Download as PPSX, PPTX





![Write Ahead Logging (WAL)
The Atomic Rule: The log entry for an insert, update or delete must be written to disk
before the change is made to the DB
The Durability Rule: All log entries for a transaction must be written to disk before the
commit record is written to disk
In WAL Systems updated page is written back to the same disk location from which it was
read.
Each log record is assigned, a unique log sequence number (LSN) at the time the record
is written to the log
The LSN of the log record corresponding to the latest update to the page is placed in a
field in the page header
Ex: All Log Record [prevLSN, TaID, type]
Ex: Update Log Record [PrevLSN, TaID, “update”, pageID, redo info, undo info]
6](https://image.slidesharecdn.com/ariesrecovery158224b-151108153245-lva1-app6891/85/ARIES-Recovery-Algorithms-6-320.jpg)


![ARIES - Logging
All Log Record [prevLSN, TaID, type]
Update Log Record [PrevLSN, TaID, “update”, pageID, redo info, undo info]
DB Buffer Log
Page 42
Page 46
TT
TaID lastLSN
1 11:[-,1,”update”, 42, a+=1,a-=1]
DPT
pageID recoveryLSN
42 1
LSN=-
B=55
A=77
LSN=-
C=22
9](https://image.slidesharecdn.com/ariesrecovery158224b-151108153245-lva1-app6891/85/ARIES-Recovery-Algorithms-9-320.jpg)
![ARIES - Logging
All Log Record [prevLSN, TaID, type]
Update Log Record [PrevLSN, TaID, “update”, pageID, redo info, undo info]
DB Buffer Log
Page 42
Page 46
TT
TaID lastLSN
1 1
2 2
1:[-,1,”update”, 42, a+=1,a-=1]
2:[-,2,”update”, 42, b+=3,b-=3]
DPT
pageID recoveryLSN
42 1
LSN=1
B=55
A=78
LSN=-
C=22
10](https://image.slidesharecdn.com/ariesrecovery158224b-151108153245-lva1-app6891/85/ARIES-Recovery-Algorithms-10-320.jpg)
![ARIES - Logging
All Log Record [prevLSN, TaID, type]
Update Log Record [PrevLSN, TaID, “update”, pageID, redo info, undo info]
DB Buffer Log
Page 42
Page 46
TT
TaID lastLSN
1 1
2 2
3 3
1:[-,1,”update”, 42, a+=1,a-=1]
2:[-,2,”update”, 42, b+=3,b-=3]
3:[-,2,”update”, 42, c+=2,c-=2]
DPT
pageID recoveryLSN
42 1
46 3
LSN=2
B=58
A=78
LSN=3
C=24
11](https://image.slidesharecdn.com/ariesrecovery158224b-151108153245-lva1-app6891/85/ARIES-Recovery-Algorithms-11-320.jpg)























![Write Ahead Logging (WAL)
The Atomic Rule: The log entry for an insert, update or delete must be written to disk
before the change is made to the DB
The Durability Rule: All log entries for a transaction must be written to disk before the
commit record is written to disk
In WAL Systems updated page is written back to the same disk location from which it was
read.
Each log record is assigned, a unique log sequence number (LSN) at the time the record
is written to the log
The LSN of the log record corresponding to the latest update to the page is placed in a
field in the page header
Ex: All Log Record [prevLSN, TaID, type]
Ex: Update Log Record [PrevLSN, TaID, “update”, pageID, redo info, undo info]
6](https://image.slidesharecdn.com/ariesrecovery158224b-151108153245-lva1-app6891/75/ARIES-Recovery-Algorithms-6-2048.jpg)


![ARIES - Logging
All Log Record [prevLSN, TaID, type]
Update Log Record [PrevLSN, TaID, “update”, pageID, redo info, undo info]
DB Buffer Log
Page 42
Page 46
TT
TaID lastLSN
1 11:[-,1,”update”, 42, a+=1,a-=1]
DPT
pageID recoveryLSN
42 1
LSN=-
B=55
A=77
LSN=-
C=22
9](https://image.slidesharecdn.com/ariesrecovery158224b-151108153245-lva1-app6891/75/ARIES-Recovery-Algorithms-9-2048.jpg)
![ARIES - Logging
All Log Record [prevLSN, TaID, type]
Update Log Record [PrevLSN, TaID, “update”, pageID, redo info, undo info]
DB Buffer Log
Page 42
Page 46
TT
TaID lastLSN
1 1
2 2
1:[-,1,”update”, 42, a+=1,a-=1]
2:[-,2,”update”, 42, b+=3,b-=3]
DPT
pageID recoveryLSN
42 1
LSN=1
B=55
A=78
LSN=-
C=22
10](https://image.slidesharecdn.com/ariesrecovery158224b-151108153245-lva1-app6891/75/ARIES-Recovery-Algorithms-10-2048.jpg)
![ARIES - Logging
All Log Record [prevLSN, TaID, type]
Update Log Record [PrevLSN, TaID, “update”, pageID, redo info, undo info]
DB Buffer Log
Page 42
Page 46
TT
TaID lastLSN
1 1
2 2
3 3
1:[-,1,”update”, 42, a+=1,a-=1]
2:[-,2,”update”, 42, b+=3,b-=3]
3:[-,2,”update”, 42, c+=2,c-=2]
DPT
pageID recoveryLSN
42 1
46 3
LSN=2
B=58
A=78
LSN=3
C=24
11](https://image.slidesharecdn.com/ariesrecovery158224b-151108153245-lva1-app6891/75/ARIES-Recovery-Algorithms-11-2048.jpg)




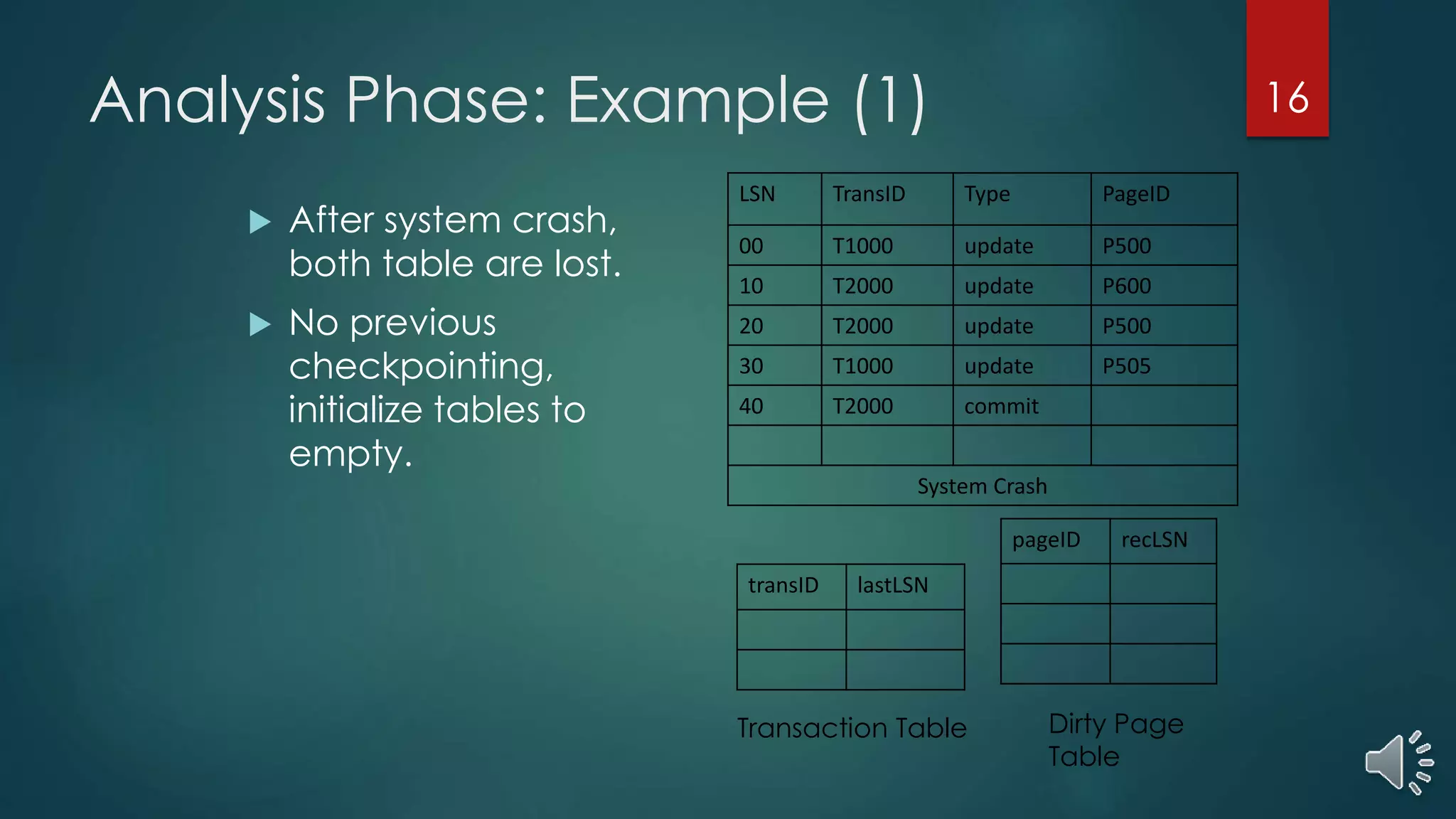
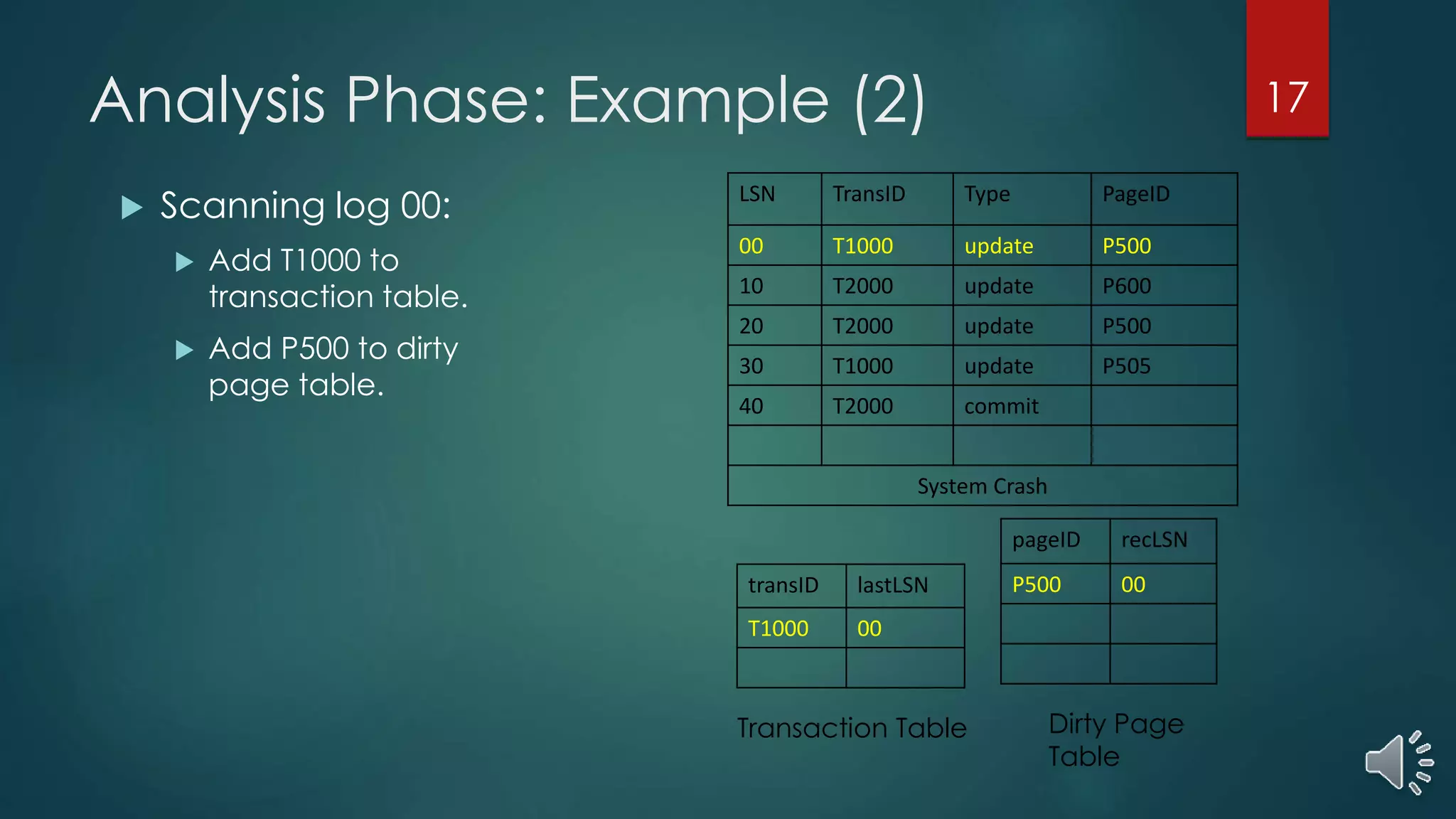

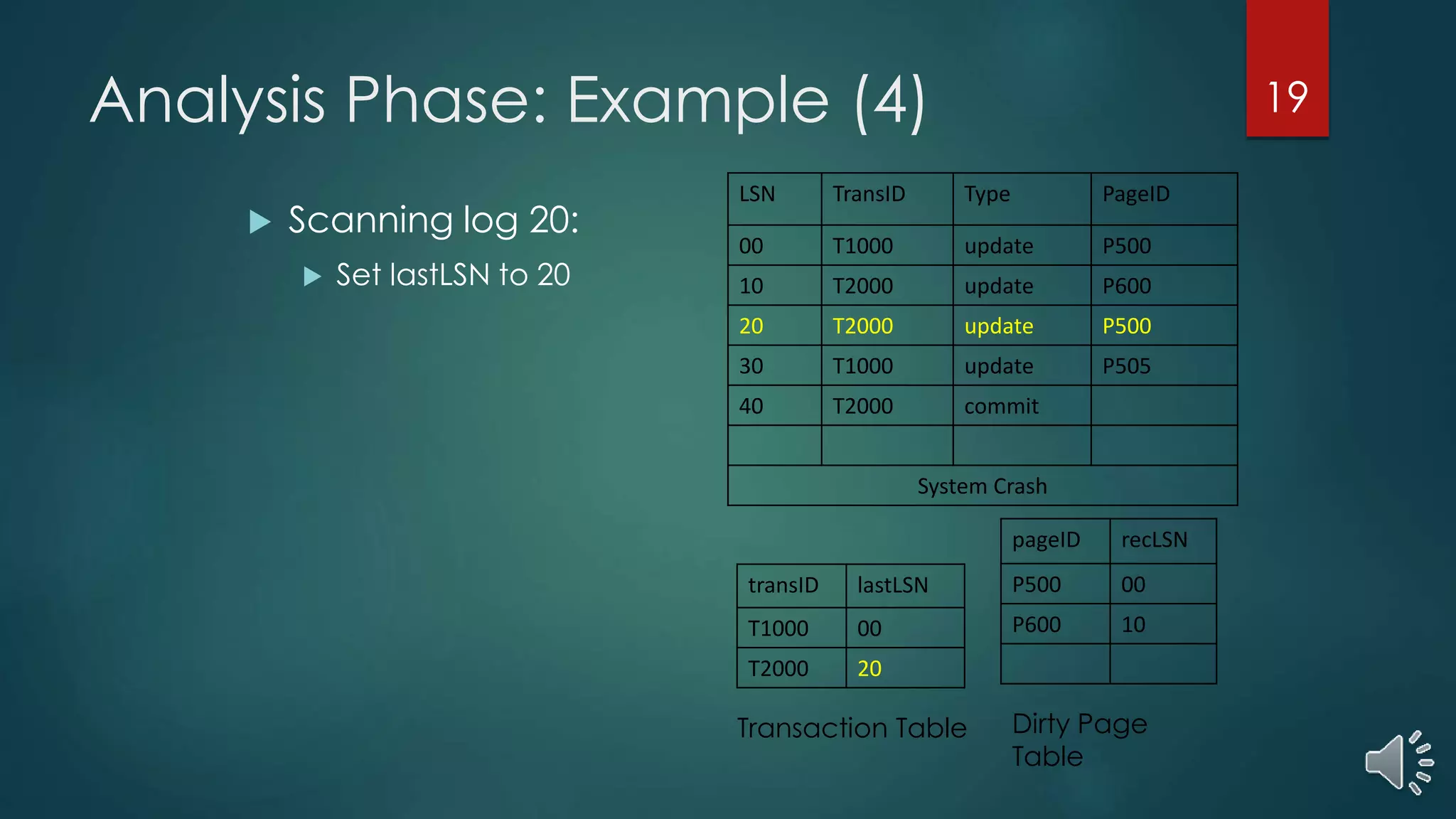











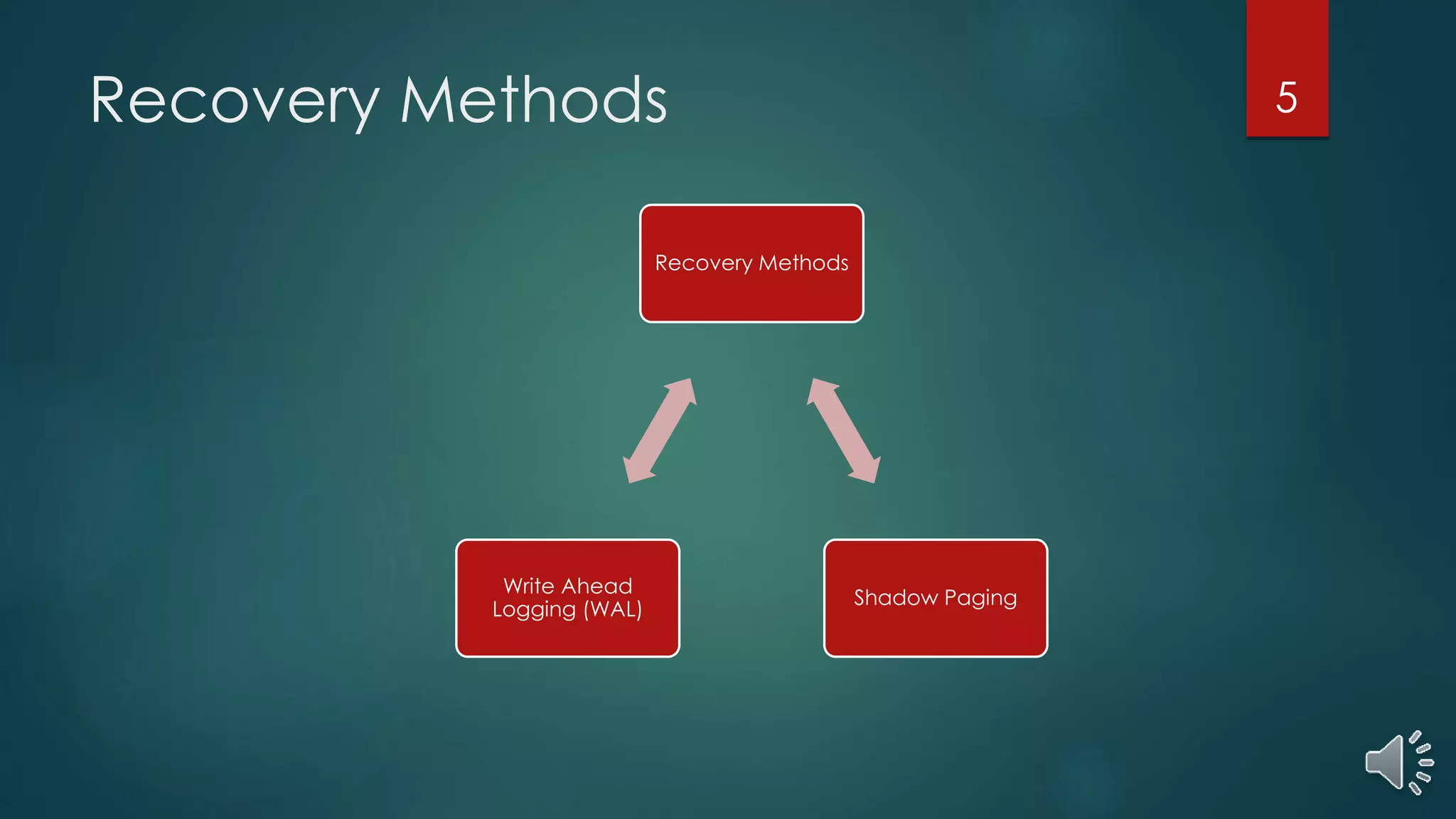
The document presents a comprehensive overview of transaction management in databases, focusing on recovery methods such as Write Ahead Logging (WAL) and Shadow Paging, as well as the ARIES recovery algorithm. It details how these methods handle concurrency, recovery efficiency, and maintenance of data integrity in the event of crashes. The ARIES methodology encompasses three recovery phases: analysis, redo, and undo, which systematically restore the database to a consistent state after failures.
Overview of transaction management, focus on concurrency control and recovery methods with a historical backdrop on ARIES development.
WAL and shadow paging are highlighted as recovery methodologies, outlining the mechanisms and challenges of each.
Discussion on ARIES features: high concurrency, logging, and efficient recovery process through fine-granularity.
Details on ARIES restart recovery phases: analysis, redo, and undo as fundamental components in the recovery process.
Algorithm and examples illustrating how ARIES handles analysis phase for restoring transaction and dirty page tables after a crash.
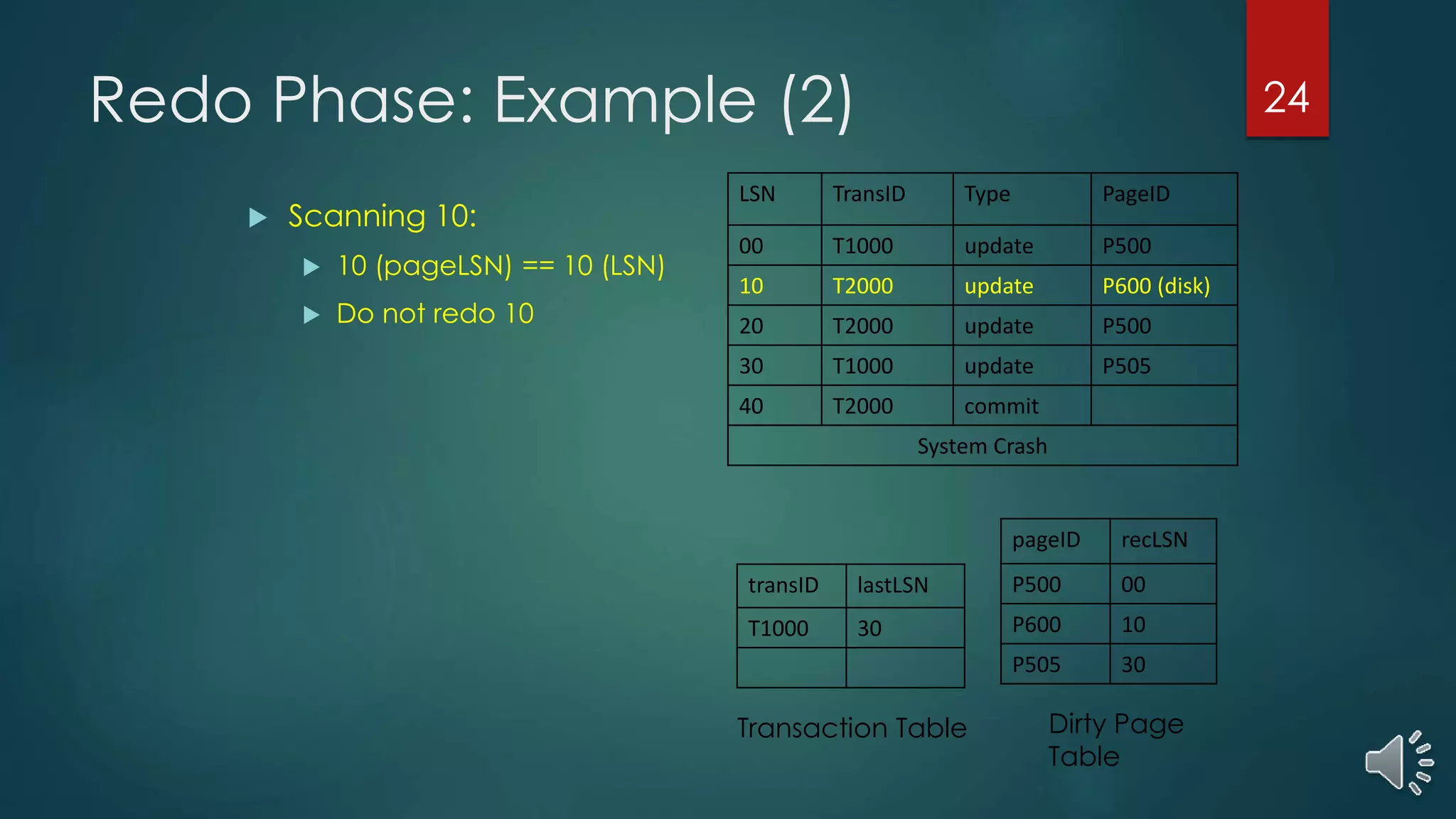
Overview of redo actions following the analysis phase, demonstrating how ARIES manages updates from the log.
Mechanics of the undo phase, showing how active transactions are handled and the CLR's role in restoring data.
Process of managing crashes during restart recovery, focusing on the logging and recovery of transactions post-crash.
Appreciation for the audience, concluding the presentation on database recovery mechanisms.



















































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)















