




![Spark Mllib in production
● ML persistence
○ Saving and loading
● Pipeline MLlib standardizes APIs for machine learning algorithms to make it easier to combine multiple algorithms into a
single pipeline, or workflow. This section covers the key concepts introduced by the Pipelines API, where the pipeline concept is
mostly inspired by the scikit-learn project.
Some concepts[5]
● DataFrame
● Transformer - one dataframe to another
● Estimator - fits on a dataframe to produce a transformer
● Pipeline A pipeline chains multiple transformers and Estimators to specify ML workflow.](https://image.slidesharecdn.com/mllibsparksigkddpresentation-170925223342/85/Apache-Spark-MLlib-Random-Foreset-and-Desicion-Trees-7-320.jpg)



![DecisionTree Classifier (MLlib Dataframe based API)
>>> from pyspark.ml.linalg import Vectors
>>> from pyspark.ml.feature import StringIndexer
>>> df = spark.createDataFrame([
... (1.0, Vectors.dense(1.0)),
... (0.0, Vectors.sparse(1, [], []))], ["label", "features"])
>>> stringIndexer = StringIndexer(inputCol="label", outputCol="indexed")
>>> si_model = stringIndexer.fit(df)
>>> td = si_model.transform(df)
>>> dt = DecisionTreeClassifier(maxDepth=2, labelCol="indexed")
>>> model = dt.fit(td)
>>> model.numNodes
https://spark.apache.org/docs/2.2.0/api/python/pyspark.ml.html#pyspark.ml.classification.DecisionTreeClassifier](https://image.slidesharecdn.com/mllibsparksigkddpresentation-170925223342/85/Apache-Spark-MLlib-Random-Foreset-and-Desicion-Trees-13-320.jpg)






![RandomForest in MLLib
DataFrame Based API
class pyspark.ml.classification.RandomForestClassifier(self, featuresCol="features", labelCol="label", predictionCol="prediction",
probabilityCol="probability", rawPredictionCol="rawPrediction", maxDepth=5, maxBins=32, minInstancesPerNode=1, minInfoGain=0.0,
maxMemoryInMB=256, cacheNodeIds=False, checkpointInterval=10, impurity="gini", numTrees=20, featureSubsetStrategy="auto",
seed=None, subsamplingRate=1.0)[source]¶
>>> import numpy>>> from numpy import allclose
>>> from pyspark.ml.linalg import Vectors
>>> from pyspark.ml.feature import StringIndexer
>>> df = spark.createDataFrame([
... (1.0, Vectors.dense(1.0)),
... (0.0, Vectors.sparse(1, [], []))], ["label", "features"])
>>> stringIndexer = StringIndexer(inputCol="label", outputCol="indexed")
>>> si_model = stringIndexer.fit(df)
>>> td = si_model.transform(df)
>>> rf = RandomForestClassifier(numTrees=3, maxDepth=2, labelCol="indexed", seed=42)
>>> model = rf.fit(td)
https://spark.apache.org/docs/2.2.0/ml-classification-regression.html#random-forest-classifier](https://image.slidesharecdn.com/mllibsparksigkddpresentation-170925223342/85/Apache-Spark-MLlib-Random-Foreset-and-Desicion-Trees-22-320.jpg)


![MLlib - Labeled point vector (RDD based)
Labeled point vector
● Prior to running any supervised machine learning algorithm using Spark MLlib, we must convert our dataset
into a labeled point vector.
○ val higgs = response.zip(features).map {
case (response, features) =>
LabeledPoint(response, features) }
higgs.setName("higgs").cache()
● An example of a labeled point vector follows:
(1.0, [0.123, 0.456, 0.567, 0.678, ..., 0.789])](https://image.slidesharecdn.com/mllibsparksigkddpresentation-170925223342/85/Apache-Spark-MLlib-Random-Foreset-and-Desicion-Trees-25-320.jpg)








![Spark Mllib in production
● ML persistence
○ Saving and loading
● Pipeline MLlib standardizes APIs for machine learning algorithms to make it easier to combine multiple algorithms into a
single pipeline, or workflow. This section covers the key concepts introduced by the Pipelines API, where the pipeline concept is
mostly inspired by the scikit-learn project.
Some concepts[5]
● DataFrame
● Transformer - one dataframe to another
● Estimator - fits on a dataframe to produce a transformer
● Pipeline A pipeline chains multiple transformers and Estimators to specify ML workflow.](https://image.slidesharecdn.com/mllibsparksigkddpresentation-170925223342/75/Apache-Spark-MLlib-Random-Foreset-and-Desicion-Trees-7-2048.jpg)



![DecisionTree Classifier (MLlib Dataframe based API)
>>> from pyspark.ml.linalg import Vectors
>>> from pyspark.ml.feature import StringIndexer
>>> df = spark.createDataFrame([
... (1.0, Vectors.dense(1.0)),
... (0.0, Vectors.sparse(1, [], []))], ["label", "features"])
>>> stringIndexer = StringIndexer(inputCol="label", outputCol="indexed")
>>> si_model = stringIndexer.fit(df)
>>> td = si_model.transform(df)
>>> dt = DecisionTreeClassifier(maxDepth=2, labelCol="indexed")
>>> model = dt.fit(td)
>>> model.numNodes
https://spark.apache.org/docs/2.2.0/api/python/pyspark.ml.html#pyspark.ml.classification.DecisionTreeClassifier](https://image.slidesharecdn.com/mllibsparksigkddpresentation-170925223342/75/Apache-Spark-MLlib-Random-Foreset-and-Desicion-Trees-13-2048.jpg)





![RandomForest in MLLib
DataFrame Based API
class pyspark.ml.classification.RandomForestClassifier(self, featuresCol="features", labelCol="label", predictionCol="prediction",
probabilityCol="probability", rawPredictionCol="rawPrediction", maxDepth=5, maxBins=32, minInstancesPerNode=1, minInfoGain=0.0,
maxMemoryInMB=256, cacheNodeIds=False, checkpointInterval=10, impurity="gini", numTrees=20, featureSubsetStrategy="auto",
seed=None, subsamplingRate=1.0)[source]¶
>>> import numpy>>> from numpy import allclose
>>> from pyspark.ml.linalg import Vectors
>>> from pyspark.ml.feature import StringIndexer
>>> df = spark.createDataFrame([
... (1.0, Vectors.dense(1.0)),
... (0.0, Vectors.sparse(1, [], []))], ["label", "features"])
>>> stringIndexer = StringIndexer(inputCol="label", outputCol="indexed")
>>> si_model = stringIndexer.fit(df)
>>> td = si_model.transform(df)
>>> rf = RandomForestClassifier(numTrees=3, maxDepth=2, labelCol="indexed", seed=42)
>>> model = rf.fit(td)
https://spark.apache.org/docs/2.2.0/ml-classification-regression.html#random-forest-classifier](https://image.slidesharecdn.com/mllibsparksigkddpresentation-170925223342/75/Apache-Spark-MLlib-Random-Foreset-and-Desicion-Trees-22-2048.jpg)


![MLlib - Labeled point vector (RDD based)
Labeled point vector
● Prior to running any supervised machine learning algorithm using Spark MLlib, we must convert our dataset
into a labeled point vector.
○ val higgs = response.zip(features).map {
case (response, features) =>
LabeledPoint(response, features) }
higgs.setName("higgs").cache()
● An example of a labeled point vector follows:
(1.0, [0.123, 0.456, 0.567, 0.678, ..., 0.789])](https://image.slidesharecdn.com/mllibsparksigkddpresentation-170925223342/75/Apache-Spark-MLlib-Random-Foreset-and-Desicion-Trees-25-2048.jpg)






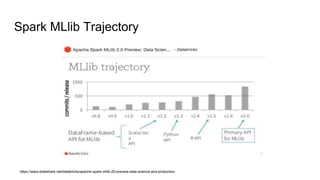
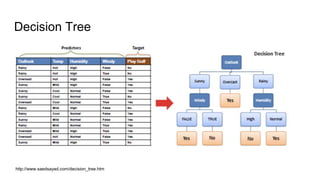
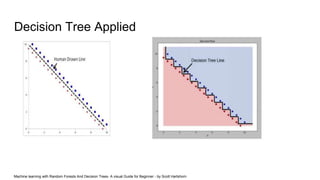
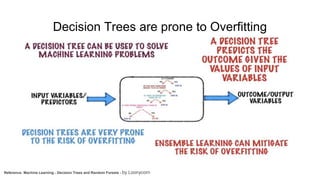
The document discusses Random Forest and Decision Trees in Spark MLlib. It provides an overview of Spark and MLlib, describes Decision Trees and Random Forest algorithms in MLlib, and demonstrates them through Jupyter notebooks using golf and Titanic datasets. The speaker then discusses parameters, advantages, and limitations of Decision Trees and Random Forest models in MLlib.



































































