Downloaded 31 times




![Workflow
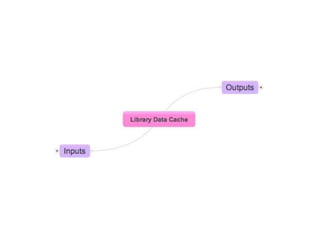
• Obtain data (possibly as ‘records’)
• Store data as statements in cache
• Evaluate data by source or collection
• Improve data using specific services, as
determined by evaluation
• Publish improved data
• [Rinse, repeat]](https://image.slidesharecdn.com/othersideoflod-140131142012-phpapp01/85/The-Other-Side-of-Linked-Open-Data-Managing-Metadata-Aggregation-5-320.jpg)









![Workflow
• Obtain data (possibly as ‘records’)
• Store data as statements in cache
• Evaluate data by source or collection
• Improve data using specific services, as
determined by evaluation
• Publish improved data
• [Rinse, repeat]](https://image.slidesharecdn.com/othersideoflod-140131142012-phpapp01/75/The-Other-Side-of-Linked-Open-Data-Managing-Metadata-Aggregation-5-2048.jpg)
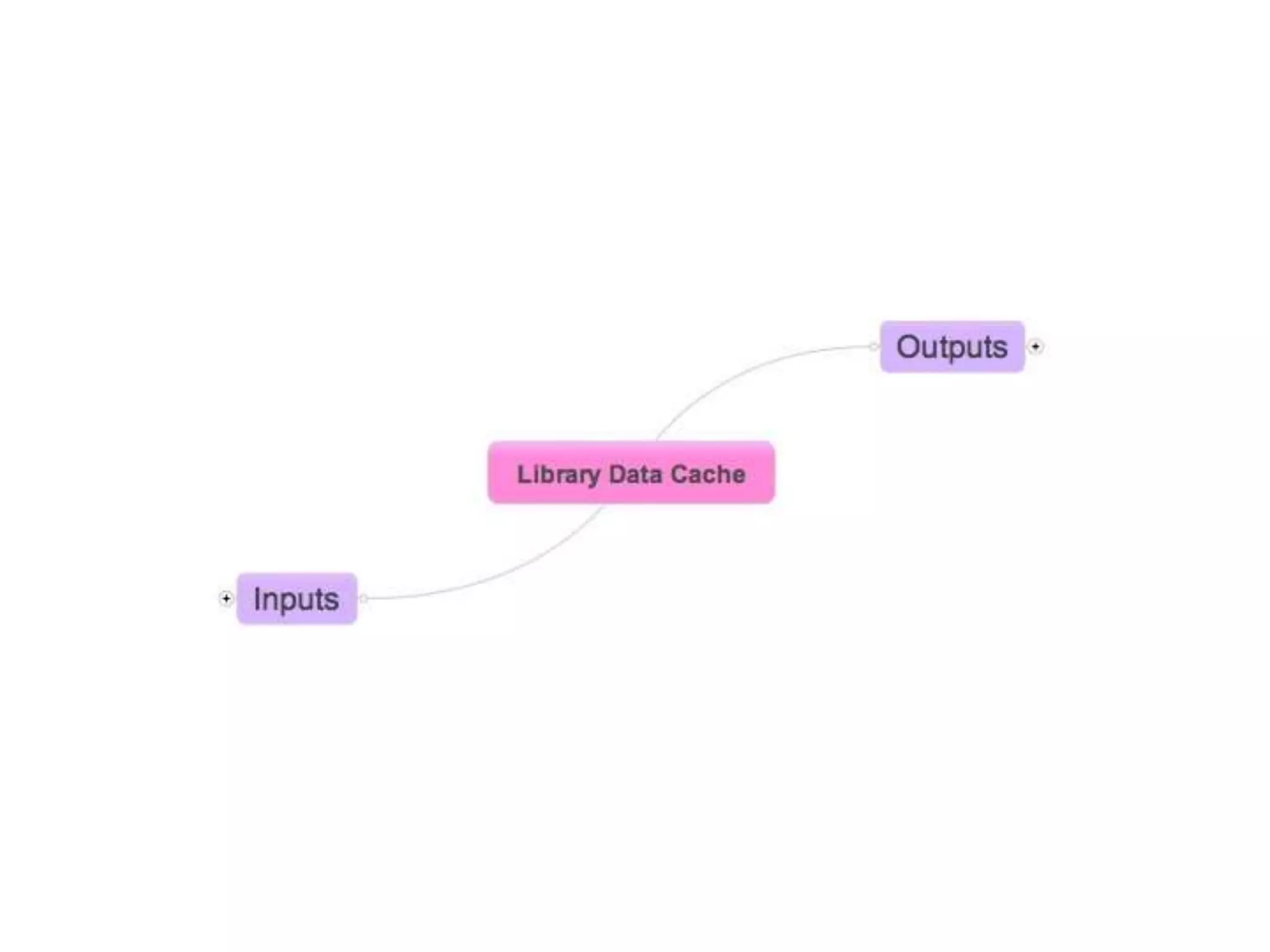
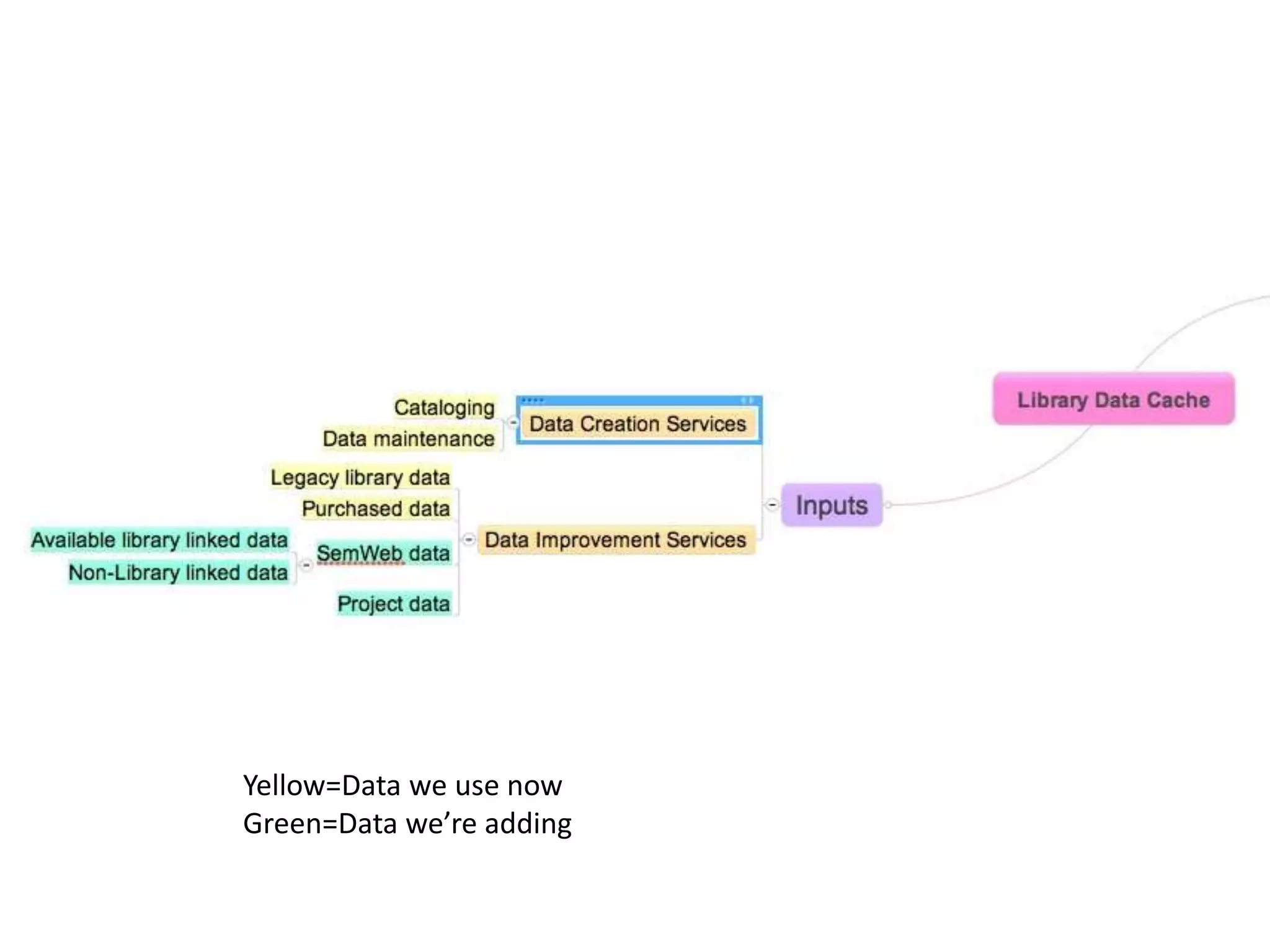

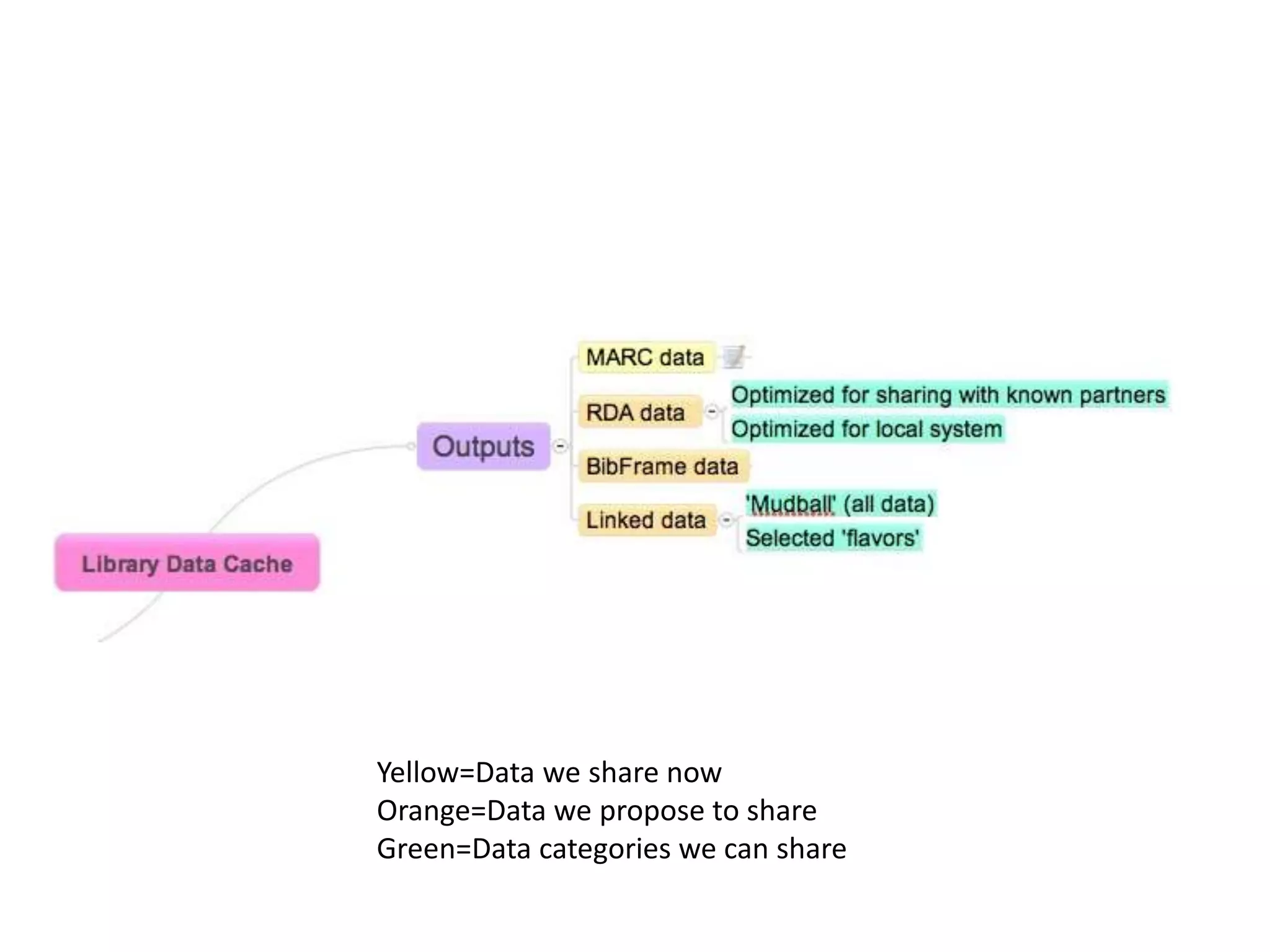


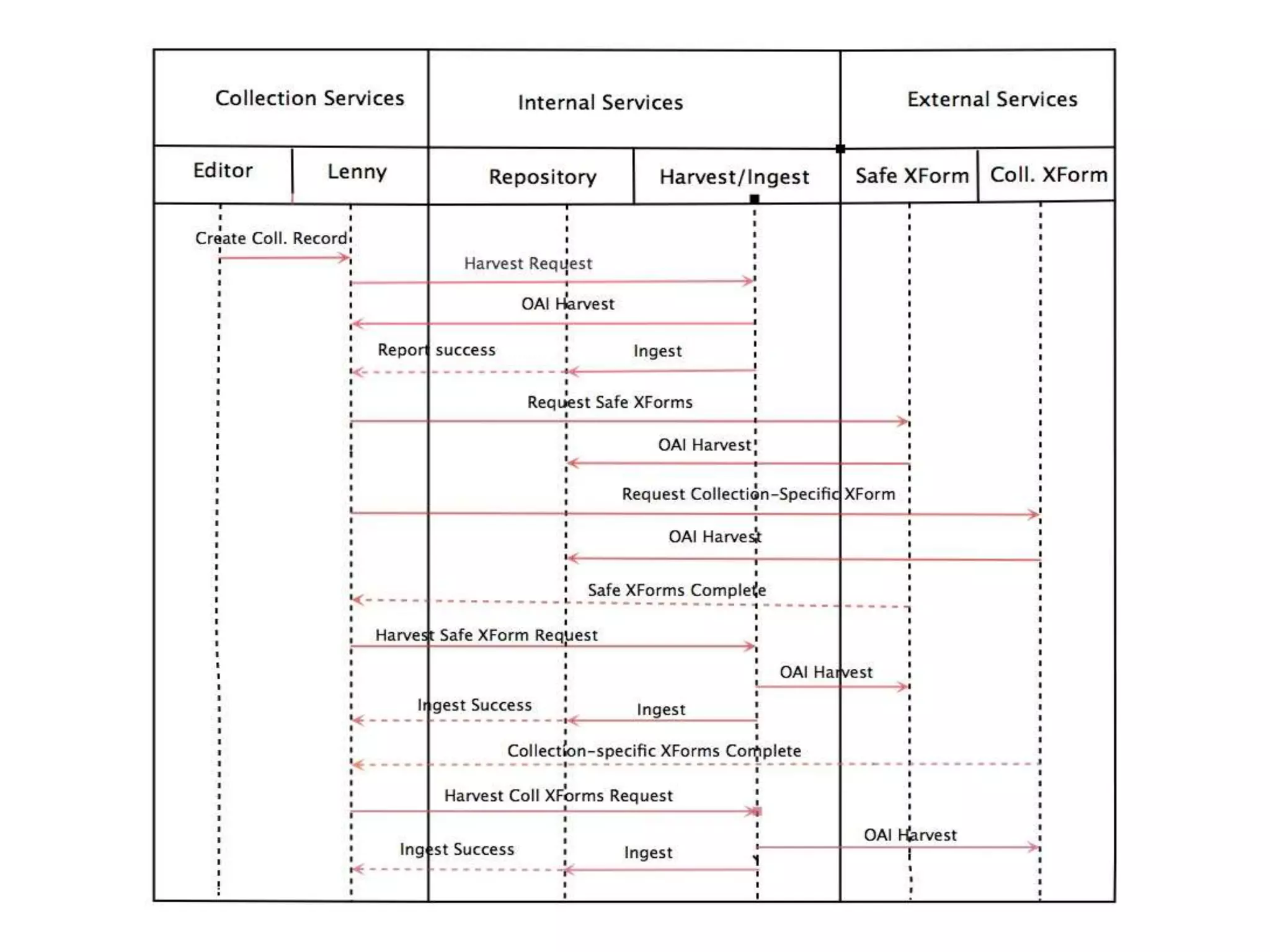



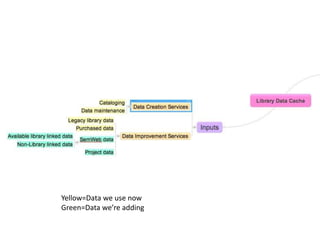
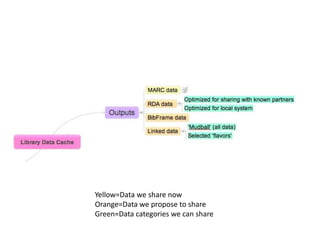
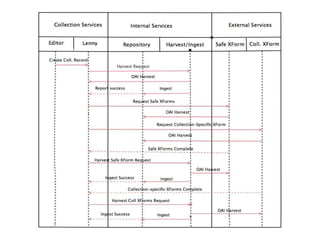
The document discusses managing metadata aggregation through linked open data (LOD). It outlines that current LOD projects only expose select data for experimentation and questions whether LOD can succeed on that basis alone without actual use. The document then proposes a workflow for managing metadata that involves obtaining data, storing it as statements in a cache rather than a database, evaluating and improving the data using specialized services, and publishing improved data in an ongoing and iterative process. It emphasizes developing automated and specialized services to continuously improve data quality and the use of a cache to manage metadata from multiple sources over time with detailed provenance.































































































