실습 환경 정보
본문서의 실습 환경 정보
• Spark 서버
– OS : Centos 7.0
– Java version : JDK 8
– Spark version : Spark 2.0.2 release
• Spark application 개발 PC
– Window 10
– Java version : JDK 8
– IDE : Eclipse Neon.2 Release (4.6.2)
본 문서에서 사용된 언어
– Interactive shell 테스트용: scala
– Spark application 개발용 : python, java
2016-12-26 3
4.
환경 설정 -server
• JDK 설치(JDK 1.8 이상일 경우 스킵 가능)
– JDK : Java SE Development Kit 의 약자로,
자바 프로그램을 개발하기 위해 필요한 라이브러리 들의 모음
– Java Runtime Environment(자바 프로그램을 실행하기 위한 모듈들)를
포함하고 있음
– 본 링크에 접속하여 자신의 OS 타입에 맞는 JDK 최신 버전을 받는다.
5.
환경 설정 -server
• JDK 설치(JDK 1.8 이상일 경우 스킵 가능)
– jdk를 다운로드 후 아래와 같이 설치
2016-12-26 5
// “/usr/java/” 경로에 준비된 jdk-{version}-linux-x64.tar.gz 옮기기
$ mv {JDK 다운로드 경로}/jdk-{version}-linux-x64.tar.gz /usr/java/
// jdk 압축 해제
$ cd /usr
$ mkdir java
$ cd /usr/java
$ tar -xf jdk-{version}-linux-x64.tar.gz
$ ln -s /usr/java/jdk1.X.X_XX latest
$ ln -s latest default
$ alternatives --install /usr/bin/java java /usr/java/jdk1.X.X_XX /bin/java 1
$ alternatives --config java
//설치된 버전의 java에 해당하는 번호로 세팅
3 개의 프로그램이 'java'를 제공합니다.
선택 명령
-----------------------------------------------
* 1 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64/jre/bin/java
+ 2 /usr/java/jdk1.X.X_XX/bin/java
현재 선택[+]을 유지하려면 엔터키를 누르고, 아니면 선택 번호를 입력하십시오: 2
6.
환경 설정 -server
• JDK 설치(JDK 1.8 이상일 경우 스킵)
– JAVA_HOME 변수 설정
• 공용 변수 저장 파일의 가장 하단부에 환경변수 추가 후 저장
• 설치한 버전의 java가 확인되면 완료
2016-12-26 6
$ vim /etc/profile
----------------vim edit display start---------------------
…
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$ANT_HOME/bin:$JAVA_HOME/bin
----------------vim edit display end---------------------
$ source /etc/profile
$ java –version
java version "1.x.x_xx“
Java(TM) SE Runtime Environment (build 1.x.x_xx-b15)
Java HotSpot(TM) 64-Bit Server VM (build 25.71-b15, mixed mode)
7.
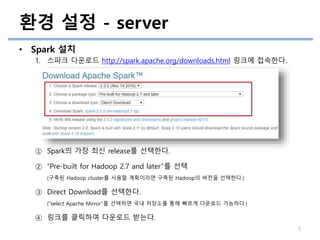
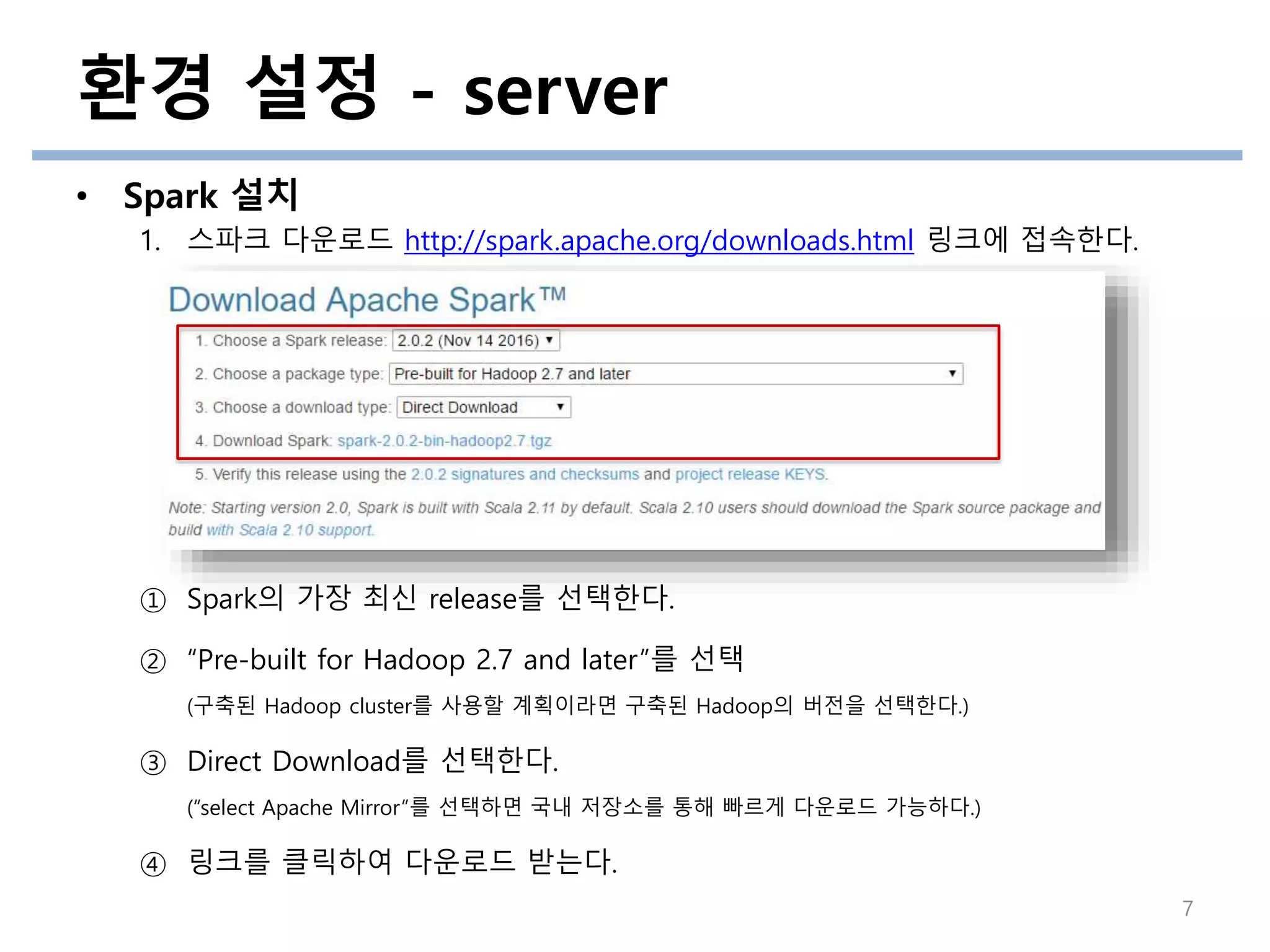
• Spark 설치
1.스파크 다운로드 http://spark.apache.org/downloads.html 링크에 접속한다.
① Spark의 가장 최신 release를 선택한다.
② “Pre-built for Hadoop 2.7 and later”를 선택
(구축된 Hadoop cluster를 사용할 계획이라면 구축된 Hadoop의 버전을 선택한다.)
③ Direct Download를 선택한다.
(“select Apache Mirror”를 선택하면 국내 저장소를 통해 빠르게 다운로드 가능하다.)
④ 링크를 클릭하여 다운로드 받는다.
환경 설정 - server
7
8.
환경 설정 -server
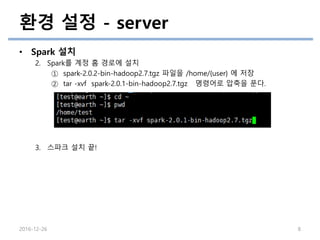
• Spark 설치
2. Spark를 계정 홈 경로에 설치
① spark-2.0.2-bin-hadoop2.7.tgz 파일을 /home/{user} 에 저장
② tar -xvf spark-2.0.1-bin-hadoop2.7.tgz 명령어로 압축을 푼다.
3. 스파크 설치 끝!
2016-12-26 8
9.
환경 설정 -server
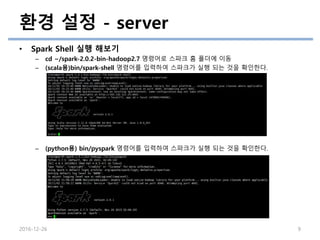
• Spark Shell 실행 해보기
– cd ~/spark-2.0.2-bin-hadoop2.7 명령어로 스파크 홈 폴더에 이동
– (scala용)bin/spark-shell 명령어를 입력하여 스파크가 실행 되는 것을 확인한다.
– (python용) bin/pyspark 명령어를 입력하여 스파크가 실행 되는 것을 확인한다.
2016-12-26 9
10.
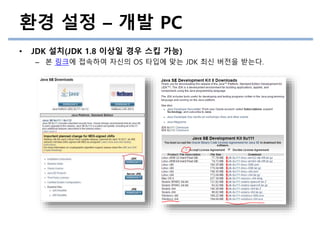
환경 설정 –개발 PC
• JDK 설치(JDK 1.8 이상일 경우 스킵 가능)
– 본 링크에 접속하여 자신의 OS 타입에 맞는 JDK 최신 버전을 받는다.
11.
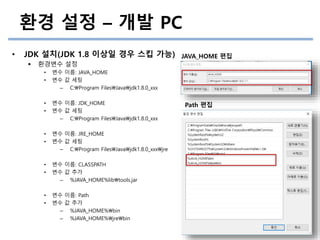
환경 설정 –개발 PC
• JDK 설치(JDK 1.8 이상일 경우 스킵 가능)
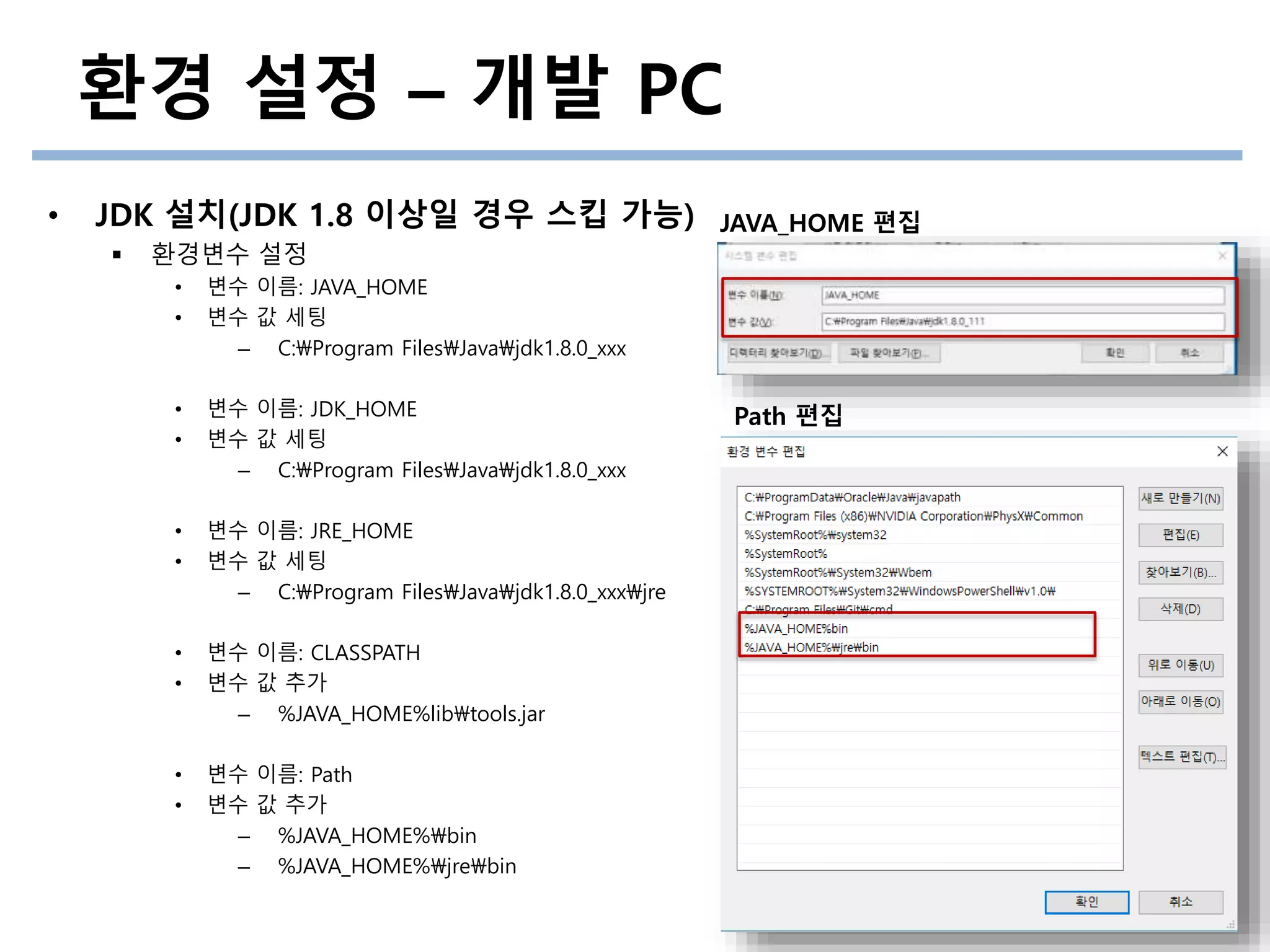
환경변수 설정
• 변수 이름: JAVA_HOME
• 변수 값 세팅
– C:Program FilesJavajdk1.8.0_xxx
• 변수 이름: JDK_HOME
• 변수 값 세팅
– C:Program FilesJavajdk1.8.0_xxx
• 변수 이름: JRE_HOME
• 변수 값 세팅
– C:Program FilesJavajdk1.8.0_xxxjre
• 변수 이름: CLASSPATH
• 변수 값 추가
– %JAVA_HOME%libtools.jar
• 변수 이름: Path
• 변수 값 추가
– %JAVA_HOME%bin
– %JAVA_HOME%jrebin
Path 편집
JAVA_HOME 편집
12.
환경 설정 –개발 PC
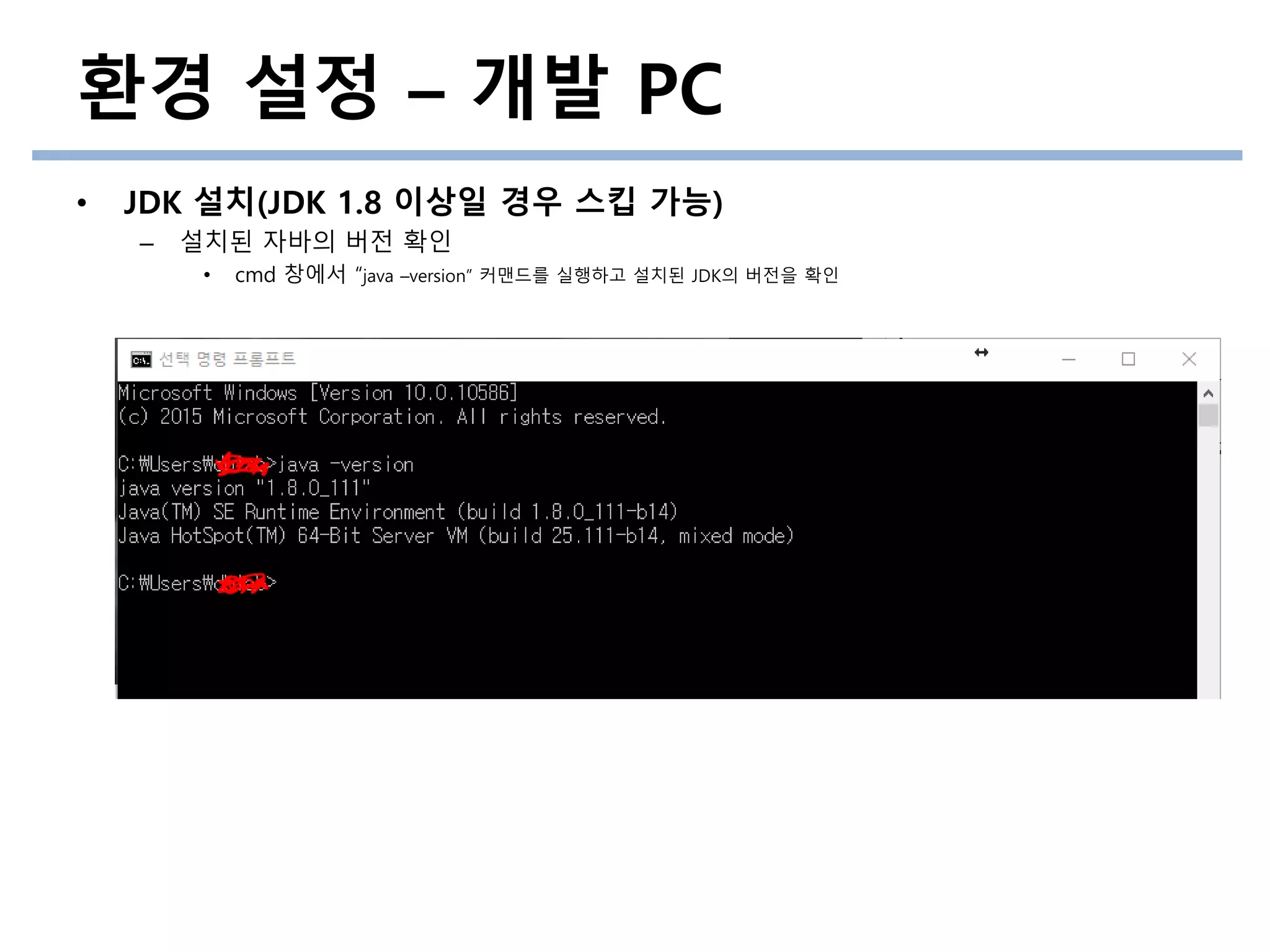
• JDK 설치(JDK 1.8 이상일 경우 스킵 가능)
– 설치된 자바의 버전 확인
• cmd 창에서 “java –version” 커맨드를 실행하고 설치된 JDK의 버전을 확인
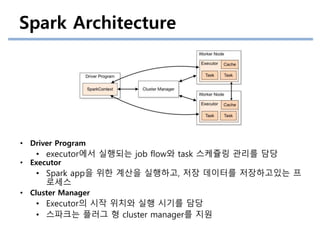
Spark Architecture
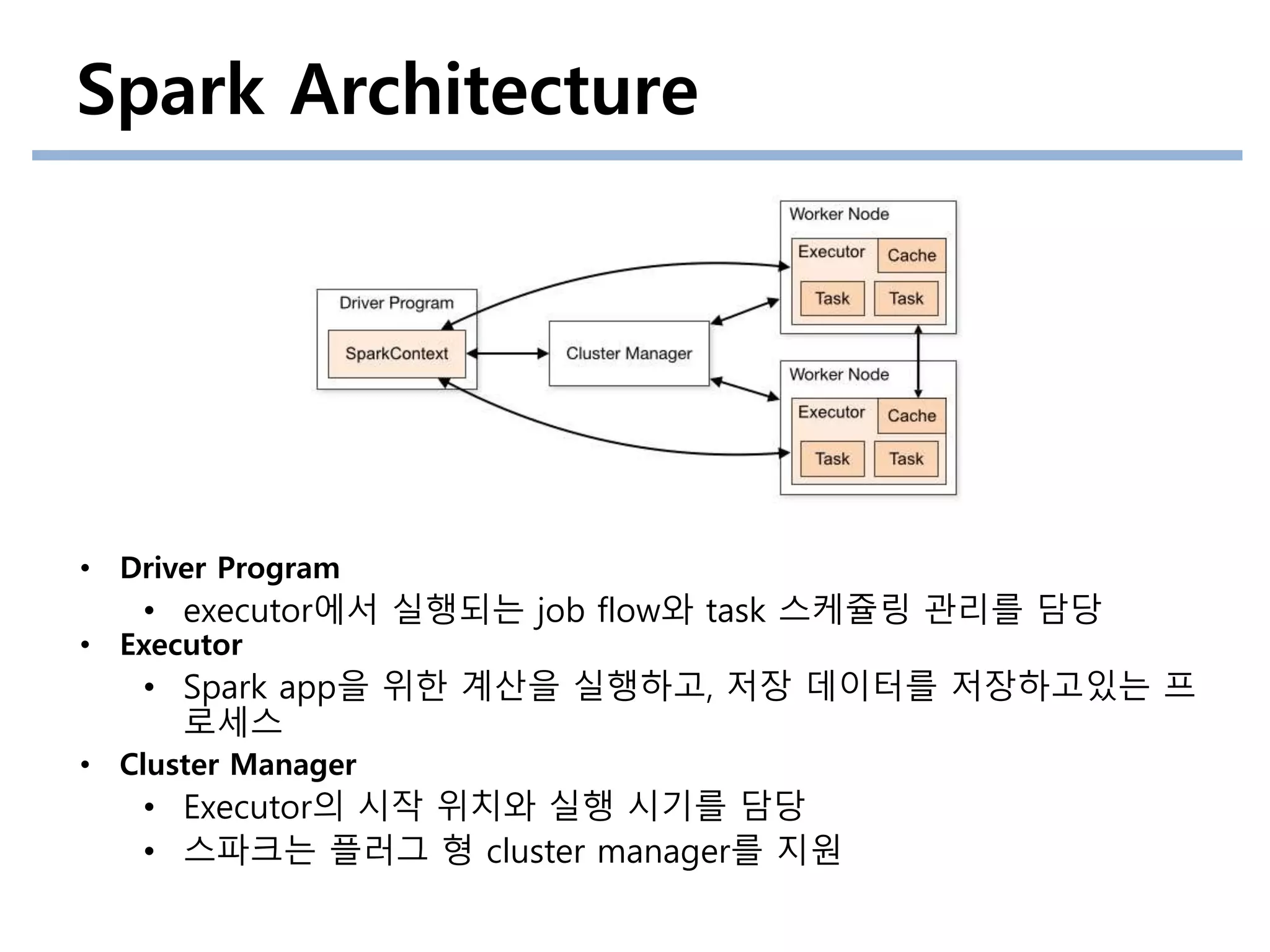
• DriverProgram
• executor에서 실행되는 job flow와 task 스케쥴링 관리를 담당
• Executor
• Spark app을 위한 계산을 실행하고, 저장 데이터를 저장하고있는 프
로세스
• Cluster Manager
• Executor의 시작 위치와 실행 시기를 담당
• 스파크는 플러그 형 cluster manager를 지원
17.
Spark 사용 방법
2016-12-2617
• Spark standalone을 활용한 분석 방법
1. spark shell을 이용한 interactive 분석
– scala interface를 통한 interactive한 분석이 가능
– python interface를 통한 interactive한 분석이 가능
– Apache zeppelin의 노트북 기능을 활용하면 code 공유도 가능
2. Spark application을 작성하여 런칭
– Python 어플리케이션 개발
– Java 어플리케이션 개발
– scala 어플리케이션 개발
18.
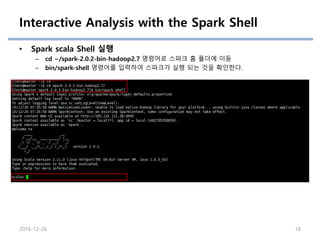
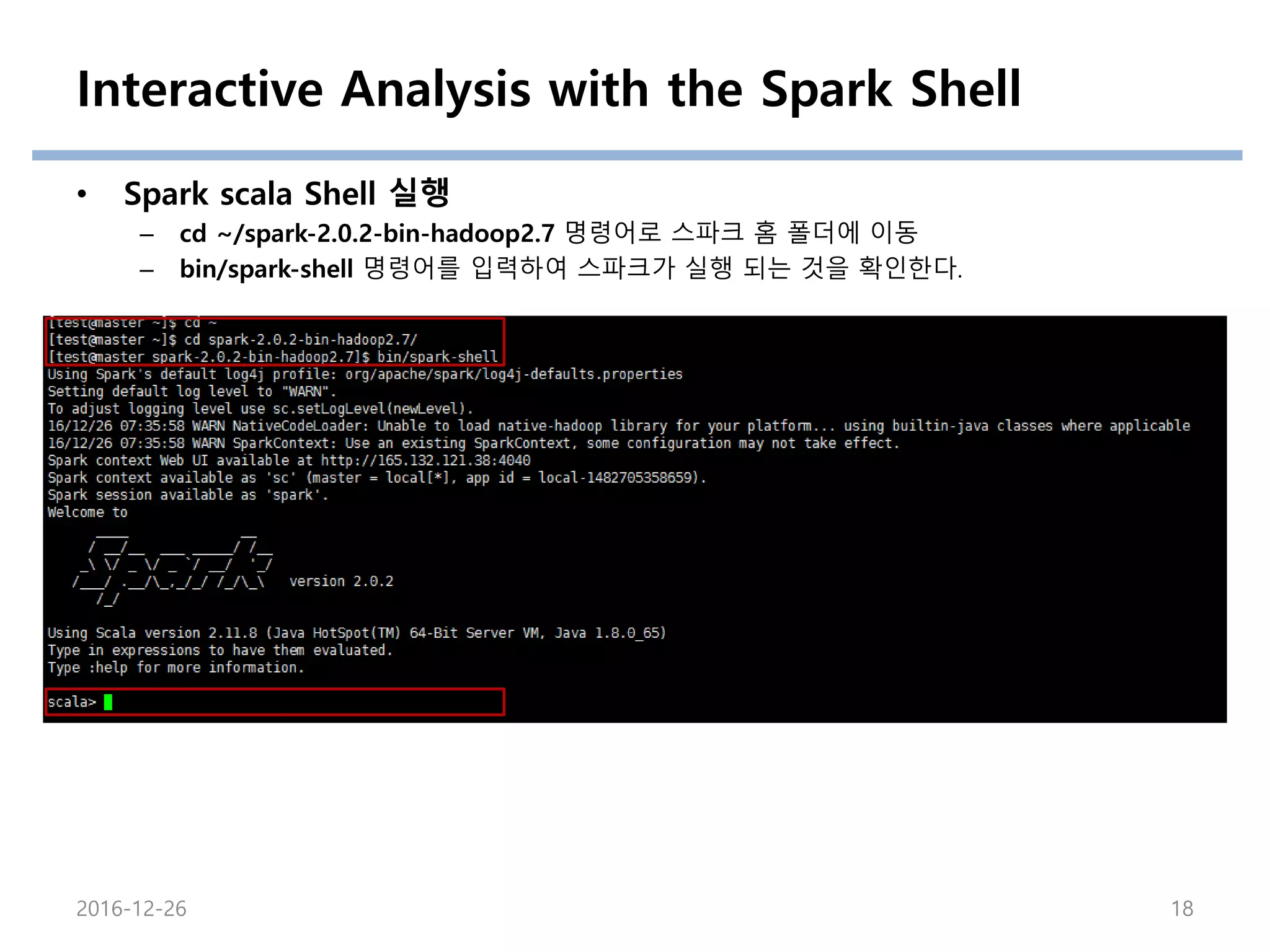
Interactive Analysis withthe Spark Shell
• Spark scala Shell 실행
– cd ~/spark-2.0.2-bin-hadoop2.7 명령어로 스파크 홈 폴더에 이동
– bin/spark-shell 명령어를 입력하여 스파크가 실행 되는 것을 확인한다.
2016-12-26 18
19.
Spark RDD Operator
2016-12-2619
RDD operation
Scala api 예제
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
Scala , java, python interface 별 RDD Operation 사용 예제
http://backtobazics.com/big-data/spark/apache-spark-map-example/
20.
Interactive Analysis withthe Spark Shell
• spark scala 예제 (1) Basic Map
// Scala 변수 List를 RDD로 로딩
scala> val numList = List(2, 1, 4, 3)
numList: List[Int] = List(2, 1, 4, 3)
scala> val nums = sc.parallelize(numList )
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
// RDD의 각 element를 제곱
scala> val squarNum = nums.map(x => x*x) //(transformation)
squarNums: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:28
// RDD를 scala 변수 list 형태로 반환
scala> val output = squarNum.collect() //(action)
output: Array[Int] = Array(4, 1, 16, 9)
2016-12-26 20
21.
Interactive Analysis withthe Spark Shell
• spark scala 예제 (2) Basic max/min/sum
// Scala 변수 List를 RDD로 로딩
scala> val numList = List(2, 1, 4, 3)
numList: List[Int] = List(2, 1, 4, 3)
scala> val nums = sc.parallelize(numList )
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
// nums RDD를 대상으로 min/max/sum을 계산
scala> nums.max() //(action)
res0: Int = 4
scala> nums.min() //(action)
res1 : Int = 1
scala> nums.sum() //(action)
res2 : Int = 10
scala> nums.fold(0)((x, y) => x + y)) //(action)
res3 : Int = 10
2016-12-26 21
22.
Interactive Analysis withthe Spark Shell
• spark scala 예제 (3) line counting
// {SPARK_HOME}에 위치하는 README.md파일을 로딩
scala> val textFile = sc.textFile("README.md")
textFile: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at <console>:24
// 읽은 파일의 총 line 수는?
scala> textFile.count() //(action)
res0: Long = 99
// 첫번째 Line의 문자열은?
scala> textFile.first() //(action)
res1: String = # Apache Spark
// “Spark”라는 문자열을 포함하고 있는 line의 수는?
scala> val SparkLine = textFile.filter(line => line.contains("Spark")) //(transformation)
SparkLine: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at filter at <console>:26
scala> SparkLine.count() //(action)
res2: Long = 19
2016-12-26 22
23.
Interactive Analysis withthe Spark Shell
• spark scala 예제 (4) word counting
// {SPARK_HOME}에 위치하는 README.md파일을 로딩
scala> val lines = sc.textFile("README.md")
// 각 라인을 word단위로 분리
scala> val words = lines.flatMap(line => line.split(" ")) //(transformation)
// case1 .Word별로 개수를 카운트
scala> val wordMap = words.map(word => (word, 1)) //(transformation)
scala> val result = wordMap.reduceByKey((a, b) => a + b) //(action)
res0: Array[(String, Int)] = Array(
(package,1),
(this,1),
(Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version),1),
(Because,1),
(Python,2),
(cluster.,1),
(its,1),
([run,1),
(general,2),
….
2016-12-26 23
Spark를 활용한 분석
2016-12-2625
• Spark standalone을 활용한 분석 방법
1. spark shell을 이용한 interactive 분석
– scala, python interface를 통한 interactive한 분석이 가능
– Apache zeppelin의 노트북 기능을 활용한 code 공유도 가능
2. Spark application을 작성하여 런칭
– Python 어플리케이션 개발
– Java 어플리케이션 개발
– scala 어플리케이션 개발
26.
Spark Application(python)
• Python어플리케이션 개발
1. 간단한 python application 작성
– Vim등의 텍스트 에디터를 이용하여 python code를 작성
2. python application 실행
– 아래의 명령어를 통해 작성한 test.py spark 어플리케이션을 실행
2016-12-26 26
from pyspark import SparkContext
logFile = “/home/{user}/spark-2.0.1-bin-hadoop2.7/README.md
sc = SparkContext("local", "Simple App")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
$ YOUR_SPARK_HOME/bin/spark-submit --master local[4] test.py
...
Lines with a: 46, Lines with b: 23
...
27.
Spark를 활용한 분석
2016-12-2627
• Spark 실행 방법
1. spark shell을 이용한 interactive 분석
– scala, python interface를 통한 interactive한 분석이 가능
– Apache zeppelin의 노트북 기능을 활용한 code 공유도 가능
2. Spark application을 작성하여 런칭
– Python 어플리케이션 개발
– Java 어플리케이션 개발
– scala 어플리케이션 개발
28.
Spark Application(java/scala)
• Scala,java 어플리케이션 개발
– Scala, java IDE를 사용하여 Project를 생성
– sbt(scala), maven(java) 등의 빌드 도구 플러그인을 활용하여
spark library와 기타 사용되는 library들의 dependencies를 관리
– 원하는 작업을 수행하는 spark application code를 작성
– 프로젝트를 컴파일 및 빌드하여 jar 파일을 생성
– 완성된 application.jar 파일은 spark-submit 커맨드를 사용하여 실행
• 자세한 내용은 아래 링크에서 확인
https://spark.apache.org/docs/latest/submitting-applications.html
2016-12-26 28
29.
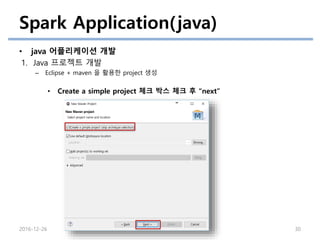
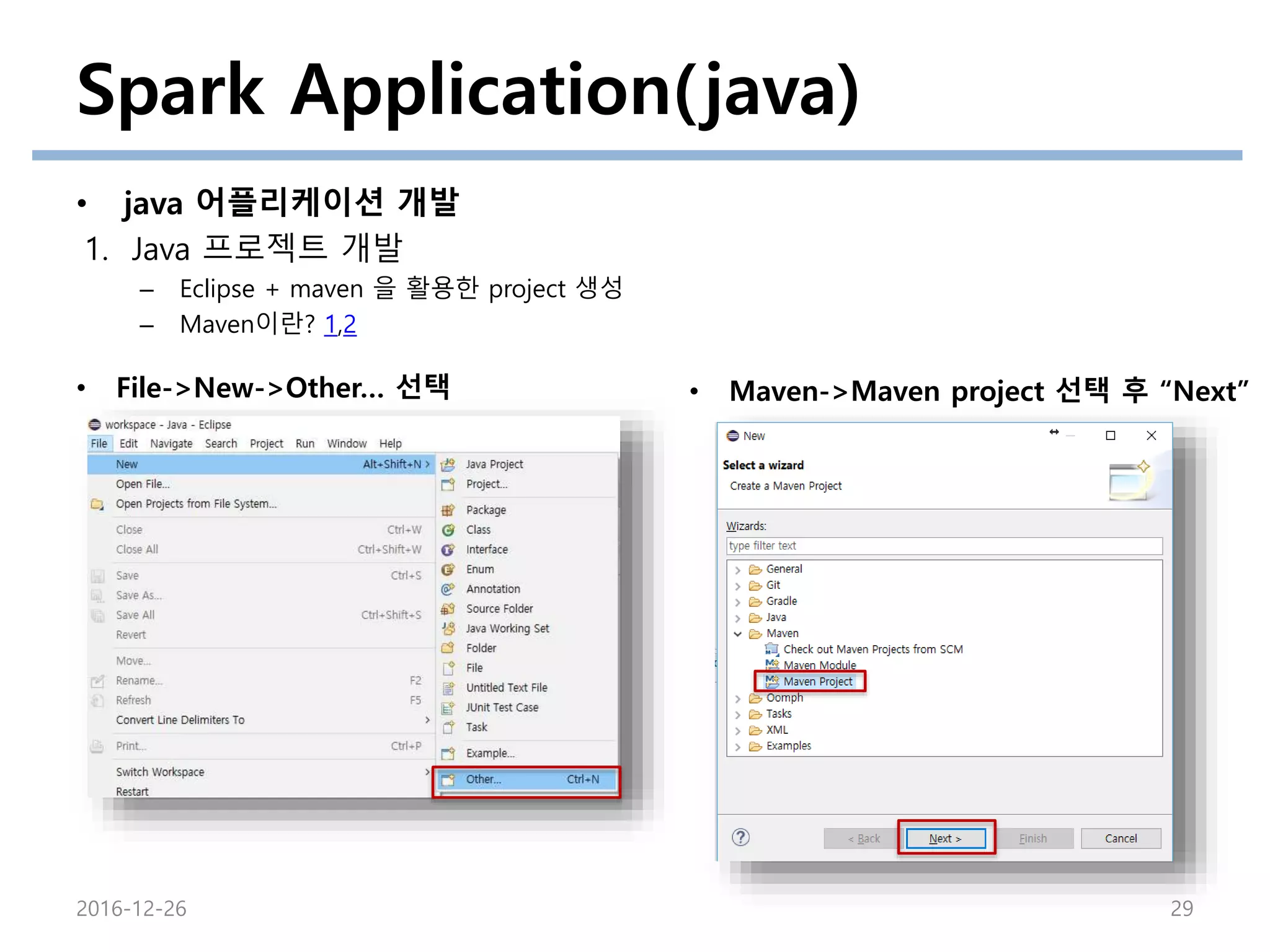
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
– Maven이란? 1,2
2016-12-26 29
• File->New->Other… 선택 • Maven->Maven project 선택 후 “Next”
30.
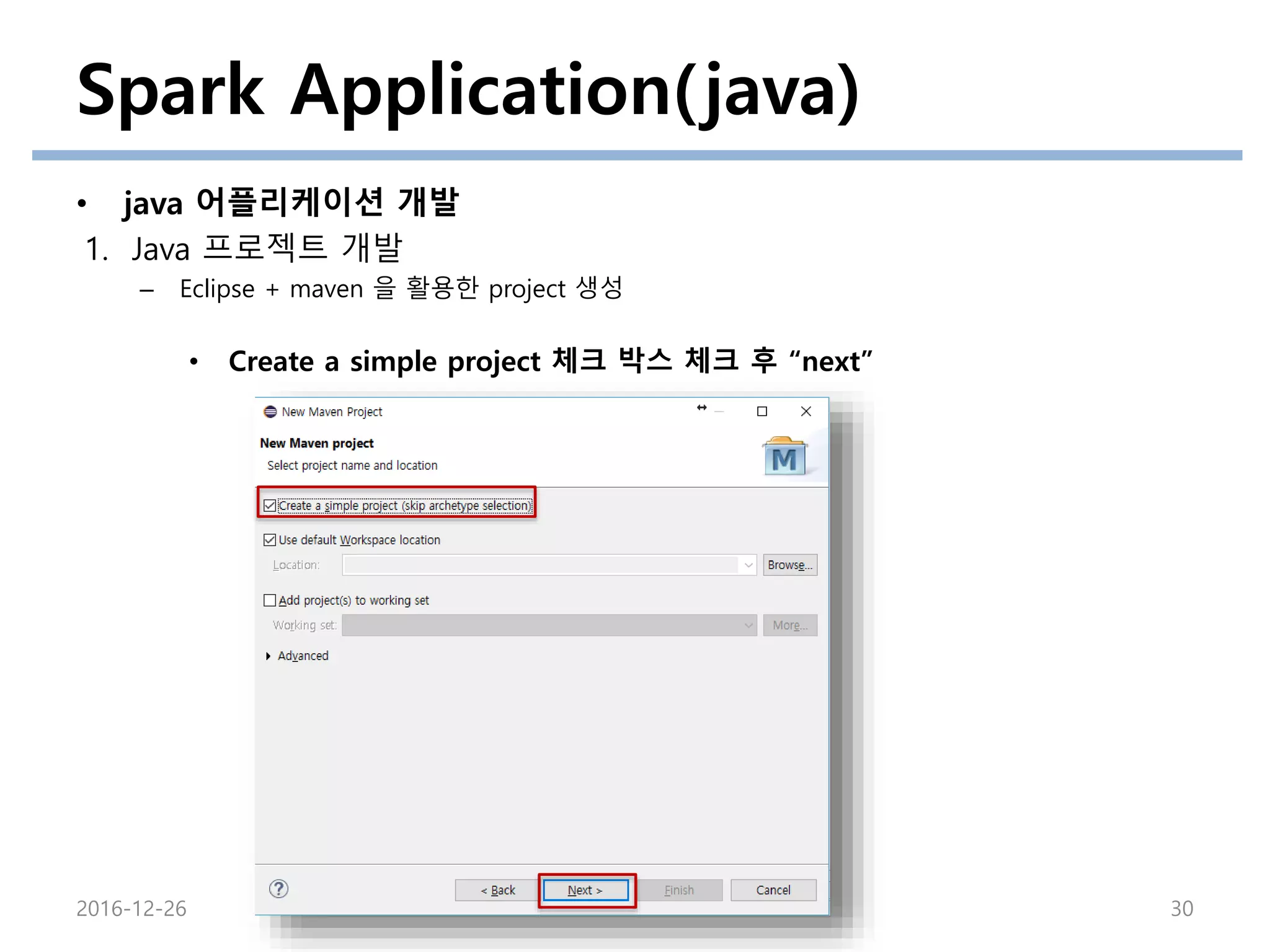
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 30
• Create a simple project 체크 박스 체크 후 “next”
31.
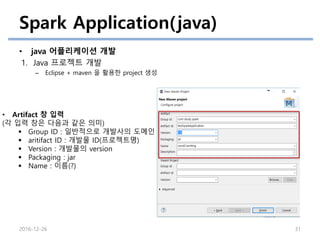
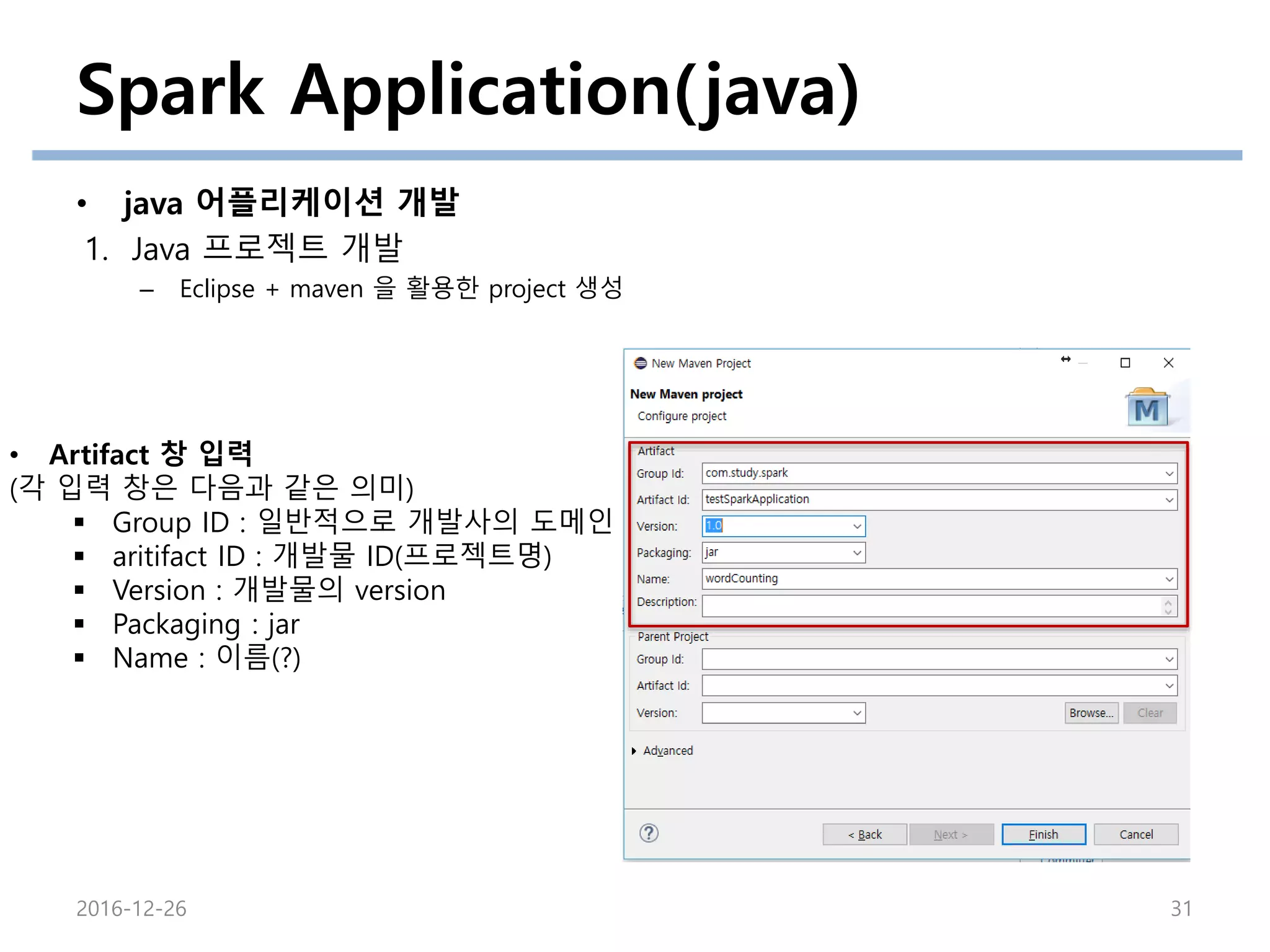
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 31
• Artifact 창 입력
(각 입력 창은 다음과 같은 의미)
Group ID : 일반적으로 개발사의 도메인
aritifact ID : 개발물 ID(프로젝트명)
Version : 개발물의 version
Packaging : jar
Name : 이름(?)
32.
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 32
• Maven 기본 JRE 변경
JRE System Library 우클릭 -> Build Path 선택 -> Configure Build Path 선택
JRE System Library [J2SE-1.5] 삭제 (Remove) 한다.
33.
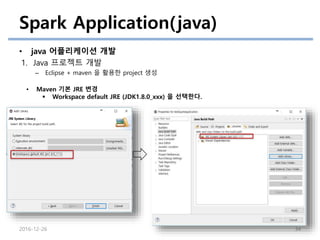
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 33
• Maven 기본 JRE 변경
JRE System Library [J2SE-1.5] 삭제 (Remove) 후 Add Library을 선택한다.
JRE System Library 을 선택 한다.
34.
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 34
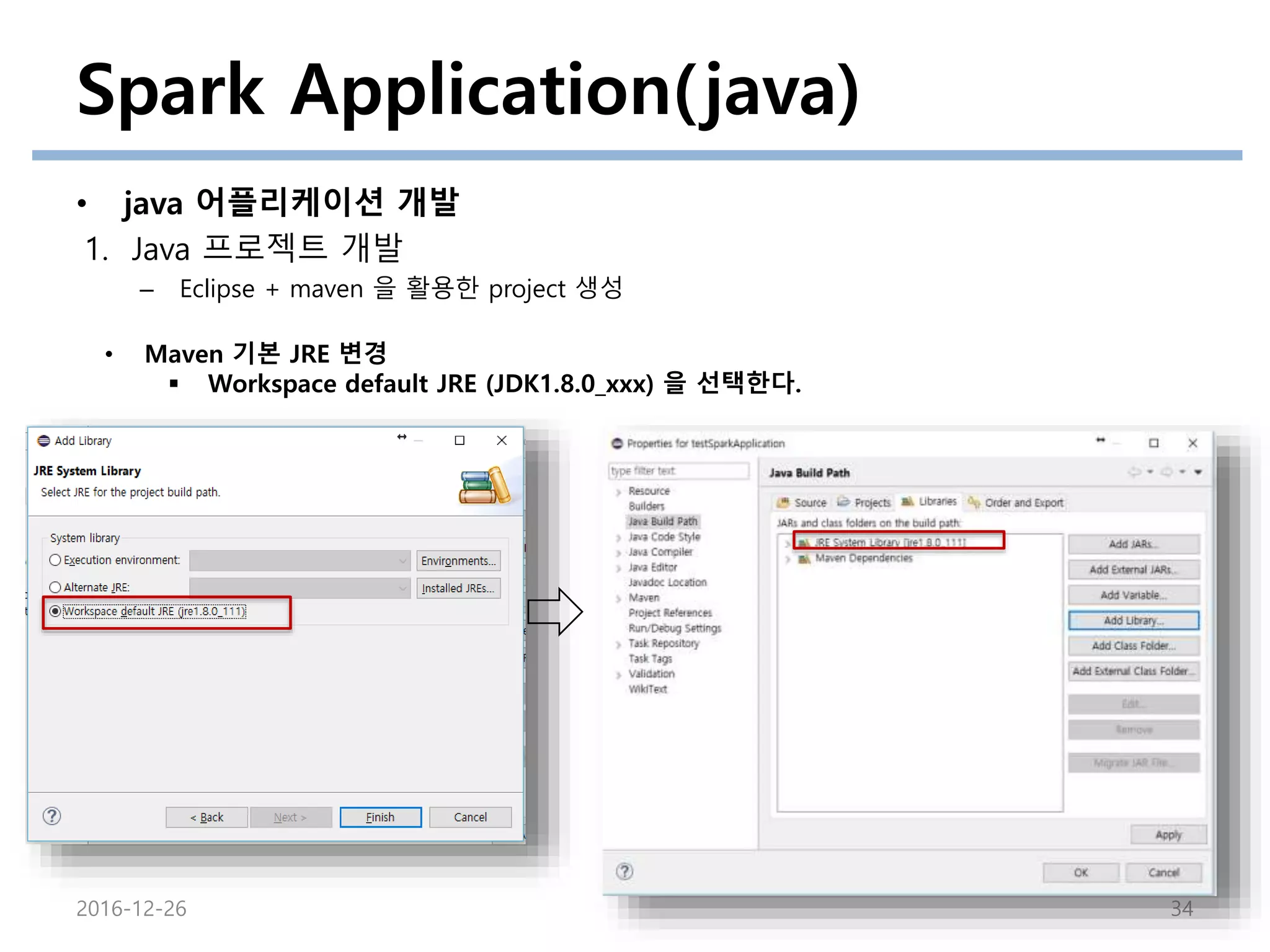
• Maven 기본 JRE 변경
Workspace default JRE (JDK1.8.0_xxx) 을 선택한다.
35.
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 35
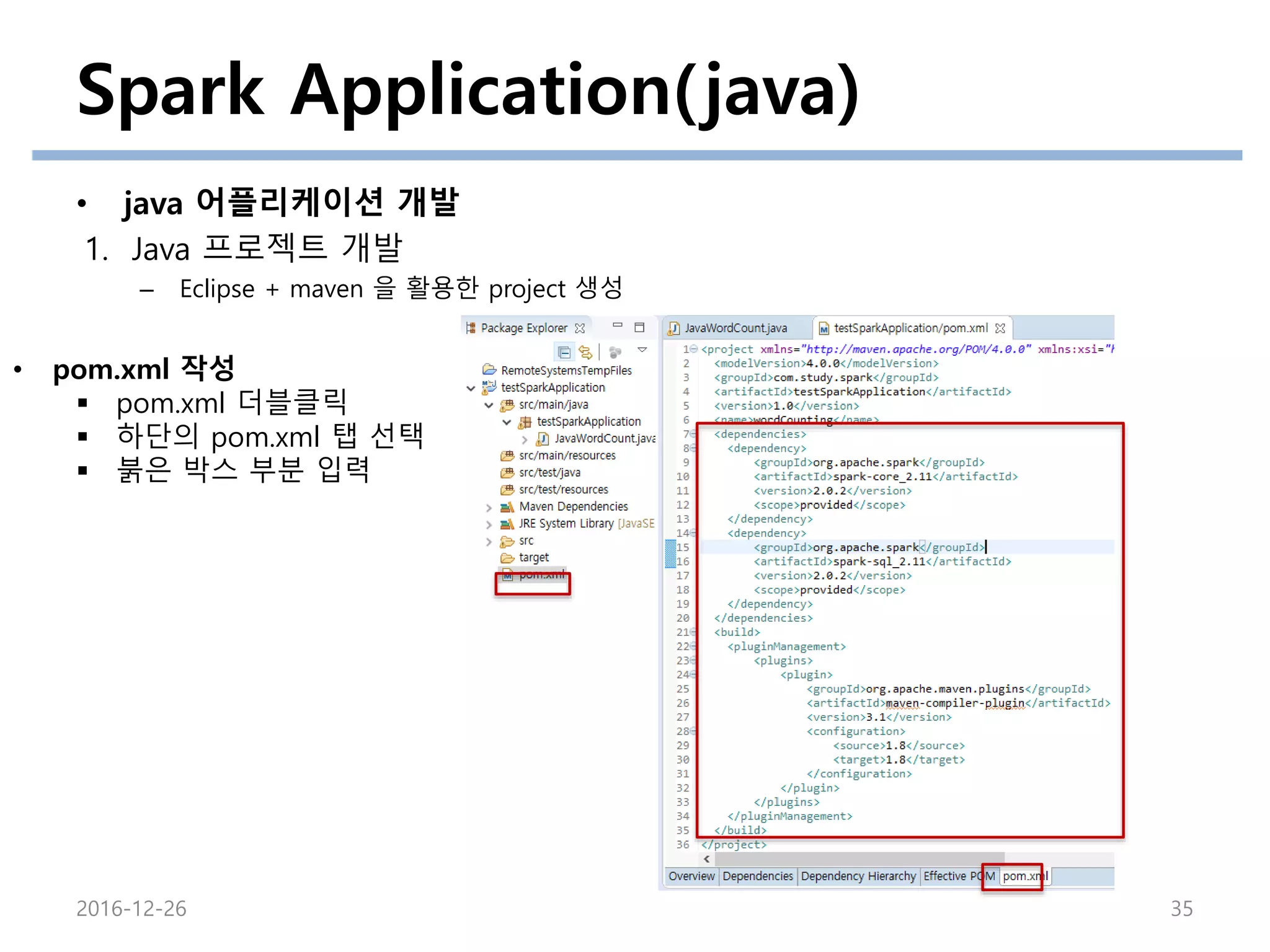
• pom.xml 작성
pom.xml 더블클릭
하단의 pom.xml 탭 선택
붉은 박스 부분 입력
36.
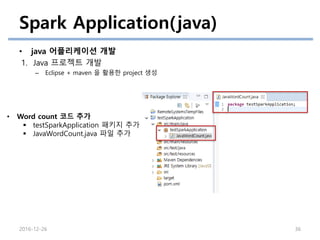
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 36
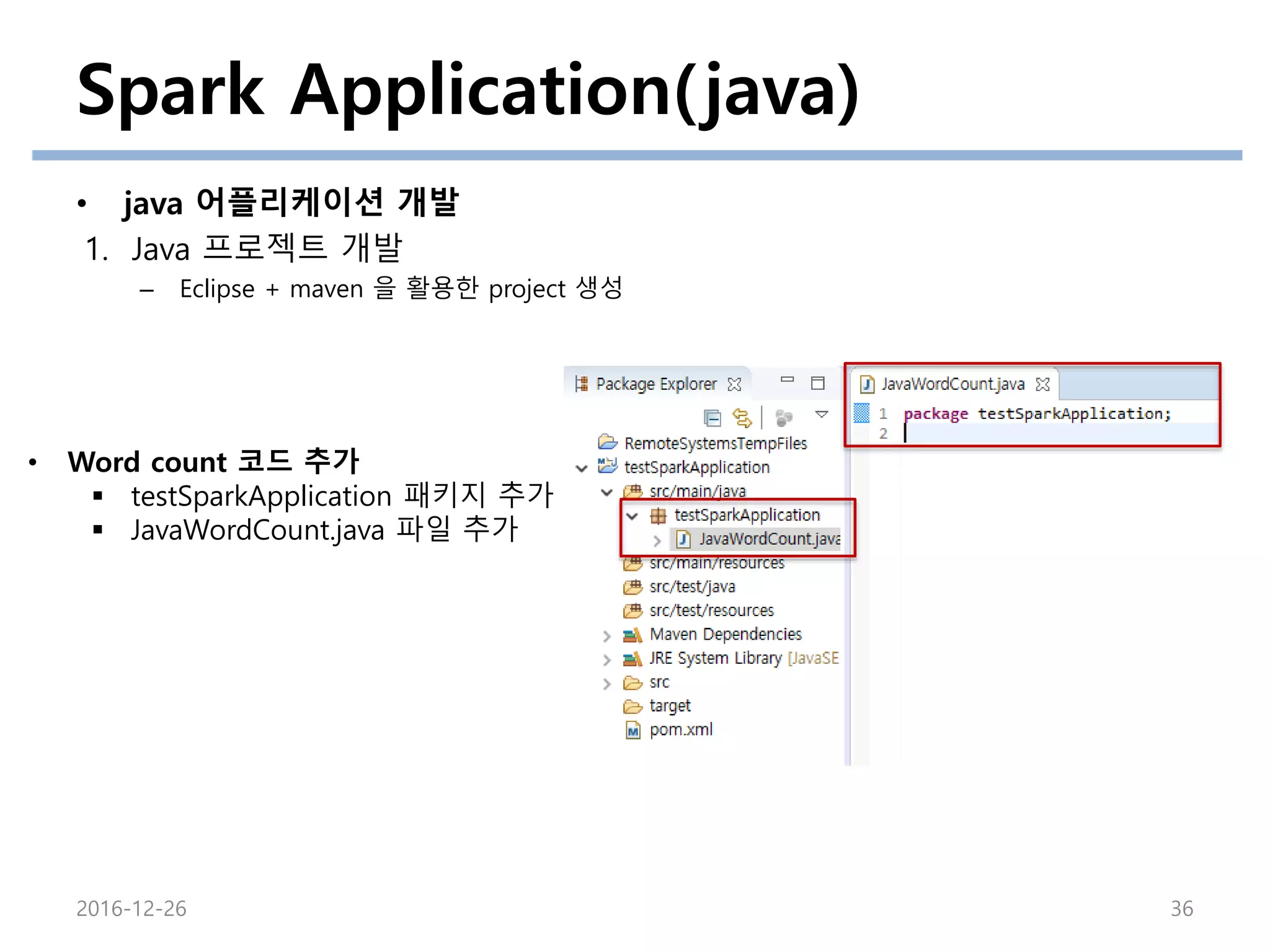
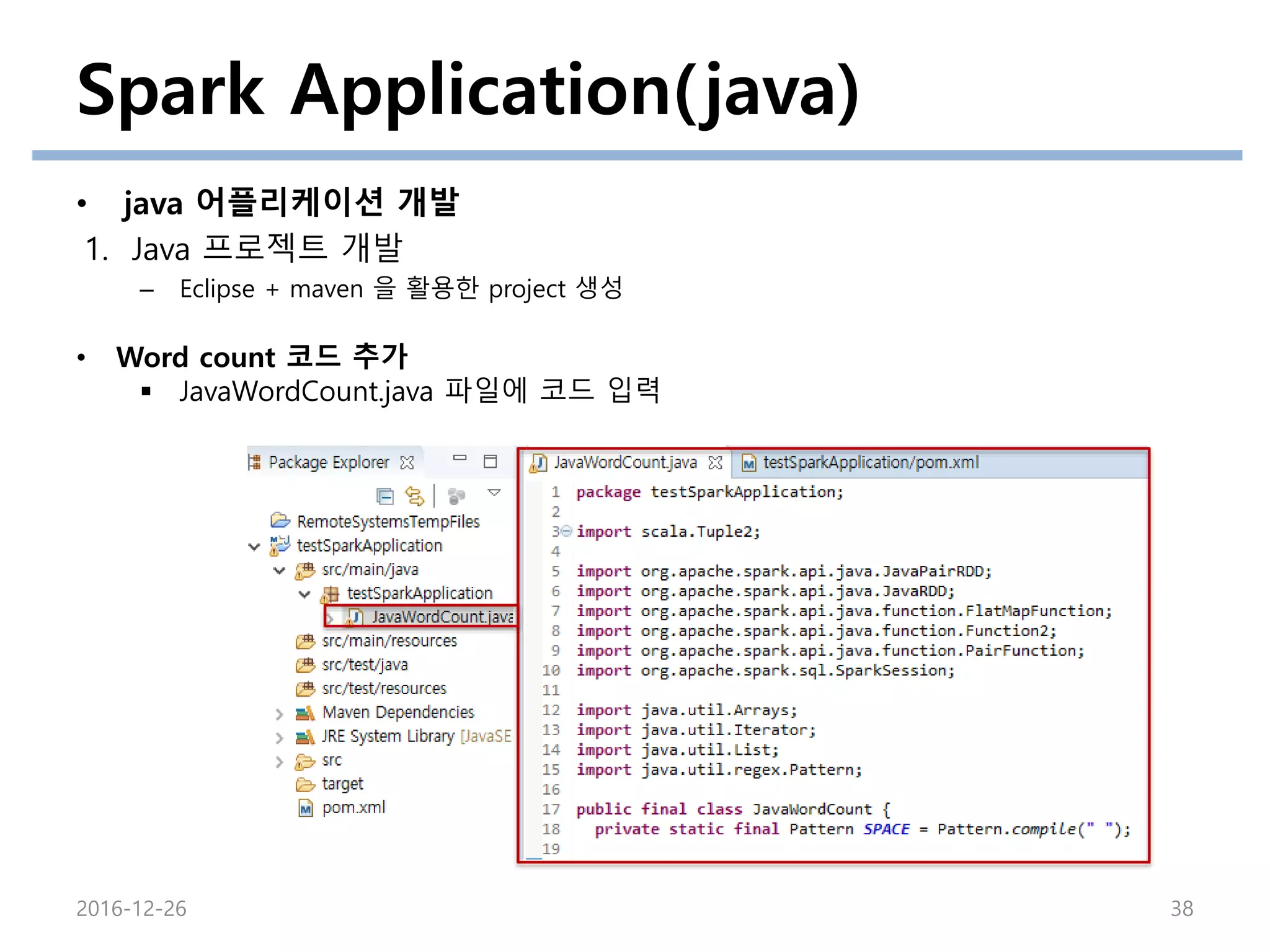
• Word count 코드 추가
testSparkApplication 패키지 추가
JavaWordCount.java 파일 추가
37.
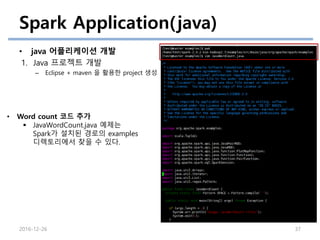
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 37
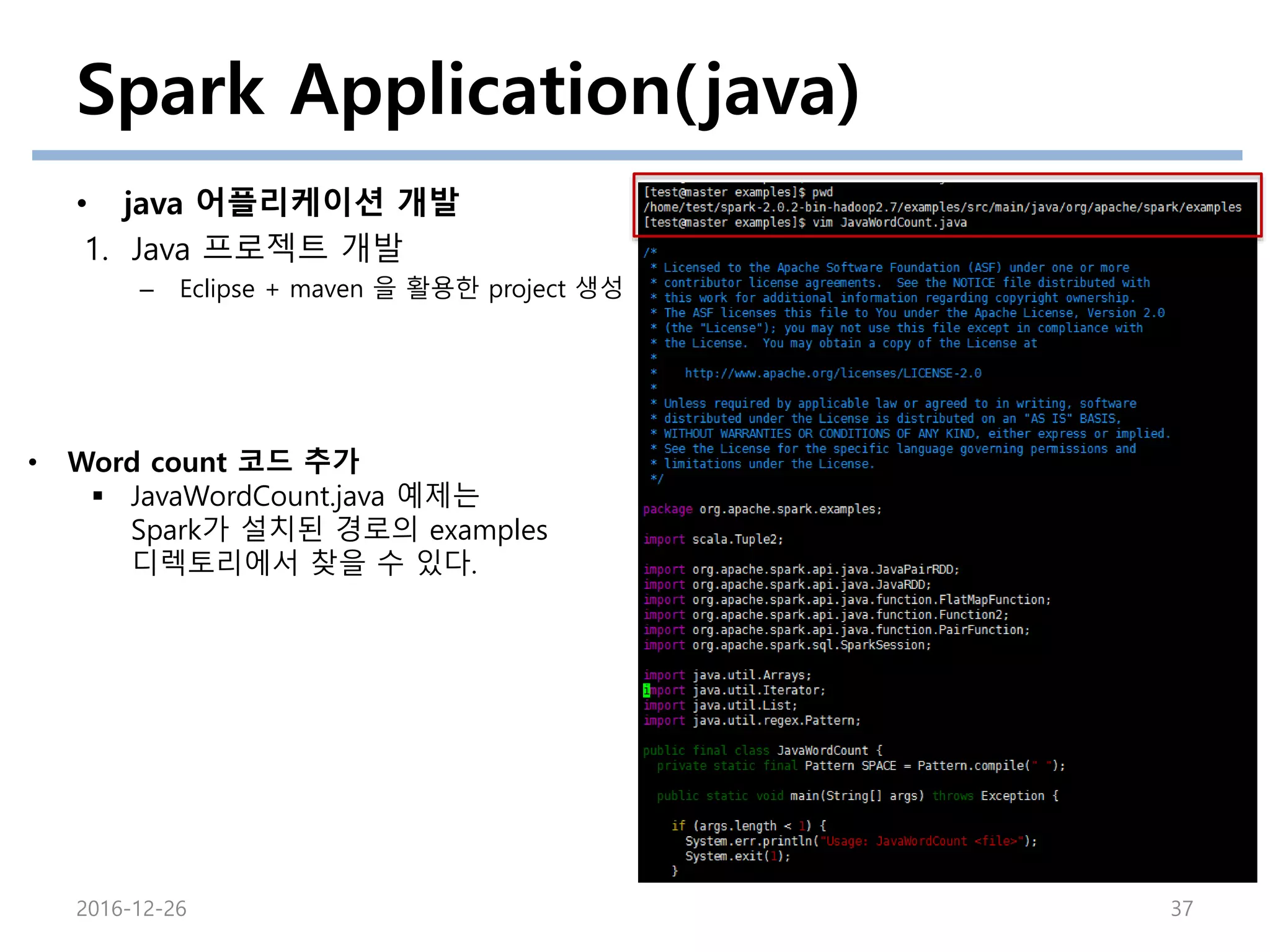
• Word count 코드 추가
JavaWordCount.java 예제는
Spark가 설치된 경로의 examples
디렉토리에서 찾을 수 있다.
38.
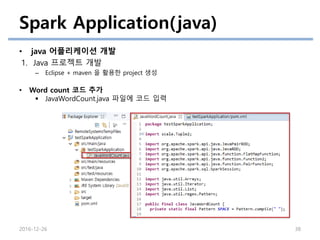
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 38
• Word count 코드 추가
JavaWordCount.java 파일에 코드 입력
39.
Spark Application(java)
• java어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 39
• Java의 함수형 프로그래밍(이론적 배경)
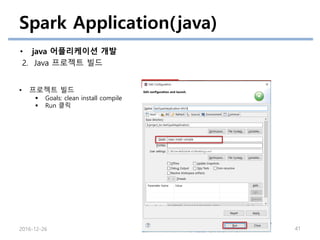
40.
Spark Application(java)
• java어플리케이션 개발
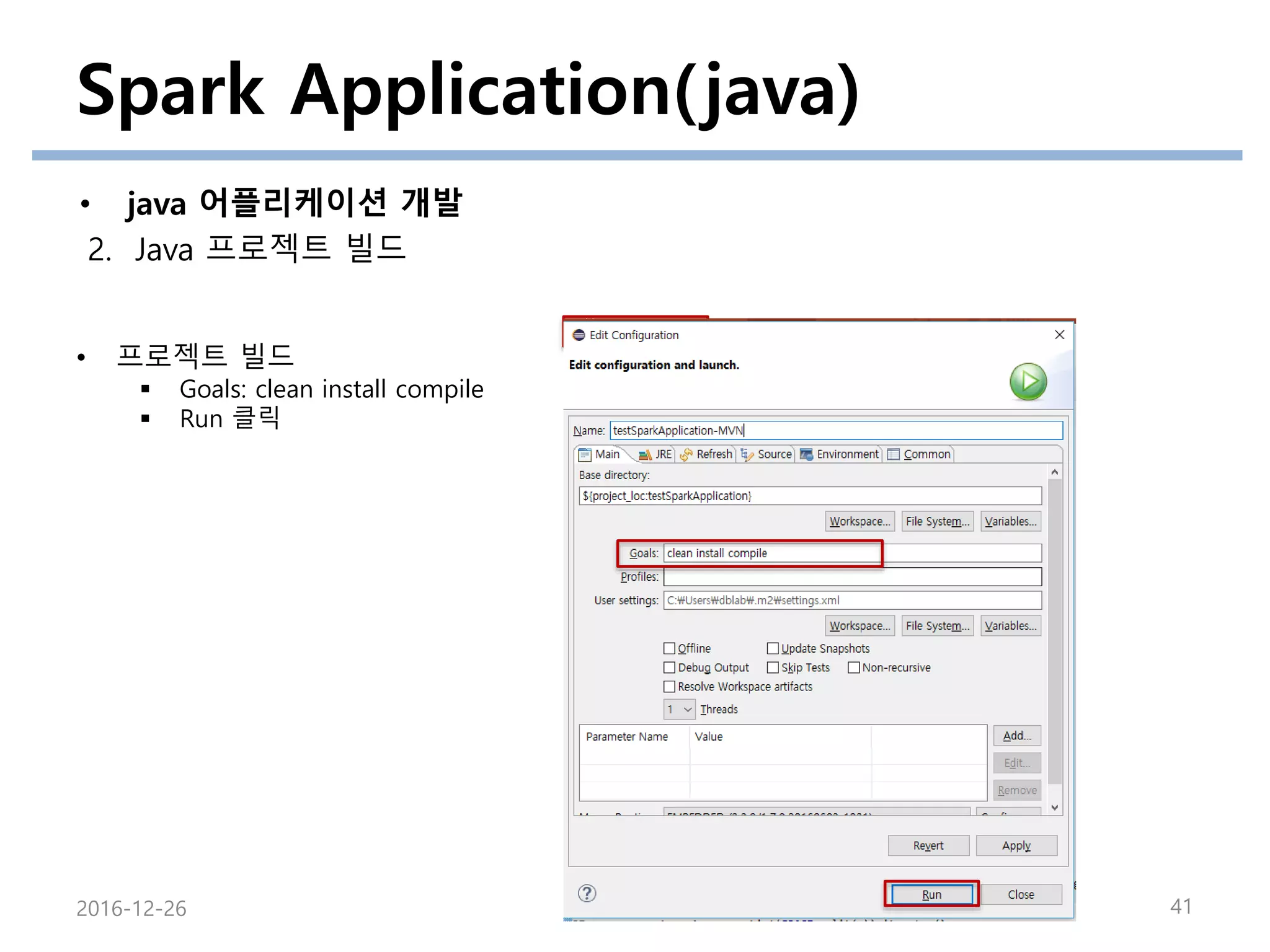
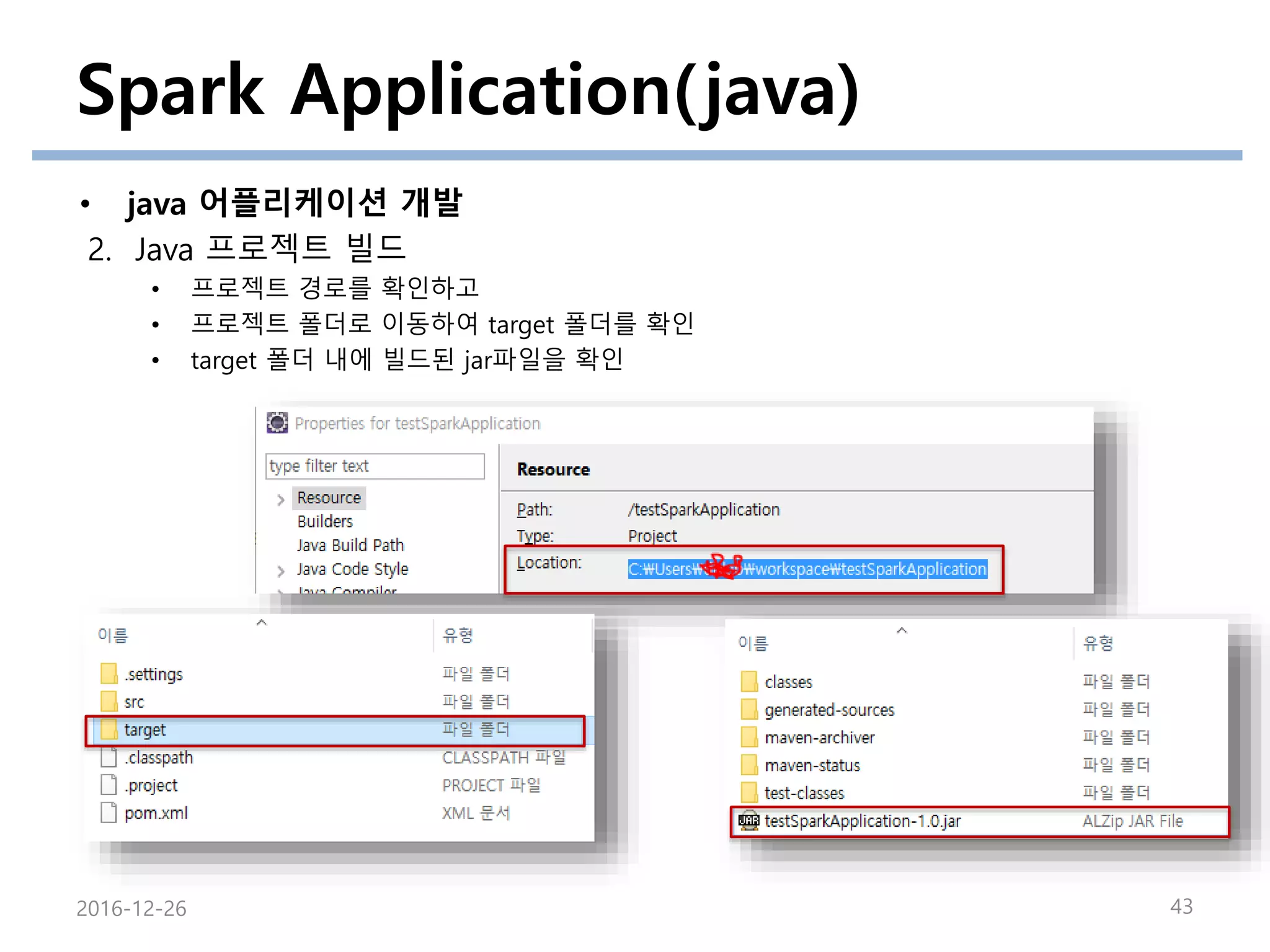
2. Java 프로젝트 빌드
2016-12-26 40
• 프로젝트 빌드
프로젝트 우클릭
-> Run as 선택
-> Maven Build … 선택
에러가 남아있다면
“alt+f5” 로
프로젝트 업데이트 실행
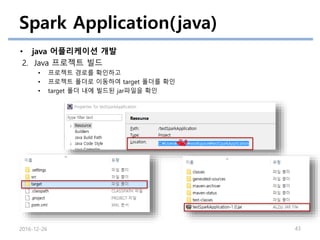
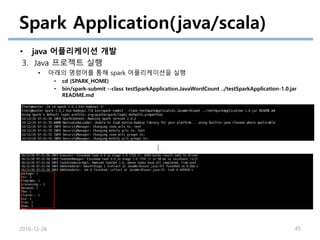
Spark Application(java/scala)
• java어플리케이션 개발
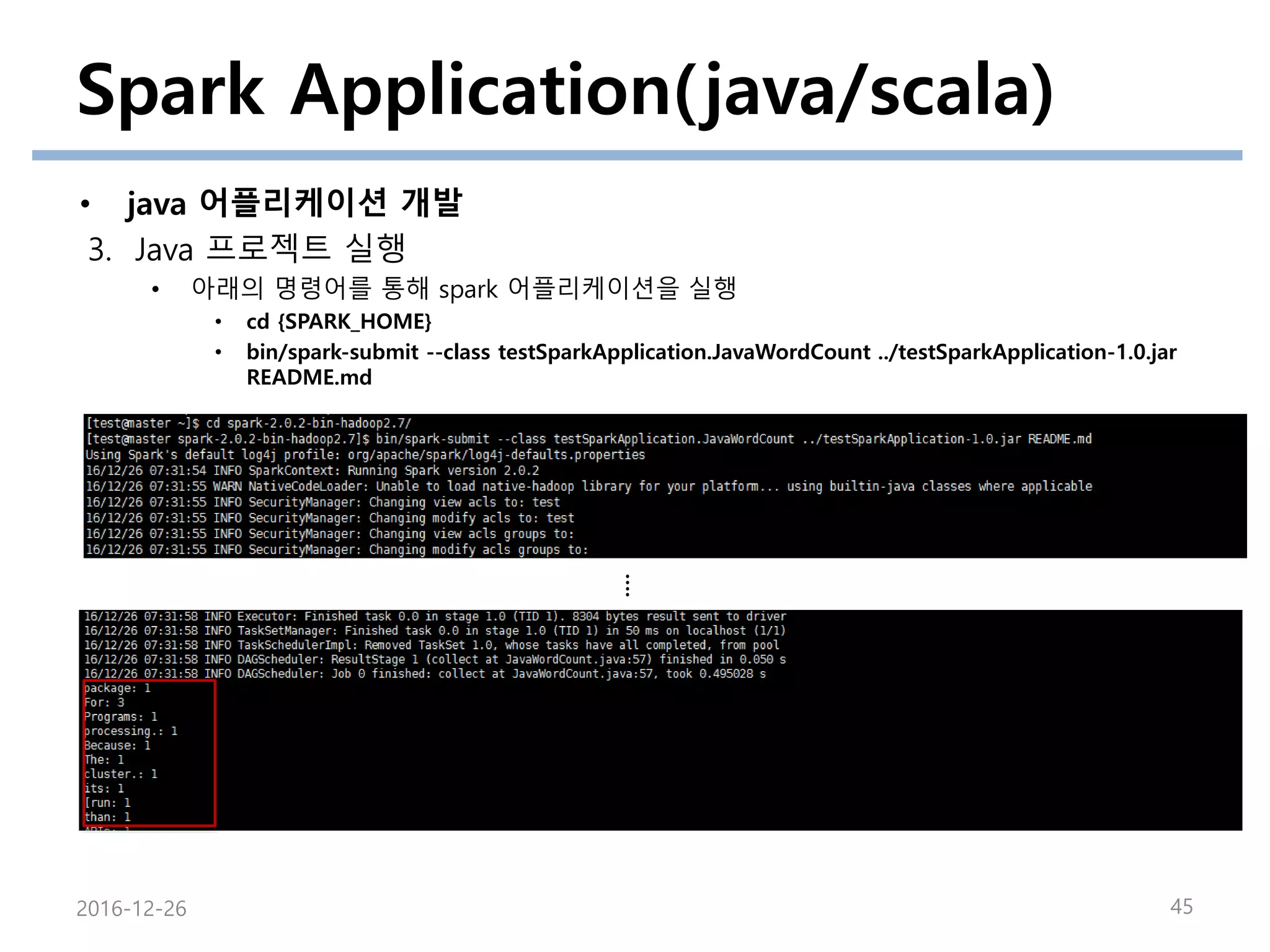
3. Java 프로젝트 실행
• 아래의 명령어를 통해 spark 어플리케이션을 실행
• cd {SPARK_HOME}
• bin/spark-submit --class testSparkApplication.JavaWordCount ../testSparkApplication-1.0.jar
README.md
2016-12-26 45
….




![환경 설정 - server
• JDK 설치(JDK 1.8 이상일 경우 스킵 가능)
– jdk를 다운로드 후 아래와 같이 설치
2016-12-26 5
// “/usr/java/” 경로에 준비된 jdk-{version}-linux-x64.tar.gz 옮기기
$ mv {JDK 다운로드 경로}/jdk-{version}-linux-x64.tar.gz /usr/java/
// jdk 압축 해제
$ cd /usr
$ mkdir java
$ cd /usr/java
$ tar -xf jdk-{version}-linux-x64.tar.gz
$ ln -s /usr/java/jdk1.X.X_XX latest
$ ln -s latest default
$ alternatives --install /usr/bin/java java /usr/java/jdk1.X.X_XX /bin/java 1
$ alternatives --config java
//설치된 버전의 java에 해당하는 번호로 세팅
3 개의 프로그램이 'java'를 제공합니다.
선택 명령
-----------------------------------------------
* 1 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64/jre/bin/java
+ 2 /usr/java/jdk1.X.X_XX/bin/java
현재 선택[+]을 유지하려면 엔터키를 누르고, 아니면 선택 번호를 입력하십시오: 2](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-5-320.jpg)





![Interactive Analysis with the Spark Shell
• spark scala 예제 (1) Basic Map
// Scala 변수 List를 RDD로 로딩
scala> val numList = List(2, 1, 4, 3)
numList: List[Int] = List(2, 1, 4, 3)
scala> val nums = sc.parallelize(numList )
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
// RDD의 각 element를 제곱
scala> val squarNum = nums.map(x => x*x) //(transformation)
squarNums: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:28
// RDD를 scala 변수 list 형태로 반환
scala> val output = squarNum.collect() //(action)
output: Array[Int] = Array(4, 1, 16, 9)
2016-12-26 20](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-20-320.jpg)
![Interactive Analysis with the Spark Shell
• spark scala 예제 (2) Basic max/min/sum
// Scala 변수 List를 RDD로 로딩
scala> val numList = List(2, 1, 4, 3)
numList: List[Int] = List(2, 1, 4, 3)
scala> val nums = sc.parallelize(numList )
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
// nums RDD를 대상으로 min/max/sum을 계산
scala> nums.max() //(action)
res0: Int = 4
scala> nums.min() //(action)
res1 : Int = 1
scala> nums.sum() //(action)
res2 : Int = 10
scala> nums.fold(0)((x, y) => x + y)) //(action)
res3 : Int = 10
2016-12-26 21](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-21-320.jpg)
![Interactive Analysis with the Spark Shell
• spark scala 예제 (3) line counting
// {SPARK_HOME}에 위치하는 README.md파일을 로딩
scala> val textFile = sc.textFile("README.md")
textFile: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at <console>:24
// 읽은 파일의 총 line 수는?
scala> textFile.count() //(action)
res0: Long = 99
// 첫번째 Line의 문자열은?
scala> textFile.first() //(action)
res1: String = # Apache Spark
// “Spark”라는 문자열을 포함하고 있는 line의 수는?
scala> val SparkLine = textFile.filter(line => line.contains("Spark")) //(transformation)
SparkLine: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at filter at <console>:26
scala> SparkLine.count() //(action)
res2: Long = 19
2016-12-26 22](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-22-320.jpg)
![Interactive Analysis with the Spark Shell
• spark scala 예제 (4) word counting
// {SPARK_HOME}에 위치하는 README.md파일을 로딩
scala> val lines = sc.textFile("README.md")
// 각 라인을 word단위로 분리
scala> val words = lines.flatMap(line => line.split(" ")) //(transformation)
// case1 .Word별로 개수를 카운트
scala> val wordMap = words.map(word => (word, 1)) //(transformation)
scala> val result = wordMap.reduceByKey((a, b) => a + b) //(action)
res0: Array[(String, Int)] = Array(
(package,1),
(this,1),
(Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version),1),
(Because,1),
(Python,2),
(cluster.,1),
(its,1),
([run,1),
(general,2),
….
2016-12-26 23](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-23-320.jpg)
![Interactive Analysis with the Spark Shell 문제
• (1) [1,2,3,4,5,6,7,8,9] list에서 홀수인 자연수들의 제곱 합을 구하세요.
– sc.parallelize(List(1,2,3,4,5,6,7,8,9)).
filter(i=>(i%2==1)).
map(x=>x*x).
sum()
• (2) “README.md” 파일의 총 word의 개수를 출력하세요
– sc.textFile("README.md").
flatMap(line=>line.split(" ")).
count()
• (3) “README.md” 파일에서 총 ‘k’가 들어가는 word의 개수를 출력하세요
– sc.textFile("README.md").
flatMap(line=>line.split(" ")).
filter(word=>word.contains("k")).
count()
2016-12-26 24](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-24-320.jpg)

![Spark Application(python)
• Python 어플리케이션 개발
1. 간단한 python application 작성
– Vim등의 텍스트 에디터를 이용하여 python code를 작성
2. python application 실행
– 아래의 명령어를 통해 작성한 test.py spark 어플리케이션을 실행
2016-12-26 26
from pyspark import SparkContext
logFile = “/home/{user}/spark-2.0.1-bin-hadoop2.7/README.md
sc = SparkContext("local", "Simple App")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
$ YOUR_SPARK_HOME/bin/spark-submit --master local[4] test.py
...
Lines with a: 46, Lines with b: 23
...](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-26-320.jpg)



![Spark Application(java)
• java 어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 32
• Maven 기본 JRE 변경
JRE System Library 우클릭 -> Build Path 선택 -> Configure Build Path 선택
JRE System Library [J2SE-1.5] 삭제 (Remove) 한다.](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-32-320.jpg)
![Spark Application(java)
• java 어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 33
• Maven 기본 JRE 변경
JRE System Library [J2SE-1.5] 삭제 (Remove) 후 Add Library을 선택한다.
JRE System Library 을 선택 한다.](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-33-320.jpg)



![Spark Application(java)
• java 어플리케이션 개발
2. Java 프로젝트 빌드
2016-12-26 42
• 프로젝트 빌드
• 콘솔창에 아래와 같은 로그가 보이면 성공
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building wordCounting 1.0
[INFO] ------------------------------------------------------------------------
[INFO]
[INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ testSparkApplication ---
[INFO] Deleting C:UsersdblabworkspacetestSparkApplicationtarget
[INFO]
[INFO] --- maven-resources-plugin:2.6:resources (default-resources) @
testSparkApplication ---
[WARNING] Using platform encoding (MS949 actually) to copy filtered resources, i.e.
build is platform dependent!
[INFO] Copying 0 resource
[INFO]
…
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 20.537 s
[INFO] Finished at: 2016-12-26T07:18:16+09:00
[INFO] Final Memory: 38M/269M
[INFO] ------------------------------------------------------------------------](https://image.slidesharecdn.com/2-161226003957/85/2-apache-spark-42-320.jpg)





![환경 설정 - server
• JDK 설치(JDK 1.8 이상일 경우 스킵 가능)
– jdk를 다운로드 후 아래와 같이 설치
2016-12-26 5
// “/usr/java/” 경로에 준비된 jdk-{version}-linux-x64.tar.gz 옮기기
$ mv {JDK 다운로드 경로}/jdk-{version}-linux-x64.tar.gz /usr/java/
// jdk 압축 해제
$ cd /usr
$ mkdir java
$ cd /usr/java
$ tar -xf jdk-{version}-linux-x64.tar.gz
$ ln -s /usr/java/jdk1.X.X_XX latest
$ ln -s latest default
$ alternatives --install /usr/bin/java java /usr/java/jdk1.X.X_XX /bin/java 1
$ alternatives --config java
//설치된 버전의 java에 해당하는 번호로 세팅
3 개의 프로그램이 'java'를 제공합니다.
선택 명령
-----------------------------------------------
* 1 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64/jre/bin/java
+ 2 /usr/java/jdk1.X.X_XX/bin/java
현재 선택[+]을 유지하려면 엔터키를 누르고, 아니면 선택 번호를 입력하십시오: 2](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-5-2048.jpg)








![Interactive Analysis with the Spark Shell
• spark scala 예제 (1) Basic Map
// Scala 변수 List를 RDD로 로딩
scala> val numList = List(2, 1, 4, 3)
numList: List[Int] = List(2, 1, 4, 3)
scala> val nums = sc.parallelize(numList )
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
// RDD의 각 element를 제곱
scala> val squarNum = nums.map(x => x*x) //(transformation)
squarNums: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:28
// RDD를 scala 변수 list 형태로 반환
scala> val output = squarNum.collect() //(action)
output: Array[Int] = Array(4, 1, 16, 9)
2016-12-26 20](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-20-2048.jpg)
![Interactive Analysis with the Spark Shell
• spark scala 예제 (2) Basic max/min/sum
// Scala 변수 List를 RDD로 로딩
scala> val numList = List(2, 1, 4, 3)
numList: List[Int] = List(2, 1, 4, 3)
scala> val nums = sc.parallelize(numList )
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
// nums RDD를 대상으로 min/max/sum을 계산
scala> nums.max() //(action)
res0: Int = 4
scala> nums.min() //(action)
res1 : Int = 1
scala> nums.sum() //(action)
res2 : Int = 10
scala> nums.fold(0)((x, y) => x + y)) //(action)
res3 : Int = 10
2016-12-26 21](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-21-2048.jpg)
![Interactive Analysis with the Spark Shell
• spark scala 예제 (3) line counting
// {SPARK_HOME}에 위치하는 README.md파일을 로딩
scala> val textFile = sc.textFile("README.md")
textFile: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at <console>:24
// 읽은 파일의 총 line 수는?
scala> textFile.count() //(action)
res0: Long = 99
// 첫번째 Line의 문자열은?
scala> textFile.first() //(action)
res1: String = # Apache Spark
// “Spark”라는 문자열을 포함하고 있는 line의 수는?
scala> val SparkLine = textFile.filter(line => line.contains("Spark")) //(transformation)
SparkLine: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at filter at <console>:26
scala> SparkLine.count() //(action)
res2: Long = 19
2016-12-26 22](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-22-2048.jpg)
![Interactive Analysis with the Spark Shell
• spark scala 예제 (4) word counting
// {SPARK_HOME}에 위치하는 README.md파일을 로딩
scala> val lines = sc.textFile("README.md")
// 각 라인을 word단위로 분리
scala> val words = lines.flatMap(line => line.split(" ")) //(transformation)
// case1 .Word별로 개수를 카운트
scala> val wordMap = words.map(word => (word, 1)) //(transformation)
scala> val result = wordMap.reduceByKey((a, b) => a + b) //(action)
res0: Array[(String, Int)] = Array(
(package,1),
(this,1),
(Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version),1),
(Because,1),
(Python,2),
(cluster.,1),
(its,1),
([run,1),
(general,2),
….
2016-12-26 23](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-23-2048.jpg)
![Interactive Analysis with the Spark Shell 문제
• (1) [1,2,3,4,5,6,7,8,9] list에서 홀수인 자연수들의 제곱 합을 구하세요.
– sc.parallelize(List(1,2,3,4,5,6,7,8,9)).
filter(i=>(i%2==1)).
map(x=>x*x).
sum()
• (2) “README.md” 파일의 총 word의 개수를 출력하세요
– sc.textFile("README.md").
flatMap(line=>line.split(" ")).
count()
• (3) “README.md” 파일에서 총 ‘k’가 들어가는 word의 개수를 출력하세요
– sc.textFile("README.md").
flatMap(line=>line.split(" ")).
filter(word=>word.contains("k")).
count()
2016-12-26 24](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-24-2048.jpg)

![Spark Application(python)
• Python 어플리케이션 개발
1. 간단한 python application 작성
– Vim등의 텍스트 에디터를 이용하여 python code를 작성
2. python application 실행
– 아래의 명령어를 통해 작성한 test.py spark 어플리케이션을 실행
2016-12-26 26
from pyspark import SparkContext
logFile = “/home/{user}/spark-2.0.1-bin-hadoop2.7/README.md
sc = SparkContext("local", "Simple App")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
$ YOUR_SPARK_HOME/bin/spark-submit --master local[4] test.py
...
Lines with a: 46, Lines with b: 23
...](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-26-2048.jpg)


![Spark Application(java)
• java 어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 32
• Maven 기본 JRE 변경
JRE System Library 우클릭 -> Build Path 선택 -> Configure Build Path 선택
JRE System Library [J2SE-1.5] 삭제 (Remove) 한다.](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-32-2048.jpg)
![Spark Application(java)
• java 어플리케이션 개발
1. Java 프로젝트 개발
– Eclipse + maven 을 활용한 project 생성
2016-12-26 33
• Maven 기본 JRE 변경
JRE System Library [J2SE-1.5] 삭제 (Remove) 후 Add Library을 선택한다.
JRE System Library 을 선택 한다.](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-33-2048.jpg)


![Spark Application(java)
• java 어플리케이션 개발
2. Java 프로젝트 빌드
2016-12-26 42
• 프로젝트 빌드
• 콘솔창에 아래와 같은 로그가 보이면 성공
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building wordCounting 1.0
[INFO] ------------------------------------------------------------------------
[INFO]
[INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ testSparkApplication ---
[INFO] Deleting C:UsersdblabworkspacetestSparkApplicationtarget
[INFO]
[INFO] --- maven-resources-plugin:2.6:resources (default-resources) @
testSparkApplication ---
[WARNING] Using platform encoding (MS949 actually) to copy filtered resources, i.e.
build is platform dependent!
[INFO] Copying 0 resource
[INFO]
…
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 20.537 s
[INFO] Finished at: 2016-12-26T07:18:16+09:00
[INFO] Final Memory: 38M/269M
[INFO] ------------------------------------------------------------------------](https://image.slidesharecdn.com/2-161226003957/75/2-apache-spark-42-2048.jpg)








































![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
















