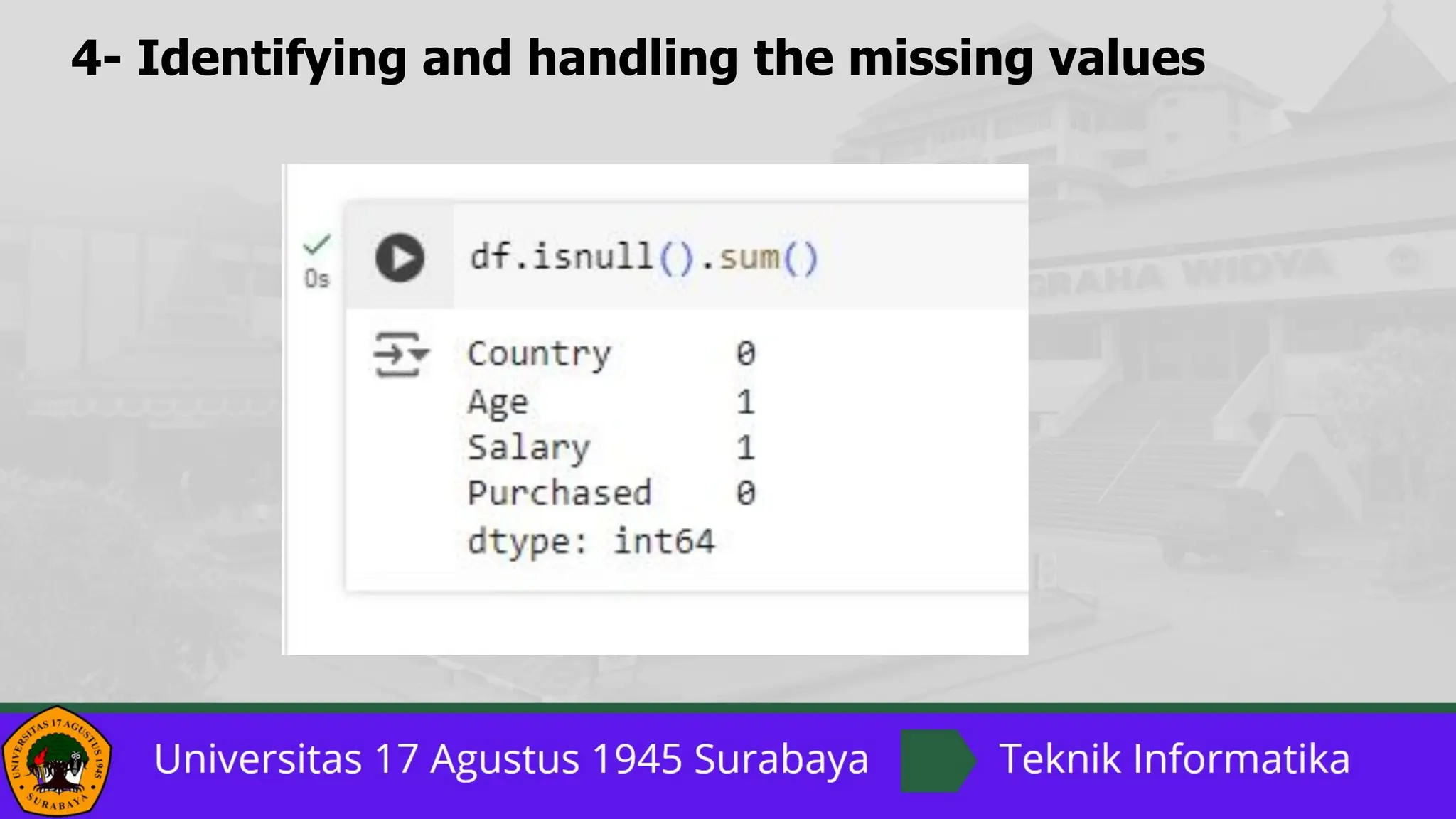
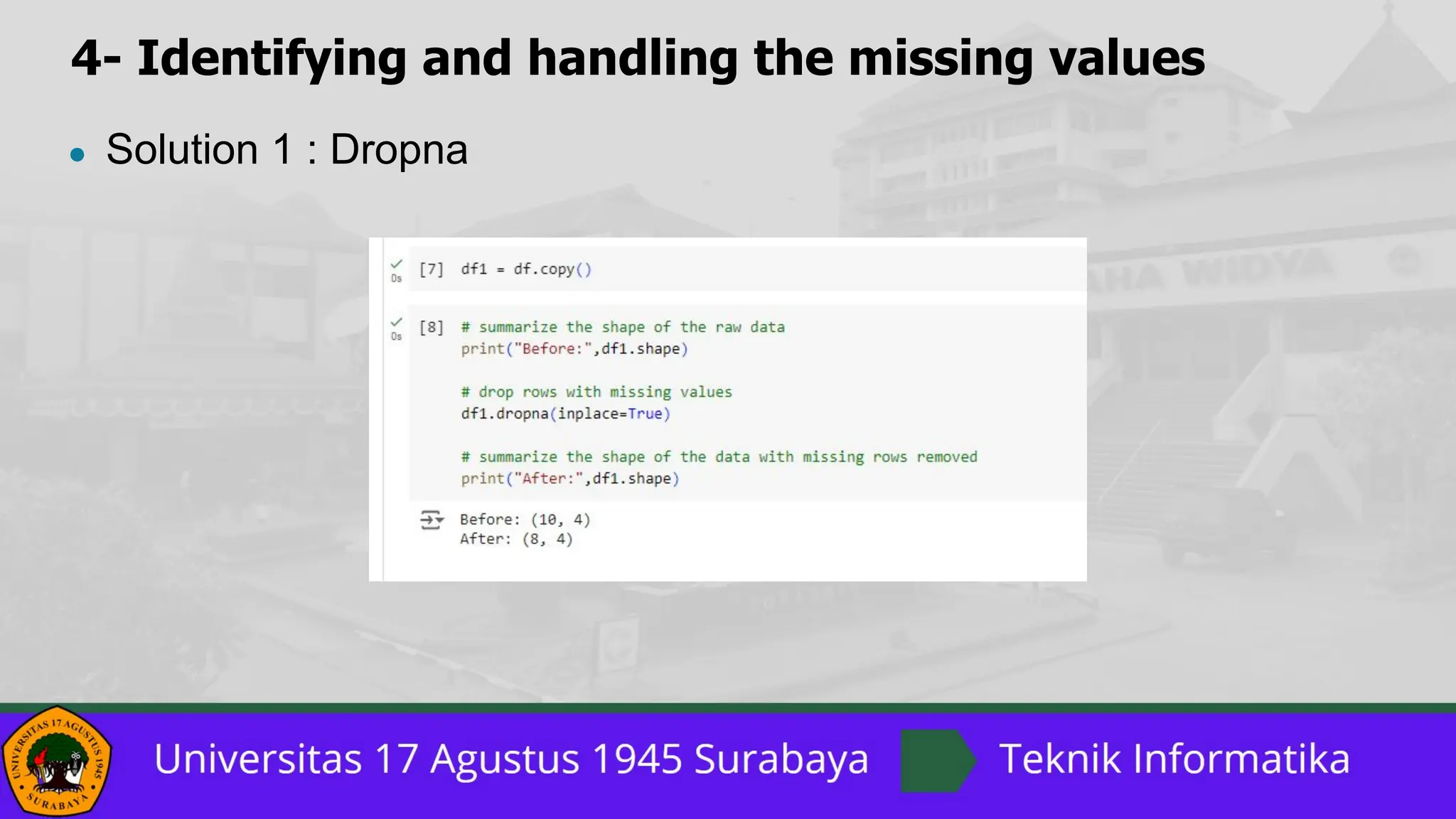
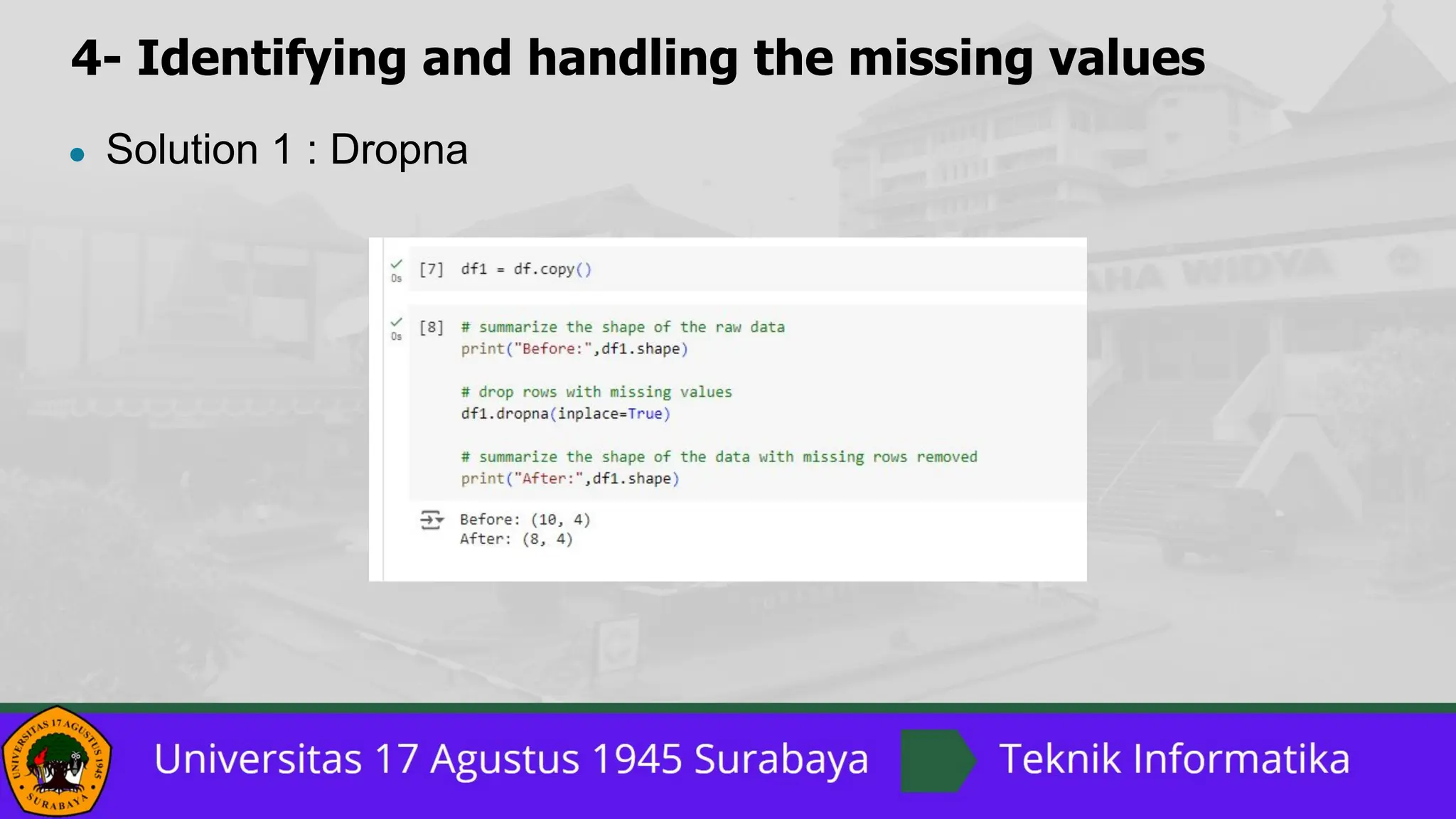
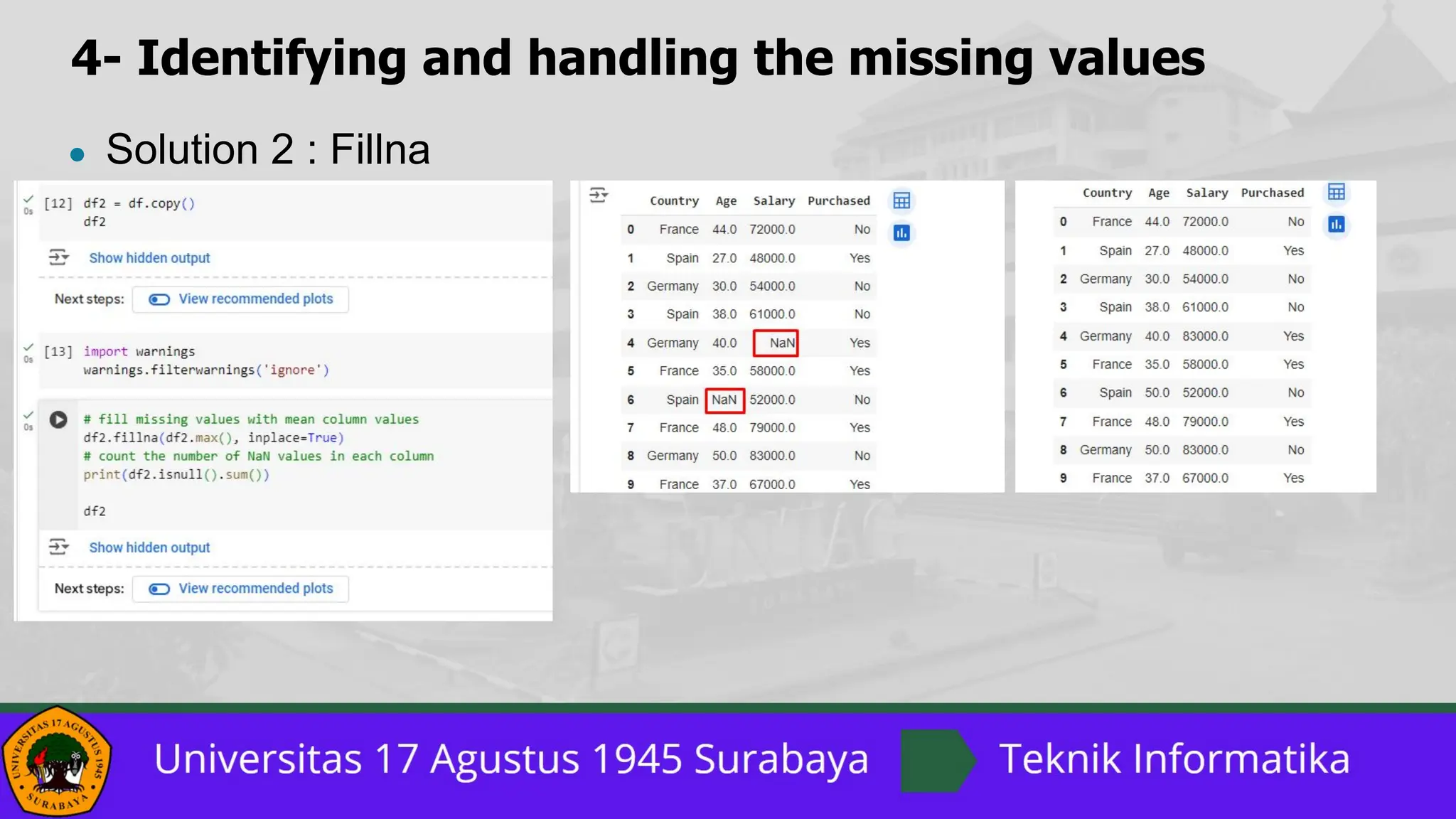
The document outlines a comprehensive guide on data preprocessing using Python for machine learning, detailing key steps such as dataset acquisition, library importation, and handling missing values. It emphasizes the importance of encoding categorical data, dataset splitting, and feature scaling, providing specific methods and solutions for each step. Additionally, it highlights the critical role of feature scaling in algorithms that rely on distance calculations and contrasts normalization with standardization techniques.


![Sub Capaian Pembelajaran
● Mampu mengidentifikasi jenis data dan teknik-teknik
mempersiapkan data agar sesuai untuk diaplikasikan dengan
pendekatan data mining tertentu [C2,A3]](https://image.slidesharecdn.com/13datapreprocessinginpython-240613010148-435ec60c/85/13_Data-Preprocessing-in-Python-pptx-1-pdf-3-320.jpg)




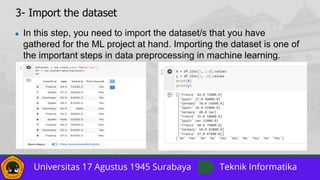

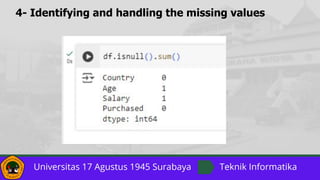

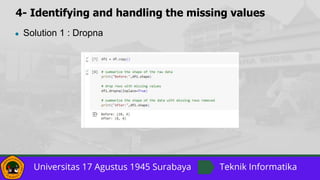
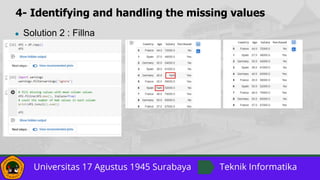








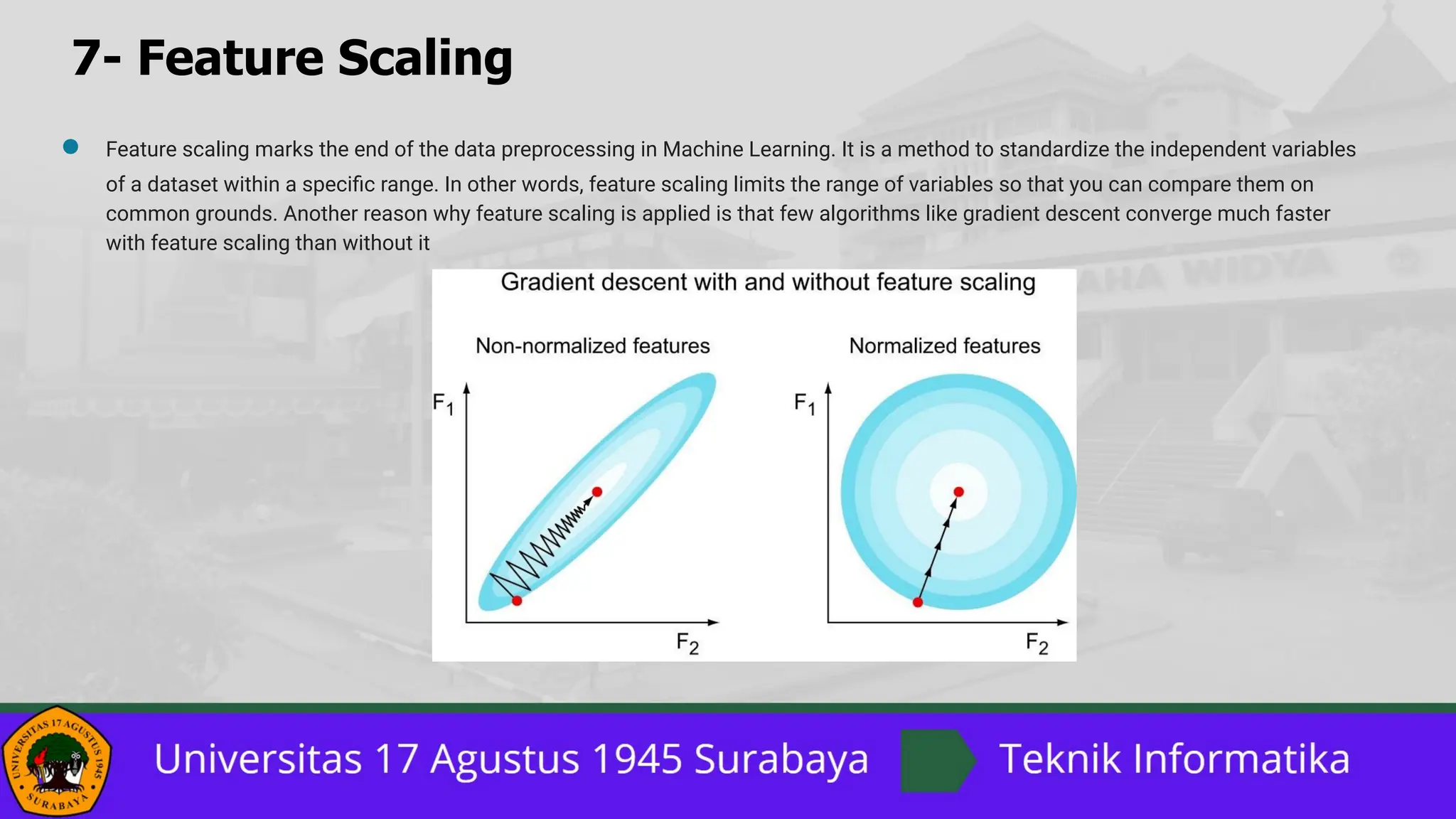
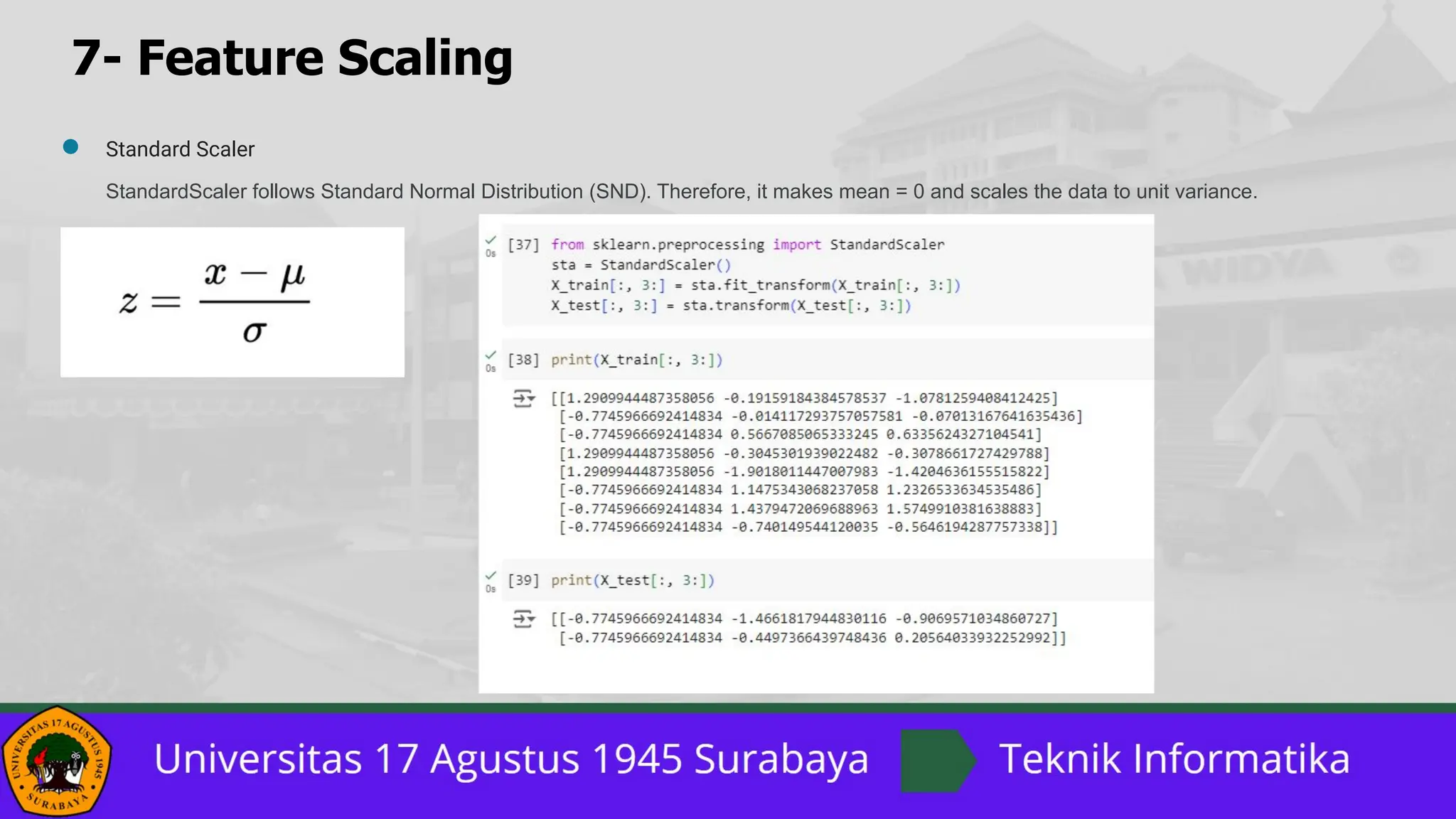
![7- Feature Scaling
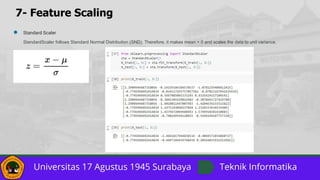
Normalization vs. Standardization
The two most discussed scaling methods are Normalization and Standardization. Normalization typically means rescales the values into a
range of [0,1]. Standardization typically means rescales data to have a mean of 0 and a standard deviation of 1 (unit variance).](https://image.slidesharecdn.com/13datapreprocessinginpython-240613010148-435ec60c/85/13_Data-Preprocessing-in-Python-pptx-1-pdf-26-320.jpg)


![Sub Capaian Pembelajaran
● Mampu mengidentifikasi jenis data dan teknik-teknik
mempersiapkan data agar sesuai untuk diaplikasikan dengan
pendekatan data mining tertentu [C2,A3]](https://image.slidesharecdn.com/13datapreprocessinginpython-240613010148-435ec60c/75/13_Data-Preprocessing-in-Python-pptx-1-pdf-3-2048.jpg)














![7- Feature Scaling
Normalization vs. Standardization
The two most discussed scaling methods are Normalization and Standardization. Normalization typically means rescales the values into a
range of [0,1]. Standardization typically means rescales data to have a mean of 0 and a standard deviation of 1 (unit variance).](https://image.slidesharecdn.com/13datapreprocessinginpython-240613010148-435ec60c/75/13_Data-Preprocessing-in-Python-pptx-1-pdf-26-2048.jpg)















































