Download as PDF, PPTX
















![Rich expressions
§Projection expression to get just some of the attributes
§ Query/Get/Scan: ProductReviews.FiveStar[0]](https://image.slidesharecdn.com/amazondynamodbfordevelopers-160502081353/85/Amazon-Dynamo-DB-for-Developers-AWS-DB-Day-23-320.jpg)
![Rich expressions
§Projection expression to get just some of the attributes
§ Query/Get/Scan: ProductReviews.FiveStar[0]
ProductReviews: {
FiveStar: [
"Excellent! Can't recommend it highly enough! Buy it!",
"Do yourself a favor and buy this." ],
OneStar: [
"Terrible product! Do not buy this." ] }
]
}](https://image.slidesharecdn.com/amazondynamodbfordevelopers-160502081353/85/Amazon-Dynamo-DB-for-Developers-AWS-DB-Day-24-320.jpg)















































![Rich expressions
§Projection expression to get just some of the attributes
§ Query/Get/Scan: ProductReviews.FiveStar[0]](https://image.slidesharecdn.com/amazondynamodbfordevelopers-160502081353/75/Amazon-Dynamo-DB-for-Developers-AWS-DB-Day-23-2048.jpg)
![Rich expressions
§Projection expression to get just some of the attributes
§ Query/Get/Scan: ProductReviews.FiveStar[0]
ProductReviews: {
FiveStar: [
"Excellent! Can't recommend it highly enough! Buy it!",
"Do yourself a favor and buy this." ],
OneStar: [
"Terrible product! Do not buy this." ] }
]
}](https://image.slidesharecdn.com/amazondynamodbfordevelopers-160502081353/75/Amazon-Dynamo-DB-for-Developers-AWS-DB-Day-24-2048.jpg)





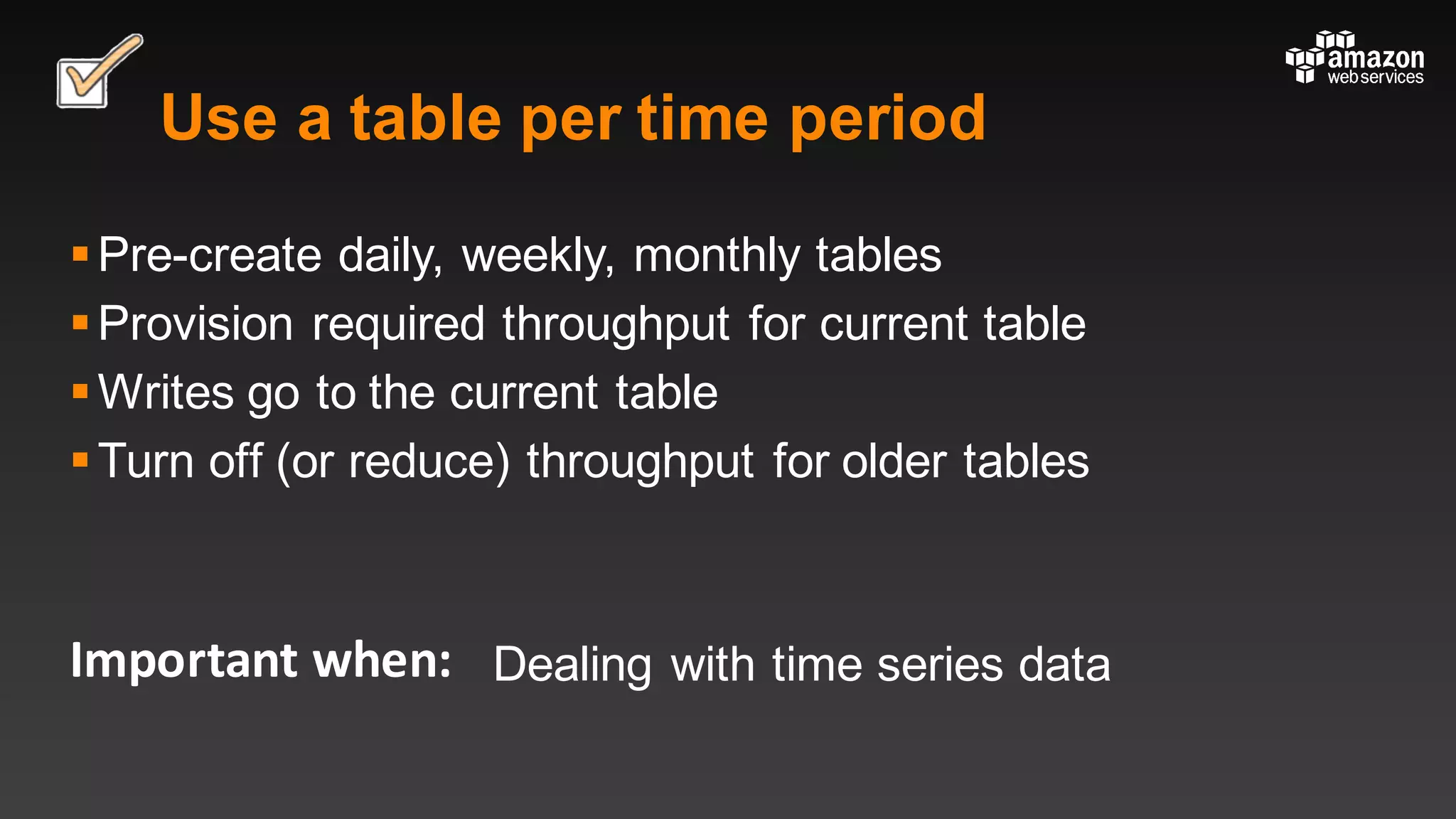

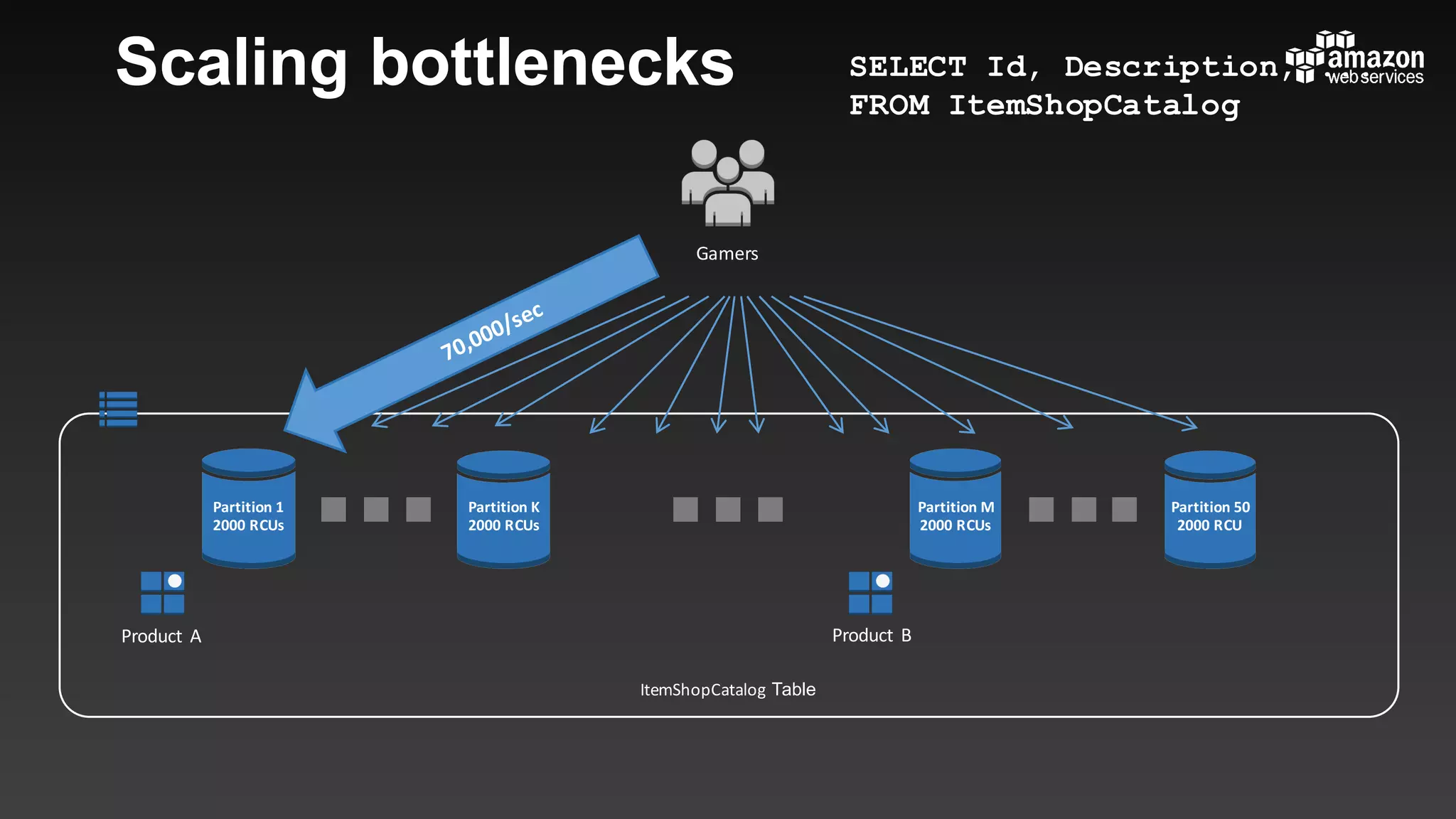







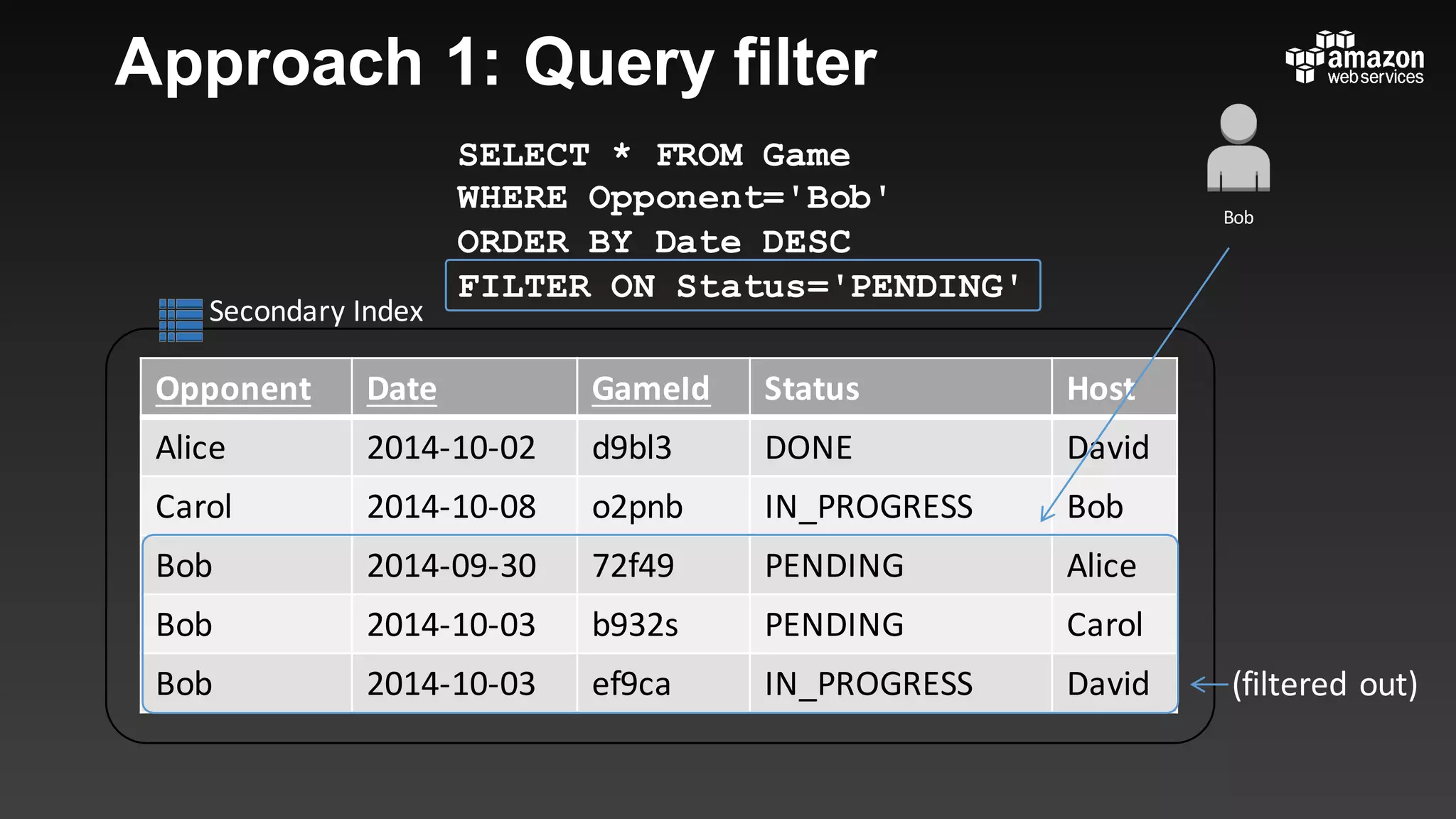
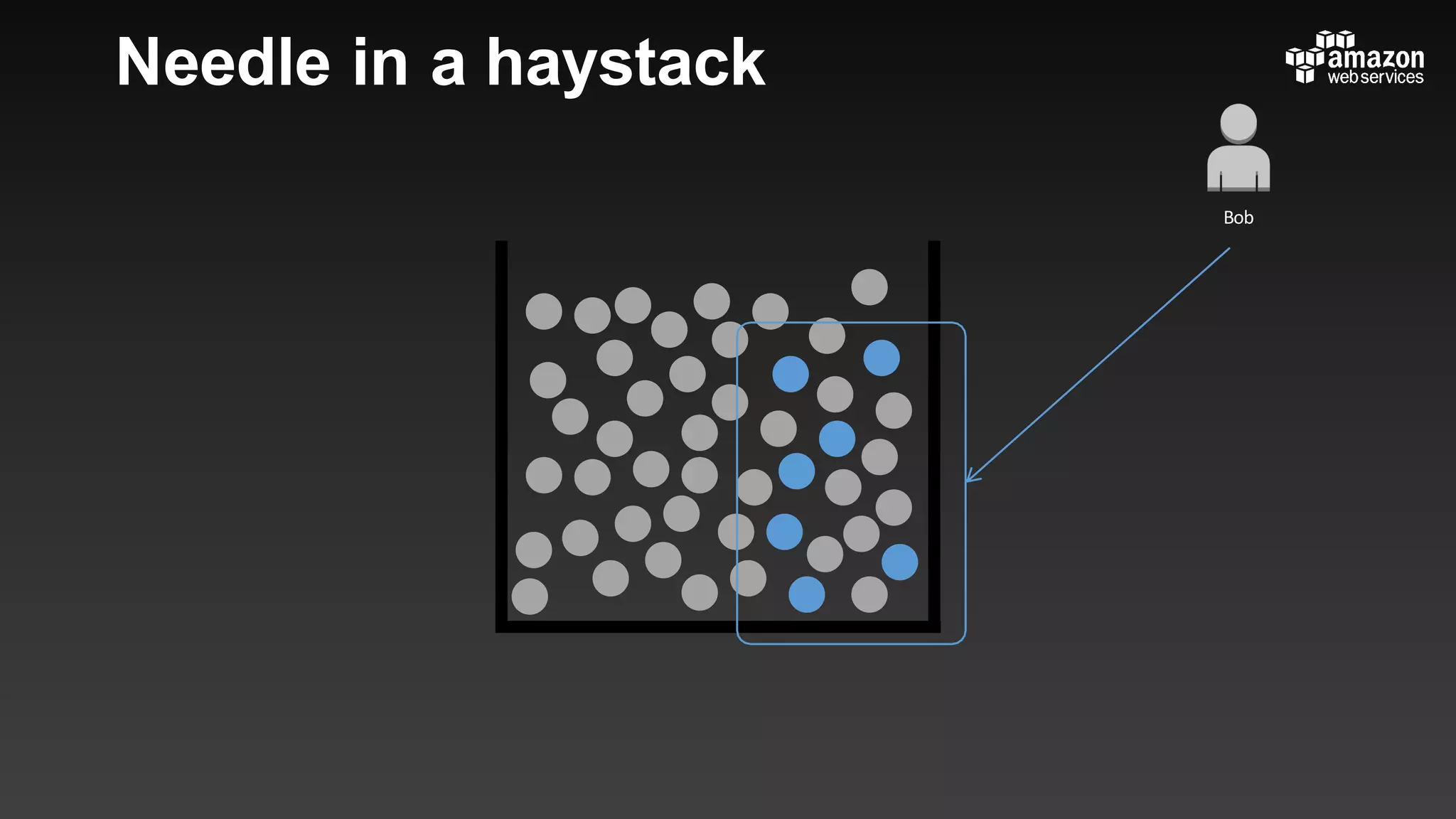



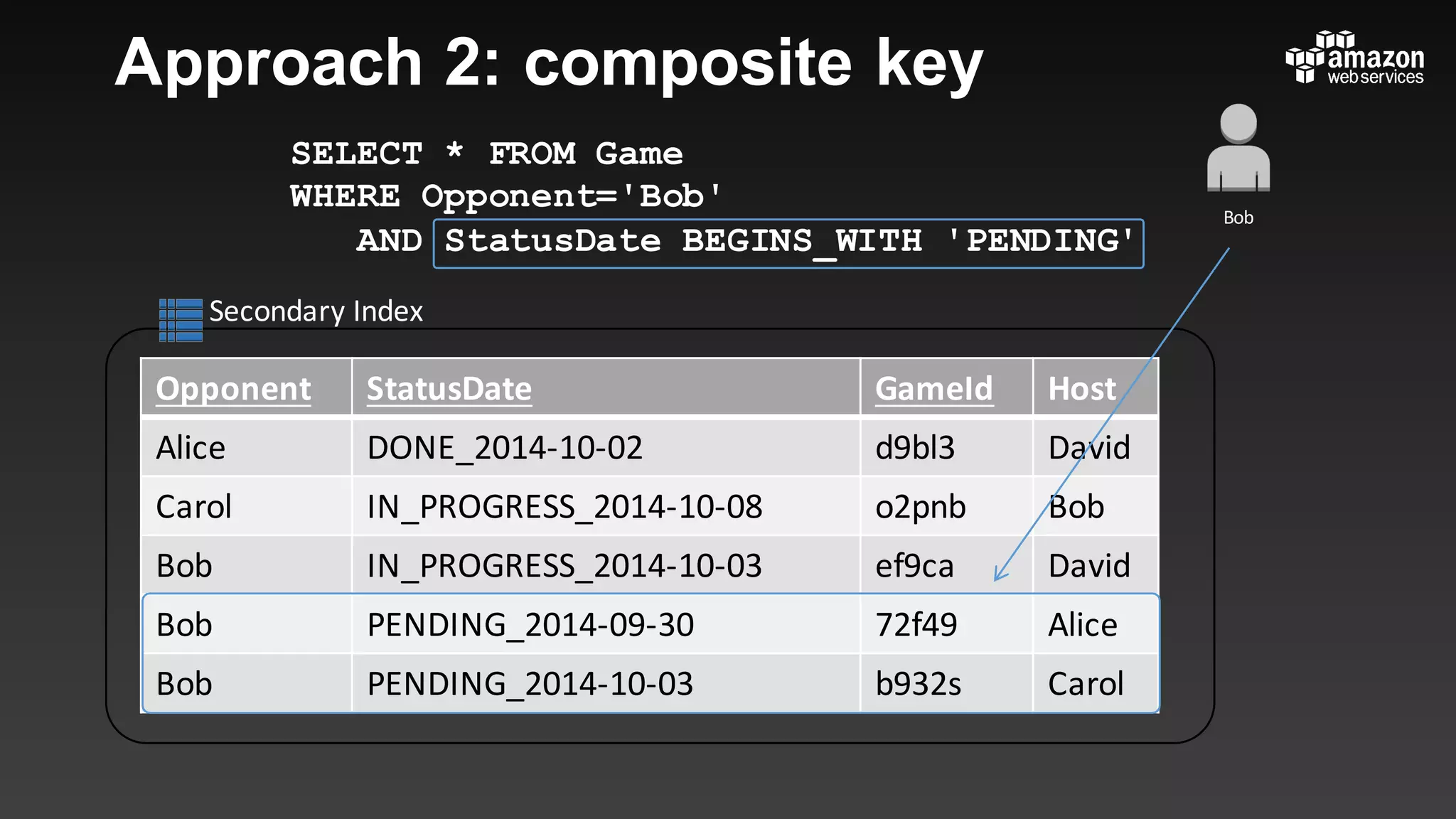
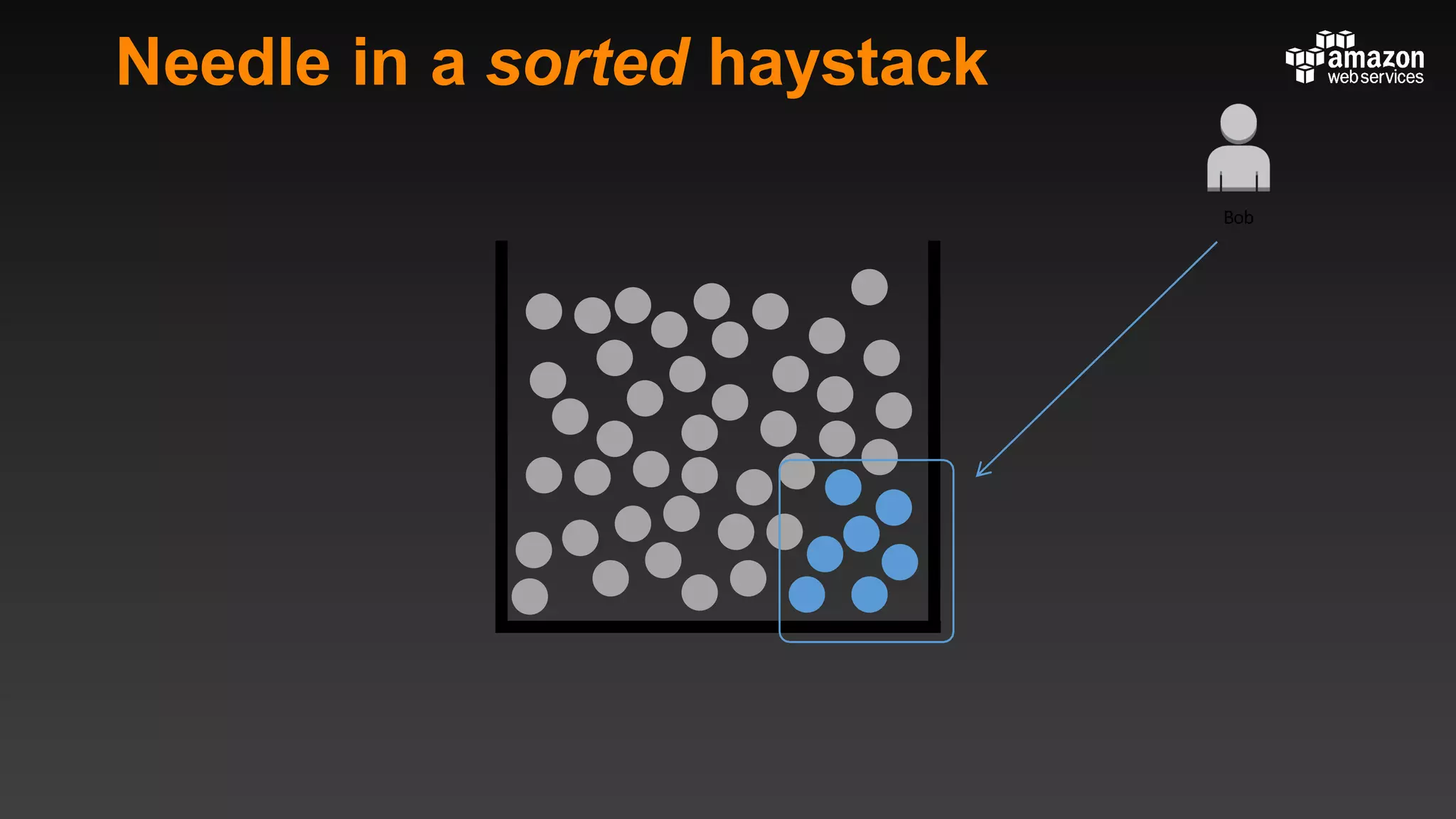




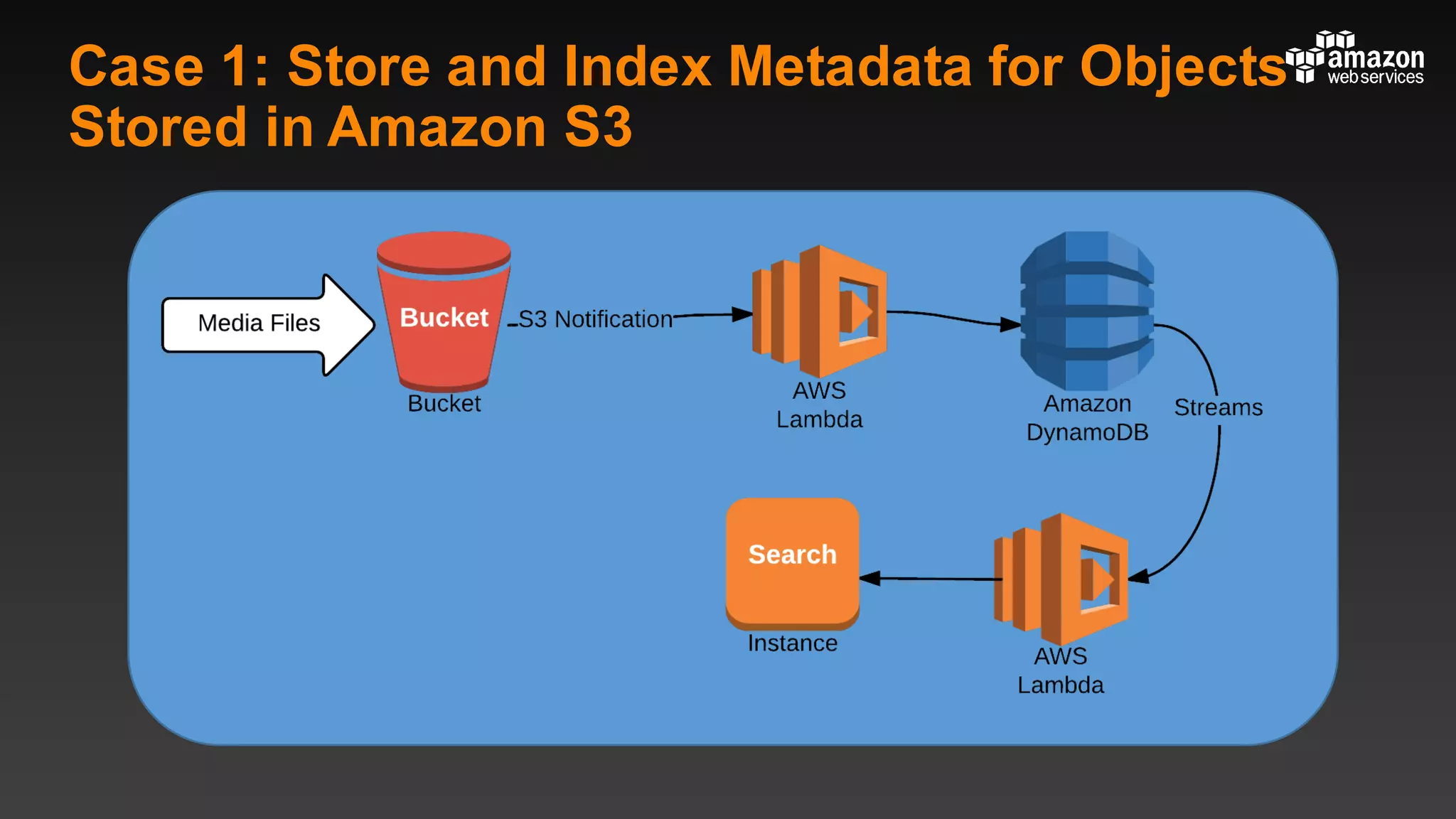



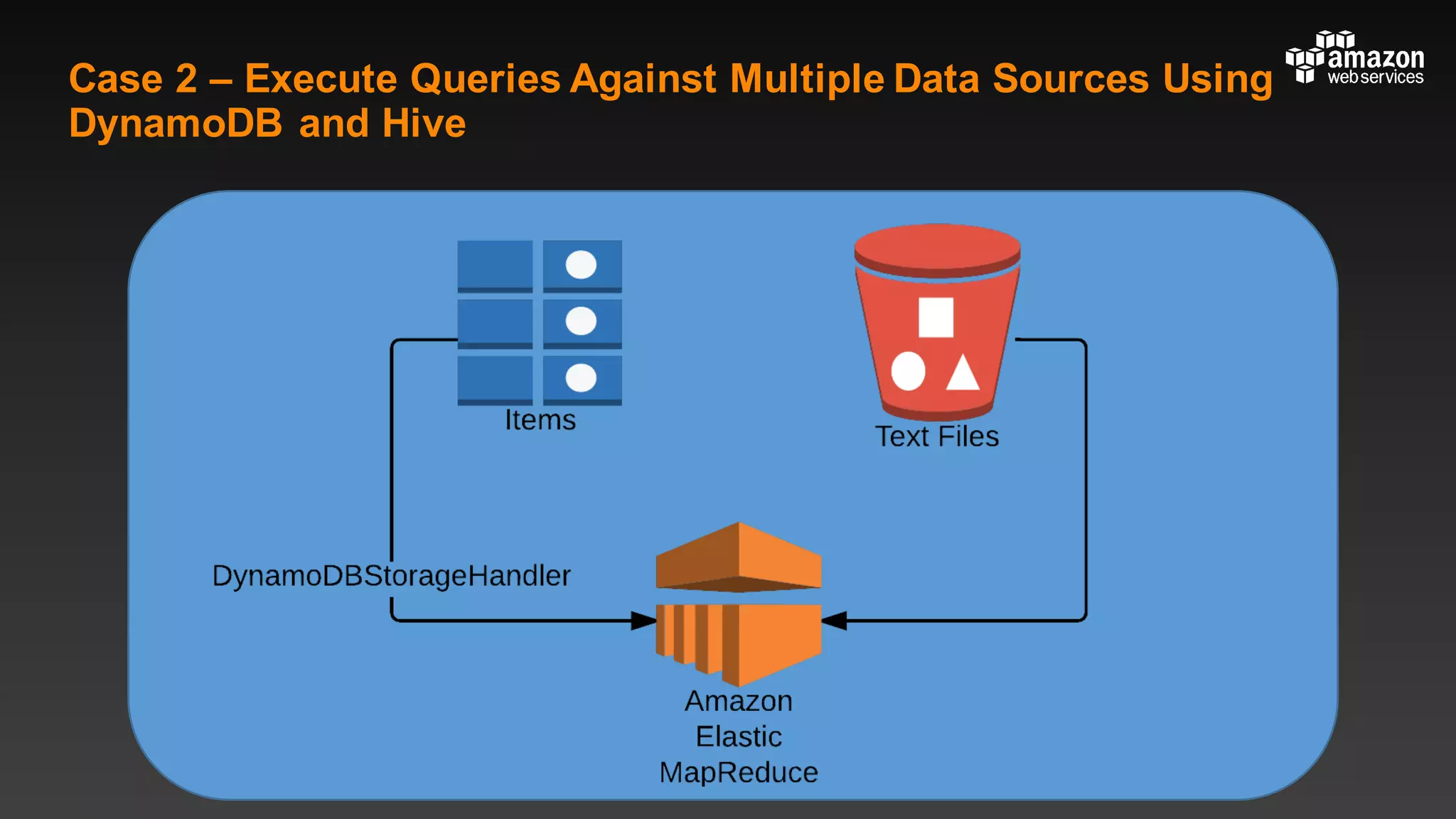

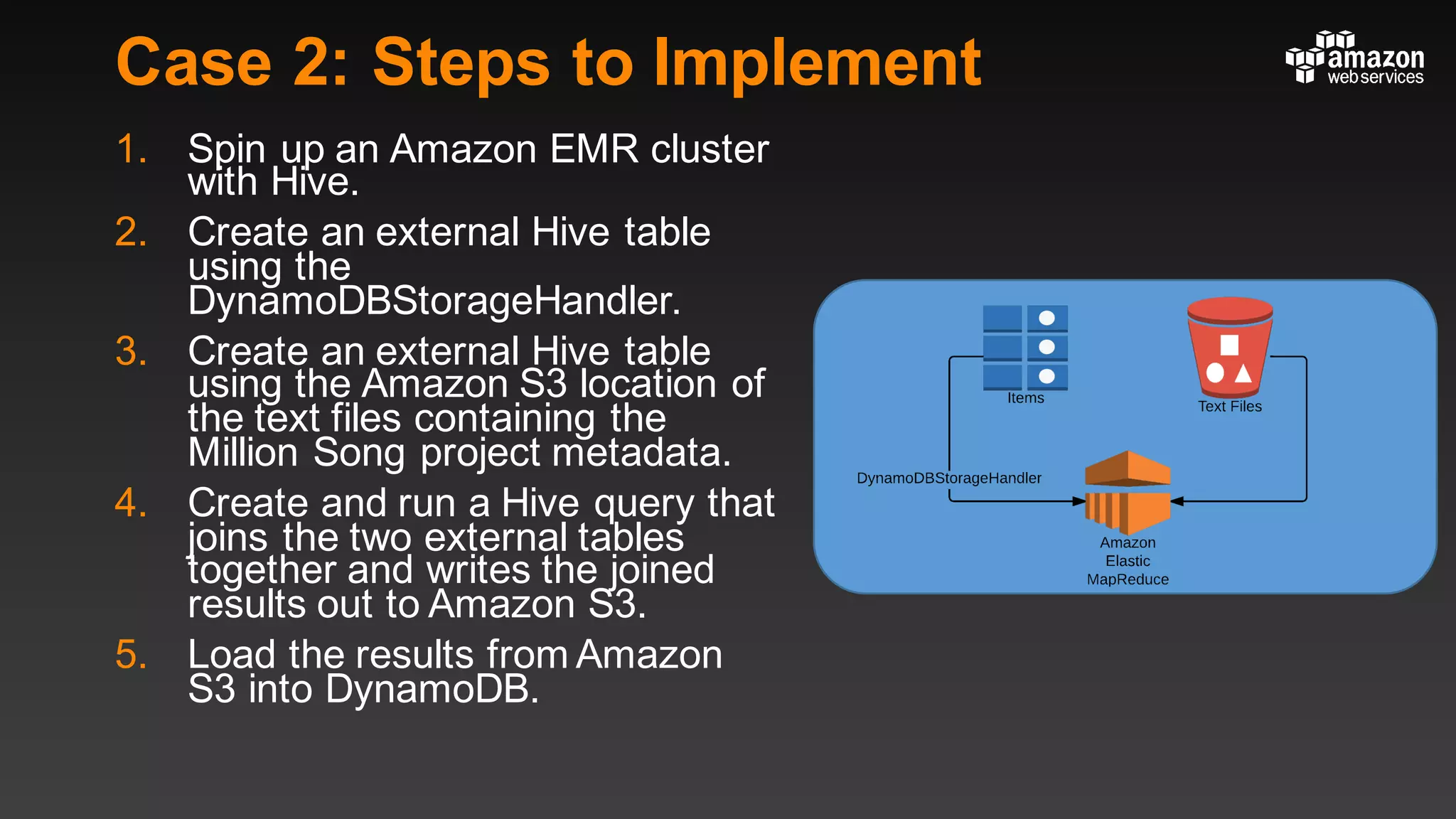

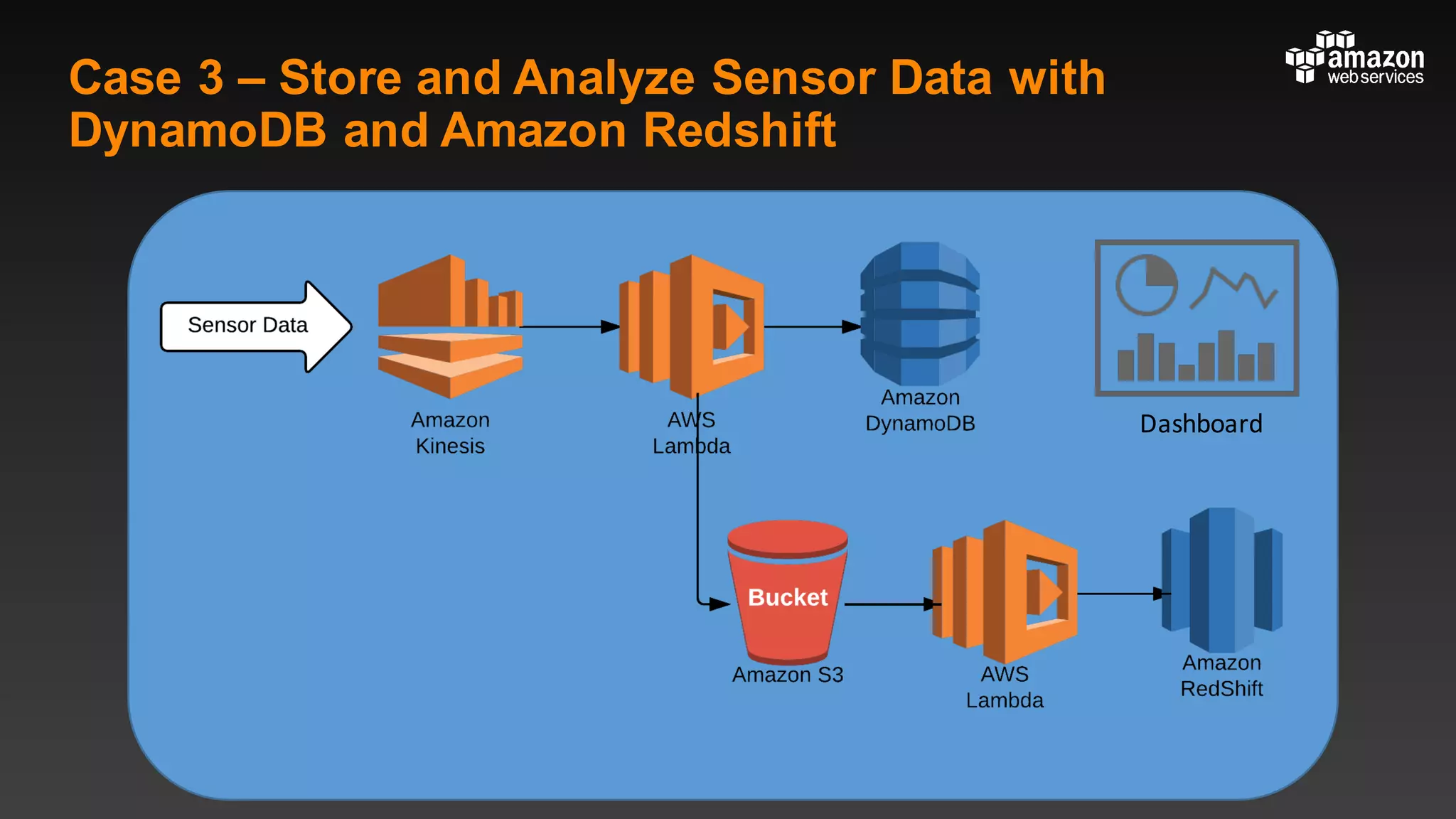

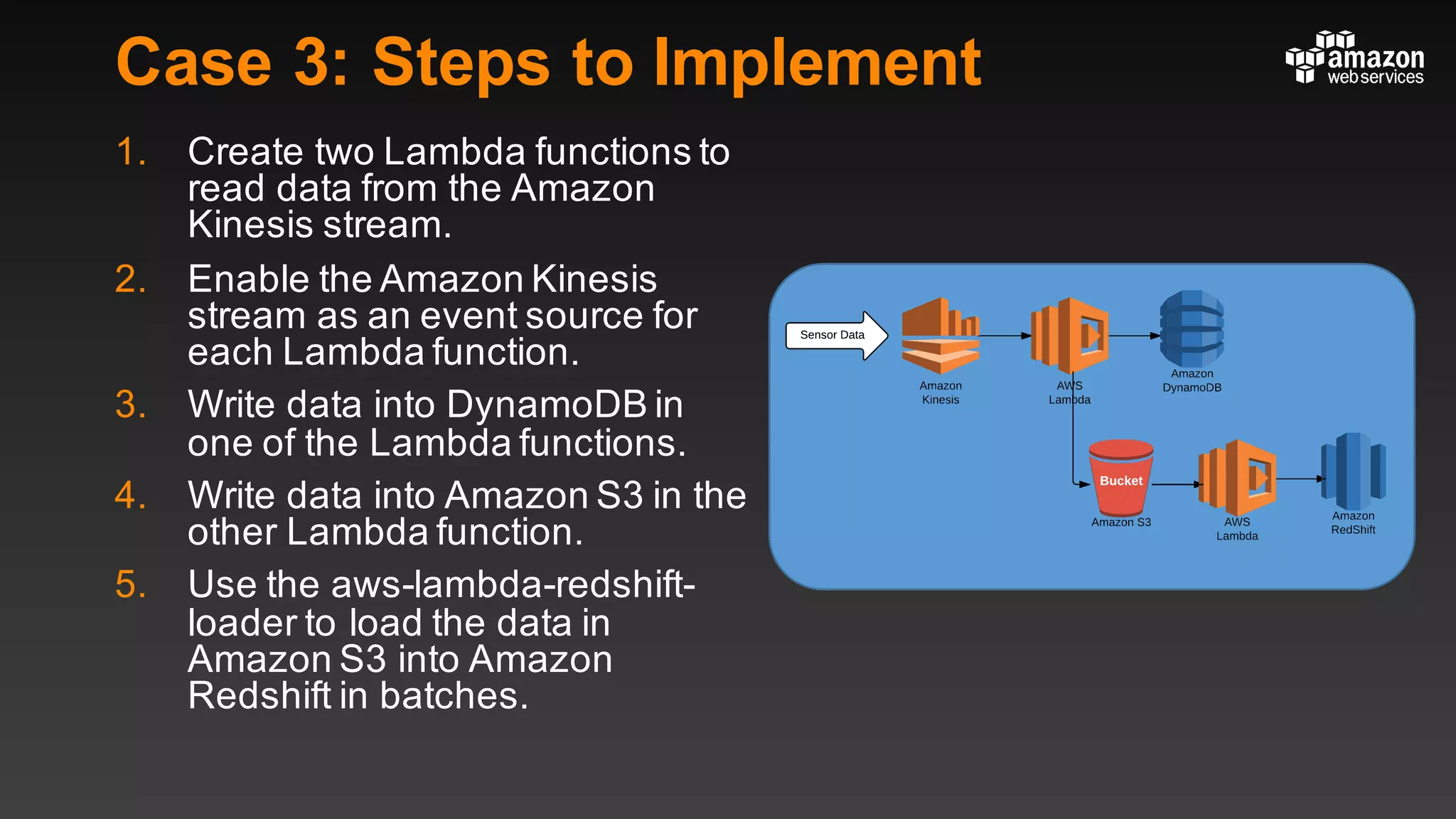



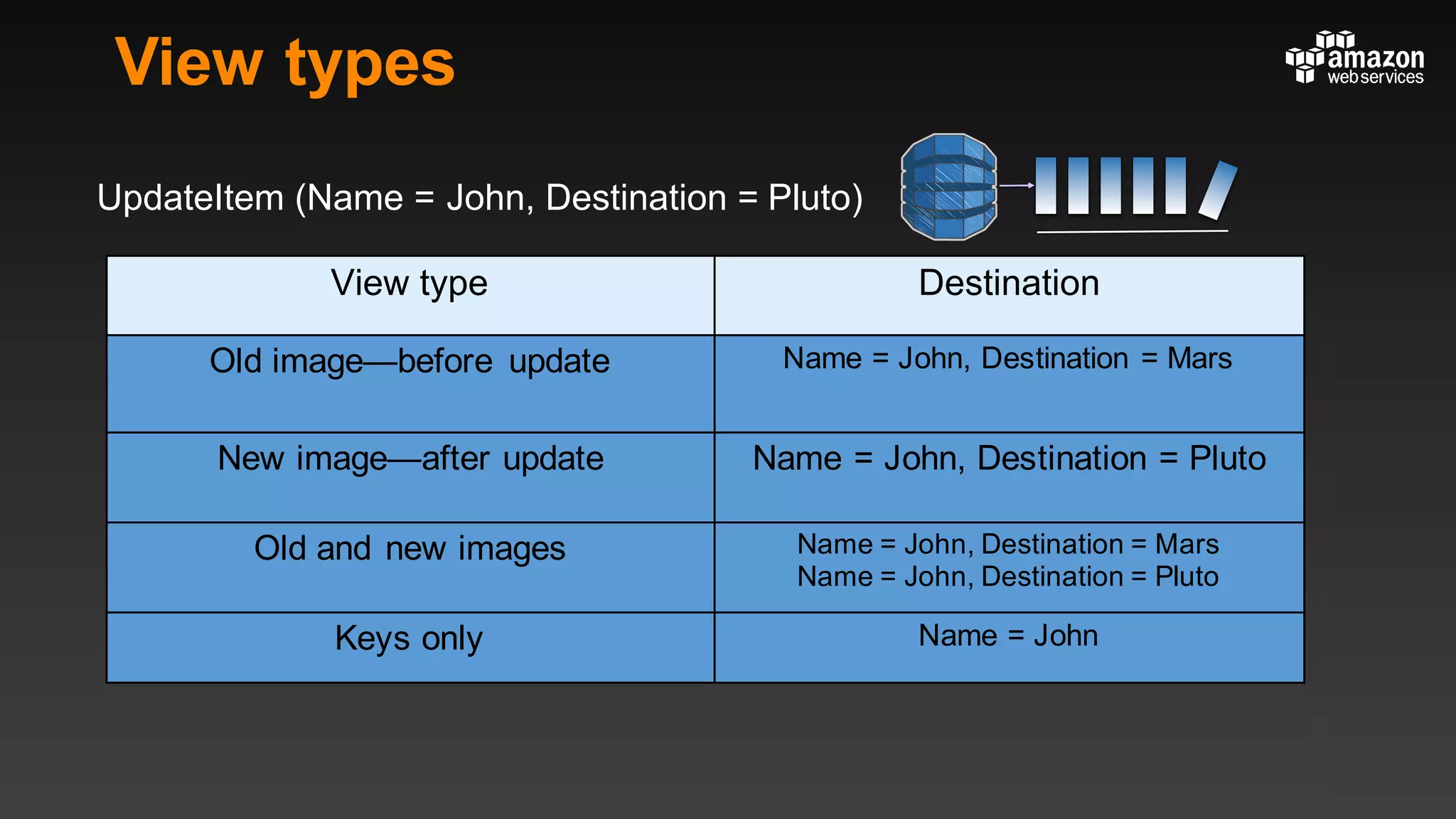
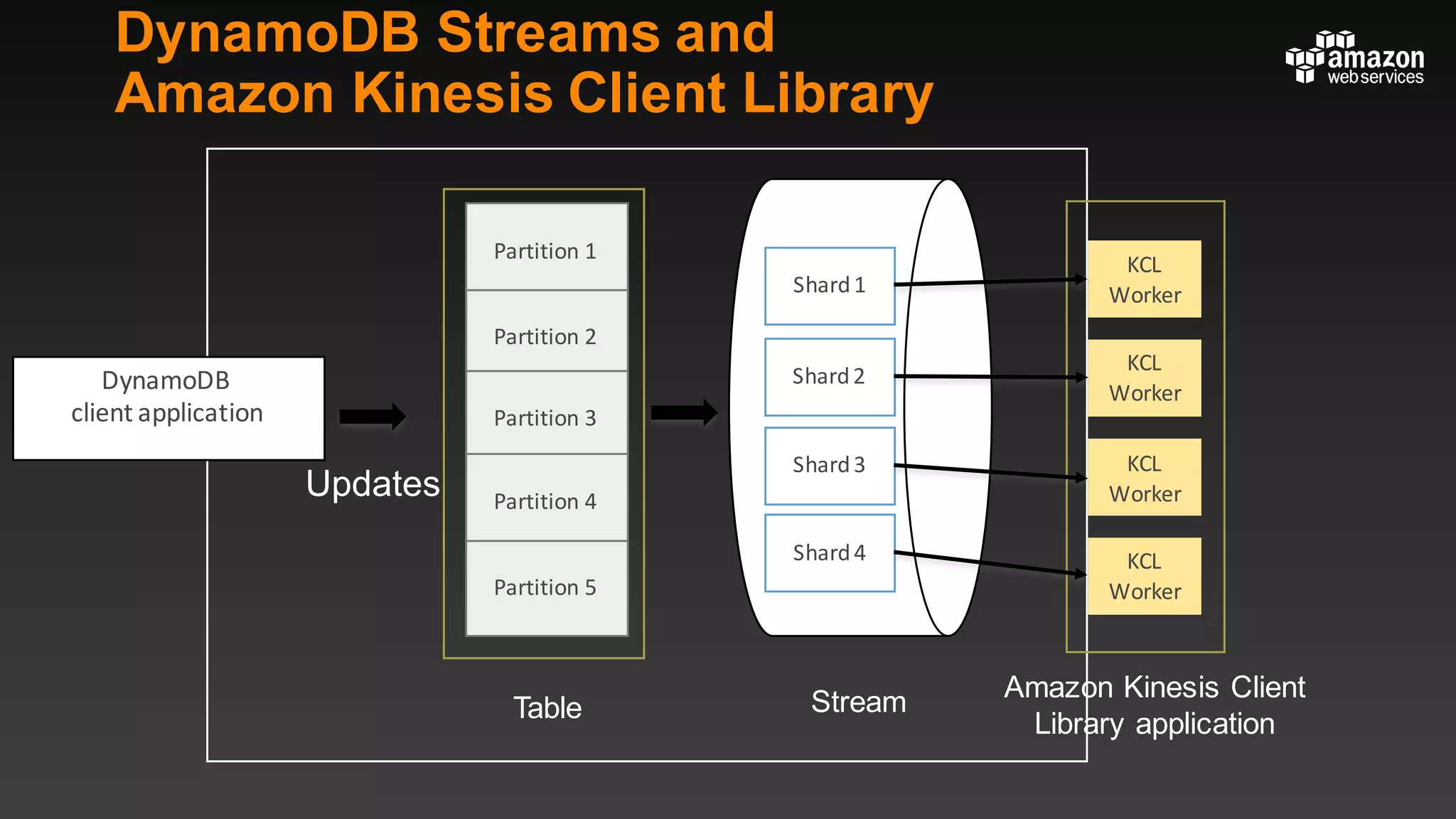
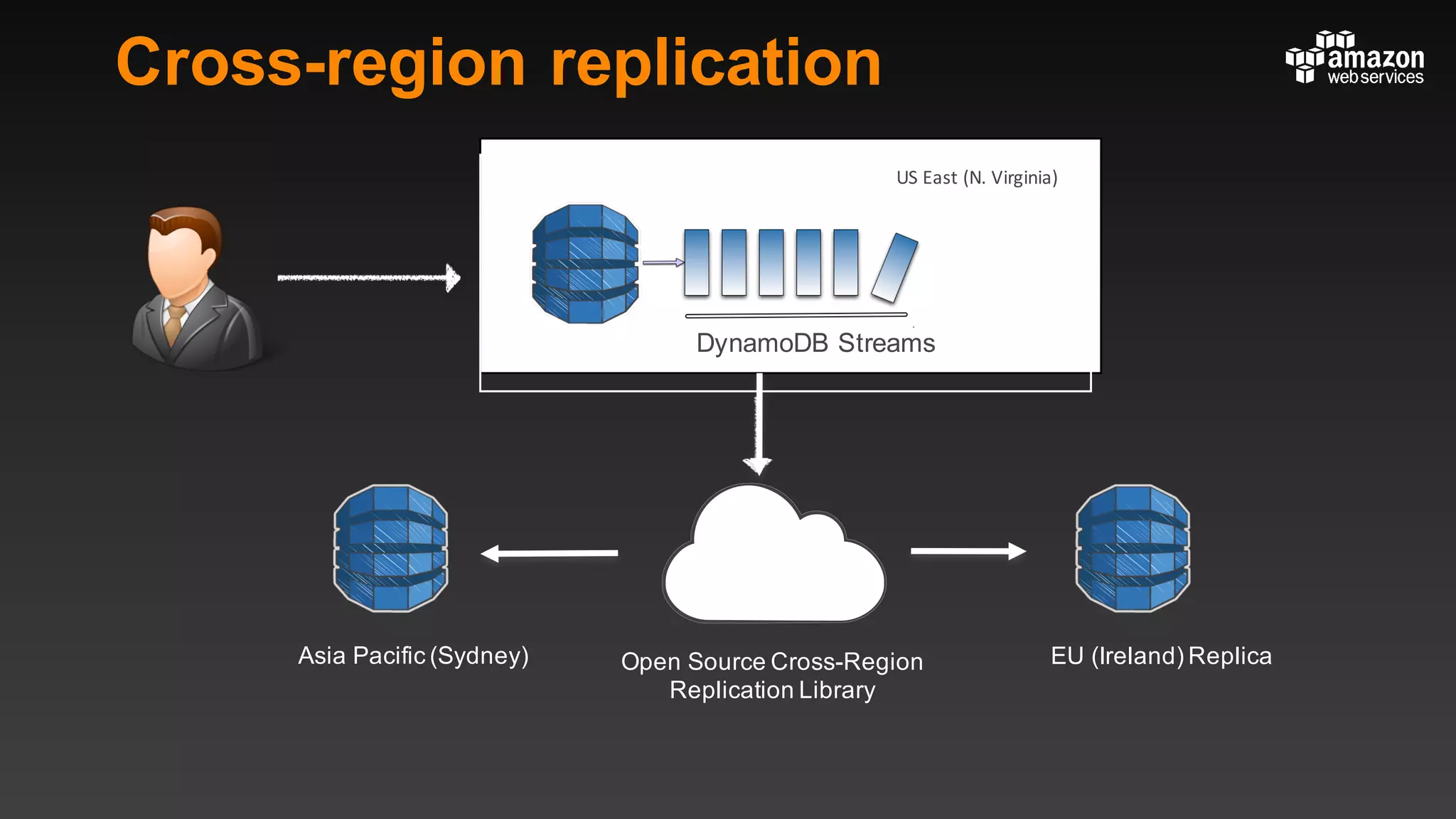





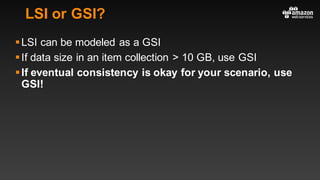
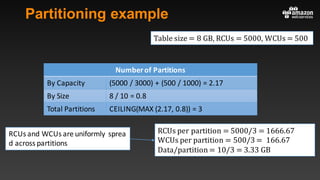
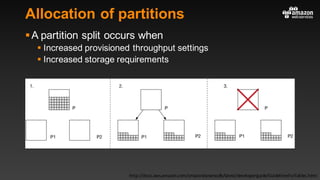
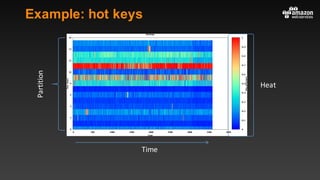
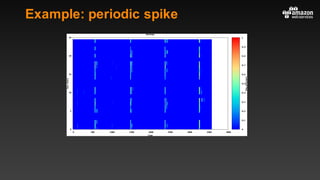
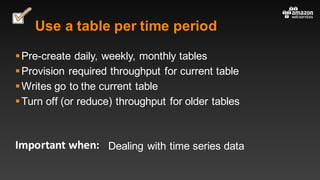
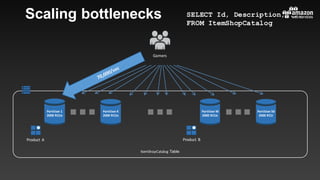
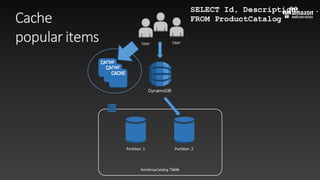
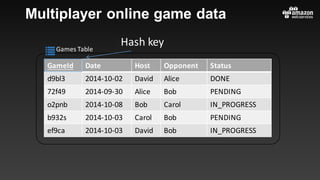
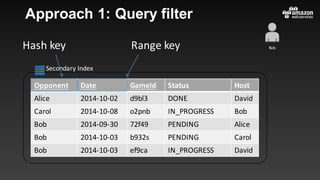
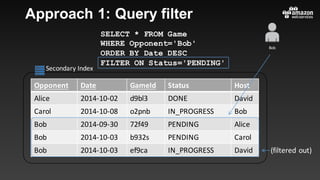
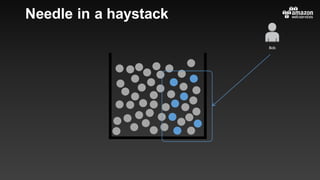
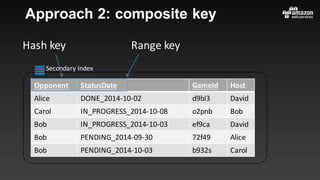
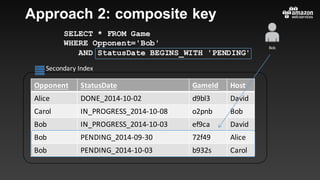
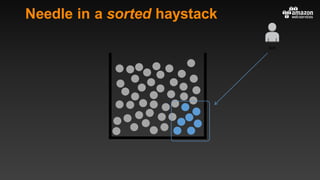
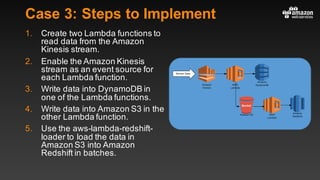
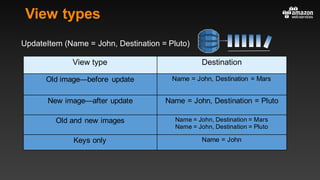
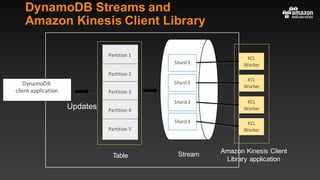
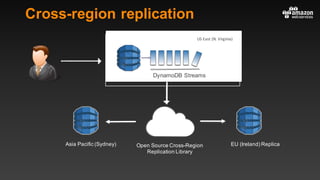
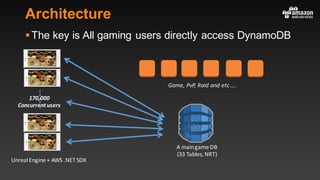
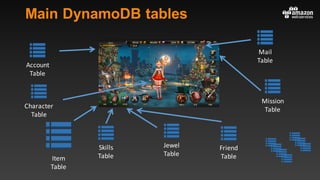
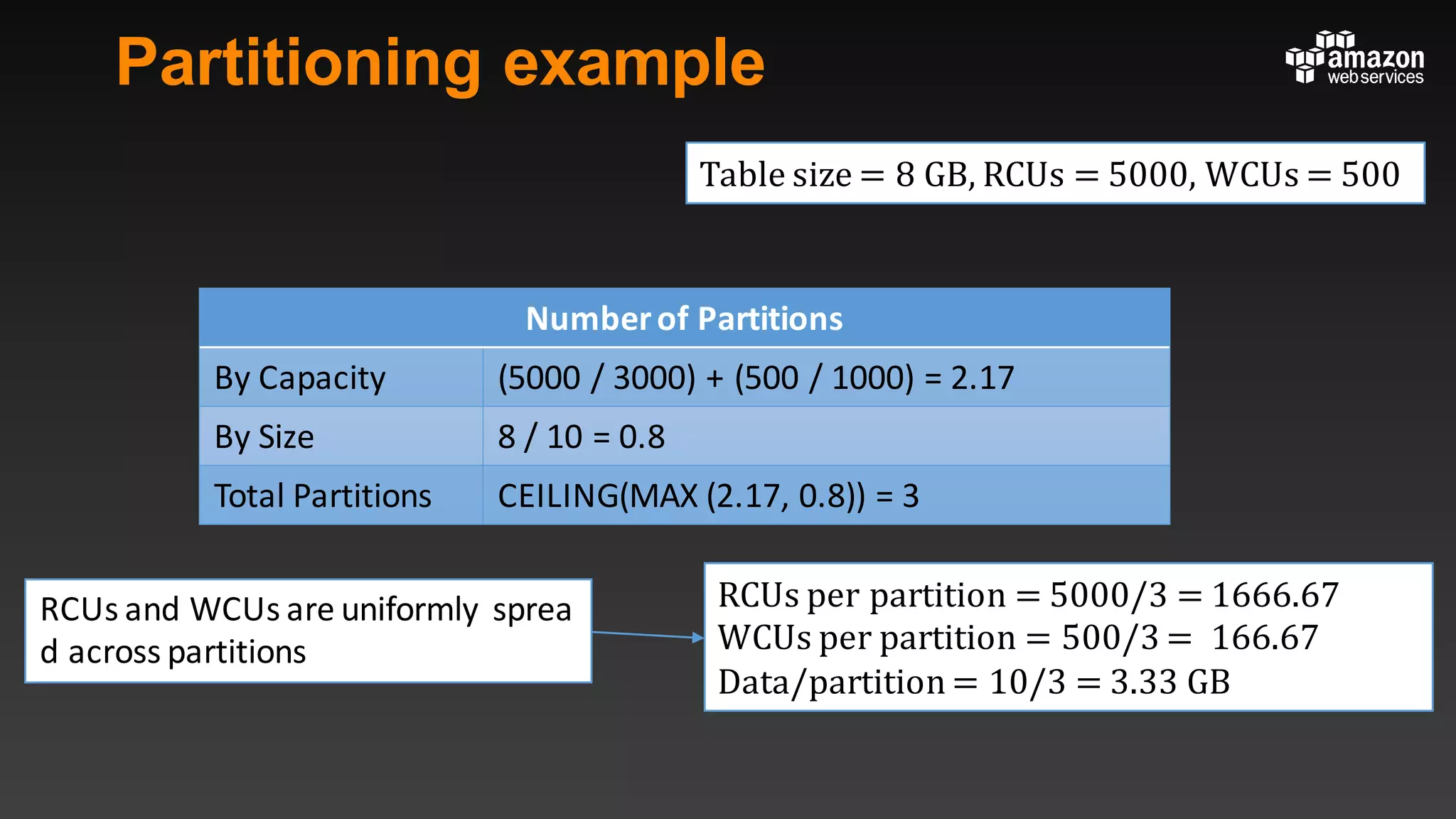
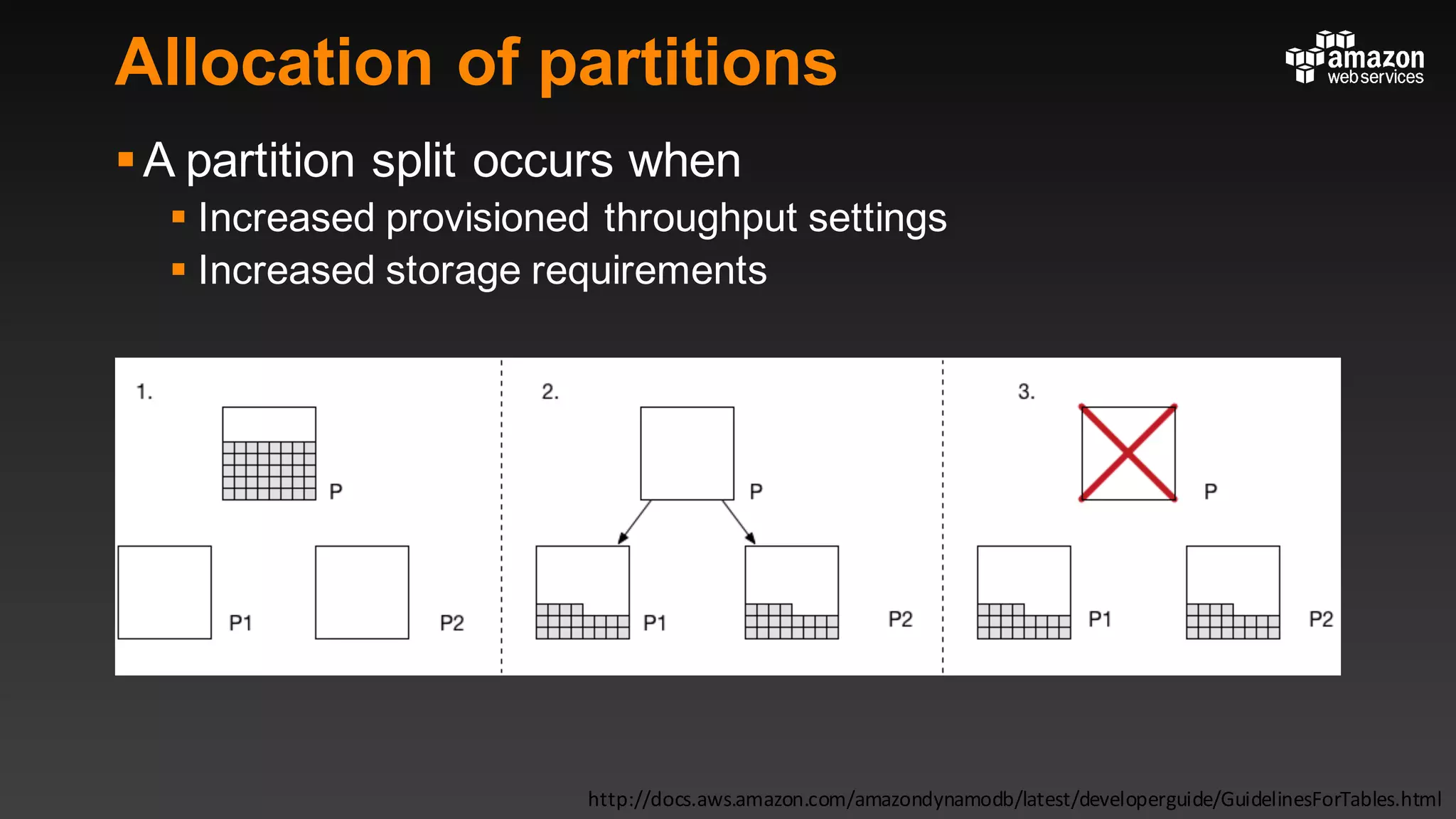
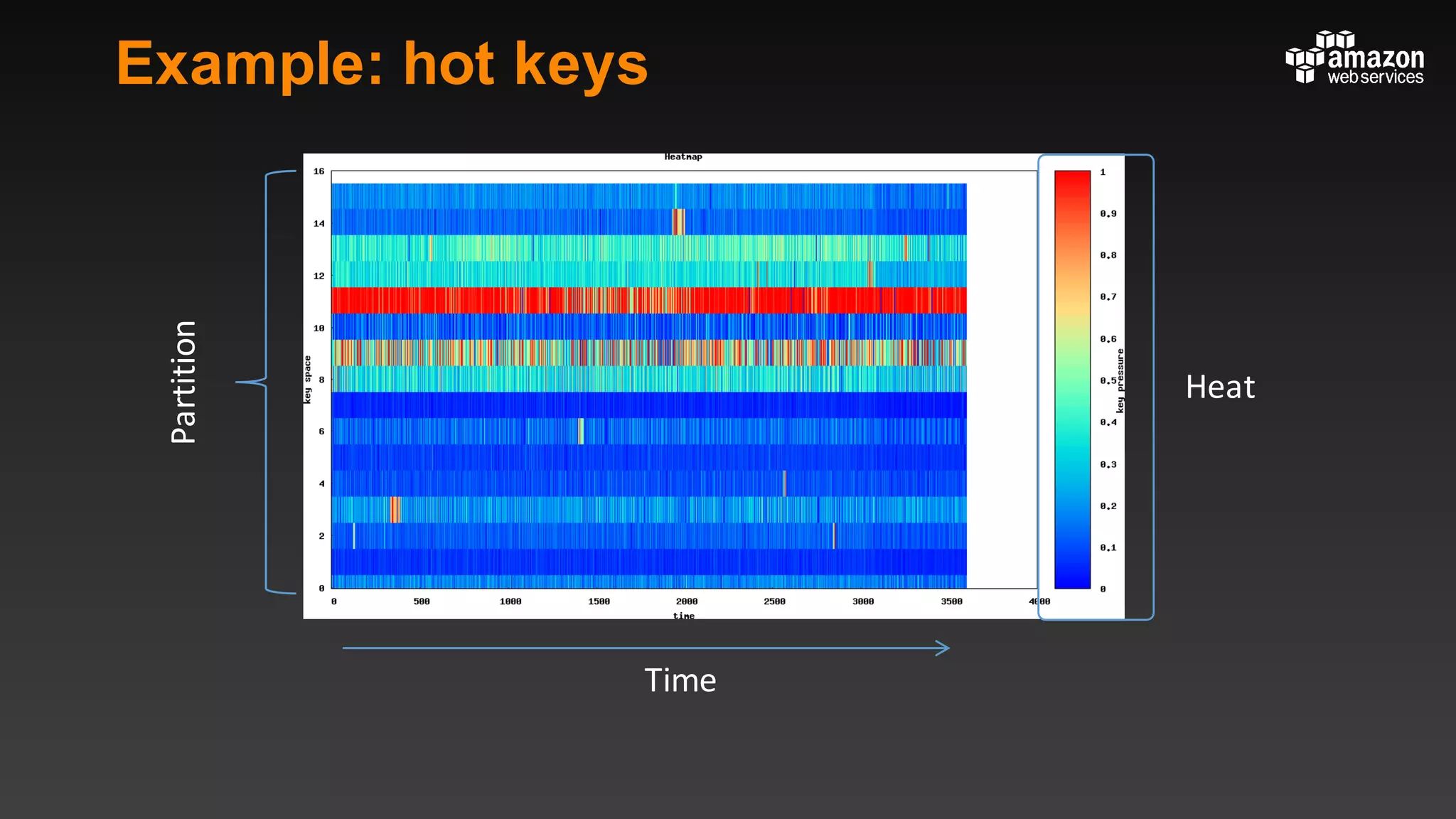
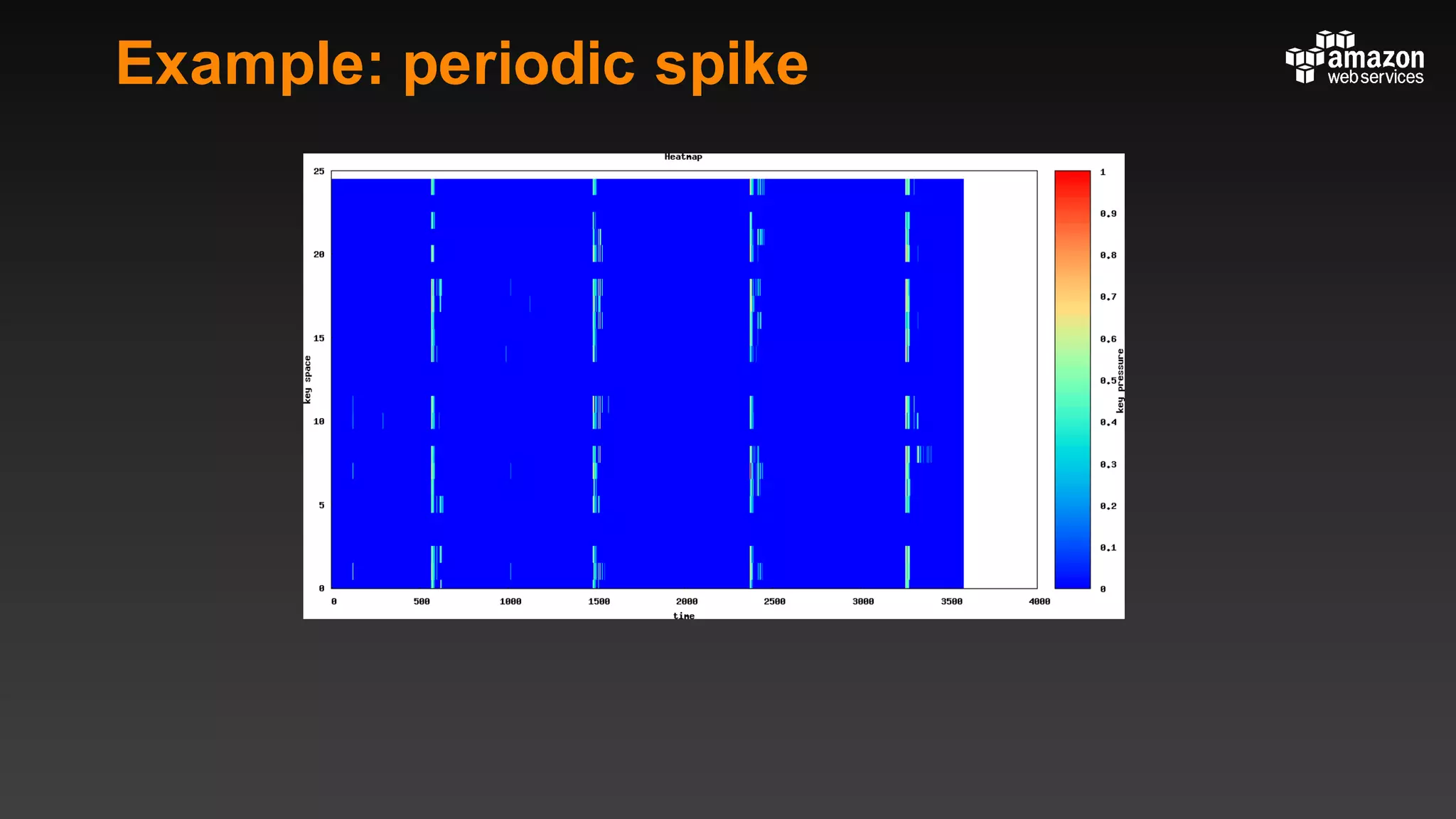
This document summarizes tips and best practices for using DynamoDB. It discusses using local secondary indexes (LSI) and global secondary indexes (GSI) to query data. It covers scaling DynamoDB tables by partitioning and provisioning throughput. Common data modeling patterns like one-to-one, one-to-many, and many-to-many relationships are presented. Best practices for time series data, caching frequently accessed items, and optimizing queries are provided. Examples of using DynamoDB for game analytics and metadata storage in S3 are also included.


















![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


















