Downloaded 121 times









![SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
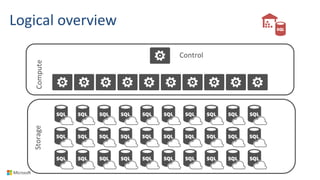
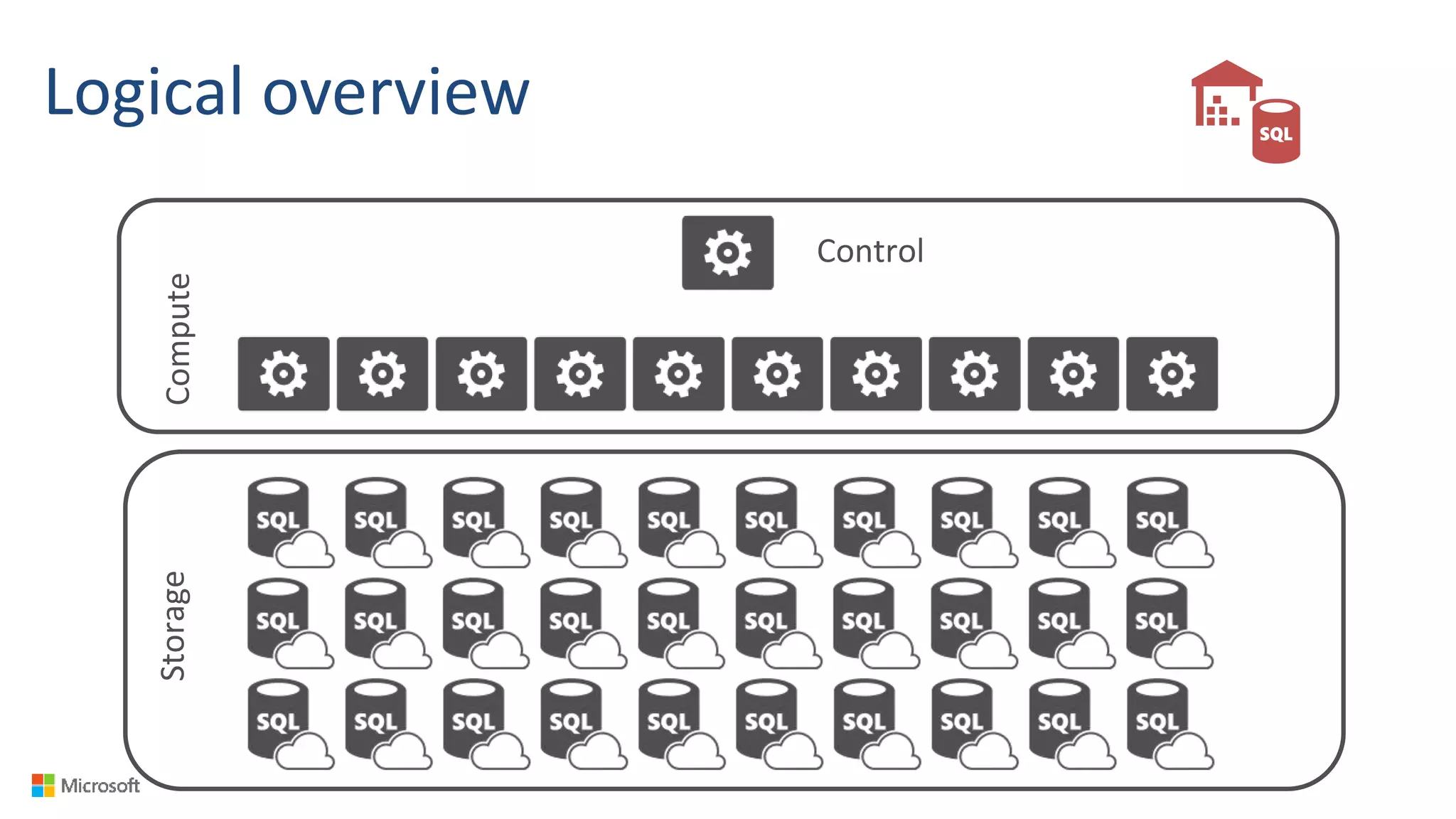
Compute
Control](https://image.slidesharecdn.com/microsoftazurebigdataanalyticscisw-kromer002-161208064151/85/Big-Data-Analytics-in-the-Cloud-with-Microsoft-Azure-18-320.jpg)
























![SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
SELECT COUNT_BIG(*)
FROM dbo.[FactInternetSales];
Compute
Control](https://image.slidesharecdn.com/microsoftazurebigdataanalyticscisw-kromer002-161208064151/75/Big-Data-Analytics-in-the-Cloud-with-Microsoft-Azure-18-2048.jpg)

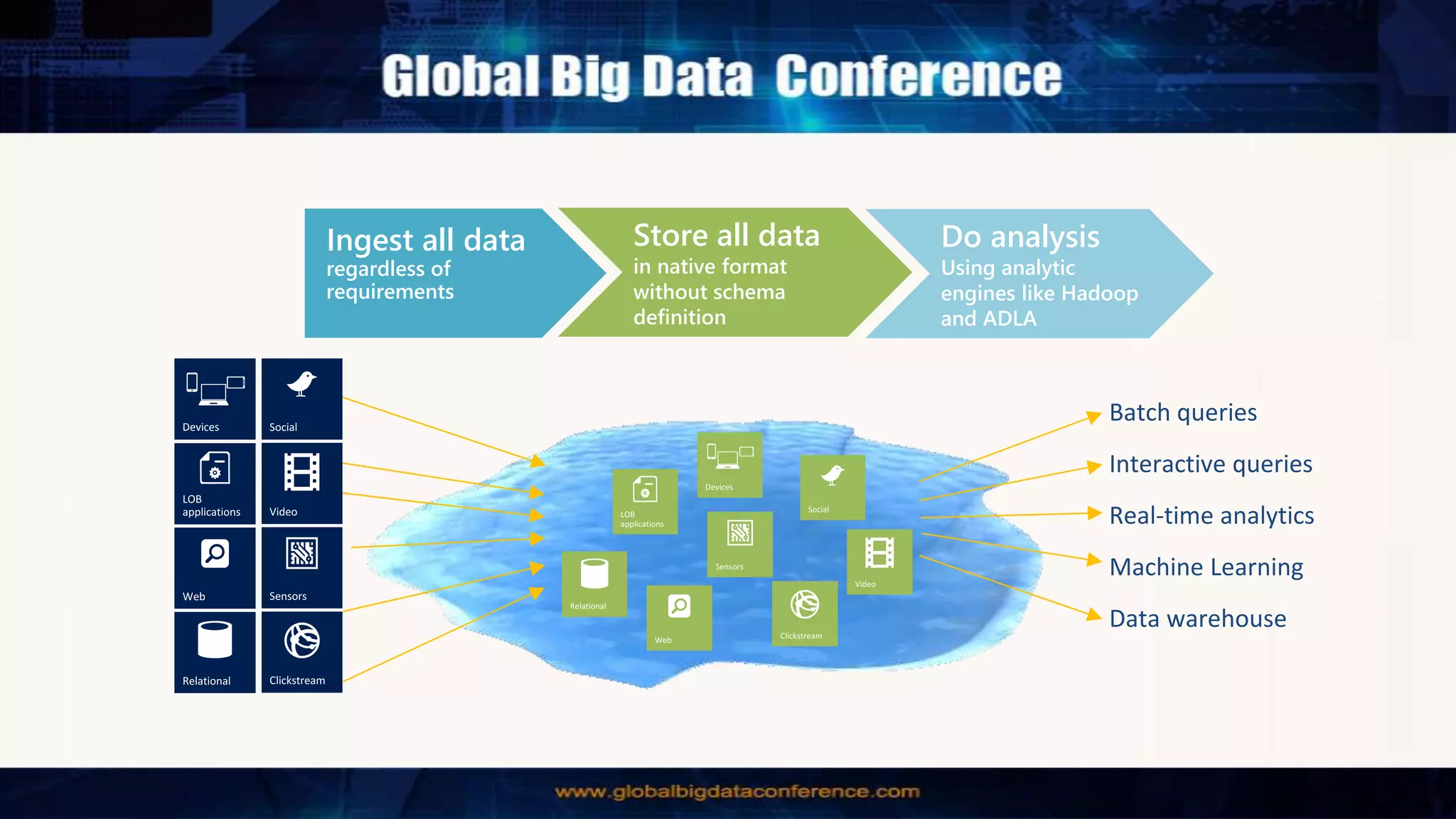



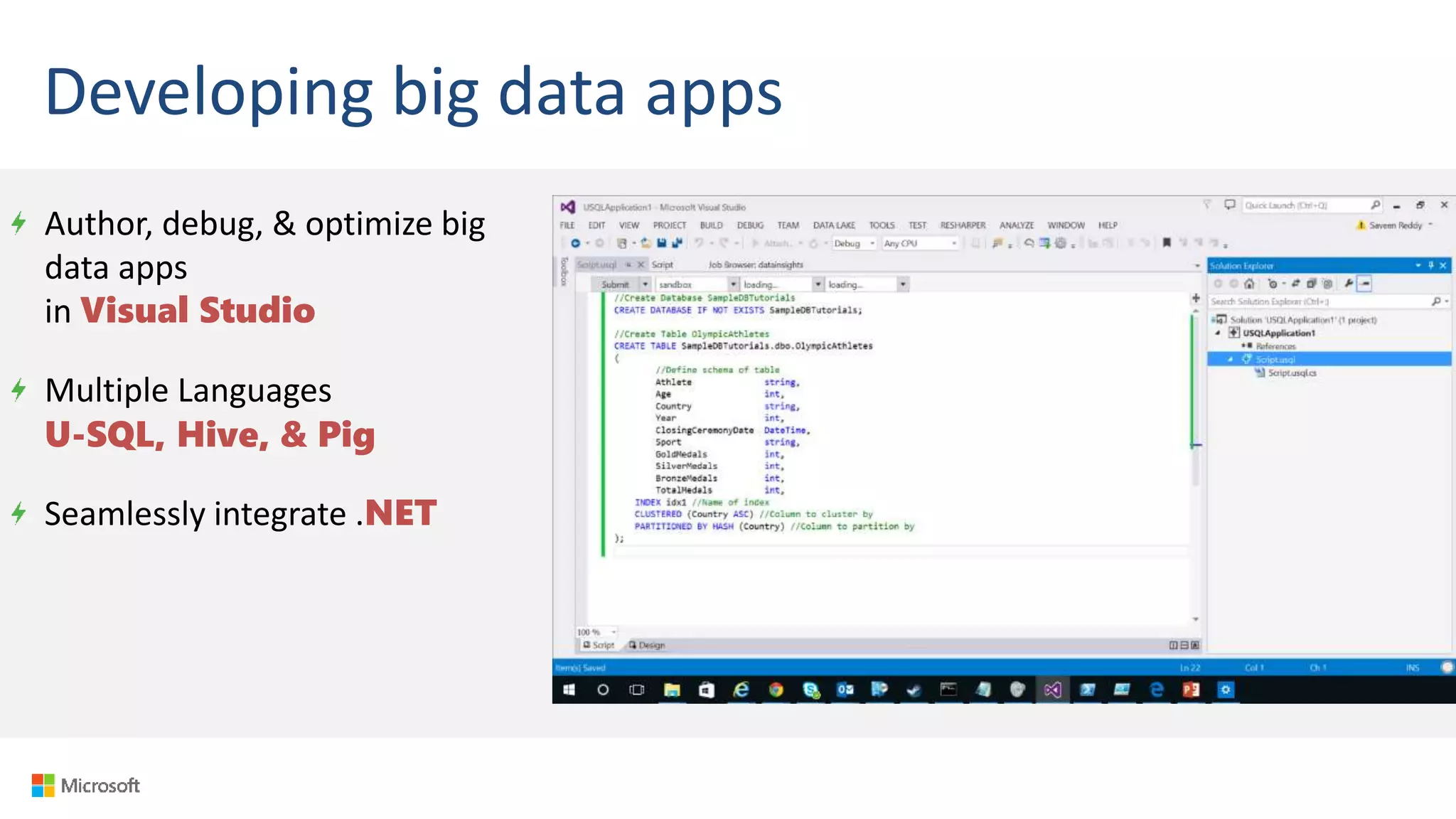
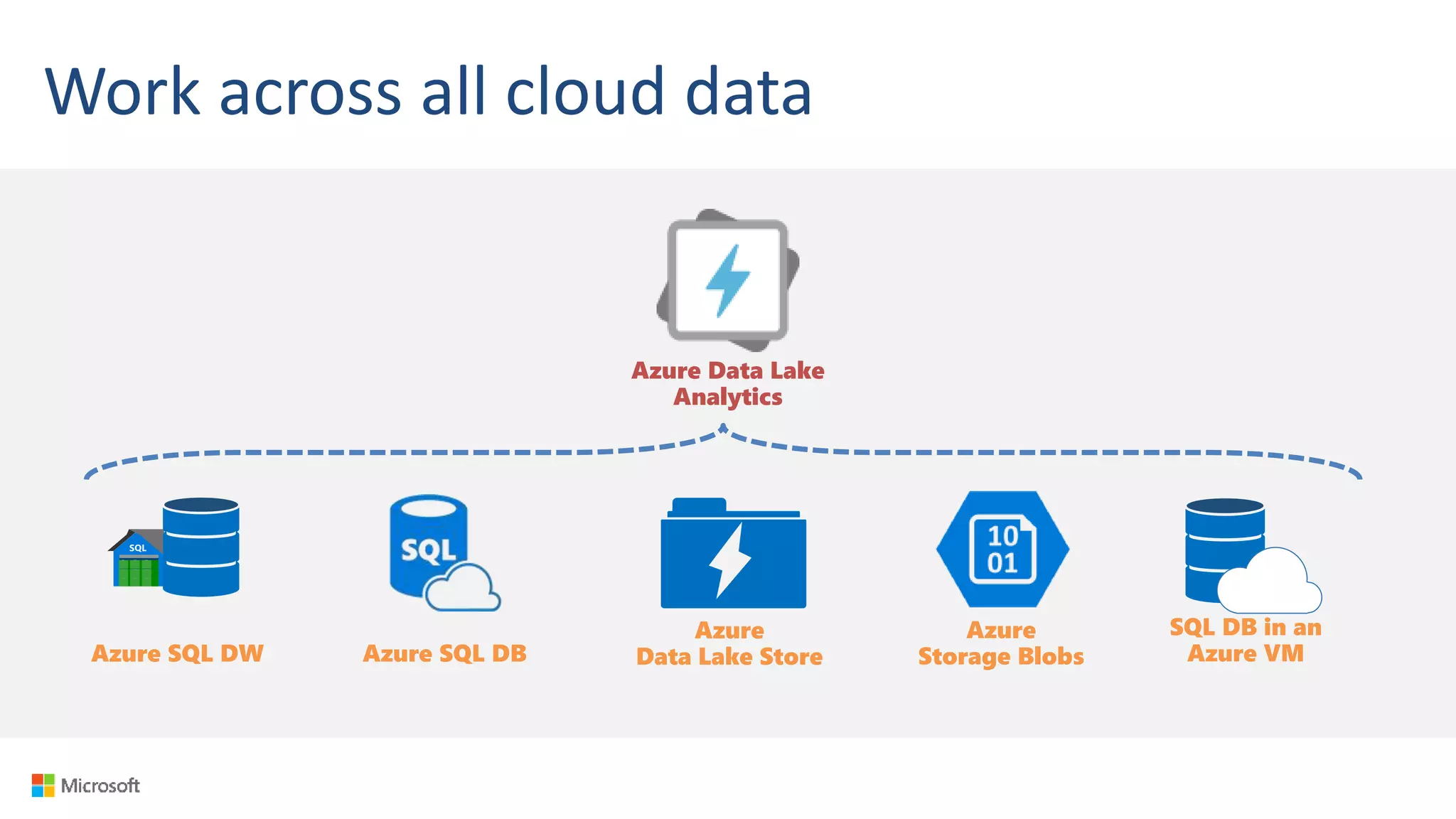

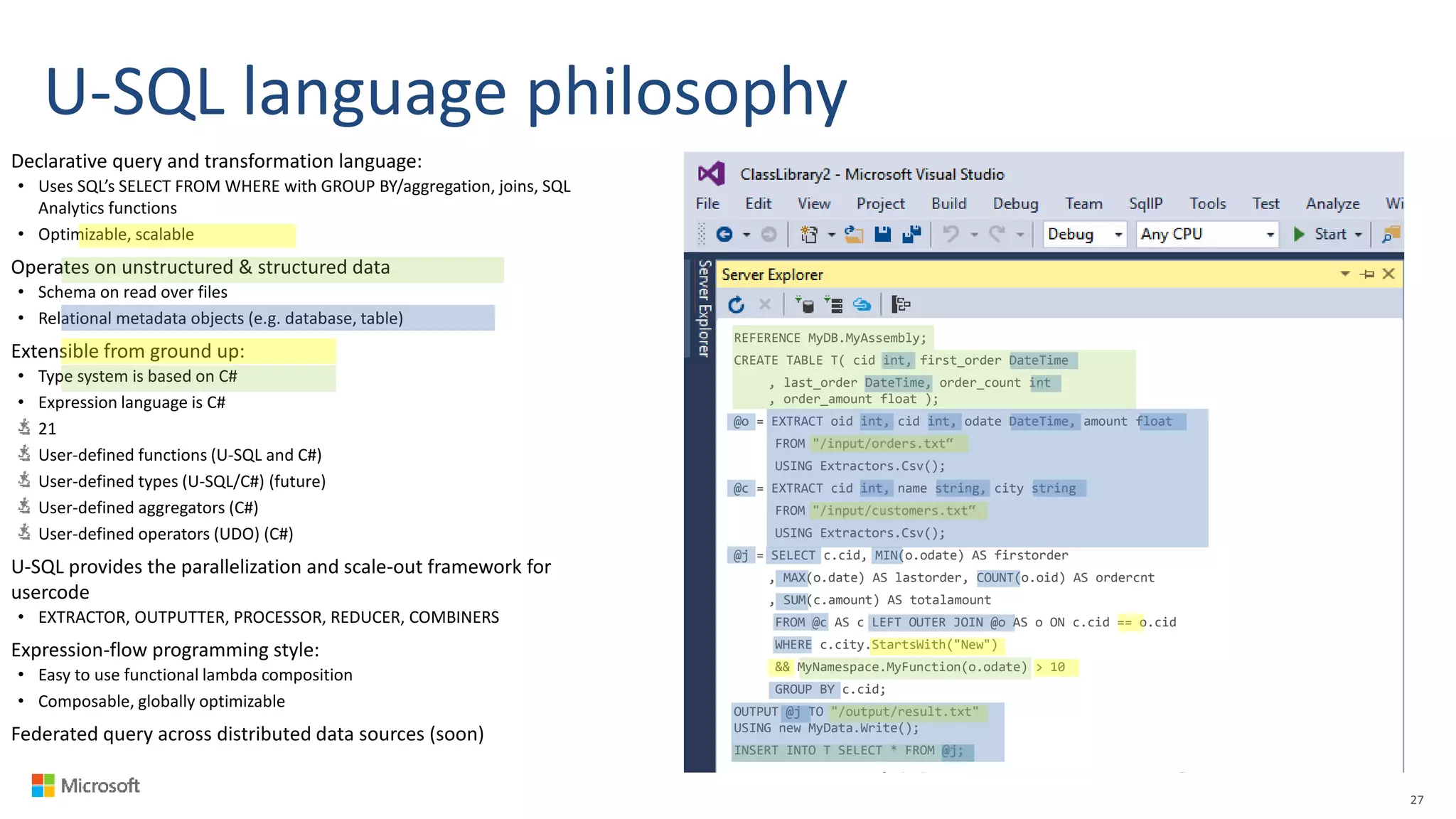
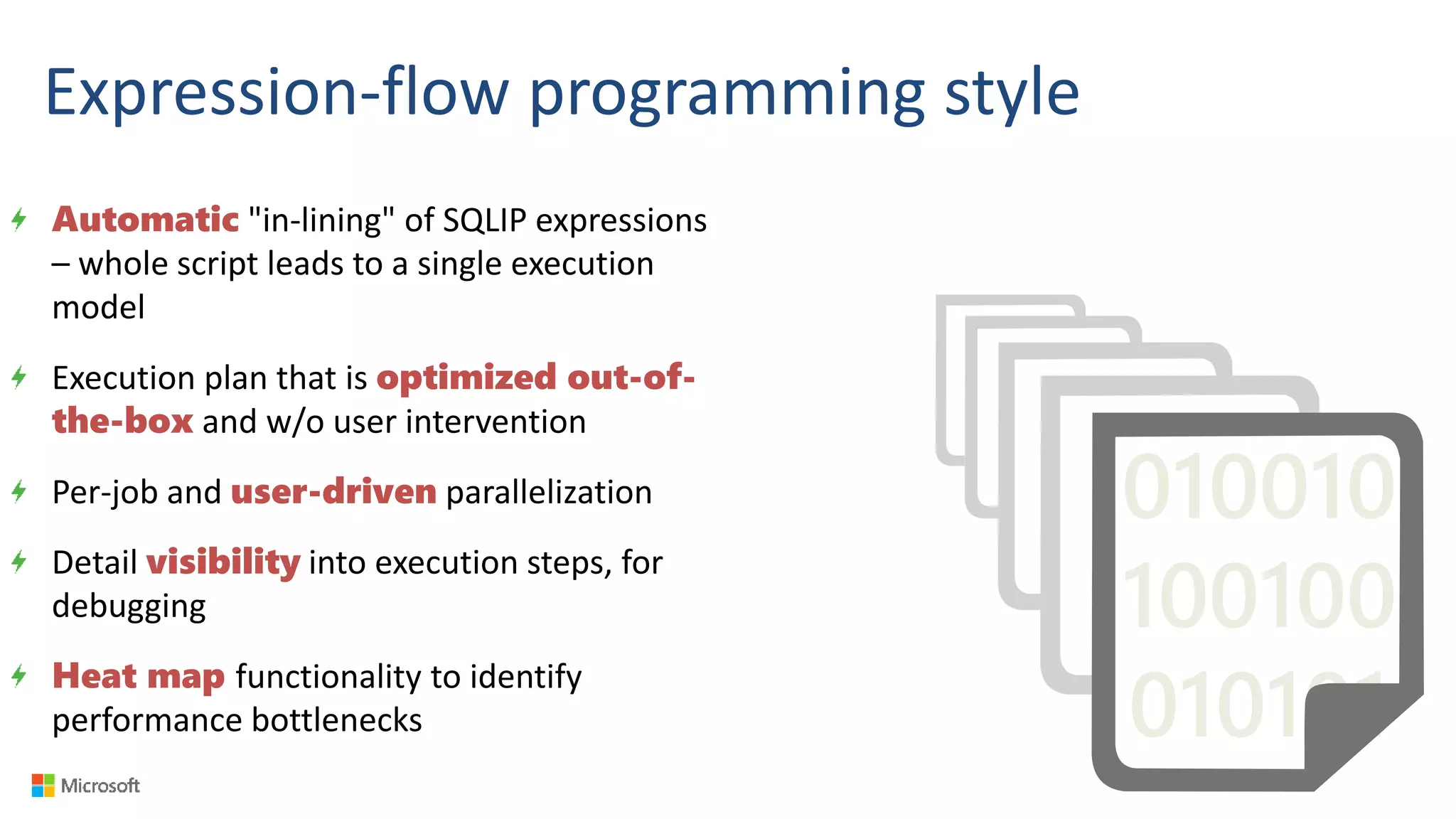

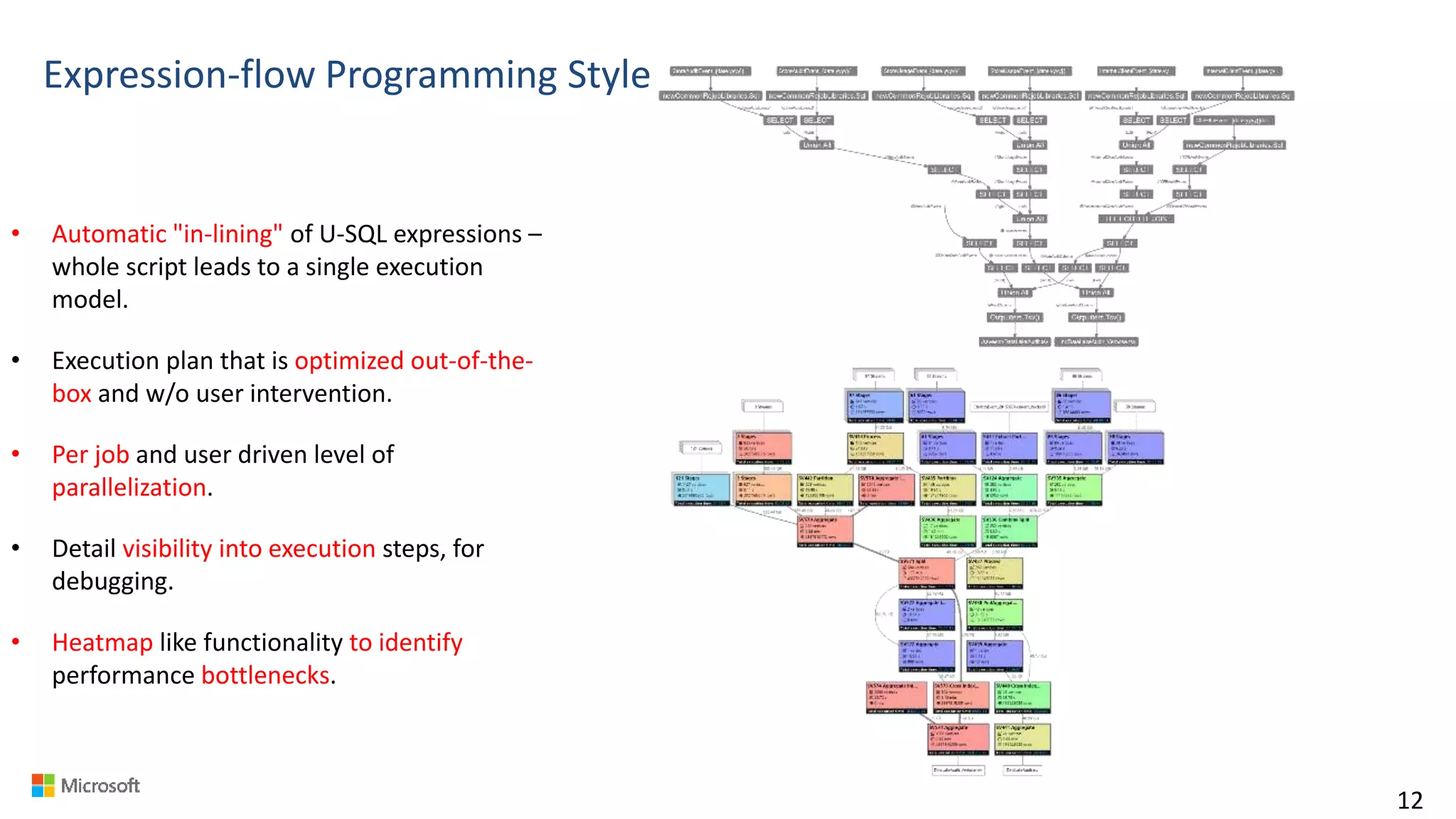


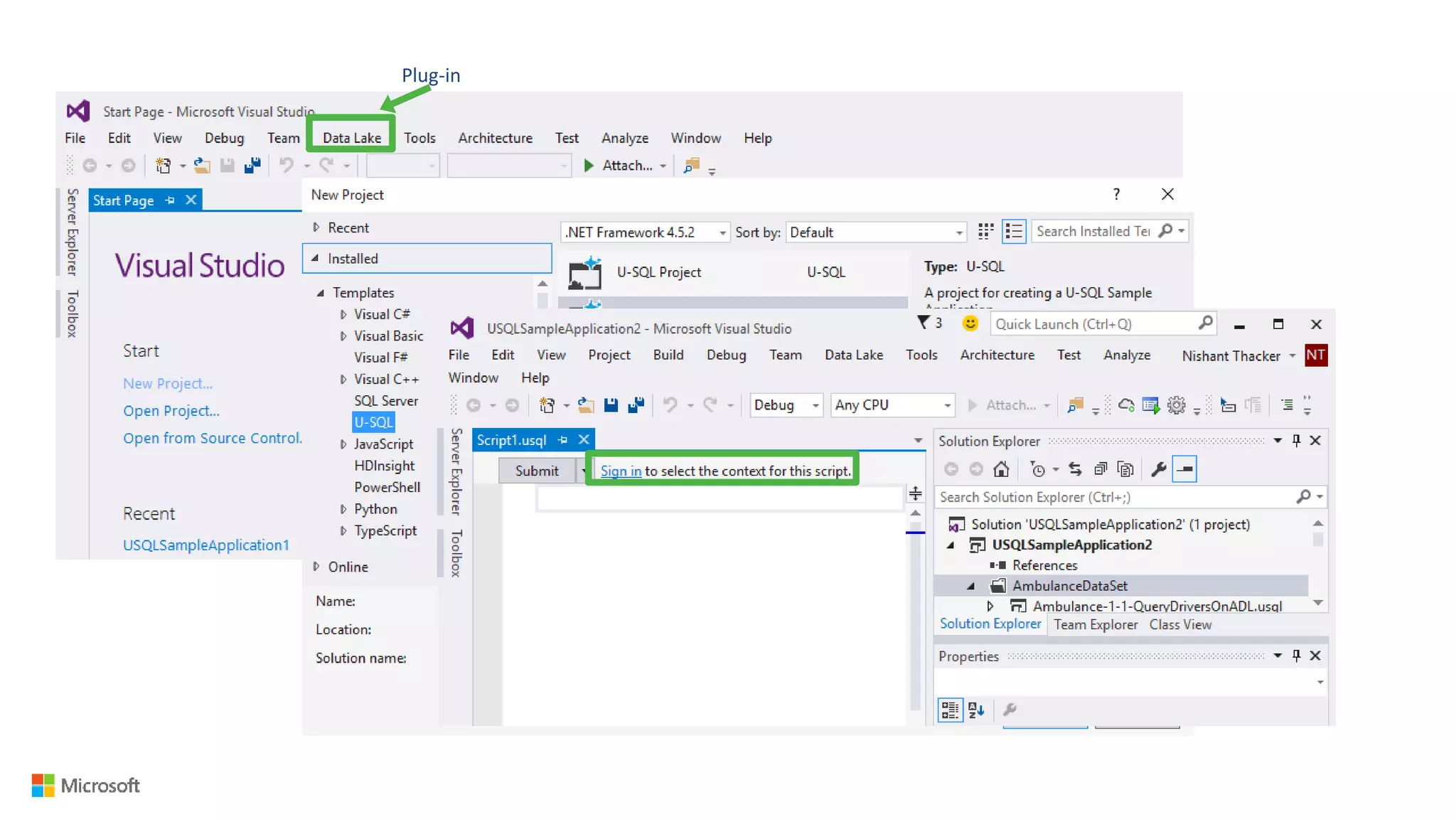

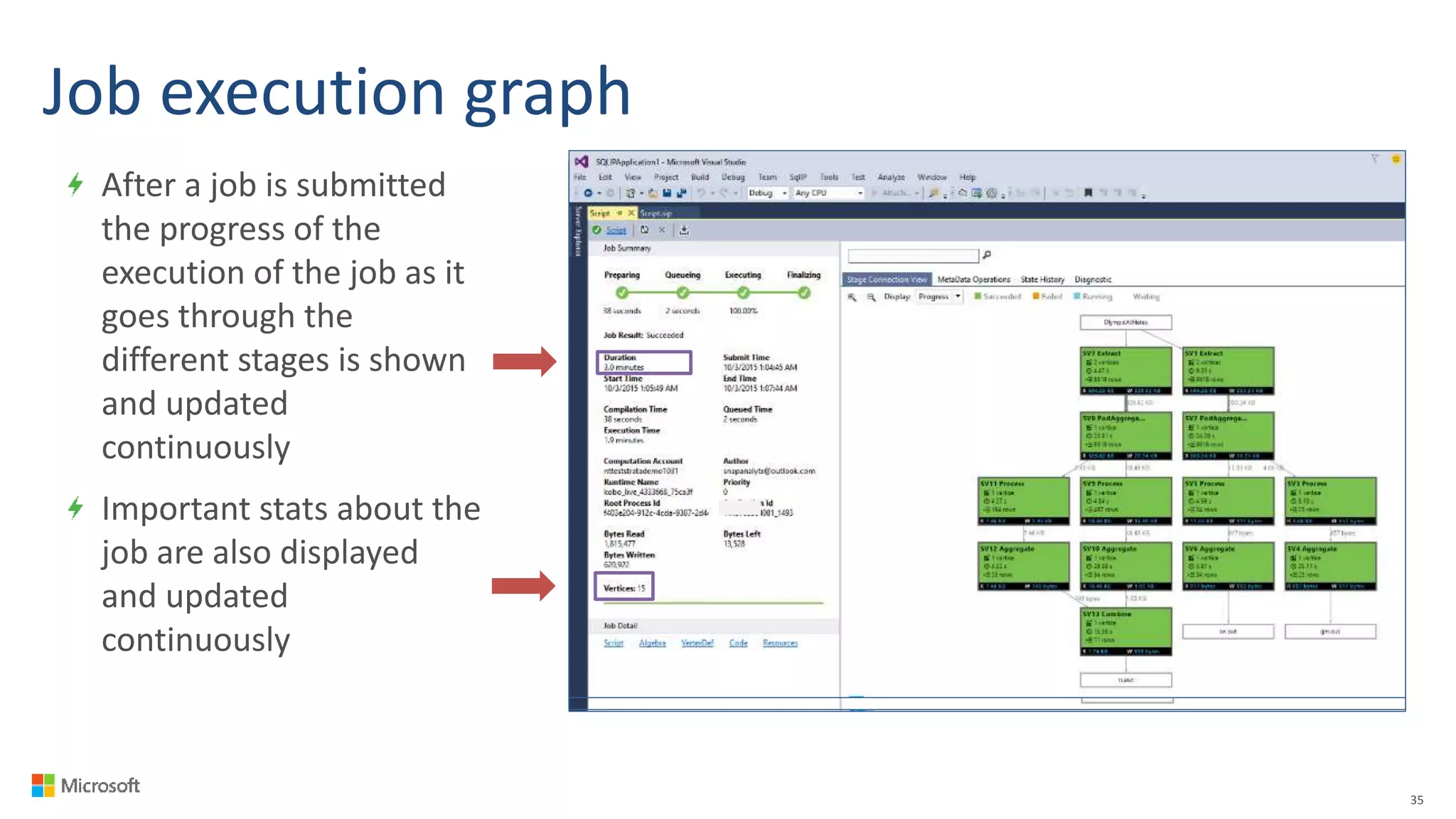
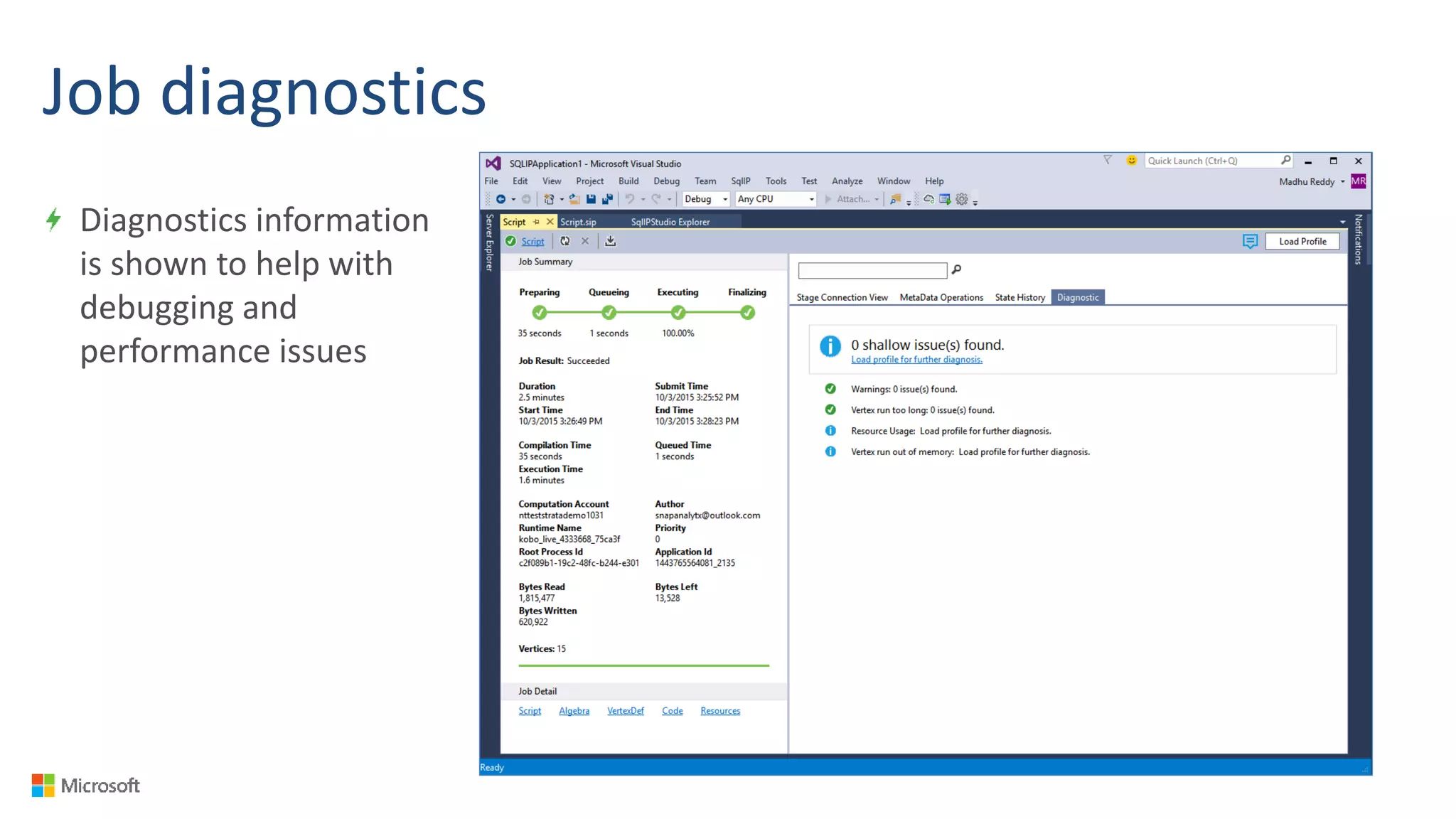



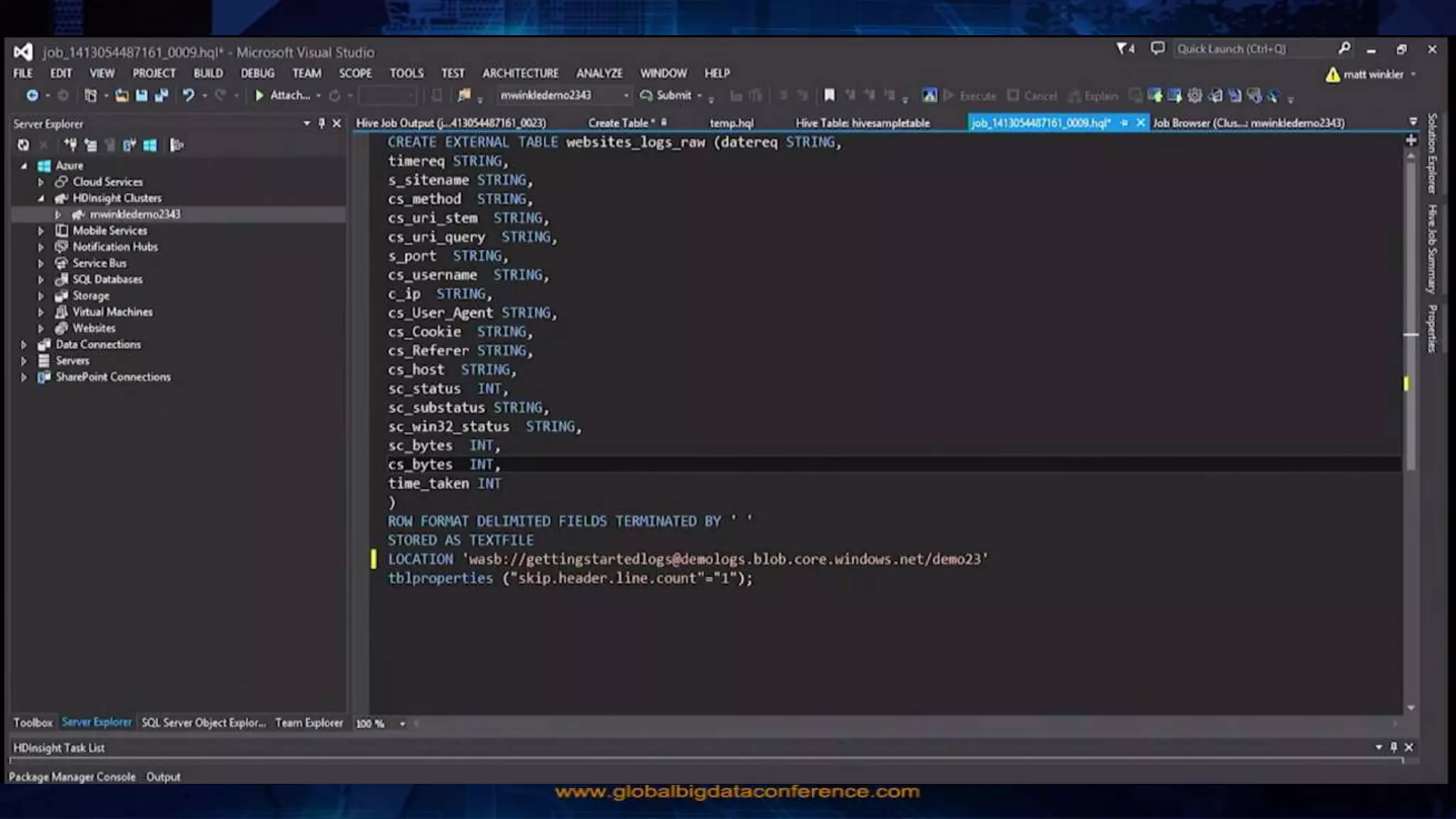
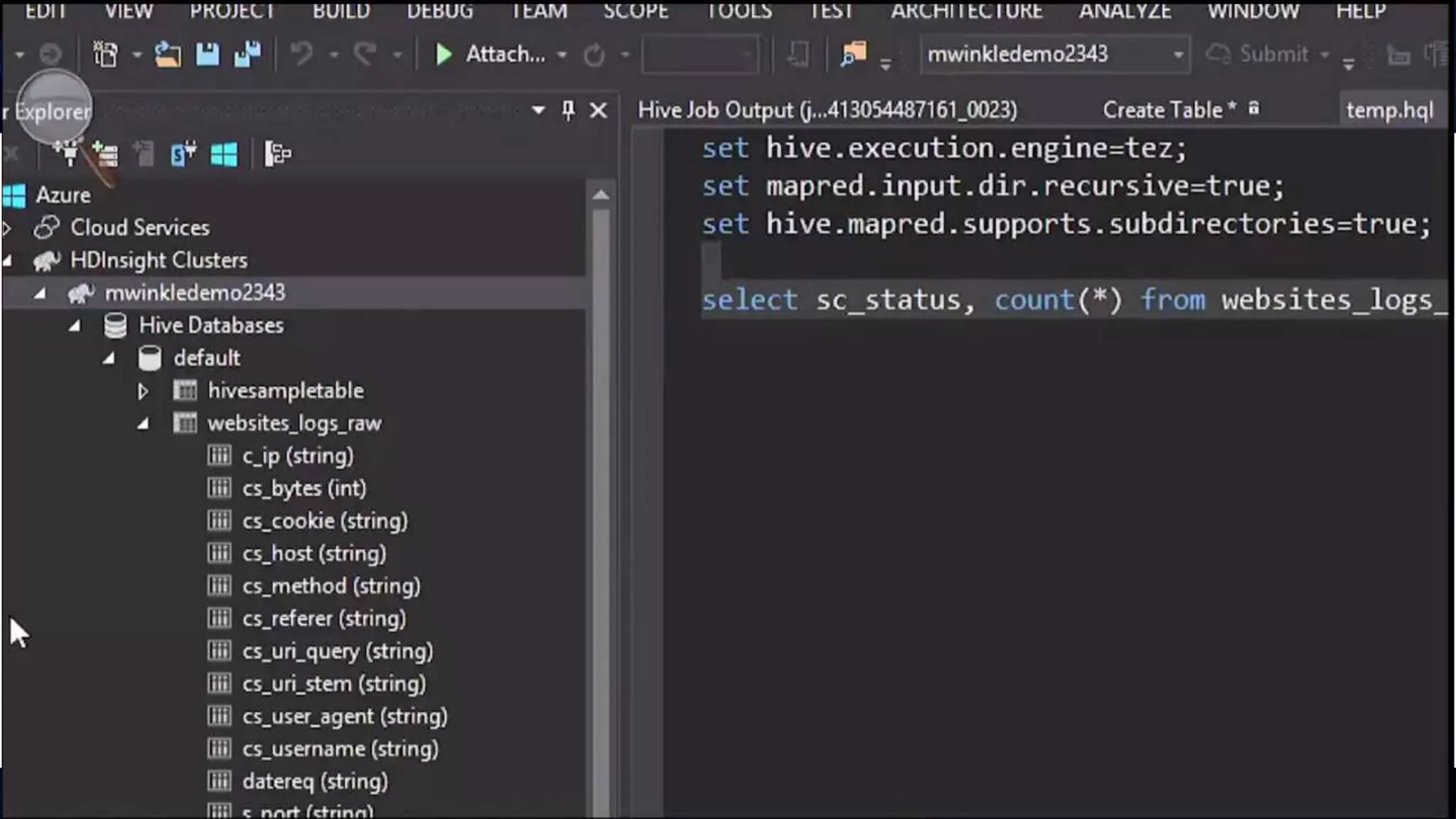
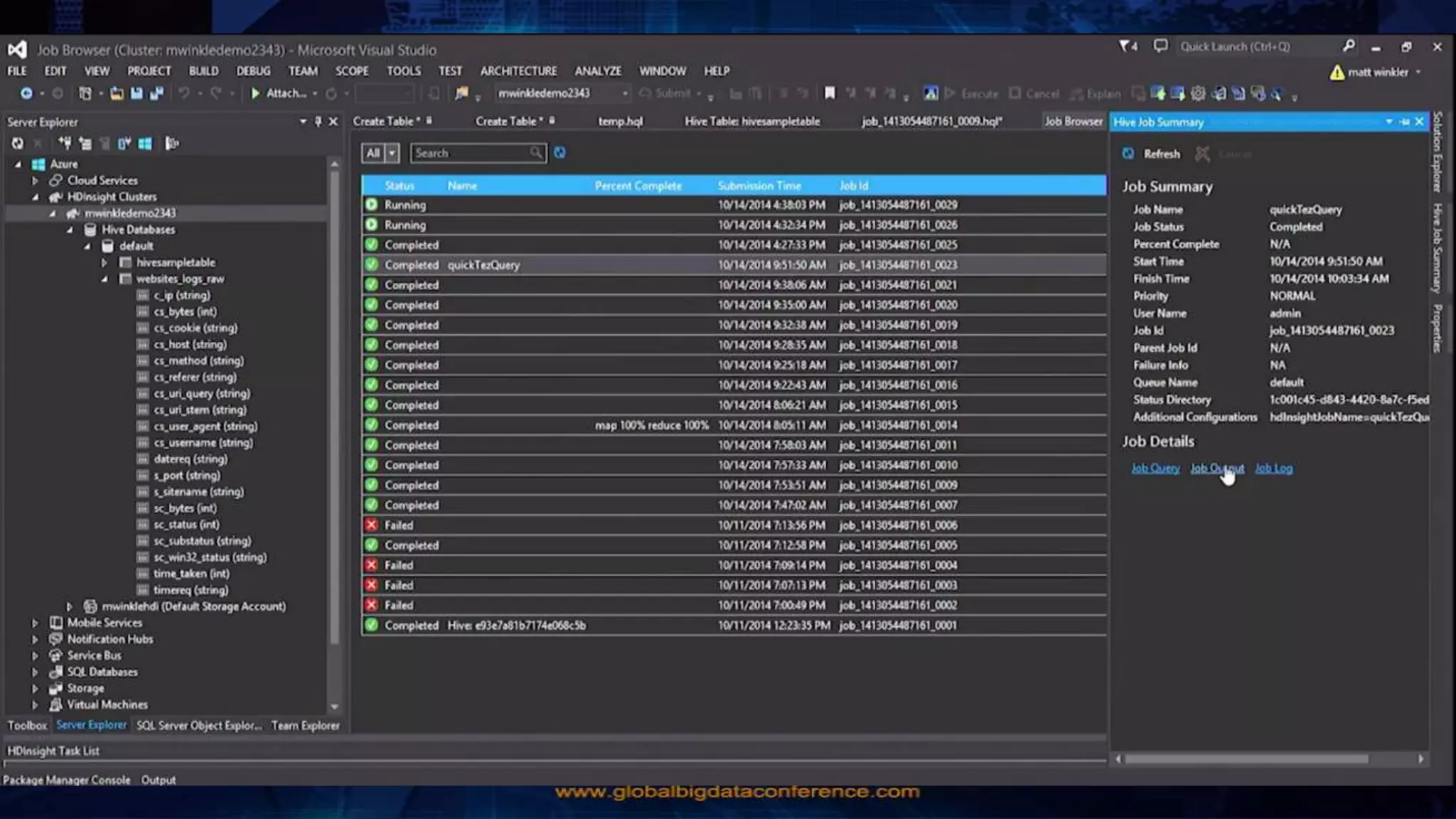


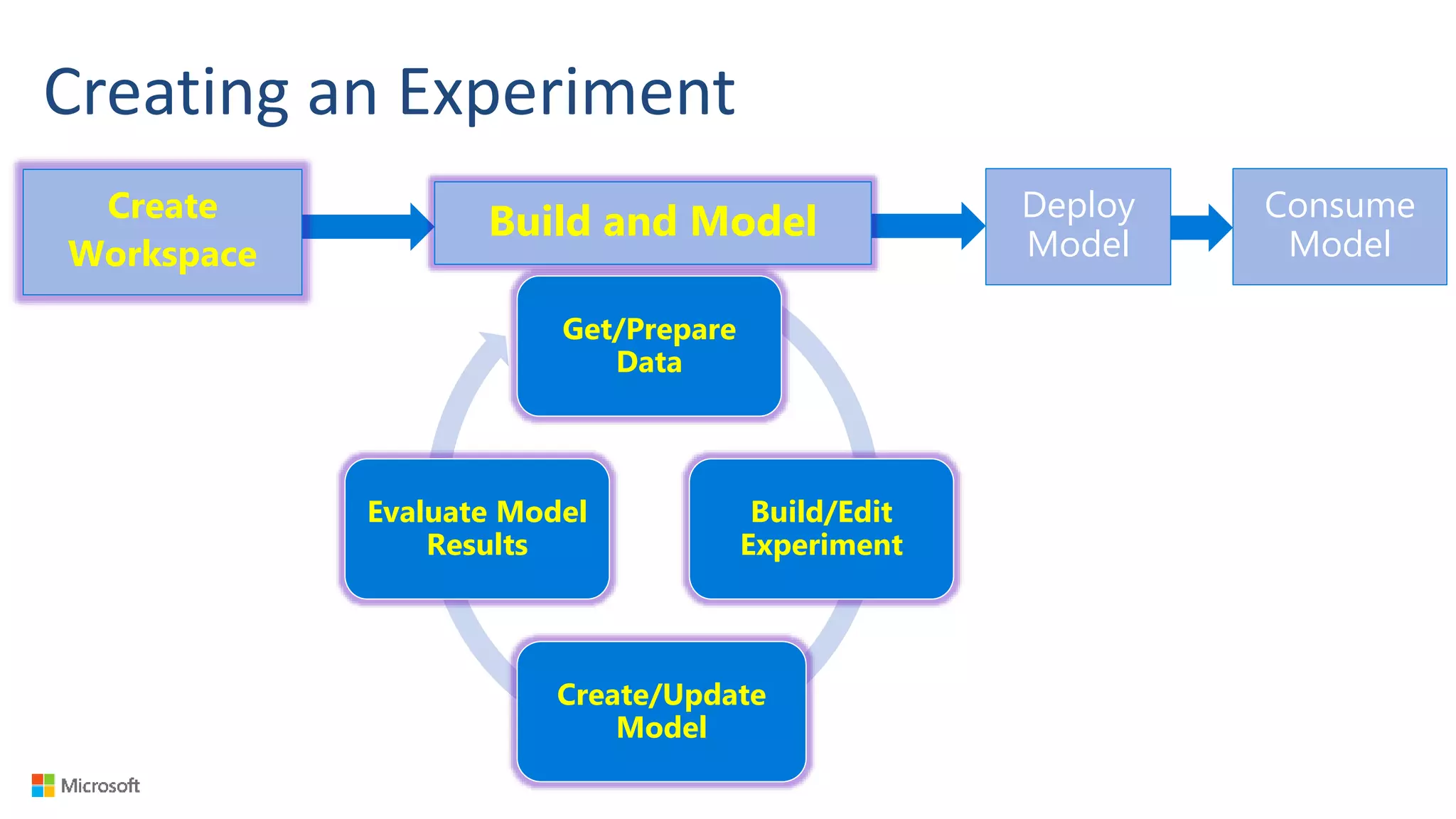
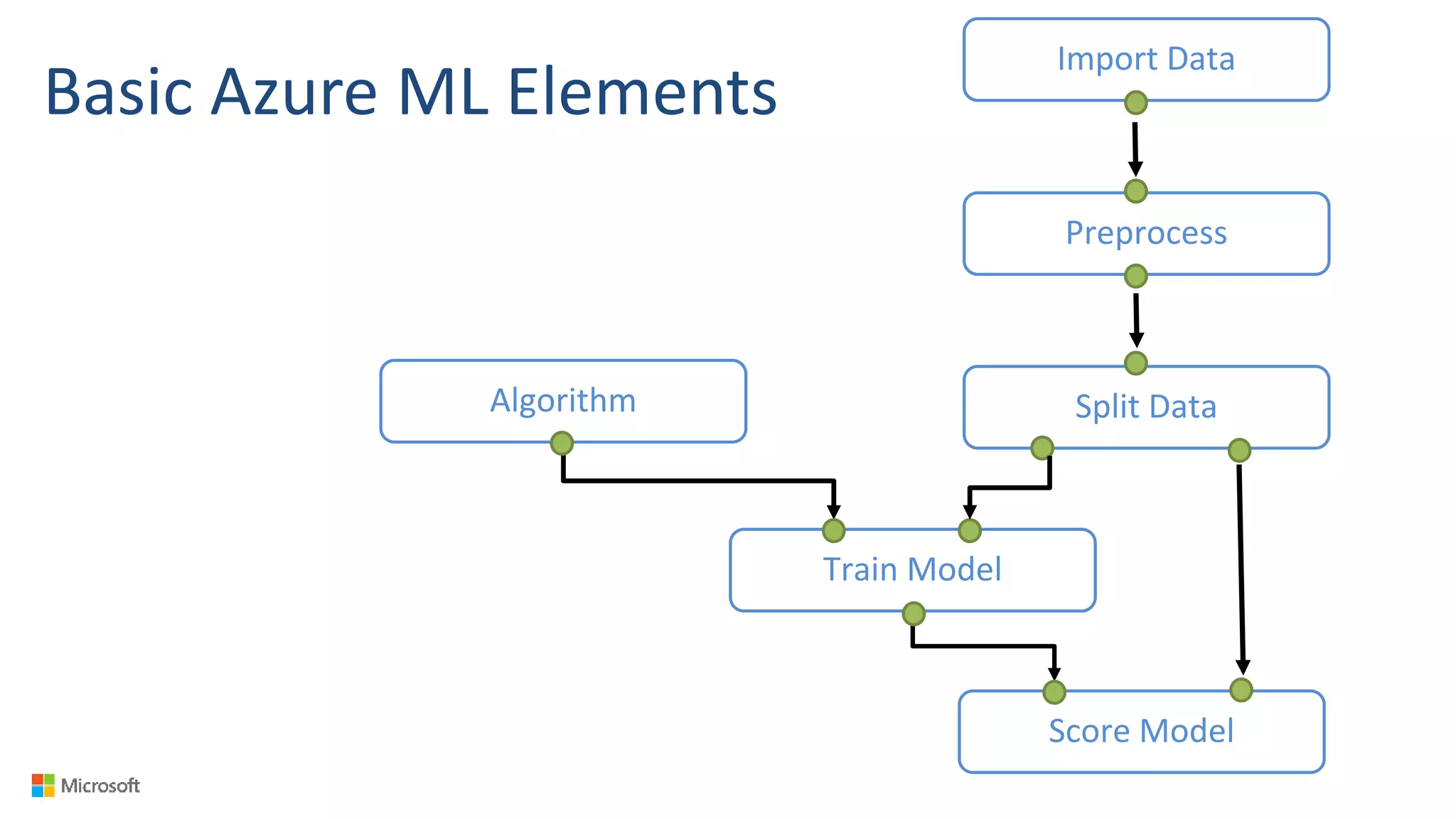
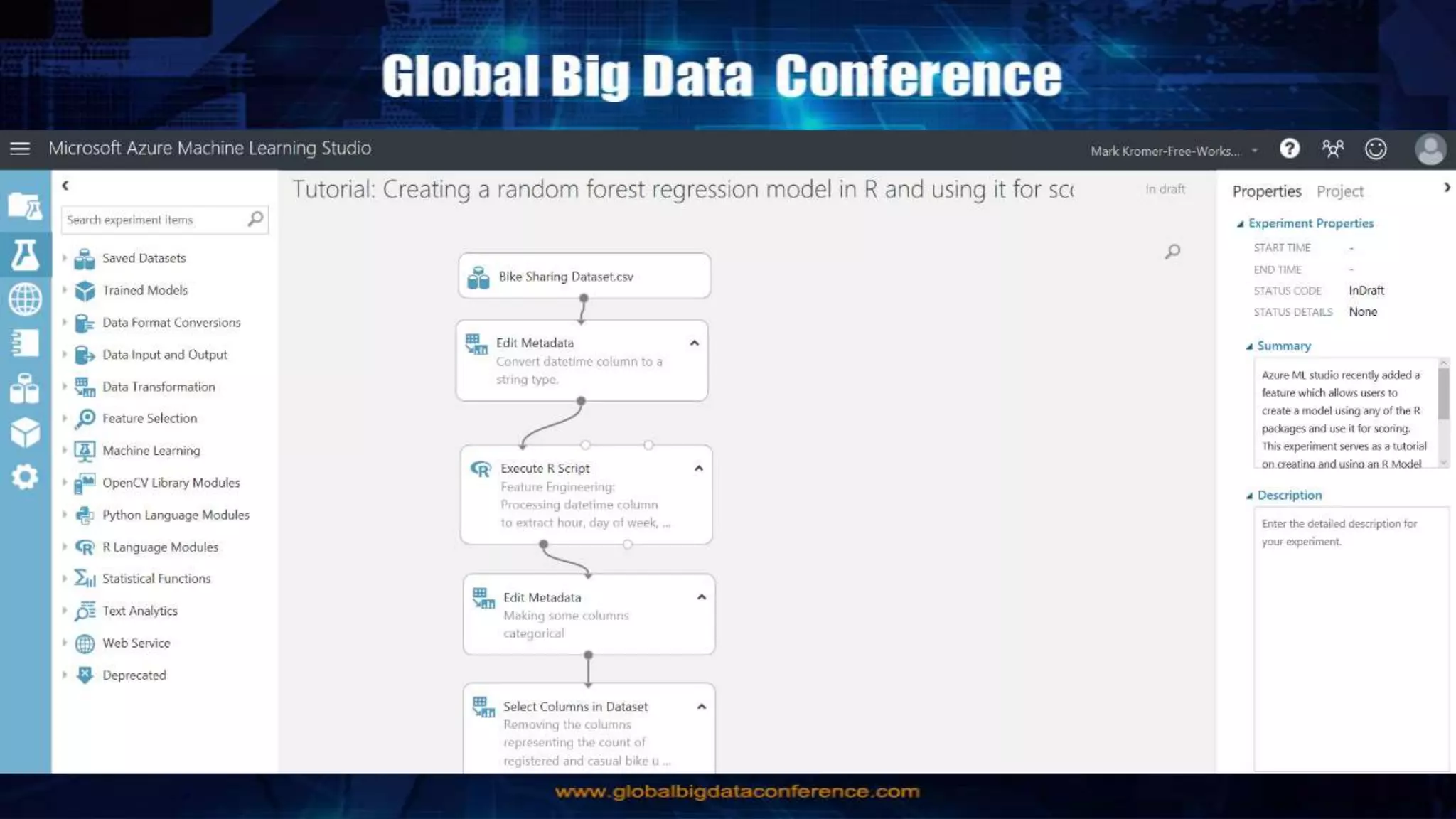
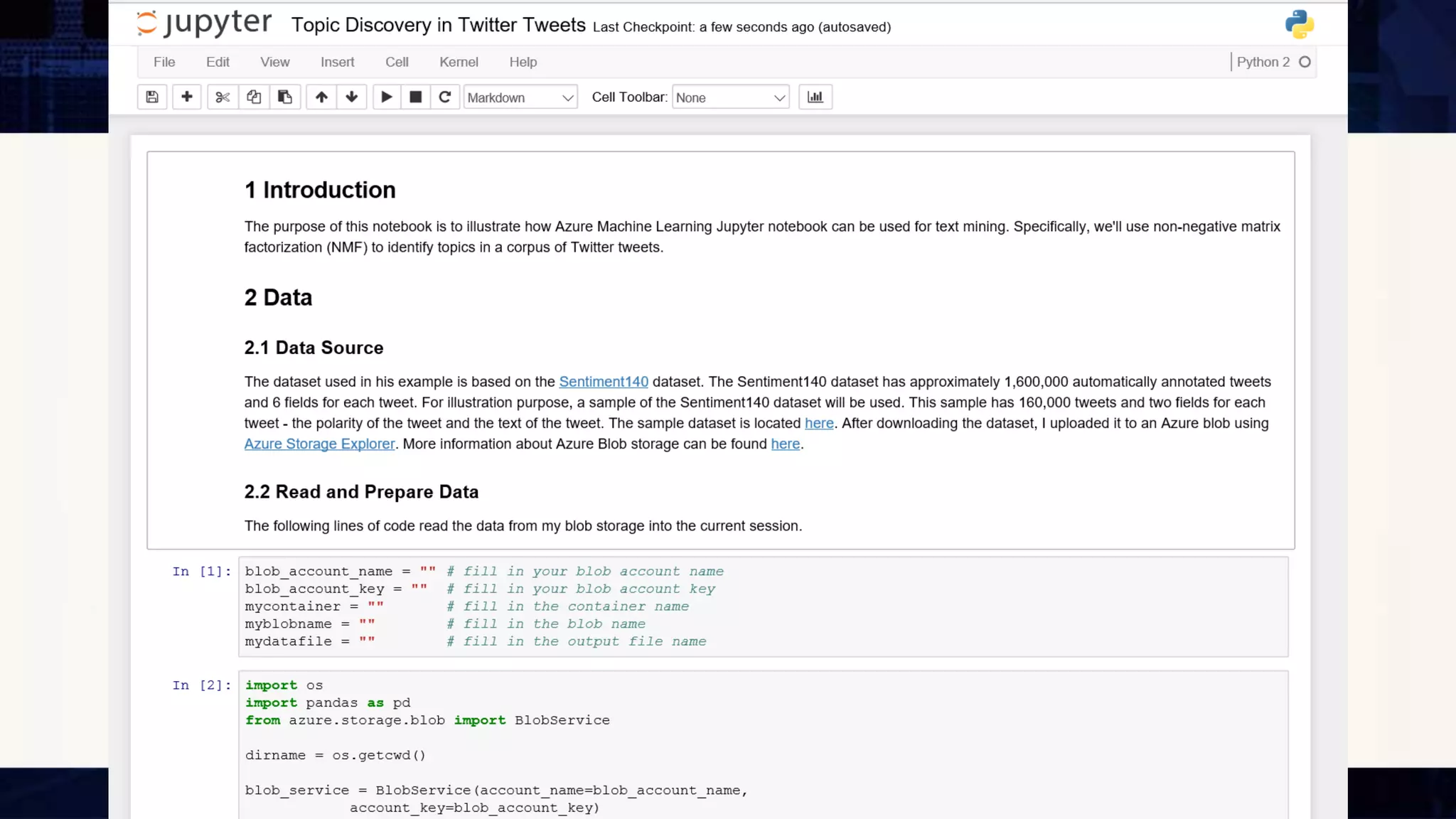


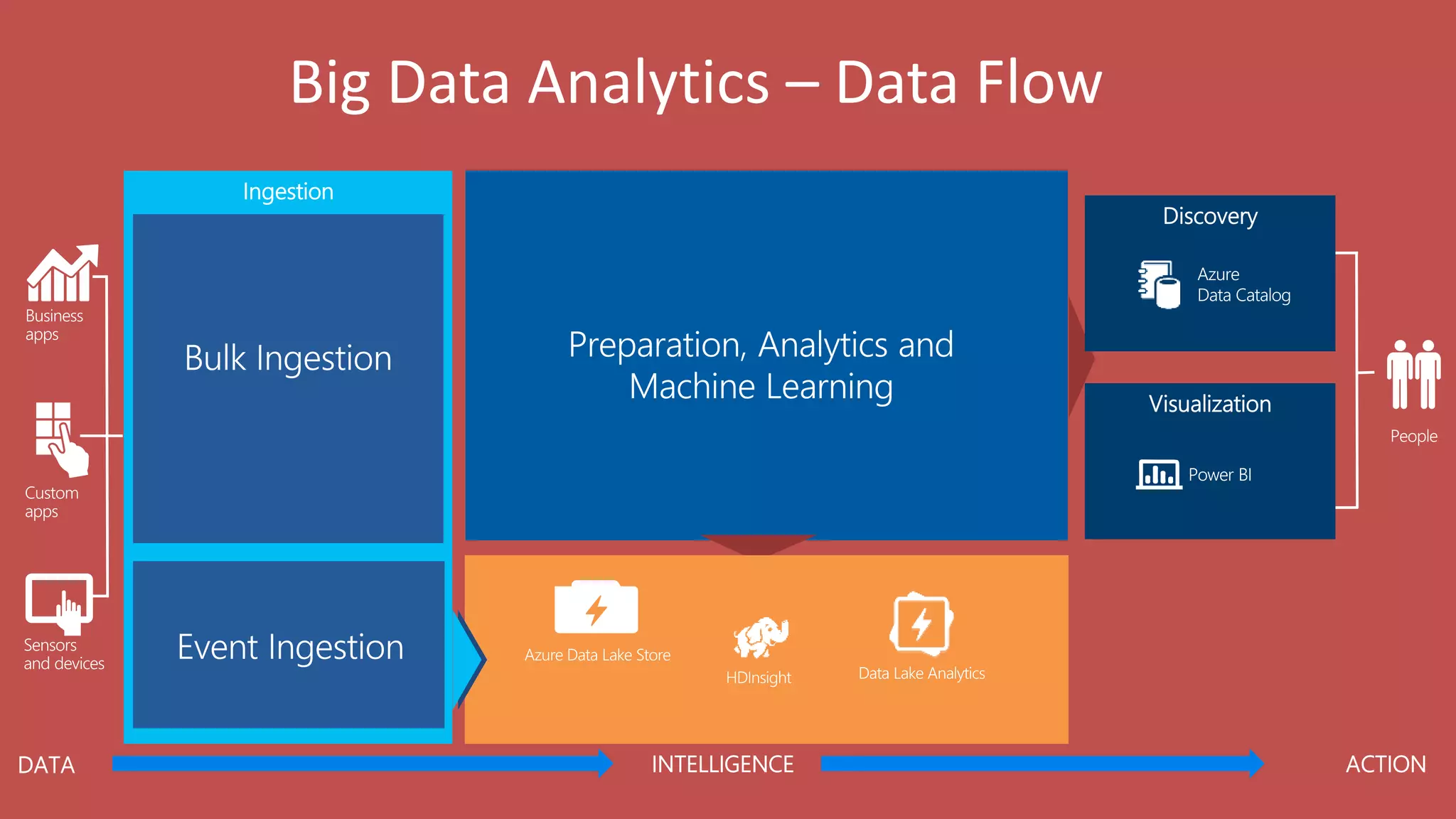
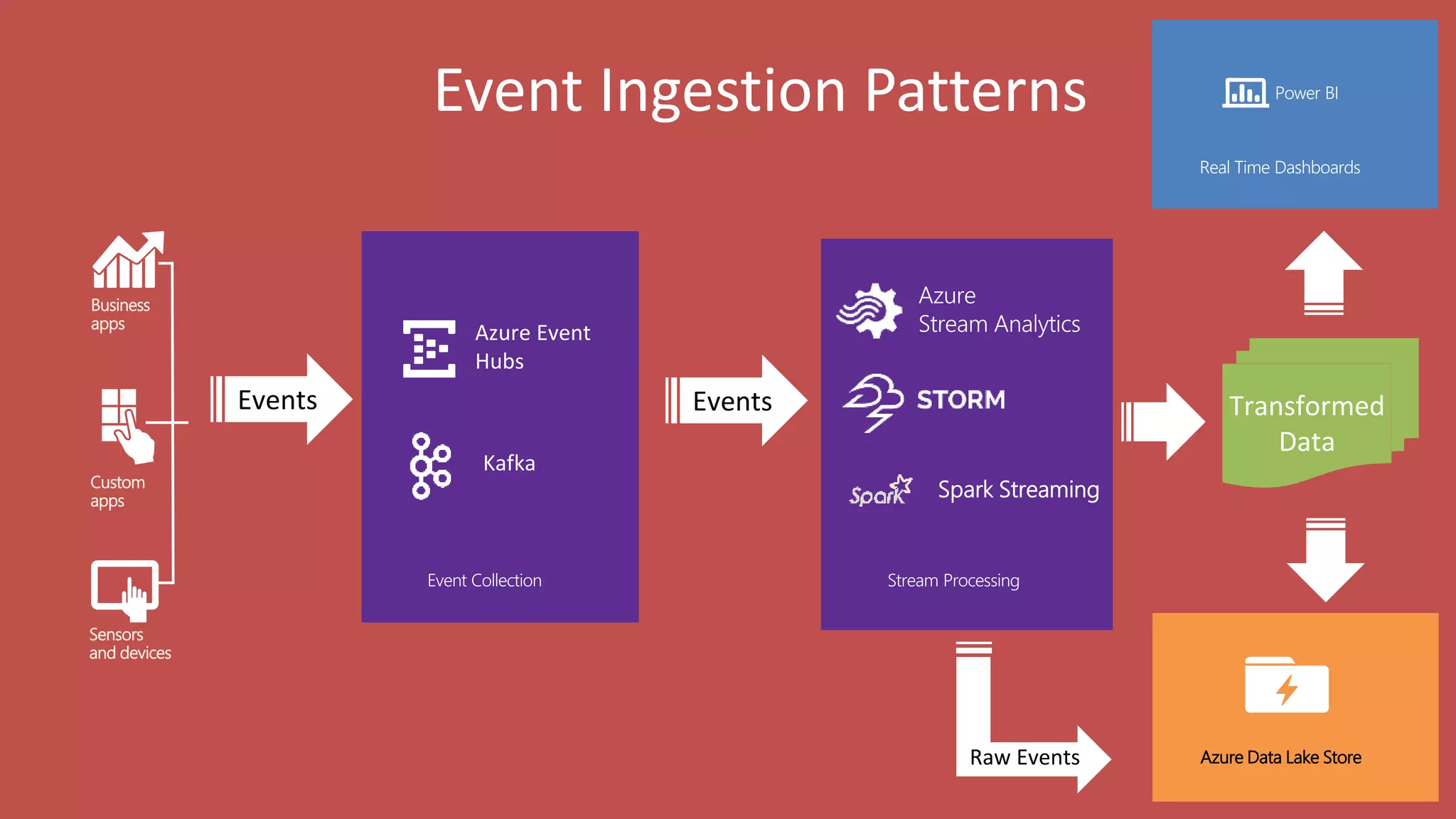
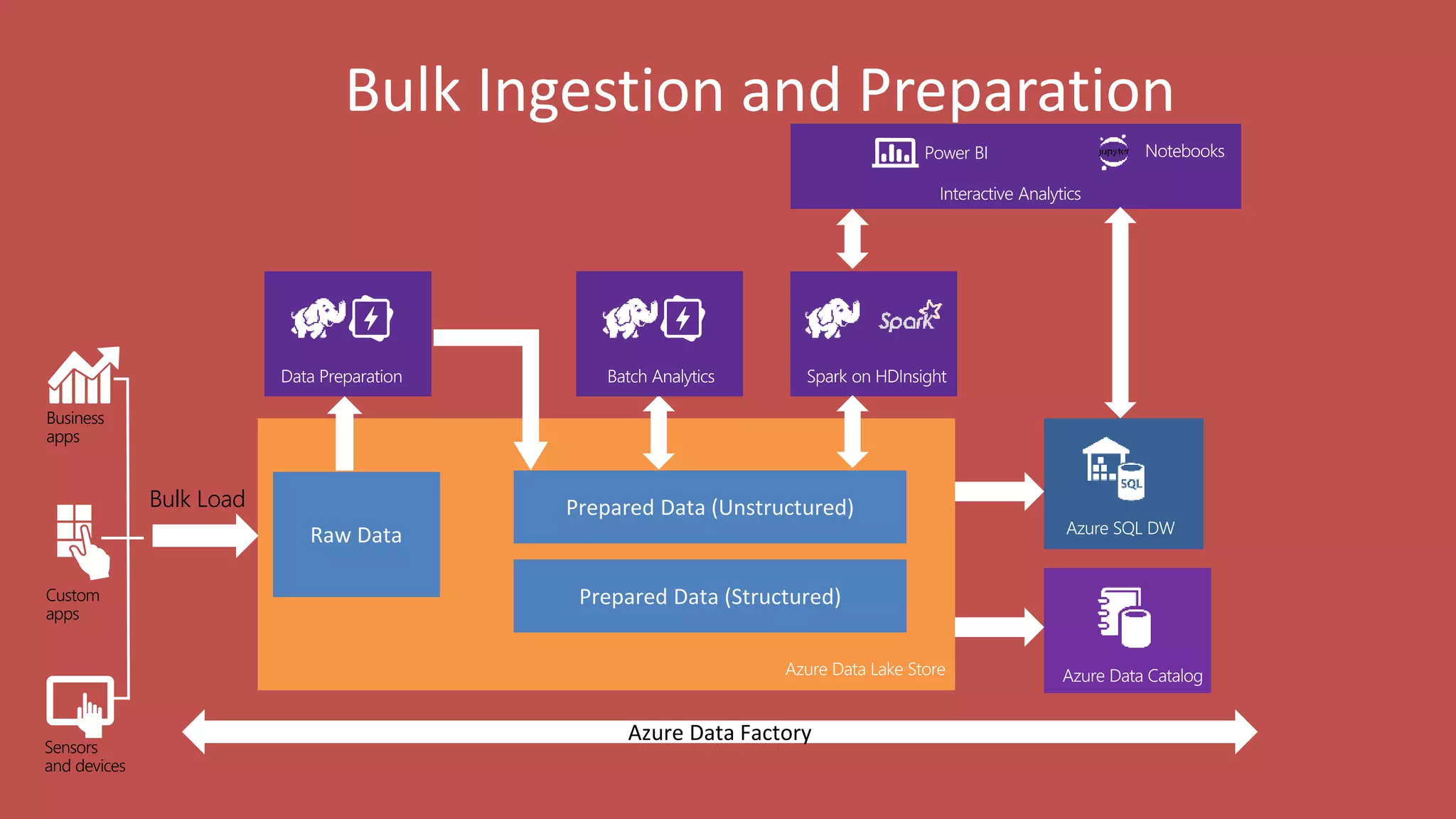
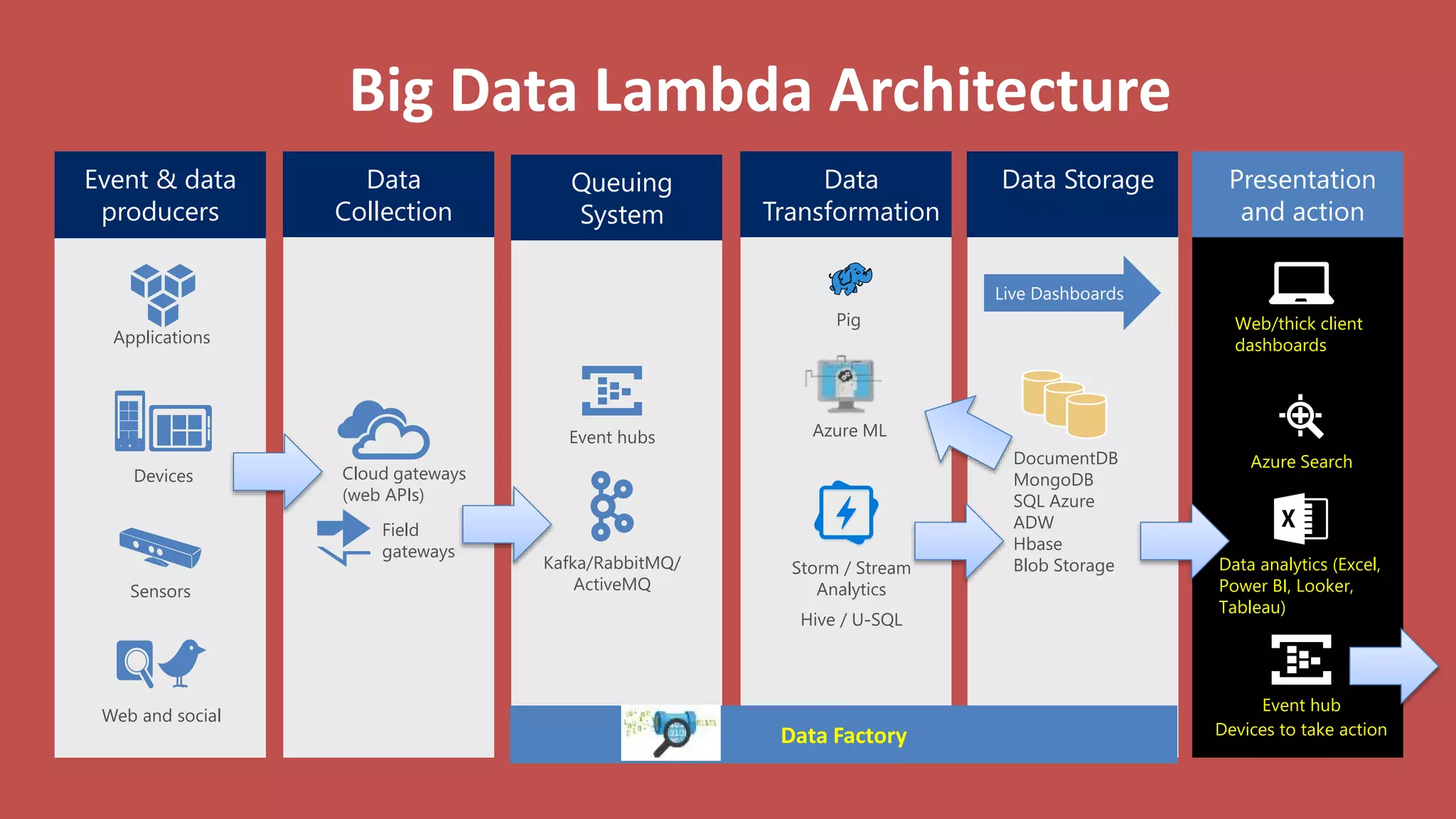

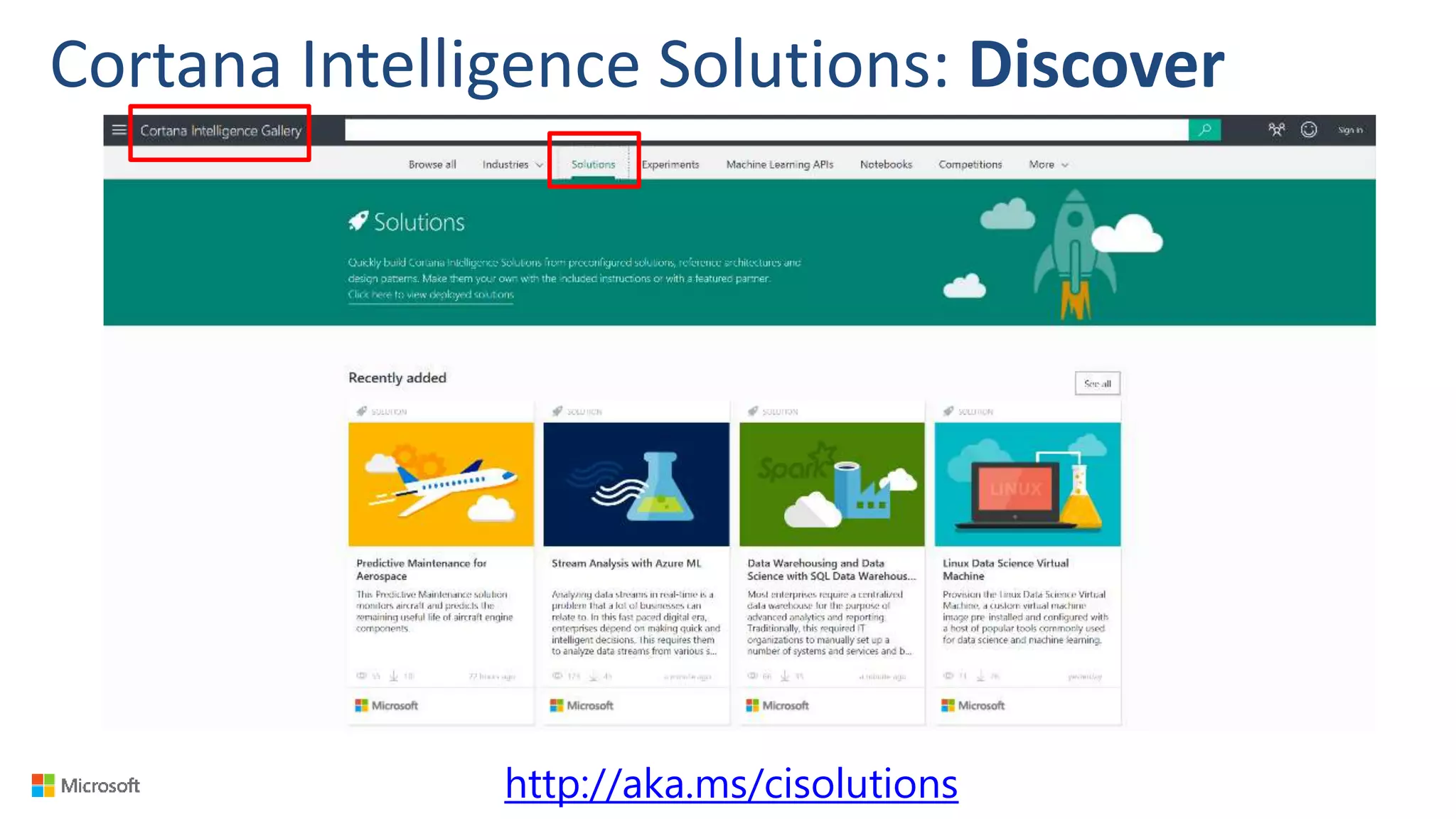
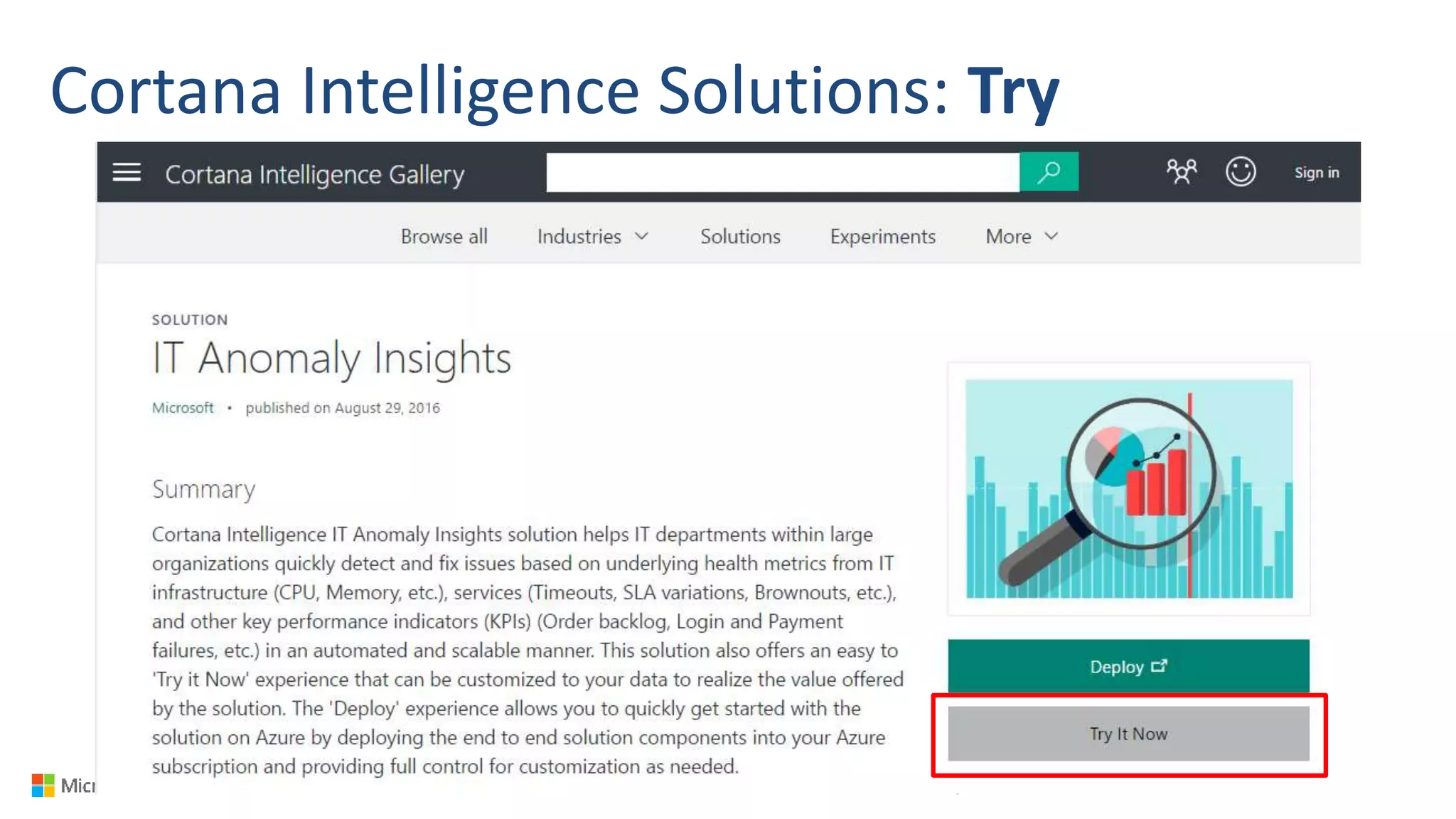
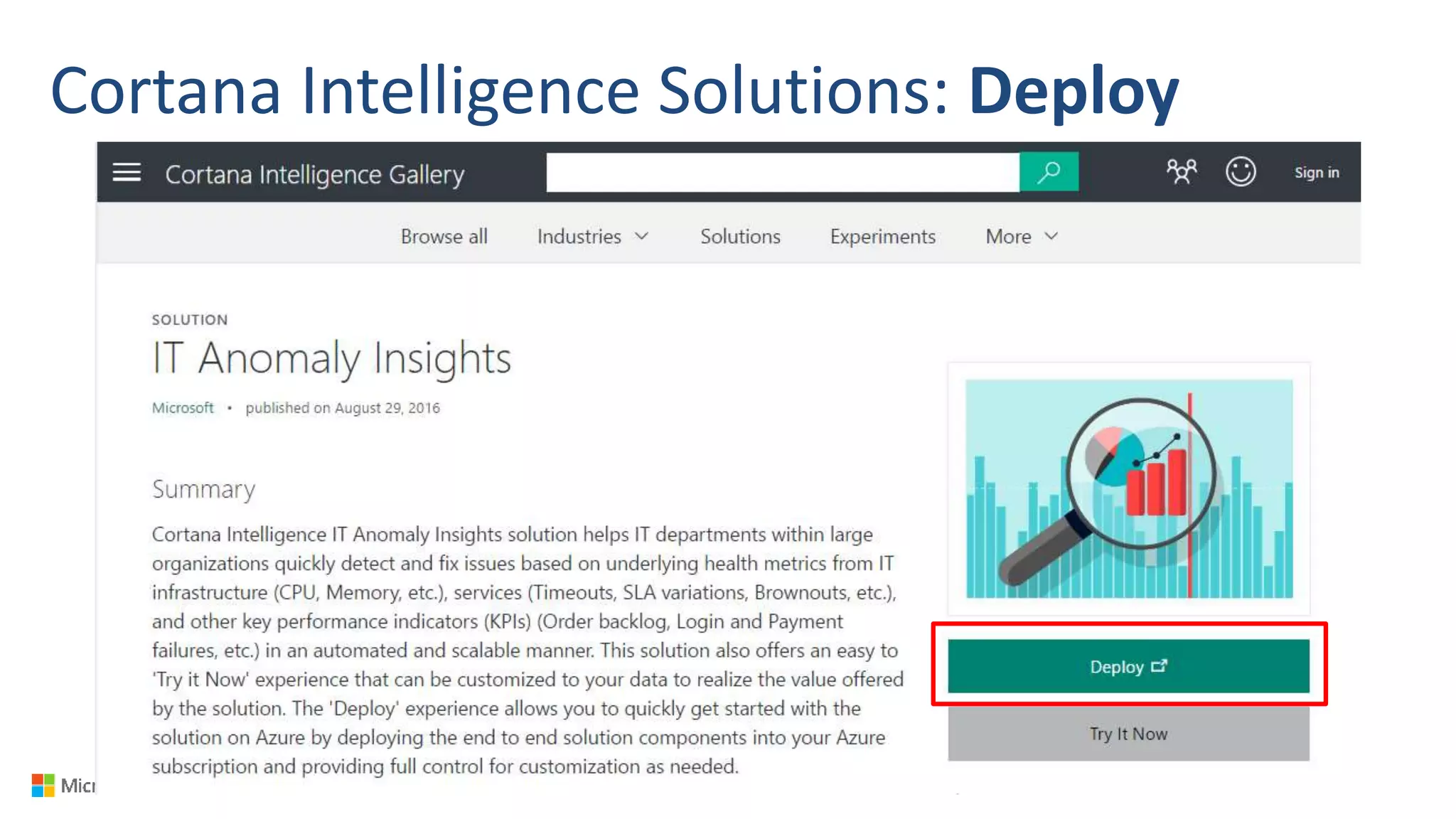
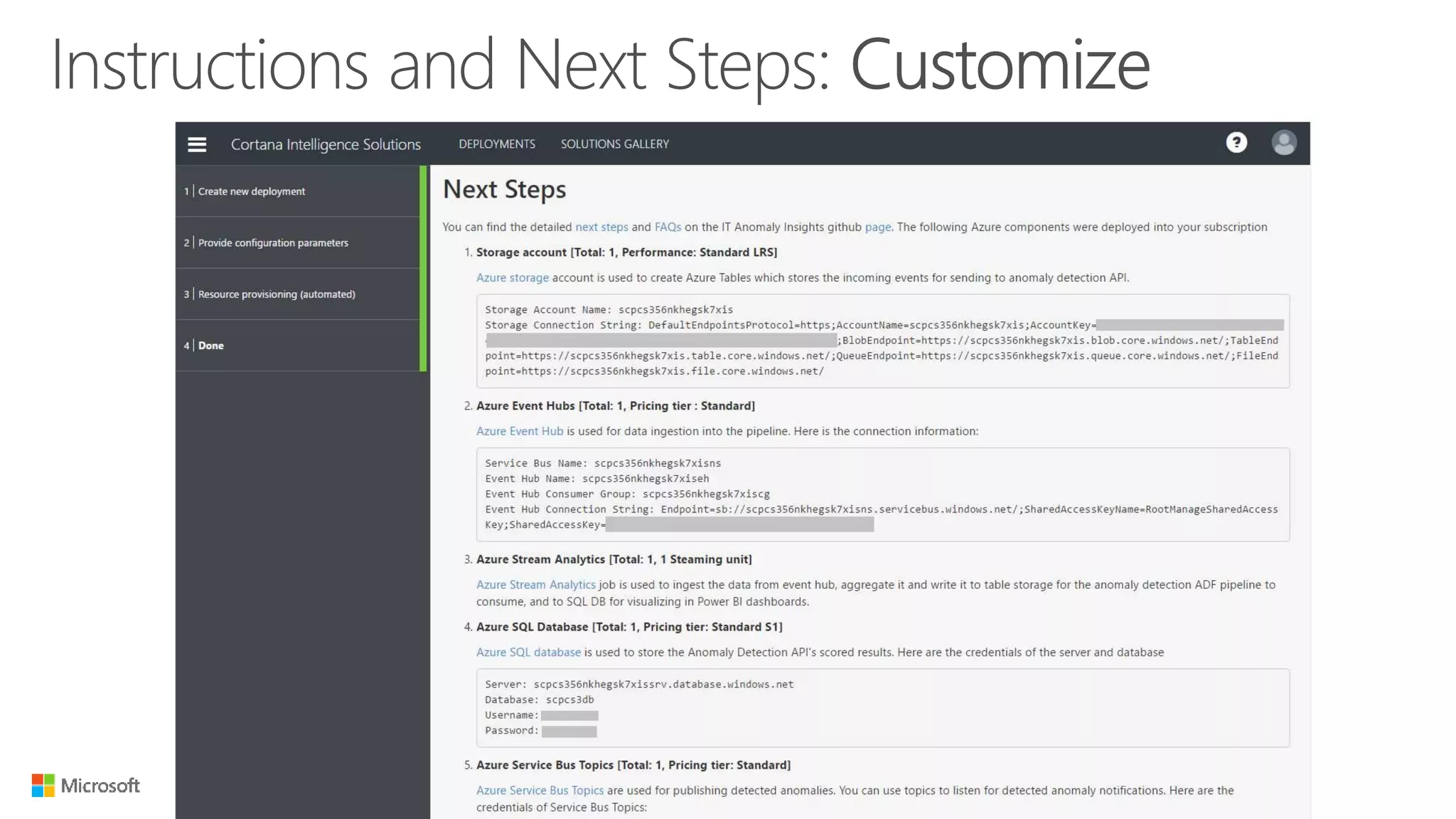

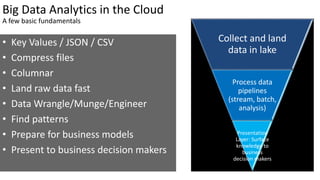
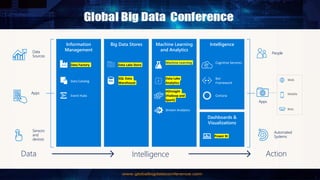
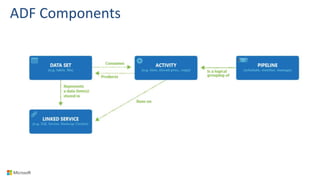
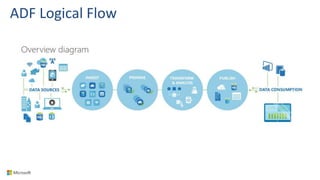
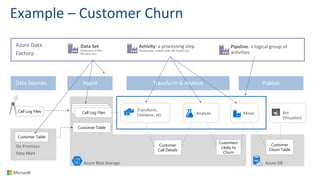
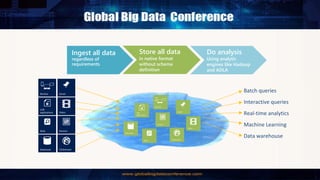
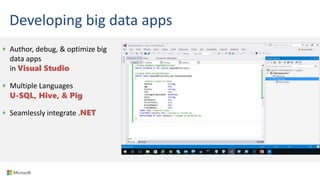
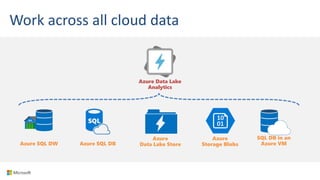
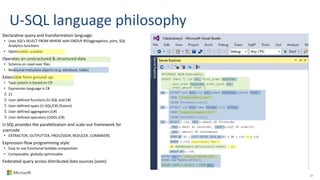
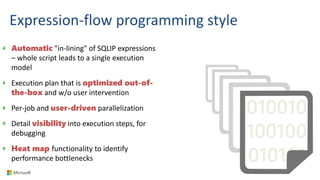
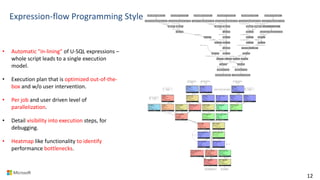
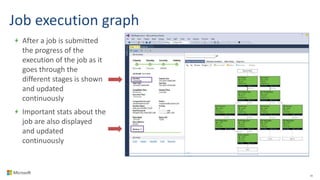
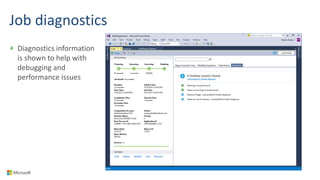
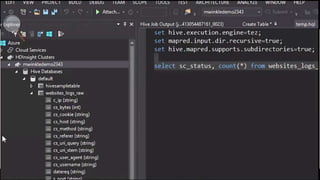
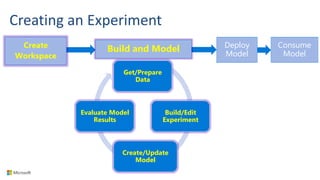
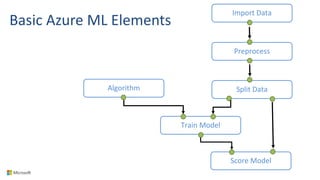
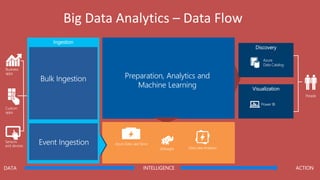
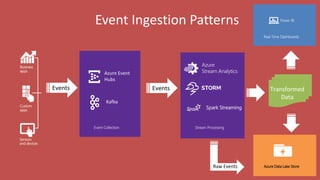
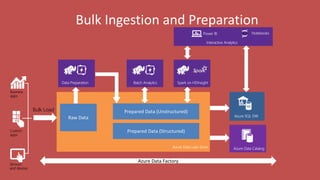
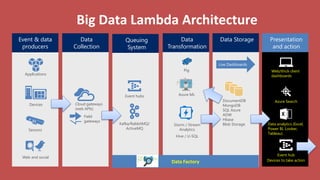
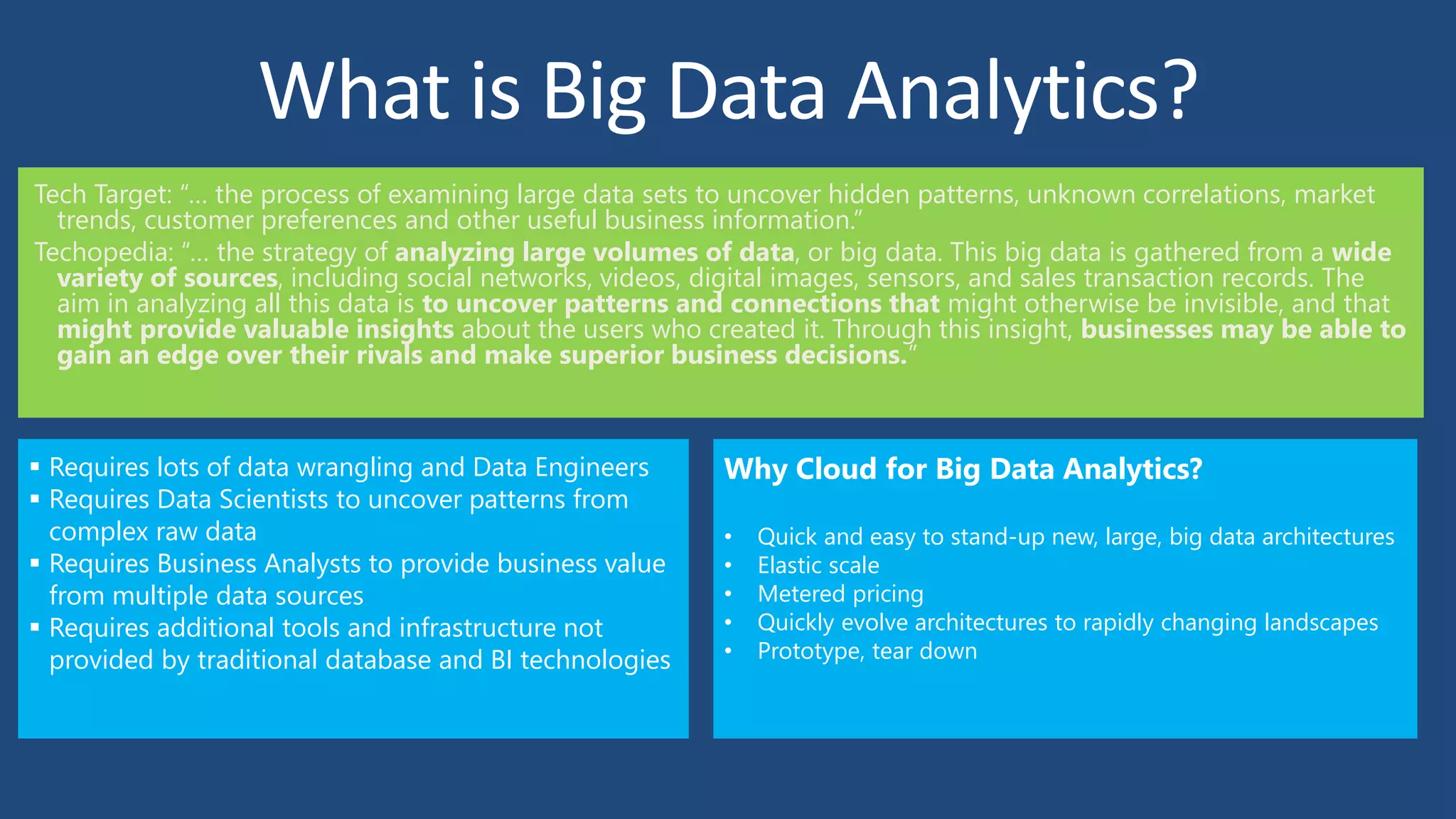
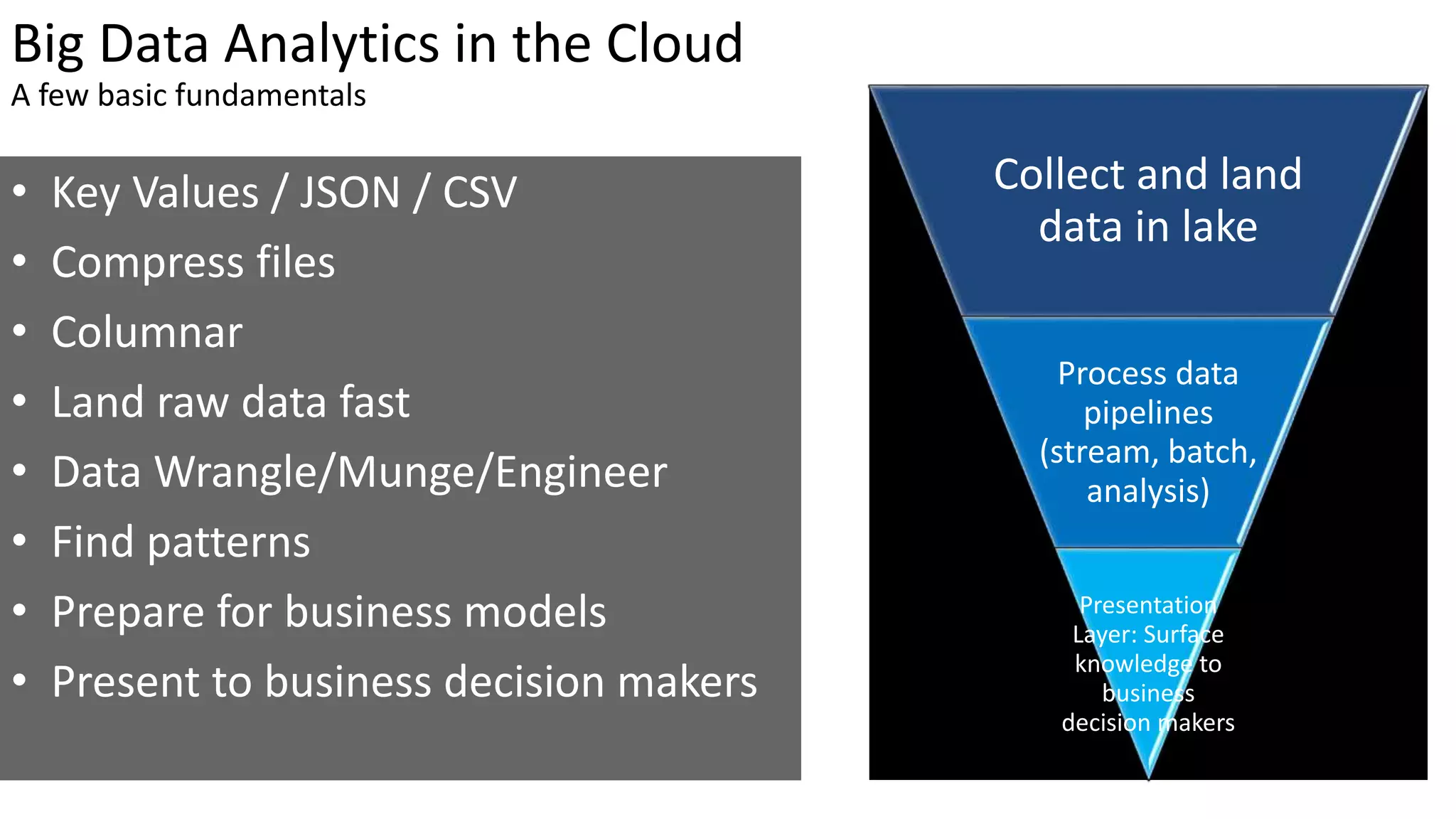
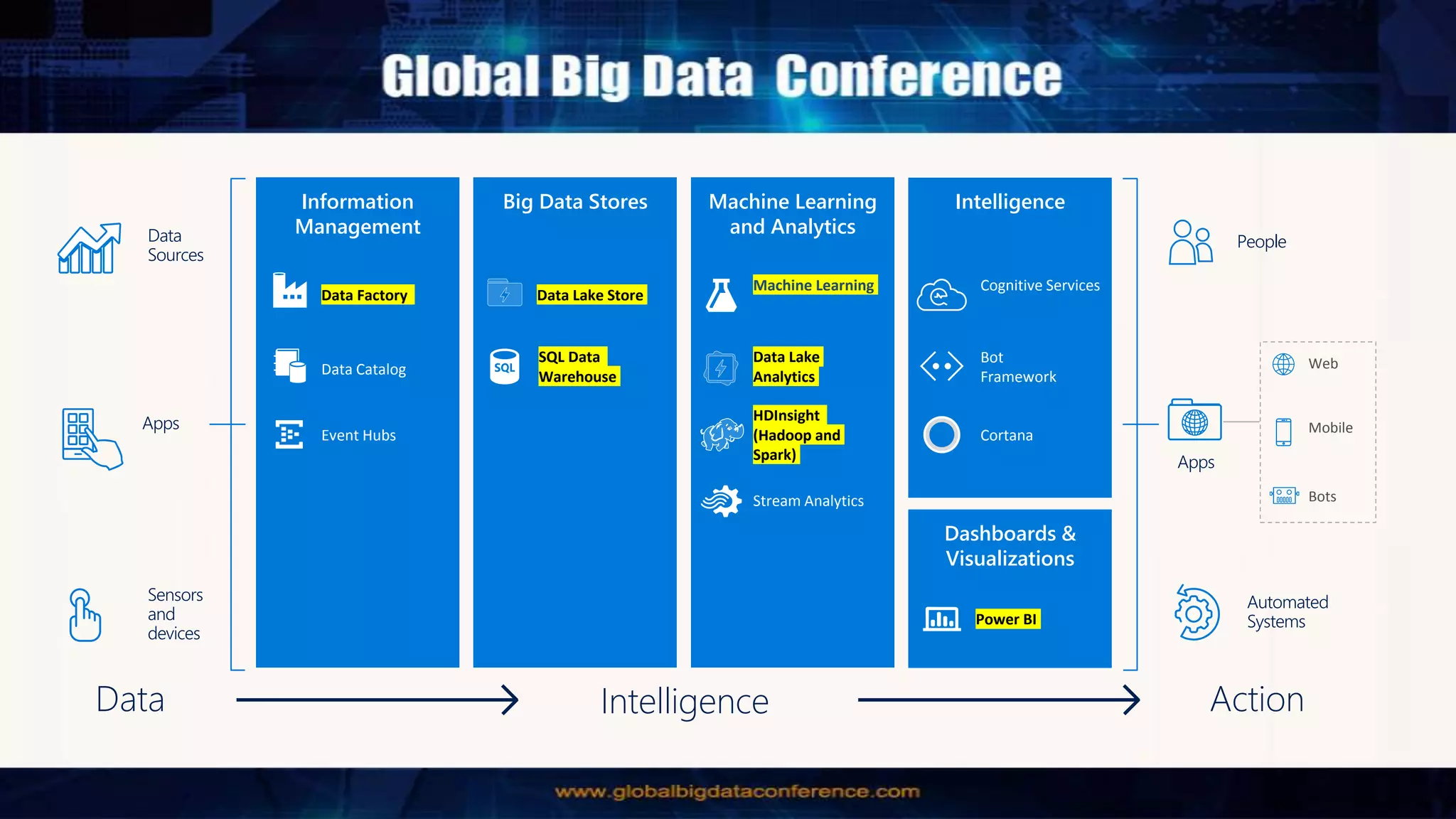
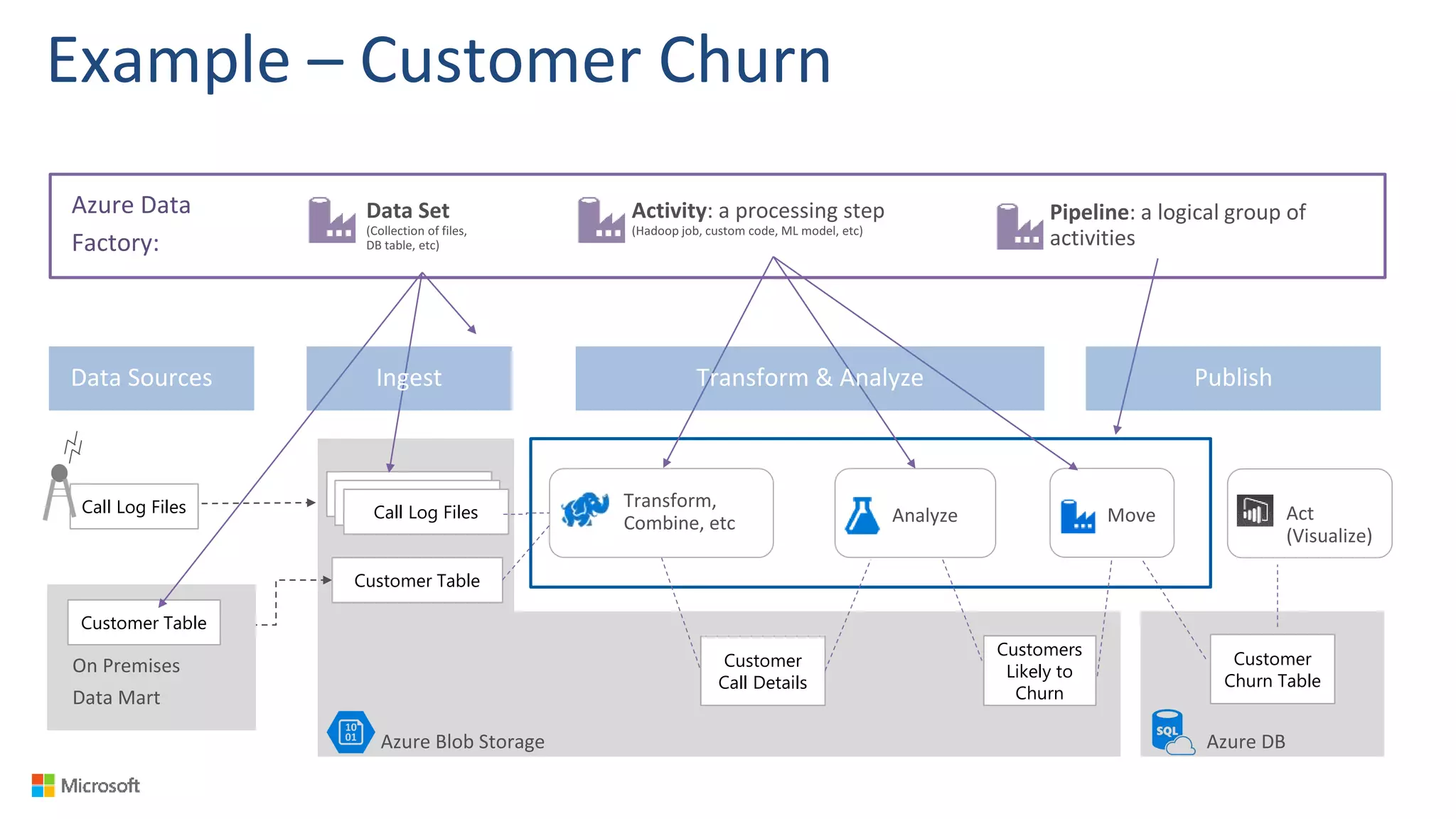
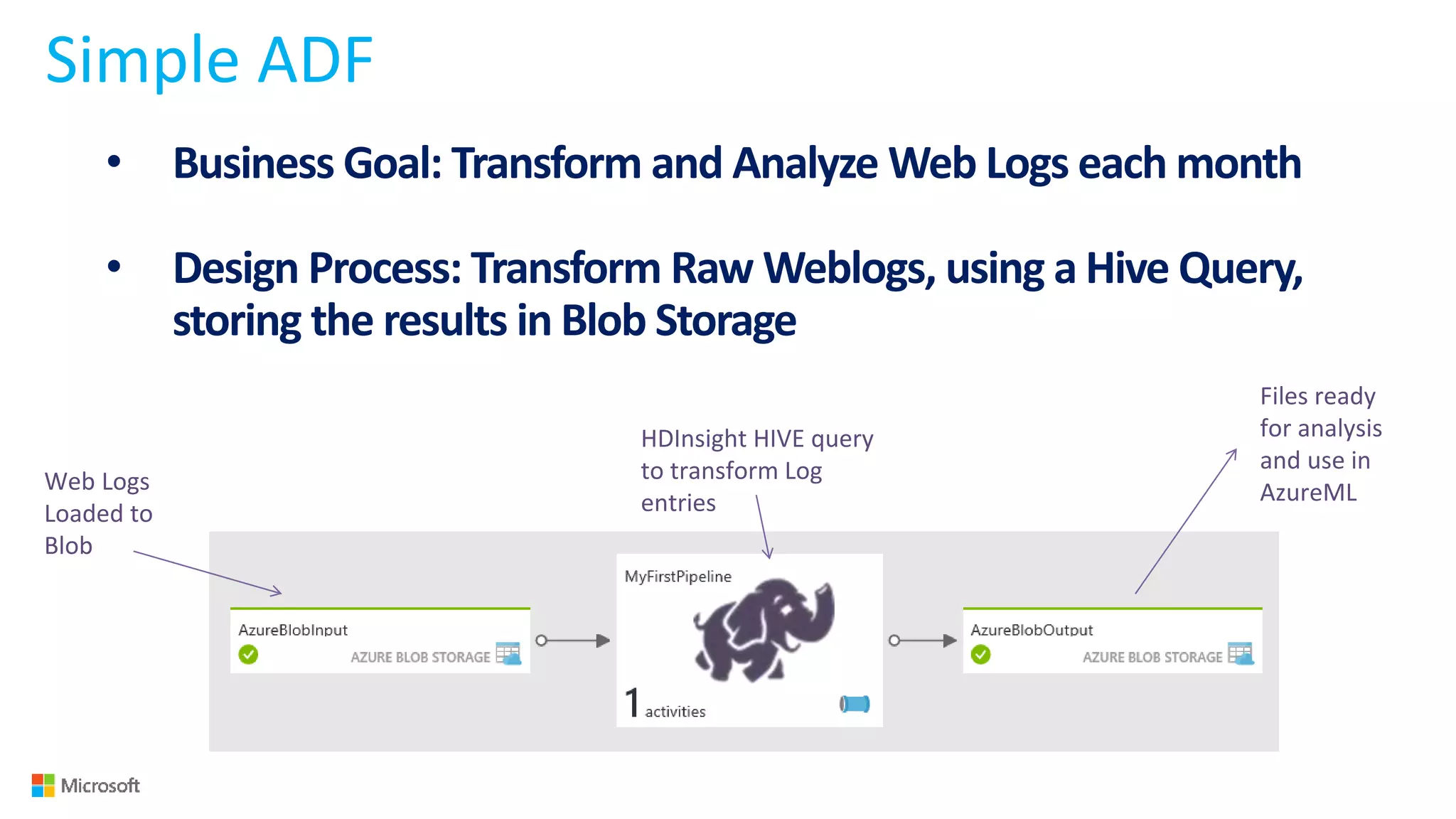
Big Data Analytics in the Cloud using Microsoft Azure services was discussed. Key points included: 1) Azure provides tools for collecting, processing, analyzing and visualizing big data including Azure Data Lake, HDInsight, Data Factory, Machine Learning, and Power BI. These services can be used to build solutions for common big data use cases and architectures. 2) U-SQL is a language for preparing, transforming and analyzing data that allows users to focus on the what rather than the how of problems. It uses SQL and C# and can operate on structured and unstructured data. 3) Visual Studio provides an integrated environment for authoring, debugging, and monitoring U-SQL scripts and jobs. This allows











































































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)