Naive Bayes Classifier, Types of Naive Bayes Classifier, Advantages, Disadvantages, Python Implementation, Support Vector Machine, SVM, Types of SVM, Working of SVM, Advantages, Disadvantages
Machine Learning
Sanjivani RuralEducation Society’s
Sanjivani College of Engineering, Kopargaon-423603
(An Autonomous Institute Affiliated to Savitribai Phule Pune University, Pune)
NAAC ‘A’ Grade Accredited
Department of Information Technology
NBAAccredited-UG Programme
Ms. K. D. Patil
Assistant Professor
2.
Contents - Classification
•Sigmoid function, Classification Algorithm in Machine Learning,
Decision Trees, Ensemble Techniques: Bagging and boosting, Adaboost
and gradient boost, Random Forest, Naïve Bayes Classifier, Support
Vector Machines. Performance Evaluation: Confusion Matrix, Accuracy,
Precision, Recall, AUC-ROC Curves, F-Measure
Machine Learning Department of Information Technology
3.
Course Outcome
• CO3:To apply different classification algorithms for various machine
learning applications.
Machine Learning Department of Information Technology
4.
Naive Bayes Classifier
MachineLearning Department of Information Technology
• Naive Bayes classifier is a straightforward and powerful algorithm for the
classification task.
• Even if we are working on a data set with millions of records with some
attributes, it is suggested to try Naive Bayes approach.
• Naive Bayes classifier gives great results when we use it for textual data
analysis. Such as in Natural Language Processing (NLP).
• It is named as "Naive" because it assumes the presence of one feature
does not affect other features. The "Bayes" part of the name refers to its
basis in Bayes’ Theorem.
• Naive Bayes is a kind of classifier which uses the Bayes Theorem.
5.
Naive Bayes Classifier
MachineLearning Department of Information Technology
• Bayes Theorem works on conditional probability.
• Conditional probability is the probability that something will happen,
given that something else has already occurred.
• Using the conditional probability, we can calculate the probability of an
event using its prior knowledge.
• Naive Bayes classifier is a straightforward and powerful algorithm for the
classification task.
• It predicts membership probabilities for each class such as the probability
that given record or data point belongs to a particular class.
• The class with the highest probability is considered as the most likely class.
6.
Naive Bayes Classifier
MachineLearning Department of Information Technology
• Naive Bayes classifier assumes that all the features are unrelated to each
other.
• Presence or absence of a feature does not influence the presence or
absence of any other feature.
• This approach is based on the assumption that the features of the input
data are conditionally independent given the class, allowing the algorithm
to make predictions quickly and accurately.
• Example:
• Spam Filtering
• Sentiment Analysis
• Fraud Detection
7.
Types of NaiveBayes Classifier
Machine Learning Department of Information Technology
• Gaussian Naive Bayes:
• When attribute values are continuous, an assumption is made that the
values associated with each class are distributed according to Gaussian
distribution i.e., Normal Distribution.
• When plotted, it gives a bell shaped curve which is symmetric about
the mean of the feature values
8.
Types of NaiveBayes Classifier
Machine Learning Department of Information Technology
• Multinomial Naive Bayes:
• Multinomial Naive Bayes is preferred to use on
data that is multinomial distributed.
• It is one of the standard classic algorithms. Which
is used in text categorization (classification).
• Each event in text classification represents the
occurrence of a word in a document.
• A multinomial distribution is a statistical
distribution that models the results of N
independent trials, where each trial can result in
one of K distinct, mutually exclusive outcomes
with fixed probabilities that sum to one.
9.
Types of NaiveBayes Classifier
Machine Learning Department of Information Technology
• Bernoulli Naive Bayes:
• Bernoulli Naive Bayes is used on the data that is distributed according
to multivariate Bernoulli distributions. i.e., multiple features can be
there, but each one is assumed to be a binary-valued (Bernoulli,
boolean) variable. So, it requires features to be binary valued.
• Example:
• One application would be text classification with ‘bag of words’
model where the 1s & 0s are “word occurs in the document” and
“word does not occur in the document” respectively.
10.
Naive Bayes Classifier
MachineLearning Department of Information Technology
• Refer the following naive bayes classifier formula to calculate probability.
P(A|B) = P(B|A) . P(A)/P(B)
Where,
P(A|B) = It is a target probability of the class
P(B|A) = It is a probability of predictor given class
P(A) = It is the prior probability a class
P(B) = It is the prior probability of predictor
11.
Naive Bayes Classifier
MachineLearning Department of Information Technology
• Advantages:
• Naive Bayes Algorithm is a fast, highly scalable algorithm.
• Naive Bayes can be used for Binary and Multiclass classification.
• It provides different types of Naive Bayes Algorithms like GaussianNB,
MultinomialNB, BernoulliNB.
• It is a simple algorithm that depends on doing a bunch of counts.
• Great choice for Text Classification problems.
• It's a popular choice for spam email classification.
• It can be easily train on small dataset.
• Disadvantages:
• It considers all the features to be unrelated, so it cannot learn the
relationship between features.
12.
Naive Bayes Classifierin Python
Machine Learning Department of Information Technology
# Import libraries
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.30)
from sklearn.naive_bayes import GaussianNB
# Build a Gaussian Classifier
model = GaussianNB()
# Model training
model.fit(X_train, y_train)
13.
Naive Bayes Classifierin Python
Machine Learning Department of Information Technology
# Predict Output
predicted = model.predict([X_test[6]])
print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0])
# Evaluation Metrics
from sklearn.metrics import (accuracy_score,confusion_matrix, f1_score,)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_pred, y_test)
F1 = f1_score(y_pred, y_test, average="weighted")
14.
Support Vector Machine
MachineLearning Department of Information Technology
• It is a supervised machine learning problem where we try to find a
hyperplane that best separates the two classes.
• SVM selects best hyperplane by finding the maximum margin between the
hyper planes that means maximum distances between the two classes.
• Example:
• Bioinformatics and Medical Applications
• Text and Natural Language Processing (NLP)
• Image Recognition and Classification
• Recommendation Systems
15.
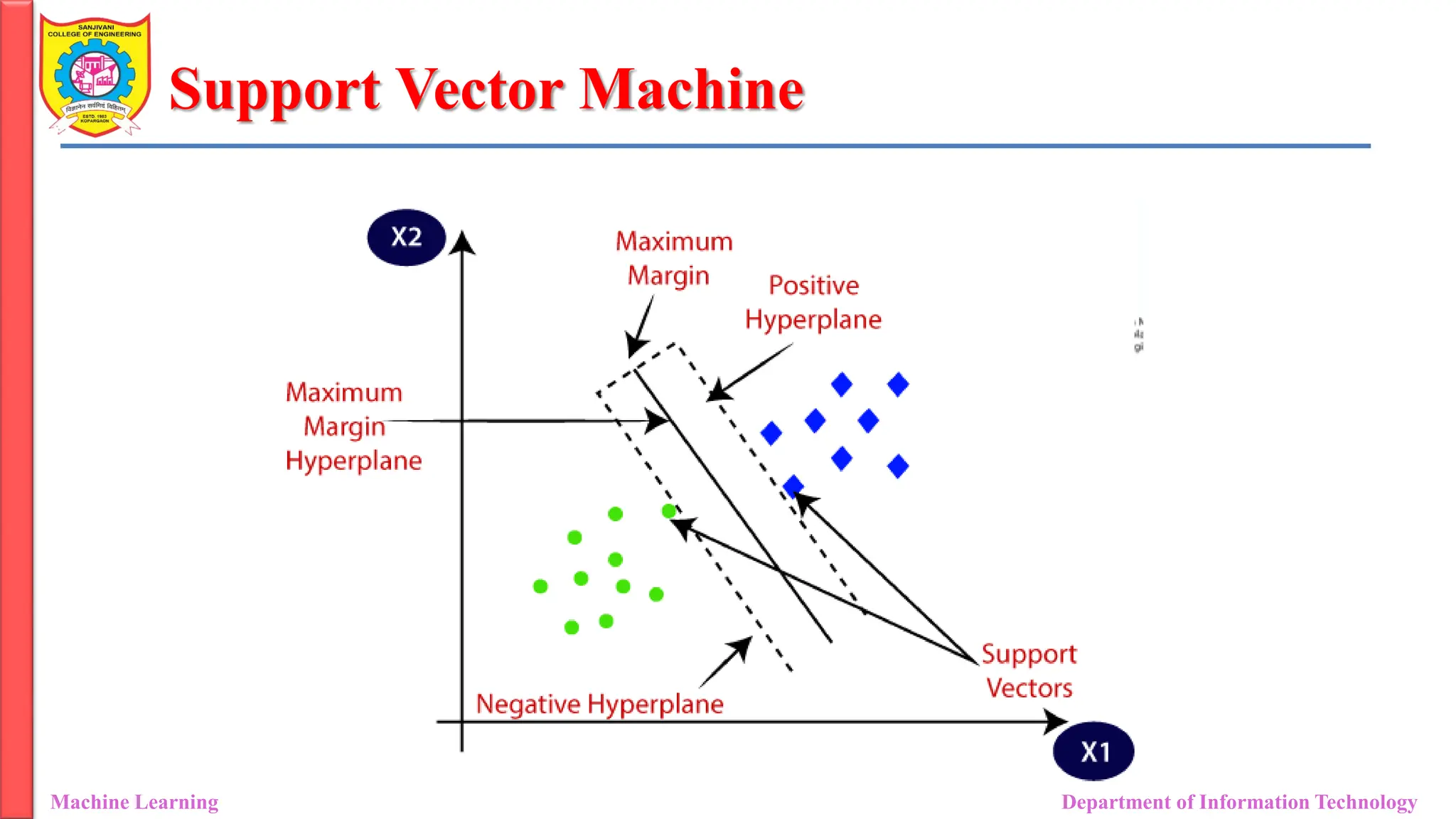
Support Vector Machine
MachineLearning Department of Information Technology
• Terminology:
• Support Vectors:
• These are the points that are closest to the hyperplane.
• A separating line will be defined with the help of these data points.
• Margin:
• It is the distance between the hyperplane and the observations
closest to the hyperplane (support vectors).
• In SVM large margin is considered a good margin.
• There are two types of margins hard margin and soft margin.
16.
Support Vector Machine
MachineLearning Department of Information Technology
• Terminology:
• Hyperplane:
• It is a decision boundary that separates different classes in feature
space.
• It is represented by the equation wx + b = 0 in linear classification.
Support Vector Machine
MachineLearning Department of Information Technology
• SVM can be of two types:
• Linear SVM:
• Linear SVM is used for linearly separable data, which means if a
dataset can be classified into two classes by using a single straight
line, then such data is termed as linearly separable data, and
classifier is used called as Linear SVM classifier.
• Non-linear SVM:
• Non-Linear SVM is used for non-linearly separated data, which
means if a dataset cannot be classified by using a straight line, then
such data is termed as non-linear data and classifier used is called
as Non-linear SVM classifier.
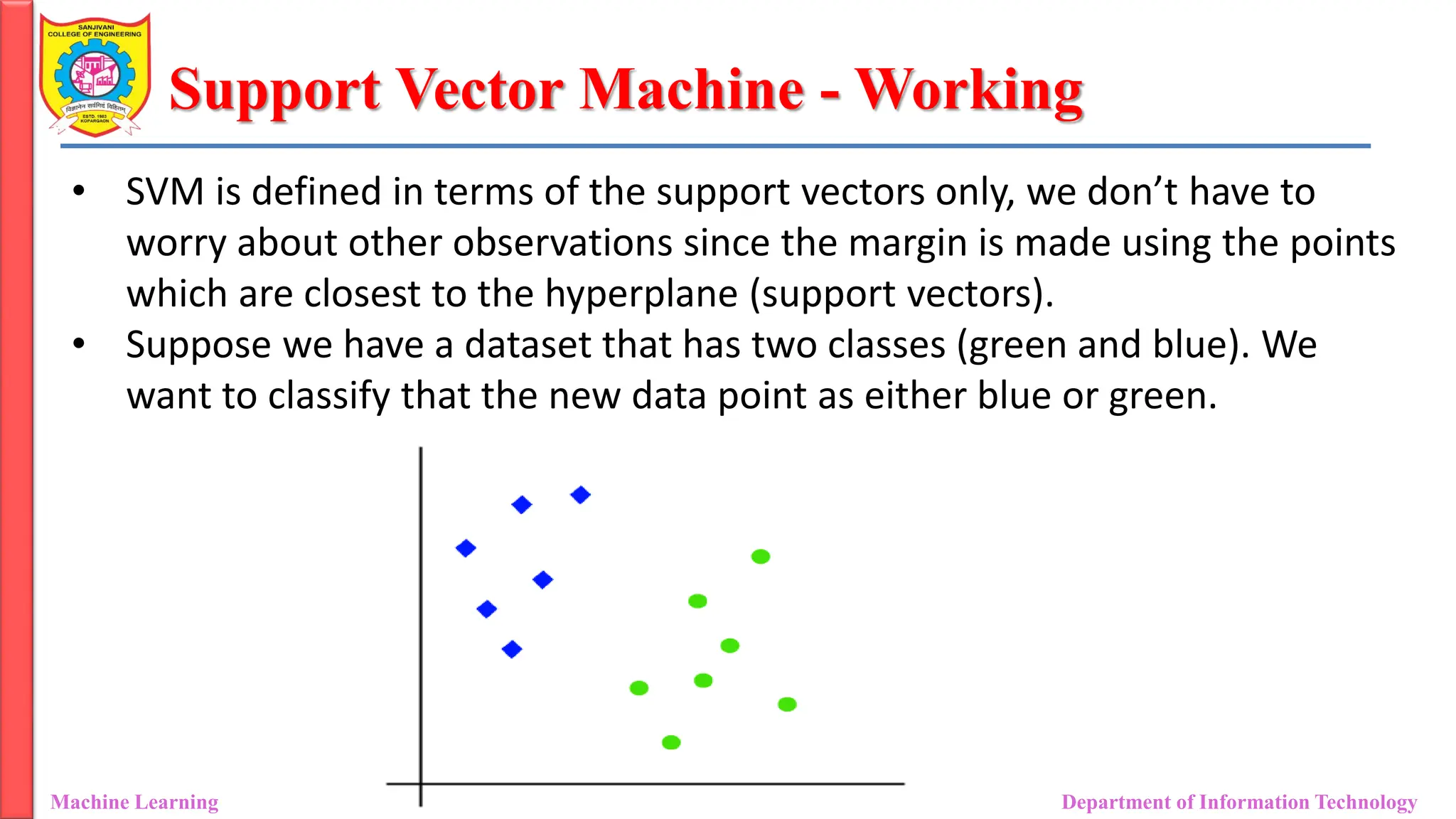
Support Vector Machine- Working
Machine Learning Department of Information Technology
• SVM is defined in terms of the support vectors only, we don’t have to
worry about other observations since the margin is made using the points
which are closest to the hyperplane (support vectors).
• Suppose we have a dataset that has two classes (green and blue). We
want to classify that the new data point as either blue or green.
21.
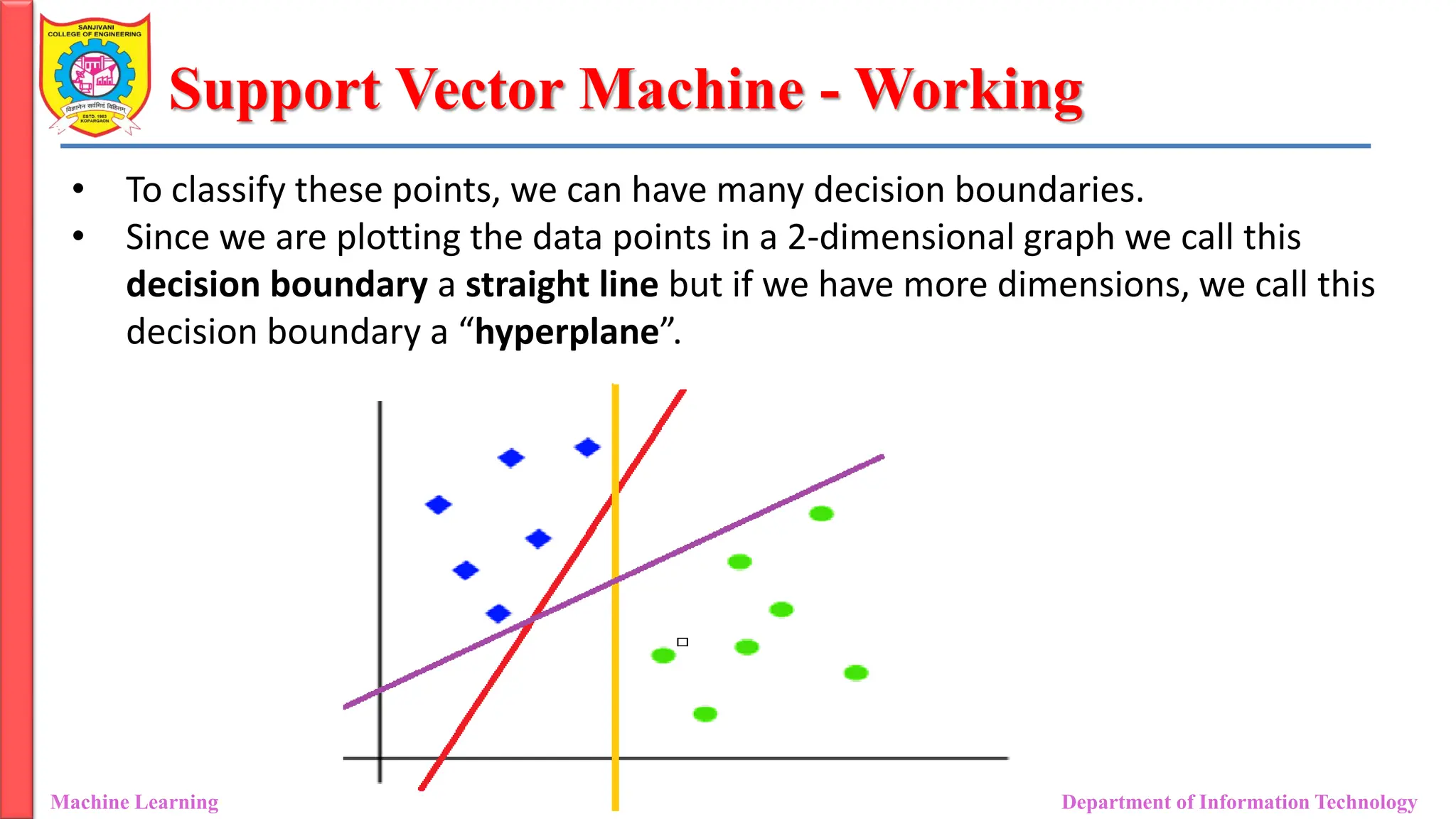
Support Vector Machine- Working
Machine Learning Department of Information Technology
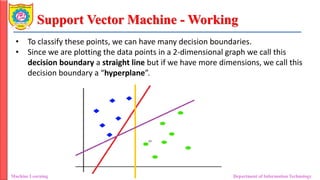
• To classify these points, we can have many decision boundaries.
• Since we are plotting the data points in a 2-dimensional graph we call this
decision boundary a straight line but if we have more dimensions, we call this
decision boundary a “hyperplane”.
22.
Support Vector Machine- Working
Machine Learning Department of Information Technology
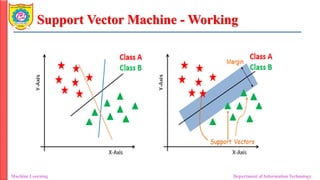
• The best hyperplane is that plane that has the maximum distance from both the
classes, and this is the main aim of SVM.
• This is done by finding different hyperplanes which classify the labels in the best
way then it will choose the one which is farthest from the data points or the one
which has a maximum margin.
Support Vector Machine- Working
Machine Learning Department of Information Technology
• Advantages of SVM
• SVM works better when the data is Linear
• It is more effective in high dimensions
• With the help of the kernel trick, we can solve any complex problem
• SVM is not sensitive to outliers
• Can help us with Image classification
• Disadvantages of SVM
• Choosing a good kernel is not easy
• It doesn't show good results on a big dataset












![Naive Bayes Classifier in Python
Machine Learning Department of Information Technology
# Predict Output
predicted = model.predict([X_test[6]])
print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0])
# Evaluation Metrics
from sklearn.metrics import (accuracy_score,confusion_matrix, f1_score,)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_pred, y_test)
F1 = f1_score(y_pred, y_test, average="weighted")](https://image.slidesharecdn.com/unit3classification-naivebayessvm-250913112732-47c49ef6/85/Unit-3_Classification-NaiveBayes_SVM-pdf-13-320.jpg)





















![Naive Bayes Classifier in Python
Machine Learning Department of Information Technology
# Predict Output
predicted = model.predict([X_test[6]])
print("Actual Value:", y_test[6])
print("Predicted Value:", predicted[0])
# Evaluation Metrics
from sklearn.metrics import (accuracy_score,confusion_matrix, f1_score,)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_pred, y_test)
F1 = f1_score(y_pred, y_test, average="weighted")](https://image.slidesharecdn.com/unit3classification-naivebayessvm-250913112732-47c49ef6/75/Unit-3_Classification-NaiveBayes_SVM-pdf-13-2048.jpg)