Downloaded 1,123 times














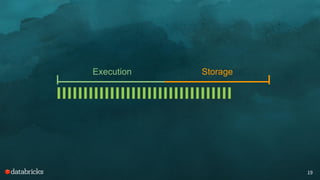















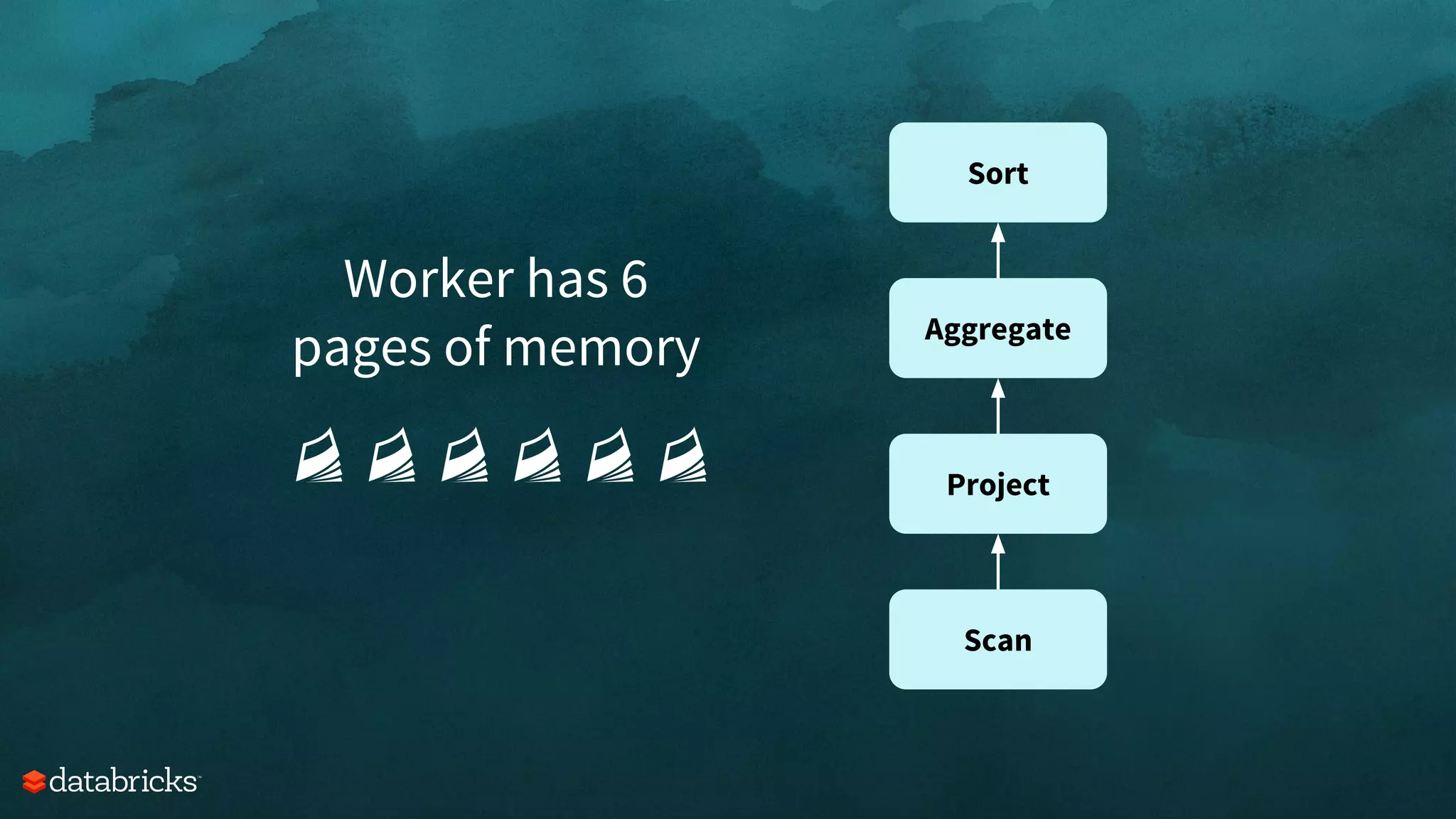
![Scan
Project
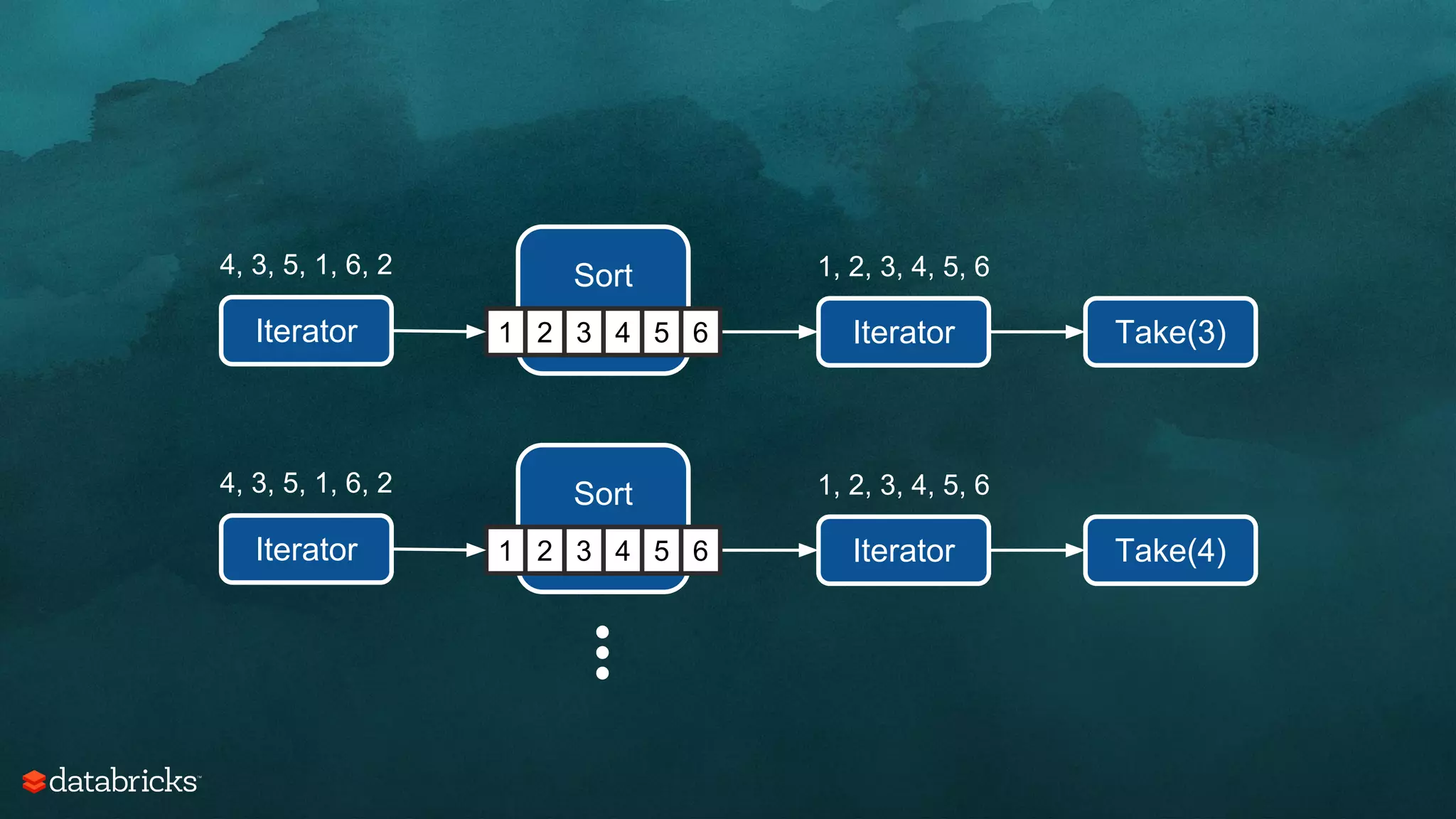
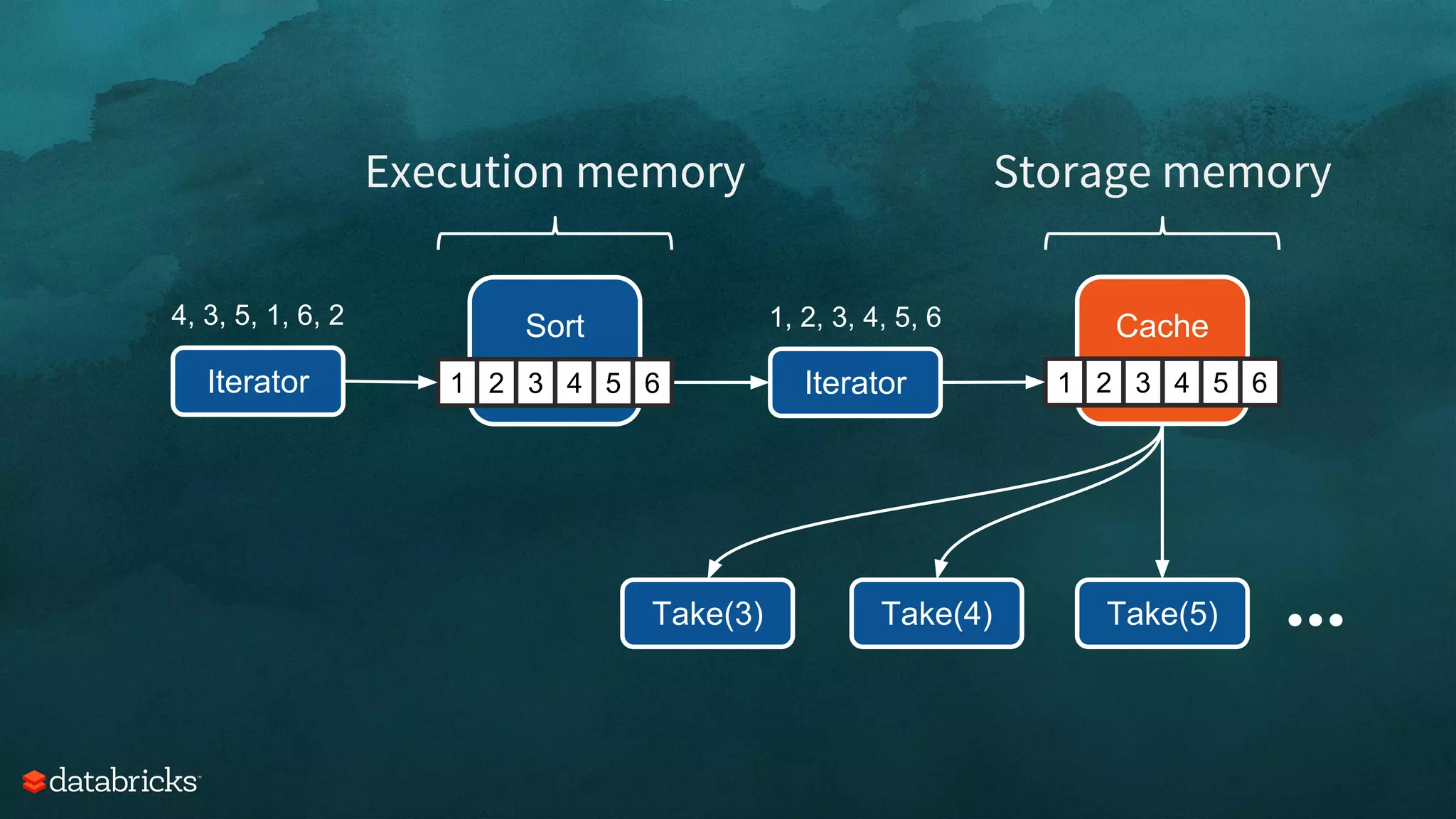
Aggregate
Sort
Map { // age → heights
20 → [154, 174, 175]
21 → [167, 168, 181]
22 → [155, 166, 188]
23 → [160, 168, 178, 183]
}](https://image.slidesharecdn.com/spark-memory-sparksummit-2016-160608234716/85/Deep-Dive-Memory-Management-in-Apache-Spark-36-320.jpg)














































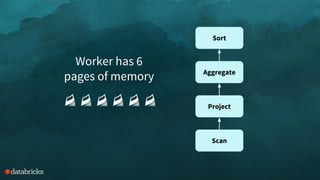
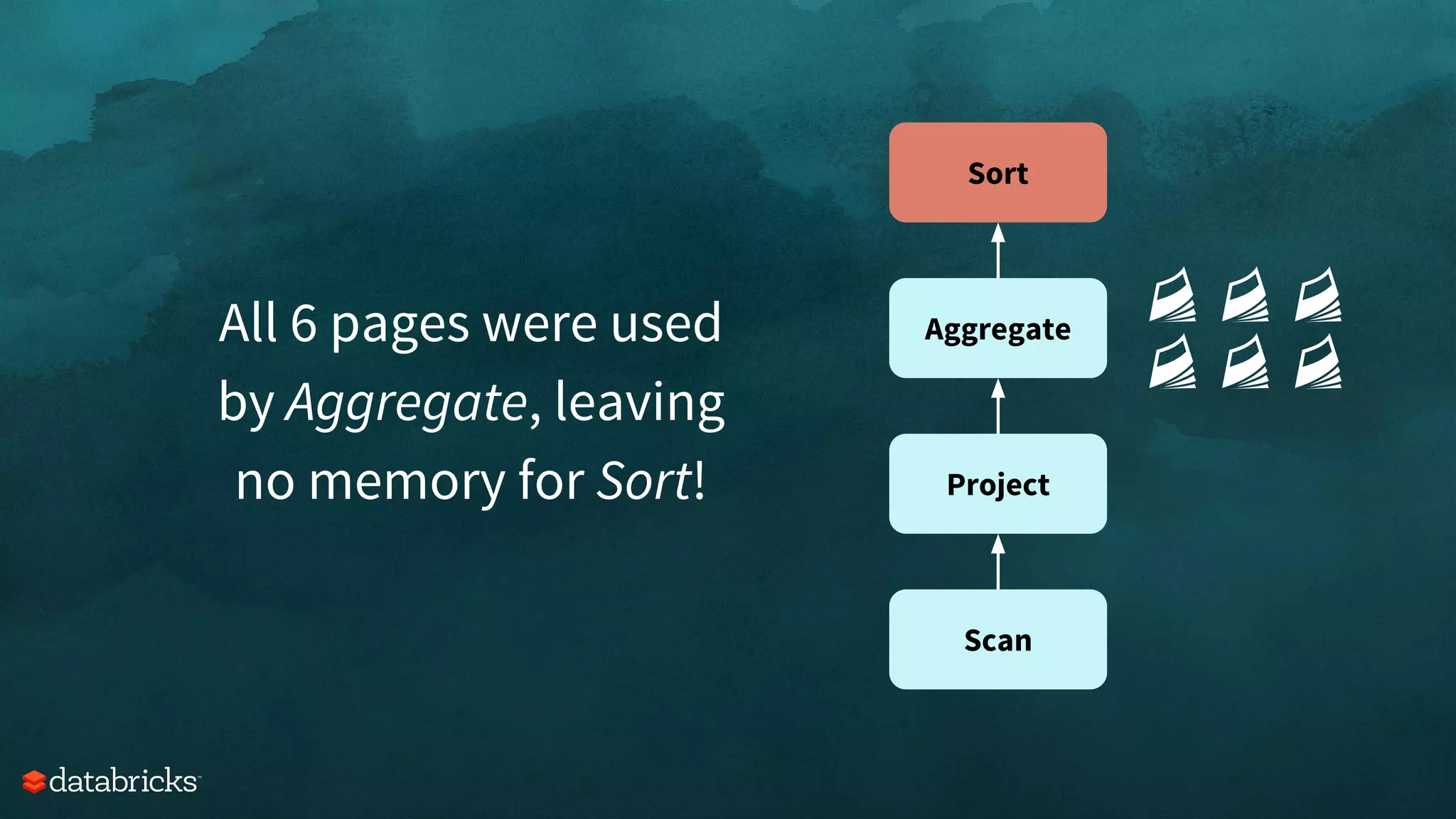
![Scan
Project
Aggregate
Sort
Map { // age → heights
20 → [154, 174, 175]
21 → [167, 168, 181]
22 → [155, 166, 188]
23 → [160, 168, 178, 183]
}](https://image.slidesharecdn.com/spark-memory-sparksummit-2016-160608234716/75/Deep-Dive-Memory-Management-in-Apache-Spark-36-2048.jpg)










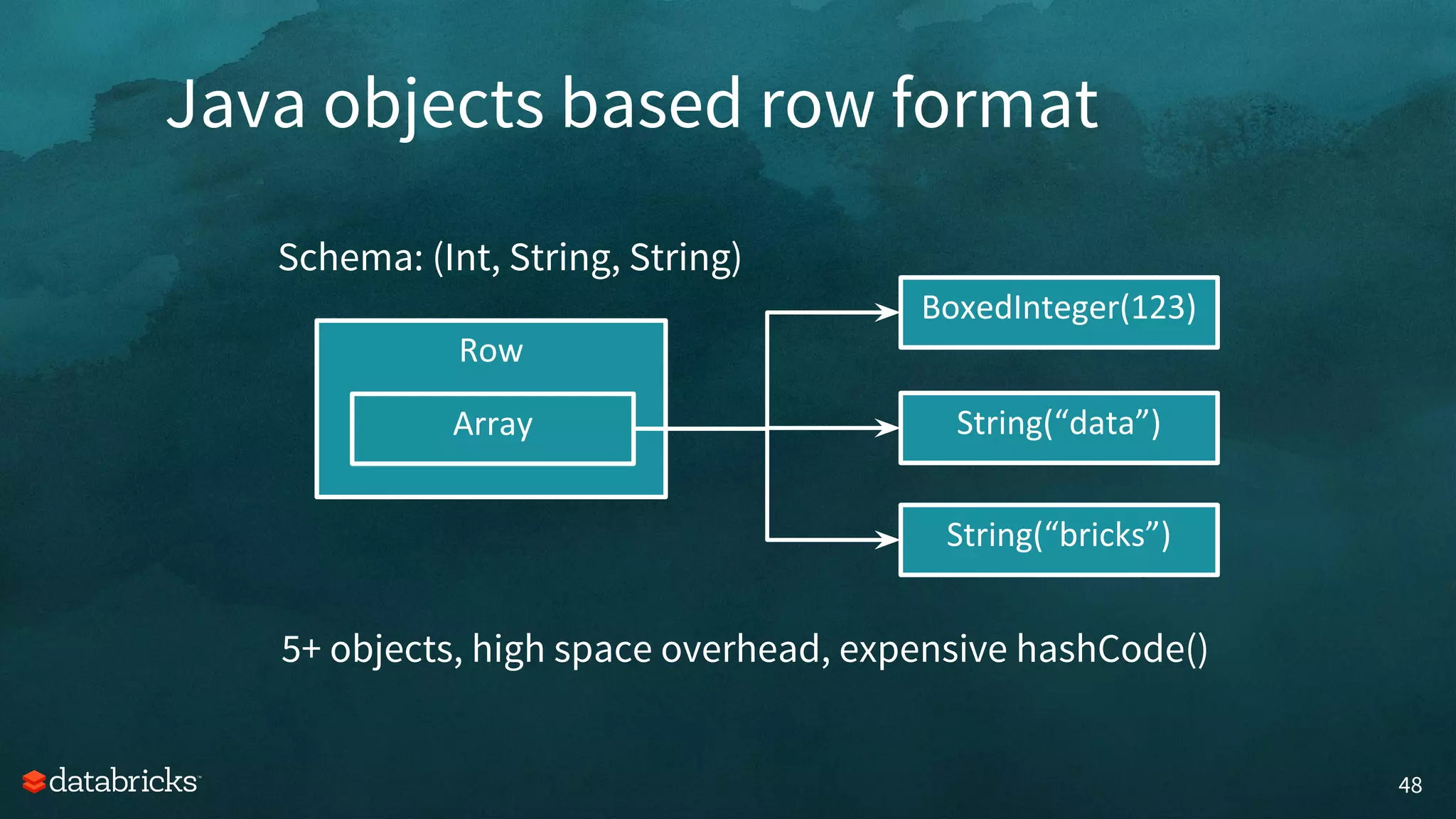







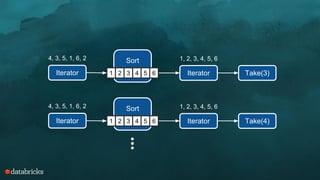
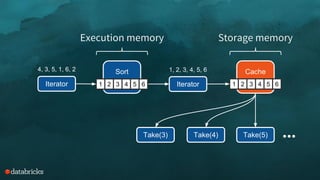
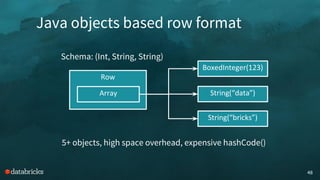
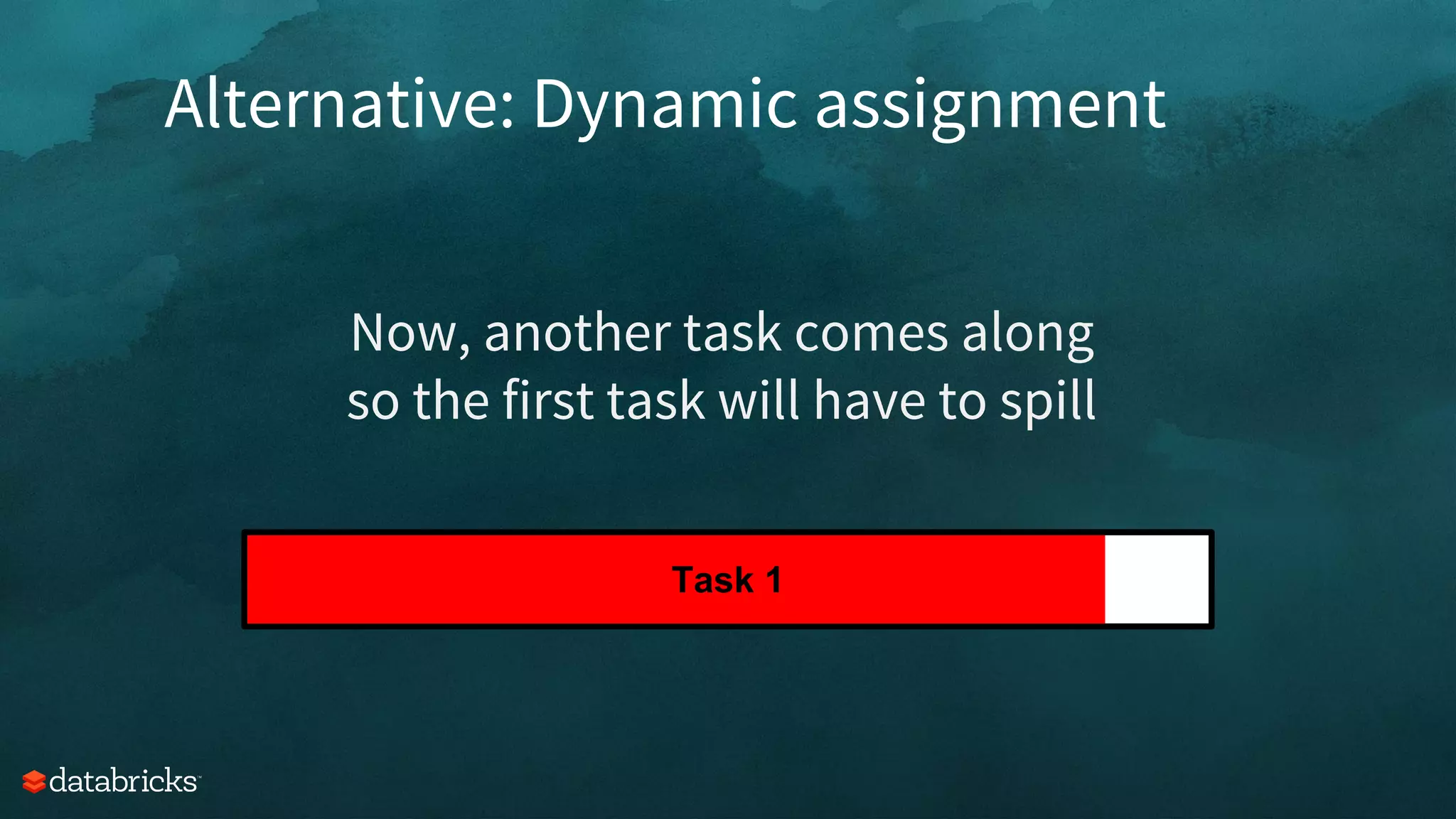
The document discusses memory management challenges in Apache Spark, focusing on efficient use of execution and storage memory. It outlines strategies for handling memory contention across various scenarios, including static and dynamic memory assignment for tasks and operators. Additionally, it introduces features from Spark 1.6 onwards, emphasizing unified memory management and the benefits of tungsten's optimized data representation.





























































































