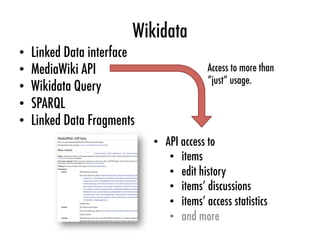
Download as PDF, PPTX









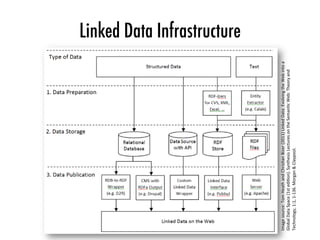












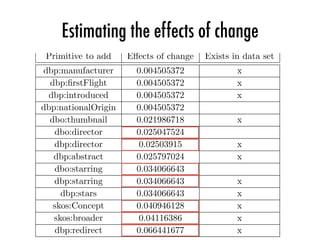
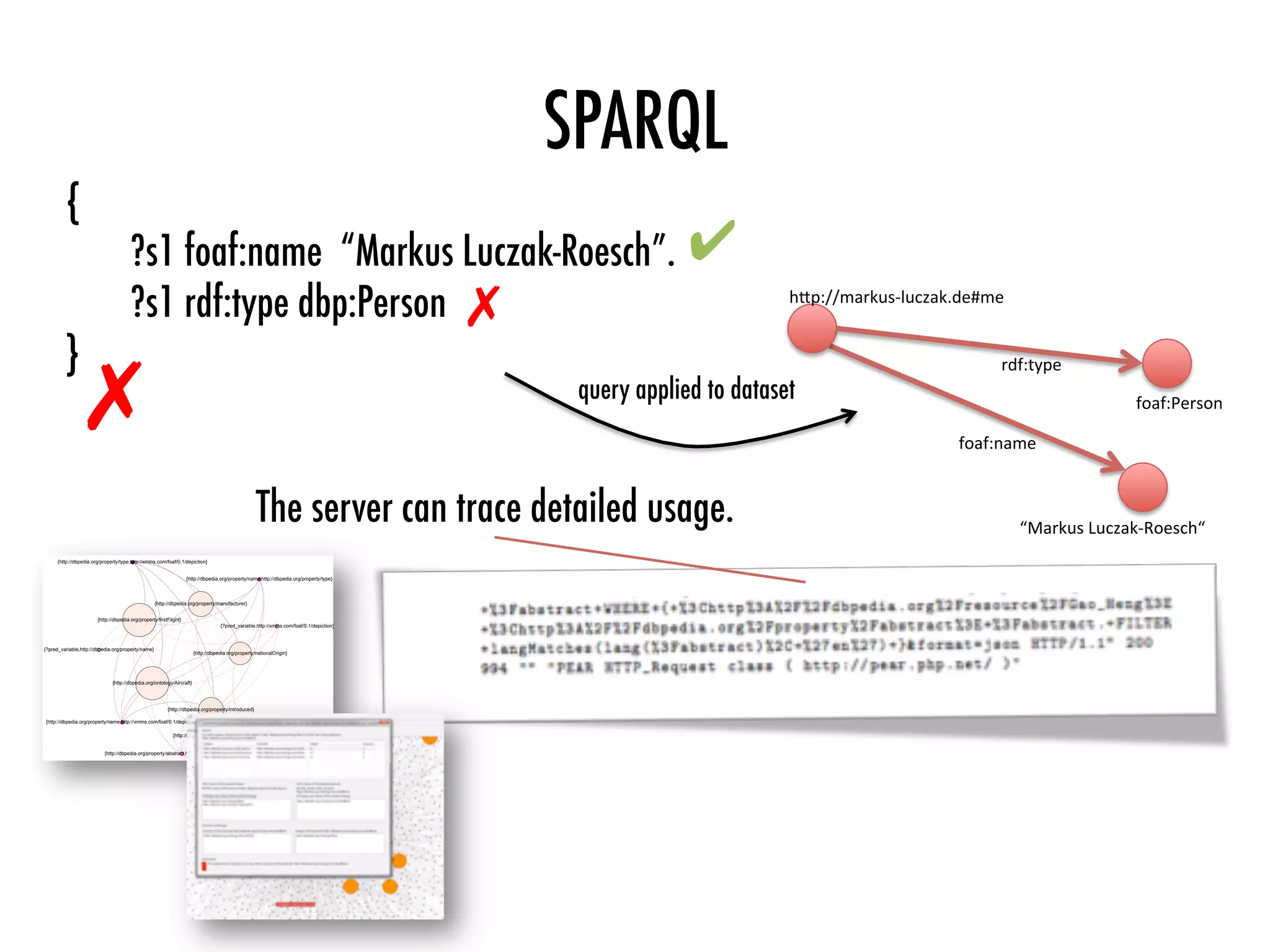
![Log files
Selected log files
Preprocessed
queries
Decomposed
queries
and
transac<on
tables
Pa=erns
Change
recommenda<ons
[0,1]](https://image.slidesharecdn.com/2016-04-21-web-of-data-usage-mining-160421103628/85/Web-of-Data-Usage-Mining-43-320.jpg)

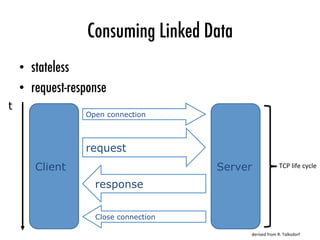
![Linked Data Fragments
Querying Datasets on the Web with High Availability 5
generic requests
high client effort
high server availability
specific requests
high server effort
low server availability
data
dump
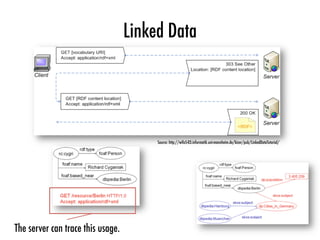
Linked Data
document
sparql
result
triple pattern
fragments
various types of
Linked Data Fragments
Fig. 1: All http triple interfaces offer Linked Data Fragments of a dataset. They differ
in the specificity of the data they contain, and thus the effort needed to create them.
3.2 Formal definitions
As a basis for our formalization, we use the following concepts of the rdf data
model [16] and the sparql query language [12]. We write U, B, L, and V to
denote the sets of all uris, blank nodes, literals, and variables, respectively.
Then, T = (U [ B) ⇥ U ⇥ (U [ B [ L) is the (infinite) set of all rdf triples. Any
tuple tp 2 (U [ V) ⇥ (U [ V) ⇥ (U [ L [ V) is a triple pattern. Any finite set of
such triple patterns is a basic graph pattern (bgp). Any more complex sparql
graph pattern, typically denoted by P, combines triple patterns (or bgps) using
specific operators [12,20]. The standard (set-based) query semantics for sparql
defines the query result of such a graph pattern P over a set of rdf triples
G ✓ T as a set that we denote by [[P]]G and that consists of partial mappings
µ : V ! (U [ B [ L), which are called solution mappings. An rdf triple t is
a matching triple for a triple pattern tp if there exists a solution mapping µ
such that t = µ[tp], where µ[tp] denotes the triple (pattern) that we obtain by
replacing the variables in tp according to µ.
For the sake of a more straightforward formalization, in this paper, we as-
sume without loss of generality that every dataset G published via some kind of
fragments on the Web is a finite set of blank-node-free rdf triples; i.e., G ✓ T ⇤
where T ⇤
= U ⇥ U ⇥ (U [ L). Each fragment of such a dataset contains triples
that somehow belong together; they have been selected based on some condition,
which we abstract through the notion of a selector:
T
xxx.xxx.xxx.xxx - - [17/Oct/2014:07:43:02 +0000]
"GET /2014/en?subject=&predicate=&object=dbpedia%3AAustin HTTP/1.1" 200
1309 "http://fragments.dbpedia.org/2014/en" …
fetches the first page of the corresponding ldf. This page contains the cnt meta-
data, which tells us how many matches the dataset has for each triple pattern.
The pattern is then decomposed by evaluating it using a) a triple pattern iter-
ator for the triple pattern with the smallest number of matches, and b) a new
bgp iterator for the remainder of the pattern. This results in a dynamic pipeline
for each of the mappings of its predecessor, as visualized in Fig. 2. Each pipeline
is optimized locally for a specific mapping, reducing the number of requests.
To evaluate a sparql query over a triple pattern fragment collection, we pro-
ceed as follows. For each bgp of the query, a bgp iterator is created. Dedicated
iterators are necessary for other sparql constructs such as UNION and OPTIONAL,
but their implementation need not be ldf-specific; they can reuse the triple
pattern fragment bgp iterators. The predecessor of the first iterator is a start
iterator. We continuously pull solution mappings from the last iterator in the
pipeline and output them as solutions of the query, until the last iterator re-
sponds with nil. This pull-based process is able to deliver results incrementally.
...
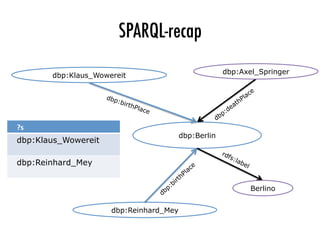
B00
= { Drago_Ibler a Architect. }
Alen_Peternac
Drago_Ibler
Juraj_Neidhardt
...
?person birthPlace Zagreb.
B0
= { ?person a Architect. ?person birthPlace Zagreb. }
Zagreb
Budapest
Rome
...
?city subject
Capitals_in_Europe.
B = { ?person a Architect. ?person birthPlace ?city. ?city subject Capitals_in_Europe. }
Fig. 2: A bgp iterator decomposes a bgp B = {tp1, . . . , tpn} into a triple pattern
iterator for an optimal tpi and, for each resulting solution mapping µ of tpi, creates
a bgp iterator for the remaining pattern B0
= {tp | tp = µ[tpj] ^ tpj 2 B} {µ[tpi]}.
Pre-print of a paper accepted to the International Semantic Web Conference 2014 (ISWC 2014).
The final publication is available at link.springer.com.
Querying Datasets on the Web with High Av
4.2 Dynamic iterator pipelines
A common approach to implement query execution in database sy
iterators that are typically arranged in a tree or a pipeline, based
results are computed recursively [10]. Such a pipelined approac
studied for Linked Data query processing [13,15]. In order to en
results and allow the straightforward addition of sparql oper
ment a triple pattern fragments client using iterators.
The previous algorithm, however, cannot be implemented by
pipeline. For instance, consider a query for architects born in Eu
SELECT ?person ?city WHERE {
?person a dbpedia-owl:Architect. # tp1
?person dbpprop:birthPlace ?city. # tp2
?city dc:subject dbpedia:Capitals_in_Europe. # tp3
} LIMIT 100
Suppose the pipeline begins by finding ?city mappings for tp
to choose whether it will next consider tp1 or tp2. The optimal
differs depending on the value of ?city:
– For dbpedia:Paris, there are ±1,900 matches for tp2, and
for tp1, so there will be less http requests if we continue w
– For dbpedia:Vilnius, there are 164 matches for tp2, and ±1
tp1, so there will be less http requests if we continue with
With a static pipeline, we would have to choose the pipeline stru
and subsequently reuse it.
In order to generate an optimized pipeline for each (sub-)qu
a divide-and-conquer strategy in which a query is decomposed d](https://image.slidesharecdn.com/2016-04-21-web-of-data-usage-mining-160421103628/85/Web-of-Data-Usage-Mining-48-320.jpg)
























![Log files
Selected log files
Preprocessed
queries
Decomposed
queries
and
transac<on
tables
Pa=erns
Change
recommenda<ons
[0,1]](https://image.slidesharecdn.com/2016-04-21-web-of-data-usage-mining-160421103628/75/Web-of-Data-Usage-Mining-43-2048.jpg)
![Linked Data Fragments
Querying Datasets on the Web with High Availability 5
generic requests
high client effort
high server availability
specific requests
high server effort
low server availability
data
dump
Linked Data
document
sparql
result
triple pattern
fragments
various types of
Linked Data Fragments
Fig. 1: All http triple interfaces offer Linked Data Fragments of a dataset. They differ
in the specificity of the data they contain, and thus the effort needed to create them.
3.2 Formal definitions
As a basis for our formalization, we use the following concepts of the rdf data
model [16] and the sparql query language [12]. We write U, B, L, and V to
denote the sets of all uris, blank nodes, literals, and variables, respectively.
Then, T = (U [ B) ⇥ U ⇥ (U [ B [ L) is the (infinite) set of all rdf triples. Any
tuple tp 2 (U [ V) ⇥ (U [ V) ⇥ (U [ L [ V) is a triple pattern. Any finite set of
such triple patterns is a basic graph pattern (bgp). Any more complex sparql
graph pattern, typically denoted by P, combines triple patterns (or bgps) using
specific operators [12,20]. The standard (set-based) query semantics for sparql
defines the query result of such a graph pattern P over a set of rdf triples
G ✓ T as a set that we denote by [[P]]G and that consists of partial mappings
µ : V ! (U [ B [ L), which are called solution mappings. An rdf triple t is
a matching triple for a triple pattern tp if there exists a solution mapping µ
such that t = µ[tp], where µ[tp] denotes the triple (pattern) that we obtain by
replacing the variables in tp according to µ.
For the sake of a more straightforward formalization, in this paper, we as-
sume without loss of generality that every dataset G published via some kind of
fragments on the Web is a finite set of blank-node-free rdf triples; i.e., G ✓ T ⇤
where T ⇤
= U ⇥ U ⇥ (U [ L). Each fragment of such a dataset contains triples
that somehow belong together; they have been selected based on some condition,
which we abstract through the notion of a selector:
T
xxx.xxx.xxx.xxx - - [17/Oct/2014:07:43:02 +0000]
"GET /2014/en?subject=&predicate=&object=dbpedia%3AAustin HTTP/1.1" 200
1309 "http://fragments.dbpedia.org/2014/en" …
fetches the first page of the corresponding ldf. This page contains the cnt meta-
data, which tells us how many matches the dataset has for each triple pattern.
The pattern is then decomposed by evaluating it using a) a triple pattern iter-
ator for the triple pattern with the smallest number of matches, and b) a new
bgp iterator for the remainder of the pattern. This results in a dynamic pipeline
for each of the mappings of its predecessor, as visualized in Fig. 2. Each pipeline
is optimized locally for a specific mapping, reducing the number of requests.
To evaluate a sparql query over a triple pattern fragment collection, we pro-
ceed as follows. For each bgp of the query, a bgp iterator is created. Dedicated
iterators are necessary for other sparql constructs such as UNION and OPTIONAL,
but their implementation need not be ldf-specific; they can reuse the triple
pattern fragment bgp iterators. The predecessor of the first iterator is a start
iterator. We continuously pull solution mappings from the last iterator in the
pipeline and output them as solutions of the query, until the last iterator re-
sponds with nil. This pull-based process is able to deliver results incrementally.
...
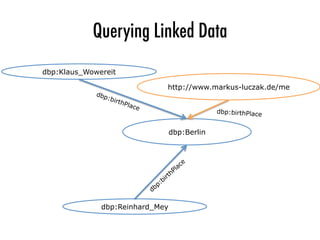
B00
= { Drago_Ibler a Architect. }
Alen_Peternac
Drago_Ibler
Juraj_Neidhardt
...
?person birthPlace Zagreb.
B0
= { ?person a Architect. ?person birthPlace Zagreb. }
Zagreb
Budapest
Rome
...
?city subject
Capitals_in_Europe.
B = { ?person a Architect. ?person birthPlace ?city. ?city subject Capitals_in_Europe. }
Fig. 2: A bgp iterator decomposes a bgp B = {tp1, . . . , tpn} into a triple pattern
iterator for an optimal tpi and, for each resulting solution mapping µ of tpi, creates
a bgp iterator for the remaining pattern B0
= {tp | tp = µ[tpj] ^ tpj 2 B} {µ[tpi]}.
Pre-print of a paper accepted to the International Semantic Web Conference 2014 (ISWC 2014).
The final publication is available at link.springer.com.
Querying Datasets on the Web with High Av
4.2 Dynamic iterator pipelines
A common approach to implement query execution in database sy
iterators that are typically arranged in a tree or a pipeline, based
results are computed recursively [10]. Such a pipelined approac
studied for Linked Data query processing [13,15]. In order to en
results and allow the straightforward addition of sparql oper
ment a triple pattern fragments client using iterators.
The previous algorithm, however, cannot be implemented by
pipeline. For instance, consider a query for architects born in Eu
SELECT ?person ?city WHERE {
?person a dbpedia-owl:Architect. # tp1
?person dbpprop:birthPlace ?city. # tp2
?city dc:subject dbpedia:Capitals_in_Europe. # tp3
} LIMIT 100
Suppose the pipeline begins by finding ?city mappings for tp
to choose whether it will next consider tp1 or tp2. The optimal
differs depending on the value of ?city:
– For dbpedia:Paris, there are ±1,900 matches for tp2, and
for tp1, so there will be less http requests if we continue w
– For dbpedia:Vilnius, there are 164 matches for tp2, and ±1
tp1, so there will be less http requests if we continue with
With a static pipeline, we would have to choose the pipeline stru
and subsequently reuse it.
In order to generate an optimized pipeline for each (sub-)qu
a divide-and-conquer strategy in which a query is decomposed d](https://image.slidesharecdn.com/2016-04-21-web-of-data-usage-mining-160421103628/75/Web-of-Data-Usage-Mining-48-2048.jpg)
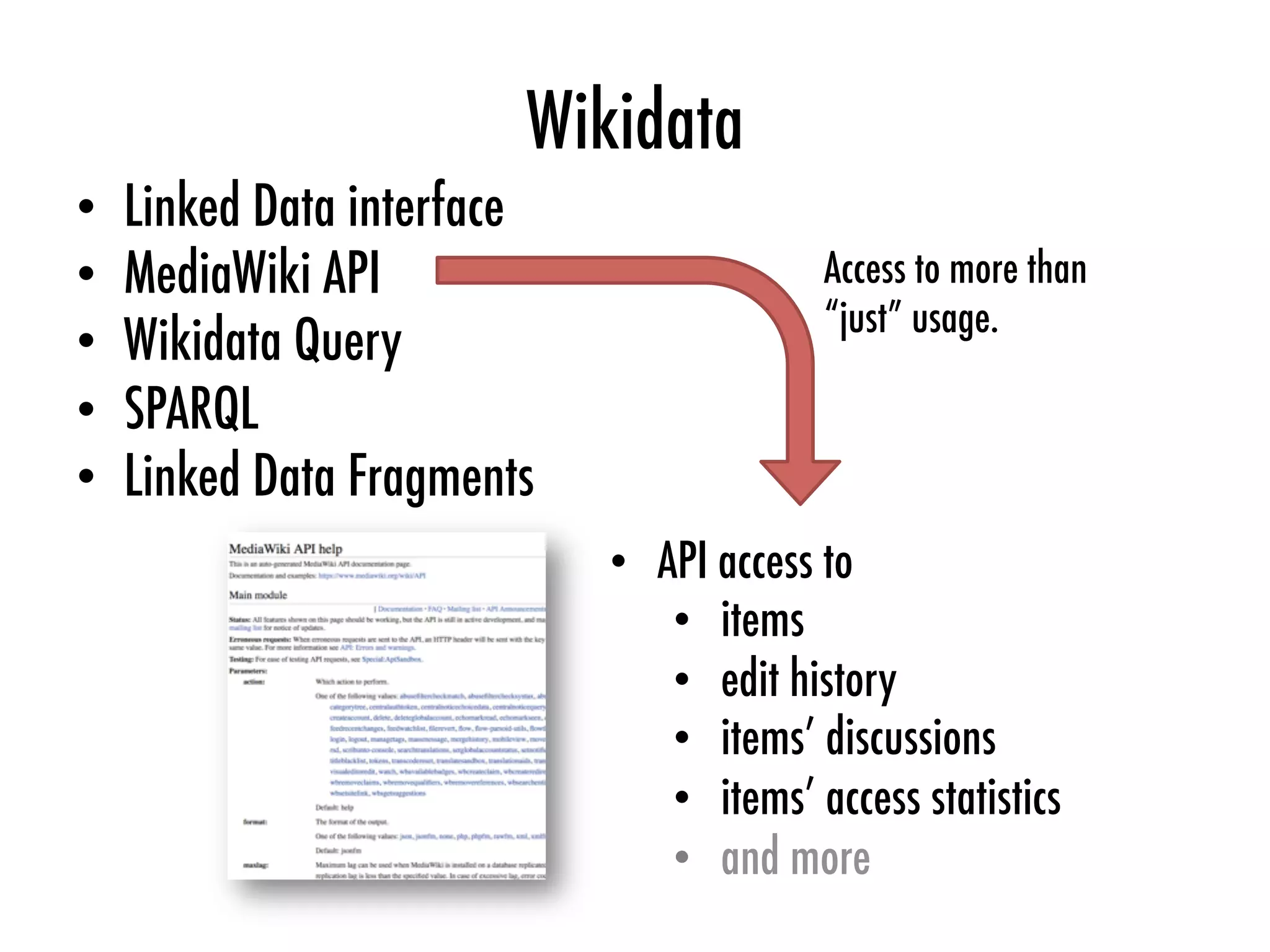



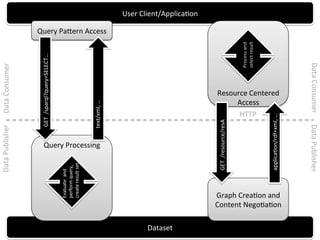
The document discusses the principles and methods of consuming linked data, focusing on content negotiation and SPARQL queries. It outlines key architectural differences, principles of linked data, and the process of querying and consuming linked data using various vocabularies and services. Additionally, it addresses challenges in querying distributed data and presents strategies for usage mining and enhancing data sets.



































































































