0% found this document useful (0 votes)
123 views5 pagesWeka Attribute Selection Guide
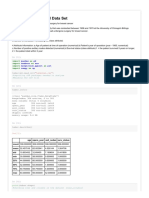
The document discusses attribute selection and ranking using information gain on a dataset with 5342 instances and 11 attributes. It shows that the top 5 ranked attributes by information gain are pgift, rfa_2a, rfa_2f=1, rfa_2f=4, and pepstrfl. Using best first search with a CFS subset evaluator, the selected attributes were Lastdate, pgift, rfa_2f=1, rfa_2f=4, and rfa_2a, totaling 5 attributes.
Uploaded by
Amelia AberaCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
123 views5 pagesWeka Attribute Selection Guide
The document discusses attribute selection and ranking using information gain on a dataset with 5342 instances and 11 attributes. It shows that the top 5 ranked attributes by information gain are pgift, rfa_2a, rfa_2f=1, rfa_2f=4, and pepstrfl. Using best first search with a CFS subset evaluator, the selected attributes were Lastdate, pgift, rfa_2f=1, rfa_2f=4, and rfa_2a, totaling 5 attributes.
Uploaded by
Amelia AberaCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 5