Downloaded 32 times







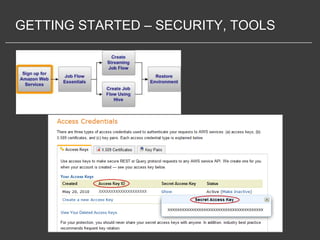
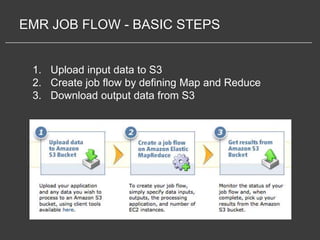
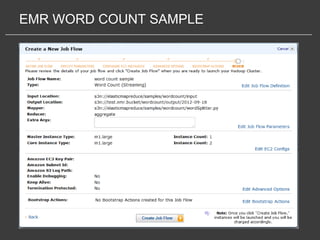
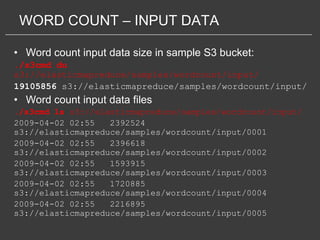
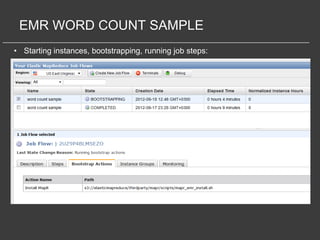
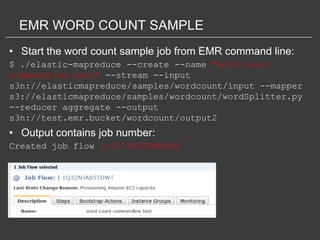
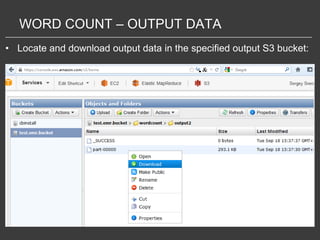

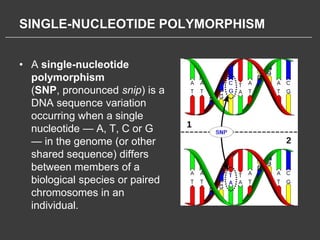

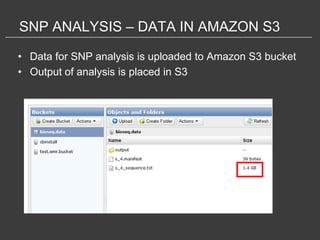
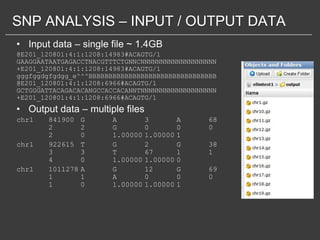











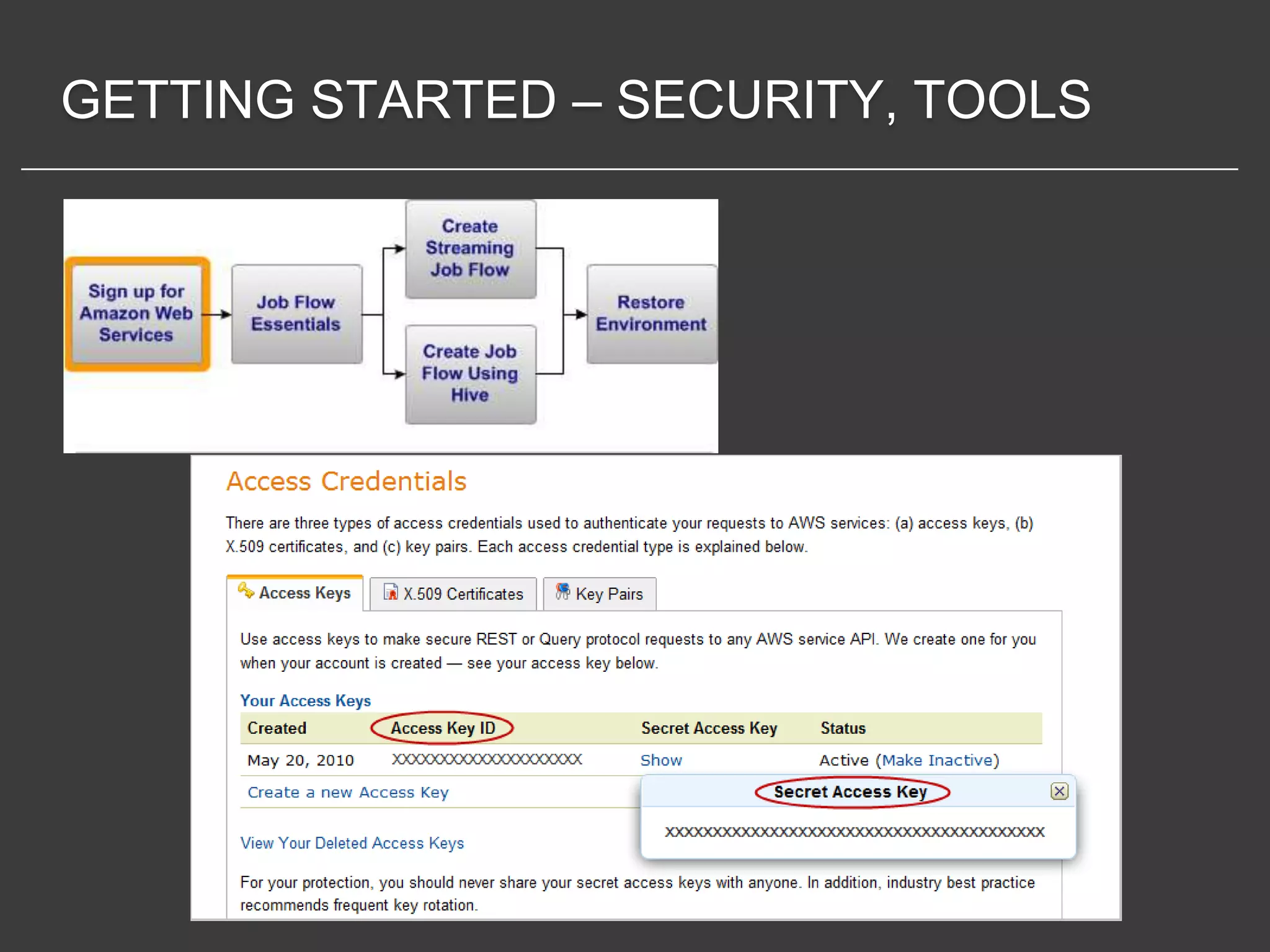
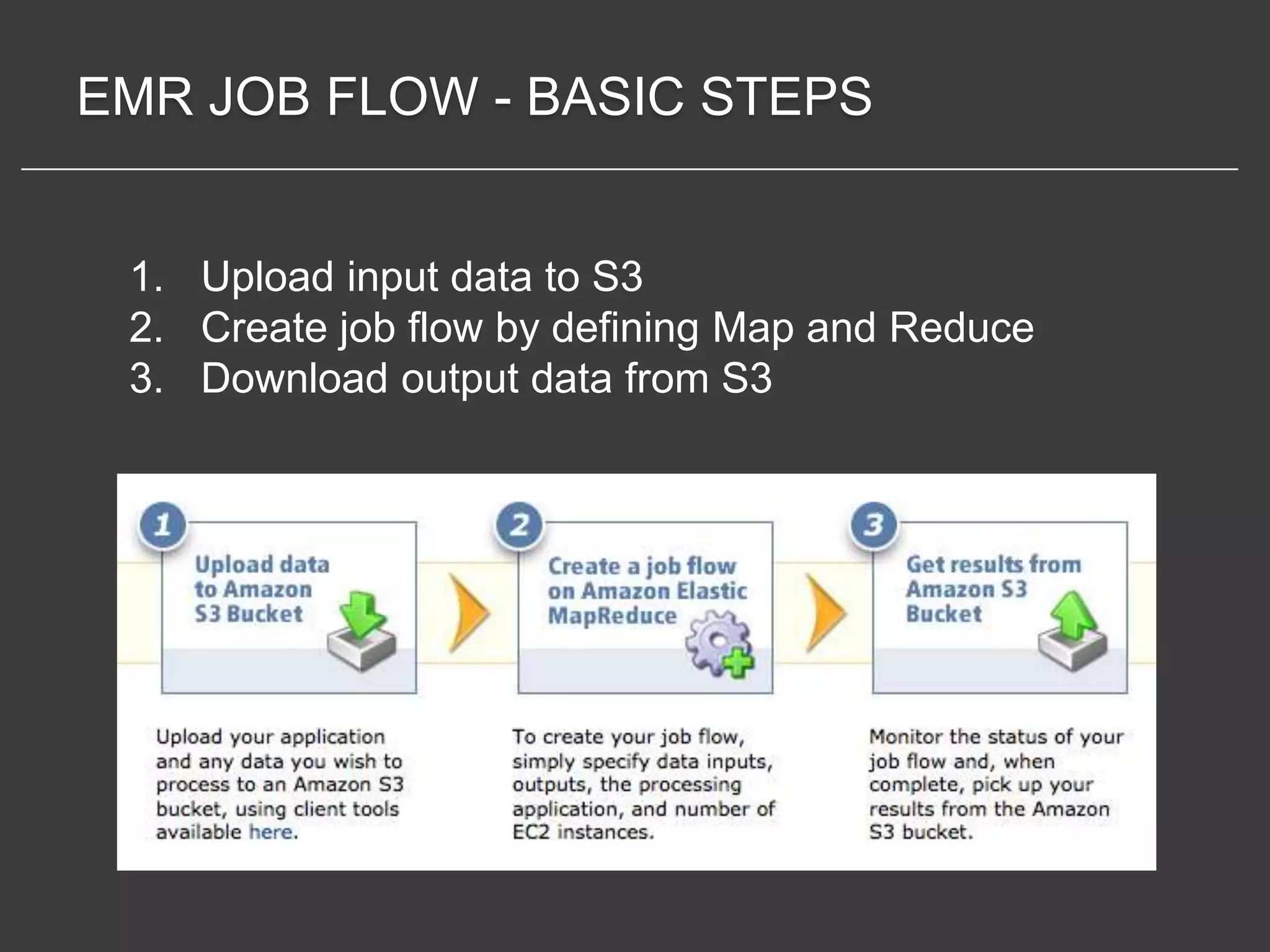
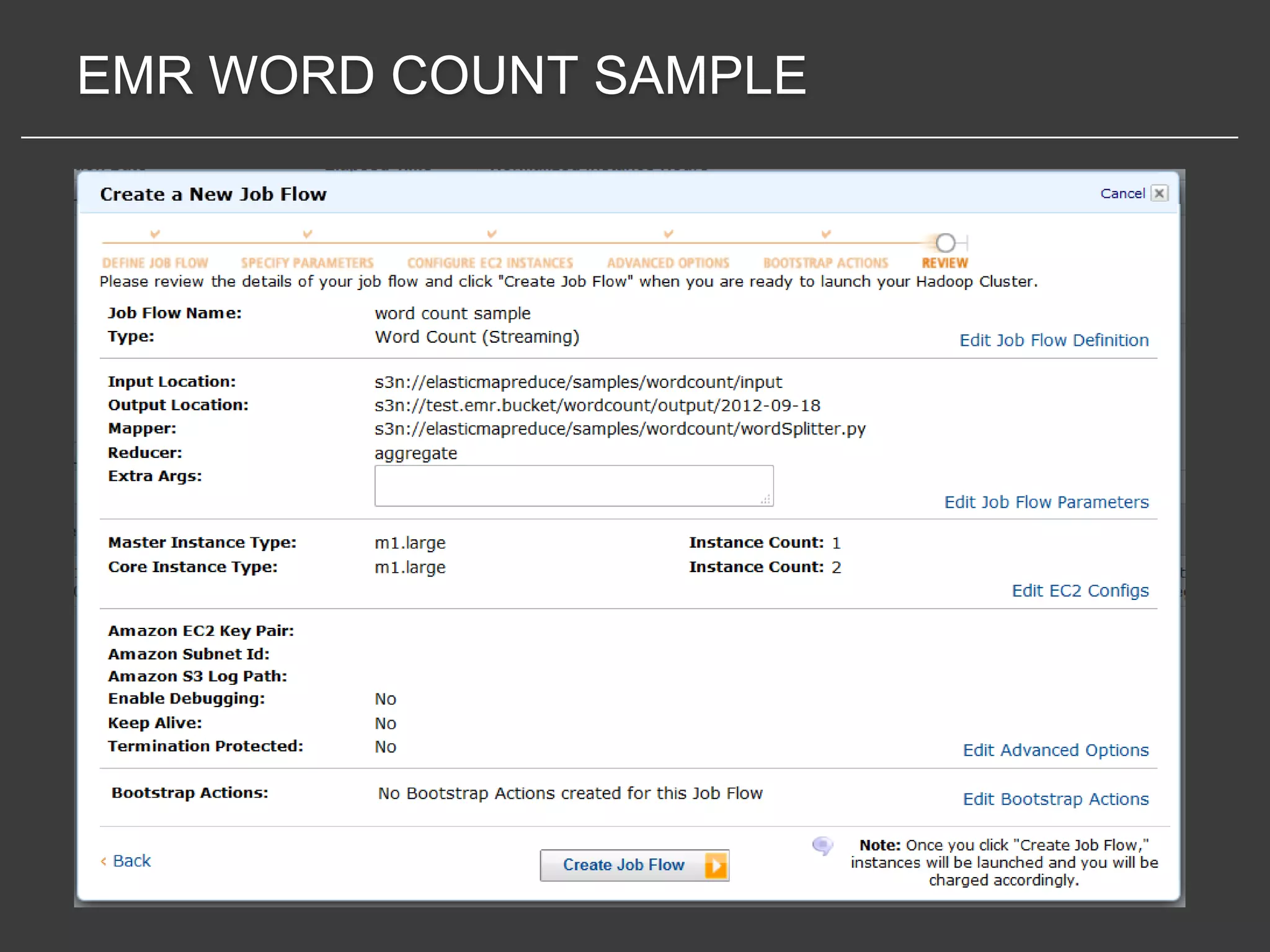
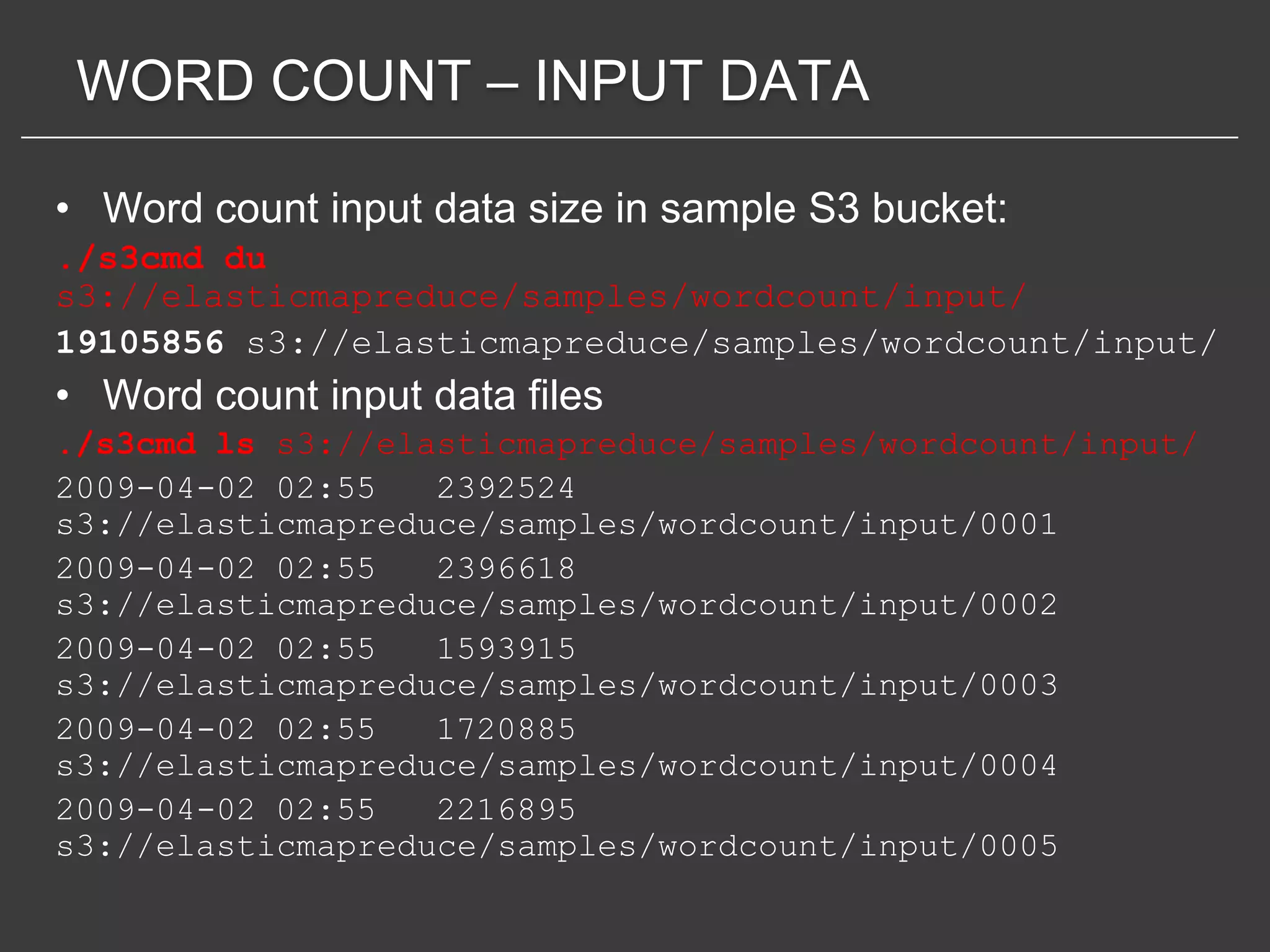
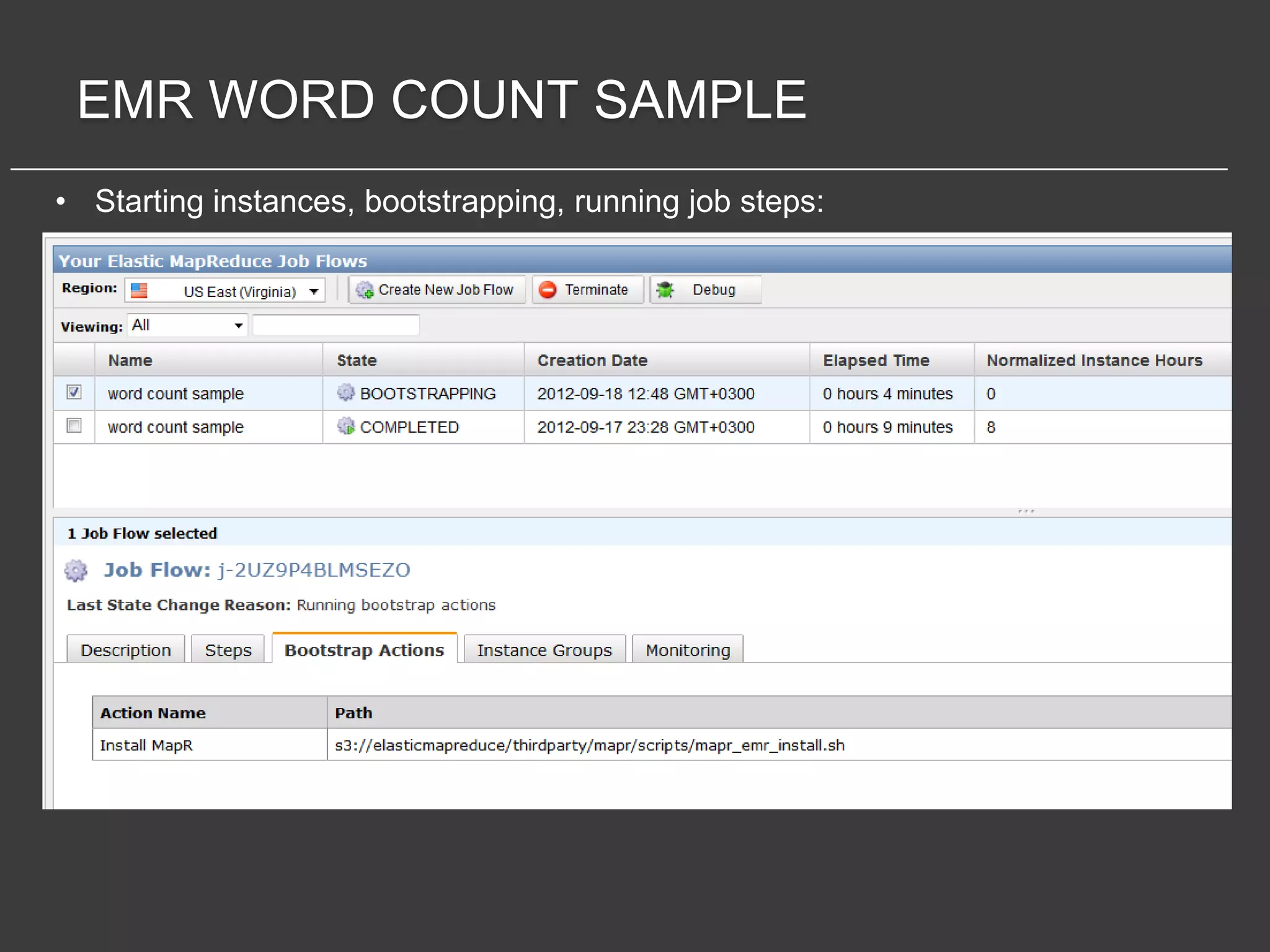
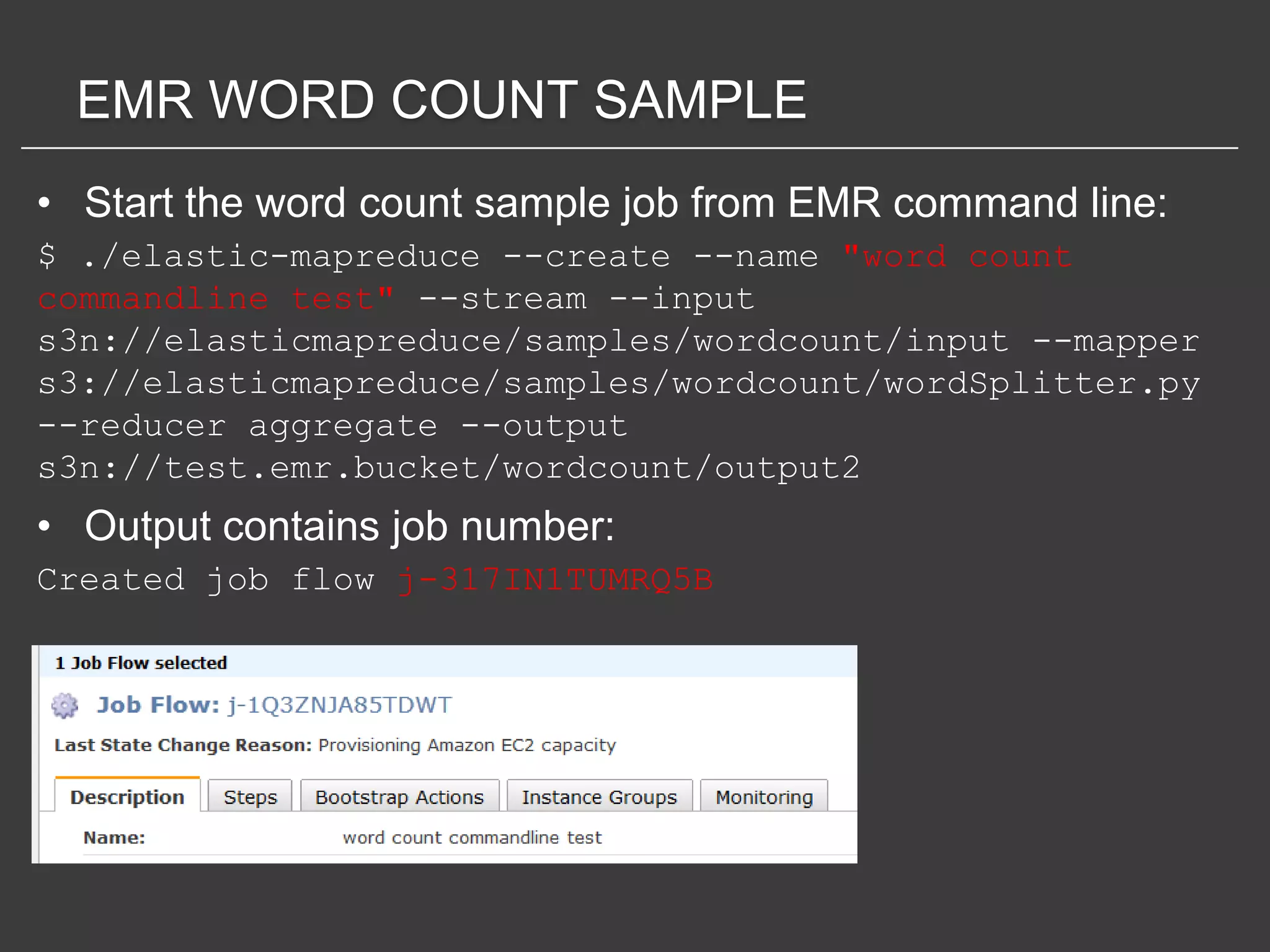
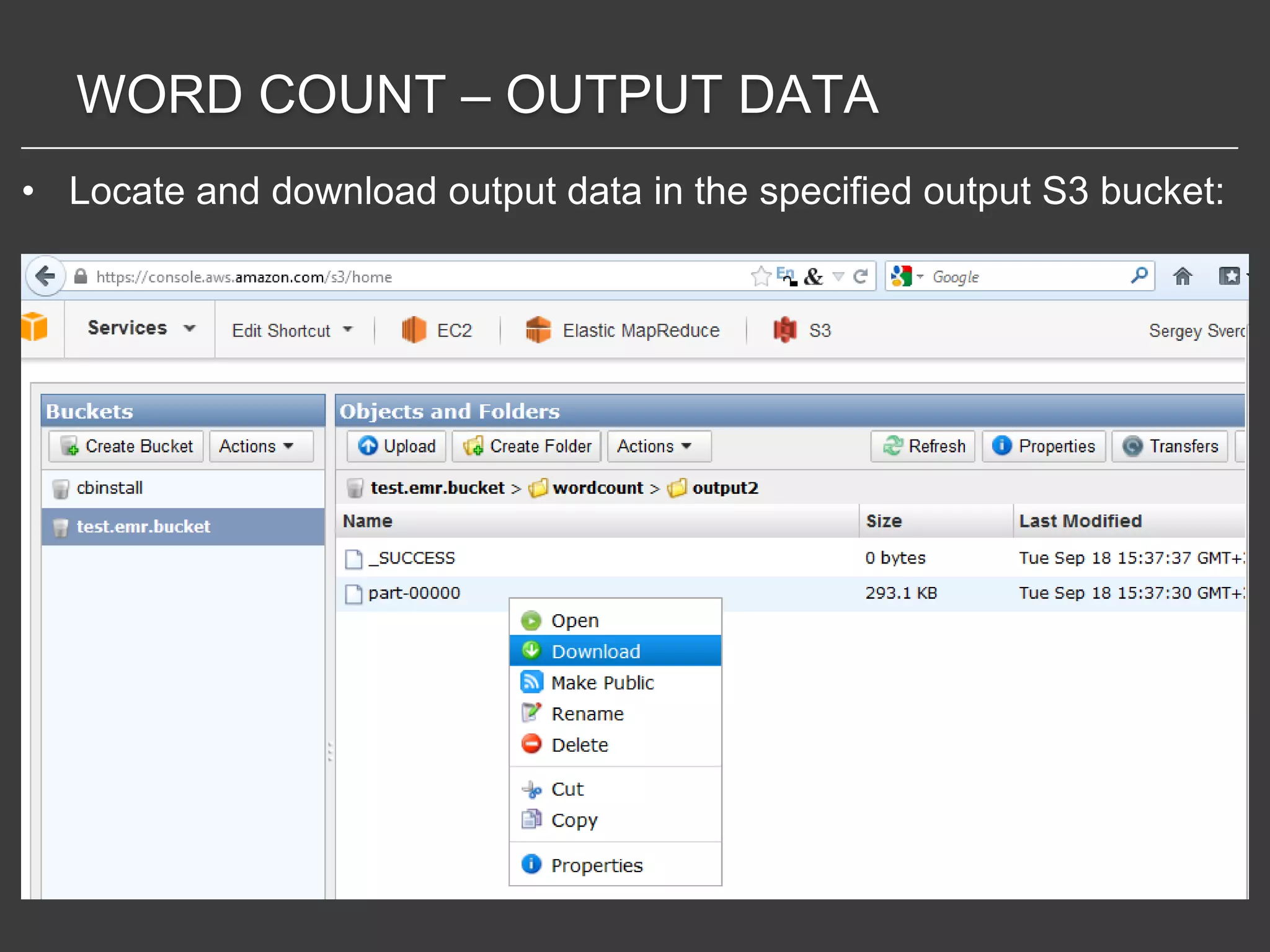

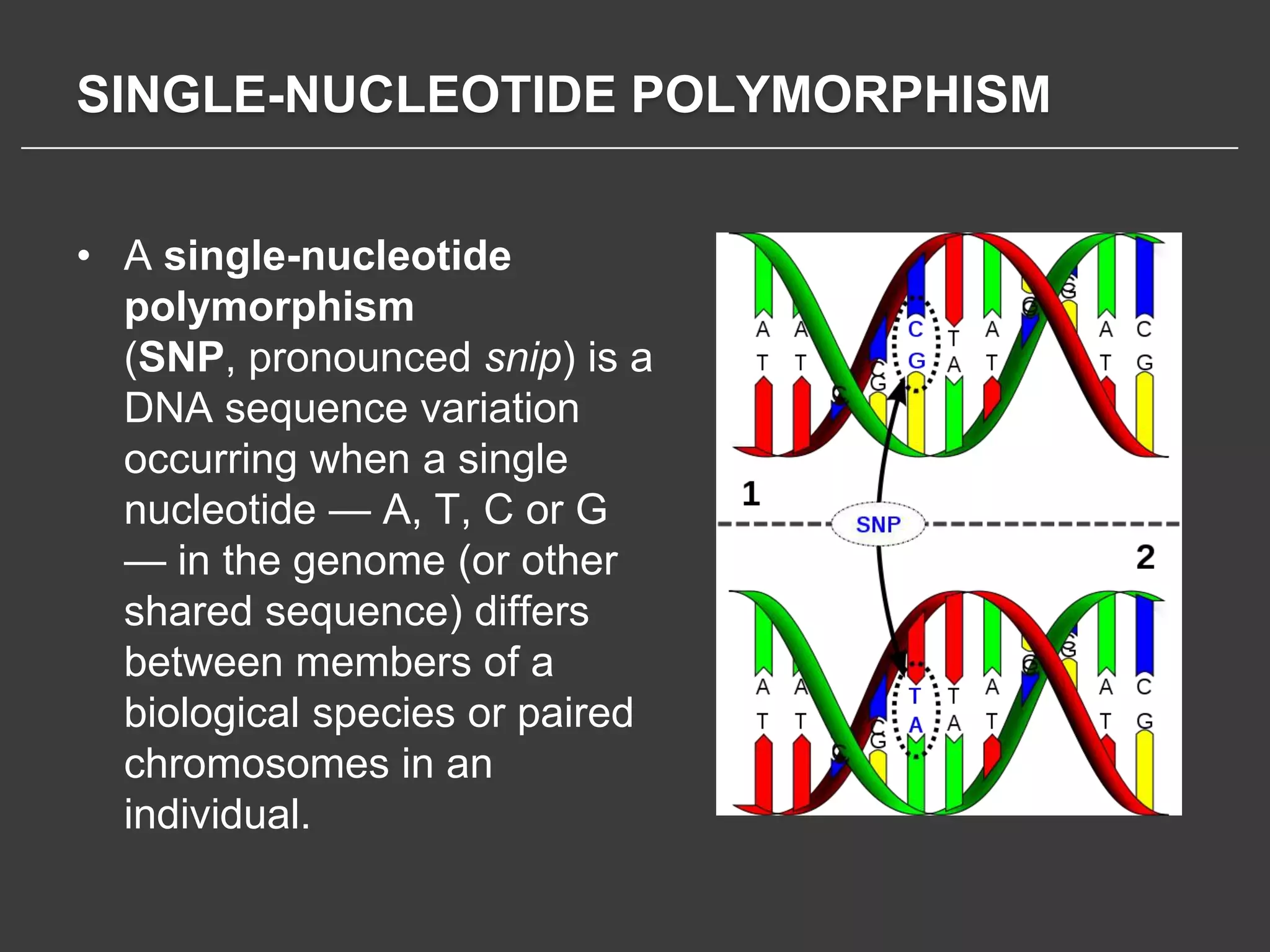

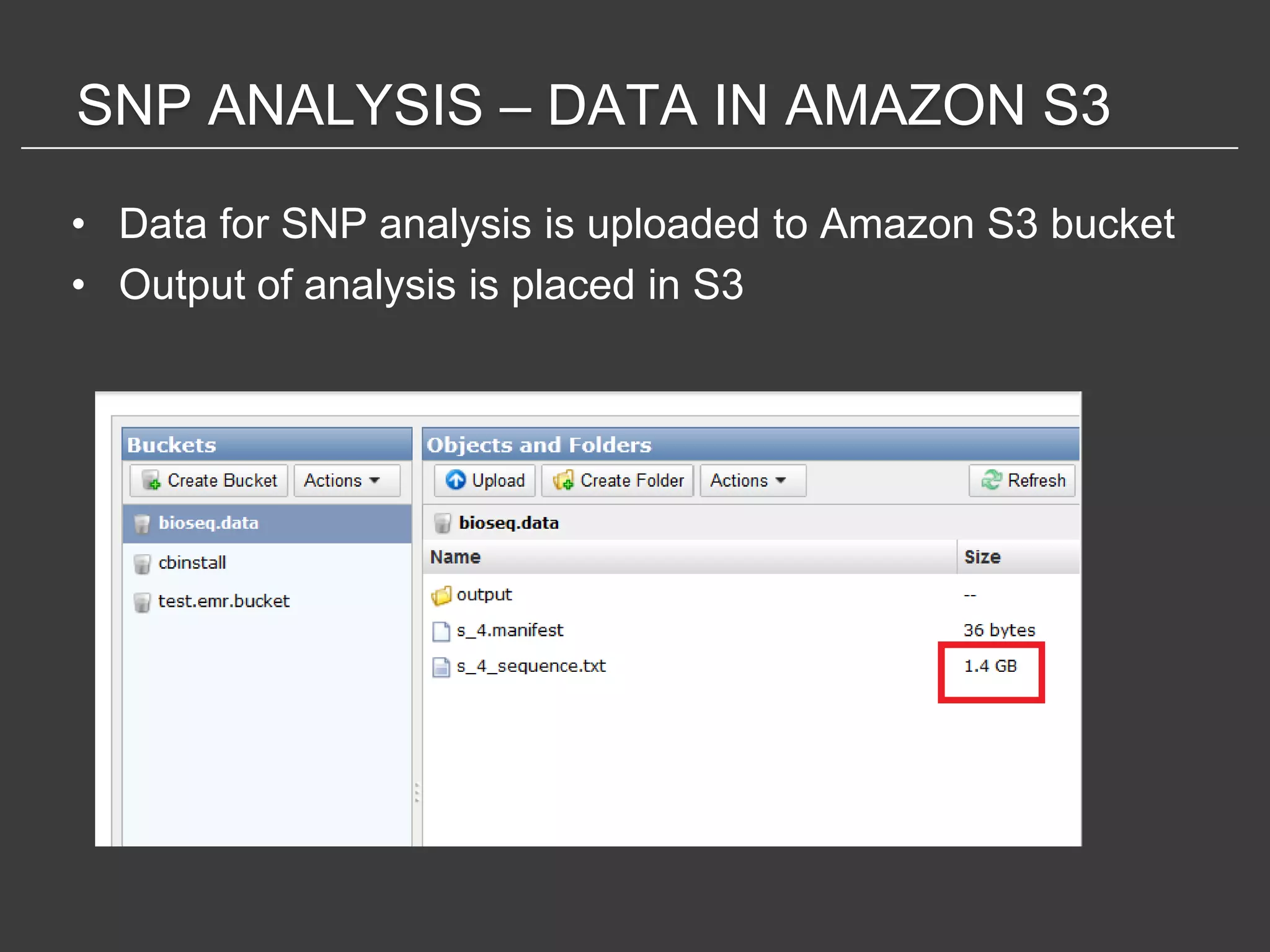
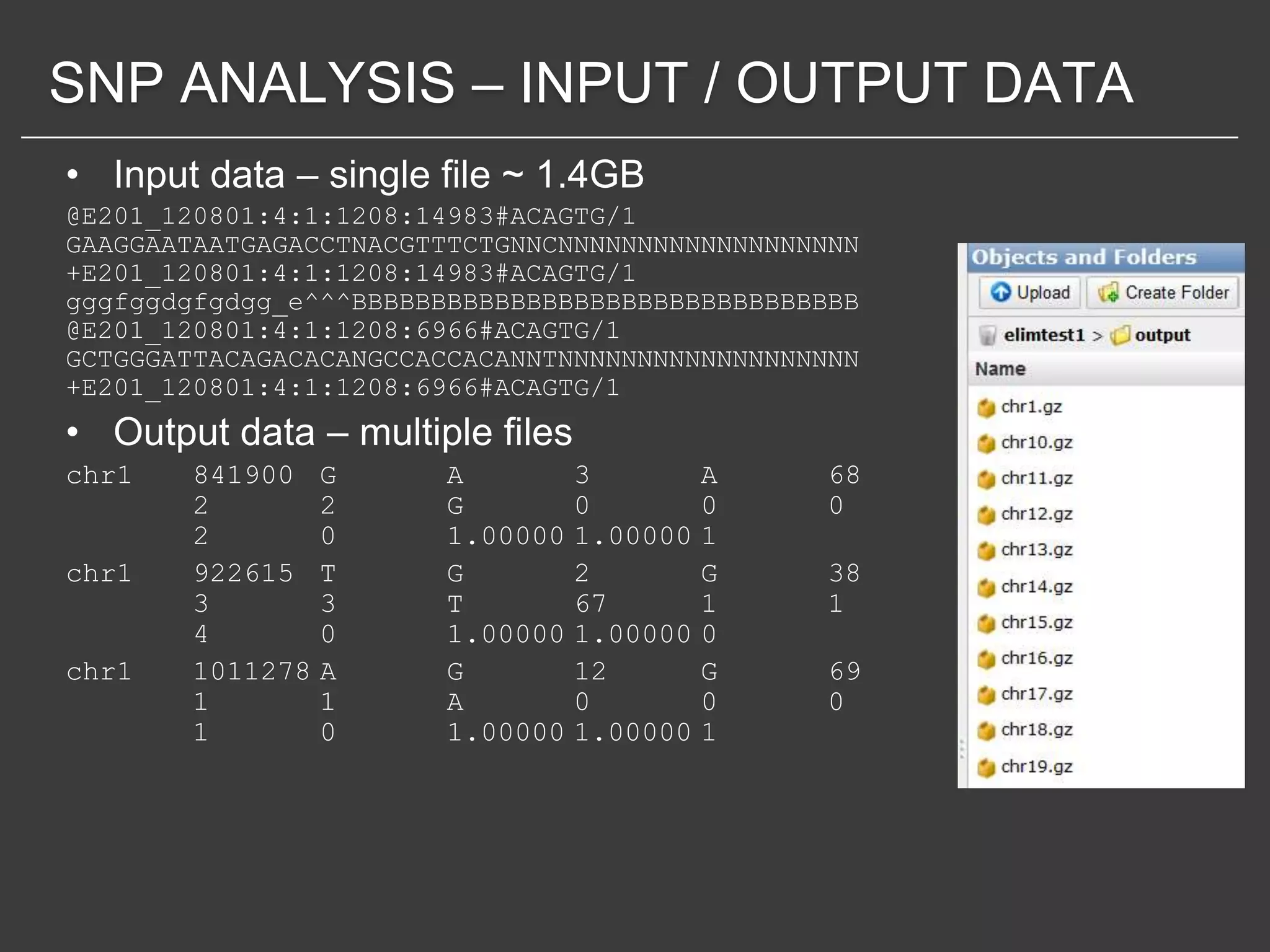





This document discusses using Amazon Elastic MapReduce (EMR) for scalable data processing. EMR allows running Apache Hadoop on the scalable resources of Amazon EC2 and storing data in Amazon S3. It provides a simple web interface and command line tools to define MapReduce jobs that can process large amounts of data across many servers. Examples shown include using EMR to perform word counting on text data and single-nucleotide polymorphism analysis on genomic sequencing data stored in S3.



























































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







