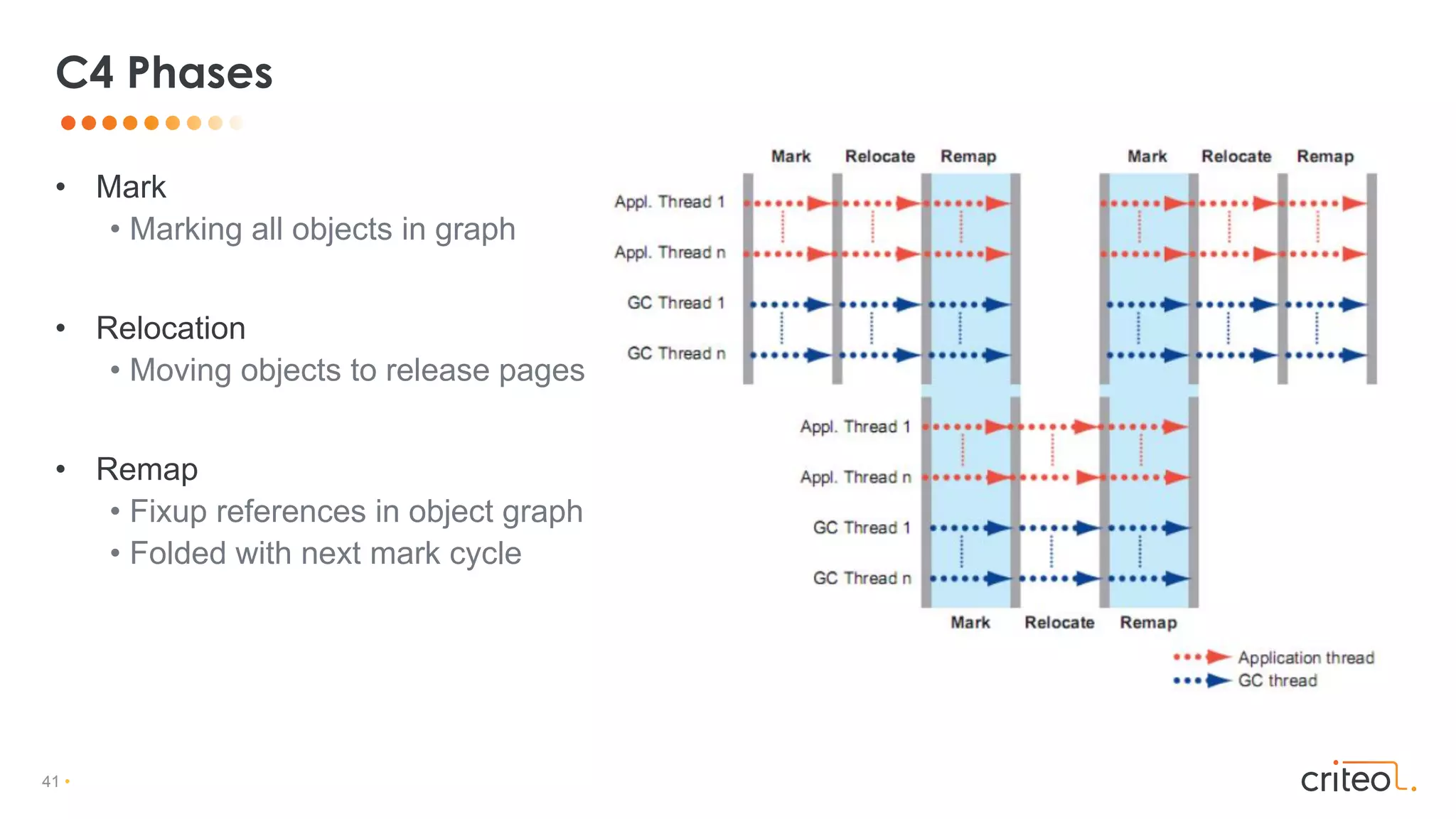
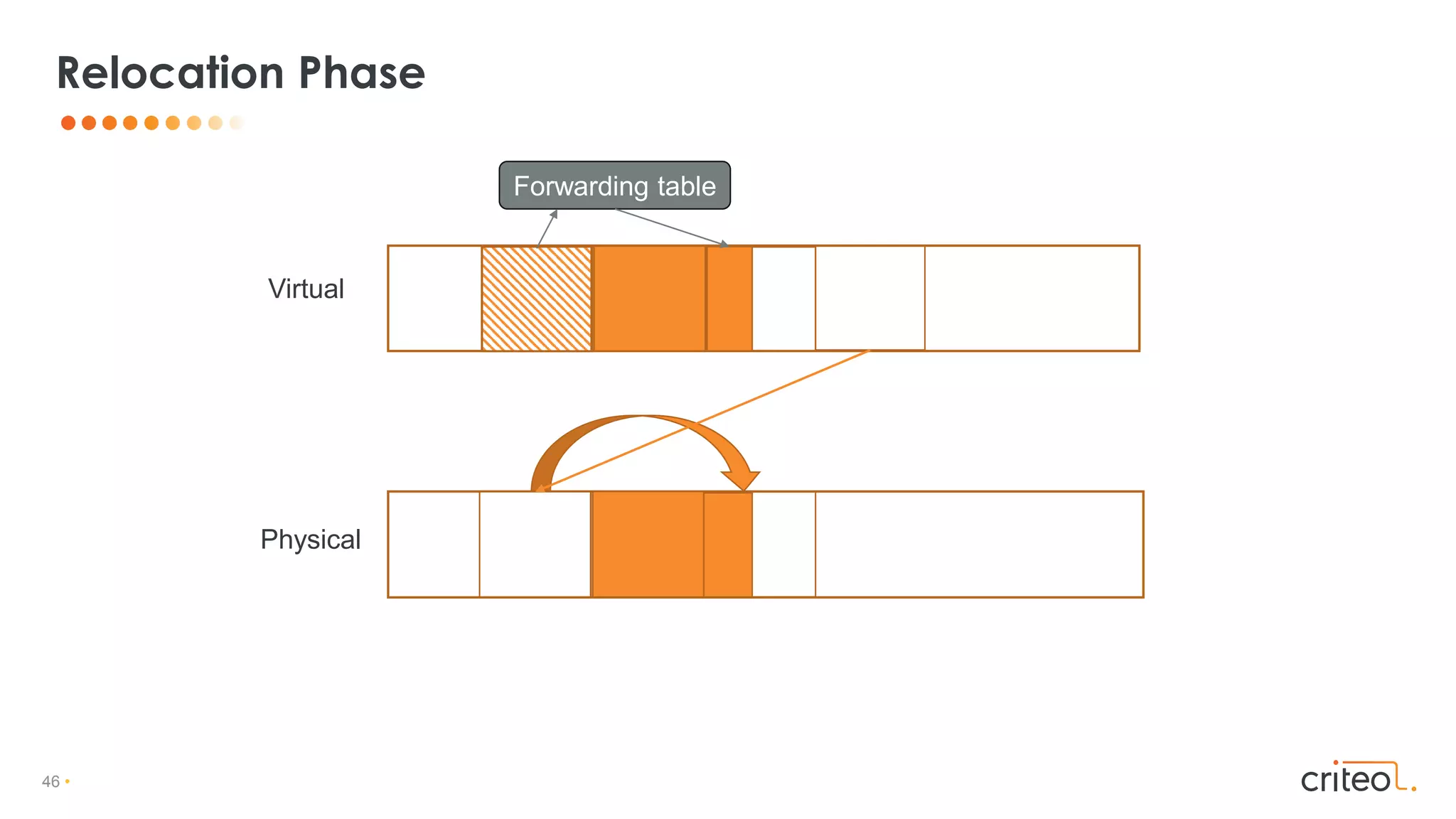
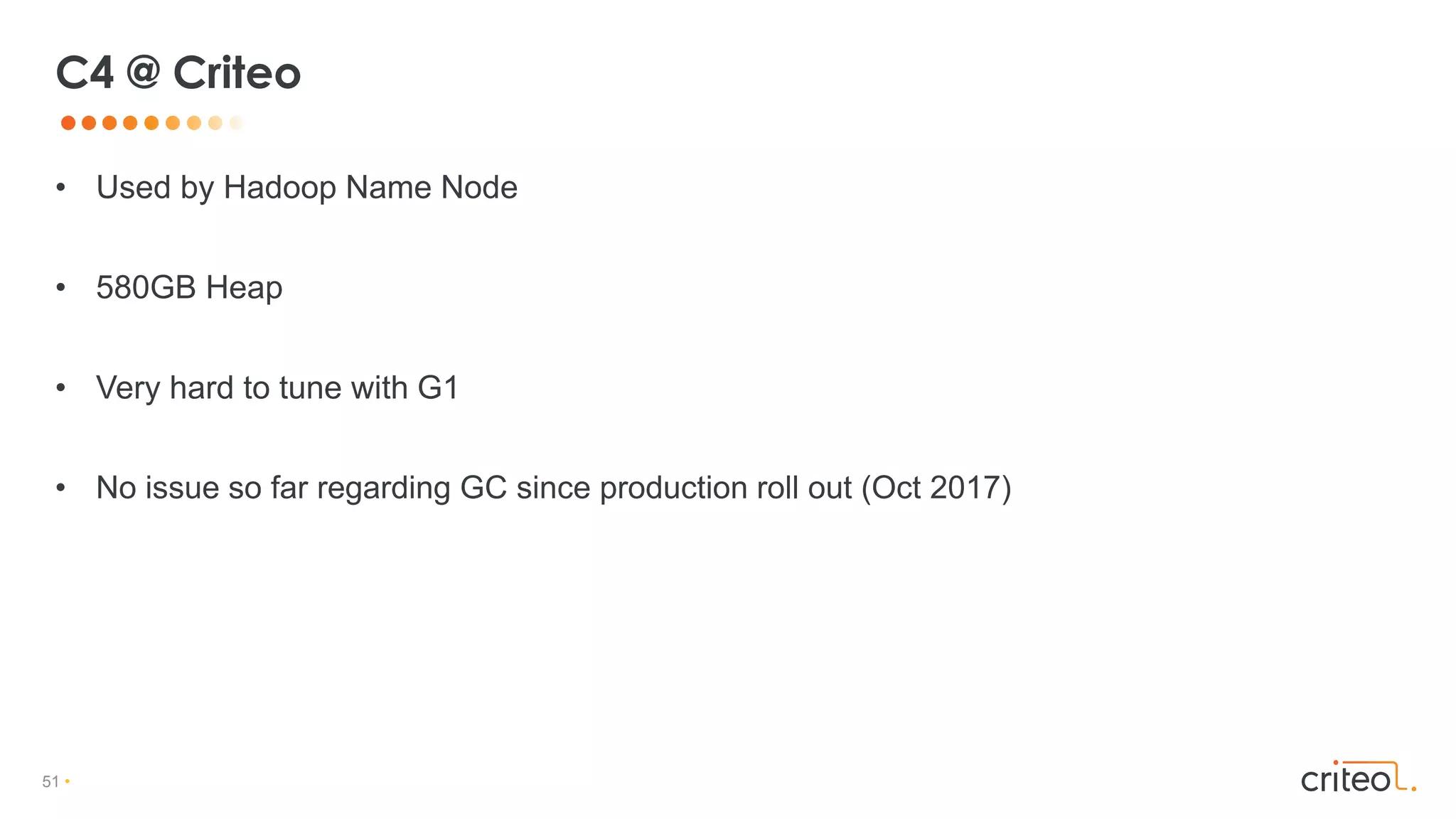
Download as PDF, PPTX


![6 •
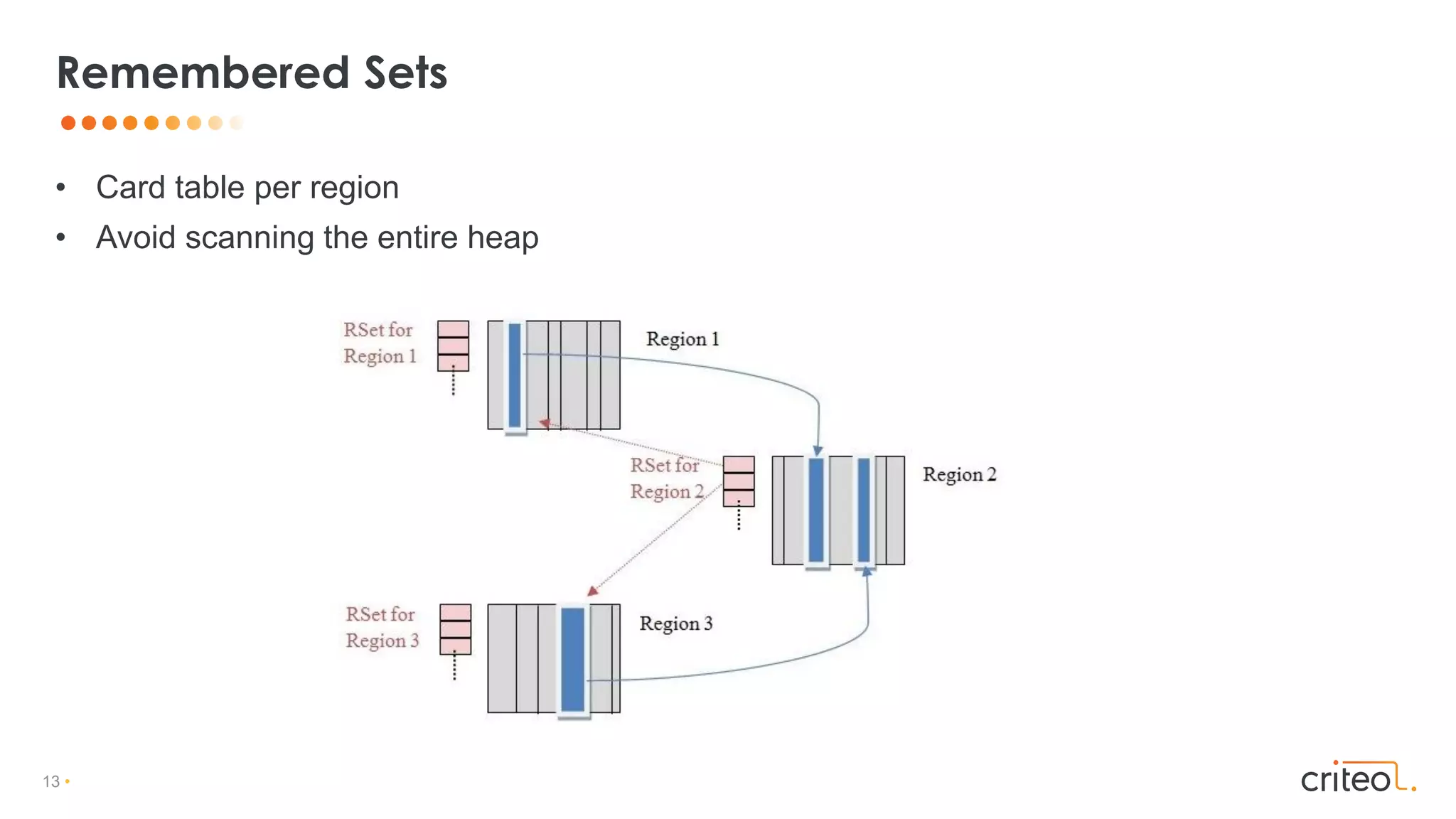
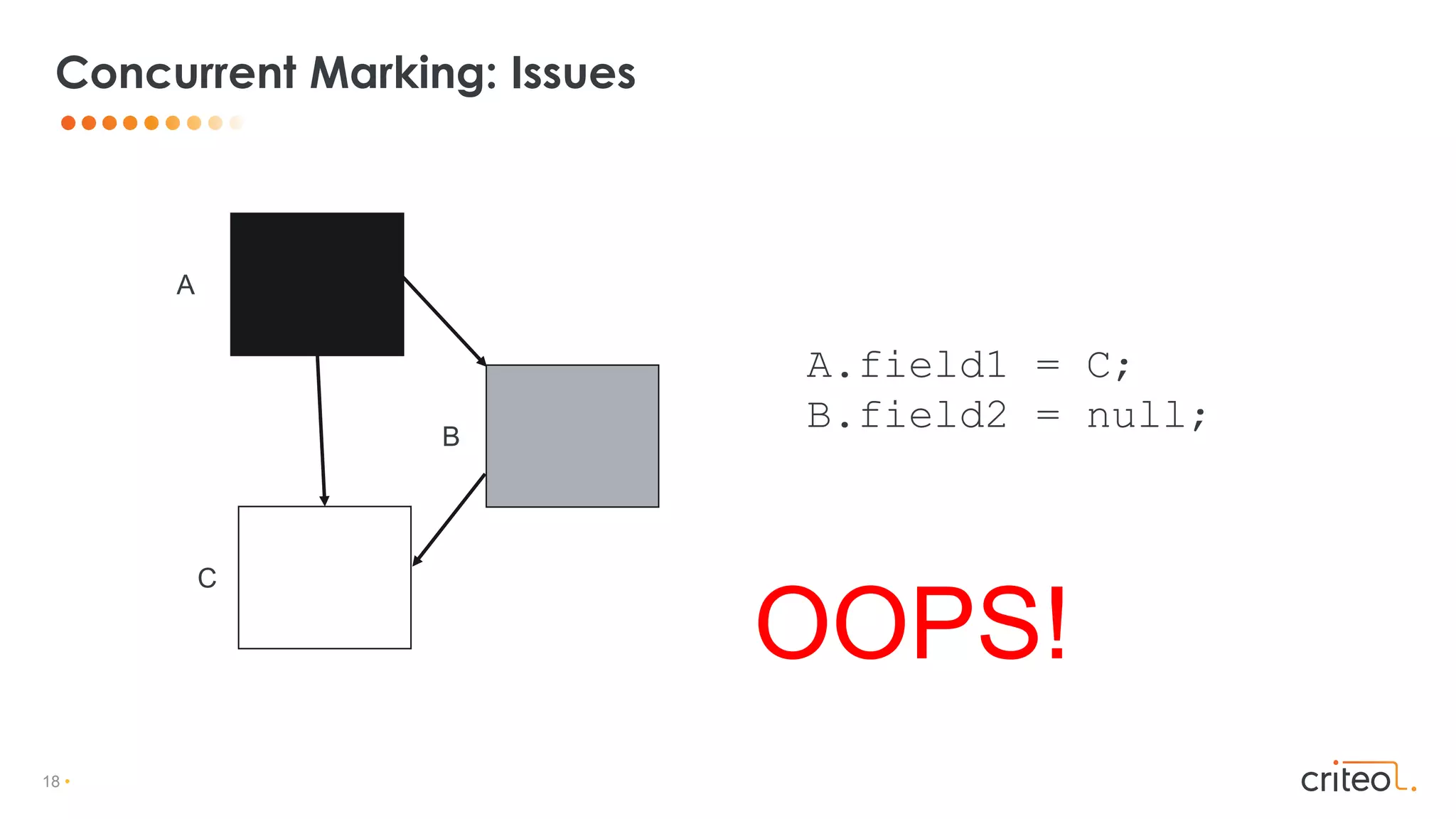
Card Table for references old -> young references
Write barrier to update card table on assignation
X.f = Y
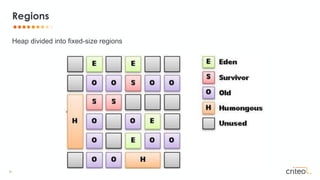
Card Table
Young 0 0 1
CARD_TABLE[&X >> 9] = 1
mov DWORD PTR [r10+0x6c],r8d
mov r11,r10
shr r11,0x9
mov r8d,0x2383000
mov BYTE PTR [r8+r11*1],r12b](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/85/Understanding-jvm-gc-advanced-6-320.jpg)



![14 •
• For each reference assignation (X.f = Y) we need to check:
• References (X & Y) are NOT in the same region
• Y is not null
• => enqueue for Remebered Set processing
• Refinement threads to process the queue
• Additional instructions added after assignation
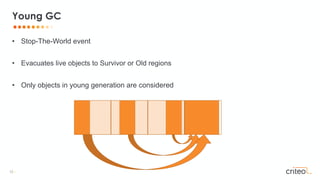
Remembered Sets: Post Write Barrier
if (!isInSameRegion(X, Y)
&& Y != null)
RSEnqueue(X)
mov DWORD PTR [rbp+0x74],r10d
mov r11,rbp
mov r8,r10
shl r8,0x3
xor r8,r11
shr r8,0x14
test r8,r8
je cont
test r10d,r10d
je cont
shr r11,0x9
movabs rcx,0x2965ecc3000
add rcx,r11
cmp BYTE PTR [rcx],0x20
je cont
mov r10,QWORD PTR [r15+0x70]
mov r11,QWORD PTR [r15+0x80]
lock add DWORD PTR [rsp-0x40],0x0
cmp BYTE PTR [rcx],0x0
je cont
mov BYTE PTR [rcx],0x0
test r10,r10
jne 0x000002965edc62bc
mov rdx,r15
movabs r10,0x7ffac2febc30
call r10
jmp cont
mov QWORD PTR [r11+r10*1-0x8],rcx
add r10,0xfffffffffffffff8
mov QWORD PTR [r15+0x70],r10](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/85/Understanding-jvm-gc-advanced-14-320.jpg)


![19 •
• 2 ways to ensure not missing any marking
• For SATB, Pre-Write Barriers, recording object for marking
• SATB barrier is only active when Marking is on (global state)
Concurrent Marking: Resolving misses
if (SATB_WriteBarrier) {
if (X.f != null)
SATB_enqueue(X.f);
}
cmp BYTE PTR [r15+0x30],0x0
jne 0x000002965edc62e5
[...]
mov r11d,DWORD PTR [rbp+0x74]
test r11d,r11d
je 0x000002965edc6253
mov r10,QWORD PTR [r15+0x38]
mov rcx,r11
shl rcx,0x3
test r10,r10
je 0x000002965edc6318
mov r11,QWORD PTR [r15+0x48]
mov QWORD PTR [r11+r10*1-0x8],rcx
add r10,0xfffffffffffffff8
mov QWORD PTR [r15+0x38],r10
jmp 0x000002965edc6253
mov rdx,r15
movabs r10,0x7ffac2febc50
call r10
jmp 0x000002965edc6253](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/85/Understanding-jvm-gc-advanced-19-320.jpg)








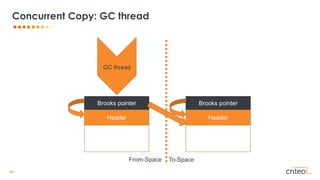
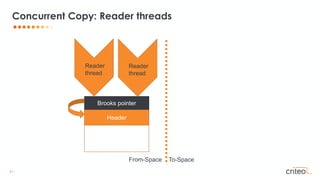
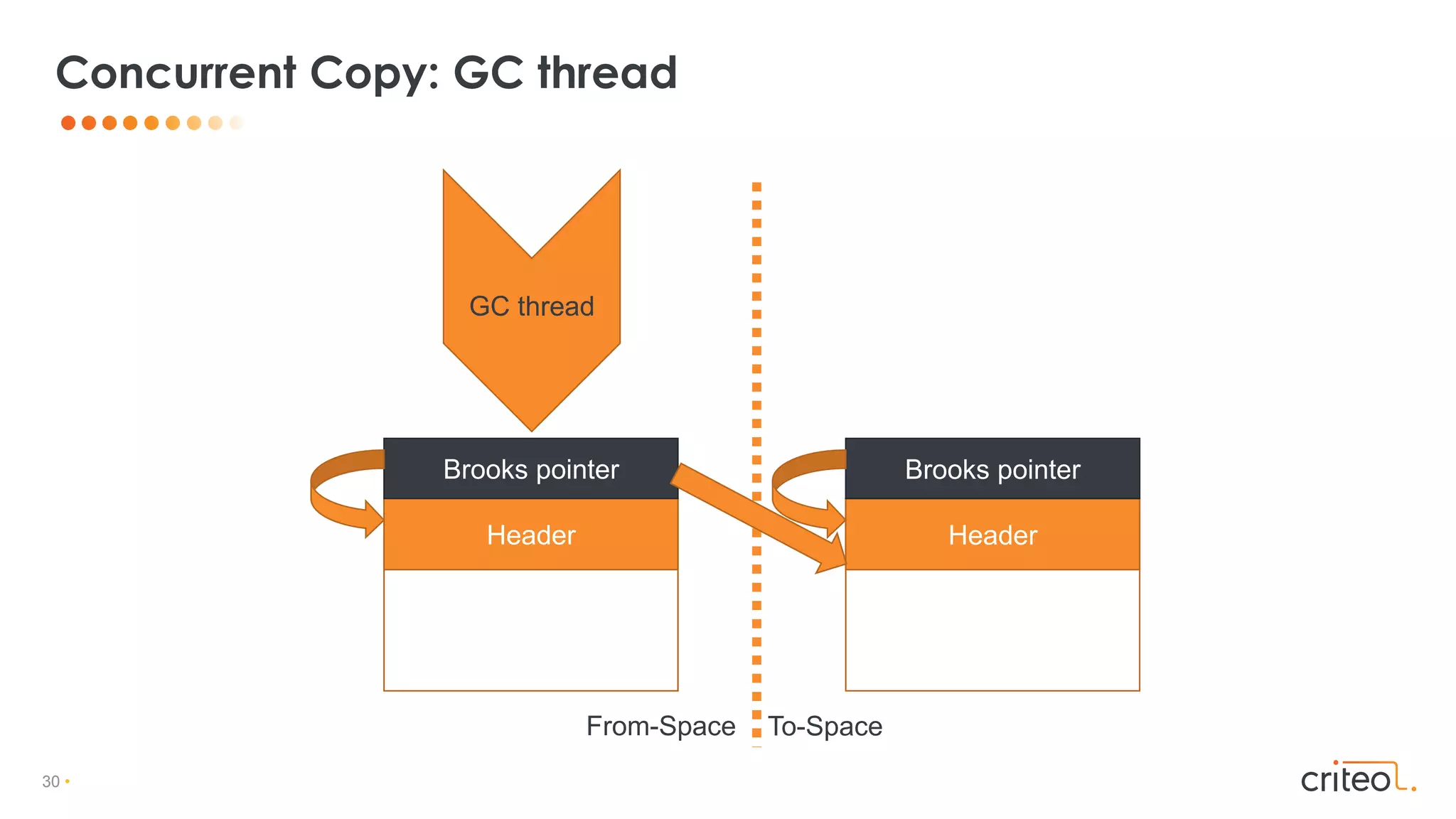
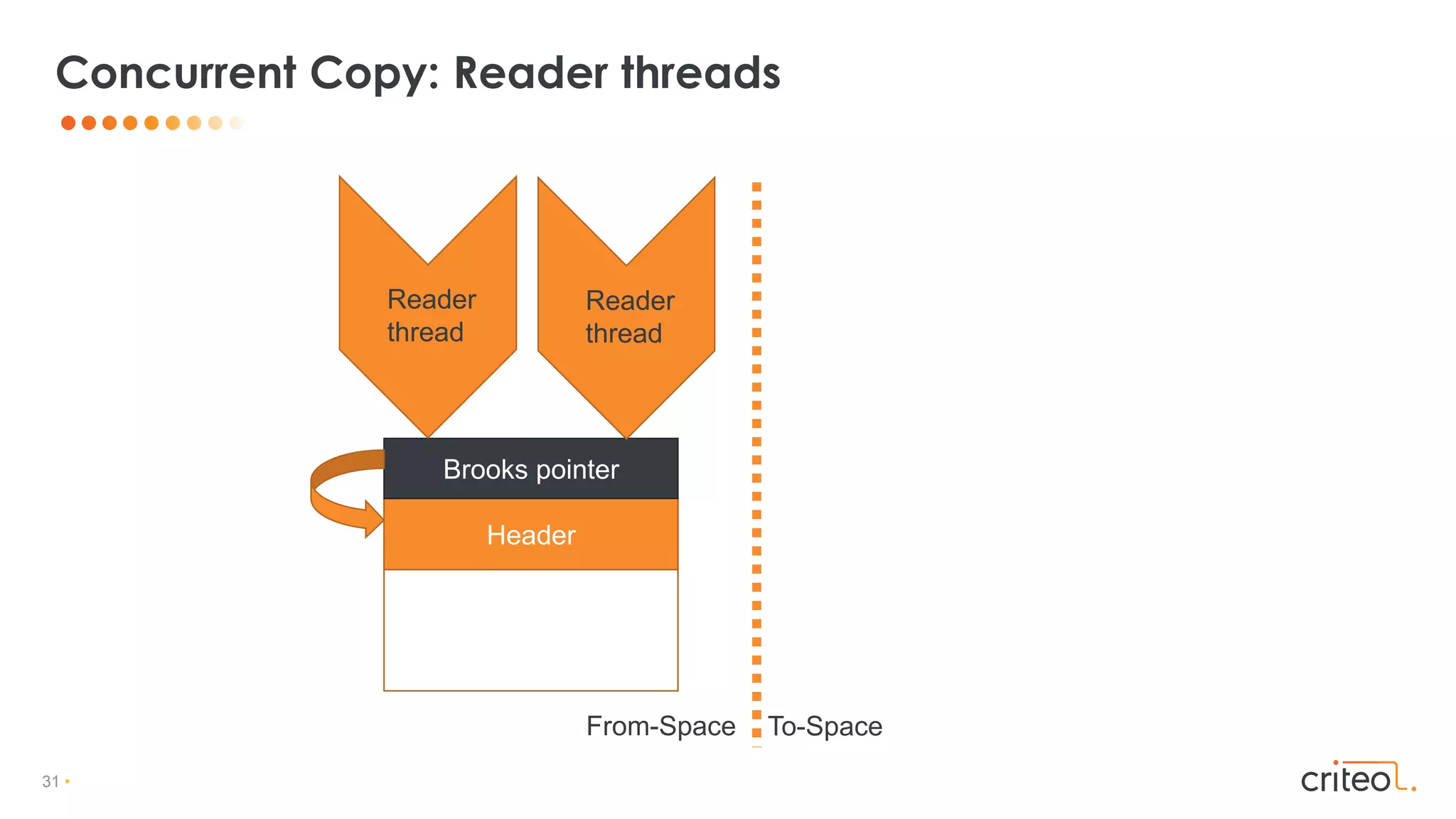
![29 •
• All objects have an additional forwarding pointer
• Placed before the regular object
• Dereference the forwarding pointer for each access
• Memory footprint overhead
• Throughput overhead
Brooks pointers
Header
Brooks pointer
mov r13,QWORD PTR [r12+r14*8-0x8]](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/85/Understanding-jvm-gc-advanced-29-320.jpg)
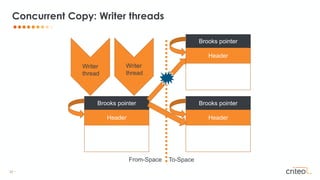
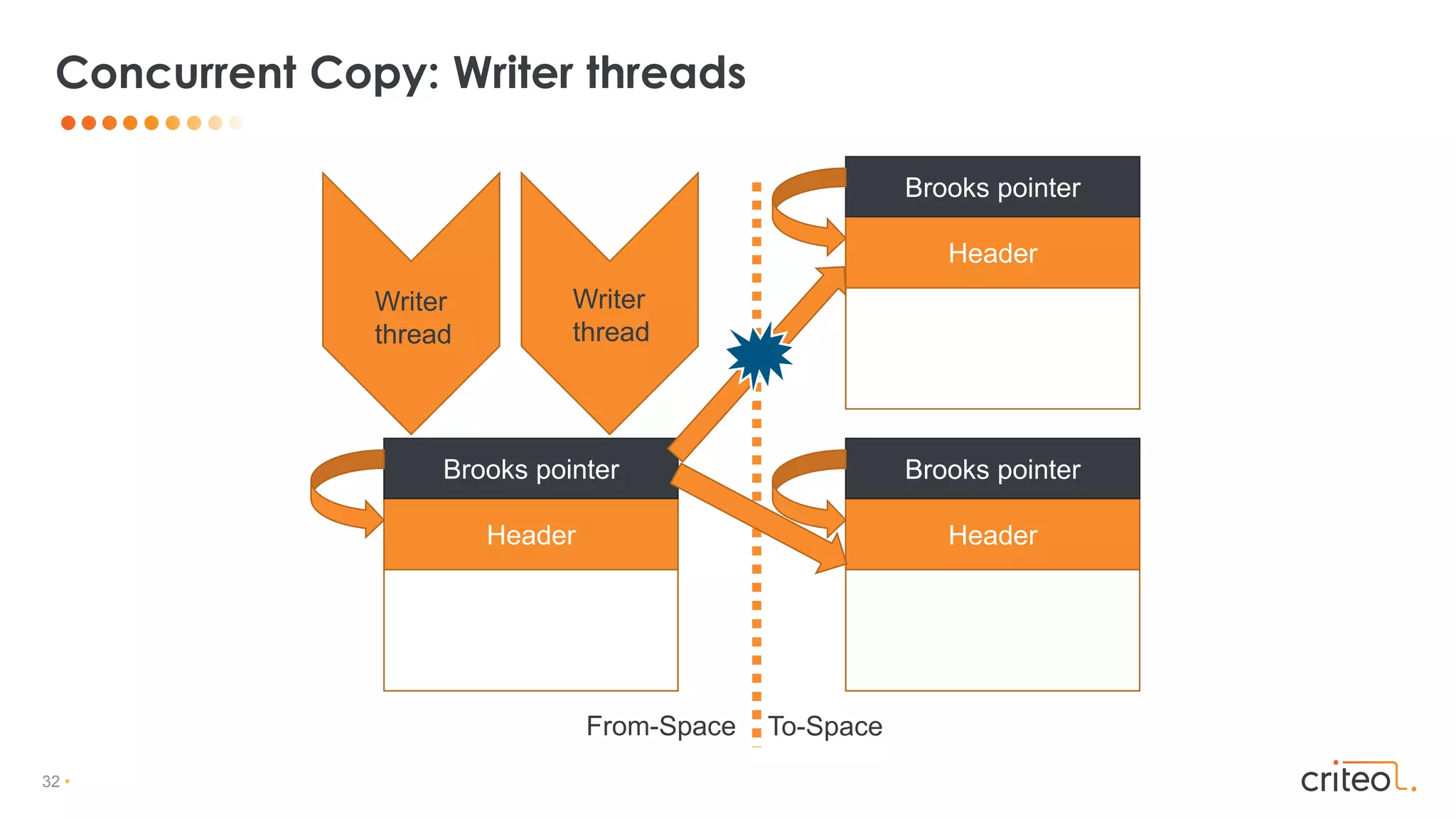
![33 •
• Any writes (even primitives) to from-space object needs to be protected
• Exotic barriers:
• acmp (pointer comparison)
• CAS
• clone
Write Barriers
if (evacInProgress
&& inCollectionSet(obj)
&& notCopyYet(obj)) {
evacuateObject(obj)
}
test BYTE PTR [r15+0x3c0],0x2
jne 0x000000000281bcbc
[...]
mov r10d,DWORD PTR [r13+0xc]
test r10d,r10d
je 0x000000000281bc2b
mov r11,QWORD PTR [r15+0x360]
mov rcx,r10
shl rcx,0x3
test r11,r11
je 0x000000000281bd0d
[...]
mov rdx,r15
movabs r10,0x62d1f660
call r10
jmp 0x000000000281bc2b](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/85/Understanding-jvm-gc-advanced-33-320.jpg)




![38 •
• States of objects stored inside reference address => Colored pointers
• NMT bit
• Generation
• Checked against a global expected value during the GC cycle
• Thread local, almost always L1 cache hits
• Register
• Relocated: x86 Implementation use trap from VM memory translation Guest/Host
• Intel EPT
• AMD NPT
LVB
test r9, rax
jne 0x3001443b
mov r10d, dword ptr [rax + 8]](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/85/Understanding-jvm-gc-advanced-38-320.jpg)
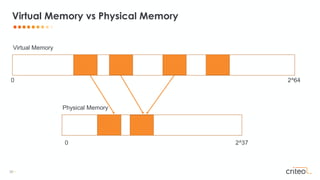

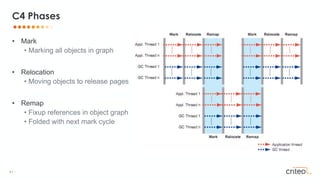

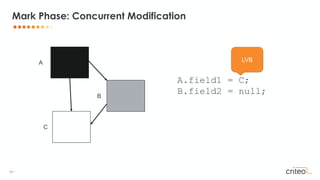


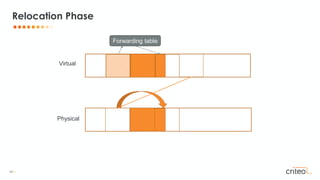





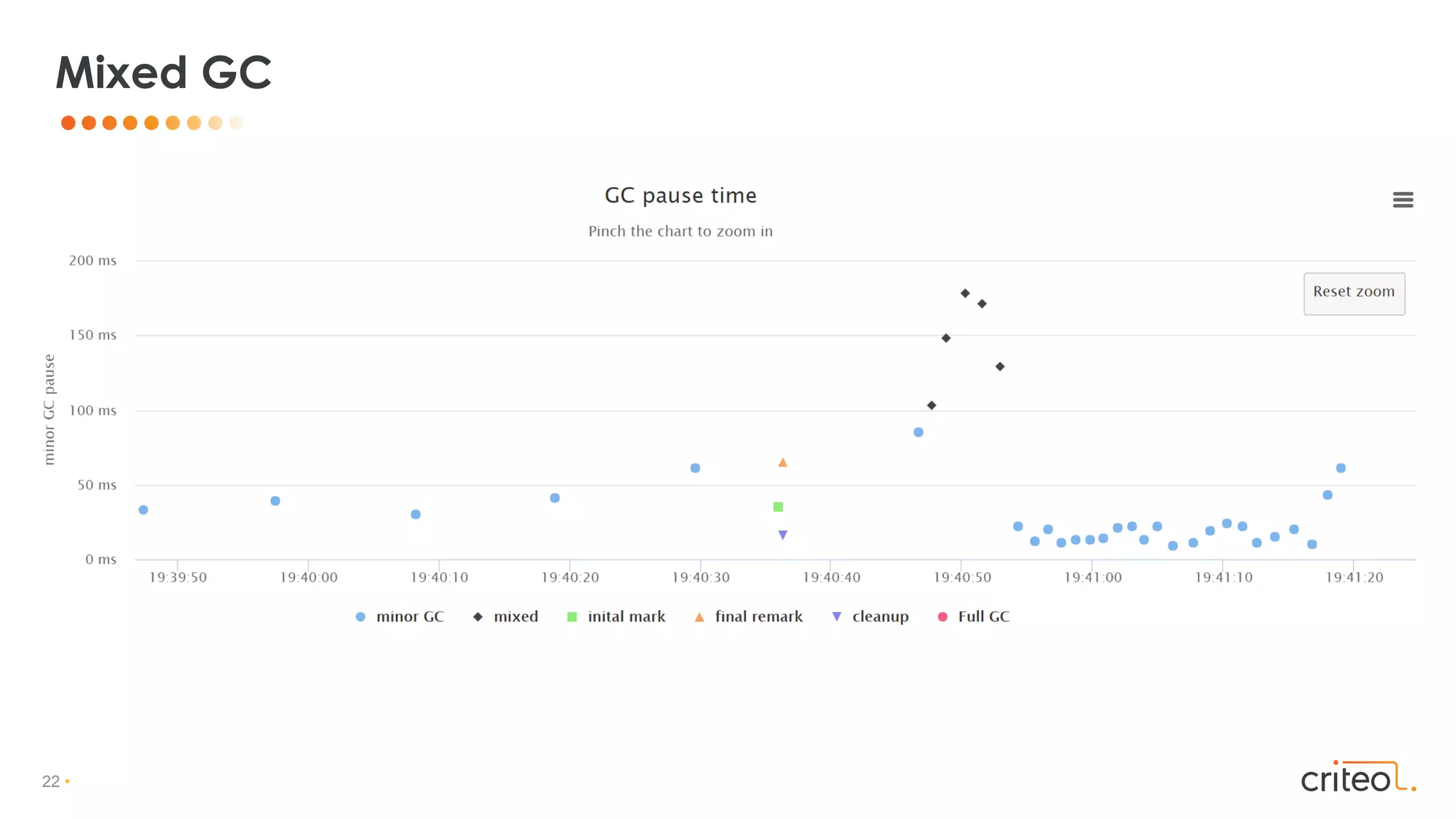
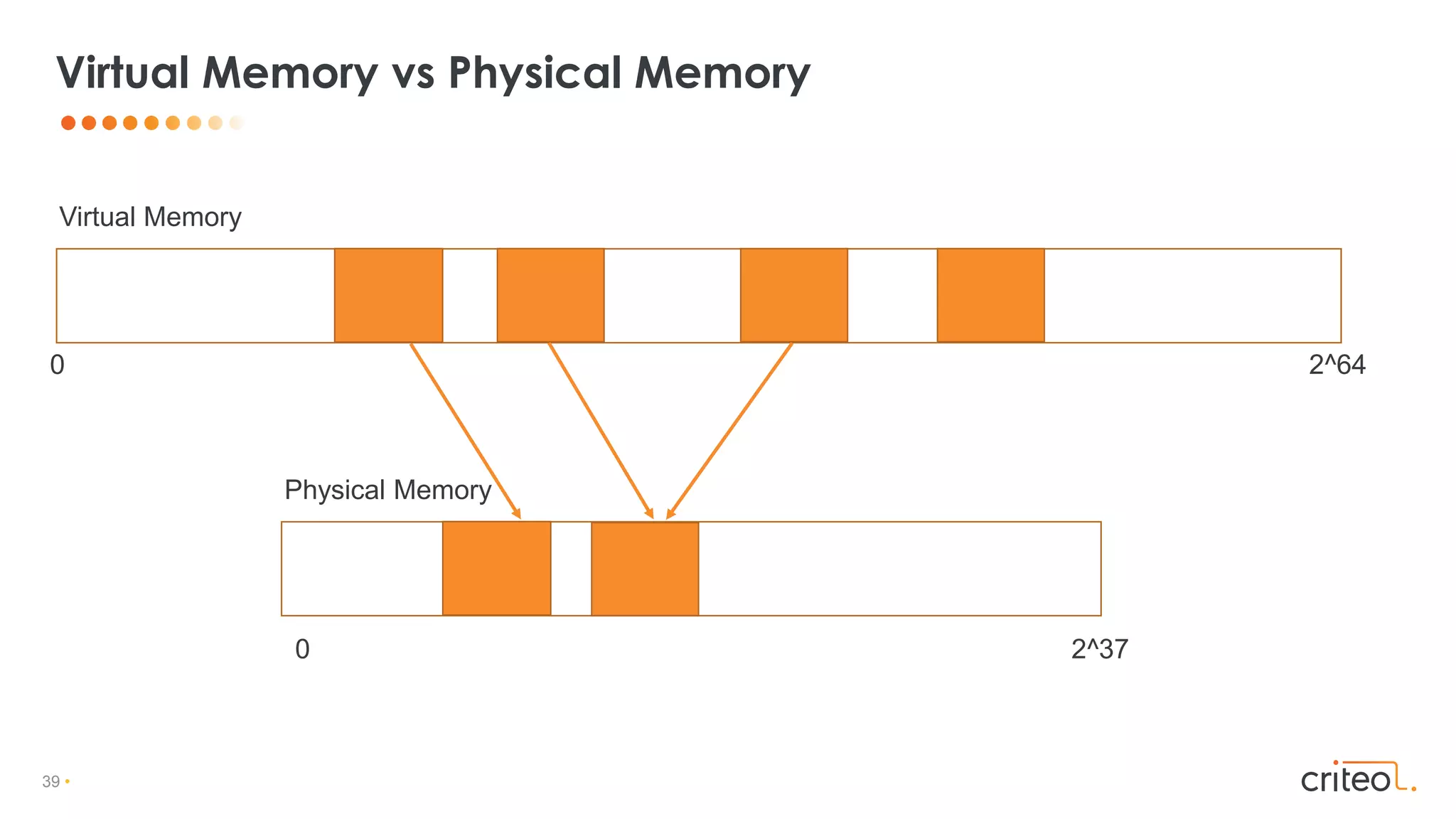
![53 •
• Non generational
• Region based (zPages, dynamically sized)
• Concurrent Marking, Compaction, Ref processing
• Use Colored Pointers & Read/Load Barrier
• Self-Healing
• Cooperation between mutator threads & GC threads
• Experimental in JDK 11 (-XX:+UnlockExperimentalVMOptions –XX:+UseZGC)
Z GC
mov r10,QWORD PTR [r11+0xb0]
test QWORD PTR [r15+0x20],r10
jne 0x00007f9594cc54b5](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/85/Understanding-jvm-gc-advanced-53-320.jpg)



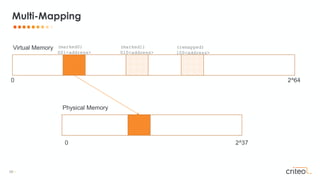











![6 •
Card Table for references old -> young references
Write barrier to update card table on assignation
X.f = Y
Card Table
Young 0 0 1
CARD_TABLE[&X >> 9] = 1
mov DWORD PTR [r10+0x6c],r8d
mov r11,r10
shr r11,0x9
mov r8d,0x2383000
mov BYTE PTR [r8+r11*1],r12b](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/75/Understanding-jvm-gc-advanced-6-2048.jpg)


![14 •
• For each reference assignation (X.f = Y) we need to check:
• References (X & Y) are NOT in the same region
• Y is not null
• => enqueue for Remebered Set processing
• Refinement threads to process the queue
• Additional instructions added after assignation
Remembered Sets: Post Write Barrier
if (!isInSameRegion(X, Y)
&& Y != null)
RSEnqueue(X)
mov DWORD PTR [rbp+0x74],r10d
mov r11,rbp
mov r8,r10
shl r8,0x3
xor r8,r11
shr r8,0x14
test r8,r8
je cont
test r10d,r10d
je cont
shr r11,0x9
movabs rcx,0x2965ecc3000
add rcx,r11
cmp BYTE PTR [rcx],0x20
je cont
mov r10,QWORD PTR [r15+0x70]
mov r11,QWORD PTR [r15+0x80]
lock add DWORD PTR [rsp-0x40],0x0
cmp BYTE PTR [rcx],0x0
je cont
mov BYTE PTR [rcx],0x0
test r10,r10
jne 0x000002965edc62bc
mov rdx,r15
movabs r10,0x7ffac2febc30
call r10
jmp cont
mov QWORD PTR [r11+r10*1-0x8],rcx
add r10,0xfffffffffffffff8
mov QWORD PTR [r15+0x70],r10](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/75/Understanding-jvm-gc-advanced-14-2048.jpg)


![19 •
• 2 ways to ensure not missing any marking
• For SATB, Pre-Write Barriers, recording object for marking
• SATB barrier is only active when Marking is on (global state)
Concurrent Marking: Resolving misses
if (SATB_WriteBarrier) {
if (X.f != null)
SATB_enqueue(X.f);
}
cmp BYTE PTR [r15+0x30],0x0
jne 0x000002965edc62e5
[...]
mov r11d,DWORD PTR [rbp+0x74]
test r11d,r11d
je 0x000002965edc6253
mov r10,QWORD PTR [r15+0x38]
mov rcx,r11
shl rcx,0x3
test r10,r10
je 0x000002965edc6318
mov r11,QWORD PTR [r15+0x48]
mov QWORD PTR [r11+r10*1-0x8],rcx
add r10,0xfffffffffffffff8
mov QWORD PTR [r15+0x38],r10
jmp 0x000002965edc6253
mov rdx,r15
movabs r10,0x7ffac2febc50
call r10
jmp 0x000002965edc6253](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/75/Understanding-jvm-gc-advanced-19-2048.jpg)







![29 •
• All objects have an additional forwarding pointer
• Placed before the regular object
• Dereference the forwarding pointer for each access
• Memory footprint overhead
• Throughput overhead
Brooks pointers
Header
Brooks pointer
mov r13,QWORD PTR [r12+r14*8-0x8]](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/75/Understanding-jvm-gc-advanced-29-2048.jpg)
![33 •
• Any writes (even primitives) to from-space object needs to be protected
• Exotic barriers:
• acmp (pointer comparison)
• CAS
• clone
Write Barriers
if (evacInProgress
&& inCollectionSet(obj)
&& notCopyYet(obj)) {
evacuateObject(obj)
}
test BYTE PTR [r15+0x3c0],0x2
jne 0x000000000281bcbc
[...]
mov r10d,DWORD PTR [r13+0xc]
test r10d,r10d
je 0x000000000281bc2b
mov r11,QWORD PTR [r15+0x360]
mov rcx,r10
shl rcx,0x3
test r11,r11
je 0x000000000281bd0d
[...]
mov rdx,r15
movabs r10,0x62d1f660
call r10
jmp 0x000000000281bc2b](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/75/Understanding-jvm-gc-advanced-33-2048.jpg)



![38 •
• States of objects stored inside reference address => Colored pointers
• NMT bit
• Generation
• Checked against a global expected value during the GC cycle
• Thread local, almost always L1 cache hits
• Register
• Relocated: x86 Implementation use trap from VM memory translation Guest/Host
• Intel EPT
• AMD NPT
LVB
test r9, rax
jne 0x3001443b
mov r10d, dword ptr [rax + 8]](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/75/Understanding-jvm-gc-advanced-38-2048.jpg)









![53 •
• Non generational
• Region based (zPages, dynamically sized)
• Concurrent Marking, Compaction, Ref processing
• Use Colored Pointers & Read/Load Barrier
• Self-Healing
• Cooperation between mutator threads & GC threads
• Experimental in JDK 11 (-XX:+UnlockExperimentalVMOptions –XX:+UseZGC)
Z GC
mov r10,QWORD PTR [r11+0xb0]
test QWORD PTR [r15+0x20],r10
jne 0x00007f9594cc54b5](https://image.slidesharecdn.com/understandingjvmgcadvanced-181017205833/75/Understanding-jvm-gc-advanced-53-2048.jpg)




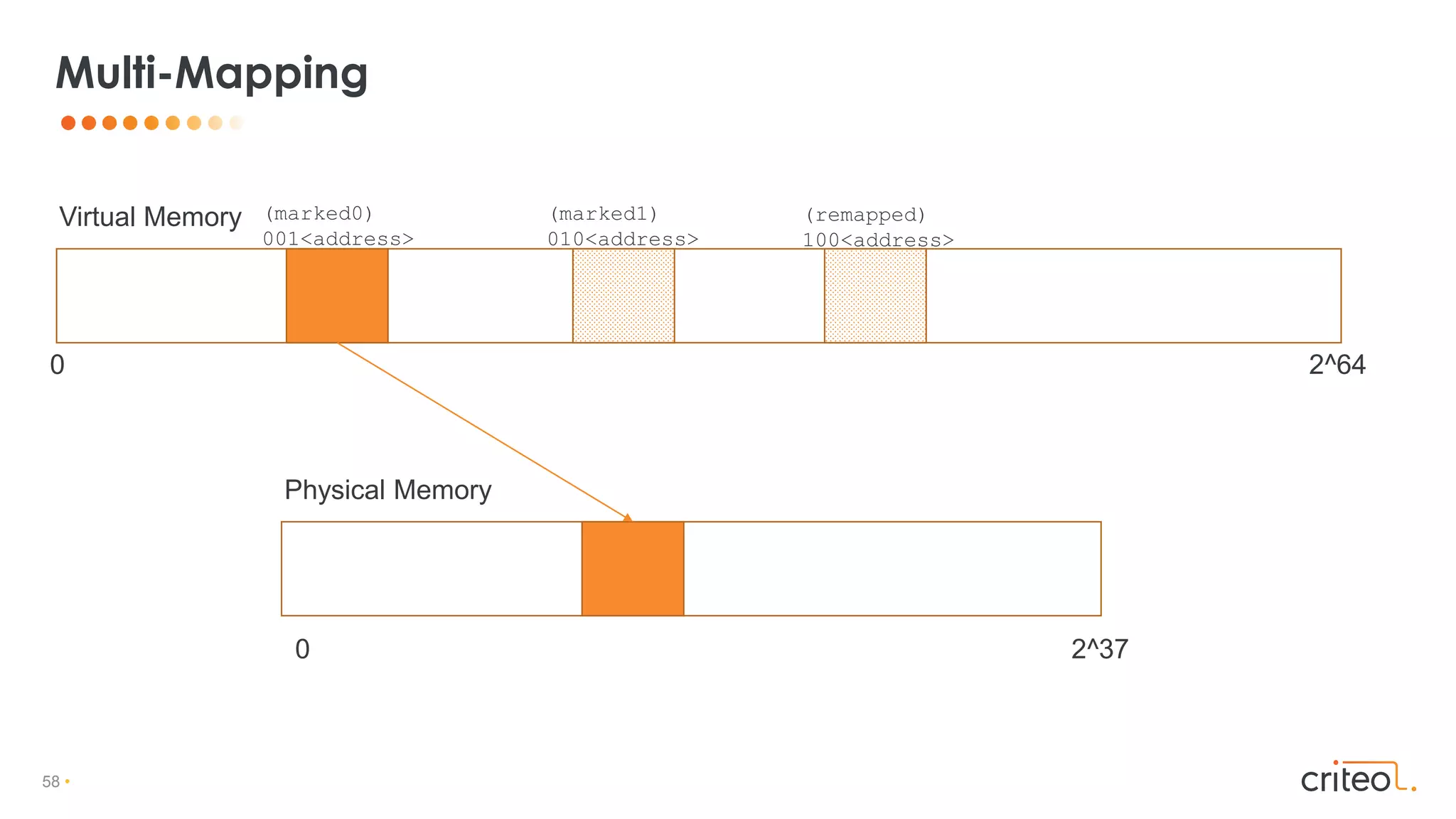












The document discusses different garbage collection (GC) algorithms used in the Java Virtual Machine (JVM). It provides an overview of GC basics, and then goes into more detail on specific algorithms including G1, Shenandoah, Azul's C4, and ZGC. For each algorithm, it describes the key phases and how they handle concurrent marking and compaction to minimize stop-the-world pauses. It also discusses techniques used for barrier methods, object relocation, and multi-mapping of memory between virtual and physical spaces.


















































































