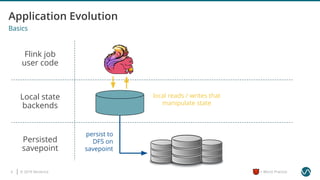
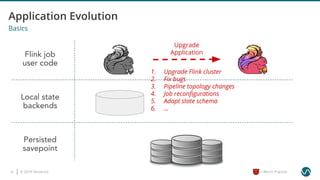
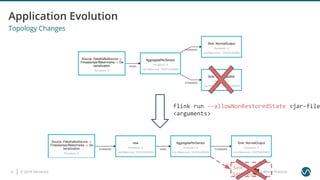
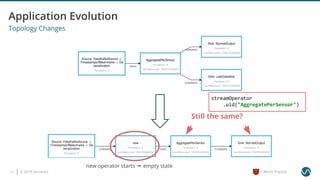
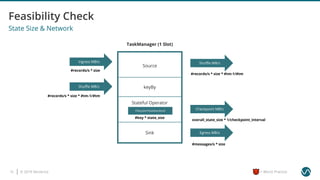
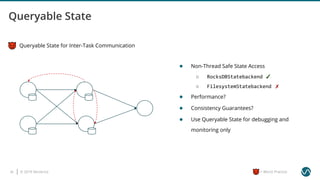
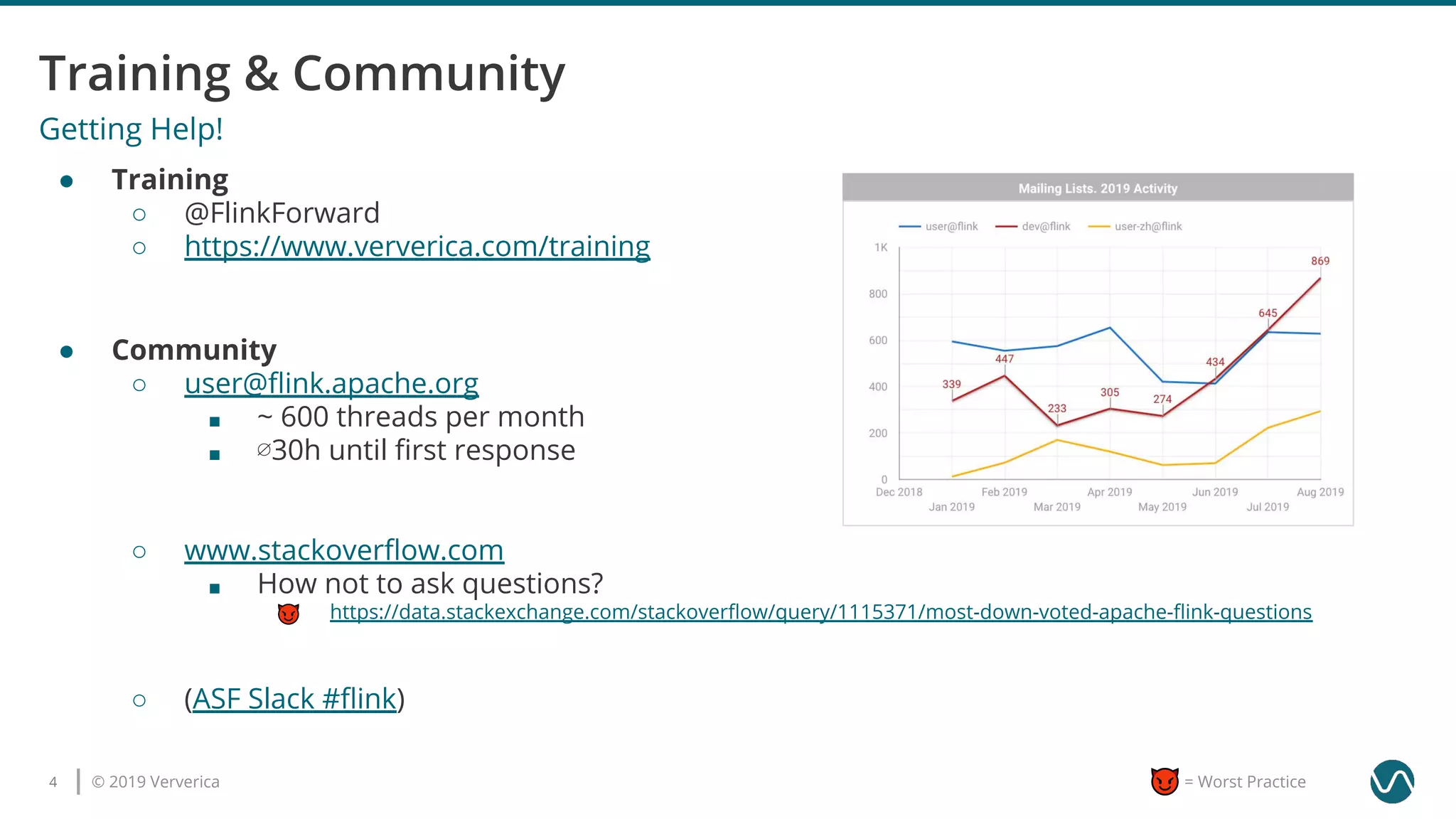
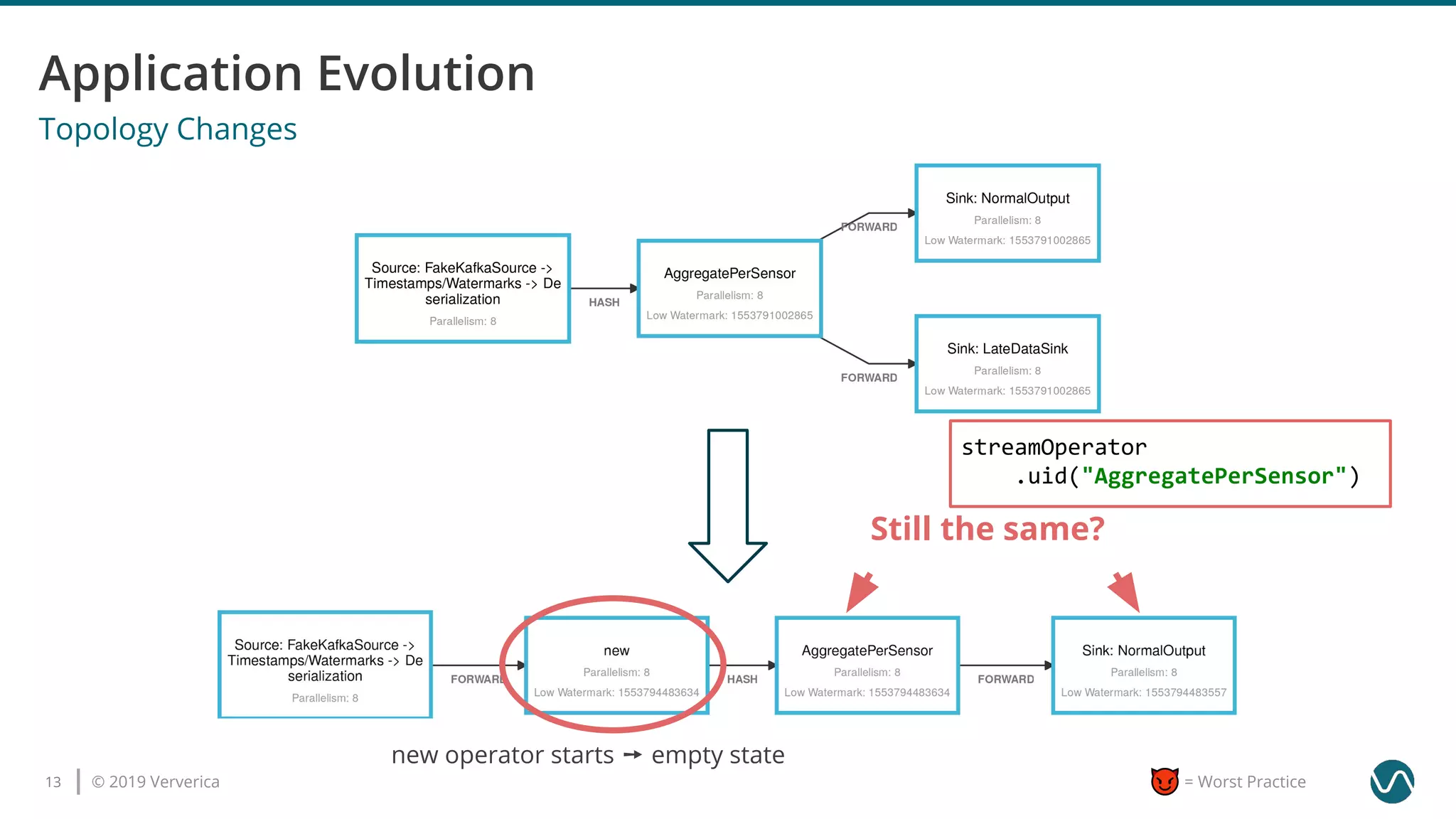
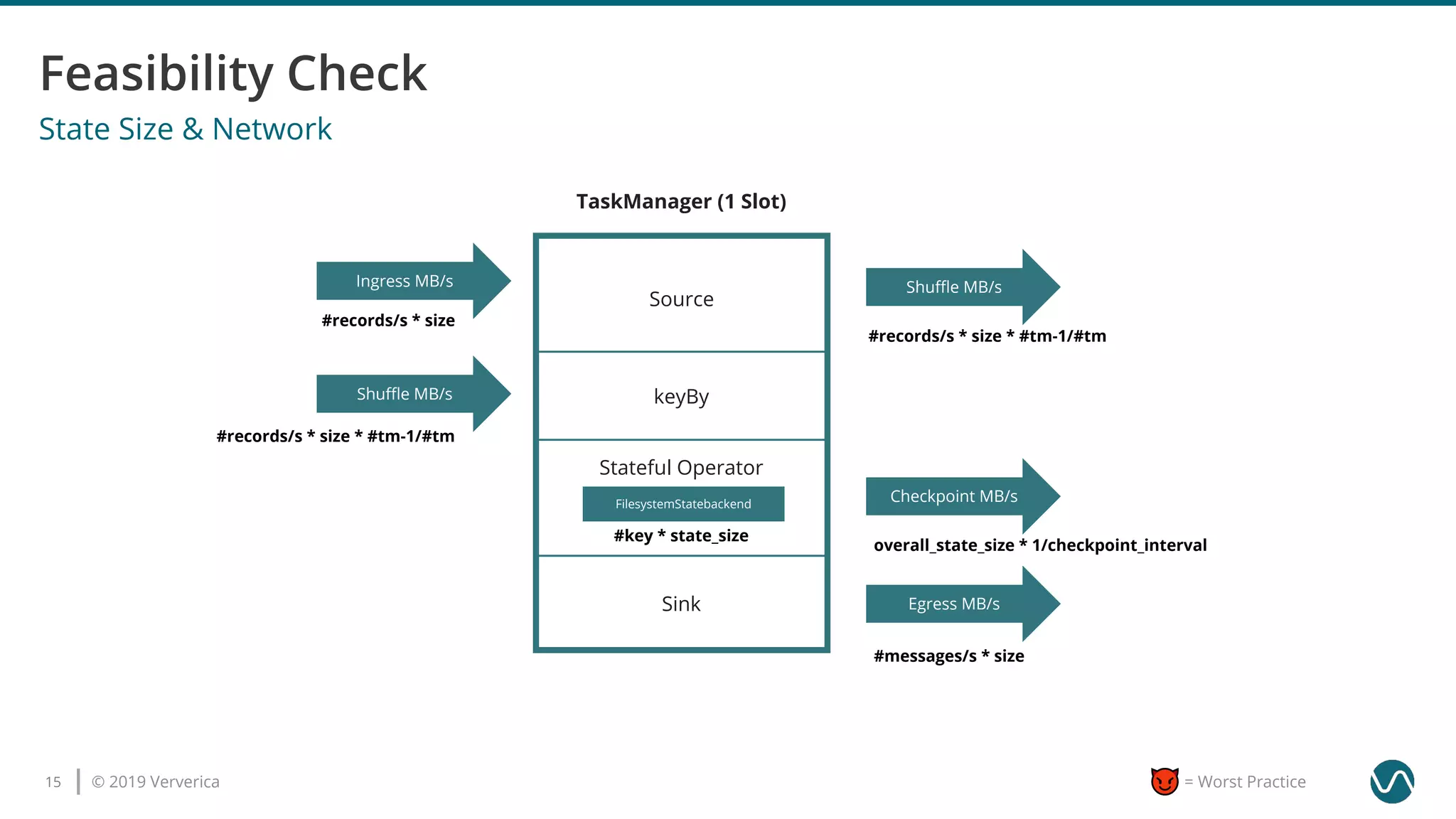
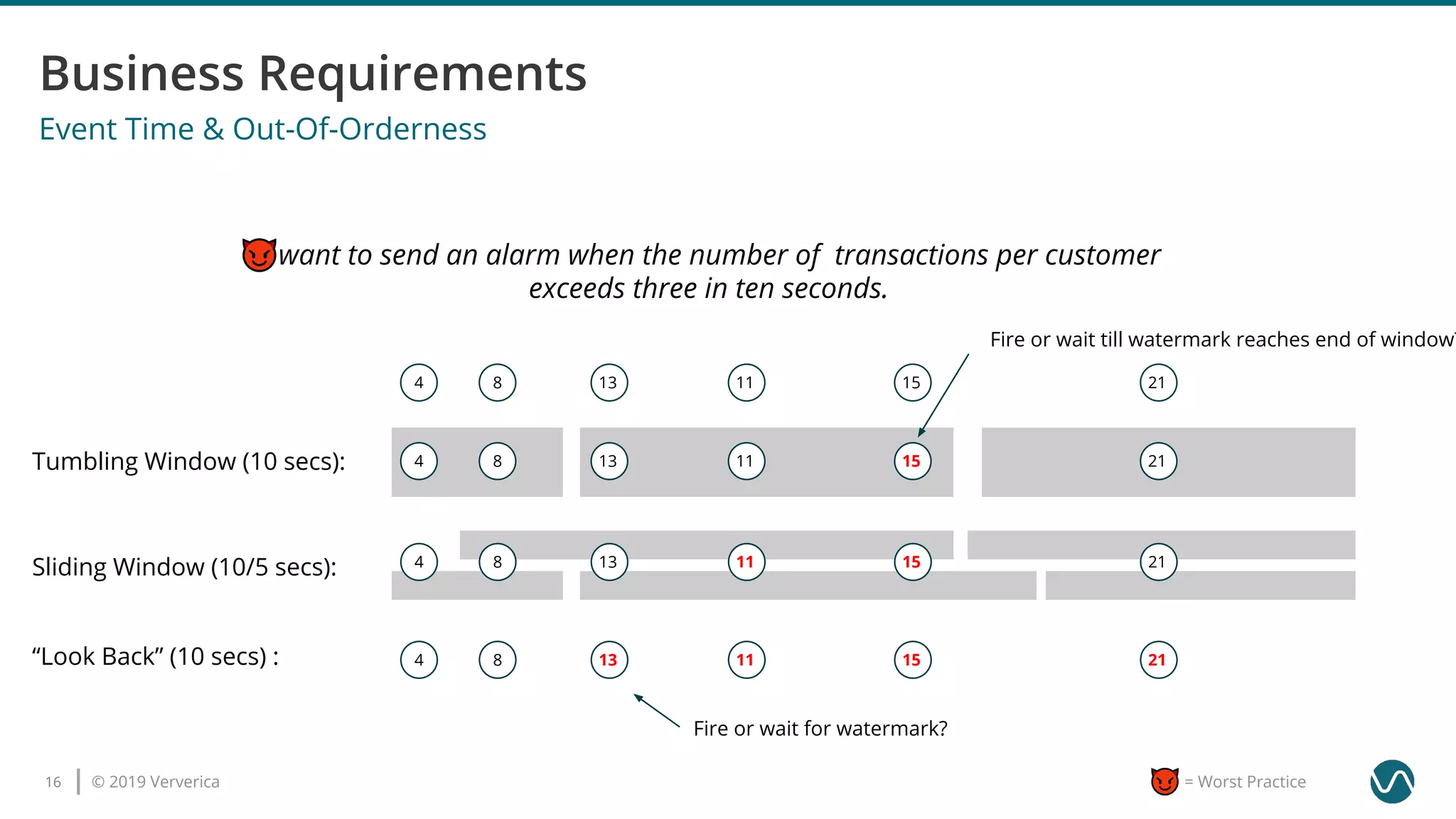
The document outlines several worst practices in developing applications using Apache Flink, emphasizing the importance of proper setup, iterative development, and understanding business requirements. It advises against neglecting consistency, delivery guarantees, and proper state management, along with pitfalls in coding practices and system configuration. The document highlights the significance of community support, monitoring, and testing strategies for effective stream processing.












![© 2019 Ververica23 = Worst Practice
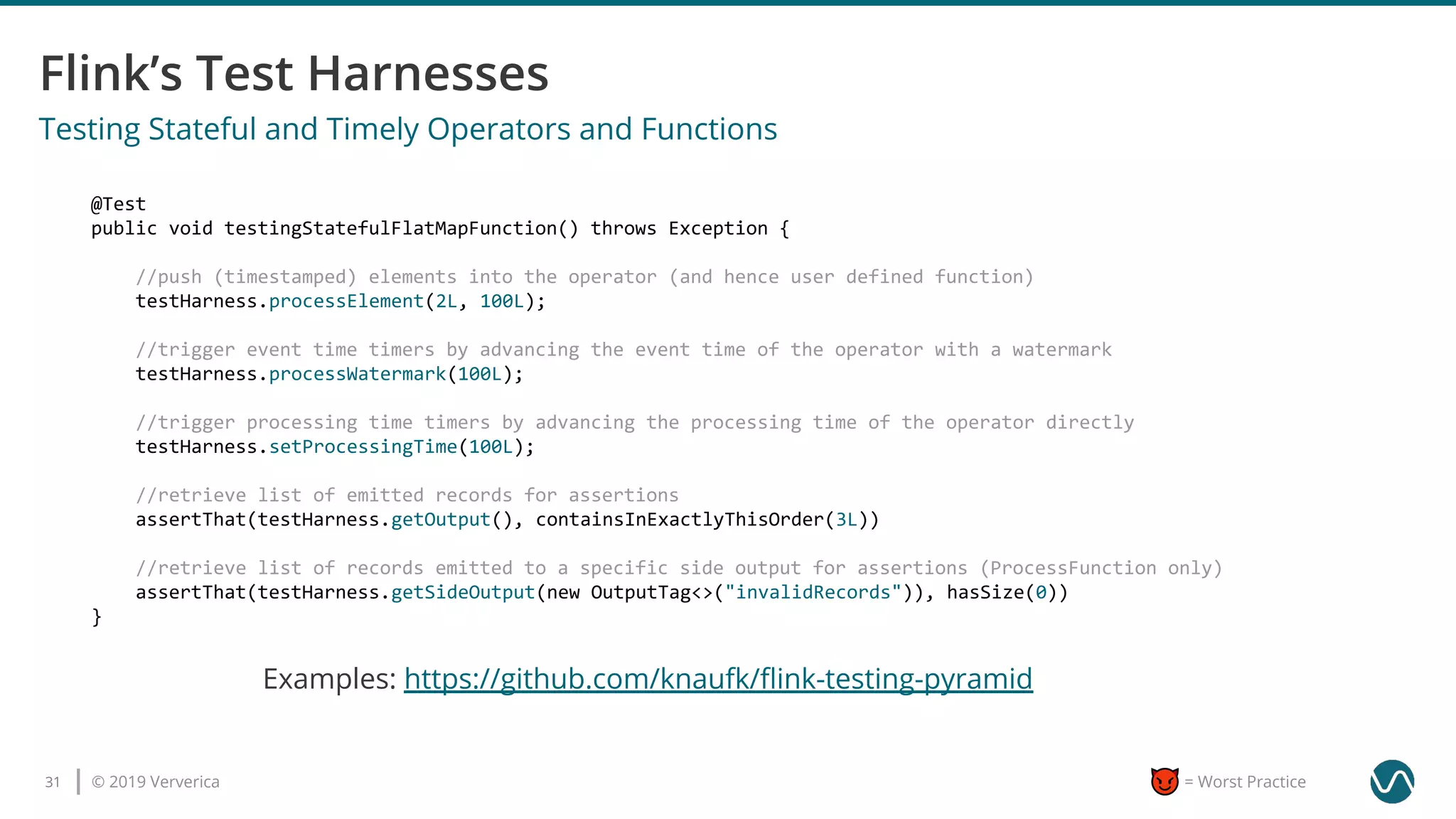
sourceStream.flatMap(new Deserializer())
.keyBy(“cities”)
.timeWindow()
.count()
.filter(new GeographyFilter(“America”))
.addSink(...)
don’t process data you don’t need
● project early
● filter early
● don’t deserialize unused fields, e.g.
public class Record {
private City city;
private byte[] enclosedRecord;
}](https://image.slidesharecdn.com/apacheflinkworstpracticeskonstantinknauf-191018084047/85/Apache-Flink-Worst-Practices-23-320.jpg)





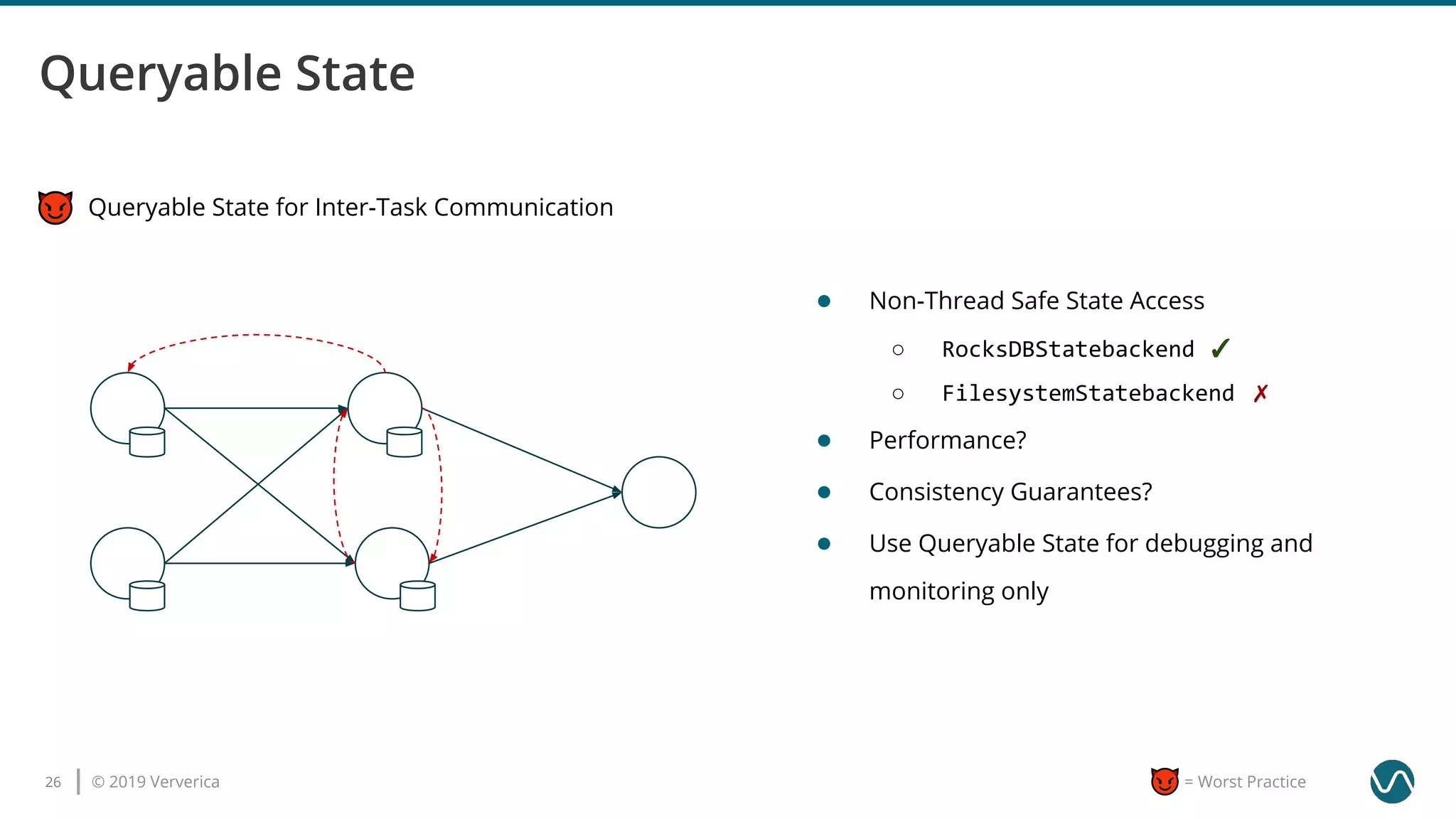
![© 2019 Ververica35 = Worst Practice
use the Flink Web Interface as monitoring system
Monitoring & Metrics
if at all start monitoring now
using latency markers in production
[1] https://flink.apache.org/news/2019/02/25/monitoring-best-practices.html
● don’t miss the chance to learn about
Flink’s runtime during development
● not sure how to start → read [1]
● not the right tool for the job →
MetricsReporters (e.g Prometheus,
InfluxDB, Datadog)
● too many metrics can bring
JobManagers down
● high overhead (in particular with
metrics.latency.granularity:
subtask)
● measure event time lag instead [2]
[2] https://flink.apache.org/2019/06/05/flink-network-stack.html](https://image.slidesharecdn.com/apacheflinkworstpracticeskonstantinknauf-191018084047/85/Apache-Flink-Worst-Practices-35-320.jpg)














![© 2019 Ververica23 = Worst Practice
sourceStream.flatMap(new Deserializer())
.keyBy(“cities”)
.timeWindow()
.count()
.filter(new GeographyFilter(“America”))
.addSink(...)
don’t process data you don’t need
● project early
● filter early
● don’t deserialize unused fields, e.g.
public class Record {
private City city;
private byte[] enclosedRecord;
}](https://image.slidesharecdn.com/apacheflinkworstpracticeskonstantinknauf-191018084047/75/Apache-Flink-Worst-Practices-23-2048.jpg)






![© 2019 Ververica35 = Worst Practice
use the Flink Web Interface as monitoring system
Monitoring & Metrics
if at all start monitoring now
using latency markers in production
[1] https://flink.apache.org/news/2019/02/25/monitoring-best-practices.html
● don’t miss the chance to learn about
Flink’s runtime during development
● not sure how to start → read [1]
● not the right tool for the job →
MetricsReporters (e.g Prometheus,
InfluxDB, Datadog)
● too many metrics can bring
JobManagers down
● high overhead (in particular with
metrics.latency.granularity:
subtask)
● measure event time lag instead [2]
[2] https://flink.apache.org/2019/06/05/flink-network-stack.html](https://image.slidesharecdn.com/apacheflinkworstpracticeskonstantinknauf-191018084047/75/Apache-Flink-Worst-Practices-35-2048.jpg)






























































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







