uploader: display binary object bytes in tensorboard dev list output
#3464
Conversation
|
FWIW I think @GalOshri had not wanted to call these "blobs" publicly, though I don't know exactly how else we would describe this. |
tensorboard dev list outputtensorboard dev list output
tensorboard dev list outputtensorboard dev list output
|
Added @GalOshri to reviewers list for his comments on the wording and appearance of the new screen output. |
tensorboard dev list outputtensorboard dev list output
| ("Tags", str(experiment.num_tags)), | ||
| ("Scalars", str(experiment.num_scalars)), | ||
| ] | ||
| if experiment.total_blob_bytes: |
There was a problem hiding this comment.
Why is this conditional? Shouldn’t we show that experiments with no
blobs have 0 blob bytes?
If this is intended to account for old servers, it should be handled
with a fieldmask in the response instead, so that “zero” and “unset”
aren’t conflated. But it doesn’t seem terribly important to me that we
treat old servers specially.
There was a problem hiding this comment.
As I wrote in the PR description:
Blob bytes is shown only if it's non-zero
Rationale: The text output is already pretty verbose, requiring tedious manual scrolling to find an experiment. We want to avoid further increasing the size of the text unnecessarily.
There was a problem hiding this comment.
I thought about it more. I agree it's better to make it unconditional, because the "name" and "description" fields show something even when there is no name or description. It's better to be consistent with that. Done making the change and updating screenshot.
| ] | ||
| if experiment.total_blob_bytes: | ||
| data.append( | ||
| ("Binary object bytes", str(experiment.total_blob_bytes)) |
There was a problem hiding this comment.
Let’s avoid whitespace in the field name. As described in #2941, this
format is designed to be easily parseable with something like:
tensorboard dev list |
awk '$1 == "Id" { id = $2 } $1 == "Scalars" && $2 > 1000 { print id }'
With spaces in "Binary object bytes", the $1 == "Scalars" would have
to be something like ($1 " " $2 " " $3) == "Binary object bytes",
which is pretty ugly.
There was a problem hiding this comment.
I think it's more important that this format be clearly intelligible to humans than that it be machine parseable. If we want to make it easier to parse, we should add some non-space delimiter between the field name and the value (like :) or (my preference), just add an actually standard output format option like JSON, rather than artificially constraining how much information we provide to users.
There was already an internal thread about the naming to try to determine what to call this field (to avoid "blob") and I don't think there is a one-word name that is sufficiently unambiguous since we need to specify that the unit here is bytes rather than the number of blobs or blob sequences.
There was a problem hiding this comment.
Either of those options—an unambiguous delimiter (: is kind of awkward
due to the URLs) or a --json/--output json flag—works for me, too.
Currently (in master), the output is clear to both humans and machines,
so I would prefer not to regress from that.
There was a problem hiding this comment.
Thanks for the discussion. I think "Binary object bytes" Is a nice tradeoff balance clarity and conciseness.
I like the --json option better than :. : feels a little awkward as @wchargin mentioned. Do you want me to add the json mode in this PR? It feels like a sufficiently distinct feature that merits a separate PR.
There was a problem hiding this comment.
It looks like "Binary object bytes" is the best option. Can we add an explanation for this in the list command help text?
Adding a JSON option seems like a good idea.
There was a problem hiding this comment.
Thanks, @GalOshri . I'll merge the PR as is soon.
I filed b/153232102 to track the proposed JSON output feature. It is sufficiently distinct from the goal of this PR to merit a separate PR.
There was a problem hiding this comment.
@wchargin I'm not sure if you want to take a look again at this PR. If you do, please let me know.
There was a problem hiding this comment.
Yes, I’ll take a look at the --json change and then revisit here.
Thanks!
| ] | ||
| if experiment.total_blob_bytes: | ||
| data.append( | ||
| ("Binary object bytes", str(experiment.total_blob_bytes)) |
There was a problem hiding this comment.
Need to update fieldmask above to actually request total_blob_bytes?
| response.experiments.add( | ||
| experiment_id="789", | ||
| name="one", | ||
| num_scalars=8, | ||
| total_tensor_bytes=1234, | ||
| total_blob_bytes=0, | ||
| num_runs=1, | ||
| num_tags=10, | ||
| ) |
There was a problem hiding this comment.
What are these test changes for? It looks like all the prod code changes
are in uploader_main.py, which isn’t covered by exporter_test, so I
don’t see why they’re relevant. (All tests pass either with or without
these changes.) I also don’t see why the changes are desirable: the RPC
path in this test invokes StreamExperiments with a fieldmask that does
not include these extra metadata fields, so why change the server to
populate them?
There was a problem hiding this comment.
Reverted the changes to this file.
|
@wcharing #3480 is merged into this PR. Conflicts are resolved. "Binary object bytes" (corresponding to the JSON key "binary_object_bytes") is now added to |
tensorflow#3464) * Motivation for features / changes * A part of fulfilling feature request b/152749189: Displaying number of blob bytes contained by an experiment in the output of `tensorboard dev list` * Technical description of changes * Pairing CL/304187797 * Use the newly added `Experiment.total_blob_bytes` field. * Adjust the ordering of the items slightly: this fits the intuitive hierarchy better IMO * Before: Scalars -> Runs -> Tags * After: Runs -> Tags -> Scalars -> Blob bytes (if exist) * Given the long length of the new label string ("Binary object bytes"), the width of the first column is increased from 12 to 20. * Screenshots of UI changes - 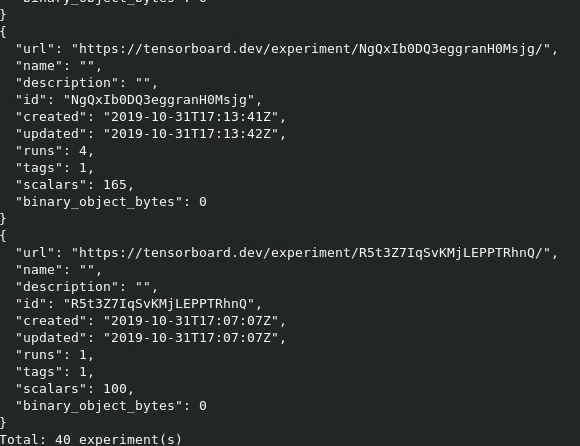 - Note the actual number of bytes in the screenshot above is incorrect. But that's due to an orthogonal issue that @ericdnielsen is fixing. * Detailed steps to verify changes work correctly (as executed by you) * Tested against a locally-running environment running on the said pairing CL.
{kind=link}
#3464) * Motivation for features / changes * A part of fulfilling feature request b/152749189: Displaying number of blob bytes contained by an experiment in the output of `tensorboard dev list` * Technical description of changes * Pairing CL/304187797 * Use the newly added `Experiment.total_blob_bytes` field. * Adjust the ordering of the items slightly: this fits the intuitive hierarchy better IMO * Before: Scalars -> Runs -> Tags * After: Runs -> Tags -> Scalars -> Blob bytes (if exist) * Given the long length of the new label string ("Binary object bytes"), the width of the first column is increased from 12 to 20. * Screenshots of UI changes -  - Note the actual number of bytes in the screenshot above is incorrect. But that's due to an orthogonal issue that @ericdnielsen is fixing. * Detailed steps to verify changes work correctly (as executed by you) * Tested against a locally-running environment running on the said pairing CL.
tensorboard dev listExperiment.total_blob_bytesfield.