0% found this document useful (0 votes)
105 views48 pagesLarge and Fast: Exploiting Memory Hierarchy
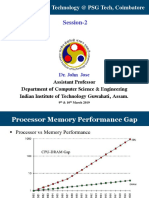
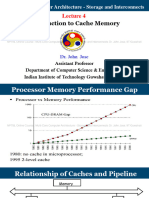
This document discusses computer memory hierarchies and caches. It begins by noting that while on-chip memory is fast, programs require more memory than can fit on chip. To address this, computers use a memory hierarchy with multiple cache levels between fast on-chip memory and slower main memory. The caches exploit locality to achieve fast average memory access times. Caches are organized with blocks and use tags, indexes, and offsets to determine hits and misses. Direct mapped and set associative mappings are described. Cache misses are classified and reducing capacity misses involves increasing cache size.
Uploaded by
api-26072581Copyright
© Attribution Non-Commercial (BY-NC)
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPT, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
105 views48 pagesLarge and Fast: Exploiting Memory Hierarchy
This document discusses computer memory hierarchies and caches. It begins by noting that while on-chip memory is fast, programs require more memory than can fit on chip. To address this, computers use a memory hierarchy with multiple cache levels between fast on-chip memory and slower main memory. The caches exploit locality to achieve fast average memory access times. Caches are organized with blocks and use tags, indexes, and offsets to determine hits and misses. Direct mapped and set associative mappings are described. Cache misses are classified and reducing capacity misses involves increasing cache size.
Uploaded by
api-26072581Copyright
© Attribution Non-Commercial (BY-NC)
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPT, PDF, TXT or read online on Scribd
/ 48