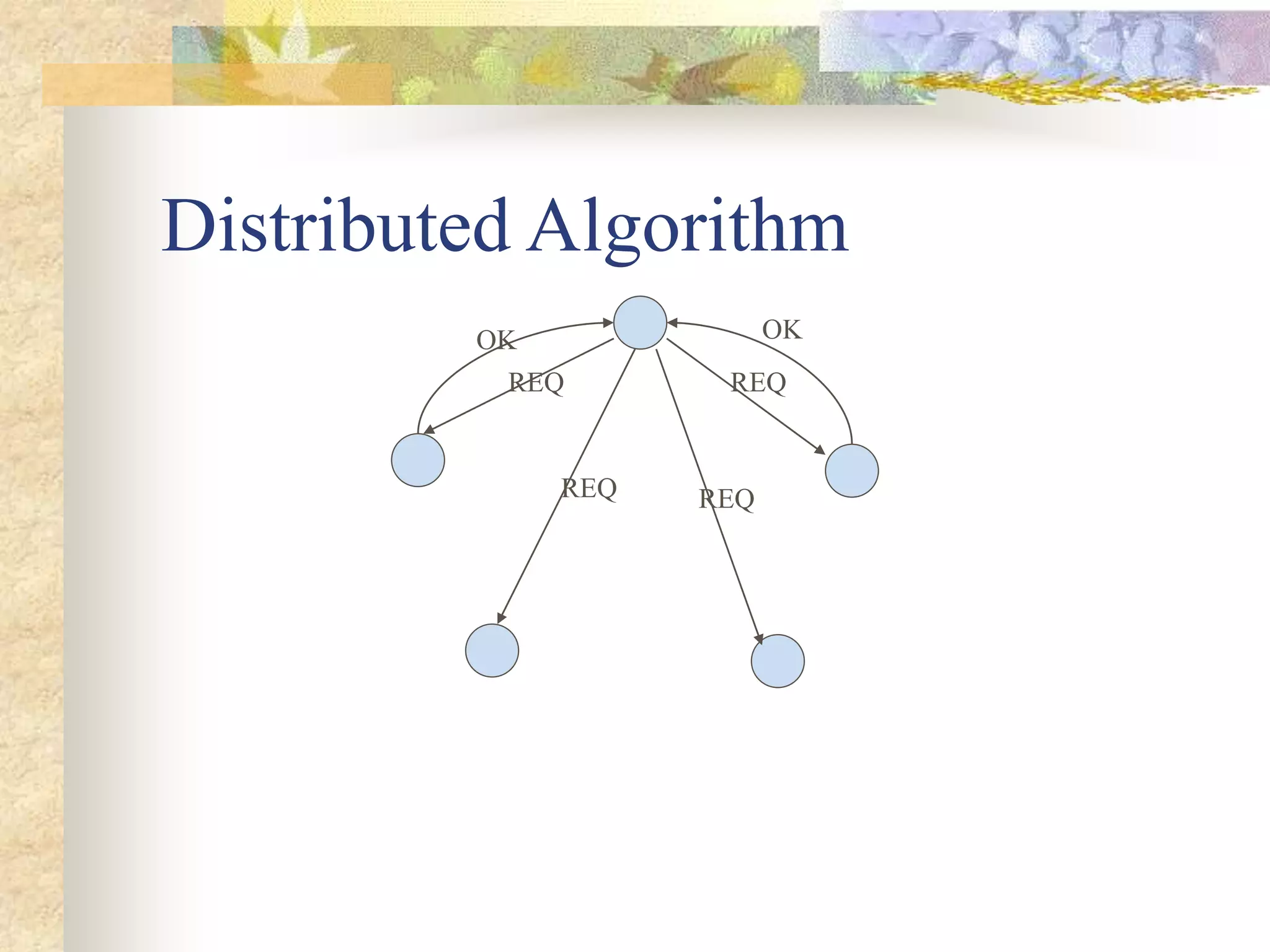
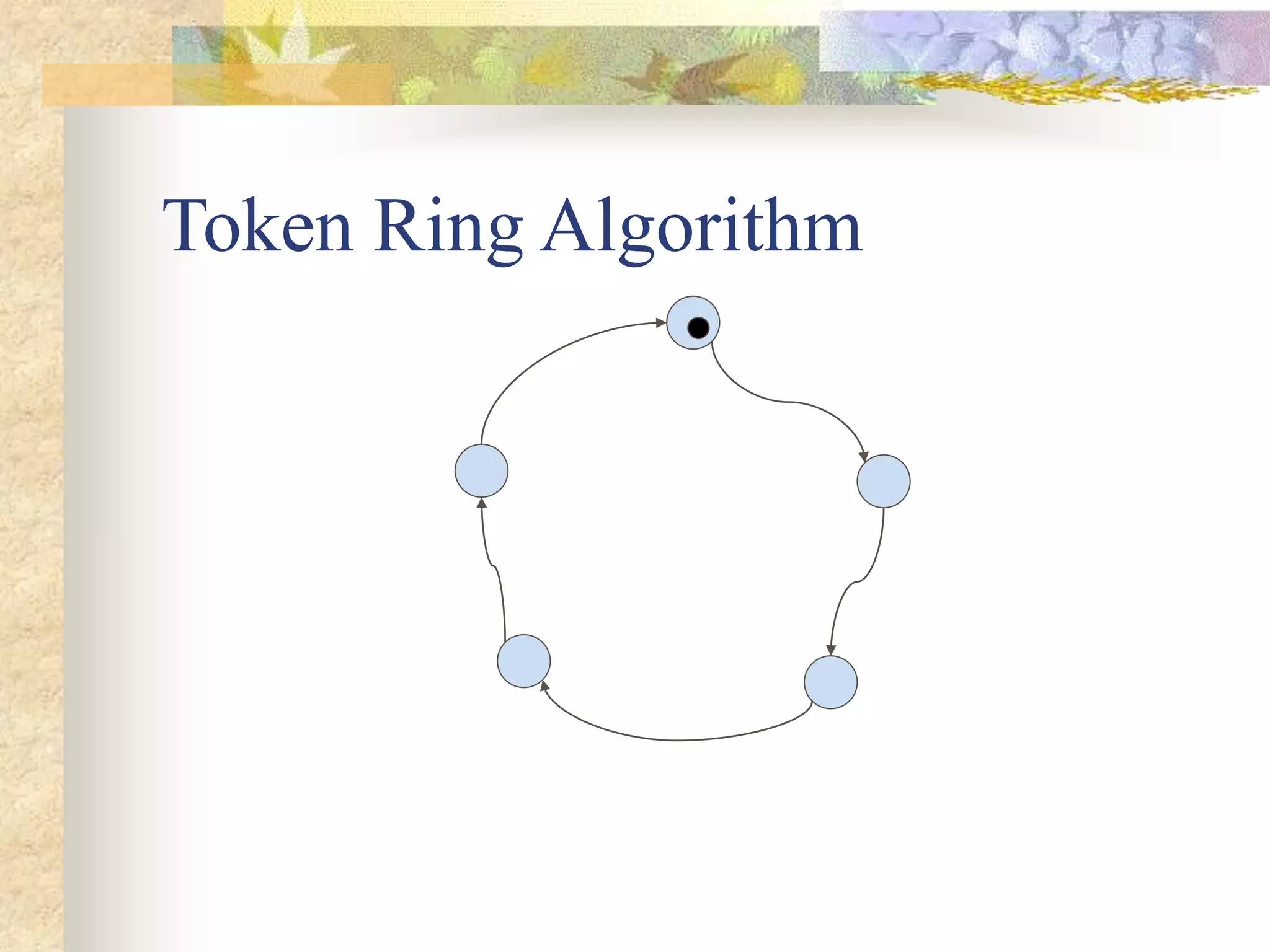
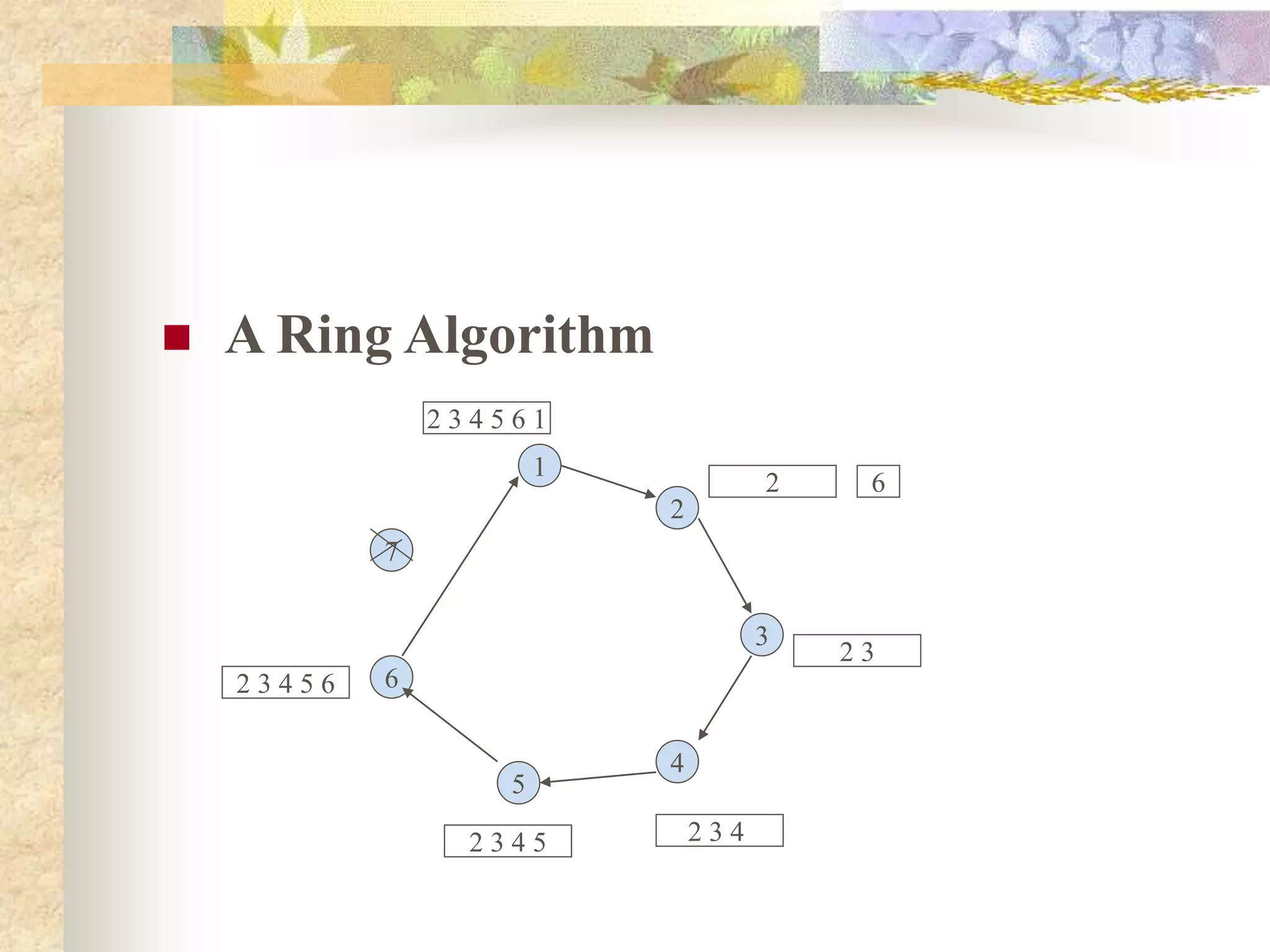
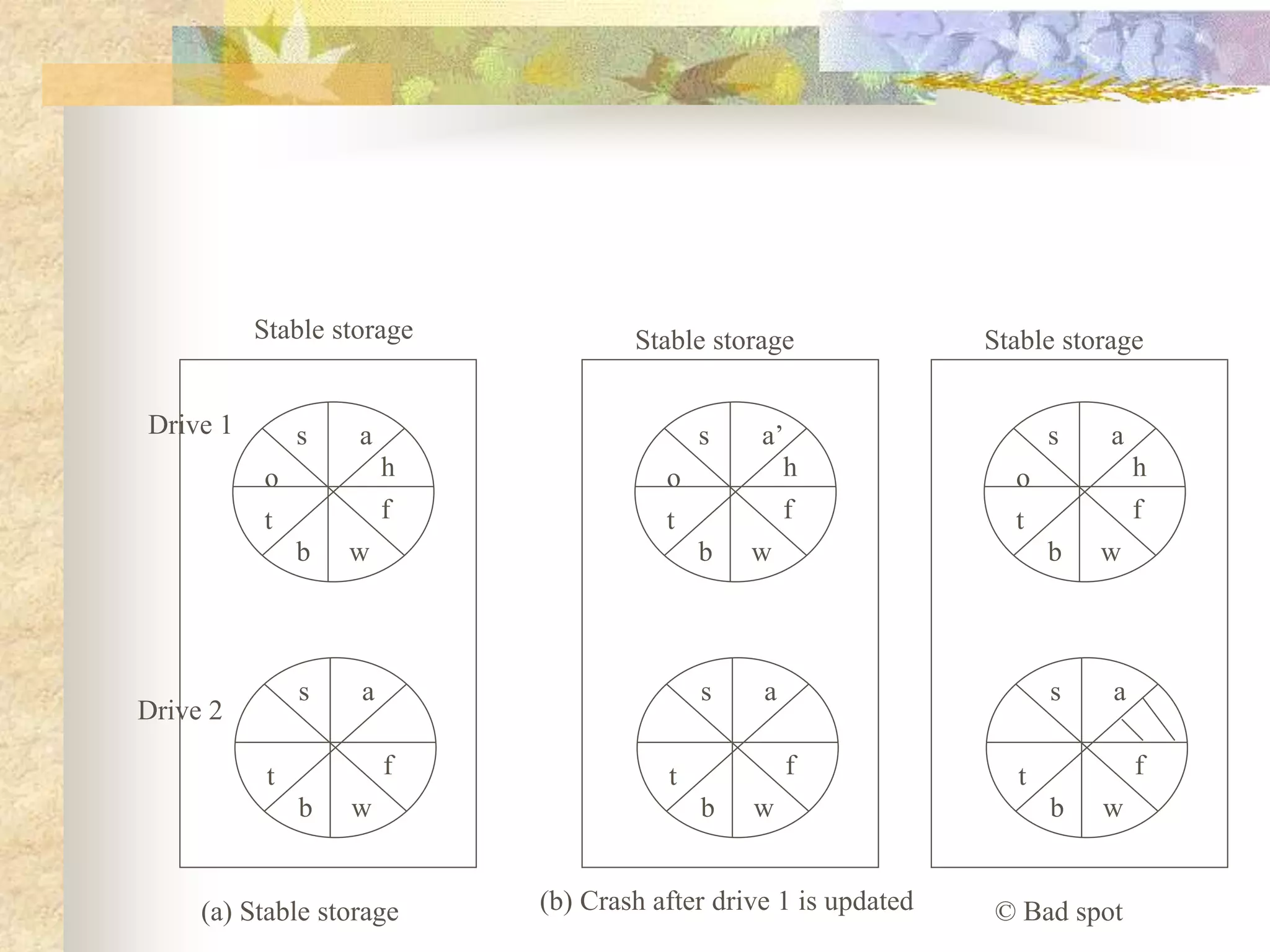
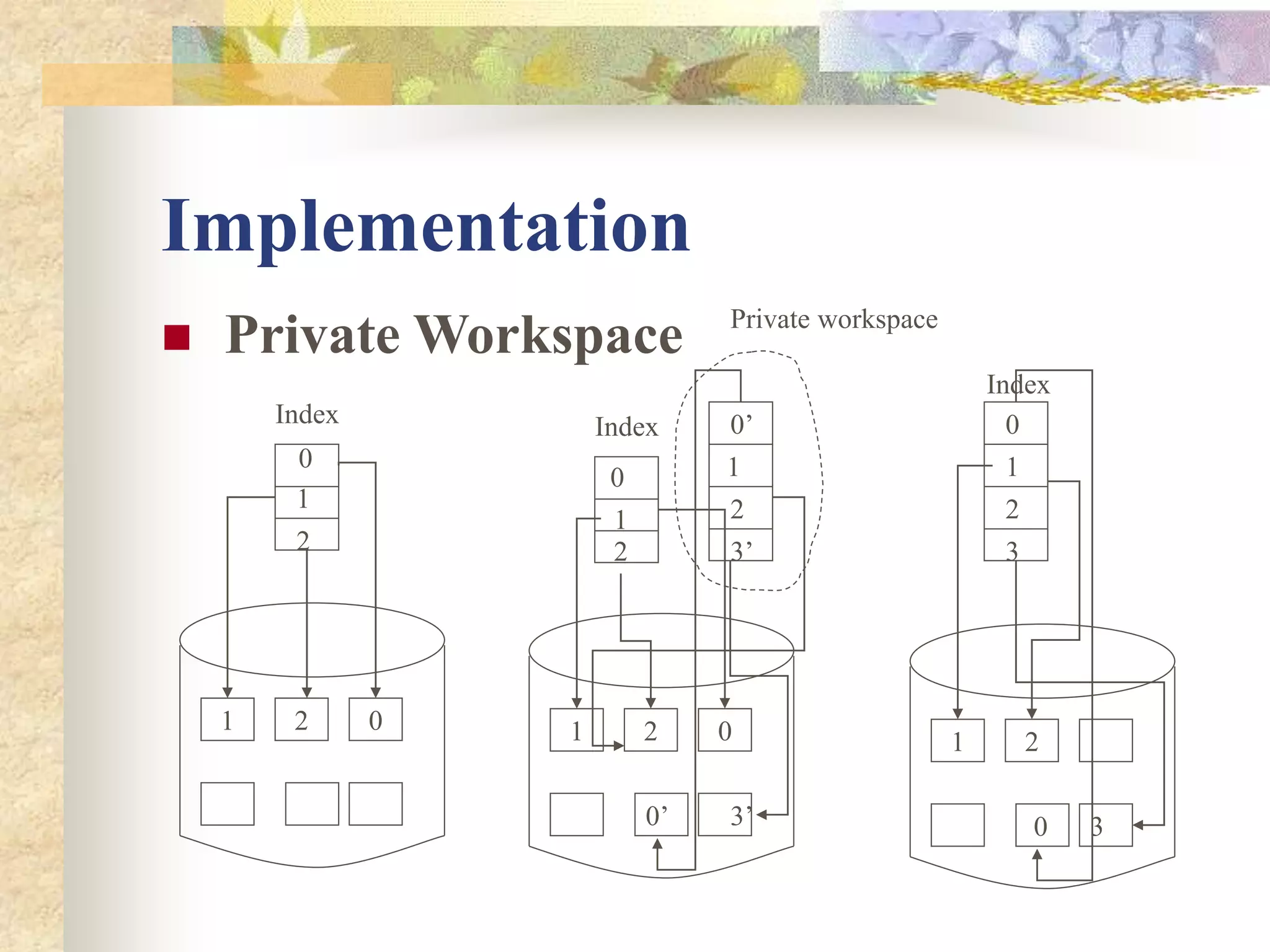
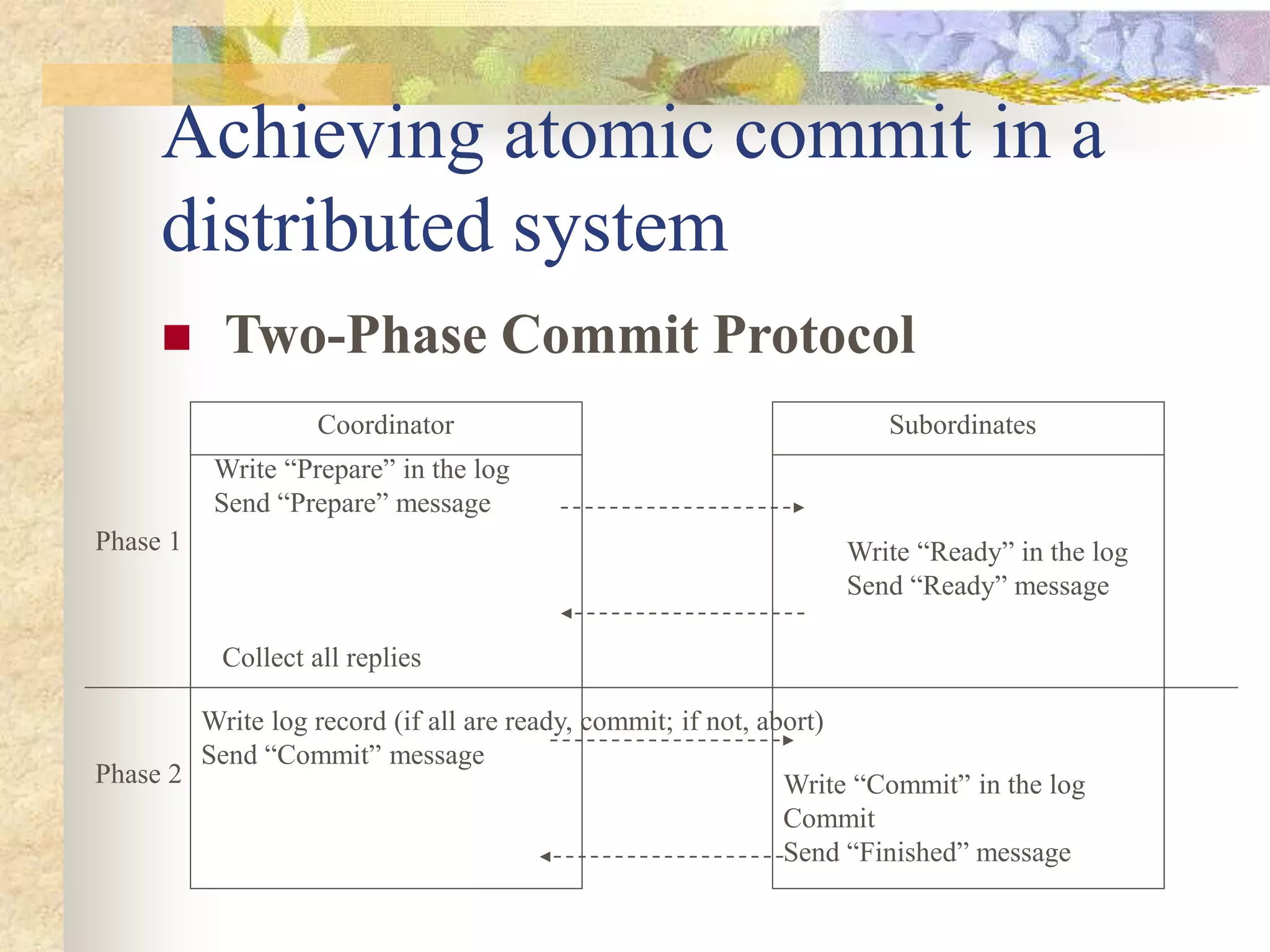
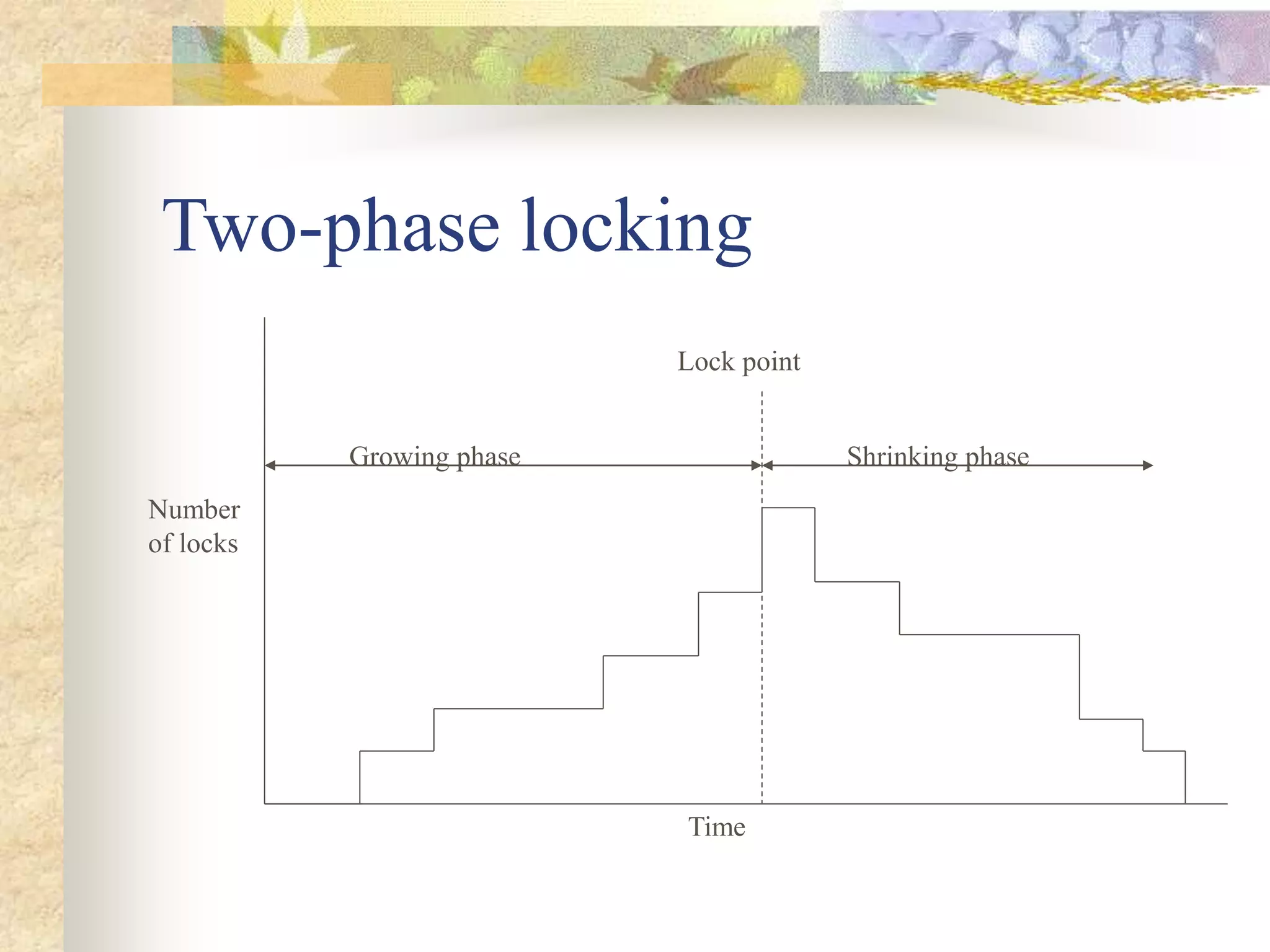
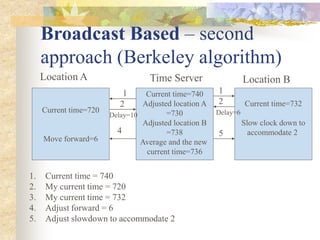
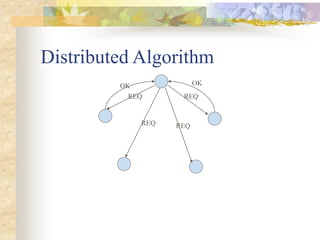
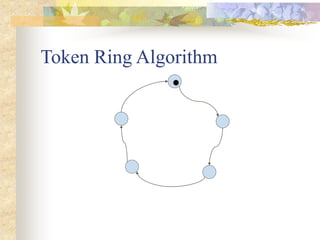
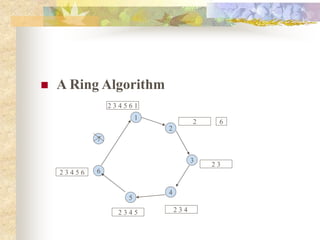
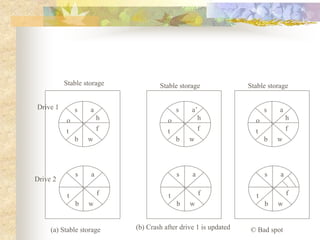
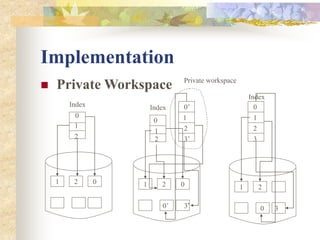
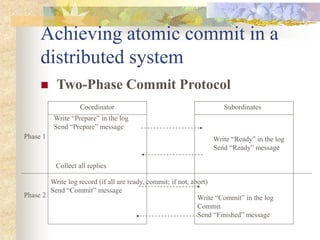
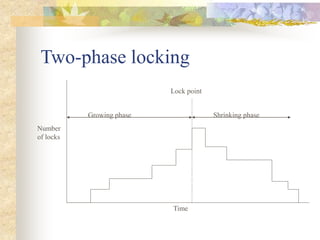
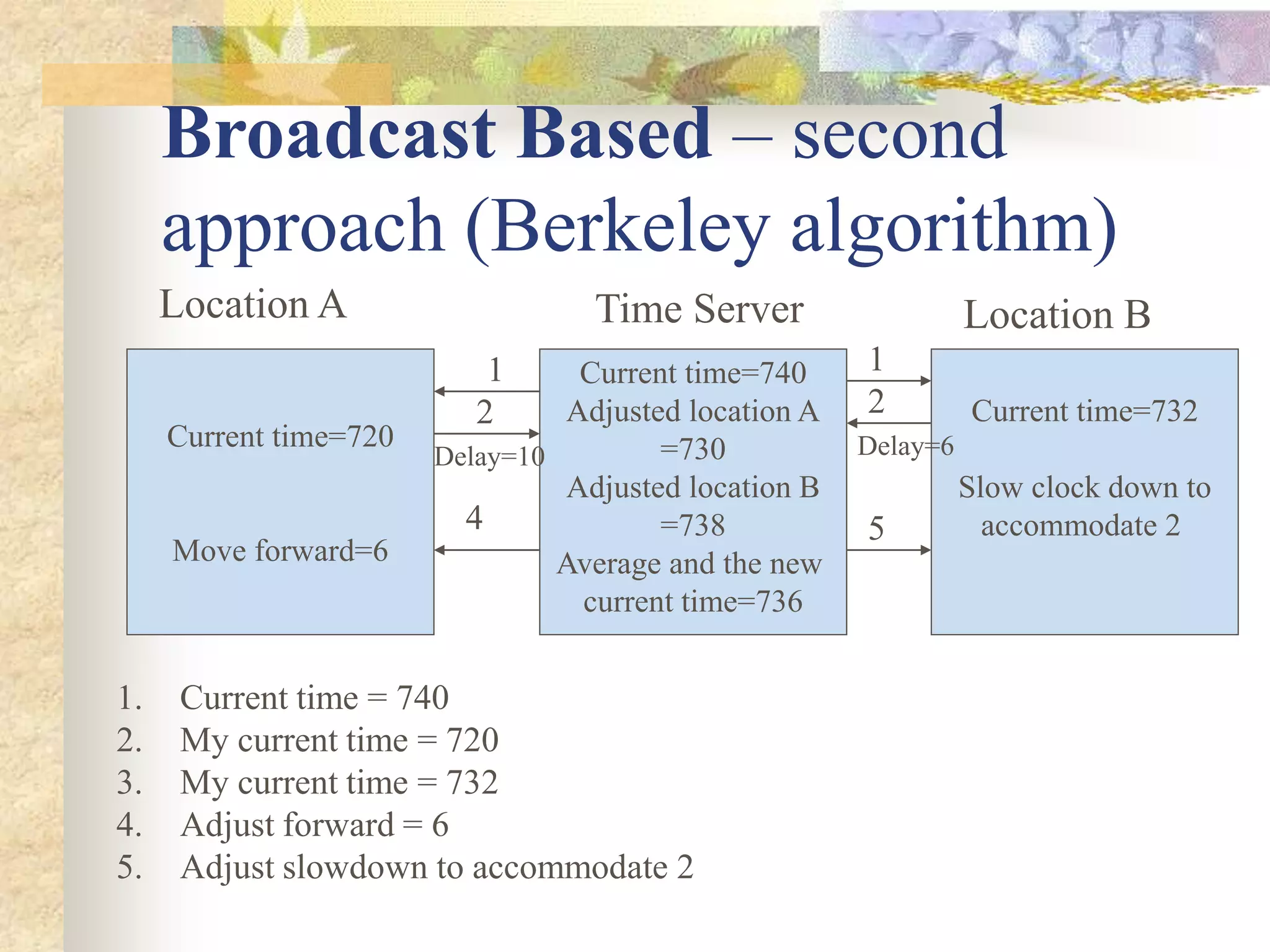
The document discusses synchronization in distributed systems, detailing the differences between centralized and distributed synchronization methods including algorithms for clock synchronization and logical clocks. It covers concepts like physical time servers, global time, mutual exclusion in distributed systems, and atomic transactions with emphasis on concurrency control mechanisms. The use of logical clocks to establish a happen-before relationship and various algorithms including Lamport’s and the two-phase commit protocol for achieving atomic commits in distributed systems are also examined.




















![Lamport’s Algorithm
Each process increments its clock counter
between every two consecutive events.
If a sends a message to b, then the message must
include T(a). Upon receiving a and T(a), the
receiving process must set its clock to the greater
of [T(a)+d, Current Clock]. That is, if the
recipient’s clock is behind, it must be advanced to
preserve the happen-before relationship. Usually
d=1.](https://image.slidesharecdn.com/synchronizationindistributedcomputing-220517071919-52387f7d/85/Synchronization-in-distributed-computing-22-320.jpg)











































![Lamport’s Algorithm
Each process increments its clock counter
between every two consecutive events.
If a sends a message to b, then the message must
include T(a). Upon receiving a and T(a), the
receiving process must set its clock to the greater
of [T(a)+d, Current Clock]. That is, if the
recipient’s clock is behind, it must be advanced to
preserve the happen-before relationship. Usually
d=1.](https://image.slidesharecdn.com/synchronizationindistributedcomputing-220517071919-52387f7d/75/Synchronization-in-distributed-computing-22-2048.jpg)