0% found this document useful (0 votes)
130 views6 pagesPolynomial Regression in Python
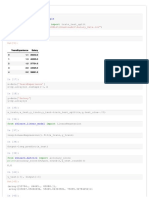
This document discusses and demonstrates polynomial linear regression. Polynomial linear regression uses higher-order polynomial terms like x^2, x^3 instead of just x to fit nonlinear datasets better than simple linear regression. The document shows implementing polynomial regression in Python on a nonlinear salary-level dataset, achieving much higher accuracy than linear regression. Polynomial regression fits the nonlinear dataset very well with accuracy over 99%, demonstrating when it should be used instead of linear regression.
Uploaded by
Gabriel GheorgheCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
130 views6 pagesPolynomial Regression in Python
This document discusses and demonstrates polynomial linear regression. Polynomial linear regression uses higher-order polynomial terms like x^2, x^3 instead of just x to fit nonlinear datasets better than simple linear regression. The document shows implementing polynomial regression in Python on a nonlinear salary-level dataset, achieving much higher accuracy than linear regression. Polynomial regression fits the nonlinear dataset very well with accuracy over 99%, demonstrating when it should be used instead of linear regression.
Uploaded by
Gabriel GheorgheCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
/ 6