Downloaded 13 times





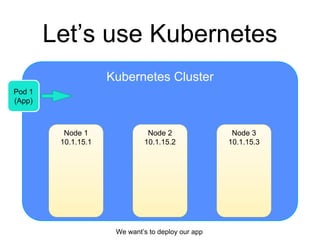

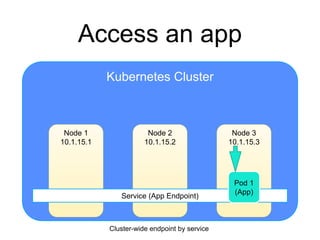
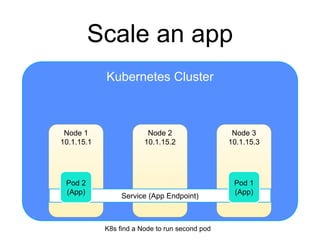
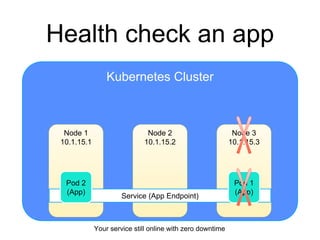

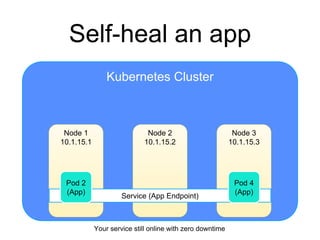

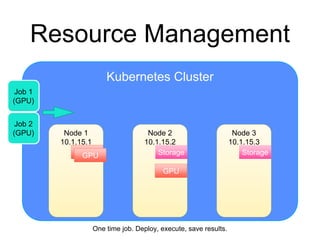

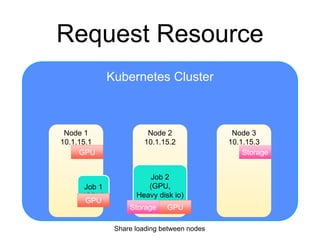

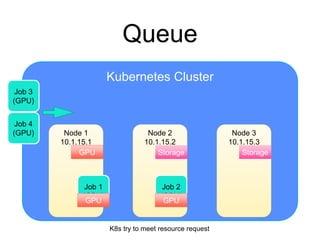
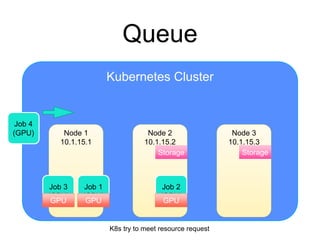
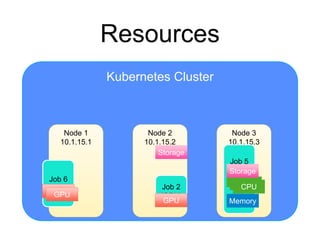


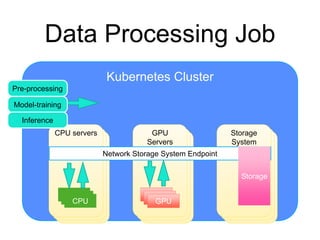








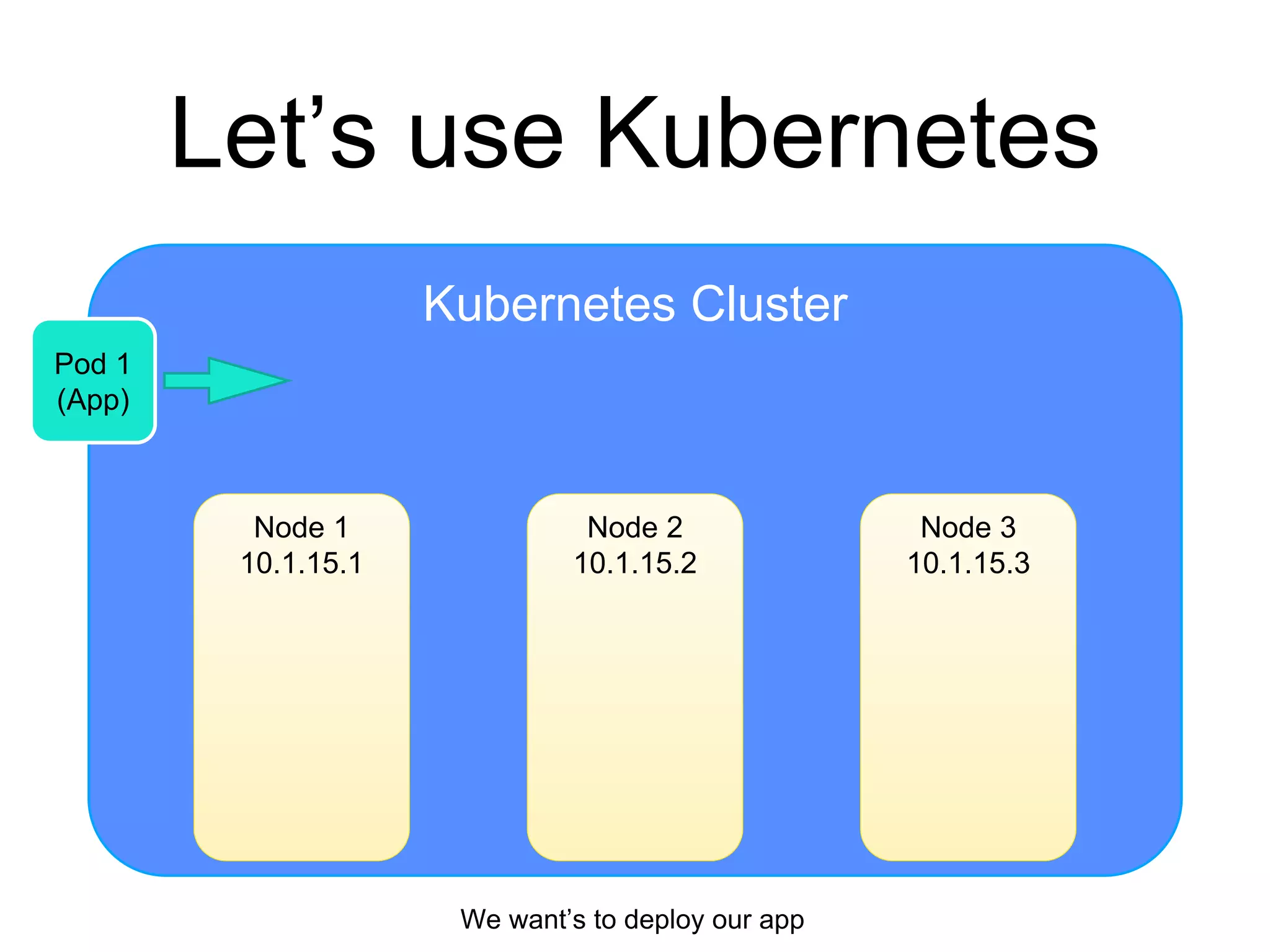
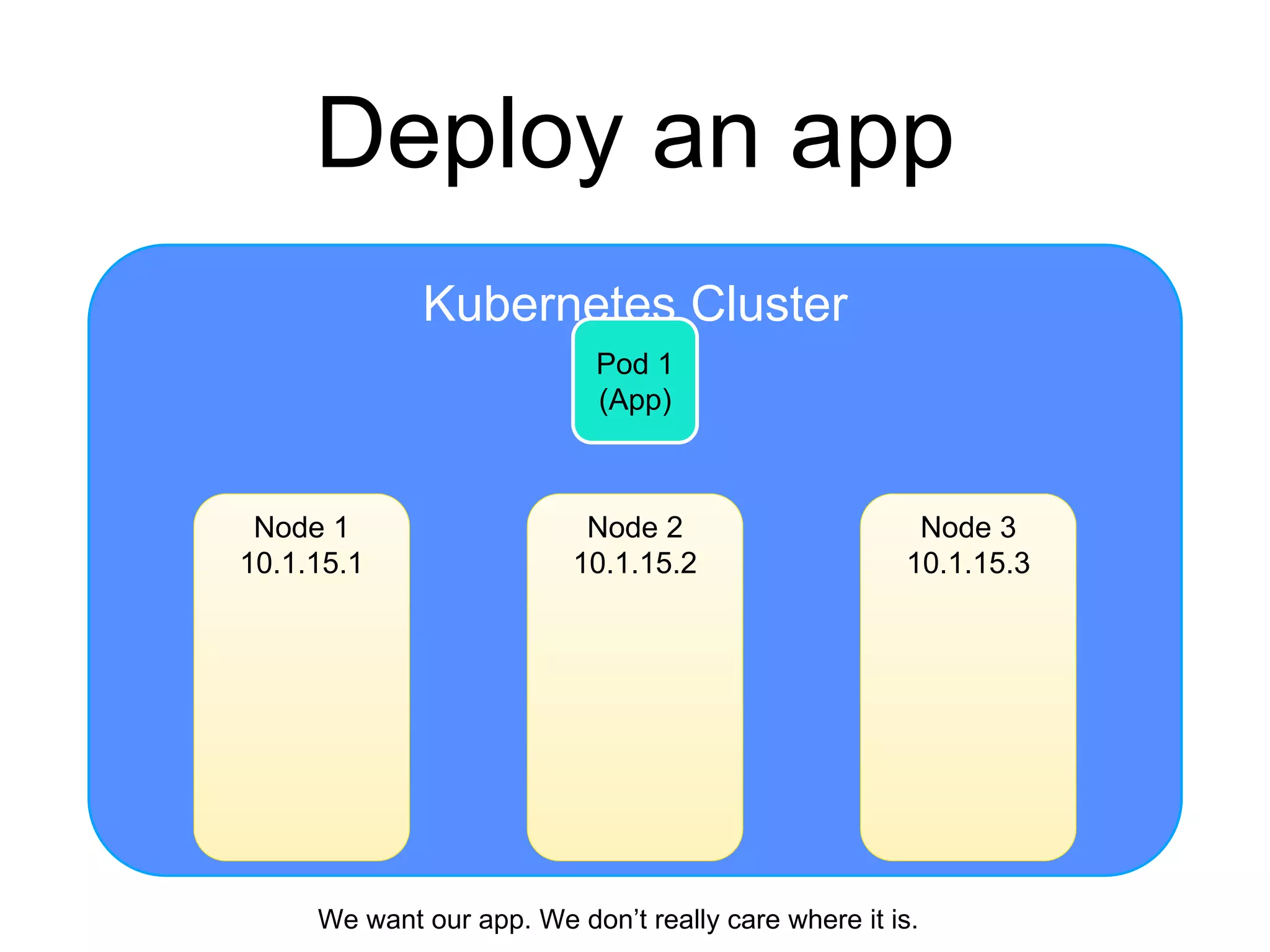
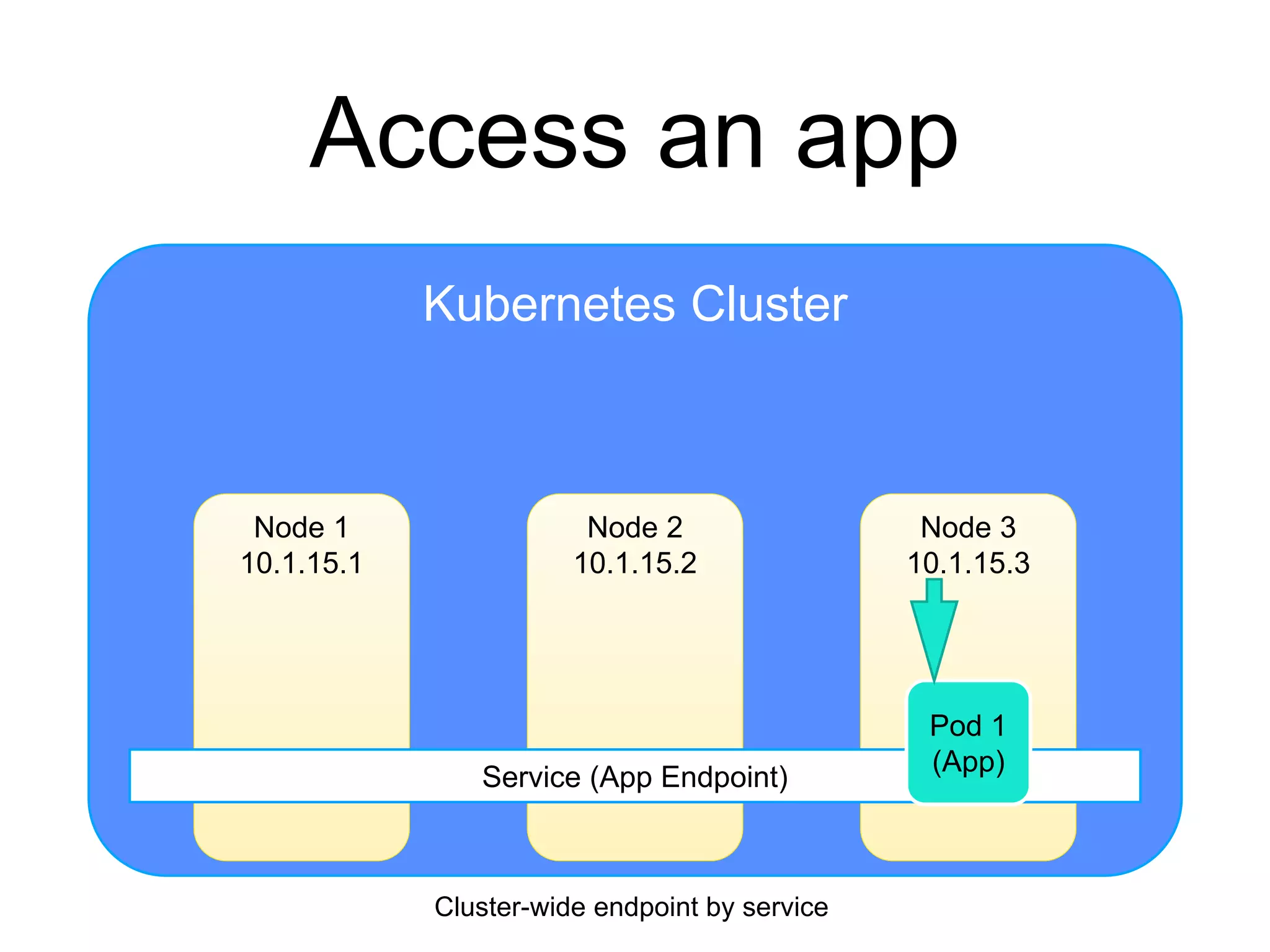
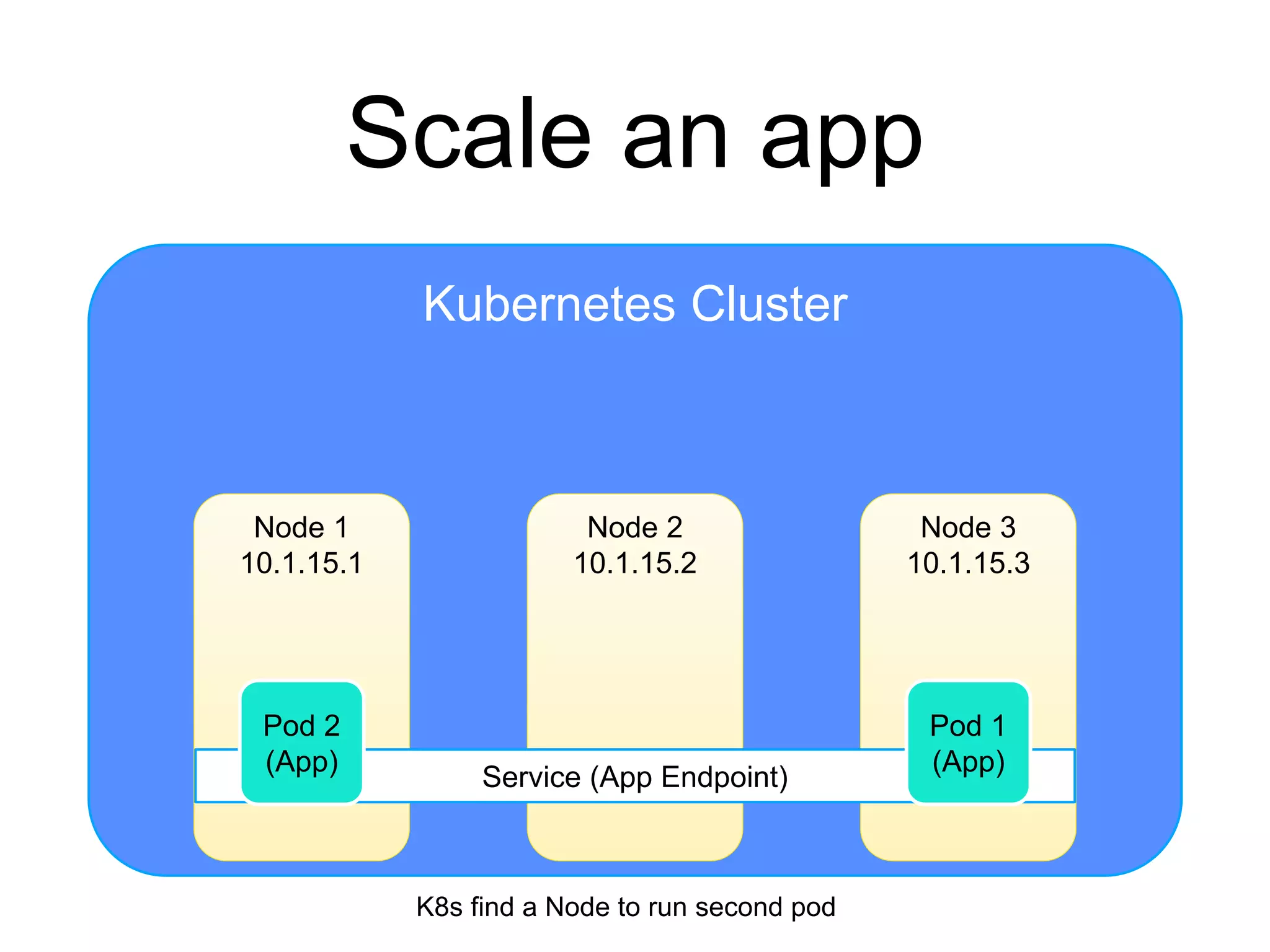
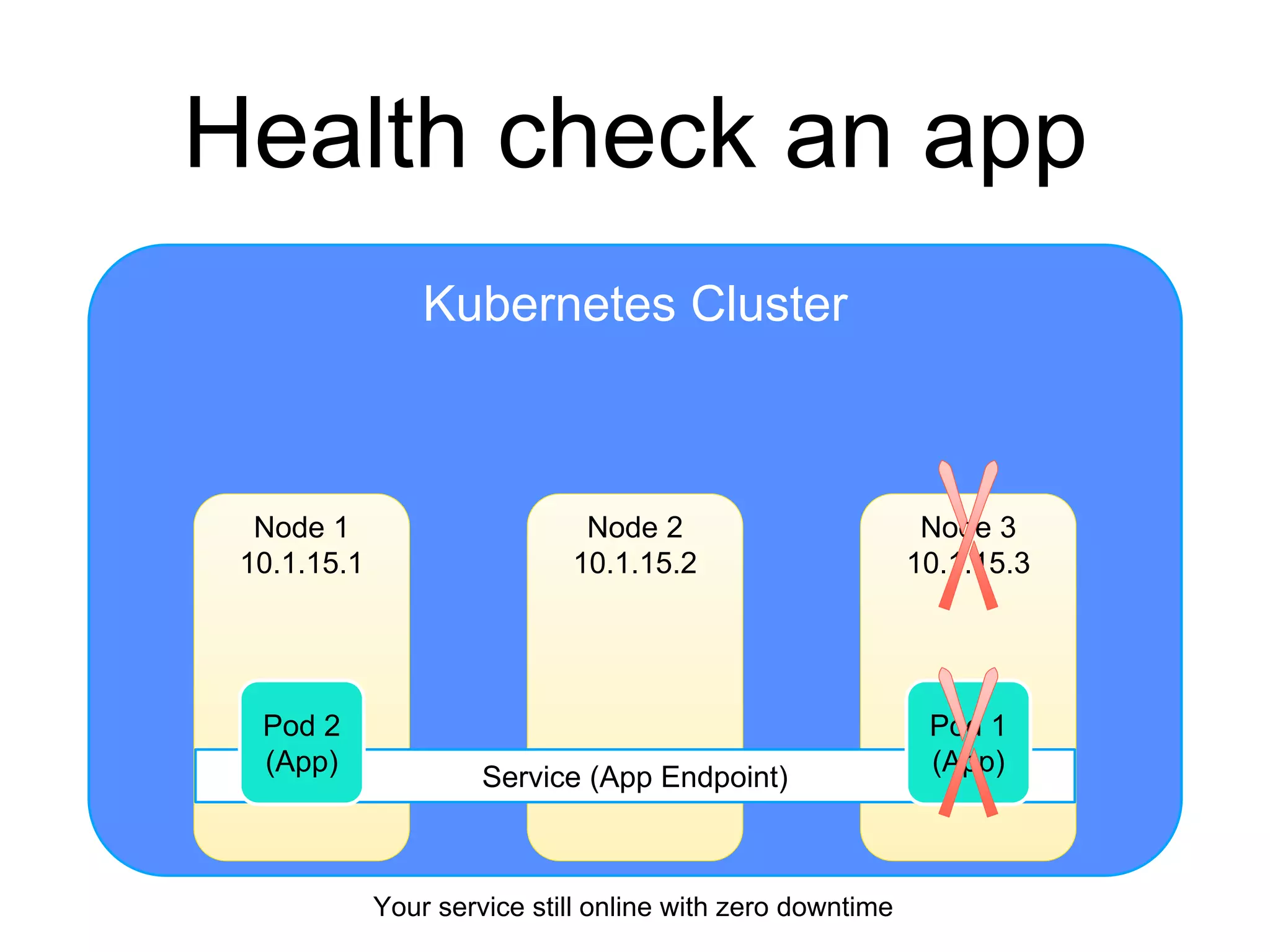
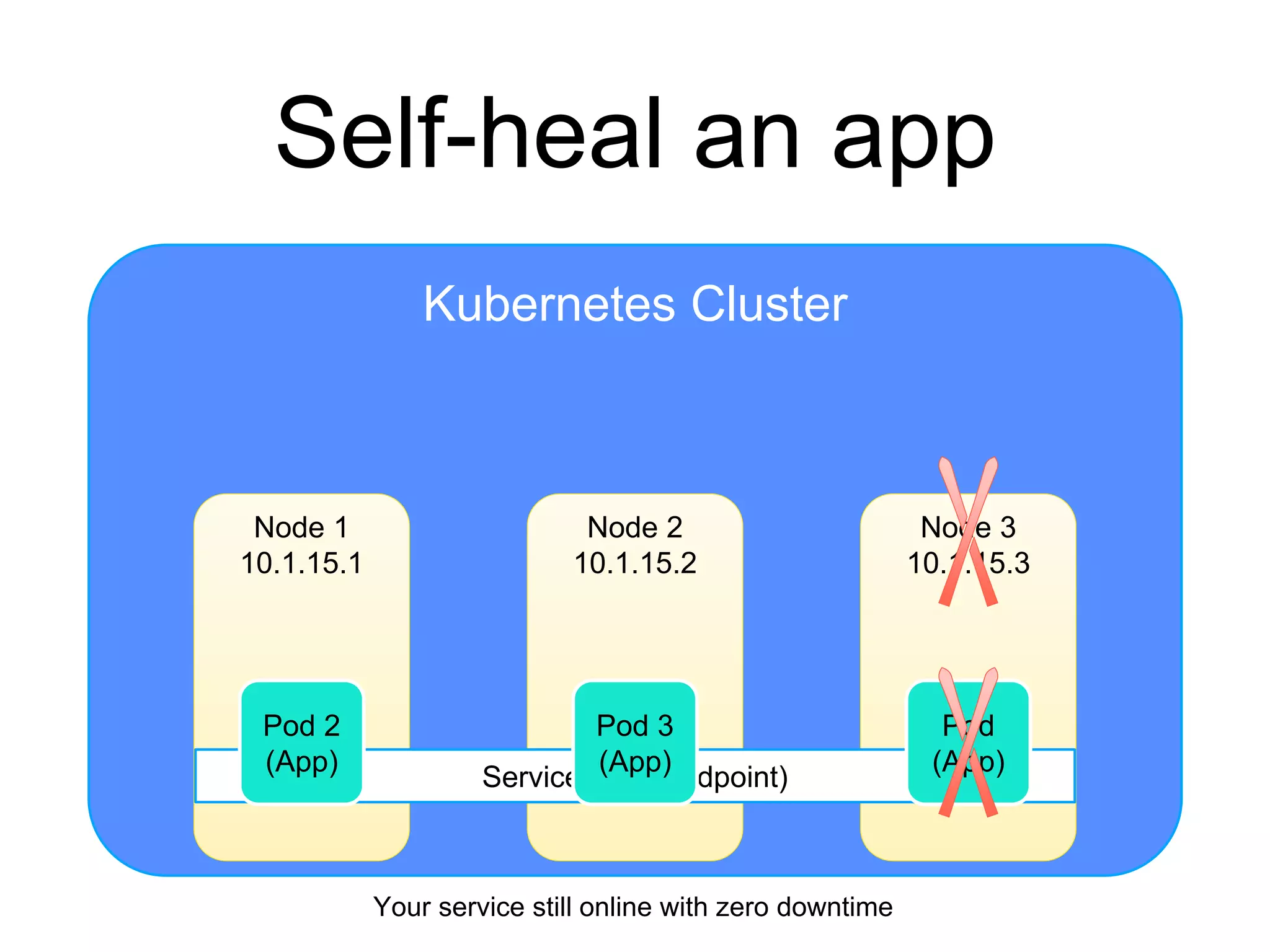
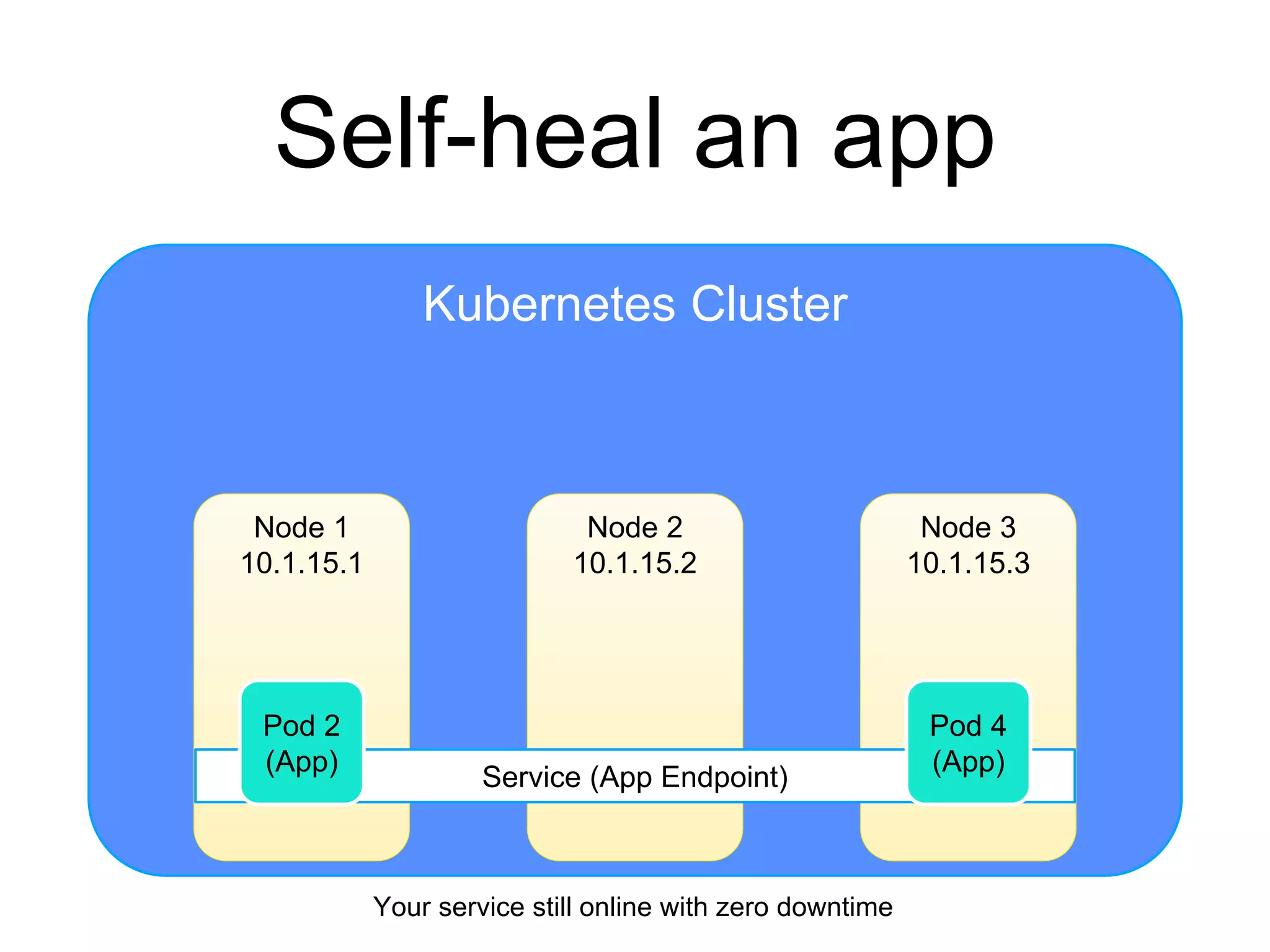

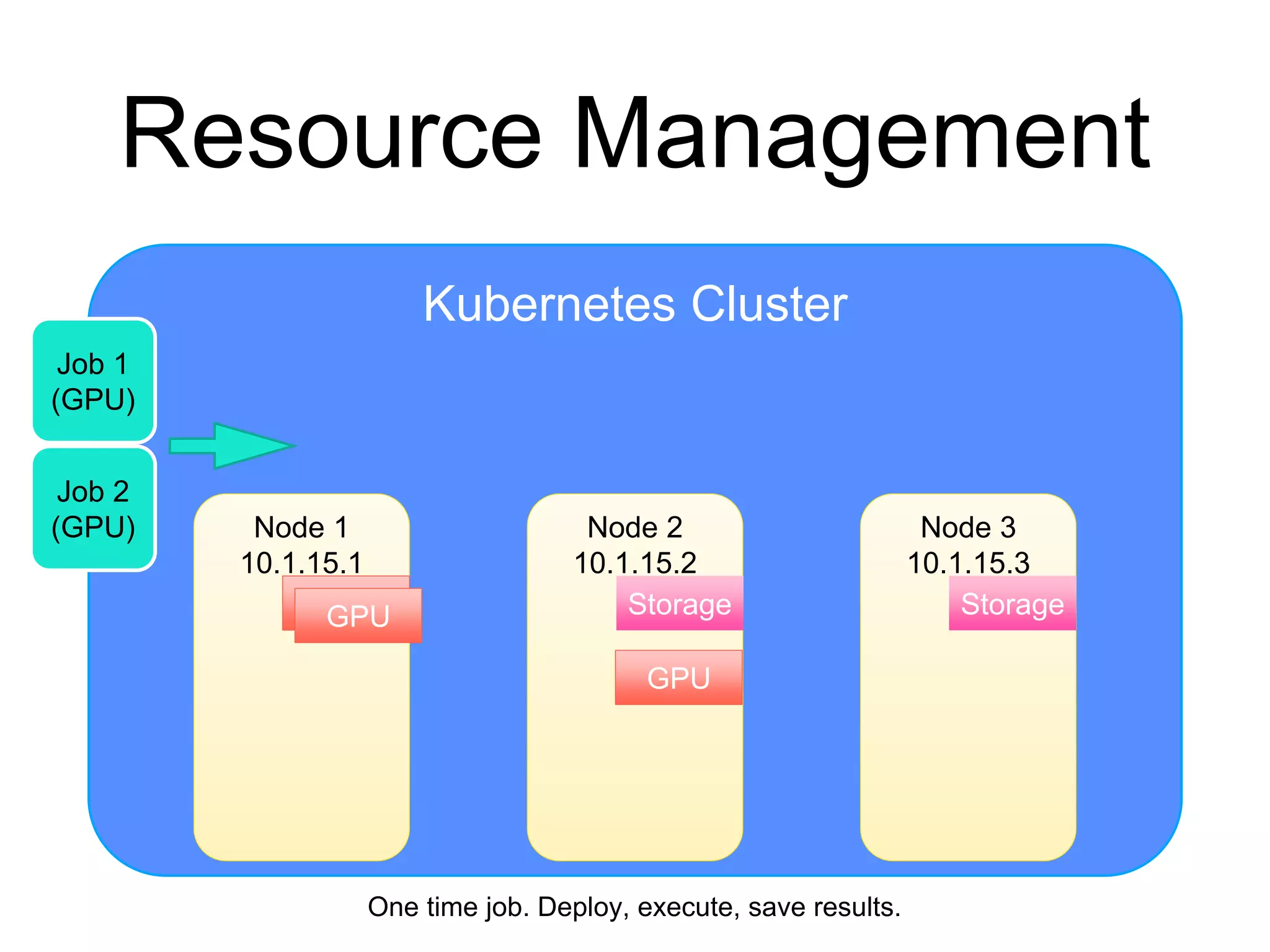
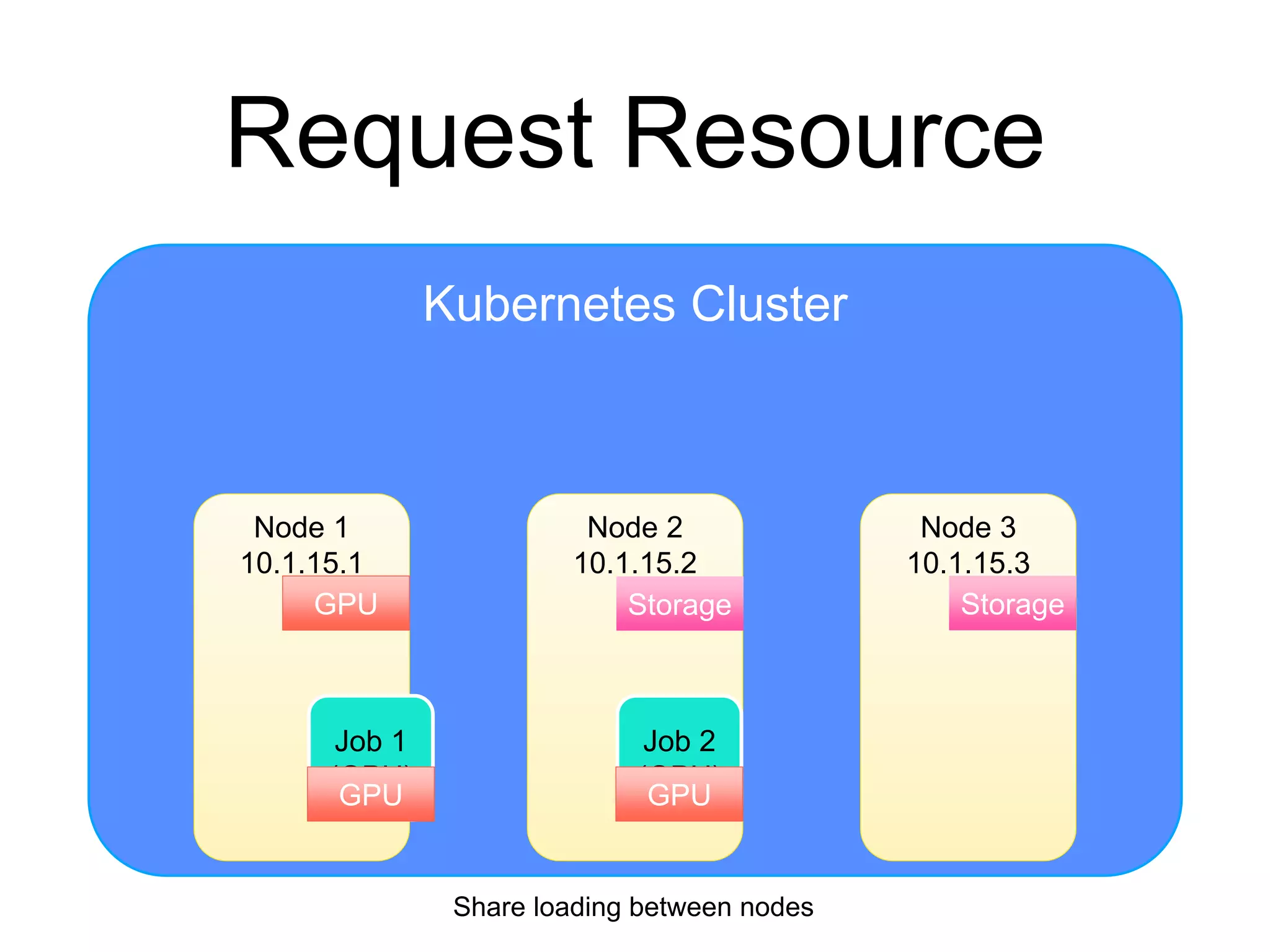
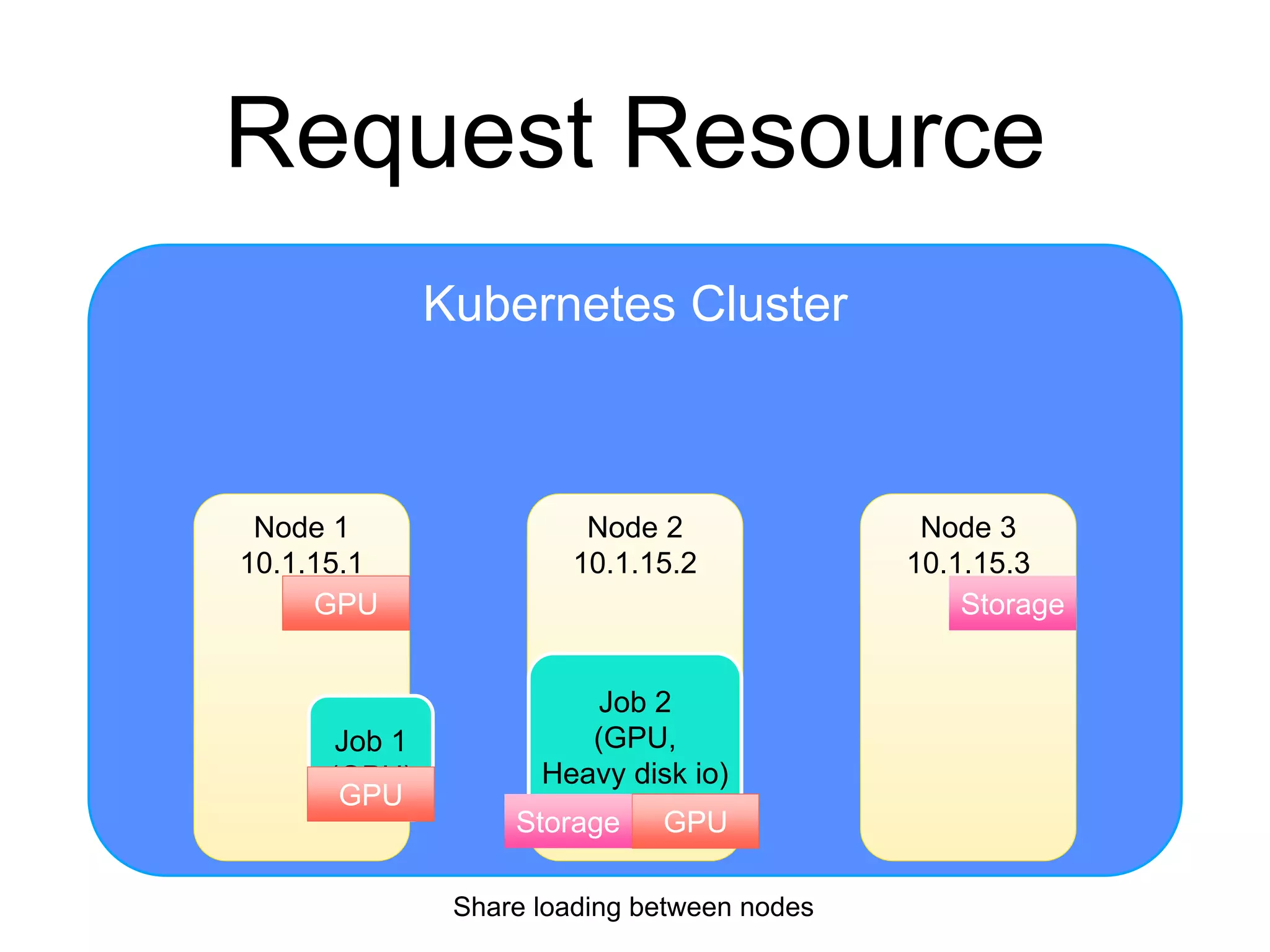
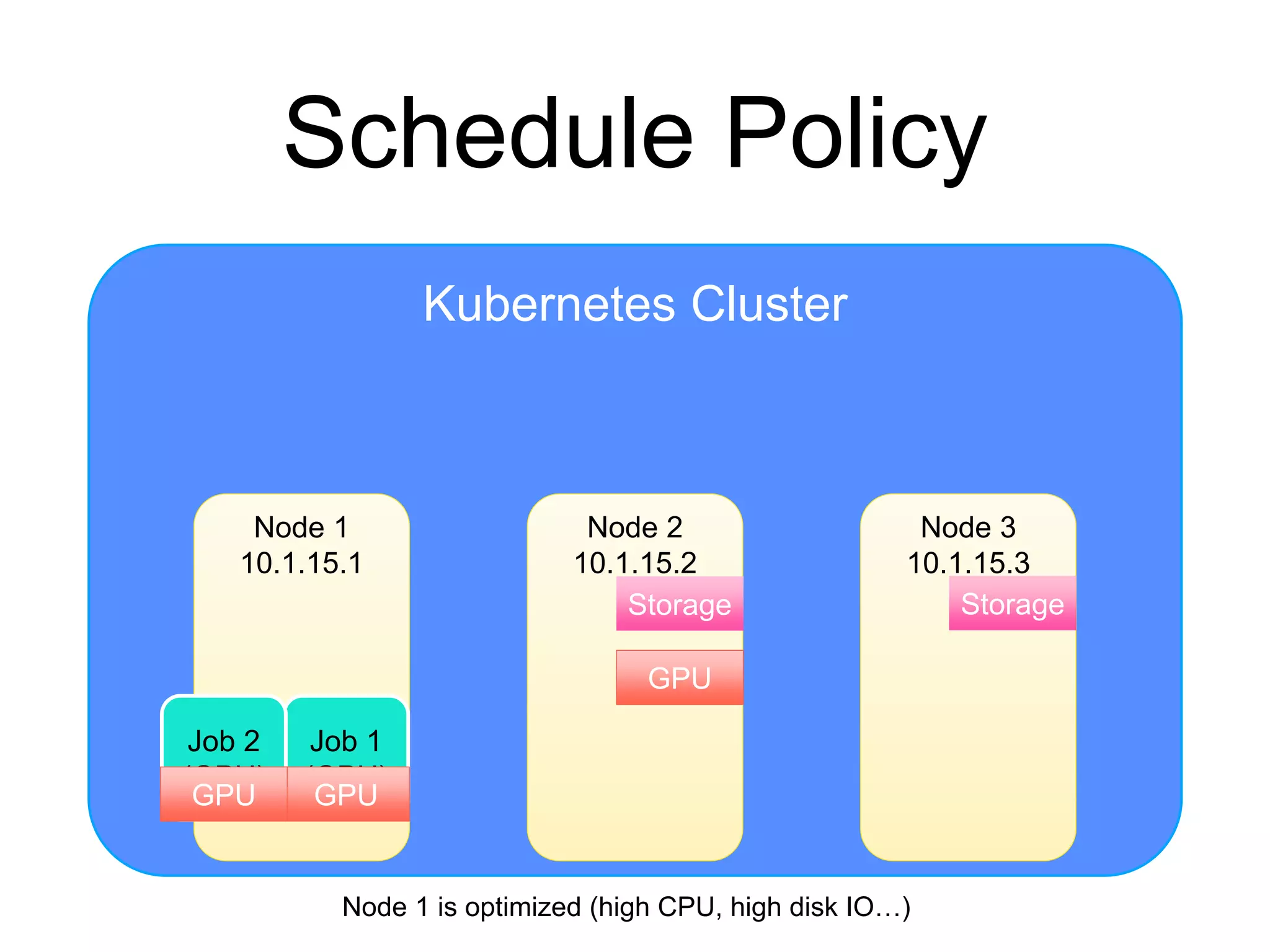
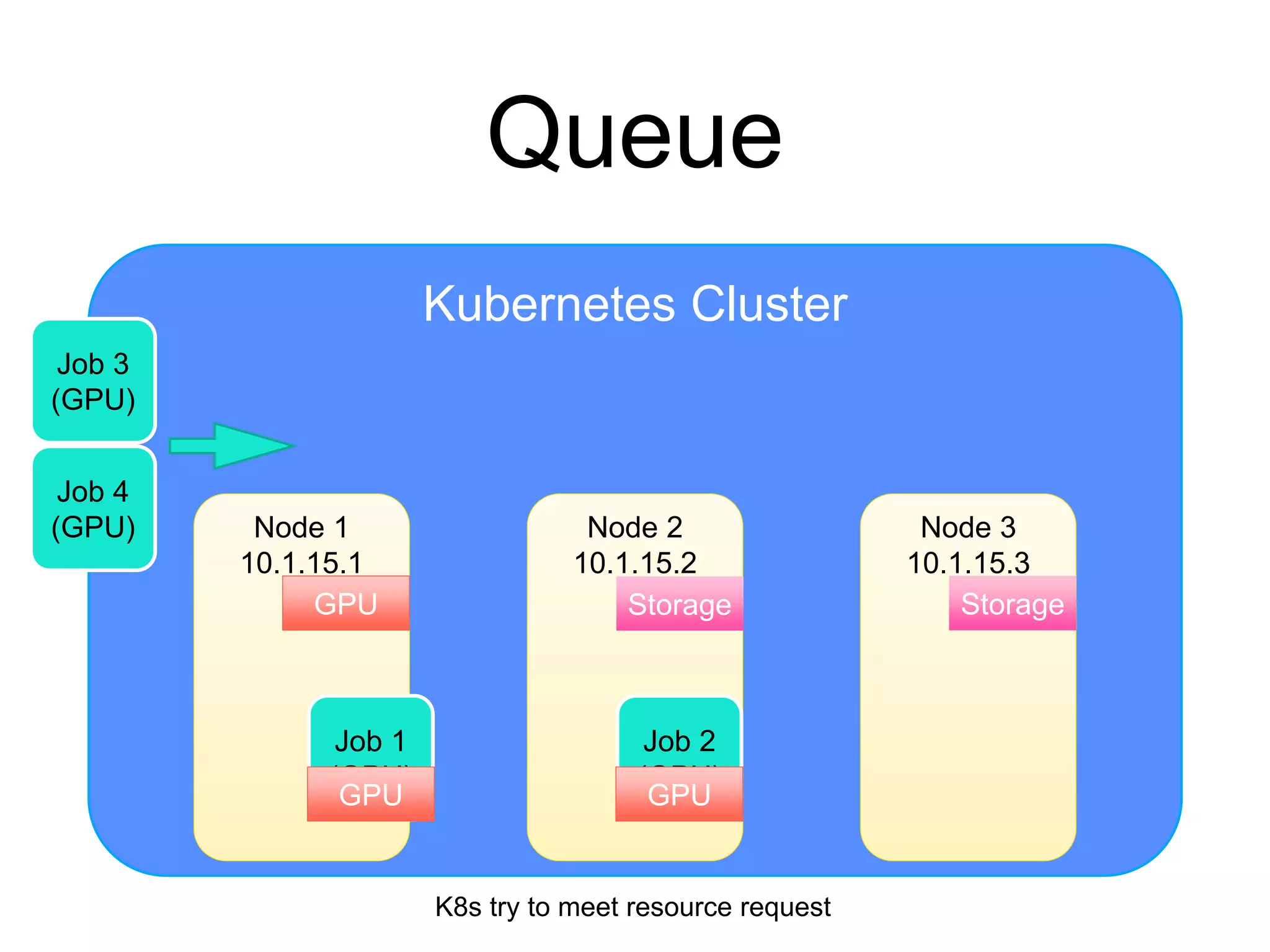
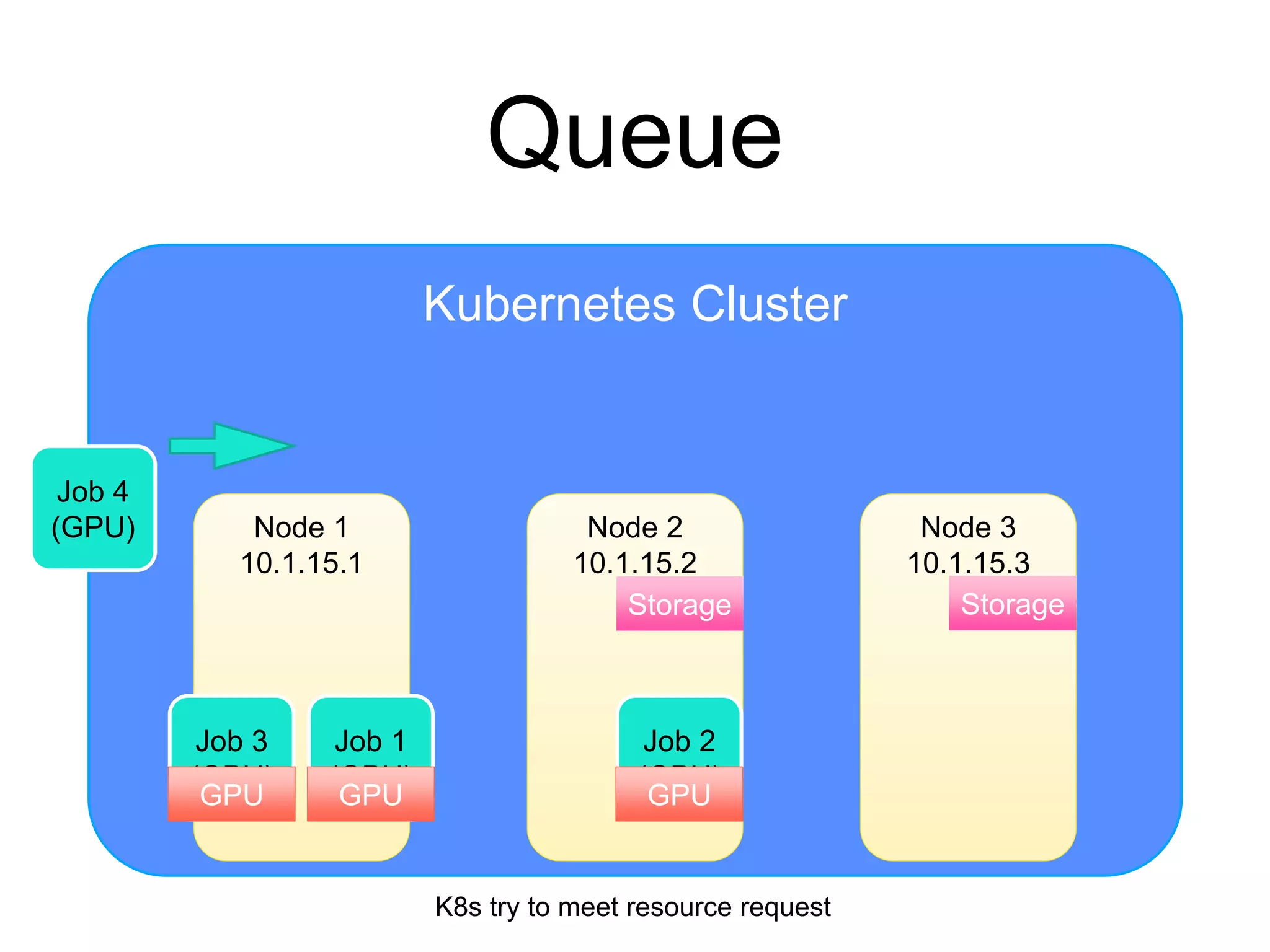
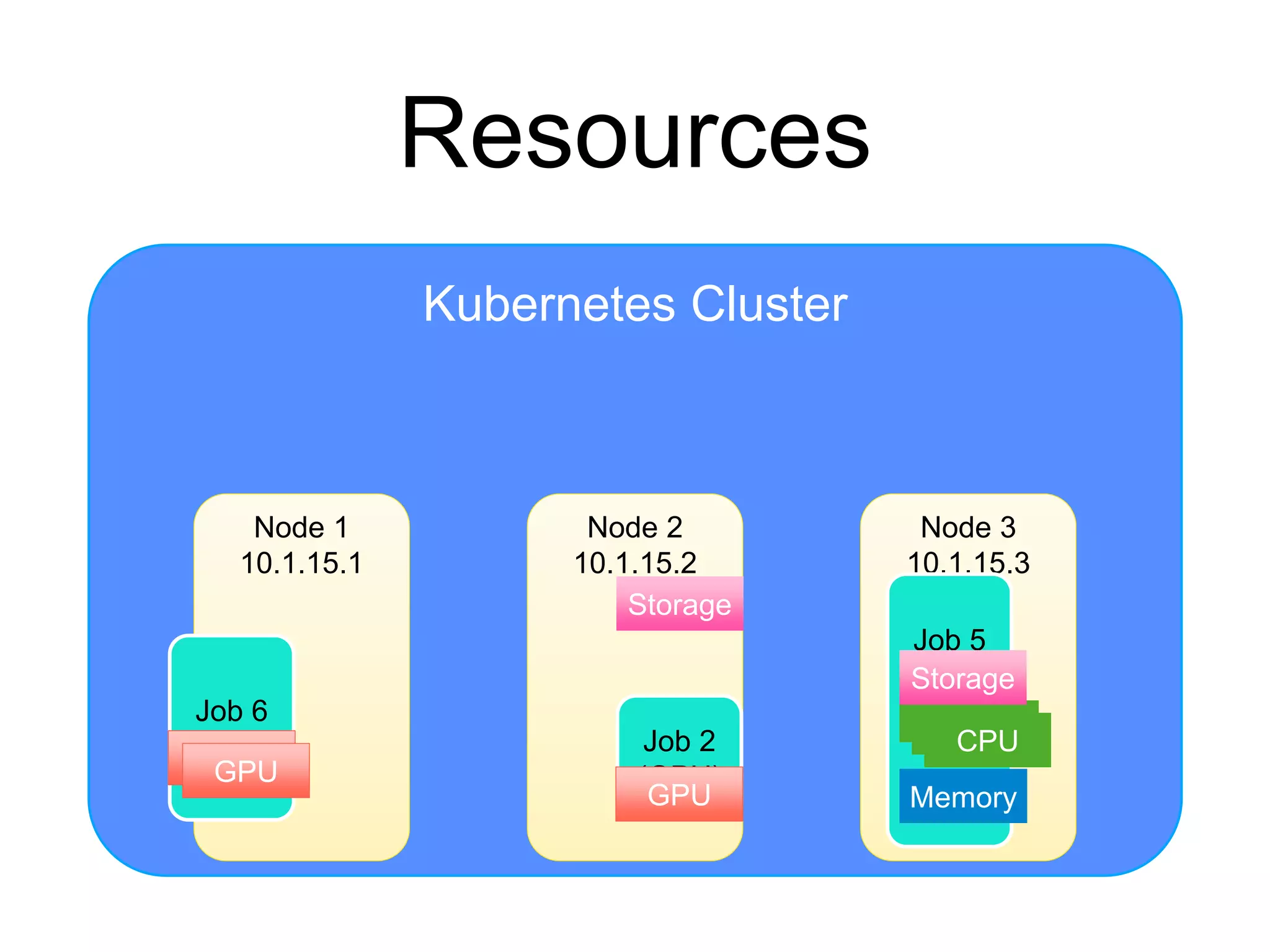


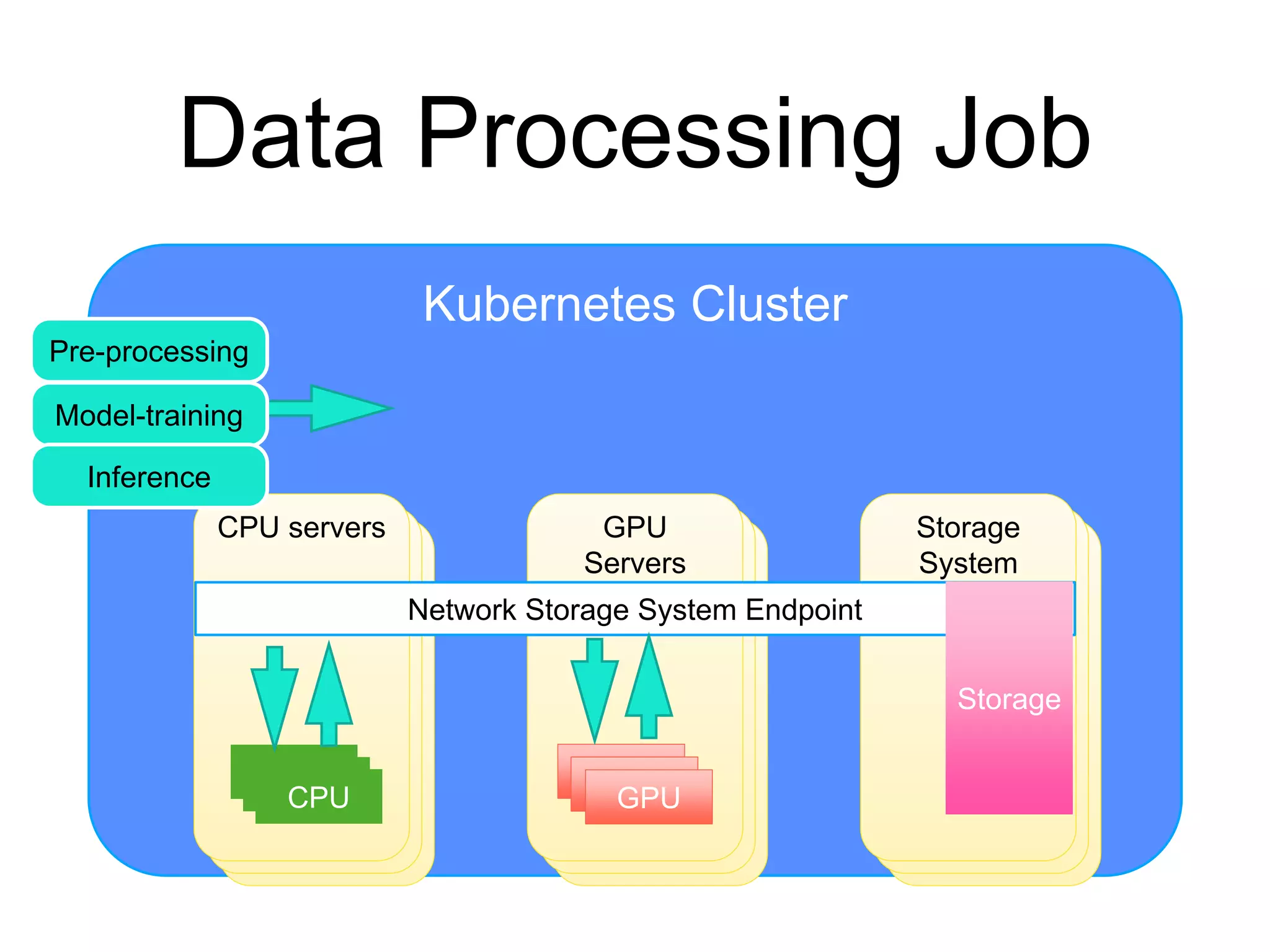




The document provides an introduction to Kubernetes, an open-source system that automates the deployment, scaling, and management of containerized applications. It covers Kubernetes architecture, cluster management, application deployment, resource request handling, and advantages of cloud versus bare metal resources. Key topics include health checks, auto-scaling, load balancing, and job scheduling in a Kubernetes environment.










































































