What is vLLM V1?
In January 2025, the vLLM team announced the alpha release of vLLM V1: a major redesign of vLLM’s internal architecture. The design goals of V1 were (a) simplify the codebase, (b) make vLLM more extensible, and (c) turn on all performance optimizations by default. This latter aspect was of particular importance to kernel developers writing optimized attention kernels.
vLLM offers a wide range of performance optimizations: continuous batching, paged attention, speculative decoding, chunked prefill, prefix caching. In V0, some of these optimizations were compatible with each other, and some were not. Making them all work smoothly together required significant changes in the codebase, which propagated all the way down to the kernel level.
In order to simplify the parts of the codebase related to scheduling, V1 also brought some significant changes in the way that batches of requests are formed. In V0, vLLM’s scheduler would always form either a “prefill batch” (e.g., a batch comprising solely waiting requests that need to be prefilled) or a “decode” batch (e.g., a batch comprising solely running requests that are being decoded). In V1, the scheduler can form a mixed batch that may contain requests that are in any state: new prefills, chunked prefills, decodes, or even speculative decodes.
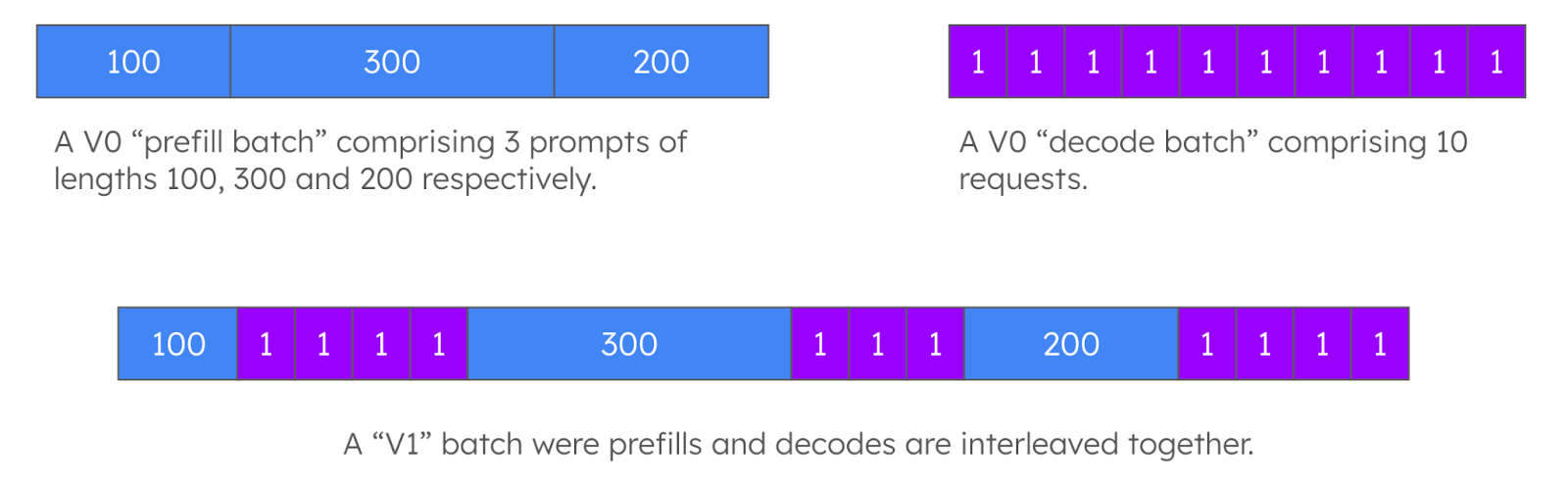
Figure 1: Batches in vLLM V1 compared to batches in vLLM V0.
Initially, the only attention backend that supported these “V1 batches” was the CUDA version of the FlashAttention package. For this reason, initially V1 could only be used on NVIDIA GPUs and GPUs from other vendors such as AMD were not supported. The attention kernels for AMD GPUs used by vLLM V0 were implemented as custom C++/HIP code, making them relatively difficult to adapt to the V1 use-case. For this reason, the team across AMD, IBM Research and Red Hat decided to develop a new attention backend for vLLM V1 based on Triton kernels, enabling AMD support in a platform-portable and more developer-friendly manner.
Terminology and Baseline
Before we dive into describing how the kernels work, it is important to understand some basic terminology. When we talk about a sequence in vLLM there are three key quantities. Firstly, the context length denotes the number of tokens for which attention has already been computed and the key-value tensors are already stored in the paged KV cache. Secondly, the query length describes the number of “new” tokens that need to be computed in this scheduled iteration. Finally, the “sequence length” denotes the sum of the context length and the query length.
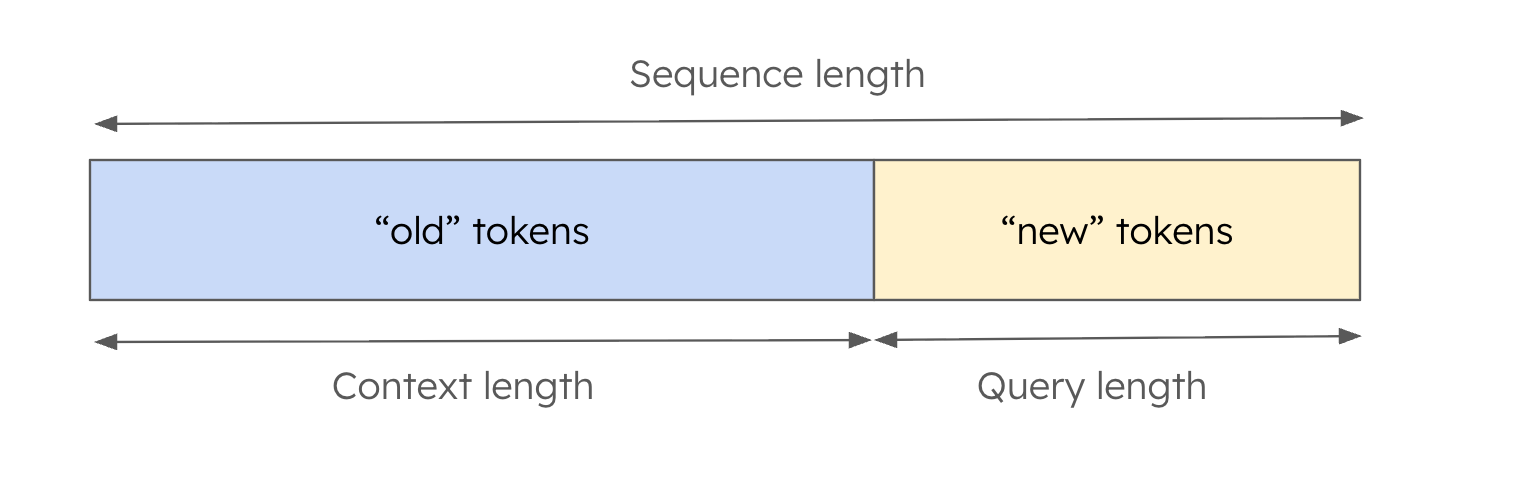
Figure 2: Some basic terminology for understanding the kernels
To understand the above, it helps to think about some corner cases:
- Context length = 0, this corresponds to a “pure” prefill operation. In this case, there is nothing in the KV cache related to this sequence and attention must be computed on the prompt from scratch.
- Context length > 0 and query length ~ 1000 tokens. This is a typical “chunked prefill” operation where we split a long prompt into smaller chunks. In this case, the new tokens need to attend to the old tokens that have already been stored in the paged KV cache.
- Context length > 0 and query length = 1 token.This is the classic “decode” operation.
- Context length > 0 and query length ~ 3 tokens. This is a typical pattern that arises when performing speculative decoding with a small draft model that produces estimates for the next few tokens that will be validated with the main model.
A Triton kernel for vLLM V1 needs to support all 4 of these cases (and everything in between!).
Initially, the only Triton kernel that existed that supported all of these scenarios was the prefix_prefill kernel. This kernel originated from the LightLLM project and provided a great way to get vLLM V1 up and running on AMD GPUs. As with all of the attention kernels described in this article, it implements the tiled softmax algorithm (specifically, the algorithm described in the FlashAttention-2 paper). When launching the kernel, we use a grid of size (batch_size, num_query_heads, query_length // BLOCK_M) where BLOCK_M is a constant set to 128. Thus, prefix prefill parallelizes the work across sequences in the batch, across query heads, and across “M blocks” in the query dimension. Each program is responsible for computing the tiled softmax along the sequence length dimension. Essentially, it iterates through the sequence length dimension in “tiles” where the size of the tiles in the sequence dimension is defined by BLOCK_N (a constant set to 64) and the size of the tiles in the query length dimension is defined by BLOCK_M. For the tiles that correspond to the context, the kernel reads the KV tensors from the paged KV cache. For the tiles that correspond to the query, the KV tensors are read from contiguous memory (since they have been computed in the same forward pass). The work performed by a given program is illustrated in Figure 3.
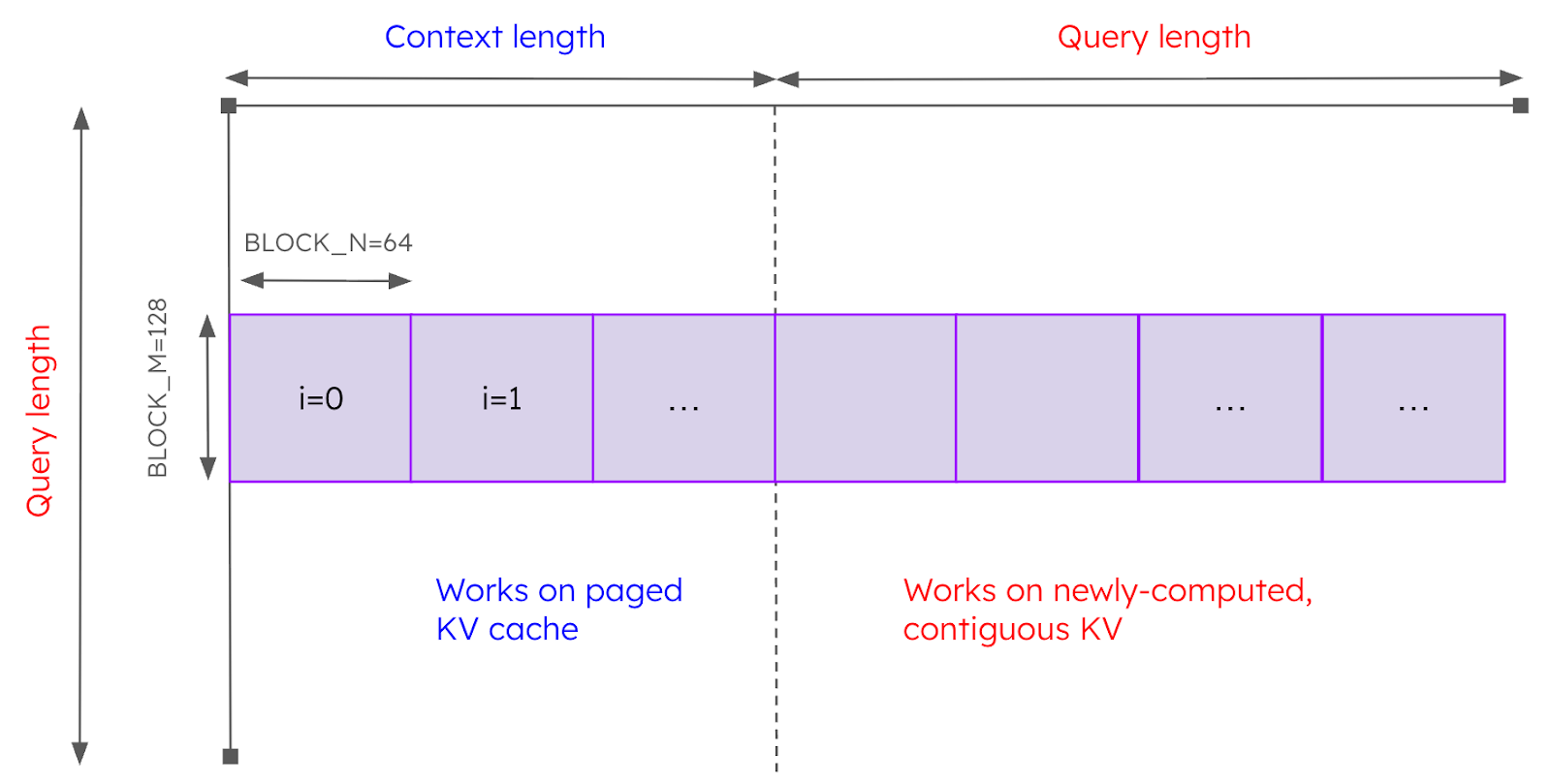
Figure 3: Work performed by one program of prefix prefill (parallelism in batch and head dimensions is not shown).
While this kernel supports all of the 4 cases described above, once the teams from IBM Research, Red Hat and AMD started running our standard performance benchmarks, we noticed that the V1 performance was roughly 6x slower than the baseline V0 performance.
Triton Kernel Optimizations
The teams at AMD, IBM Research, and Red Hat then embarked on a sequence of optimization to try to improve the performance of vLLM V1 on AMD GPUs. We organize these optimizations into 3 chronological phases:
- Optimizations for the prefix prefill kernel.
- Split approach that uses a specialized kernel for decode sequences.
- A new unified Triton kernel for both prefill and decodes (and everything in between).
We will now discuss each of these phases.
Phase 1: Optimizations for the prefix prefill kernel
This phase of the optimization was carried out by AMD and relates to improving the performance of the baseline prefix prefill kernel described above.
Reduced warp count from 8 to 4
In the prefix prefill kernel there was a high spilling rate that significantly impacted execution speed. AMD GPUs MI3xx have only 512 Vector General Purpose Registers (VGPRs), which are distributed evenly over warps scheduled on particular SIMD. If the kernel needs more registers, for instance, by handling too big chunks of memory, then some registers will be flushed into scratch memory HBM and reused for immediate execution, later, spilled data will be restored for compute. 8 warps means that 2 warps are scheduled on one SIMD thus each warp has 256 VGPRs. We cut back the number of active warps to eliminate register spilling. This change alone yielded a ~3-5x speedup, and was among the lowest-hanging fruit that substantially improved kernel performance.
Parameterized scheduling and kernel configuration for autotuning
The first step reduced parallelization of execution of warps on SIMD as well as possibility for warp scheduler interleave fetch, decode, and execution of instructions within one SIMD. In order to increase flexibility the kernel needs to be refactored to correctly scale the processed data by one program. We exposed key kernel launch parameters (e.g. block size, number of warps, pipeline stages, unrolling, prefetching, and so on) so that an autotuner can explore optimal configurations specific to sequence length, KV cache page size, and hardware characteristics. Through the autotune, we took the best suitable config for many real-world scenarios. Autotune itself was adding latency by figuring out what kernel to call and whether it is already in cache. In order to avoid it, it was decided to directly send autotuned parameters to the kernel.
Aligned block memory accesses in the cache loop
Paged KV cache layout is not trivial, it is key_cache (num_blocks, num_heads, head_size // x, block_size, x) v_cache (num_blocks, num_heads, head_size, block_size). This layout makes it tricky, especially for key, to generate offsets inside load instruction and vectorise it. Load vectorization brings a significant part of kernel performance as well as reducing register pressure. Inside the inner cache-reading loop to handle previously computed prefill chunks, we restructured loads to use constant offsets (i.e. computed at compilation time) so the triton compiler has the best knowledge of data to be loaded. This forced the compiler to generate vectorized global loads, improving memory bandwidth efficiency. Moreover, this alignment unlocked loop unrolling and pipelining opportunities that the compiler could exploit, further reducing overhead in memory-bound regions.
Refactored online softmax logic
In AMD, we noticed that the way computation of online softmax was implemented wasn’t ideal. It had extra computations for P scales and Acc scales. The compute happened inside hot loops and resulted in extra register usage as well as compute time (vector ops are synchronous). We rewrote the softmax portion in the prefix prefill kernel to use fewer intermediate registers (e.g., restructuring accumulations, reordering operations). The resulting lower register pressure reduced spill risk and improved instruction-level parallelism in the Triton’s Triton-generated code.
Streamline inner-loop execution
As part of the optimization effort, we eliminated redundant edge-case condition checks from inner loops that do not operate on boundary tiles. By specializing loop bodies based on tile position, non-edge loops can now execute without conditional branches that previously guarded against out-of-bounds accesses. This reduces control-flow divergence and enables the compiler to generate more efficient straight-line code, improving instruction throughput and overall kernel performance – especially for large, well-aligned workloads.
Phase 2: Split approach for decode sequences
This phase of the optimization effort began when the Red Hat and IBM Research teams noticed that the way that the prefix prefill kernel was being used for decode sequences (case 3 above) was highly sub-optimal. For these sequences, the query length is always 1 token. If we think about how the tile is laid out in the query length dimension we can immediately see that because BLOCK_M is set to 128, we need to mask out all but one row of the tile, meaning that we are doing ~100x the amount of work that we actually need to do.
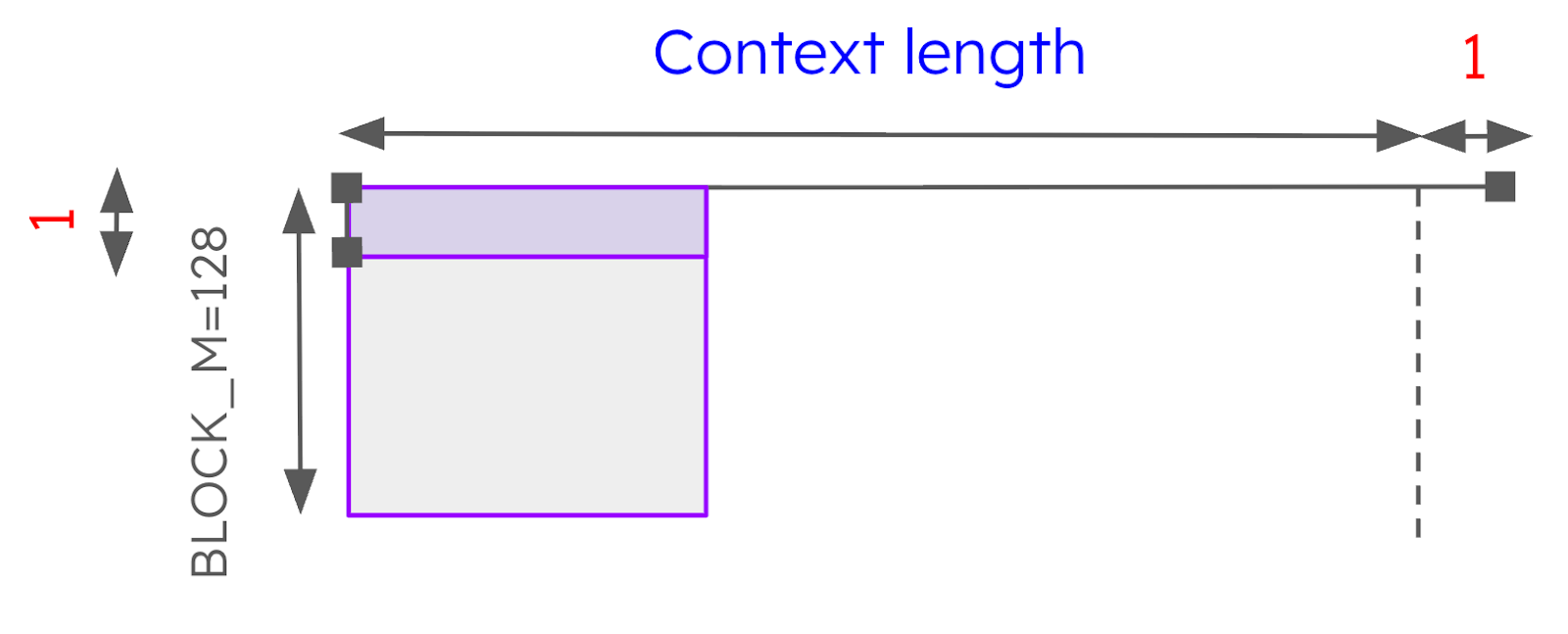
Figure 4: Prefix prefill is not efficient for decode sequences.
While it may seem obvious that we should just reduce BLOCK_M for decode sequences, there is no free lunch here because vLLM packs decode and prefills within the same batch, and the value of BLOCK_M is a compile-time constant, and thus must be the same for all sequences within the batch. Thus, optimizing BLOCK_M for decode sequences will have an adverse effect on the other sequences within the same batch.
Based on the above observation, the first thing that the IBM Research team tried was to modify the prefix prefill kernel such that if the query length is 1, the program terminates immediately. Thus, the prefix prefill is used solely to compute the sequences in the batch with query length > 1. We then launch a second, newly-written, Triton kernel, paged_attention_2d, which terminates immediately if the query length is > 1, and for the sequences with query length = 1 (e.g., decodes), it computes paged attention in a highly optimized way. The name “2D” refers to the grid that we use to launch the kernel: it is a grid of shape (batch_size, num_query_heads). Note that prefix prefill uses a 3D grid with the extra dimension corresponding to the query length dimension. Since decodes don’t expose this additional level of parallelism, it is not needed (more on 3D kernels later).
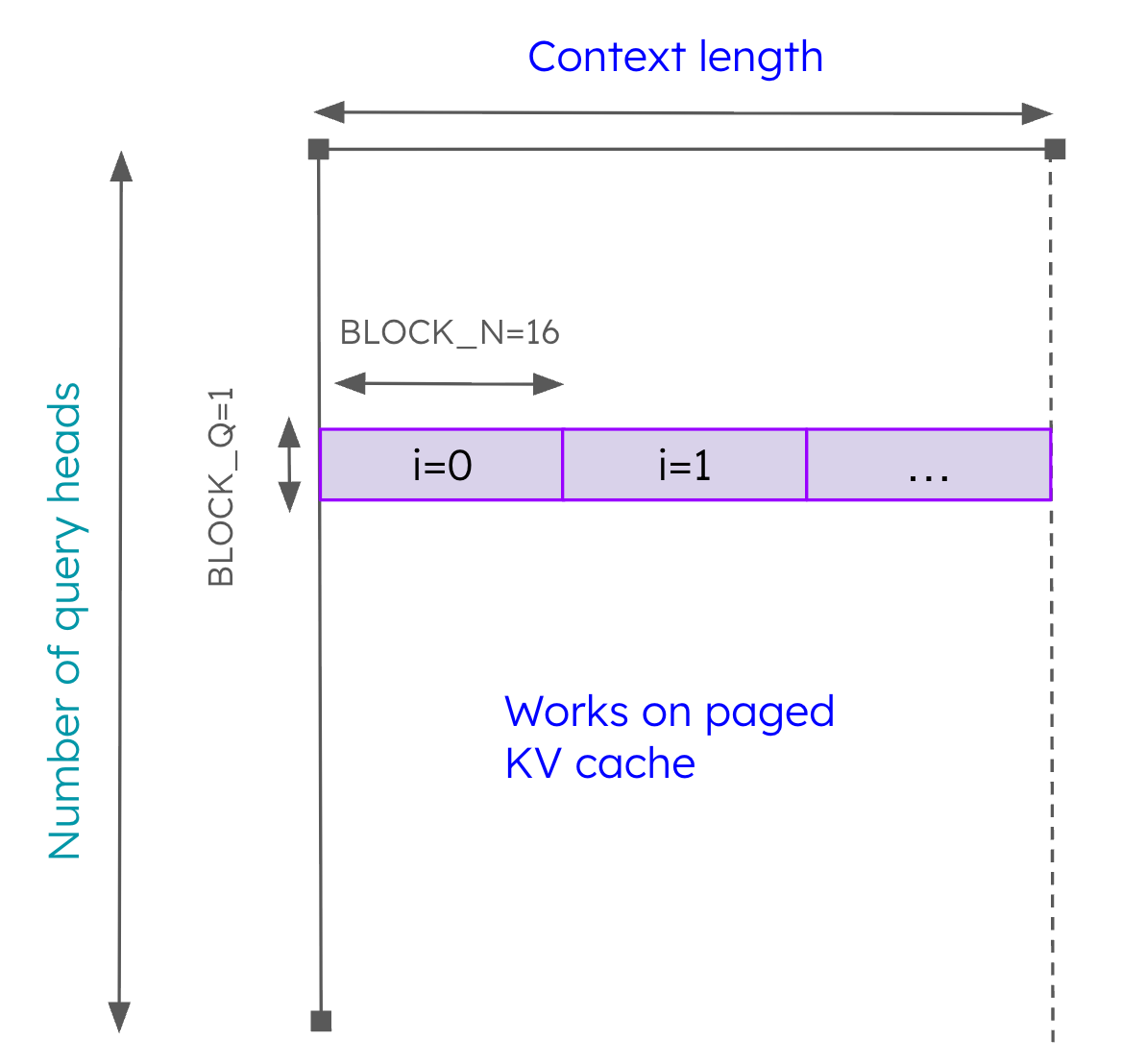
Figure 5: Work performed by one program of paged_attention_2D
The work performed by this kernel is illustrated in Figure 5. Each program operates on a single query head (shown in the y-axis) and performs the tiled softmax along the context length dimension (shown in the x-axis). Since this kernel is working solely on paged KV cache, we set BLOCK_N=16 tokens to align with the default page size used in vLLM. Since there is no redundant “blocking” in the query dimension, we are not doing orders of magnitude more work that is necessary. Using this kernel in combination with prefix prefill led to around a 3.7x improvement in throughput.
However, the kernel did not perform well for models that use grouped query attention (GQA). The reason for this is that it treats all query heads as independent, even if they share the same KV head. To overcome this limitation, we introduced additional blocking in the query head dimension (shown in Figure 6). Rather than launching the kernel with a grid of shape (batch_size, num_query_heads), we use the grid of shape (batch_size, num_kv_heads). Each program performs the tiled softmax algorithm for QpKV query heads where QpKV=num_query_heads/num_kv_heads. By bundling together query heads that share the same KV head within the same tile, we can ensure that less data needs to be moved from the GPU VRAM to the compute cores. Additionally, we found that by rounding up BLOCK_Q to a multiple of 16, we can ensure that the matmuls will get mapped to the matrix cores, leading to additional performance boost. In total, we found that these GQA-related optimizations brought around a 25% boost in throughput.
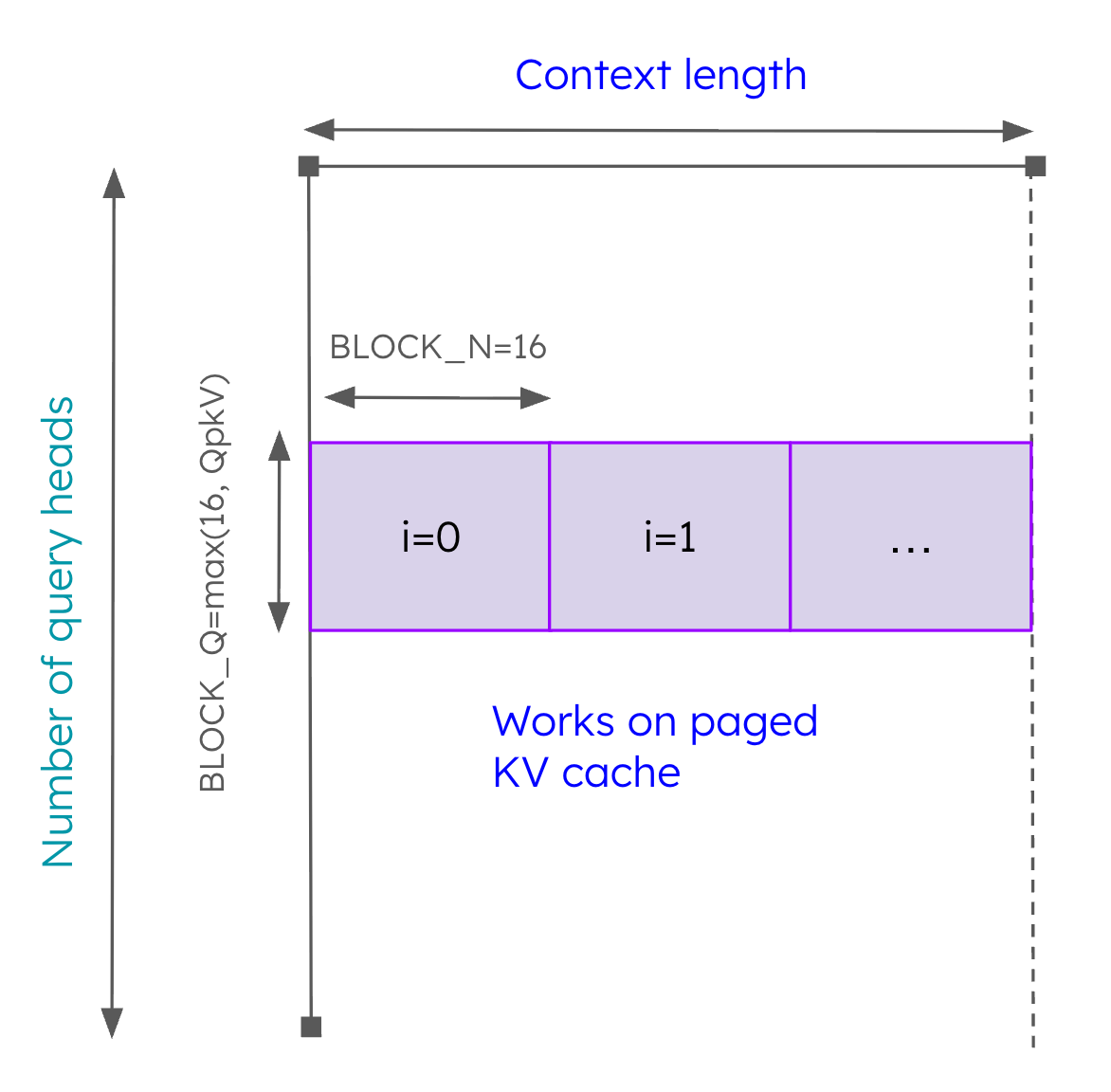
Figure 6: Work performed by one program of paged_attention_2D with GQA optimizations
Phase 3: Unified attention kernel
While performance was now significantly improved, the “split” approach still left something to be desired. In particular. “splitting” the work across two kernels (one for decode sequences, and one for everything else) has a number of downsides. Firstly, we need to maintain the code for two complex kernels. Secondly, in low-latency scenarios, we can be negatively affected by CPU-based launch overheads. Finally, the “split” solution does not consider the case of speculative decodes where the query length is not exactly 1, but may still be small. In this case, the use of prefix_prefill will again be highly inefficient.
To overcome these limitations, the IBM Research team developed the unified_attention_2d Triton kernel (see Figure 7). This kernel again redefines the shape of the launch grid to be (total_num_q_blocks, num_kv_heads), where total_num_q_blocks is a quantity proportional to the sum of the query lengths across the whole batch. Each program performs the tiled softmax algorithm along the sequence length dimension (the z-axis in Figure 7). Blocking is performed along the query head dimension using a BLOCK_Q of size exactly QpkV (shown on the y-axis in Figure 7) as well as along the “flattened” batch dimension (shown on the x-axis in Figure 7) using BLOCK_M = 16/QpkV. With this approach, we bundle work across query heads and across tokens in the query dimension into the same matmuls, meaning we can pack more work into the same tensor core instructions in the case that QpKV<16. Note that the blocking in the flattened batch dimension (the “Q blocks”) has to be defined carefully such that each Q block contains tokens from only one sequence within the batch (notice how some of the Q blocks are masked out in Figure 7 at the end of each query). This constraint is necessary; otherwise, tiles will need to handle multiple sequences at the same time, hugely complicating the logic.
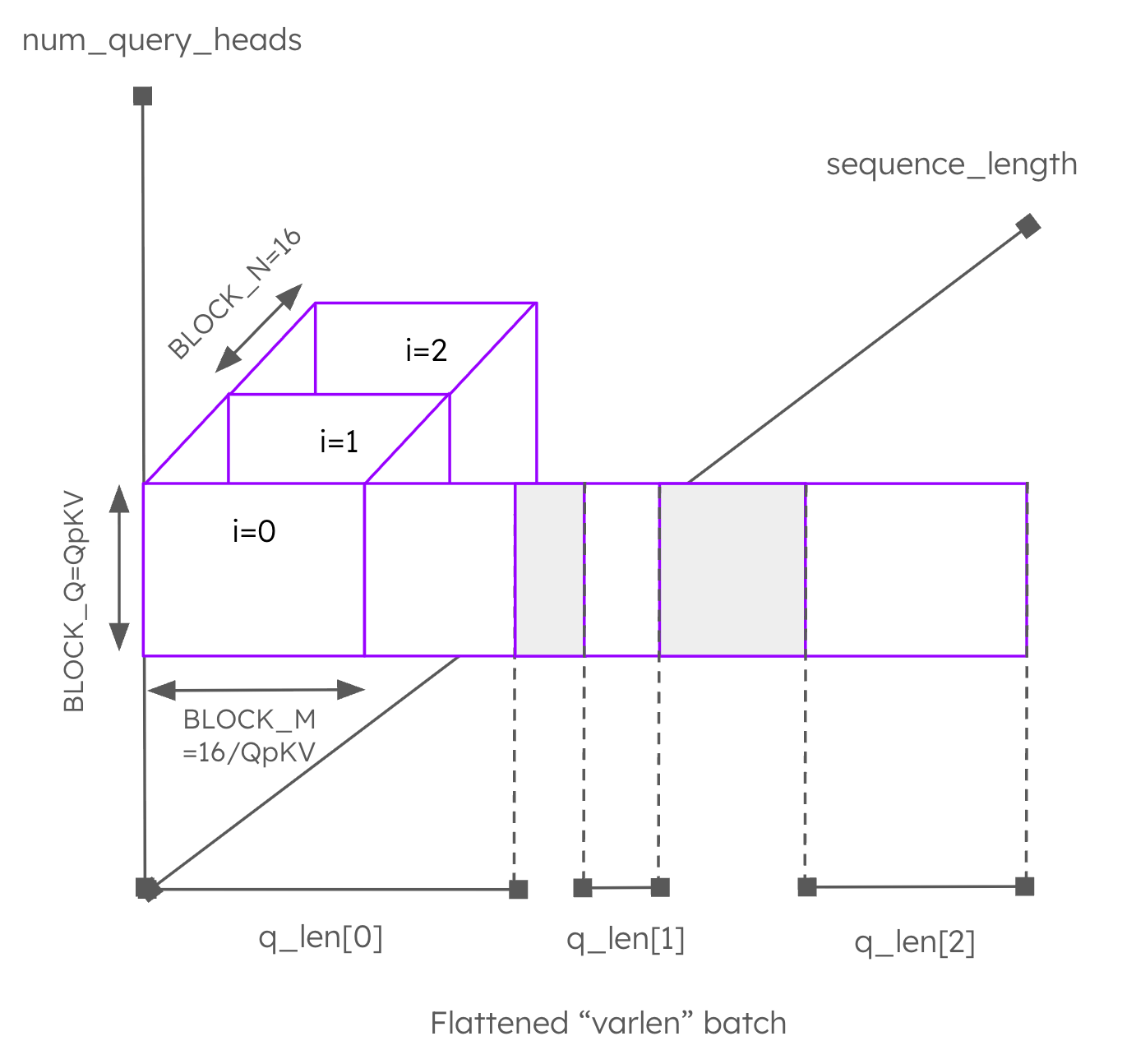
Figure 7: Work performed by one program of the unified_attention_2d kernel.
We now have a single kernel that can be used for V1 batches comprising only 239 lines of code, making it much easier to maintain in the long term. However, experiments by the AMD team showed that in some scenarios, the Triton kernels were still underperforming. In particular, the AMD team found that C++/HIP decode kernels written for vLLM V0 were still delivering better performance when the number of output tokens was very long. We established that the reason for this is that the unified Triton kernel was not taking advantage of any parallelism along the context length dimension. To address this, the IBM Research team developed an extension of the above kernel, unified_attention_3d, following the idea of Flash-Decoding to split the work along the context length dimension, creating additional parallelism, at the expense of a final reduction step.
The 3D kernel is needed most when there isn’t sufficient parallelism in either the head number dimension (num_kv_heads) or the flattened batch dimension (tot_num_q_blocks) to fully occupy the GPU. This often happens if the batch is relatively small or if the query lengths within the batch are very short (e.g., pure decode). However, if the batch is very large or the batch contains a few very long queries then the 2D kernel admits sufficient parallelism and the overhead of performing the final reduction step may not be worth it. For this reason, the IBM Research team implemented a simple heuristic to decide when to use the 2D kernel vs. the 3D kernel.
The AMD team then contributed additional optimizations on top of the unified attention 2D/3D kernel to bring vLLM V1 performance to where it is today.
SWA loop boundary adjustments and configuration updates:
Optimized the sliding window attention (SWA) mechanism to restrict computation strictly to the active window range. Previously, the kernel evaluated attention scores across the entire sequence length and subsequently discarded values outside the target window, leading to unnecessary memory reads and compute overhead. The new implementation introduces range-aware indexing and masking logic that dynamically limits query–key interactions to the relevant subset of tokens. This change not only reduces the quadratic computational cost in long-sequence scenarios but also improves memory locality, cache efficiency, and overall throughput—particularly beneficial for streaming or incremental decoding workloads.
‘cg’ cache modifier for KV and Q blocks (conditional on reuse):
Applied cache modifiers to optimize global memory loads – particularly beneficial on AMD GPUs in memory-bound regimes.
2D attention grid reordering for improved XCD mapping:
Redesigned the 2D attention grid layout to enhance spatial locality and cross-die data reuse. The new mapping strategy reorders block indices so that workgroups processing adjacent query–key tiles are preferentially co-located on the same XCD (cross-compute die). This alignment ensures that tiles sharing overlapping key/value regions execute on the same memory domain, significantly improving L2 cache residency and reducing cross-die traffic. By minimizing remote memory accesses and improving temporal reuse of shared data, this optimization enhances effective memory bandwidth and leads to more consistent latency scaling across multi-die configurations.
Increased BLOCK_M to reduce data reloading:
Adjusted the tile height (BLOCK_M) to better balance register utilization and memory access efficiency. By increasing the number of rows processed per block, each thread group now reuses loaded query and key data across a larger set of computations before eviction, significantly reducing redundant global memory reads. This change improves the compute-to-memory ratio, increases arithmetic intensity, and enhances overall throughput—especially for longer sequence lengths where memory bandwidth often becomes the primary bottleneck. The new configuration also allows better overlap between memory prefetch and compute, further improving hardware utilization.
Specialized prefill configuration tuning:
Introduced specialized parameter presets tailored for prefill-phase workloads within the split-kernel execution model. These presets automatically tune key kernel parameters – such as tile dimensions, warp count, and pipeline depth – to maximize GPU occupancy and data reuse specific to prefill characteristics. By aligning tile sizes and memory prefetch patterns with the typically larger batch and sequence dimensions of prefill operations, the new configuration improves cache utilization, reduces global memory traffic, and maintains high arithmetic intensity.
Revised kernel selection logic (2D vs. 3D):
Enhanced vLLM’s kernel selection heuristic to more accurately choose between 2D and 3D launch configurations based on the current sequence length, batch shape, and token distribution. The updated logic accounts for workload geometry and GPU occupancy characteristics, ensuring that each launch strategy is applied in the regime where it performs best. This adaptive selection improves kernel efficiency across a wide range of input patterns—minimizing idle threads, improving memory access regularity, and delivering more consistent performance across both small-batch and large-context workloads.
Expanded grid splits for 3D decode:
Increased the degree of partitioning along the third launch dimension to generate a larger overall grid, thereby improving GPU occupancy and parallelism. This adjustment allows more thread blocks to be scheduled concurrently, ensuring better utilization of available SMs, particularly in large-sequence decode workloads where per-block computation can otherwise limit concurrency. The change enhances load balancing across the device and leads to more consistent performance scaling with sequence length.
Performance Benchmark
This blog describes a large number of optimizations contributed to open-source over several months. The performance improvement for each optimization can be found in the PRs linked from the text above. In this section, we aim to evaluate the cumulative effect of this effort and show that vLLM V1 (based on Triton) now outperforms V0 (based on C++/HIP) in realistic heterogeneous serving benchmarks on AMD GPUs.
We will compare the performance of vLLM V0 and V1 for the model mistralai/Mistral-Small-24B-Instruct-2501 on a single AMD MI300x GPU. All experiments were performed using publicly available docker images and the built-in benchmarking tool of vLLM so should be easily reproducible. We used the following docker images for V0 and V1 respectively:
Comparing the performance of V0 and V1 is complicated by the fact that the two versions have different default settings. In particular, the value of max-num-seqs, the parameter that controls the maximum number of sequences that vLLM can process concurrently, is set to 256 by default in V0, whereas in V1 it is set to 1024. Similarly, in V0 chunked prefill is disabled by default, whereas V1 enables chunked prefill by default, and the chunked prefill parameter max-num-batched-tokens defaults to 8192 for this particular model. These parameters can significantly affect performance and potentially mask any differences between V0 and V1 related to the different kernel implementations. For this reason we run 4 different experiments to try to control these effects and isolate the benefits of the kernel work described in this blog.
V0 (default settings, other than disable prefix caching)
VLLM_USE_V1=0 vllm serve mistralai/Mistral-Small-24B-Instruct-2501 \ --no-enable-prefix-caching
V0 (increase max. number of sequences):
VLLM_USE_V1=0 vllm serve mistralai/Mistral-Small-24B-Instruct-2501 \ --no-enable-prefix-caching \ --max-num-seqs 1024
V0 (increase max. number of sequences and enable chunked prefill):
VLLM_USE_V1=0 vllm serve mistralai/Mistral-Small-24B-Instruct-2501 \ --no-enable-prefix-caching \ --max-num-seqs 1024 \ --enable-chunked-prefill \ --max-num-batched-tokens 8192
V1 (default settings, other than disable prefix caching):
VLLM_USE_V1=1 vllm serve mistralai/Mistral-Small-24B-Instruct-2501 \ --no-enable-prefix-caching
Client (Benchmark):
In all 4 experiments, we use the built-in benchmarking tool of vLLM to hit the server with a heterogeneous serving workload:
vllm bench serve \ --model mistralai/Mistral-Small-24B-Instruct-2501 \ --dataset-name sharegpt \ --dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \ --ignore_eos
Results
In Figure 8, 9 and 10 we compare the performance of the 4 configurations above in terms of the total token throughput, the time to first token (TTFT) and the inter-token latency (ITL). We can even, when we adjust the default parameters of V0 to match those of V1, we see around 10% improvement in all metrics when using the Triton kernels developed and optimized for vLLM V1.
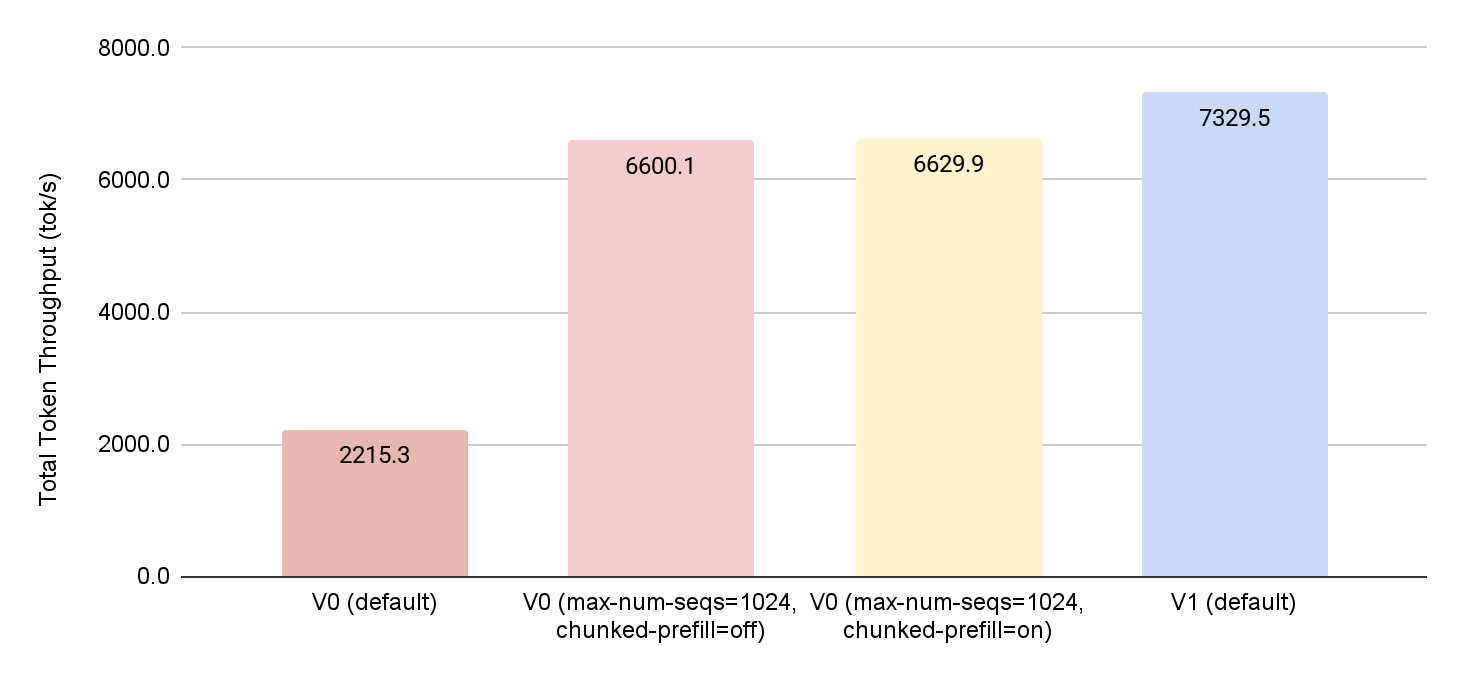
Figure 8: Comparing the different vLLM configurations in terms of total token throughput (tokens/second)
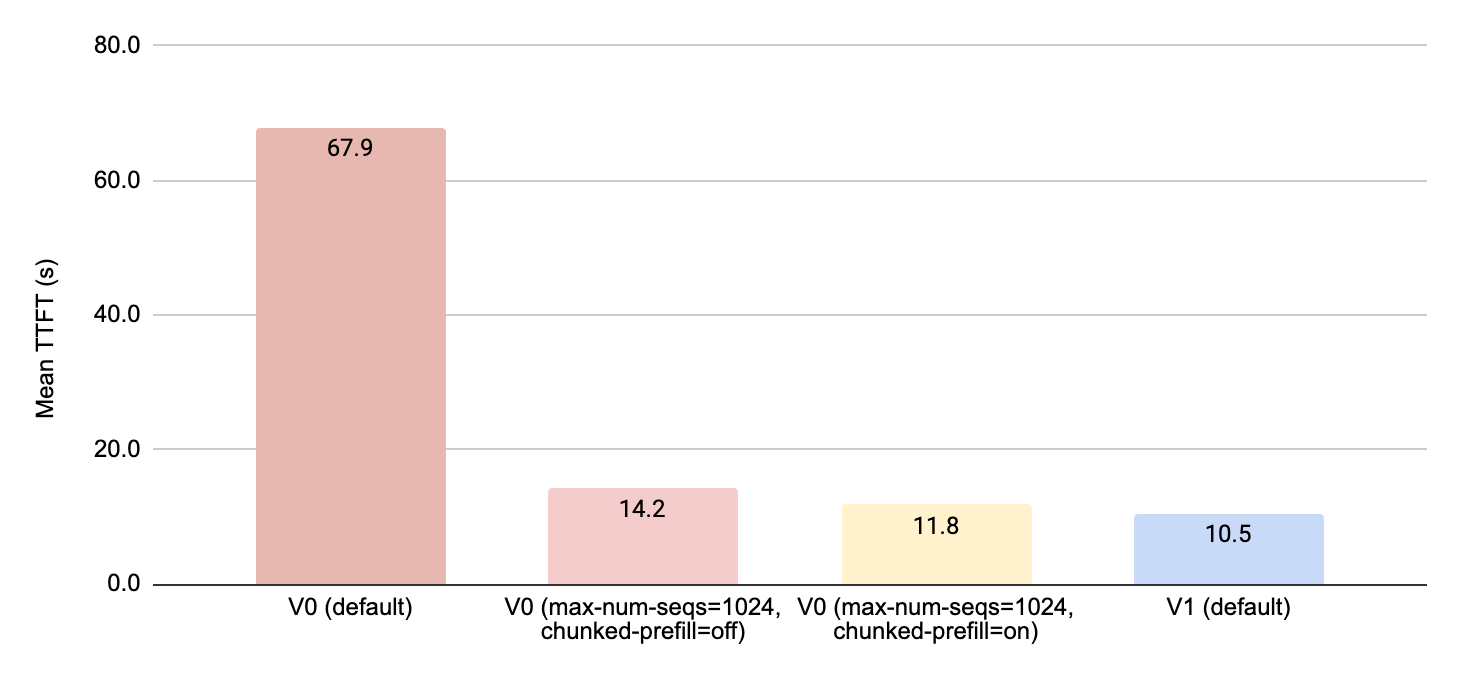
Figure 9: Comparing the different vLLM configurations in terms of time-to-first-token (TTFT) in seconds
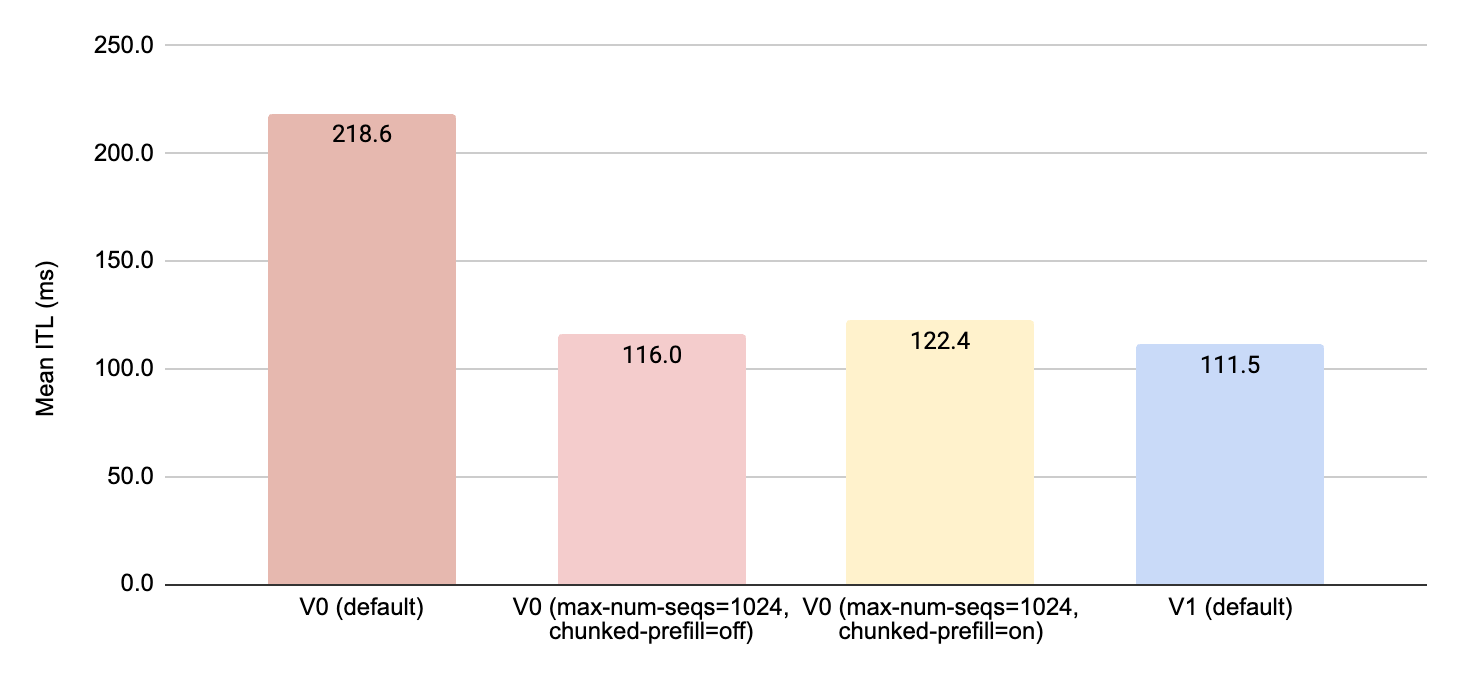
Figure 10: Comparing the different vLLM configurations in terms of inter-token latency (ITL) in milliseconds.
Conclusion
In this blog we have described how teams across AMD, IBM Research, and Red Hat built an optimized attention backend for vLLM V1 by writing optimized Triton kernels and contributing them to open-source. We have shown that vLLM V1, based on Triton, can deliver 10% higher throughput on an AMD MI300x GPU vs. vLLM V0, which uses a custom C++/HIP implementation. We hope that the details and insights presented in this blog are useful for Triton developers writing kernels for attention or other operations. If you have ideas about how vLLM performance can be improved further, then please reach out!
Acknowledgments
This work was carried out by a large team across 3 different organizations – thank you to everyone involved.
IBM Research
Burkhard Ringlein, Jan van Lunteren, Chih-Chieh Yang, Sara Kokkila Schumacher, Thomas Parnell, Mudhakar Srivatsa, Raghu Ganti
AMD
Aleksandr Malyshev, Vinayak Gokhale, Mehmet Kaymak, Ali Zaidy, Joe Shajrawi
Red Hat
Sage Moore, Tyler Michael Smith, Robert Shaw