Downloaded 148 times



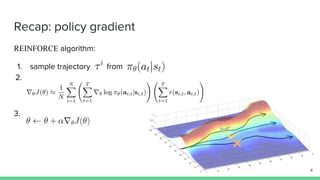






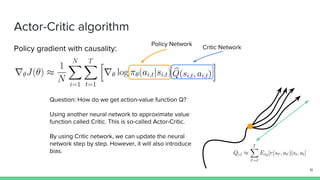
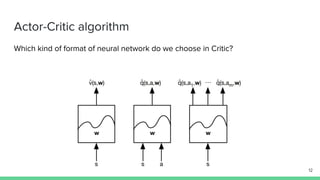
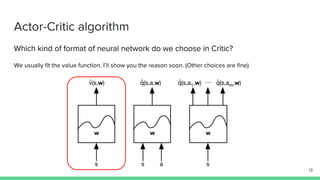
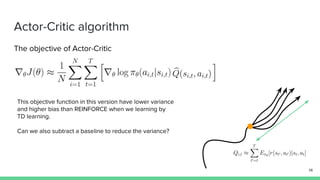


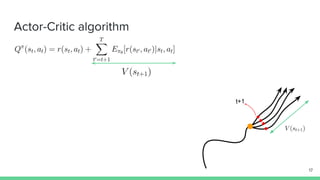








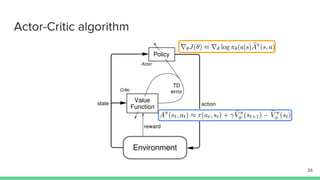

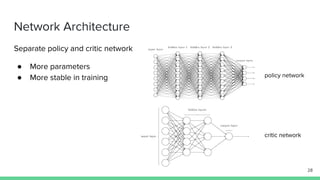
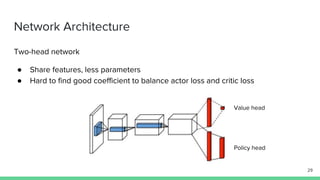
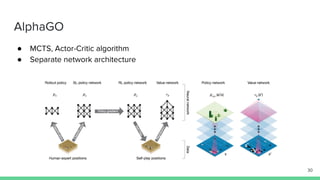
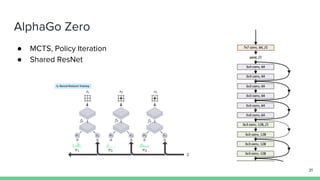



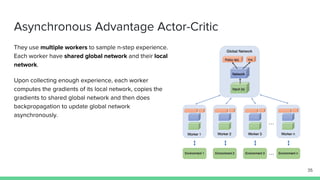


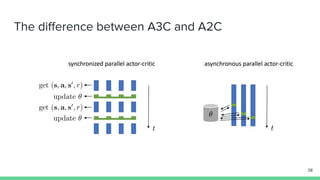

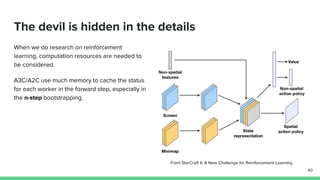




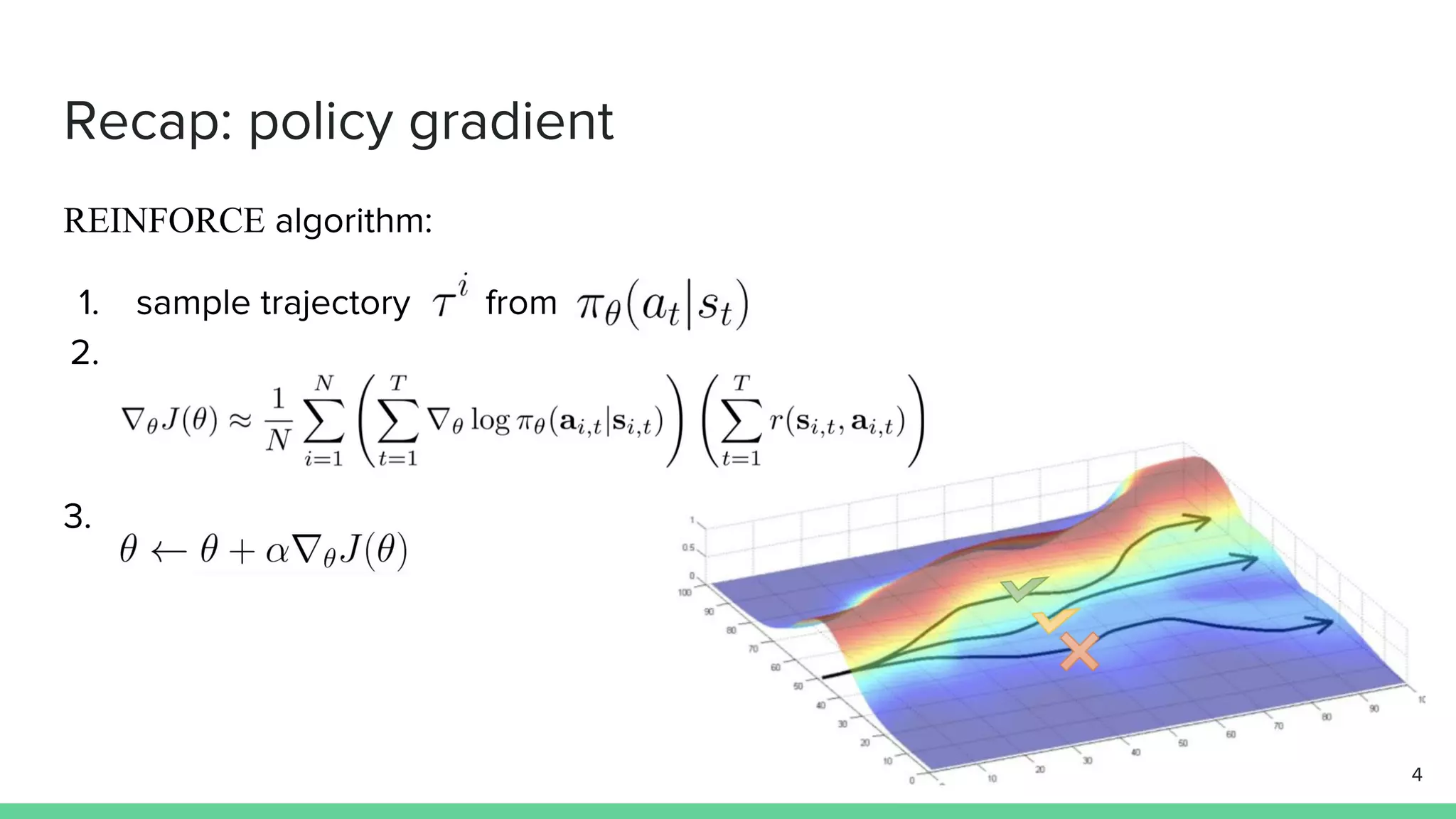






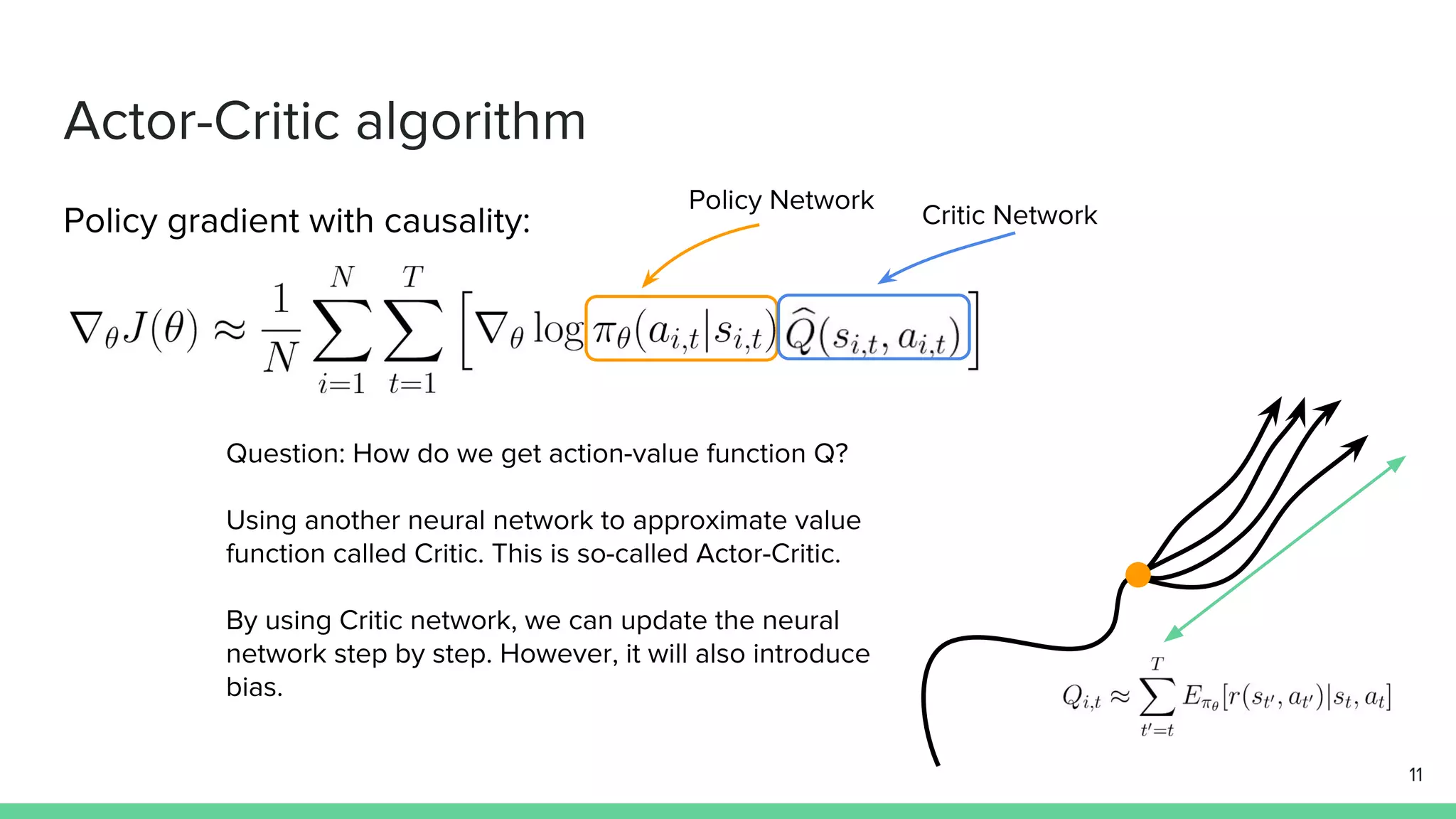
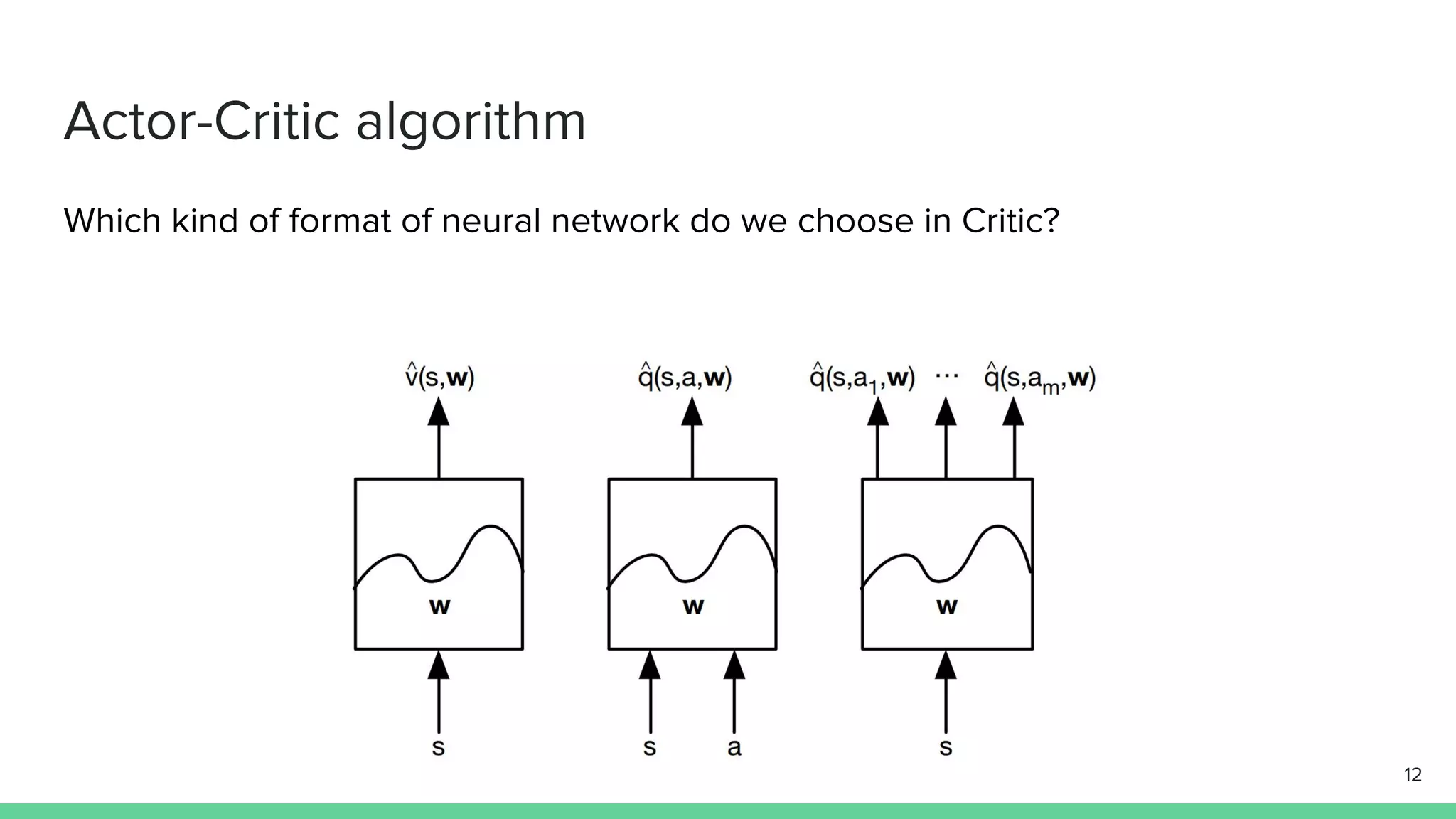
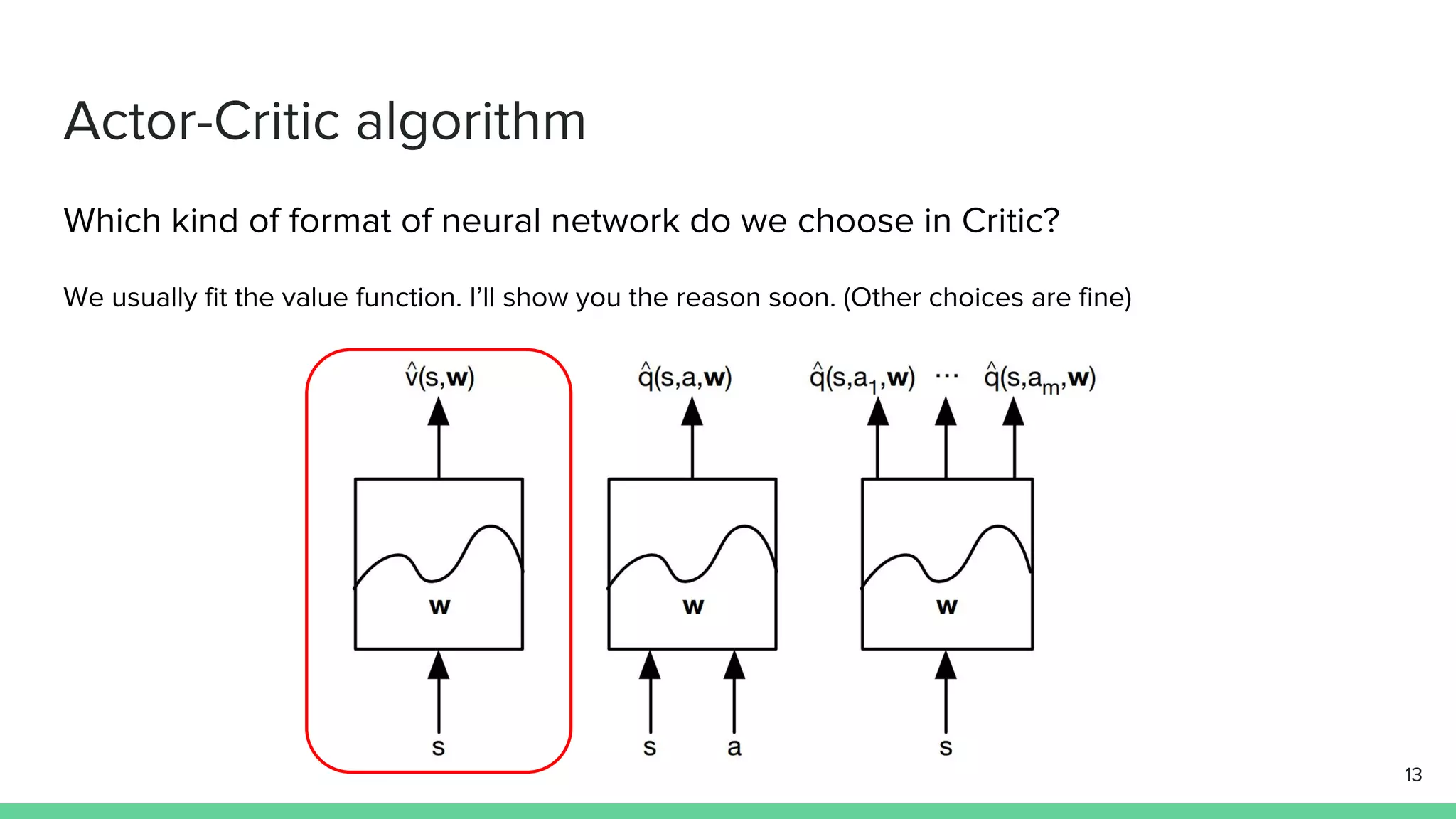
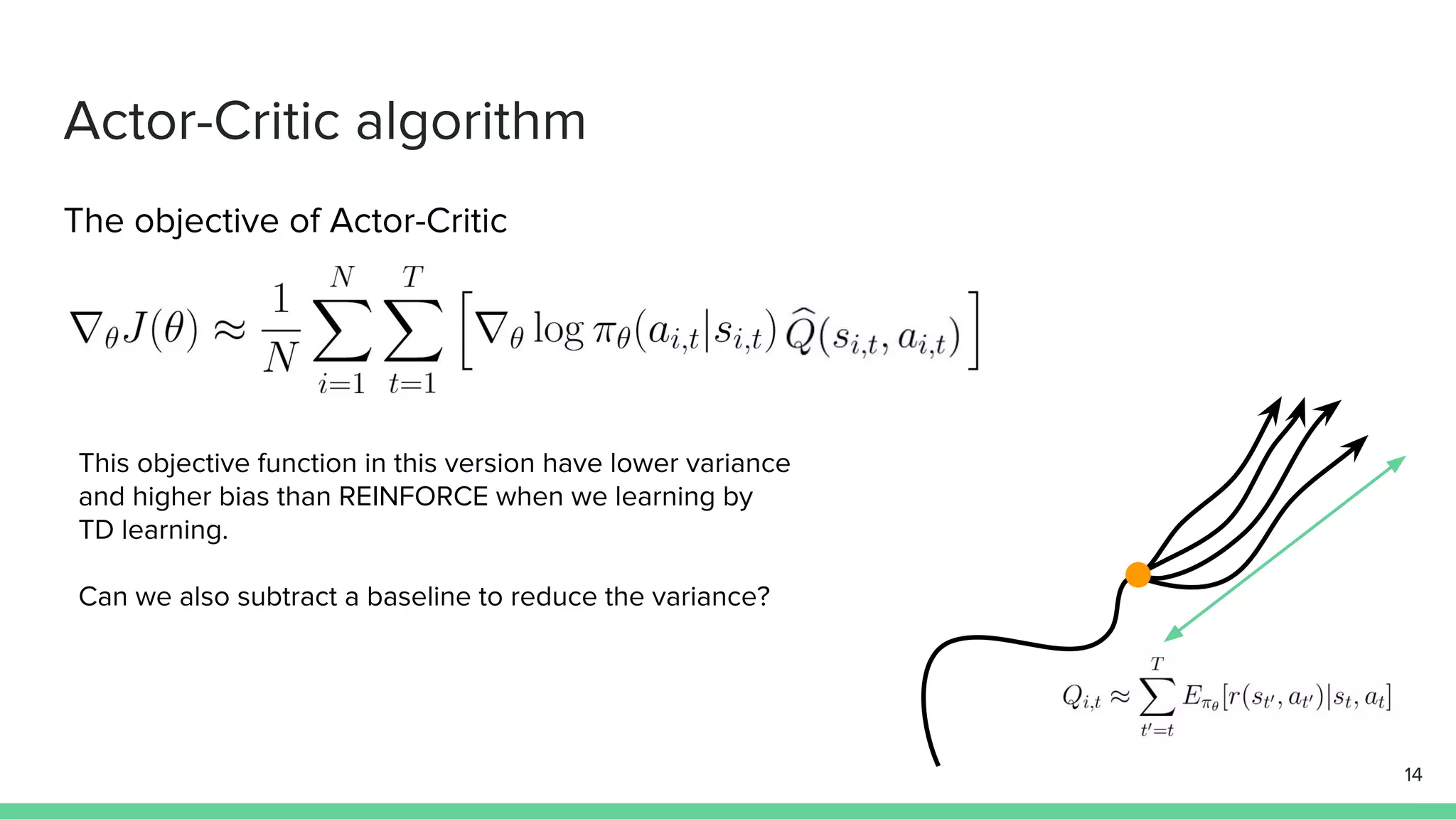











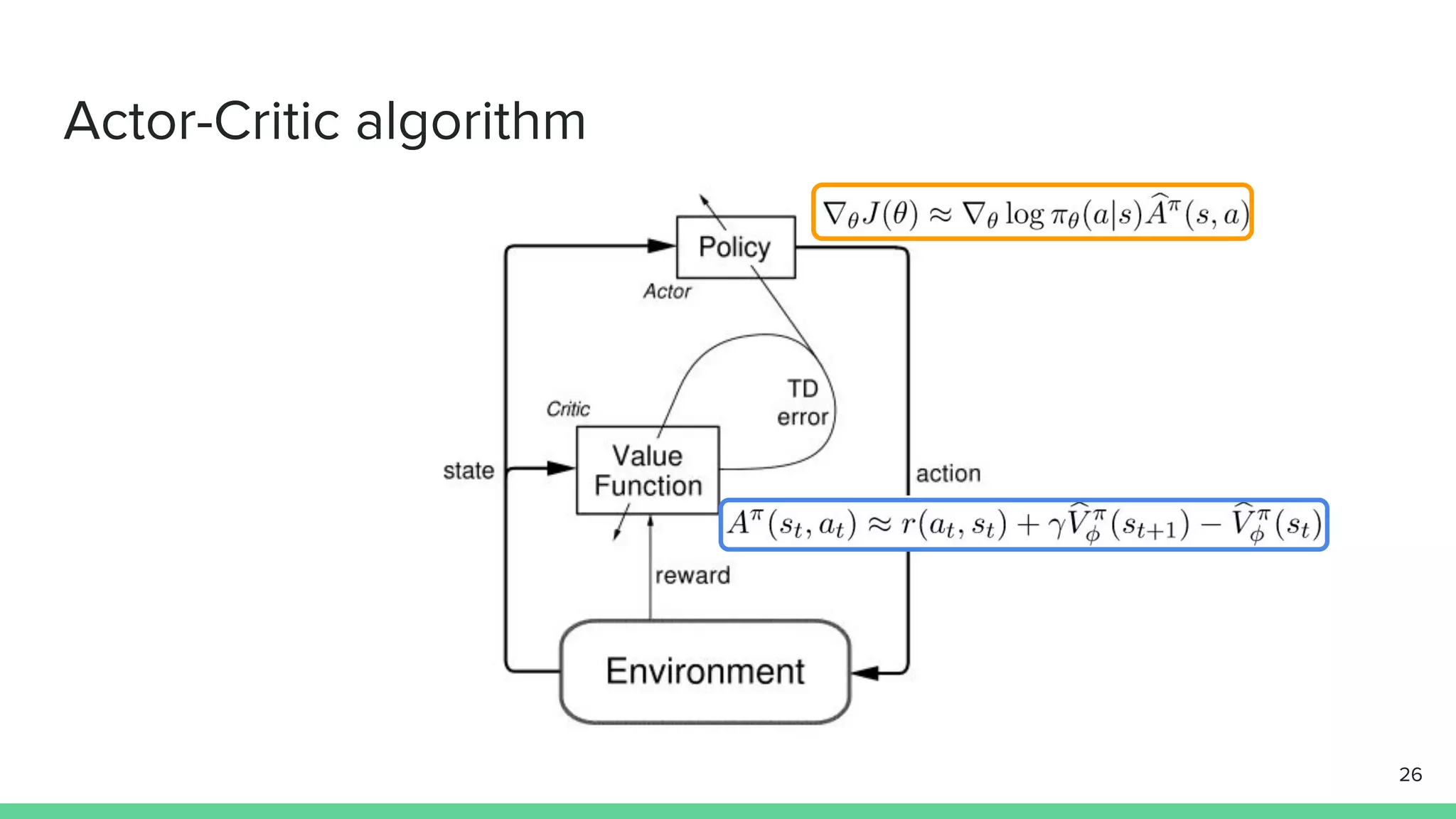

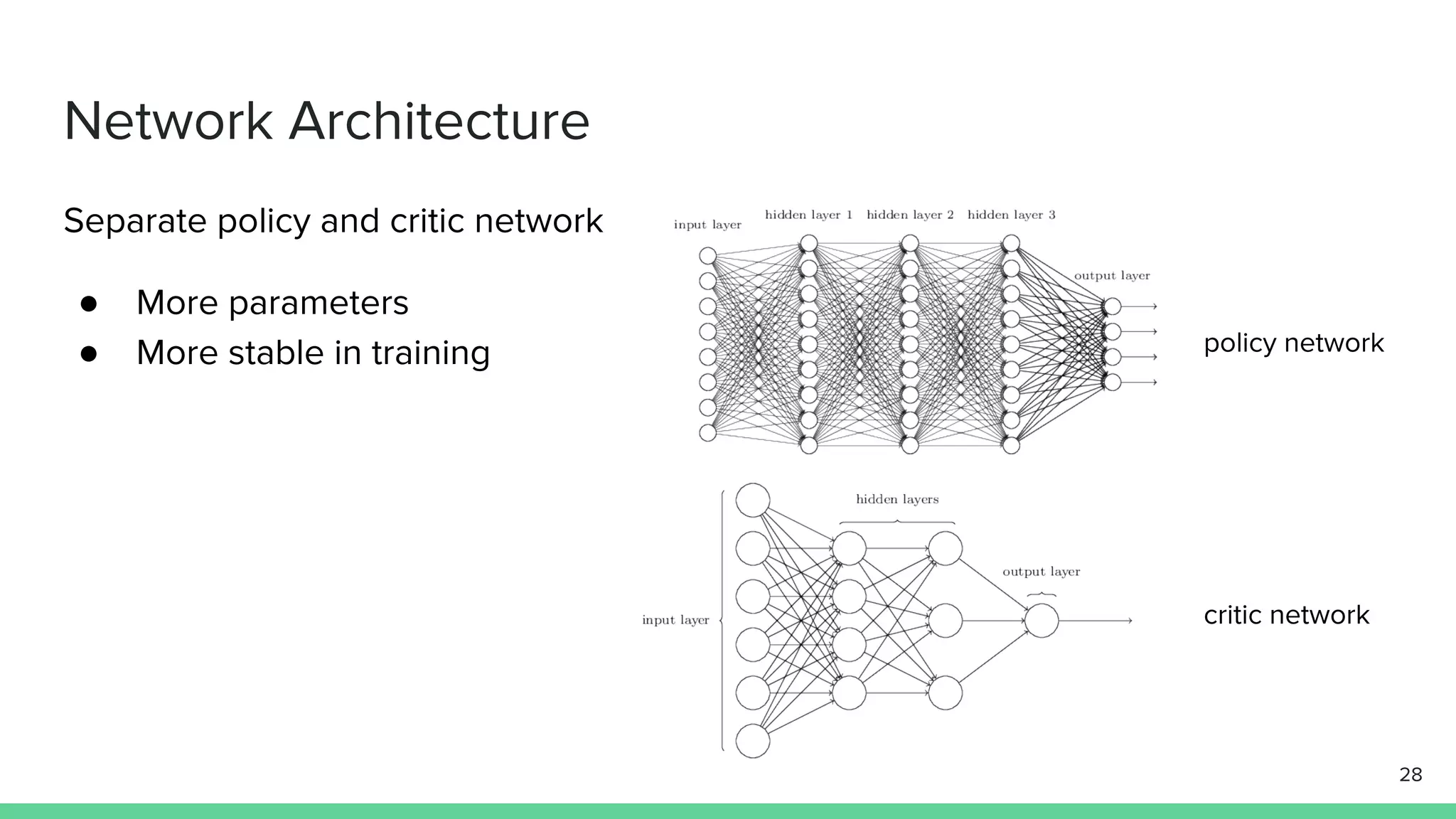
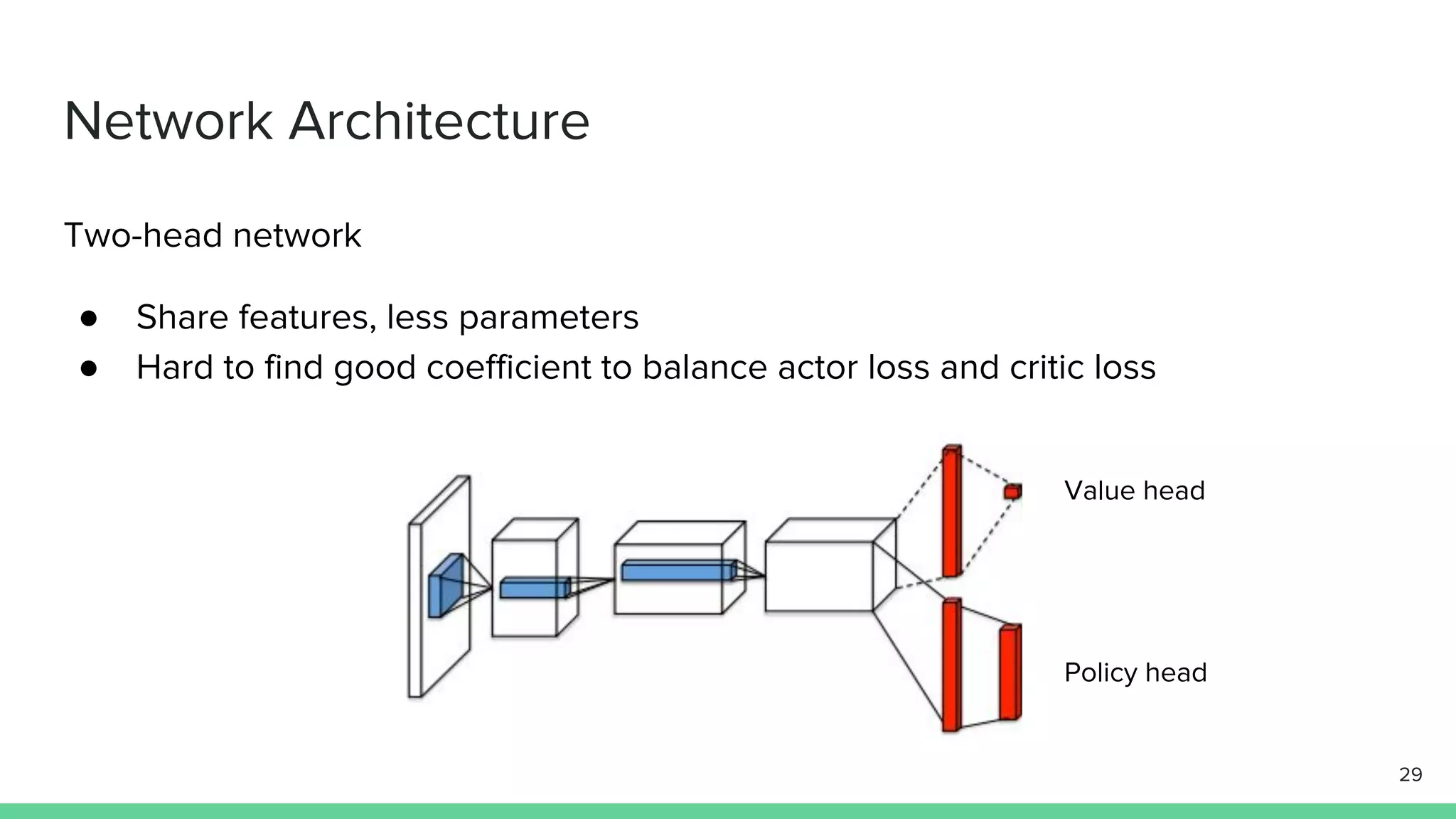
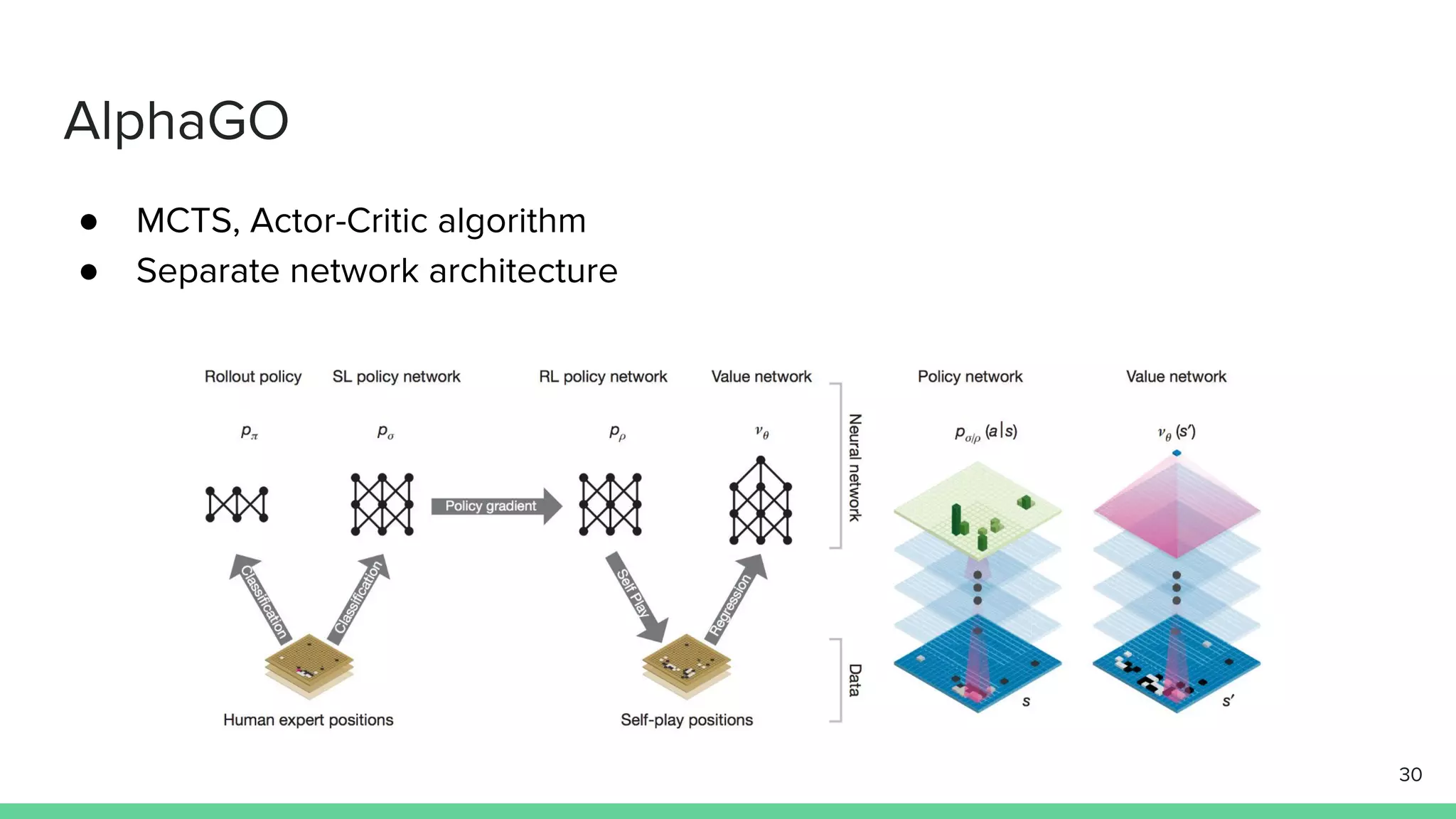
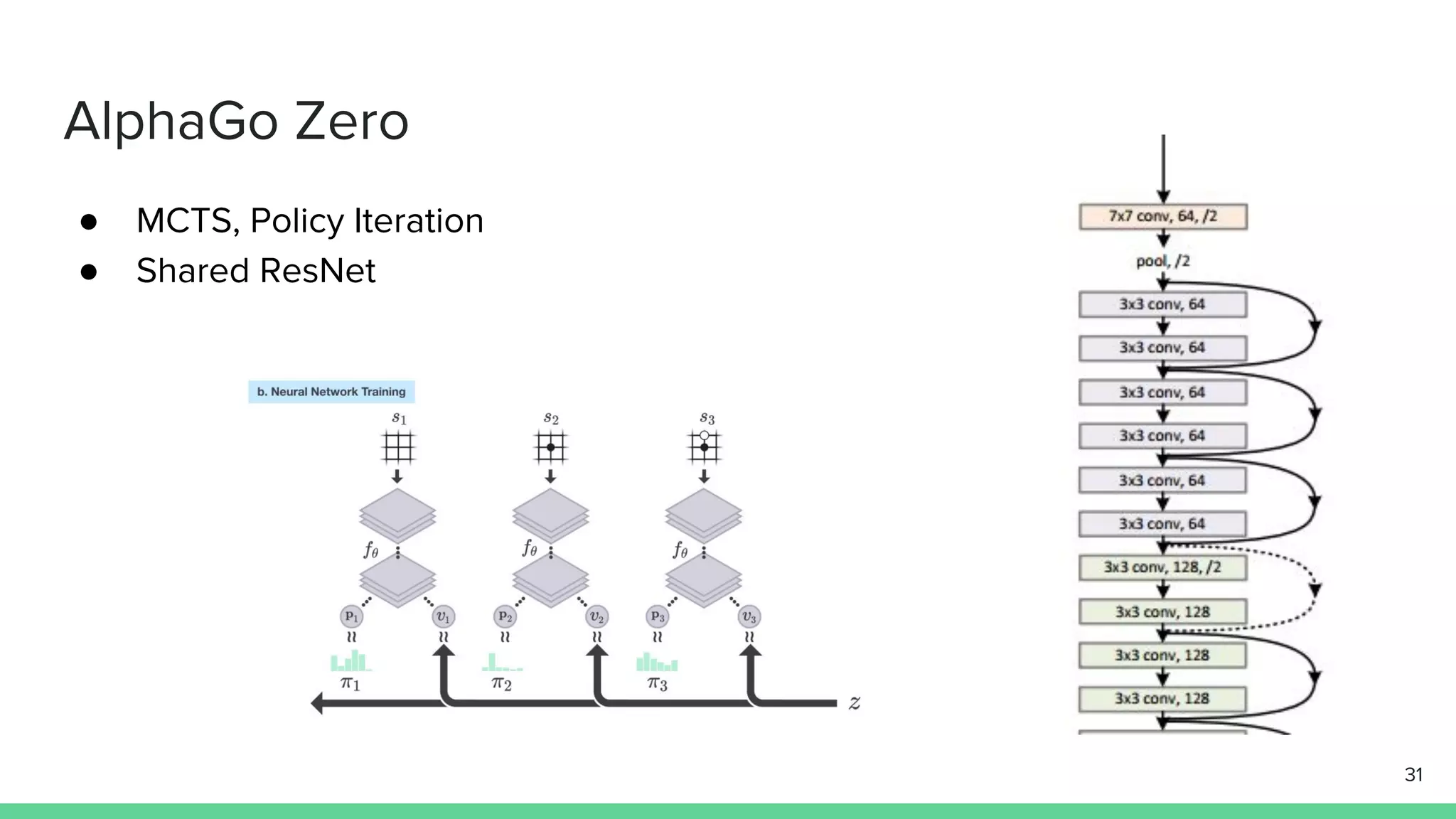



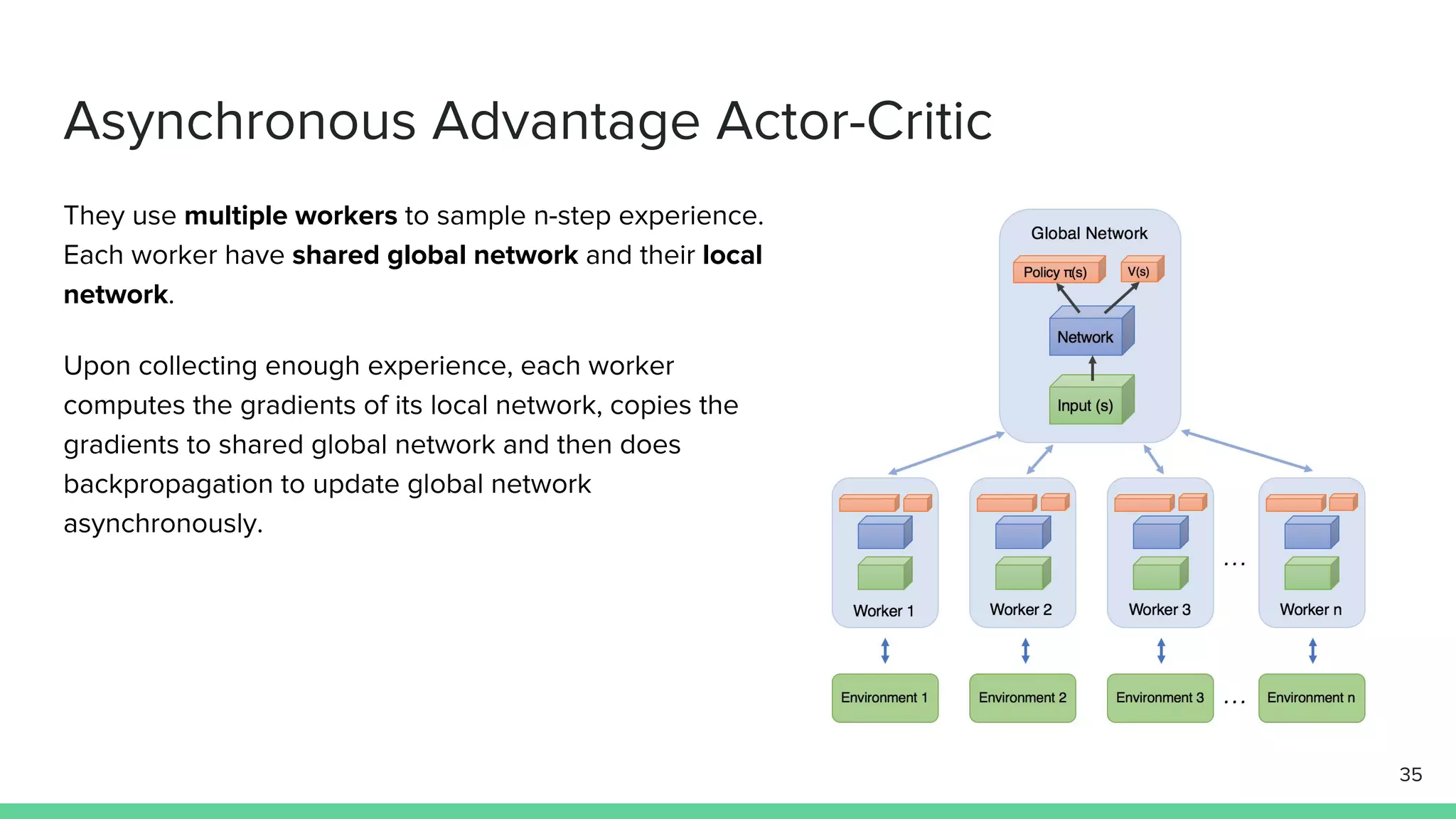


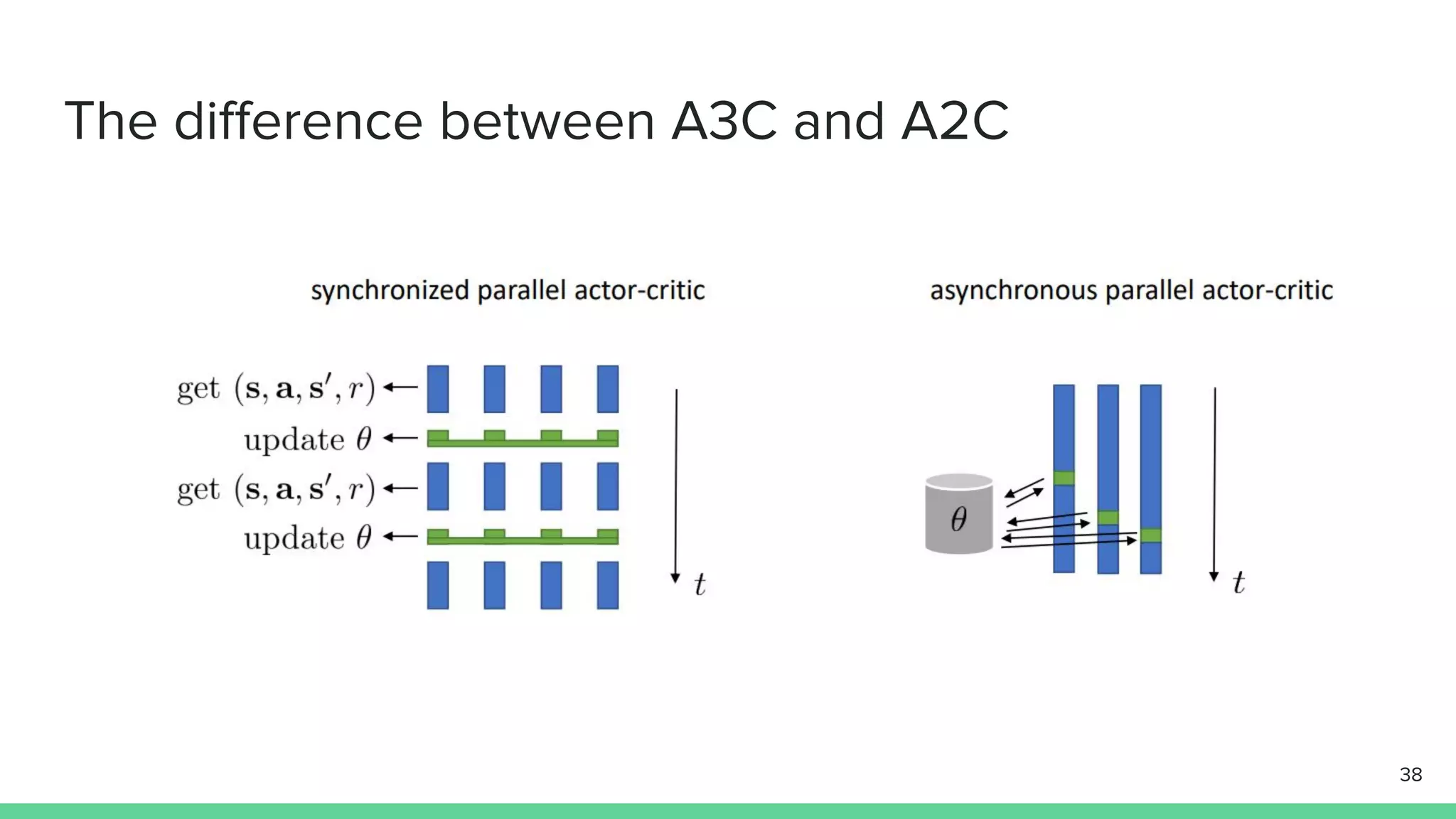

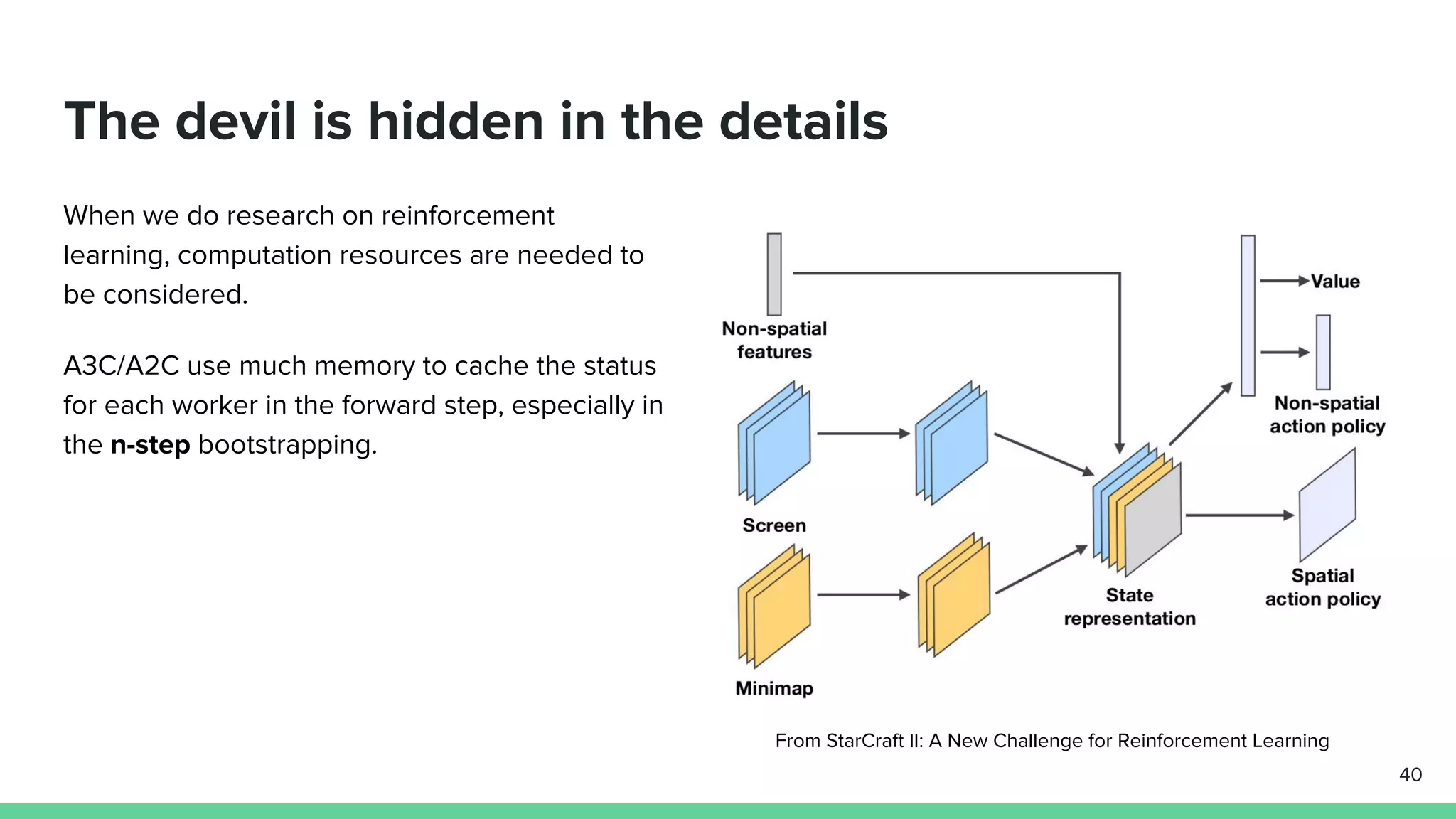


The document discusses the actor-critic algorithm in reinforcement learning, detailing its structure, objectives, and advantages over traditional policy gradient methods. It explains the roles of the actor and critic networks, how they interact, and strategies to overcome issues like bias and correlation during training. Additionally, various advanced actor-critic algorithms are mentioned, including A3C and A2C, highlighting their differences and applications.













































































