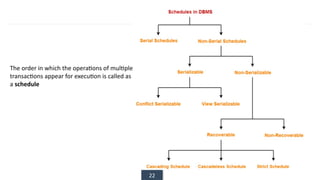
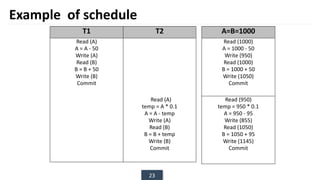
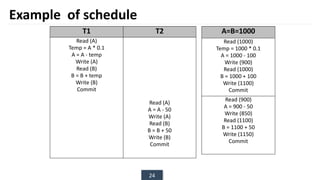
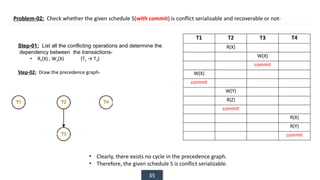
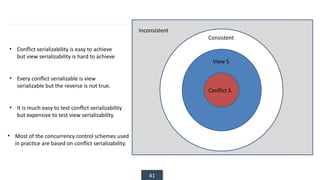
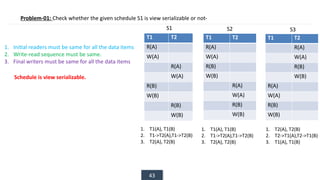
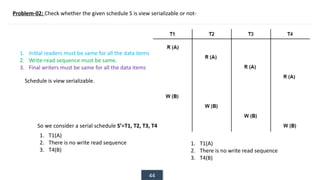
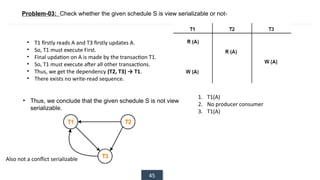
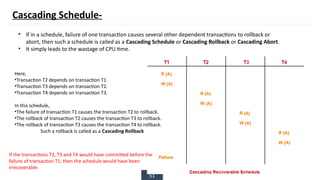
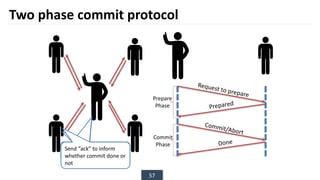
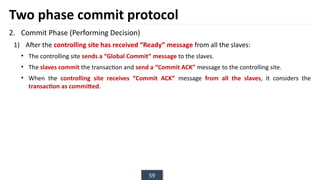
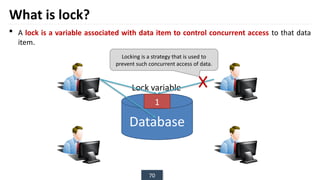
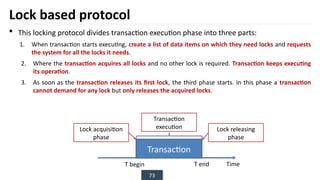
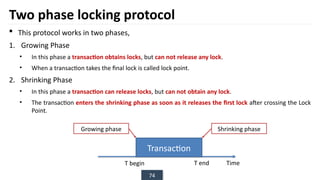
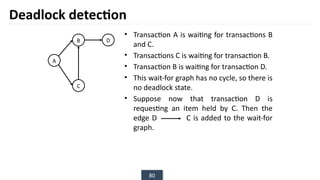
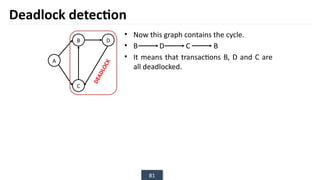
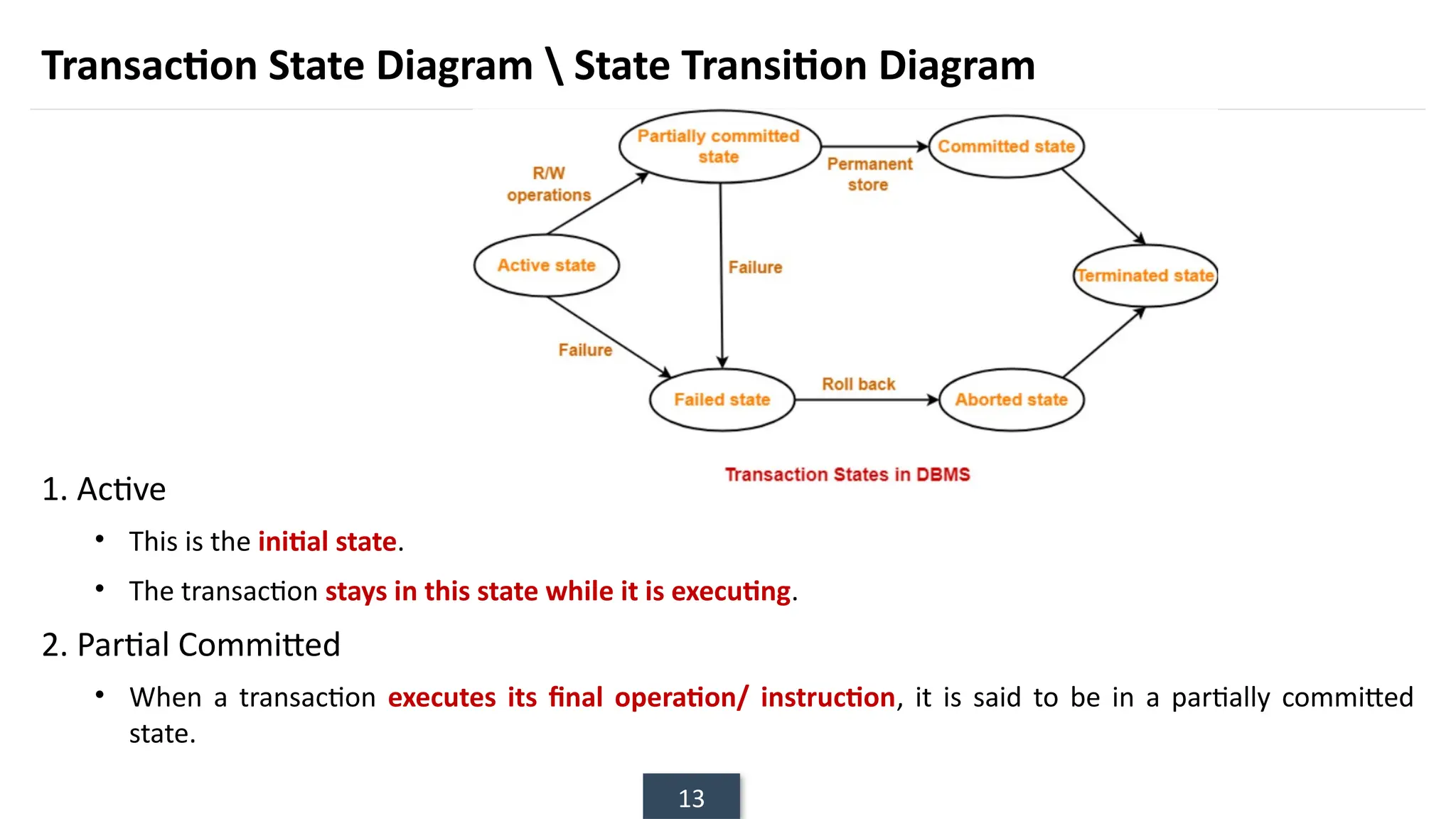
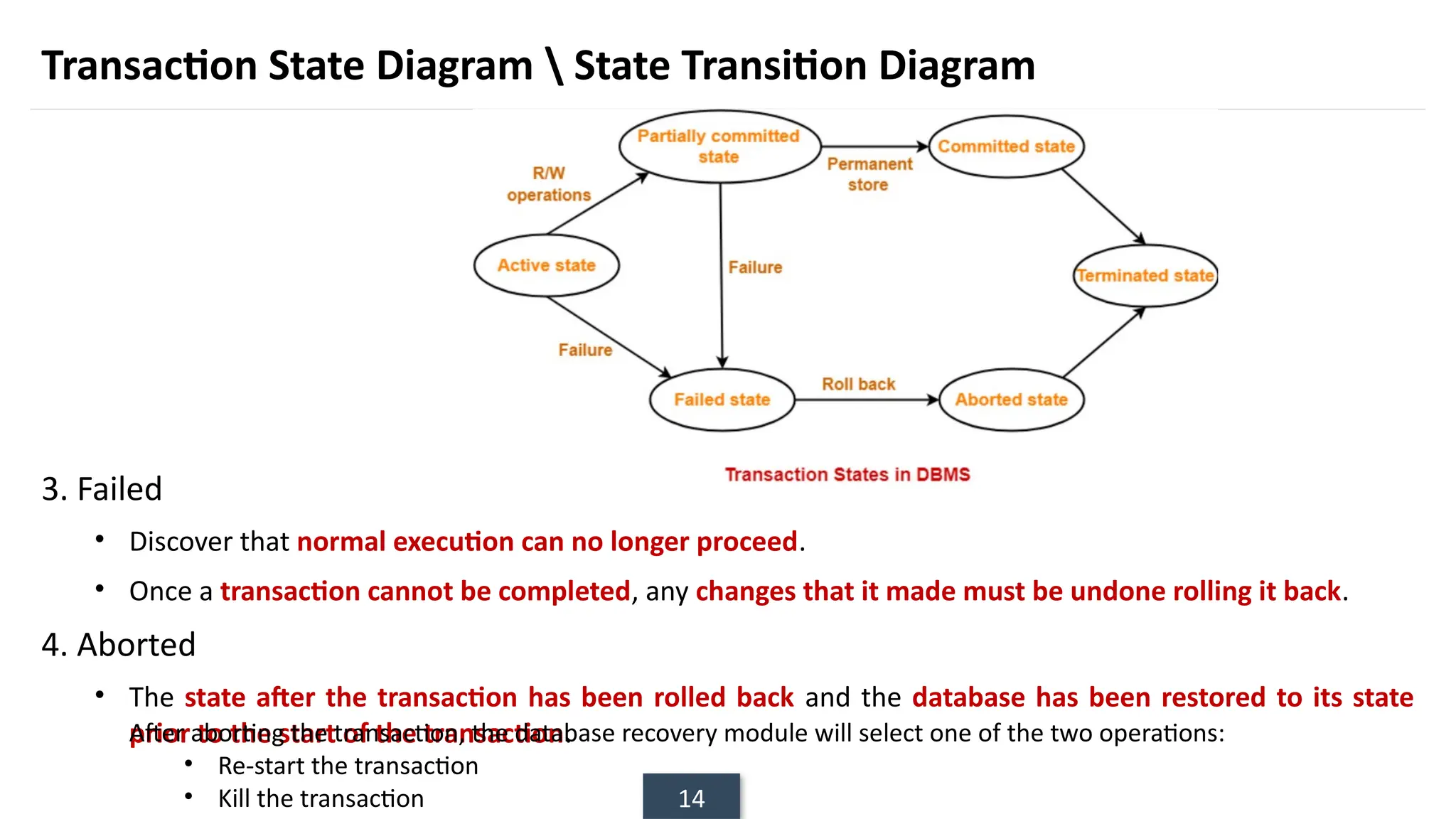
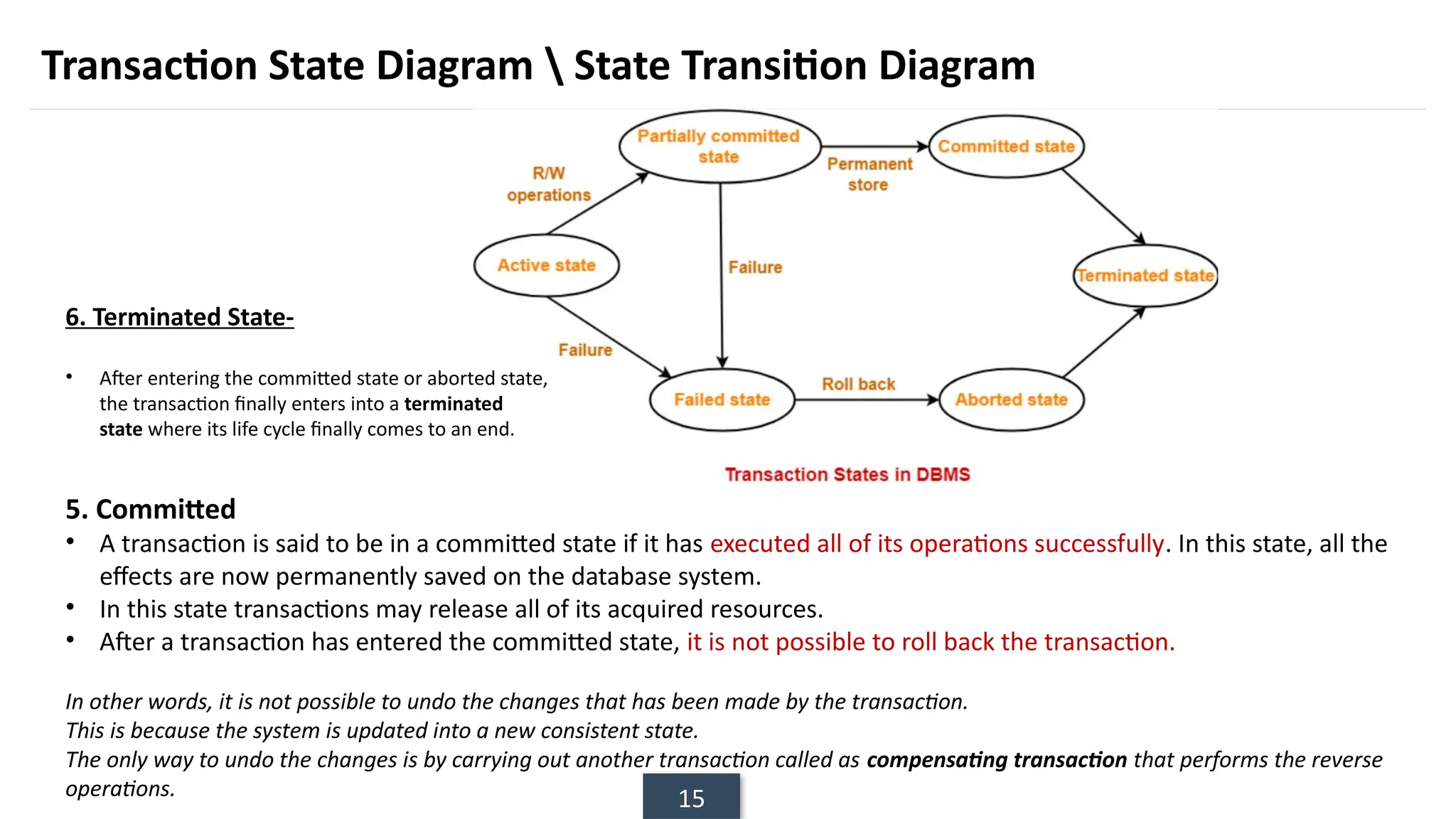
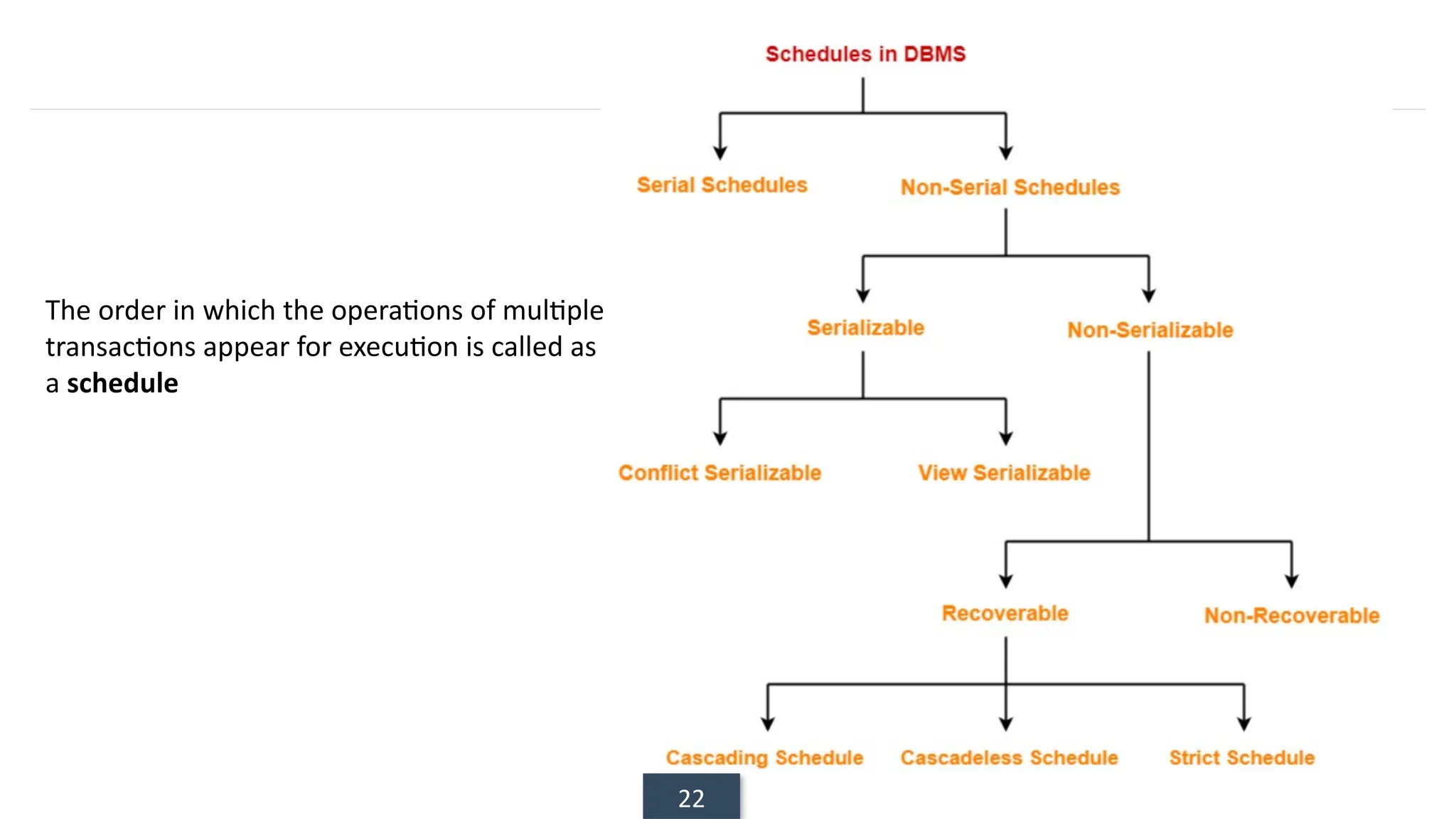
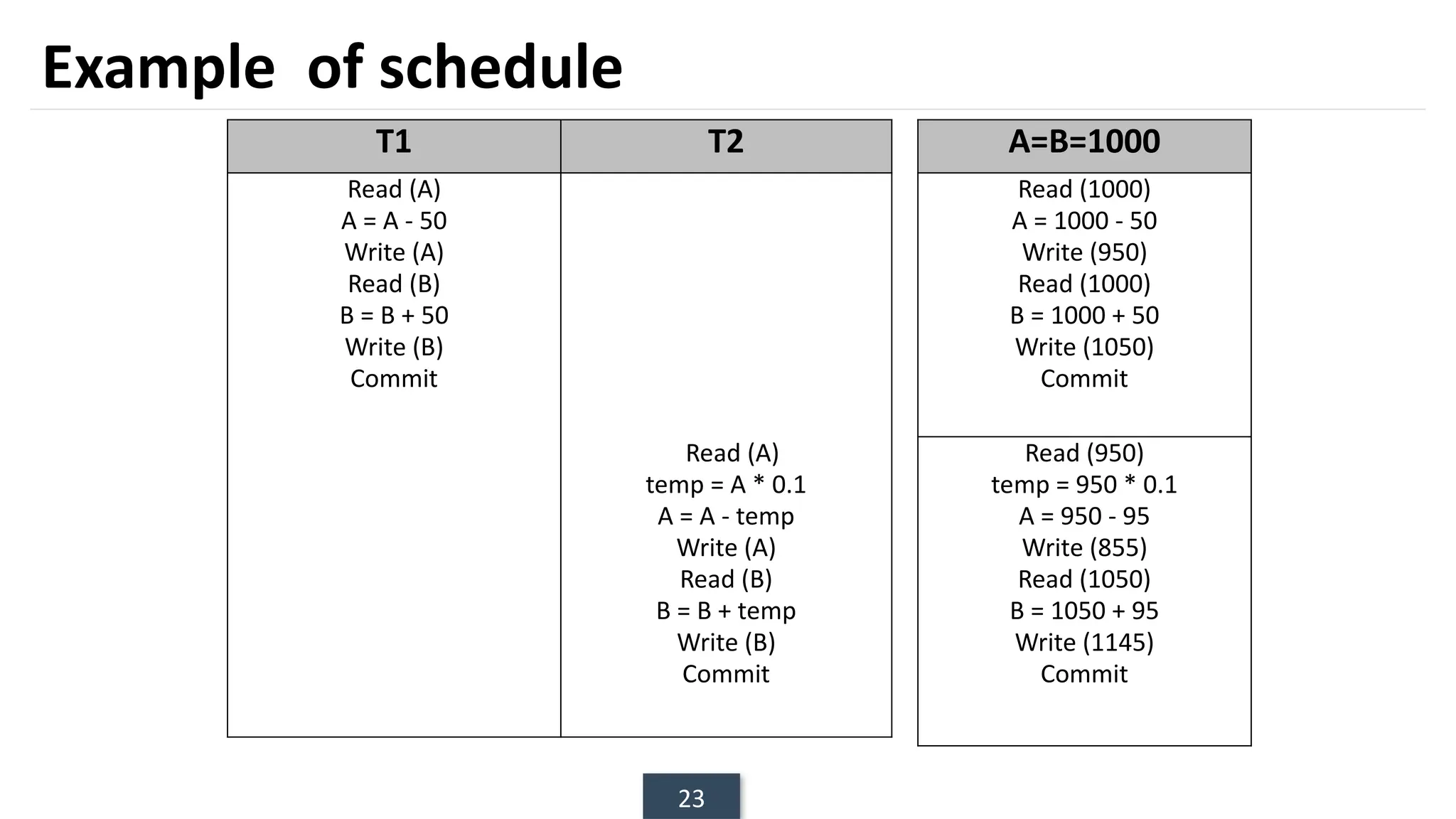
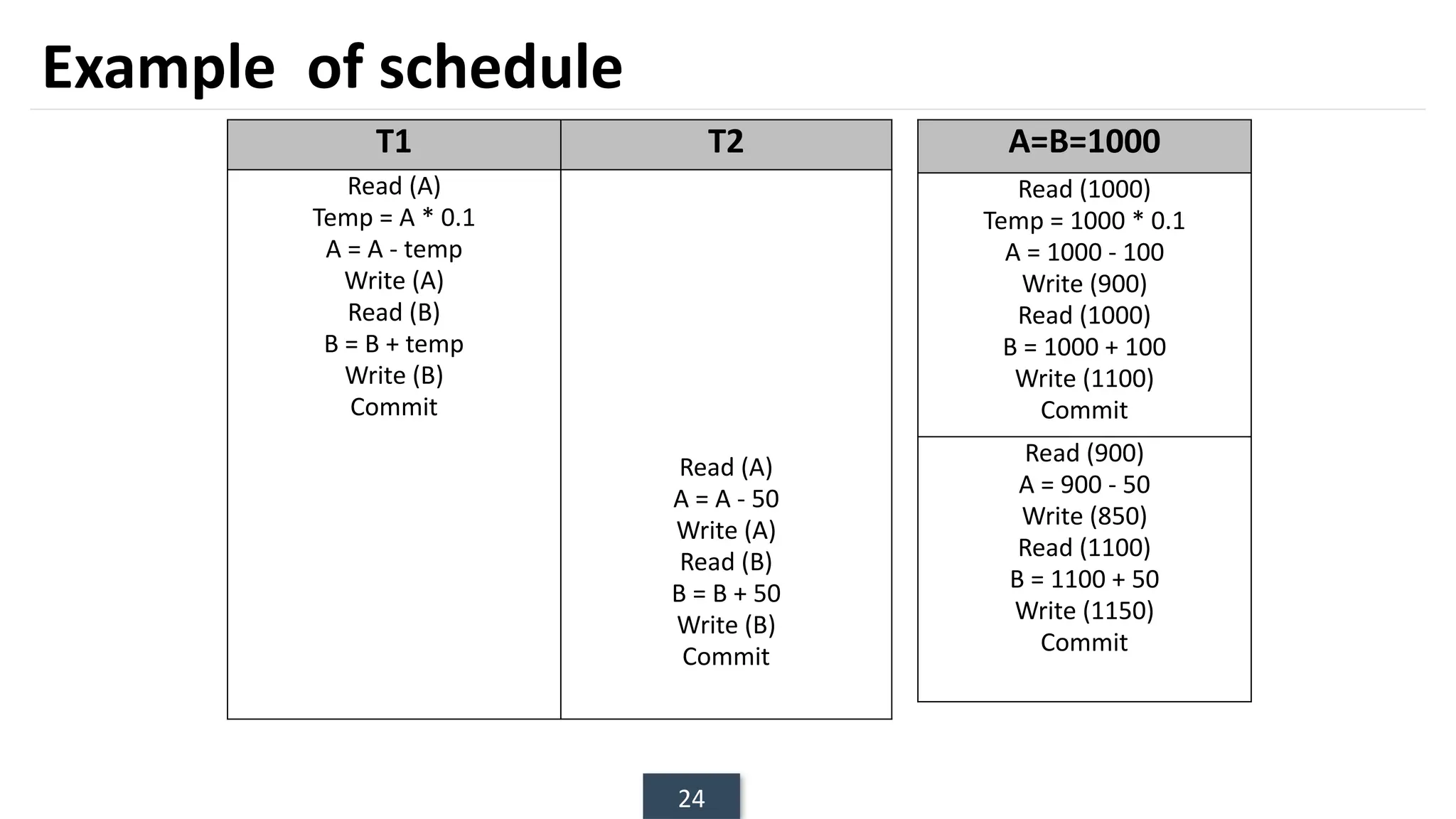
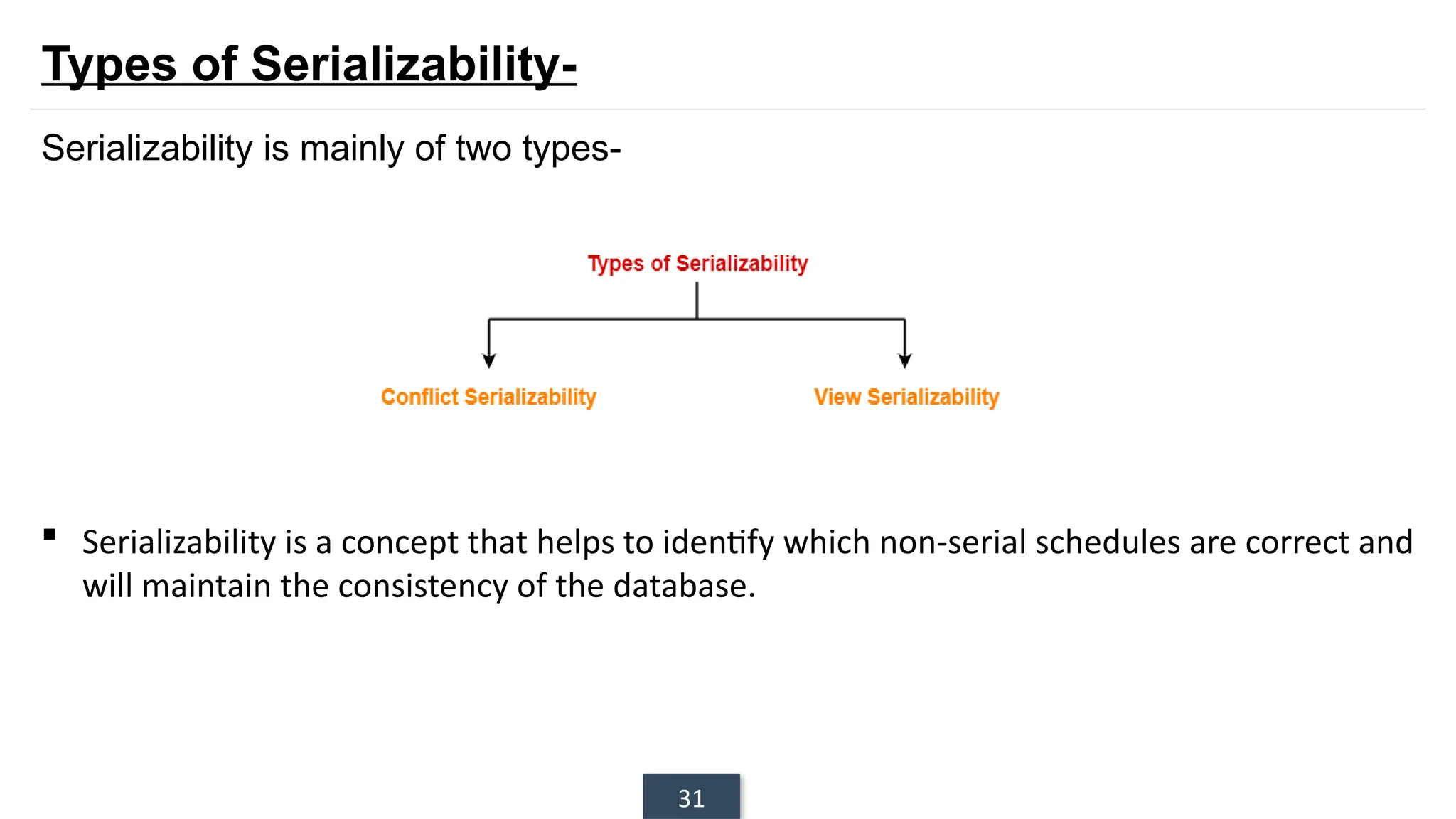
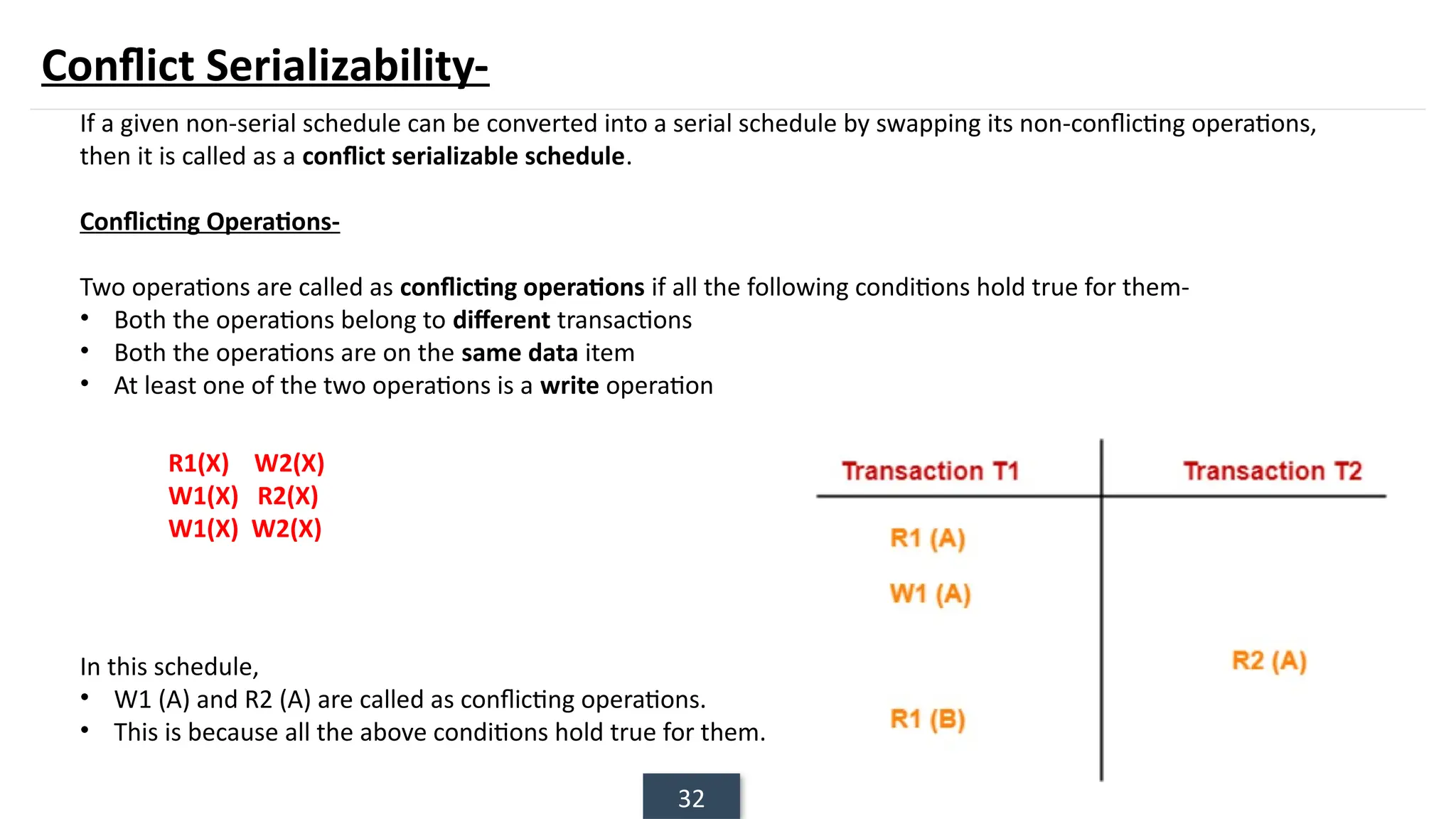
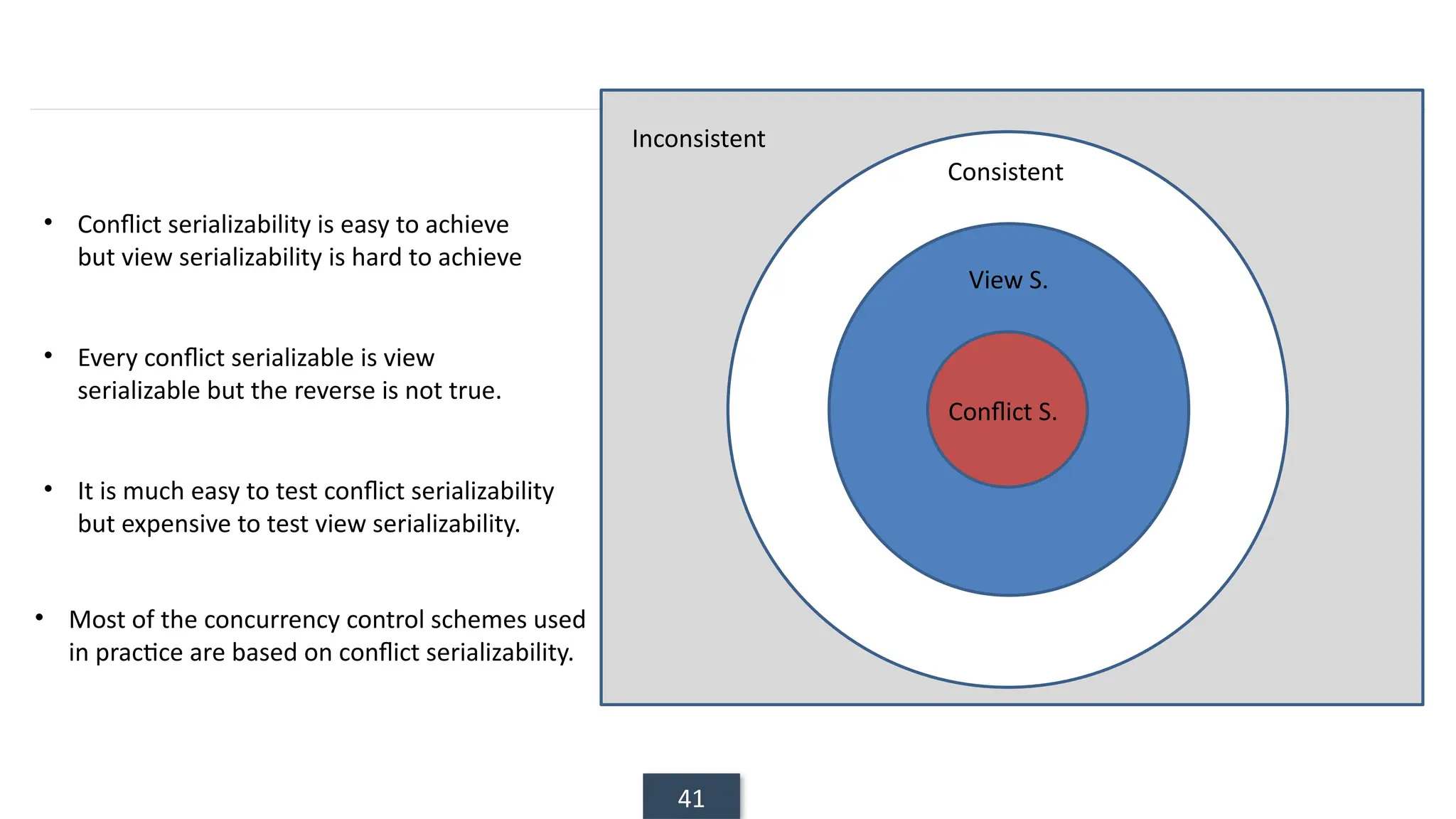
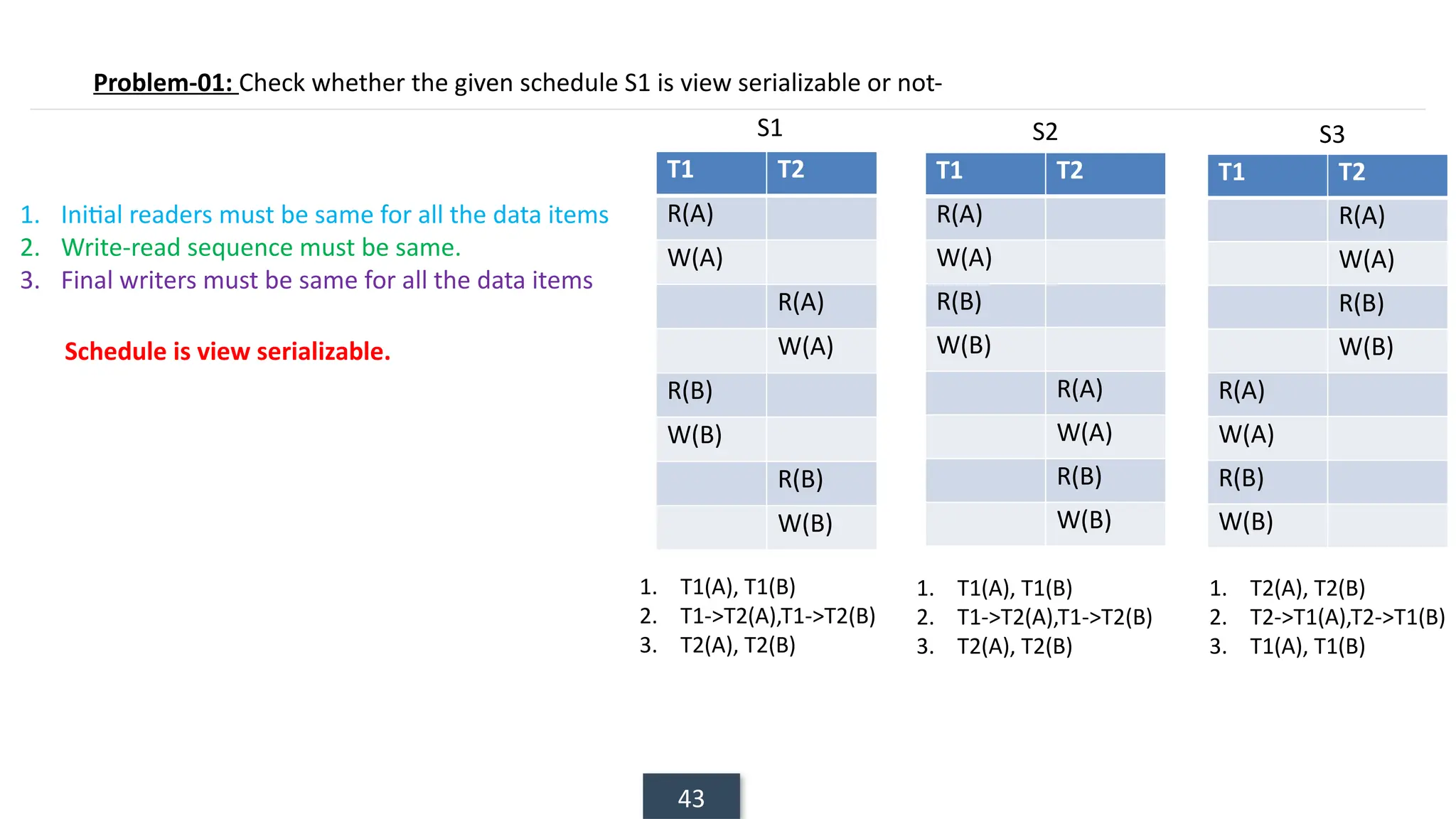
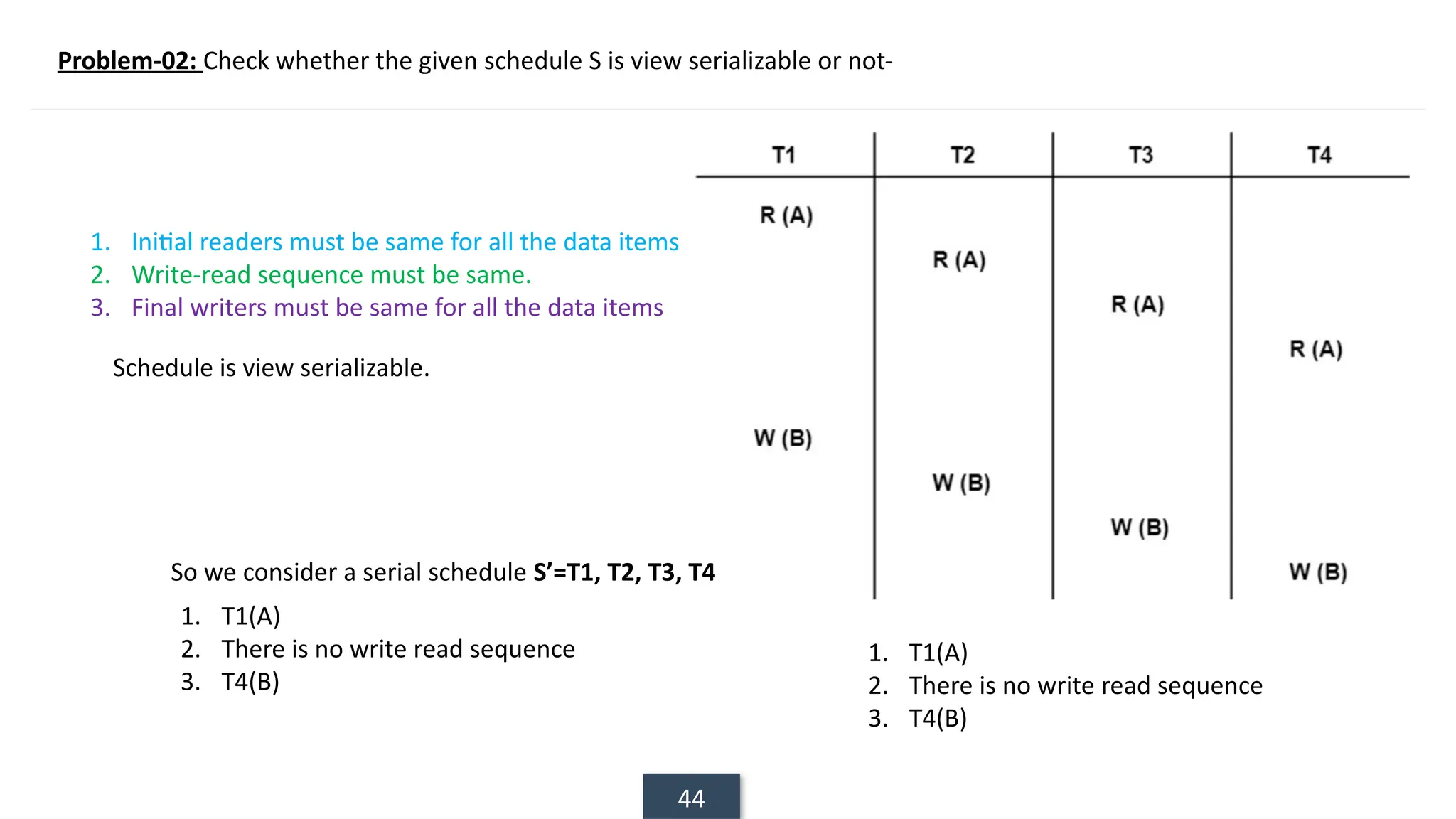
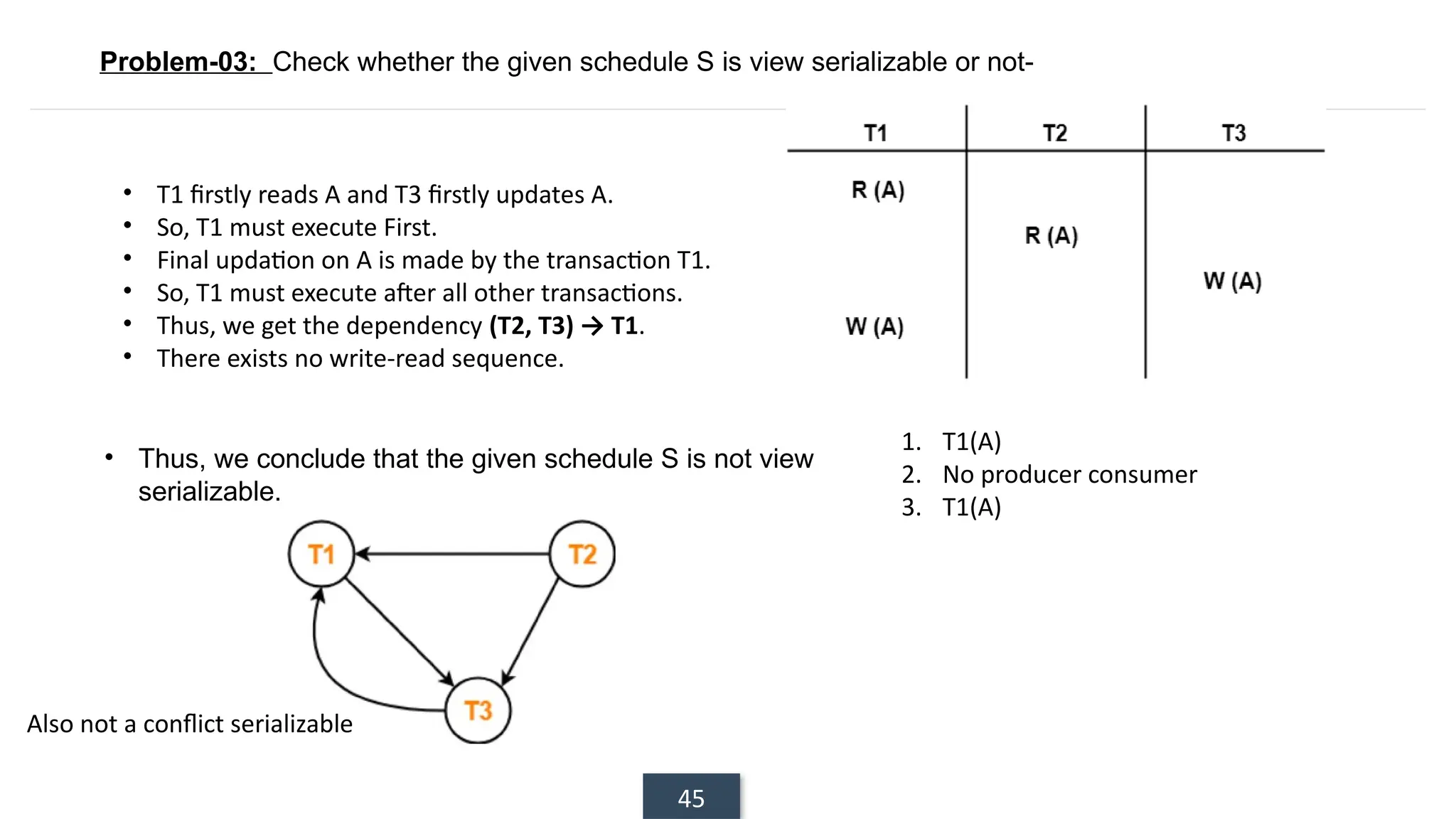
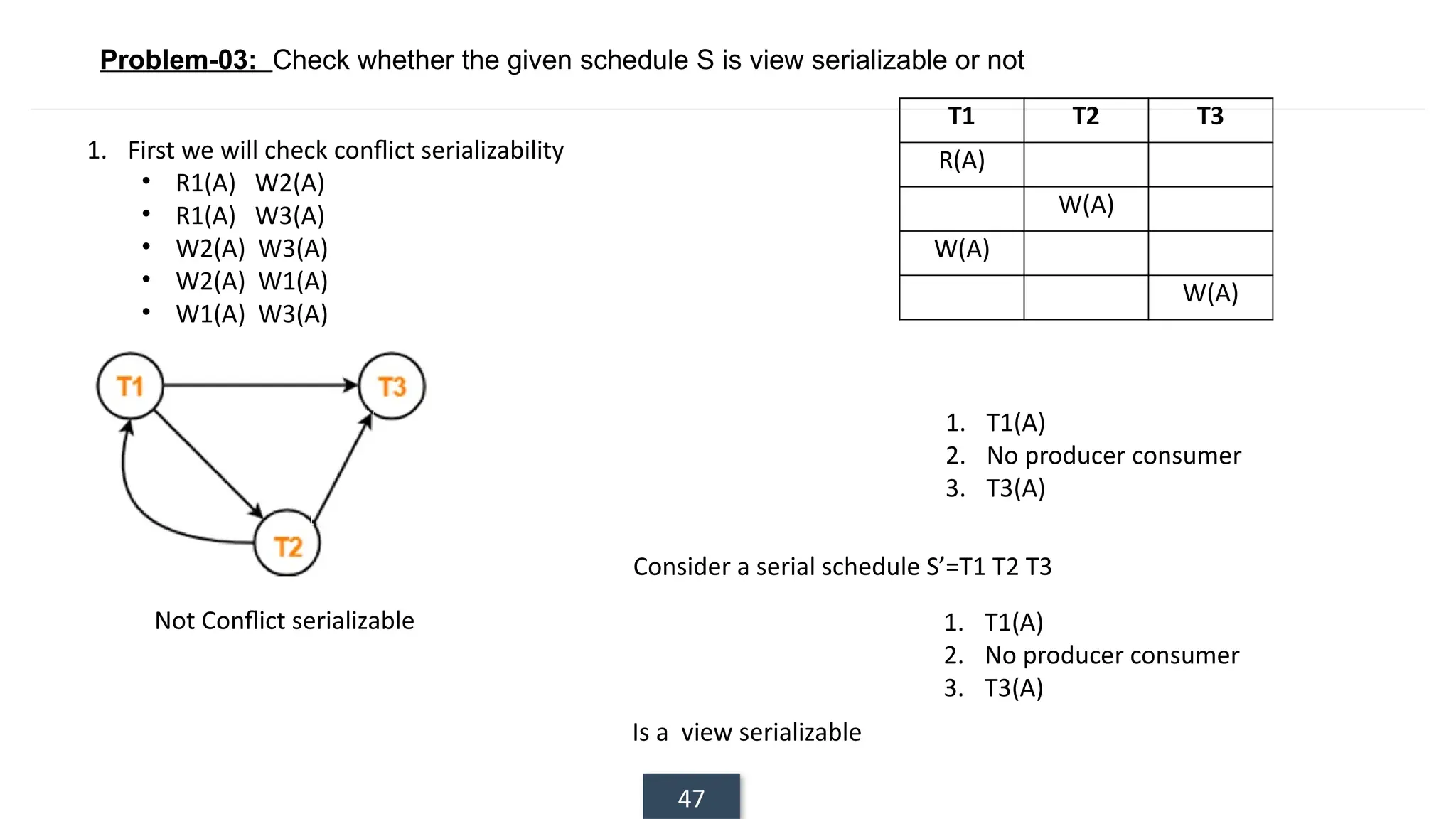
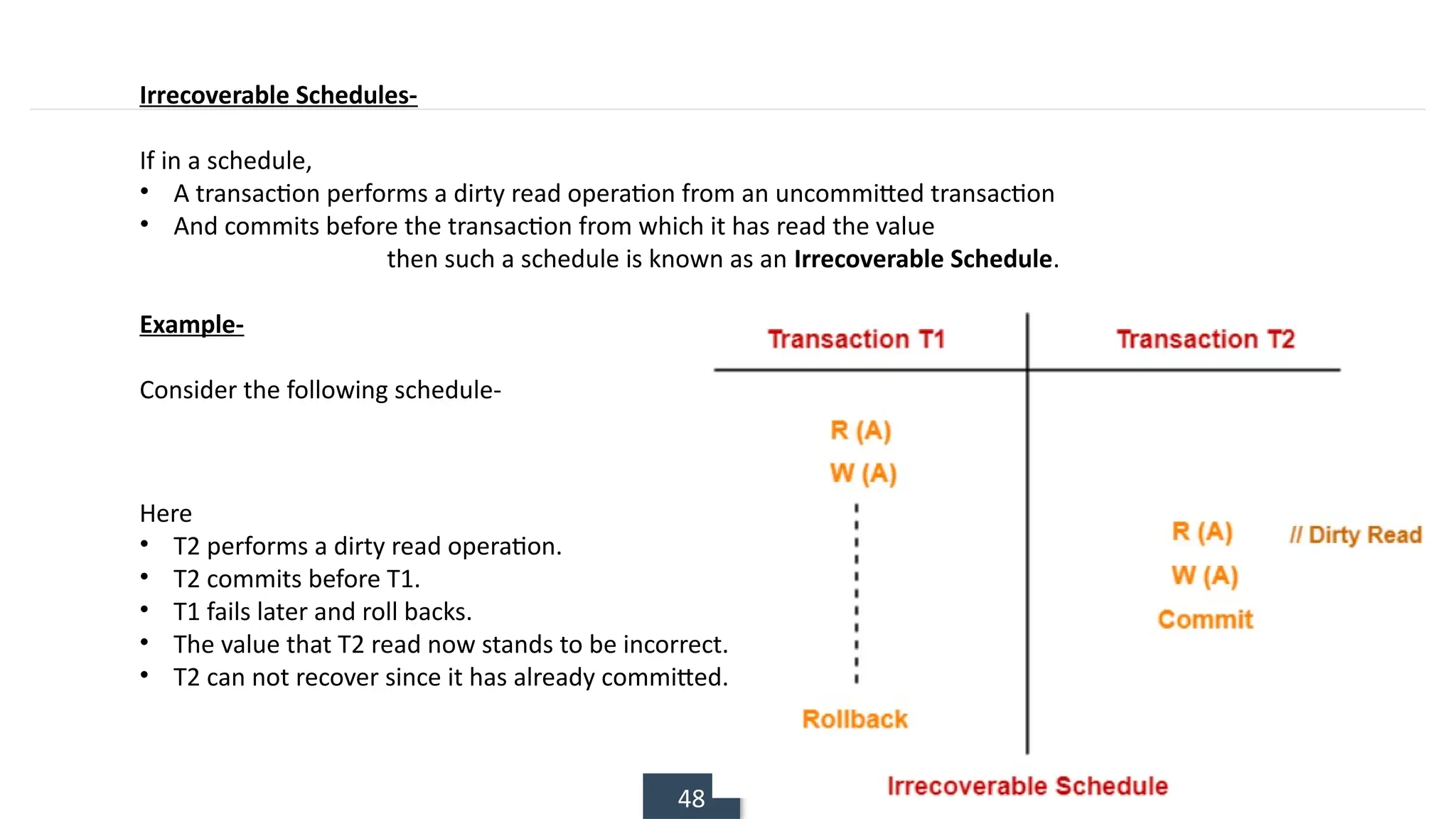
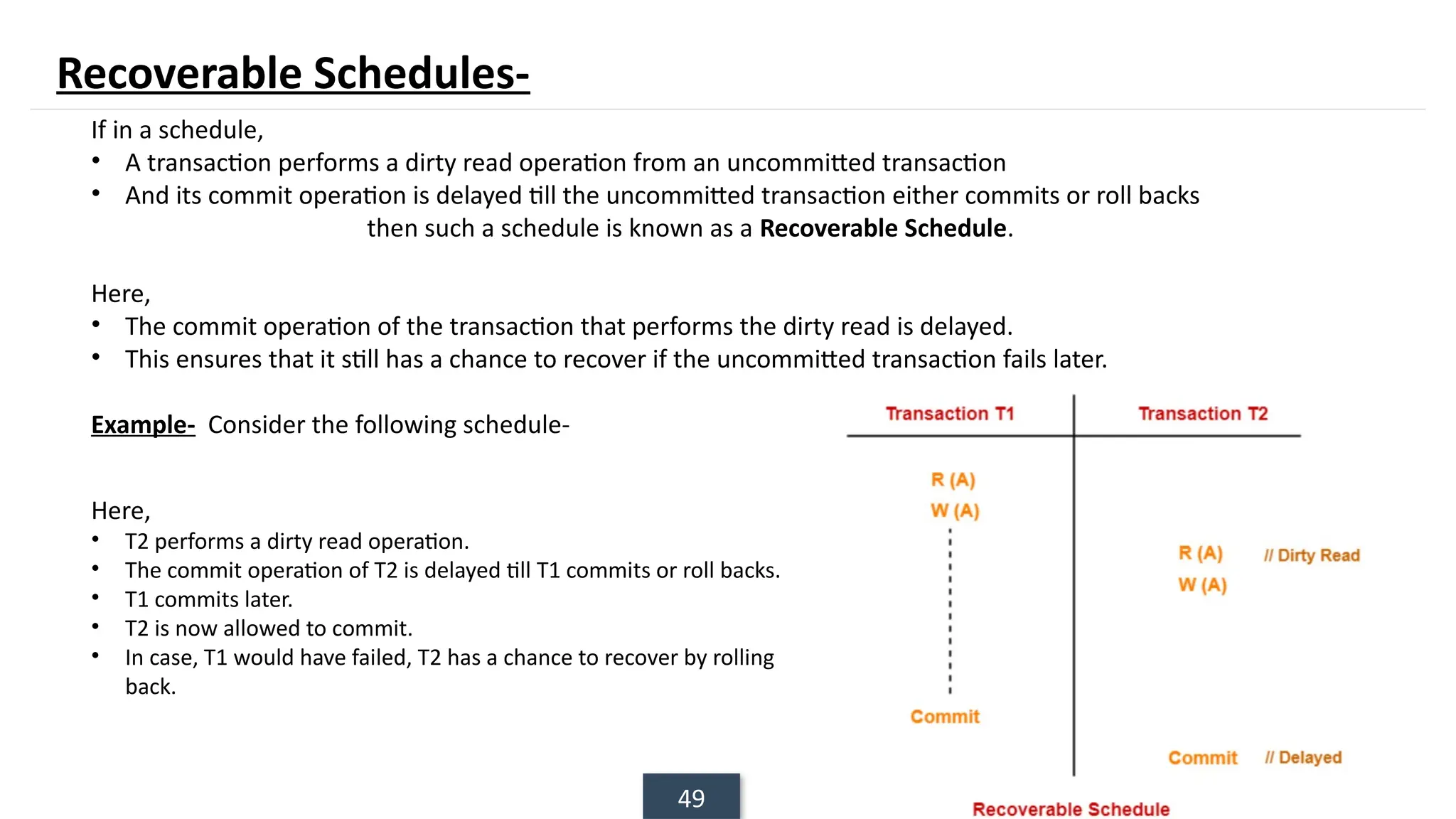
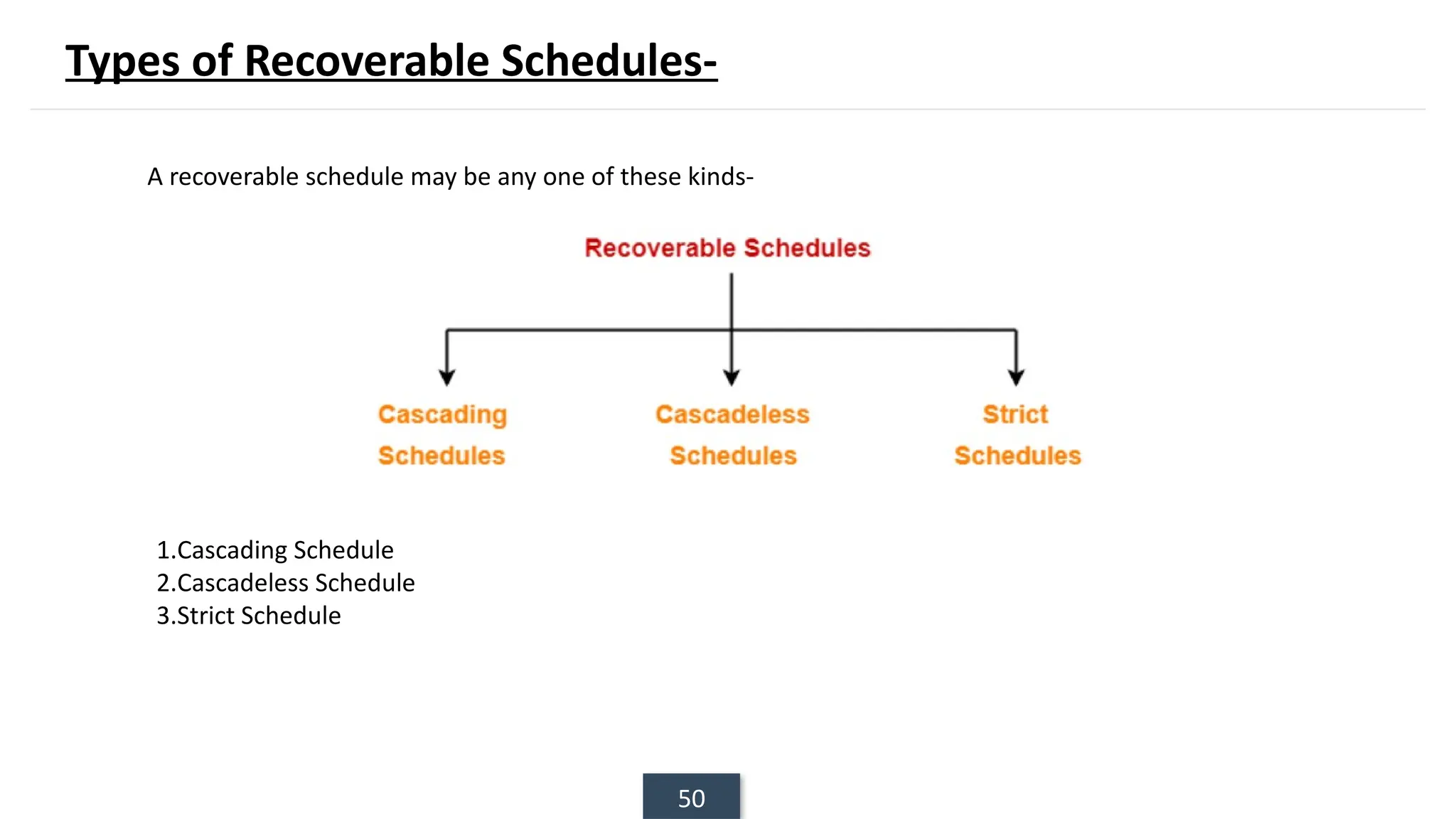
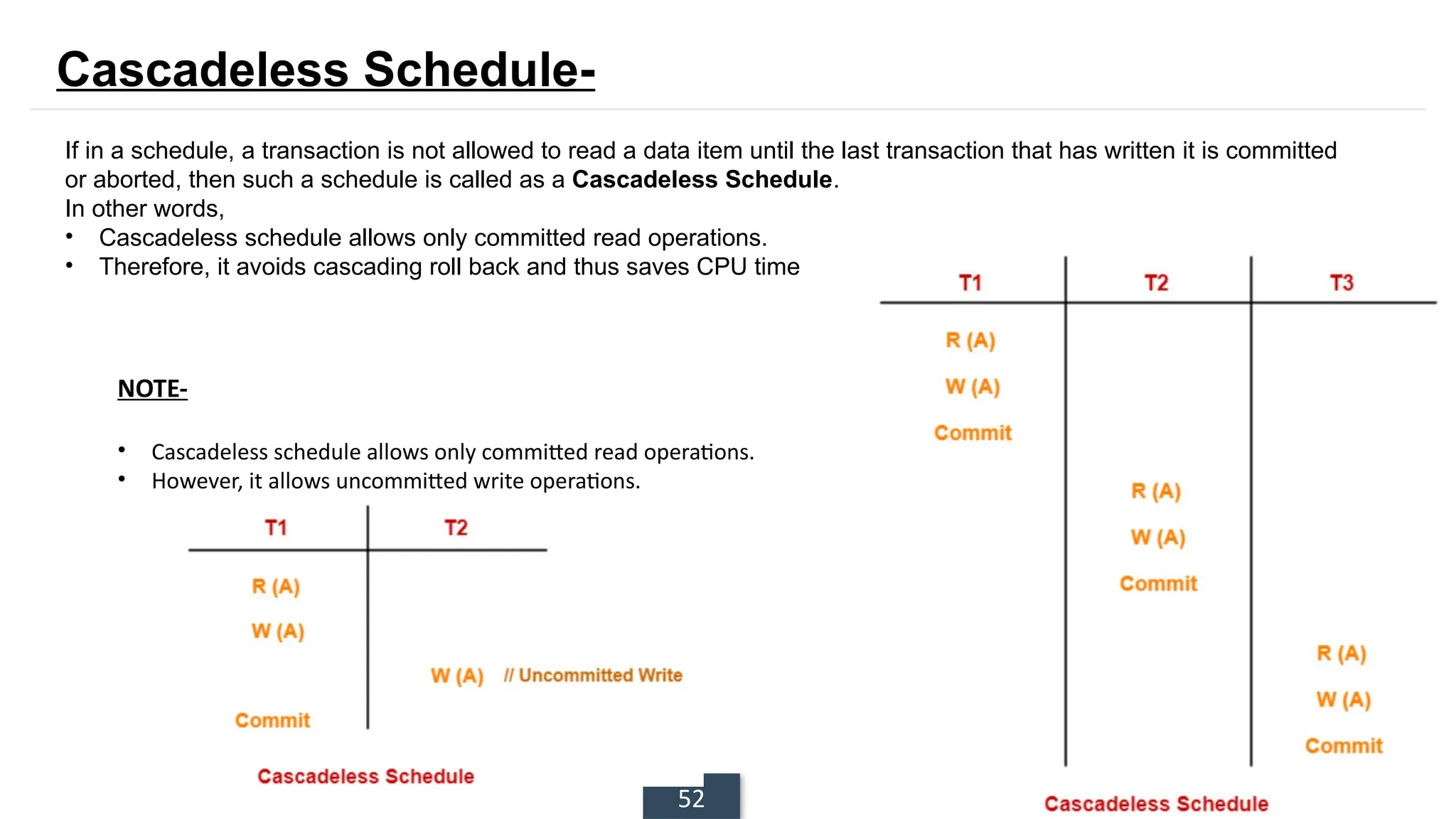
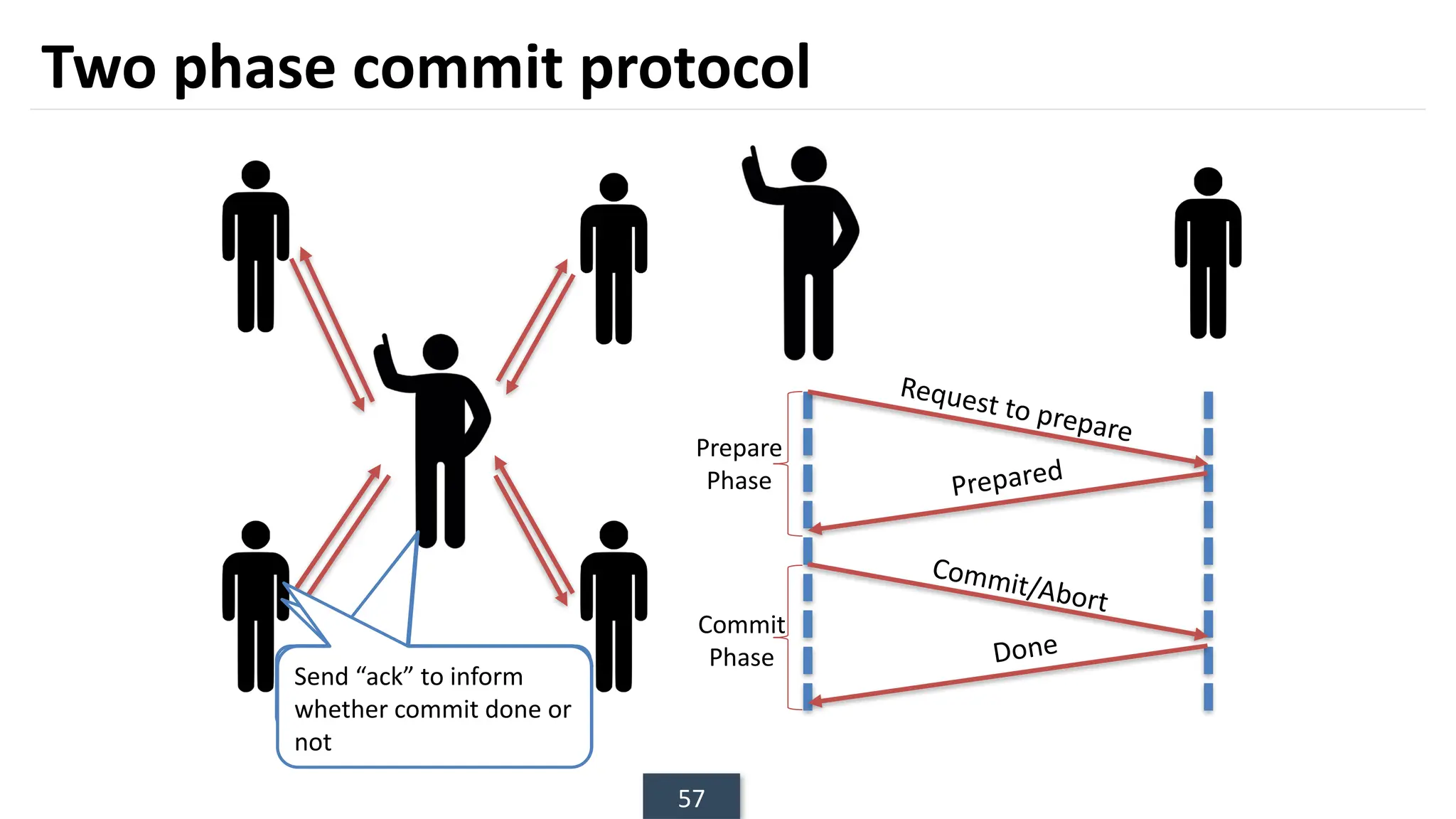
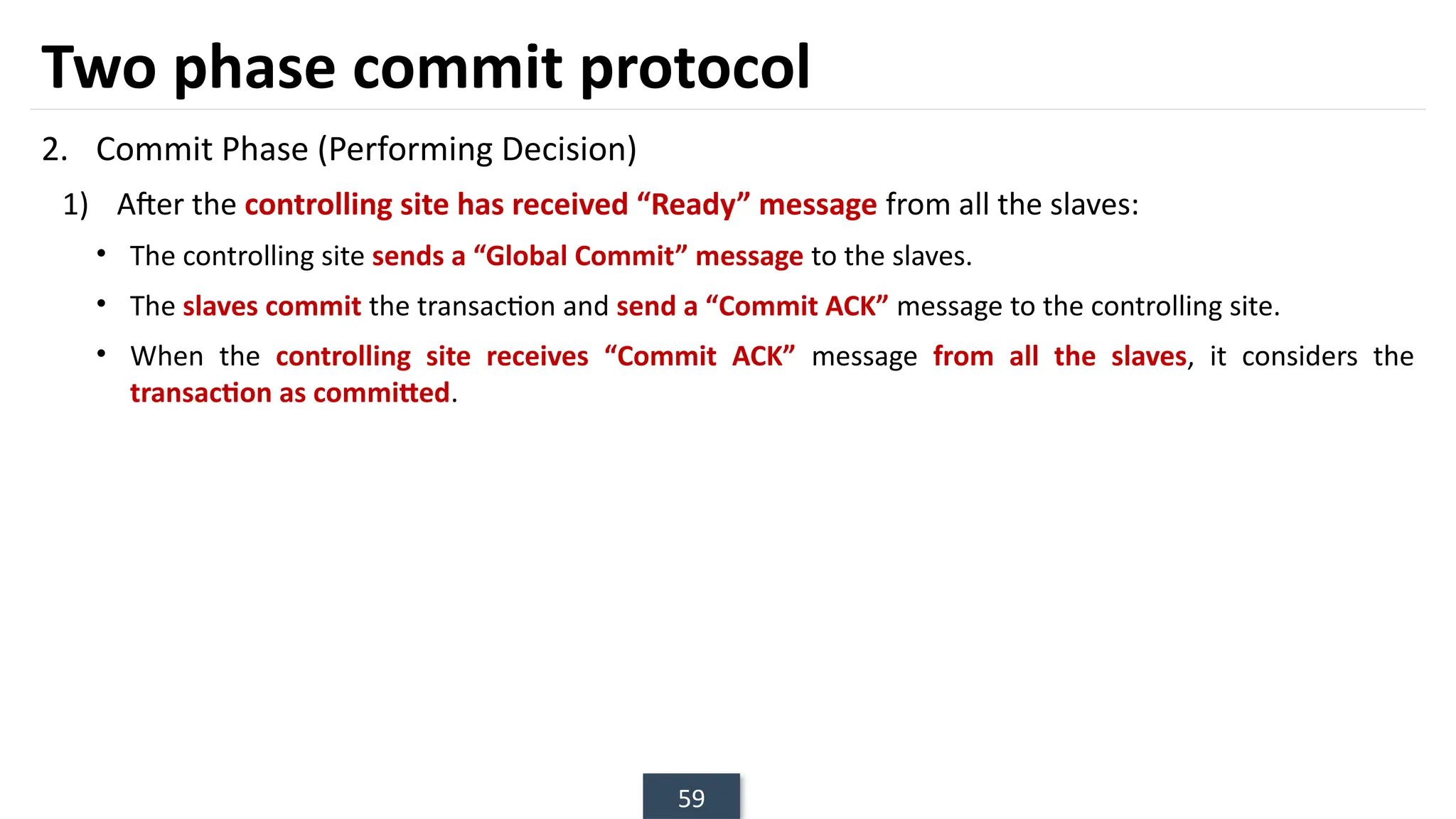
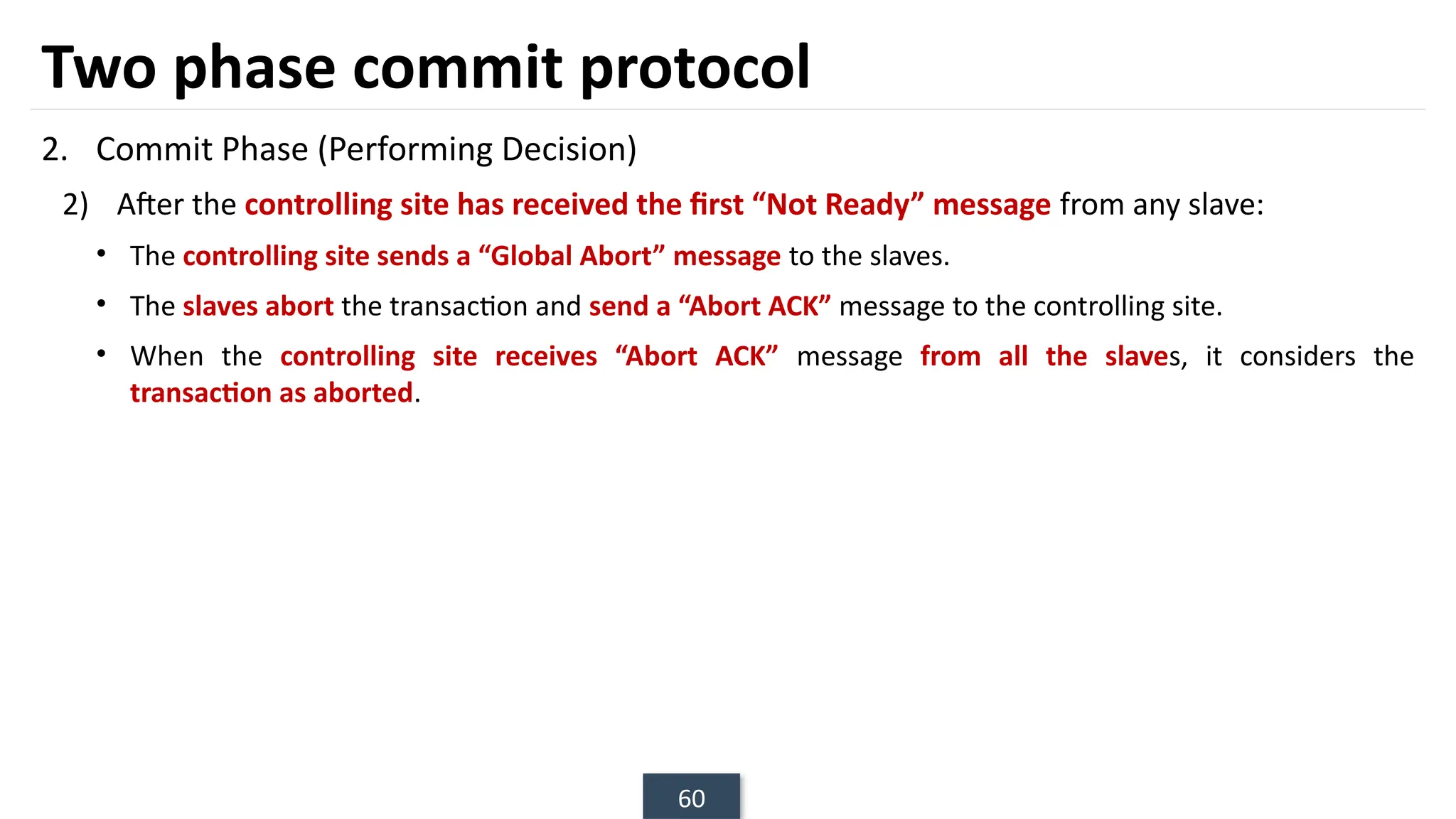
The document discusses transaction processing concepts including transaction properties, serializability, concurrent executions, and various concurrency problems. It details the ACID properties (Atomicity, Consistency, Isolation, Durability) of transactions, examples of transaction operations, and issues caused by concurrent execution such as dirty reads and lost updates. Additionally, it explains scheduling of transactions and the importance of serializability in maintaining database consistency.













































































































































![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
















