Downloaded 35 times

















![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
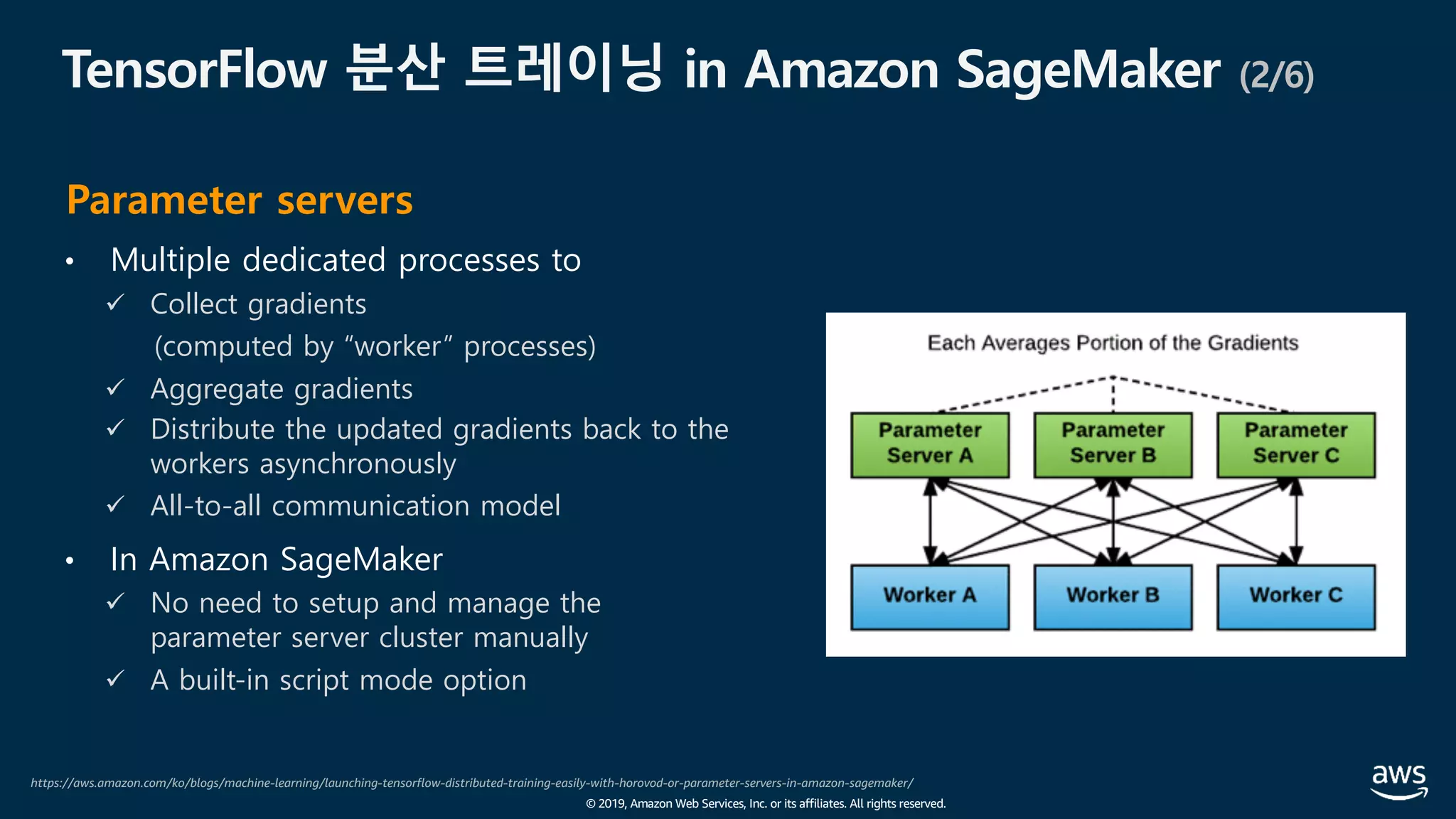
Horovod (3/9)
2. 사용할 GPU 세팅
config = tf.ConfigProto()
config.gpu_options.visible_device_list =
str(hvd.local_rank())
3. Learning Rate 조정 및
Horovod 분산 Optimizer 추가
opt = tf.train.MomentumOptimizer(
lr=0.01 * hvd.size())
opt = hvd.DistributedOptimizer(opt)
4. Synchronize initial state between workers
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
with tf.train.MonitoredTrainingSession(hooks=hooks,...) as mon_sess:
...
# OR
bcast_op = hvd.broadcast_global_variables(0)
sess.run(bcast_op)
5. Use checkpoints only on the first worker
ckpt_dir = "/tmp/train_logs" if hvd.rank() == 0 else None
with tf.train.MonitoredTrainingSession(checkpoint_dir=ckpt_dir, …)
as mon_sess:
...
1. 라이브러리 초기화
import horovod.tensorflow as hvd
hvd.init()
* Horovod for TensorFlow, Keras, and PyTorch
import horovod.tensorflow as hvd
import horovod.keras as hvd
import horovod.tensorflow.keras as hvd
import horovod.torch as hvd
# more frameworks coming
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-21-320.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (4/9)
실행 예
# Use AWS Deep Learning AMI
laptop$ ssh ubuntu@<aws-ip-1>
aws-ip-1$ source activate tensorflow_p27
aws-ip-1$ ssh-keygen
aws-ip-1$ cat /home/ubuntu/.ssh/id_rsa.pub
[copy contents of the pubkey]
aws-ip-1$ exit
laptop$ ssh ubuntu@<aws-ip-2>
aws-ip-2$ source activate tensorflow_p27
aws-ip-2$ cat >> /home/ubuntu/.ssh/authorized_keys
[paste contents of the pubkey]
aws-ip-2$ exit
laptop$ ssh ubuntu@<aws-ip-1>
aws-ip-2$ ssh aws-ip-2
[will ask for prompt, say yes]
aws-ip-2$ exit
aws-ip-1$ mpirun -np 2 -H aws-ip-1,aws-ip-2
wget https://raw.githubusercontent.com/uber/horovod
/master/examples/tensorflow_mnist.py
aws-ip-1$ mpirun -bind-to none -map-by slot
-x HOROVOD_HIERARCHICAL_ALLREDUCE=1
-x LD_LIBRARY_PATH -x PATH
-mca btl_tcp_if_exclude lo,docker0
–np 16 -H aws-ip-1:8,aws-ip-2:8
python tensorflow_mnist.py
# Pro tip: hide mpirun args into mpirun.sh
aws-ip-1$ mpirun.sh
–np 16 –H aws-ip-1:8,aws-ip-2:8
python tensorflow_mnist.py
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-22-320.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (5/9)
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to
# process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list =
str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.MomentumOptimizer(
lr=0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to synchronize initial state
hooks =[hvd.BroadcastGlobalVariablesHook(0)]
# Only checkpoint on rank 0
ckpt_dir = "/tmp/train_logs"
if hvd.rank() == 0 else None
# Make training operation
train_op = opt.minimize(loss)
# The MonitoredTrainingSession takes care of
# session initialization, restoring from a
# checkpoint, saving to a checkpoint, and
# closing when done or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint
_dir=ckpt_dir, config=config, hooks=hooks) as mon
_sess:
while not mon_sess.should_stop():
# Perform synchronous training
mon_sess.run(train_op)
[참고] 예제 코드 – Horovod for TensorFlow
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-23-320.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (6/9)
[참고] 예제 코드 – Estimator API
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used
config = tf.ConfigProto()
config.gpu_options.visible_device_list =
str(hvd.local_rank())
# Build model...
def model_fn(features, labels, mode):
loss = ...
opt = tf.train.MomentumOptimizer(
lr=0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
return tf.estimator.EstimatorSpec(...)
# Broadcast initial variable state.
hooks =
[hvd.BroadcastGlobalVariablesHook(0)]
# Only checkpoint on rank 0
ckpt_dir = "/tmp/train_logs"
if hvd.rank() == 0 else None
# Create the Estimator
mnist_classifier = tf.estimator.Estimator(
model_fn=cnn_model_fn,
model_dir=ckpt_dir,
config=tf.estimator.RunConfig(
session_config=config))
mnist_classifier.train(
input_fn=train_input_fn,
steps=100,
hooks=hooks)
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-24-320.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (7/9)
import mxnet as mx
import horovod.mxnet as hvd
from mxnet import autograd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank
context = mx.gpu(hvd.local_rank())
num_workers = hvd.size()
# Build model
model = ...
model.hybridize()
# Create optimizer
optimizer_params = ...
opt = mx.optimizer.create('sgd', **optimizer_params)
# Initialize parameters
model.initialize(initializer, ctx=context)
# Fetch and broadcast parameters
params = model.collect_params()
if params is not None:
hvd.broadcast_parameters(params, root_rank=0)
# Create DistributedTrainer, a subclass of gluon.Trainer
trainer = hvd.DistributedTrainer(params, opt)
# Create loss function
loss_fn = ...
# Train model
for epoch in range(num_epoch):
train_data.reset()
for nbatch, batch in enumerate(train_data, start=1):
data = batch.data[0].as_in_context(context)
label = batch.label[0].as_in_context(context)
with autograd.record():
output = model(data.astype(dtype, copy=False))
loss = loss_fn(output, label)
loss.backward()
trainer.step(batch_size)
[참고] 예제 코드 – Horovod for MxNet
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-25-320.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (8/9)
[참고] 예제 코드 – Horovod for Keras
import keras
from keras import backend as K
import tensorflow as tf
import horovod.keras as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used
config = tf.ConfigProto()
config.gpu_options.visible_device_list =
str(hvd.local_rank())
K.set_session(tf.Session(config=config))
# Build model...
model = ...
opt = keras.optimizers.Adadelta(lr=1.0 * hvd.size())
# Add Horovod Distributed Optimizer.
opt = hvd.DistributedOptimizer(opt)
model.compile(
loss='categorical_crossentropy’,
optimizer=opt,
metrics=['accuracy'])
# Broadcast initial variable state.
callbacks = [hvd.callbacks.BroadcastGlobalVariabl
esCallback(0)]
...
model.fit(
x_train,
y_train,
callbacks=callbacks,
epochs=10,
validation_data=(x_test, y_test))
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-26-320.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (9/9)
[참고] 예제 코드 – Horovod for PyTorch
import torch
import horovod.torch as hvd
# Initialize Horovod
hvd.init()
# Horovod: pin GPU to local rank
torch.cuda.set_device(hvd.local_rank())
# Build model...
model = Net()
model.cuda()
optimizer = optim.SGD(model.parameters())
# Wrap optimizer with DistributedOptimizer
optimizer = hvd.DistributedOptimizer(
optimizer,
named_parameters=model.named_parameters())
# Horovod: broadcast parameters
hvd.broadcast_parameters(
model.state_dict(),
root_rank=0)
for epoch in range(100):
for batch_idx, (data, target) in ...:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-27-320.jpg)



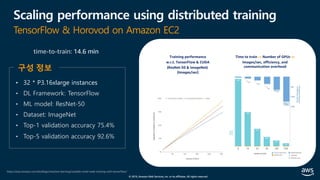

![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
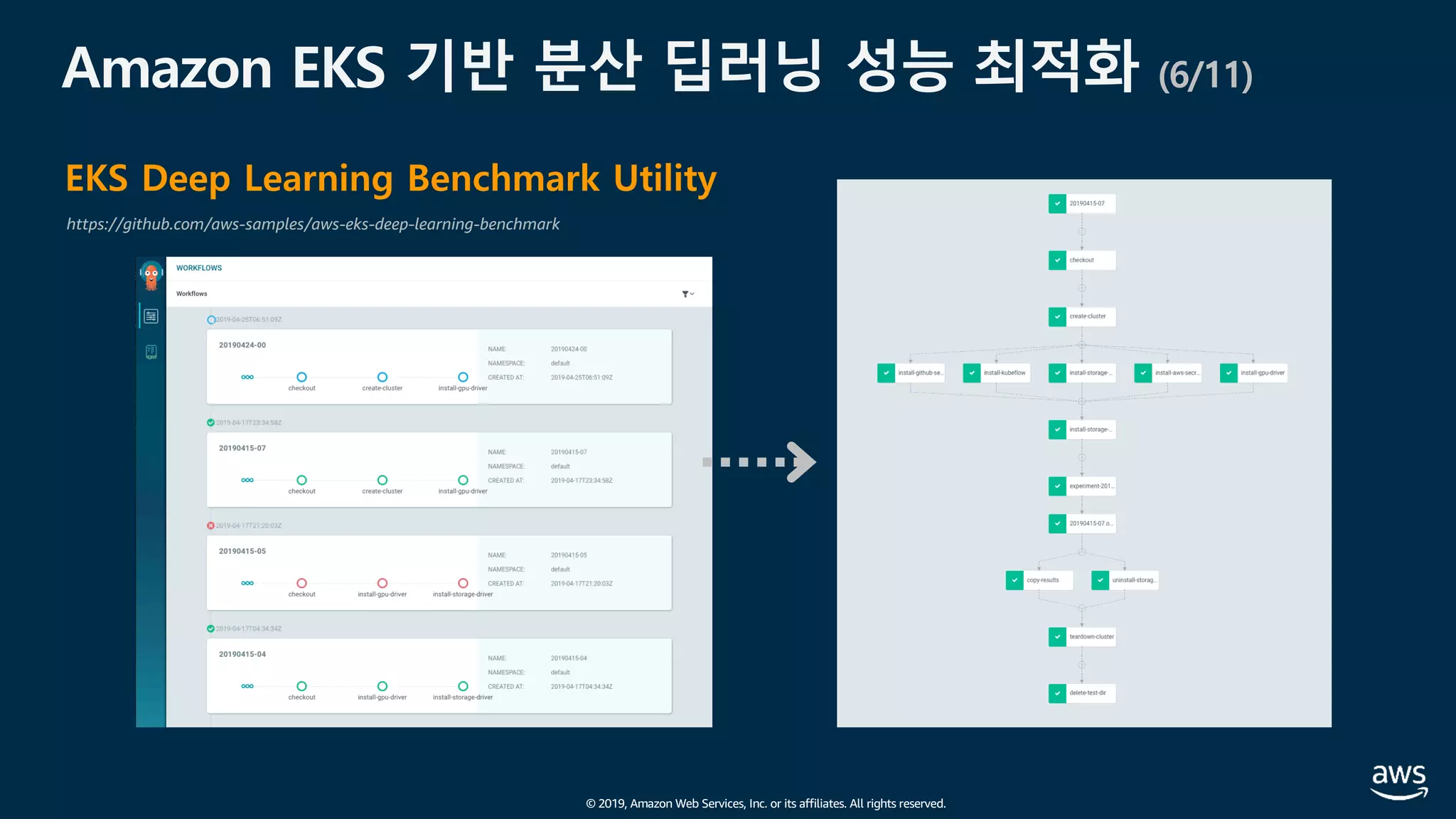
Amazon EKS 기반 분산 딥러닝 성능 최적화 (1/11)
[참고] Modular and Scalable Amazon EKS Architecture
https://aws.amazon.com/ko/quickstart/architecture/amazon-eks/](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-34-320.jpg)



![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon EKS 기반 분산 딥러닝 성능 최적화 (5/11)
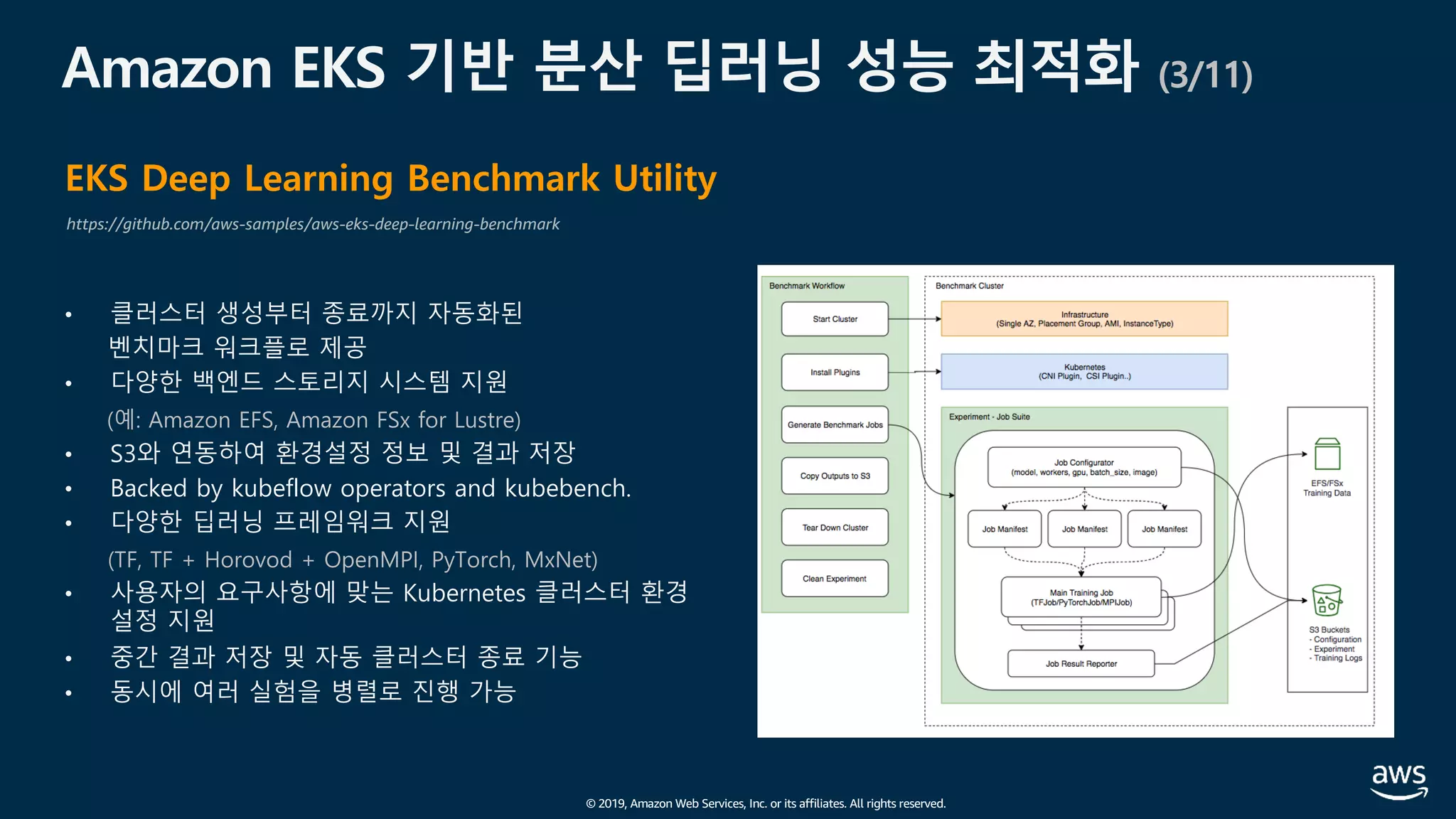
EKS Deep Learning Benchmark Utility
https://github.com/aws-samples/aws-eks-deep-learning-benchmark
• Run the benchmmark jobs
s3ResultPath: 's3://kubeflow-pipeline-data/benchmark/',
s3DatasetPath: 's3://eks-dl-benchmark/imagenet/',
clusterConfig: 's3://kubeflow-pipeline-data/benchmark/cluster_config.yaml',
experiments: [{
experiment: 'experiment-20190415-01',
trainingJobConfig: 's3://kubeflow-pipeline-data/benchmark/mpi-job-imagenet.yaml',
trainingJobPkg: 'mpi-job',
trainingJobPrototype: 'mpi-job-custom',
// Change to upstream once https://github.com/kubeflow/kubeflow/pull/3062 is merged
trainingJobRegistry: 'github.com/jeffwan/kubeflow/tree/make_kubebench_reporter_optional/kubeflow',
}],
githubSecretName: 'github-token',
githubSecretTokenKeyName: 'GITHUB_TOKEN',
image: 'seedjeffwan/benchmark-runner:20190424',
name: '20190424-00',
namespace: 'default',
nfsVolume: 'benchmark-pv',
nfsVolumeClaim: 'benchmark-pvc',
region: 'us-west-2',
trainingDatasetVolume: 'dataset-claim',
s3SecretName: 'aws-secret',
s3SecretAccesskeyidKeyName: 'AWS_ACCESS_KEY_ID',
s3SecretSecretaccesskeyKeyName: 'AWS_SECRET_ACCESS_KEY',
storageBackend: 'fsx',
kubeflowRegistry: 'github.com/jeffwan/kubeflow/tree/make_kubebench_reporter_optional/kubeflow'
1. Update your workflow
setting using ks command
2. Update benchmark
workflow manifest directly](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-38-320.jpg)








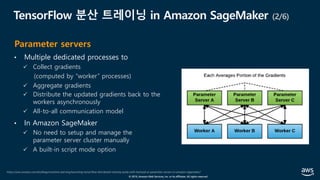







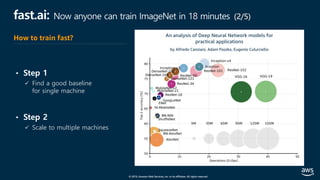

![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
fast.ai: Now anyone can train ImageNet in 18 minutes (4/5)
All-Reduce - NVIDIA NCCL*
• Sync gradient after backprop
Distributed Data Parallel - PyTorch
NCCL: NVIDIA Collective Communications Library
• Optimization: Overlap sync with computation
Data
BackpropForward
Sync
BackpropForward
Data
BackpropForward
Sync
BackpropForward
Sync Sync
Gradients
Gradients
GradientsGradients
Gradients
Gradients GPU0
batch0_0
GPU1
batch0_1
GPU2
batch0_2
GPU3
batch0_3
GPU4
batch0_4
GPU5
batch0_5
분산 아키텍처
[참고] apex.parallel.DistributedDataParallel](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-57-320.jpg)


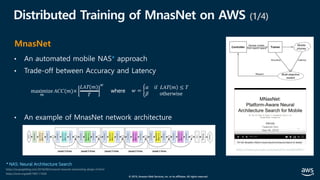

![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Distributed Training of MnasNet on AWS (3/4)
...
I0923 16:15:22.086650 140202663954176 saver.py:1276] Restoring parameters from ./results_hvd/model.ckpt-62560
I0923 16:15:22.418808 140202663954176 session_manager.py:491] Running local_init_op.
I0923 16:15:22.426828 140202663954176 session_manager.py:493] Done running local_init_op.
I0923 16:15:47.475176 140202663954176 evaluation.py:277] Finished evaluation at 2019-09-23-16:15:47
I0923 16:15:47.475430 140202663954176 estimator.py:1979] Saving dict for global step 62560: global_step = 62560, loss =
2.1191003, top_1_accuracy = 0.74759614, top_5_accuracy = 0.9215545
I0923 16:15:47.475846 140202663954176 estimator.py:2039] Saving 'checkpoint_path' summary for global step 62560:
./results_hvd/model.ckpt-62560
I0923 16:15:47.476232 140202663954176 error_handling.py:93] evaluation_loop marked as finished
I0923 16:15:47.476345 140202663954176 mnasnet_main_hvd.py:1041] Eval results at step 62560: {'loss': 2.1191003,
'top_1_accuracy': 0.74759614, 'top_5_accuracy': 0.9215545, 'global_step': 62560}. Hvd rank 0
I0923 16:15:47.476416 140202663954176 mnasnet_main_hvd.py:1051] Finished training up to step 62560. Elapsed seconds 40649.
실행 예 (2/2)
• time-to-train: ≈ 11.29 hrs
• Top-1 accuracy : 74.76%
• Top-5 accuracy : 92.16%](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/85/AWS-Dev-Day-AWS-AWS-AWS-62-320.jpg)


















![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (3/9)
2. 사용할 GPU 세팅
config = tf.ConfigProto()
config.gpu_options.visible_device_list =
str(hvd.local_rank())
3. Learning Rate 조정 및
Horovod 분산 Optimizer 추가
opt = tf.train.MomentumOptimizer(
lr=0.01 * hvd.size())
opt = hvd.DistributedOptimizer(opt)
4. Synchronize initial state between workers
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
with tf.train.MonitoredTrainingSession(hooks=hooks,...) as mon_sess:
...
# OR
bcast_op = hvd.broadcast_global_variables(0)
sess.run(bcast_op)
5. Use checkpoints only on the first worker
ckpt_dir = "/tmp/train_logs" if hvd.rank() == 0 else None
with tf.train.MonitoredTrainingSession(checkpoint_dir=ckpt_dir, …)
as mon_sess:
...
1. 라이브러리 초기화
import horovod.tensorflow as hvd
hvd.init()
* Horovod for TensorFlow, Keras, and PyTorch
import horovod.tensorflow as hvd
import horovod.keras as hvd
import horovod.tensorflow.keras as hvd
import horovod.torch as hvd
# more frameworks coming
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-21-2048.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (4/9)
실행 예
# Use AWS Deep Learning AMI
laptop$ ssh ubuntu@<aws-ip-1>
aws-ip-1$ source activate tensorflow_p27
aws-ip-1$ ssh-keygen
aws-ip-1$ cat /home/ubuntu/.ssh/id_rsa.pub
[copy contents of the pubkey]
aws-ip-1$ exit
laptop$ ssh ubuntu@<aws-ip-2>
aws-ip-2$ source activate tensorflow_p27
aws-ip-2$ cat >> /home/ubuntu/.ssh/authorized_keys
[paste contents of the pubkey]
aws-ip-2$ exit
laptop$ ssh ubuntu@<aws-ip-1>
aws-ip-2$ ssh aws-ip-2
[will ask for prompt, say yes]
aws-ip-2$ exit
aws-ip-1$ mpirun -np 2 -H aws-ip-1,aws-ip-2
wget https://raw.githubusercontent.com/uber/horovod
/master/examples/tensorflow_mnist.py
aws-ip-1$ mpirun -bind-to none -map-by slot
-x HOROVOD_HIERARCHICAL_ALLREDUCE=1
-x LD_LIBRARY_PATH -x PATH
-mca btl_tcp_if_exclude lo,docker0
–np 16 -H aws-ip-1:8,aws-ip-2:8
python tensorflow_mnist.py
# Pro tip: hide mpirun args into mpirun.sh
aws-ip-1$ mpirun.sh
–np 16 –H aws-ip-1:8,aws-ip-2:8
python tensorflow_mnist.py
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-22-2048.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (5/9)
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to
# process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list =
str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.MomentumOptimizer(
lr=0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to synchronize initial state
hooks =[hvd.BroadcastGlobalVariablesHook(0)]
# Only checkpoint on rank 0
ckpt_dir = "/tmp/train_logs"
if hvd.rank() == 0 else None
# Make training operation
train_op = opt.minimize(loss)
# The MonitoredTrainingSession takes care of
# session initialization, restoring from a
# checkpoint, saving to a checkpoint, and
# closing when done or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint
_dir=ckpt_dir, config=config, hooks=hooks) as mon
_sess:
while not mon_sess.should_stop():
# Perform synchronous training
mon_sess.run(train_op)
[참고] 예제 코드 – Horovod for TensorFlow
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-23-2048.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (6/9)
[참고] 예제 코드 – Estimator API
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used
config = tf.ConfigProto()
config.gpu_options.visible_device_list =
str(hvd.local_rank())
# Build model...
def model_fn(features, labels, mode):
loss = ...
opt = tf.train.MomentumOptimizer(
lr=0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
return tf.estimator.EstimatorSpec(...)
# Broadcast initial variable state.
hooks =
[hvd.BroadcastGlobalVariablesHook(0)]
# Only checkpoint on rank 0
ckpt_dir = "/tmp/train_logs"
if hvd.rank() == 0 else None
# Create the Estimator
mnist_classifier = tf.estimator.Estimator(
model_fn=cnn_model_fn,
model_dir=ckpt_dir,
config=tf.estimator.RunConfig(
session_config=config))
mnist_classifier.train(
input_fn=train_input_fn,
steps=100,
hooks=hooks)
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-24-2048.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (7/9)
import mxnet as mx
import horovod.mxnet as hvd
from mxnet import autograd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank
context = mx.gpu(hvd.local_rank())
num_workers = hvd.size()
# Build model
model = ...
model.hybridize()
# Create optimizer
optimizer_params = ...
opt = mx.optimizer.create('sgd', **optimizer_params)
# Initialize parameters
model.initialize(initializer, ctx=context)
# Fetch and broadcast parameters
params = model.collect_params()
if params is not None:
hvd.broadcast_parameters(params, root_rank=0)
# Create DistributedTrainer, a subclass of gluon.Trainer
trainer = hvd.DistributedTrainer(params, opt)
# Create loss function
loss_fn = ...
# Train model
for epoch in range(num_epoch):
train_data.reset()
for nbatch, batch in enumerate(train_data, start=1):
data = batch.data[0].as_in_context(context)
label = batch.label[0].as_in_context(context)
with autograd.record():
output = model(data.astype(dtype, copy=False))
loss = loss_fn(output, label)
loss.backward()
trainer.step(batch_size)
[참고] 예제 코드 – Horovod for MxNet
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-25-2048.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (8/9)
[참고] 예제 코드 – Horovod for Keras
import keras
from keras import backend as K
import tensorflow as tf
import horovod.keras as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used
config = tf.ConfigProto()
config.gpu_options.visible_device_list =
str(hvd.local_rank())
K.set_session(tf.Session(config=config))
# Build model...
model = ...
opt = keras.optimizers.Adadelta(lr=1.0 * hvd.size())
# Add Horovod Distributed Optimizer.
opt = hvd.DistributedOptimizer(opt)
model.compile(
loss='categorical_crossentropy’,
optimizer=opt,
metrics=['accuracy'])
# Broadcast initial variable state.
callbacks = [hvd.callbacks.BroadcastGlobalVariabl
esCallback(0)]
...
model.fit(
x_train,
y_train,
callbacks=callbacks,
epochs=10,
validation_data=(x_test, y_test))
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-26-2048.jpg)
![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Horovod (9/9)
[참고] 예제 코드 – Horovod for PyTorch
import torch
import horovod.torch as hvd
# Initialize Horovod
hvd.init()
# Horovod: pin GPU to local rank
torch.cuda.set_device(hvd.local_rank())
# Build model...
model = Net()
model.cuda()
optimizer = optim.SGD(model.parameters())
# Wrap optimizer with DistributedOptimizer
optimizer = hvd.DistributedOptimizer(
optimizer,
named_parameters=model.named_parameters())
# Horovod: broadcast parameters
hvd.broadcast_parameters(
model.state_dict(),
root_rank=0)
for epoch in range(100):
for batch_idx, (data, target) in ...:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
( source code from https://github.com/horovod/horovod )](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-27-2048.jpg)




![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon EKS 기반 분산 딥러닝 성능 최적화 (1/11)
[참고] Modular and Scalable Amazon EKS Architecture
https://aws.amazon.com/ko/quickstart/architecture/amazon-eks/](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-34-2048.jpg)


![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Amazon EKS 기반 분산 딥러닝 성능 최적화 (5/11)
EKS Deep Learning Benchmark Utility
https://github.com/aws-samples/aws-eks-deep-learning-benchmark
• Run the benchmmark jobs
s3ResultPath: 's3://kubeflow-pipeline-data/benchmark/',
s3DatasetPath: 's3://eks-dl-benchmark/imagenet/',
clusterConfig: 's3://kubeflow-pipeline-data/benchmark/cluster_config.yaml',
experiments: [{
experiment: 'experiment-20190415-01',
trainingJobConfig: 's3://kubeflow-pipeline-data/benchmark/mpi-job-imagenet.yaml',
trainingJobPkg: 'mpi-job',
trainingJobPrototype: 'mpi-job-custom',
// Change to upstream once https://github.com/kubeflow/kubeflow/pull/3062 is merged
trainingJobRegistry: 'github.com/jeffwan/kubeflow/tree/make_kubebench_reporter_optional/kubeflow',
}],
githubSecretName: 'github-token',
githubSecretTokenKeyName: 'GITHUB_TOKEN',
image: 'seedjeffwan/benchmark-runner:20190424',
name: '20190424-00',
namespace: 'default',
nfsVolume: 'benchmark-pv',
nfsVolumeClaim: 'benchmark-pvc',
region: 'us-west-2',
trainingDatasetVolume: 'dataset-claim',
s3SecretName: 'aws-secret',
s3SecretAccesskeyidKeyName: 'AWS_ACCESS_KEY_ID',
s3SecretSecretaccesskeyKeyName: 'AWS_SECRET_ACCESS_KEY',
storageBackend: 'fsx',
kubeflowRegistry: 'github.com/jeffwan/kubeflow/tree/make_kubebench_reporter_optional/kubeflow'
1. Update your workflow
setting using ks command
2. Update benchmark
workflow manifest directly](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-38-2048.jpg)














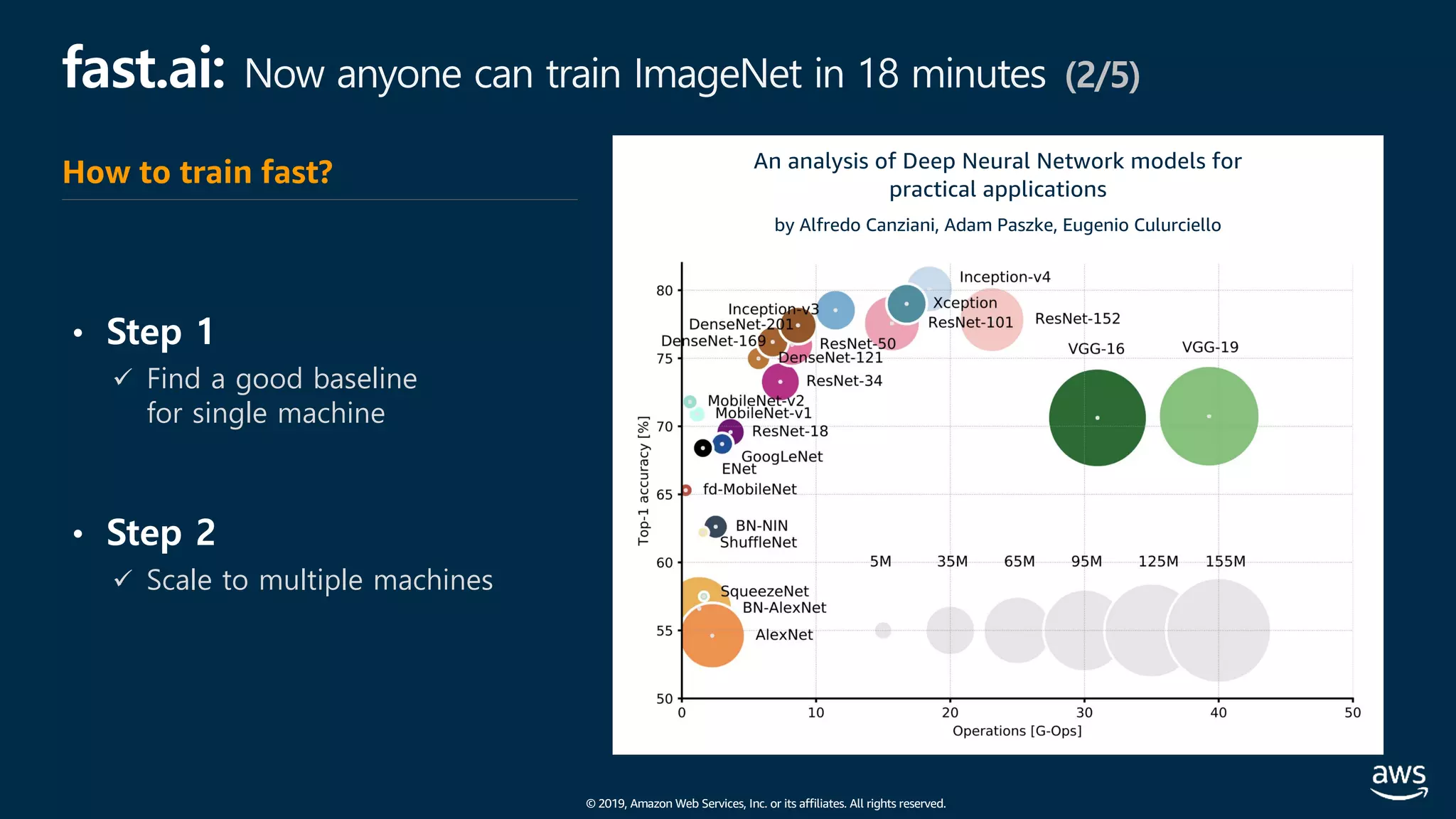

![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
fast.ai: Now anyone can train ImageNet in 18 minutes (4/5)
All-Reduce - NVIDIA NCCL*
• Sync gradient after backprop
Distributed Data Parallel - PyTorch
NCCL: NVIDIA Collective Communications Library
• Optimization: Overlap sync with computation
Data
BackpropForward
Sync
BackpropForward
Data
BackpropForward
Sync
BackpropForward
Sync Sync
Gradients
Gradients
GradientsGradients
Gradients
Gradients GPU0
batch0_0
GPU1
batch0_1
GPU2
batch0_2
GPU3
batch0_3
GPU4
batch0_4
GPU5
batch0_5
분산 아키텍처
[참고] apex.parallel.DistributedDataParallel](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-57-2048.jpg)


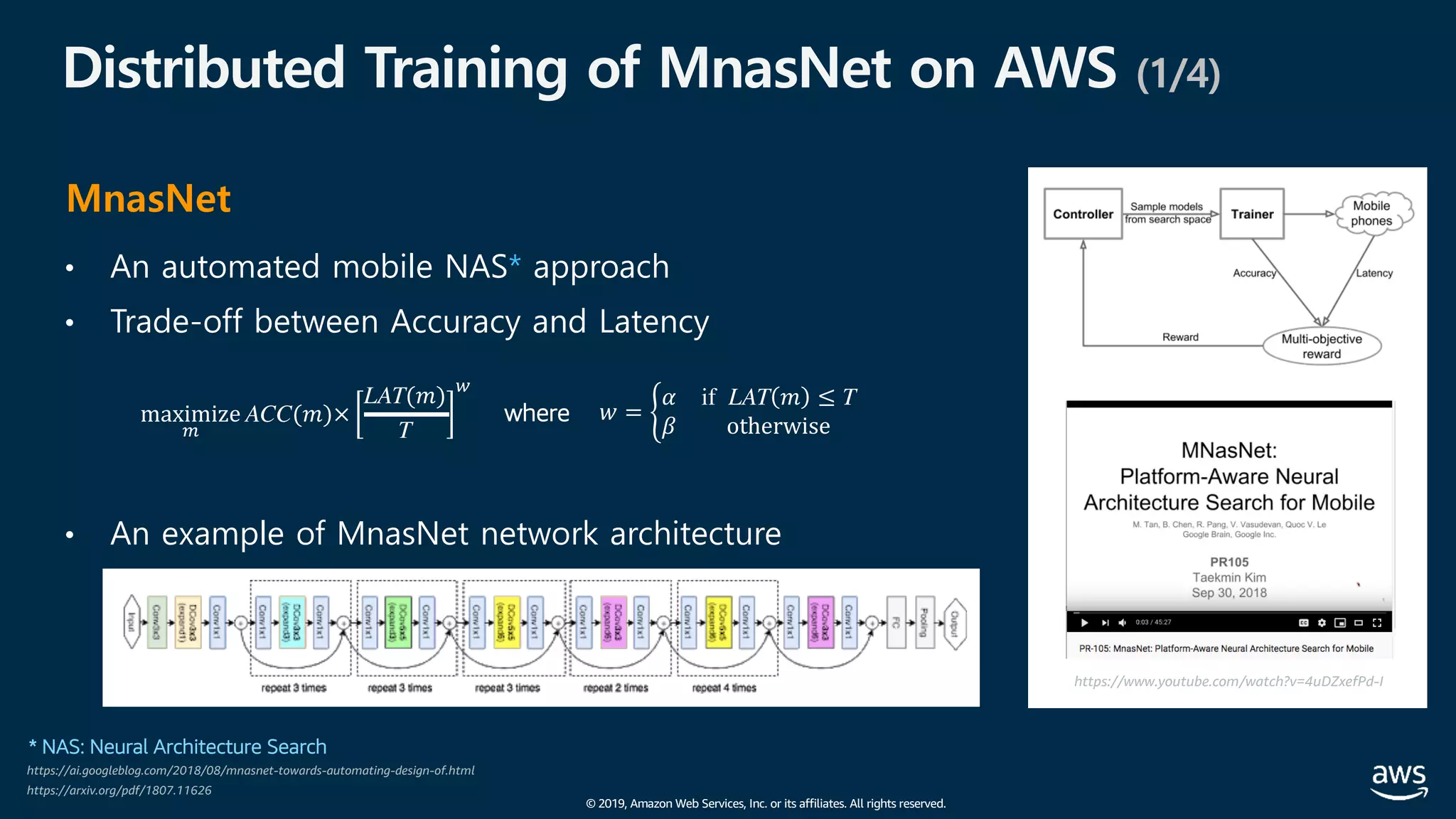

![© 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Distributed Training of MnasNet on AWS (3/4)
...
I0923 16:15:22.086650 140202663954176 saver.py:1276] Restoring parameters from ./results_hvd/model.ckpt-62560
I0923 16:15:22.418808 140202663954176 session_manager.py:491] Running local_init_op.
I0923 16:15:22.426828 140202663954176 session_manager.py:493] Done running local_init_op.
I0923 16:15:47.475176 140202663954176 evaluation.py:277] Finished evaluation at 2019-09-23-16:15:47
I0923 16:15:47.475430 140202663954176 estimator.py:1979] Saving dict for global step 62560: global_step = 62560, loss =
2.1191003, top_1_accuracy = 0.74759614, top_5_accuracy = 0.9215545
I0923 16:15:47.475846 140202663954176 estimator.py:2039] Saving 'checkpoint_path' summary for global step 62560:
./results_hvd/model.ckpt-62560
I0923 16:15:47.476232 140202663954176 error_handling.py:93] evaluation_loop marked as finished
I0923 16:15:47.476345 140202663954176 mnasnet_main_hvd.py:1041] Eval results at step 62560: {'loss': 2.1191003,
'top_1_accuracy': 0.74759614, 'top_5_accuracy': 0.9215545, 'global_step': 62560}. Hvd rank 0
I0923 16:15:47.476416 140202663954176 mnasnet_main_hvd.py:1051] Finished training up to step 62560. Elapsed seconds 40649.
실행 예 (2/2)
• time-to-train: ≈ 11.29 hrs
• Top-1 accuracy : 74.76%
• Top-5 accuracy : 92.16%](https://image.slidesharecdn.com/20190926-devday-aiml3-younghwan-final-190930020120/75/AWS-Dev-Day-AWS-AWS-AWS-62-2048.jpg)





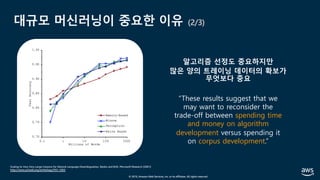
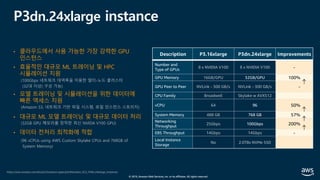
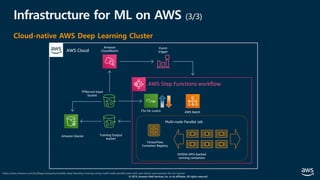
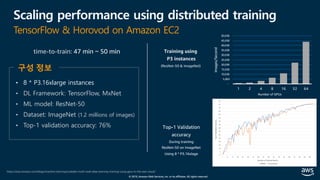
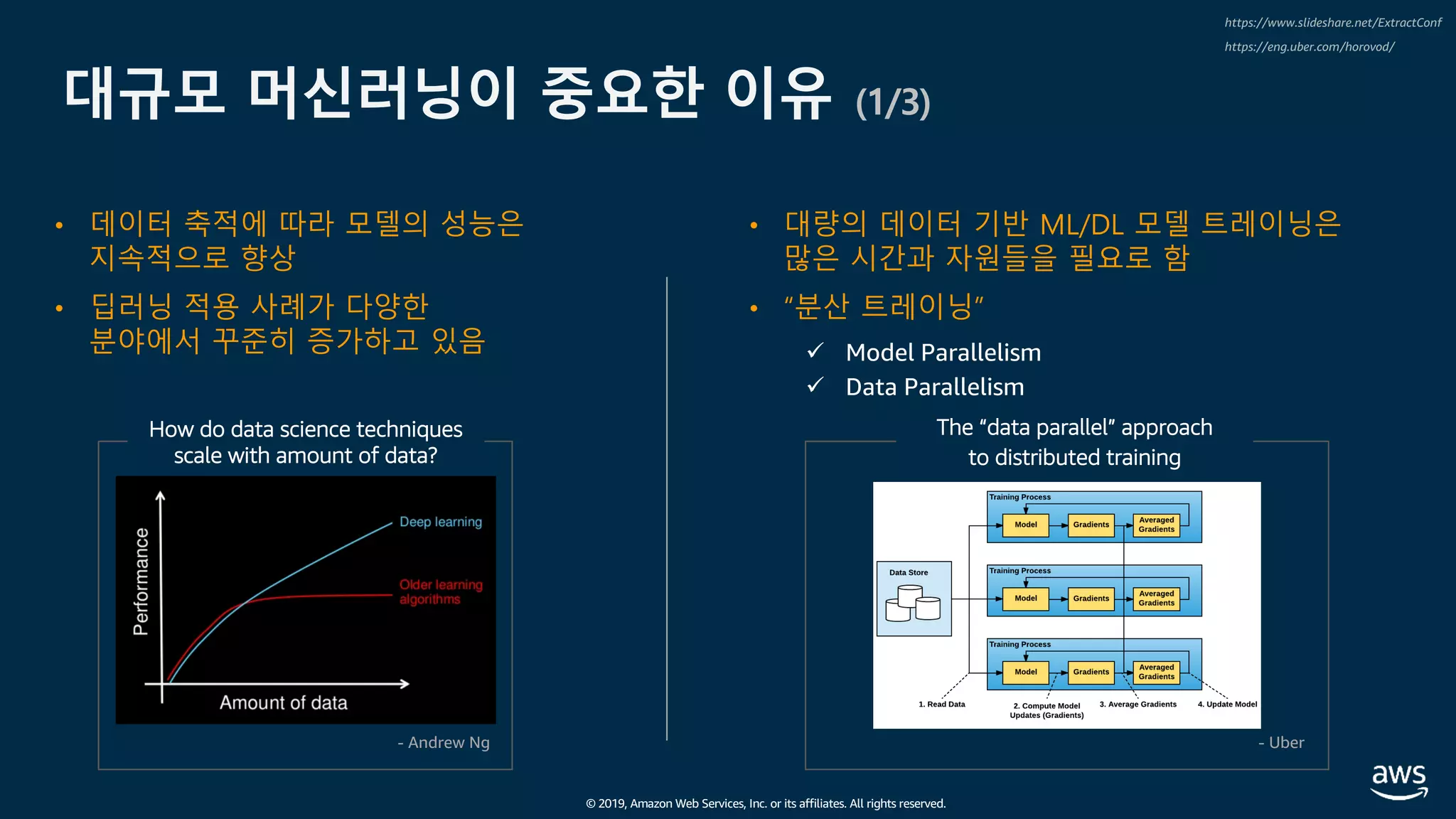
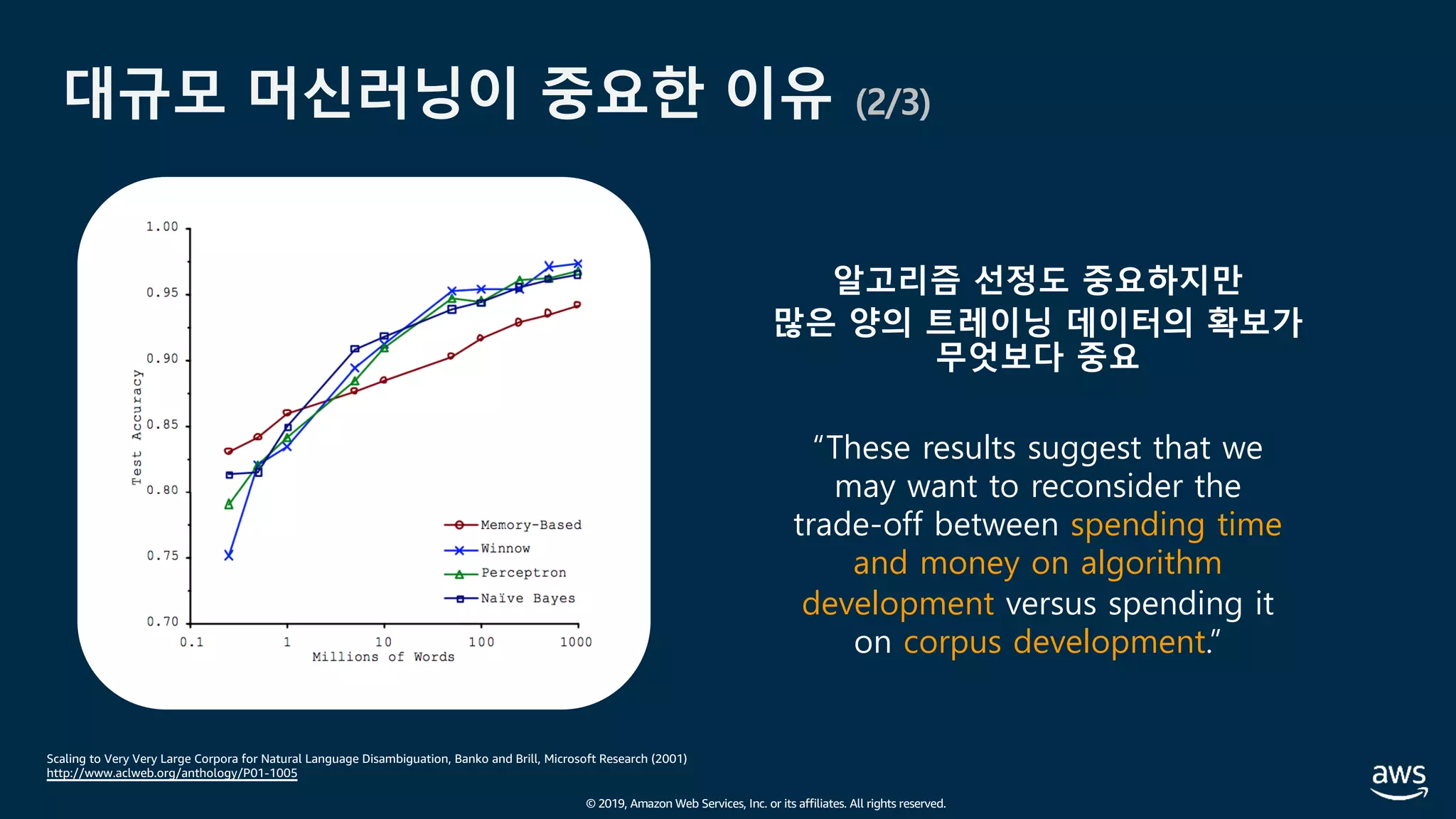
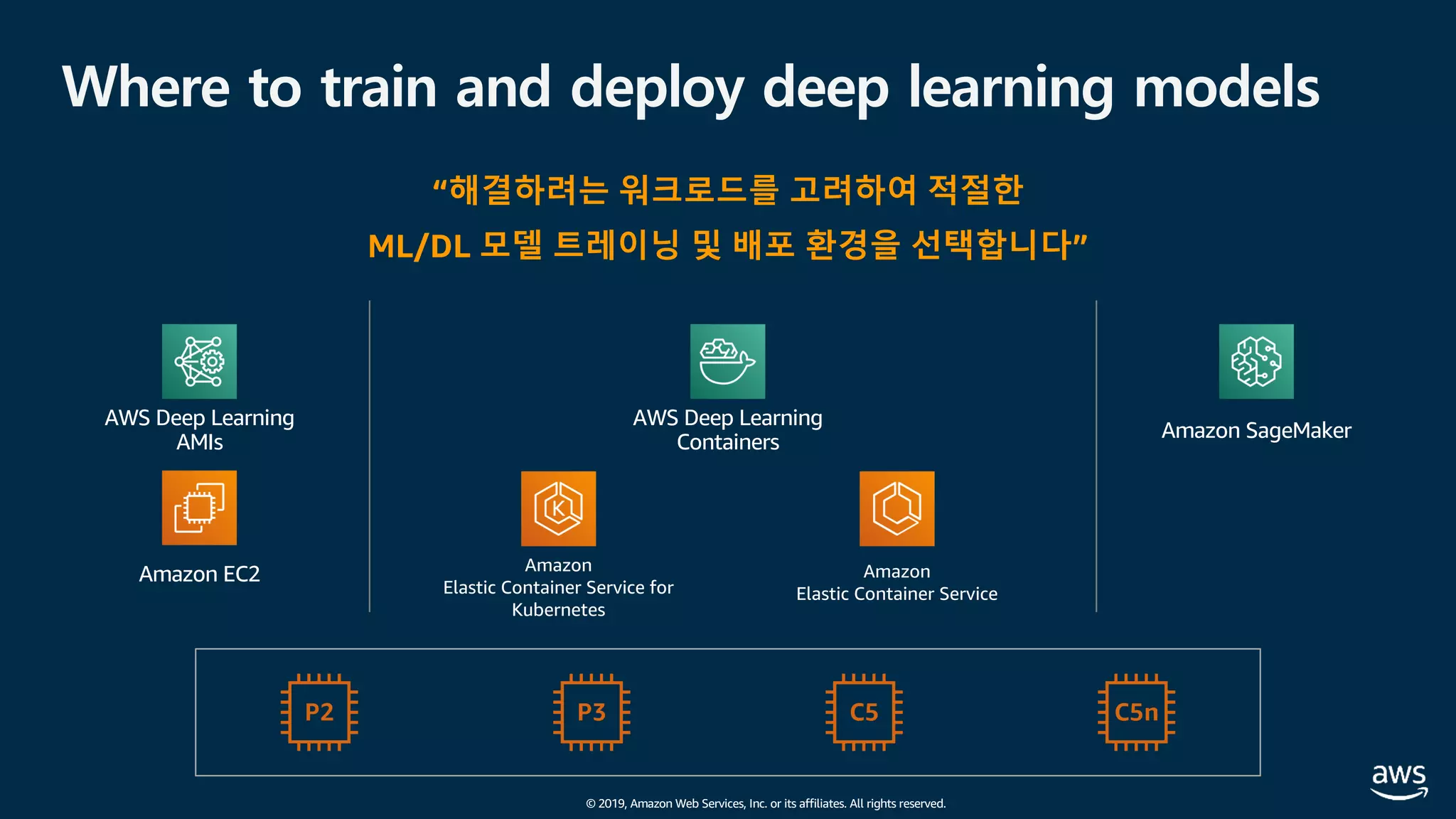
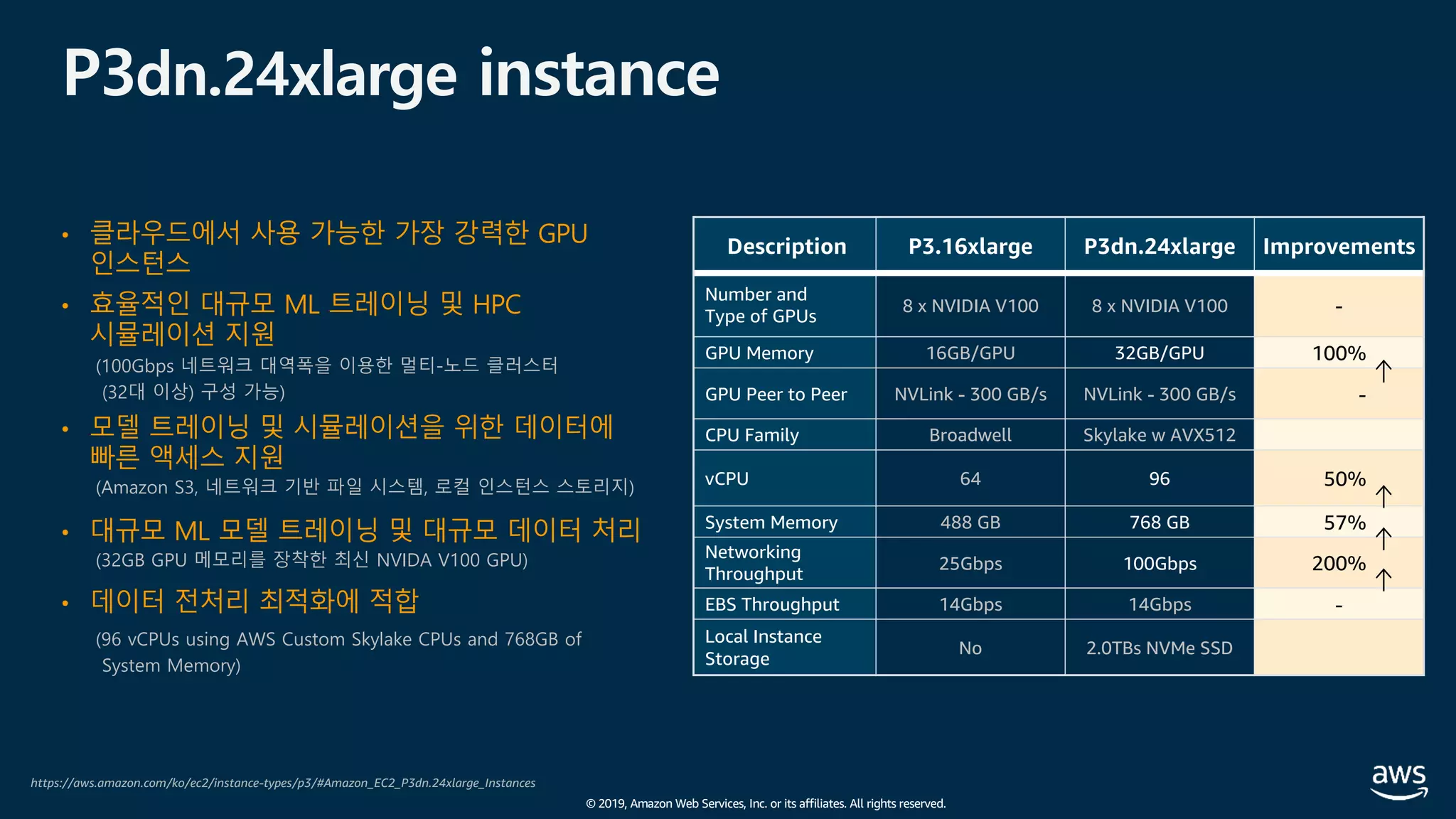
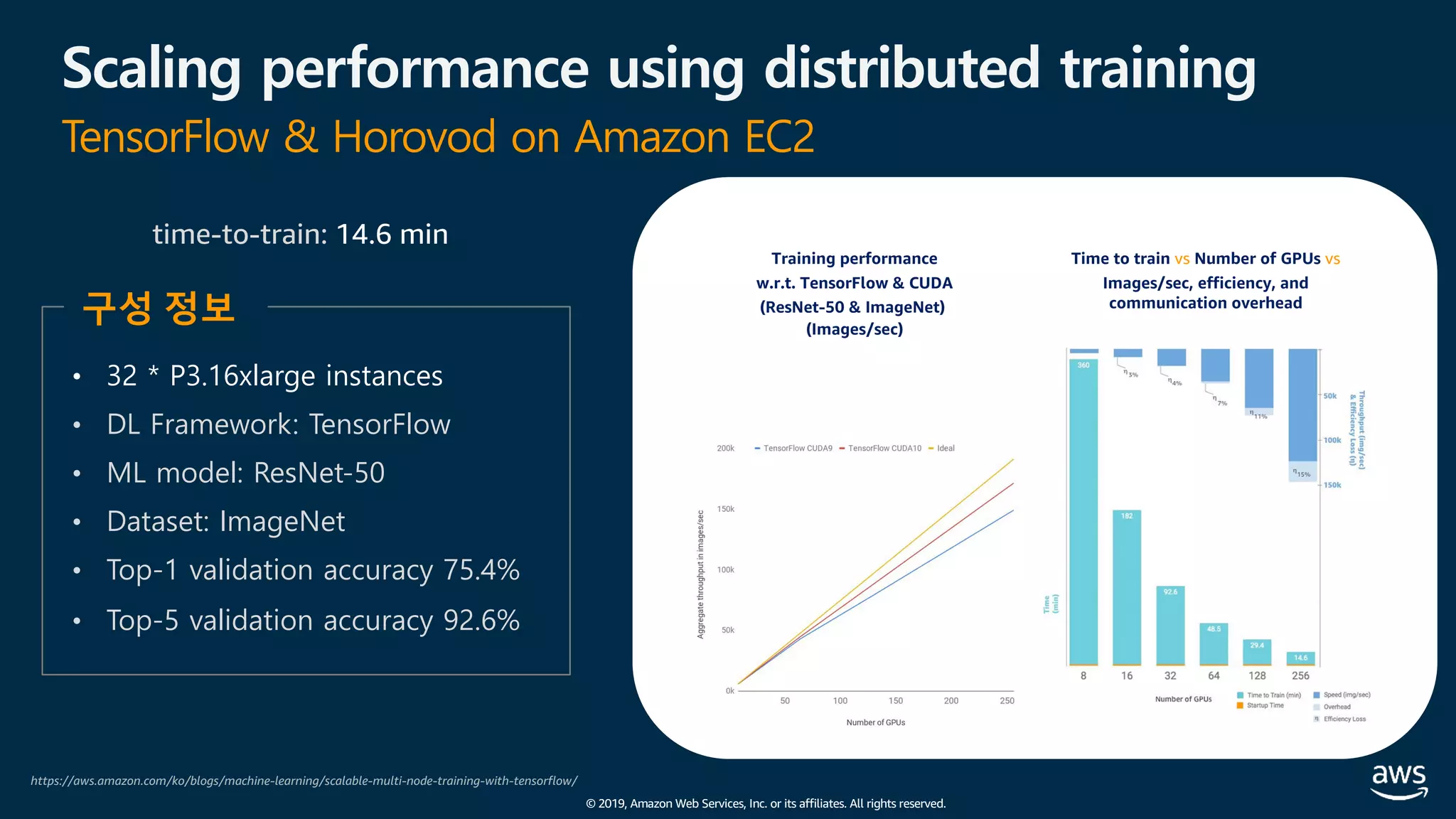
The document presents practical techniques for machine learning automation and optimization on AWS, specifically focusing on infrastructure for large-scale machine learning training using frameworks like TensorFlow and Horovod. It highlights the importance of distributed training, the efficiency of AWS resources, and considerations for optimizing model performance. Additionally, it provides insights into various AWS services and instance types useful for machine learning and deep learning applications.



















![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=600ounds&width=560&fit=bounds)













![[AWS Dev Day] 실습워크샵 | 모두를 위한 컴퓨터 비전 딥러닝 툴킷, GluonCV 따라하기](https://cdn.slidesharecdn.com/ss_thumbnails/gluoncv-190930065523-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




![[AWS Dev Day] 인공지능 / 기계 학습 | Intel on AWS, AI/ML Service 성능 향상을 위한 협력 모델 - 서...](https://cdn.slidesharecdn.com/ss_thumbnails/awsdevdayseoul2019intelonawsaimlservice-190930015001-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[금융사를 위한 AWS Generative AI Day 2023] 7_다양한 AI 워크로드를 위한 최적의 ...](https://cdn.slidesharecdn.com/ss_thumbnails/7aiacceleratorawsaws-230818064304-2a40fb19-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





![[AWS Dev Day] 인공지능 / 기계 학습 | 개발자를 위한 수백만 사용자 대상 기계 학습 서비스 확장 하기 - 윤석찬 AWS 수석테...](https://cdn.slidesharecdn.com/ss_thumbnails/scalableawsmlservicefromzerotomillions-190927015651-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=600ounds&width=560&fit=bounds)














![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








