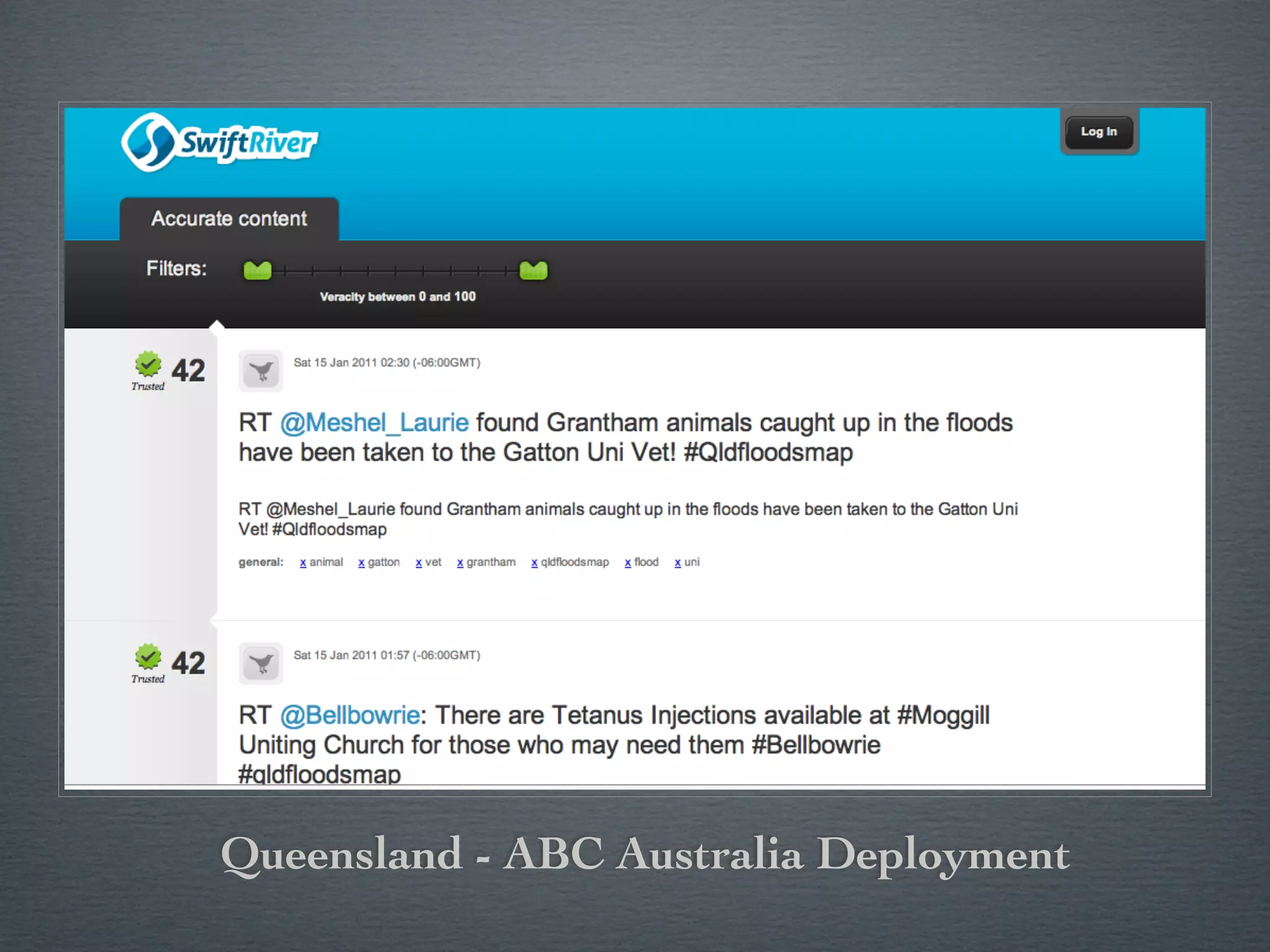
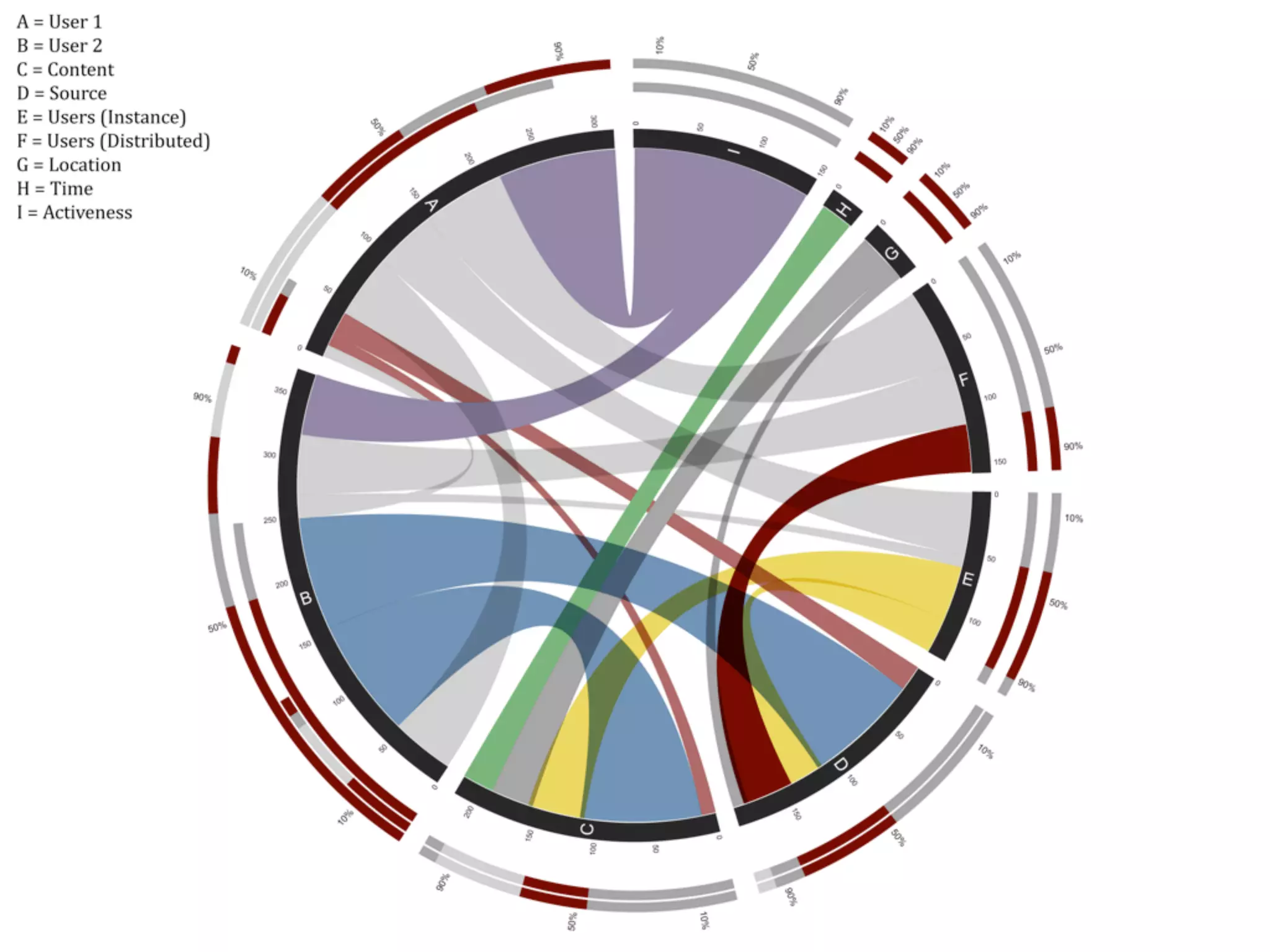
Swift River is a platform for curating real-time data streams and identifying important information. It aims to [1] give more people access to tools for analyzing large amounts of data, [2] organize unstructured information into a more usable structure, and [3] surface key details from overwhelming datasets. The platform includes tools like Sweeper for viewing and filtering live data feeds. It also provides APIs that can tag text with keywords, detect the location of information, and measure influence online.




















![TWEET ANALYSIS 3
We want to break up the tweet into the following
parts:
{
'text': ['PBS addresses mental health needs in the aftermath of the Haiti
earthquake'],
'hashtags': ['#Haiti', '#health', '#earthquake'],
'names': ['@directrelief', '@PIH', '@NewsHour'],
'urls': ['http://bit.ly/bNhyK6'],
}](https://image.slidesharecdn.com/swiftoverview2011-110318014336-phpapp01/85/SwiftRiver-2011-Overview-30-320.jpg)



































![TWEET ANALYSIS 3
We want to break up the tweet into the following
parts:
{
'text': ['PBS addresses mental health needs in the aftermath of the Haiti
earthquake'],
'hashtags': ['#Haiti', '#health', '#earthquake'],
'names': ['@directrelief', '@PIH', '@NewsHour'],
'urls': ['http://bit.ly/bNhyK6'],
}](https://image.slidesharecdn.com/swiftoverview2011-110318014336-phpapp01/75/SwiftRiver-2011-Overview-30-2048.jpg)





















































































