At JetBrains, we’ve spent 25 years building tools for developers. Over the past two years, we’ve seen that AI isn’t just changing how developers write code – it’s beginning to reshape the entire process of product development.
Not only is AI making developers more productive, helping with everything from code completion to testing and deployment, but we’re also seeing the rise of tools like Lovable, Replit, and Bolt, which enable people without coding skills to create simple apps.
While these tools are great for building MVPs or quick prototypes, they hit a wall the moment you need multiple services, non-trivial business logic, or complex frontend operations. They’re built for solo creators, not teams working on production codebases.
At JetBrains, we believe great products still require teams. They depend on the work of product managers who understand the business, designers who craft great user experiences, and engineers who build solid architecture. They are built on collaboration, creative thinking, and the unique expertise and experience each role brings to the table.
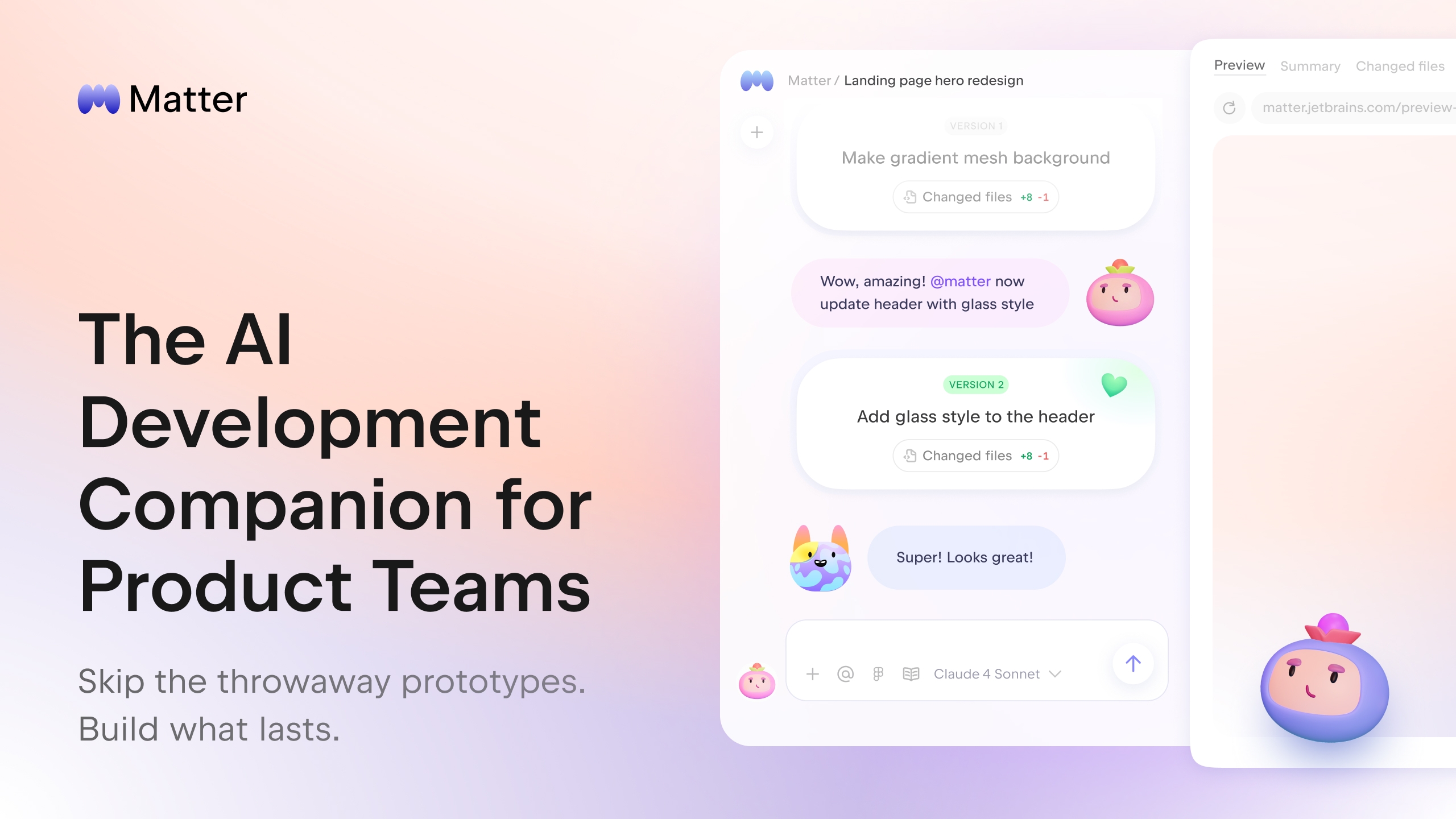
That’s why we built Matter – an AI development companion for product teams working on complex codebases.
Today, we’re opening the Early Access Program for Matter, and we would love for your team to check it out!
At this stage, Matter works with web-based projects only.
What is Matter?
Matter is an AI-powered, cloud-based tool that allows your team to prototype and test new ideas directly in your existing codebase without writing code.
It enables real-time collaboration with teammates and live preview sharing – providing an experience similar to what you get with a design tool.
Matter connects to your GitHub repository, where it provides an isolated environment for safe experimentation and allows you to see and share changes in real time. You can also create GitHub pull requests directly from its interface.
How it works:
- Connect your project
Link Matter to your existing repository and get a live preview running in minutes. Everything happens in an isolated environment, so there’s no risk to your production code.
- Invite your teammates
Add your teammates, including product managers, designers, and developers, to the project, where you can all collaborate on prototypes.
- Modify with Matter
Use simple prompts like “Make this a single-page checkout“ or “Add a product review section“ to modify your app instantly. Matter’s AI agent handles the implementation so you don’t have to do any coding.
- See changes instantly
Every change appears immediately in your live preview. Test interactions, click through flows, and see exactly how your ideas work in real-world implementations.
- Collaborate in real time
Say goodbye to localhost:3000 – Matter lets you share working prototypes instantly with teammates and stakeholders. Whether you’re explaining ideas to decision-makers or validating ideas with customers, you get feedback in minutes with functional demos instead of static mockups.
- Hand off what you built
Matter integrates directly with GitHub and allows you to create a GitHub pull request from its interface. Used to a more traditional handoff? No problem – Matter can create an issue draft, generating both the code and the documentation for you.
For developers: Focus on what matters most
Developers, what if your team’s designers could work on that “update button color” ticket themselves? What if the product manager could prototype the new checkout flow without pulling you into yet another alignment meeting?
You’d have more time for the things you enjoy the most – architectural decisions, performance optimizations, or other tasks that require deep engineering work.
With Matter, your non-technical teammates can work directly in the codebase. They can iterate on the UI, test interactions, and hand you a working prototype by creating a GitHub pull request. Everything happens in an isolated environment, so there’s no risk to your production code.
This changes the way you work, allowing you to:
- Join design discussions earlier – When everyone works with actual code instead of specs and mockups, you can contribute to feature design from the start.
- Reclaim your focus – No more P3 bug fixes for typos and padding tweaks. No more rebuilding Figma mockups from scratch. Designers iterate on the UI, while you focus on the architecture and complex challenges that require your expertise.
- Ship faster, together – Tighter feedback loops mean faster iteration. When PMs and designers can validate ideas in hours, the whole team moves faster.
The best part? Your expertise remains essential, but is focused where it has the greatest impact.
For product managers and designers: Build independently
You’ve been designing in Figma, writing specs in Notion, and hoping developers interpret your vision correctly. Then comes the feedback: “This will take three sprints” or “We can’t do that with our current architecture”.
What if you could test your ideas directly in the real codebase instead of just writing a spec?
With Matter, you can build functional prototypes and working features without having to do any coding.
This unlocks your ability to:
- Ship faster – Speed up the time-to-market for new features and test product hypotheses faster.
- Speak the same language – Hand off working prototypes simply by creating GitHub pull requests.
- Move independently – Make UI changes, fix copy, and adjust layouts without waiting for a developer’s calendar to open up.
The JetBrains way
At JetBrains, we’ve always believed in empowering people to do their best work. We build tools that enhance creativity and make the hard things easier.
Matter is built on this same principle. We’re giving PMs and designers the ability to test ideas without creating bottlenecks for engineering. We’re giving developers the freedom to focus on the problems that most require their expertise. And we’re giving your business a more effective team thanks to a tighter feedback loop.
Whether you’re a developer who wants to focus on complex problems, a designer who wants to see ideas come to life faster, or a PM who needs to validate hypotheses quickly, Matter gives you the tools to do your best work.


When it comes to writing short scripts or CRUDs, Python is a great choice. With its rich ecosystem and broad adoption, it can be easily used to scrape some data or to perform data analysis. However, maintaining a large codebase in Python can be very problematic.
Python’s dynamic typing and mutable nature, while offering flexibility for rapid development, may present additional considerations in larger codebases. Event-loop-based coroutines can be tricky and may lead to subtle issues in practice . Finally, the single-threaded and dynamically typed nature of this language makes Python code significantly less efficient than most of its modern competitors.
JVM is one of the fastest runtime platforms, making Java nearly as efficient as C. Most benchmarks show that Python code is 10 to 100 times slower than Java code. One big research paper compared the performance of multiple languages and showed that Python code is 74x more CPU-expensive than code in C, where Java code is only 1.8x more expensive. However, due to its long-standing commitment to backward compatibility, Java can feel verbose for certain tasks. Kotlin, building on that same ecosystem and offering the same efficiency, gives you access to a powerful typesystem, with modern language features focused on performance and developer ergonomics.
Those are the key reasons we can hear from companies or teams that decide to switch from Python to Kotlin. The Kotlin YouTube channel recently published Wolt’s success story, but that is only one voice among many. Kotlin is an all-around sensible choice for a range of projects, as it shares many similarities with Python. At the same time, Kotlin offers better performance, safety, and a much more powerful concurrency model. Let’s see those similarities and differences in practice.
Similarities between Python and Kotlin
When teaching Kotlin to both Python and Java developers, I was often surprised to discover that many Kotlin features are more frequently reported as intuitive by Python developers than their Java counterparts. Both languages offer concise syntax. Let’s compare some very simple use cases in both languages:
val language = "Kotlin"
println("Hello from $language")
// prints "Hello from Kotlin"
val list = listOf(1, 2, 3, 4, 5)
for (item in list) {
println(item)
}
// prints 1 2 3 4 5 each in a new line
fun greet(name: String = "Guest") {
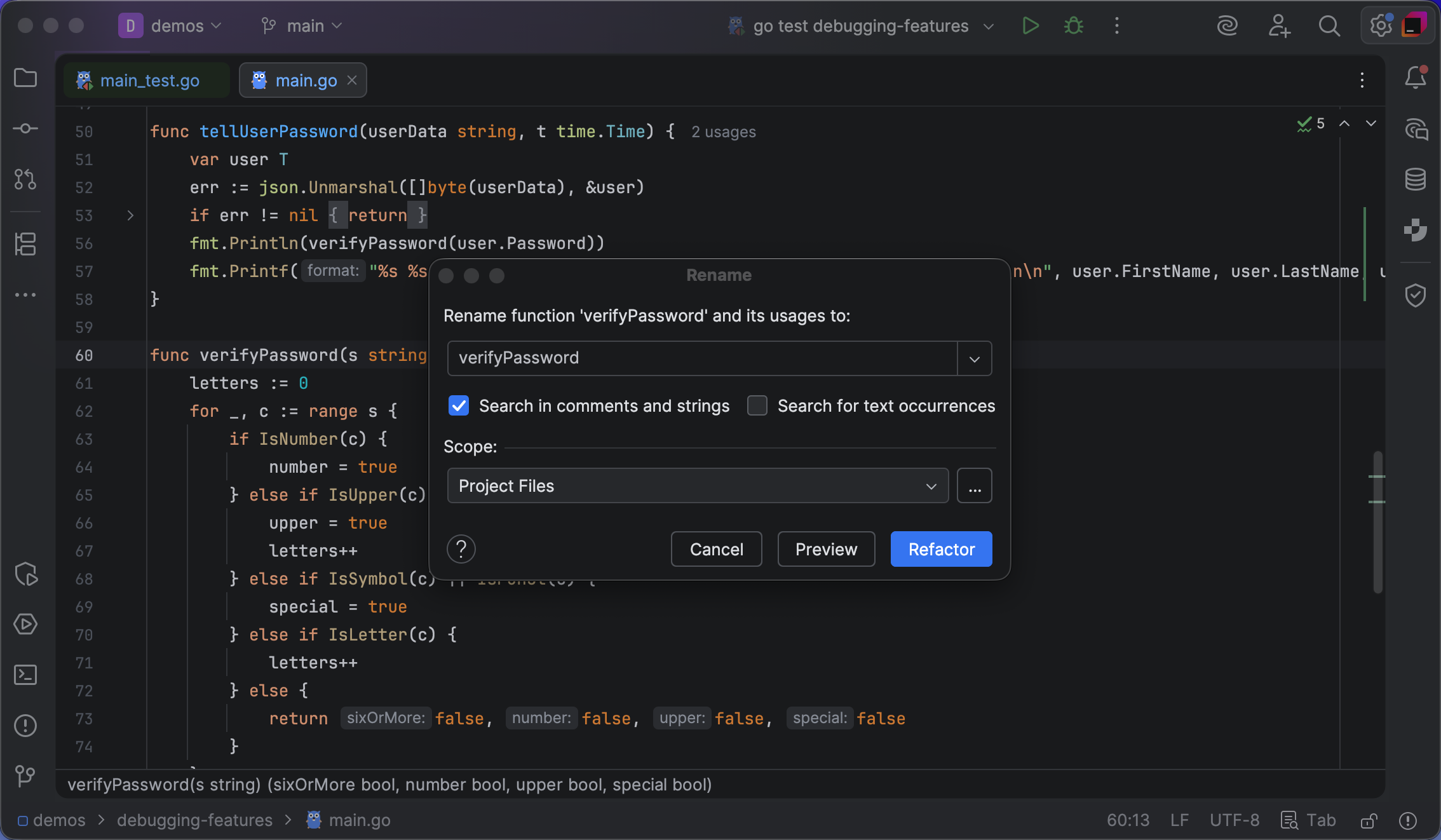
println("Hello, $name!")
}
greet() // prints "Hello, Guest!"
language = "Python"
print(f"Hello from {language}")
# prints "Hello from Python"
list = [1, 2, 3, 4, 5]
for item in list:
print(item)
# prints 1 2 3 4 5 each in a new line
def greet(name="Guest"):
print(f"Hello, {name}!")
greet() # prints "Hello, Guest!"
At first glance, there are only minor syntactic differences. Kotlin presents features well-known to Python developers, like string interpolation, concise loops, and default parameters. However, even in this simple example, we can see some advantages that Kotlin has over Python. All properties are statistically typed, so language is of type String, and list is of type List<Int>. That not only allows for low-level optimizations, but it also brings enhanced safety and better IDE support. All variables in the code above are also defined as immutable, so we cannot accidentally change their values. To change them, we would need to use var instead of val. The same goes for the list I used in this snippet – it is immutable, so we cannot accidentally change its content. To create a mutable list, we would need to use mutableListOf and type it as MutableList<Int>. This strong distinction between mutable and immutable types is a great way to avoid accidental changes, which are often the source of bugs in Python programs.
There are other advantages of Kotlin over Python that are similarly apparent in the above example. Python’s default arguments are static, so changing them influences all future calls. This is a well-known source of very sneaky bugs in Python programs. Kotlin’s default arguments are evaluated at each call, so they are safer.
Kotlin
fun test(list: MutableList<Int> = mutableListOf()) {
list.add(1)
println(list)
}
test() // prints [1]
test() // prints [1]
test() // prints [1]
Python
def test(list=[]): list.append(1) print(list) test() # prints [1] test() # prints [1, 1] test() # prints [1, 1, 1]
Let’s talk about classes. Both languages support classes, inheritance, and interfaces. To compare them, let’s look at a simple data class in both languages:
Kotlin
data class Post( val id: Int, val content: String, val publicationDate: LocalDate, val author: String? = null ) val post = Post(1, "Hello, Kotlin!", LocalDate.of(2024, 6, 1)) println(post) // prints Post(id=1, content=Hello, Kotlin!, publicationDate=2024-06-01, author=null)
Python
@dataclass
class Post:
id: int
content: str
publication_date: date
author: Optional[str] = None
post = Post(1, "Hello, Python!", datetime.date(2024, 6, 1))
print(post) # prints Post(id=1, content='Hello, Python!', publication_date=datetime.date(2024, 6, 1), author=null)
Kotlin has built-in support for data classes, which automatically allows such objects to be compared by value, destructured, and copied. Python requires an additional decorator to achieve similar functionality. This class is truly immutable in Kotlin, and thanks to static typing, it requires minimal memory. Outside of that, both implementations are very similar. Kotlin has built-in support for nullability, which in Python is expressed with the Optional type from the typing package.
Now, let’s define a repository interface and its implementation in both languages. In Kotlin, we can use Spring Data with coroutine support, while in Python, we can use SQLAlchemy with async support. Notice that in Kotlin, there are two kinds of properties: Those defined inside a bracket are constructor parameters, while those defined within braces are class properties. So in SqlitePostRepository, crud is expected to be passed in the constructor. The framework we use will provide an instance of PostCrudRepository, which is generated automatically by Spring Data.
Kotlin
interface PostRepository {
suspend fun getPost(id: Int): Post?
suspend fun getPosts(): List<Post>
suspend fun savePost(content: String, author: String): Post
}
@Service
class SqlitePostRepository(
private val crud: PostCrudRepository
) : PostRepository {
override suspend fun getPost(id: Int): Post? = crud.findById(id)
override suspend fun getPosts(): List<Post> = crud.findAll().toList()
override suspend fun savePost(content: String, author: String): Post =
crud.save(Post(content = content, author = author))
}
@Repository
interface PostCrudRepository : CoroutineCrudRepository<Post, Int>
@Entity
data class Post(
@Id @GeneratedValue val id: Int? = null,
val content: String,
val publicationDate: LocalDate = LocalDate.now(),
val author: String
)
Python
class PostRepository(ABC):
@abstractmethod
async def get_post(self, post_id: int) -> Optional[Post]:
pass
@abstractmethod
async def get_posts(self) -> List[Post]:
pass
@abstractmethod
async def save_post(self, content: str, author: str) -> Post:
pass
class SqlitePostRepository(PostRepository):
def __init__(self, session: AsyncSession):
self.session = session
async def get_post(self, post_id: int) -> Optional[Post]:
return await self.session.get(Post, post_id)
async def get_posts(self) -> List[Post]:
result = await self.session.execute(select(Post))
return result.scalars().all()
async def save_post(self, content: str, author: str) -> Post:
post = Post(content=content, author=author)
self.session.add(post)
await self.session.commit()
await self.session.refresh(post)
return post
class Post(Base):
__tablename__ = "posts"
id: Mapped[int] = Column(Integer, primary_key=True, index=True)
content: Mapped[str] = Column(String)
publication_date: Mapped[date] = Column(Date, default=date.today)
author: Mapped[str] = Column(String)
Those implementations are very similar in many ways, and the key differences between them result from choices made by the frameworks, not the languages themselves. Python, due to its dynamic nature, encourages the use of untyped objects or dictionaries; however, such practices are generally discouraged in modern times. Both languages provide numerous tools for libraries to design effective APIs. On the JVM, these languages often depend on annotation processing, whereas in Python, decorators are more common. Kotlin leverages a mature and well-developed Spring Boot ecosystem, but it also offers lightweight alternatives such as Ktor or Micronaut. Python has Flask and FastAPI as popular lightweight frameworks, and Django as a more heavyweight framework.
In a backend application, we also need to implement services, which are classes that implement business logic. They often do some collection or string processing. Kotlin provides a comprehensive standard library with numerous useful functions for processing collections and strings. All those functions are named and called in a very consistent way. In Python, we can make nearly all transformations available in Kotlin, but to do so, we need to use many different kinds of constructs. In the code below, I needed to use top-level functions, methods on lists, collection comprehensions, or even classes from the collections package. Those constructs are not very consistent, some of them are not very convenient, and are not easily discoverable. You can also see that complicated notation for defining lambda expressions in Python harms collection processing APIs. Collection and string processing in Kotlin is much more pleasant and productive.
Kotlin
class PostService(
private val repository: PostRepository
) {
suspend fun getPostsByAuthor(author: String): List<Post> =
repository.getPosts()
.filter { it.author == author }
.sortedByDescending { it.publicationDate }
suspend fun getAuthorsWithPostCount(): Map<String?, Int> =
repository.getPosts()
.groupingBy { it.author }
.eachCount()
suspend fun getAuthorsReport(): String =
getAuthorsWithPostCount()
.toList()
.sortedByDescending { (_, count) -> count }
.joinToString(separator = "n") { (author, count) ->
val author = author ?: "Unknown"
"$author: $count posts"
}
.let { "Authors Report:n$it" }
}
Python
class PostService:
def __init__(self, repository: "PostRepository") -> None:
self.repository = repository
async def get_posts_by_author(self, author: str) -> List[Post]:
posts = await self.repository.get_posts()
filtered = [post for post in posts if post.author == author]
sorted_posts = sorted(
filtered,
key=lambda p: p.publication_date,
reverse=True
)
return sorted_posts
async def get_authors_with_post_count(self) -> Dict[Optional[str], int]:
posts = await self.repository.get_posts()
counts = Counter(p.author for p in posts)
return dict(counts)
async def get_authors_report(self) -> str:
counts = await self.get_authors_with_post_count()
items = sorted(counts.items(), key=lambda kv: kv[1], reverse=True)
lines = [
f"{(author if author is not None else 'Unknown')}: {count} posts"
for author, count in items
]
return "Authors Report:n" + "n".join(lines)
Before we finish our comparison, let’s complete our example backend application by defining a controller that exposes our service through HTTP. Until now, I have used Spring Boot, which is the most popular framework for Kotlin backend development. This is how it can be used to define a controller:
Kotlin
@Controller
@RequestMapping("/posts")
class PostController(
private val service: PostService
) {
@GetMapping("/{id}")
suspend fun getPost(@PathVariable id: Int): ResponseEntity<Post> {
val post = service.getPost(id)
return if (post != null) {
ResponseEntity.ok(post)
} else {
ResponseEntity.notFound().build()
}
}
@GetMapping
suspend fun getPostsByAuthor(@RequestParam author: String): List<Post> =
service.getPostsByAuthor(author)
@GetMapping("/authors/report")
suspend fun getAuthorsReport(): String =
service.getAuthorsReport()
}
However, we noticed that many Python developers prefer a lighter and simpler framework, and their preferred choice for such functionality is Ktor. Ktor allows users to define a working application in just a couple of lines of code. This is a complete Ktor Server application that implements a simple in-memory text storage (it requires no other configuration or dependencies except Ktor itself):
Kotlin
fun main() = embeddedServer(Netty, port = 8080) {
routing {
var value = ""
get("/text") {
call.respondText(value)
}
post("/text") {
value = call.receiveText()
call.respond(HttpStatusCode.OK)
}
}
}.start(wait = true)
I hope that this comparison helped you see both the key similarities and differences between Python and Kotlin. As we’ve seen, Kotlin has many features that are very intuitive for Python developers. At the same time, Kotlin offers many improvements over Python, especially in terms of safety. It has a powerful static type system that prevents many common bugs, built-in support for immutability, and a very rich and consistent standard library.
To summarize, I believe it’s fair to say that both languages are very similar in many ways, but Kotlin brings a number of improvements – some small, some big. In addition, Kotlin offers some unique features that are not present in Python, the biggest one probably being a concurrency model based on coroutines.
kotlinx.coroutines vs. Python asyncio
The most modern approach to concurrency in Kotlin and Python is based on coroutines. In Python, the most popular library for this purpose is asyncio, while in Kotlin, there is the Kotlin kotlinx.coroutines library. Both libraries can start lightweight asynchronous tasks and await their completion. However, there are some important differences between them.
Let’s start with the hallmark feature of kotlinx.coroutines: first-class support for structured concurrency. Let’s say that you implement a service like SkyScanner, which searches for the best flight offers. Now, let’s suppose a user makes a search, which results in a request or the opening of a WebSocket connection to our service. Our service needs to query multiple airlines to return the best offers. Let’s then suppose that this user left our page soon after searching. All those requests to airlines are now useless and likely very costly, because we have a limited number of ports available to make requests. However, implementing explicit cancellation of all those requests is very hard. Structured concurrency solves that problem. With kotlinx.coroutines, every coroutine started by a coroutine is its child, and when the parent coroutine is cancelled, all its children are cancelled too. This way, our cancellation is automatic and reliable.
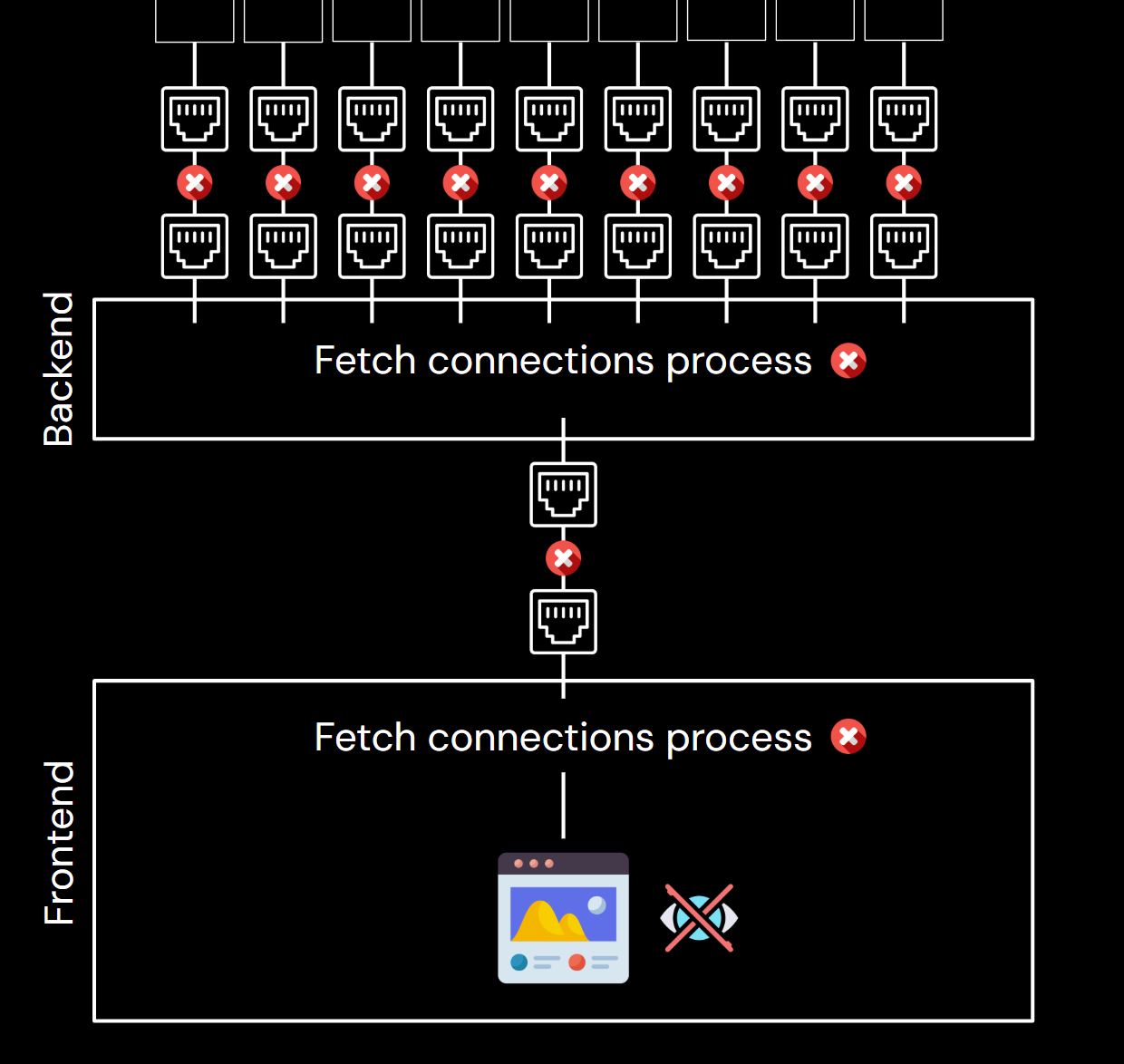
However, structured concurrency goes even further. If getting a resource requires loading two other resources asynchronously, an exception in one of those two resources will cancel the other one too. This way, kotlinx.coroutines ensures that we use our resources in the most efficient way. In Python, asyncio introduced TaskGroup in version 3.11, which offers some support for structured concurrency, but it is far from what kotlinx.coroutines offer, and it requires explicit usage.
Kotlin
suspend fun fetchUser(): UserData = coroutineScope {
// fetchUserDetails is cancelled if fetchPosts fails
val userDetails = async { api.fetchUserDetails() }
// fetchPosts is cancelled if fetchUserDetails fails
val posts = async { api.fetchPosts() }
UserData(userDetails.await(), posts.await())
}
The second important difference is thread management. In Python, asyncio runs all tasks on a single thread. Notice that this is not utilizing the power of multiple CPU cores, and it is not suitable for CPU-intensive tasks. Using kotlinx.coroutines, coroutines can typically run on a thread pool (by default as big as the number of CPU cores). This way, coroutines better utilize the power of modern hardware. Of course, coroutines can also run on a single thread if needed, which is quite common in client applications.
Another big advantage of coroutines is their testing capabilities. kotlinx.coroutines provides built-in support for testing asynchronous code over a predetermined simulated timeframe, removing the need to wait while the code is tested in real time. This way, we can test asynchronous code in a deterministic way, without any flakiness. We can also easily simulate all kinds of scenarios, like different delays from dependent services. In Python, testing asynchronous code is possible using third-party libraries, but this method is not as powerful and convenient as with coroutines.
Kotlin
@Test
fun `should fetch data asynchronously`() = runTest {
val api = mockk<Api> {
coEvery { fetchUserDetails() } coAnswers {
delay(1000)
UserDetails("John Doe")
}
coEvery { fetchPosts() } coAnswers {
delay(1000)
listOf(Post("Hello, world!"))
}
}
val useCase = FetchUserDataUseCase(api)
val userData = useCase.fetchUser()
assertEquals("John Doe", userData.user.name)
assertEquals("Hello, world!", userData.posts.single().title)
assertEquals(1000, currentTime)
}
Finally, kotlinx.coroutines offer powerful support for reactive streams through the Flow type. It is perfect for representing websockets or streams of events. Flow processing can be easily transformed using operators consistent with collection processing. It also supports backpressure, which is essential for building robust systems. Python has async generators, which can be used to represent streams of data, but they are not as powerful and convenient as Flow.
Kotlin
fun notificationStatusFlow(): Flow<NotificationStatus> =
notificationProvider.observeNotificationUpdate()
.distinctUntilChanged()
.scan(NotificationStatus()) { status, update ->
status.applyNotification(update)
}
.combine(
userStateProvider.userStateFlow()
) { status, user ->
statusFactory.produce(status, user)
}
Performance comparison
One of the key benefits of switching from Python to Kotlin is performance. Python applications can be fast when they use optimized native libraries, but Python itself is not the fastest language. As a statically typed language, Kotlin can be compiled to optimized bytecode that runs on the JVM platform, which is a highly optimized runtime. In consequence, Kotlin applications are typically faster than Python applications.
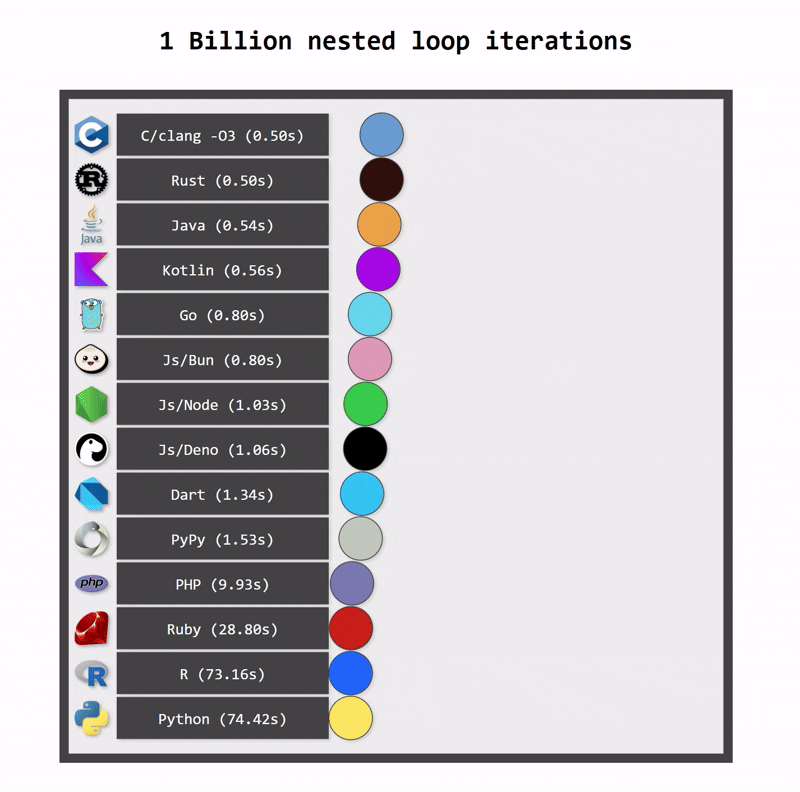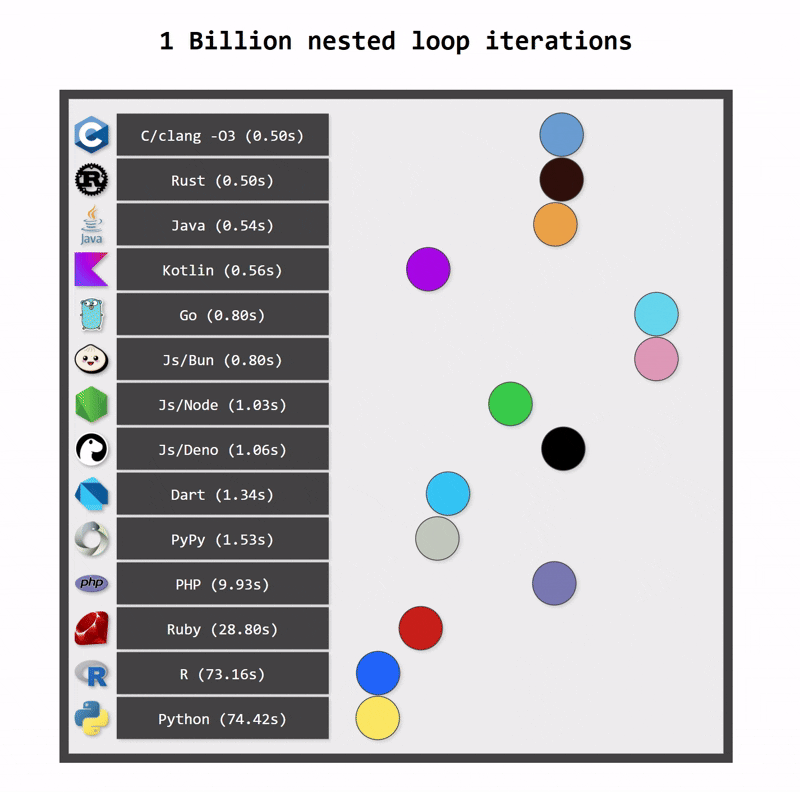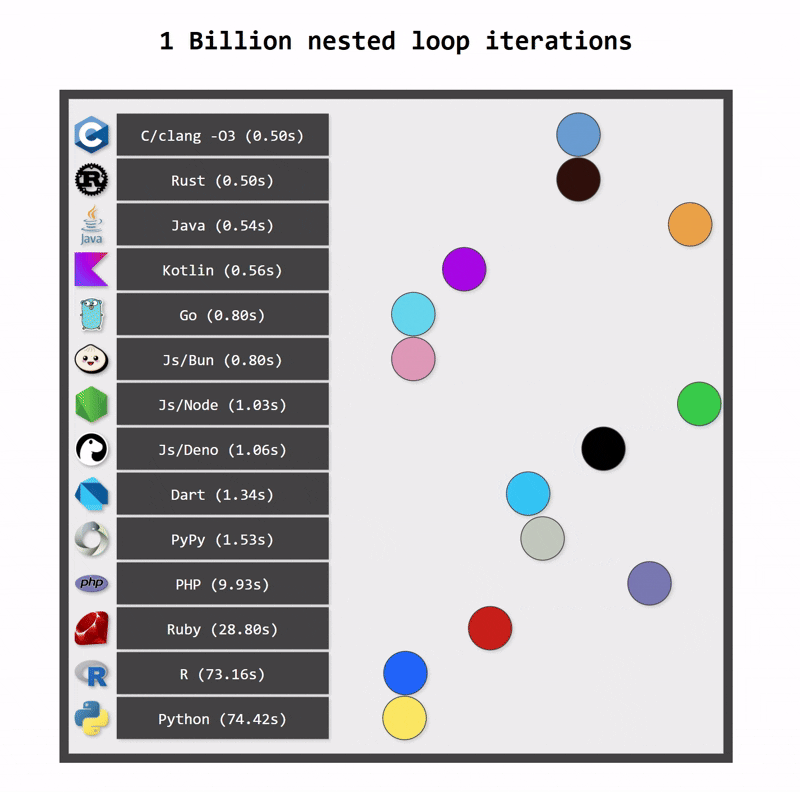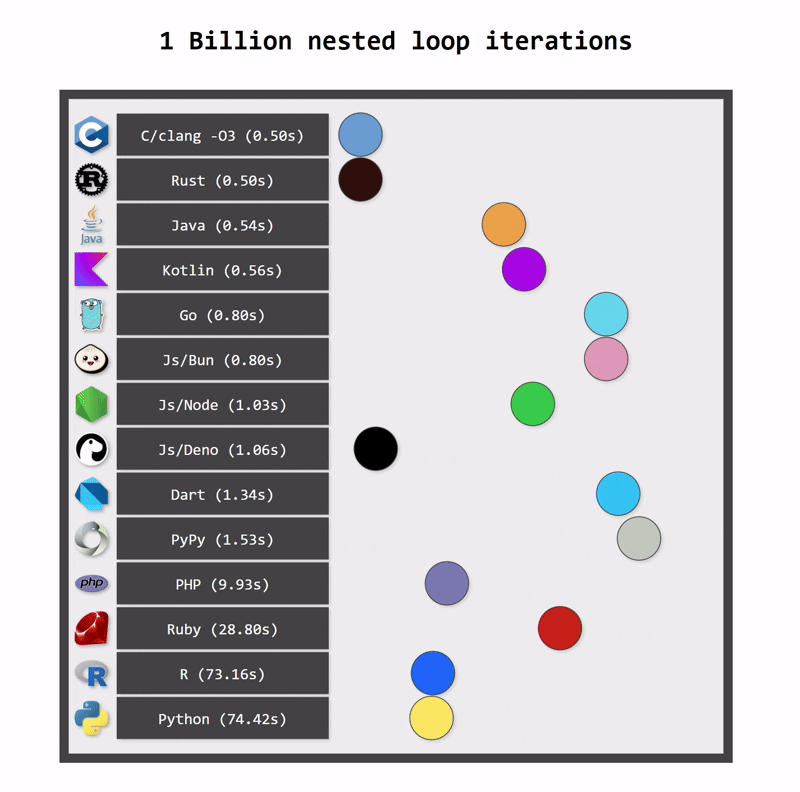
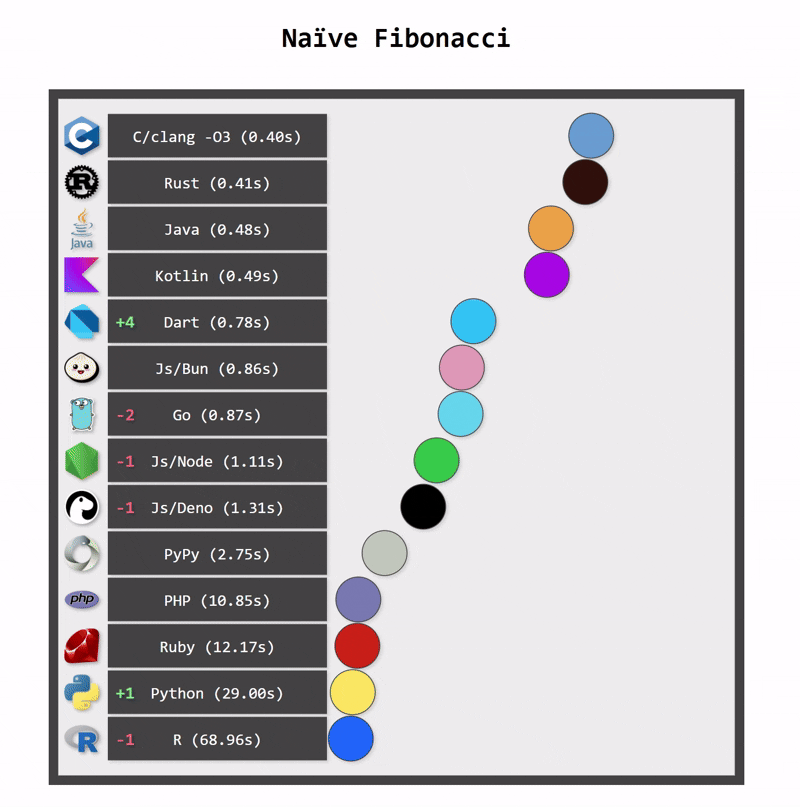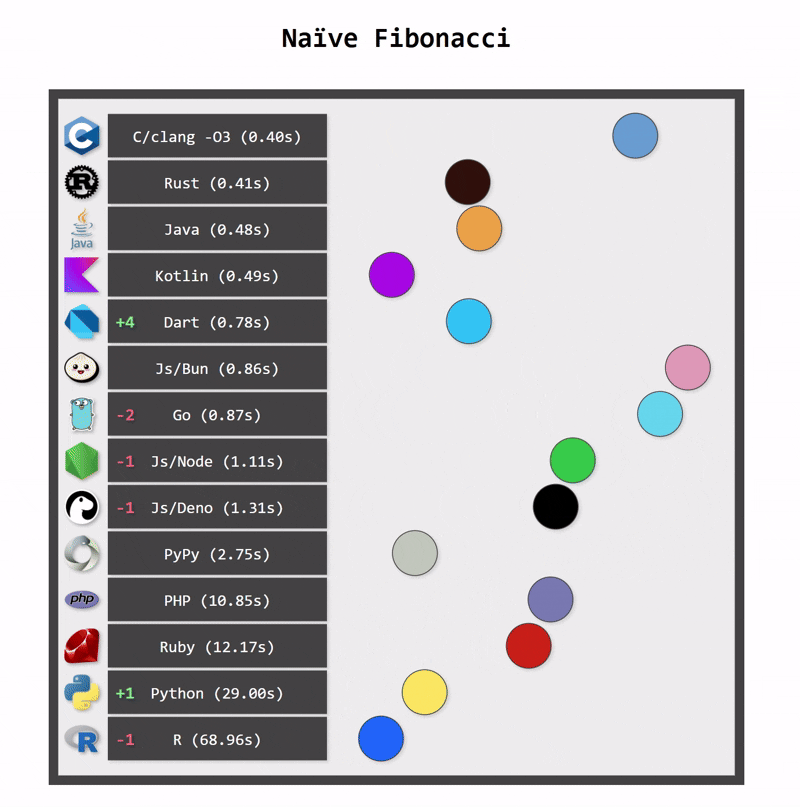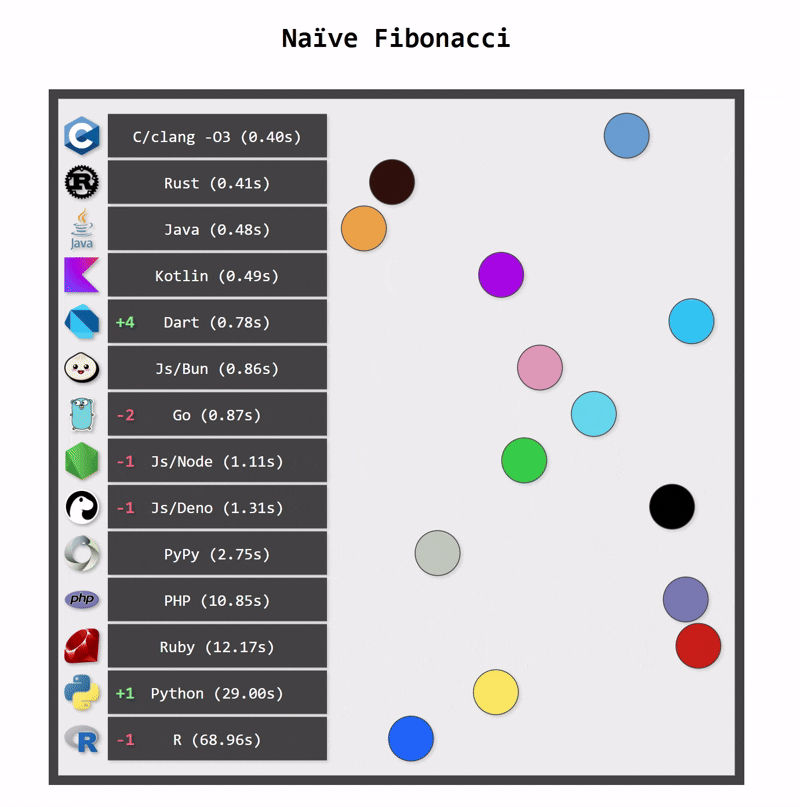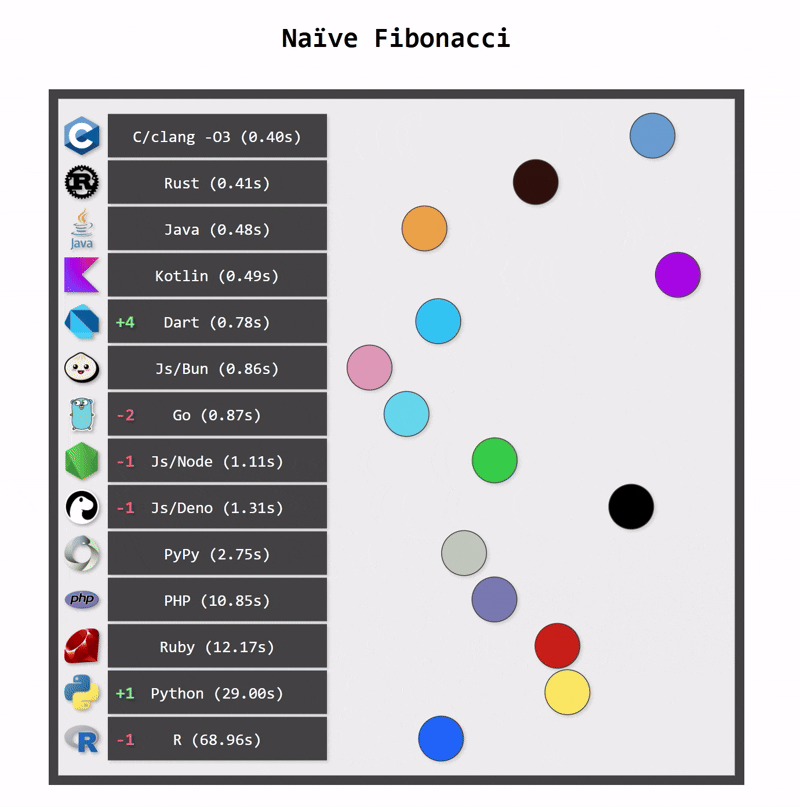
Kotlin applications also use fewer resources. One reason for this is Kotlin’s more efficient memory management (a consequence of static typing). Another reason is structured concurrency, which ensures that resources are cancelled when they are no longer needed.
Interoperability
Kotlin is fully interoperable with Java. This means that Kotlin applications can use everything from the rich Java ecosystem. Everything that can be used in Java can easily be used in Kotlin as well (see interoperability guide).
It is also possible to bridge between Kotlin and Python using libraries like JPype or Py4J. Nowadays, some libraries support further interoperability, like zodable, which allows generating Zod schemas from Kotlin data classes.
Summary
I love Kotlin and I love Python. I’ve used both languages extensively throughout my career. In the past, Python had many clear advantages over Kotlin, such as a richer ecosystem, more libraries, and scripting capabilities. In some domains, like artificial intelligence, I still find Python to be a better choice. However, for backend development, Kotlin is clearly the better option today. It offers similar conciseness and ease of use as Python, but it is faster, safer, and scales better. If you consider switching from Python to Kotlin for your backend development, it is a transition worth making.
]]>You can explore these new additions in the Rider 2025.3 EAP 6 build – let’s take a closer look at what you can expect.
A single home for performance insights
The Monitoring tool window now serves as a central hub for tracking your application’s runtime behavior – CPU usage, memory allocation, garbage collection, environment variables, and performance issues are all tracked within a single interface.
With the inclusion of Database and ASP.NET issue detection, the tool automatically highlights slow queries, excessive database connections, or long-running MVC actions and Razor handlers. These now appear alongside other runtime insights such as UI freezes, GC pressure, and performance hotspots.
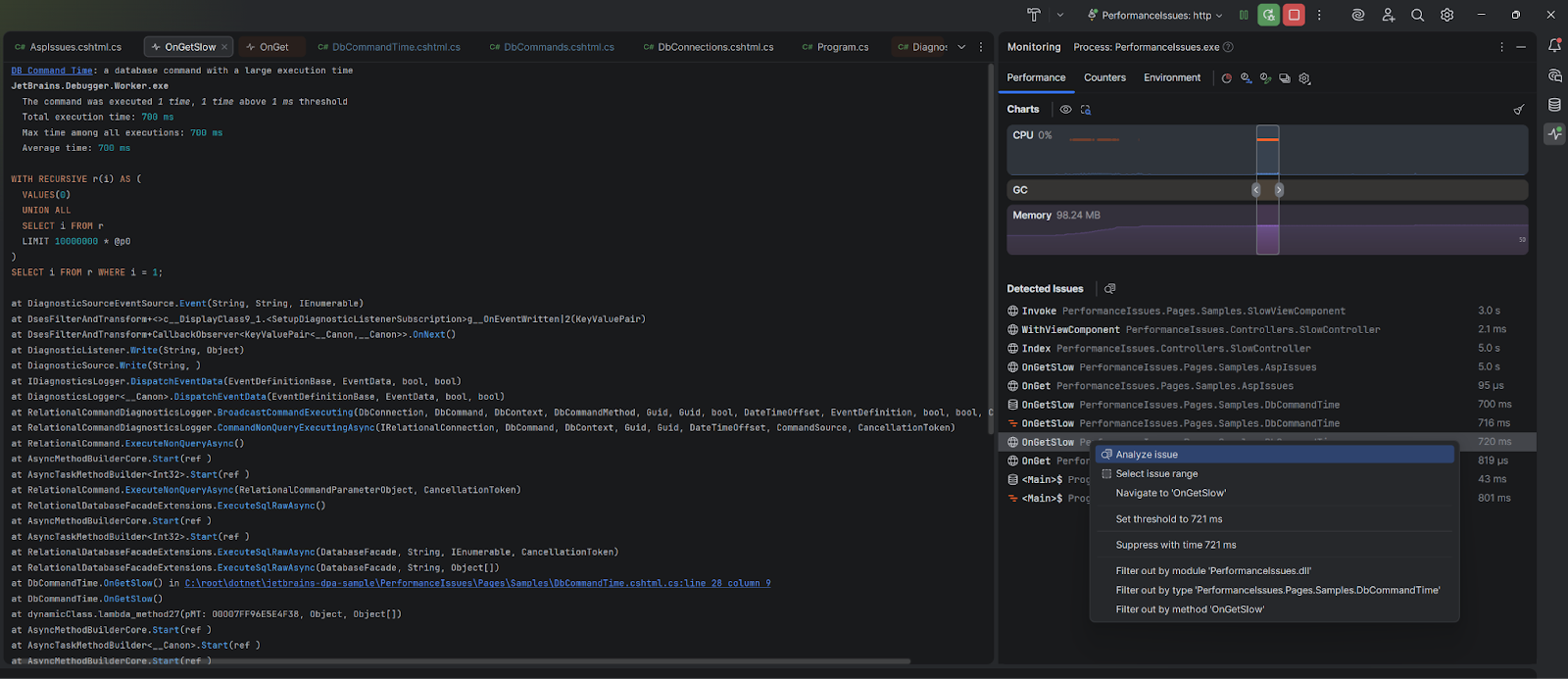
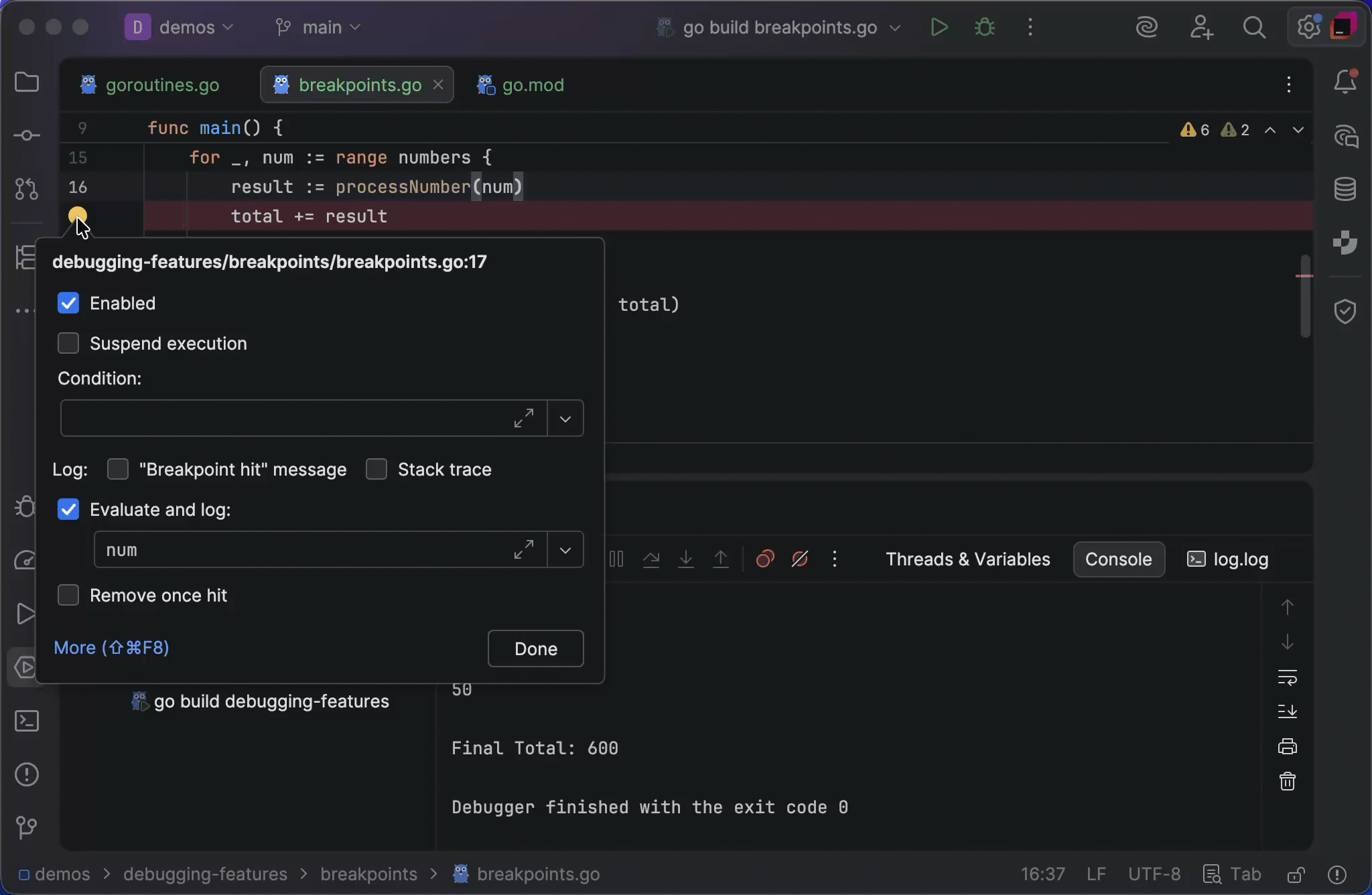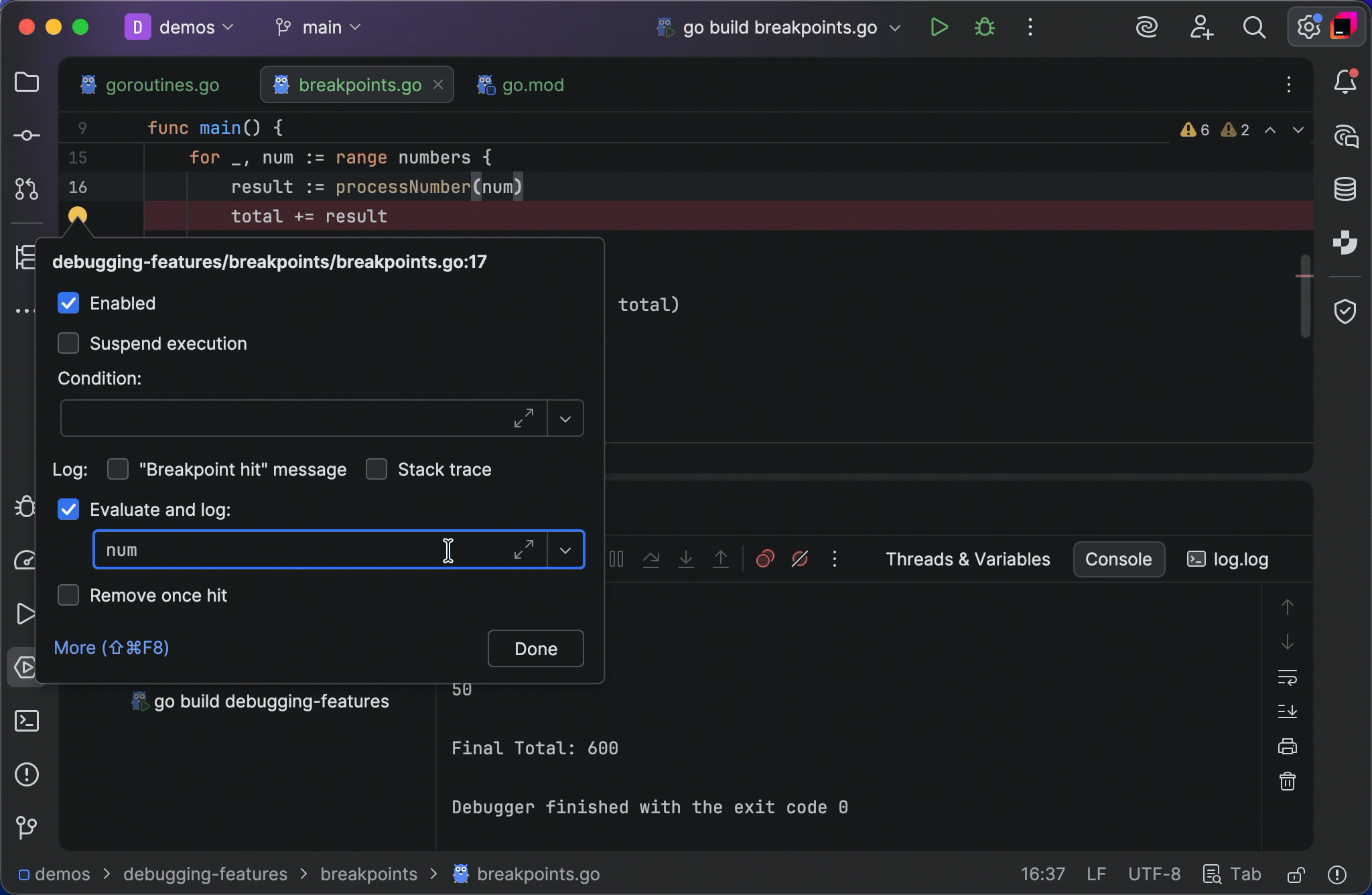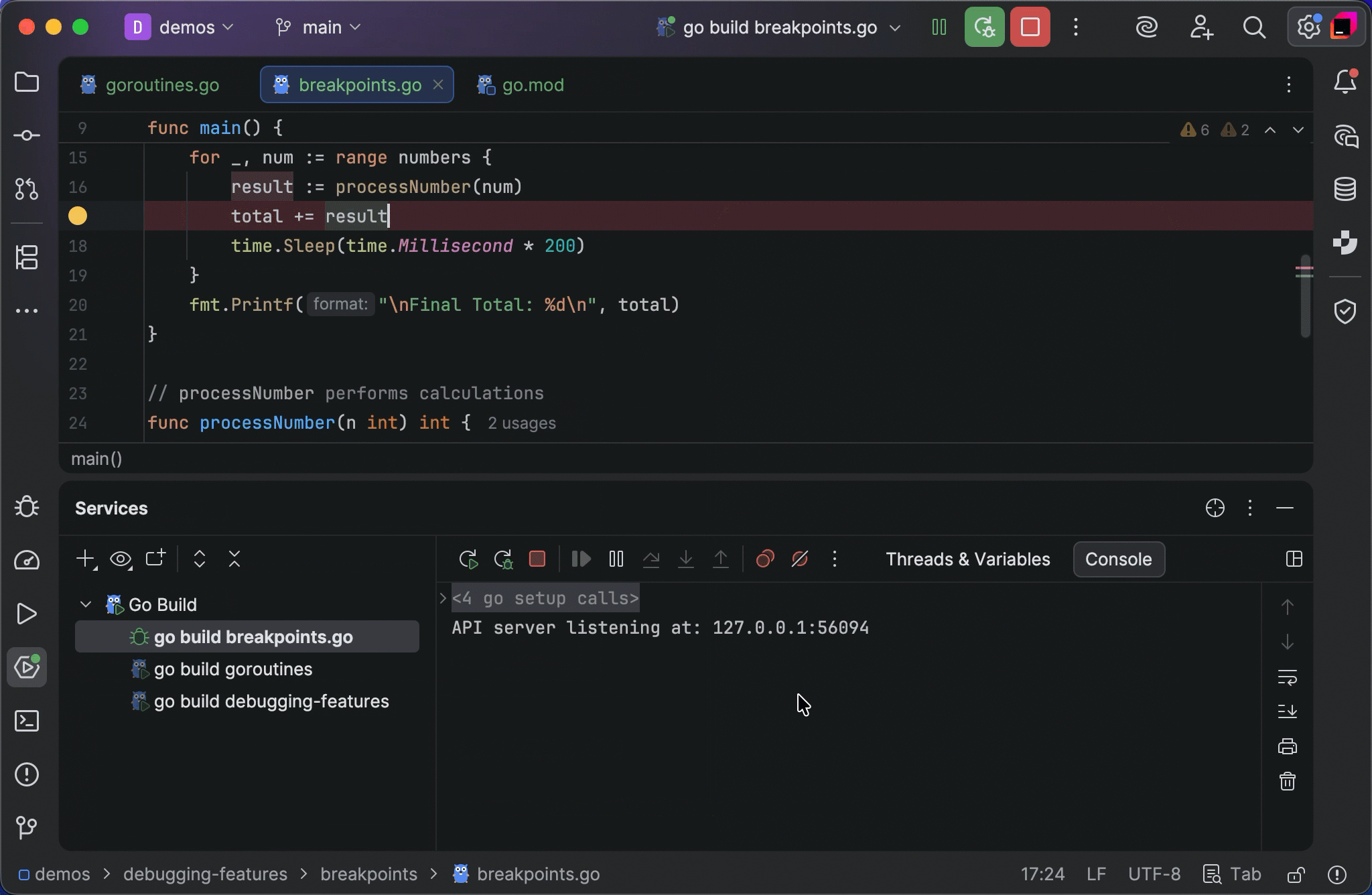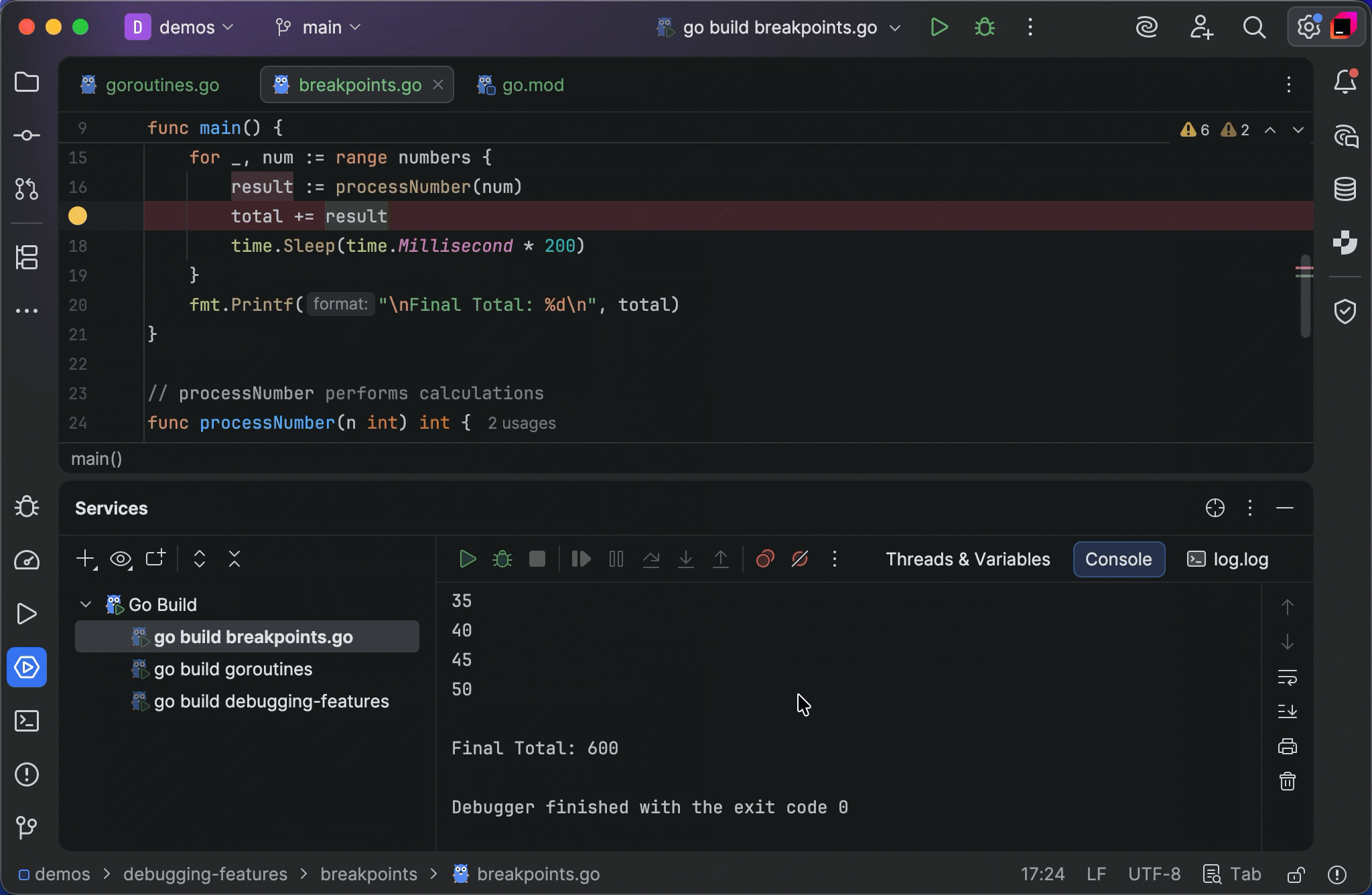
Detected issues appear directly beneath the live performance charts. You’ll see issue types like DB Command Time, DB Connections, and slow MVC actions. If you have a dotUltimate subscription, these general issue types will be replaced with names of the specific methods responsible. A dotUltimate subscription will also let you investigate each entry further using the bundled dotTrace profiler, allowing you to explore call stacks, query details, and execution times with just a couple clicks.
There’s no need to wait until your session ends to see what’s going on. ASP.NET and database issues now appear and update in real time, so you can spot and understand performance bottlenecks as they happen.
You can configure thresholds and manage the inspections by going to Settings/Preferences | Build, Execution, Deployment | Monitoring | Inspections.
Compatibility and availability
ASP.NET and database issue detection is available on Windows, Linux, and macOS. You can find additional information on supported OSs and application types in our documentation.
If you have a dotUltimate subscription, you can take your investigation even further with the bundled dotTrace profiler, which lets you jump straight to the problematic line in your source code.
___________________________________________________________________________
With everything unified in the Monitoring tool window, you no longer need to juggle multiple tools or wonder where to look when performance issues arise. Database bottlenecks, ASP.NET inefficiencies, and runtime anomalies are now captured and visualized in one place, giving you the full picture of your application’s health at a glance.
Ready to try it out? Download Rider 2025.3 EAP 6, start running or debugging your application, and the Monitoring tool window will open automatically.
You’ll be able to troubleshoot performance issues more quickly and intuitively than ever. As always, we’d love to hear your feedback. Let us know what you think in the comments below!
]]>Our Education Research team with our Strategic Research and Market Intelligence and JetBrains Academy teams addressed this gap by surveying a diverse audience on a wide range of topics. The collaboration combined their strengths: JetBrains Research brought expertise in conducting studies and writing research papers, while SRMI and JetBrains Academy brought experience with large-scale industry surveys. The dataset is available online, and we encourage you to explore it yourself!
Our researchers will present insights from the study this October 23rd at ACM CompEd, a SIGCSE family conference. And in this blog post, we will tell you about the survey and the paper to be presented, including:
- Why this kind of study is important
- How the survey was set up
- What applications the results have in the real-world
- How you can work with the data and collaborate with us
The importance of the big picture in computer science education
While individual studies have examined specific aspects of CS learning, few have captured the global picture at scale. Studies are often limited in terms of sample demographics, for example, in types of education (both formal, like university, and informal, like self-paced courses or bootcamps), participant number or country. This limitation leaves educators and policymakers without the necessary insights into how people worldwide approach CS education today. Especially considering that many people learn online, we need more collaboration and broader studies revealing higher-level trends that might otherwise be missed.
Recognizing this gap, our Education Research, our Strategic Research and Market Intelligence, and JetBrains Academy teams conducted a comprehensive survey of CS learners, representing 18,032 participants across 173 countries (paper, dataset). Our initial goal was to better understand how people learn to program today, in order to make our tools more supportive for learners. While working on the survey, we realized that the dataset has potential for other researchers; this realization led to the paper and making the dataset available on Zenodo.
The study has many advantages over similar work done previously. For one, it explicitly includes self-taught learners, which has been rare in previous studies. On top of that, it includes:
- A wide range of topics and questions
- A diverse set of learners to ensure broad representation
This post will describe the details of the study’s methodology and discuss both its key findings and potential applications.
Our computer science education survey
A primary goal of our study was to survey a broad sample size of CS learners about diverse topics. The results have been – and continue to be – useful here at JetBrains to improve our educational products. And the impact doesn’t have to end within our company or with our products: this dataset is available for anybody to explore!
With our comprehensive survey, we want to provide an example of collaboration between industry and academia. Industry resources can help academic researchers tap into a broader pool of participants or at a larger scale; and by agreeing on open data sharing, the data and results are available to the entire research community. These are just some ways we can work together to learn about CS education and, ultimately, to help CS students.
The rest of this section will describe the methodology behind the dataset, including survey design, data collection, and data processing. The next section will discuss insights that have already been gained from the survey, plus further potential applications.
Data collection
Our Strategic Research and Market Intelligence team prepared the survey and piloted it internally at JetBrains before a wider external release. The survey contained 87 questions (a mix of open and multiple-choice; all can be found here), organized into the following 10 topics:
- Demographics. Basic demographic identifiers: age, gender, geographical location, and language preferences.
- Formal Education. Educational level, institution types, and fields of study.
- Career. Career trajectory, industry experience, professional development, and job-seeking behaviors.
- Learning Topics and Formats. Subject areas studied, self-assessed proficiency, educational platforms, and course preferences.
- Coding Experience. Technology adoption patterns and development practices.
- Development Tools. IDE usage patterns and tool preferences.
- AI Integration. AI tool usage in learning contexts (for the state of things at data collection).
- Learning Challenges. Obstacles, reasons for quitting, and methods to overcome learning difficulties.
- Study Habits. Learning routines, environments, productivity strategies, and device usage.
- Motivation. Drivers for CS education engagement.
With many topics, and many questions, there is both the opportunity to gain a better understanding of CS education and also see relationships between categories that might otherwise be missed.
In addition, our team:
- Localized the survey questions into ten languages, namely:
- English, Chinese, French, German, Japanese, Korean, Brazilian Portuguese, Russian, Spanish, and Turkish
- Recruited participants with:
- Targeted advertisements on social media platforms
- Invitations to a list of people who have already given consent to be contacted by JetBrains for research purposes
- External survey panels to ensure responses from underrepresented regions such as Japan and Ukraine
- Collected the data in the first half of 2024
After collecting the initial data, our team did a sanity check, removing suspicious responses, similar to other large surveys’ methodologies (see Stack Overflow or DevEco). Examples of suspicious responses include low reported age in combination with high experience or unusually quick response times, i.e., less than five seconds per question.
Following the sanity check, the dataset contained 18,032 responses from 173 countries. Note that 14,396 of these are full responses, meaning that these respondents completed all questions in the survey.
Data processing
For this survey, data processing comprised two main steps: (i) translating all responses into English and (ii) coding the responses into categories for analysis. The following table contains example responses and their labels for the open-ended question Do you have any methods of overcoming frustration and/or the feeling that you want to give up on your studies?

For both steps, our research team used GPT-4o. While coding the responses into categories, we had to manually review the LLM output. For example, we checked the number of clusters per question, the naming of clusters for each question, and how the responses were distributed across these clusters.This manual review was necessary because the LLM would group some of the inputs into an Other category even though they might actually belong to a category; in some cases, multiple responses marked as Other would form a new category.
In addition to data processing, our researchers were careful to address potential sampling bias (details can be found in the paper). They followed industry standards in weighing the data (see, for example, the detailed methodology for DevEco or the methodology for DeveloperNation’s Pulse Report), assigning a weight to each response so that underrepresented groups would have more influence in the analysis. The main feature of the weighting process was to divide the results into:
- External: collected from social network ads, together with responses from peer referrals
- Internal: collected from JetBrains social networks and the JetBrains email list
One goal of weighting external responses was to elevate responses from underrepresented countries. Based on previous internal research, our team determined what the expected distribution should look like and applied the post-stratification method to it.
For the internal responses, in addition to the country bias, potential biases include a higher proportion of JetBrains product users and a higher amount of experience in software engineering overall. In this case, the weighting technique, a type of calibration, involved using information from the external responses for the country bias, plus a series of calculations.
By applying the weighting methodology to both the internal and external responses, our team reduced potential biases. This ensured the study remained as unbiased as possible across the diverse global sample.
The full dataset, including categorization and data weighting, is available as supplementary material. The supplementary material, in particular the dataset, is intended to be accessible (and useful!) to researchers regardless of their technical background.
Real-world applications
In the paper, our team presented the following example research directions and their corresponding results. We will go into more detail about them in the rest of this section. which might inspire you for your own analysis based on the dataset:
- Learning challenges
- Emerging learning formats, including massive open online courses (MOOCs) and code schools
- In-Integrated developer environment (–IDE) learning practices
These are just a sample of what could be explored. For example, you could look at the table from the previous section and pick out a topic to explore further, like learning motivations. Or, you could look at how AI integrations look today compared to data collection. Or see if there is a relationship between students’ learning routines and frequency of quitting. What would your research idea be?
Learning challenges
First, we will look at what frustrations students identify when studying CS. Previous studies on this topic have looked specifically at why some students drop out of formal CS programs at universities, why some students persevere in the same type of program, and the challenges faced in different learning modes such as massive open online courses (MOOCs) and in-IDE learning. Our dataset builds on this body of work, complementing their results. Some of the relevant survey questions are listed below.

The first two of the above questions were multiple-choice, and only the third one was open-ended. For the multiple-choice questions, participants could pick more than one answer.
For the first question, the participants selected several challenges, both at the theoretical and practical levels. The top five choices and their percentages are shown in the following infographic.

There are some students who find learning CS so challenging that they decide to abandon their studies. The survey participants reported Unengaging content as a top reason for leaving, followed by Heavy workload and time constraints. These and the rest of the top five reasons are depicted below.

Despite the challenges, many CS learners find ways to stay motivated and continue learning. Commonly reported methods of overcoming frustration are listed in the image below. Note that this question was the only open-ended one of the bunch, so the responses were categorized during data processing.
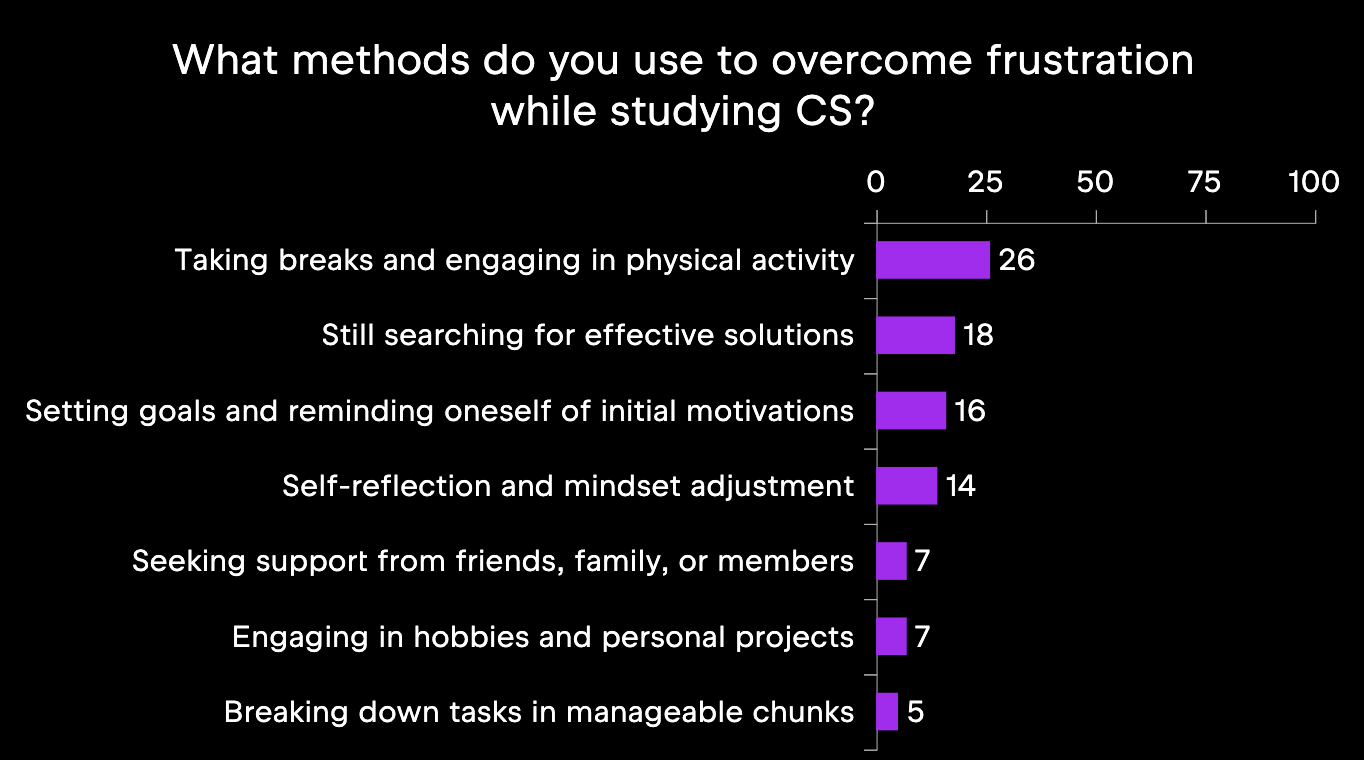
The students who answered this question reported a variety of methods, but one of the most common responses was that they are still looking for an effective way to overcome frustrations in CS learning. For educators and those creating CS courses, this is a valuable insight!
In summary, studying CS involves challenges like abstract concepts, heavy workloads, and unengaging content, which can lead to frustration and course dropout. To cope, students try to offset the frustration with physical activity and internal motivations, but many still need support in this. Our dataset can offer answers to questions about student behavior beyond what is reported here.
Learning formats
In this subset of questions, we were interested in the most popular learning formats and what the participants’ experience with them was. Although we already know that it is possible to study CS with in-IDE courses or with MOOCs, we were interested in a more systematic view of learning formats and in including more formal education options like university. The relevant survey questions are listed below; all three were multiple-choice.

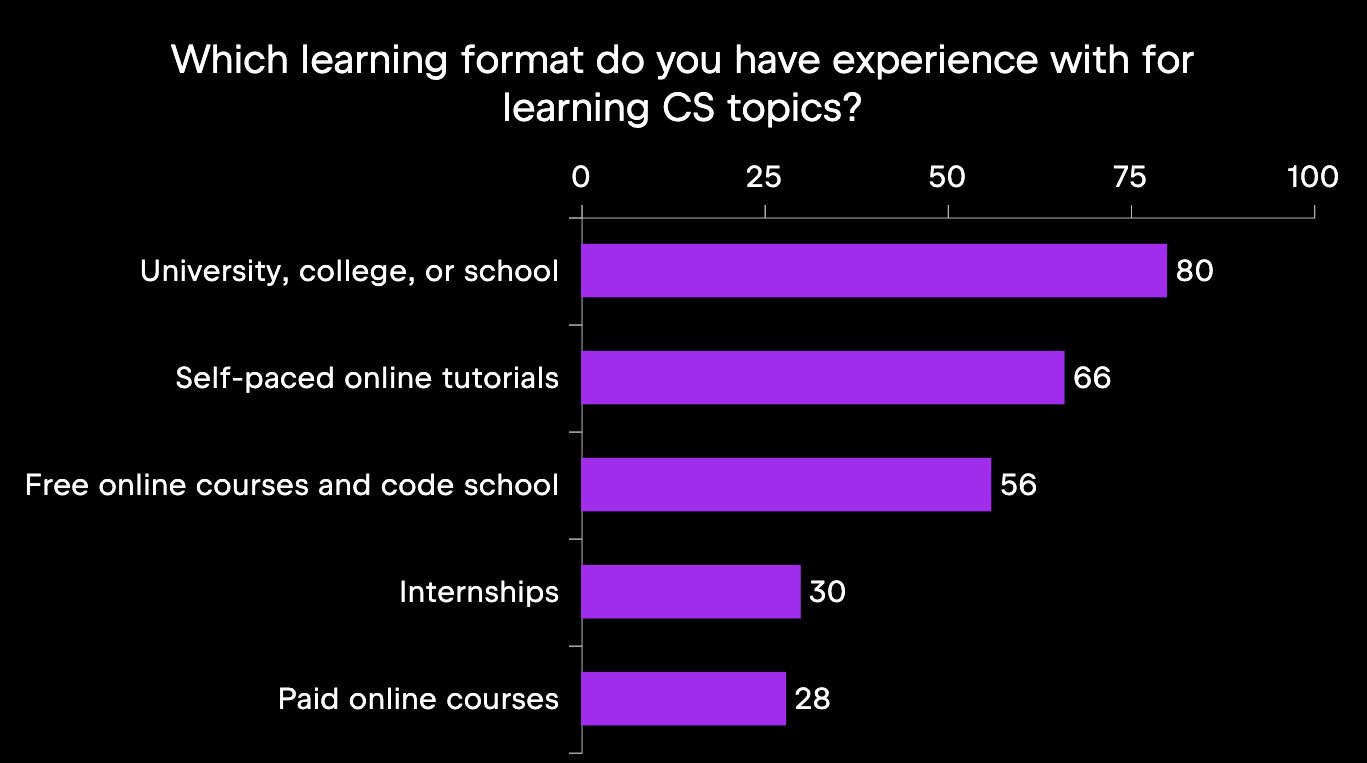
First, we will look at the most common learning formats, depicted in the below infographic. The most popular format is to learn at university, college, or school at about 80%; the second most popular are self-paced online tutorials with two-thirds of the participants reporting this experience. Internships and paid online courses, for example, are less common, at about 30% for each.
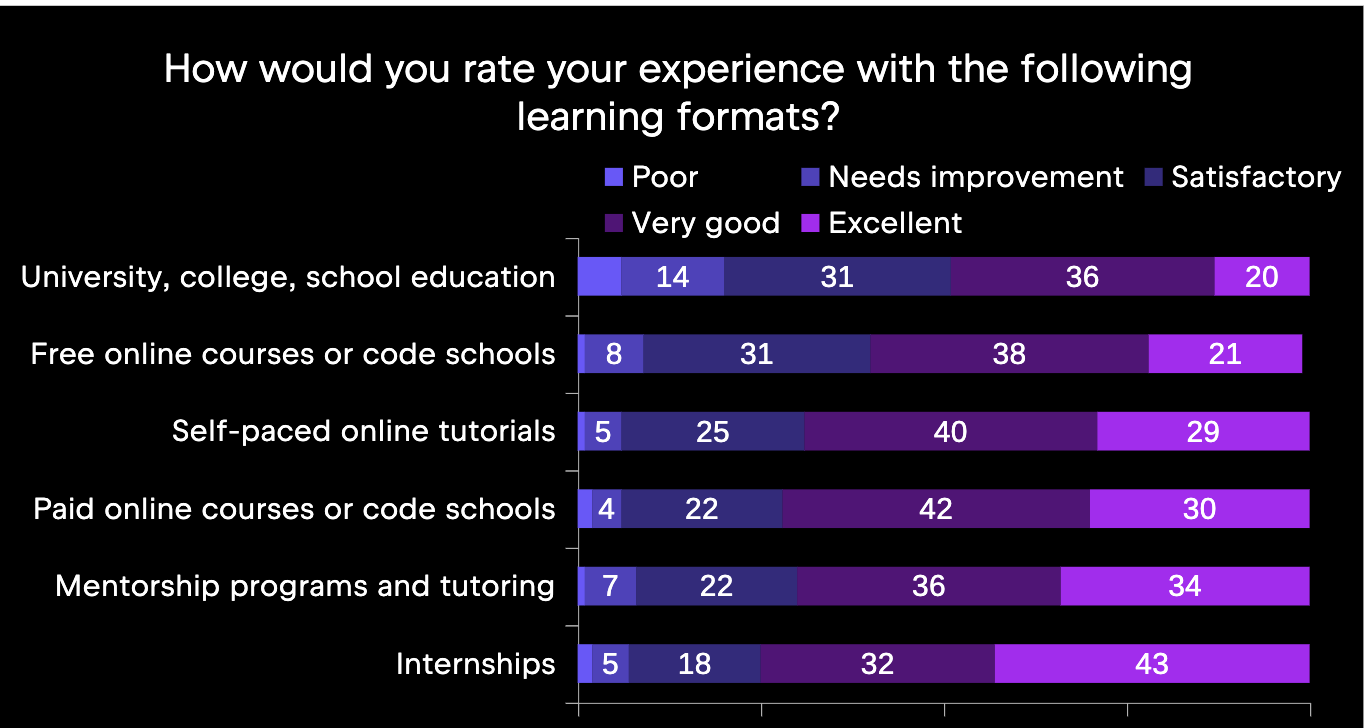
Interestingly, while formal CS studies are very popular, our survey participants rated this format as the worst. More positively rated learning formats include both the more common self-paced online tutorials, and the less common paid online courses and internships. Check out the ratings in the below image.
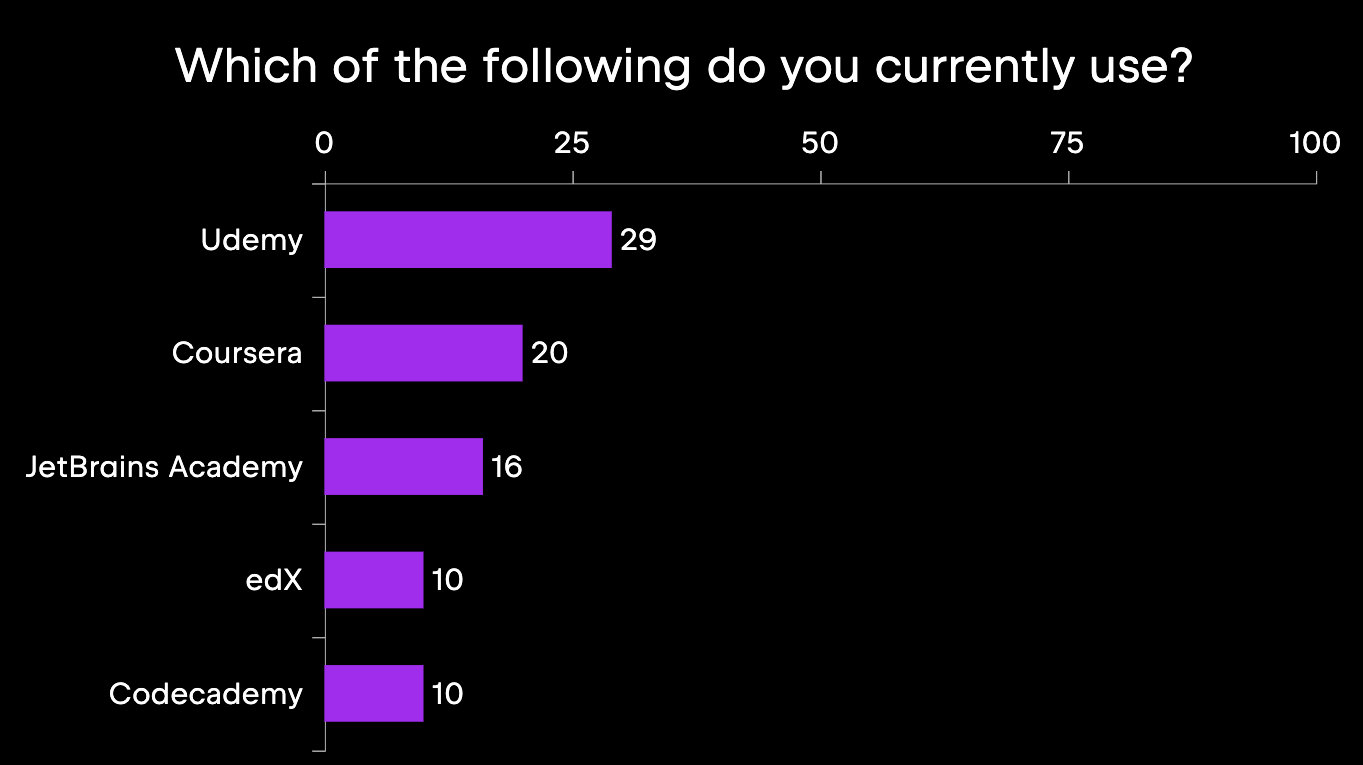
As far as which online courses are the most popular, we can see in the following image that Udemy is used by about 30% of respondents, followed by Coursera at 20% and JetBrains Academy at just above 15%.
From this data, it is clear that students are exploring alternative learning formats, in addition to the traditional formal schooling path, and that they often rate the former better than the latter. As our dataset is available online, it can be used by any researcher to target more narrow topics or specific correlations not reported here – and we think there are many more patterns to explore!
In-IDE learning
Finally, we will look at CS learners’ challenges with in-IDE learning, a format that can be found in a subset of online CS courses. In-IDE learning is new and is becoming more and more popular, as the student can learn to code inside of a professional IDE, i.e., with an industry tool. For this topic, our researchers identified a subset of survey respondents based on answers to the following questions.

For example, if a respondent indicated that they recently studied CS and currently use a MOOC such as JavaRush or JetBrains Academy, it is very likely that they are familiar with in-IDE learning. After identifying a subset, we then looked at their responses to the following question:

The top responses in this subset parallel what we saw above in the previous subsection about general CS learning challenges: as shown in the below figure, the most common reported challenge is Understanding abstract and complex concepts.

Where this subset differs from the broader dataset is in the subsequent categories: Hard to choose learning materials, courses, and platforms moved up to the top three, and categories like Getting stuck on a particular problem fell further down in importance. As in-IDE learning is quite new, it makes sense that getting oriented within the IDE presents a bigger challenge to students than completing specific tasks.
As this research direction concerns a very new learning format, it shows the most potential for future studies about CS learners. In addition, we reported this subset’s data as an example of how our dataset can be mined for information about particular groups, whether based on geographical location, area of study, or, as was done here, learning format subset.
Want to collaborate with us?
Our CS education dataset contains both broad topics and a broad demographic. In this way, it is suitable for the quantitative analysis of many CS-learning-related topics. Researchers can focus on specific subsets of the data or examine interactions between multiple variables to uncover new insights about CS education effectiveness.
This project also shows the potential of industry-academia partnerships in educational research. The benefits of combining industry resources with academic rigor include the following:
- We can conduct studies at scales previously impossible for individual institutions.
- We can accelerate progress in understanding educational effectiveness and help institutions make evidence-based decisions about curriculum design, teaching methods, and student support services.
- The commitment to open data sharing ensures that insights benefit the entire research community rather than remaining proprietary.
The Edu Research lab welcomes inquiries about dataset usage, research partnerships, and suggestions for future survey topics. Whether you’re investigating specific aspects of CS education or proposing new research directions, we’re eager to support studies that advance our understanding of effective computer science learning.
To discuss collaboration opportunities or share your research ideas for future global surveys:
Want to learn more about research insights and take part in future JetBrains studies? Join our JetBrains Tech Insights Lab!
]]>But A2A is just the beginning. Koog 0.5.0 brings a host of improvements that make agents more persistent, tools smarter, and strategy design more intuitive. Let’s dive into the highlights.
💡 Non-graph API for strategies
Koog 0.5.0 introduces a non-graph API for defining agent strategies. You can now create and modify agent strategies directly in Kotlin, without working with graphs. The new non-graph API keeps most of Koog’s core features, including state management and history compression, so you can prototype custom strategies faster.
You can now streamline your development cycle. Start simple with the out-of-the-box AIAgent using the default strategy. Then, experiment with the non-graph API to quickly test and find the best configuration for your task through straightforward code. Once you’re ready, scale it into a graph workflow to take full advantage of persistence for maximum reliability, as well as nested event tracing for deeper insights to build and test strategies more efficiently.
🔁 Agent persistence and checkpointing improvements
Complex AI workflows often depend on persistence – the ability to save and restore state without losing context or causing unintended side effects. Since we introduced persistence in Koog 0.4.0, we’ve continued to build on it to make agent state management much more reliable and flexible.
The new RollbackToolRegistry enables agents to undo side effects from tool calls when checkpointing, ensuring that rollbacks don’t leave your environment in an inconsistent state.
You can now also toggle between full state-machine persistence and message history persistence, giving you control over how much of the agent’s internal state to preserve.
⚒️ Tool API enhancements
Tools are the backbone of Koog’s agent capabilities. This release refines the Tool API to make tool development and integration smoother.
Tool descriptors are now automatically generated for class-based tools across all platforms. With this update, defining tools on multiplatform works just as smoothly as on the JVM, removing redundant setup and keeping your Tool API definitions concise and consistent.
With improvements to subgraphWithTask and subgraphWithVerification, finishTools is no longer required, and neither is the SubgraphResult type. You can now specify any input type, output type (including primitive types), task, tools, and models, and everything works automatically. There’s no more boilerplate – Koog infers and generates it all for you.
👋 Introducing AIAgentService
Managing multiple agents is now easier with the new AIAgentService. It allows you to run and manage multiple AI agents as single-use, state-managed services.
🧑⚖️ New components and smarter interactions
Koog 0.5.0 also introduces new components that enhance reasoning and control in agent systems.
LLM as a judge is a new component that uses large language models to evaluate outputs or guide decision-making processes.
In version 0.5.0, we’ve added a strategy for iterative tool calling with structured outputs. This makes it much easier to obtain typed results from any agent without having to write custom code.
Streaming now supports tool calls, allowing the use of tools while receiving results from an LLM on the fly. With this update, front-end integrated agents can now stream partial outputs to the user interface while still invoking tools as needed.
Wrapping up
Koog 0.5.0 isn’t just about connecting agents – it’s about empowering them to be smarter, more persistent, and easier to design. Whether you’re experimenting with lightweight strategies, managing long-lived agent sessions, or creating sophisticated toolchains, this release brings significant improvements across the board.
✨ Try Koog 0.5.0
If you’re building agents that need to be more connected, persistent, and easier to design, Koog 0.5.0 is the right choice. Explore the docs, build systems of multiple AI agents, and experiment faster while still benefiting from Koog’s advanced features.
🤝 Your contributions make a difference
We’d like to take this opportunity to extend a huge thank-you to the entire community! Your feedback, issue reports, and pull requests have been invaluable for the development of Koog!
A special shoutout to this release’s top contributors:
- Stan – refactored the streaming API to support tool calls.
- Siarhei Luskanau – added the iOS target and enabled web support for demo-compose-app.
- Didier Villevalois – added an option to dynamically adjust context window sizes for Ollama.
- Ruben Cagnie – implemented support for the tool-calling strategy in structured output.
Whether you’re just getting started or already publishing on JetBrains Marketplace, you’ll find new ideas, practical techniques, and stories from plugin developers who’ve been there.

The talks on this year’s agenda include:
- Keynote by Ivan Chirkov, Jakub Chrzanowski, and Robert Novotny
- From Template to Marketplace: Creating Your First Plugin by Dmitrii Derepko
- Developing a Language Plugin: LSP Versus the Joy of Learning by Aleksandr Slepchenkov
- Kotlin Notebook Meets IntelliJ Platform by Jakub Chrzanowski
- Building in Constrained Environments: Lessons From YouTrack Apps by Tommaso Gionfriddo
- AI-Powered Test Generation Straight From Your Debugger by Michael Solovev
- Making an IntelliJ Plugin Remote Development-Friendly by Nikita Katkov
- How to Investigate UI Freezes by Konstantin Nisht
You can choose whether to attend just a few individual sessions or watch every one of them. We hope you enjoy the talks, and we encourage you to ask questions!
We’ll stream the presentations live on YouTube, and all the sessions will remain available after the event is over so you can catch up on any you missed.
]]>Ever wondered if there’s a software engineer, somewhere, who actually knows what they’re doing? Well, I finally found the one serene, omnicompetent guru who writes perfect code. I can’t disclose the location of her mountain hermitage, but I can share her ten mantras of Go excellence. Let’s meditate on them together.
1. Write packages, not programs
The standard library is great, but the universal library of free, open-source software is Go’s biggest asset. Return the favour by writing not just programs, but packages that others can use too.
Your main function’s only job should be parsing flags and arguments, and handling errors and cleanup, while your imported “domain” package does the real work.
Flexible packages return data instead of printing, and return errors rather than calling panic or os.Exit. Keep your module structure simple: ideally, one package.
Tip: Use Structure view (Cmd-F12) for a high-level picture of your module.
2. Test everything
Writing tests helps you dogfood your packages: awkward names and inconvenient APIs are obvious when you use them yourself.
Test names should be sentences. Focus tests on small units of user-visible behaviour. Add integration tests for end-to-end checks. Test binaries with testscript.
Tip: Use GoLand’s “generate tests” feature to add tests for existing code. Run with coverage can identify untested code. Use the debugger to analyse test failures.
3. Write code for reading
Ask a co-worker to read your code line by line and tell you what it does. Their stumbles will show you where your speed-bumps are: flatten them out and reduce cognitive load by refactoring. Read other people’s code and notice where you stumble—why?
Use consistent naming to maximise glanceability: err for errors, data for arbitrary []bytes, buf for buffers, file for *os.File pointers, path for pathnames, i for index values, req for requests, resp for responses, ctx for contexts, and so on.
Good names make code read naturally. Design the architecture, name the components, document the details. Simplify wordy functions by moving low-level “paperwork” into smaller functions with informative names (createRequest, parseResponse).
Tip: In GoLand, use the Extract method refactoring to shorten long functions. Use Rename to rename an identifier everywhere.
4. Be safe by default
Use “always valid values” in your programs, and design types so that users can’t accidentally create values that won’t work. Make the zero value useful for literals, or write a validating constructor that guarantees a valid, usable object with default settings. Add configuration using WithX methods:
widget := NewWidget().WithTimeout(time.Second)
Use named constants instead of magic values. http.StatusOK is self-explanatory; 200 isn’t. Define your own constants so IDEs like GoLand can auto-complete them, preventing typos. Use iota to auto-assign arbitrary values:
const (
Planet = iota // 0
Star // 1
Comet // 2
// ...
)
Prevent security holes by using os.Root instead of os.Open, eliminating path traversal attacks:
root, err := os.OpenRoot("/var/www/assets")
if err != nil {
return err
}
defer root.Close()
file, err := root.Open("../../../etc/passwd")
// Error: 'openat ../../../etc/passwd: path escapes from parent'
<code data-enlighter-language="generic" class="EnlighterJSRAW"></code>
Don’t require your program to run as root or in setuid mode; let users configure the minimal permissions and capabilities they need.
Tip: Use Goland’s Generate constructor and Generate getter and setter functions to help you create always valid struct types.
5. Wrap errors, don’t flatten
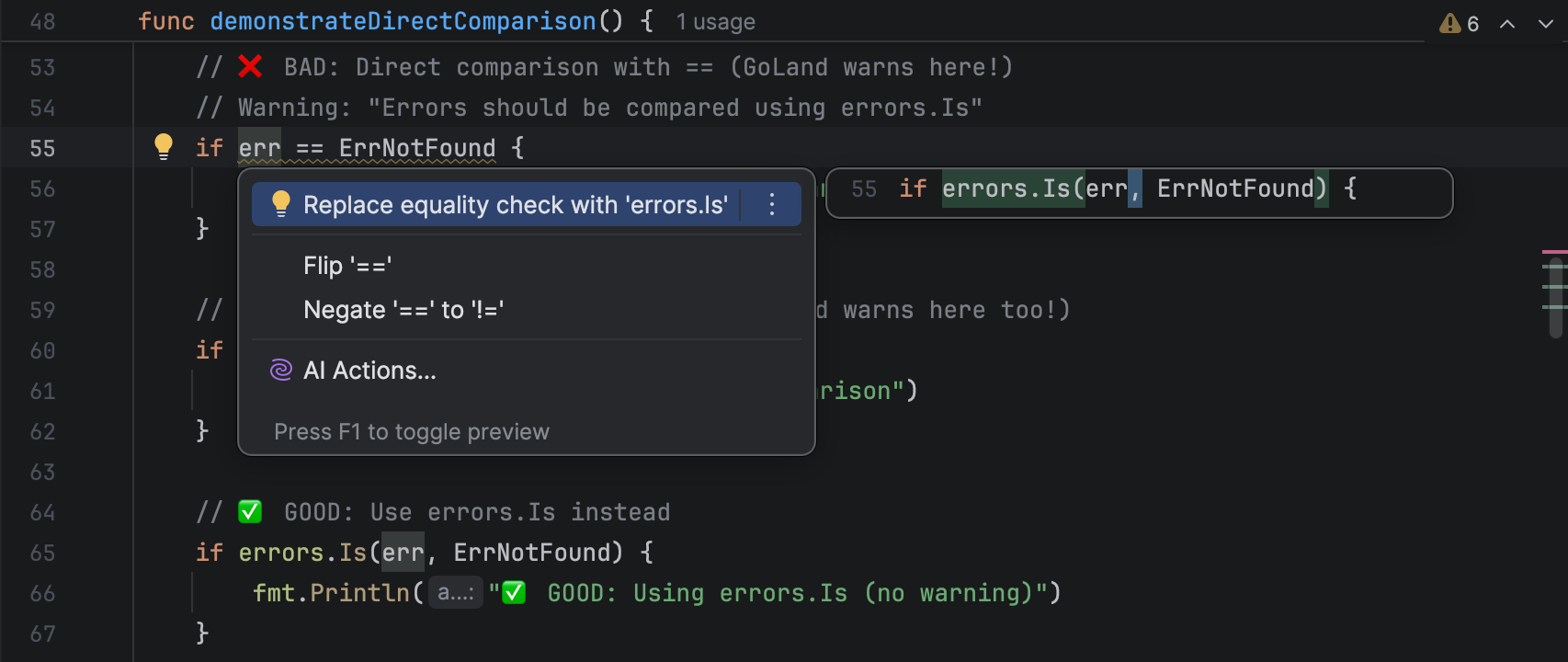
Don’t type-assert errors or compare error values directly with ==, define named “sentinel” values that users can match errors against:
var ErrOutOfCheese = "++?????++ Out of Cheese Error. Redo From Start."
Don’t inspect the string values of errors to find out what they are; this is fragile. Instead, use errors.Is:
if errors.Is(err, ErrOutOfCheese) {
To add run-time information or context to an error, don’t flatten it into a string. Use the %w verb with fmt.Errorf to create a wrapped error:
return fmt.Errorf("GNU Terry Pratchett: %w", ErrOutOfCheese)
This way, errors.Is can still match the wrapped error against your sentinel value, even though it contains extra information.
Tip: GoLand will warn you against comparing or type-asserting error values.
6. Avoid mutable global state
Package-level variables can cause data races: reading a variable from one goroutine while writing it from another can crash your program. Instead, use a sync.Mutex to prevent concurrent access, or allow access to the data only in a single “guard” goroutine that takes read or write requests via a channel.
Don’t use global objects like http.DefaultServeMux or DefaultClient; packages you import might invisibly change these objects, maliciously or otherwise. Instead, create a new instance with http.NewServeMux (for example) and configure it how you want.
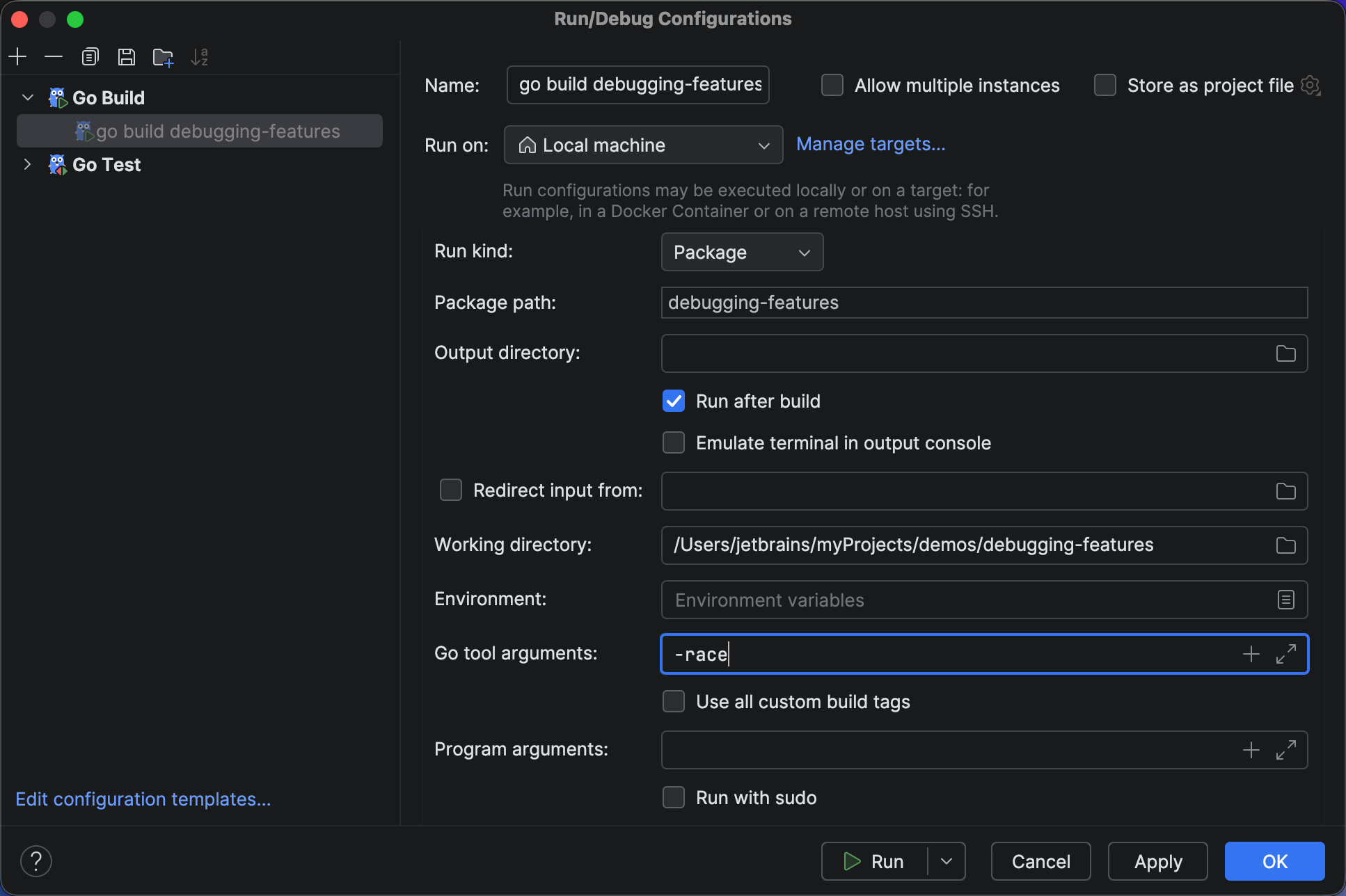
Tip: Use GoLand’s Run/Debug Configurations settings to enable the Go race detector for testing concurrent code.
7. Use (structured) concurrency sparingly
Concurrent programming is a minefield: it’s easy to trigger crashes or race conditions. Don’t introduce concurrency to a program unless it’s unavoidable. When you do use goroutines and channels, keep them strictly confined: once they escape the scope where they’re created, it’s hard to follow the flow of control. “Global” goroutines, like global variables, can lead to hard-to-find bugs.
Make sure any goroutines you create will terminate before the enclosing function exits, using a context or waitgroup:
var wg sync.WaitGroup wg.Go(task1) wg.Go(task2) wg.Wait()
The Wait call ensures that both tasks have completed before we move on, making control flow easy to understand, and preventing resource leaks.
Use errgroups to catch the first error from a number of parallel tasks, and terminate all the others:
var eg errgroup.Group
eg.Go(task1)
eg.Go(task2)
err := eg.Wait()
if err != nil {
fmt.Printf("error %v: all other tasks cancelled", err)
} else {
fmt.Println("all tasks completed successfully")
}
When you take a channel as the parameter to a function, take either its send or receive aspect, but not both. This prevents a common kind of deadlock where the function tries to send and receive on the same channel concurrently.
func produce(ch chan<- Event) {
// can send on `ch` but not receive
}
func consume(ch <-chan Event) {
// can receive on `ch` but not send
}
Tip: Use GoLand’s profiler and debugger to analyse the behaviour of your goroutines, eliminate leaks, and solve deadlocks.
8. Decouple code from environment
Don’t depend on OS or environment-specific details. Don’t use os.Getenv or os.Args deep in your package: only main should access environment variables or command-line arguments. Instead of taking choices away from users of your package, let them configure it however they want.
Single binaries are easier for users to install, update, and manage; don’t distribute config files. If necessary, create your config file at run time using defaults.
Use go:embed to bundle static data, such as images or certificates, into your binary:
import _ "embed" //go:embed hello.txt var s string fmt.Println(s) // `s` now has the contents of 'hello.txt'
Use xdg instead of hard-coding paths. Don’t assume $HOME exists. Don’t assume any disk storage exists, or is writable.
Go is popular in constrained environments, so be frugal with memory. Don’t read all your data at once; handle one chunk at a time, re-using the same buffer. This will keep your memory footprint small and reduce garbage collection cycles.
Tip: Use GoLand’s profiler to optimise your memory usage and eliminate leaks.
9. Design for errors
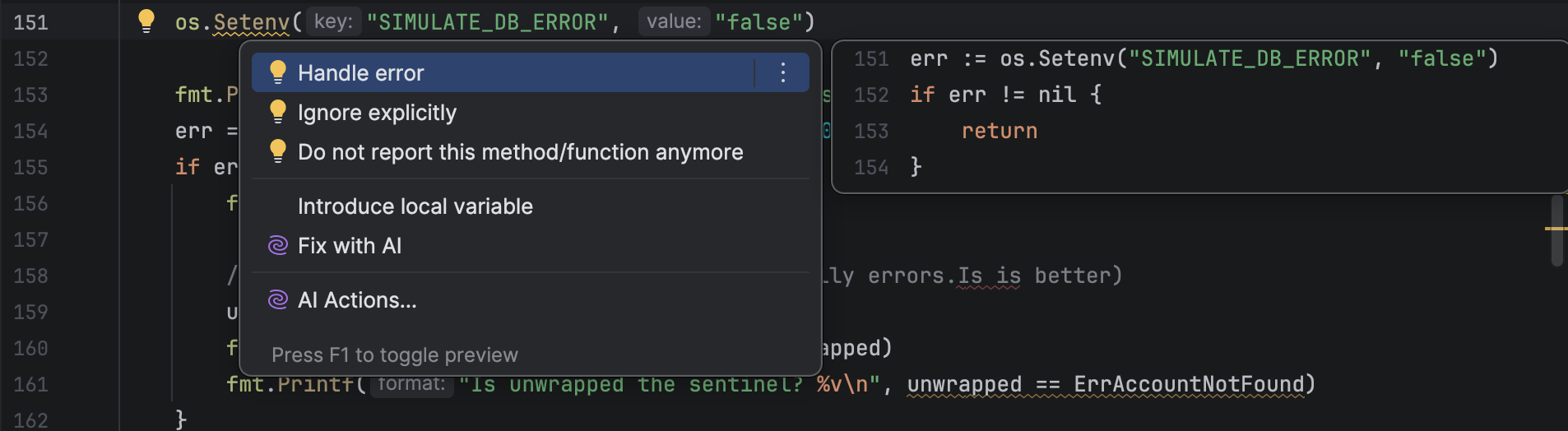
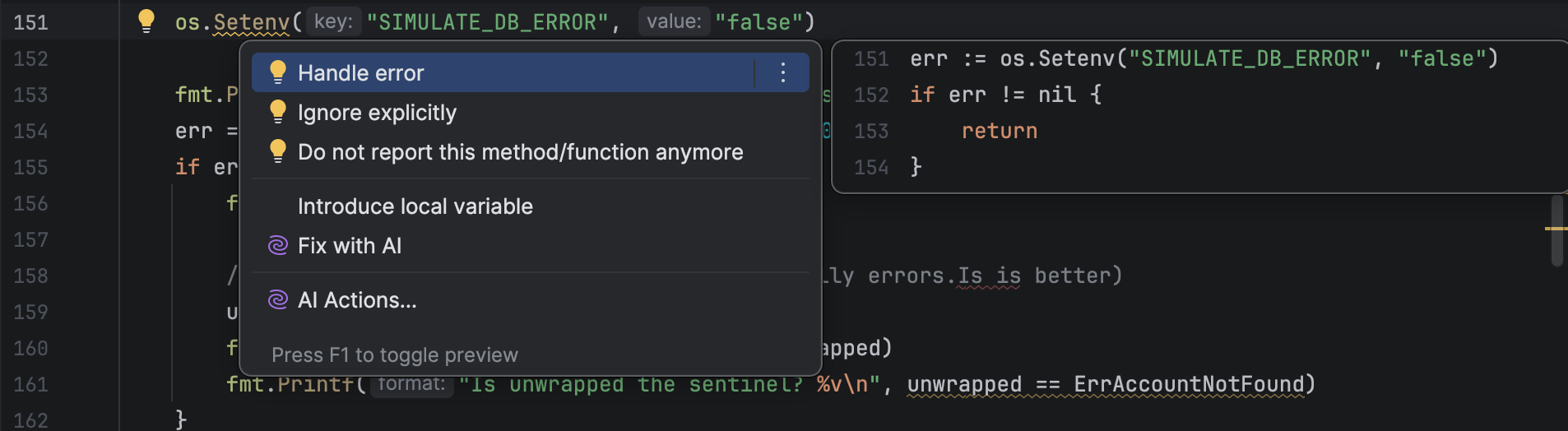
Always check errors, and handle them if possible, retrying where appropriate. Report run-time errors to the user and exit gracefully, reserving panic for internal program errors. Don’t ignore errors using _: this leads to obscure bugs.
Show usage hints for incorrect arguments, don’t crash. Rather than prompting users interactively, let them customise behaviour with flags or config.
Tip: GoLand will warn you about unchecked or ignored errors, and offer to generate the handling code for you.
10. Log only actionable information
Logorrhea is irritating, so don’t spam the user with trivia. If you log at all, log only actionable errors that someone needs to fix. Don’t use fancy loggers, just print to the console, and let users redirect that output where they need it. Never log secrets or personal data.
Use slog to generate machine-readable JSON:
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
logger.Error("oh no", "user", os.Getenv("USER"))
// Output:
// {"time":"...","level":"ERROR","msg":"oh no",
// "user":"bitfield"}
Logging is not for request-scoped troubleshooting: use tracing instead. Don’t log performance data or statistics: that’s what metrics are for.
Tip: Instead of logging, use GoLand’s debugger with non-suspending logging breakpoints to gather troubleshooting information.
Guru meditation
My mountain-dwelling guru also says, “Make it work first, then make it right. Draft a quick walking skeleton, using shameless green, and try it out on real users. Solve their problems first, and only then focus on code quality.”
Software takes more time to maintain than it does to write, so invest an extra 10% effort in refactoring, simplifying, and improving code while you still remember how it works. Making your programs better makes you a better programmer
]]>With this goal in mind, we launched CodeCanvas publicly in 2024 and started accumulating users. We dove into the issues they faced in their development workflows and how we could address them as a product.
Over the last year, we have implemented many new features and fixes to make a product that would truly help developers. Today, we’re announcing that we have decided to discontinue the development of CodeCanvas in its current form.
Why we are making this decision
The rapid development of AI during the last several years has drastically changed the software development landscape. While CDEs make for a perfect environment to run AI agents in because of their isolated nature, we have concluded that the current CDE setup of CodeCanvas is too niche, if not obsolete, in the increasingly AI-enabled tech industry of today.
User and customer needs have changed and we cannot meet them with CodeCanvas the way it is right now, so we chose to drastically shift our focus and sunset CodeCanvas.
What’s next
Here’s what’s going to happen to CodeCanvas as a product:
- We will no longer be providing new CodeCanvas licenses or subscription upgrades starting October 16, 2025.
- We will continue providing support for our existing users until January 1, 2026. Before this deadline, our team will gladly consult our paid clients regarding migration options.
- Our existing users will be able to use CodeCanvas for six months, until March 31, 2026.
- After March 31, 2026, CodeCanvas public artifacts will no longer be available and your instance will stop working.
If you have any questions or require assistance, please reach out to us.
Closing words
As a team, we have reflected on what professional developers need in the AI-enabled tech landscape of today. To meet those needs, we have decided to develop a new, more modern solution.
We are now creating an AI-first, cloud-native product that will help professional teams adopt AI and work with autonomous AI agents, and CDEs will play an important role in the final product design. Stay tuned for more updates!
We would like to extend our gratitude to every single user of CodeCanvas. Our goal in creating CodeCanvas was to make development more enjoyable for you as developers, and you gave us lots of useful information that will help us make our new product even better. Thank you for being part of our journey – we hope to see you again once our new solution is up and running!
Kindly,
The CodeCanvas team
In this report, we present findings from the Developer Ecosystem Survey 2025. Alongside the numbers, you’ll also hear commentary from Brent Roose, JetBrains Developer Advocate for PHP, and insights from other community experts explaining what’s shaping PHP today and where the ecosystem is heading.
If you’d like to see what the ecosystem looked like just a year ago, check out the State of PHP 2024.
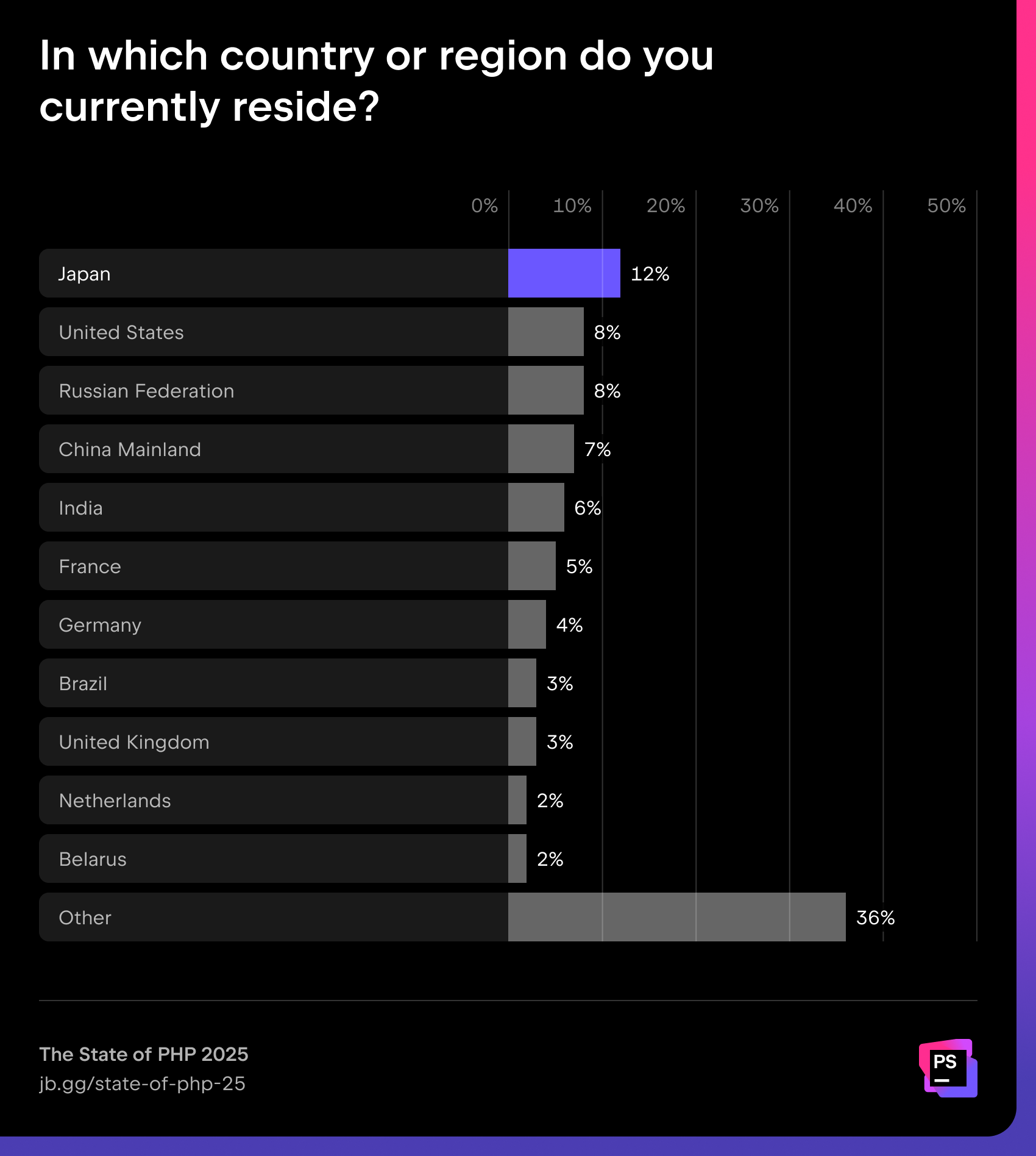
Participants
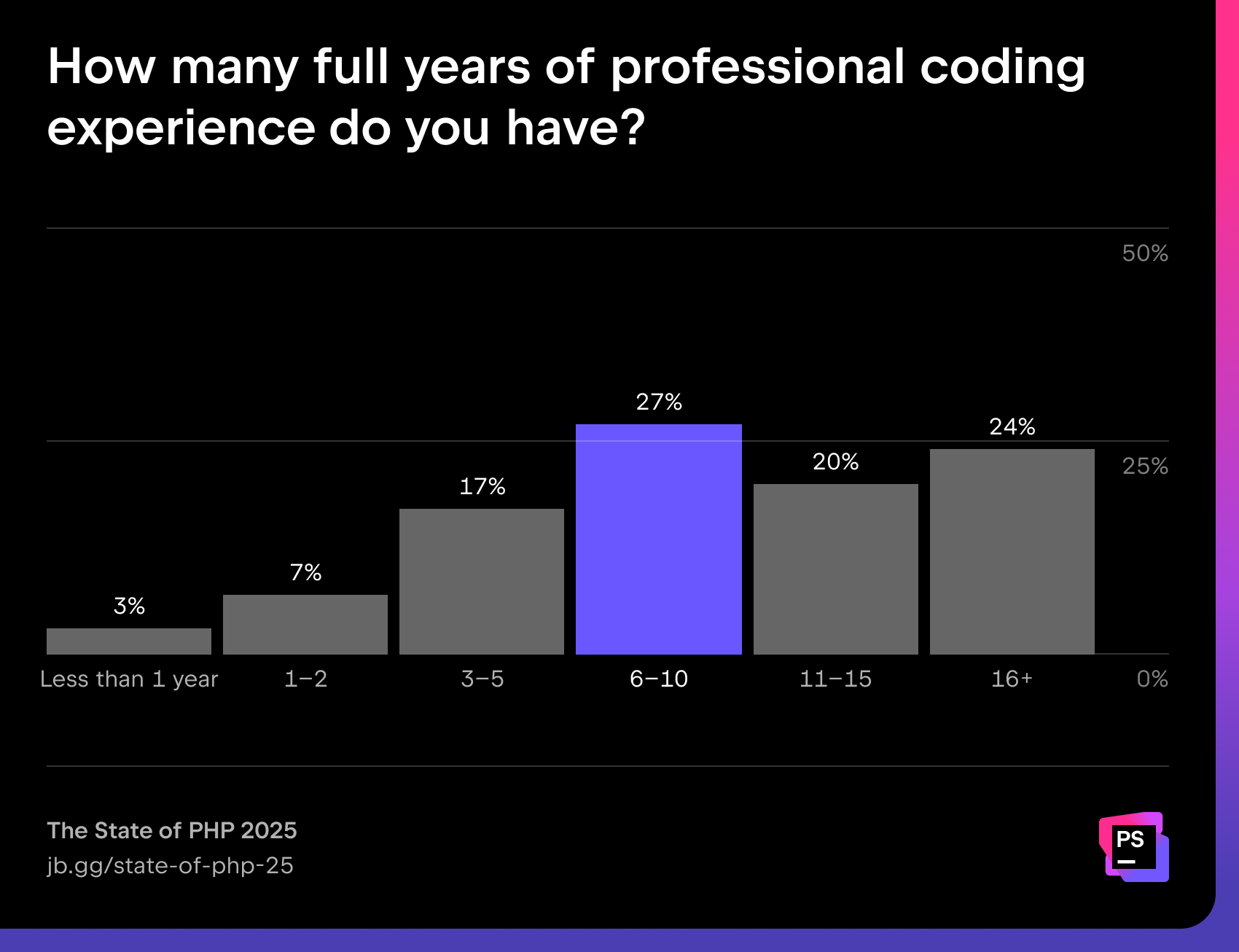
This year, we collected responses from 1,720 developers who indicated PHP as their main programming language, with the largest populations living in Japan, the United States, Russia, China, and France.
88% of PHP developers have more than three years of experience, with the largest single group falling in the six-to-ten-year range.
Team size and work environment
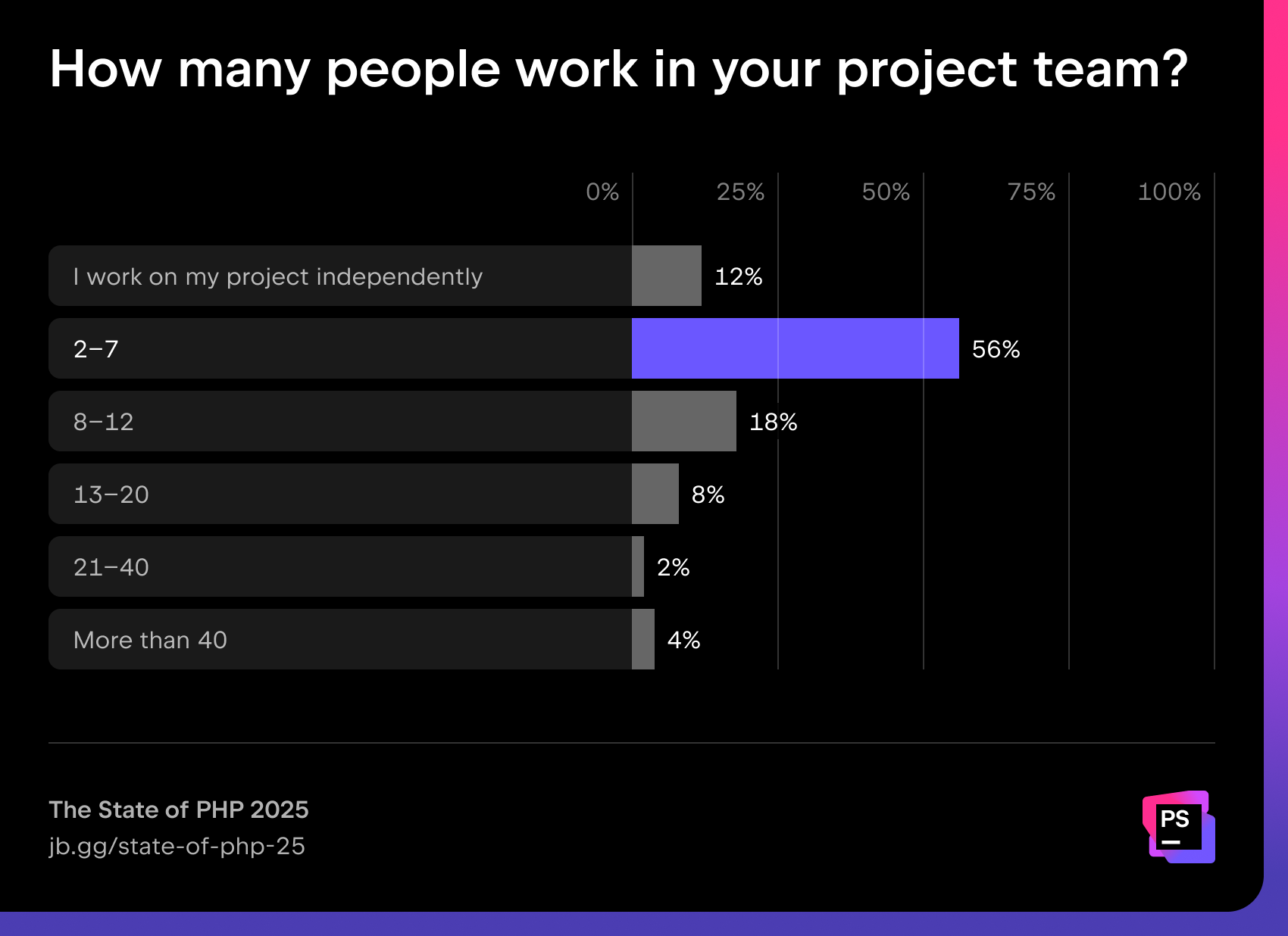
More than half of PHP developers (56%) work in small teams of two to seven people, while 12% work independently.
Language adoption and usage
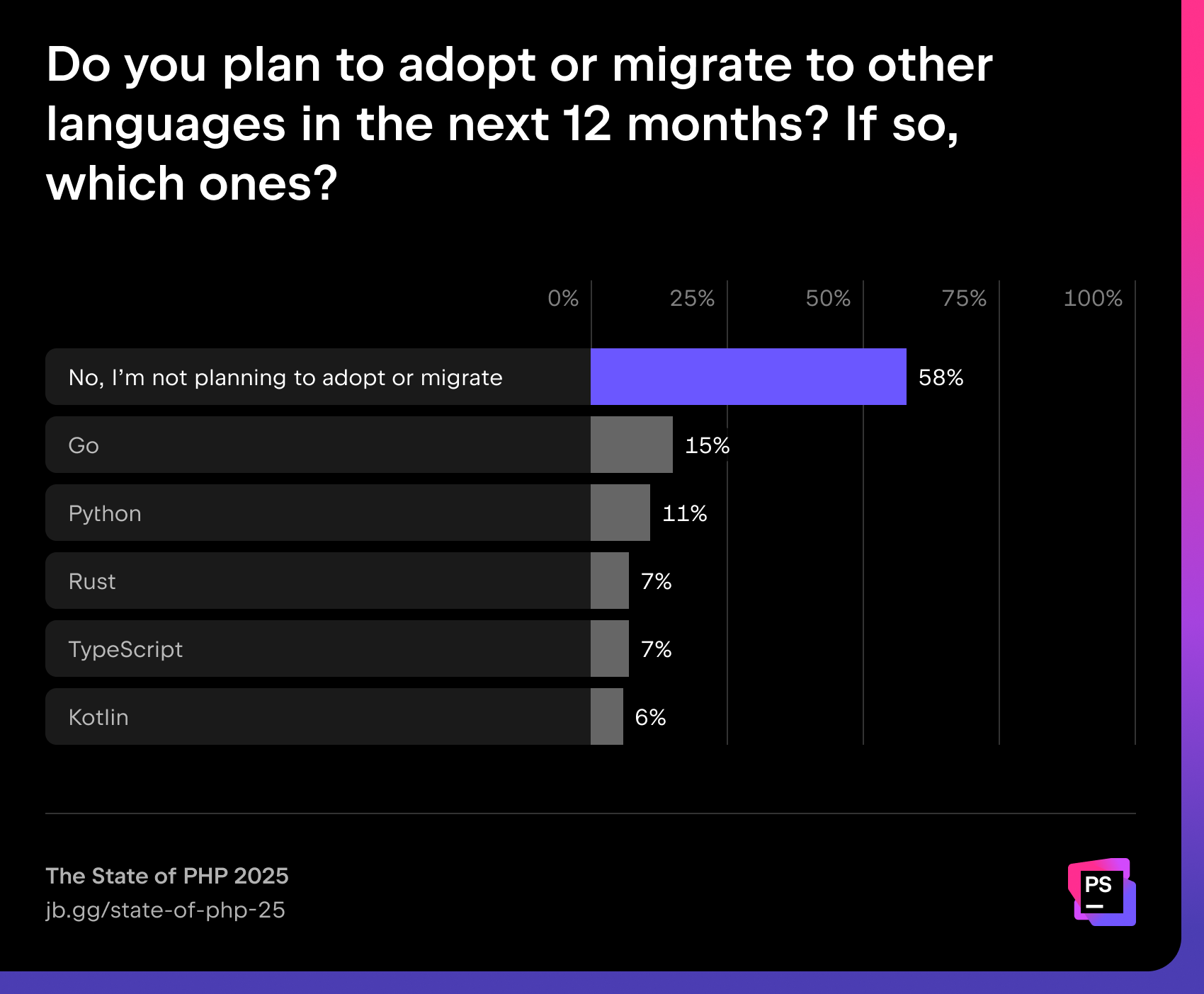
The majority of PHP developers (58%) do not plan to migrate to other languages in the next year. For those who do, Go and Python are the most attractive alternatives.
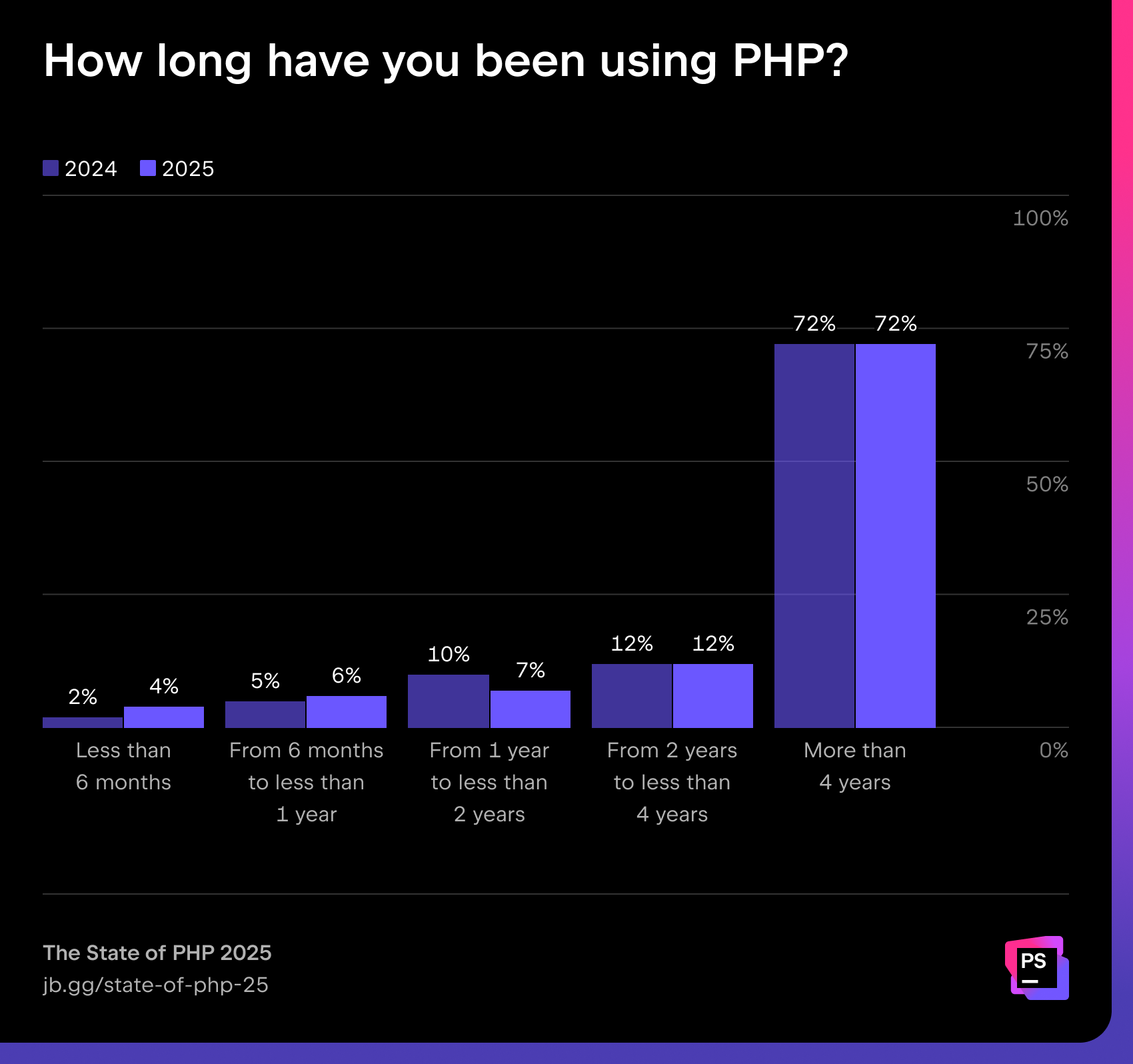
The share of newcomers is slowly growing: 4% have been using PHP for less than six months (up from 2% last year), and 6% for less than one year. Still, almost three-quarters (72%) of developers report over four years of PHP usage, underlining the ecosystem’s maturity.
“Important to note is that these numbers aren’t talking about people leaving PHP – they are about adopting languages besides PHP. I think it’s great to see so many PHP developers who are adding other languages to their toolbelt. PHP has areas where it shines, but there are also problems that are better solved with languages like Go or Rust. Working together across those language barriers leads to great results.”

“It’s great to see more newcomers in PHP. It’s not surprising given the amount of positive buzz around PHP for the past couple of years, but it’s nice to see the numbers proving this trend as well.”
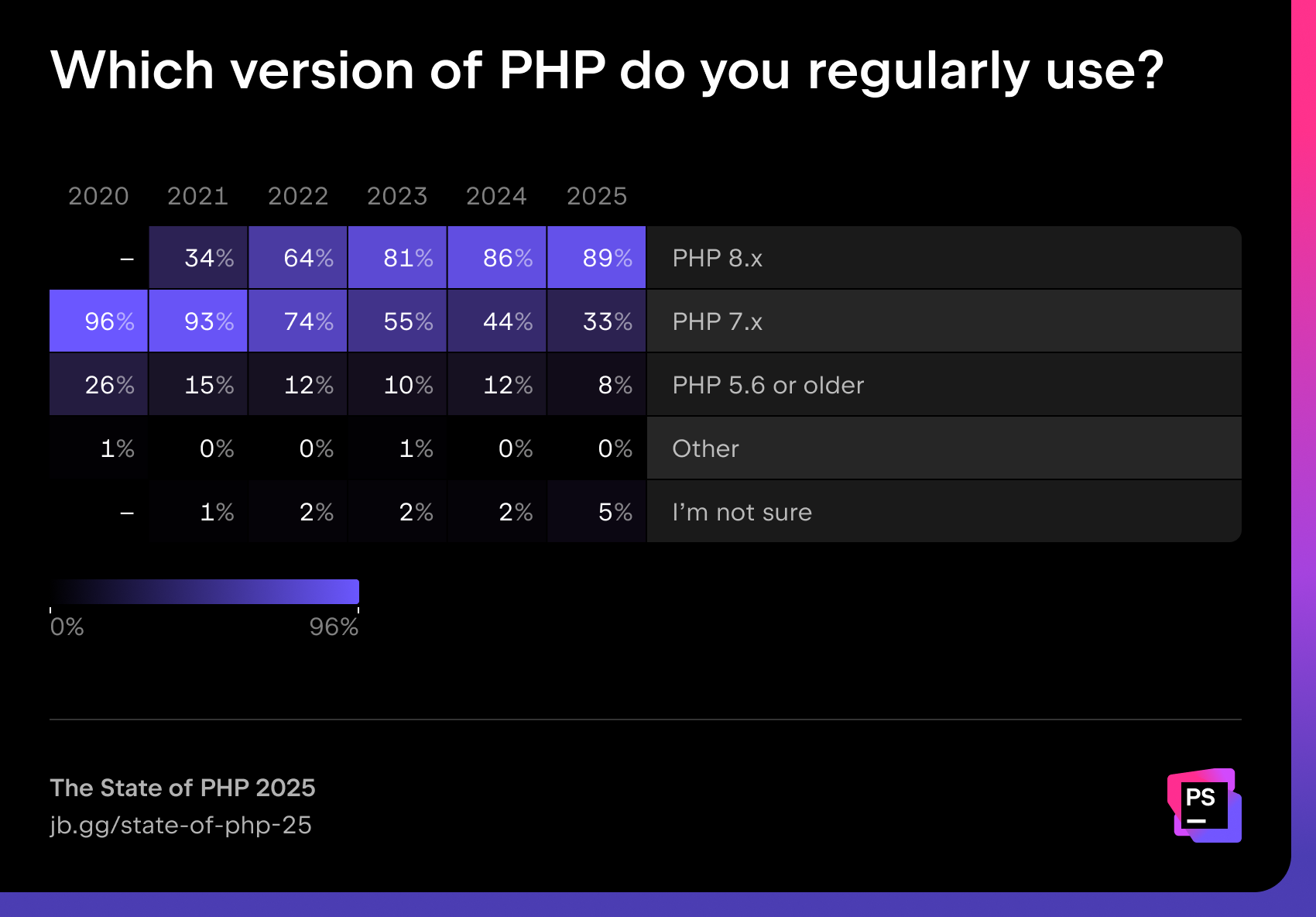
The trend toward modernization continues: PHP 8.x dominates with 89% usage, while PHP 7.x has dropped to 33%. Legacy versions (5.6 and earlier) are now down to 8%, though not entirely gone. Read Brent’s blog post for a more in-depth analysis of PHP versions’ usage.
“I think the open-source community plays a vital role in pushing the PHP community forward to adopt more secure and performant versions. The best part is that by using tools like Rector, upgrading becomes almost trivial. I speak from experience: The yearly upgrade is so well worth it.”
PHP frameworks and CMSs
No major shifts occurred in framework adoption: Laravel continues to lead with 64% usage, followed by WordPress (25%) and Symfony (23%). Other frameworks like CodeIgniter, Yii, and CakePHP hold smaller but stable shares.

“We’re thrilled to see Laravel adoption continuing to grow, driven by innovations like Laravel Cloud and AI integrations such as Laravel Boost and MCP. Laravel remains focused on providing a comprehensive, modern full-stack solution that makes PHP development more productive and accessible than ever.”

“Symfony contributors continue to push the boundaries of what can be expressed through type annotations, creating a virtuous cycle where codebases, static analyzers, and IDEs continuously improve to enhance developer experience and verifiability. Informal communication channels between all stakeholders make this progress even smoother and more efficient.”

PHP development environments
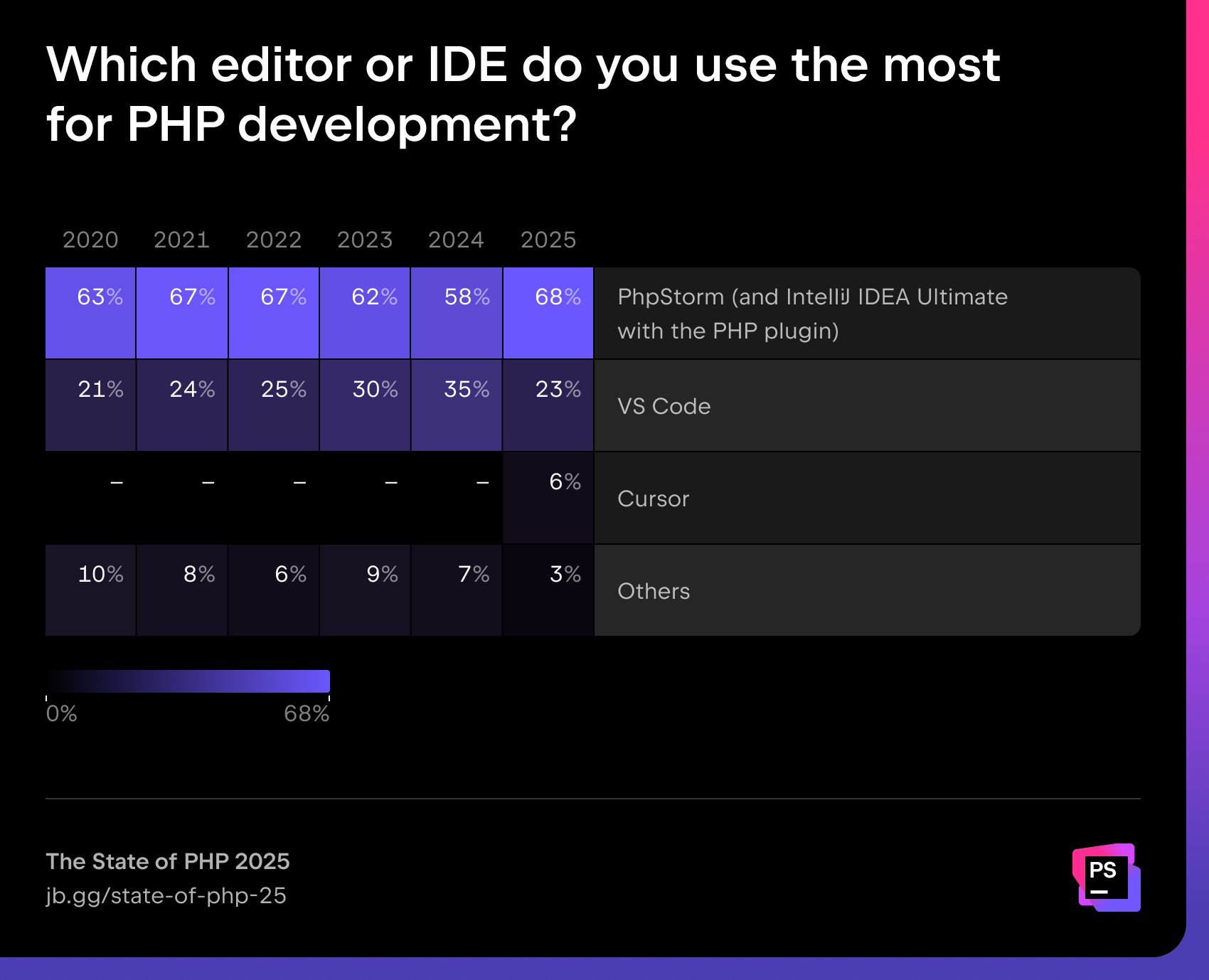
Most used IDE or editor
One of the most striking changes is in tooling: The share of those using either PhpStorm or IntelliJ IDEA with the PHP plugin has gone up by 10 percentage points, to 68%. Visual Studio Code’s share has dropped to 23%, while new players like Cursor (6%) have also entered the scene.
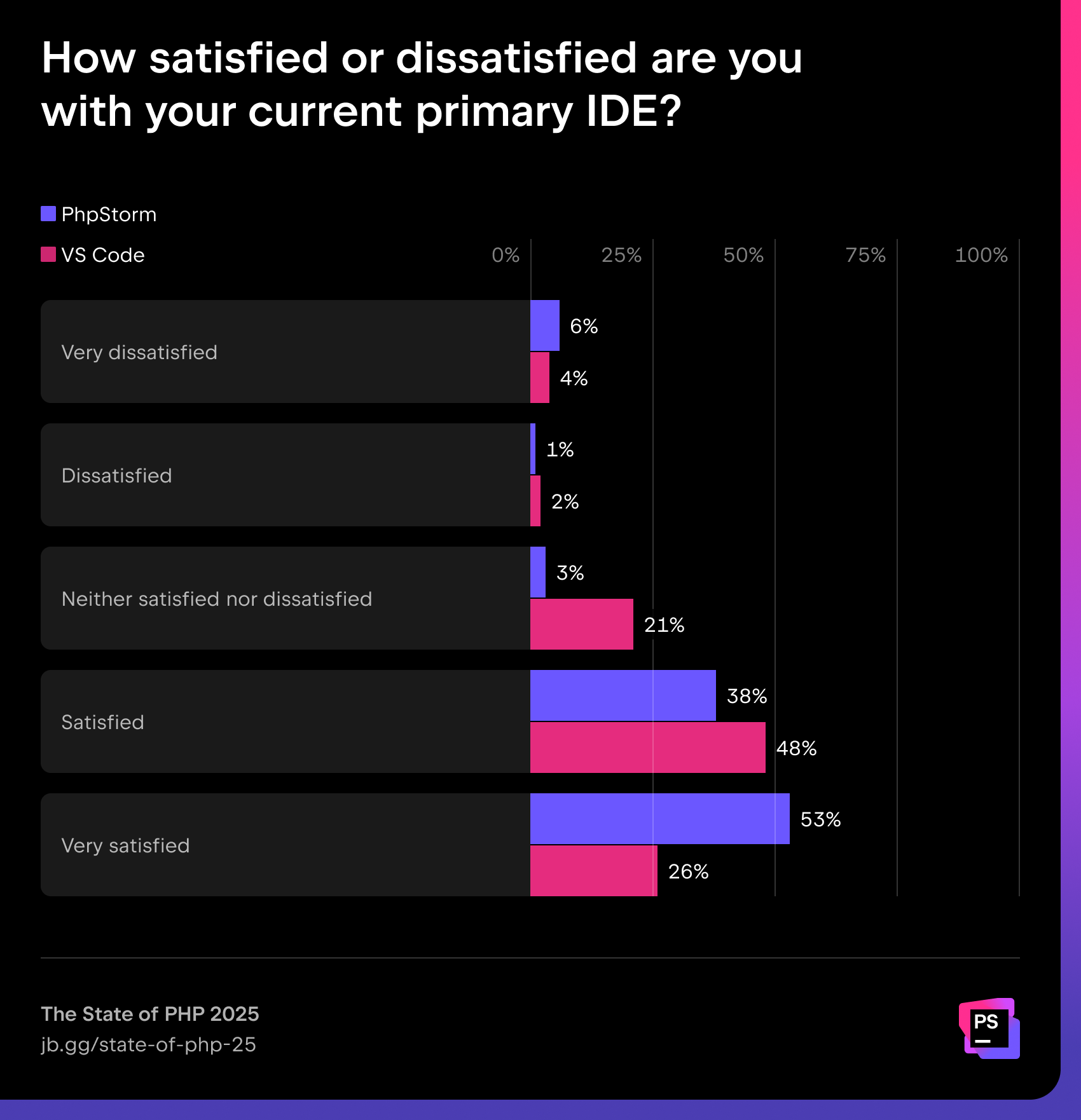
Satisfaction with coding tools
We also asked PHP developers how satisfied they are with their primary IDE. Among them, 53% of PhpStorm users gave their IDE the highest possible rating, compared to just 26% of VS Code users.
IDE or editor of choice per framework
PhpStorm dominates in Symfony (83%) and leads in Laravel (62%), while WordPress developers remain more split, with VS Code remaining a popular choice (37%).
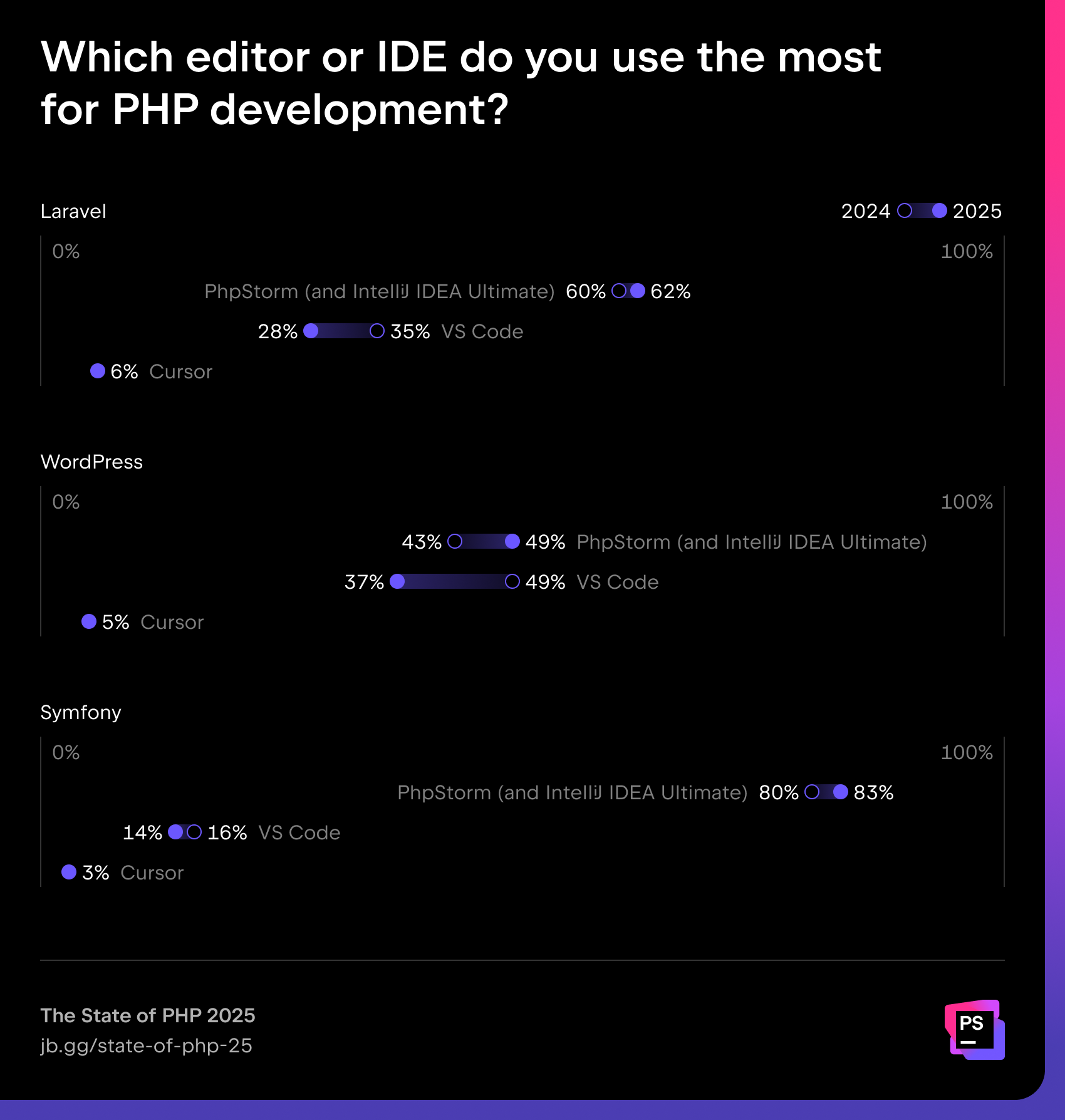
Did you know Laravel support is now free for all PhpStorm users? This blog post has the full story.
Debugging and testing
When it comes to debugging, most developers still rely on var_dump-style approaches (59%), though debugger adoption (e.g. Xdebug) has risen slightly to 39%.
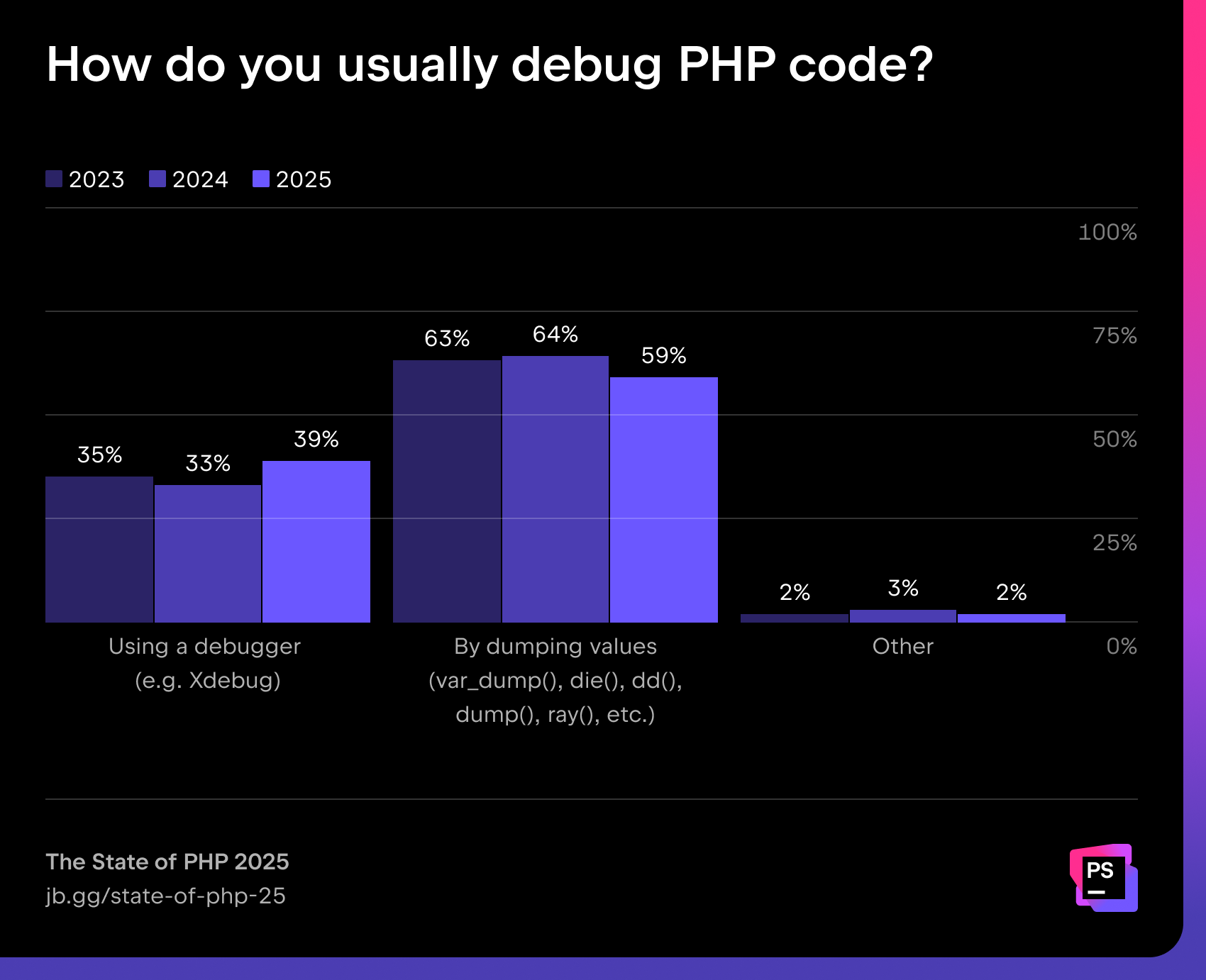
“Xdebug’s usage seems to be pretty stable throughout the years and across several surveys: between 30% and 35%. While I definitely still do my fair share of “dd” or “log” debugging, there are times where having a debugger at hand and knowing how to use it saves so much time. It’s a skill that takes practicing and doesn’t come overnight – which is why I made this short video to help folks get started with Xdebug.”
PHPUnit (50%) remains the standard, but Pest adoption has gained four percentage points to reach 17%, showing momentum toward modern, developer-friendly testing frameworks.
“I’m super-happy to see more and more people choosing Pest as their go-to testing framework – the growth in this year’s survey really reflects the quality of our recent releases.
Since the survey, we’ve actually released Pest 4, which introduces test sharding, profanity checking, and the revolutionary browser testing. Having proper browser testing in the PHP world is truly a game-changer, so I expect adoption to increase even more next year!”

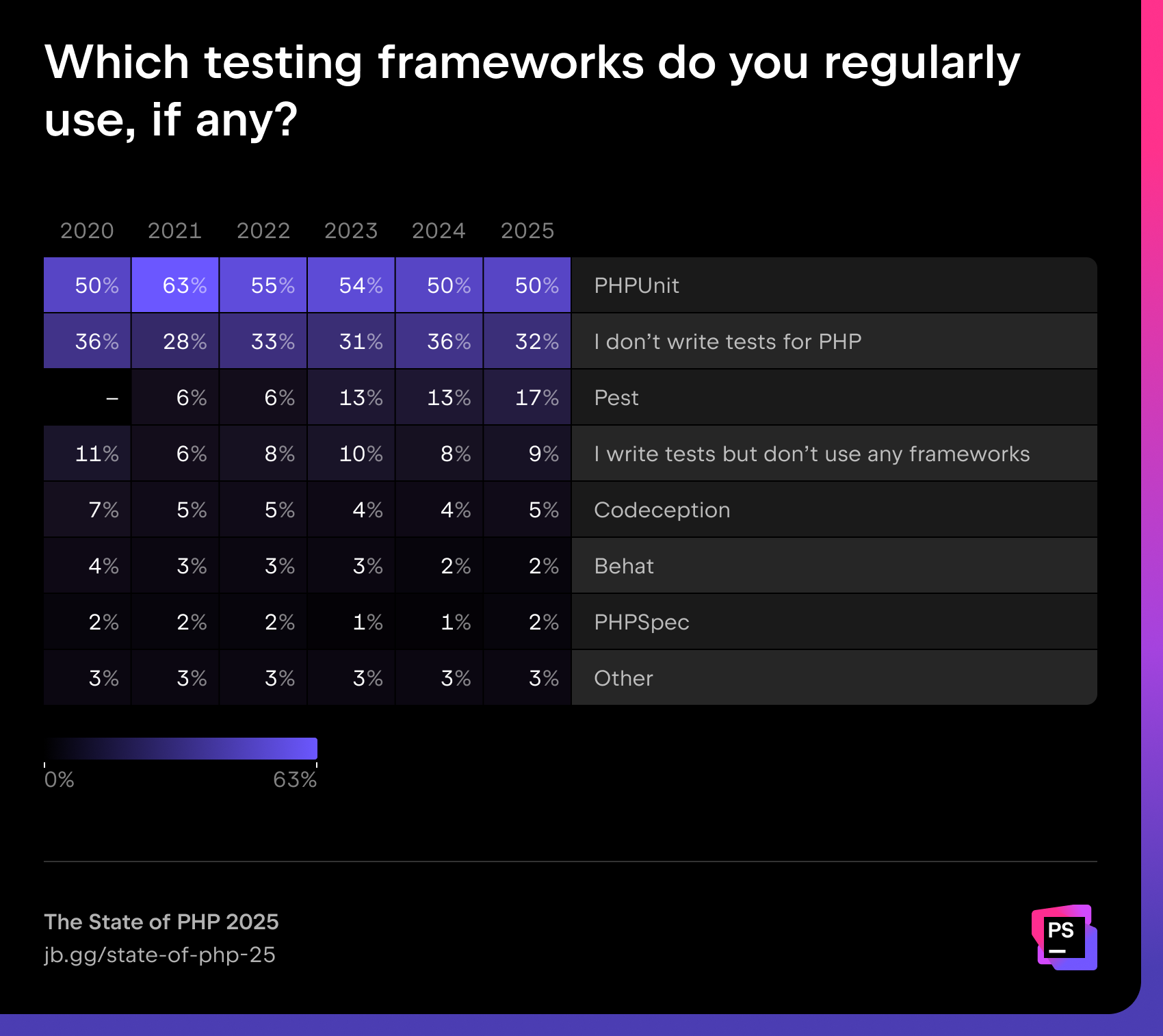
However, 32% of developers still don’t write tests at all, which highlights a persistent gap in testing culture.
Code quality tools
The clear winner in 2025 is PHPStan, which jumped to 36% usage, up nine percentage points from last year. Tools like PHP CS Fixer (30%) and PHP_CodeSniffer (22%) remain widely used, while Rector (10%) continues its steady rise. Still, 42% of respondents don’t use any code quality tools regularly, leaving room for further improvement.

| 💡Have you tried JetBrains Qodana? This static analysis and codebase auditing tool brings inspections from PhpStorm into your CI/CD pipeline, along with unique and custom code-quality and security checks. Use it to clean up and secure your team’s code before merging to the main branch. |
Adoption of AI
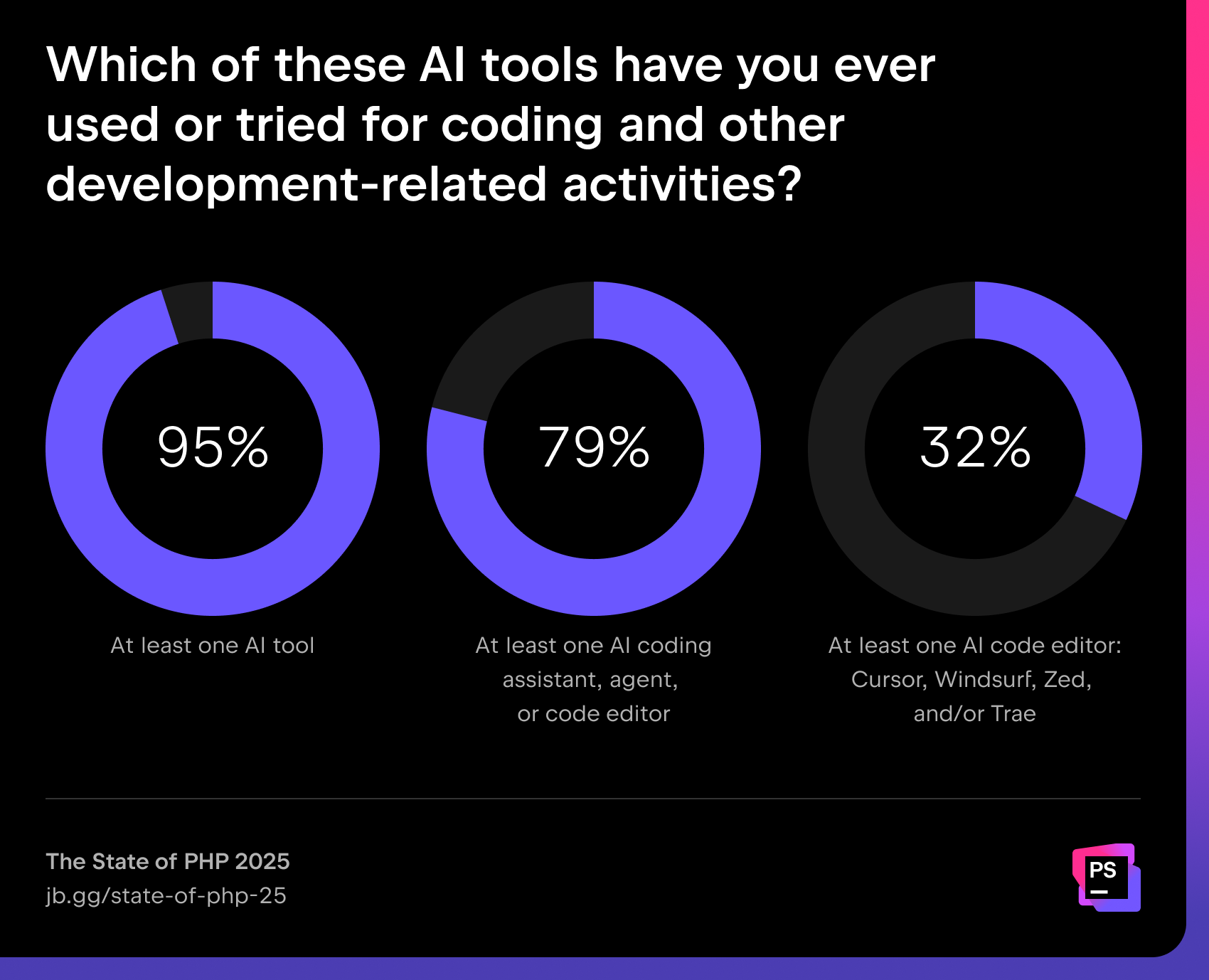
AI has gone mainstream: 95% of developers have tried at least one AI tool, and 80% regularly use AI assistants or AI-powered editors.
ChatGPT leads daily use with 49%, though its share has dropped since 2024. GitHub Copilot (29%) and JetBrains AI Assistant (20%) follow, with the latter tripling its adoption since last year.
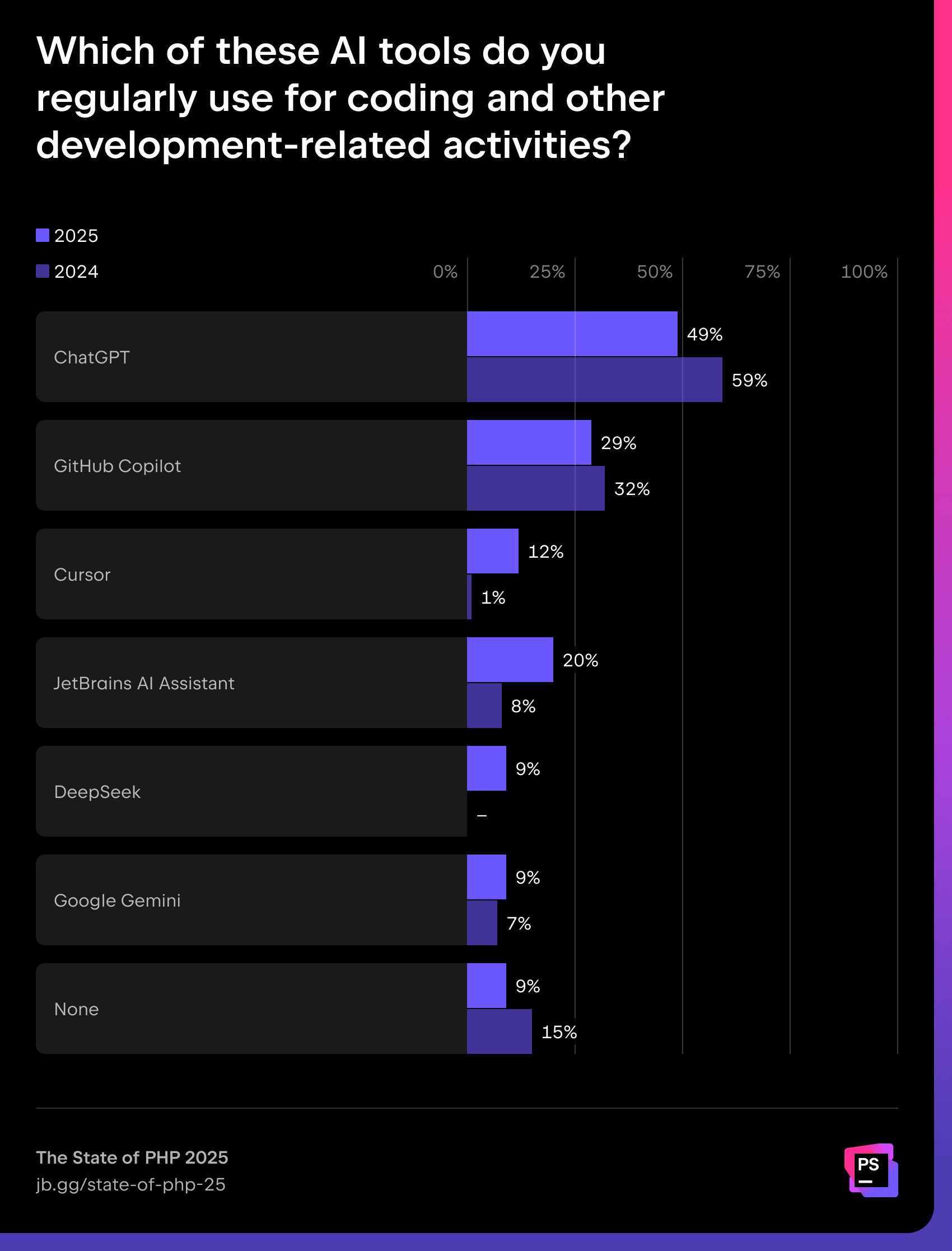
“AI is here to stay. It’s great to see the increased adoption of AI overall, and the drop in ChatGPT usage in favor of more specialized tooling. We can expect more of this moving forward, with new tools entering the scene, and the ones giving us the best boost earning their place in our daily stack.”

Looking ahead, 72% of respondents are likely to try AI coding agents in the next year, while only 8% say it’s unlikely.
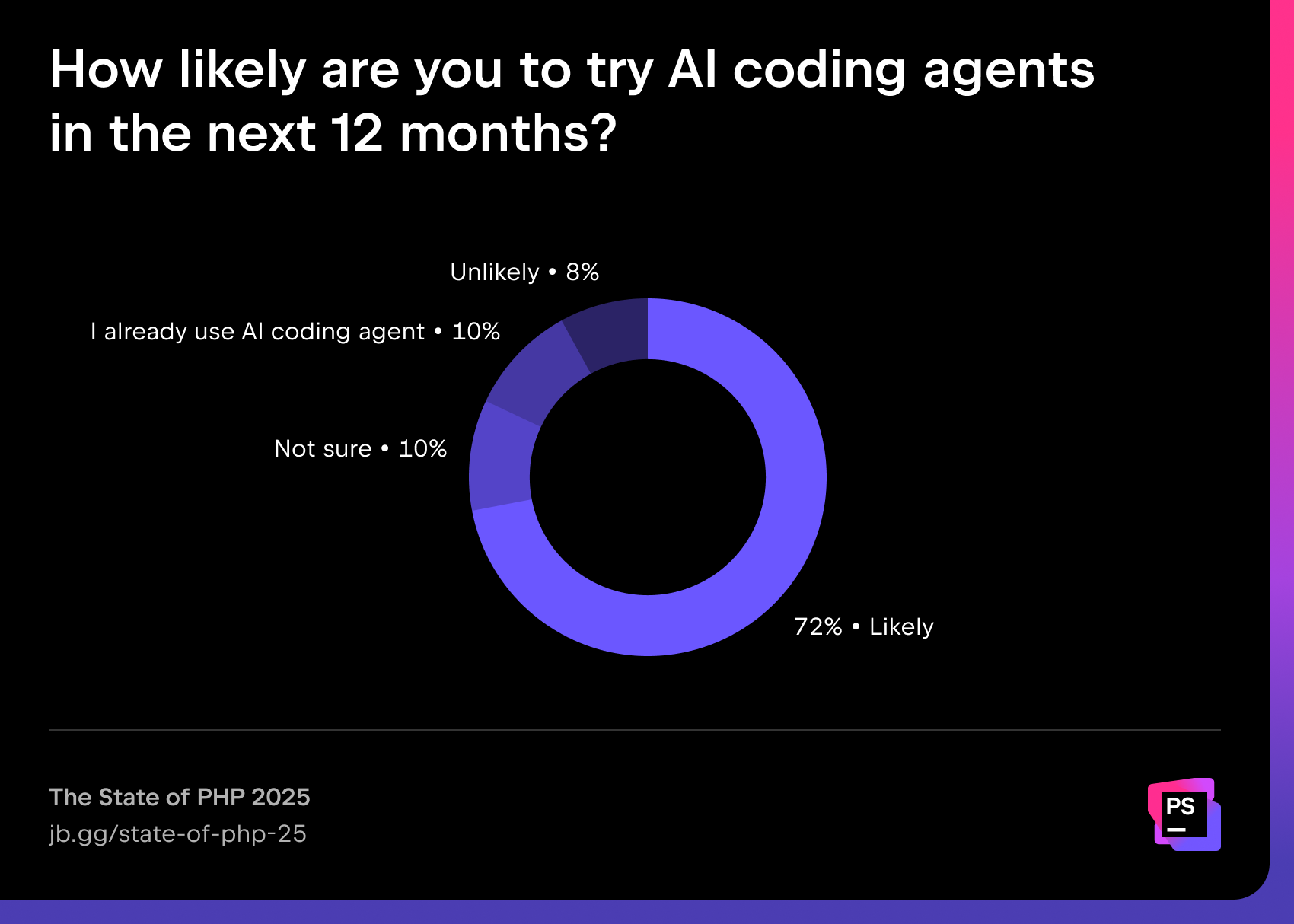
To support developers in this shift, earlier this year JetBrains introduced an AI coding agent called Junie. Unlike other coding assistants, Junie is built to work directly with your JetBrains IDE, project context, and team practices, delivering actionable and trustworthy support. With AI agents rapidly becoming part of everyday workflows, Junie brings the reliability, integration, and developer focus you expect from JetBrains to this new wave of tools.
At the same time, not every company is ready to embrace AI yet. 11% respondents report that their organization is unlikely to try AI coding agents in the next 12 months. Apart from the data privacy and security concerns (44%) and intellectual property questions (24%), many companies also struggle with a lack of knowledge about such tools (22%).
Ecosystem highlights 2025
FrankenPHP
“One of my personal highlights in PHP this year is FrankenPHP becoming a project backed by the PHP Foundation. I think there’s a lot of potential for the project to become the de-facto standard runtime for PHP, which would be huge. FrankenPHP has a lot of performance optimizations that work out of the box for any PHP application, it’s portable across systems, and it has worker mode, which allows for asynchronous request handling in PHP, which can speed up applications by a factor of three compared to using PHP FPM.”
Learn more about FrankenPHP from Kévin Dunglas on PHPverse 2025:
PHPverse
This year also marked a special milestone – PHP turned 30 years old. We celebrated with JetBrains PHPverse, an online birthday event that drew more than 26,000 viewers worldwide. If you missed it, don’t worry – the recordings are available to watch on demand:
Catch the next edition of PHPverse – sign up here to be the first to know when registration opens.
What this means for PHP
The 2025 results confirm that PHP remains a stable, professional, and evolving ecosystem. Its strong developer base, continued dominance of Laravel and WordPress, increasing adoption of modern tooling, and rapid embrace of AI-powered workflows show that PHP is far from being “legacy”.
Disclaimer: Despite all the measures we’ve taken to secure a representative pool of respondents, these results might be slightly skewed toward users of JetBrains products, as they might have been more likely to take the survey. Read more about our methodology.
]]>The survey has been running since 2017 and has since grown into one of the most comprehensive studies of its kind.
The 2025 edition is based on responses from 24,534 developers across 194 countries, offering a truly global overview of the profession.
Let’s explore what stood out the most in 2025.
AI proficiency is becoming a core skill
AI is becoming a standard in developers’ lives: 85% of developers regularly use AI tools for coding and development, and 62% rely on at least one AI coding assistant, agent, or code editor.
Still, 15% of developers have not yet adopted AI tools in their daily work. Whether their hesitancy is due to skepticism, security concerns, or mere personal preference, this significant minority represents an interesting opposition to the mainstream trend.
AI at the workplace
For the majority who have embraced AI, the benefits are tangible. Nearly nine out of ten developers save at least an hour every week, and one in five saves eight hours or more. That’s the equivalent of an entire workday!

There’s no wonder 68% expect employers to require proficiency in AI tools in the near future. AI work has already become as common as data processing (25% vs. 29%).
Looking to the future
When asked about the increasing role of AI in society, developers express a mix of optimism, curiosity, and anxiety.
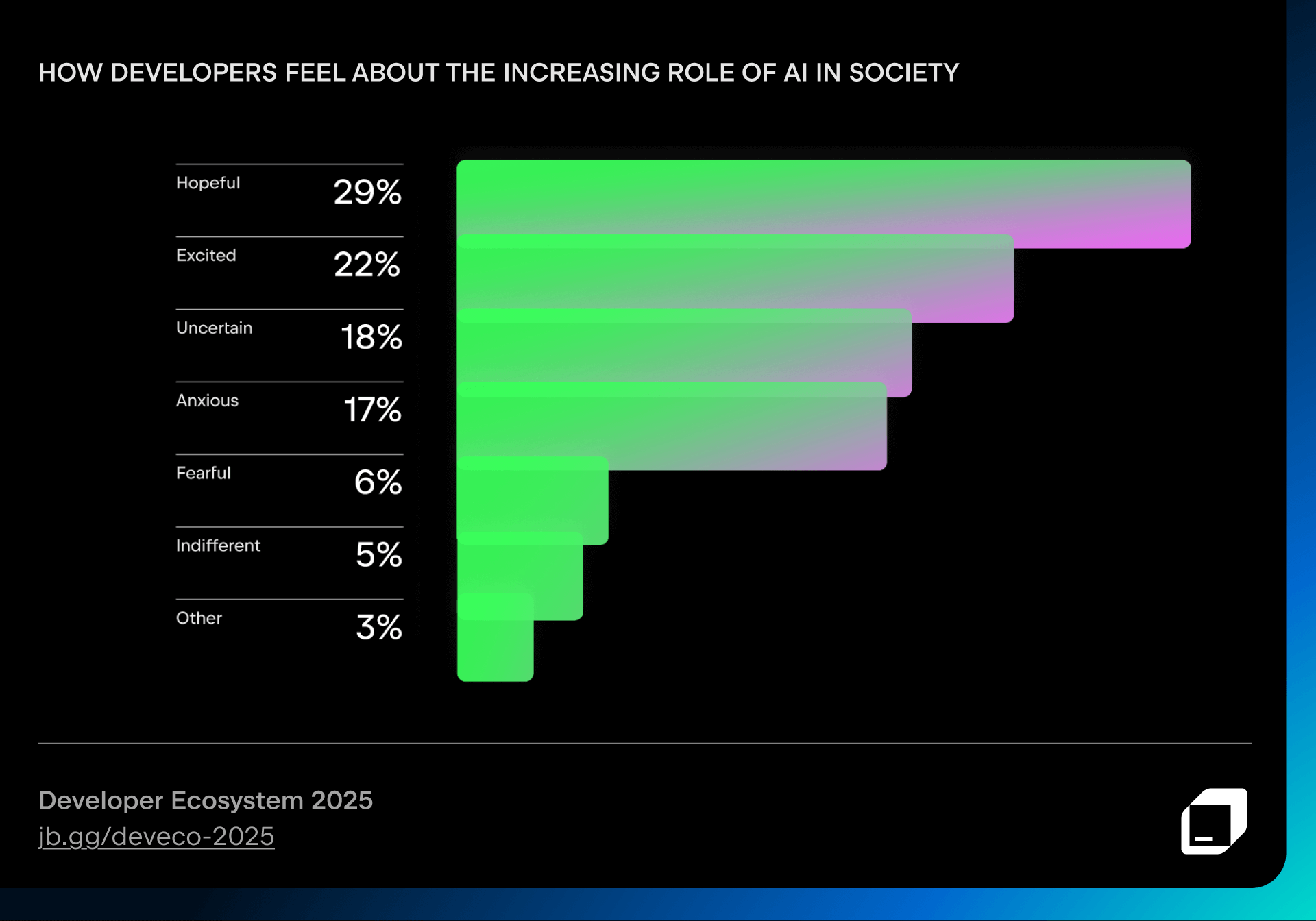
Most developers are happy to let AI handle repetitive tasks, such as generating boilerplate code, writing documentation, or summarizing changes, but they prefer to stay in charge of creative and complex tasks, like debugging or designing application logic.
Here are the top five development activities that respondents are most likely to delegate to AI:
- Writing boilerplate, repetitive code
- Searching for development-related information on the internet
- Converting code to other languages
- Writing code comments or code documentation
- Summarizing recent code changes
Biggest concerns around AI in coding and software development
Despite the enthusiasm surrounding AI, many people still have reservations. Here are the top five concerns our respondents reported having about AI in software development:
- The inconsistent quality of AI-generated code
- AI tools’ limited understanding of complex code and logic
- Privacy and security risks
- The potential negative impact on their own coding and development skills
- AI’s lack of context awareness
Languages and tools
The programming languages that developers choose reveal the state of the industry and which technologies are gaining traction now.
TypeScript has seen the most dramatic rise in real-world usage over the past five years. Rust, Go, and Kotlin have also continued to steadily amass market share – although their gains have not been quite as impressive as TypeScript’s.
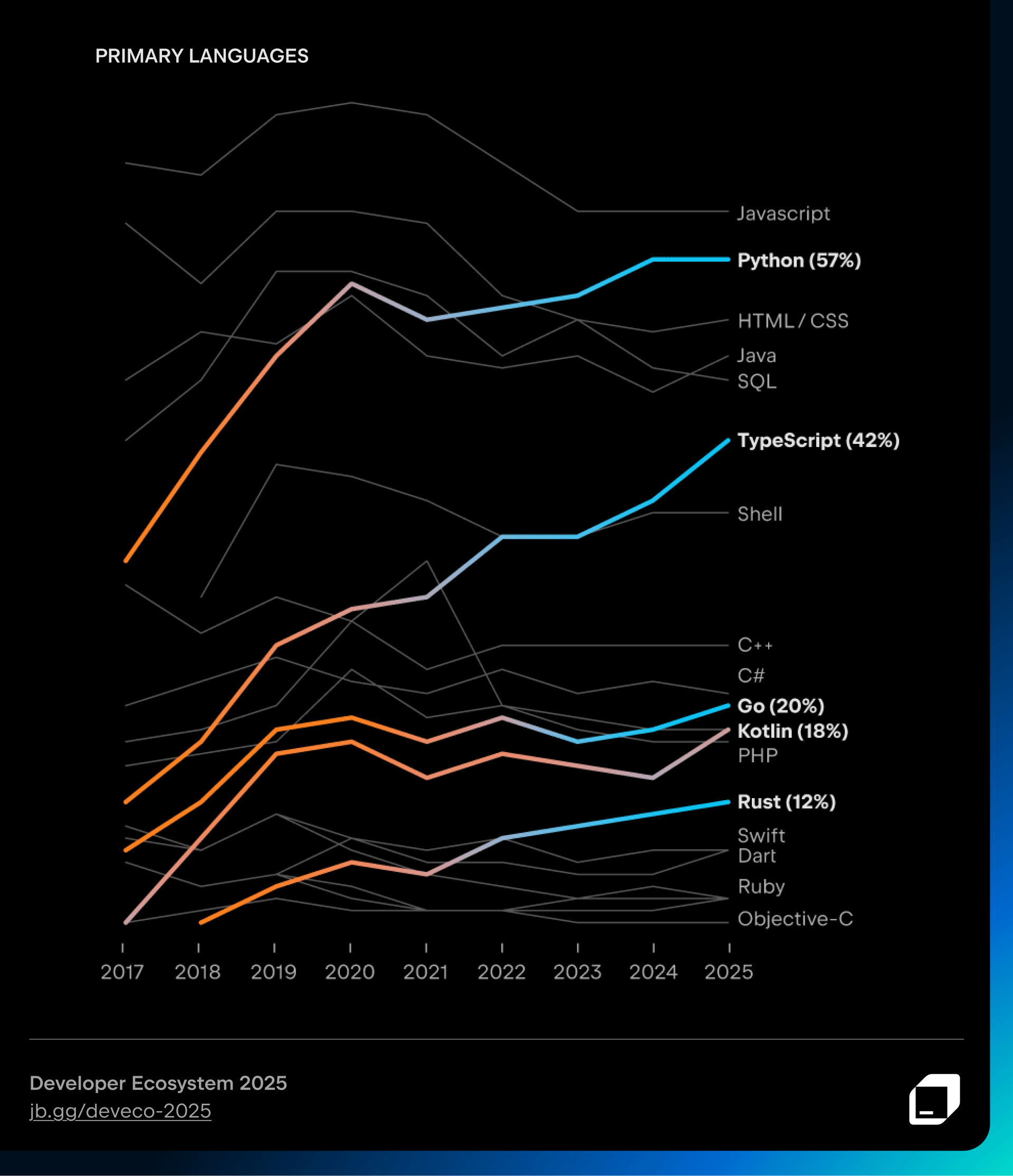
Meanwhile, PHP, Ruby, and Objective-C continue to decline steadily, reflecting how developer preferences and project demands have shifted over time.
The JetBrains Language Promise Index ranks languages based on growth, stability, and developers’ willingness to adopt them. According to the index, in 2025, TypeScript, Rust, and Go boast the highest perceived growth potential, while JavaScript, PHP, and SQL appear to have reached their maturity plateau.
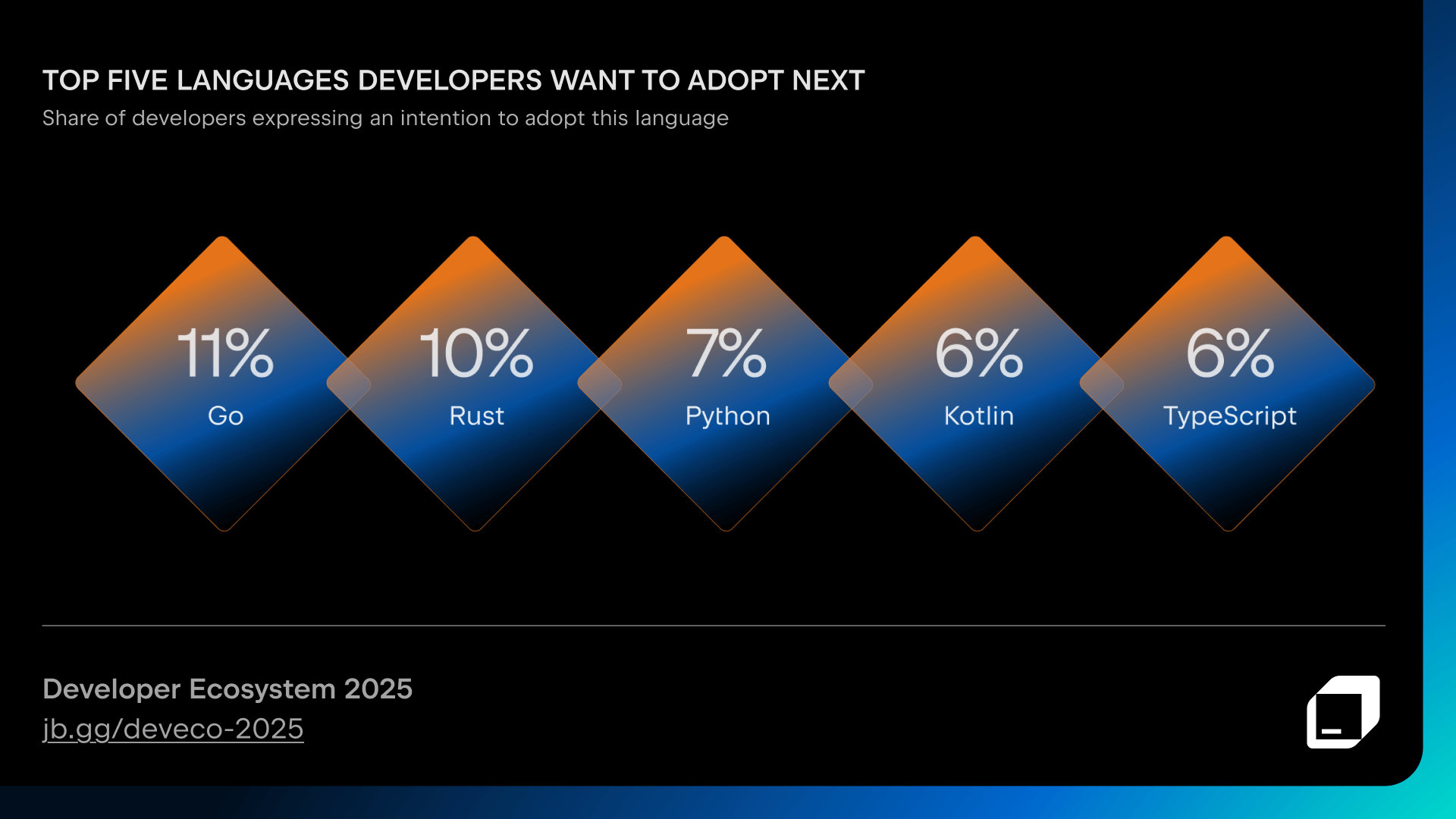
The top five languages that developers want to adopt next are:
- Go (11%)
- Rust (10%)
- Python (7%)
- Kotlin (6%)
- TypeScript (6%)
Surprisingly, Scala leads among the top-paid developers with 38%, despite being used by only 2% of all developers as a primary language. Sometimes, it seems, niche expertise quite literally pays off. You can explore this phenomenon in more detail with our IT Salary Calculator.
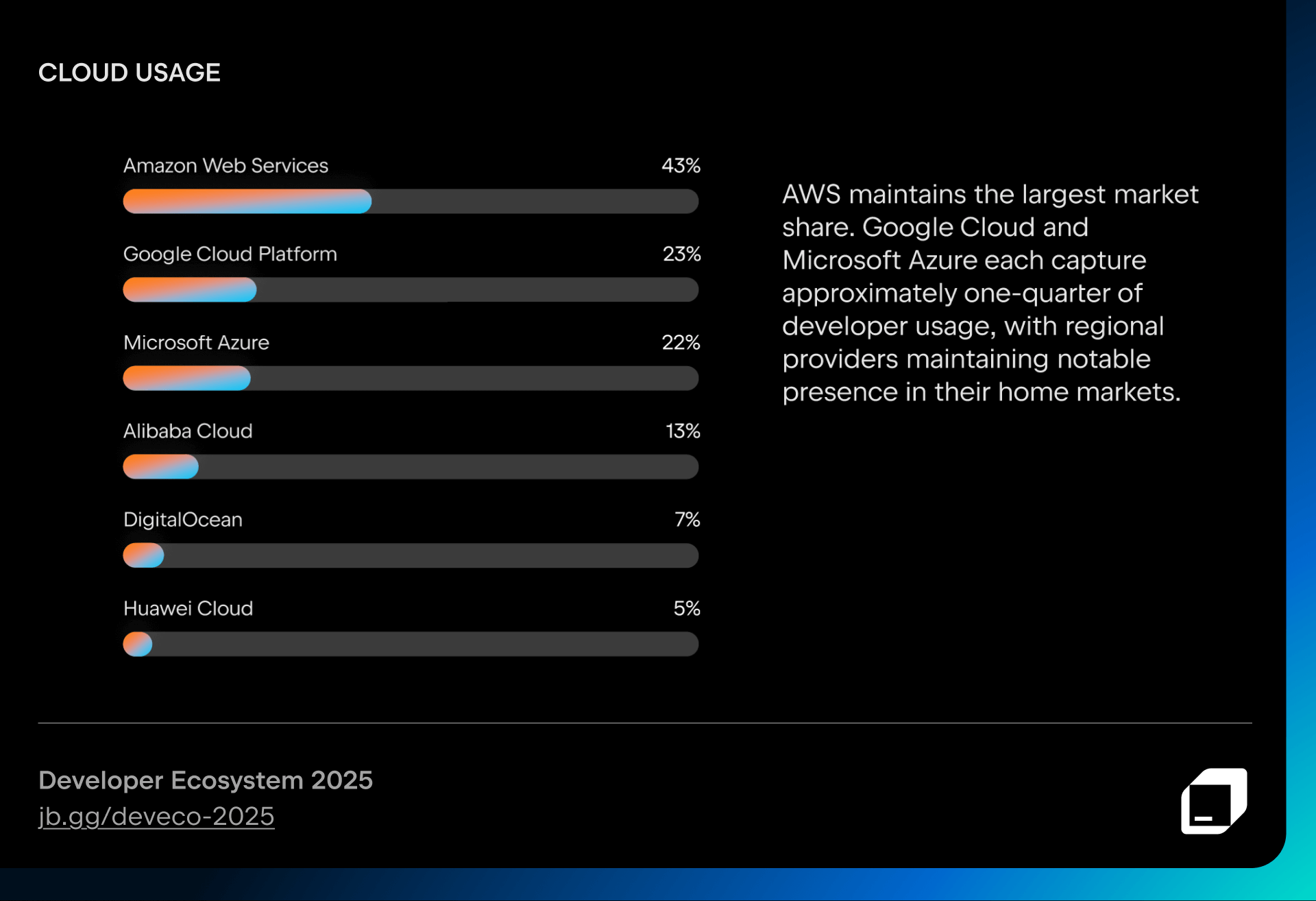
In the world of cloud services, regional providers maintain a strong presence in their home countries, showing that developers often choose cloud providers based on where they work or what’s most available in their region.
Developer productivity: Rethinking what it means to be productive
Last year, companies focused almost exclusively on measuring technical performance – build time, velocity, and mean time to recovery.
In 2025, we have seen a major rebalancing. It’s no longer about DORA metrics – it’s developer productivity that now matters most.
Developers themselves highlight both technical (51%) and non-technical (62%) factors as critical to their performance. Internal collaboration, communication, and clarity are now just as important as faster CI pipelines or better IDEs.
While tech decision-makers dream of reducing technical debt and improving collaboration, developers want transparency, constructive feedback, and clarity of goals. Yet, 66% of developers don’t believe current metrics reflect their true contributions.
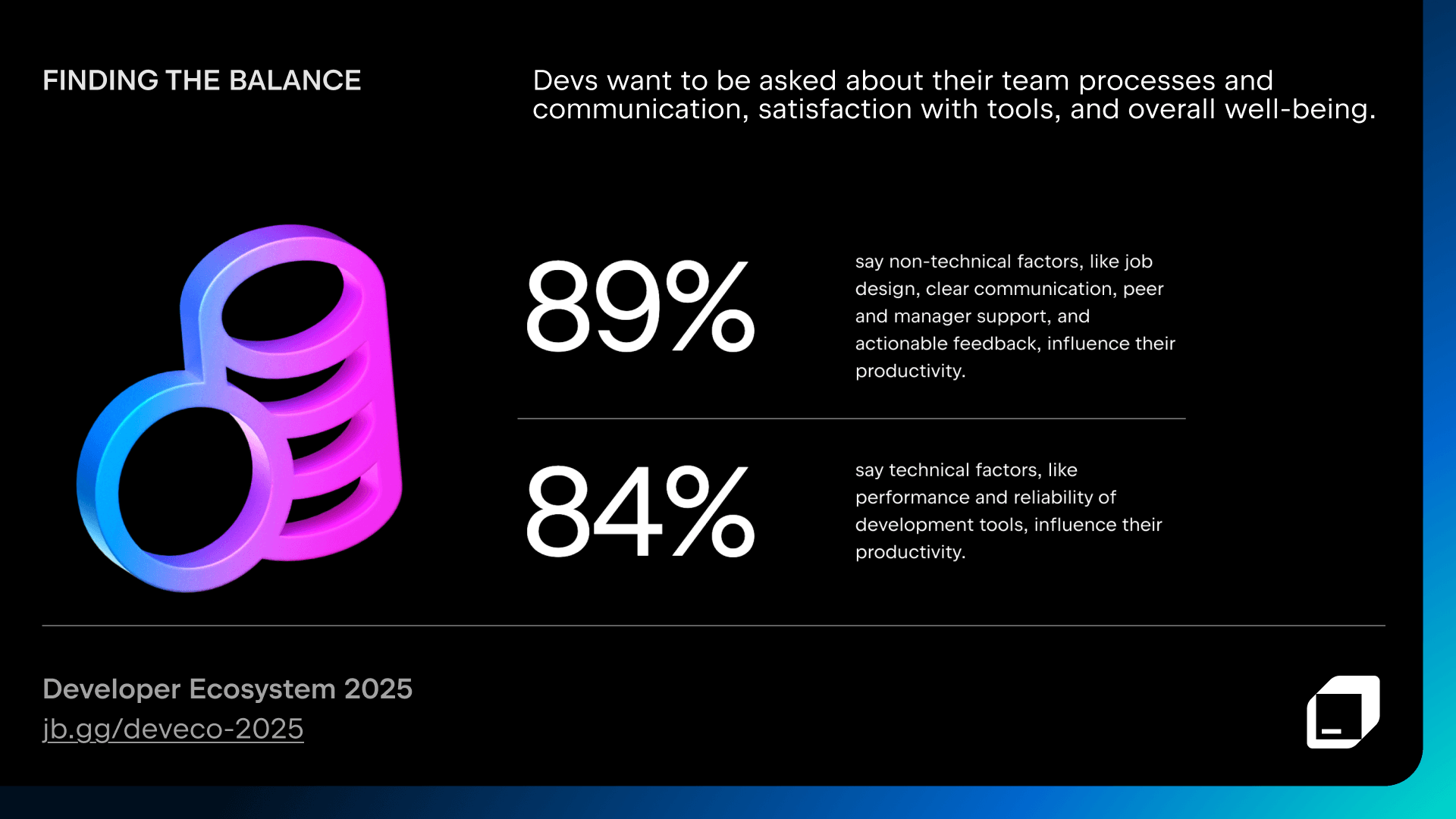
The data suggests it’s time to rethink how we measure success and to build work environments that reward not just results, but the way they’re achieved.
For more on how teams are reimagining productivity and developer experience, explore The State of Developer Experience and Productivity 2025 by JetBrains.
Developer reality
Every developer’s work tells its own story, and the data highlights just how diverse those stories can be.
Globally, developers experience the job market in strikingly different ways: 57% describe it as “favorable” in Japan, while 66% find it “challenging” in Canada. The industry may be global, but opportunity still depends on where you are.
61% of junior developers find the job market challenging, while 54% of senior developers share this concern.
As developers progress in their careers, they face entirely different types of challenges. The data shows a clear transformation from technical focus to coordination responsibilities, such as context switching, as experience increases.
Despite all the challenges, developers love what they do: 52% of developers code for fun even after coding all day. 57% prefer to do it while listening to music, while 25% enjoy the quiet.
And in one of the most delightful constants of this survey: Developers love cats just as much as dogs! 🐱 🐶
Methodology
The survey ran from April to June 2025 and included 24,534 developers after data cleaning. We balanced our responses by geography, employment, programming languages, and JetBrains product use.
Wrapping up
The Developer Ecosystem Survey 2025 results reveal a field that’s changing fast, shaped by AI and growing self-awareness among developers. They’re using tools that make them more productive, while questioning how they define productivity in the changing landscape.
Explore the full data and uncover your own insights using the Developer Ecosystem Data Playground. Check out the infographic for more insights about the current developer ecosystem.
Join the conversation
What surprised or excited you most about the findings? Share your thoughts on X or other social media platforms, mentioning @jetbrains and using the hashtag #DevEcosystem25. Your feedback helps us make our reports even more informative and useful.
Be part of the 2026 report
Want to contribute to next year’s Developer Ecosystem Survey? Join our JetBrains Tech Insights Lab! As a participant, you’ll engage in surveys, interviews, and UX studies that not only improve JetBrains products but also provide invaluable insights for the developer community. Plus, you can enter various prize draws and earn valuable rewards.
Let’s navigate the ever-changing tech landscape together. See you in the 2026 edition!
]]>In a live session, TeamCity Solutions Engineers, Ricardo Leite and Daniel Gallo, will walk you through the powerful features introduced in the most recent release and give you an exclusive look at what’s next on our roadmap.

Whether you’re looking to optimize your existing TeamCity setup or considering an upgrade, this webinar will give you the insights and practical knowledge you need to maximize your use of TeamCity.
Save the date
📆 October 22, 2025
⏰ 4:00–5:00 pm (UTC)
What you can expect from the session:
- Hands-on demonstrations of the latest TeamCity features with real-world scenarios showing exactly when and how to use them.
- Configuration walkthroughs to help you implement these features in your own pipelines.
- A roadmap preview so you can see what’s on the horizon.
- An update on changes to our licensing model, including the removal of renewal discounts for new license purchases, and why acting now can help you save.
Speakers


The two most notable improvements that these releases bring are:
- MPS-38681 – Invisible references can now be excluded from usage highlighting.
- MPS-36481 – The <generate> task in Ant now recognizes two additional project properties to configure the location of the log files:
- mps.log.config.file points to the JUL properties file, in which the location for the log files (both absolute and relative) can be specified.
- mps.log.dir specifies the directory for log files.
Check out all the updates in each particular version below:
MPS 2025.2.1
Download MPS 2025.2.1 here.
See the full list of fixed issues here.
MPS 2025.1.1
Download MPS 2025.1.1 here.
See the full list of fixed issues here.
MPS 2024.3.4
Download MPS 2024.3.4 here.
See the full list of fixed issues here.
MPS 2024.1.5
This release fixes a version-specific issue that caused occasional freezes after invalidating caches (MPS-37659).
Download MPS 2024.1.5 here.
See the full list of fixed issues here.
Your JetBrains MPS team