Downloaded 17 times







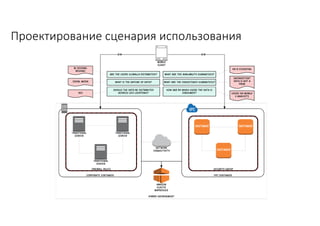
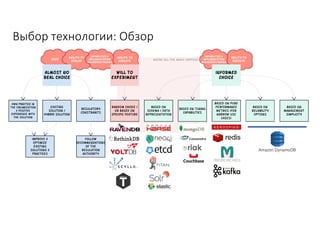
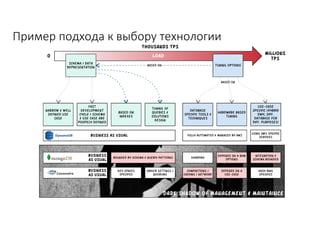

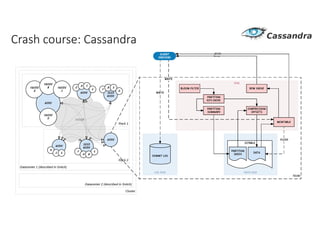
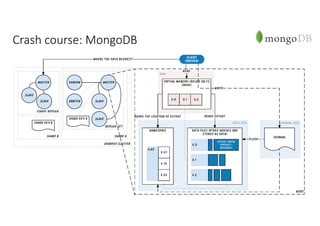

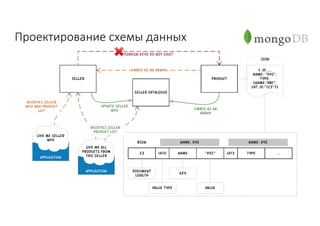
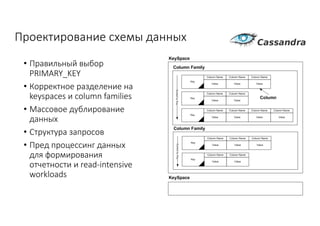
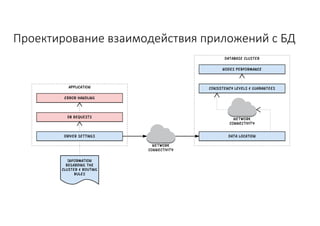
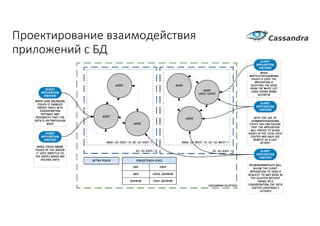
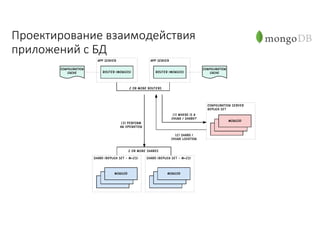
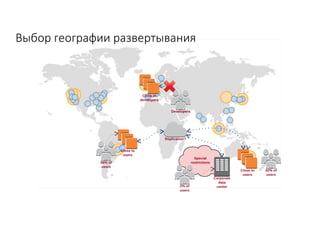
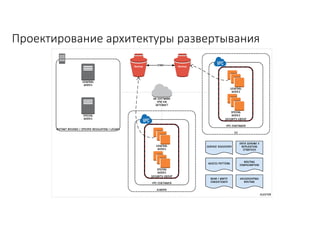
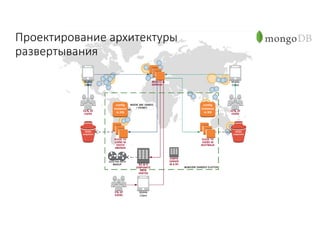
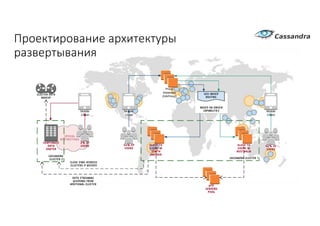

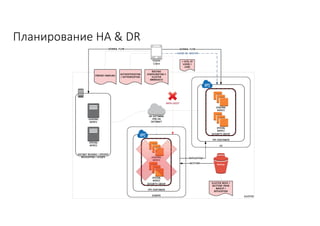
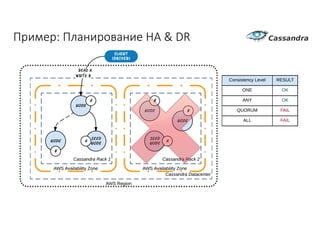
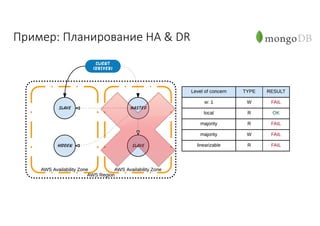
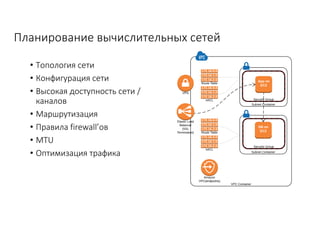
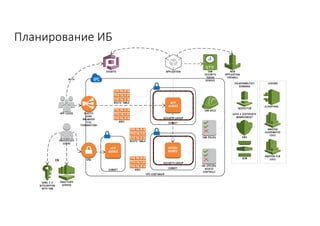

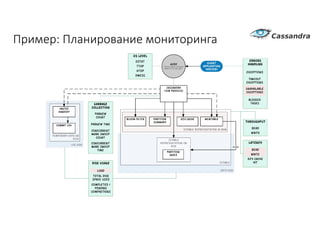
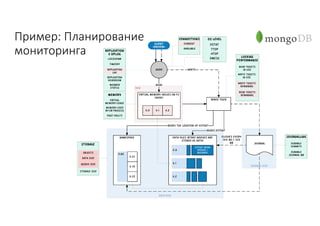






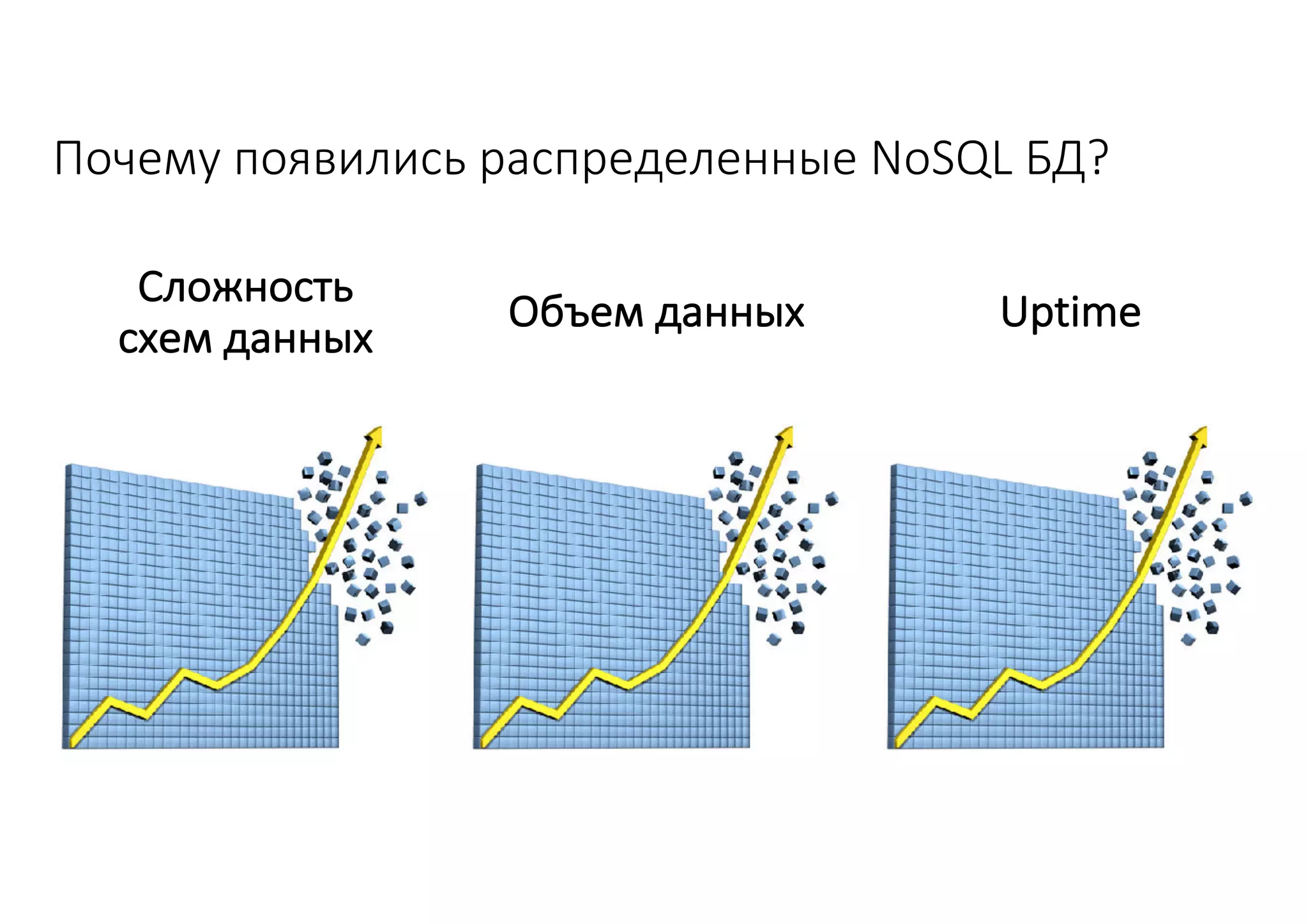
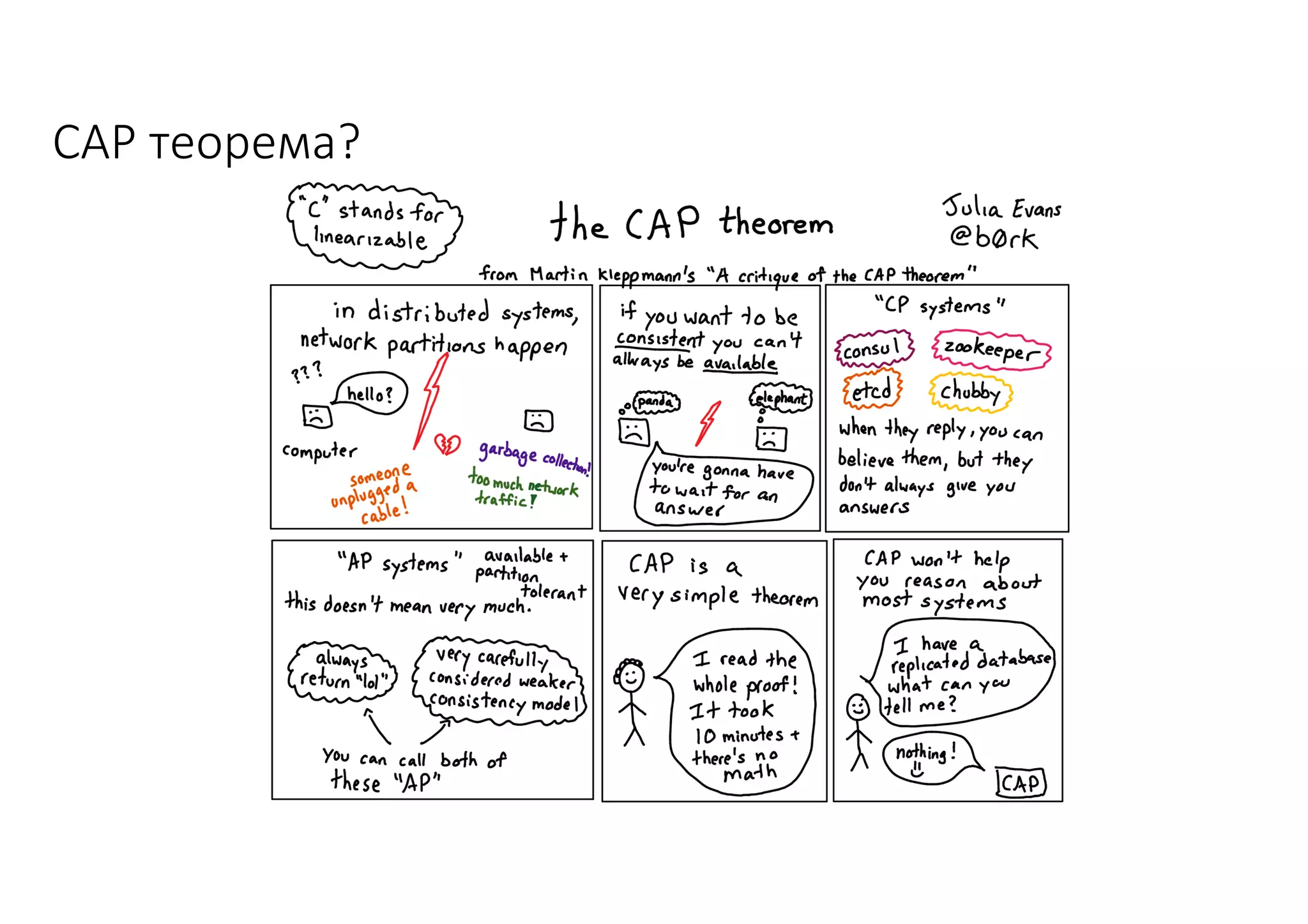
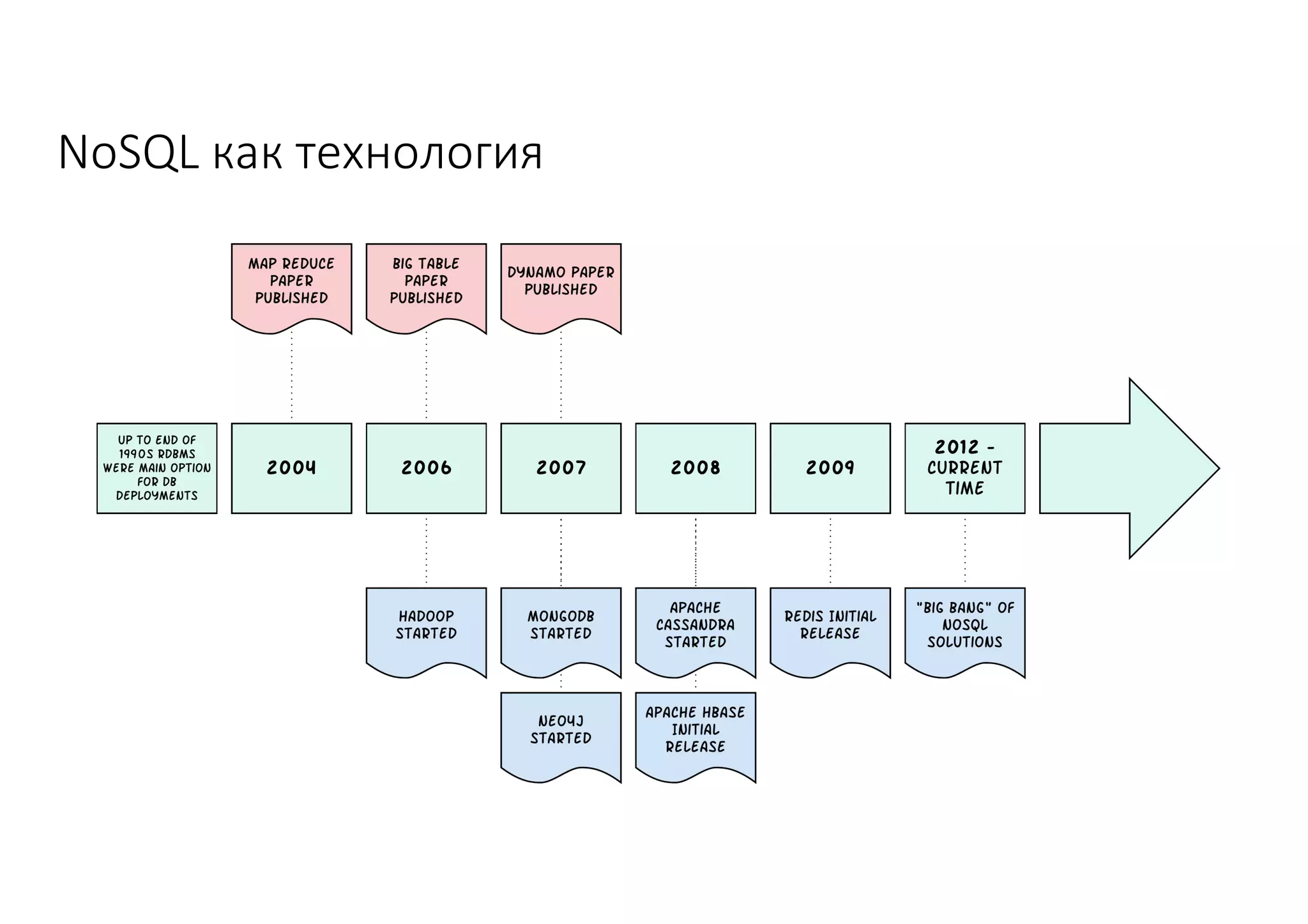

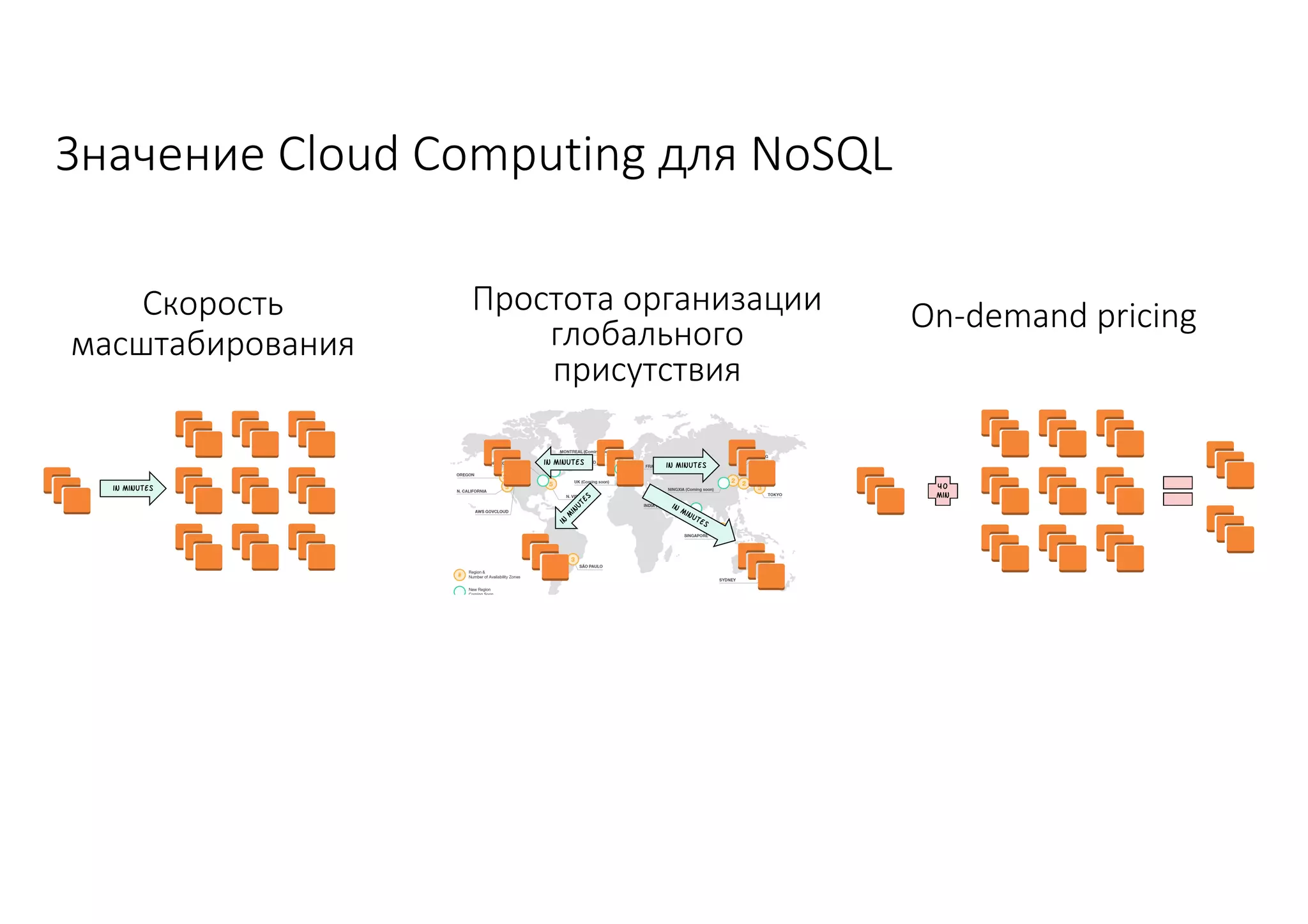



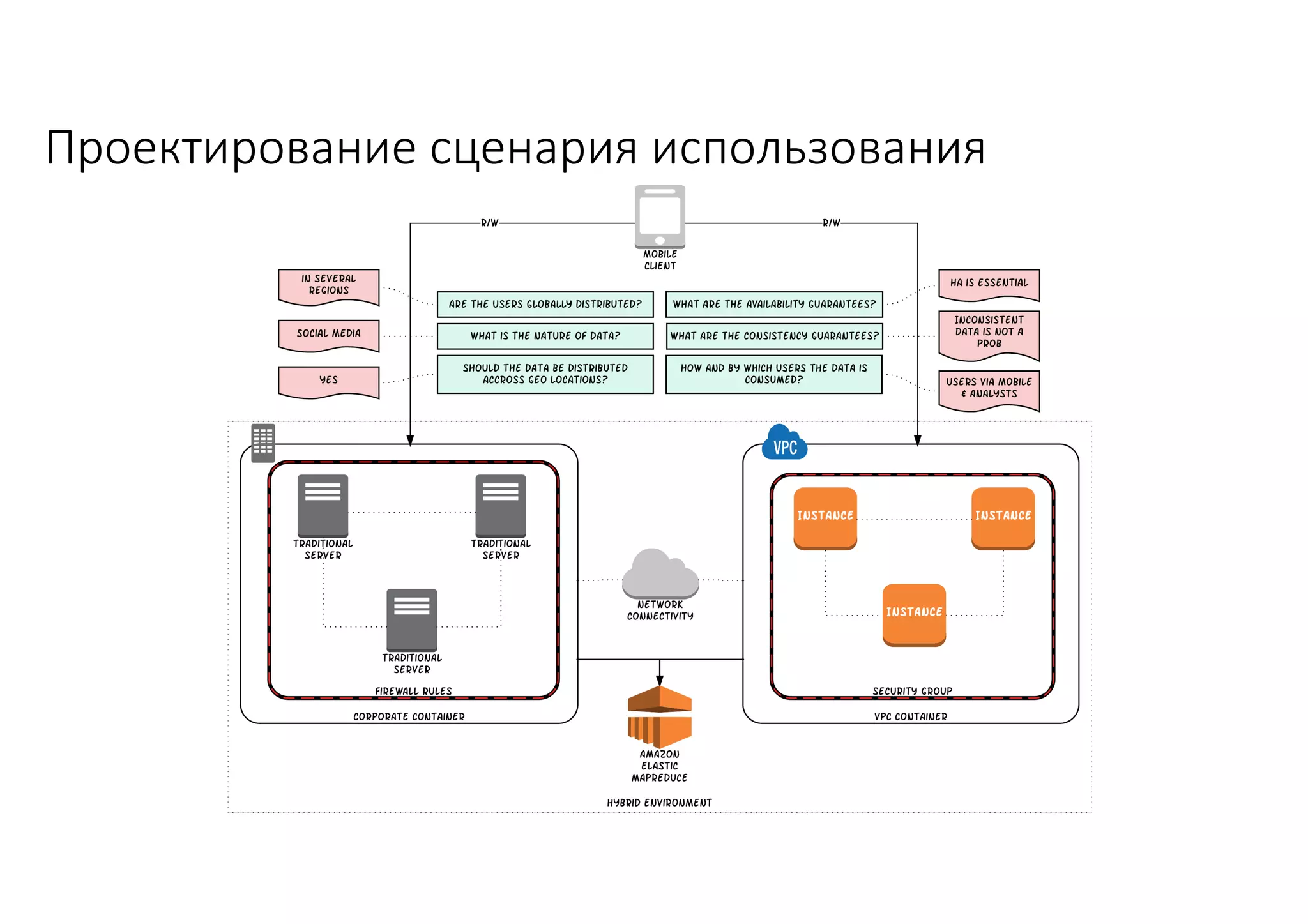
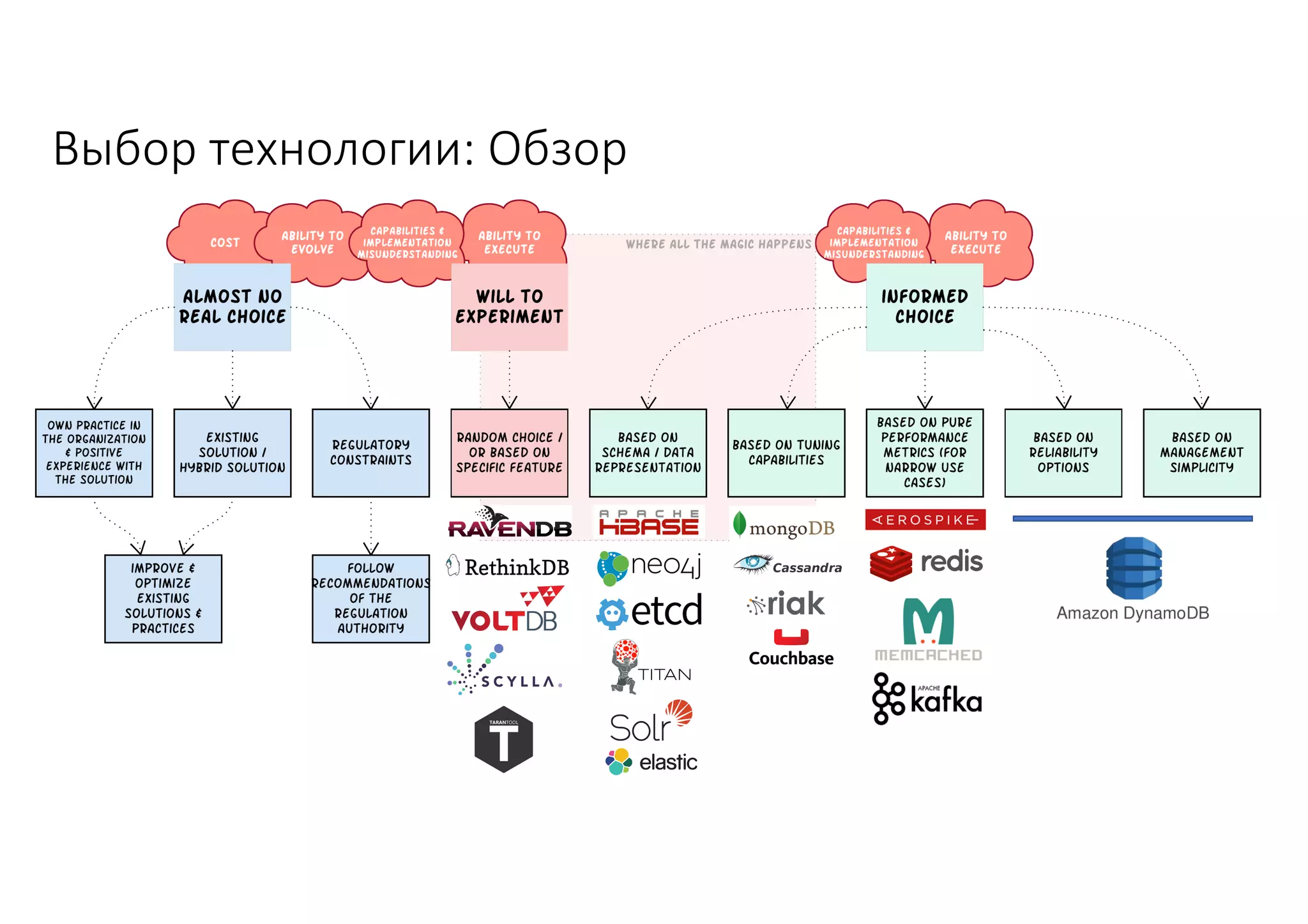
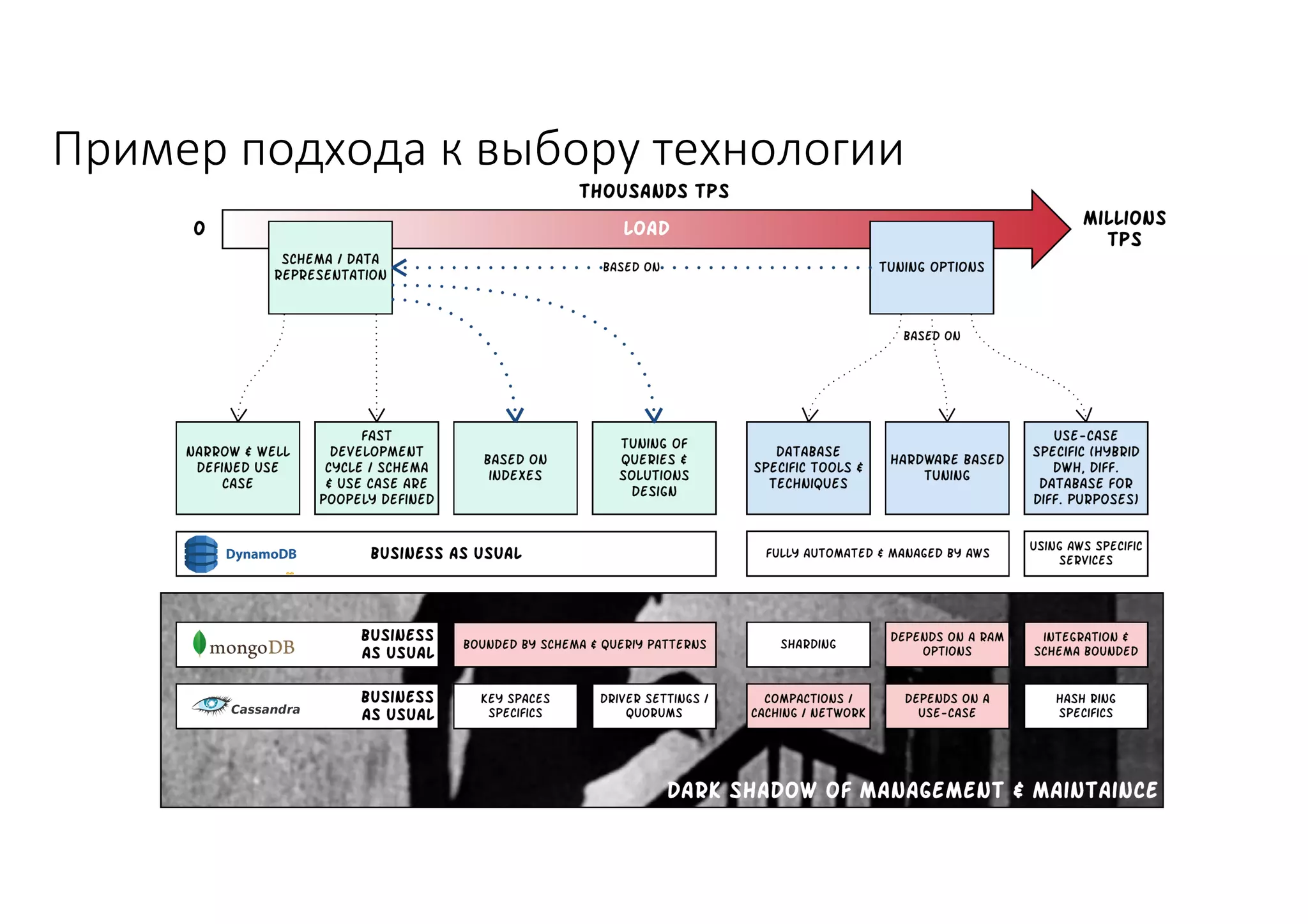

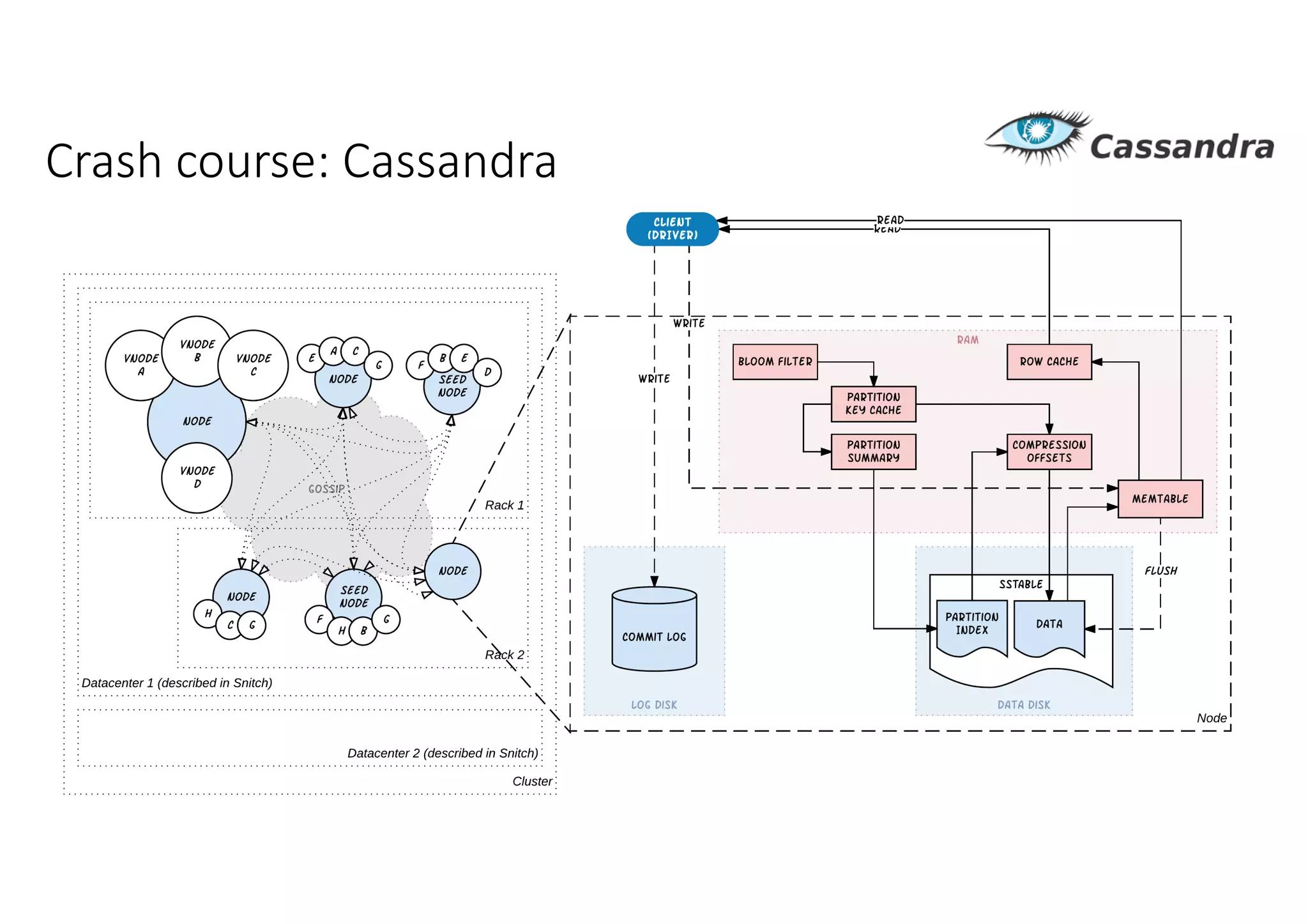
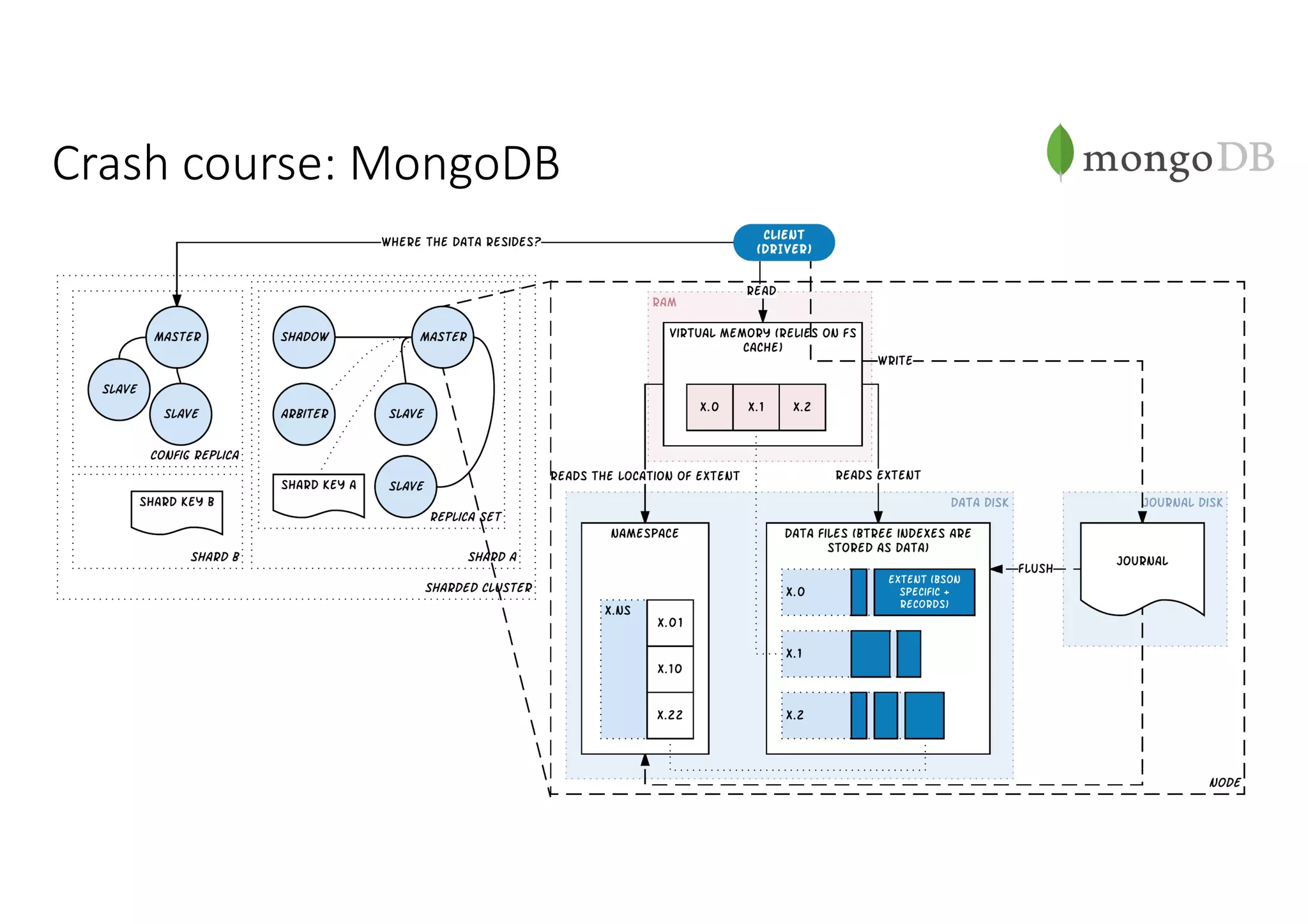

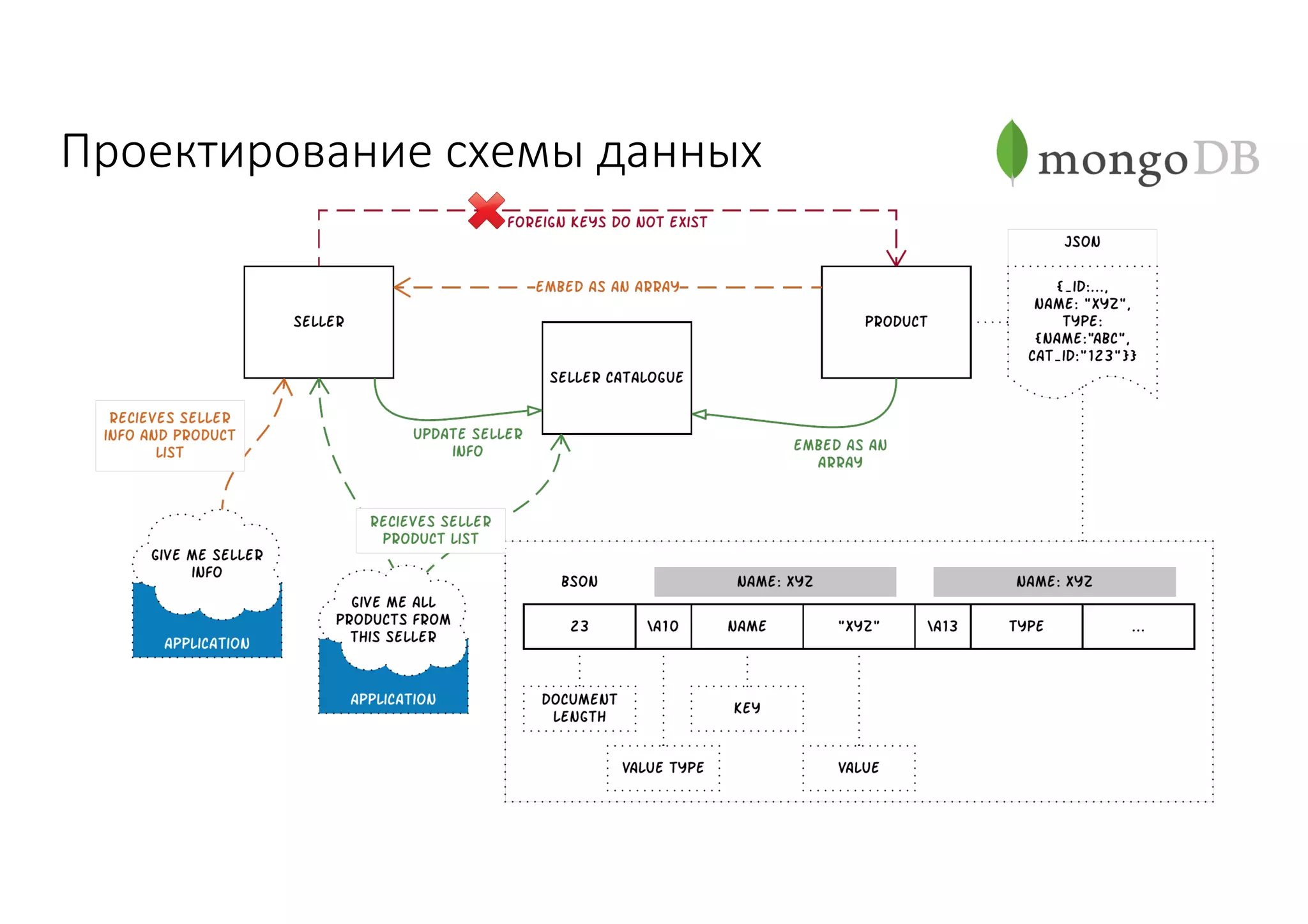
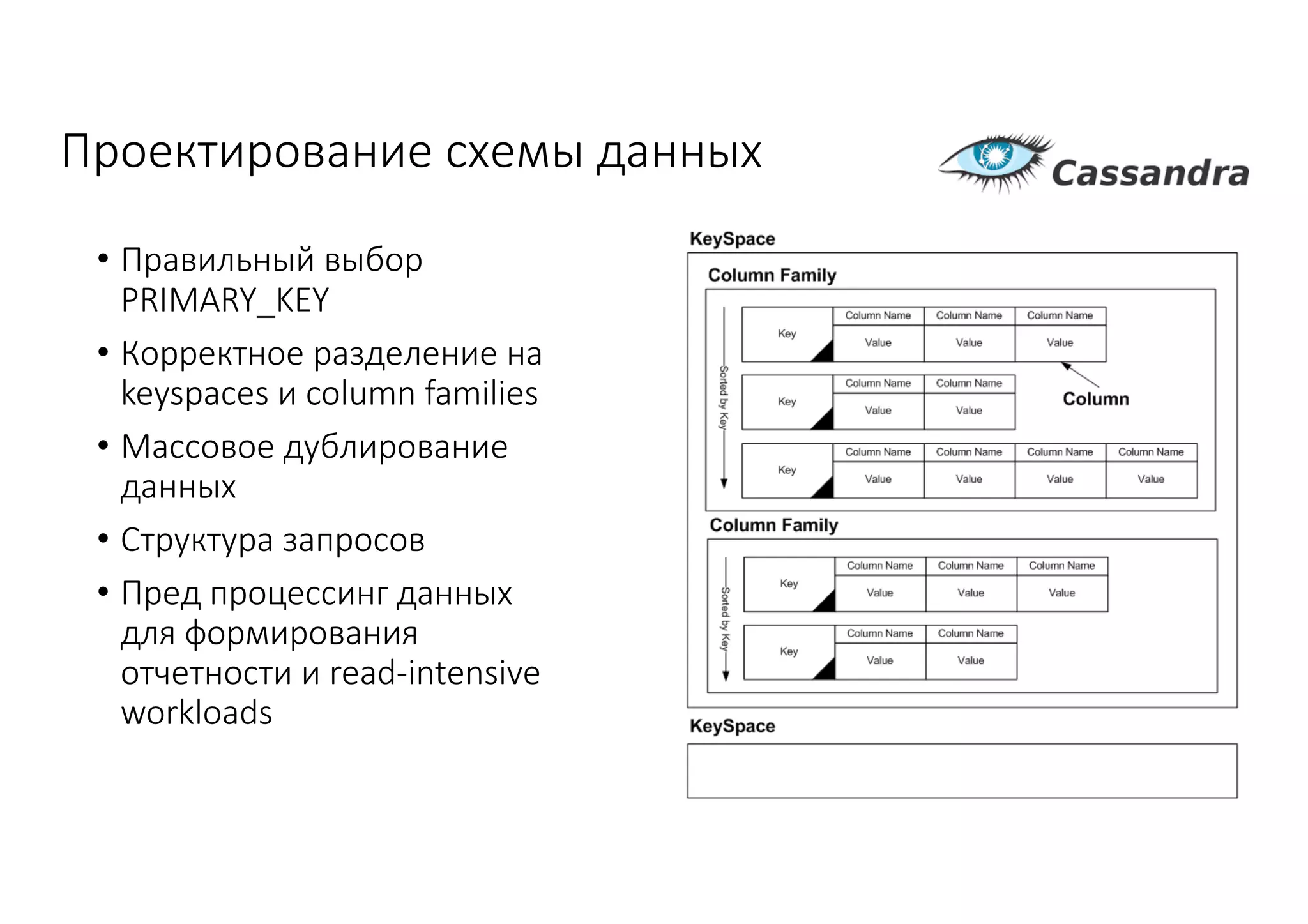
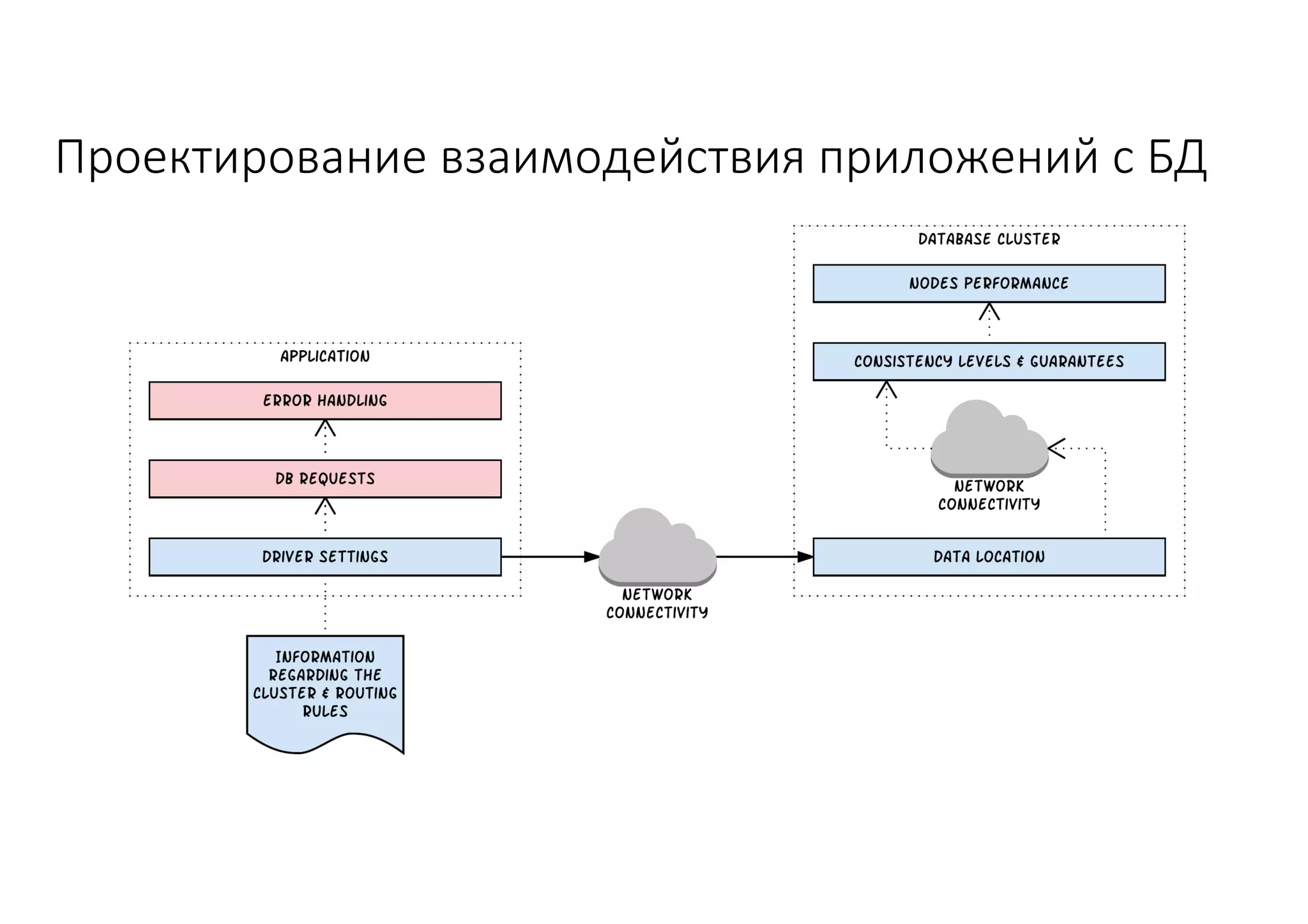
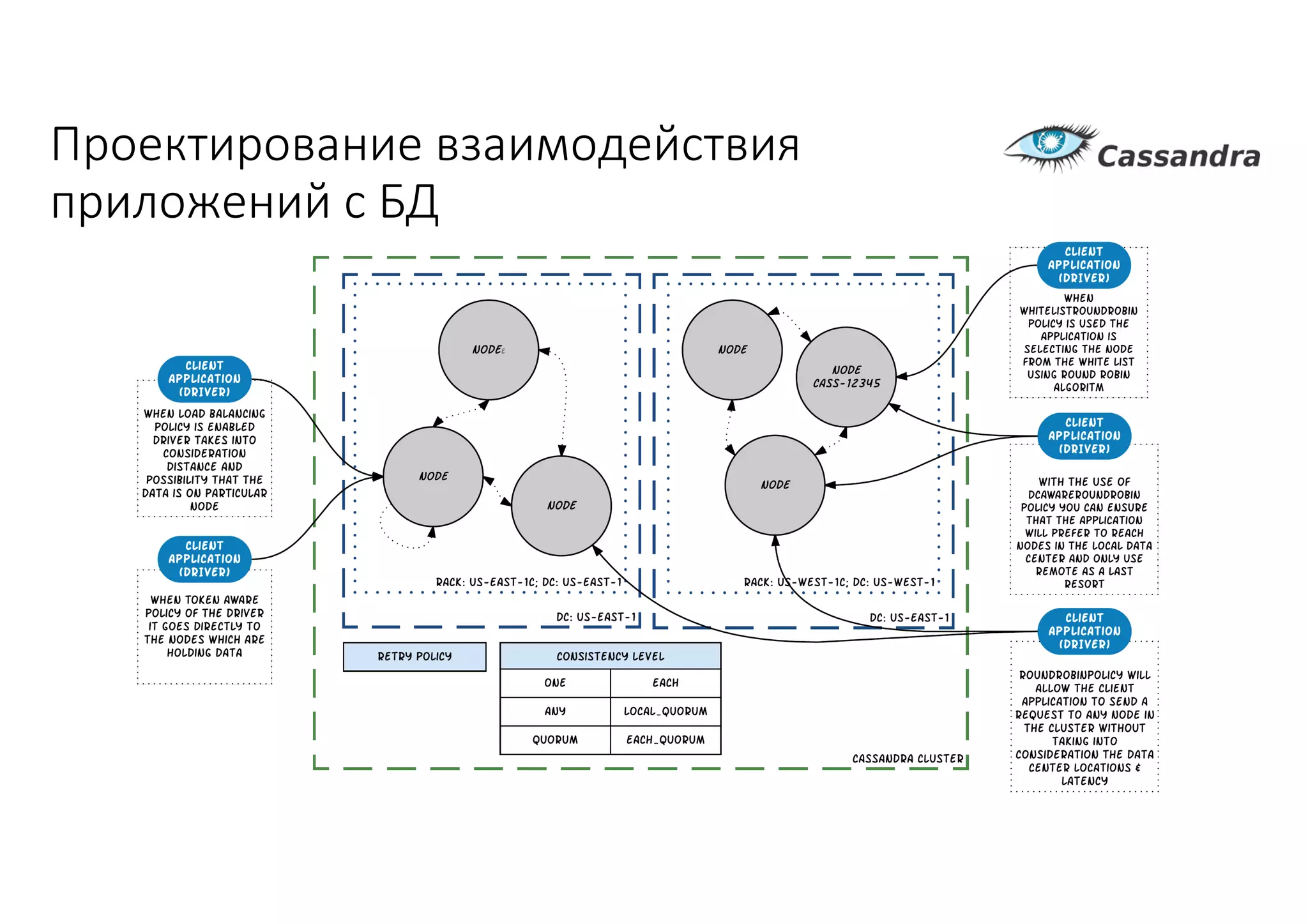
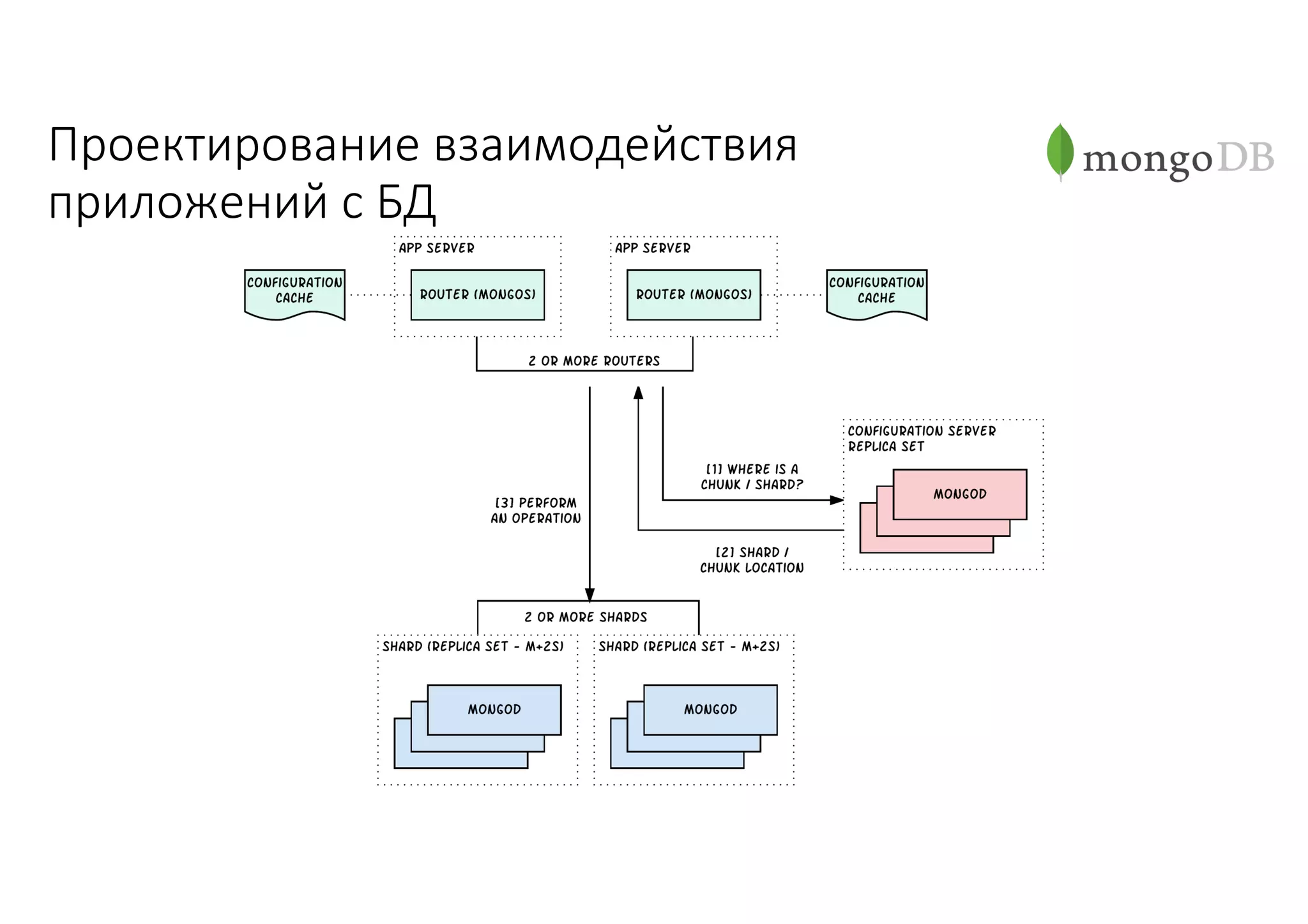
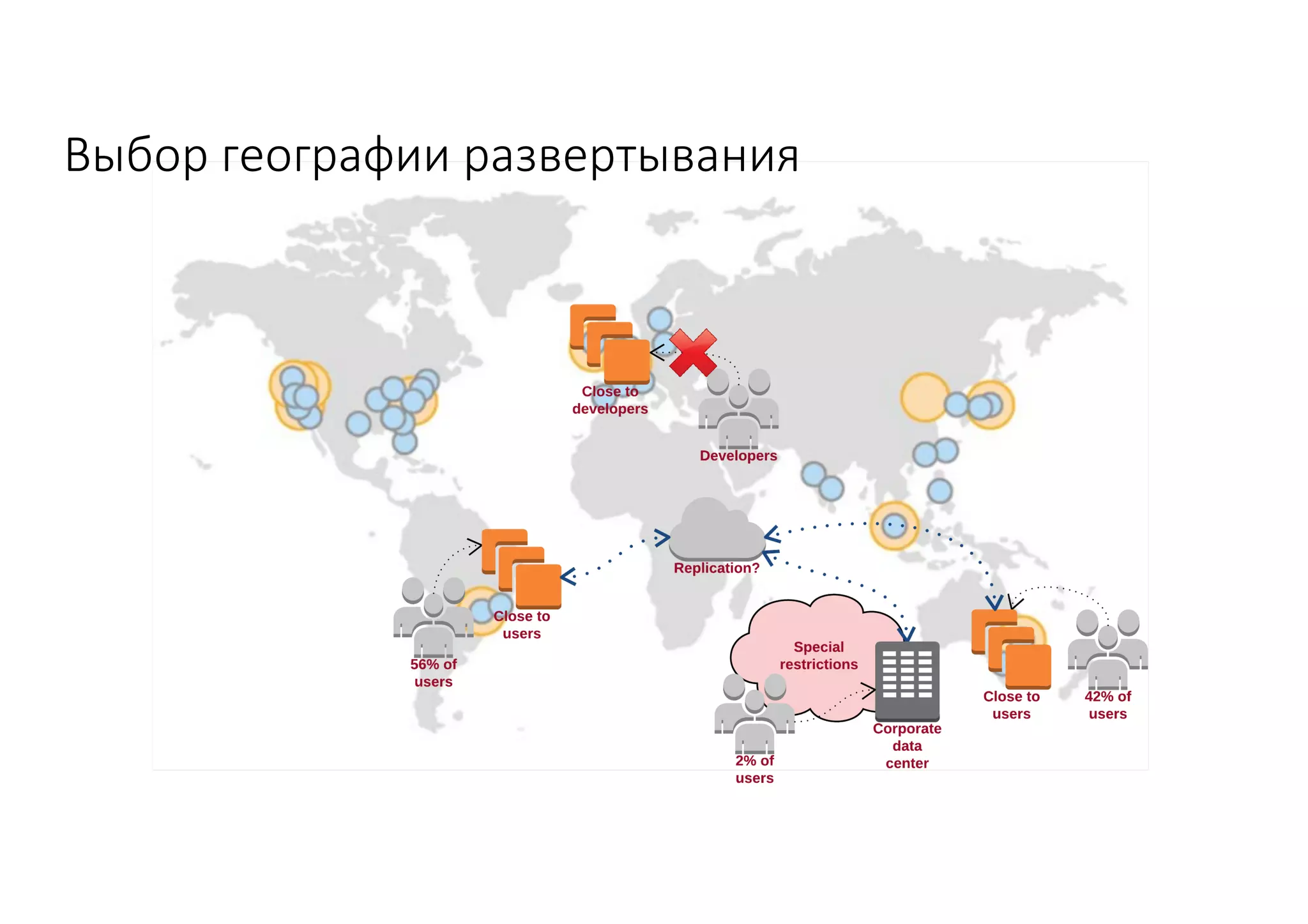
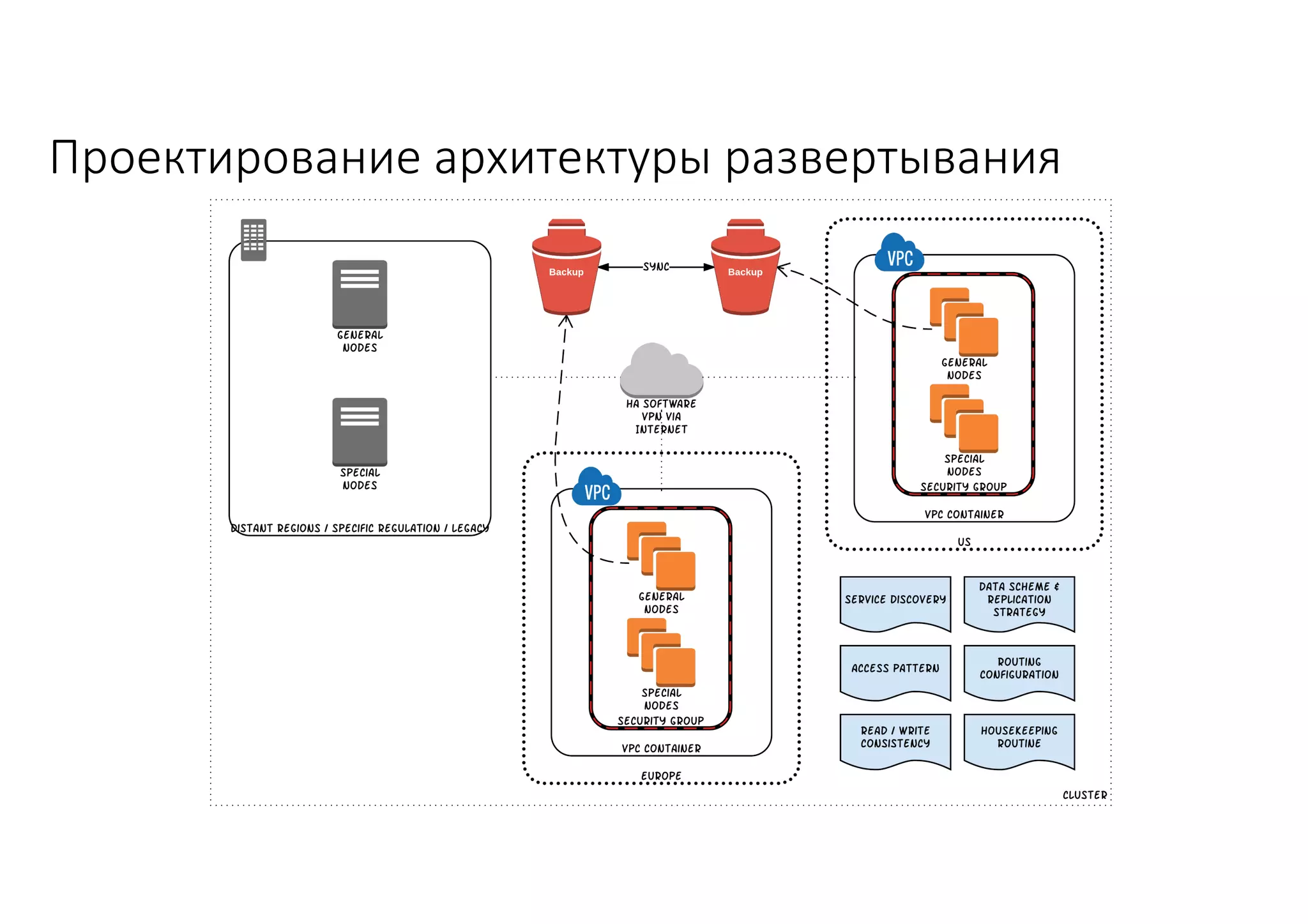
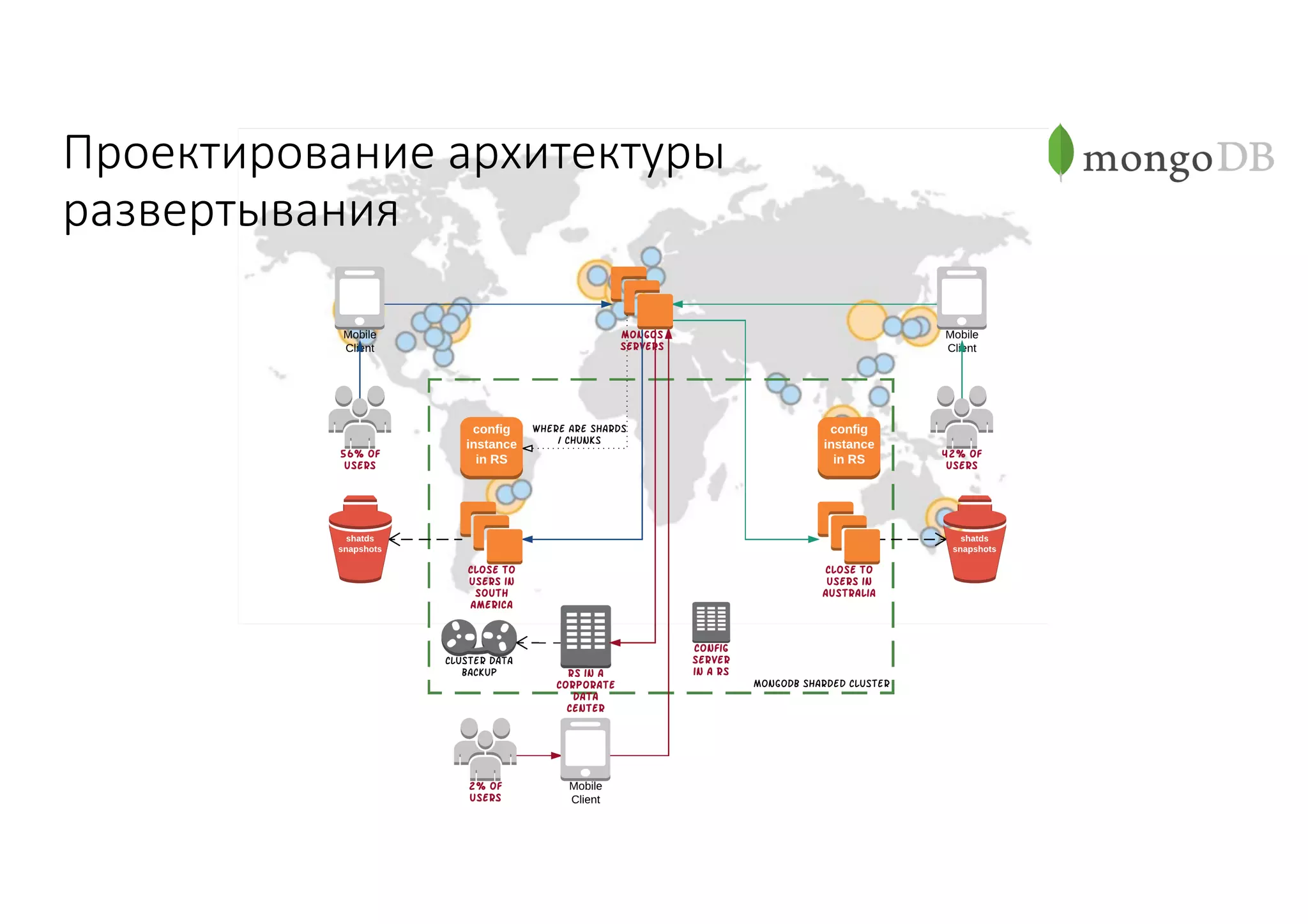
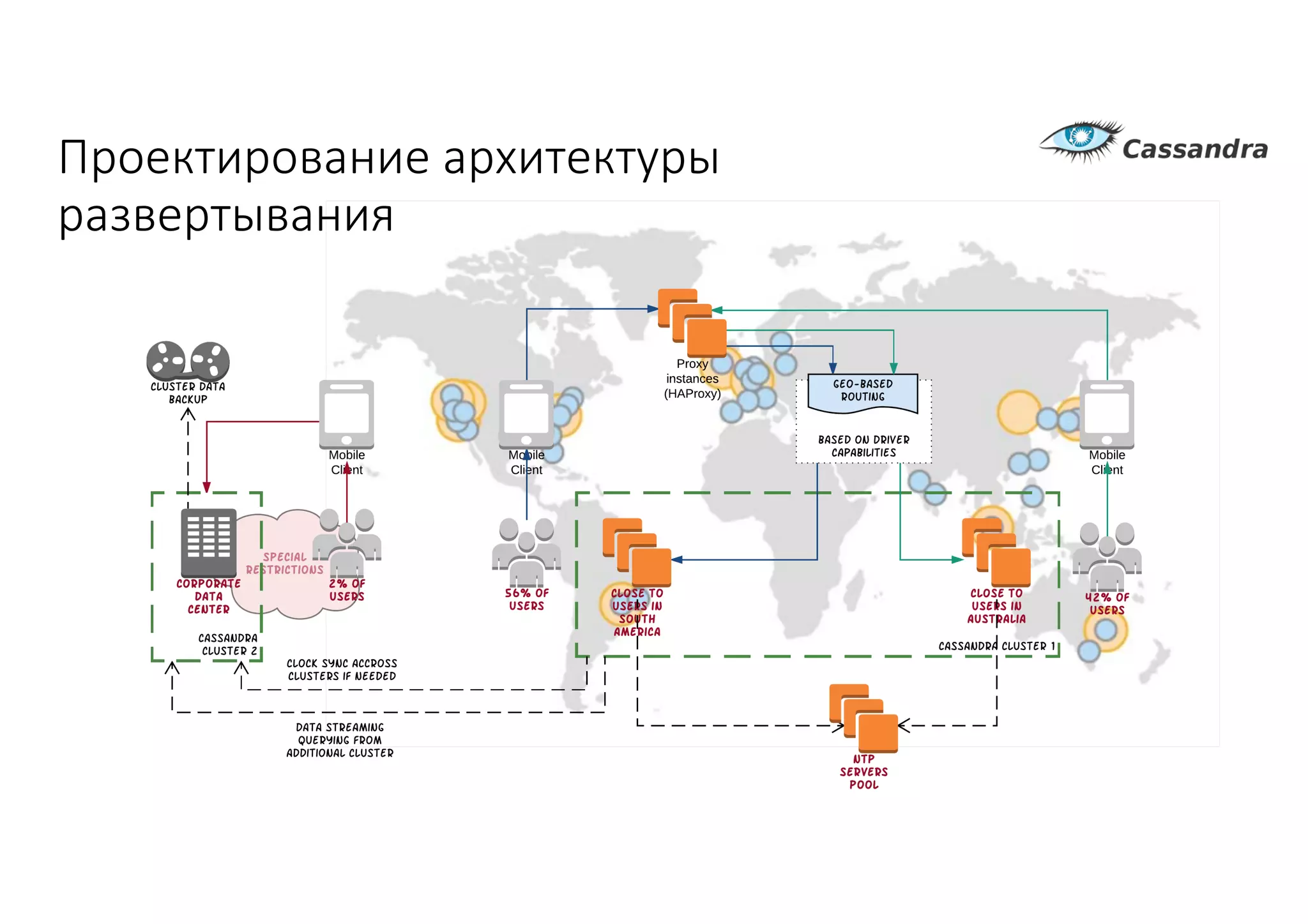
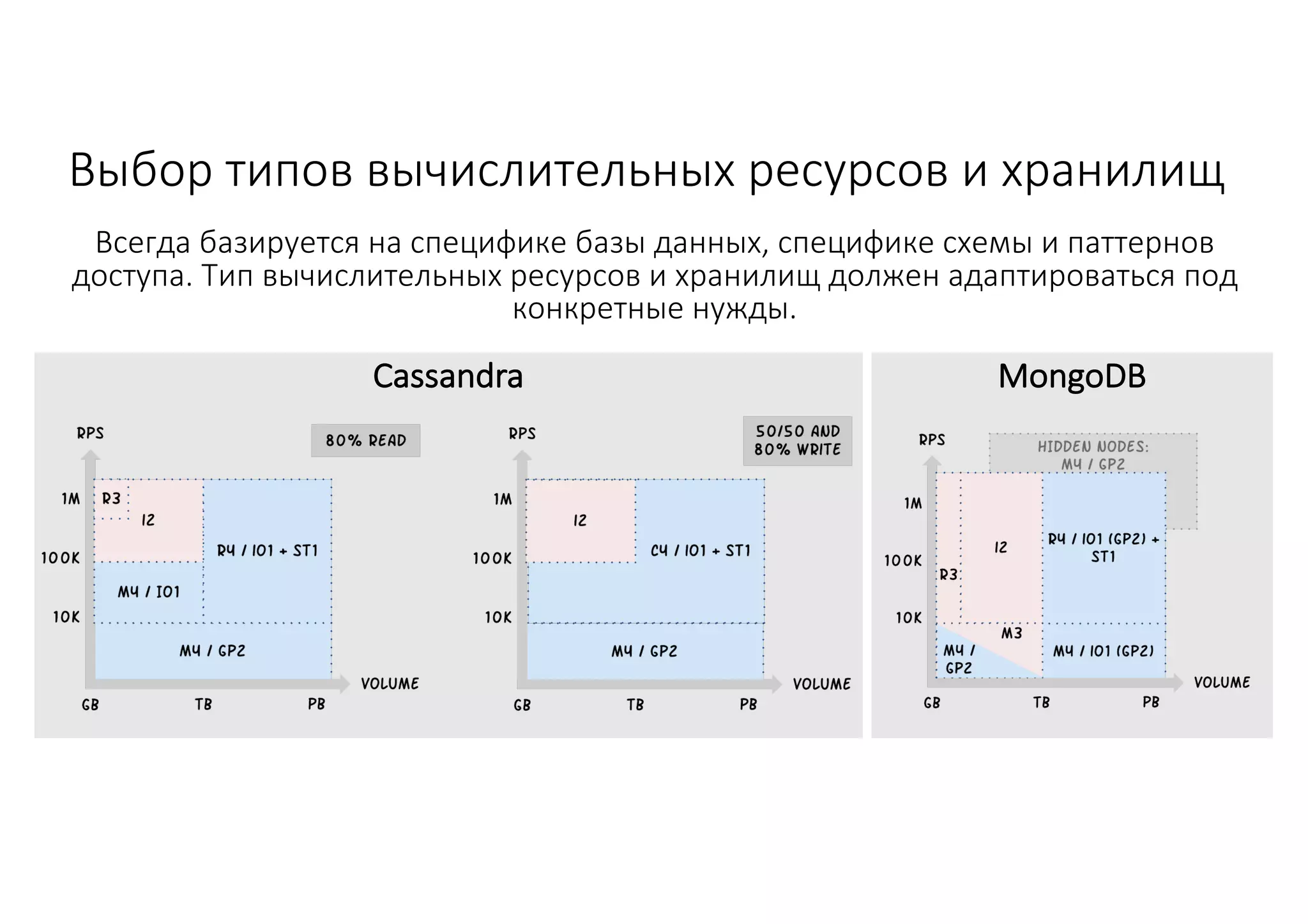
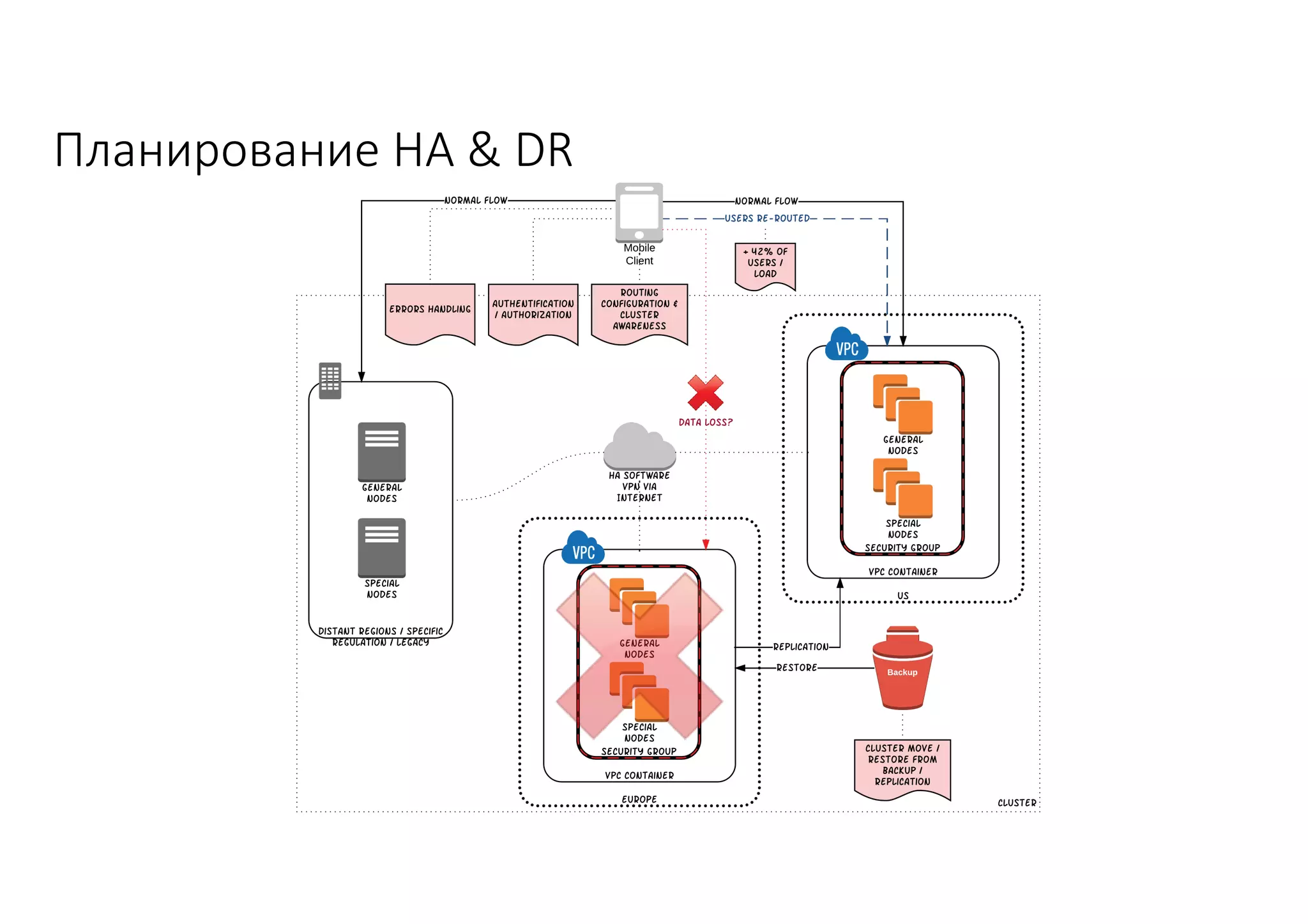
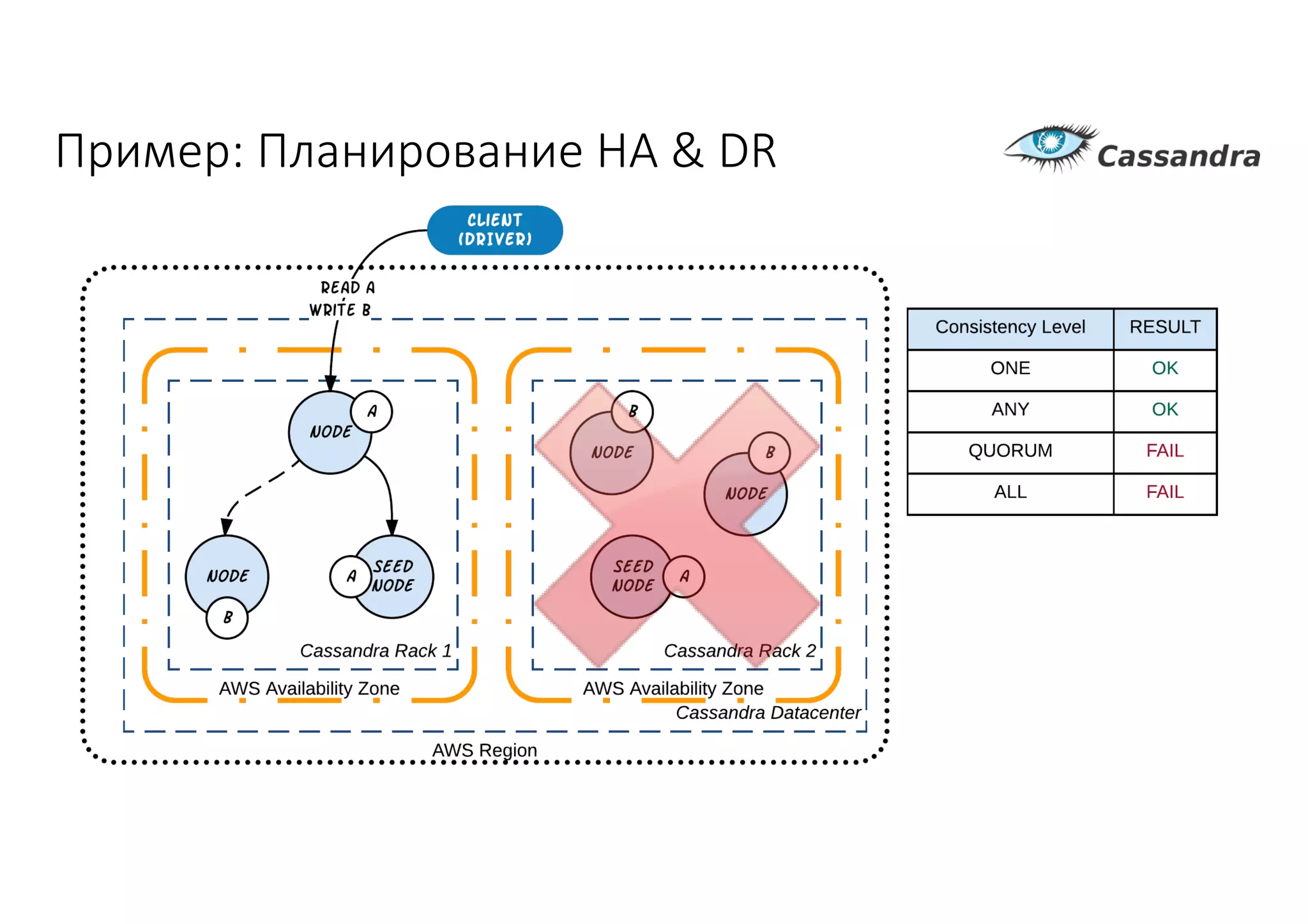
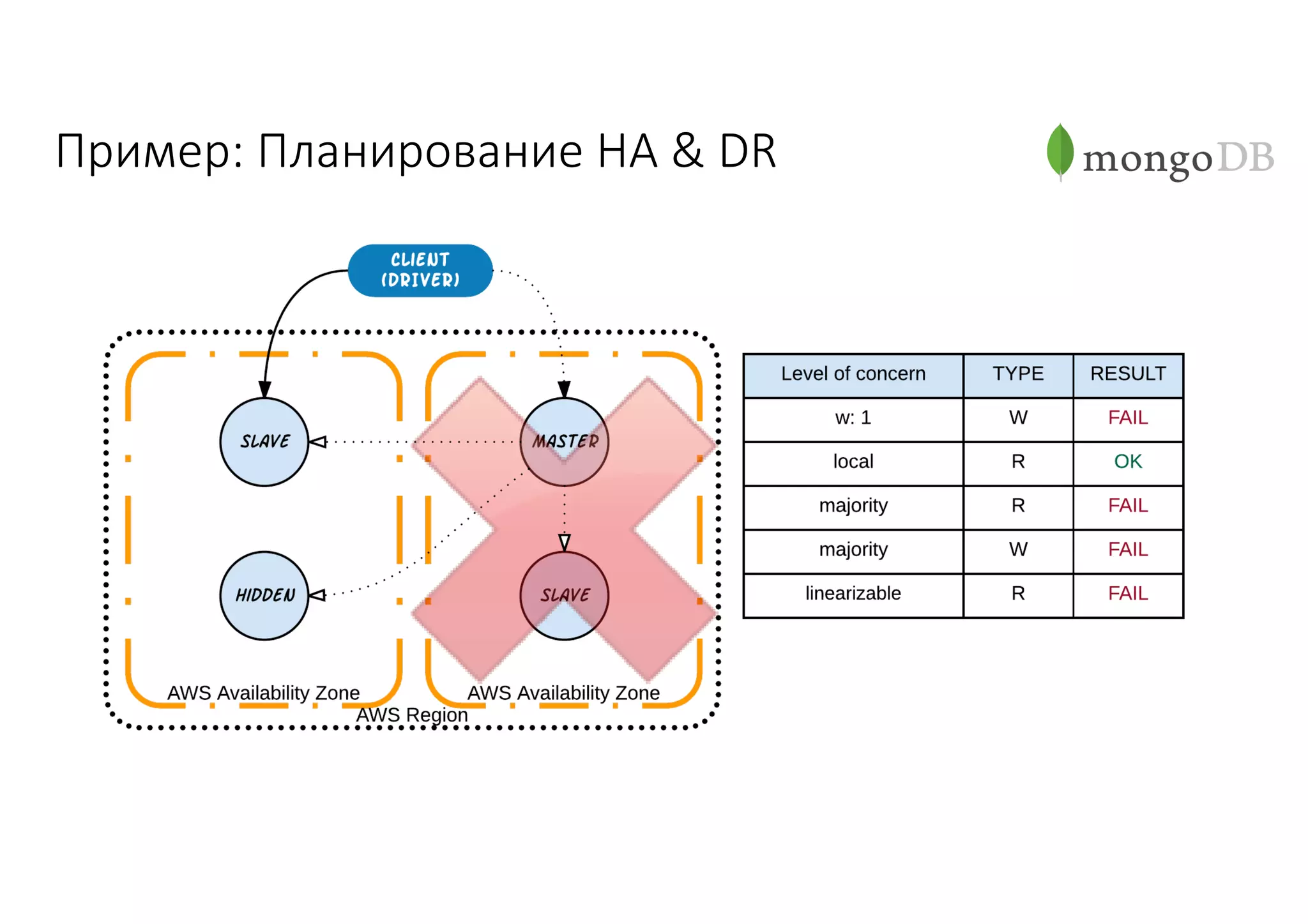
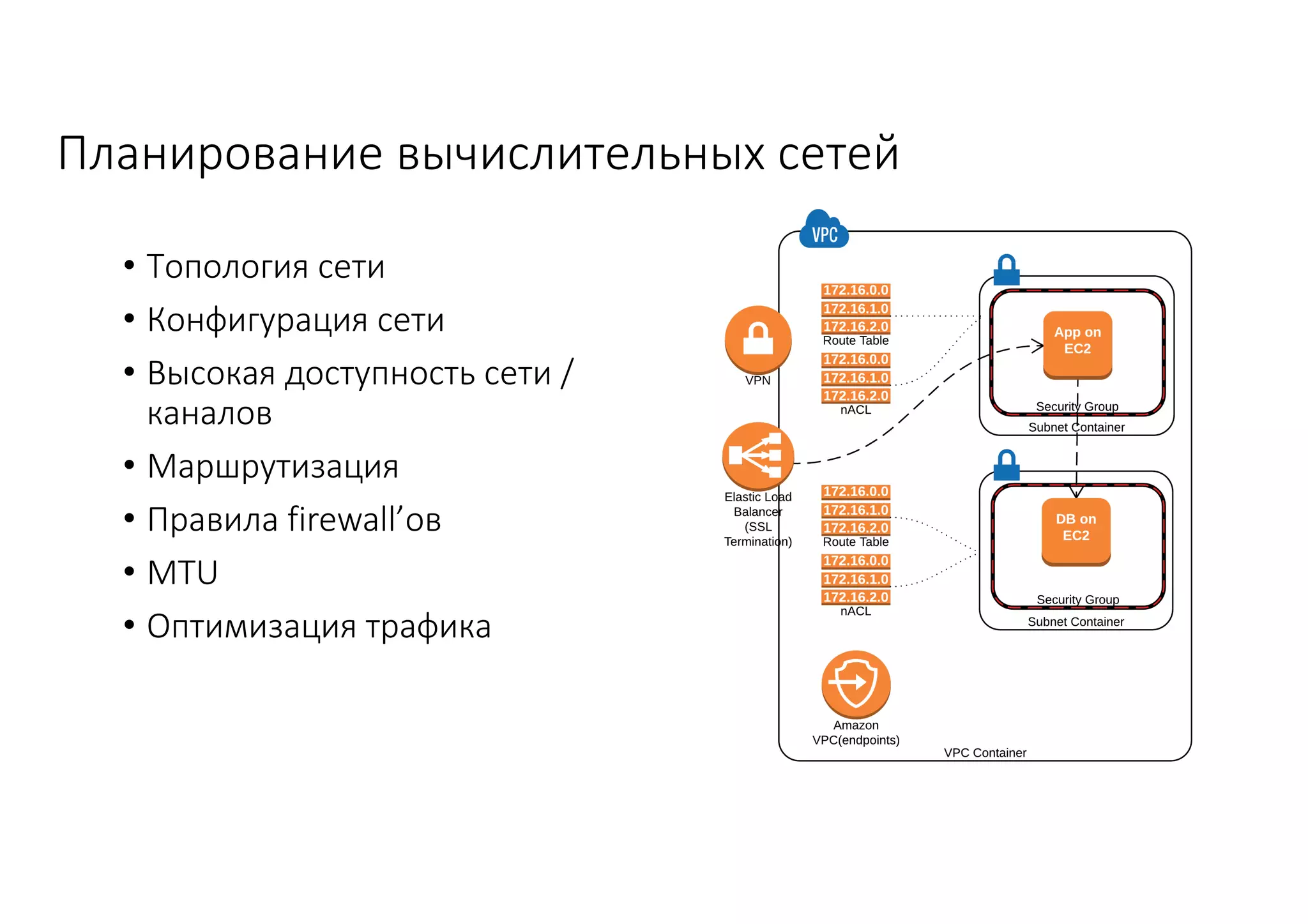
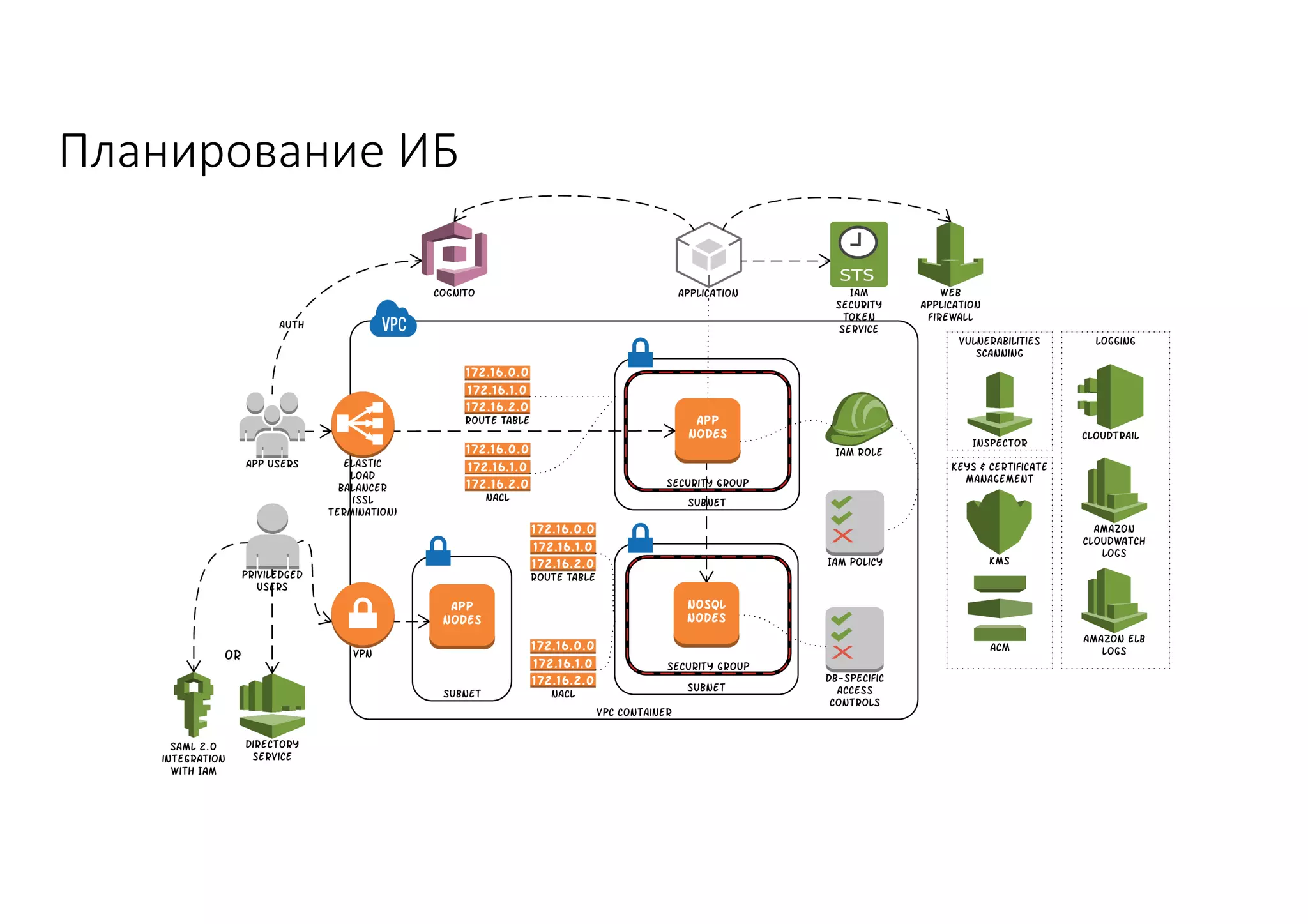

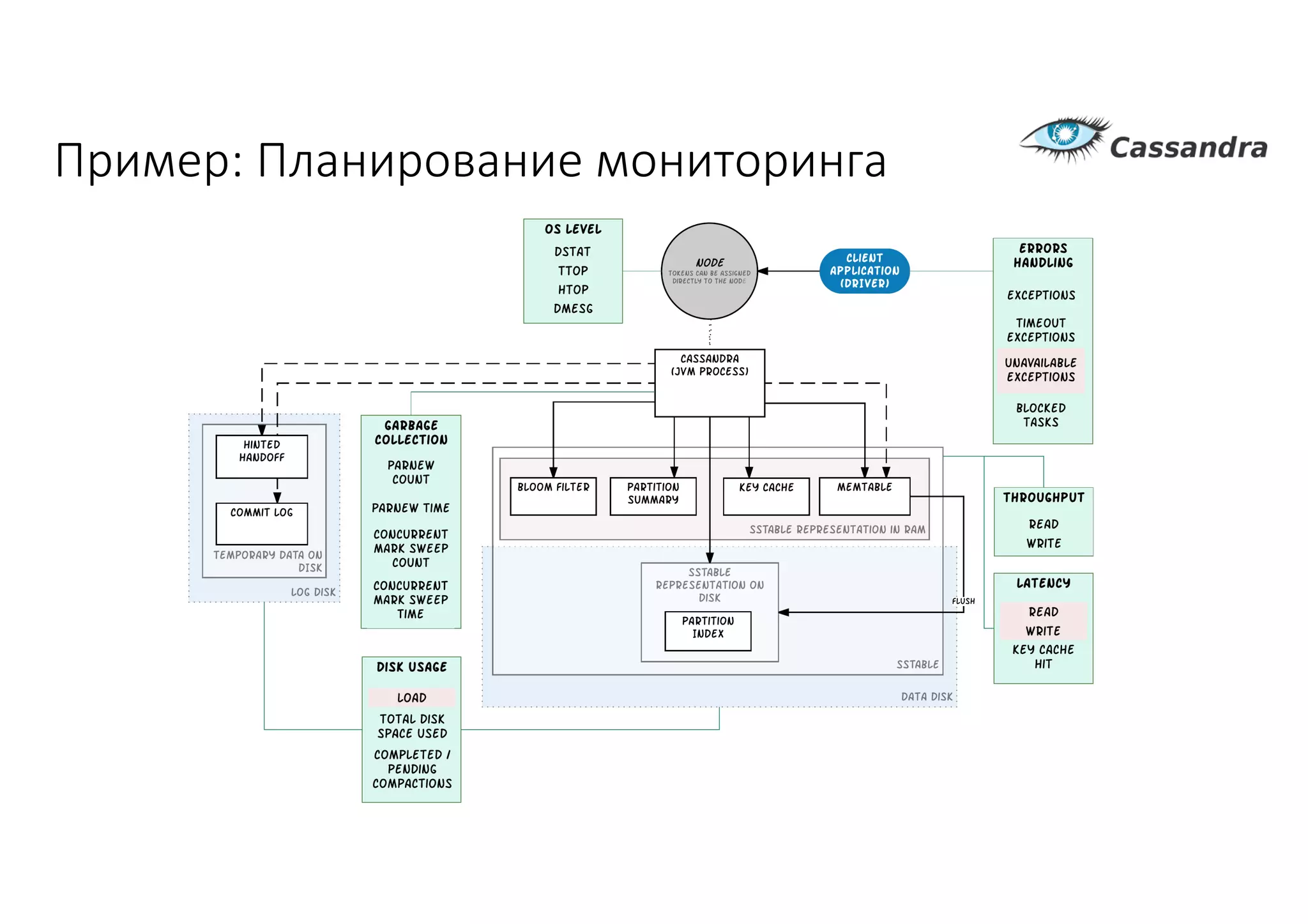
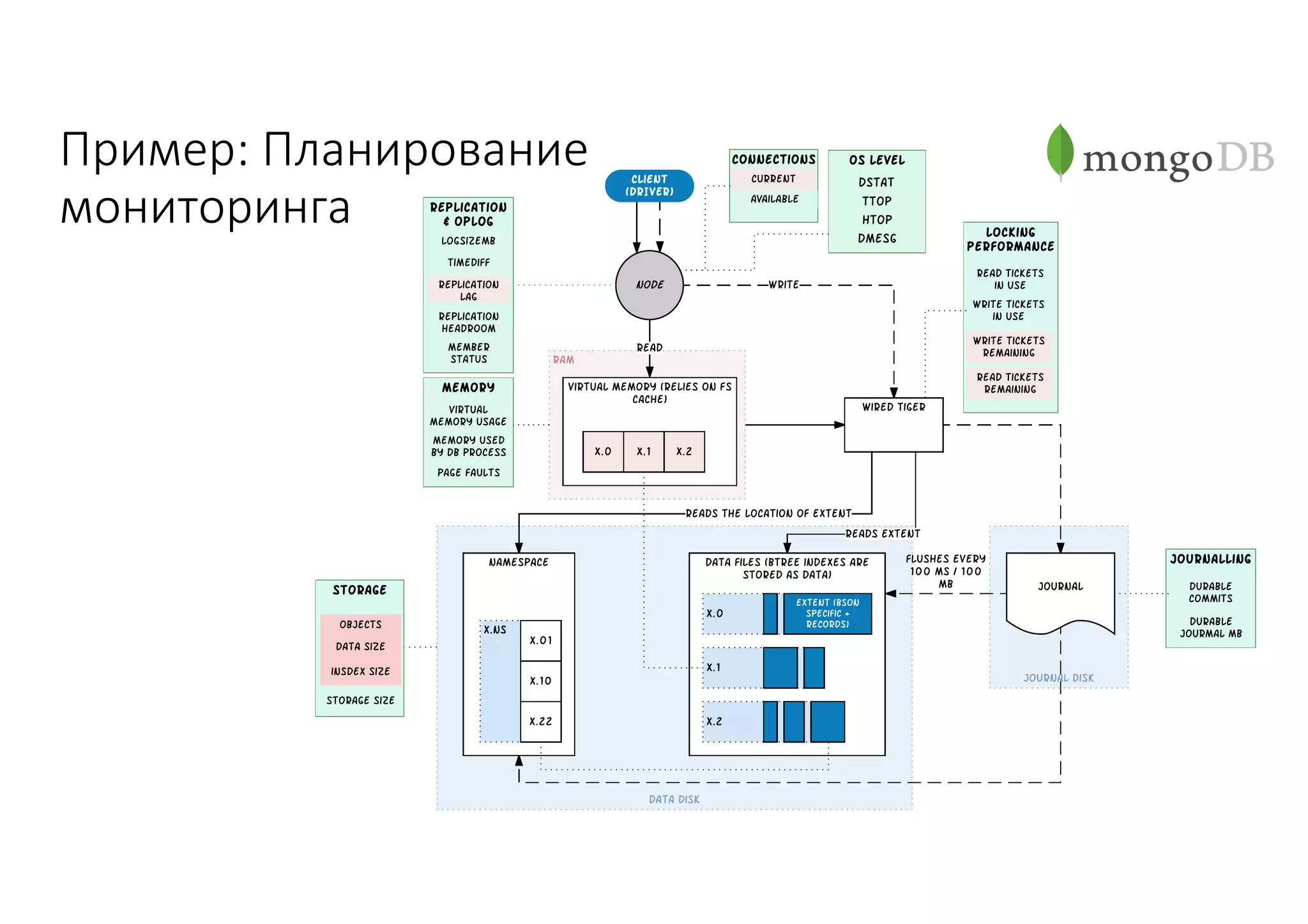





Документ рассматривает проектирование глобально распределенных кластеров NoSQL на платформе AWS, включая подходы к созданию систем и выбор технологий, таких как Cassandra и MongoDB. Обсуждаются причины, по которым появились распределенные NoSQL базы данных, и предоставляются практические рекомендации по проектированию схем данных, их взаимодействию с приложениями и планированию мониторинга. В заключении подчеркивается важность адаптации решений к специфике каждого проекта и проведение пробного тестирования выбранной технологии.


































