BIOINFORMATICS
• Original definition-Paulien Hogeweg
• “Application of informational technology and computer science to the field
of molecular biology”
• Discipline where techniques such as applied mathematics, computer science,
statistics, artificial intelligence are integrated to form biological problems
• Three components:
Development of new algorithms and statistics for accessing relationship
among large set of biological data ( DNA sequence data)
Application of these tools for analysis and interpretation of various
biological data(nucleotide sequences, amino acid sequence)
Development of database for an efficient storage, access and management of
various biological information
4.
Computational biology andbioinformatics
Computational biology and bioinformatics are related branches but with subtle
difference
Computational biology- use of computer technology to solve a question
Development of algorithms and statistical models to analyse biological data
Ramachandran plot
Bioinformatics- Multipurpose computerised analysis of
biological data to make statistical or comparative
inference
Collection and storage of biological information
Derives knowledge from computer analysis of
biological data
databases
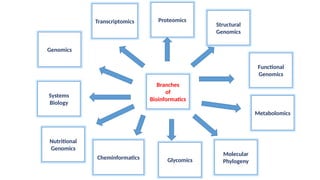
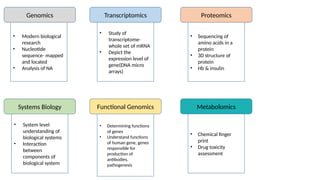
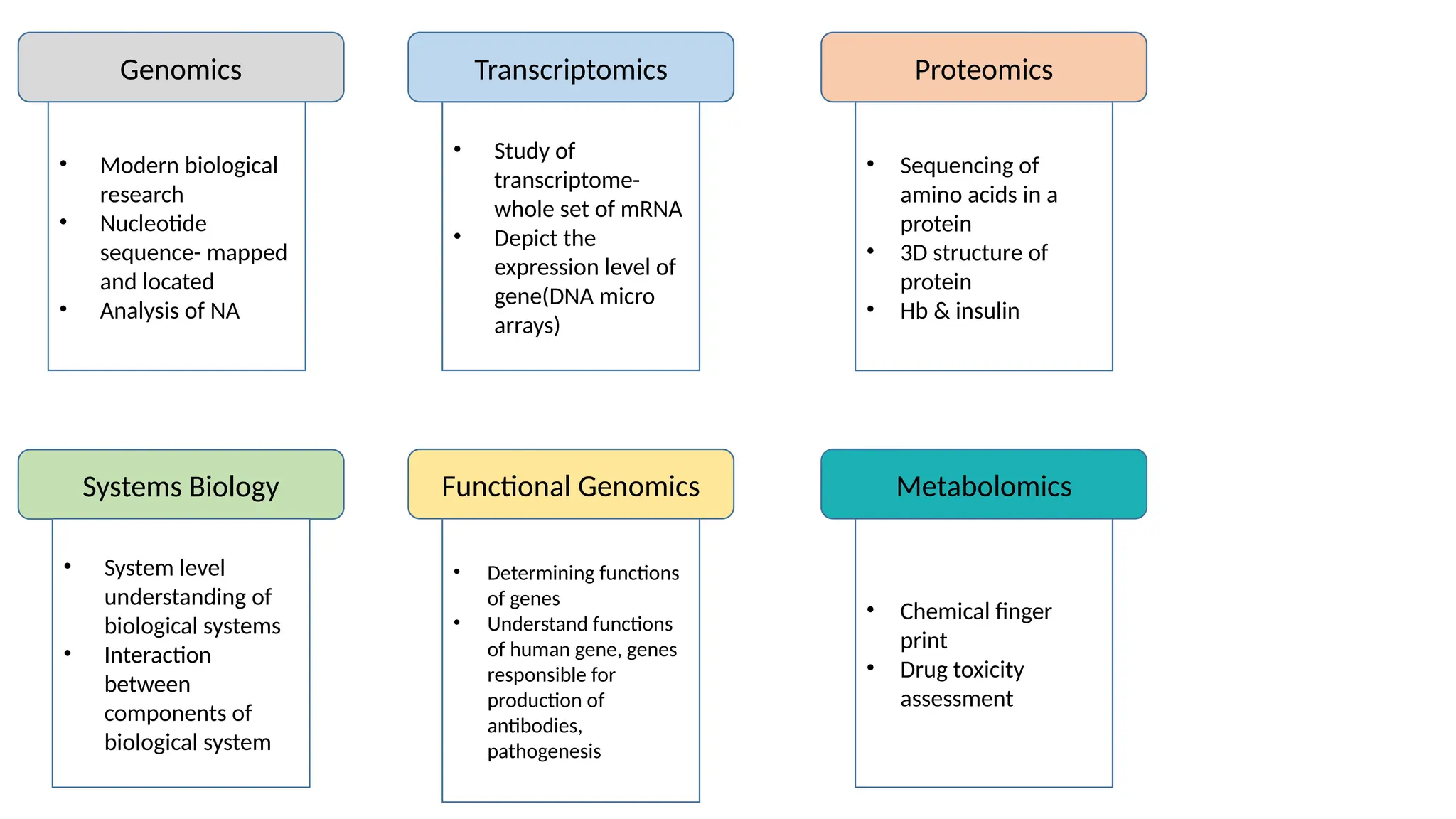
• Modern biological
research
•Nucleotide
sequence- mapped
and located
• Analysis of NA
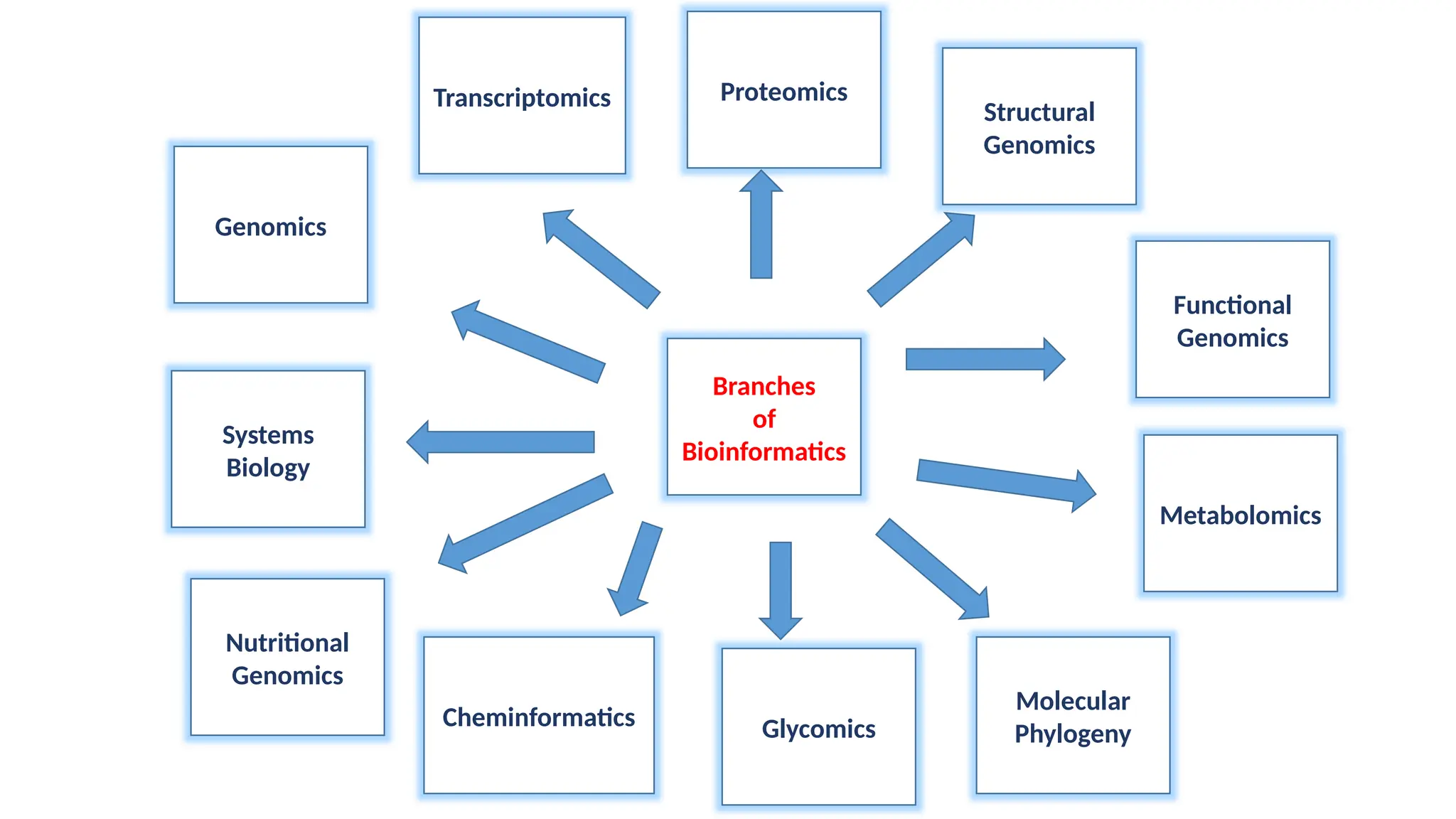
Genomics
• Study of
transcriptome-
whole set of mRNA
• Depict the
expression level of
gene(DNA micro
arrays)
• Sequencing of
amino acids in a
protein
• 3D structure of
protein
• Hb & insulin
Transcriptomics Proteomics
Systems Biology Functional Genomics Metabolomics
• System level
understanding of
biological systems
• Interaction
between
components of
biological system
• Determining functions
of genes
• Understand functions
of human gene, genes
responsible for
production of
antibodies,
pathogenesis
• Chemical finger
print
• Drug toxicity
assessment
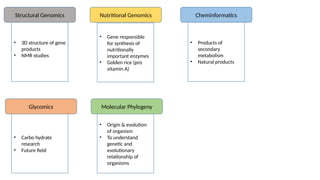
7.
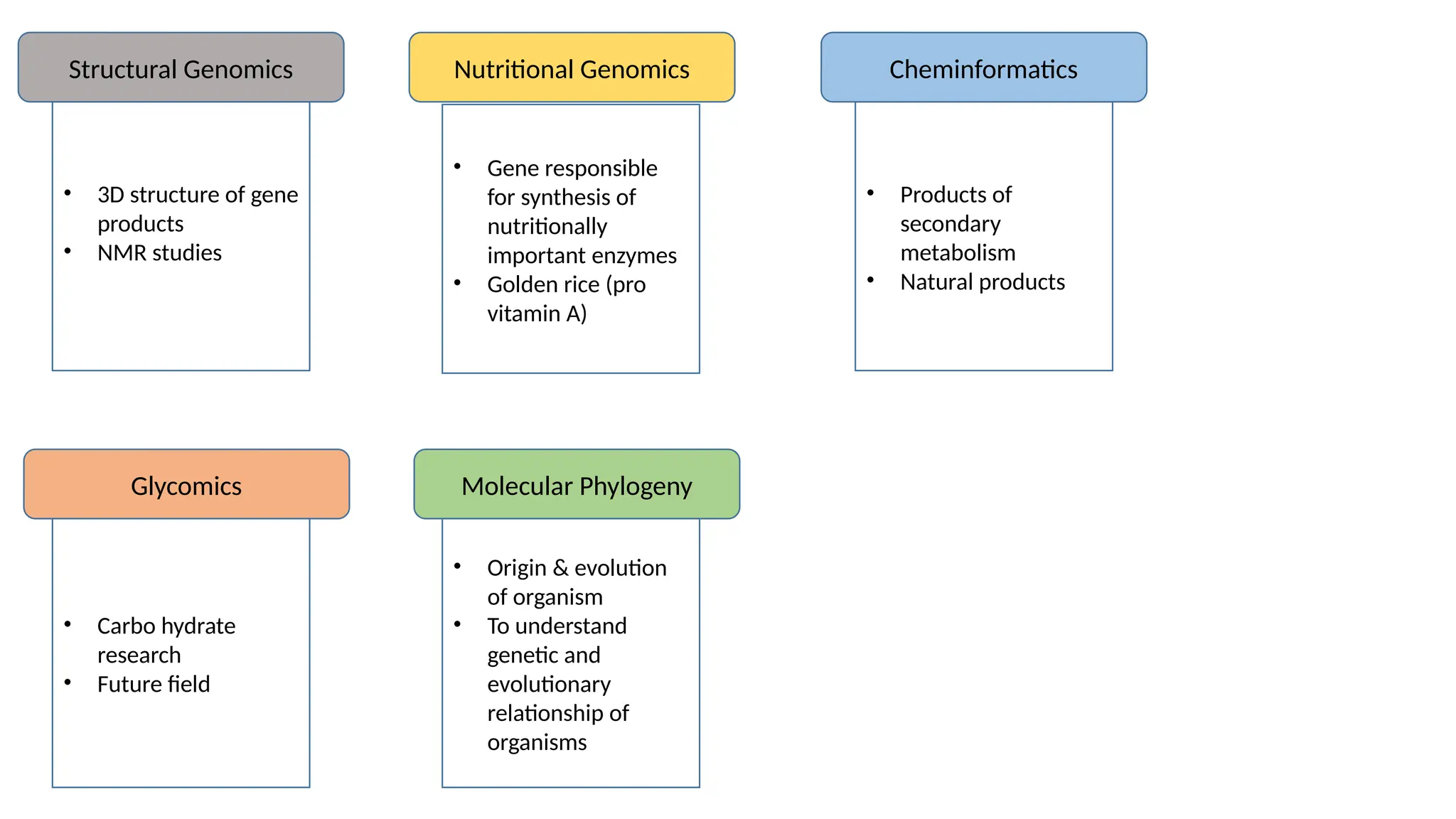
• 3D structureof gene
products
• NMR studies
Structural Genomics
• Gene responsible
for synthesis of
nutritionally
important enzymes
• Golden rice (pro
vitamin A)
• Products of
secondary
metabolism
• Natural products
Nutritional Genomics Cheminformatics
Glycomics Molecular Phylogeny
• Carbo hydrate
research
• Future field
• Origin & evolution
of organism
• To understand
genetic and
evolutionary
relationship of
organisms
8.
SCOPE OF BIOINFORMATICS
The main scope of bioinformatics is to fetch all the relevant data
and process into useful information
Management and analysis of a wide set of biological data
It is used in human genome sequencing where large sets of data are
being handled
Bioinformatics plays a major role in the research and development
of the biomedical field
Bioinformatics uses computational coding for several applications
that involve finding gene and protein functions and sequences,
developing evolutionary relationships, and analysing the three
dimensional shape of proteins
Research work based on genetic disease and microbial disease
entirely depend on bioinformatics where the derived information
can be vital to produce personalised medicine
9.
Biological databases
• Collectionof data that is structured, searchable, update periodically and cross
referenced
• Biological databases are developed to perform several functions such as:
i. Databases aid in systematization of results from biological experiments and
analysis
ii. Database makes biological data available to scientists at one place and help the
to obtain data for their research and cross validation
iii. Biological data in databases are available in computer readable form and this
forms the first fundamental step of biological data analysis
10.
Classification of Biologicaldatabases
• Based on data types
1. Genome databases- human, mouse, yeast, C. elegans, flybase
2. Sequence database
a) Nucleotide databases: Alternative splicing, EMBL-bank, Ensembl, Genomes
server, Genome MOT, EMBL- Align, Simple queries, dbSTS queries, Parasites,
Mutations and IMGT
b) Protein databases: Swiss- Prot, TrEMBL, Inter Pro, CluSTr, IPI, GOA, GO,
Proteome analysis, HPI, IntEnz, TrEmBL new, SP_ML, NEWT and PANDIT
3. Structure database- PDB, MSD, NDB, FSSP and DALI
4. Micro array database- Array Express and MIAME
5. Chemical database- chEBI
6. Pathway database- BRENDA, KEGG and BioSilico
7. Enzyme database- EC enzyme database, REBASE
8. disease database- OMIM, OMIA
9. Literature database- MEDLINE, Flybase archives
11.
• Based onmaintainer status: NCBI, EMBL, SIB
• Based on data access
1. Publically available
2. Available with copyright
3. Browsing only, accessible but not downloadable
4. Academic, but not freely available
5. Proprietary, commercial
6. Restricted SQL queries against underlying DBMS
• Based on data source
1. Primary data(archival)
a. Nucleotide : Gen Bank/ EMBL/ DDBJ
b. protein: Uniprot, TrEMBL
c. structure: PDB
d. literature: Medline(PubMed)
12.
2. Secondary database(curated)
a.Genomic: RefSeq, TIGR gene indices of human
b. Proteomic: Prosite, Swiss-Prot
• Database design- Relational and object oriented
• Organism-Bacteria, Virus, Human etc
13.
Primary databases
1. NUCLEOTIDESEQUENCE DATABASE
i. GenBank
• Hosted by NCBI
• Offers all publically available nucleotide sequence, their protein translation and
their bibliographic and annotated information
• Facilitate and encourages direct submission of sequences data by providing vary
simple and user friendly process
• Researches from anywhere in the world can submit their data to GenBank
• The information in GenBank is growing exponentially and is assumed to continue
growing with a doubling time of approximately 30 months
• http://www.ncbi.nlm.nih.gov/genbank/
14.
ii. EMBL
• Nucleotidesequence database hosted at UK by EMBL European Bioinformatics
Institute
• Non profit research institution supported by 20 European countries and Australia
• Collects nucleotide sequence data from individual researches, genome sequencing
projects and patent applications
• First established in 1974
• Contains taxonomic and non taxonomic divisions
• Sequences are stored in the database as they would exist in biological state
• Stored data generally correspond to wild type sequences without mutation or
genetic manipulations
https://www.ebi.ac.uk/
15.
iii. DDBJ
• DNAData Bank of Japan
• Started on 1986
• Now hosted at National Institute of Genetics
• Gather data mainly from scientists in Japan and also from researchers all over
the world and share these nucleotide data with EMBL and GenBank
• Each database entry includes details of sequence, submitter’s details,
bibliographic references, biological significance and the scientific name and
taxonomy of the organism
• http://www.ddbj.nig.ac.jp
16.
2. PROTEIN SEQUENCEDATABASE
i. TrEMBL
• Translated EMBL is a computer-annotated supplement of SwissProt
• Developed by SwissProt groups at SIB and EBI in1996
• Contains translations of all coding sequences in EMBL except for coding
sequences already included in SwissProt
• Created to accommodate the enormous sequence information and the time
consuming curating process
• Two major sections: SP-TrEMBL and REM-TrEMBL
• SP-TrEMBL contains the entries which will finally merge into SwissProt
• REM-TrEMBL contains sequences that will not get include in SwissProt
17.
ii. Uniprot
• Uniprotis a freely accessible database of protein sequence and
functional information
• It contains large amount of information about the biological function
of proteins derived from the research literature
• Nowadays it combines a network of sister databases centralising all
levels of annotation produced for protein sequences
• https://www.uniprot.org/help/linking_to_uniprot
18.
3. STRUCTURE DATABASES
PDB
•Protein Data Bank is the main primary database used for the production of 3D
structure of proteins and nucleic acid
• This is the single world-wide archive of structural data and is maintained by
Research Collaboratory for Structural Bioinformatics
• Knowledge can be used to help derive the role played by higher level
structure of molecules in human health and disease and in drug development
• The data obtained from x-ray crystallography and NMR spectroscopy are
submitted to the PDB
• https://pdbj.org/help/faq_data03
19.
4. LITERATURE DATABASE
Medline(PubMed)
•Bibliographic database
• Free database accessing the MEDLINE database of citations and some full
text articles on life science and fields such as medicine, nursing, healthcare
system and preclinical sciences
• Developed and maintained by National Centre for Biotechnology Information
• New journals are not included automatically in PubMed
• It also provide access to additional relevant websites and links to other NCBI
molecular biology resources
• https://pubmed.ncbi.nlm.nih.gov/
20.
1. PROTEOMIC
i. Prosite
•Prosite a part of Swiss prot is a database of protein families and domains
• Consists of entries describing the families, domains and functional sites as well as
amino acid patterns, signature and profiles in them
• Help to identify to which known protein family a new sequence belongs
• Prosite offers tools for protein sequence analysis and motif detection
• Basis of Prosite is regular expression describing characteristic subsequences of specific
protein families and domains
• Part of EXPAST proteomic analysis servers
• https://prosite.expasy.org/
Secondary databases
21.
ii. PRINTS
• Printsis a database of protein which uses a different approach of
pattern recognition called ‘fingerprinting’
• Provides both a detailed annotation resource for protein families, and
a diagnostic tool for new protein sequences
• Prints database, a very high quality database is created with a great
deal of manual effort
22.
iii. BLOCKS
• Blocksdatabase are databases which represents protein families in
terms of multiple aligned ungapped segments
• Derive from most highly conserved regions in a group of protein or
protein family
• Ungapped multiple alignments of short regions are called blocks
• Database was constructed from sequences of protein families using a
fully automated method
• WWW. http://blocks.fhcrc.org
23.
iv. Swiss prot
•Swiss prot is a high quality, manually annotated non-redundant protein
sequence database
• Created in 1986
• Developed by the Swiss Institute of Bioinformatics and the European
Bioinformatics Institute
• Provides high level of annotations including description of function of the
protein, post-transcriptional modifications
• Aim of the database is to provide all known relevant information about a
particular protein
• http://www.ebi.ac.uk/swissprot/
24.
v. TIGR Database
•It provides a collection of molecular biology database comprising DNA
and protein sequence, gene expression, function, cellular role etc.
• Maintained at the Institute of Genomic Research which is a part of J.
Craig Venter Institute in USA
• http://cmr.tigr.org/tigr-scripts/CMR/CmrHomePage.cgi
25.
RNA databases
Information onsequence of ribonucleotides in RNA, coding and non-coding RNA
sequences, functions of RNA molecules and their spatial structures is available in
databases
i. Rfam
• Stores non coding RNA families
• Rfam also contains multiple sequence alignments and models
• Allow user to view and download multiple sequence alignments, read annotation
and examine species distribution of family members
• Also provides link to Wikipedia so that entries can be created or edited by users
• https://rfam.xfam.org/
26.
ii. Gt RNA
•Gt RNA database stores genomic tRNA ribonucleotide sequences and
secondary structures
• Index of RNA structures provides a lot of information about RNA
• Including indexes of the locations of molecular structures in the PDB
database
• Data on ribonucleic acid sequences in RNA can also be found in
GenBank
• http://gtrnadb.ucsc.edu/
27.
Curated databases
• Datacollected by human efforts through consultation, verification and
aggregation of existing source and interpreting new raw data
• Machine readable
• Source pre-existing data
• Updations are followed
• E.g.: Swiss prot
Uncurated databases
• Follows automated curation
• Provides quick updates and tend to be larger
• Less accuracy
• E.g.: PDB
28.
Functional databases
• Itprovides information on the physiology role of gene produced
• Enzyme activity
• collect and experiment biological information
29.
REFERENCES
• Zhumur Ghoshand Bibekanand Mallick(2008) ‘Bioinformatics-
Principles and Applications’ Oxford University press pg: 3-133
• K. Vijayakumaran Nair,etal. (2019) ‘Informatics- Bioinformatics and
Molecular Biology ‘ Academia . Pg: 145-158
• Andrzej Polanski, Mark Kimmel.(2007). ‘Bioinformatics’ Springer New
York . Pg: 349-354
• D.R.Westhead etal.(2003). ‘Bioinformatics’ Viva Books Pvt. Ltd. Pg: 35-
49