0% found this document useful (0 votes)
91 views10 pagesResearch Methodology Guide
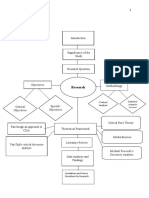
The document outlines the key steps in the research methodology process, including defining a problem statement, developing research questions and hypotheses, choosing appropriate data collection methods like experiments and surveys, sampling strategies, data analysis including descriptive statistics and validity/reliability testing, and describing associations between variables. It discusses important considerations for research design such as controlling for biases, ensuring sample representation, and establishing the validity and reliability of measurement instruments and collected data.
Uploaded by
farabi nawarCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
91 views10 pagesResearch Methodology Guide
The document outlines the key steps in the research methodology process, including defining a problem statement, developing research questions and hypotheses, choosing appropriate data collection methods like experiments and surveys, sampling strategies, data analysis including descriptive statistics and validity/reliability testing, and describing associations between variables. It discusses important considerations for research design such as controlling for biases, ensuring sample representation, and establishing the validity and reliability of measurement instruments and collected data.
Uploaded by
farabi nawarCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
/ 10