Downloaded 12 times









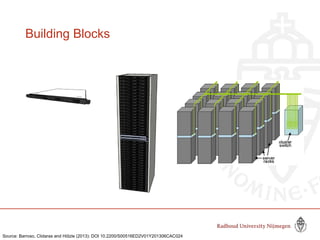
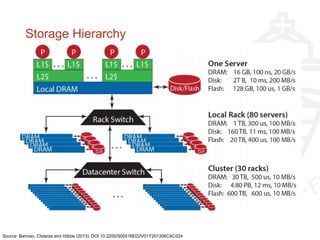

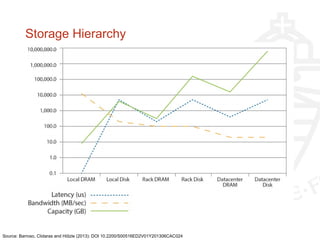
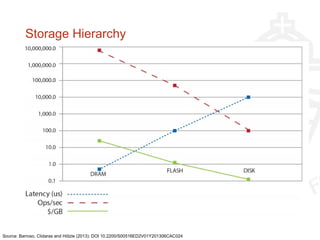
















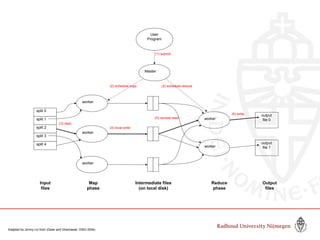










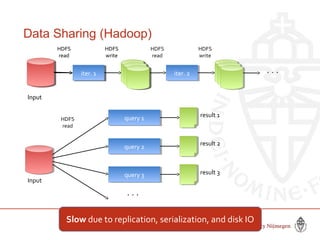
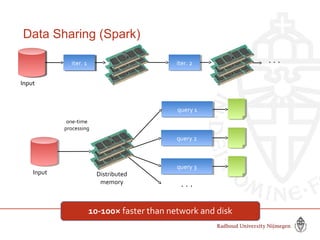





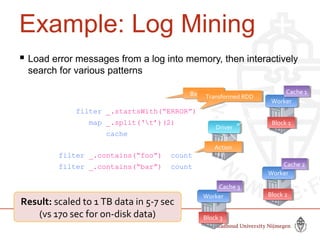

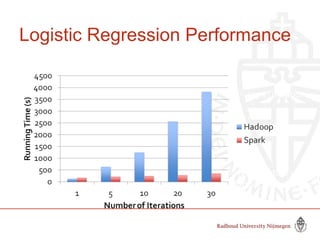


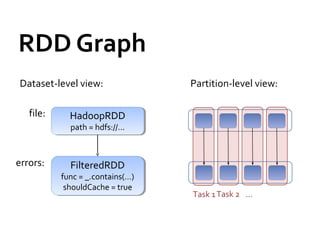


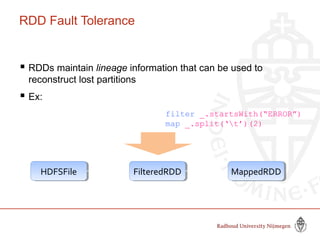













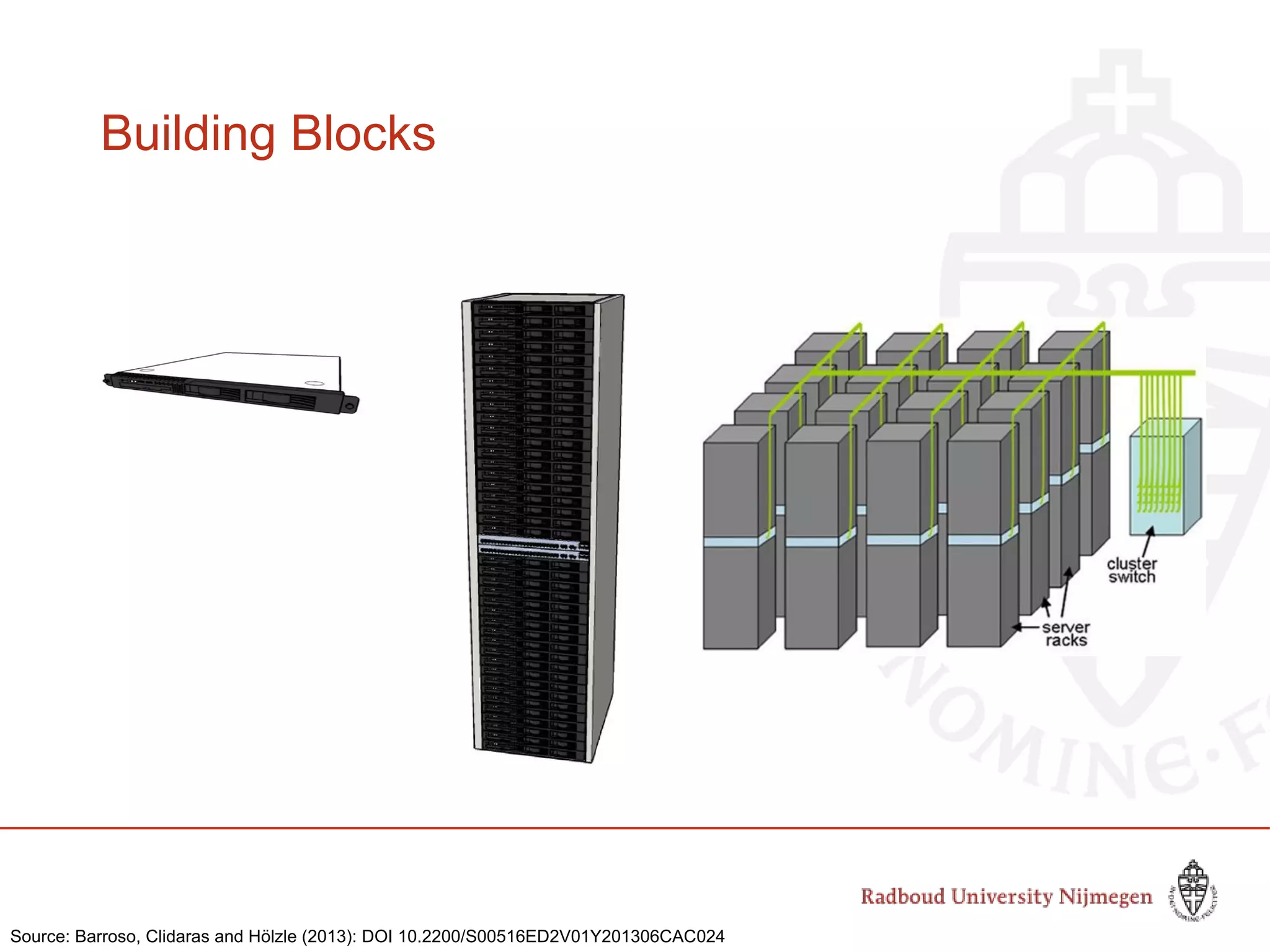
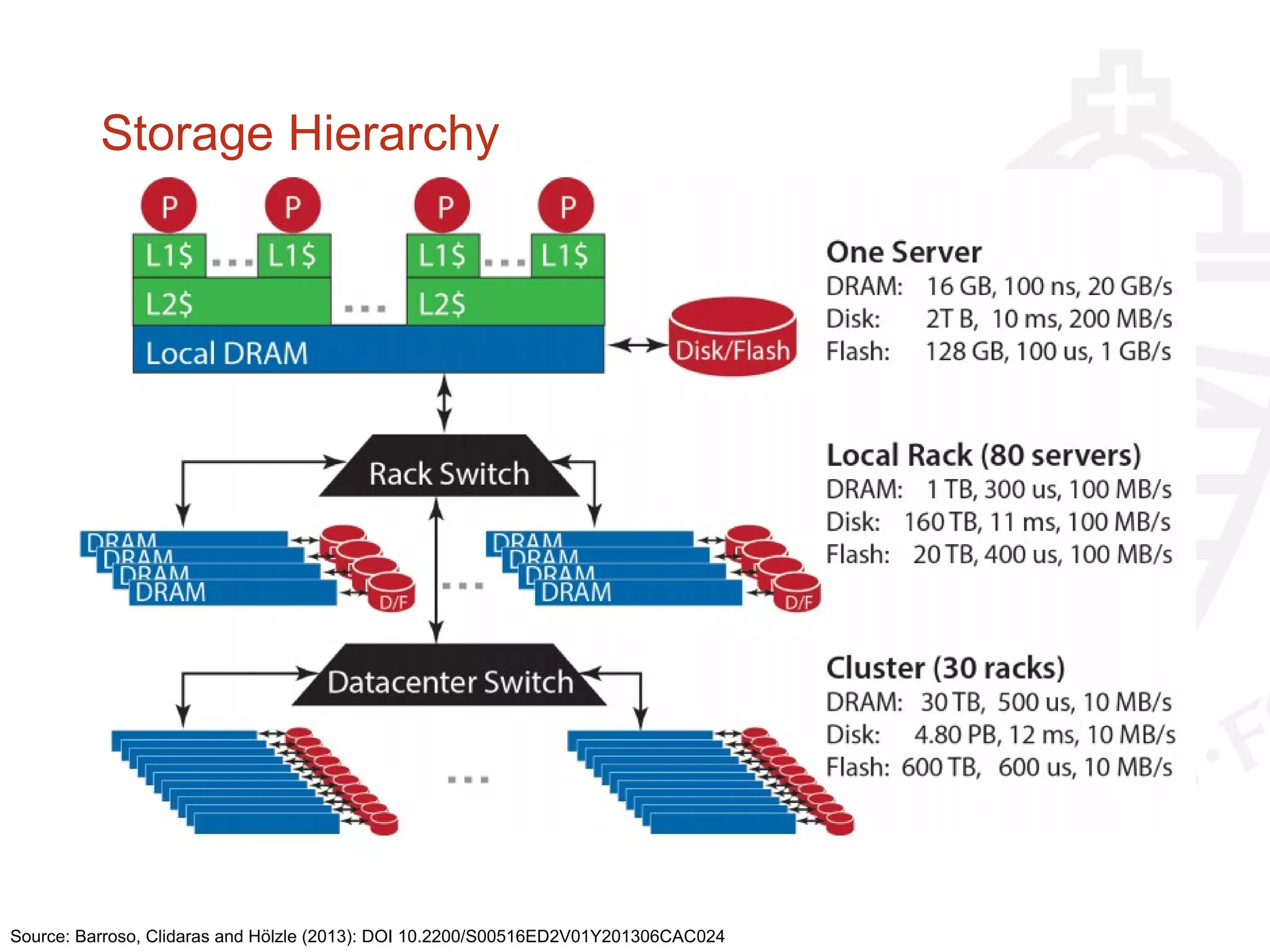

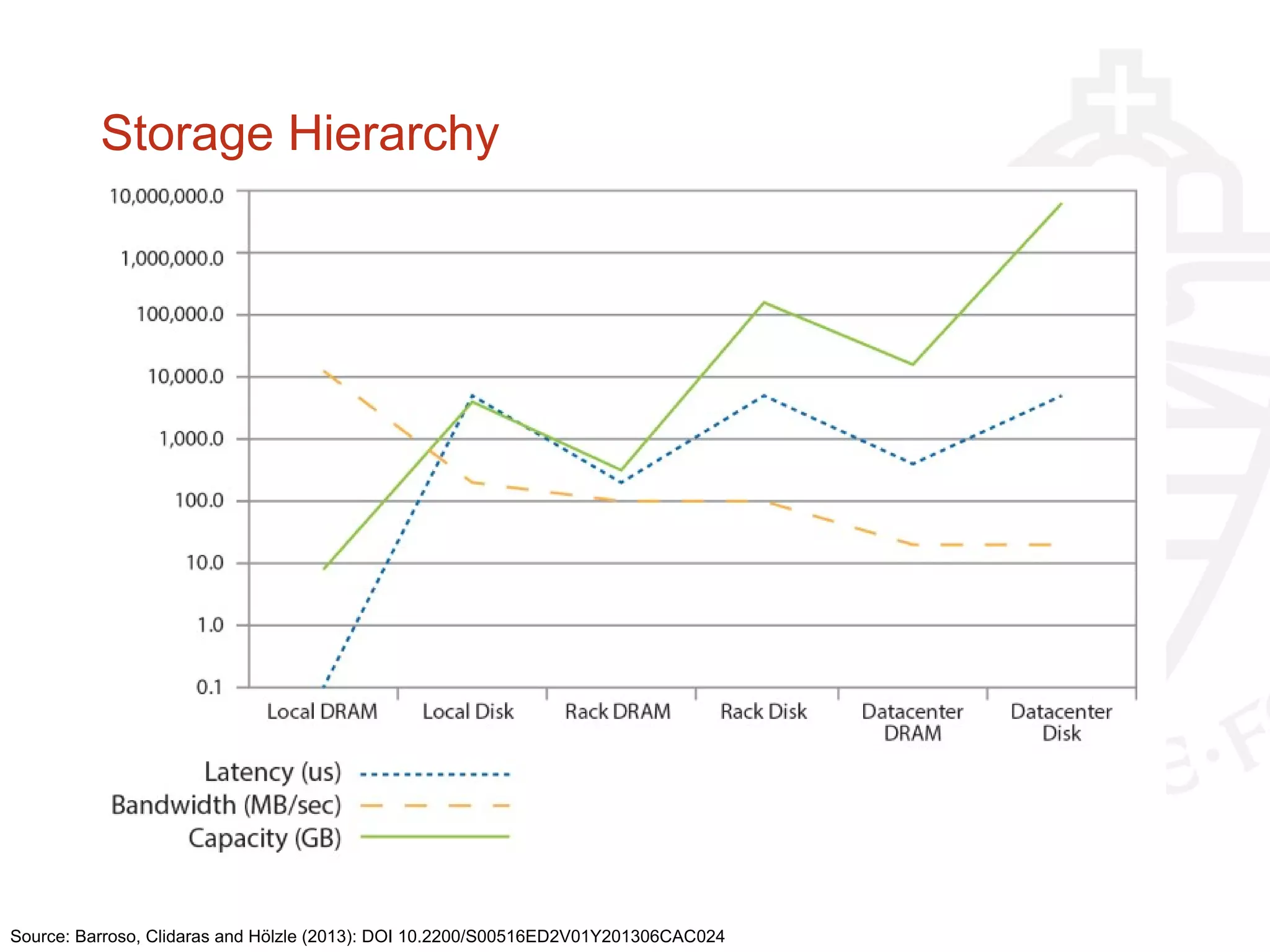
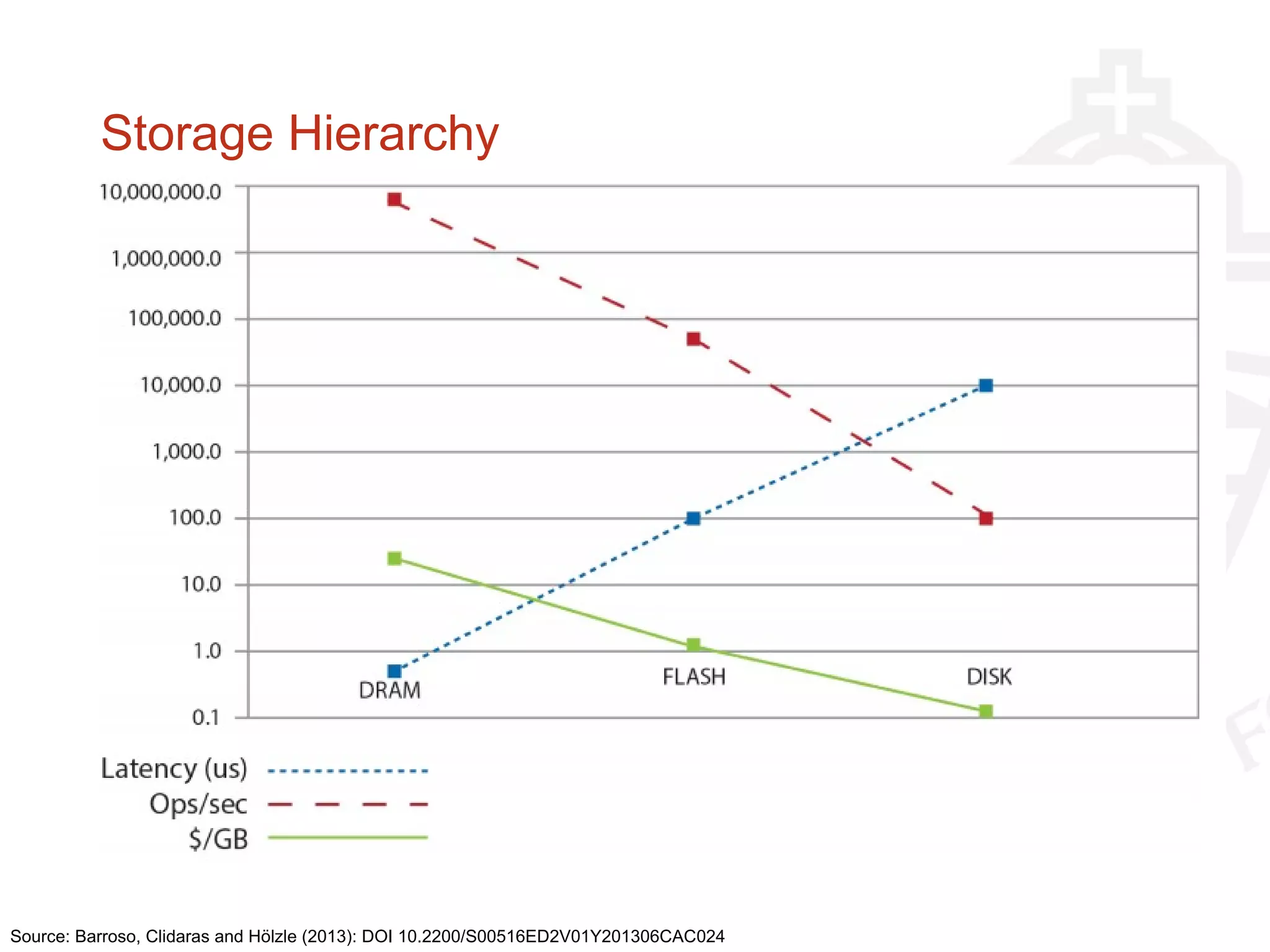















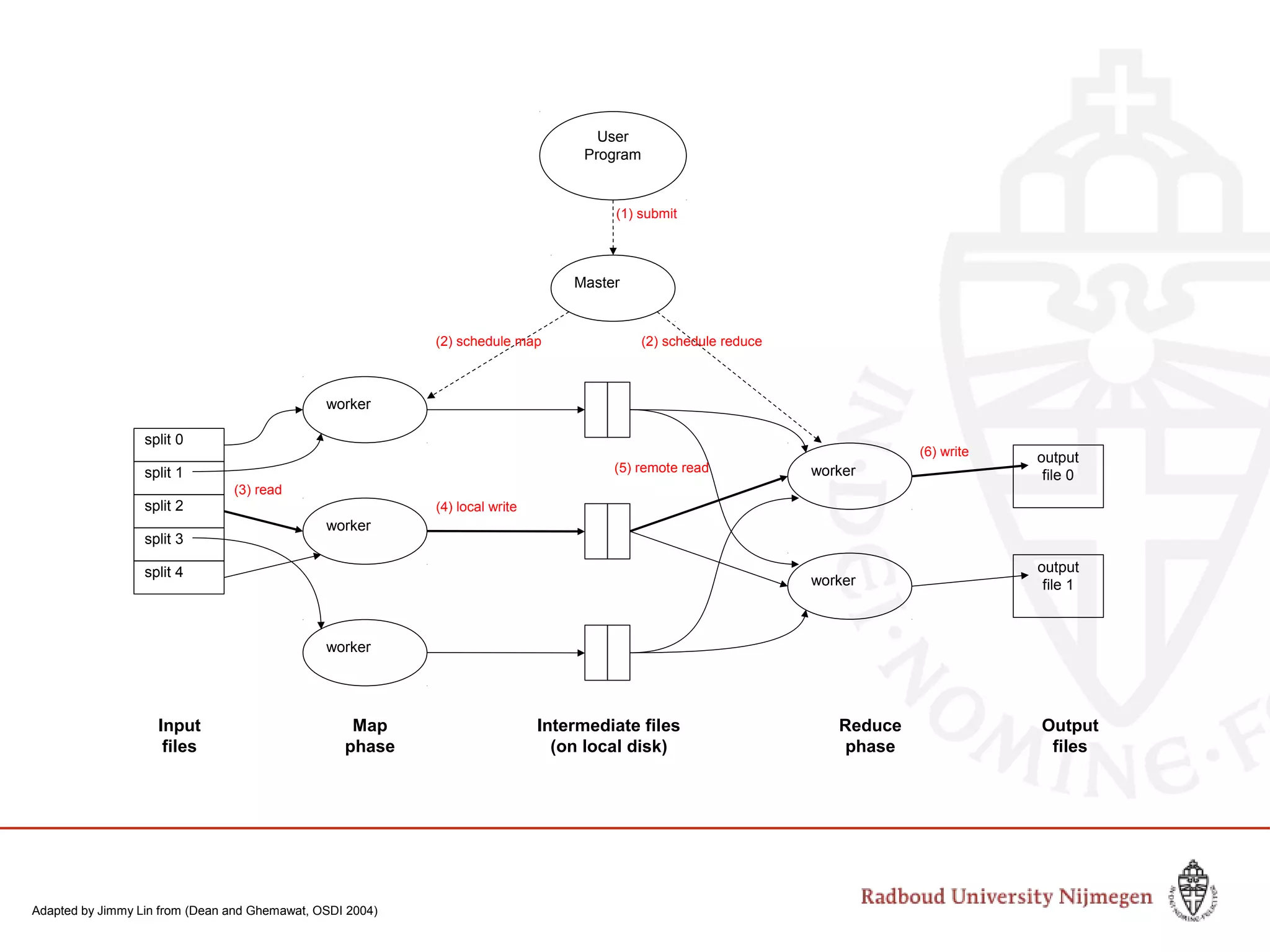











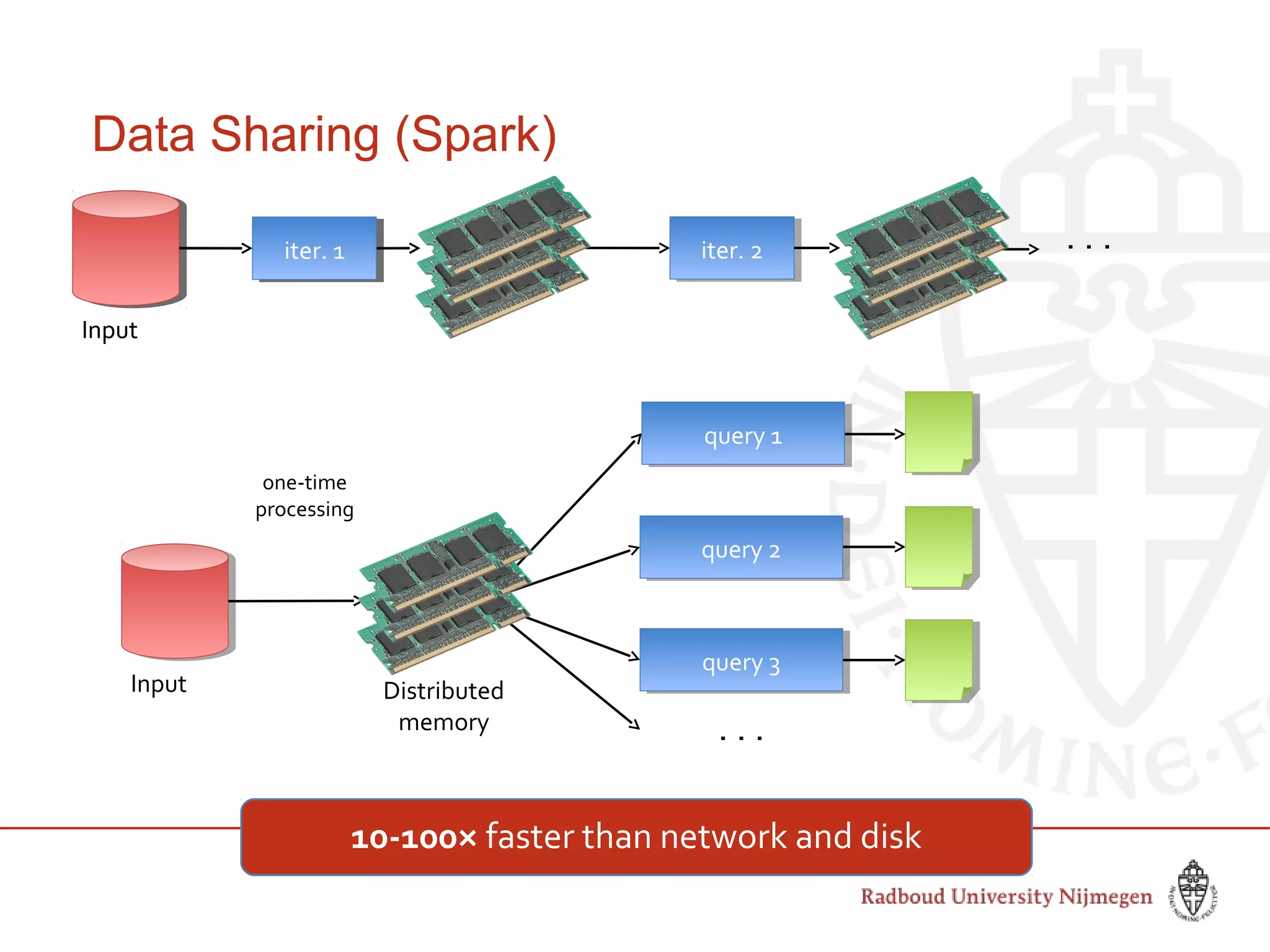
















This document provides information about big data and Hadoop. It discusses how big data is defined in terms of large volumes, variety of data types, and velocity of data ingestion. It then summarizes the MapReduce programming model used in Hadoop for distributed processing of large datasets in parallel across clusters. Key aspects covered include how MapReduce handles scheduling, data distribution, synchronization, and fault tolerance. The document also notes some of the deficiencies of Hadoop, such as sources of latency, its lack of indexes, and its limitations for complex multi-step data analysis workflows.




















































































