Download to read offline




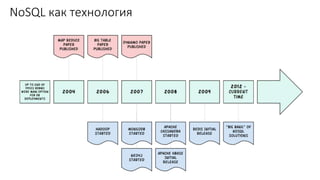




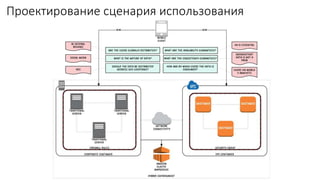
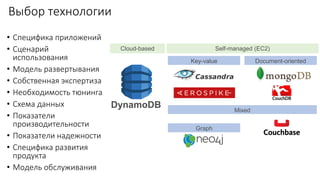

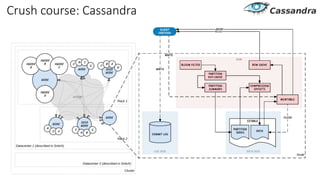
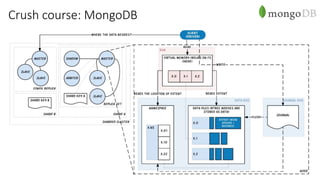

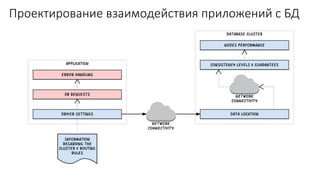
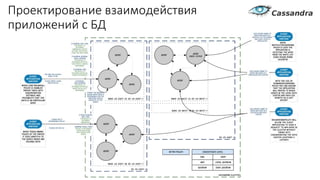
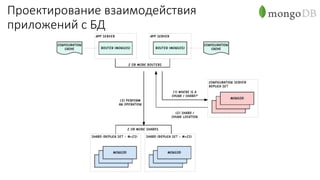
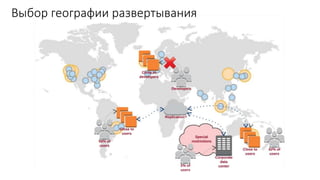
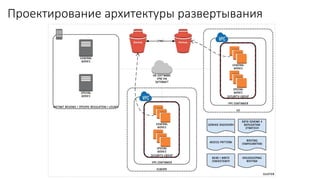
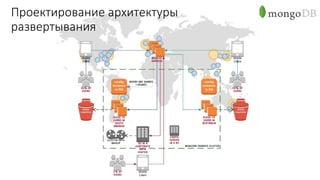
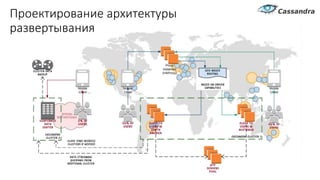

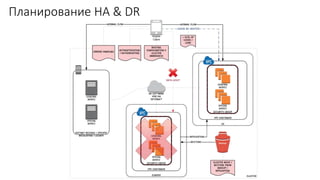
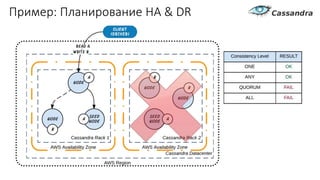
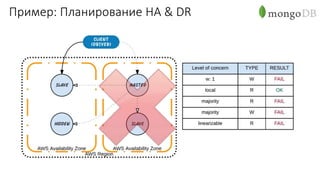
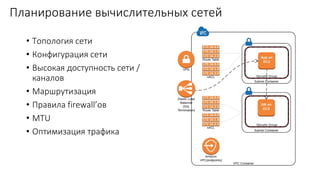
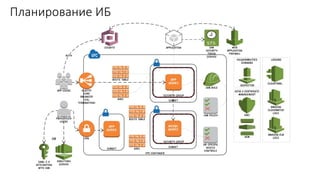

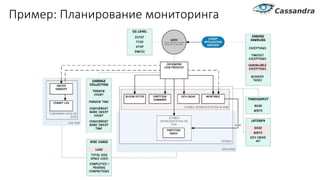
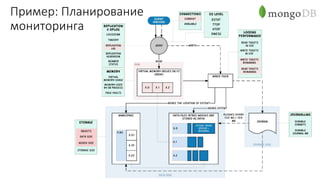







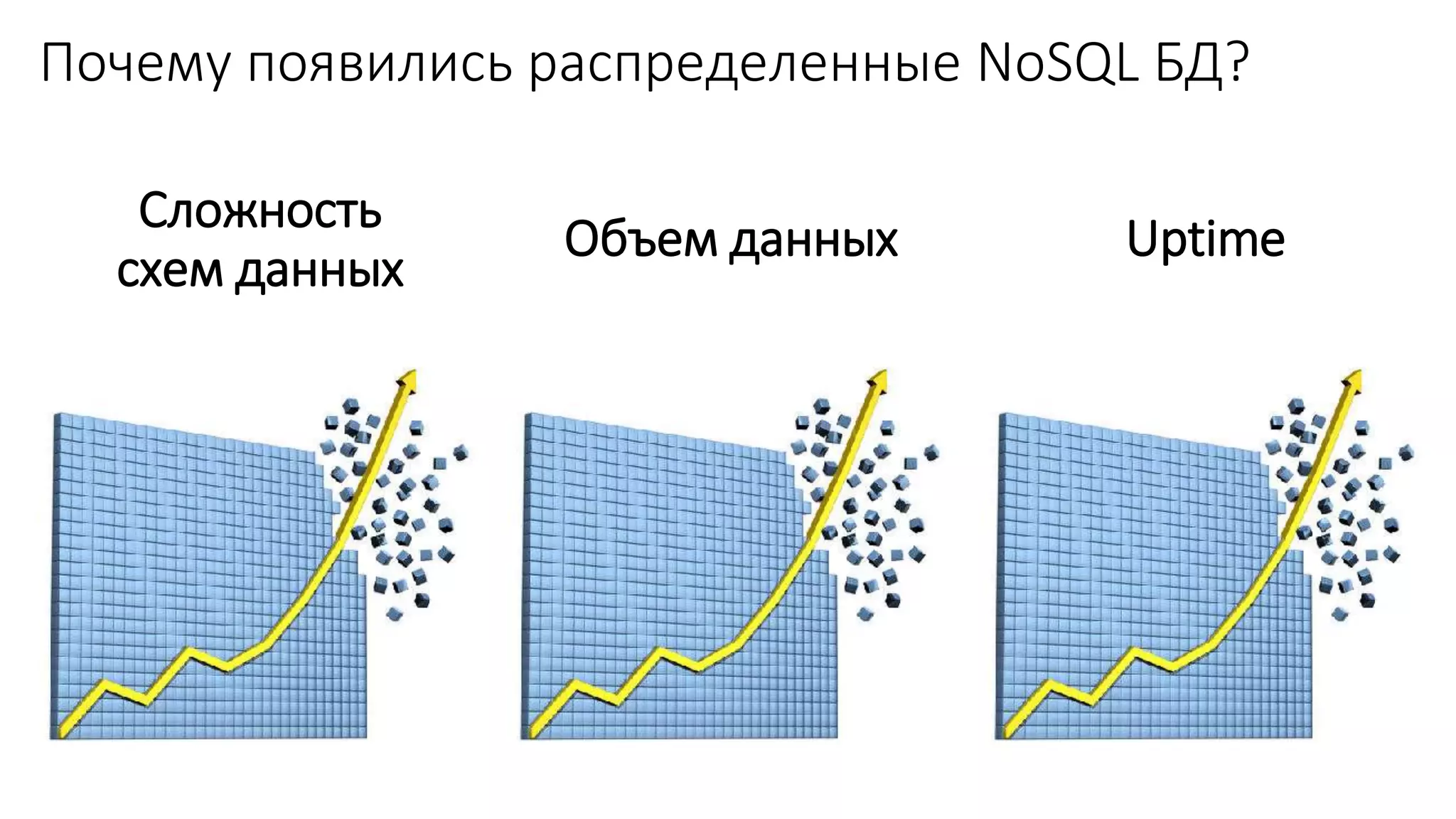
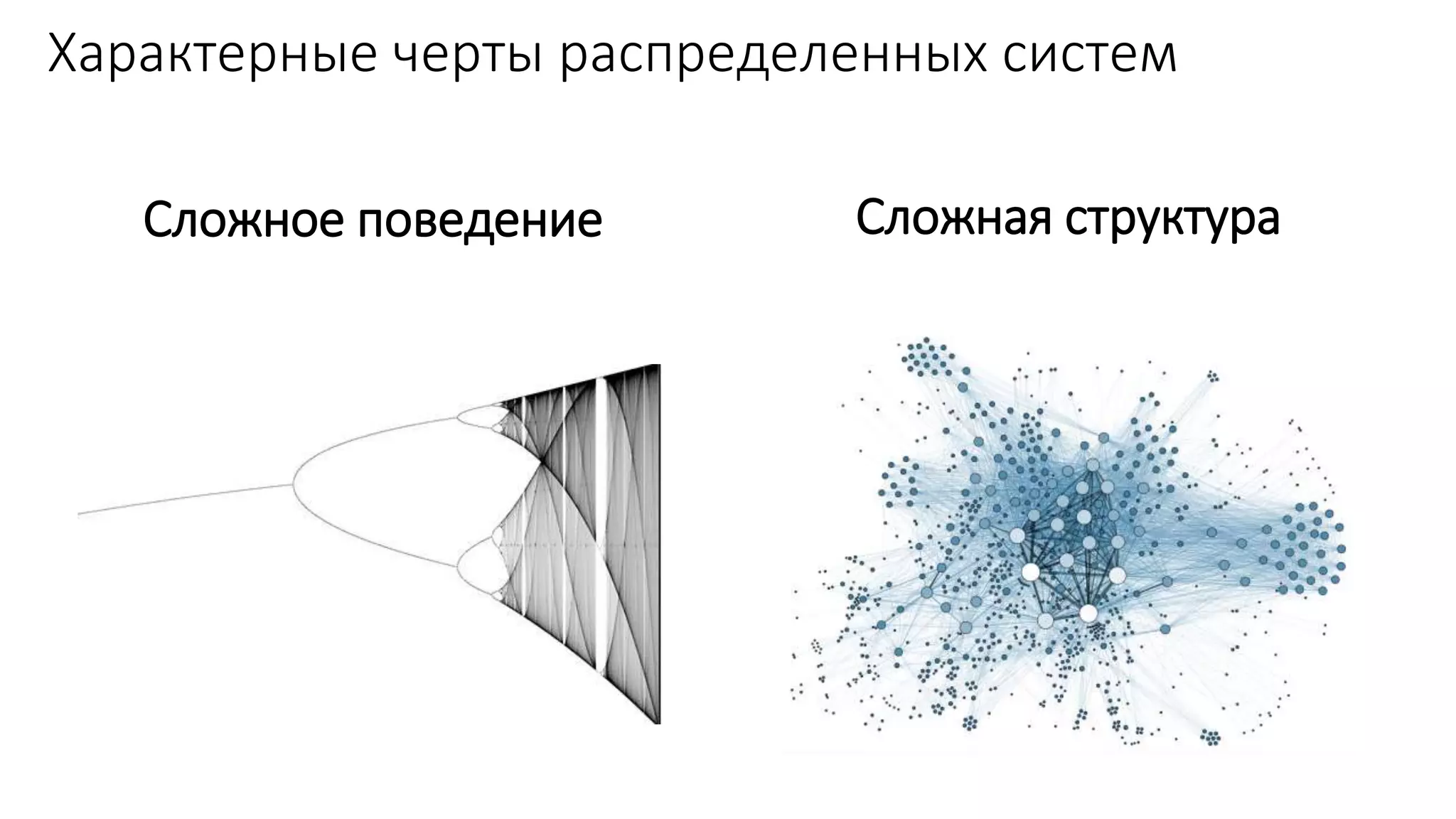
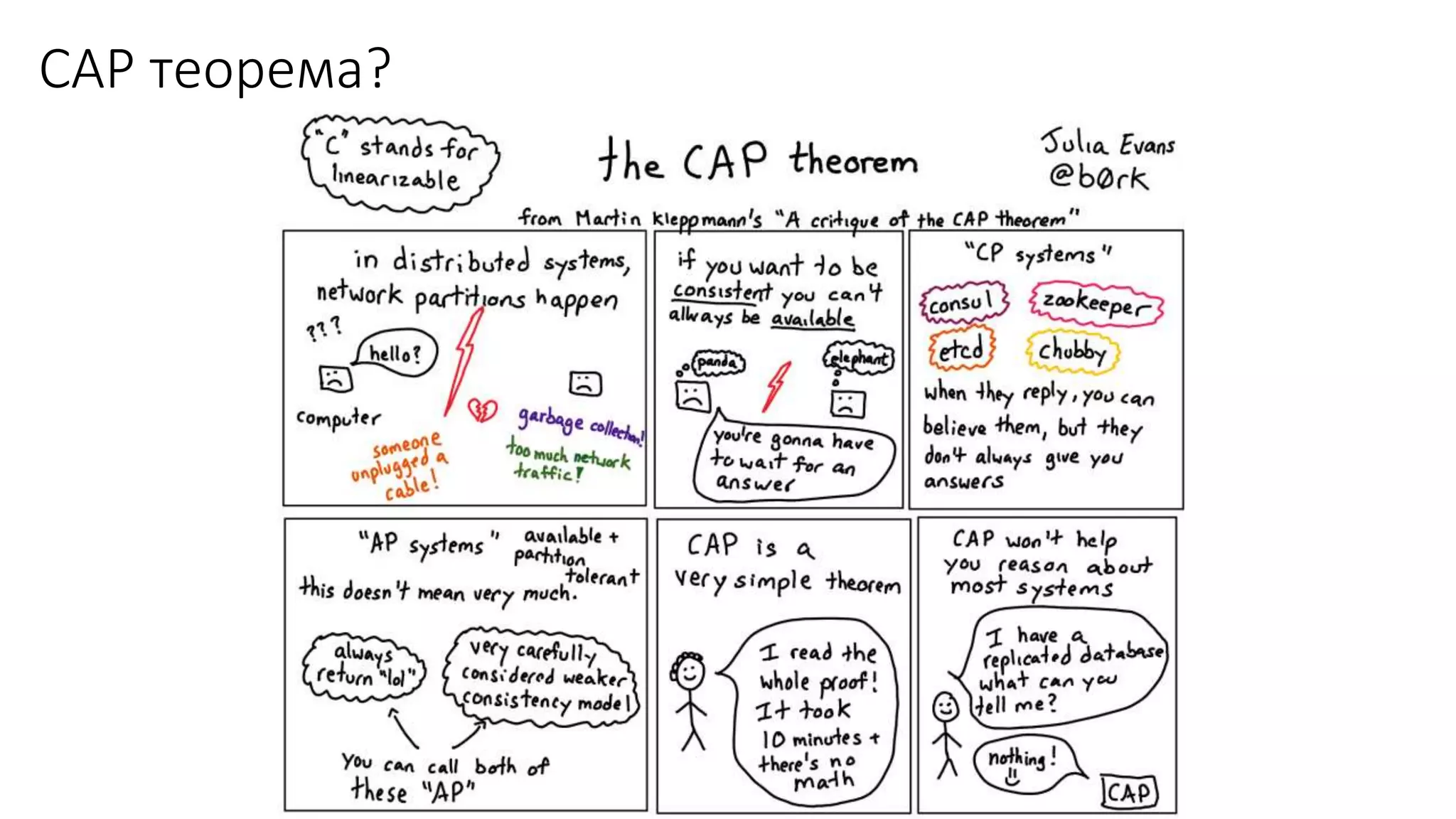
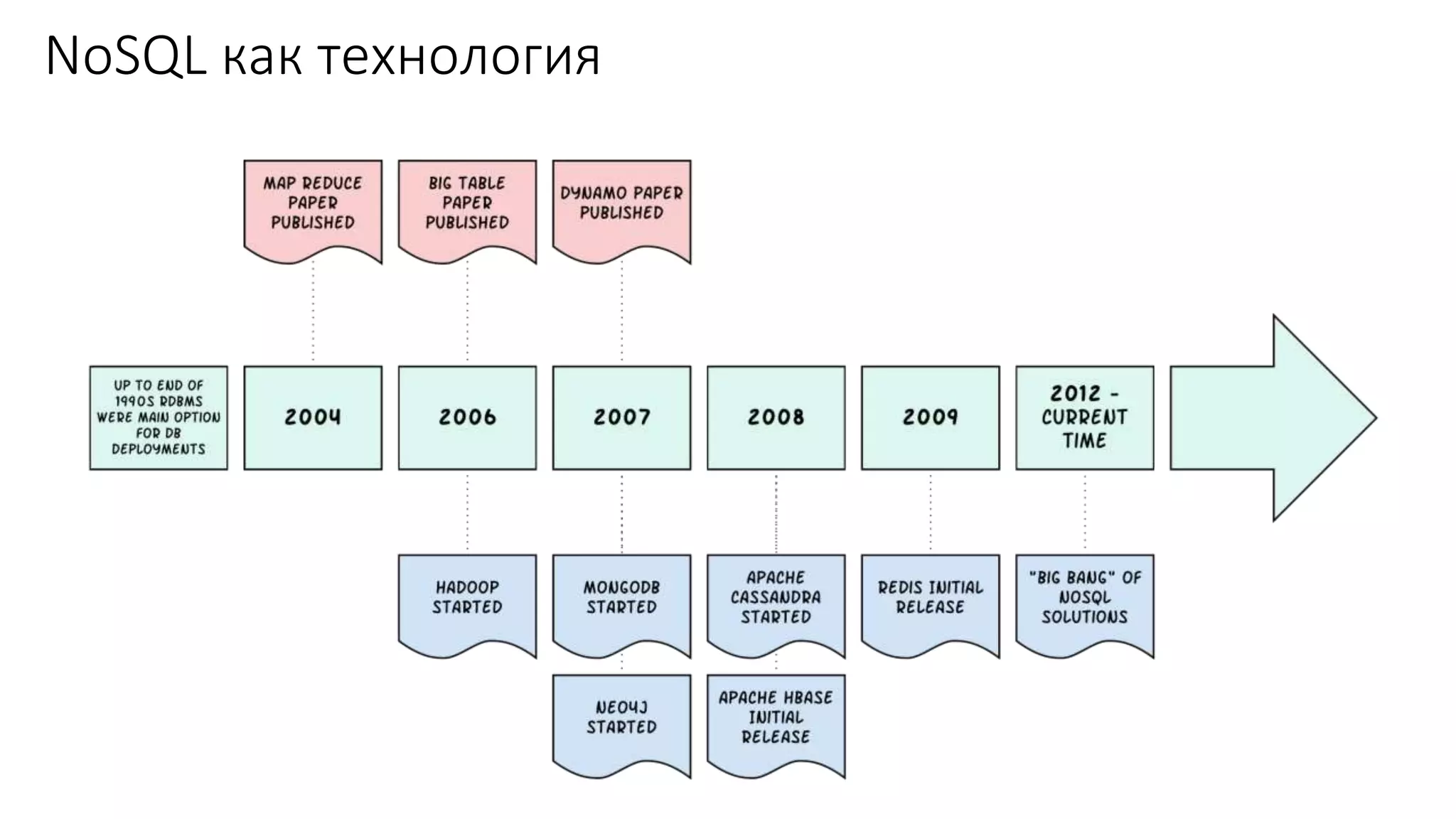

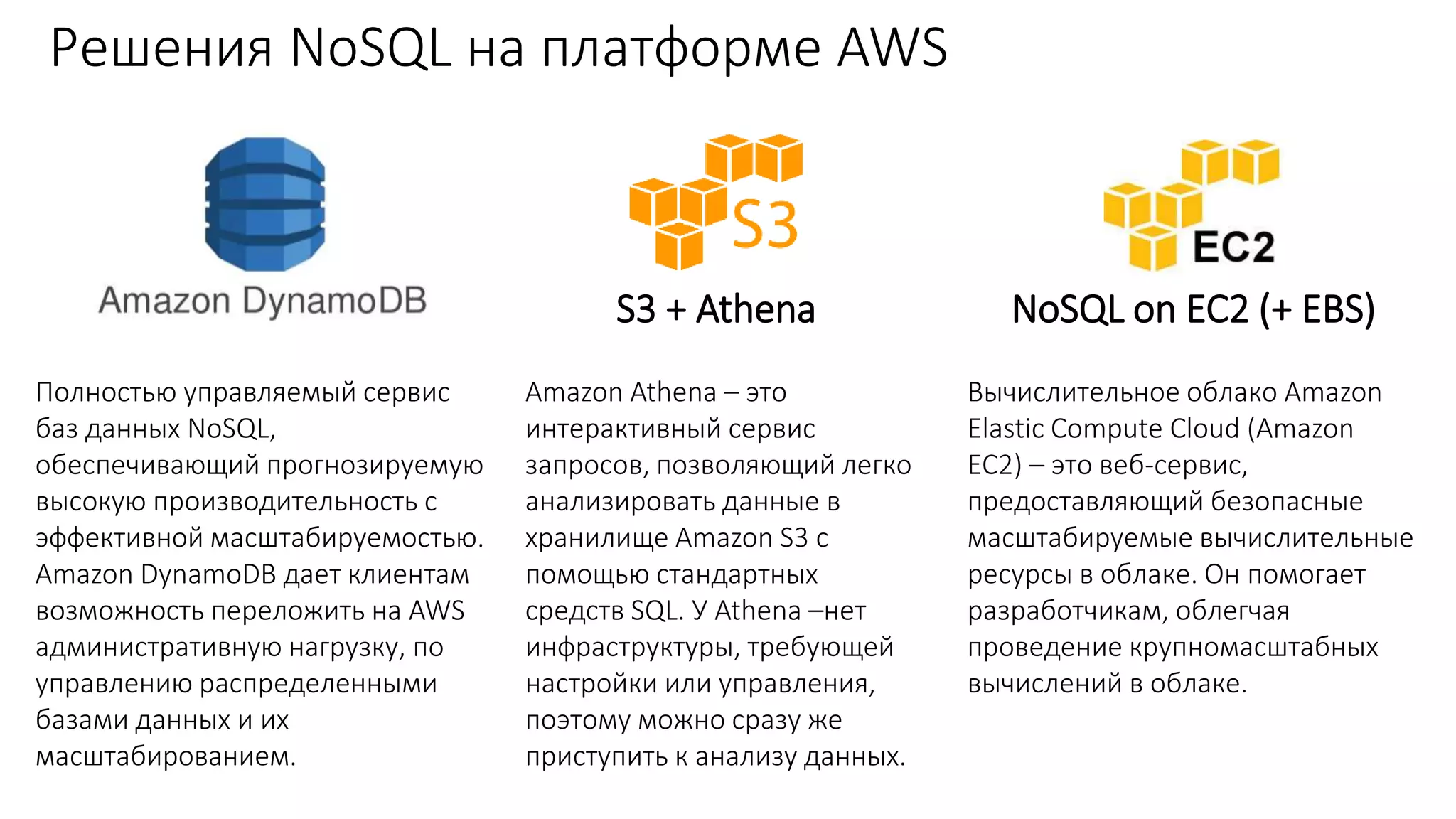


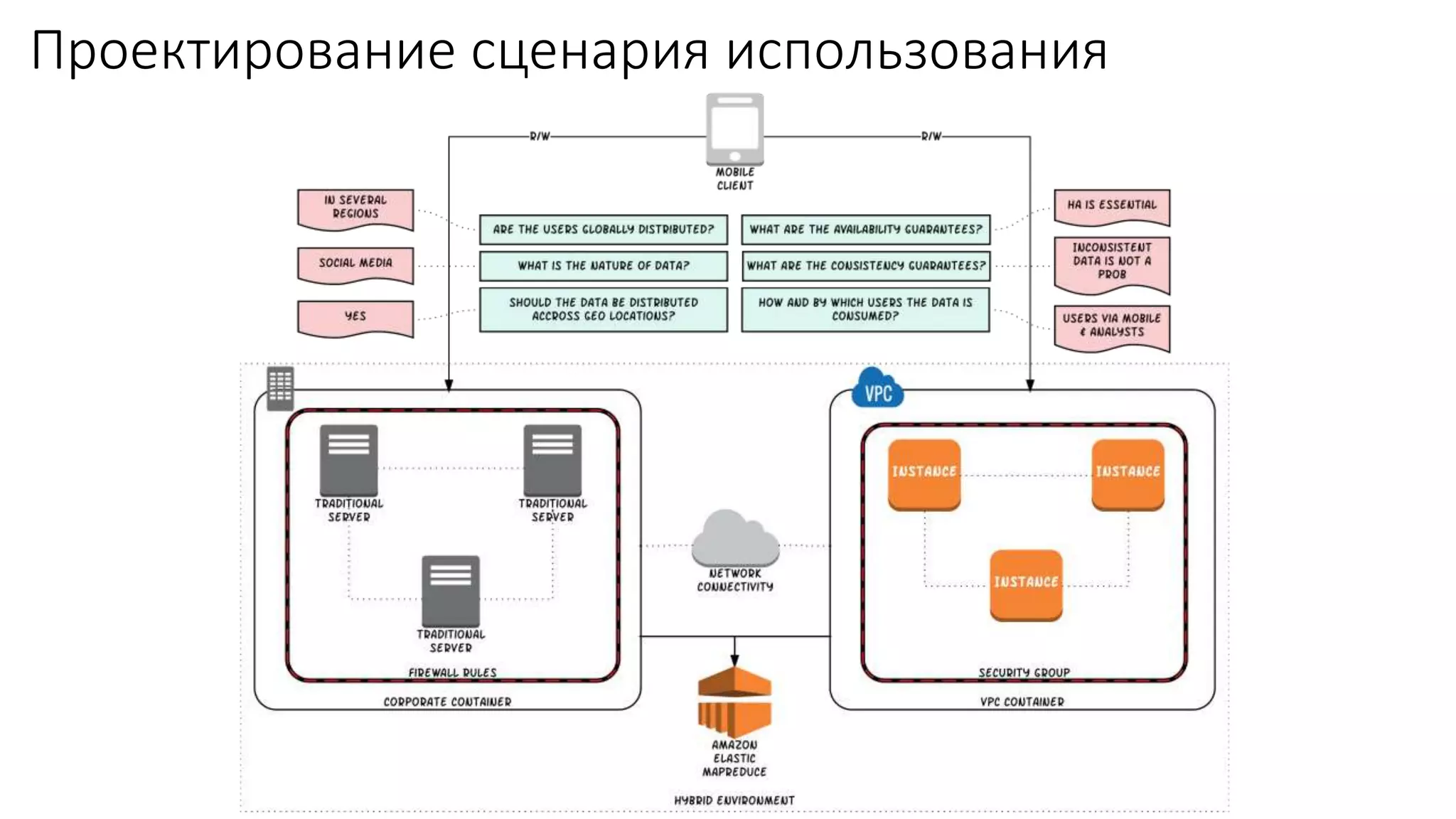
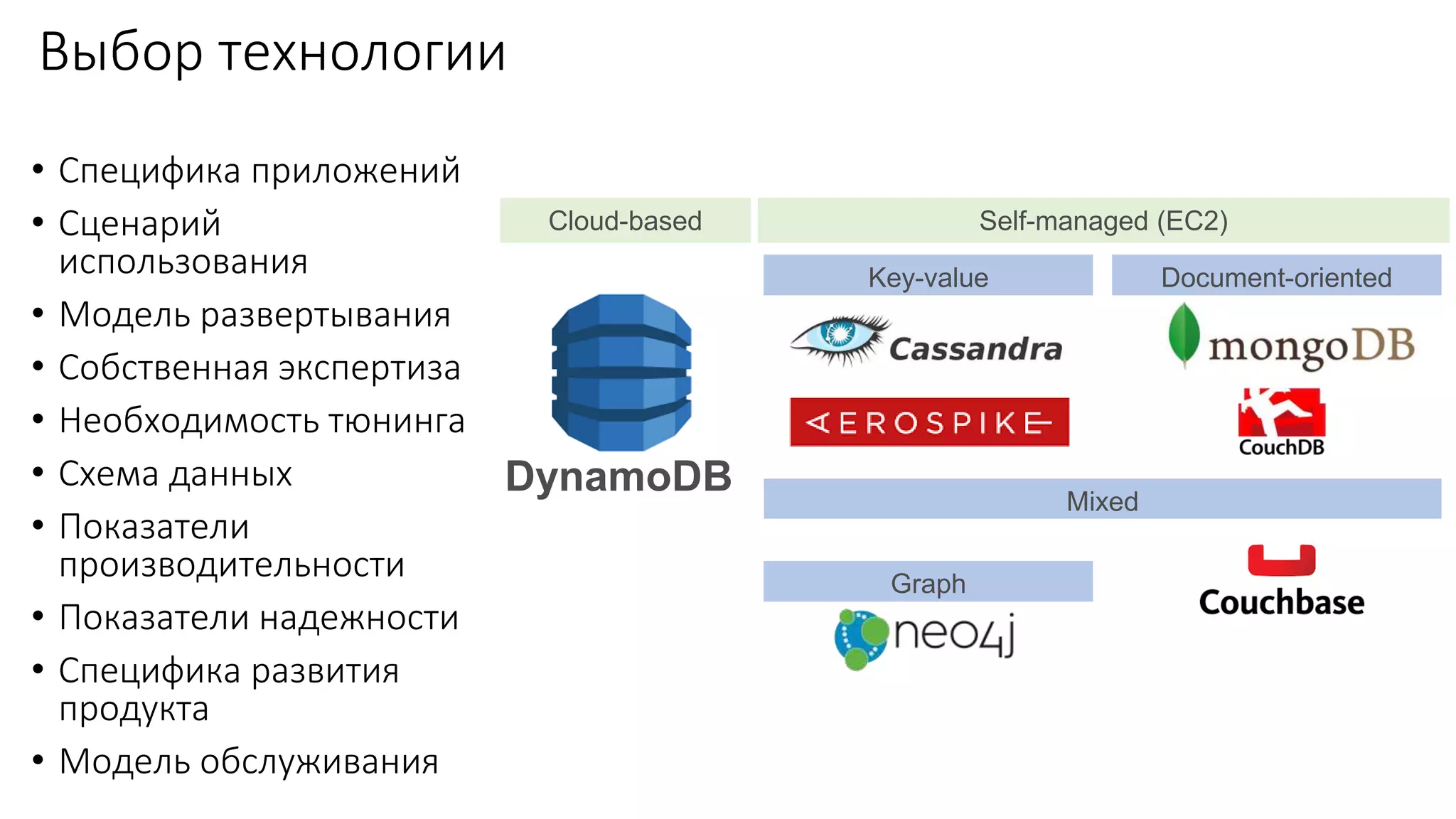

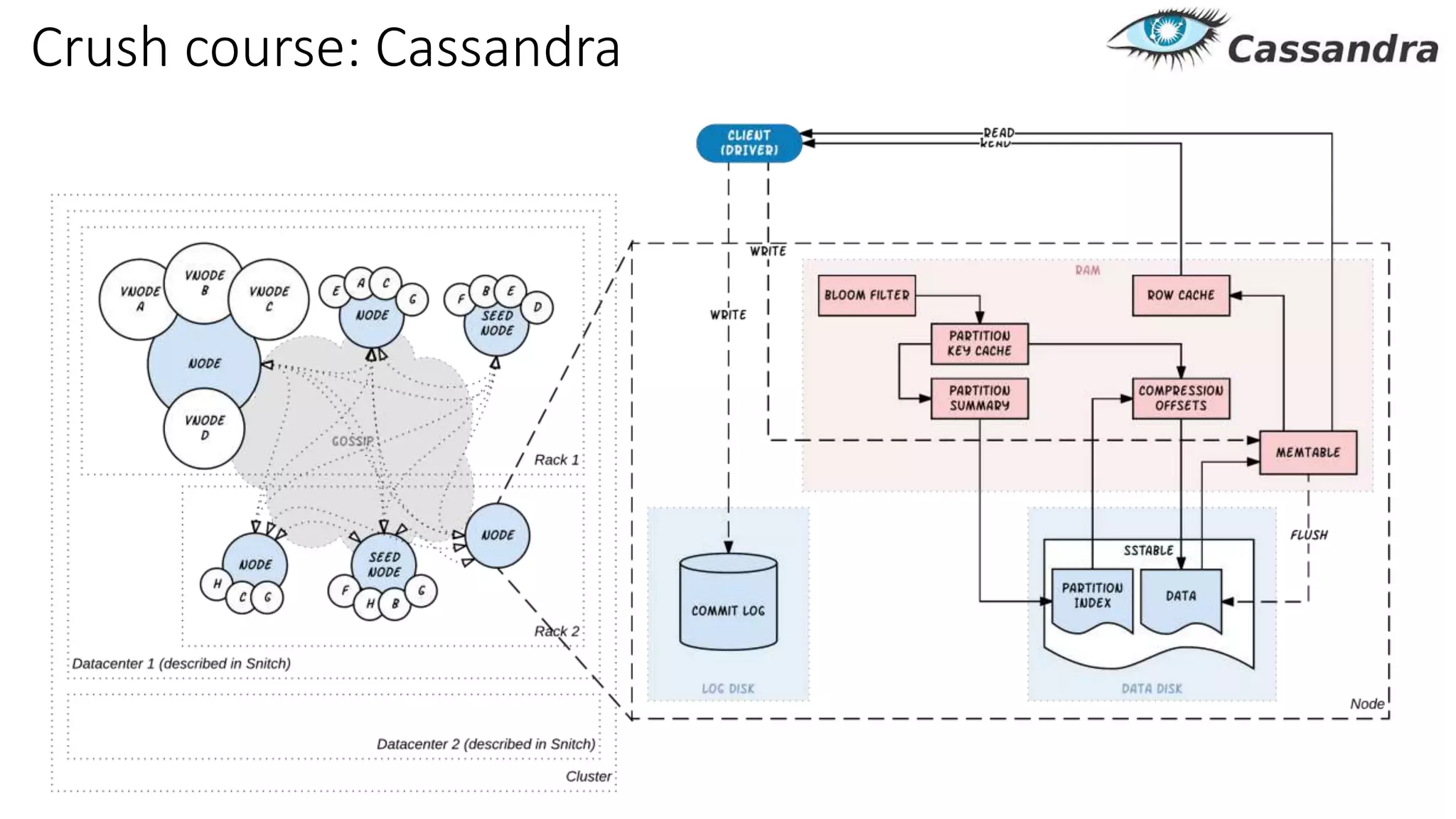
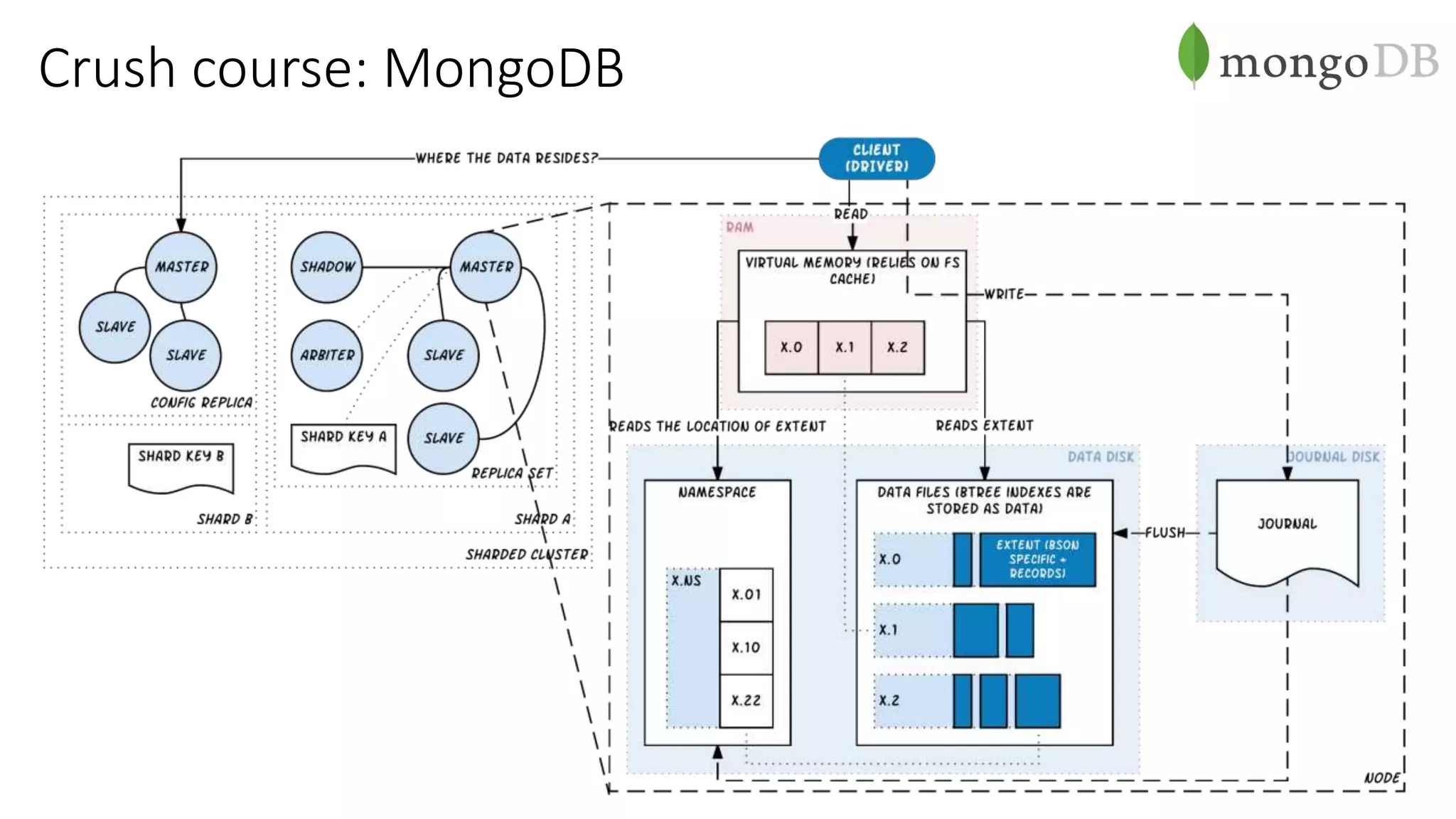

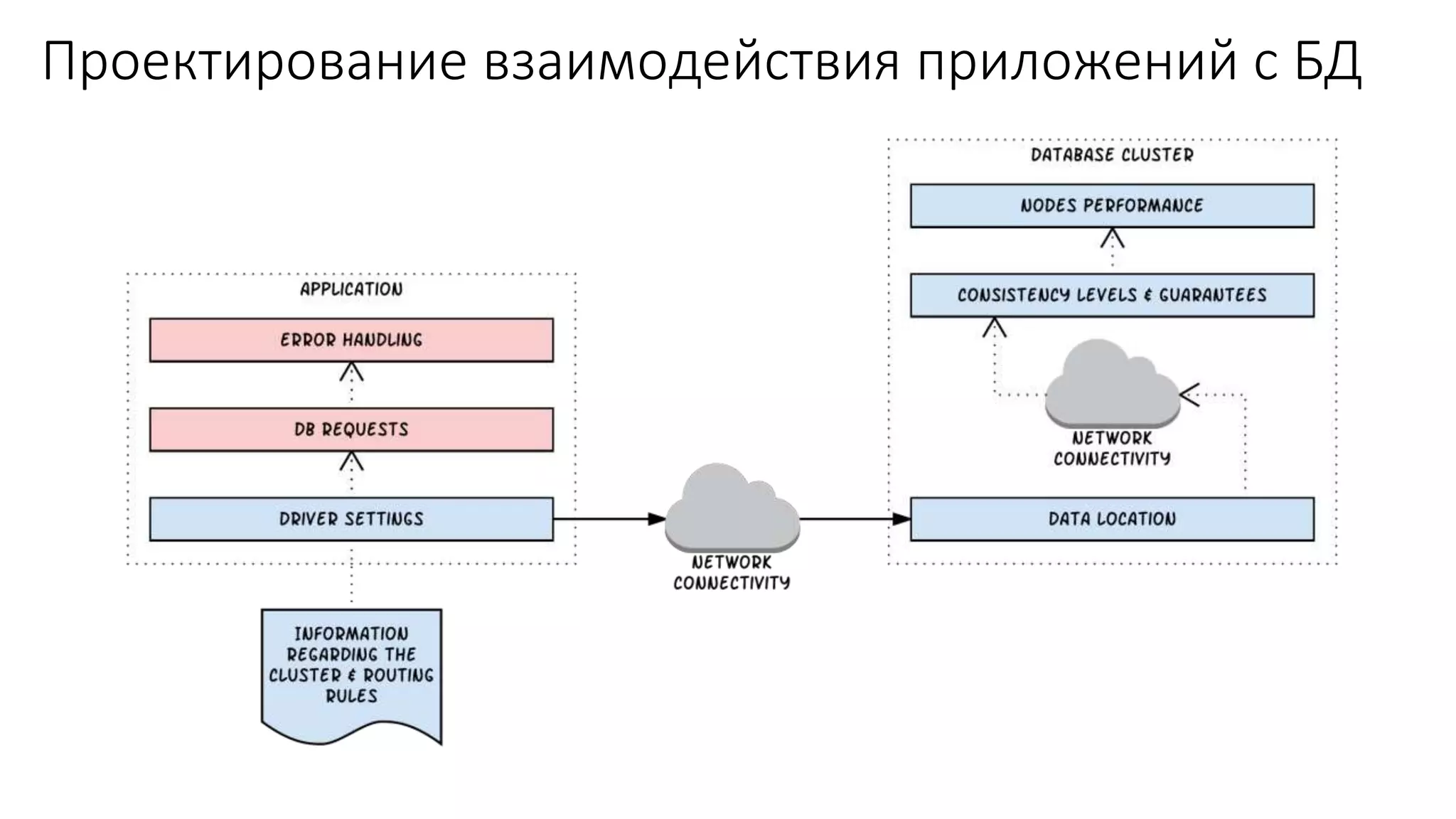
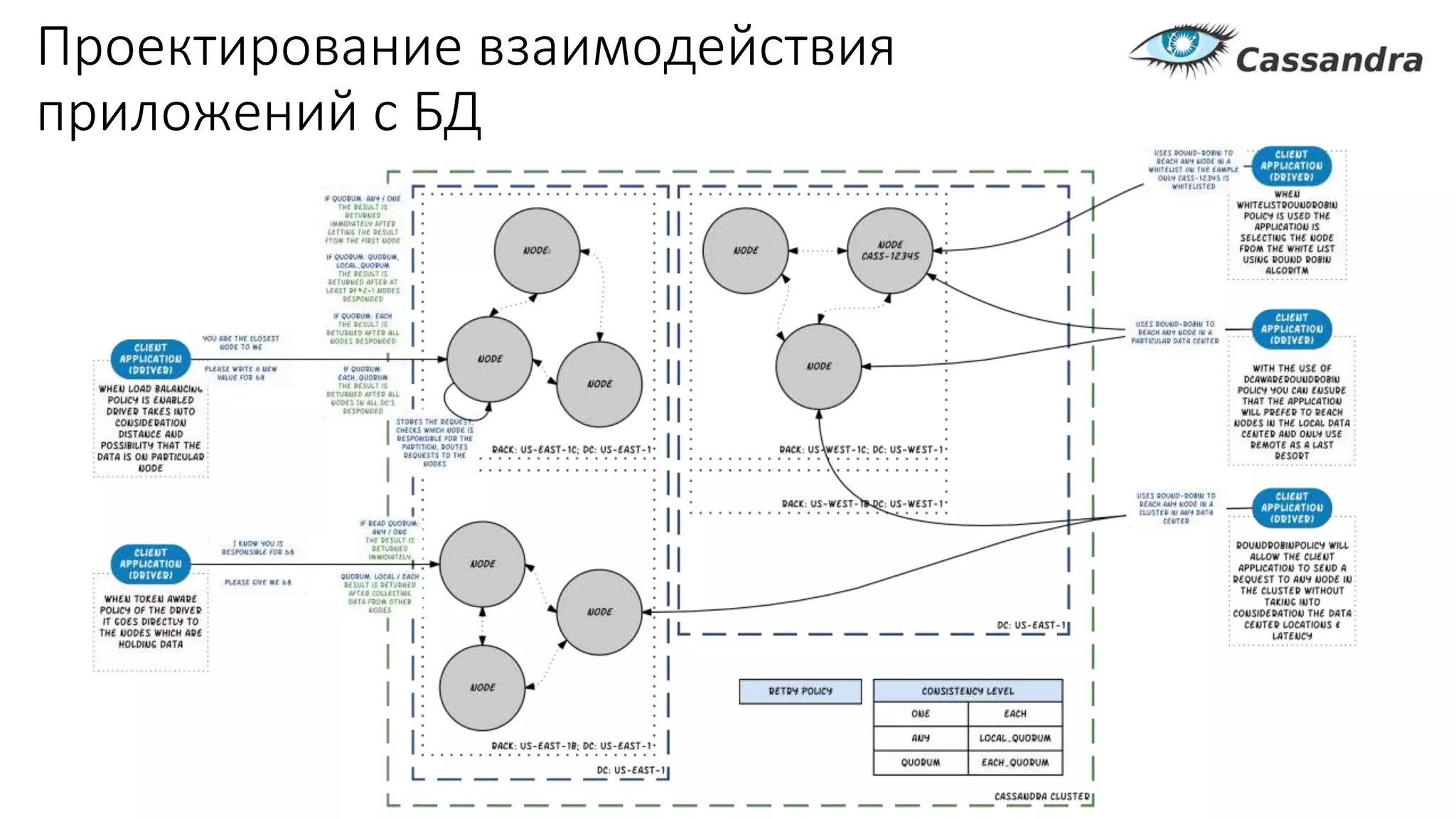
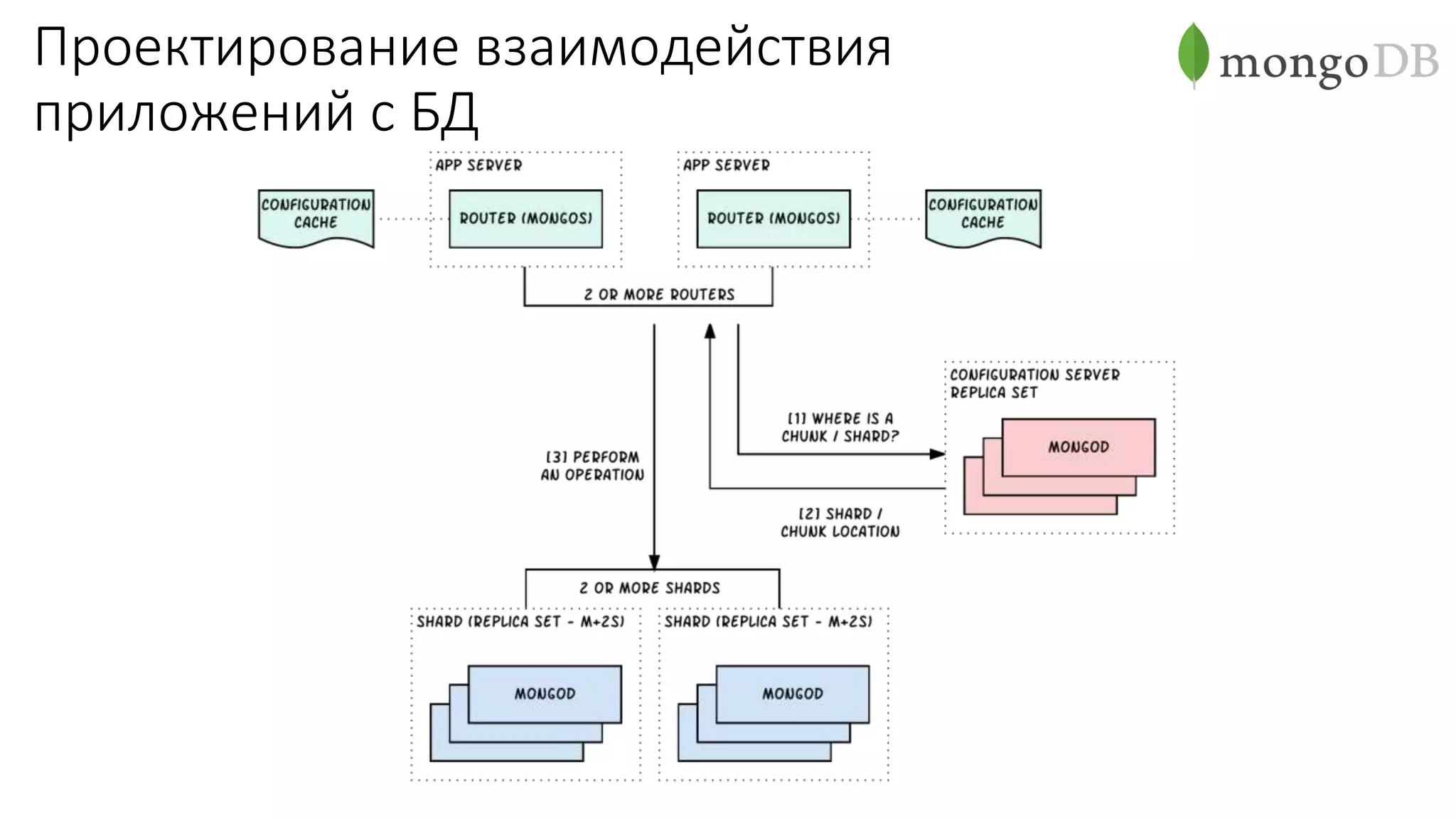
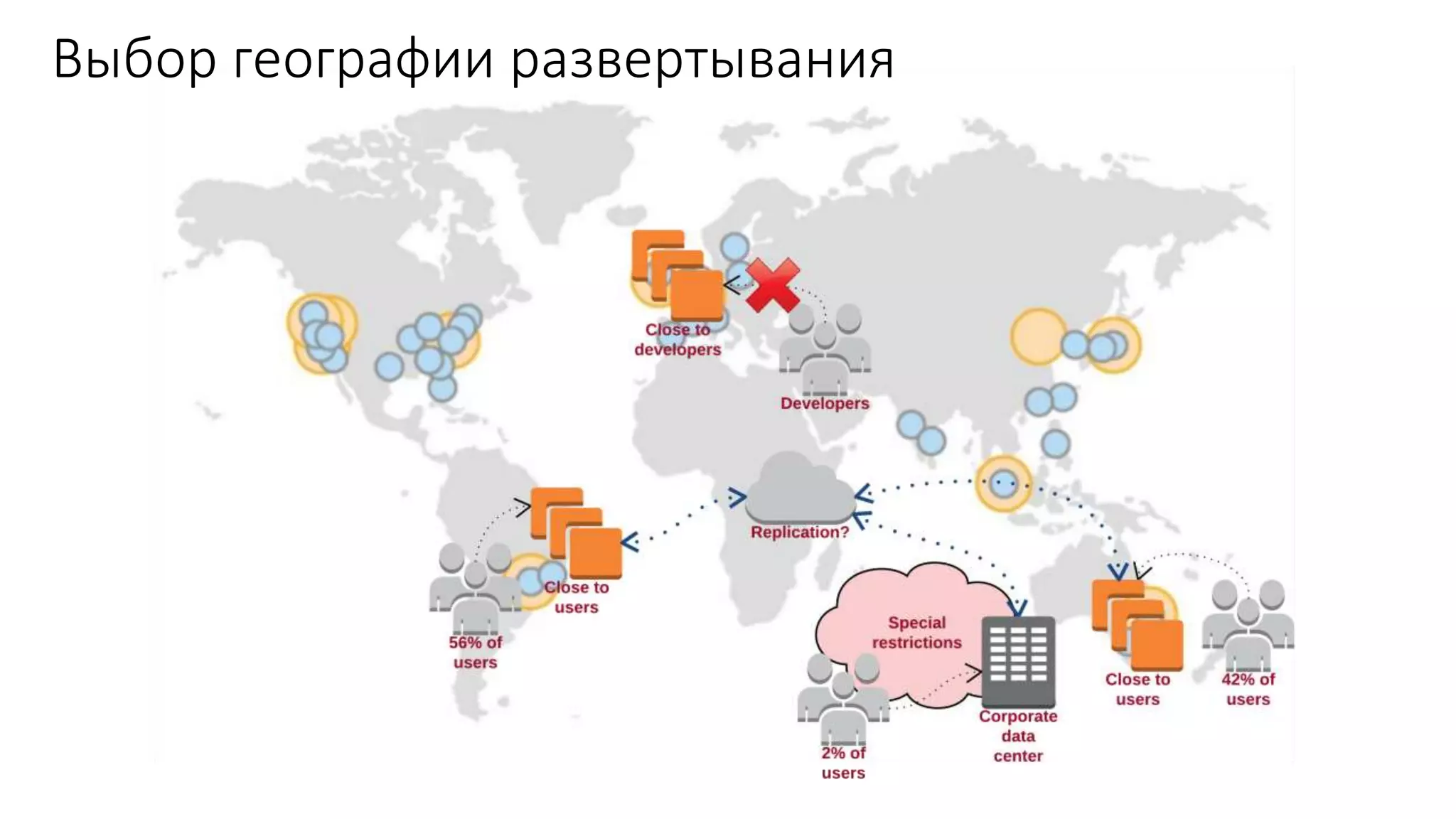
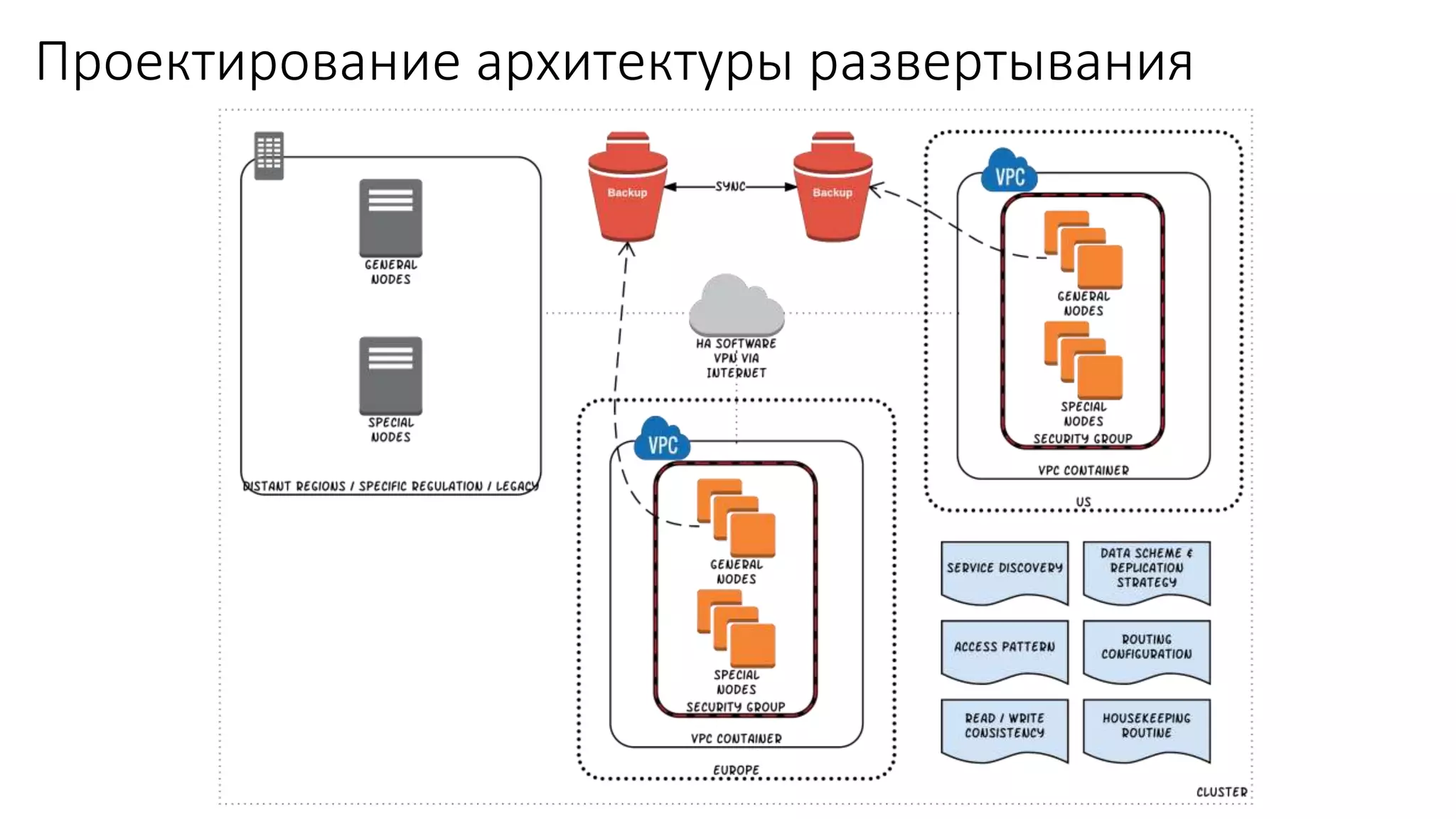
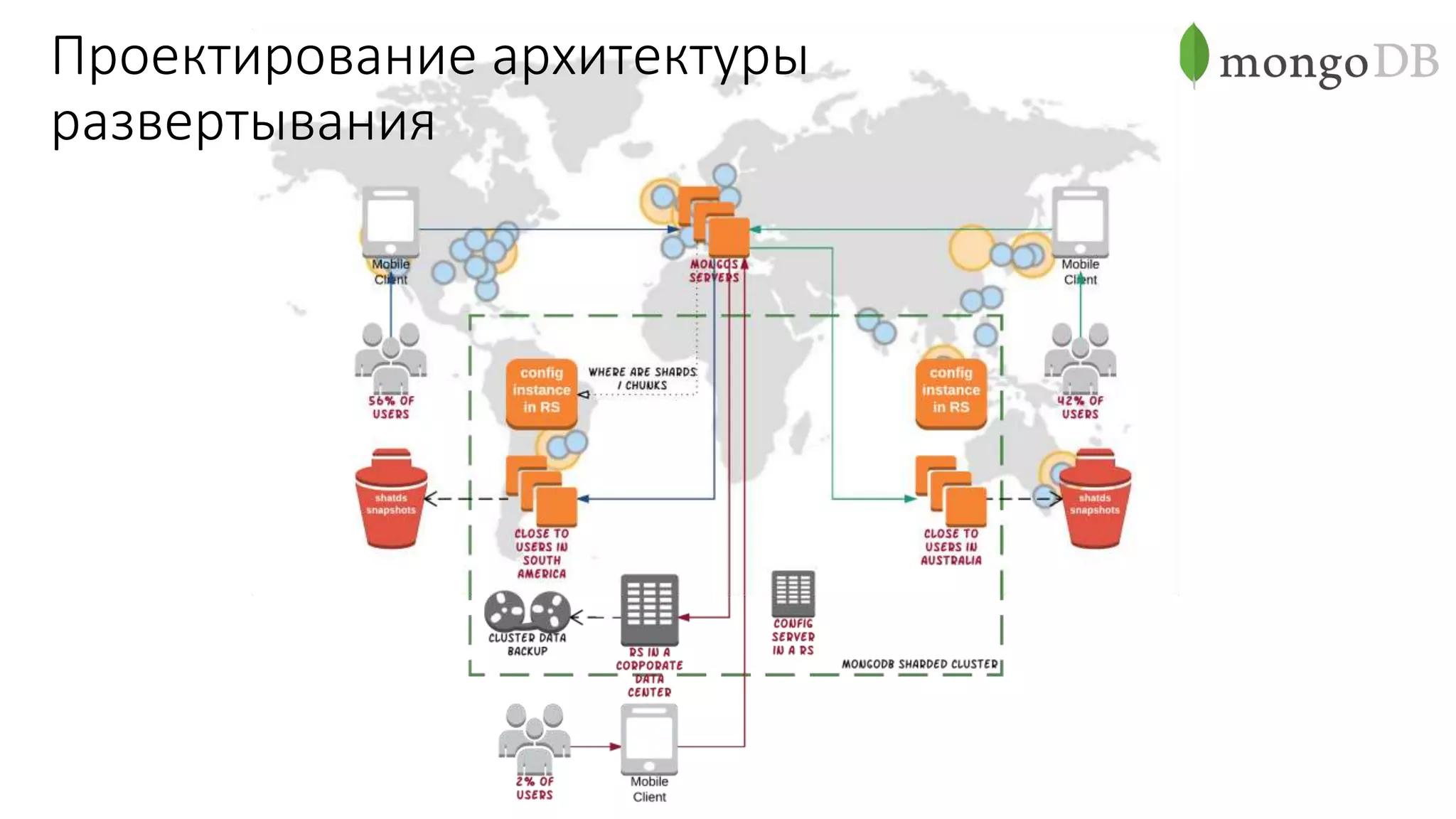
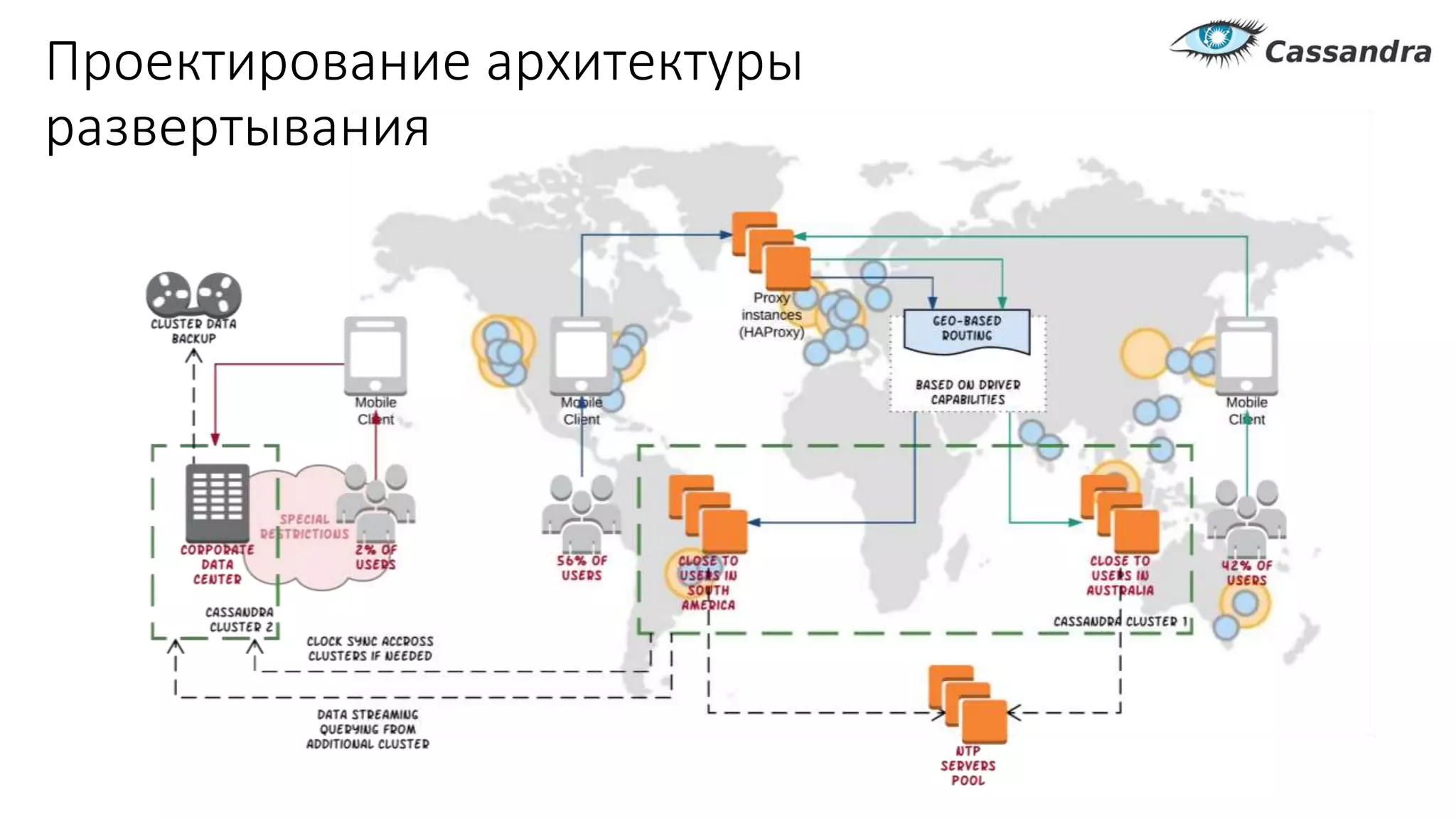
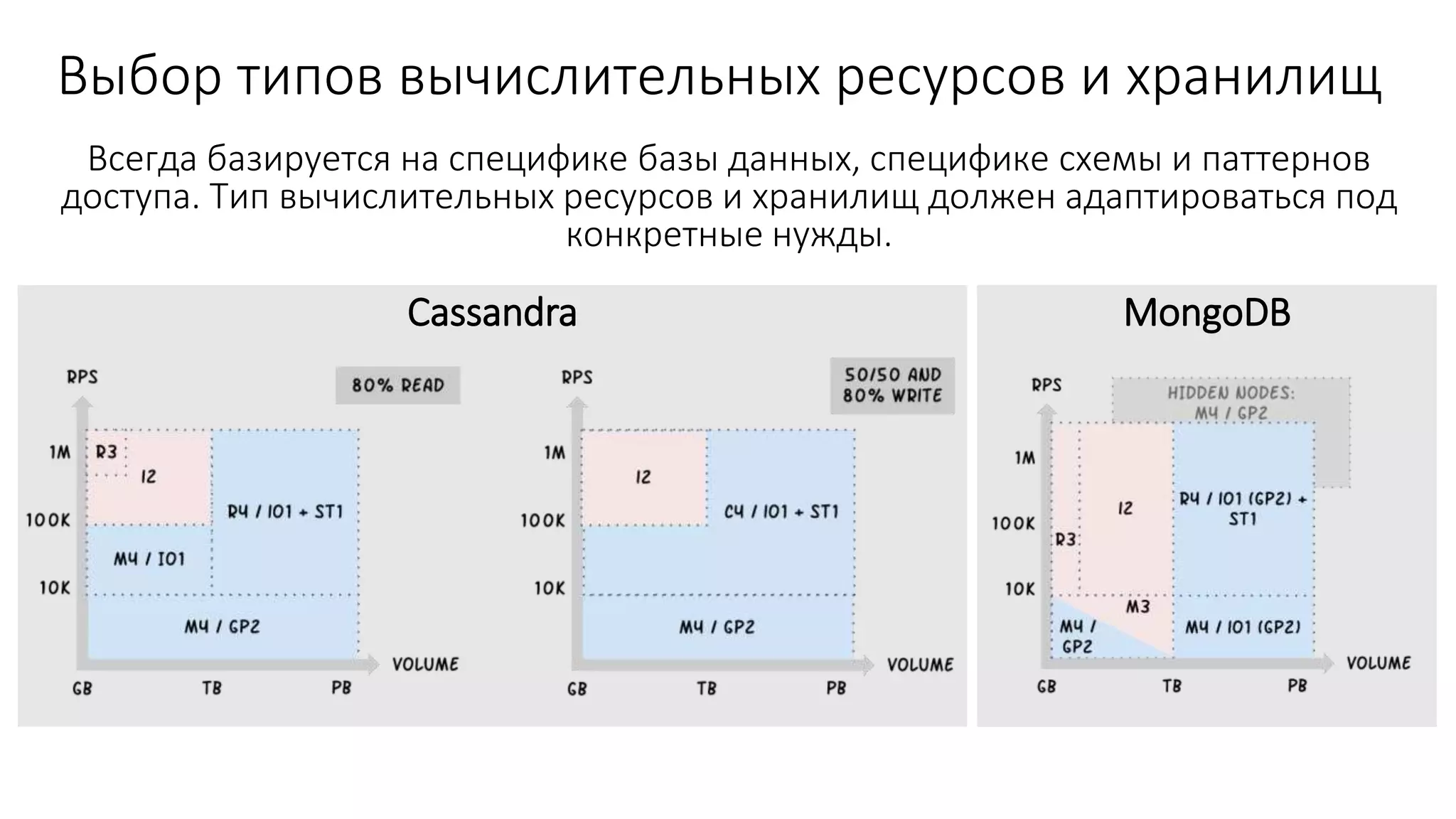
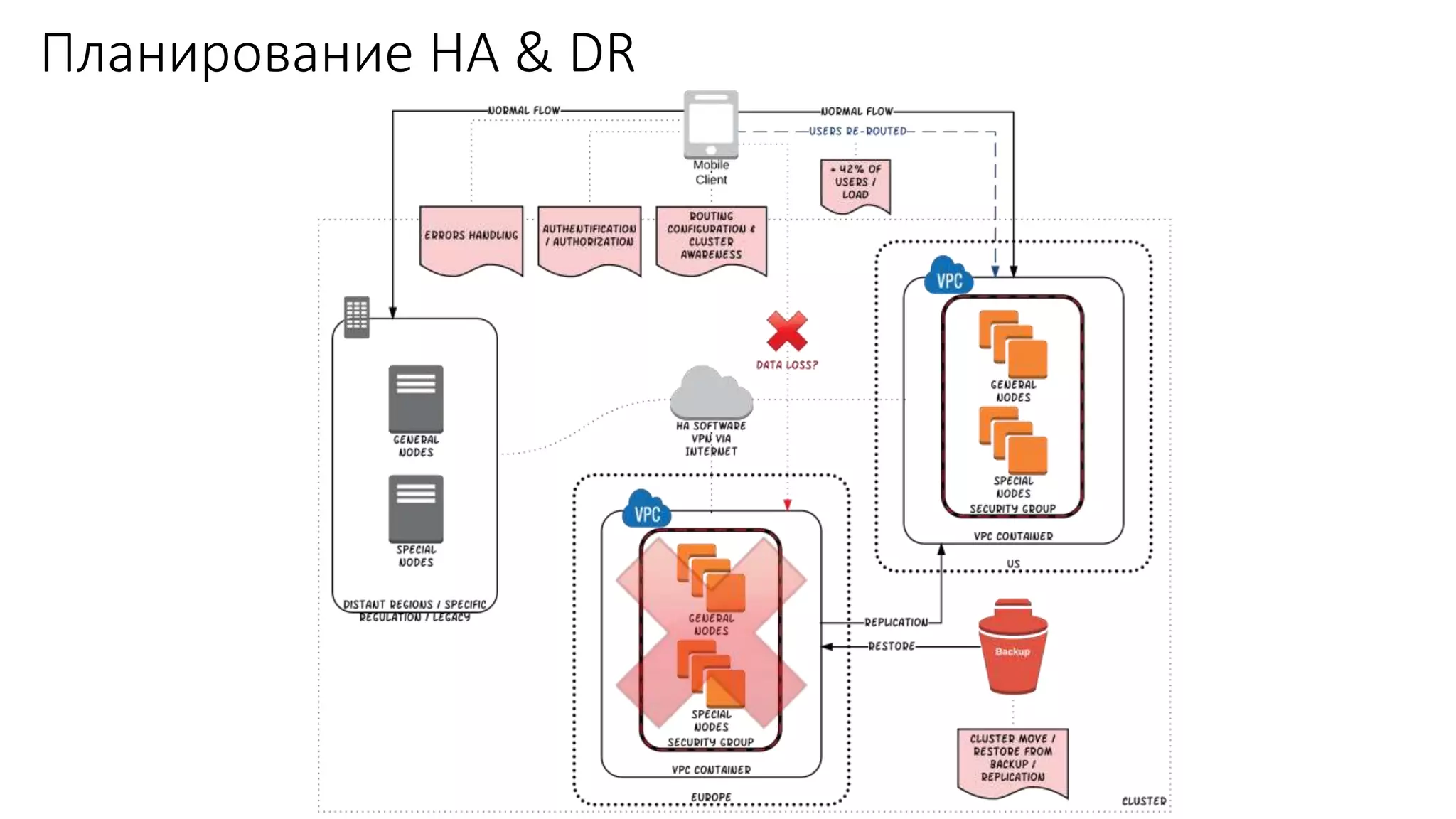
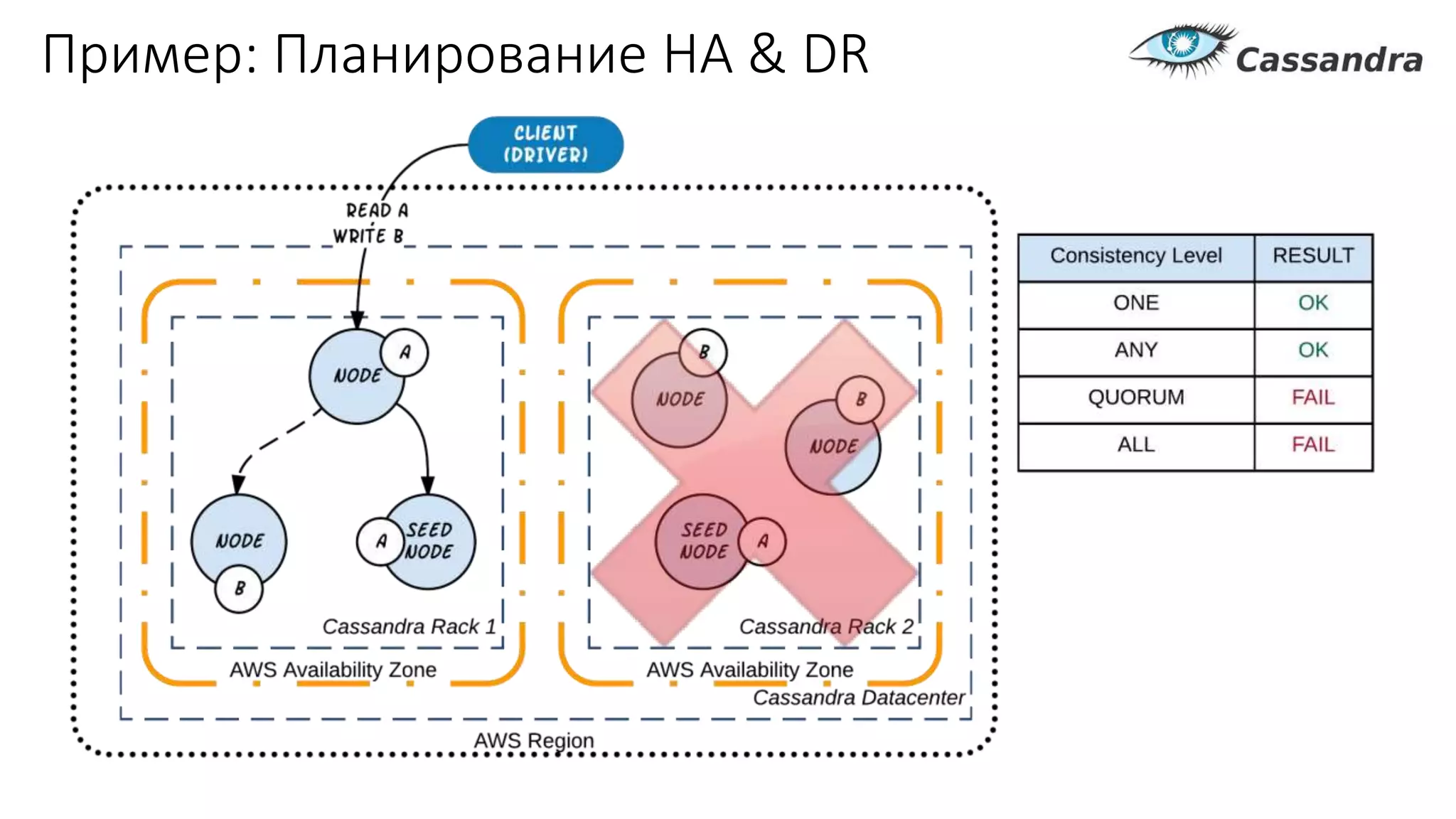
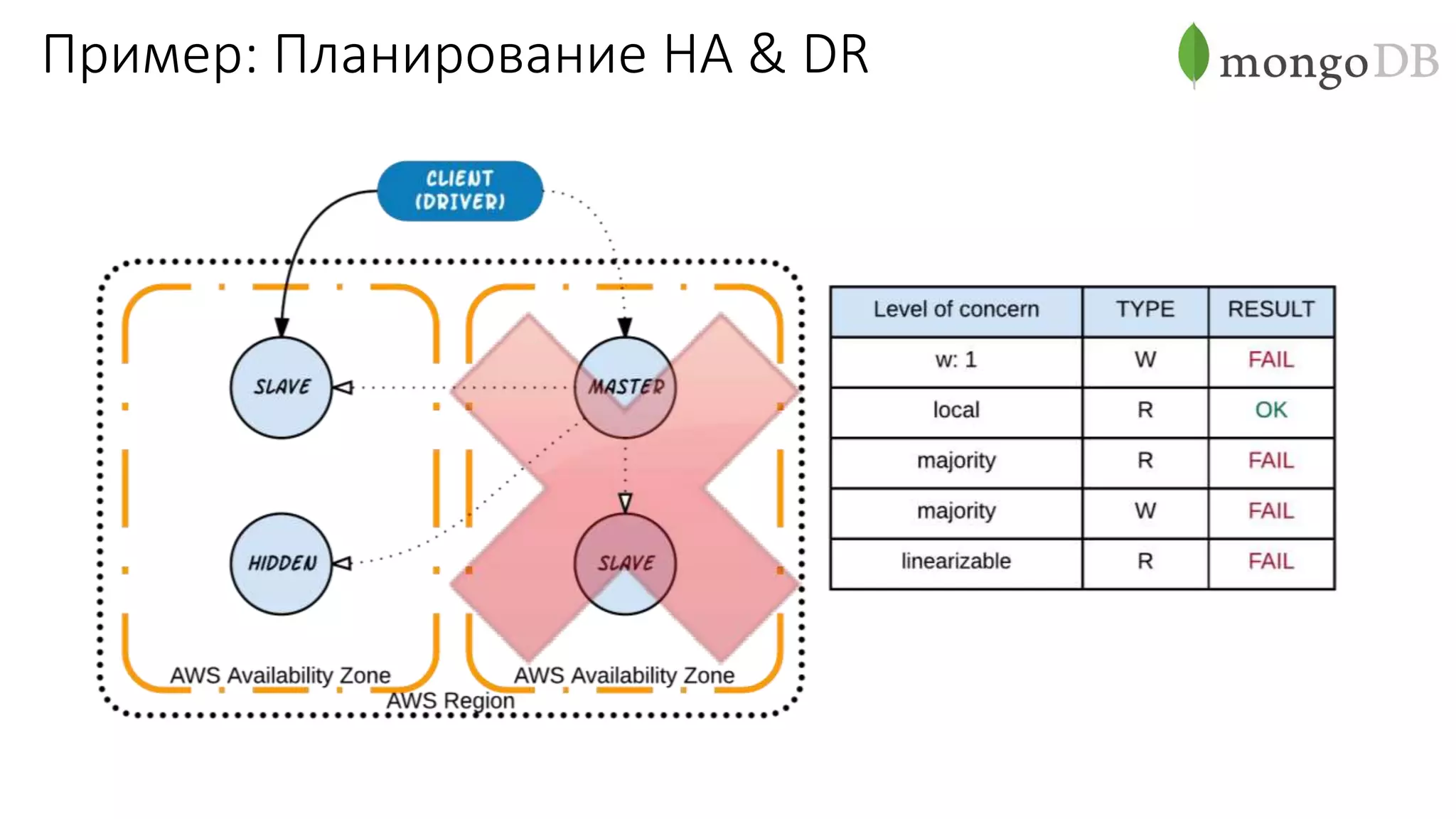
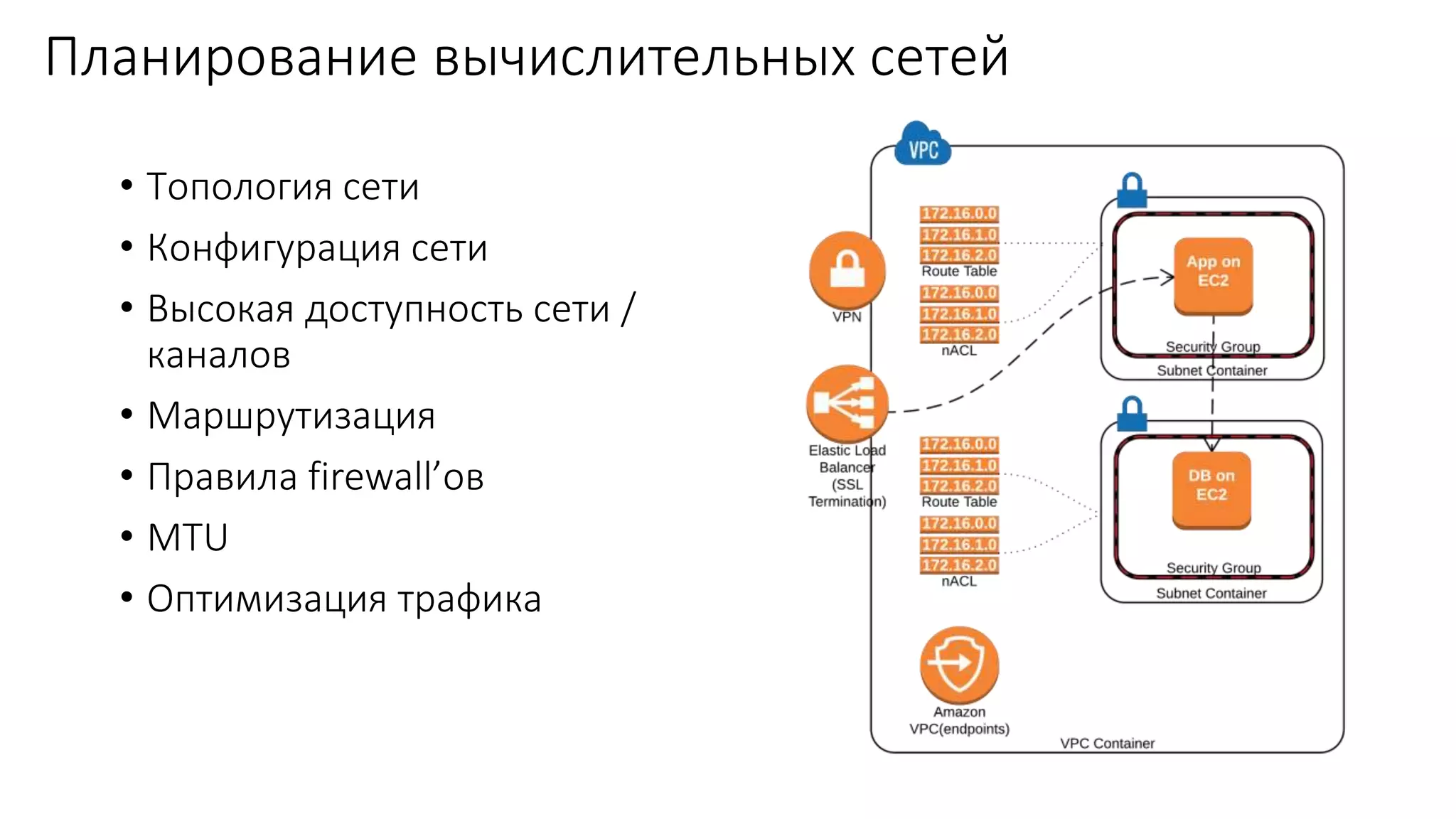
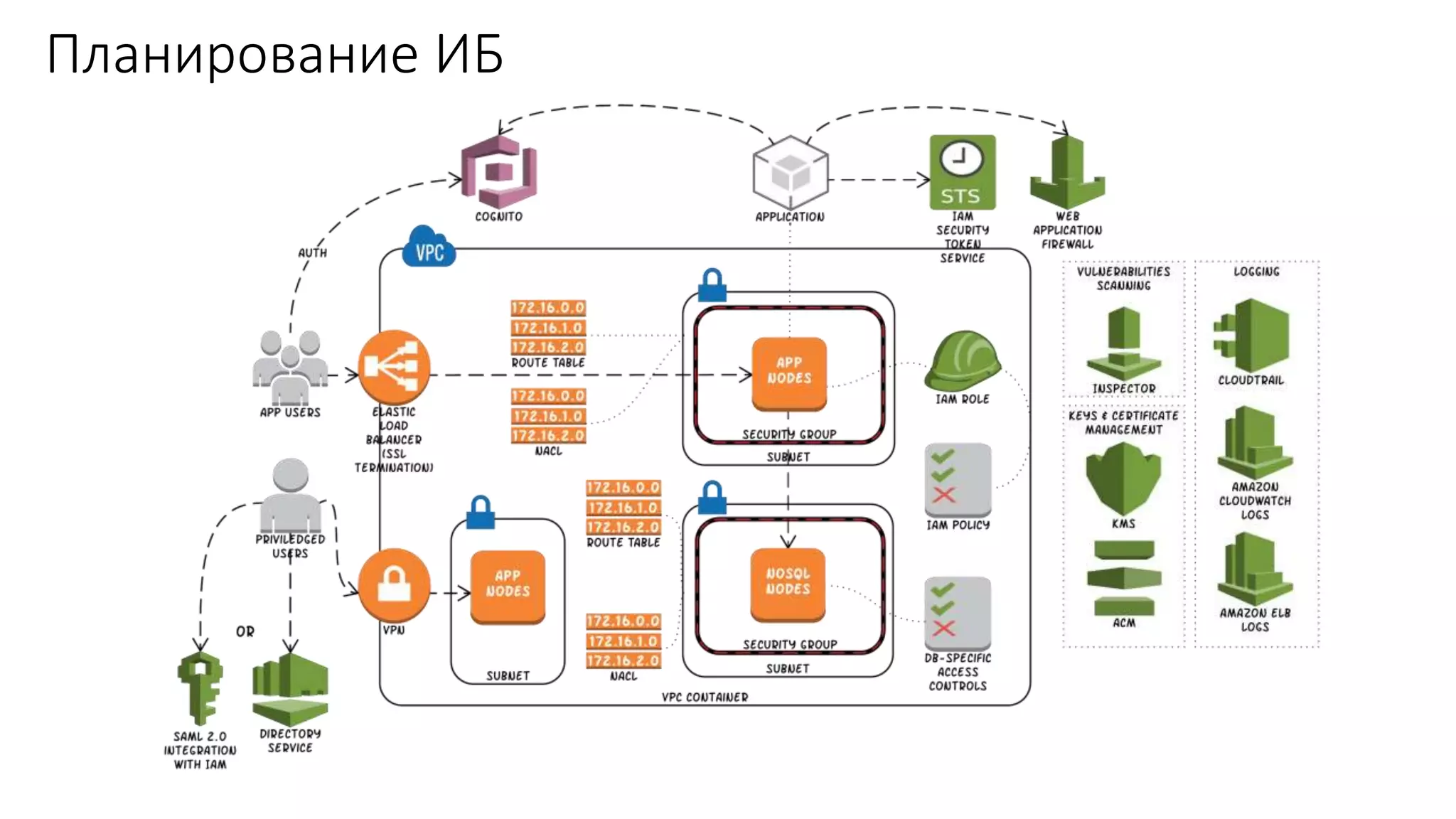

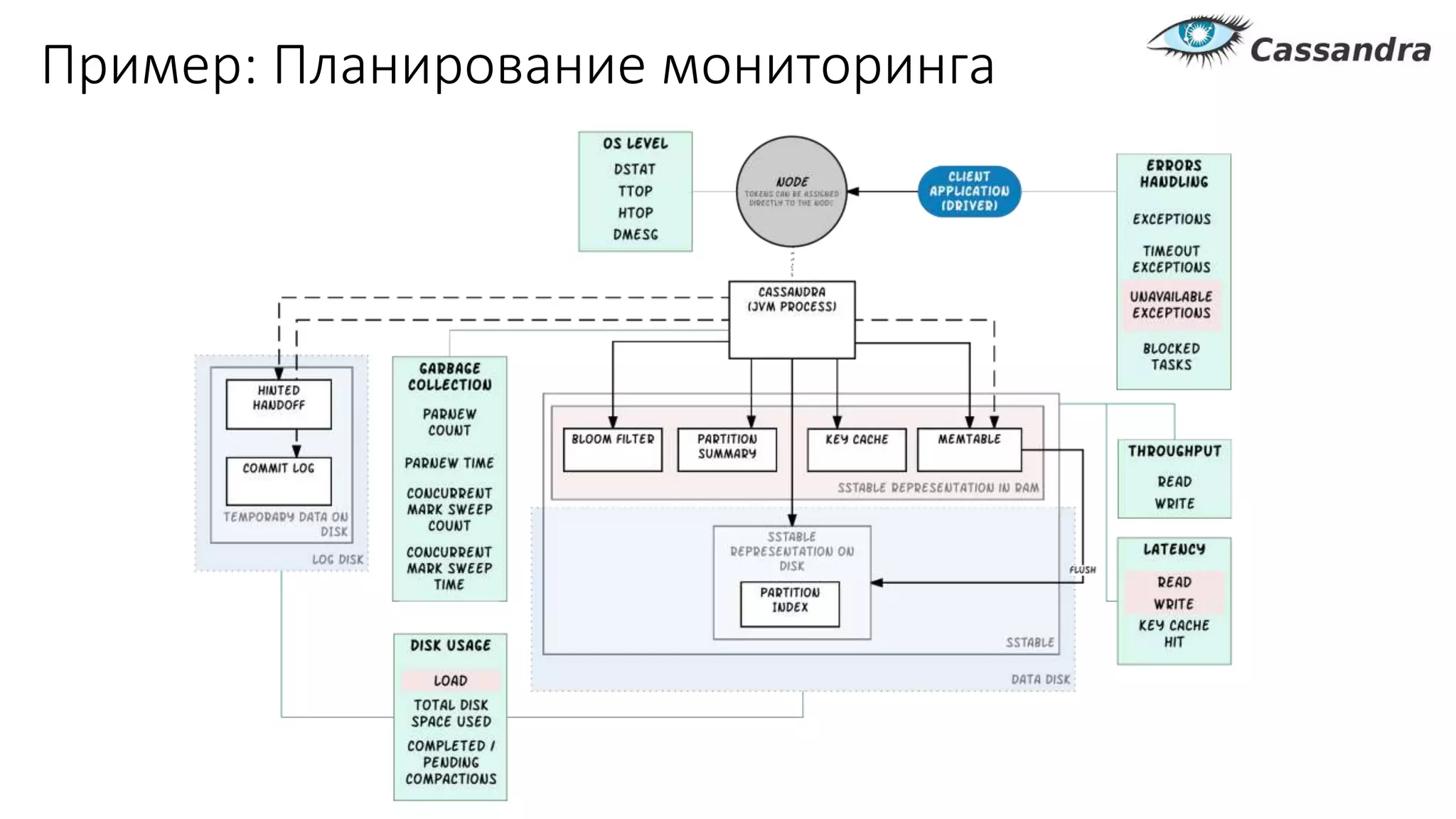
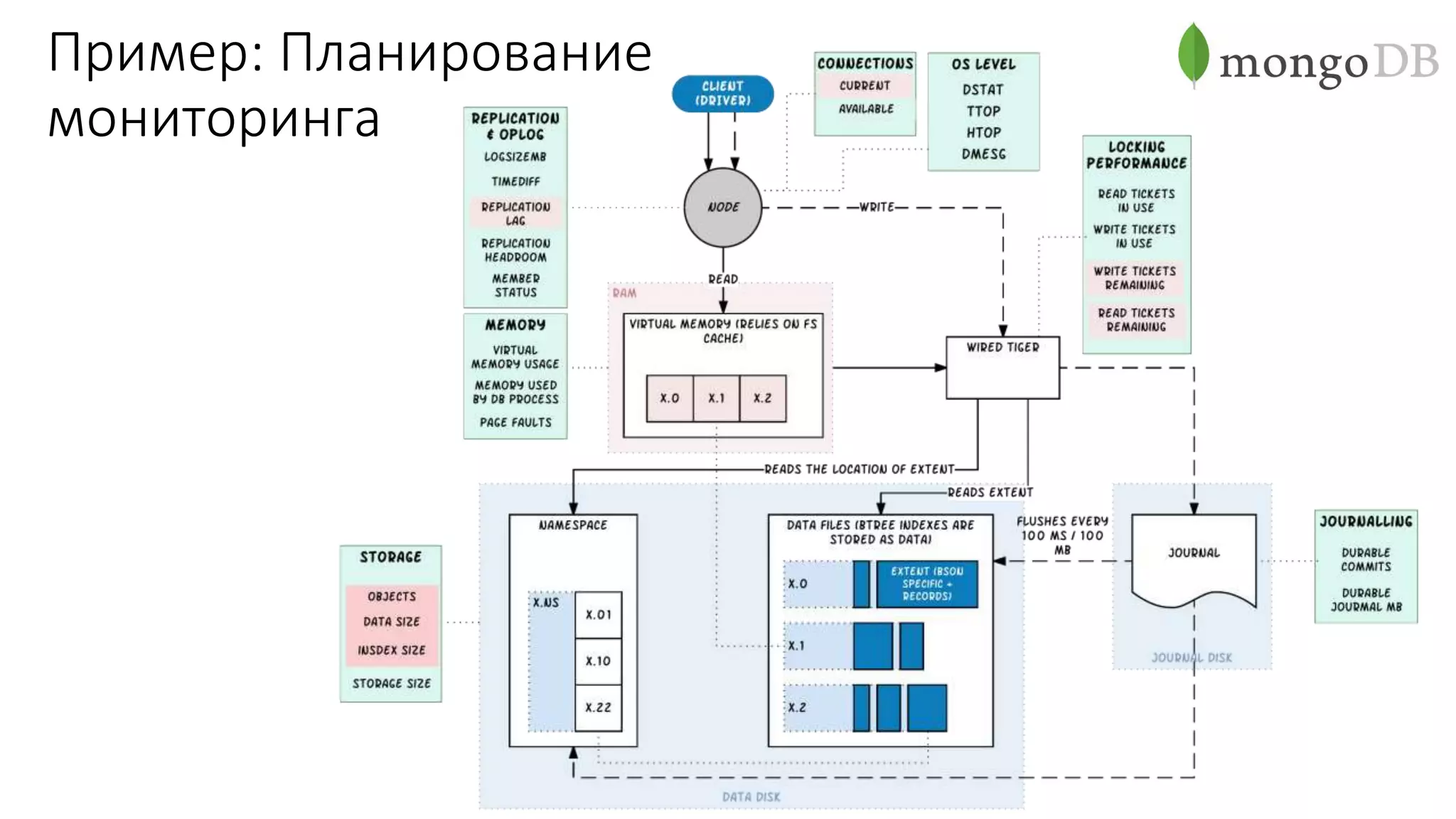





Документ рассматривает проектирование глобально распределенных кластеров NoSQL на платформе AWS, подчеркивая важность учета специфики баз данных и сценариев использования. Обсуждаются различные подходы, технологии, особенности проектирования и мониторинга, а также преимущества использования сервисов, таких как Amazon DynamoDB и Amazon S3 с Athena. В конце документа подчеркивается, что одно универсальное решение не существует, и выбор технологии должен уточняться в зависимости от контекста и требований приложения.


































































