0% found this document useful (0 votes)
49 views27 pagesCPUlogic Design 11 Cache
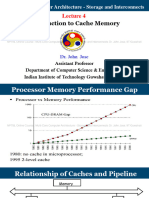
This document discusses CPU logic design and cache memory. It describes the memory hierarchy from fastest to slowest components and their typical sizes and access times. It shows a diagram of the processor, instruction cache, and data cache. The rest of the document discusses key cache parameters like size, block size, placement, mapping algorithms, replacement algorithms, and write strategies. It provides examples to explain direct mapping, set associative mapping and fully associative placement. It also describes how blocks are identified in the cache using address tags and valid bits and how CPU addresses are divided for caching.
Uploaded by
sharoofyCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
49 views27 pagesCPUlogic Design 11 Cache
This document discusses CPU logic design and cache memory. It describes the memory hierarchy from fastest to slowest components and their typical sizes and access times. It shows a diagram of the processor, instruction cache, and data cache. The rest of the document discusses key cache parameters like size, block size, placement, mapping algorithms, replacement algorithms, and write strategies. It provides examples to explain direct mapping, set associative mapping and fully associative placement. It also describes how blocks are identified in the cache using address tags and valid bits and how CPU addresses are divided for caching.
Uploaded by
sharoofyCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
/ 27